Nonparametric Bayesian Double Articulation Analyzer for Direct Language Acquisition from Continuous Speech Signals
Human infants can discover words directly from unsegmented speech signals without any explicitly labeled data. In this paper, we develop a novel machine learning method called nonparametric Bayesian double articulation analyzer (NPB-DAA) that can dir…
Authors: Tadahiro Taniguchi, Ryo Nakashima, Shogo Nagasaka
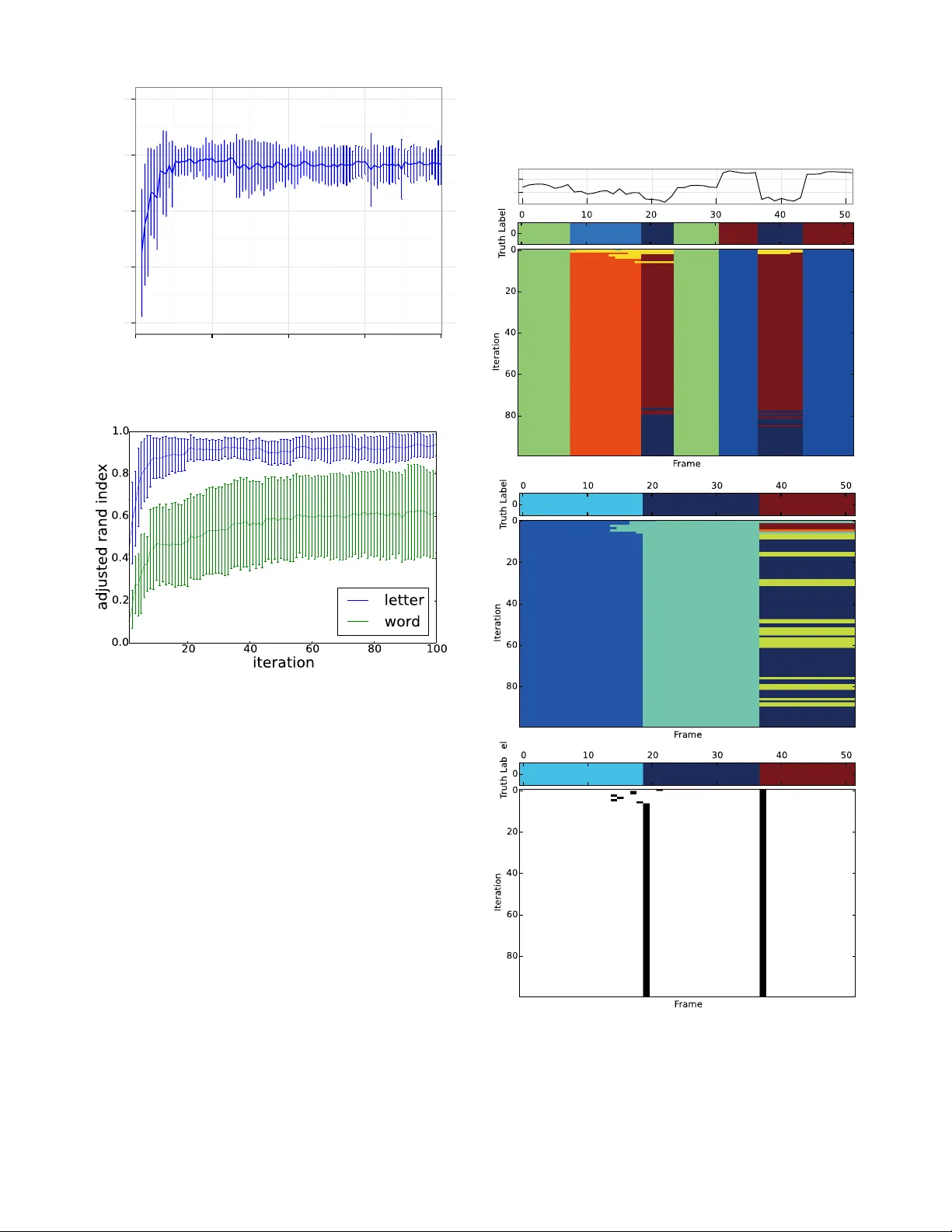
1 Nonparametric Bayesian Double Articulation Analyzer f or Direct Language Acqui sition fr om Continuous Speech Signals T adahiro T aniguchi 1 , Shog o Nagasa ka 2 , Ryo Na kashima 2 Abstract —Human infants can discov er words directly fr om unsegmented speech signals without any explicitly labeled data. The main problem of t his paper is to deve lop a computational model that can estimate language and acoustic models, and discov er words d irectly from contin uous hu man speech signals in an unsupervised manner . Fo r t his purpose, we propose an integrativ e generative model that combines a langu age model and an acoustic model in to a single generativ e model called the “hierar ch ical Dirichlet pr ocess hidden language model” (HDP-HLM). The HDP-HLM is obtained by extending the hierarchical Dirichlet p rocess hidden semi-M arko v model (HDP - HSMM) proposed by Johnson et al. An i nference procedure fo r the HDP-HLM is derived using the blocked Gibbs sampler originally proposed for the HDP-HSMM. This proc edu re enables the simultaneous and direct in ference of language and acoustic models from continu ous speech signals. Based on th e HDP-HLM and its inference proce d ure, we develop a nov el machine learn- ing method called n onparametric B ayesia n double articulation analyzer ( NPB-D AA) th at can directly acquire l anguage and acoustic models from observed continuous speech signals. B y assuming HDP-HLM as a generativ e model of observ ed time series data, and by in ferring latent variables of the model, the method can analyze latent doub le articul ation stru cture, i.e., hierarchically organized latent words and phonemes, of the d ata in an u nsupervised mann er . W e also carried out two evaluation experiments using synthetic d ata and actu al human continuous speech signals represe n ting Japanese vo wel seq uences. In the word acquisition and ph oneme categorization tasks, the NPB- D AA outperformed a con ventional double articulation analyzer (D AA) and baseline automatic speech recognition system whose acoustic model was trained in a su pervised manner . T he main contributions of this paper are as f ollows: (1) W e develop a probabilistic generativ e model that integrates l anguage and acoustic models, i. e., HDP-HLM. (2) W e derive an inference method for this, and propose the NPB-DAA. (3) W e show th at the NPB-D AA can discover words directly from continuous human speech signals in an unsup ervised manner . Index T erms —Language acquisition , child dev elopment, Bayesian nonparametrics, latent variable model I . I N T RO D U C T I O N I NF ANTS mu st solve the word segmentatio n p roblem in order to acquire langua ge from con tinuous speech signals to which they ar e exp osed. T he word segmentation pr oblem is that of iden tifying word bou ndaries in continuo us speech. If the speech signals are given to infants as isolated words, the task is easy fo r them. However , it has been known th at This research was parti ally supported by a Grant-in-Aid for Y oung Scien- tists (B) 2012-2014 (24700233) funded by the Ministry of Education, Culture, Sports, Science, and T echnol ogy , Japan. 1 T . T aniguch i is with Colle ge of Information Science and Engineering, Ritsumeik an Univ ersity , 1-1-1 Noji Higashi, Kusatsu , Shiga 525-8577, Japan taniguchi@em. ci.ritsumei.a c.jp 1 S. Nagasaka and R. Nakashima a re with th e Graduate School of Informa tion Science and Engi neering, Ritsumeikan Uni versity , 1-1- 1 Noji Higashi, K usatsu, Shiga 525-857 7, Japan { s.na gasaka, nakashima } @em.ci .ritsumei.ac. jp a relatively small nu mber of infant-directed utteranc es consist of an isolated word [1 ]. If infants had kn owledge abou t words and ph onemes inn ately , the p roblem co uld be solved relatively easily . On the contrary , the fact that each language has different lists of pho nemes and words clear ly shows that in fants have to acquire them throug h developmental processes. From the viewpoint o f statistical learning, the learning problem , i.e., direct language acq uisition from co ntinuou s speech sign als, is very difficult because infants do not have access to the tru th labels of speech r ecognition results. In other words, the languag e acquisition process must be co mpletely unsuper vised.The main p roblem o f this pap er is to d ev elo p a computatio nal mo del that can estimate language and acou stic models, and discover word s directly fro m continuous huma n speech signals. Most moder n automatic speech reco gnition (ASR) systems have a lan guage mod el that represents k nowledge about word s and their distributional probab ilities as well as an a coustic model that r epresents knowledge abou t ph onemes and the ir acoustic feature s, e.g ., [ ? ], [ ? ]. Both are usually traine d us- ing large tran scribed speech datasets and linguistic co rpora throug h sup ervised learn ing. Howev er, infants do not h av e access to suc h explicitly labeled datasets. They have to acquire both langua ge and acoustic mode ls from raw acoustic speech signals in an unsupe rvised m anner . The question about what kin d of cues hum an infants utilize to discover words from continuou s spee ch signals arises. Saffran et al. listed three types of cu es for word segmenta- tion: 1) pr osodic, 2) distributional, and 3) c o-occur rence [2 ]. 1) Pro sodic cu es r ely on a coustic infor mation, such a s post- utterance pauses, stressed syllables, and acou stically distinc- ti ve final syllables. 2) Distrib u tional c ues rep resent th e statisti- cal relation ships between p airs of n eighbo ring sp eech sou nds. 3) Co-occurren ce c ues are used by children to learn words by detecting sounds that co-occu r with certain entities in the en v ironmen t. A lthough many researcher s had con sidered the distributional cues to be too complex for infants to use, Saffran reported that word segmentation fro m flu ent speech can be accomplished by 8-month -old infants based on solely on distributional cues [3] . It is also repo rted that th e distributional cues seem to be used by infants by the age of 7 mo nths, which is earlier than m ost other cues [4]. T hese results imply that infants h av e a f undam ental m echanism that can estimate word segments using distributional cues. In additio n to this fun- damental segmentation mech anism u sing distributional cues, the prosodic and co-occurr ence cues are believed to help the word segmentatio n task only a s sup plemental cu es [ 2]. Fr om the viewpoint of phonemic category a cquisition, distributional patterns of sou nds have b een considered to provide infants with clues ab out the phon emic structure of a language as 2 well [5]. Based on th ese findings, in this paper, we focu s on dis- tributional cu es. W e explore the fun damental computational mechanism that can discover word s f rom sp eech sign als u sing only d istributional cues, an d develop an unsu pervised machin e learning m ethod which can discover pho nemes and words directly fr om unsegmented speech signals In this p aper, we pr opose an u nsuperv ised learning method called the nonpar ametric Bayesian doub le articulation analyzer (NPB-D AA) that can auto matically estimate dou ble ar ticula- tion stru ctures, i.e., hierarchically organized laten t words and phone mes, emb edded in speech sig nals. W e pro pose th is as a computatio nally valid explanatio n for the simu ltaneous acq ui- sition of language and acoustic models. T o d ev elo p the NPB- D AA, we introduce a probabilistic ge nerative mod el called th e hierarchica l Dirichlet process hid den langu age m odel (H DP- HLM) as well as its inference algorithm . The remain der of this paper is o rganized as follows. Sec- tion II de scribes the backgro und of the propo sed meth od. Section I II presen ts the HDP-HLM by extending hierarchical Dirichlet p rocess-hidd en semi-Markov m odel (HDP-HSMM) propo sed by Johnson et al. [ 6]. The HDP-HLM is an prob a- bilistic gene rativ e model that integrates acoustic and language models for continuo us speech signals. Sectio n IV describes the inference p rocedu re of HDP-HLM, and our pr oposed NPB- D AA. Section s V a nd VI ev alu ate the effecti veness of th e propo sed method using sy nthetic data an d a ctual sequential vo wel speech signals. Section VI I conclud es th is paper . I I . B AC K G RO U N D A. W or d segmentation using distrib ution al cu es in transcribed data W ith respect to statistical co mputation al models, m any kinds o f unsup ervised machine learning method s for word segmentation ha ve been p roposed in the last two decad es [ 7]– [15]. Brent [7] proposed m odel-ba sed dynam ic pro grammin g 1 (MBDP-1) for r ecovering deleted word boundar ies in a natural-lan guage text. Th e MBDP-1 p resumes that there is an inf ormation sour ce generating the text explicitly and seg- ments the target te xt so as to maxim ize the text’ s prob- ability . V enkataraman [8] pro posed a statistical model f or segmentation and word discovery from ph oneme sequences by impr oving Bren t’ s algorithm . Recently , Bayesian non parametrics, includ ing the hierar- chical Dirichlet process and hierarchical Pitm an-Y or pro- cess, have enabled more sophisticated methods f or word segmentation. These models have fully Bayesian g enerative models and make it possible to calcu late the appro priately smoothed n-gram probability fo r a word that has a long context. Theo retically , they can tr eat an in finite n umber o f possible words. Go ldwater [9], [10] p roposed an HDP-b ased word segmenta tion method and showed that takin g context into account is imp ortant for statistical word segmentation. Mochihashi et a l. [11] proposed a nested Pitman -Y or language model (NPYLM), in which a letter n-g ram model based on a hierarchica l Pitman -Y or languag e m odel is emb edded in the word n -gram m odel. They also developed the fo rward filtering backward samp ling proc edure to achie ve efficient blocked Gibbs sampling and hence infer word boundar ies. Howe ver , all of the above mentioned word segmentatio n methods presum e th at tran scribed phon eme sequ ences or text data without any reco gnition err ors can be obtained b y the learning system. In p ractice, before acqu iring a language model con taining an in ventory of word s, a learning system, i.e., an infant, has to recogn ize sp eech signals withou t any knowledge of words, on ly with the knowledge of p honeme s and/or syllables in an acoustic m odel. In such a recognitio n task, the ph oneme re cognition e rror rate inevitably beco mes high. T o overcome this pro blem, several research ers have p ro- posed word discovery methods utilizing c o-occur rence cues. B. Lexical acquisition using co-occurr en ce cues Roy et al. [ 16] ambitio usly implemente d a co mputation al model that enables a r obot to a utonom ously d iscover words from raw multimodal sensory input. Their results were imper- fect compa red with recen t state-of-art results. Howe ver , their results showed it was possible to develop cognitive models that can proc ess raw sensor data and acq uire a lexicon without the need fo r human tran scription or labeling. Iwahashi et al. [17] im plemented a n inter activ e lear ning method for a robot to a cquire spoken words throug h huma n- robot in teraction using audio-visual interfaces. Th eir learning process was carr ied out on -line, incrementa lly , actively , an d in an unsu pervised manner . I wahashi et al. [18] also p roposed a method that enables a robot to learn linguistic knowl- edge throug h h uman-r obot co mmunicatio n in an u nsupervised manner . The mod el co mbines speech, visual, and b ehavioral informa tion in a prob abilistic fram ew or k. Thou gh its per for- mance was still limited, the mod el is co nsidered to be a m ore sophisticated m odel than that pro posed in Roy et al. ’ s pr evious study [16] from the viewpoint of statistical mach ine lear ning. On the basis o f this work, Iwahashi et al. [ 19] developed an integrated o nline m achine learning system combinin g speech, visual, an d tactile informatio n obtained thr ough interactio n. It enabled robots to learn b eliefs regarding speech units, word s, the concepts o f objects, motions, grammar, and p ragmatic and commun icativ e cap abilities. They called th e system LCor e. Araki et a l. [ 20] built a robo t that formed object categories and ac quired their name s by combinin g a mu ltimodal laten t Dirichlet allocation (MLDA) and the NPYLM. Th ey showed that the iterative lear ning o f MLD A and NPYLM increases word segmentation per forman ce by u sing distributional cue s and c o-occur rence cues simultaneo usly , but they repo rted that the pr ediction accu racy decreases as the phonem e recognitio n error rate increases. T o overcome this problem , Nakamur a et al. integrated statistical mo dels for word segmentatio n an d multimoda l categorizatio n. Th ey showed that a robot c an autonom ously form o bject categories and related words fro m continuo us speech signals and con tinuous visual, audito ry , and haptic inf ormation by up dating its lang uage and catego rization models iteratively [2 1]. Not only object informatio n, but also place infor mation can be used as co -occurr ence cues. T agu chi et al. [22] p roposed a method for the un supervised learning of place-na mes from 3 informa tion pairs that consist o f spoken u tterances an d the mobile robo t’ s estimate d curre nt location without any prior linguistic knowledge o ther than a ph oneme acou stic mo del. They optimized a word list u sing a mo del selection m ethod based on d escription length criterion. C. W or d se gmen tation using distributional c ues in noisy inp ut As described above, it becomes clear that u sing co- occurre nce cues can mitigate th e ill effects o f phoneme recog - nition erro rs in a word discovery task. Howev er, whether or not the word discovery task can be achiev ed solely from raw speech signals is still an o pen question. Neubig et al. [2 4] extended th e u nsuperv ised mor pholog ical analyzer pr oposed by M ochihashi et al. and enabled it to analy ze phon eme lattices. Heymann et al. [25] modified Neubig et al. ’ s algorithm and propo sed a subop timal two-stage algorithm. Heymann et al. reported that their p roposed metho d ou tperform ed the original method in an experimen t that used lattice input generated ar tificially fro m text input. In addition, they u sed the d iscovered lan guage mod el for p honeme rec ognition in an iterative m anner and reported that recogn ition p erform ance was improved [26]. Elsner et al. [27] proposed a com putational model that jointly perf orms word segmentatio n and learns an explicit mode l of p honetic variation. Howe ver, they did not start with acoustic sound, but w ith dictated noisy text, i.e., recogn ized phoneme sequen ces with err ors. Their m odel doe s not includ e acoustic mo del learning. They showed tha t th e ill effect of ph oneme recog nition errors can be mitigated to some extent by using distribu- tional inf ormation mor e approp riately . Howe ver , all of these methods, except for I wahashi et al., u sed an acoustic model previously trained in a supervised manner . Theref ore, th ese models a re insufficient as a con structiv e mod el for langu age acquisition from raw speech signals. Hence, the unsuperv ised learning of an acoustic mo del is also an importan t p roblem. D. Unsupervised lea rning of a n acoustic mo del In contrast with the word segmentation task, the acquisition of an aco ustic model is basically a ca tegorization task of the feature vectors transfo rmed from con tinuous speec h signals. Mixture models, in cluding hidden Ma rkov models (HMMs) and Gaussian mixtu re models, h av e been used to model phone me category acquisition. For example, Lake et al. [2 8] used an on line mixture estimatio n mo del for vo wel category learning. The mo del was or iginally p roposed by V allabha et al. [ ? ] . However , th e pho neme acquisition h as proven to b e complex categorization task in a feature space. The distrib ution of the feature vectors of each phonem e ov er lap with each other, and the actu al soun d of the phonem e d epends o n its context. Feldman et al. [29] pointed out tha t feedb ack infor mation from segmented words is important for ph onetic category acquisition. T hey dem onstrated th is effect th rough simulatio ns using Bayesian m odels. Lee et al. [30] pr oposed a h ierarchical Bayesian model that can discover a proper set of sub- word un its and an acoustic model in an unsu pervised manner . Howe ver , their mo del did not estima te th e lang uage mo del. L ee et al. [31] also prop osed a hierarchical Bayesian model simultaneously d iscovering th e phone tic in ventor y and the Letter-to-Sound m apping rules on the basis of transcribed data only . The meth od is not a completely unsu pervised lea rning meth od from raw speech signals, but does auto matically determine relations between sounds and transcribed alp habets a nd f orms an acoustic m odel in an unsupervised manner . There hav e been several stud ies ab out th e simu ltaneous unsuper vised lear ning of acoustic and lang uage models. How- ev er, a very small nu mber of statistical lear ning methods that can simultan eously acquire in tegrated aco ustic and lan guage models ha ve b een prop osed. Brandl et al. [32] attem pted to develop an unsuper vised learning meth od that enab les a robot to simu ltaneously obtain phon emes, syllables, and words from aco ustic speech . They did not successfully build su ch a system, but reported their preliminary results. W alter et al. [33] propo sed a word discovery method that uses an HMM-based method f or finding aco ustic unit d escriptors in p arallel with a dynamic tim e warpin g tech nique fo r findin g word segments. Howe ver , their model is still he uristic from the viewpoint o f probab ilistic comp utational m odels. As Feldman et a l. p ointed out, word segmentation an d phonetic category a cquisition are undou btedly mutually dep endent. T herefor e, a theo retically integrated probab ilistic generative m odel for the simu ltaneous acquisition of langu age and acoustic models is desirable. V ery recently , Kamper et al. [ ? ] and Lee et al. [ ? ]prop osed probab ilistic com putational models that a chieved unsuper vised direct word discovery from continuo us speech sig nals. How- ev er, they did not provide an explicit, integrated pr obabilistic generative mod el f or unsupervised simultan eous lear ning o f languag e a nd acou stic models. T o dev elo p such an integrated theoretical mo del, the authors introduced the general con cept of dou ble articulation analysis. E. Double articula tion analysis From a gen eral point of view , unsuper vised word d iscovery from raw sp eech sign als is regarde d as a dou ble articulation analysis of the time series da ta representing a speech signal. The double articulatio n structur e is a well-known two-layer hierarchica l structure, i.e., a word sequen ce is generated from a language model, a word is a sequence of phon emes, and each phone me outputs observation data during the per iod it persists. The word discovery problem becomes a gen eral problem abou t analyzing the time series data that potentially h av e a doub le articulation stru cture by estimating the latent acou stic model as well a s the latent language mod el. T aniguch i et al. [3 4] propo sed a d ouble articulation ana- lyzer (DAA) by com bining th e sticky HDP-HMM an d the NPYLM. The sticky HDP-HMM proposed b y F o x e t al. is an nonp arametric Bayesian extension of HMM [35]. They applied the D AA to hu man motion d ata to extract u nit motion from un segmented human m otion data. Howev er, they simply used the two nonpar ametric Bayesian method s sequ entially . They did no t in tegrate the two models into a single gener ati ve model. Therefor e, if th ere are many r ecognition or categoriza- tion errors in the result of the first latent letter recognition process, i.e., segmentation process by the sticky HDP-HM M, 4 Phone mes (La ten t lett ers ) Words (La ten t wo rds ) Segme nt L angu age mode l B B B BA CB CA BCA A A A C C C Obs ervat ion dat a Generation Generation Continuous speech Chu nk Inference A B C Aco ust ic mo del Generation Inference Inference Inference BA CB CA BCA BD Fig. 1. Overvie w of unsupervised lea rning of language and acousti c models through human-robot inte raction, and the generati ve process of speech signal assumed in the D AA the perfo rmance of the subseq uent process, i.e., un supervised chunk ing b y the NPYL M, dete riorates. In the terminology of a DAA, a latent letter and a laten t word basically cor respond to a ph oneme and a word in speec h signals, re spectiv ely . In this paper, we call this method “con ventio nal D AA ” in order to differentiate it from the D AA newly pro posed in this paper, i.e., NPB-D AA. Con ventional D AA has b een suc cessfully applied to human motion data and driving behavior d ata, which were also considered to potentially ha ve a double articulation structure. Con ventional DAA has been used f or various purpo ses, e.g., se g mentation [36], predictio n [37], [38], data min ing [39], to pic modelin g [40], [41], an d video su m- marization [ 42]. Conv en tional D AA owes its successful resu lt with respe ct to driving behavior data to the fact th at driving behavior data were con tinuous and smoo th comp ared with raw speech sign als. For a driving letter, wh ich cor respond s to a phone me in continu ous speech signals, the r ecognition err or rate w as still lo w . Howe ver, it is e xp ected that a straightfo rward application of the conventional D AA to raw speech signals will inevitably tu rn out b adly . Therefo re, based on the backgr ound mention ed above, in this p aper, we pr opose an integrated pro babilistic genera ti ve model, HDP-HLM, representing a latent dou ble articu lation structure that contains bo th a language mode l and an acoustic model. By assumin g HDP-HL M a s a gen erative mode l of observed time series data, and by inferring latent variables of the model, we can analyze laten t d ouble articu lation stru cture of the data in an unsup ervised man ner . A novel do uble articu- lation an alyzer is developed on the basis of the HDP-HLM and its inf erence algorithm. Th is HDP-H LM-based do uble articulation analysis method is called NPB-D AA. I I I . G E N E R A T I V E M O D E L In this section , we p ropose a novel g enerative model, th e HDP-HLM, for time series data that po tentially has a do uble articulation stru cture, by extending HDP-HSMM [6]. As in - dicated in its name, HDP-HLM latently contains a la nguage model. In contrast with the co n ventio nal case where a latent state tr ansits to the next state on the b asis o f a Ma rkov process in the HDP-HMM, a late nt word in the HDP-HL M transits to the next laten t word on the basis of a lang uage mod el. An illustrativ e overview of the pr oposed meth od an d th e target task are shown in Fig. 1. W e can natur ally de riv e an inference proced ure for the HDP-HLM b ased on the b locked Gibb s sampler . First, we briefly d escribe the HDP-HSMM. W e then describe the HD P-HLM. A. HDP-HSMM HDP-HSMM is a nonpar ametric Bay esian extension of the conventional hidd en semi-Markov mod el (HSMM) [6] , [43]. Un like HDP-HMM, which is an no nparametr ic Bayesian extension of conv entio nal hidden M arkov model (HMM ) [3 5], [44], the HDP-HSMM explicitly mod els the d uration tim e of a hidde n state. A g raphical model of the HDP-HSMM is shown in Fig. 2. Th e generative pro cess of the HDP-HSMM 5 … … … … … … β α π i γ ∞ ∞ θ i z 1 z 2 z s x t 1 x t 1 x t 2 x t 2 x t s x t s λ y t 1 y t 1 2 y t 2 y t 2 y t s y t s t 1 =1 t 1 =D 1 t 2 =D +1 1 t 2 =D +D 1 2 t s =T t s =T−D +1 s D 1 D 2 D s 2 2 2 2 2 1 1 1 1 1 1 1 1 1 2 2 2 … Fig. 2. Model of the HDP-HSMM [6] is described as follows. β ∼ GEM ( γ ) (1) π i ∼ DP ( α , β ) i = 1 , 2 , . . . , ∞ (2) ( θ i , ω i ) ∼ H × G i = 1 , 2 , . . . , ∞ (3) z s ∼ π z s − 1 s = 1 , 2 , . . . , S (4) D s ∼ g ( ω z s ) (5) x t = z s t = t 1 s , t 1 s + 1 , . . . , t 2 s (6) y t = h ( θ x t ) (7) t 1 s = ∑ s ′ < s D s ′ (8) t 2 s = t 1 s + D s − 1 (9) where GEM and DP represent the stick br eaking process and Dirichlet pro cess, respectiv ely [44], [ 45]. The para meters γ and α are hy perpar ameters o f the DP, β is a global transition probab ility that becomes th e b ase measure of the transition probab ility distributions, and π i is a transition probability distribution related to the i - th su per state. V ariable z s is the s -th sup er state in the seq uence of super states, D s is th e fram e duration of z s , and the variables x t and y t are a hidden state and an observation at time frame t , r espectively . Parameters of an emission distribution and a du ration distribution fo r the i - th super state are describ ed as θ i and ω i . Additionally , H and G are b ase measures f or emission distribution and d uration distribution. The function h and g represent emission and duration d istributions, respectively . The time fr ames t 1 s and t 2 s are fr ames correspo nding to a start p oint an d a end po int of a se g ment corr espondin g to z s . In contrast with the case wher e HMM assumes that a hidd en state x t transits to the n ext h idden state x t + 1 accordin g to a Markov process, the hidden semi-Markov M odel (HSMM) assumes that a hidden super state z s transits to n ext hid den super state z s + 1 after a prob abilistically dete rmined duratio n time D s , which is samp led from a du ration distribution g ( ω z s ) The sup er state z s is samp led fr om a categorical distribution π z s − 1 related to the previous super state z s − 1 . When the super state z s and duration time D s are sampled, a sequence of hidden states { x t | 1 + ∑ s − 1 s ′ = 1 D s ′ ≤ t ≤ ∑ s s ′ = 1 D s ′ } are determined to be z s . An o bservation d atum y t at time t is assumed to be drawn from an emission distribution h wh ose pa rameter is θ x t . Observation data y t are gener ated by h ( θ x t ) for D s steps. An efficient samp ling inf erence procedu re based on the backward filtering fo rward samplin g technique was pr oposed for constructing a blocked Gibb s samp ler [ 6]. A similar algorithm was pr oposed for HDP-HMM by Fox et al. [35]. The algorithm is d eriv ed from a weak -limit approxim ation of the number o f hidden super states. The computation al cost of the message passing algor ithm can be reduced to O ( T d max N 2 ) , where T is the leng th of the observed data, N is th e state cardinality , and d max is the maximal duration of a su per state for truncation. Th e order is a lmost th e same as th at of the backward filtering for ward sampling algorith m for the HDP- HMM, except for the constant factor d max . B. HDP-HLM The generative model f or time series data th at poten- tially have a doub le articu lation structure c an be obtained by extending the HDP-HSMM. A gra phical mod el o f the propo sed HDP-HLM is shown in Fig. 3. In the g enerative model of HDP-HLM, the super state z s correspo nds to a word in spoken langu age, which is the fun damental ide a of th e extension. The i - th super state z s = i has a ph oneme sequenc e w i = ( w i 1 , . . . , w ik , . . . , w iL i ) , w here L i is the length of the i -th word w i . The generative process of the HDP-HLM is described as follows. β LM ∼ GEM ( γ LM ) (10) π LM i ∼ DP ( α LM , β LM ) i = 1 , 2 , . . . , ∞ (11) β W M ∼ GEM ( γ W M ) (12) π W M j ∼ DP ( α W M , β W M ) j = 1 , 2 , . . . , ∞ (13) w ik ∼ π W M w ik − 1 i = 1 , 2 , . . . , ∞ , k = 1 , 2 , . . . , L i (14) ( θ j , ω j ) ∼ H × G j = 1 , 2 , . . . , ∞ (15) z s ∼ π LM z s − 1 s = 1 , 2 , . . . , S (16) l sk = w z s k s = 1 , 2 , . . . , S (17) k = 1 , 2 , . . . , L z s (18) D sk ∼ g ( ω l sk ) s = 1 , 2 , . . . , S (19) k = 1 , 2 , . . . , L z s (20) x t = l sk t = t 1 sk , . . . , t 2 sk (21) t 1 sk = ∑ s ′ < s D s ′ + ∑ k ′ < k D sk ′ + 1 (22) t 2 sk = t 1 sk + D sk − 1 (23) y t = h ( θ x t ) t = 1 , 2 , . . . , T (24) where β W M is the base measure and α W M and γ W M are hyperp arameters of a word model, which gen erates words, i.e., 6 γ LM Language model (Word bigram) γ WM i=1,…,∞ α WM j=1,…,∞ Word model (Letter bigram) z 1 z s-1 z s z s+1 z S Latent words (Super state sequence) w i i=1,…,∞ l s1 l sk l sL Latent letters D s 1 D sk x 1 x t 1 s 1 x T Acoustic model ω j θ j G H y T Observation D s1 D sk D sL Duration β LM α LM π LM i β WM π WM j x t 2 s 1 x t 1 s k x t 2 s k x t 1 sL x t 2 sL j=1,…,∞ y t 2 sL y t 1 sL y t 1 s k y t 2 s k y t 1 s 1 y t 2 s 1 y 1 D sL z s z s z s z s z s z s z s Fig. 3. Model of the propose d HDP-HLM latent letter sequences. Furthermore , DP ( α W M , β W M ) outputs π W M j , represen ting the transition probability from latent letter j to the next latent letter . By contrast, β LM is the base measure, α LM and γ LM are hype rparameter s of the languag e m odel, and DP ( α LM , β LM ) outputs π LM i , represen ting the transition probab ility from latent word i to the next laten t word. The superscripts LM a nd W M indicate lang uage m odel (LM) o r word mo del (WM), r espectiv ely . Th e latent letters con tained in the i -th latent word w i are seq uentially sampled from π W M w ik − 1 . The k -th latent letter of the i -th laten t word is rep resented by w ik . The emission distribution h and the duration distrib u tion g have parameter s θ j and ω j for the j -th la tent letter , re- spectiv ely . Th e base measures H an d G generate θ j and w j , respectively . V ariab le z s is the s -th laten t word in th e sequen ce of latent words, and c orrespon ds to the super state in HDP- HSMM, D s is the frame du ration o f z s , l sk = w z s k is the k - th latent letter of the s -th latent word, a nd D sk is the fr ame duration of l sk . The variable x t and y t are a hidden state and an observation at time fram e t , rspectively . T he time fr ames t 1 sk and t 2 sk are fr ames cor respond ing to a start po int and a en d point of a segment correspon ding to l sk , respectively . In contrast with HMMs, the duratio n distribution is explic- itly deter mined for ea ch laten t letter l sk in the HDP- HLM. T he HDP-HLM inherits this pro perty fr om th e HDP-HSMM [6]. The du ration time D sk of latent letter l sk , wh ich is the k -th latent letter o f the s -th laten t word z s in a sample d word se- quence, is drawn fro m the d uration distribution g ( ω l sk ) , where ω l sk is the duration par ameter for latent letter l sk . The dur ation of a latent word w z s becomes D s = ∑ L z s k = 1 D sk . I f we assum e that g is a Poisson distribution, the dura tion distribution o f a latent word z s also follows a Poisson distribution. In this case, the Poisson parame ter of the duration d istribution becomes ∑ L z s k = 1 ω l sk . This relatio n owes to the repr oductive prope rty of Poisson distributions. In th e HDP-HLM, latent word z s determines a latent letter sequence l sk = w z s k ( k = 1 , 2 , . . . , L z s ) . Based on the determin ed sequence w z s , du ration D sk of l sk is d rawn, and observations y t are drawn from an emission distribution h ( θ x t ) correspon ding to x t = l s ( t ) k ( t ) . The maps s ( t ) and k ( t ) repr esent the indices of words and letters, resp ectiv ely , in a latent word sequen ce at time t . Using this gen erativ e mod el, a continu ous time series data with a latent doub le articulatio n structure can be generated . In this p aper, we assume that o bserved time series data y t represents a feature vector of the spee ch signal at time t an d is gen erated in th is way . Generally , the HDP-HLM can be ap plied to any k ind o f time series data that h as a d ouble articulation structur e. From the viewpoint of langua ge acq uisition, we re view the generative mod el. In th e co n ventio nal DAA [34], a DAA is composed of two separated machine learning methods, i.e., sticky HDP-HMM for encoding o bservation d ata to letter sequences and NPYLM for chun king letter sequence s into 7 word sequence s. On the one han d, the transition prob abilities π LM i and π W M i correspo nd to the word bigram and letter bigram models in the NPYLM, respectively . Therefo re, ( π LM , π W M ) contains information regard ing a language mod el. On the other h and, { ω j , θ j } j = 1 , 2 ,..., ∞ contains in formatio n regarding an aco ustic model, which co rrespon ds to a sticky HDP-HMM in co n vention al D AA. The HDP-HLM ass u mes that the l an guage model con sists of a word bigram model. Mo chihashi et al. compared the bigram and trigram language m odels and sh owed that the trigram as- sumption hardly improved the word se g mentation performan ce although computatio nal cost an d complexity incre ased [11]. Therefo re, the bigra m assumption mu st be a pprop riate fo r a word segmentation and word discovery task. If we de riv e an efficient infer ence proc edure for this two- layer h ierarchical gen erative mod el, the inference p rocedu re can inf er the acou stic model and langu age model simu ltane- ously . I V . I N F E R E N C E A L G O R I T H M In this section, we der i ve an ap proxim ated blocked Gib bs sampler for the HDP-HL M. The sampler can simu ltaneously infer latent letters, latent words, a languag e m odel, and an acoustic mod el. Concurren tly , th e inf erence procedur e can estimate the overall double articulatio n structure from con tinu- ous time series data. T herefor e, we propose the unsupervised machine learnin g method NPB-D AA. T he overall in ference proced ure is shown in Algorithm 1. A. Inference of latent wor ds: z s In the HDP-HSMM, a back ward filtering forward sampling proced ure is ad opted instead of th e direct assignme nt pro- cedure. When each laten t state stro ngly depends on other neighbo ring latent states, th e dir ect assignme nt proced ure, which is a naiv e implem entation of the Gib bs sampler, re sults in a poor m ixing rate [ 6]. John son et al. showed that a b locked Gibbs sampler using a b ackward filterin g for ward sampling proced ure that can simultan eously samp le all hid den states of a n ob served sequence outper forms a d irect-assignmen t Gibbs sampler . By exten ding the backward filtering forward- sampling proced ure and makin g it applicable to HDP-HLM, we can o btain an in ference pro cedure for HDP-HLM. The calculation of the backward m essages for super states i in HDP-HSMM is as follows. B t ( i ) = P ( y t + 1 : T | z s ( t ) = i , F t = 1 ) (25) = ∑ j B ∗ t ( j ) P ( z s ( t + 1 ) = j | z s ( t ) = i ) (26) B ∗ t ( i ) = P ( y t + 1 : T | z s ( t + 1 ) = i , F t = 1 ) (27) = T − t ∑ d = 1 B t + d ( i ) P ( D t + 1 = d | z s ( t + 1 ) = i ) × P ( y t + 1 : t + d | z s ( t + 1 ) = i , D t + 1 = d ) (28) B T ( i ) = 1 (29) where F t is a variable indicating that t is the bound ary of th e super state. If F t = 1, z s ( t ) 6 = z s ( t + 1 ) . The variable B t ( i ) in (25) represents the pro bability that the latent sup er state z s ( t ) = i and th at it transitions into a different super state at the next time step. Prob ability B t ( i ) is ob tained by marginalizin g over all super states j at time step t + 1. V ariable B ∗ t ( j ) in (27) represents the p robability that the latent super state becom es j from time step t + 1. This p robability can be ob tained b y marginalizing over the d uration variable in (28). Pro bability P ( y t + 1 : t + d | z s ( t + 1 ) = i , D t + 1 = d ) in (28) shows the emission probab ility of observed data y t + 1 : t + d giv en the c ondition that the duratio n D t + 1 of z s ( t + 1 ) is d . In the HDP- HSMM, all time steps with th e same super state z share the same emission distribution. Theref ore, the likelihoo d of a sup er state z s ( t + 1 ) , i.e., P ( y t + 1 : t + d | z t + 1 , D t + 1 = d ) , can be calculated easily . Surprisingly , in H DP-HLM, the exact same procedu re of calculating backward messages as that of HDP-HSMM c an be used. W e obtain a message passing algorithm fo r HDP- HLM by rep lacing a super state z s in HDP-HSMM with latent word z s in HDP-HLM. Only the likeliho od of the latent word w s , i.e., P ( y t + 1 : t + d | z s ( t + 1 ) = i , D t + 1 = d ) , is different between the two message passing algorithms. The likelihood of the occurre nce of latent word z s ( t + 1 ) = i th en becom es P ( y t + 1 : t + d | z s ( t + 1 ) = i , D t + 1 = d ) = ∑ r ∈ R ( L i , d ) L i ∏ k = 1 P ( r k | ω w ik ) × r k ∏ m = 1 P ( y t + m + ∑ k − 1 k ′ = 1 r k ′ | θ w ik ) . ( 30) R ( L i , d ) = ( r | | r | = L i , | r | ∑ k = 1 r k = d ) (31) where | x | indicates the number of elements in vector x , and r = ( r i , r 2 , . . . , r L i ) is an L i -partition of d uration d . By substituting (30) into (28), we can obtain a formula to calculate the backward message of HDP-HLM. The calcu lation of ( 30) lo oks co mplicated at first glance . Howe ver , the value of (30) can be efficiently calculated using dynamic prog ramming . If we define forward message α t ( k ) as the pr obability th at the k -th latent letter in the relevant latent word w i transits to the next laten t letter at time t after emitting o bservations, for ward message α t ( k ) can be recursively calculated as follows: α t ( k ) = t − k + 1 ∑ d ′ = 1 α t − d ′ ( k − 1 ) P ( d ′ | ω w ik ) d ′ − 1 ∏ t ′ = 0 P ( y t − t ′ | θ w ik ) (3 2) α 0 ( 0 ) = 1 . (33) As a result, P ( y t + 1 : t + d | z s ( t + 1 ) = i , D t + 1 = d ) = α d ( L i ) . By applying the calculation for mula shown above, backward mes- sages B t ( i ) and B ∗ t ( i ) can be calculated. Using the calculation proced ure for b ackward messages, the fo rward samplin g pro- cedure pr oposed in th e HDP-H SMM ca n be emp loyed. The backward filtering for ward sampling pr ocedur e ena bles the blocked Gibbs samp ler to dir ectly samp le laten t word s fr om observation da ta witho ut explicitly samp ling laten t letters in HDP-HLM. 8 In the forward samp ling proced ure, super state z s and its duration D s are sampled iteratively using backward messages as follows. P ( z s = i | y 1: T , z s − 1 = j , F D sum s = 1 ) = P ( z s = i | z s − 1 = j ) B D sum s ( i ) P ( y D sum s | z s = i ) (34) P ( D s = d | y 1: T , z s = i , F D sum s = 1 ) = P ( D s = d ) × P ( y D sum s + 1: D sum s + d | D s = d , z s = i , F D sum s = 1 ) B D sum s + d ( i ) B ∗ D sum s ( i ) (35) where D sum s = ∑ s ′ < s D s ′ . For further details, please refer to the original p aper, in which th e HDP-HSMM was intr oduced [6]. B. Samplin g a letter seq uence for a latent wor d : w i The sam pled z s is only an index of a latent word . Concrete letter sequences w i for each la tent word i should be samp led accordin g to the co rrespond ence of each sub- sequence o f time series data y k = ( y k 1 , y k 2 , . . . , y k T k ) to each laten t word. When a latent word z s is given, the gen erativ e model of the observation in the range of a latent word z s can be regarded as an HDP-HSMM whose super states correspo nd to latent letters. Therefore, in the proposed model, ea ch sub- sequence o f o bservation data corr esponding to a latent word can be co nsidered an ob served sequ ence generated by an HDP-HSMM. If only a single sub -sequence o f ob servations correspo nds to a late nt word, a latent letter sequ ence could be sampled u sing an or dinal samplin g proc edure in the H DP- HSMM. Howe ver, observations co ntaining th e same latent word have to share the same laten t le tter sequence w . There- fore, latent letter sequ ences for observations with the sam e latent word a re simultan eously sampled, g iv en that they hav e the same latent letter sequence. W e employ an appro ximate sampling p rocedu re based o n samp ling impo rtance resamplin g (SIR) [4 6]. If we define the observations shar ing the same latent word as y 1: k = { y 1 , y 2 , . . . , y k } an d the shared laten t letter sequence as w , th e po sterior probab ility P ( w | y 1: k ) beco mes P ( w | y 1: k ) ∝ P ( w ) P ( y 1: k | w ) (36) = P ( w | y j ) | {z } sam pl ing P ( y j ) k ∏ i 6 = j P ( y i | w ) | {z } weight (37) where P ( y j ) in (37), re presenting th e likelihood of the observation, can be calcu lated u sing th e backward filterin g proced ure in the HDP-HSMM. Probability P ( y i | w ) ca n also be calcu lated in the same way as (30) if w is g i ven. The HDP- HSMM also pr ovides a samplin g proced ure for P ( w | y j ) . Therefo re, if we consider P ( w | y j ) as the proposed distribution and P ( y j ) ∏ k i 6 = j P ( y i | w ) as a weigh t, the SIR proced ure c an be employed [ 46]. Specifically , after a set of w are sam pled from the pro posed distribution P ( w | y j ) j = 1 , 2 , . . . , k , a final sample is drawn f rom the set with a prob ability p roportio nal to each sample’ s weig ht. Using this p rocedu re, the pro posed model can ap proxim ately sample a laten t letter sequenc e w i for the i - th latent word . C. Sampling mod el parameters After sampling latent words { z s } for each o bservation data and sampling letter sequences for the latent w or ds, o ther parameters c an b e upd ated. Parameters o f the languag e model, i.e., { π LM i } and β LM , c an be updated on th e b asis of laten t word sequences. Parameters of the word mod el, i.e., { π W M j } and β W M , can be updated on th e basis of sampled letter sequences fo r latent words. Parameters f or the aco ustic mod el, i.e., { ω j } an d { θ j } , can b e updated if each hidden state x t is determined fo r each y t . Dur ing th e SIR p rocess f or sam pling a letter sequence, { ¯ w m s } in Algorithm 1 are subsidiarily obtained. T o accelerate the mixing r ate, the subsidiar y sampling results { ¯ w m s } obtained in the SIR are used for updating the ac oustic model p arameters. These parame ters can be sam pled in the same way as the HDP-HSMM . For more details, we refer to the original paper in wh ich the HDP-HSMM wer e in tro- duced [6]. Finally , the overall sampling pr ocedur e is obtained, as describ ed in Algor ithm 1. D. NPB-D A A Based on the g enerative m odel, HDP-HLM, and its infer- ence algorithm shown in Algorithm 1, the prop osed NPB-D AA is ob tained, finally . By assuming HDP-HLM a s a generative model of observed tim e series d ata, and by in ferring laten t variables of the mod el, we can a nalyze latent do uble articu- lation structur e, i.e., hierarchica lly organ ized laten t words and phone mes, of the d ata in an unsupervised m anner . W e call the novel un supervised doub le ar ticulation analyzer NPB-D AA. V . E X P E R I M E N T 1 : S Y N T H E T I C DA TA W e cond ucted an exper iment using a synthetic da taset that explicitly has a double ar ticulation structur e to validate our propo sed meth od. A. Condition s T o validate the ab ility of our proposed m ethod to infer a laten t d ouble articu lation stru cture in tim e series data, we applied the pro posed NPB-D AA b ased on the HDP-HL M to synthetic time series data. The conv en tional D AA was em- ployed as a com parative method. The time series data ar e gen - erated using fi ve letters { j } j ∈ J = { 1 , 2 , 3 , 4 , 5 } and four word s { w } w ∈ W = { [ 1 , 3 , 5 ] , [ 3 , 2 ] , [ 4 , 1 , 5 , 2 ] , [ 1 , 5 ] } wher e J is a set of letters and W is a set of words. The fou r words were gene rated random ly . Th e sequen ce w i = [ w i 1 , w i 2 , . . . , w iL i ] re presents a word that is generated by c ombining { w i 1 , w i 2 , . . . , w iL i } se- quentially where w ik denotes the k -th letter of w i . The duration s of the letters wer e assumed to f ollow Poisson distributions and their parameters were drawn from a Gamma distribution whose parameters were α = 50 , β = 10. The emission distribution was assumed to be a Gaussian d istribution whose pa rameters were µ = 5 i , σ 2 ∈ { 0 . 1 , 0 . 5 , 1 . 0 } , where i represents the index of latent letters. Th e variance o f the emission d istribution was changed in stages, an d the inferen ce results were compa red. Forty time series data items were genera ted f rom 20 ty pes of laten t w or d sequ ences. Six teen o f them were pairs o f words in W , e.g., ([ 1 , 3 , 5 ] , [ 1 , 5 ]) , an d ([ 3 , 2 ] , [ 3 , 2 ]) . Four of 9 Algorithm 1 Blocked Gib bs sampler fo r HDP-HLM Initialize all p arameters. Observe M time series data { y m 1: T m } m ∈{ 1 , 2 ,..., M } . repeat for m = 1 to M do // Backward filtering procedur e For each i ∈ { 1 , 2 , . . . , N } , initialize messages B T ( i ) = 1. for t = T to 1 do For each i ∈ { 1 , 2 , . . . , N } , compu te back ward mes- sages B t − 1 ( i ) an d B ∗ t − 1 ( i ) using (2 5)–(28). end for // Forward sampling pr ocedure Initialize s = 1 and D sum s = 0 while D sum s < T m do // Sampling a super state repr esenting a latent word z s ∼ p ( z s | y m 1: T m , z s − 1 , F D sum s = 1 ) // Samplin g duratio n of the super state D s ∼ p ( D s | z s , F D sum s = 1 ) D sum s + 1 ← D sum s + D s s ← s + 1 end while S m ← s − 1 // Samplin g a ten tati ve latent letter sequences for s = 1 to S m do ¯ w m s ∼ P ( w | y m D sum s − 1 + 1: D sum s , { π W M j , ω j , θ j } j = 1 , 2 ,..., J ) end for end for // Update model parame ters Sample acou stic model par ameters { ω j , θ j } on the basis of tentatively sampled latent letter sequences { ¯ w m s } . Sample language model p arameter { π LM i } , β LM on the basis of sam pled super states , i.e., latent words. Sample a word inv en tory { w i } i = 1 , 2 ,..., N using SIR pro ce- dure (see ( 37)). Sample a w or d model { π W M i } , β W M on the basis o f sampled word inventory { w i } i = 1 , 2 ,..., N . until a predetermined exit condition is satisfied. them were thr ee-word sen tences, e.g., ([ 3 , 2 ] , [ 1 , 3 , 5 ] , [ 1 , 5 ]) . A sequence of latent words is represented b y ( w 1 , w 2 , . . . , w n ) . T wo observations we re gen erated from each word sequence. W e set the param eters of the NPB-D AA as follows: the hyperp arameters for the latent lan guage model we re γ LM = 10 . 0 , α LM = 10 . 0, and th e maximum numbe r of words was six for weak- limit approx imation. The hyp erparame ters for the laten t word mod el were γ W M = 10 . 0 , α W M = 10 . 0, an d the maximum number of letters was se ven for weak-limit ap- proxim ation. The hyp erparameter s o f the duration distrib u tions were set to α = 50 and β = 10, and those of the emission distributions wer e set to µ 0 = 0 , σ 2 0 = 1 . 0 , κ 0 = 0 . 01 , ν 0 = 1 . The Gibbs Sampling proced ure was iter ated 100 times. For the conventional DAA, we set the hy perpar ameters of the sticky HDP-HMM to b e as similar to those of the N PB- D AA as possible. In this cond ition, the latticelm so ftware 1 developed by Neub ig et al. was used for NPYLM. The hyperp arameters of the NPYLM used in the conventional DAA were set to α = 0 . 1 a nd d = 0 . 1. The hy perpar ameters in the NPB-DAA were heuristically giv en in a to p-down mann er by referring to the size of the state space an d the ap proxim ate dur ation of a phon eme. Those of the Pitman -Y or lang uage model were set to the default values of the software. B. Results The average log-likelihood is shown in Fig . 4, wh ere erro r bars r epresent the standard d eviation of 30 trials. Th ese results show that the p roposed in ference p rocedu re worked appro pri- ately , grad ually sampling mor e pr obable latent v ar iables as the iterations incre ased. In co ntrast with ordinal spe ech rec ognition tasks, the target task (language ac quisition and do uble articulatio n an alysis) is an un supervised lea rning task. Specifically , it is a clustering task. Therefor e, it is difficult to ev alu ate the metho ds’ pe rfor- mance fro m the viewpoint o f pr ecision and recall be cause the estimated index of a cluster and the label correspond ing to the gr ound truth data are usually different. W e ev aluated the obtained result using the adjusted ran d in dex ( ARI), which quantifies the performan ce of a clustering task [47]. If all data items are clustered rando mly o r only to one cluster , the ARI b ecomes 0. By contrast, if the results of clu stering ar e the same a s those of the gro und truth data, the ARI becomes 1. T able I sho ws th e ARI for the estimated latent letters. The ARI for estimated latent letters shows h ow accurately each metho d estimated latent letters, which correspon d to phone mes in speech sign als. T able II shows the ARI for estimated latent words. Th e ARI for e stimated latent words shows h ow accu rately each me thod estimated latent letters, which correspo nd to words in speech signals. In both tables, each colum n shows ARIs for different σ 2 . A h igher ARI implies more a ccurate estimation of the latent v aria bles. Although the ARI for the laten t letters obtain ed by conven- tional D AA decreases when th e variance σ 2 increases, that of NPB-D AA d id not decr ease as much . As the ARIs for latent words show , the perfor mance of word segmentation by conv en tional D AA was poo r , even w hen the ARI for laten t letters was larger than 0 . 8 . In contr ast, the ARI for latent words estimated by NPB-D AA was over 0 . 5 in all cond itions. This shows tha t th e NPB-DAA can mitigate th e ill effects of phone me recog nition erro rs in the w o rd se g mentation task, and obtained knowledge about words can imp rove pho neme recog- nition pe rforman ce by using con textual inform ation. Fig. 5 shows th e chang e in ARI thr ough iterations in the case of σ 2 = 1 . 0. This shows th at the ARI also increased g radually while log likelihood inc reases, as in Fig . 4. These results suggest th at the NPB-D AA is an ap propr iate genera ti ve mo del because better word segmentation per forman ce cor responde d to higher likelihood of the mod el. 1 latti celm: http://www .phontron.c om/latticelm/index.html 10 −70 −60 −50 −40 −30 02 55 07 5 100 Iter ation Log likelihood Fig. 4. L og-lik elihood profile through Gibbs sampling ( σ 2 = 1 . 0) Fig. 5. A RI profile through Gibbs sampling ( σ 2 = 1 . 0) T o check the effects of the limit on weak -limit appr oxi- mation, we r an an experiment wh ere the max imum num ber of letters was 2 0 for weak-limit approxim ation. The ARI f or the estimated latent words were { 0 . 6 82 , 0 . 65 0 , 0 . 60 4 } , those for e stimated latent letter s were { 0 . 967 , 0 . 899 , 0 . 8 78 } , and the estimated num ber of latent letters were { 5 . 6 , 6 . 3 , 6 . 6 } on av er age for σ 2 = { 0 . 1 , 0 . 5 , 1 . 0 } . T his result shows that our model can work appr opriately to estimate the nu mber o f laten t states owing to the natu re of Bayesian nonp arametrics when the limit is sufficiently large. An examp le of estimated latent variables is shown in Fig. 6, which shows the resu lts for time series d ata gen erated f rom the latent word sequence ([ 3 , 2 ] , [ 1 , 3 , 5 ] , [ 1 , 5 ]) . The inpu t time series data is shown at very top o f the figu re. The to p of each panel shows th e tru e laten t letters or latent words, wher eas the panel beneath shows the inferr ed r esults. The vertical axes represent the itera tion of the Gibb s sampling. I n Fig. 6, th e figure in the midd le sh ows a latent word sequen ce estimated using the pro posed method , and the fig ure at the botto m shows the estimated b ound aries of th e latent words. These results show that the in ference pr ocedur e work s co nsistently an d can estimate an a dequate bou ndary for the laten t words given th e data. 1 0 2 0 y Fig. 6. E xample of inference results for sample data ([ 3 , 2 ] , [ 1 , 3 , 5 ] , [ 1 , 5 ]) and σ 2 = 1 . 0: (top) observ ation data, (upper middle) latent lette rs, (lower middle) laten t words, and (bottom) the boundarie s of latent words. Diffe rent colors denote diffe rent states. 11 T ABLE I A R I F O R E S T I M A T E D L ATE N T L E T T E R S σ 2 0.1 0.5 1.0 Con vent ional D AA (stick y HDP-HMM) 0.845 0.832 0.649 NPB-D AA 0.984 0.895 0.938 T ABLE II A R I F O R E S T I M AT E D L A T E N T W O R D S σ 2 0 . 1 0 . 5 1 . 0 Con vent ional D AA (stick y HDP-HMM + NPYLM) 0.122 0.107 0.125 NPB-D AA 0.594 0.509 0.618 These results show that th e pro posed m ethod is a mor e effecti ve m achine learning method for estimating a latent double articula tion structure emb edded in time series data. V I . E X P E R I M E N T 2 : C O N T I N U O U S J A PA N E S E V O W E L S P E E C H S I G NA L In the second experiment, we evaluated our prop osed method using Japanese vo we l speech sign als to test the app li- cability o f the pr oposed m ethod to actu al h uman co ntinuou s speech signal. A. Condition s W e prepare d four data sets. Each dataset corr esponds to a speaker , an d consisted of 60 audio d ata items. W e asked two male and two female Japan ese speakers to rea d 30 a rtificial sentences aloud two times at a natural spee d, and recor ded his/her v o ice. The 30 s en tences were prepared using fi ve words { aioi, aue, ao , ie, uo } , which consisted of five Japanese vo wels { a, i, u, e, o } representing { ¨ a, i, W B , e fl , o fl } in pho netic sym bols respectively . By reord ering the five words, we p repared 25 two-word sentences, e.g., “ao aioi, ” “uo au e, ” and “aio i aioi, ” and fiv e thre e-word senten ces, i.e., “uo aue ie, ” “ie ie uo, ” “aue ao ie, ” “ao ie ao , ” and “aioi uo ie. ” Th e set of two-word sentences co nsisted o f all types o f word pair s (5 × 5 = 25). The set o f thr ee-word sen tences were generated randomly . The recorded data we re encoded into 13-dimensio nal mel- frequen cy cepstrum co efficient (MFCC) time series data using the HMM T oo lkit (HTK) 2 . The frame size an d shift wer e set to 25 and 10 ms, respectively . T welve-dim ensional MFCC data was obtain ed as input data by eliminating power information from the original 1 3-dimen sional MFCC data. As a result, 1 2- dimensiona l time series d ata at a frame rate of 100 Hz were obtained. The hy perparam eters for the latent language model were set to γ LM = 10 . 0 and α LM = 10 . 0, and the maximum numb er of words was set to sev en for weak-limit approxim ation. The hyperp arameters for the latent word model were γ W M = 1 0 . 0 and α W M = 10 . 0, and th e maximum number of letters was se ven f or weak-limit ap proxim ation. The hyp erparam eters of the du ration distributions wer e set to α = 20 0 an d β = 10 , an d 2 Hidden Marko v Model T oolkit: http: //htk.eng.cam.ac.uk/ those of the emission d istributions were set to µ 0 = 0 , σ 2 0 = 1 . 0 , κ 0 = 0 . 01 , a nd ν 0 = 17 = ( dimension + 5 ) . For the conventional DAA, we set the hy perpar ameters of the sticky HDP-HMM to be as similar to those of th e NPB- D AA as possible. The hyp erparam eters for the NPYLM used in the con ventiona l DAA wer e set to α = 0 . 1 and d = 0 . 1. The Gib bs samplin g proced ure was iterated 100 times. With different random number seeds, 20 trials were performed . The parameters in th e NPB-D AA were given in a top- down manner heuristically by ref erring to the size of the state space and the appro ximate du ration o f a ph oneme. Th ose of the Pitman-Y or lan guage m odel were set to the default values of the software. As a b aseline meth od, we em ployed a n open-sour ce contin- uous speech recogn ition en gine, Julius, 3 which is widely used in Japanese speech recognition tasks. Julius’ s acoustic mod el is trained b y using a large num ber of sp eech d ata in a super vised manner . W e p repared four condition s for Julius. Th e first one was called “Julius (p honem e + NPYL M). ” In this c ondition, we used Julius as a p honem e reco gnition system b y prepa ring a ph oneme d ictionary c ontaining five Japanese vowels { a, i, u, e, o } . Mo reover , Julius’ s dictionar y also c ontains silB and silE to represent silence due to system req uirements. Af ter encod- ing continuo us speech signals into phoneme seq uences u sing Julius as a p honeme recog nizer, unsup ervised morph ological analysis based on the NPYLM was condu cted to discover words and a language m odel. Th e secon d con dition was called “Julius (p honem e + latticelm ). ” In this con dition, we also u sed latticelm, which is an unsupervised morpholo gical analyzer for lattice outp ut f rom an ASR system. T he m ethod was proposed by Neubig et al. as an extension of Mochihashi’ s NPYLM [24]. In this c ondition, the latticelm software was used too . In the th ird and fourth cond itions, called “Julius (mon o- phone + w o rd dictionary)” and “Julius (triphone + word dictio- nary), ” respec ti vely , we pre pared a co mplete word dictio nary that co ntained a ll of the words that ap peared in the ta rget speech signal, i.e., { aioi, au e, ao, ie, uo } , for Julius. This condition pr ovides almost an u pper bou nd for the per formanc e of our task. Excep t for in “Julius (tripho ne + word dictionary), ” Julius uses a mo noph one-based acou stic mode l co ntained in the dic tation k it. The acoustic model is trained in a superv ised manner using a large number of labeled speech d ata. “Julius (triphon e + word d ictionary) ” used a triphon e-based acoustic model for co mparison. B. Results W e p rovided word and letter grou nd truth labels to all frames of th e speech signal data and evaluated the relatio nship between the truth labels and estimated latent letter and word indices. The results are shown in T able III. Check marks in the AM and L M colum ns ind icate that the me thod u sed a pretrain ed acoustic model (AM) and the gi ven true language mod el (LM), 3 Open-Source Large V ocab ulary CSR Engine Julius: http:/ /julius.sourcefor ge.jp/ . The Linux bina ry dictation-kit-v4.3.1-linux.tgz was used in this e xperiment. The softwar e encodes the recorded data into 36-dimensio nal MFCC data inc luding dynamic feature s and uses them for speech recognition . 12 T ABLE III A R I F O R E S T I M A T E D L ATE N T L E T T E R S A N D W O R D S Method Letter ARI W ord ARI AM L M NPB-D AA (MAP) 0.596 0.529 NPB-D AA 0.561 0.401 Con vent ional DAA 0.590 0.090 Julius (phoneme dict ionary + NPYL M) 0.486 0.297 X Julius (phoneme dict ionary + latticel m) 0.554 0.337 X Julius (monophone + word dictionary) 0.586 0.487 X X Julius (triphone + word dictionary) 0.548 0.616 X X respectively . Letter AR I shows the ARI of phoneme clustering. A h igh Letter ARI m eans more accura te pho neme acquisition and reco gnition. W ord ARI sh ows the ARI of word c lustering. A h igher W ord ARI mea ns mor e accur ate word discovery and recogn ition. Each row co rrespon ds to each method ex- plained in th e co nditions. T he results of “NPB-DAA ” and “Con ventio nal DAA ” show the ARI averaged over 20 trials. In contr ast, “NPB-D AA ( MAP)” ob tained the max imum a posteriori prob ability (MAP) o f the 20 trials. An advantage of the NPB-D AA is that the method can calculate the p osterior probab ility of a given dataset after the learnin g phase because the NPB-DAA is derived from a generative mod el, i.e., HDP- HLM, wh ich in tegrates the language and acoustic mo dels. In contrast with the conv en tional D AA and similar methods that do n ot have appr opriate generative m odels, the NPB-DAA can ob tain an ap propr iate learnin g result by referrin g to the probab ility . The rows with MAP in T able I II show that this probab ility is an ad equate criterion fo r selecting a learn ing result. The results show that the “NPB-D AA (MAP)” outper formed not on ly the conventional D AA but also Julius-based word discovery systems whose a coustic mod els were trained in supervised manner . One reason is that the acoustic mo dels of the D AAs were tr ained only from on e p articipant’ s speech signals, in con trast, Julius’ s acou stic model was trained b y the speech signals o f many speakers. In other word s, NPB- D AA acqu ired spea ker - depend ent acoustic model in contrast with that Julius used speaker-indepen dent ac oustic mo del. This adaptation o f acou stic mod el to th e sp eaker must have increased the NPB-D AA ’ s perfor mance. The results show that a n aiv e app lication of the NPYLM to recog nized phoneme sequenc es results in po or word ac- quisition p erform ance, especially in conventional DAA. Be- cause the theo ry of the NPYLM does no t presum e that letter sequences have recognition erro rs, the existence of phon eme recogn ition error d eteriorates word segmen tation perfor mance. The metho ds that simp ly apply an NPYLM to ob tained phone me sequen ces, i.e., the conventional D AA and Julius (phon eme dictionary + NPYLM), output bad results in th e word ARI comp ared with tho se o f the letter ARI. Howev er, latticelm, which pr esumes phoneme recognition errors to some extent, could not dramatically imp rove the perf ormanc e of word acquisition in our experimental setting. In co ntrast, “Julius (tripho ne + word d ictionary )” improved its word ARI perfo rmance with respect to letter ARI p erfor- mance. “Julius ( monop hone + word dictionary)” also kept its perfor mance high with respect to the w o rd recog nition task compare d with th e phonem e re cognition task . W e n ote that the word erro r r ate was 32. 8% and the phon eme error rate was 28.1% in Ju lius (mo nopho ne + word dictionary). In th e research field of ASR, it is wid ely k nown that a good languag e mo del improves word and phone me re cognition per- forman ce. Th e NPB-D AA cou ld not improve th e performan ce of word ARI with re spect to letter ARI p erform ance. Ho wever , it obtain ed an adequ ate languag e mo del and prevented the score of the word ARI from becomin g far worse than that of the letter A RI. T o ach ie ve such an err or-proof word ac- quisition, the d irect inf erence of latent words are imp ortant in NPB-D AA. In the inferen ce pro cedure described in Section III, latent words ar e sampled directly without samp ling latent letters while marginalizing all possible latent letter sequen ces. This achieves an effect similar to that of a given langu age model in th e infe rence process T ypical examples of the estimation re sults a re shown in T able IV for NPB-D AA and con vention al D AA. Ea ch nu mber in parentheses r epresents an estimated phoneme lab el, each space represents a phone me boun dary , each number in bold style rep resents a sampled index of a word, a nd “ / ” re presents a b ound ary between su ccessi ve words. For examp le, “ao ie” was d i v ided into two words, i.e., “5 0 1 ” and “6 3 4 6 , ” in the NPB-DAA results, and their word indices were 3 a nd 4 . In T able IV, the samp led letters co rrespond ing to the word “ie” are u nderlined . Althou gh con vention al D AA could not estimate “ie” as a single word, the NPB-DAA co uld estimate “ie” to b e a single word: “4. ” In the co n vention al D AA results, se veral pho neme recognition errors can be fou nd. The errors completely deterio rated the fo llowing chunkin g proce ss, i.e., unsuper vised mor pholog ical analysis using a NPYL M, as past research has freq uently pointed out. As sh own in T ab le IV, NPB-D AA had some ph oneme recog nition errors. Howe ver, in the NPB-D AA, laten t words are sampled on the ba sis of the marginalized phon eme distribution bef ore sampling con crete phone me sequences. This prop erty of the sampling procedu re seemed to imp rove the performan ce of NPB-DAA. An example o f th e estimated latent variables is shown in Fig. 7, which sho ws the results for time s er ies data correspond- ing to a vo we l sequence, “ao ie ao. ” The inp ut time series d ata, i.e., 12-dime nsional MFCC time series data, ar e sh own at the top o f th e figur es. T he midd le and the botto m figures show the inf erence process. The top of each figur e shows the tru e latent letters or latent word s, wh ereas the bottom sh ows th e inferred result. The vertical axes represent the numbe r of Gibbs sampling iterations. Th is shows that th e in ference proc edure worked f or h uman vo wel seq uence data, and could estima te an adequ ate unit fo r each word. Let us fu rther examine the ch aracteristics of the segmenta- tion results of the NPB-DAA. T able IV shows that some of th e estimated latent words hav e a latent letter “6” at their head or tail. The latent letter “6” represents silence observed during the transition fr om on e vo wel to an other . Silence in sp eech signals 13 T ABLE IV E X A M P L E W O R D D I S C OV E RY R E S U LT S V o wel sequence Estimated NPB-DAA results Estimated con ventiona l DAA results ao ie 3 (5 0 1) / 4 (6 3 4 6) 226 (2 0 3 4 1 5 4 1) ao ie ao 3 (5 0 1) / 4 (6 3 4 6) / 3 (5 0 1) / 0 (6 4 6) 494 (3) / 675 (2 3 0) / 374 ( 1 5 4 1 2 0 1) aue ie 6 (6 5 1 2 6 4) / 4 (6 3 4 6) 329 (2 3 8 4 5 4 1) ie ie 4 (6 3 4 6) / 4 (6 3 4 6) 389 ( 5 4 1 4 1 5 4 1) ie uo 4 (6 3 4 6) / 5 (5 1 2) / 3 (5 0 1) 401 ( 5 4 1 8 0 1) ie aioi 4 (6 3 4 6) / 1 (5 6 4 6 3 6 1) / 4 (6 3 4 6) 813 ( 5 4 1 2 4 5) / 832 (4 3 0 3 4 5 1) and th e transition al soun ds obser ved between two phon emes were treated in the sam e manner as other uttered sou nds in ou r model. T he qu estion of whether suc h sign als sho uld be tre ated in the same way as other sound s in a gen erativ e model calls for fur ther inv estigatio n. I n ou r mod el, a ph oneme is simply represented by a single Gaussian distribution, alth ough many past spe ech reco gnition systems assign a richer structure to a pho neme, e.g., a th ree-state left-to-r ight HM M with GMM emission distributions. There is roo m for in vestigating whether a phone me mod el, i.e., a latent letter, should itself have a more comp lex structure, or if a do uble articulation hier archy is sufficient fro m the viewpoint o f unsupervised word discovery tasks. An inter esting result that represents a cha racteristic of th e NPB-D AA is the laten t word “ 4 (6 3 4 6 )” estimated at the e nd of “ie a ioi. ” Th e speech signa ls co rrespond ing to this “ 4 ” wer e a kind of tran sitional sound ob served following “aio i. ” The NPB-D AA directly inferred the latent word by marginalizing latent letters. In this case, it seems th at “ 4 ” was more likely than o ther latent words, and the NPB-D AA hen ce gen erated this result. This can be regarded as a side ef f ect of our approa ch, i.e., th e ma rginalization of latent letter sequen ces in a latent word. W e are confiden t that the marginalizatio n of latent letters and the direct infer ence o f word seque nces are importan t to impr oving the perf ormanc e o f the unsup ervised word segmentatio n of continu ous speech signals, b ut there is room to consider this side ef fec t. Note that the NPB-DAA performed unsupervised word discovery under the co ndition th at the training data consisted of spe ech sign als utter ed b y on e speaker, in con trast with Julius, whose acoustic model was traine d using many speak- ers’ speech signals. Speaker-independ ent, unsup ervised word discovery fro m continuou s spe ech signals remain s a challeng- ing problem because the acoustic features of phonem es heavily depend on the speaker . When we gave four sp eakers’ speech signals to th e NPB-DAA at the same time, th e L etter ARI and the W ord ARI decreased to 0 . 297 and 0 . 104 , respectively . By contrast, those pro duced by Julius with a tr iphone acoustic model and a true word dictio nary were 0 . 552 and 0 . 599, respectively . In the exp eriment, 12 0 aud io da ta items that were rec orded by askin g two male and two fem ale Japanese speakers to read 30 a rtificial sentenc es were used, i.e., a half of the data items used in the main expe riment d ue to computatio nal cost. It was ob served that speaker “dep endent” phone me models we re o btained by the NPB-D AA, i.e. , speech signals represen ting the same pho neme utter ed b y d eferent persons ten ded to b e c lustered to different latent letters. T o develop a machine learning method that e nables a r obot to obtain language an d acoustic models ind ependen t of speakers, or au tomatically ada pting to different speakers is one of our future challeng es. V I I . C O N C L U S I O N In this pap er , we propo sed NPB-D AA for direct and si- multaneou s ac quisition of lan guage and acou stic mode ls from continuo us speech signals in a n un supervised m anner . For this pur pose, we p roposed an in tegrati ve generative m odel called the HDP-HLM by extend ing HDP-HSMM. Based o n the gen erative model, we derived an in ference pr ocedur e by extending the b locked Gib bs sampler originally proposed f or HDP-HSMM. The m ethod is expected to enable a develop- mental rob ot to simultaneo usly obtain language and ac oustic models directly fro m con tinuous speech signals. T o evaluate the pe rforman ce of the p roposed meth od, two experiments were p erformed . In the first experiment, the p roposed method was applied to synth etic data, and it was shown that t h e method can successfully infer latent words embedd ed in time series data in an u nsupervised manner . In the second experimen t, we applied the pr oposed method to actual human Japanese vo wel sequences. T he resu lt sh owed that the proposed metho d outperf ormed a con vention al two-stage sequential method, conv en tional D AA, and a baselin e ASR m ethod. One o f the most impo rtant challenges in our future work is to achiev e comp lete hu man lan guage ac quisition from speech signals. W e d id no t achieve co mplete languag e acquisition from speech signals th at includes consonan ts as w ell as vowels in this stud y . Languag e acqu isition from mor e n atural speech signals like ch ild-directed speech b y hu man pare nts are also part o f our f uture work. T o achieve these aims, we still have two main p roblems: fea ture extraction and computationa l cost. T o address these pr oblems, mor e soph isticated featu re ex- traction method s are ne eded. Deep learn ing has gained at- tention r ecently because of its impressive feature extraction perfor mance. Integrating a deep learning method into the NPB- D AA shou ld improve its perfor mance. Computation al co st is a nother pro blem. Even though the size of the dataset used in the Exp eriment 2 was very sma ll, it to ok ap proxim ately 2 40 m inutes for 100 iterations using an Intel Xeo n CPU E5-2 650 v2 2.6 0 GHz, 8 cores × 16 CPU. In p articular, the com putational cost of th e blocked Gibbs sampler was O ( T L max d 3 max N 2 max ) , wh ere L max is the max imum number of latent letters fo r a word, d max is the max imum duration of a word, and N max is the maximum numb er of words. 14 MFCC ``a’’ ``a’’ ``o’’ ``i’’ ``e’’ ``o’’ ``ao’’ ``ao’’ ``ie’’ Fig. 7. Example of inference results for “ao ie ao. ” MFCC feature vect ors are plotte d in the top panel. The middle and bottom panels show the infer ence results of latent letters and latent words, respecti vely . Dif ferent colors denotes dif ferent states. T o apply the proposed m ethod to a larger dataset, improving its co mputation al cost will be necessary . Currently , the accu racy o f the lan guage acq uisition is still limited, as shown in T able III. In this pa per , we focu sed on a lang uage acquisition method b ased on d istributional cues and propo sed a mathem atical mod el for lang uage acqu isition. Obviously , d istributional cues ar e no t enou gh for mo re ac- curate languag e acq uisition. As suggested b y several com- putational and robotic stud ies, making use of co-occu rrence cues improves the accuracy of languag e acqu isition [2 1]–[23]. The propo sed HDP-HLM is a fully probab ilistic generative model. Th erefore, intro ducing othe r factors into consideratio n is relatively easier than for other heu ristic models. This is also advantage of o ur appr oach. Combining pro sodic and co- occurre nce cues into the NPB-DAA, and ob taining a more accurate and mor e p lausible constru ctiv e developmental lan- guage a cquisition mo del is also a direction f or futu re resear ch. R E F E R E N C E S [1] R. N. Aslin , J. Z. W oodward, N. P . LaMendo la, and T . G. B eve r, “Model s of word segmenta tion in fluent maternal speech to infants, ” in Signal to syntax: Bootstrapping from speech to grammar in e arly acquisit ion , J. L. Morgan and K. Demuth, Eds. Psych ology Press, 1995, pp. 117—-134. [2] J. R. Saf fran, E. L. Newport, and R. N. Aslin, “W ord Segmenta tion: The Role of Distrib utional Cues, ” Journal of Memory and Language , vol. 35, no. 4, pp. 606–621, 1996. [3] J. R. Saffra n, R. N. Aslin, and E. L . Ne wport, “Stat istical learning by 8-month-old infants.” Science, vol. 274, no. 5294, pp. 1926–1928, 1996. [4] E. D. Thiessen and J. R. Saffran, “When cues collid e: use of stress and statistica l cues to word boundaries by 7- to 9-month-old infa nts.” De velopmenta l psychology , vol. 39, no. 4, pp. 706–716, 2003. [5] P . K. Kuhl, “Cracking the speech code: H o w inf ants learn langua ge, ” Acoustic al Science and T echnology , vol. 28, no. 2, pp. 71–83, 2007. [6] M. J. Johnson and A. S. Will sky , “Baye sian nonparametri c hidden semi- Marko v m odels, ” Journal of Machi ne Learning Researc h , vol. 14, pp. 673–701, February 2013. [7] M. R. Brent, “ An ef ficient, probabi listically sound algorithm for seg- mentati on and word discove ry , ” Machine L earning, vol. 34, pp. 71–105, 1999. [8] A. V enkata raman, “ A s tatist ical model for word discov ery in transcri bed speech, ” Computati onal Linguist ics , vol. 27, no. 3, pp. 351–372, 2001. [9] S. Goldwate r, T . L . Grif fiths, M. Johnson, and T . Griffit hs, “Conte xtual depende ncies in unsupervise d word segmentat ion, ” in Proceedi ngs of the 21st Internat ional Conference on Computatio nal Linguistics and the 44th annual m eetin g of the Associati on for Computat ional Linguistic s , 2006, pp. 673–680. [10] S. Goldwater , T . L. Grif fiths, and M. J ohnson, “ A Bayesian frame work for word segmenta tion: explori ng the ef fects of conte xt, ” Cogniti on , vol. 112, no. 1, pp. 21–54, Jul. 2009. [11] D. Mochihashi, T . Y amada, and N. Ueda, “Baye sian unsupervised word se gmentation with nested Pitman-Yor language modeling, ” in Proceedi ngs of the Joint Conferenc e of the 47th Annual Meeting of the A CL and the 4th Internation al Joint Conference on Natural L anguage Processing of the AFNLP (ACL-IJCNLP) , 2009, pp. 100–10 8. [12] M. Johnson and S. Goldwater , “Impro ving nonparameteri c Bayesian inferen ce: experi ments on unsupervised word segmentati on with adaptor grammars, ” in Proceedings of Human Language T echnol ogies The 2009 Annual Confere nce of the North American Chapter of the Association for Computational Linguisti cs , 2009, pp. 317–325. [13] M. Chen , B. Chang, and W . Pei, “ A joint model for unsuperv ised Chinese word segmentati on, ” in Confer ence on Em pirica l Methods in Natura l Language Processing (EMNLP), 2014, pp. 854–863. [14] P . Magistry , “Unsupervize d word segmentati on : the case for Mandari n Chinese, ” in Proceedi ngs of the 50th Annual Meeting of the Associati on for Computation al Linguistics: Short Papers , vol. 2, 2012, pp. 383–387. [15] S. Sakti , A. Finch, R. Isotani, H. Kawai, and S. Nakamura, “Un- supervised determina tion of effici ent Korean L VCSR units using a Bayesia n Dirichlet process model, ” in IEEE Interna tional Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2011, pp. 4664– 4667. [16] D. K. Roy and A. P . Pentlan d, “Learning words from s ights and sounds: a computational model, ” Cogniti ve Science , vol. 26, no. 1, pp. 113–146, 2002. [17] N. Iwahashi, “Interac tiv e learning of spoken words and their meanings through an audio-visua l inte rface, ” IEICE Tr ansactions on Informatio n and Systems , no. 2, pp. 312–321, 2008. [18] ——, “Language ac quisition through a huma n-robot interf ace by combining speech, visual, and beha vioral information, ” Information Science s , vol. 156, pp. 109–121, 2003. [19] N. Iwa hashi, K. Sugiura, R . T aguchi, T . Naga i, and T . T aniguc hi, “Robots that learn to communicate: A dev elopmental approach to personally and physical ly situated human-robot con versation s, ” in Dialog with Robots Pape rs from the AAAI Fall Symposium , 2010, pp. 38–43. [20] T . Araki, T . Nakamura, T . Nagai, S. Nagasaka, T . T aniguc hi, and N. Iwa- hashi, “Online learni ng of concepts and words using multimodal LDA and hierarchic al Pitman-Y or Language Model, ” IEEE /RSJ Internati onal Conferen ce on Intel ligent Robots and Systems (IROS) , pp. 1623–1630, Oct. 2012. 15 [21] T . Nakamura, T . Nagai , K. Funakoshi, S. Nagasaka, T . T aniguchi, and N. Iwahashi, “Mutual learning of an object concept and language model based on MLDA and NPYLM, ” in IEEE/RSJ Interna tional Confe rence on Intelligent Robots and Systems (IROS) , 2014, pp. 600 – 607. [22] R. T aguchi, Y . Y amada, K. Hattori, T . Um ezaki , and M. Hoguro, “Learning place -names from spoken utte rances and locali zation results by mobile robot, ” in Interspee ch , 2011, pp. 1325–1328. [23] A. T anigu chi, T . T aniguchi, and T . Inamura, “Lexic al acquisiti on rela ted to places of mobile robot based on ambiguous syllabl e recognition , ” in IEEE/RSJ Internati onal Confe rence on Intelligent Robots and Systems (IR OS), 2015, submitted. [24] G. Neubig, M. Mimura, S. Mori, and T . Kawaha ra, “Bayesian learning of a lang uage model from continuo us speech, ” IE ICE Transac tions on Information and Systems , vol. E95-D, no. 2, pp. 614–625, 2012. [25] J. Heymann and O. W alter , “Unsupervise d word segmentat ion from noisy input, ” in IE EE W orkshop on Automatic Speech Recogniti on and Understand ing (ASR U) , 2013, pp. 458–463. [26] J. Heymann , O. W alter , R. Haeb-umbach, and B. Raj, “Itera tiv e bayesia n word segment ation for unsupervised vocab ulary discove ry from phoneme lattice s, ” in IEEE Internationa l Confe rence on A coustic s, Speech and Signal Processing (ICASSP) , 2014, pp. 4085–4089 . [27] M. Elsner , S. Goldwa ter , N. Feldman, and F . W ood, “ A joint learning model of word segmentat ion, le xical acqu isition, and phonetic v ariabil- ity , ” in Proceedi ngs of the 2013 Conference on Empirical Methods in Natural Language Processing , Seattl e, W ashington, USA, 2013, pp. 42– 54. [28] B. M. Lake, G. K. V allabha, and J. L. McClel land, “Model ing unsuper - vised peceptua l cate gory learning, ” IEEE Tran sactions on Autnomous Mental Deve lopment , vol. 1, no. 1, pp. 35–43, 2009. [29] N. H . Feldman, T . L. Griffiths, S. Goldwat er, and J. L. Morgan, “A role for the dev eloping lexicon in phonetic cat egory acquisition . ” Psychologi cal re vie w , vol. 120, no. 4, pp. 751–78, 2013. [30] C. Lee and J. Glass, “ A nonparametric Bayesia n approa ch to acoustic model discovery , ” in Proceedings of the 50th Annual Meeting of the Associati on for Computationa l L inguisti cs: Long Papers , 2012, pp. 40– 49. [31] C.-y . Lee, Y . Zhang, and J. Glass, “Joint learning of phonetic units and word pronuncia tions for ASR, ” in Proceedin gs of the 2013 Conferenc e on E mpirical Methods in Natural Language Processing , 2013, pp. 182– 192. [32] H. Brandl , B. Wrede, F . Joublin, and C. Goerick, “A self-refer ential childl ike model to acquire phones, syllables and words from aco ustic speech, ” IEEE Internat ional Conference on De velopmen t and Learning , pp. 31–36, Aug. 2008. [33] O. W alter , T . Korth als, R. Haeb-Umbach, and B. Raj, “ A hierarchi cal system for word discover y exploiti ng DTW -based initial ization, ” in IEEE W orkshop on Automatic Speech Recognition and Understanding (ASR U), 2013, pp. 386–391. [34] T . T aniguchi and S. Nagasaka, “Double articu lation analyze r for unseg- mented human motion using Pitman-Y or langua ge model and infinite hidden Markov model , ” in IEEE/SICE Inte rnational Sym posium on System Integrat ion (SII) , 2011, pp. 250–255. [35] E. B. Fox, E. B. Sudderth, M. I. Jordan, and A. S. W illsky , “ A stick y HDP-HMM with applicati on to speaker diariza tion, ” The Annals of Applied Statistics , vol. 5, no. 2A, pp. 1020–1056, 2009. [36] K. T akenak a, T . Bando, S. Nagasaka, T . T aniguc hi, and K . Hitomi, “Conte xtual scene s egmen tation of drivin g behavi or based on double ar- ticul ation analyzer . ” in IEEE/RSJ Internatio nal Conference on Intell igent Robots and Systems (IR OS) , 2012, pp. 4847–4852. [37] T . T aniguchi, S. Nagasaka, K. Hitomi, N. P . Chandrasiri, and T . Bando, “Semioti c prediction of dri ving beha vior using unsupervised double articu lation ana lyzer , ” in IEEE Intelligent V ehicle s Symposium (IV) , 2012, pp. 849–854. [38] T . T aniguchia, S. Nagasaka, K. Hitomi , K. T akena ka, and T . Band o, “Unsupervi sed hierarchical modeling of driving beha vior and predic- tion of conte xtual changing points, ” IEEE Transact ions on Intelli gent Tra nsportation Systems, vol. PP , pp. 1–15, 2014, in press. [39] S. Nagasaka, T . T aniguchi, G. Y amashita, K. Hitomi, and T . Bando, “Finding meaningful robust chunks from drivin g beha vior base d on double articul ation analyz er , ” in IEEE /SICE Intl Symposium on System Inte gration (SII) , 2012, pp. 535–540. [40] T . Bando, K. T akenak a, S. Nagasaka, and T . T aniguchi , “Unsupe rvised dri ve topic finding from drivi ng beha vioral data, ” in IEEE Inte lligent V ehicles Symposium (IV) , 2013, pp. 177–182. [41] ——, “ Automatic dri ve annot ation via multimodal latent topic model, ” in IEEE/RSJ Inte rnational Conference on Intelli gent Robots and Systems (IR OS), 2013, pp. 2744–27 49. [42] K. T aken aka, T . Bando, S. Naga saka, and T . T aniguchi, “Driv e video summarizati on based on double articula tion structure of dri ving behav- ior , ” in A CM Multime dia , 2012, pp. 1169–1172. [43] K. P . Murphy , “Hidden semi-Ma rkov models (HSMMs), ” T ech. Rep. Nov ember , 2002. [Online]. A vai lable: http:/ /www .cs.ubc.ca/ ∼ murphyk/P apers/segment . pdf [44] Y . W . T eh, M. I. Jordan, M. J. Beal, and D. M. Blei, “Hierarchic al Dirichl et processes, ” Journal of the american s tatist ical associa tion , vol . 101, no. 476, 2006. [45] J. Sethuraman, “A constructi ve definiti on of Dirichlet priors, ” Statist ica Sinica, vol. 4, no. 2, pp. 639–650, 1994. [46] S. Thrun, W . Bur gard, and D. Fox, Probabilistic Robotics (Inte lligent Robotic s and Autonomous Agents series) . The MIT Press, 2005. [47] L. Hubert and P . Arabie , “Comparing parti tions, ” Journal of classifica tion , vol. 2, no. 1, pp. 193–218, 1985. ad
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment