Reinforcement Learning for Joint Optimization of Multiple Rewards
Finding optimal policies which maximize long term rewards of Markov Decision Processes requires the use of dynamic programming and backward induction to solve the Bellman optimality equation. However, many real-world problems require optimization of …
Authors: Mridul Agarwal, Vaneet Aggarwal
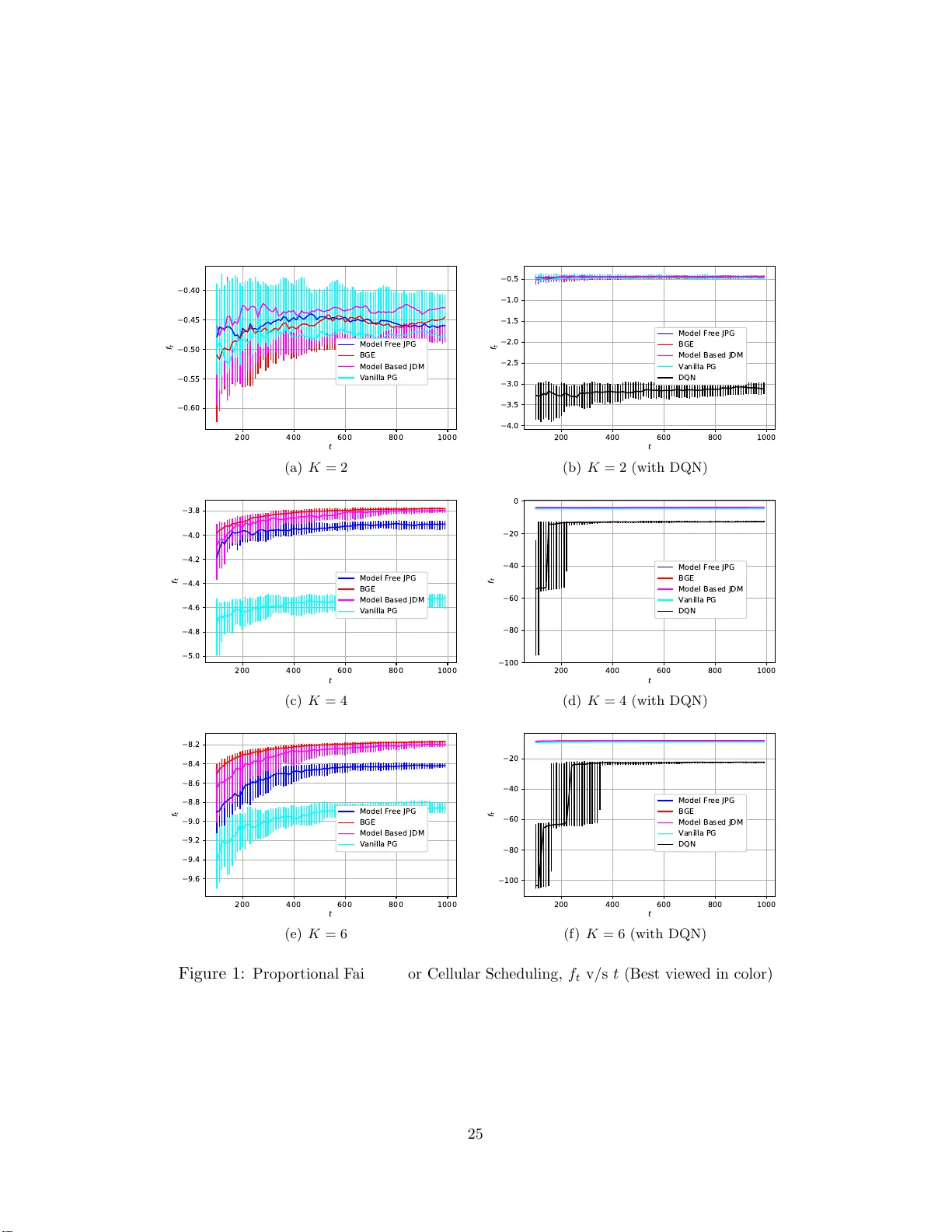
Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards Reinforcemen t Learning for Join t Optimization of Multiple Rew ards Mridul Agarwal and V aneet Aggarwal Purdue Universit y , W est Lafa y ette IN 47907 Editor: Abstract Finding optimal policie s which maximize long term rewards of Markov Decision P ro cess e s requires the use of dynamic prog ramming and backw ard indu ction to solve the Bellman op- timalit y equation. Howev er, man y real-world problems require optimization of a n ob jective that is non-linear in cumulativ e rew ards for whic h dynamic pro gramming ca nnot b e applied directly . F or example, in a reso ur ce allo cation pr o blem, one of the ob jectives is to maximize long-term fairness a mo ng the users. W e notice that when an ag ent aim to optimize s ome function o f the sum o f rewards is consider ed, the problem lo ses its Markov nature. This pap er addresses a nd formalizes the problem of optimizing a non-linear function of the lo ng term av erage of rewards. W e prop ose mo del-ba sed and mo del-free algorithms to learn the po licy , wher e the mo del-ba s ed p olicy is shown to achiev e a regr et o f ˜ O LK D S q A T for K ob jectiv es co mbined with a concav e L -Lipschitz function. F urther , using the fa irness in cellular base-s tation scheduling, and queueing s ystem scheduling as examples, the pr op osed algorithm is s hown to significa ntly o utper form the co nv en tional RL approa ches. 1. In tro duction Man y p ractical app lications of sequential decision m aking often ha v e m ultiple ob jectiv es. F or example, a hydro-p o we r p ro ject ma y hav e conflicting gains w ith resp ect to p o wer genera- tion and flo od managemen t (Castelletti et al., 2013). S imilarly , a b uilding climate control ler can ha ve conflicting ob jectiv es of saving energy and maximizing comfort of the residents of the bu ilding (Kw ak et al., 2012). Video str eaming applicatio ns also account for multi ple ob jectiv es l ik e stall duration and av erage vid eo qu alit y (Elgabli et al., 2018). Access of files f rom cloud storage aims to optimize the latency of file downloa d and the cost to store the files (Xiang et al., 2015). Many applications also requir e to allo cate resources fairly to m ultiple clien ts (Lan et al., 2010 ) w h ic h can b e mo delled as optimizing a f unction of the ob jectiv es of the ind ividual clien ts. This p ap er aims to pr o vide a no v el formulatio n for decision making among multiple ob j ective s using reinforcemen t learning app r oac hes and to analyze the p erformance of the prop osed algorithms. W e consider a setup where w e wan t to optimize a p ossibly nonlin ear join t ob jectiv e function of long-term r ew ards of all the ob jectiv es (or, d ifferen t ob jectiv es). As an example, man y prob lems in resour ce allo cation for netw orkin g and computation r esources use fairness among the long-term a verage r ew ards of the user s as the metric of c hoice (Lan et al., 2010; Kw an et al. , 2009; Bu et al., 2006; L i et al., 2018; Aggarw al et al., 2011; Margolies et al., 2016; W ang et al., 2014; Ibrahim et al., 2010), whic h is a non-linear m etric. F or fairness 1 Agar w al, Aggar w al optimization, a controlle r w an ts to optimize a fairn ess ob jectiv e among the different agen ts, e.g., p rop ortional fairness, α -fairness, or improv e the wo rst-case a v erage r eward of the users (Altman et al., 2008). In such situations, the o v erall join t ob jectiv e fun ction cannot b e written as su m u tilit y at eac h time in stan t. This prohibits the ap p lication of standard single-agen t reinforcement learning based p olicies as the bac kw ard indu ction step u p date cannot b e directly applied h ere. F or example, if a pro cess has 2 agen ts and T > 1 steps, and all the resource w as allocated to the fir st agent till T − 1 steps. Then, at T th step the resource s h ould b e allo cated to the second agen t to ensure fairness. This r equ ires the need to trac k past allo cation of all the resour ces and n ot ju st the current state of the system. W e also note that the optimal p olicy cannot tak e a deterministic action in a state in general, and thus the optimal p olicy is not a deterministic p olicy in general. Consider a case wher e a sc heduler needs to fairly allo cate a resource b et ween t w o us er s , and the system h as only one state. A deterministic p olicy p olicy will allo cate the resource to only one of the user, and hence is not optimal. W e d efine a no v el m ulti-agen t form ulation, making several pr actical assumptions, whic h optimizes the j oin t function of the av erage p er-step rewards of the differen t ob jectiv es to allevia te th e n eed for main taining history . SARSA and Q-Learning algorithms (Sutton and Barto, 2018b), and their deep neural net w ork based DQN algorithm (Mnih et al., 2015) provide p olicies that d ep end only on the current state, hence are su b-optimal. F urther, these algorithms learn a Q-v alue fun ction whic h can b e compu ted based on a dynamic programming approac h, whic h is not v alid in our work. Using ev aluations on fair resource allo cation and net w ork r outing p roblems, we v erify that algorithms based on fin ding fixed p oint of Bellman equations do not p erform w ell. This fu rther motiv ates the need for n o v el RL based algorithms to optimize non-linear functions. W e f urther n ote that ev en though m ulti-agen t reinforcemen t learning algorithms h a v e b een w idely studied, (T an, 1993; Sh oham et al., 2003 ; Bu¸ soniu et al., 2010; Ono and F uku moto, 1996), there are no con v ergence pro ofs to the optimal join t ob jectiv e fun ction without the kno wledge of the transition probabilit y , to the b est of our kno wledge. This pap er assumes no kno wledge of the state transition p r obabilit y of th e ob jectiv es and aims to pr o vide al- gorithms for the decision making of the d ifferen t ob jectiv es. W e provide t w o algorithms; The fi rst is a mo del-based algorithm that learns the transition probability of the next state giv en the cur ren t state and action. The second algorithm is mo del-free, which uses p olicy gradien ts to fi nd the optimal p olicy . The pr op osed mo del-based algorithm uses p osterior sampling with Dirichlet d istribution. W e sho w that the prop osed algorithm con v erges to an optimal p oint wh en the join t ob j ective function is Lipschitz con tin uous. Since the optimal p olic y is a sto c hastic p olicy , p olicy search space is not-finite. W e show that the problem is con v ex under a certain class of fun ctions and can b e efficien tly solv ed. I n setups wh ere the join t ob jectiv e fu nction is max-min, the setup reduces to a linear programming optimizatio n problem. In addition, we sho w that the prop osed algorithm ac hieve s a regret b oun d sub -linear in the n umber of time-steps and n umber of ob jectiv es. T o obtain the regret b ound, we use a Bellman err or b ased analysis to analyze sto chastic p olicies. The Bellman error q u an tifies the differen ce in r ewards for deviating fr om th e true MDP for one step and then follo wing the true MDP thereafter. Using this analysis, our regret b ound c haracterizes the gap b et w een the optimal ob jectiv e 2 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards and the ob jectiv e ac h iev ed b y the algorithm in T time-steps. W e show a regret b ound of ˜ O K D S q A T , wh ere K, T denotes the n umber of ob jectiv es, and time steps, resp ectiv ely . The prop osed mo del-free algorithm can b e easily im p lemen ted usin g deep neur al net- w orks for an y differen tiable ob jectiv e function. F urther, we note that the rew ard functions of the differen t ob j ectiv es can b e v ery d ifferen t, and can optimize different metrics for the ob jectiv es. As long as there is a join t ob jectiv e fun ction, th e differen t ob jectiv es can mak e decisions to optimize th is fun ction and ac hiev e the optimal decision at conv ergence. The pr op osed framework wo rks for any num b er of ob jectiv es, while is no v el ev en for a single agen t ( K = 1). In th is case, the agent wish es to optimize a non -linear conca v e fu nction of the a v erage rew ard. Since this function is not assumed to b e monotone, optimizing the function is not equiv alen t to optimizing the a v erage rew ard. F or an y general non-linear conca ve function, regret b ound is analyzed for mo del-based case. W e also present ev aluation r esults for b oth the algorithms for optimizing prop ortional fairness of m ultiple agen ts connecting to a cellular base station. W e compare the obtained p olicies with existing asymptotically optimal algorithm (Blind Gradient Es timator or BGE) of optimizing prop ortional fairness for wireless net wo rks (Margolies et al., 2016) and SARS A based R L solution p rop osed b y (P erez et al., 2009). W e deve lop ed a simulatio n en vironment for wireless net w ork for m ultiple num b er of agen ts and states for eac h agen t. T he pr op osed algorithm significan tly outp erform the SARSA based solution, and it nearly ac hiev es the p erforman ce of the asymptotically optimal BGE algo rithm. W e also considered α -fairness for an infinite state space to show the scalabilit y of the prop osed mo del-free algorithm. In this case, the d omain-sp ecific algorithm wa s n ot a v ailable, w hile we sh ow that we outp erf orm Deep Q-Net w ork (DQN) based algorithm (Mnih et al., 2015). Finally, a queueing system is considered whic h mo dels m ultiple roads merging in to a single lane. The queue selectio n problem is mo deled using the prop osed framew ork and the prop osed approac h is sho wn to impro v e the fair latency rew ard metric among the queues significan tly as compared to the DQN and the longest-queue-first p olic ies. Key con tributions of our p ap er are: • A s tr ucture f or join t fu nction optimization with m ultiple ob jectiv es based on a v erage p er-step rew ards. • Pa reto Op timalit y guarantees w h en the joint ob jectiv e is an elemen t-wise m on otone func- tion. • A mo del-based algorithm using p osterior sampling with Diric hlet distrib ution, and its regret b ounds . • A mo del-free p olicy gradien t algorithm which can b e efficien tly implemente d using neural net w orks. • Ev aluatio n results and comparison with existing heuristics for optimizing f airness in cel- lular n et w orks, and queueing s ystems. The rest of the pap er is organized as follo w s. Section 2 describ es related works in the field of RL and MARL. Section 3 describ es the problem formulati on. P areto optimalit y 3 Agar w al, Aggar w al of th e prop osed framew ork is shown in S ection 4. The p rop osed mo del based algorithm and mo del free algorithm are d escrib ed in Sections 5 and 6, resp ecti ve ly . In S ection 7, the prop osed algorithms are ev aluated for cellular s c heduling p roblem. Section 8 concludes the pap er with some fu ture w ork d irections. 2. Related W ork Reinforcemen t learning for single agen t has b een extensiv ely stu died in past (Sutton and Barto, 2018b). Dynamic Programming was used in many problems b y find ing cost to go at eac h stage (Pu terman, 1994; Bertsek as , 1995). These mo dels optimize linear additiv e utilit y and utilize the p o w er of Bac kwa rd Induction. F ollo wing the su ccess of Deep Q Net w orks (Mnih et al., 2015), many new algorithms ha v e b een devel op ed for reinforcemen t learning (Sch u lman et al., 2015; Lillicrap et al., 2015; W ang et al., 2015; Sc h ulman et al., 2017). These pap ers fo cus on single agen t control, and pro vide a framework for implementi ng scalable algorithms. Sample efficient algorithms based on rate of con ve rgence analysis hav e also b een stud ied for mo del based RL algorithms (Agra w al and Jia, 2017; Osb and et al., 2013 ), and f or mod el free Q learning (Jin et al., 2018). Ho w ev er, sample efficien t algorithms use tabular imp lemen tation instead of a deep learning based implemen tation. Owing to h igh v ariance in the p olicies obtained by standard Mark o v Decision P r o cesses and Reinforcemen t Learning formulations, v arious authors work ed in reducing the risk in RL approac hes (Garcıa and F ern´ andez, 2015). Ev en though the risk fun ction (e.g., Conditional V alue at Risk (CV aR)) is n on-linear in the rew ards, this function is not only a function of long-term a v erage rew ards of the single agen t bu t also a fun ction of the higher order momen ts of the rew ards of the single agen t. Thus, the pr op osed framework do es not ap p ly to the risk measures. Ho we v er, for b oth the risk measure and general non -linear conca ve function of a verage rew ards, optimal p olicy is non-Marko vian. Non-Mark o vian Decision Pro cesses is a class of decision pro cesses wh ere either r ew ards, the next state transitions, or b oth d o not only dep ends on the cur rent state and actions but also on the history of states an d actions leading to w ards the cur ren t state. O n e can augment the state sp ace to includ e the history along with the current state and m ak e the new pro cess Mark o vian (Th i´ ebaux et al. , 2006). Ho w ev er, th is increases the memory f o otprint of any Q-learning algorithm. (McCallum , 1995) consid ers only H states of history to construct an app ro ximate MDP and then use Q -learnin g. (Li et al., 2006) pr o vide guarantees on Q- learning for non-MDPs where an agen t observes and work according to an abstract MDP instead of the ground MDP . T he states of the abstract MDP are an abstraction of the states of the ground MDP . (Hutter, 2014) extend th is setup to work with abstractions of histories. (Ma jeed and Hutter, 2018 ) consider a setup for History-based Decision Pr o cess (HDP). They pro vide con v ergence guarante es f or Q-learning algorithm for a sub-class of HDP wh ere for histories h and h ′ , Q ( h, a ) = Q ( h ′ , a ) if the last observed state is identic al for b oth h and h ′ . They call this sub -class Q -v alue u niform Decision Pro cess (QDP) and this subsu mes the abstract MDPs. W e note that our work is differen t from these as the Q -v alues constructed using join t ob jectiv e is n ot indep endent of history . In most applications suc h as financial markets, swarm rob otics, wireless channel access, etc., th er e are multiple agen ts that make a decision (Blo em b ergen et al., 2015), and the 4 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards decision of an y agent can p ossibly affect th e other agen ts. In early w ork on m ulti-agen t reinforcemen t learning (MARL) for s to c h astic games (Littman , 1994), it w as recognized that no agen t wo rks in a v acuum. In his seminal pap er, Littman (Littman , 1994 ) fo cused on only t w o agen ts that had opp osite and opp osing goals. This means that they could use a single rewa rd fu nction whic h one tried to maximize and the other tried to m inimize. The agen t h ad to wo rk with a comp eting agen t and h ad to b eha v e to maximize their reward in th e w orst p ossible case. In MARL, the agen ts select actions sim ultaneously at the cu rrent state and receiv e rewards at the next state. Differen t from the framew orks that solv e for a Nash equilibrium in a s to c h astic game, the goal of a r einforcemen t learning algorithm is to learn equilibrium strategies through interac tion with the environmen t (T an, 1993; Shoham et al., 2003; Bu¸ soniu et al., 2010 ; Ono and F ukumoto, 1996; Sh alev-Sh w artz et al., 201 6 ). (Roijers et al., 2013; L iu et al., 2014; Nguyen et al., 2020) considers the m ulti-ob jectiv e Mark o v Decision Pro cesses. Similar to our work, they consider function of exp ected cu- m ulativ e rewa rds. Ho w ev er, they work with linear com bination of the cumulativ e rewards whereas w e consider a p ossibly non-linear fu nction f . F urther, b ased on the joint ob jectiv e as a fun ction of exp ecte d a v erage r ew ards, we pro vide regret guaran tees for our algorithm. F or joint decision making, (Zhang and S hah, 2014, 2015) studied the pr oblem of fairness with multiple agen ts and related th e fairness to multi-ob jective MDP . Th ey considered maximin fairness and us ed Linear Pr ogramming to obtain optimal p olicies. F or general functions, linear pr ogramming based app roac h pro vided by (Zhang and Shah, 2014) will not directly work. This pap er also optimizes join t action of agen ts u sing a cen tralized con troller and p rop ose a mo d el based algorithm to ob tain optimal p olicies. Based on our assumptions, maximin f airness b ecomes a sp ecial case of our f orm ulation and optimal p oli- cies can b e obtained using the prop osed mo del based algorithm. W e also prop ose a mo del free reinforcemen t learning algorithm that can b e used to obtain optimal p olicies for an y general d ifferen tiable fun ctions of a v erage p er-step rewards of individual agen ts. Recen tly , (Jiang and L u, 2019) considered the p roblem of m aximizing fairness among m ultiple agen ts. Ho w ev er, they do n ot pr o vide a con v ergence analysis for th eir algorithm. W e attempt to close this gap in the u nderstandin g of the prob lem of maximizing a conca ve and Lipsc hitz function of m ultiple ob jectiv es with our work. 3. Problem F orm ulation W e consider an infi nite h orizon d iscoun ted Mark o v decision p ro cess (MDP) M defined b y the tuple S , A , P , r 1 , r 2 , · · · , r K , ρ 0 . S denotes a finite set of state space of size S , and A denotes a finite set of A actions. P : S × A → [0 , 1] S denotes the probabilit y transition distribution. K denotes the n umber of ob jective s and [ K ] = { 1 , 2 , · · · , K } is the set of K ob jectiv es. Let r k : S × A → [0 , 1] b e the b ounded reward fu nction for ob jectiv e k ∈ [ K ]. Lastly , ρ 0 : S → [0 , 1] is the distrib ution of in itial state. W e motiv ate our c hoice of b ounds on rewards from the fact that man y pr oblems in practice require explicit r ew ard sh aping. Hence, the con troller or the learner is a w are of the b ounds on the rew ards. W e consider the b ound s to b e [0 , 1] for our case wh ic h is easy to satisfy b y r eward sh aping. W e use a sto chastic p olicy π : S × A → [0 , 1] whic h return s the probabilit y of selecting action a ∈ A for an y giv en state s ∈ S . F ollo wing p olicy π on the MDP , the agen t observes a sequ en ce of random v ariables { S t , A t } t where S t denotes th e state of the agen t at time 5 Agar w al, Aggar w al t and A t denotes th e action tak en b y the agent at time t . The exp ected discoun ted long term reward and exp ected p er step rew ard of the ob jectiv e k are giv en b y J P ,k π and λ P ,k π , resp ectiv ely , when the join t p olicy π is follo w ed. F ormally , for discount factor γ ∈ (0 , 1), J P ,k π and λ P ,k π are defined as J P ,k π = E S 0 ,A 0 ,S 1 ,A 1 , ··· " lim τ →∞ τ X t =0 γ t r k ( S t , A t ) # (1) S 0 ∼ ρ 0 ( S 0 ) , A t ∼ π ( A t | S t ) , S t +1 ∼ P ( ·| S t , A t ) λ P ,k π = E S 0 ,A 0 ,S 1 ,A 1 , ··· " lim τ →∞ 1 τ τ X t =0 r k ( S t , A t ) # (2) = lim γ → 1 (1 − γ ) J P ,k π (3) Equation (3) follo ws f r om the Lauren t s er ies expansion of J k π (Puterman, 1994). F or b revit y , in the rest of the pap er E S t ,A t ,S t +1 ; t ≥ 0 [ · ] will b e denoted as E ρ,π ,P [ · ], where S 0 ∼ ρ 0 , A t ∼ π ( ·| S t ) , S t +1 ∼ P ( ·| S t , A t ). Th e exp ected p er step rew ard satisfies the follo wing Bellman equation h P ,k π ( s ) + λ P ,k π = E a ∼ π h r k ( s, a ) i + E a ∼ π " X s ′ P ( s ′ | s, a ) h P ,k π ( s ′ ) # (4) where h k π ( s ) is th e bias of p olicy π for state s . W e also define the discounted v alue fu nction V P ,k γ ,π ( s ) and Q-v alue functions Q P ,k γ ,π ( s, a ) as follo ws: V P ,k γ ,π ( s ) = E A 0 ,S 1 ,A 1 , ··· " lim τ →∞ τ X t =0 γ t r k ( S t , A t ) | S 0 = s # (5) Q P ,k γ ,π ( s, a ) = E S 1 ,A 1 , ··· " lim τ →∞ τ X t =0 γ t r k ( S t , A t ) | S 0 = s , A 0 = a # = r k ( s, a ) + E a ∼ π [ X s ′ P ( s ′ | s, a ) V P ,k γ ,π ( s ′ )] (6) F urther, the bias h P ,k π ( s ) and the v alue function V P ,k γ ,π are related as h P ,k π ( s 1 ) − h P ,k π ( s 2 ) = lim γ → 1 V P ,k γ ,π ( s 1 ) − V P ,k γ ,π ( s 2 ) , wh ere s 1 , s 2 ∈ S . (7) F or notation simplicit y , w e may drop the sup erscript P when discussing ab out v ariables for the true MDP . Note that eac h p olicy induces a Mark o v Chain on the states S with transition pr ob- abilities P π ,s ( s ′ ) = P a ∈A π ( a | s ) P ( s ′ | s, a ). After d efining a p olicy , w e can no w define the diameter of the MDP M as: Definition 1 ( Diameter) Consider the M arkov Chain induc e d by the p olicy π on the MDP M . L et T ( s ′ |M , π , s ) b e a r ando m variable that denotes the first time step when 6 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards this Markov Chain e nters state s ′ starting f r om state s . Then, the diameter of the MDP M is define d as: D ( M ) = max π max s ′ 6 = s E T ( s ′ |M , π , s ) (8) F urther, starting f r om an arbitrary initial state distribution, the state d istribution may tak e a while to con v erge to the steady s tate distrib ution. F or any p olicy π , let P t π ,s = ( P π ,s ) t b e the t -step probabilit y d istribution of the states when p olicy π is applied to MDP with transition probabilities P starting from state s . W e are no w r eady to state our first assu mption on the MDP . W e assum e that the Mark o v Decisio n Pr o cess is ergo dic. This implies that: 1. for an y p olicy all states, s ∈ S , comm unicate with eac h other; 2. for any p olicy , the pro cess con v erges to the s teady state distribution exp onentia lly fast. F ormally , we ha v e Assumption 1 The Markov D e cision Pr o c ess, M , is er go dic. Then, we have, 1. The diameter, D , of M is finite. 2. F or any p olicy π , for some C > 0 and 0 ≤ ρ < 1 , we have k P t π ,s − d π k T V ≤ C ρ t (9) wher e d π is the ste ady state distribution induc e d by p olicy π on the MDP. The agen t aim to collab orative ly optimize the function f : R K → R , wh ic h is defi ned ov er the long-term rew ards of the ind ividual ob jectiv es. W e mak e certain practical assu mptions on th is join t ob jectiv e function f , whic h are listed as follo ws: Assumption 2 The obje ctive function f is jointly c onc ave. Henc e for any arbitr ary distri- bution D , the f ol lowing holds. f ( E x ∼D [ x ]) ≥ E x ∼D [ f ( x )] ; x ∈ R K (10) The ob jectiv e function f represents the utilit y obtained from th e exp ected p er step rew ard for eac h ob jectiv e. These utility fun ctions are often conca v e to reduce v ariance for a risk a v erse decision mak er (Pratt, 196 4). T o mo d el this conca ve utilit y function, we assume the ab o v e form of Jensen’s inequalit y . Assumption 3 The function f is assume d to b e a L − Lipschitz function, or | f ( x ) − f ( y ) | ≤ L k x − y k 1 ; x , y ∈ R K (11) Assumption 3 ensures that for a small change in long run rew ards for an y ob jectiv e do es not cause un b oun ded c hanges in the ob jectiv e. Based on Assu m ption 2, we maximize the function of exp ected su m of rewards for eac h ob jectiv e. F urther to ke ep the formulat ion indep enden t of time horizon or γ , w e maximize the f unction o v er exp ected p er-step rew ards of eac h ob jectiv e. Hence, our goal is to find the optimal p olicy as the solution for the follo wing optimization p roblem. π ∗ = arg max π f ( λ 1 π , · · · , λ K π ) (12) 7 Agar w al, Aggar w al If f ( · ) is also monotone, we note that the optimal p olicy in (12) can b e sh own to b e P areto optimal. Th e d etailed p ro of will b e pr esen ted later in Section 4. An y online algorithm A starting with no prior kno wledge w ill requir e to obtain estimates of transition probabilities P and obtain rewards r k , ∀ k ∈ [ K ] for eac h state action pair. Initially , when algorithm A does n ot ha v e go o d estimates of th e m o del, it accumulate s a r egret for not w orking as p er optimal p olicy . W e define a time d ep endent regret R T to ac h iev e an optimal solution defined as the difference b et w een the optimal v alue of the function and th e v alue of th e fu nction at time T , or R T = E S t ,A t " f λ 1 π ∗ , · · · , λ K π ∗ − f 1 T T X t =0 r 1 ( S t , A t ) , · · · , 1 T T X t =0 r K ( S t , A t ) ! # (13) The r egret defi n ed in Equation (13) is the exp ected deviation b et we en the v alue of the function obtained from the exp ected rewards of the optimal p olicy and the v alue of the function obtained from the observ ed rew ards fr om a tra jectory . F ollo wing the w ork of (Roijers et al., 2013), w e note that the outer exp ectatio n comes for run n ing the decision pro cess for a different set of u s ers or runn ing a separate and indep enden t instance for the same set of users. Since the realizat ion can b e differen t from the exp ected rewa rds, the function v alues can s till b e differen t ev en when follo win g the optimal p olic y . W e note that we do not require f ( · ) to b e monotone. Th us, ev en for a single ob jectiv e, optimizing f ( E [ P t r t ]) is n ot equiv alen t to optimizing E [ P t r t ]. Hence, the prop osed frame- w ork can b e used to op timize functions of cumulati ve or long term a ve rage r ew ard for single ob jectiv e as w ell. In th e follo w ing sections, w e fir st show that the join t-ob jectiv e function of a v erage re- w ards allo ws us to obtain Pareto -optimal p olicies with an additional assumption of mono- tonicit y . Then, we will pr esen t a mo d el-based algorithm to obtain this p olicy π ∗ , and r egret accum ulated b y the algorithm. W e will present a mo del-free algorithm in Section 6 whic h can b e efficient ly imp lemen ted using Deep Neur al Net works. 4. Obtaining P areto-Optimal Policies Man y multi-o b jectiv e or multi- agen t formulati ons requir e the p olicies to b e P areto-Optimal (Roijers et al., 2013; Sener and Koltun, 201 8 ; V an Moffaert and Now ´ e, 2014). The conflict- ing rew ards of v arious agen ts may not allo w us to attain simulta neous optimal av erage rew ards for any agen t with any join t p olicy . Hence, an envy-free P areto optimal p olicy is desired. W e n o w pro vide an additional assumption on the join t ob jectiv e fun ction, and sho w that th e optimal p olicy s atisfying Equ ation (12) is P areto optimal. Assumption 4 If f is an element-wise monotonic al ly strictly incr e asing function. Or, ∀ k ∈ [ K ] , the function satisfies, x k > y k = ⇒ f x 1 , · · · , x k , · · · , x K > f x 1 , · · · , y k , · · · , x K (14) Elemen t w ise increasing pr op erty m otiv ates the agen ts to b e s trategic as by increasing its p er-step a v erage rewa rd, agen t can increase the joint ob jectiv e. Based on Equation (14), w e notice that the solution for Equation (12) is Pa reto optimal. 8 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards Definition 2 A p olicy π ∗ is said to b e Pa r eto optimal if and only if ther e is exists no other p olicy π such that the aver age p er-step r ewar d is at le ast as high for al l agents, and strictly higher for at le ast one agent. In other wor ds, ∀ k ∈ [ K ] , λ k π ∗ ≥ λ k π and ∃ k , λ k π ∗ > λ k π (15) Theorem 1 Solution of E q uation (12) , or the optimal p olicy π ∗ is P ar eto Optimal. Pro of W e will p ro v e the result using con tradiction. Let π ∗ b e the solution of Equation (12) and not b e P areto optimal. Then there exists some p olicy π for whic h the follo win g equation holds, ∀ k ∈ [ K ] , λ k π ≥ λ k π ∗ and ∃ k , λ k π > λ k π ∗ (16) F rom elemen t-wise monotone increasing prop erty in Equation (14), we obtain f ( λ 1 π ∗ , · · · , λ k π , · · · , λ K π ∗ ) > f ( λ 1 π ∗ , · · · , λ k π ∗ , · · · , λ K π ∗ ) (17) = arg max π ′ f ( λ 1 π ′ , · · · , λ K π ′ ) (18) This is a con tradiction. Hence, π ∗ is a P areto optimal solution. This result shows that algorithms presented in th is pap er can b e u sed to optimally allocate resources among multiple agen ts usin g a v erage p er step allocations. 5. Model-based Algorithm RL p roblems t ypically optimize the cumulativ e rewa rds, whic h is a linear fu nction of rew ards at eac h time step b ecause of the addition op eration. Th is allo ws the Bellman Optimalit y Equation to requ ire on ly the knowledge of the current state to select the b est action to optimize future rew ards (Puterman, 1994). Ho w ev er, since our con troller is optimizing a join t n on-linear fu nction of the long-term r ew ards fr om multiple sources, Bellman Optimalit y Equations cannot b e written as a fu nction of the curren t state exclusiv ely . Our goal is to find the optimal p olicy as s olution of Equation (12). Using a v erage p er-step r eward and infinite horizon allo ws u s to us e Mark o v p olicie s. An intuitio n in to w h y this works is there is alwa ys infinite time av ailable to optimize the joint ob jectiv e f . The ind ividual long-term av erage-rew ard for eac h agen t is still linearly additiv e ( 1 τ P τ t =0 r k ( S t , A t )). F or infinite h orizon optimization problems (or τ → ∞ ), we can u se steady s tate d istribution of the state to obtain exp ected cum ulativ e rewa rds. F or all k ∈ [ K ], w e use λ k π = X s ∈S X a ∈A r k ( s, a ) d π ( s, a ) (19) where d π ( s, a ) is the steady state joint distrib ution of the state and actions u nder p olicy π . Equation (19) suggests th at we can transform the optimization problem in terms of optimal 9 Agar w al, Aggar w al p olicy to optimal steady-state distrib ution. Thus, we ha v e the join t optimizati on p roblem in the f ollo wing form wh ic h uses steady state distrib u tions d ∗ = arg max d f X s ∈S ,a ∈A r 1 ( s, a ) d ( s, a ) , · · · , X s ∈S ,a ∈A r K ( s, a ) d ( s, a ) (20) with the follo wing set of constrain ts, X a ∈A d ( s ′ , a ) = X s ∈S ,a ∈A P ( s ′ | s, a ) d ( s, a ) ∀ s ′ ∈ S (21) X s ∈S ,a ∈A d ( s, a ) = 1 (22) d ( s, a ) ≥ 0 ∀ s ∈ S , a ∈ A (23) Constrain t (21) denotes the transition structure f or the underlyin g Mark o v Pro cess. Con- strain t (22), and constrain t (23) ensures that the solution is a v alid probabilit y distribution. Since f ( · · · ) is join tly conca ve, argum en ts in Equation (20) are linear, and the constraints in Equation (21,22,23) are linear, this is a conv ex optimizatio n problem. Since con v ex op- timizatio n problems can b e solv ed in p olynomial time (Bub ec k et al., 2015), w e can use standard approac hes to solv e Equation (20). After solving the optimization problem, w e find the optimal p olicy from the obtained steady state distribu tion d ∗ ( s, a ) as, π ∗ ( a | s ) = P r ( a, s ) P r ( s ) = d ∗ ( a, s ) P a ∈A d ∗ ( s, a ) (24) The prop osed mo d el-based algorithm estimates the transition pr ob ab ilities by in teract- ing with the environmen t. W e n eed the steady state distribution d π to exist for an y p olicy π . W e n ote that when th e priors of th e transition p robabilities P ( ·| s, a ) are a Diric hlet dis- tribution f or eac h s tate and action pair, suc h a steady state distr ib ution exists. Prop osition 1 formalizes th e r esu lt of the existence of a steady state distribu tion w hen th e tr an s ition probabilit y is sampled fr om a Diric hlet distr ibution. Prop osition 1 F or MDP M with state sp ac e S and action sp ac e A , let the tr ansition pr ob abilities P c ome f r om a Dirichlet distribution. Then, any p olicy π for M wil l have a ste ady state distribution ˆ d π given as ˆ d π ( s ′ ) = X s ∈S ˆ d π ( s ) X a ∈ b A π ( a | s ) P ( s ′ | s, a ) ∀ s ′ ∈ S . (25) Pro of The transition probabilities P ( s ′ | s, a ) follo w Dirichlet d istribution, and hence they are strictly p ositiv e. F urth er, as the p olicy π ( a | s ) is a probability d istribution on actions con- ditioned on s tate, π ( a | s ) ≥ 0 , P a π ( a | s ) = 1. So, there is a non zero transition probabilit y to reac h f rom state s ∈ S to state s ′ ∈ S . No w, note that all the en tries of th e transition probabilit y matrix are strictly p ositiv e. And, hence the Mark o v Chain ind uced o v er the MDP M b y any p olicy π is 1) irreducible, 10 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards as it is p ossible to r eac h any state fr om an y other state, and 2) ap eriod ic, as it is p ossible to reac h an y state in a single time s tep from an y other state. T ogether, we get the existence of the steady-state d istribution (Lawler, 201 8 ). T o complete the s etup for our algorithm, w e mak e few more assump tions stated b elo w . Assumption 5 The tr ansition pr ob abilities P ( ·| s, a ) of the Markov De cision Pr o c ess have a Dirichlet prior for al l state action p airs ( s, a ) . Since we assu me that trans ition probabilities of the MDP M f ollo w Diric hlet distribu - tions, all p olicies on M ha v e a steady-state distribution. Algorithm 1 Mo del-Based Joint Decision Making Algorithm 1: pro cedure Mod el Based Online ( S , A , [ K ] , f , r ) 2: Initialize N ( s, a, s ′ ) = 1 ∀ ( s, a, s ′ ) ∈ S × A × S 3: Initialize ν 0 ( s, a ) = 0 ∀ ( s, a ) ∈ S × A 4: Initialize π 1 ( a | s ) = 1 |A| ∀ ( a, s ) ∈ A × S 5: Initialize e = 1 6: for time s teps t = 1 , 2 , · · · do 7: Observe current state S t 8: Sample actio n to play A t ∼ π e ( ·| S t ) 9: Pla y A t , obtain rew ard r t ∈ [0 , 1] K and observ e next state S t +1 10: Up date N ( S t , A t , S t +1 ) ← N ( S t , A t , S t +1 ) + 1, ν e ( S t , A t ) ← ν e ( S t , A t ) + 1 11: if ν e ( S t , A t ) ≥ m ax { 1 , P e ′ = T h P ,k π ( s )( s ) (104) where P π ( s ′ | s ) = P a π ( a | s ) P ( s ′ | s, a ) and r k π ( s ) = P a π ( a | s ) r k ( s, a ). W e also define another op erator, ¯ T h ( s ) = ( min s,a r k ( s, a ) − λ k π + < P π ( ·| s ) , h >, s 6 = s ′ h P ,k π ( s ′ ) , s = s ′ (105) Note that ( T − ¯ T ) h P ,k π ( s ) = r k π ( s, a ) − min s,a r k ( s, a ) ≥ 0, for all s . Hence, we hav e ¯ T h ( s ) ≤ T h ( s ) = h P ,k π ( s ), f or all s . F urther, for an y tw o v ectors u, v , where all the elements of u are not sm aller than w we h av e ¯ T u ≥ ¯ T w . Hence, w e ha v e ¯ T n h P ,k π ( s ) ≤ h P ,k π ( s ) for all s . Unrolling the recurrence, w e ha v e h P ,k π ( s ) ≥ ¯ T n h P ,k π ( s ) = E − ( λ k π − min s,a r k ( s, a ))( n ∧ τ ) + h P ,k π ( S n ∧ τ ) (106) F or lim n → ∞ , w e ha v e h P ,k π ( s ) ≥ h P ,k π ( s ′ ) − D , completing the pro of. A.2 Bounding t he bias span for MDP w ith transition probabilities P k e Lemma 7 (Bounded Span of optimal MDP) F or a MDP with r ewar ds r k ( s, a ) and tr ansition pr ob abilities P k e ∈ P t e , for p olicy π e , the diffe r enc e of bias of any two states s , and s ′ , is u pp er b ounde d by the diameter of the true MDP D as: h P k e ,k π e ( s ) − h P k e ,k π e ( s ′ ) ≤ D ∀ s, s ′ ∈ S . (107) Pro of Note that λ P k e ,k π e ≥ λ P ′ ,k π e for all P ′ ∈ P t e . No w, consider the follo wing Bellman equation: h P k e ,k π e ( s ) = r k π e ( s, a ) − λ P k e ,k π e + < P k π e ,e ( ·| s ) , h P k e ,k π e > = T h P k e ,k π e ( s ) (108) 37 Agar w al, Aggar w al where r π e ( s ) = P a π e ( a | s ) r k ( s, a ) and P k π e ,e ( s ′ | s ) = P a π ( a | s ) P k e ( s ′ | s, a ). Consider t w o states s, s ′ ∈ S . Also, let τ b e a random v ariable defin ed as: τ = min { t ≥ 1 : S t = s ′ , S 1 = s } (109) W e also define another op erator, ¯ T h ( s ) = ( min s,a r k ( s, a ) − λ P k e ,k π e + < P π e ( ·| s ) , h >, s 6 = s ′ h P k e ,k π e ( s ′ ) , s = s ′ (110) where P π e ( ·| s ) = P a π e ( a | s ) P ( s ′ | s, a ). No w, for an y s ∈ S , note that h ( s ) = T h ( s ) (111) = max P ′ ∈P t e r k π e ( s ) − λ P k e ,k π e + < P ′ π e , h > (112) ≥ r k π e ( s ) − λ P k e ,k π e + < P π e , h > (113) ≥ m in s,a r k ( s, a ) − λ P k e ,k π e + < P π e , h > (114) = ¯ T h ( s ) (115) F urther, for an y t w o vecto rs u, v , where all the elemen ts of u are not smaller than w w e ha v e ¯ T u ≥ ¯ T w . Hence, we hav e ¯ T n h P ,k π ( s ) ≤ h P ,k π ( s ) for all s . Unr olling the recurr ence, we ha v e h P k e ,k π ( s ) ≥ ¯ T n h P k e ,k π ( s ) = E − ( λ k π − min s,a r k ( s, a ))( n ∧ τ ) + h P k e ,k π ( S n ∧ τ ) (116) F or lim n → ∞ , w e ha v e h P k e ,k π ( s ) ≥ h P k e ,k π ( s ′ ) − D , completing the pro of. 38 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards App endix B. Pro of of Lemmas from main text B.1 Pro of of Lemma 1 Pro of Note that for all s ∈ S , w e ha v e: V ˜ P ,k γ ,π ( s ) = E a ∼ π h Q ˜ P , k γ ,π ( s, a ) i (117) = E a ∼ π " B ˜ P , k γ ,π ( s, a ) + r ( s , a ) + γ X s ′ ∈S P ( s ′ | s, a ) V ˜ P , k γ π ( s ′ ) # (118) where Equation (118) follo ws from the definition of the Bellman error for state action p air s, a . Similarly , for the true MDP , w e ha v e, V P ,k γ ,π ( s ) = E a ∼ π h Q P ,k γ ,π ( s, a ) i (119) = E a ∼ π " r ( s, a ) + γ X s ′ ∈S P ( s ′ | s, a ) V P ,k γ ,π ( s ′ ) # (120) Subtracting Equation (120) fr om Equation (118), w e get: V ˜ P , k γ ,π ( s ) − V P ,k γ ,π ( s ) = E a ∼ π " B ˜ P , k γ ,π ( s, a ) + γ X s ′ ∈S P ( s ′ | s, a ) V ˜ P , k γ ,π − V ˜ P , k γ ,π ( s ′ ) # (121) = E a ∼ π h B ˜ P , k γ ,π ( s, a ) i + γ X s ′ ∈S P π V ˜ P , k γ ,π − V ˜ P ,k γ ,π ( s ′ ) (122) Using the vect or form at for the v alue fun ctions, we hav e, ¯ V π , ˜ P γ − ¯ V π ,P γ = ( I − γ P π ) − 1 E a ∼ π h B ˜ P , k γ ,π ( s, a ) i (123) No w, con v erting the v alue function to a verage p er-step rew ard w e ha v e, λ ˜ P , k π 1 S − λ k P ,π 1 S = lim γ → 1 (1 − γ ) ¯ V ˜ P , k γ ,π − ¯ V P ,k γ ,π (124) = lim γ → 1 (1 − γ ) ( I − γ P π ) − 1 E a ∼ π h B ˜ P , k γ ,π ( s, a ) i (125) = X s,a d π ( s, a ) B ˜ P ,k π ( s, a ) ! 1 S (126) where the last equation follo ws from the definition of o ccupancy measures b y Puterman (1994), and th e existence of the limit lim γ → 1 B ˜ P , k γ ,π in Equation (125) from Equation (134). 39 Agar w al, Aggar w al B.2 Pro of of Lemma 2 Pro of S tarting with the definition of Bellman err or in Equ ation (26), we get B ˜ P , k π ( s, a ) = lim γ → 1 Q ˜ P , k γ ,π ( s, a ) − r ( s, a ) + γ X s ′ ∈S P ( s ′ | s, a ) V ˜ P , k γ ,π ( s ′ ) !! (127) = lim γ → 1 r ( s, a ) + γ X s ′ ∈S ˜ P ( s ′ | s, a ) V ˜ P ,k γ ,π ( s ′ ) ! − r ( s, a ) + γ X s ′ ∈S P ( s ′ | s, a ) V ˜ P ,k γ ,π ( s ′ ) !! (128) = lim γ → 1 γ X s ′ ∈S ˜ P ( s ′ | s, a ) − P ( s ′ | s, a ) V ˜ P , k γ ,π ( s ′ ) (129) = lim γ → 1 γ X s ′ ∈S ˜ P ( s ′ | s, a ) − P ( s ′ | s, a ) V ˜ P , k γ ,π ( s ′ ) + V ˜ P ,k γ ,π ( s ) − V ˜ P , k γ ,π ( s ) ! (130) = lim γ → 1 γ X s ′ ∈S ˜ P ( s ′ | s, a ) − P ( s ′ | s, a ) V ˜ P , k γ ,π ( s ′ ) − X s ′ ∈S ˜ P ( s ′ | s, a ) V ˜ P ,k γ ,π ( s ) + X s ′ ∈S P ( s ′ | s, a ) V ˜ P , k γ ,π ( s ) ! (131) = lim γ → 1 γ X s ′ ∈S ˜ P ( s ′ | s, a ) − P ( s ′ | s, a ) V ˜ P , k γ ,π ( s ′ ) − V ˜ P , k γ ,π ( s ) ! (132) = X s ′ ∈S ˜ P ( s ′ | s, a ) − P ( s ′ | s, a ) lim γ → 1 γ V ˜ P , k γ ,π ( s ′ ) − V ˜ P , k γ ,π ( s ) ! (133) = X s ′ ∈S ˜ P ( s ′ | s, a ) − P ( s ′ | s, a ) h ˜ P ,k π ( s ′ ) ! (134) ≤ ˜ P ( ·| s, a ) − P ( ·| s, a ) 1 k h ˜ P , k π ( · ) k ∞ (135) ≤ ǫ s,a ˜ D (136) where Eq u ation (129) comes from the assump tion that th e r ew ards are known to the agent . Equation (133) follo w s f r om the fact th at the difference b et we en v alue function at t w o states is b ounded. Equ ation (134) comes from the definition of bias term Puterman (199 4 ) where h is th e bias of the p olicy π when ru n on th e samp led MDP . Equation (135) follo ws from H¨ older’s inequ ality . In Equation (136 ), k h ( · ) k ∞ is b ounded b y the diameter ˜ D of the sampled MDP(from Lemma 6). Also, the ℓ 1 norm of p robabilit y ve ctor difference is b ound ed from the definition. Additionally , note that the ℓ 1 norm in Equation (135 ) is b ou n ded b y 2. Thus the Bell- man error is lo ose up p er b oun ded by 2 ˜ D for all state-action pairs. 40 Reinf orceme nt Learning f or Jo int Optimiza tion of Mul tiple Rew ards B.3 Pro of of Lemma 3 Pro of F r om the result of W eissman et al. (2003), the ℓ 1 distance of a p r obabilit y distribu - tion o v er S even ts with n samples is b ounded as: P k P ( ·| s, a ) − ˆ P ( ·| s, a ) k 1 ≥ ǫ ≤ (2 S − 2) exp − n ( s, a ) ǫ 2 2 ≤ (2 S ) exp − n ( s, a ) ǫ 2 2 (137) Th us, for ǫ = q 2 n ( s,a ) log(2 S 20 S At 7 ) ≤ q 14 S n ( s,a ) log(2 At ) ≤ q 14 S n ( s,a ) log(2 AT ), we h av e P k P ( ·| s, a ) − ˆ P ( ·| s, a ) k 1 ≥ s 14 S n ( s, a ) log(2 At ) ! ≤ (2 S ) exp − n ( s, a ) 2 2 n ( s, a ) log(2 S 20 S At 7 ) (138) = 2 S 1 2 S 20 S At 7 (139) = 1 20 AS t 7 (140) W e su m o v er the all the p ossib le v alues of n ( s, a ) till t time-step to b ound th e probabilit y that the ev en t E t do es not occur as: t X n ( s,a )=1 1 20 S At 7 ≤ 1 20 S At 6 (141) Finally , summin g ov er all the s, a , we get P k P ( ·| s, a ) − ˆ P ( ·| s, a ) k 1 ≥ s 14 S n ( s, a ) log(2 At ) ∀ s, a ! ≤ 1 20 t 6 (142) 41
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment