Meta-Learning Deep Energy-Based Memory Models
We study the problem of learning associative memory -- a system which is able to retrieve a remembered pattern based on its distorted or incomplete version. Attractor networks provide a sound model of associative memory: patterns are stored as attrac…
Authors: Sergey Bartunov, Jack W Rae, Simon Osindero
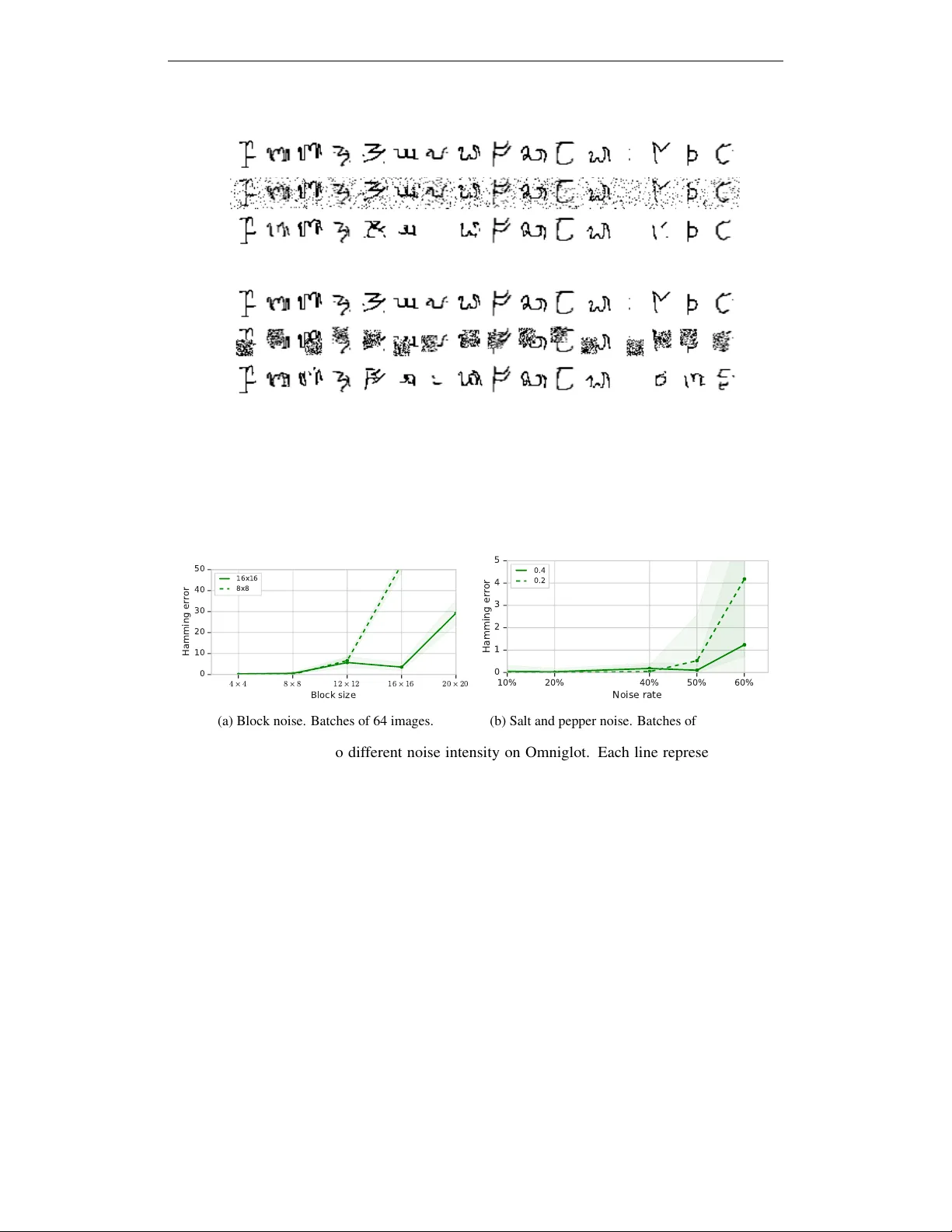
Published as a conference paper at ICLR 2020 M E T A - L E A R N I N G D E E P E N E R G Y - B A S E D M E M O RY M O D E L S Sergey Bartunov DeepMind London, United Kingdom bartunov@google.com Jack W Rae DeepMind London, United Kingdom jwrae@google.com Simon Osindero DeepMind London, United Kingdom osindero@google.com Timoth y P Lillicrap DeepMind London, United Kingdom countzero@google.com A B S T R A C T W e study the problem of learning an associativ e memory model – a system which is able to retriev e a remembered pattern based on its distorted or incomplete version. Attractor networks provide a sound model of associativ e memory: patterns are stored as attractors of the network dynamics and associative retrie v al is performed by running the dynamics starting from a query pattern until it conv erges to an attractor . In such models the dynamics are often implemented as an optimization procedure that minimizes an energy function, such as in the classical Hopfield network. In general it is dif ficult to derive a writing rule for a given dynamics and energy that is both compressive and fast. Thus, most research in energy- based memory has been limited either to tractable energy models not e xpressive enough to handle complex high-dimensional objects such as natural images, or to models that do not of fer fast writing. W e present a no vel meta-learning approach to energy-based memory models (EBMM) that allows one to use an arbitrary neural architecture as an energy model and quickly store patterns in its weights. W e demonstrate experimentally that our EBMM approach can build compressed memories for synthetic and natural data, and is capable of associati ve retrie val that outperforms existing memory systems in terms of the reconstruction error and compression rate. 1 I N T R O D U C T I O N Associativ e memory has long been of interest to neuroscience and machine learning communities (W illshaw et al., 1969; Hopfield, 1982; Kanerv a, 1988). This interest has generated many proposals for associativ e memory models, both biological and synthetic. These models address the problem of storing a set of patterns in such a way that a stored pattern can be retrieved based on a partially known or distorted v ersion. This kind of retriev al from memory is known as auto-association. Due to the generality of associativ e retriev al, successful implementations of associative memory models have the potential to impact many applications. Attractor networks provide one well-grounded foundation for associati ve memory models (Amit & Amit, 1992). Patterns are stored in such a way that they become attractors of the update dynamics defined by the network. Then, if a query pattern that preserves suf ficient information for association lies in the basin of attraction for the original stored pattern, a trajectory initialized by the query will con ver ge to the stored pattern. A variety of implementations of the general attractor principle hav e been proposed. The classical Hopfield network (Hopfield, 1982), for e xample, defines a simple quadratic energy function whose parameters serve as a memory . The update dynamics in Hopfield networks iterativ ely minimize the energy by changing elements of the pattern until it conv erges to a minimum, typically corresponding to one of the stored patterns. The goal of the writing process is to find parameter values such that 1 Published as a conference paper at ICLR 2020 E ( x ; ¯ ✓ ) Input x Energy E x Input x Energy E ✓ =w r i t e ( { x 1 , x 2 , x 3 } ; ¯ ✓ ) E ( x ; ✓ ) x 1 x 2 x 3 ˜ x Query read( ˜ x ; ✓ ) Figure 1: A schematic illustration of EBMM. The energy function is modelled by a neural network. The writing rule is then implemented as a weight update, producing parameters θ from the initializa- tion ¯ θ , such that the stored patterns x 1 , x 2 , x 3 become local minima of the ener gy (see Section 3). Local minima are attractors for gradient descent which implements associativ e retriev al starting from a query ˜ x , in this case a distorted version of x 3 . the stored patterns become attractors for the optimization process and such that, ideally , no spurious attractors are created. Many different learning rules have been proposed for Hopfield energy models, and the simplicity of the model af fords compelling closed-form analysis (Storke y & V alabre gue, 1999). At the same time, Hopfield memory models ha ve fundamental limitations: (1) It is not possible to add capacity for more stored patterns by increasing the number of parameters since the number of parameters in a Hopfield network is quadratic in the dimensionality of the patterns. (2) The model lacks a means of modelling the higher-order dependencies that e xist in real-world data. In domains such as natural images, the potentially large dimensionality of an input makes it both ineffecti ve and often unnecessary to model global dependencies among raw input measurements. In fact, many auto-correlations that e xist in real-world perceptual data can be efficiently compressed without significant sacrifice of fidelity using either algorithmic (W allace, 1992; Candes & T ao, 2004) or machine learning tools (Gregor et al., 2016; T oderici et al., 2017). The success of existing deep learning techniques suggests a more efficient recipe for processing high-dimensional inputs by modelling a hierarchy of signals with restricted or local dependencies (LeCun et al., 1995). In this paper we use a similar idea for b uilding an associati ve memory: use a deep network’ s weights to store and r etrieve data . Fast writing rules A v ariety of energy-based memory models ha ve been proposed since the original Hopfield network to mitigate its limitations (Hinton et al., 2006b; Du & Mordatch, 2019). Restricted Boltzmann Machines (RBMs) (Hinton, 2012) add capacity to the model by introducing latent variables, and deep v ariants of RBMs (Hinton et al., 2006b; Salakhutdino v & Larochelle, 2010) afford more e xpressiv e energy functions. Unfortunately , training Boltzmann machines remains challenging, and while recent probabilistic models such as variational auto-encoders (Kingma & W elling, 2013; Rezende et al., 2014) are easier to train, they nev ertheless pay the price for expressivity in the form of slow writing. While Hopfield networks memorize patterns quickly using a simple Hebbian rule, deep probabilistic models are slow in that the y rely on gradient training that requires many updates (typically thousands or more) to settle ne w inputs into the weights of a network. Hence, writing memories via parametric gradient based optimization is not straightforw ardly applicable to memory problems where fast adaptation is a crucial requirement. In contrast, and by explicit design, our proposed method enjoys fast writing , requiring fe w parameter updates (we employ just 5 steps) to write new inputs into the weights of the net once meta-learning is complete. It also enjoys fast r eading , requiring fe w gradient descent steps (again just 5 in our e xperiments) to retrie ve a pattern. Furthermore, our writing rules are also fast in the sense that they use O ( N ) operations to store N patterns in the memory – this scaling is the best one can hope for without additional assumptions. W e propose a novel approach that le verages meta-learning to enable f ast storage of patterns into the weights of arbitrarily structured neural networks, as well as fast associativ e retriev al. Our networks output a single scalar value which we treat as an energy function whose parameters implement a distributed storage scheme. W e use gradient-based reading dynamics and meta-learn a writing rule in the form of truncated gradient descent over the parameters defining the ener gy function. W e show that the proposed approach enables compression via efficient utilization of netw ork weights, as well as fast-con ver ging attractor dynamics. 2 Published as a conference paper at ICLR 2020 2 R E T R I E V A L I N E N E R G Y - B A S E D M O D E L S W e focus on attractor networks as a basis for associativ e memory . Attractor networks define update dynamics for iterativ e ev olution of the input pattern: x ( k +1) = f ( x ( k ) ) . For simplicity , we will assume that this process is discrete in time and deterministic, ho we ver there are examples of both continuous-time (Y oon et al., 2013) and stochastic dynamics (Aarts & Korst, 1988). A fixed-point attractor of deterministic dynamics can be defined as a point x for which it con ver ges, i.e. x = f ( x ) . Learning the associative memory in the attractor network is then equiv alent to learning the dynamics f such that its fixed-point attractors are the stored patterns and the corresponding basins of attraction are sufficiently wide for retrie v al. An energy-based attractor netw ork is defined by the energy function E ( x ) mapping an input object x ∈ X to a real scalar value. A particular model may then impose additional requirements on the energy function. F or example if the model has a probabilistic interpretation, the energy function is usually a neg ative unnormalized logarithm of the object probability log p ( x ) = − E ( x ) + const , implying that the energy has to be well-behav ed for the normalizing constant to exist. In our case no such constraints are put on the energy . The attractor dynamics in energy-based models is often implemented either by iterativ e energy optimization (Hopfield, 1982) or sampling (Aarts & K orst, 1988). In the optimization case considered further in the paper , attractors are con veniently defined as local minimizers of the ener gy function. While a particular energy function may suggest a number of different optimization schemes for retriev al, con vergence to a local minimum of an arbitrary function is NP-hard. Thus, we consider a class of energy functions that are dif ferentiable on X ⊆ R d , bounded from below and define the update dynamics ov er k = 1 , . . . , K steps via gradient descent: read ( ˜ x ; θ ) = x ( K ) , x ( k +1) = x ( k ) − γ ( k ) ∇ x E ( x ( k ) ) , x (0) = ˜ x . (1) W ith appropriately set step sizes { γ ( k ) } K k =0 this procedure asymptotically con verges to a local minimum of energy E ( x ) (Nesterov, 2013). Since asymptotic con vergence may be not enough for practical applications, we truncate the optimization procedure (1) at K steps and treat x ( K ) as a result of the retrie val. While vanilla gradient descent (1) is suf ficient to implement retrie val, in our experiments we emplo y a number of extensions, such as the use of Nestero v momentum and projected gradients, which are thoroughly described in Appendix B. Relying on the generic optimization procedure allows us to translate the problem of designing update dynamics with desirable properties to constructing an appropriate energy function, which in general is equally difficult. In the next section we discuss ho w to tackle this difficulty . 3 M E T A - L E A R N I N G G R A D I E N T - B A S E D W R I T I N G RU L E S As discussed in previous sections, our ambition is to be able to use any scalar -output neural network as an energy function for ass ociate retriev al. W e assume a parametric model E ( x ; θ ) dif ferentiable in both x and θ , and bounded from below as a function of x . These are mild assumptions that are often met in the existing neural architectures with an appropriate choice of acti vation functions, e.g. tanh. The writing rule then compresses input patterns X = { x 1 , x 2 , . . . , x N } into parameters θ such that each of the stored patterns becomes a local minimum of E ( x ; θ ) or , equiv alently , creates a basin of attraction for gradient descent in the pattern space. This property can be practically quantified by the reconstruction error, e.g. mean squared error , between the stored pattern x and the pattern read ( ˜ x ; θ ) retrie ved from a distorted version of x : L ( X, θ ) = 1 N N X i =1 E p ( ˜ x i | x i ) || x i − read ( ˜ x i ; θ ) || 2 2 . (2) Here we assume a kno wn, potentially stochastic distortion model p ( ˜ x | x ) such as randomly erasing certain number of dimensions, or salt-and-pepper noise. While one can consider loss (2) as a function of network parameters θ and call minimization of this loss with a conv entional optimization method 3 Published as a conference paper at ICLR 2020 Query Iteration 1 Iteration 2 Iteration 3 Iteration 4 Iteration 5 Original Query Iteration 1 Iteration 2 Iteration 3 Iteration 4 Iteration 5 Original 130 120 110 100 90 80 70 60 50 Energy Figure 2: V isualization of gradient descent iterations during retriev al of Omniglot characters (largest model). Four random images are sho wn from the batch of 64. a writing rule — it will require many optimization steps to obtain a satisfactory solution and thus does not fall into our definition of fast writing rules (Santoro et al., 2016). Hence, we explore a different approach to designing a fast writing rule inspired by recently proposed gradient-based meta-learning techniques (Finn et al., 2017) which we call meta-learning energy-based memory models (EBMM). Namely we perform many write and read optimization procedures with a small number of iterations for several sets of write and read observations, and backpropagate into the initial parameters of θ — to learn a good starting location for fast optimization. As usual, we assume that we hav e access to the underlying data distrib ution p d ( X ) ov er data batches of interest X from which we can sample sufficiently man y training datasets, even if the actual batch our memory model will be used to store (at test time) is not av ailable at the training time (Santoro et al., 2016). The straightforward application of gradient-based meta-learning to the loss (2) is problematic, because we generally cannot e valuate or differentiate through the e xpectation over stochasticity of the distortion model in a way that is reliable enough for adaptation, because as the dimensionality of the pattern space grows the number of possible (and representati ve) distortions gro ws exponentially . Instead, we define a different writing loss W , minimizing which serv es as a proxy for ensuring that input patterns are local minima for the energy E ( x ; θ ) , but does not require costly retrie val of exponential number of distorted queries. W ( x , θ ) = E ( x ; θ ) + α ||∇ x E ( x ; θ ) || 2 2 + β || θ − ¯ θ || 2 2 . (3) As one can see, the writing loss (3) consists of three terms. The first term is simply the energy v alue which we would like to be small for stored patterns relativ e to non-stored patterns. The condition for x to be a local minimum of E ( x ; θ ) is two-fold: first, the gradient at x is zero, which is captured by the second term of the writing loss, and, second, the hessian is positive-definite. The latter condition is difficult to e xpress in a form that admits efficient optimization and we found that meta-learning using just first two terms in the writing loss is sufficient. Finally , the third term limits deviation from initial or prior parameters ¯ θ which we found helpful from optimization perspectiv e (see Appendix D for more details). W e use truncated gradient descent on the writing loss (3) to implement the writing rule: write ( X ) = θ ( T ) , θ ( t +1) = θ ( t ) − η ( t ) 1 N N X i =1 ∇ θ W ( x i , θ ( t ) ) , θ (0) = ¯ θ (4) T o ensure that gradient updates (4) are useful for minimization of the reconstruction error (2) we train the combination of retrie val and writing rules end-to-end, meta-learning initial parameters ¯ θ , 4 Published as a conference paper at ICLR 2020 2K 4K 6K 8K 10K 12K 14K 16K Memory size 0 5 10 15 20 25 Hamming error MANN Memory network EBMM conv EBMM FC (a) Omniglot. 2K 4K 6K 8K 10K 12K 14K 16K Memory size 5 10 15 20 25 30 Square error (b) CIF AR. Figure 3: Distortion (reconstruction error) vs rate (memory size) analysis on batches of 64 images. learning rate schedules r = ( { γ ( k ) } K k =1 , { η ( t ) } T t =1 ) and meta-parameters τ = ( α, β ) to perform well on random sets of patterns from the batch distribution p d ( X ) : minimize E X ∼ p d ( X ) [ L ( X, write ( X ))] for ¯ θ , r , τ . (5) In our experiments, p ( X ) is simply a distribution o ver batches of certain size N sampled uniformly from the training (or testing - during ev aluation) set. Parameters θ = write ( X ) are produced by storing X in the memory using the writing procedure (4) . Once stored, distorted versions of X can be retriev ed and we can ev aluate and optimize the reconstruction error (2). Crucially , the proposed EBMM implements both read ( x , θ ) and write ( X ) operations via truncated gradient descent which can be itself differentiated through in order to set up a tractable meta-learning problem. While truncated gradient descent is not guaranteed to conv erge, reading and writing rules are trained jointly to minimize the reconstruction error (2) and thus ensure that they con v erge sufficiently fast. This property turns this potential dra wback of the method to its advantage ov er prov ably con ver gent, but slo w models. It also relaxes the necessity of stored patterns to create too well-behav ed basins of attraction because if, for example, a stored pattern creates a nuisance attractor in the dangerous proximity of the main one, the gradient descent (1) might successfully pass it with appropriately learned step sizes γ . 4 E X P E R I M E N T S In this section we experimentally e valuate EBMM on a number of real-world image datasets. The performance of EBMM is compared to a set of relev ant baselines: Long-Short T erm Mem- ory (LSTM) (Hochreiter & Schmidhuber, 1997), the classical Hopfield network (Hopfield, 1982), Memory-Augmented Neural Networks (MANN) (Santoro et al., 2016) (which are a v ariant of the Differentiable Neural Computer (Grav es et al., 2016)), Memory Networks (W eston et al., 2014), Dif ferentiable Plasticity model of Miconi et al. (2018) (a generalization of the Fast-weights RNN (Ba et al., 2016)) and Dynamic Kanerva Machine (W u et al., 2018). Some of these baselines failed to learn at all for real-world images. In the Appendix A.2 we pro vide additional e xperiments with random binary strings with a larger set of representati ve models. The experimental procedure is the follo wing: we write a fixed-sized batch of images into a memory model, then corrupt a random block of the written image to form a query and let the model retrie ve the originally stored image. By v arying the memory size and repeating this procedure, we perform distortion/rate analysis, i.e. we measure how well a memory model can retriev e a remembered pattern for a gi ven memory size. Meta-learning have been performed on the canonical train splits of each dataset and testing on the test splits. Batches were sampled uniformly , see Appendix A.7 for the performance study on correlated batches. W e define memory size as a number of float32 numbers used to represent a modifiable part of the model. In the case of EBMM it is the subset of all network weights that are modified by the gradient descent (4) , for other models it is size of the state, e.g. the number of slots × the slot size for a Memory Network. T o ensure fair comparison, all models use the same encoder (and decoder , when applicable) networks, which architectures are described in Appendix C. In all experiments EBMM used K = 5 read iterations and T = 5 write iterations. 5 Published as a conference paper at ICLR 2020 Query Iteration 1 Iteration 2 Iteration 3 Iteration 4 Iteration 5 Original Query Iteration 1 Iteration 2 Iteration 3 Iteration 4 Iteration 5 Original 280 260 240 220 200 180 160 Energy MemNet Figure 4: V isualization of gradient descent iterations during retrieval of CIF AR images. The last column contains reconstructions from Memory networks (both models use 10k memory). 4 . 1 O M N I G L O T C H A R A C T E R S W e begin with experiments on the Omniglot dataset (Lake et al., 2015) which is no w a standard e valuation of fast adaptation models. For simplicity of comparison with other models, we do wnscaled the images to 32 × 32 size and binarized them using a 0 . 5 threshold. W e use Hamming distance as the e valuation metric. For training and ev aluation we apply a 16 × 16 randomly positioned binary distortions (see Figure 2 for example). W e explored two v ersions of EBMM for this e xperiment that use parts of fully-connected (FC, see Appendix C.2) and con volutional (con v , Appendix C.3) layers in a 3-block ResNet (He et al., 2016) as writable memory . Figure 3a contains the distortion-rate analysis of different models which in this case is the Hamming distance as a function of memory size. W e can see that there are two modes in the model behaviour . For small memory sizes, learning a lossless storage becomes a hard problem and all models hav e to find an ef ficient compression strategy , where most of the difference between models can be observed. Howe ver , after a certain critical memory size it becomes possible to rely just on the autoencoding which in the case of a relatively simple dataset such as Omniglot can be efficiently tackled by the ResNet architecture we are using. Hence, e ven Memory Networks that do not employ any compression mechanisms be yond using distributed representations can retrie ve original images almost perfectly . In this experiment MANN has been able to learn the most efficient compression strategy , but could not make use of larger memory . EBMM performed well both in the high and low compression regimes with con volutional memory being more ef ficient ov er the fully-connected memory . Further, in CIF AR and ImageNet experiments we only use the conv olutional version of EBMM. W e visualize the process of associative retriev al in Figure 2. The model successfully detected distorted parts of images and clearly managed to retrie ve the original pixel intensities. W e also show ener gy lev els of the distorted query image, the recalled images through 5 read iterations, and the original image. In most cases we found the energy of the retrie ved images matching ener gy of the originals, howe ver , an error w ould occur when they sometimes do not match (see the green example). 4 . 2 R E A L I M AG E S F R O M C I FA R - 1 0 W e conducted a similiar study on the CIF AR dataset. Here we used the same network architecture as in the Omniglot e xperiment. The only difference in the e xperimental setup is that we used squared error as an ev aluation metric since the data is continuous RGB images. 6 Published as a conference paper at ICLR 2020 4K 7K 9K 12K 14K 16K 18K Memory size 30 40 50 60 70 80 90 Square error MANN Memory network Energy memory (conv) (a) Distortion-rate analysis on ImageNet. Query Original EBMM MemNet DNC (b) Retrieval of 64x64 ImageNet images (all models hav e ≈ 18K memory). Figure 5: ImageNet results. Figure 3b contains the corresponding distortion-rate analysis. EBMM clearly dominates in the comparison. One important reason for that is the ability of the model to detect the distorted part of the image so it can a void paying the reconstruction loss for the rest of the image. Moreover , unlik e Omniglot where images can be almost perfectly reconstructed by an autoencoder with a large enough code, CIF AR images have much more v ariety and larger channel depth. This makes an efficient joint storage of a batch as important as an ability to provide a good decoding of the stored original. Gradient descent iterations sho wn in Figure 4 demonstrate the successful application of the model to natural images. Due to the higher complexity of the dataset, the reconstructions are imperfect, ho wever the original patterns are clearly recognizable. Interestingly , the learned optimization schedule starts with one big gradient step providing a coarse guess that is then gradually refined. 4 . 3 I M AG E N E T 6 4 X 6 4 W e further inv estigate the ability of EBMM to handle complex visual datasets by applying the model to 64 × 64 ImageNet. Similarly to the CIF AR experiment, we construct queries by corrupting a quarter of the image with 32 × 32 random masks. The model is based on a 4-block version of the CIF AR network. While the network itself is rather modest compared to existing ImageNet classifiers, the sequential training regime resembling lar ge-state recurrent networks pre vents us from using anything significantly bigger than a CIF AR model. Due to prohibitiv ely expensi ve computations required by experimenting at this scale, we also had to decrease the batch size to 32. The distortion-rate analysis (Figure 5a) shows the behaviour similar to the CIF AR experiment. EBMM pays less reconstruction error than other models and MANN demonstrates better performance than Memory Networks for smaller memory sizes; ho we ver , the asymptotic beha viour of these two models will likely match. The qualitativ e results are shown in Figure 5b. Despite the arguably more dif ficult images, EBMM is able to capture shape and color information, although not in high detail. W e belie ve this could likely be mitigated by using larger models. Additionally , using techniques such as perceptual losses (Johnson et al., 2016) instead of nai ve pixel-wise reconstruction errors can improve visual quality with the existing architectures, b ut we leav e these ideas for future work. 4 . 4 A N A LY S I S O F E N E R G Y L E V E L S W e were also interested in whether energy v alues provided by EBMM are interpretable and whether they can be used for associativ e retriev al. W e took an Omniglot model and inspected energy le vels of different types of patterns. It appears that, despite not being explicitly trained to, EBMM in many cases could discriminate between in-memory and out-of-memory patterns, see Figure 6. Moreover , distorted patterns had ev en higher energy than simply unknown patterns. Out-of-distribution patterns, here modelled as binarized CIF AR images, can be seen as clear outliers. 7 Published as a conference paper at ICLR 2020 150 100 50 0 50 0 50 100 150 200 250 Memories Non-memories Distorted memories CIFAR images Figure 6: Energy distrib utions of dif ferent classes of patterns under an Omniglot model. Memories are the patterns written into memory , non-memories are other randomly sampled images and distorted memories are the written patterns distorted as during the retriev al. CIF AR images were produced by binarizing the original RGB images and serve as out-of-distrib ution samples. 5 R E L AT E D W O R K Deep neural networks are capable of both compression (Parkhi et al., 2015; Kraska et al., 2018), and memorizing training patterns (Zhang et al., 2016). T aken together , these properties make deep networks an attracti ve candidate for memory models, with both exact recall and compressi ve capabilities. Howe ver , there exists a natural trade-of f between the speed of writing and the realizable capacity of a model (Ba et al., 2016). Approaches similar to ours in their use of gradient descent dynamics, b ut lacking fast writing, hav e been proposed by Hinton et al. (2006a) and recently revisited by Xie et al. (2016); Nijkamp et al. (2019); Du & Mordatch (2019). Krotov & Hopfield (2016) also extended the classical Hopfield network to a lar ger family of non-quadratic energy functions with more capacity . In general it is difficult to derive a writing rule for a gi ven dynamics equation or an energy model which we attempt to address in this w ork. The idea of meta-learning (Thrun & Pratt, 2012; Hochreiter et al., 2001) has found many successful applications in fe w-shot supervised (Santoro et al., 2016; V inyals et al., 2016) and unsupervised learning (Bartunov & V etrov, 2016; Reed et al., 2017). Our model is particularly influenced by w orks of Andrychowicz et al. (2016) and Finn et al. (2017), which experiment with meta-learning ef ficient optimization schedules and, perhaps, can be seen as an ultimate instance of this principle since we implement both learning and inference procedures as optimization. Perhaps the most prominent existing application of meta-learning for associative retrie v al is found in the Kanerva Machine (W u et al., 2018), which combines a variational auto-encoder with a latent linear model to serve as an addressable memory . The Kanerv a machine benefits from a high-le vel representation e xtracted by the auto-encoder . Howe ver , its linear model can only represent con vex combinations of memory slots and is thus less expressi ve than distrib uted storage realizable in weights of a deep network. W e described literature on associative and energy-based memory in Section 1, but other types of memory should be mentioned in connection with our work. Many recurrent architectures aim at maintaining efficient compressi ve memory (Gra ves et al., 2016; Rae et al., 2018). Models de veloped by Ba et al. (2016) and Miconi et al. (2018) enable associati ve recall by combining standard RNNs with structures similar to Hopfield network. And, recently Munkhdalai et al. (2019) explored the idea of using arbitrary feed-forward networks as a k ey-v alue storage. Finally , the idea of learning a surrogate model to define a gradient field useful for a problem of interest has a number of incarnations. Putzk y & W elling (2017) jointly learn an energy model and an optimizer to perform denoising or impainting of images. Marino et al. (2018) use gradient descent on an energy defined by variational lo wer bound for improving v ariational approximations. And, Belanger et al. (2017) formulate a generic framework for energy-based prediction driv en by gradient descent dynamics. A detailed explanation of the learning through optimization with applications in control can be found in (Amos, 2019). Modern deep learning made a departure from the earlier works on energy-based models such as Boltzmann machines and approach image manipulation tasks using techniques such as aforementioned v ariational autoencoders or generativ e adversarial networks (GANs) (Goodfello w et al., 2014). While 8 Published as a conference paper at ICLR 2020 these models indeed constitute state of the art for learning powerful prior models of data that can perform some kind of associati ve retriev al, they naturally lack f ast memory capabilities. In contrast, the approach proposed in this w ork addresses the problem of jointly learning a strong prior model and an efficient memory which can be used in combination with these techniques. For e xample, one can replace the plain reconstruction error with a perceptual loss incurred by a GAN discriminator or use EBMM to store representations extracted by a V AE. While both V AEs and GANs can be also be equipped with memory (as done e.g. by W u et al. (2018)), energy-based formulation allo ws us to employ arbitrary neural network parameters as an associativ e storage and make use of generality of gradient-based meta-learning. As we show in the additional experiments on binary strings in Appendix A.2, EBMM is applicable not only to high-dimensional natural data, but also to uniformly generated binary strings where no prior can be useful. At the same time, e valuation of non-memory baselines in Appendix A.3 demonstrates that the combination of a good prior and memory as in EBMM achieves significantly better performance than just a prior, e ven suited with a much larger netw ork. 6 C O N C L U S I O N A N D F U T U R E W O R K W e introduced a nov el learning method for deep associativ e memory systems. Our method benefits from the recent progress in deep learning so that we can use a v ery lar ge class of neural networks both for learning representations and for storing patterns in network weights. At the same time, we are not bound by slo w gradient learning thanks to meta-learning of fast writing rules. W e sho wed that our method is applicable in a v ariety of domains from non-compressible (binary strings; see Appendix) to highly compressible (natural images) and that the resulting memory system uses av ailable capacity efficiently . W e believe that more elaborate architecture search could lead to stronger results on par with state-of-the-art generativ e models. The existing limitation of EBMM is the batch writing assumption, which is in principle possible to relax. This would enable embedding of the model in reinforcement learning agents or into other tasks requiring online-updating memory . Employing more significantly more optimization steps does not seem to be necessary at the moment, ho wev er , scaling up to larger batches or sequences of patterns will face the bottleneck of recurrent training. Implicit differentiation techniques (Liao et al., 2018), rev ersible learning (Maclaurin et al., 2015) or synthetic gradients (Jaderberg et al., 2017) may be promising directions towards o vercoming this limitation. It would be also interesting to explore a stochastic v ariant of EBMM that could return different associations in the presence of uncertainty caused by compression. Finally , man y general principles of learning attractor models with desired properties are yet to be discovered and we belie ve that our results provide a good moti vation for this line of research. R E F E R E N C E S Emile Aarts and Jan K orst. Simulated annealing and boltzmann machines. 1988. Daniel J Amit and Daniel J Amit. Modeling brain function: The world of attractor neural networks . Cambridge univ ersity press, 1992. Brandon Amos. Differ entiable optimization-based modeling for machine learning . PhD thesis, PhD thesis. Carnegie Mellon Uni versity , 2019. Marcin Andrychowicz, Misha Denil, Ser gio Gomez, Matthew W Hof fman, David Pfau, T om Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent. In Advances in Neural Information Pr ocessing Systems , pp. 3981–3989, 2016. Antreas Antoniou, Harrison Edwards, and Amos Stork ey . Ho w to train your maml. arXiv preprint arXiv:1810.09502 , 2018. Jimmy Ba, Geoffre y E Hinton, V olodymyr Mnih, Joel Z Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past. In Advances in Neur al Information Pr ocessing Systems , pp. 4331–4339, 2016. 9 Published as a conference paper at ICLR 2020 Serge y Bartunov and Dmitry P V etrov . F ast adaptation in generativ e models with generative matching networks. arXiv pr eprint arXiv:1612.02192 , 2016. David Belanger , Bishan Y ang, and Andre w McCallum. End-to-end learning for structured prediction energy networks. In Pr oceedings of the 34th International Conference on Machine Learning- V olume 70 , pp. 429–439. JMLR. or g, 2017. Emmanuel Candes and T erence T ao. Near optimal signal recov ery from random projections: Uni versal encoding strategies? arXiv preprint math/0410542 , 2004. Junyoung Chung, Caglar Gulcehre, K yungHyun Cho, and Y oshua Bengio. Empirical ev aluation of gated recurrent neural networks on sequence modeling. arXiv pr eprint arXiv:1412.3555 , 2014. Y ilun Du and Igor Mordatch. Implicit generation and generalization in energy-based models. arXiv pr eprint arXiv:1903.08689 , 2019. Chelsea Finn, Pieter Abbeel, and Serge y Levine. Model-agnostic meta-learning for fast adaptation of deep networks. arXiv pr eprint arXiv:1703.03400 , 2017. Ian Goodfellow , Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David W arde-Farley , Sherjil Ozair, Aaron Courville, and Y oshua Bengio. Generati ve adversarial nets. In Advances in neural informa- tion pr ocessing systems , pp. 2672–2680, 2014. Alex Graves, Greg W ayne, Malcolm Reynolds, T im Harley , Ivo Danihelka, Agnieszka Grabska- Barwi ´ nska, Ser gio Gómez Colmenarejo, Edw ard Grefenstette, T iago Ramalho, John Agapiou, et al. Hybrid computing using a neural network with dynamic external memory . Natur e , 538(7626):471, 2016. Karol Gregor , Frederic Besse, Danilo Jimenez Rezende, Ivo Danihelka, and Daan W ierstra. T o wards conceptual compression. In Advances In Neural Information Pr ocessing Systems , pp. 3549–3557, 2016. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-lev el performance on imagenet classification. In Proceedings of the IEEE international confer ence on computer vision , pp. 1026–1034, 2015. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , pp. 770–778, 2016. Geoffre y Hinton, Simon Osindero, Max W elling, and Y ee-Whye T eh. Unsupervised discovery of nonlinear structure using contrastiv e backpropagation. Cognitive science , 30(4):725–731, 2006a. Geoffre y E Hinton. A practical guide to training restricted boltzmann machines. In Neural networks: T ric ks of the trade , pp. 599–619. Springer , 2012. Geoffre y E Hinton, Simon Osindero, and Y ee-Whye T eh. A fast learning algorithm for deep belief nets. Neural computation , 18(7):1527–1554, 2006b. Sepp Hochreiter and Jürgen Schmidhuber . Long short-term memory . Neural computation , 9(8): 1735–1780, 1997. Sepp Hochreiter , A Stev en Y ounger, and Peter R Conwell. Learning to learn using gradient descent. In International Confer ence on Artificial Neural Networks , pp. 87–94. Springer , 2001. John J Hopfield. Neural networks and physical systems with emergent collectiv e computational abilities. Pr oceedings of the national academy of sciences , 79(8):2554–2558, 1982. Max Jaderberg, W ojciech Marian Czarnecki, Simon Osindero, Oriol V inyals, Ale x Graves, Da vid Silver , and Koray Kavukcuoglu. Decoupled neural interfaces using synthetic gradients. In Pr oceedings of the 34th International Conference on Mac hine Learning-V olume 70 , pp. 1627–1635. JMLR. org, 2017. Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Eur opean confer ence on computer vision , pp. 694–711. Springer , 2016. 10 Published as a conference paper at ICLR 2020 Pentti Kanerva. Sparse distrib uted memory . MIT press, 1988. Diederik P Kingma and Max W elling. Auto-encoding variational bayes. arXiv pr eprint arXiv:1312.6114 , 2013. T im Kraska, Alex Beutel, Ed H Chi, Jeffrey Dean, and Neoklis Polyzotis. The case for learned index structures. In Pr oceedings of the 2018 International Conference on Management of Data , pp. 489–504. A CM, 2018. Dmitry Krotov and John J Hopfield. Dense associative memory for pattern recognition. In Advances in Neural Information Pr ocessing Systems , pp. 1172–1180, 2016. Brenden M Lake, Ruslan Salakhutdino v , and Joshua B T enenbaum. Human-level concept learning through probabilistic program induction. Science , 350(6266):1332–1338, 2015. Y ann LeCun, Y oshua Bengio, et al. Con volutional networks for images, speech, and time series. The handbook of brain theory and neur al networks , 3361(10):1995, 1995. Renjie Liao, Y uwen Xiong, Ethan Fetaya, Lisa Zhang, KiJung Y oon, Xaq Pitkow , Raquel Urta- sun, and Richard Zemel. Revi ving and improving recurrent back-propagation. arXiv preprint arXiv:1803.06396 , 2018. Ilya Loshchilo v and Frank Hutter . Fixing weight decay regularization in adam. arXiv preprint arXiv:1711.05101 , 2017. Dougal Maclaurin, David Duvenaud, and Ryan Adams. Gradient-based hyperparameter optimization through re versible learning. In International Confer ence on Mac hine Learning , pp. 2113–2122, 2015. Joseph Marino, Y isong Y ue, and Stephan Mandt. Iterati ve amortized inference. arXiv pr eprint arXiv:1807.09356 , 2018. Thomas Miconi, Jeff Clune, and K enneth O Stanley . Dif ferentiable plasticity: training plastic neural networks with backpropagation. arXiv pr eprint arXiv:1804.02464 , 2018. Tsendsuren Munkhdalai, Alessandro Sordoni, T ong W ang, and Adam T rischler . Metalearned neural memory . ArXiv , abs/1907.09720, 2019. Y urii Nesterov . Intr oductory lectur es on con ve x optimization: A basic course , volume 87. Springer Science & Business Media, 2013. Y urii E Nesterov . A method for solving the con ve x programming problem with con ver gence rate o (1/kˆ 2). In Dokl. akad. nauk Sssr , volume 269, pp. 543–547, 1983. Erik Nijkamp, Song-Chun Zhu, and Y ing Nian W u. On learning non-con vergent short-run mcmc tow ard energy-based model. arXiv pr eprint arXiv:1904.09770 , 2019. Omkar M Parkhi, Andrea V edaldi, Andrew Zisserman, et al. Deep face recognition. In BMVC , volume 1, pp. 6, 2015. Patrick Putzk y and Max W elling. Recurrent inference machines for solving in verse problems. arXiv pr eprint arXiv:1706.04008 , 2017. Jack W Rae, Serge y Bartunov , and Timothy P Lillicrap. Meta-learning neural bloom filters. 2018. Scott Reed, Y utian Chen, Thomas P aine, Aäron van den Oord, SM Eslami, Danilo Rezende, Oriol V in yals, and Nando de Freitas. Few-shot autore gressive density estimation: T owards learning to learn distributions. arXiv pr eprint arXiv:1710.10304 , 2017. Danilo Jimenez Rezende, Shakir Mohamed, and Daan W ierstra. Stochastic backpropagation and approximate inference in deep generativ e models. arXiv preprint , 2014. Ruslan Salakhutdinov and Hugo Larochelle. Efficient learning of deep boltzmann machines. In Pr oceedings of the thirteenth international confer ence on artificial intelligence and statistics , pp. 693–700, 2010. 11 Published as a conference paper at ICLR 2020 Adam Santoro, Serge y Bartunov , Matthew Botvinick, Daan W ierstra, and T imothy Lillicrap. Meta- learning with memory-augmented neural networks. In International confer ence on machine learning , pp. 1842–1850, 2016. Amos J Storkey and Romain V alabregue. The basins of attraction of a new hopfield learning rule. Neural Networks , 12(6):869–876, 1999. Sebastian Thrun and Lorien Pratt. Learning to learn . Springer Science & Business Media, 2012. George T oderici, Damien V incent, Nick Johnston, Sung Jin Hwang, David Minnen, Joel Shor , and Michele Co vell. Full resolution image compression with recurrent neural networks. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pp. 5306–5314, 2017. Dmitry Ulyanov , Andrea V edaldi, and V ictor Lempitsky . Deep image prior . In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pp. 9446–9454, 2018. Oriol V in yals, Charles Blundell, Timothy Lillicrap, Daan W ierstra, et al. Matching networks for one shot learning. In Advances in neural information pr ocessing systems , pp. 3630–3638, 2016. Gregory K W allace. The jpeg still picture compression standard. IEEE transactions on consumer electr onics , 38(1):xviii–xxxi v , 1992. Jason W eston, Sumit Chopra, and Antoine Bordes. Memory networks. arXiv pr eprint arXiv:1410.3916 , 2014. David J Willsha w , O Peter Buneman, and Hugh Christopher Longuet-Higgins. Non-holographic associativ e memory . Natur e , 222(5197):960, 1969. Y an W u, Gregory W ayne, Karol Gregor , and T imothy Lillicrap. Learning attractor dynamics for generati ve memory . In Advances in Neural Information Pr ocessing Systems , pp. 9401–9410, 2018. Jianwen Xie, Y ang Lu, Song-Chun Zhu, and Y ingnian W u. A theory of generati ve con vnet. In International Confer ence on Machine Learning , pp. 2635–2644. PMLR, 2016. KiJung Y oon, Michael A Buice, Caswell Barry , Robin Hayman, Neil Burgess, and Ila R Fiete. Specific evidence of lo w-dimensional continuous attractor dynamics in grid cells. Natur e neur oscience , 16 (8):1077, 2013. Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol V inyals. Understanding deep learning requires rethinking generalization. arXiv preprint , 2016. 12 Published as a conference paper at ICLR 2020 T able 1: Number of error bits in retrieved binary patterns. M E T H O D # PA T T E R N S 16 32 48 64 96 H O P FI E L D N E T W O R K , H E B B RU L E 0.4 5.0 9.8 13.0 16.5 H O P FI E L D N E T W O R K , S T O R K E Y R U L E 0.0 0.9 6.3 11.3 17.1 H O P FI E L D N E T W O R K , P S E U D O - I N V E R S E R U L E 0.0 0.0 0.3 4.3 22.5 D I FF E R E N T I A B L E P L A S T I C I T Y ( M I C O N I E T A L . , 2 0 1 8 ) 3.0 13.2 20.8 26.3 34.9 M A N N ( S A N T O RO E T A L . , 2 0 1 6 ) 0.1 0.2 1.8 4.25 9.6 L S T M ( H O C H R E I T E R & S C H M I D H U B E R , 1 9 9 7 ) 30 58 63 64 64 M E M O RY N E T W O R K S ( W E S T O N E T A L . , 2 0 1 4 ) 0.0 0.0 0.0 0.0 10.5 EBMM RNN 0.0 0.0 0.1 0.5 4.2 A A D D I T I O N A L E X P E R I M E N TA L D E TA I L S W e train all models using AdamW optimizer (Loshchilov & Hutter, 2017) with learning rate 5 × 10 − 5 and weight decay 10 − 6 , all other parameters set to AdamW defaults. W e also apply gradient clipping by global norm at 0 . 05 . All models were allowed to train for 2 × 10 6 gradient updates or 1 week whichev er ended first. All baseline models always made more updates than EBMM. One instance of each model has been trained. Error bars sho wed on the figures correspond to 5- and 95-percentiles computed on a 1000 of random batches. In all experiments we used initialization scheme proposed by He et al. (2015). A . 1 F A I L U R E M O D E S O F B A S E L I N E M O D E L S Image retriev al appeared to be dif ficult for a number of baselines. LSTM failed to train due to quadratic growth of the hidden-to-hidden weight matrix with increase of the hidden state size. Even moderately large hidden states were prohibiti ve for training on a modern GPU. Differential plasticity additionally struggled to train when using a deep representation instead of the raw image data. W e hypothesize that it was challenging for the encoder-decoder pair to train simultaneously with the recurrent memory , because in the binary experiment, while not performing the best, the model managed to learn a memorization strategy . Finally , the Kanerv a machine could not handle the relati vely strong noise we used in this task. By design, Kanerv a machine is agnostic to the noise model and is trained simply to maximize the data likelihood, without meta-learning a particular de-noising scheme. In the presence of the strong noise it failed to train on sequences longer than 4 images. A . 2 E X P E R I M E N T S W I T H R A N D O M B I NA RY PA T T E R N S Besides highly-structured patterns such as Omniglot or ImageNet images we also conducted experi- ments on random binary patterns – the classical setting in which associati ve memory models have been e valuated. While such random patterns are not compressible in e xpectation due to lack of any internal structure, by this experiment we examine the efficienc y of a learned coding scheme, i.e. ho w well can each of the models store binary information in the floating point format. W e generate random 128 -dimensional patterns, each dimension of which takes values of − 1 or +1 with equal probability , corrupt half of the bits and use this as a query for associativ e retriev al. W e compare EBMM employing a simple fully recurrent network (an RNN using the same input at each iteration, see Appendix C.1) as an energy model, against a classical Hopfield network (Hopfield, 1982) using different writing rules (Storke y & V alabregue, 1999) and a recently proposed differential plasticity model (Miconi et al., 2018). It is worth noting the dif ferentiable plasticity model is a generalized variant of Fast W eights (Ba et al., 2016), where the plasticity of each activ ation is 13 Published as a conference paper at ICLR 2020 modulated separately . W e also consider an LSTM (Hochreiter & Schmidhuber, 1997), Memory network (W eston et al., 2014) and a Memory-Augmented Neural Network (MANN) used by Santoro et al. (2016) which is a variant of the DNC (Gra ves et al., 2016). Since the Hopfield network has limited capacity that is strongly tied to input dimensionality and that cannot be increased without adding more inputs, we use its memory size as a reference and constrain all other baseline models to use the same amount of memory . F or this task it equals to 128 ∗ (128 − 1) / 2 + 128 to parametrize a symmetric matrix and a frequency vector . W e measure Hamming distance between the original and the retriev ed pattern for each system, varying the number of stored patterns. W e found it difficult to train the recurrent baselines on this task, so we let all models clamp non-distorted bits to their true values at retrie val which significantly stabilized training. As we can see from the results shown in T able 1, EBMM learned a highly efficient associative memory . Only the EBMM and the memory network could achie ve near -zero error when storing 64 vectors and e ven though EBMM could not handle 96 vectors with this number of parameters, it w as the most accurate memory model. A . 3 E V A L U A T I O N O F N O N - M E M O RY BA S E L I N E S For a more complete experimental study , we additionally ev aluate a number of baselines which have no capacity to adapt to patterns that otherwise w ould be written into the memory b ut still learn a prior ov er a domain and hence can serve as a form of associati ve memory . One should note, ho wev er , that ev en though such models can, in principle, achie ve relati vely good performance by pretraining on large datasets and adopting well-designed architectures, the y ultimately fail in situations where a strong memory is more important a good prior . One v ery distincti ve example of such setting is the binary string experiment presented in the previous section, where no prior can be useful at all. EBMM, in contrast, naturally learn both the prior in the form of shared features and memory in the form of writable weights. Our first non-memory baseline is a V ariational Auto-encoder (V AE) model with 256 latent Gaussian variables and Bernoulli likelihood. V AE defines an energy equal to the ne gativ e joint log-likelihood: E ( x , z ) = − log N ( z | 0 , I ) − log p ( x | z ) . W e consider attractor dynamics similar to the one used by W u et al. (2018). W e start from a configuration x (0) = ˜ x , z (0) = µ ( x ) , where µ ( x ) is the output of a Gaussian encoder q ( z | x ) = N ( z | µ ( x ) , diag ( σ ( x ))) . Then we alternate between updating these two parts of the configuration as follows: z ( t +1) = z ( t ) − γ ∇ z E ( x , z ( t ) ) , x ( t +1) = arg max x E ( x , z ( t +1) ) . Since we use a simple factorized Bernoulli likelihood model, the exact minimization with respect to x can be performed analytically . One can hope that under certain circumstances a well-trained V AE would assign lo wer energy le vels to less distorted versions of ˜ x and an image W e used 50, 100 and 200 iterations for Omniglot, CIF AR and ImageNet experiments respecti vely , in each case also performing a grid search for the learning rate γ . Another baseline is a Denoising Auto-encoder (D AE) which is trained to reconstruct the original pattern x from its distorted version ˜ x using a bottleneck of 256 hidden units. This model is trained exactly as our model using (2) as an objectiv e and hence, in contrast to V AE, can adapt to a particular noise pattern, which makes it a stronger baseline. Finally , we consider the Deep Image Prior (Ulyanov et al., 2018), a method that can be seen as a very special case of the ener gy-based model which also iterativ ely adapts parameters of a con volutional network to generate the most plausible reconstruction. W e used the network pro vided by the authors and performed 2000 Adam updates for each of the images. Similarly to ho w it was implemented in the paper , the network was instructed about location of the occluded block which arguably is a strong advantage o ver all other models. 14 Published as a conference paper at ICLR 2020 B A S E L I N E O M N I G L O T C I FA R I M A G E N E T 25% B L O C K N O I S E V A R I ATI O N A L A U T O - E N C O D E R 109.08 544.72 1889.79 D E N O I S I N G A U T O - E N C O D E R 36.08 24.66 141.07 D E E P I M AG E P R I O R – – 170.36* 15% S A LT A N D P E P P E R N O I S E V A R I ATI O N A L A U T O - E N C O D E R 84.08 430.33 1385.29 D E N O I S I N G A U T O - E N C O D E R 9.57 8.82 69.20 D E E P I M AG E P R I O R – – 467.92 T able 2: Reconstruction errors (Hamming for Omniglot, squared for CIF AR and ImageNet) for non-memory baselines. *Location of the distorted block was used. 2K 4K 6K 8K 10K 12K 14K 16K Memory size 0 10 20 30 40 50 Hamming error EBMM conv DKM Figure 7: Reconstruction error on Omniglot. Dynamic Kanerva Machine is compared to EBMM with con volutional memory . 15% salt and pepper noise is used. The quantitati ve results of the comparison are provided in the T able 2. Clearly , the most ef ficient of the baselines is D AE, largely because it was explicitly trained against a kno wn distortion model. In contrast, V AE failed to recov er from noise producing a significantly shifted observation distrib ution. Deep Image Prior performed significantly better , ho wev er , since it only adapts to a single distorted image instead of a whole distrib ution, it could not o ver -perform DAE with a much simpler architecture. As expected, none of the non-memory baselines performed even comparably to models with memory we consider in the main experiments section. A . 4 C O M PA R I S O N W I T H D Y N A M I C K A N E RV A M A C H I N E As we reported earlier , Dynamic Kanerva Machine failed to perform better than a random guess under the strong block noise we used in the main paper . In this appendix we e valuate DKM in simpler conditions where it can be reasonably compared to EBMM. Thus, we trained DKM on batches of 16 images and used a relativ ely simple 15% salt and pepper noise. Figure 7 contains the reconstruction error in the same format as Figure 3a. One can see that DKM generally performs poorly and does not show a consistent improvement with increasing memory size. As can be seen on Figure 8, DKM is able to retriev e patterns that are visually similar to the originally stored ones, b ut also introduces a fair amount of undesirable v ariability and occasionally con v erges to a spurious pattern. The errors increase with stronger block noise and larger batch sizes. A . 5 G E N E R A L I Z A T I O N T O D I FF E R E N T D I S T O RT I O N M O D E L S In this experiment we assess ho w EBMM trained with one of block noise of one size performs with dif ferent levels of noise. Figure 9 contains the generalization analysis with dif ferent kinds of noise on Omniglot. 15 Published as a conference paper at ICLR 2020 Figure 8: An example of a retrie val of a single batch by Dynamic Kanerv a Machine. A model with 12K memory was used. T op: salt and pepper noise, bottom: 16 × 16 block noise. First line: original patterns, middle line: distorted queries, bottom line: retrieved patterns. 4 × 4 8 × 8 1 2 × 1 2 1 6 × 1 6 2 0 × 2 0 Block size 0 10 20 30 40 50 Hamming error 16x16 8x8 (a) Block noise. Batches of 64 images. 10% 20% 40% 50% 60% Noise rate 0 1 2 3 4 5 Hamming error 0.4 0.2 (b) Salt and pepper noise. Batches of 16 images. Figure 9: Generalization to different noise intensity on Omniglot. Each line represents a model trained with a certain noise lev el. All models use 16K memory . One can see that regardless of noise type, EBMM successfully generalizes to weaker noise and generalization to slightly stronger noise is also observed. One should note though that 20 × 20 block noise already cov ers almost 40% of the image and hence may completely occlude certain characters. Generally we found salt and pepper noise much simpler which originally moti vated us to focus on block occlusions. Howe ver , as we indicate on the figure, the model used in the e xperiment with this kind of noise was only trained on batches of 16 images and hence the comparison of absolute values between Figures 9a and 9b is not possible. The relativ e performance degradation with increasing noise rate is still representativ e though. W e did not observe generalization from type of noise to another . Perhaps, the very dif ferent kinds of distortions were not compatible with learned basins of attraction. In general, this is not v ery surprising as, arguably , no model can be expected to adapt to all possible distortion models without a relev ant supervision of some sort. For this e xperiment we did not anyho w fine-tune model parameters, including the meta-parameters of the reading gradient descent. Hence, it is possible that some amount of fine-tuning and, perhaps, a custom optimization strategy for the modelled ener gy may lead to an improvement. 16 Published as a conference paper at ICLR 2020 Query Iteration 1 Iteration 2 Iteration 3 Iteration 4 Iteration 5 Original Query Iteration 1 Iteration 2 Iteration 3 Iteration 4 Iteration 5 Original 120 110 100 90 80 70 60 50 Energy Figure 10: Iterativ e reading on MNIST . The model is learned on Omniglot. B AT C H S A M P L I N G 4 K M E M O RY 5 K M E M O RY U N I F O R M ( U N C O R R E L A T E D ) 7 . 1 8 5 . 3 7 2 C L A S S E S ( C O R R E L AT E D ) 6 . 2 2 2 . 5 7 T able 3: Hamming error of models trained on differently constructed Omniglot batches of 32 images. A . 6 G E N E R A L I Z A T I O N T O M N I S T A natural question is whether a model trained on one task or dataset strictly overfits to its features or whether it can generalize to similar , b ut pre viously unseen tasks. One of the standard experiments to test this ability is transfer from Omniglot to MNIST , since both datasets consist of handwritten characters, which, howe ver , dif fer enough to present a distributional shift. Dev eloping such transfer capabilities is out of scope for this paper , but a simple check confirmed that EBMM can successfully retrie ve upscaled (to match the dimensionality) and binarized MNIST characters as one can see on Figure 10. One can see that although some amount of artifacts is introduced the retrie ved images are clearly recognizable and the energy levels are as adequate as in the Omniglot experiment. As in the previous experiment, we did not fine-tune the model. A . 7 E X P E R I M E N T S W I T H C O R R E L A T E D B A T C H E S One of the desirable properties of a memory model would be an efficient consolidation of similar patterns, e.g. corresponding to the same class of images, in the interest of better compression. W e do not observe this property in the models trained on uniformly sampled, uncorrelated batches, perhaps because the model was never incenti vized to do so. Howe ver , we performed a simple experiment where we trained EBMM on the Omniglot images, making sure that each batch of 32 images has characters of exactly two classes. For this purpose we employed a modified con volutional model (see Appendix C.5) in which the memory weights are located in the second residual layer instead of the third as in the main architecture. As we found experimentally , this way the model could compress more visual correlations in the batch. The results can be found in T able 3. It is e vident that training on correlated batches enabled better compression and EBMM is able to learn an efficient consolidation strategy if the meta-learning is set up appropriately . 17 Published as a conference paper at ICLR 2020 B R E A D I N G I N E B M M B . 1 P R O J E C T E D G R A D I E N T D E S C E N T W e described the basic reading procedure in section 2, howe ver , there is a number of e xtensions we found useful in practice. Since in all experiments we work with data constrained to the [0 , 1] interv al, one has to ensure that the read data also satisfies this constraint. One strategy that is often used in the literature is to model the output as an argument to a sigmoid function (logits). This may not work well for values close to the interval boundaries due to v anishing gradient, so instead we adopted a projected gradient descent, i.e. x ( k +1) = proj ( x ( k ) − γ ( k ) ∇ x E ( x ( k ) )) , where the proj function clips data to the [0 , 1] interv al. Quite interestingly , this formulation allo ws more flexible behavior of the energy function. If a stored pattern x has one of the dimensions exactly on the feasible interval boundary , e.g. x j = 0 , then ∇ x j E ( x ) does not necessarily hav e to be zero, since x j will not be able to go beyond zero. W e provide more information on the properties of storied patterns in further appendices. B . 2 N E S T E RO V M O M E N T U M Another extension we found useful is to employ Nesterov momentum (Nesterov, 1983) into the optimization scheme and we use it in all our experiments. ˆ x ( k ) = project ( x ( k − 1) + ψ ( k ) v ( k − 1) ) , v ( k ) = ψ ( k ) v ( k − 1) − γ ( k ) ∇ E ( ˆ x ( k ) ) x ( k ) = project ( v ( k ) ) . B . 3 S T E P S I Z E S T o encourage learning con verging attractor dynamics we constrained step sizes γ to be a non- increasing sequence: γ ( k ) = γ ( k − 1) σ ( η ( k ) ) , k > 1 Then the actual parameters to meta-learn is the initial step size γ (1) and the logits η . W e apply a similar parametrization to the momentum learning rates ψ . B . 4 S T E P - W I S E R E C O N S T RU C T I O N L O S S As has often been found helpful in the literature (Belanger et al., 2017; Antoniou et al., 2018) we apply the reconstruction loss (2) not just to the final iterate of the gradient descent, but to all iterates simultaneously: L K ( X, θ ) = K X k =1 1 N N X i =1 E h || x i − x ( k ) i || 2 2 i . C A R C H I T E C T U R E D E TA I L S Below we provide pseudocode for computational graphs of models used in the experiments. All modules containing memory parameters are specifically named as memory . C . 1 G AT E D R N N W e used a fairly standard recurrent architecture only equipped with an update gate as in (Chung et al., 2014). W e unroll the RNN for 5 steps and compute the energy value from the last hidden state. 18 Published as a conference paper at ICLR 2020 hidden_size = 1024 input_size = 128 # 128 * (128 - 1) / 2 + 128 parameters in total dynamic_size = (input_size - 1) // 2 state = repeat_batch(zeros(hidden_size)) memory = Linear(input_size, dynamic_size) gate = Sequential([ Linear(input_size + hidden_size, hidden_size), sigmoid ]) static = Linear(input_size + hidden_size, hidden_size - dynamic_size) for hop in xrange(5): z = concat(x, state) dynamic_part = memory(x) static_part = static(z) c = tanh(concat(dynamic_part, static_part)) u = gate(z) state = u * c + (1 - u) * state energy = Linear(1)(state) C . 2 R E S N E T , F U L LY - C O N N E C T E D M E M O RY channels = 32 hidden_size = 512 representation_size = 512 static_size = representation_size - dynamic_size state = repeat_batch(zeros(hidden_size)) encoder = Sequential([ ResBlock(channels * 1, kernel=[3, 3], stride=2, downscale=False), ResBlock(channels * 2, kernel=[3, 3], stride=2, downscale=False), ResBlock(channels * 3, kernel=[3, 3], stride=2, downscale=False), flatten, Linear(256), LayerNorm() ]) gate = Sequential([ Linear(hidden_size), sigmoid ]) hidden = Sequential([ Linear(hidden_size), tanh ]) x = encoder(x) memory = Linear(input_size, dynamic_size) dynamic_part = memory(x) 19 Published as a conference paper at ICLR 2020 static_part = Linear(static_size)(x) x = tanh(concat(dynamic_part, static_part)) for hop in xrange(3): z = concat(x, state) c = hidden(z) c = LayerNorm()(c) u = gate(z) state = u * c + (1 - u) * c h = tanh(Linear(1024)()(state)) energy = Linear(1)(h) The encoder module is also shared with all baseline models together with its transposed version as a decoder . C . 3 R E S N E T , C O N V O L U T I O N A L M E M O RY channels = 32 x = ResBlock(channels * 1, kernel=[3, 3], stride=2, downscale=True)(x) x = ResBlock(channels * 2, kernel=[3, 3], stride=2, downscale=True)(x) def resblock_bottleneck(x, channels, bottleneck_channels, downscale=False): static_size = channels - dynamic_size z = x x = Conv2D(bottleneck_channels, [1, 1])(x) x = LayerNorm()(x) x = tanh(x) if downscale: memory_part = Conv2D(dynamic_size, kernel=[3, 3], stride=2, downscale=True)(x) static_part = Conv2D(static_size, kernel=[3, 3], stride=2, downscale=True)(x) else: memory_part = Conv2D(dynamic_size, kernel=[3, 3], stride=1, downscale=False)(x) static_part = Conv2D(static_size, kernel=[3, 3], stride=1, downscale=False)(x) x = concat([static_part, memory_part], -1) x = LayerNorm)(x) x = tanh(x) z = Conv2D(channels, kernel=[1, 1])(z) if downscale: z = avg_pool(z, [3, 3] + [1], stride=2) x += z return x x = resblock_bottleneck(x, channels * 4, channels * 2, False) x = resblock_bottleneck(x, channels * 4, channels * 2, True) recurrent = Sequential([ Conv2D(hidden_size, kernel=[3, 3], stride=1), LayerNorm(), tanh ]) update_gate = Sequential([ Conv2D(hidden_size, kernel=[1, 1], stride=1), LayerNorm(), 20 Published as a conference paper at ICLR 2020 sigmoid ]) hidden_size = 128 hidden_state = repeat_batch(zeros(4, 4, hidden_size)) for hop in xrange(3): z = concat([x, hidden_state], -1) candidate = recurrent(z) u = update_gate(z) hidden_state = u * candidate + (1. - u) * hidden_state x = Linear(1024)(x) x = tanh(x) energy = Linear(1) C . 4 R E S N E T , I M A G E N E T This network is effecti vely a slightly larger version of the ResNet with con volutional memory described abov e. channels = 64 dynamic_size = 8 x = ResBlock(channels * 1, kernel=[3, 3], stride=2, downscale=True)(x) x = ResBlock(channels * 2, kernel=[3, 3], stride=2, downscale=True)(x) x = resblock_bottleneck(x, channels * 4, channels * 2, True) x = resblock_bottleneck(x, channels * 4, channels * 2, True) recurrent = Sequential([ Conv2D(hidden_size, kernel=[3, 3], stride=1), LayerNorm(), tanh ]) update_gate = Sequential([ Conv2D(hidden_size, kernel=[1, 1], stride=1), LayerNorm(), sigmoid ]) hidden_size = 256 hidden_state = repeat_batch(zeros(4, 4, hidden_size)) for hop in xrange(3): z = concat([x, hidden_state], -1) candidate = recurrent(z) u = update_gate(z) hidden_state = u * candidate + (1. - u) * hidden_state x = Linear(1024)(x) x = tanh(x) energy = Linear(1) C . 5 R E S N E T , C O N V O L U T I O N A L L O W E R - L E V E L M E M O RY This architecture is similar to other con volutional architectures with only dif ference is that dynamic weights are in the second residual block. 21 Published as a conference paper at ICLR 2020 channels = 32 dynamic_size = 8 def resblock(x, channels): static_size = channels - dynamic_size z = x memory_part = Conv2D(dynamic_size, kernel=[3, 3], stride=2, downscale=True)(x) static_part = Conv2D(static_size, kernel=[3, 3], stride=2, downscale=True)(x) x = concat([static_part, memory_part], -1) x = LayerNorm)(x) x = tanh(x) memory_part = Conv2D(dynamic_size, kernel=[3, 3], stride=2, downscale=True)(x) static_part = Conv2D(static_size, kernel=[3, 3], stride=2, downscale=True)(x) y = concat([static_part, memory_part], -1) y += x y = nonlinear(LayerNorm)(y)) x += y z = Conv2D(channels, [1, 1])(z) z = avg_pool(z, [3, 3], 2) x += z return x x = ResBlock(channels * 1, kernel=[3, 3], stride=2, downscale=True)(x) x = resblock(x, channels * 2) x = ResBlock(channels * 4, kernel=[3, 3], stride=2, downscale=True)(x) recurrent = Sequential([ Conv2D(hidden_size, kernel=[3, 3], stride=1), LayerNorm(), tanh ]) update_gate = Sequential([ Conv2D(hidden_size, kernel=[1, 1], stride=1), LayerNorm(), sigmoid ]) hidden_size = 256 hidden_state = repeat_batch(zeros(4, 4, hidden_size)) for hop in xrange(3): z = concat([x, hidden_state], -1) candidate = recurrent(z) u = update_gate(z) hidden_state = u * candidate + (1. - u) * hidden_state x = Linear(1024)(x) x = tanh(x) energy = Linear(1) 22 Published as a conference paper at ICLR 2020 0 1 2 3 4 5 I t e r a t i o n s ( 1 0 5 ) 0.005 0.010 0.015 0.020 0.025 0.030 0.035 Loss With grad loss Without grad loss Figure 11: Effect of including the ||∇ x E ( x ) || 2 term in the writing loss (3) on Omniglot. C . 6 T H E RO L E O F S K I P - C O N N E C T I O N S I N E N E R G Y M O D E L S Gradient-based meta-learning and EBMM in particular rely on the expressi veness of not just the forward pass of a netw ork, but also the backward pass that is used to compute a gradient. This may require special considerations about the network architecture. One may notice that all energy models considered above hav e an element of recurrency of some sort. While the recurrency itself is not crucial for good performance, skip-connections, of which recurrency is a special case, are. W e can illustrate this by considering an energy function of the follo wing form: E ( x ) = o ( h ( x )) , h ( x ) = f ( x ) + g ( f ( x )) . Here we can think of h as a representation from which the energy is computed. W e allo w the representation to be first computed as f ( x ) and then to be refined by adding g ( f ( x )) . During retriev al, we use gradient of the energy with respect to x which can be computed as d dx E ( x ) = do dh dh dx = do dh ( d f dx + dg d f d f dx ) . One can see, that with a skip-connection the model is able to refine the gradient together with the energy v alue. A simple way of incorporating such skip-connections is via recurrent computation. W e allow the model to use a gating mechanism that can modulate the refinement and pre vent from unneces- sary updates. W e found that usually a small number of recurrent steps (3-5) is enough for good performance. D E X P L A N A T I O N S O N T H E W R I T I N G L O S S Our setting de viates from the standard gradient-based meta-learning as described in (Finn et al., 2017). In particular , we are not using the same loss function (naturally defined by the ener gy function) in adaptation and inference phases. As we explain in section 3, writing loss (3) besides just the ener gy term also contains the gradient term and the prior term. Even though we found it suf ficient to use just the ener gy v alue as the writing loss, perhaps not surprisingly , minimizing the gradient norm appeared to help optimization especially in the early training (see Figure 11) and lead to better final results. W e use an individual learning rate per each writable layer and each of the three loss terms, initialized at 10 − 4 and learned together with other parameters. W e used softplus function to ensure that all learning rates remain non-negati ve. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment