Large-Scale Traffic Signal Control Using a Novel Multi-Agent Reinforcement Learning
Finding the optimal signal timing strategy is a difficult task for the problem of large-scale traffic signal control (TSC). Multi-Agent Reinforcement Learning (MARL) is a promising method to solve this problem. However, there is still room for improv…
Authors: Xiaoqiang Wang, Liangjun Ke, Zhimin Qiao
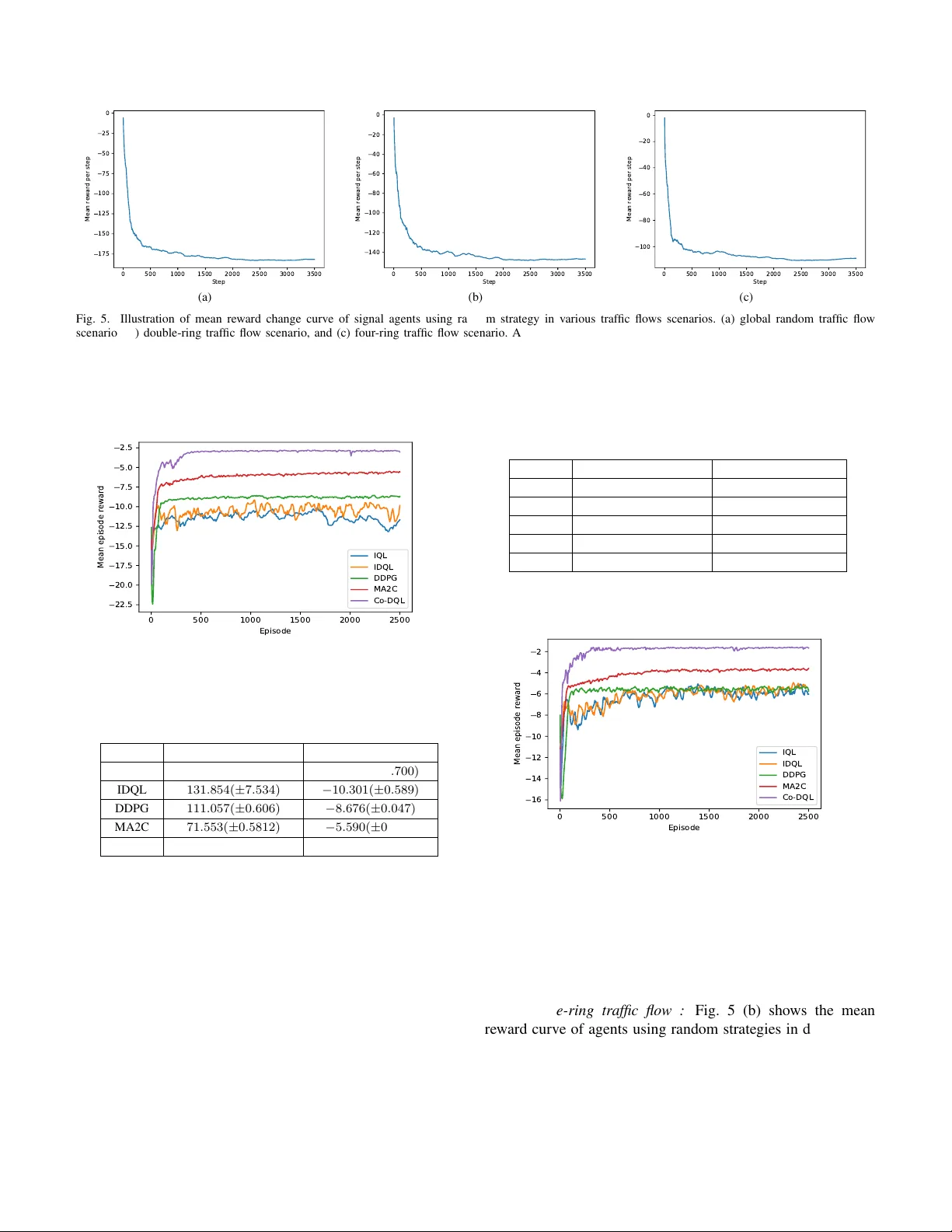
This is the author’ s version of an article that has been published in IEEE T ransaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 Lar ge-scale T raf fic Signal Control Using a Nov el Multi-Agent Reinforcement Learning Xiaoqiang W ang, Liangjun K e, Member , IEEE, Zhimin Qiao, and Xinghua Chai Abstract —Finding the optimal signal timing strategy is a difficult task for the pr oblem of large-scale traffic signal con- trol (TSC). Multi-Agent Reinf orcement Learning (MARL) is a promising method to solve this problem. Howev er , there is still room f or improv ement in extending to large-scale problems and modeling the beha viors of other agents for each individual agent. In this paper , a new MARL, called Cooperative double Q-learning (Co-DQL), is proposed, which has several prominent features. It uses a highly scalable independent double Q-learning method based on double estimators and the upper confidence bound (UCB) policy , which can eliminate the over -estimation problem existing in traditional independent Q-learning while ensuring exploration. It uses mean field approximation to model the interaction among agents, thereby making agents learn a better cooperative strategy . In order to improv e the stability and robustness of the learning process, we introduce a new reward allocation mechanism and a local state sharing method. In addition, we analyze the conv ergence properties of the proposed algorithm. Co-DQL is applied to TSC and tested on various traffic flow scenarios of TSC simulators. The results show that Co-DQL outperf orms the state-of-the-art decentralized MARL algorithms in terms of multiple traffic metrics. Index T erms —T raffic signal control, mean field approximation, multi-agent reinf orcement learning, double estimators. I . I N T RO D U C T I O N T RAFFIC congestion is becoming a great puzzling prob- lem in urban, mainly due to the difficulty of effecti v e utilization of limited road resources (e.g. road width). By regulating traffic flo w of road network, the traffic signal control (TSC) at intersections plays an important role in utilizing the road resources and helping to reduce traffic congestion [1]. Many researchers have de voted efforts to TSC, with the aim of minimizing the average waiting time in the whole traffic system and maximizing social welfare [2]. When traffic signals are large-scale, the traditional control methods such as pre-timed [3] and actuated control systems [4] may fail to deal with the dynamic of the traf fic conditions or lack the ability to foresee traffic flow . Intelligent computing methods (such as genetic algorithm [5], swarm intelligence [6], neuro- fuzzy networks [7] [8]), ho wev er , in many cases, suffer from a slow con vergence rate. Reinforcement learning (RL) [9] is a promising adaptiv e decision-making method in many fields. It has been applied to cope with TSC [10] [11]. It can not only X. W ang, L. Ke and Z. Qiao are with State Ke y Labora- tory for Manufacturing Systems Engineering, School of Automation Science and Engineering, Xi’an Jiaotong University , Xi’an, Shaanxi, 710049, China. (e-mail: wangxq5127@stu.xjtu.edu.cn; keljxjtu@xjtu.edu.cn; qiao.miracle@gmail.com)(Corresponding author: Liangjun Ke.). X. W ang and X. Chai are with CETC Key Laboratory of Aerospace Information Applications, Shijiazhuang, Hebei, China (e-mail: cetc54008@yeah.net). make real-time decisions according to traffic flo w , but also predict future traffic flow . Especially in recent years, RL has made tremendous progress which significantly attributes to the success of deep learning [12]. By using deep neural network to approximate the value function or action-value function (such as DQN [13], DDPG [14]), RL can be adapted to the problems with large-scale state space or action space. As for TSC with multiple signalized intersections, a straight- forward idea is centralized, in which TSC is considered as a single-agent learning problem [5] [15]. Howe ver , a centralized approaches often need to collect all traffic data in the network as the global state [16], which may lead to high latency and failure rate. In addition, as the number of intersections increases, the joint state space and action space of the agent will increase exponentially to a large extent, which incurs the curse of dimension. Consequently , a centralized method often requires very heavy computational and communication burden. An alternative way is multi-agent reinforcement learning (MARL) in which each signalized intersection is regarded as an agent. A challenge of a MARL approach is how to response to the dynamic interaction between each signal agent and the environment, which significantly af fects the adaptiv e decision-making of other signals [17]. Moreover , most of the current MARL methods are only studied on very limited- size traffic network problems [18] [19]. Howe ver , in urban traffic systems, it is often necessary to consider all the signals in a global coordination manner . In [20] [21], each signal is regarded as an independent agent for training. Although this class of approaches can easily be extended to large-scale scenarios, they directly ignore the actions of other agents in the road network system and implicitly suggest that the en vironment is static. This makes it dif ficult for agents to learn fa vorable strategies with conv ergence guarantee. In [22], a max-plus method is proposed to deal with large-scale TSC problem, but this approach requires additional computation during execution. Multi-agent A2C [23] is dev eloped from IA2C which is scalable and belongs to a decentralized MARL algorithm, but it may be uneasy to determine the appropriate attenuation factor to weaken the state and reward information from other agents. In this work, we present a decentralized and scalable MARL method which is named after Cooperative double Q-learning (Co-DQL) and apply it to TSC. The new approach adopts a highly scalable independent double Q-learning method, with the aim of av oiding the problem of over -estimation suffered from traditional independent Q-learning [24]. At the mean time, it can ensure exploration by using the upper confidence bound (UCB) [25] rule. In order to make agents learn a better Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 1 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 cooperativ e strategy for large-scale problems, it employs mean field theory [26], which has been studied in [27]. It approxi- mately treats the interactions within the population of agents as the interaction between a single agent and a virtual agent av eraged by other indi viduals, which potentially transmits the action information among all agents in the environment. Furthermore, we introduce a new re ward allocation mechanism and a local state sharing method to make the learning process of agents more stable and robust. T o theoretically support the effecti veness of the proposed algorithm, we provide the con ver gence proof for the proposed algorithm under some mild conditions. Numerical experiment is performed on various traffic flow scenarios of TSC simulators. The empirical results show that the proposed method outperforms several state-of- the-art decentralized MARL algorithms in terms of multiple traffic metrics. The paper is organised into six sections. Section II describes the background on RL. Section III presents the proposed method and analyzes the con ver gence properties. Section IV introduces the application of Co-DQL to TSC problem. Sec- tion V describes the setup and conditions of the experiments in detail, and makes a comparative analysis and discussion on the experimental results. Section VI summarises this paper . I I . B AC K G RO U N D O N R E I N F O R C E M E N T L E A R N I N G A. Single-Agent RL Q-learning is one of the most popular RL methods and it solves sequential decision-making problems by learning esti- mates for the optimal value of each action. The optimal value can be expressed as Q ∗ ( s, a ) = max π Q π ( s, a ) . Howe ver , it is not easy to learn the values of all the actions in all states when the state space or action space is larger . In this case, we can learn a parameterized action-value function Q ( s, a ; θ ) . When taking action a t in state s t and observing the immediate re ward r t +1 and resulting state s t +1 , the standard Q-learning updates the parameters as follows: θ t +1 = θ t + α Y Q t − Q ( s t , a t ; θ t ) ∇ θ t Q ( s t , a t ; θ t ) , (1) where t is the time step, α is the learning rate and the target Y Q t is defined as: Y Q t ≡ r t +1 + γ max a Q ( s t +1 , a ; θ t ) , (2) where the constant γ ∈ [0 , 1) is the discount factor that trades of f the importance of immediate and later rew ards. After updating gradually , it can conv erge to optimal action-v alue function. Note that Q-learning approximates the value of the next state by maximizing ov er the estimated action values in the corresponding state, namely , max a Q t ( s t +1 , a ; θ t ) and it is an estimate of E { max a Q t ( s t +1 , a ; θ t ) } , which in turn is used to approximate max a E { Q t ( s t +1 , a ; θ t ) } . This method of approximating the maximum expected v alue has a positiv e deviation [24] [28] [29], which leads to over -estimation of the optimal v alue and may damage the performance. B. Multi-Agent RL The single-agent RL is based on Markov decision process (MDP) theory , while for MARL, it mainly stems from Markov game [30], which generalizes the MDP and was proposed as the standard framework for MARL [31]. W e can use a tuple to formalize Marko v game, namely ( N , S , A 1 , 2 ,...,N , r 1 , 2 ,...,N , p ) , where N being the number of agents in the game system, S = { s 1 , . . . , s n } is a finite set of system states, n being the number of states in the system, A k is the action set of agent k ∈ { 1 , . . . , N } ; r k : S × A 1 × . . . × A N × S → R is the re ward function of agent k , determining the immediate re ward, p : S × A 1 × . . . × A N → µ ( S ) is the transition function. Each agent has its own strate gy and chooses actions according to its strategy . Under the joint strategy π , ( π 1 , . . . , π N ) , at each time step, the system state is transferred by taking the joint action a = ( a 1 , . . . , a N ) selected according to the joint strategy and each agent receives the immediate re ward as the consequence of taking the joint action. T o measure the performance of a strategy , either the future discounted rew ard or the av erage reward over time can b e used, depending on the policies of other agents. This results in the following definition for the expected discounted rew ard for agent k under a joint policy π and initial state s (0) = s ∈ S : V π k ( s ) = E π ( ∞ X t =0 γ t r k ( t + 1) | s (0) = s ) , (3) while the av erage re ward for agent k under this joint policy is defined as: J π k ( s ) = lim T →∞ 1 T E π ( T X t =0 r k ( t + 1) | s (0) = s ) . (4) On the basis of Eq. (3) (the most used form), the action- value function Q π k : S × A 1 × . . . × A N → R of agent k under the joint strategy π can be written as follows according to Bellman equation: Q π k ( s, a ) = r k ( s, a ) + γ E s 0 ∼ p [ V π k ( s 0 )] , (5) where V π k ( s ) = E a ∼ π [ Q π k ( s, a )] and s 0 is the system state at the next time step. The commonly used MARL methods are generally based on Q-learning. The general multi-agent Q-learning frame work is shown in Algorithm 1. MARL enables each agent to learn the optimal strategy to maximize its cumulativ e re ward. Howe ver , the v alue function of each agent is related to the joint strategy π of all agents, so it is in general impossible for all players in a game to maximize their payoff simultaneously . For MARL, an important solution concept is Nash equilibrium . Given these opponent strategies, the best r esponse of agent k to a vector of opponent strategies is defined as the strategy π ∗ k that achiev es the maximum expected reward, which is given as follo ws: E { r k | π 1 , . . . , π k , . . . , π N } ≤ E { r k | π 1 , . . . , π ∗ k , . . . , π N } , ∀ π k . (6) Then the Nash equilibrium is represented by a joint strategy π ∗ , ( π ∗ 1 , . . . , π ∗ N ) in which each agent acts with the best r esponse π ∗ k to others and all other agents follow the joint Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 2 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 Algorithm 1: general multi-agent Q-learning framework Input: Initial Q value of all state-action pairs for each agent k Output: Conv ergent Q value for each agent k 1 Initialize Q k ( s, a ) = 0 , ∀ s, a , k ; 2 while not termination condition do 3 for all ag ents k do 4 select action a k 5 ex ecute joint action a = ( a 1 , . . . a N ) ; 6 observe new state s 0 , rewards r k ; 7 for all ag ents k do 8 Q k ( s, a ) = (1 − α ) Q k ( s, a ) + α [ r k ( s, a ) + γ V k ( s 0 )] policy π ∗ − k of all agents except k , where the joint policy π ∗ − k , π ∗ 1 , . . . , π ∗ k − 1 , π ∗ k +1 , . . . , π ∗ N . In this case, as long as all other agents keep their policies unchanged, no agent can benefit by changing its policy . Many MARL algorithms revie wed stri ve to con verge to Nash equilibrium . In addition, the Q-function will ev entually con ver ge to the Nash Q-value Q ∗ = ( Q ∗ 1 , . . . , Q ∗ N ) received in a Nash equilibrium of the game. I I I . D E S C R I P T I O N O F T H E P RO P O S E D M E T H O D Co-DQL is dev eloped from a new algorithm, called in- dependent double Q-learning method, which is also firstly proposed in this paper . In the following, we first present the independent double Q-learning method, and then introduce Co-DQL, finally , we analyze its conv ergence properties. A. Independent Double Q-learning Method Most MARL methods are based on Q-learning. Howe ver , as described in Section II-A, traditional RL methods cause the problem of over -estimation, which to some extent harms the performance of RL methods. In [24], a double Q-learning algorithm is proposed, which uses double estimators instead of max a Q t ( s t +1 , a ) to approximate max a E { Q t ( s t +1 , a ) } , which is helpful to av oid the problem of over -estimation in standard Q-learning. Inspired by independent Q-learning [21], we de velop an independent double Q-learning method based on the UCB rule. For each agent k , it is associated with two different action-value functions, each of which is updated with a value from the other action-value function for the next state. More specifically , suppose that the two action-v alue functions are Q a k and Q b k , and one of them is randomly selected for updating each time. The updating process of the action-v alue function Q a k is as follo ws. Firstly , the maximal valued action a ∗ k in the next state s 0 is selected according to the action-value function Q a k , namely , a ∗ k = argmax a Q a k ( s 0 , a ) . Then we use the value Q b k ( s 0 , a ∗ k ) to update Q a k : Q a k ( s, a ) ← Q a k ( s, a ) + α r k + γ Q b k ( s 0 , a ∗ k ) − Q a k ( s, a ) , (7) instead of using the value Q a k ( s 0 , a ∗ k ) = max a Q a k ( s 0 , a ) to update Q a k in independent Q-learning. The updating of Q b k is similar to this. Here two multi-layer neural networks are used to fit the two Q functions, which are expressed as Q a k ( s, a ; θ t ) and Q b k s, a ; θ 0 t respectiv ely . Usually the latter is called target Q-function (or target network). The update mode is similar to the one of deep double Q-learning [28] and the target value Y k,t ≡ r k,t +1 + γ Q b k ( s t +1 , argmax a Q a k ( s t +1 , a ; θ t ) , θ 0 t ) . In order to make the target network update smoother , we adopt the soft target update [14] instead of copying the network weights directly [13]: θ 0 ← − τ θ + (1 − τ ) θ 0 , (8) where τ 1 . The soft update method makes the weights of the target Q-function change slowly , so does the target v alues. Compared with the direct copy of the weights, the soft update method can enhance the learning stability [13]. T o balance e xploration and exploitation, the UCB explo- ration strategy is used to select an action to be performed by the agent k : a k = argmax c ∈ A k ( Q k ( s k , c ) + s ln R s k R s k ,c ) , (9) where R s k denotes the number of times state s k has been visited and R s k ,c denotes the number of times action c has been chosen in this state until now . If action c has been chosen rarely in some states, then the second term will dominate the first term and action c will be explored. As learning progresses, the first term dominates the second term and the UCB strategy ultimately becomes a greedy one. Although -greedy strategy is easier to implement for problems with larger state space, we prefer the UCB strategy if possible, since in the preliminary test we observe that the UCB strategy is slightly better than the -greedy strategy [32]. From the perspectiv e of exploration mechanism, the exploratory action selection for UCB is based on both the learnt Q-values and the number of times an action has been chosen in the past, hence it tends to be more inclined to explore those actions that are rarely explored. In this method, agent k just regards other agents as a part of the en vironment. Therefore, this method ignores the dynamic resulting from the actions of the other agents and the con ver gence is not guarantee. In order to learn a better cooperativ e strategies and make learning process more stable and robust, we introduce Co-DQL, which uses mean field approximation, a new re ward allocation mechanism and local state sharing method. B. Cooperative Double Q-learning Method W ith the number of agents increasing, the dimension of joint action a increases exponentially , so when the number of agents is relatively large, it is often not feasible to directly calculate the joint action function Q k ( s, a ) for each agent k . Mean field approximation is first proposed in [27] to deal with the problem. Its core idea is that the interactions within the population of agents are approximated by those between an agent and the average of its neighboring agents 1 . Specifically , 1 The neighborhood size is a user-specific parameter . It can take a value from [1, N ] where N is the total number of agents. Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 3 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 a very natural approach is to decompose the joint action-v alue function as follows: Q k ( s k , a ) = E l ∼ d [ Q k ( s k , a k , a l )] , (10) where d is the uniform distrib ution on the index set N ( k ) which is the set of the neighboring agents of agent k and the size of the index set is N k = |N ( k ) | . Suppose that each agent has C discrete actions { 1 , 2 , . . . , C } . Then the action a k of agent k can be coded using one-hot, namely , a k , [ a k, 1 , a k, 2 , . . . , a k,C ] , where each component corresponds to a possible action, and obviously at any time only one component is one and the others are zero. Hence the mean action a k can be expressed as: a k , [ a k, 1 , a k, 2 , . . . , a k,C ] , where each component a k,i = E l ∼ d [ a l,i ] for i ∈ { 1 , 2 , . . . , C } , simply recorded as a k = E l ∼ d [ a l ] . Intuiti vely , a k can be seen as the empirical distribution of the actions taken by the neighbors of agent k [27]. Naturally , there is the following relationship between the one-hot coding action a l of agent l and the mean action: a l = a k + δ l,k , (11) where δ l,k is a small fluctuation. Under the premise of twice- differentiable, using T aylor expansion theory , the mean field approximation is expressed by the following formulation on the basis of Eq. 10: Q k ( s k , a ) = E l ∼ d [ Q k ( s k , a k , a l )] = E l ∼ d [ Q k ( s k , a k , a k ) + ∇ Q k ( s k , a k , a k ) · δ l,k + 1 2 δ l,k · ∇ 2 Q k ( s k , a k , ξ l,k ) · δ l,k ] = Q k ( s k , a k , a k ) + ∇ Q k ( s k , a k , a k ) · E l ∼ d [ δ l,k ] + 1 2 E l ∼ d [ δ l,k · ∇ 2 Q k ( s k , a k , ξ l,k ) · δ l,k ] = Q k ( s k , a k , a k ) + 1 2 E l ∼ d [ R k ( a l )] ≈ Q k ( s k , a k , a k ) , (12) where E l ∼ d [ δ l,k ] = 0 is easily known from Eq. 11, and R k ( a l ) , δ l,k · ∇ 2 Q k ( s k , a k , ξ l,k ) · δ l,k denotes the T aylor polynomial’ s remainder with ξ l,k = a k + l,k · δ l,k and l,k ∈ [0 , 1] [27]. Under some mild conditions, it can be prov ed that R k ( a l ) is a random variable close to zero and can be omitted [27]. For large-scale TSC, this way of implicit modeling the behavior of other agents has great advantages, which makes the input dimension of each agent k ’ s Q-function drastically reduce, and the joint action dimension decreases from C N k to constant C 2 . It is worth noting that we only need to pay attention to the actions of the current time step, rather than the historical behavior of the neighbors. This is mainly due to the fact that the traffic state dynamics is Markovian, which will be further discussed in Section IV -A. For partially observable Marko v traffic scenarios, each agent k can get its own re ward r k and local observation s k at each time step. The goal of MARL in cooperativ e situation is to maximize the global benefits or minimize the regrets 2 . Howe ver , there may be the so-called credit assignment 2 In this paper , regrets refer to the waiting time of vehicles, the length of queues, etc. problem [33] in MARL, so each agent often does not directly regard the global reward as its rew ard. Instead, we set each agent to maintain its own reward. In addition, if each agent only considers its own immediate reward, then the agent may become selfish, which may be harmful to cooperation. Based on the abov e considerations, we propose to allocate each agent’ s rew ard according to the following formulation: ˆ r k = r k + α · X i ∈N ( k ) r i , (13) where α ∈ [0 , 1] is a discount factor that can be flexibly used to balance selfishness and cooperation. If α is set to 0, then each signal agent only considers the immediate rew ard of its o wn intersection, greedily maximizing the throughput of its own intersection, which may damage the global reward of the road network; if α is set to 1, this means that each agent may get the global rew ard and suffers from credit assignment problem as described earlier . Specifically , we make 0 < α < 1 . The idea behind is as follo ws: F or each signal agent k , despite the action selection may be not always beneficial to the neighboring agents, the reallocated rew ard received after an action depends on its o wn immediate reward and the immediate re ward of the neighboring agents. Once the immediate rewards of the neighboring agents are lo w , the second term of Eq. 13 will tak e a small value which means the action taken by signal agent k may be not so great for the neighboring agents. While higher immediate rew ards of the neighboring agents will encourage signal agent k and accordingly the second term of Eq. 13 will take a larger value. This reward allocation mechanism in Eq. 13 in turn affects the action selection of agent k , with the aim of maximizing the global re ward of the road network. The rew ard allocation mechanism is similar to the one mentioned in [23], but we do not strictly limit the distance between agent k and the neighboring agents. The local state sharing method is described below . For agent k , the average of the local state of its neighboring agents is taken as the additional input of agent k ’ s action-value function. Hence, the state of agent k can be represented as: ˆ s k = h s k , 1 N k X i ∈N ( k ) s i i , (14) where ˆ s k represents agent k ’ s joint state. This method implic- itly shares state information among agents, and if the dimen- sion of local state is assumed to be | s | , its joint dimension is constant | s | 2 , which is independent of the number of agents. Based on the abo ve introduction, Cooper ative double Q- learning (Co-DQL) algorithm is proposed. Compared with the centralized control method [16] [34], this algorithm re- duces the joint input dimension of action-value function from C N k · | s | N k to C 2 · | s | 2 at the cost of a small amount of communication and calculation [27], which avoids the curse of dimension in large-scale problems. The pseudo code of Co- DQL is giv en in Algorithm 2. In this algorithm, multi-layer perceptions parameterized by φ and φ − are used to represent the two action-value functions of each agent. Co-DQL works as follo ws: Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 4 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 Step 0 Initialize: For each k = 1 , . . . , N , initialize neural network parameters φ k , φ − ,k and initialize mean action a k for agent k . Step 1 Check the termination condition: If a problem- specific stopping condition is met, stop and sav e the training neural network model. Step 2 Select action: For each k = 1 , . . . , N , according to the current observation ˆ s k of agent k , select action a k under the UCB policy . Step 3 Execute action: For each k = 1 , . . . , N , agent k ex ecutes action a k (all agents execute action syn- chronously), gets immediate reward r k and next state observation s 0 k . Step 4 Obtain samples: For each k = 1 , . . . , N , compute the mean action a k , re ward ˆ r k after reallocation and next local state ˆ s 0 k after sharing. Step 5 Store samples in buffer: For each k = 1 , . . . , N , store the results of step 4 as a tuple sample ˆ s , a , ˆ r , ˆ s 0 , a in replay buf fer D k ; If the number of samples stored in the D k is less than the minimum number of samples required for training, goto Step 1, otherwise the next step is executed sequentially . Step 6 Compute sample target values: For each k = 1 , . . . , N , M samples are randomly extracted from D k and the target value Y Co − DQL k is calculated according to the sample data. Step 7 Update Neural Network Parameters: For each k = 1 , . . . , N , the gradient of the parameter φ k is obtained from the loss function, and φ k is updated according to the learning rate, then φ − ,k is softly updated with update rate τ . Goto Step 1. For most RL algorithms, the termination condition is gen- erally set to be that the number of episodes experienced by agents reachs the preset number . The preset number of episodes is usually selected according to the training situation of the algorithm in the gi ven problem. The action-value function Q a k ( ·| φ ) (parameterized by φ ) is trained by minimizing the loss: ` ( φ k ) = Q a k ( ˆ s k , a k , a k ; φ ) − Y Co − DQL k 2 , (15) where Y Co − DQL k is the target v alue of agent k and is calculated by the following formulation: Y Co − DQL k = ˆ r k + γ Q b k ( ˆ s 0 k , argmax a k Q a k ( ˆ s 0 k ,a k ,a k ; φ ) , a 0 k ; φ − ) , (16) In Co-DQL, the mean field approximation makes ev ery independent agent learn the awareness of collaboration with the others. Moreover , the re ward allocation mechanism and the local state sharing method of agents improv e the stability and robustness of the training process compared with the independent agent learning method. In order to theoretically support the effecti veness of our proposed Co-DQL algorithm, we provide the con vergence proof under some assumptions in the next subsection. Algorithm 2: Co-DQL Input: Initial parameters φ and mean action a for all agents Output: Parameters φ for all agents 1 Initialize Q a k ( ·| φ ) , Q b k ( ·| φ − ) and a k for all k ∈ { 1 , . . . , N } 2 while not termination condition do 3 For each agent k , select action a k using the UCB exploration strategy from Eq. 9 4 T ake the joint action a = ( a 1 , . . . a N ) and observe the re ward r = ( r 1 , . . . , r N ) and the next observations s 0 = ( s 0 1 , . . . , s 0 N ) 5 Compute a , ˆ r , ˆ s and ˆ s 0 6 Store ˆ s , a , ˆ r , ˆ s 0 , a in replay buf fer D 7 for k = 1 to N do 8 Sample M experiences ˆ s , a , ˆ r , ˆ s 0 , a from D 9 Compute target value Y Co − DQL k by Eq. 16 10 Update the Q network by minimizing the loss L ( φ k ) = 1 M X Q a k ( ˆ s k , a k , a k ; φ ) − Y Co − DQL k 2 11 Update the parameters of the target network for each agent k with updating rate τ φ − k ← τ φ k + (1 − τ ) φ , k C. Conver g ence Analysis In pre vious literature, the conv ergence of mean field Q- learning under the set of tabular Q-functions and the con ver- gence of when Q-function is represented by other function approximators have been proved [35] [27]. Under similar constraints, we de velop the conv ergence proof of Co-DQL, which is the mean field RL with double estimators. Assuming that there are only a limited number of state- action pairs, for each agent k , we can write updating rules of two functions Q a k and Q b k of agent k according to Section III-A and Section III-B: Q a k ( s, a k , a k ) ← (1 − α ) Q a k ( s, a k , a k ) + α ( r + γ Q b k ( s 0 , a ∗ k , a k )) Q b k ( s, a k , a k ) ← (1 − α ) Q b k ( s, a k , a k ) + α ( r + γ Q a k ( s 0 , b ∗ k , a k )) , (17) where a ∗ k = argmax a k Q a k ( s 0 , a k , a k ) , and b ∗ k = argmax a k Q b k ( s 0 , a k , a k ) . At any update time step, either of the two of Eq. 17 is updated. Our goal is to prove that both Q a = ( Q a 1 , . . . , Q a N ) and Q b = ( Q b 1 , . . . , Q b N ) con verge to Nash Q-values. Our proof follows the con vergence proof framew ork of single agent Double Q-learning [24], and we use the following assumptions and lemma. Assumption 1. Each action-value pair is visited infinitely often, and the r ewar d is bounded by some constant K . Assumption 2. Agent’ s policy is Gr eedy in the Limit with Infinite Exploration (GLIE). In the case with the Boltzmann policy , the policy becomes gr eedy w .r .t. the Q-function in the limit as the temperatur e decays asymptotically to zer o. Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 5 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 Assumption 3. F or each stage game [ Q 1 t ( s ) , . . . , Q N t ( s )] at time t and in state s in training, for all t, s, j ∈ { 1 , . . . , N } , the Nash equilibrium π ∗ = [ π 1 ∗ , . . . , π N ∗ ] is r ecognized either as 1) the global optimum or 2) a saddle point expr essed as: 1) E π ∗ [ Q j t ( s )] ≥ E π [ Q j t ( s )] , ∀ π ∈ Ω( Q k A k ) ; 2) E π ∗ [ Q j t ( s )] ≥ E π j E π − j ∗ [ Q j t ( s )] , ∀ π j ∈ Ω( A j ) and E π ∗ [ Q j t ( s )] ≤ E π j ∗ E π − j [ Q j t ( s )] , ∀ π − j ∈ Ω( Q k 6 = j A k ) . Lemma 1. The random pr ocess { ∆ t } defined in R as ∆ t +1 ( x ) = (1 − α t ( x )) ∆ t ( x ) + α t ( x ) F t ( x ) con ver ges to zer o with probability 1 (w .p.1) when 1) 0 ≤ α t ( x ) ≤ 1 , P t α t ( x ) = ∞ , P t α 2 t ( x ) < ∞ ; 2) x ∈ X , the set of possible states, and | X | < ∞ ; 3) k E [ F t ( x ) |= t ] k W ≤ γ k ∆ t k W + c t , wher e γ ∈ [0 , 1) and c t con ver ges to zer o w .p.1; 4) v ar [ F t ( x ) |= t ] ≤ K (1 + k ∆ t k 2 W ) with constant K > 0 . Her e F t denotes the filtration of an increasing sequence of σ -fields including the history of processes; α t , ∆ t , F t ∈ F t and k · k W is a weighted maximum norm [30]. Pr oof. Similar to the proof of Theorem 1 in [36] and Corollary 5 in [37]. Our theorem and proof sketches are as follows: Theorem 1. In a finite-state stochastic game, if Assumption 1,2 & 3, and Lemma 1’ s first and second conditions are met, then both Q a and Q b as updated by the rule of Algorithm 2 in Eq. 17 will con ver ge to the Nash Q-value Q ∗ = ( Q ∗ 1 , . . . , Q ∗ N ) with pr obability one. Pr oof. W e need to sho w that the third and fourth conditions of Lemma 1 hold so that we can apply it to prove Theorem 1. Obviously , the updates of functions Q a and Q b are symmetri- cal, so as long as one of them is proved to conv erge, the other must con verge. By subtracting two sides of Eq. 17 by Q ∗ , and then the following formula can be obtained by comparing with the equation in Lemma 1: ∆ t ( s, a ) = Q a t ( s, a ) − Q ∗ ( s, a ) F t ( s t , a t ) = r t + γ Q b t ( s t +1 , a ∗ ) − Q ∗ ( s t , a t ) , (18) where a ∗ = argmax a Q a ( s t +1 , a t , a t ) . Let = t = { Q a 0 , Q b 0 , s 0 , a 0 , α 0 , r 1 , s 1 , . . . , s t , a t } denote the σ -fields generated by all random v ariables in the history of the stochastic game up to time t . Note that Q a t and Q b t are two random variables deriv ed from the historical trajectory up to time t . Given the fact that all Q a τ and Q b τ with τ < t are F t -measurable, both ∆ t and F t are therefore also F t - measurable. Since the re ward is bounded by some constant K in Assumption 1, then V ar[ r t ] < ∝ , the fourth condition in the lemma holds. Next, we sho w that the third condition of the lemma holds. W e can rewrite Eq. 18 as follows: F t ( s t , a t ) = F Q t ( s t , a t ) + γ ( Q b t ( s t +1 , a ∗ ) − Q a t ( s t +1 , a ∗ )) , (19) where F Q t = r t + γ Q a t ( s t +1 , a ∗ ) − Q ∗ ( s t , a t ) is the value of F t if normal MF-Q would be under consideration. In [17], k E [ F Q t |= t ] k W ≤ γ k ∆ t k W has been proved, so in order to meet the third condition, we identify c t = γ ( Q b t ( s t +1 , a ∗ ) − Q a t ( s t +1 , a ∗ )) and it is sufficient to show that ∆ ba t = Q b t − Q a t con ver ges to zero. The update of ∆ ba t depends on whether Q b or Q a is updated, so ∆ ba t +1 ( s t , a t ) = ∆ ba t ( s t , a t ) + α t F b t ( s t , a t ) , or ∆ ba t +1 ( s t , a t ) = ∆ ba t ( s t , a t ) − α t F b t ( s t , a t ) , (20) where F a t ( s t , a t ) = r t + γ Q b t ( s t +1 , a ∗ ) − Q a t ( s t , a t ) and F b t ( s t , a t ) = r t + γ Q a t ( s t +1 , b ∗ ) − Q b t ( s t , a t ) . W e define ξ ba t = 1 2 α t , then E [ ∆ ba t +1 ( s t , a t ) |= t ] = ∆ ba t ( s t , a t ) + E [ α t F b t ( s t , a t ) − α t F a t ( s t , a t ) |= t ] = ∆ ba t ( s t , a t ) + E [ α t γ ( Q a t ( s t +1 , b ∗ ) − Q b t ( s t +1 , a ∗ )) − α t ( Q b t ( s t , a t ) − Q a t ( s t , a t )) |= t ] = (1 − ξ ba t ( s t , a t )) ∆ ba t ( s t , a t ) + ξ ba t ( s t , a t ) E [ F ba t ( s t , a t ) |= t ] , where E [ F ba t ( s t , a t ) |= t ] = γ E [ Q a t ( s t +1 , a ∗ ) − Q b t ( s t +1 , a ∗ ) |= t ] . At each time step, one of the following two cases must hold. Case 1: E [ Q a t ( s t +1 , b ∗ ) |= t ] ≥ E [ Q b t ( s t +1 , a ∗ ) |= t ] . W e hav e Q a t ( s t +1 , a ∗ ) = max Q a t ( s t +1 , a ) ≥ Q a t ( s t +1 , b ∗ ) , therefore | E [ F ba t ( s t , a t ) |= t ] | = γ E [ Q a t ( s t +1 , b ∗ ) − Q b t ( s t +1 , a ∗ ) |= t ] ≤ γ E [ Q a t ( s t +1 , a ∗ ) − Q b t ( s t +1 , a ∗ ) |= t ] ≤ k ∆ ba t k . Case 2: E [ Q a t ( s t +1 , b ∗ ) |= t ] < E [ Q b t ( s t +1 , a ∗ ) |= t ] . W e hav e E [ Q b t ( s t +1 , b ∗ ) |= t ] ≥ E [ Q b t ( s t +1 , a ∗ ) |= t ] . Then | E [ F ba t ( s t , a t ) |= t ] | = γ E [ Q b t ( s t +1 , e ∗ ) − Q a t ( s t +1 , b ∗ ) |= t ] ≤ γ E [ Q b t ( s t +1 , b ∗ ) − Q a t ( s t +1 , b ∗ ) |= t ] ≤ k ∆ ba t k . Hence, no matter which of the above cases is hold, we can obtain the satisfactory result, that is, | E [ F ba t ( s t , a t ) |= t ] | ≤ k ∆ ba t k . Then, we can apply Lemma 1 and get the conv ergence of ∆ ba t to 0, the third condition is thus hold. Finally , with all conditions are satisfied, Theorem 1 is proved. I V . A P P L I C A T I O N O F C O - D Q L T O T S C This section first uses MDP notations to represent the key elements of TSC problem, so that MARL can be used in TSC. T o facilitate the training and ev aluation of the MARL model applied to TSC problem, we also introduce the TSC simulators. A. Description of TSC Based on MDP Notations Although we model the entire traffic network in a decen- tralized way as a multi-agent structure, the global state of the whole traf fic system is still Markov , namely , the ne xt state only depends on the current state: s t +1 = f ( s t , a t ) , (21) where s t and s t +1 denotes the state of traf fic system at time step t and t + 1 , a t denotes the joint action of the traffic Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 6 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 E n v i r o n m en t T r a ff ic li g h t 1 T r a f f ic li g h t 2 T r a ff ic li g h t N … E n v i r o n m en t Fig. 1. The architecture diagram of Co-DQL for TSC. For each k = 1 , . . . , N , ˆ s k denotes the local state information after sharing, ¯ a k represents the mean action information, a k means the action will be executed, r k , ˆ r k represent the immediate reward before and after reallocation, respectively . The red arrow , blue arrow and green arrow represent the transfer of reward information, action information and state information, respectively . system at time step t . Therefore, it can be modeled using the framew ork of MARL described in Section II-B. When to cope with TSC problem, there are many different MDP settings. Their differences lie in the definition of action space, state space or reward function, etc. [11] [23] [38] [39] [40] [41]. Here, we focus on the following two kinds of MDP settings. Note that it may be potential to extend our method to other kinds of settings. Since the source code of our method is open 3 , an interested reader can try to test or extend it to deal with other kinds of MDP settings. 1) A simplified MDP setting for TSC pr oblem: Suppose a road network has N signalized intersections, i.e., N signal agents. The action of signal agent k at time step t can be written as a k,t , and its local observation or state is s k,t . W e set the signal agent’ s actions at each intersection has only two possible cases { 0 , 1 } : Green traffic lights for incoming traffic in the north and south directions and red traffic lights in the east and west directions at the same time, or contrary to that, so the action space is { 0 , 1 } N . The local state, which is the observation vector s k,t , is the waiting queue density (or queue length) on all the one-way lanes (or edges) connected to the intersection k : s k,t = [ q [ kn ] , q [ k s ] , q [ k w ] , q [ k e ]] , where q [ kn ] , q [ k s ] , q [ k w ] and q [ k e ] represent the waiting queue den- sity in four directions related to intersection k respecti vely , and they are the lanes of vehicles driving in the direction of inter- section k . The value space of each of them can be expressed as { 0 , 1 , 2 , . . . , max q } , where max q is the maximum capacity of vehicles on an lane between every two intersections. For the peripheral signal agent of the system, if there is no road connected to it in a certain direction, the number of vehicles in that direction is always zero. For simplicity , it is assumed that a normally traveling vehicle has the same speed and can start or stop immediately . For any signal agent k , the rew ard at time step t can be calculated by the number of vehicles waiting on all lanes 3 https://github .com/Brucewangxq/lar ger real net tow ards the intersection, that is, r k,t = − X j ∈{ n,s,w,e } | q t [ k j ] | , (22) where q t [ k j ] is the number of vehicles that have zero speed on lane k j leading to intersection k . T o avoid changing traffic signal too frequently , the action can be taken e very ∆ t time steps, that is, a Markov state transition occurs only once e very ∆ t time steps. Then from the T -th to T + 1 -th state transition, the signal agent obtains the sum of the rewards in ∆ t time steps, that is, R T = T ∆ t − 1 X t =( T − 1)∆ t r t ( s t , a t ) , (23) Our goal is to minimize the total waiting time of vehicles in the traffic network: max π J = E T max X T =1 γ T − 1 1 ∆ t T ∆ t − 1 X t =( T − 1)∆ t r t ( s t , a t ) , (24) where T max denotes the total number of state transitions, and the joint action a changes e very ∆ t time steps. In this simplified situation, all other agents are treated as the neighboring agents of each agent. Fig. 1 shows how to apply Co-DQL to TSC. The input information of each agent includes the shared local state information and the mean action information calculated from actions of the neighboring agents in the previous time step. Each agent receives a reallocated rew ard after performing an action. 2) A more r ealistic MDP setting for TSC pr oblem: In the literature of RL for TSC, there are sev eral standard action definitions, such as phase duration [38], phase switch [39] [40] and phase itself [41] [23] [11]. Here, we follow the last definition and pre-define a set of feasible phases for each signal agent. Specifically , we adopt the definition of feasible phases in [23], which defines fiv e feasible phases for each signal agent, including east-west straight, east-west left-turn, and three straight and left-turn for east, west and north-south. These fi ve feasible phases constitute the action space, each phase corresponds to an action. Each signal agent selects one of them to implement for a duration of ∆ t at each Markov time step. In addition, a yello w time t y < ∆ t is enforced after each phase switch to ensure safety . After comprehensively understanding a variety of com- monly used state definitions [41] [38] [23], we tend to follow the one in [23] and define local state as s k,t = { w ait k,t [ lane ] , w av e k,t [ lane ] } , (25) where lane is each incoming lane of intersection k . wait measures the cumulative delay [s] of the first vehicle and w ave measures the total number [veh] of approaching ve- hicles along each incoming lane. In our experiment, we use laneAreaDetector in Simulation of Urban Mobility (SUMO) [42] [43] to obtain the state information, and in prac- tice, the state information can be obtained by near-intersection induction-loop detectors as described in [23]. Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 7 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 0 10 20 30 40 50 60 0 10 20 30 40 50 60 -3 -1 -9 -38 -2 -35 -3 -4 0 -2 -8 -6 -1 -3 -4 0 (a) 0 10 20 30 40 50 60 0 10 20 30 40 50 60 -3 0 -1 -22 0 -62 -10 -5 -1 0 -21 0 -2 0 0 -3 (b) 0 10 20 30 40 50 60 0 10 20 30 40 50 60 -2 -11 -1 -93 -4 -18 -1 -2 -2 -5 -15 -28 0 0 -4 -3 (c) Fig. 2. Illustration of the grid traffic signal system simulator. (a) global random traffic flow , (b) double-ring traffic flow , and (c) four-ring traffic flow . Each rectangle represents a signalized intersection and each two adjacent intersections are connected by two one-way lanes. The color of each lane implies the lev el of congestion and the number in the rectangle represents the immediate rew ard for the intersection. T ABLE I P A R A ME T E R S ET T I N GS F OR S IM U L A T OR Parameter T ype V alue [ unit of measur e ] Normal driving time between two nodes 5 [ t ] Initial vehicles in simulator 100 [ veh ] New vehicles added 5;4;3 [ veh/t ] Shortest route length 2 [ n ] Longest route length 20 [ n ] Signal agent action time interval 4 [ t ] Initial random seed number 10 t means discrete time step, veh is the abbreviation of vehicle, n denotes node, i.e. intersection. 5;4;3 [ veh/t ] means that the number of new vehicles added per time step is optional and can be set to 5,4 or 3 as needed. Similar to the definition of reward in the simplified TSC problem mentioned earlier, we also further consider the cu- mulativ e delay of the first car as a regularizer: r k,t = − X lane | q k,t +∆ t [ lane ] + β · wait k,t +∆ t [ lane ] | , (26) where β is the regularization rate and typically chosen to approximately scale different reward terms into the same range. Note that the re wards are only measured at time t + ∆ t . Compared to other rew ard definitions such as wav e [38] and appropriateness of green time [44], the reward we defined emphasizes traf fic congestion and travel delay , and it is directly correlated to state and action [23]. B. Description of the Simulation Platform 1) A simplified TSC simulator: The simulation platform used in Section V -B is a grid TSC system based on OpenAI- gym [45]. There are three different scenarios in the experi- ment: global random traf fic flow , double-ring traf fic flow and four-ring traffic flow which correspond to the three subfigures of Fig. 2 respectiv ely . Each rectangle denotes a signalized intersection and the number in the rectangle represents the immediate reward for the intersection. Every two adjacent intersections are con- nected by two one-way lanes. The color of each lane in the picture ranges from green to red, which vaguely means the number of vehicles waiting (at zero speed) on the lane, i.e. the lev el of congestion. Green means unimpeded and red indicates serious congestion. During the operation of the simulator , a certain number of vehicles will be generated at each time step and scattered randomly in the road network. And e very newly generated vehicle will have a randomly generated route according to a certain rule, and the v ehicle will follow the route and finally the vehicle will be removed from the road network when it reaches the destination. Among these three scenarios, the one difference is that the rules of generating a driving route of a vehicle, which results in different lev el of congestion at dif ferent intersections. This can simulate the real information of the traffic flow between the main and secondary roads in the city . In the actual traffic network, serious congestion does often occur only in certain specific sections. The other difference is that the number of new vehicles added per time step is v arious, which can be used to simulate different lev els of traf fic congestion. The primary parameters of the simulator are listed in T able I. The normal dri ving time between two intersections, that is, the distance between two intersections, indicates that normal driving vehicles need 5 time steps from one intersection to an adjacent intersection. The initial number (note that it is not the number after resetting the simulator when training model) of vehicles in simulator is used to obtain random seeds. The shortest route length is 2, which means that the shortest distance that a vehicle generated in the simulator can travel is two intersections. The longest route length is 20, which means that the longest distance that a vehicle generated in the simulator can trav el is twenty intersections. The action time interval of signal agent is 4, which means that a signal agent must keep at least 4 time steps before it can change one action. 2) A mor e r ealistic TSC simulator: W e take the road network in some areas of Xi’an as the prototype of the real road network to design a TSC simulator based on SUMO, which has 49 signalized intersections on the real road network. Fig. 3 and Fig. 4 sho w the overall road network view and a local view of two adjacent intersections, respectiv ely . The cars driving on the road network have the following properties: the length is 5 m , the acceleration is 5 m/s , and the deceleration is 10 m/s . As for the setting of signal agents’ action time Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 8 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 Fig. 3. Overall view of the realistic road network with asymmetric geometry . Fig. 4. Local view of two adjacent intersections of the realistic road network. interval ∆ t , as discussed in [23], if ∆ t is too long, signal agent will not be adaptive enough, if ∆ t is too short, the agent decision will not be deliv ered on time due to computational cost and communication latency , and it may be unsafe since the action is switched too frequently . Some recent works suggested ∆ t = 10 s, t y = 5 s [38], ∆ t = 5 s, t y = 2 s [23]. W e adopt the latter setting in the simulator to ensure that each signal agent is more adaptive. In order to ev aluate the robustness and optimality of algo- rithms in a challenging TSC scenario, we design intensive, stochastic, time-variant traffic flo ws to simulate the peak- hour traffic, instead of fixed congestion levels in the simpli- fied TSC simulator . The simulation time of each episode is 60 min and we set up four traf fic flow groups. Specifically , four traffic flow groups are generated as multiples of “unit” flows 1100 v eh/hr , 660 v eh/hr , 920 v eh/hr , and 552 v eh/hr . The first two traffic flows are simulated during the first 40 min , as [0 . 4 , 0 . 7 , 0 . 9 , 1 . 0 , 0 . 75 , 0 . 5 , 0 . 25] unit flows with 5 min intervals, while the last two traffic flows are generated during a shifted time window from 15 min to 55 min , as [0 . 3 , 0 . 8 , 0 . 9 , 1 . 0 , 0 . 8 , 0 . 6 , 0 . 2] unit flows with 5 min interv als. V . N U M E R I C A L E X P E R I M E N T S A N D D I S C U S S I O N S A. Implementation Details of Algorithms In order to analyze the performance of the proposed algo- rithm, we compared it with sev eral popular RL methods in the same traffic scenarios. Details of the implementation of Co-DQL and the other methods are described as follows: Co-DQL: The procedure described in Section III-B is implemented. Multilayer fully connected neural network is used to approximate the Q-function of each agent. W e use the ReLU-acti vation between hidden layers, and transform the final output of Q-network with it. All agents share the same Q-network, the shared Q-network takes an agent embedding as input and computes Q-value for each candidate action. W e also feed in the action approximation a k and sharing joint state ˆ s k . W e use the Adam optimizer with a learning rate of 0.0001. The discounted factor γ is set to 0.95, the mini-batch size is 1024, and the reward allocation factor α is set to 1 /n , where n represents the number of neighbor agents. The size of replay buf fer is 5 × 10 5 and τ = 0 . 01 for updating the target networks. The network parameters will be updated once an episode samples are added to the replay buf fer . Multi-Agent A2C (MA2C): The start-of-the-art MARL (decentralized) algorithms for large-scale TSC. The hyper- parameters of the algorithm in the e xperiment are basically consistent with the original one [23]. Independent Q-learning (IQL): It has almost the same hyper - parameters settings as Co-DQL. And the network architecture is identical to Co-DQL, except a mean action and sharing joint state are not fed as an addition input to the Q-network. Independent double Q-learning (IDQL): The parameter set- ting of this method is almost the same as that of independent Q-learning. The main difference is that the double estimators are used when calculating the target value. Deep deterministic policy gradient (DDPG): This is an off- policy algorithm too. It consists of two parts: actor and critic. Each agent is trained with DDPG algorithm and we share the critic among all agents in each experiment and all of the actors are kept separate. It uses the Adam optimizer with a learning rate of 0.001 and 0.0001 for critics and actors respectiv ely . The settings of other parameters are the same as those of Co-DQL. It is notew orthy that all the hyper-parameter settings of all algorithms may affect the performance of the algorithm to a certain extent. B. Experiments in The Simplified TSC Simulator By training and ev aluating the proposed method in different traffic scenarios, we can demonstrate that the proposed method is promising. Next, we will analyze the performance of the algorithms in three scenarios. 1) global random traf fic flow: As shown in the Fig. 5 (a), under the condition that signal agents adopt a random strategy , the mean reward reaches stable after about 2000 time steps, which means that the traffic flow of the simulator reaches a stable state too. In order to ensure the div ersity of training samples and av oid over -fitting some traffic flow states as far as possible, we record 10 discrete simulator states (i.e. vehicle position, dri ving status, signal status) after 2000 time steps as random seeds and it will be used to train and ev aluate these methods. In the global random traffic flow , we set the number of new vehicles added at each time step to 5, which corresponds to a high lev el of traffic congestion. Result Analysis . W e run 2500 episodes for training all fiv e models, and regularly save the trained models. The mean rew ard curve of signal agents is shown in Fig. 6. It can be seen from the figure that IQL suffers the lowest training performance. Although IDQL is just slightly better than IQL, the results tend to indicate that ov er-estimation of action-v alue function will damage the performance of signal control and Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 9 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 0 500 1000 1500 2000 2500 3000 3500 Step 175 150 125 100 75 50 25 0 Mean reward per step (a) 0 500 1000 1500 2000 2500 3000 3500 Step 140 120 100 80 60 40 20 0 Mean reward per step (b) 0 500 1000 1500 2000 2500 3000 3500 Step 100 80 60 40 20 0 Mean reward per step (c) Fig. 5. Illustration of mean reward change curve of signal agents using random strategy in v arious traffic flows scenarios. (a) global random traffic flow scenario, (b) double-ring traffic flow scenario, and (c) four-ring traffic flo w scenario. At the beginning, there are fewer vehicles running in the simulator . As vehicles are added to the simulator at each time step, there are more and more vehicles in the road network, and the mean reward of signal agents is getting smaller . As the vehicle arriving at the destination will be removed from the simulator , the level of congestion will reaches a stable range. W e intercept a certain number of simulator states after stabilization as the selectable initial state of the simulator when training and ev aluating MARL models. 0 500 1000 1500 2000 2500 Episode 22.5 20.0 17.5 15.0 12.5 10.0 7.5 5.0 2.5 Mean episode reward IQL IDQL DDPG MA2C Co-DQL Fig. 6. Reward curve of signal agent during training in the global random traffic flo w scenario. T ABLE II M O DE L P E R FO R M A NC E I N G L O BA L R AN D O M T R AFFI C F L OW S C E NA R IO Method A verage Delay Time [t] Mean Episode Reward IQL 148 . 500( ± 8 . 963) − 11 . 602( ± 0 . 700) IDQL 131 . 854( ± 7 . 534) − 10 . 301( ± 0 . 589) DDPG 111 . 057( ± 0 . 606) − 8 . 676( ± 0 . 047) MA2C 71 . 553( ± 0 . 5812) − 5 . 590( ± 0 . 045) Co-DQL 36 . 981( ± 0 . 509) − 2 . 889( ± 0 . 040) t means discrete time step. that using double estimators can improve the performance to a certain e xtent. Interestingly , the performance of DDPG is better than that of IDQL, it may be due to the advantages of actor-critic structure. Although MA2C and Co-DQL both hav e more robust learning ability , Co-DQL greatly outperforms all the other methods. Co-DQL uses mean field approximation to directly model the strategies of other agents, thus it can learn a good cooperativ e strategies and maximize the total re ward of the road network. For each algorithm, the best model obtained in the training process is used to test in this scenario. W e ev aluate all of them ov er 100 episodes. T able II shows the results of ev aluation. A verage delay time is calculated from the total delay time of vehicles in the road network during an episode. The standard T ABLE III M O DE L P E R FO R M A NC E I N D O U BL E - R IN G T R A FFIC F LO W S CE N AR I O Method A verage Delay Time [t] Mean Episode Reward IQL 89 . 838( ± 5 . 645) − 5 . 615( ± 0 . 353) IDQL 83 . 921( ± 2 . 273) − 5 . 245( ± 0 . 142) DDPG 86 . 581( ± 1 . 182) − 5 . 411( ± 0 . 074) MA2C 58 . 857( ± 0 . 779) − 3 . 679( ± 0 . 049) Co-DQL 26 . 046( ± 0 . 751) − 1 . 628( ± 0 . 047) t means discrete time step. 0 500 1000 1500 2000 2500 Episode 16 14 12 10 8 6 4 2 Mean episode reward IQL IDQL DDPG MA2C Co-DQL Fig. 7. Reward curve of signal agent during training in the double-ring traffic flow scenario. deviation is gi ven in parentheses after the mean value. Co- DQL greatly reduces the average delay time compared with the other methods. The test results are basically consistent with the trained model performance, which shows the validity of our trained model. 2) double-ring traf fic flow : Fig. 5 (b) shows the mean rew ard curve of agents using random strategies in double-ring traffic flo w scene. Similarly , 10 simulator states are selected as seeds. In this scenario, we set the number of new vehicles added to the network at each time step to 4, which corresponds to a medium lev el of traffic congestion. The other parameters of the simulator are the same as those in Section V -B1. Result Analysis . Similarly , we train all the models in this scenario and sav e the model with the best training perfor - Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 10 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 0 500 1000 1500 2000 2500 Episode 14 12 10 8 6 4 2 Mean episode reward IQL IDQL DDPG MA2C Co-DQL Fig. 8. Rew ard curve of signal agent during training in the four-ring traffic flow scenario. T ABLE IV M O DE L P E R FO R M A NC E I N F O U R - R I N G T R A FFIC F L OW S C EN A RI O Method A verage Delay Time [t] Mean Episode Reward IQL 168 . 526( ± 2 . 673) − 7 . 900( ± 0 . 125) IDQL 143 . 986( ± 3 . 761) − 6 . 749( ± 0 . 176) DDPG 116 . 823( ± 1 . 610) − 5 . 476( ± 0 . 075) MA2C 77 . 633( ± 0 . 660) − 3 . 639( ± 0 . 031) Co-DQL 37 . 174( ± 0 . 937) − 1 . 743( ± 0 . 044) t means discrete time step. mance. The mean re ward curve is sho wn in Fig. 7. As expected, the training performance of Co-DQL method still outperforms all the other methods. In addition, mainly due to the information transfer among agents, MA2C can obtain better training results in contrast to the independent agent methods, that is, IQL and IDQL. Howe ver , although the con ver gence rates of DDPG, IQL and IDQL are different, the final training results are basically similar . This may be because the problem of double-ring traffic flo w is relatively simple, so these three methods can achiev e relativ ely consistent results. In this scenario, the ev aluation results are shown in T able III. Co-DQL can obtain shorter a verage delay time and smaller standard de viations than other methods. 3) four-ring traffic flow: Select seeds for the four-ring traffic flow according to the curve of Fig. 5 (c). In order to simulate traffic conditions with low level of traffic congestion, we set the number of new vehicles added to the road network at each time step to 3. The other parameters of the simulator are set in the same way as other scenarios. Result Analysis . The training curve in this scenario is shown in Fig. 8, and the test results are shown in T able IV. In this scenario, the training performance of IDQL is significantly better than that of IQL without double estimators. The learning process of Co-DQL and MA2C is relati vely stable and the standard deviation in the ev aluation process is smaller than that of IQL, IDQL and DDPG, this may be due to that they share information among agents. But ultimately , Co- DQL achiev es the shortest average delay time by means of mean field approximation for opponent modeling and local information sharing. 0 200 400 600 800 1000 1200 1400 Episode 1500 1400 1300 1200 1100 1000 900 Mean episode reward IQL IDQL DDPG MA2C Co-DQL Fig. 9. Reward curve of signal agent during training on the real road network with asymmetric geometry . C. Experiment in The Mor e Realistic TSC Simulator Experiment Settings . Experiment with the simulator setup described in Section IV -B2. Regarding MDP setting, the regularization rate β in re ward is set to 0 . 2 v eh/s , and the regularization factors of wav e , w ait , and re ward are 5 v eh , 100 s , and 2000 v eh . Here, we train all MARL models around 1400 episodes given episode horizon T = 720 steps, then ev aluate the trained models ov er 10 episodes. Result Analysis . The mean episode reward curve during the training in this scenario is shown in Fig. 9. In this challenging scenario, DDPG suffers from the worst training performance, which may be due to the time-varying traffic flo w leading to a large variance of critics, so it can not effecti vely guide the learning of actors. Surprisingly , although the training performance of MA2C is much better than that of DDPG, it has no obvious advantage over IQL and IDQL. This may be due to MA2C is more sensitive to the number of agents, and the setting of many hyper-parameters in volv ed is also a big challenge. As expected, Co-DQL achiev es the best training performance. In this more realistic simulator, we have the opportunity to consider more traffic metrics than in the simplified one. T able V sho ws the ev aluation results using ten different random seeds, in which A vg. V ehicle Speed is calculated by dividing the total distance trav eled by the dri ving time, A vg. Intersection Delay is calculated by di viding the total delay time of each intersection by the total number of vehicles at the intersection, and A vg. Queue Length is calculated by the queue length of each time period, and T rip Delay refers to the total delay time of vehicles in the dri ving process, and T rip Arrived Rate is calculated by dividing the number of vehicles that have arriv ed at the destination before the end of the simulation by the total number of vehicles. The comparison results in terms of all measures are relativ ely consistent. According to the results, over -estimation makes a difference in the performance between IQL and IDQL, and the use of double estimators in IDQL always has a slight advantage ov er IQL according to most of the measurements. Compared with IQL, IDQL and DDPG, Co-DQL and MA2C show more robust test performance (less standard deviation), which shows that information sharing among agents brings benefits Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 11 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 T ABLE V M O DE L P E R FO R M A NC E I N R E A L R OA D N ET W O R K W I T H A S Y M ME T R I C G E O M ET RY Metrics IQL IDQL DDPG MA2C Co-DQL Mean Episode Reward − 1160 . 52( ± 190 . 62) − 1076 . 34( ± 193 . 53) − 1296 . 68( ± 140 . 87) − 1108 . 52( ± 83 . 41) − 930 . 38( ± 87 . 45) A vg. V ehicle Speed [m/s] 4 . 33( ± 0 . 49) 4 . 53( ± 0 . 45) 3 . 81( ± 0 . 35) 4 . 65( ± 0 . 23) 5 . 35( ± 0 . 26) A vg. Intersection Delay [s/veh] 28 . 52( ± 5 . 55) 27 . 17( ± 5 . 42) 33 . 01( ± 4 . 50) 27 . 98( ± 2 . 57) 20 . 31( ± 2 . 55) A vg. Queue Length [veh] 10 . 03( ± 2 . 05) 10 . 01( ± 2 . 12) 12 . 53( ± 1 . 87) 9 . 80( ± 1 . 21) 7 . 51( ± 1 . 29) T rip Delay[s] 278 . 38( ± 35 . 35) 254 . 20( ± 46 . 04) 311 . 34( ± 30 . 01) 253 . 23( ± 14 . 01) 177 . 73( ± 16 . 70) T rip Arrived Rate 0 . 74( ± 0 . 08) 0 . 80( ± 0 . 07) 0 . 57( ± 0 . 05) 0 . 79( ± 0 . 03) 0 . 91( ± 0 . 03) IQL IDQL DDPG MA2C Co-DQL 12 10 8 6 4 2 0 Mean episode reward Global random traffic flow Double-ring traffic flow Four-ring traffic flow Fig. 10. Mean episode reward comparison for testing the corresponding model in different traffic flow scenarios of simplified TSC. IQL IDQL DDPG MA2C Co-DQL 0 20 40 60 80 100 120 140 160 Average delay time global random traffic flow double-ring traffic flow four-ring traffic flow Fig. 11. Mean delay time comparison for testing the corresponding model in different traf fic flow scenarios of simplified TSC. to cooperation among agents, and Co-DQL achiev es the best av erage performance with respect to multiple measures, which shows the adv antage of mean field approximation in agent behavior modeling. D. Discussions Firstly , we discuss the performance of different algorithms in three traffic flow scenarios with the simplified MDP setting. As seen from Fig. 10 (blue bar), all methods hav e a smaller mean episode re ward in the global random traf fic flow scenario than in the other scenarios, which is due to the highest lev el of traffic congestion and the largest traffic volume in this scenario. According to Fig. 11 (green bar), although the mean episode reward lev el of each e valuation model in the four-ring traffic flo w scenario is moderate, the number of vehicles in this scenario is small, which may lead to greater average vehicle delay . Although the traffic volume of double-ring traffic flow scenario is larger than that of four-ring traffic flow scenario, the ev aluation results in the former scenario (orange bar) are ev en slightly better than the latter (green bar), regardless of the mean episode reward of agent or the average waiting time of vehicle. The analysis shows that the double-ring traffic flow scenario just needs the cooperation between two groups of agents, namely , the cooperation of signal agents in the inner and outer loop, while the four-ring traffic flow scenario needs the collaboration among four groups, so the cooperation task of signal agents in the latter may be more complex. Experimental results on multiple scenarios show that the performance of the algorithm with double estimator is always better than that without double estimator . Compared with the simplified situation, in the more realistic case, MA2C does not achiev e the desired performance. Co-DQL can still get more training reward and better ev aluation performance than the state-of-the-art decentralized MARL algorithms. In addition, we also conducted an experiment on a 7 × 7 grid road network simulator , the setting and results about the experiment are shown in the supplementary materials. One can notice that Co-DQL can achieve the best results. In the society of RL, a hot topic is how to use it in reality . Because the uncertainty brought by the exploration behavior of RL model in the training process is a potential safety hazard for the application of TSC in practice, the training stage of our model is completed in a TSC simulator in a similar way as most RL models [15] [16] [23], and the model deployed in reality is generally the model trained in the simulator . Although there is a gap between the simulator and the real en vironment, simulation to reality (sim2real) [46], as a branch of RL, has been widely studied in order to bridge the gap. V I . C O N C L U S I O N When to design a MARL algorithm, a critical challenge is how to make the agents efficiently cooperate, and one of the breach of realize is properly estimating the Q values and sharing local information among agents. Along this line of thought, this paper developed Co-DQL, which takes advantage of some important ideas studied in the literature. In more detail, Co-DQL employs an independent double Q-learning method based on double estimators and the UCB exploration, which can eliminate the o ver-estimation of traditional inde- pendent Q-learning while ensuring exploration. It adopts mean field approximation to model the interaction among agents so that agents can learn a better cooperative strategy . In addition, we presented a rew ard allocation mechanism and a local state Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 12 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 sharing method. Based on the characteristics of TSC, we gav e the details of the algorithmic elements. T o v alidate the performance of the proposed algorithm, we tested Co-DQL on various traffic flow scenarios of TSC simulators. Compared with se veral state-of-the-art MARL algorithms (i.e., IQL, IDQL, DDPG and MA2C), Co-DQL can achiev e promising results. In the future, we hope to further test Co-DQL on the real city road network, and we will consider other approaches on large-scale MARL such as hierarchical architecture [41] [47]. In addition, note that the local optimization of an agent’ s rew ard (throughput) may reduce the neighboring agents’ re- wards in a nonlinear way . Such a nonlinearity is typical in traffic flow . Using the linear weighted function with a constant α may not fully capture the nonlinear throughput relationship between neighboring intersections. Also, each agent’ s rew ard will appear multiple times, depending on the number of connected neighboring intersections. For instance, an intersection with fiv e legs will receiv e more weights than a three-leg intersection that may cause a biased optimal solution. Hence, it may be interesting to further study on the rew ard allocation mechanism. So far , a great number of methods hav e been proposed for TSC, such as max pressure [48], cell transmission model [49]. It may be interesting to comprehensiv ely compare these meth- ods. Furthermore, parameters heavily affect the performance of an algorithm, it is interesting to study ho w to automatically adjust them so as to achie ve the promising quality . Finally , it may be interesting to study our method on the other MDP settings for TSC problem. A C K N O W L E D G M E N T This work was supported by the National Natural Science Foundation of China (No. 61973244, 61573277). R E F E R E N C E S [1] K.-L. A. Y au, J. Qadir, H. L. Khoo, M. H. Ling, and P . K omisarczuk, “ A survey on reinforcement learning models and algorithms for traffic signal control, ” ACM Computing Surveys (CSUR) , vol. 50, no. 3, p. 34, 2017. [2] Q. W u and J. Guo, “Optimal bidding strategies in electricity markets using reinforcement learning, ” Electric P ower Components and Systems , vol. 32, no. 2, pp. 175–192, 2004. [3] B. Y in, M. Dridi, and A. El Moudni, “T raffic network micro-simulation model and control algorithm based on approximate dynamic program- ming, ” IET Intelligent T ransport Systems , vol. 10, no. 3, pp. 186–196, 2016. [4] P . Koonce and L. Rodegerdts, “Traf fic signal timing manual. ” United States. Federal Highway Administration, T ech. Rep., 2008. [5] H. Ceylan and M. G. Bell, “Traf fic signal timing optimisation based on genetic algorithm approach, including driv ers routing, ” T ransportation Resear ch P art B: Methodological , vol. 38, no. 4, pp. 329–342, 2004. [6] J. Garc ´ ıa-Nieto, E. Alba, and A. C. Oliv era, “Swarm intelligence for traffic light scheduling: Application to real urban areas, ” Engineering Applications of Artificial Intelligence , vol. 25, no. 2, pp. 274–283, 2012. [7] J. Qiao, N. Y ang, and J. Gao, “T wo-stage fuzzy logic controller for signalized intersection, ” IEEE T ransactions on Systems, Man, and Cybernetics-P art A: Systems and Humans , vol. 41, no. 1, pp. 178–184, 2010. [8] D. Srinivasan, M. C. Choy , and R. L. Cheu, “Neural networks for real- time traffic signal control, ” IEEE Tr ansactions on intelligent transporta- tion systems , vol. 7, no. 3, pp. 261–272, 2006. [9] R. S. Sutton and A. G. Barto, Reinforcement learning: An intr oduction . MIT press, 2018. [10] M. Wiering, J. v . V eenen, J. Vreeken, and A. Koopman, “Intelligent traffic light control, ” 2004. [11] L. Prashanth and S. Bhatnagar , “Reinforcement learning with function approximation for traffic signal control, ” IEEE T ransactions on Intelli- gent T ransportation Systems , vol. 12, no. 2, pp. 412–421, 2010. [12] Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning, ” natur e , vol. 521, no. 7553, p. 436, 2015. [13] V . Mnih, K. Kavukcuoglu, D. Silver , A. A. Rusu, J. V eness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al. , “Human-level control through deep reinforcement learning, ” Natur e , vol. 518, no. 7540, p. 529, 2015. [14] T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver , and D. Wierstra, “Continuous control with deep reinforcement learning, ” arXiv preprint , 2015. [15] H. W ei, G. Zheng, H. Y ao, and Z. Li, “Intellilight: A reinforcement learning approach for intelligent traffic light control, ” in Pr oceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining . A CM, 2018, pp. 2496–2505. [16] N. Casas, “Deep deterministic policy gradient for urban traffic light control, ” arXiv preprint , 2017. [17] C. Claus and C. Boutilier , “The dynamics of reinforcement learning in cooperativ e multiagent systems, ” AAAI/IAAI , vol. 1998, no. 746-752, p. 2, 1998. [18] S. Shamshirband, “ A distributed approach for coordination between traffic lights based on game theory . ” Int. Arab J. Inf. T echnol. , vol. 9, no. 2, pp. 148–153, 2012. [19] I. Arel, C. Liu, T . Urbanik, and A. K ohls, “Reinforcement learning-based multi-agent system for network traffic signal control, ” IET Intelligent T ransport Systems , vol. 4, no. 2, pp. 128–135, 2010. [20] M. Abdoos, N. Mozayani, and A. L. Bazzan, “Traf fic light control in non-stationary en vironments based on multi agent q-learning, ” in 2011 14th International IEEE conference on intelligent tr ansportation systems (ITSC) . IEEE, 2011, pp. 1580–1585. [21] M. T an, “Multi-agent reinforcement learning: Independent vs. cooper- ativ e agents, ” in Pr oceedings of the tenth international conference on machine learning , 1993, pp. 330–337. [22] L. Kuyer, S. Whiteson, B. Bakker, and N. Vlassis, “Multiagent rein- forcement learning for urban traffic control using coordination graphs, ” in Joint Eur opean Conference on Machine Learning and Knowledge Discovery in Databases . Springer, 2008, pp. 656–671. [23] T . Chu, J. W ang, L. Codec ` a, and Z. Li, “Multi-agent deep reinforcement learning for large-scale traffic signal control, ” IEEE T ransactions on Intelligent T ransportation Systems , 2019. [24] H. V . Hasselt, “Double q-learning, ” in Advances in Neural Information Pr ocessing Systems , 2010, pp. 2613–2621. [25] P . Auer , N. Cesa-Bianchi, and P . Fischer , “Finite-time analysis of the multiarmed bandit problem, ” Machine learning , vol. 47, no. 2-3, pp. 235–256, 2002. [26] H. E. Stanley , Phase transitions and critical phenomena . Clarendon Press, Oxford, 1971. [27] Y . Y ang, R. Luo, M. Li, M. Zhou, W . Zhang, and J. W ang, “Mean field multi-agent reinforcement learning, ” arXiv preprint , 2018. [28] H. V an Hasselt, A. Guez, and D. Silver , “Deep reinforcement learning with double q-learning, ” in Thirtieth AAAI confer ence on artificial intelligence , 2016. [29] J. E. Smith and R. L. W inkler, “The optimizers curse: Skepticism and postdecision surprise in decision analysis, ” Management Science , vol. 52, no. 3, pp. 311–322, 2006. [30] L. S. Shapley , “Stochastic games, ” Proceedings of the national academy of sciences , vol. 39, no. 10, pp. 1095–1100, 1953. [31] M. L. Littman, “Markov games as a framework for multi-agent rein- forcement learning, ” in Machine learning pr oceedings 1994 . Elsevier , 1994, pp. 157–163. [32] K. Prabuchandran, H. K. AN, and S. Bhatnagar , “Multi-agent reinforce- ment learning for traffic signal control, ” in 17th International IEEE Confer ence on Intelligent T ransportation Systems (ITSC) . IEEE, 2014, pp. 2529–2534. [33] A. K. Agogino and K. Tumer , “ Analyzing and visualizing multiagent rew ards in dynamic and stochastic domains, ” Autonomous Agents and Multi-Agent Systems , vol. 17, no. 2, pp. 320–338, 2008. [34] R. Lowe, Y . W u, A. T amar , J. Harb, O. P . Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperati ve-competitiv e environ- ments, ” in Advances in Neural Information Processing Systems , 2017, pp. 6379–6390. Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 13 This is the author’ s version of an article that has been published in IEEE Transaction on Cybernetics. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TCYB.2020.3015811 [35] M. Li, Z. Qin, Y . Jiao, Y . Y ang, J. W ang, C. W ang, G. Wu, and J. Y e, “Efficient ridesharing order dispatching with mean field multi-agent reinforcement learning, ” in The W orld W ide W eb Conference . ACM, 2019, pp. 983–994. [36] T . Jaakkola, M. I. Jordan, and S. P . Singh, “Conv ergence of stochastic iterativ e dynamic programming algorithms, ” in Advances in neur al information processing systems , 1994, pp. 703–710. [37] C. Szepesv ´ ari and M. L. Littman, “ A unified analysis of v alue-function- based reinforcement-learning algorithms, ” Neural Computation , vol. 11, no. 8, pp. 2017–2060, 1999. [38] M. Aslani, M. S. Mesgari, and M. Wiering, “ Adaptive traffic signal control with actor-critic methods in a real-world traffic network with different traffic disruption events, ” Tr ansportation Researc h P art C: Emer ging T echnolo gies , vol. 85, pp. 732–752, 2017. [39] S. El-T anta wy , B. Abdulhai, and H. Abdelgawad, “Multiagent rein- forcement learning for integrated network of adapti ve traffic signal controllers (marlin-atsc): methodology and large-scale application on downto wn toronto, ” IEEE T ransactions on Intelligent T ransportation Systems , vol. 14, no. 3, pp. 1140–1150, 2013. [40] J. Jin and X. Ma, “ Adapti ve group-based signal control by reinforcement learning, ” T ransportation Researc h Pr ocedia , vol. 10, pp. 207–216, 2015. [41] T . T an, F . Bao, Y . Deng, A. Jin, Q. Dai, and J. W ang, “Cooperativ e deep reinforcement learning for large-scale traffic grid signal control, ” IEEE T ransactions on Cybernetics , 2019. [42] T . Chu, S. Qu, and J. W ang, “Large-scale traffic grid signal control with regional reinforcement learning, ” in 2016 American Contr ol Conference (ACC) . IEEE, 2016, pp. 815–820. [43] L. Codeca and J. H ¨ arri, “Monaco sumo traffic (most) scenario: A 3d mobility scenario for cooperative its, ” in SUMO 2018, SUMO User Confer ence, Simulating Autonomous and Intermodal T ransport Systems , 2018. [44] K. T . K. T eo, K. B. Y eo, Y . K. Chin, H. S. E. Chuo, and M. K. T an, “ Agent-based traffic flow optimization at multiple signalized intersec- tions, ” in 2014 8th Asia Modelling Symposium . IEEE, 2014, pp. 21–26. [45] G. Brockman, V . Cheung, L. Pettersson, J. Schneider , J. Schul- man, J. T ang, and W . Zaremba, “Openai gym, ” arXiv pr eprint arXiv:1606.01540 , 2016. [46] F . Sadeghi, A. T oshe v , E. Jang, and S. Levine, “Sim2real viewpoint in variant visual servoing by recurrent control, ” in Proceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2018, pp. 4691–4699. [47] A. S. V ezhnevets, S. Osindero, T . Schaul, N. Heess, M. Jaderberg, D. Silver , and K. Kavukcuoglu, “Feudal networks for hierarchical rein- forcement learning, ” in Pr oceedings of the 34th International Confer ence on Machine Learning-V olume 70 . JMLR. org, 2017, pp. 3540–3549. [48] P . V araiya, “Max pressure control of a network of signalized intersec- tions, ” T ransportation Resear ch P art C: Emerging T echnologies , vol. 36, pp. 177–195, 2013. [49] S. T imotheou, C. G. Panayiotou, and M. M. Polycarpou, “Distributed traffic signal control using the cell transmission model via the alternating direction method of multipliers, ” IEEE T ransactions on Intelligent T ransportation Systems , vol. 16, no. 2, pp. 919–933, 2014. Copyright (c) 2020 IEEE. Personal use is permitted. For any other purposes, permission must be obtained from the IEEE by emailing pubs-permissions@ieee.org. Page 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment