Model predictive control with stage cost shaping inspired by reinforcement learning
This work presents a suboptimality study of a particular model predictive control with a stage cost shaping based on the ideas of reinforcement learning. The focus of the suboptimality study is to derive quantities relating the infinite-horizon cost …
Authors: Lukas Beckenbach, Pavel Osinenko, Stefan Streif
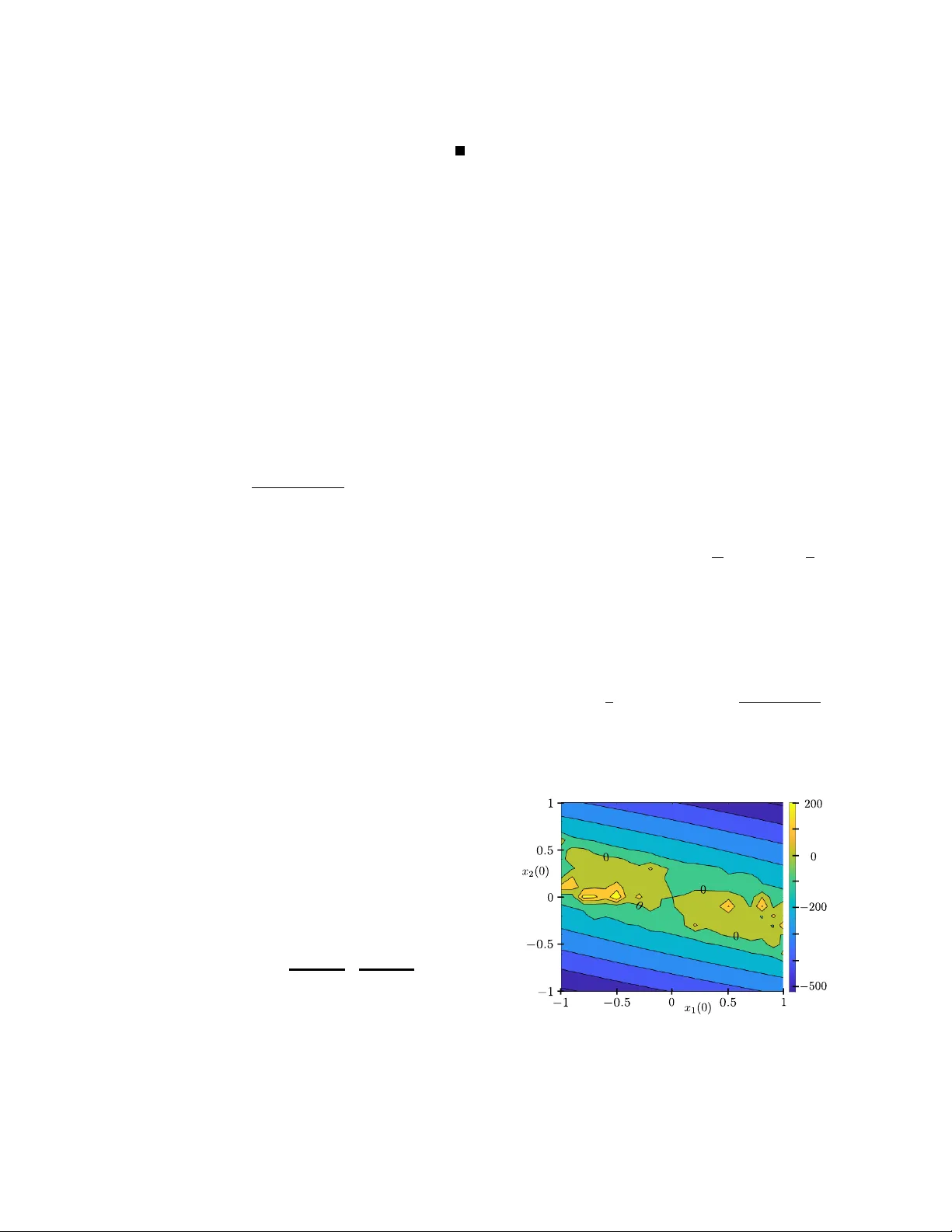
Model pr edictiv e contr ol with stage cost shaping inspir ed by r einf or cement lear ning Lukas Beckenbach, P av el Osinenko and Stef an Streif Abstract — This work pr esents a suboptimality study of a particular model predicti ve control with stage cost shaping based on the ideas of reinf orcement lear ning. The f ocus of the study is to derive quantities r elating the infinite-horizon cost under the said variant of model predictive control to the respecti ve infinite-horizon value function. The basis control scheme in volv es usual stabilizing constraints comprising of a terminal set and a terminal cost in the form of a local L yapunov function. The stage cost is adapted using the principles of Q- learning, a particular appr oach to reinfor cement learning. The work is concluded by case studies with two systems for wide ranges of initial conditions. I . I N T R O D U C T I O N Briefly , MPC con verts an infinite-horizon potential control problem to tractable, finite-horizon, online optimizations. Since several control setups are av ailable for the corre- sponding finite-horizon optimization, dif ferent performances with respect to the original infinite-horizon problem can be expected. In particular , unconstrained MPC in the sense of minimizing solely a truncation of the infinite-horizon cost each time step without any stabilizing so-called terminal constraints was studied rigorously [5], [9], [16]. Though the question of suboptimality under stabilizing terminal con- straint was addressed in various setups [6], [21], they require preliminary assumptions on the LF and/or the terminal set, of which some are re vie wed and relaxed herein. Problem formulation. Consider in the follo wing the discrete-time system x k +1 = f ( x k , u k ) , k = 0 , 1 , . . . , x 0 ∈ X , (1) with state x k ∈ X ⊂ R n x and control u k ∈ U ⊂ R n u . The map f : X × U → X is continuous in both arguments and ( ¯ x, ¯ u ) = (0 , 0) is the unique equilibrium point, i. e., f ( x, u ) = x if and only if x = ¯ x and u = ¯ u . In this work, deterministic and fully av ailable dynamics are considered, whereas there exist approaches of adapting the model, e. g., by neural netw orks [13]. W ith (1), the infinite-horizon optimal control problem (IHOCP) amounts to solving ∀ x 0 ∈ X : V ∞ ( x 0 ) := min { u k } ∞ k =0 ∞ X k =0 l ( x k , u k ) , s.t. (1) (2) where the stage cost (or state-input penalty) has the form l : X × U → R ≥ 0 , with l ( ¯ x, ¯ u ) = 0 , l ( x, u ) > 0 for ( x, u ) 6 = ( ¯ x, ¯ u ) and l ( x, ¯ u ) ≤ l ( x, u ) for an y x and u . Denote U ad the The authors are with the Automatic Control and System Dynamics Laboratory , T echnische Univ ersit ¨ at Chemnitz, 09107 Chemnitz, Germany , { lukas.beckenbach,pavel.osinenko, stefan.streif } @etit.tu-chemnitz.de admissible set, containing control sequences { u k } ∞ k =0 , with u k ∈ U and u k → ¯ u for k → ∞ , for which f ( x k , u k ) ∈ X , f ( x k , u k ) → ¯ x for k → ∞ and P ∞ k =0 l ( x k , u k ) < ∞ . It is assumed that U ad 6 = ∅ . The minimizer { u ∞ k } ∞ k =0 ∈ U ad associated with (2) may be given in a closed form as a feedback, i. e., there exists a function µ ∞ : X → U such that u ∞ k = µ ∞ ( x k ) . Let F : X f → U and X f ⊂ X containing { ¯ x } in the interior . A nonlinear MPC (NMPC) optimization problem for time k , with terminal cost and terminal set constraint, may be given by ˜ V ∞ MPC ( x k ) := min { u k ( i ) } N − 1 i =0 N − 1 X i =0 l ( x k ( i ) , u k ( i )) + F ( x k ( N )) (3a) s.t. x k ( i + 1) = f ( x k ( i ) , u k ( i )) , x k (0) = x k (3b) x k ( i ) ∈ X , u k ( i ) ∈ U (3c) x k ( N ) ∈ X f . (3d) Constraints in state and input in (3c) are commonly included whereas (3d) is the so-called stabilizing constraint. Certain assumptions on the terminal cost F – namely , F being a local LF with controller µ F such that x ∈ X f ⇒ f ( x, µ F ( x )) ∈ X f and ∆ µ F ( x ) F ( x ) having a specific decay rate – allows relating ˜ V ∞ MPC ( x k ) to the IHOCP . The main drawback of this approach is that the state sequence is forced to con ver ge to X f after N steps, which may render the minimizer of (3) possibly suboptimal with respect to the first N elements of the infinite sum in (2). Q-learning-inspir ed stage cost shaping. The aim of this work is to in vestigate a particular adaptation scheme of the stage cost in the MPC scheme (3) in the form l 7→ c · l . This specific approach is motiv ated by the fact that online adaptation or learning, in general, may use only limited or single (the current) state-input values ( x k , u k ) . Although “buf fers”, as it was suggested in [12], can be utilized, the presented adaptation scheme uses solely the current data. Other methods of incorporating learning into MPC include data-based constraint design for rob ust MPC [23] or terminal cost adaptation in MPC through means of iterative learning control [17]. The adaptation scheme is based on the principles of Q-learning as follows. Interpreting c · l as an approximation to the Q-function ∀ ( x, u ) ∈ X × U : Q ( x, u ) = l ( x, u ) + min a ∈ U Q ( f ( x, u ) , a ) , (4) the coefficients c should be updated so as to minimize the temporal differ ence [20]. More details on this approach are giv en in the subsequent sections. The aim of the work is to deriv e suboptimality bounds of the respectiv e MPC scheme under such an adaptation of the stage cost. Particular realiza- tions of the coef ficient update rule are discussed in Section II- C. The case studies of Section IV present comparison of the baseline MPC with the suggested stage-cost-shaping MPC for wide ranges of initial conditions. Notation. The natural numbers including zero are denoted by N 0 := N ∪ { 0 } . F or any scalar functions W 1 ( x k , k ) : R n x × N 0 → R ≥ 0 and W 2 ( x k ) : R n x → R ≥ 0 , denote ∆ u W 1 ( x k , k ) := W 1 ( f ( x k , u ) , k + 1) − W 1 ( x k , k ) and ∆ u W 2 ( x k ) := W 2 ( f ( x k , u )) − W 2 ( x k ) the dif ference of subsequent function values along the state recursion (1) under some u ∈ R n u . I I . S U B O P T I M A L I T Y D E S C R I P T I O N A N D A L G O R I T H M In the follo wing, some ke y assumptions on the function F are introduced, one of which can be found frequently in MPC literature [4], [8]. Furthermore, optimality and stability related statements are presented, summarizing the objec- tiv e of this work. Specifically , a suboptimality comparison is suggested for the case of the predictive scheme under parametrized decay of a local LF (3). A. Central Assumptions and Suboptimality Estimate Essentially , a key ingredient to ensure stability is the existence of a local controller inside the set, which the terminal predicted state is sought to reach. This means: Assumption 1: There exists a local controller µ F : X f → U and a local LF F : X f → R ≥ 0 such that ∀ x k ∈ X f : ∆ µ F ( x k ) F ( x k ) ≤ − α F ( x k ) . It is not until later in the analysis that the function F ( x ) is required to hav e a decay of magnitude of the stage cost [2], [7], [8]: Assumption 2: There exists a local controller µ F : X f → U and a local LF F : X f → R ≥ 0 such that ∀ x k ∈ X f : ∆ µ F ( x k ) F ( x k ) = − ¯ α k l ( x k , µ F ( x k )) , where 1 ≤ ¯ α k < ∞ , for all k ∈ N 0 . The function F in Assumption 2 can be re garded as the infinite tail inside X f under the stage cost l , obtained, e. g., by local LQ analysis [2]. Pr oposition 1: Let W : X → R ≥ 0 be a LF on X , i. e., W ( ¯ x ) = 0 and positive for an y x ∈ X − { ¯ x } , and µ : X → U the control policy , with µ ( ¯ x ) = ¯ u and { µ ( ˜ x k ) } ∞ k =0 ∈ U ad , where ˜ x k +1 = f ( ˜ x k , µ ( ˜ x k )) under some ˜ x 0 ∈ X . Furthermore, let W and µ be such that ∀ k ∈ N 0 : ∆ µ ( ˜ x k ) W ( ˜ x k ) ≤ − c k l ( ˜ x k , µ ( ˜ x k )) , (5) for some sequence { c k } ∞ k =0 , with c k ∈ (0 , ¯ c ) , 0 < ¯ c < ∞ . Denote δ 0 = W ( x 0 ) − V ∞ ( x 0 ) for any x 0 ∈ X and (∆ l ) k := c k l ( ˜ x k , µ ( ˜ x k )) − l ( ˜ x k , µ ( ˜ x k )) . It holds that ∞ X k =0 l ( ˜ x k , µ ( ˜ x k )) ≤ V ∞ ( x 0 ) + δ 0 − ∞ X k =0 (∆ l ) k , (6) where furthermore ∞ X k =0 (∆ l ) k ≤ δ 0 . (7) Pr oof: By (5), for an y k , M ∈ N 0 , M ≥ k , W ( ˜ x k + M +1 ) − W ( ˜ x k ) ≤ − M X i = k c k l ( ˜ x i , µ ( ˜ x i )) = − M X i = k l ( ˜ x i , µ ( ˜ x i )) − M X i = k (∆ l ) i . W ith ˜ x k + M +1 → ¯ x and thus W ( ˜ x k + M +1 ) → 0 for M → ∞ , and k = 0 , ∞ X i =0 l ( ˜ x i , µ ( ˜ x i )) ≤ W ( ˜ x 0 ) − ∞ X i =0 (∆ l ) i ⇔ ∞ X i =0 l ( ˜ x i , µ ( ˜ x i )) | {z } < ∞ ≤ V ∞ ( x 0 ) + δ 0 − ∞ X i =0 (∆ l ) i , using δ 0 as defined. By optimality , V ∞ ( x 0 ) is smaller or equal the v alue on the left-hand side in the above inequality . Therefore, the sum o ver (∆ l ) i is bounded by δ 0 as 0 ≤ ∞ X i =0 l ( ˜ x i , µ ( ˜ x i )) − V ∞ ( x 0 ) ≤ δ 0 − ∞ X i =0 (∆ l ) i ⇒ ∞ X i =0 (∆ l ) i ≤ δ 0 . Since ˜ x i → ¯ x , l ( ˜ x i , µ ( ˜ x i )) → 0 for i → ∞ , and thus (∆ l ) i → 0 . With the boundedness of c i ≤ ¯ c , the limit of the sequence of partial sums of the left-hand side in the abov e inequality is a real number and the infinite series is con vergent and finite. If W ( x ) ≡ V ∞ ( x ) , (5) changes to an equation with c k = 1 , for all k ∈ N 0 , and thus (∆ l ) k = δ 0 = 0 . Assuming that (in general) δ 0 ≥ 0 , (7) moti vates to search for such functions that yield (5) with c k ≥ 1 v alues. Roughly speaking, the above states that the initial discrepancy δ 0 > 0 may be partially compensated for by increasing the decay . B. Setup of the Receding Horizon Scheme For a gi v en sequence c k ( i ) ∈ R > 0 , i = 0 , . . . , N − 1 , define the follo wing value function at time step k for a state x ∗ k ∈ X ˜ V ∞ ( x ∗ k , k ) := min { u k ( i ) } N − 1 i =0 N − 1 X i =0 c k ( i ) l ( x k ( i ) , u k ( i )) + F ( x k ( N )) (8a) s.t. x k ( i + 1) = f ( x k ( i ) , u k ( i )) , x k (0) = x k (8b) x k ( i ) ∈ X , u k ( i ) ∈ U (8c) x k ( N ) ∈ X f ⊂ X . (8d) The state sequence associated with the minimizing control sequence { u ∗ k (0) , . . . , u ∗ k ( N − 1) } to (8) is denoted by { x ∗ k (1) , . . . , x ∗ k ( N ) } , whereas x ∗ k +1 = x k +1 = f ( x k , u ∗ k (0)) is the state along (1) under the first element of the control sequence, with x ∗ k = x k = x ∗ k (0) . It is assumed in the following that such a minimizing sequence to (8) exists at time k = 0 . Due to the time-inv ariance of the dynamics (1) as well as the constraints (8c) and (8d), the control action is recursiv ely feasible for subsequent times [14]. It can be sho wn that a decay of the form ∀ k ∈ N 0 : ∆ u ∗ k (0) ˜ V ∞ ( x ∗ k , k ) ≤ − c k (0) l ( x ∗ k , u ∗ k (0)) , (9) can be obtained through one inequality constraint ov er all coefficients in (8). That is, the coefficients must lie in the set W k − 1 3 c k ( i ) , i = 0 , . . . , N − 1 , defined by W k − 1 := { C ( i ) ∈ R > 0 , i = 0 , . . . , N − 1 : N − 1 X i =1 ( C ( i − 1) − c k − 1 ( i )) l ( x ∗ k − 1 ( i ) , u ∗ k − 1 ( i )) + F ( f ( x ∗ k − 1 ( N ) , µ F ( x ∗ k − 1 ( N )))) − F ( x ∗ k − 1 ( N )) + C ( N − 1) l ( x ∗ k − 1 ( N ) , µ F ( x ∗ k − 1 ( N ))) ≤ 0 } , (10) which contains the coefficients, controls and states to (8) of preceding time step k − 1 (associated with ˜ V ∞ ( x ∗ k − 1 , k − 1) , and thus denoted with the suf fix k − 1 ). For k = 0 , certain initial coefficients c 0 ( i ) ∈ R > 0 are used in ˜ V ∞ ( x 0 , 0) , which may be determined by some of fline optimization or chosen “suitably” (see Section III-B for a discussion). Pr oposition 2: Let Assumption 1 hold. Let c 0 ( i ) ∈ R > 0 , i = 0 , . . . , N − 1 . If for all k ∈ N and all i ∈ { 0 , . . . , N − 1 } , c k ( i ) ∈ W k − 1 , then (9) holds for all k ∈ N 0 . Pr oof: Consider the inequality (10) in W k − 1 at time k − 1 7→ k . Adding P N − 1 i =1 c k ( i ) l ( x ∗ k ( i ) , u ∗ k ( i )) and F ( x ∗ k ( N )) to both sides reads N − 1 X i =1 c k +1 ( i − 1) l ( x ∗ k ( i ) , u ∗ k ( i )) + c k +1 ( N − 1) l ( x ∗ k ( N ) , µ F ( x ∗ k ( N ))) + F ( f ( x ∗ k ( N ) , µ F ( x ∗ k ( N )))) ≤ N − 1 X i =1 c k ( i ) l ( x ∗ k ( i ) , u ∗ k ( i )) + F ( x ∗ k ( N )) = ˜ V ∞ ( x ∗ k , k ) − c k (0) l ( x ∗ k (0) , u ∗ k (0)) . Define the feasible sequences { ˜ x k +1 (0) , . . . , ˜ x k +1 ( N ) } := {{ x ∗ k (1) , . . . , x ∗ k ( N ) } , f ( x ∗ k N , µ F ( x ∗ k ( N ))) } and { ˜ u k +1 (0) , . . . , ˜ u k +1 ( N − 1) } := { u ∗ k (1) , . . . , u ∗ k ( N − 1) , µ F ( x ∗ k ( N )) } . Substituting this into the left-hand side of the inequality gives ˜ V ∞ ( x ∗ k +1 , k + 1) ≤ N − 1 X i =0 c k +1 ( i ) l ( ˜ x k +1 ( i ) , ˜ u k +1 ( i )) + F ( ˜ x k +1 ( N )) by optimality of ˜ V ∞ ( x ∗ k +1 , k + 1) . Remark 1: By the intermediate calculation of coef ficients satisfying (10), at each time k after solving (8), stability can be enforced using a local LF with any decay α F . That is, no stage cost related minimum decay rate is required inside the terminal set X f . This reduces Assumption 2 to the more general Assumption 1. Recall from, e. g., [10], that for a time-v ariant LF function W ( x, k ) with controller µ ( x ) there exist α 1 , α 2 ∈ K ∞ and α 3 ∈ K such that for all x ∈ X , k ∈ N 0 , α 1 ( k x k ) ≤ W ( x, k ) ≤ α 2 ( k x k ) and ∆ µ ( x ) W ( x, k ) ≤ − α 3 ( k x k ) . Thus, for stability , the value function in (8) must be bounded, which is equiv alent to bounded coef ficients for non-zero and bounded stage costs. C. Coefficient Update In order to obtain some what meaningful coefficients c k ( i ) and respecti v e update laws, aspects of Q-learning [22], and more specifically the Q-function, can be transferred into the above context. That is, for updating the coefficients, considering algorithms from Q-learning may be beneficial since an adaptation to the optimal decay rate is sought that minimizes the difference between the terms in (7). The Q-function Q : X × U → R ≥ 0 , formally defined as in (4), is commonly replaced by some parametric architecture Q ( x, u ) := h w ∗ , ϕ ( x, u ) i , where w ∗ ∈ R p are the parameters to a regressor ϕ : X × U → R p , comprising some basis functions. Since [11] ∀ x ∈ X : V ∞ ( x ) = min u ∈ U Q ( x, u ) , the function Q seeks to approximate the infinite-horizon optimal value. In order to transfer this approach to the (online) predictive scheme, the stage cost may be used as r e gr essor . The under - lying hypothesis in choosing particularly ϕ ( x, u ) ≡ l ( x, u ) , i. e., Q ( x, u ) ≡ w ∗ l ( x, u ) , is that the optimal v alue function V ∞ may be expressed as a certain magnitude, or factor , of the stage cost l . T emporal differ ence update. For computation of w ∗ , certain offline iterativ e routines are available [1], approximat- ing V ∞ a priori o ver samples in the state-input space. The temporal difference method [20] is one particular approach that can be used to compute w ∗ by iterating through w j = arg min C l ( x, u ) − C l ( x, u ) + min a ∈ U w j − 1 l ( f ( x, u ) , a ) 2 , (11) j = 0 , 1 , . . . , until k w j − w j − 1 k ≤ ε w for all x, u (samples) and some ε w > 0 . Then, take w ∗ := w j . Remark 2: The above update rule refers to an off-policy learning as “hypothetical” actions a are compared to find the respectiv e minimum [19]. In the presented case, ho wever , sample control actions are not necessary as the minimum of l o ver u is at a = ¯ u for all times. For online adaptation, ho wever , the parameters must be updated using only the current state and control obtained through (8). This can be achie ved using (11) for j = k with x = x k and u = u k . In this case, observe that the updated parameter correlates to the coefficient used in the subsequent time step in (8), i. e., w k = c k +1 , ∀ k ∈ N 0 . Remark 3: There exists approaches which handle the is- sue of providing samples online and utilize parameters w ∈ R p , p > 1 . In [11], the use of recursiv e least-squares is suggested, updating the parameters each p time steps, using the past p state-action values. Provided, such “b uf fer” can be used, the parameters can be updated by sampling a minibatch uniformly from that b uf fer [12]. Remark 4: One should be a ware of the distinct T D ( λ ) [3], [20] approaches, representing a rele vance weighting 0 ≤ λ ≤ 1 of recent temporal differences to earlier ones [18]. In the case p = 1 , the analogue online update rule to (11) for any of the N coef ficients may then read as c k +1 ( i ) = arg inf C ∈ R > 0 l ( x ∗ k ( i ) , u ∗ k ( i )) − C l ( x ∗ k ( i ) , u ∗ k ( i )) + c k ( i ) min a ∈ U l ( f ( x ∗ k ( i ) , u ∗ k ( i )) , a ) 2 , (12) i = 0 , . . . , N − 1 . It needs to be pointed out that different update rules may be used for the individual c k ( i ) . Note that the coefficient is pulled out of the minimization objective in the last term on the right-hand side in (12) as it does not change the minimum (which is also true for (11)). The infimum is used since the feasible set is open. As the stability constraint (10) must be satisfied, certain modifications to the respectiv e update rule are necessary . For instance, in the optimization (12), which for all coefficients C + = [ c k +1 (0) , . . . , c k +1 ( N − 1)] > reads as C + = arg inf [ C 0 ,...,C N − 1 ] > ∈ R N > 0 N − 1 X i =0 ( β i − C i l ( x ∗ k ( i ) , u ∗ k ( i ))) 2 (13) with β i = l ( x ∗ k ( i ) , u ∗ k ( i )) + c k ( i ) l ( f ( x ∗ k ( i ) , u ∗ k ( i )) , ¯ u ) , the set (10) serves as optimization constraint. For k = 0 , an initial guess of coefficients c 0 ( i ) , i = 0 , . . . , N − 1 , is required, which is a crucial step in the sense that it may influence the performance severely . Un- fortunately , no rule for choosing c 0 can be deriv ed to this point (see also Section III-B). Summarizing, the algorithm is depicted in T able I. Algorithm: 1) Initialize: Choose F , µ , X f and c 0 ( i ) ∈ R > 0 , i = 0 , . . . , N − 1 Set k = 0 . Then, 2) Obtain state x k . 3) Solve (8) using c k ( i ) , i = 0 , . . . , N − 1 , to obtain { u ∗ k ( i ) } N − 1 i =0 and { x ∗ k ( i ) } N i =0 4) Solve (13) under the constraint set W k to obtain c k +1 ( i ) ∈ W k , i = 0 , . . . , N − 1 5) Apply the first element of the sequence u ∗ k (0) to (1) 6) k 7→ k + 1 , go to 2) T ABLE I P RO C ED U R E O F T H E O N L IN E S C HE M E . Allocation. As an alternative to an additional online optimization as in (13), the coef ficients may be specified as the following: Looking at the set W k , one can choose c k +1 ( i − 1) = c k ( i ) , i = 1 , . . . , N − 1 . (14) Then, to ensure the inequality (10) in step k , c k +1 ( N − 1) l ( x ∗ k ( N ) , µ F ( x ∗ k ( N )) ≤ F ( x ∗ k ( N )) − F ( f ( x ∗ k ( N ) , µ F ( x ∗ k ( N )))) , (15) which, under Assumption 2, may be restated as the specific allocation c k +1 ( N − 1) = F ( x ∗ k ( N )) − F ( f ( x ∗ k ( N ) , µ F ( x ∗ k ( N )))) l ( x ∗ k ( N ) , µ F ( x ∗ k ( N )) = ¯ α k . (16) Pr oposition 3: Let Assumption 2 hold. If the initial coef- ficients are c 0 ( i ) = 1 , for all i ∈ { 0 , . . . , N − 1 } , then the following bound reg arding the decay rate (9) holds: ∀ k ∈ N 0 : 1 ≤ c k (0) ≤ ¯ c = sup k ∈ N 0 ¯ α k < ∞ . (17) Pr oof: The result follows directly from (14) and (16). Observe that for F fulfilling Assumption 1, smaller decay rates can be obtained in (9) than under Assumption 2 due to the dif ferent local decay rates of F . It should be noted, howe ver , that the abo ve allocation does not represent an y learning strate gy b ut mainly addresses the issue of main- taining stability while providing a specific coef ficient upper bound which can be used in Proposition 1. I I I . D I S C U S S I O N In the following, the temporal difference update is exam- ined under the assumption that the stability related constraint (10) is satisfied while furthermore the initialization of the scheme is discussed. A. Online Adaptation T o elaborate on the meaning of the update (12) for the individual coefficients, it is assumed that, under (12), the stability constraint is satisfied for all times: Assumption 3: For any k ∈ N 0 , under the sequences { x ∗ k ( i ) } N i =0 and { u ∗ k ( i ) } N − 1 i =0 from (8), the coefficients c k +1 ( i ) , i = 0 , . . . , N − 1 , obtained through (12) lie in W k . This is purely to demonstrate certain properties of the update and does not affect the functionality of the algorithm. As mentioned previously , it is desirable to ha v e (∆ l ) k in (6) as large as possible. Observe the following: Pr oposition 4: Let Assumption 1 and 3 hold. Let x ∗ k ( i ) and u ∗ k ( i ) , i = 0 , . . . , N − 1 be the solution to (8) for any k ∈ N 0 . If, for any k ∈ N 0 , c k ( i ) ∈ (0 , 1] and ( x ∗ k ( i ) , u ∗ k ( i )) 6 = ( ¯ x, ¯ u ) , then ∆ c k ( i ) := c k +1 ( i ) − c k ( i ) > 0 , (18) under (12), for an y i ∈ { 0 , . . . , N − 1 } . Pr oof: If c k ( i ) ∈ (0 , 1] and ( x ∗ k ( i ) , u ∗ k ( i )) 6 = ( ¯ x, ¯ u ) , then (12) yields c k +1 ( i ) l ( x ∗ k ( i ) , u ∗ k ( i )) − l ( x ∗ k ( i ) , u ∗ k ( i )) = c k ( i ) min a ∈ U l ( f ( x ∗ k ( i ) , u ∗ k ( i )) , a ) ⇔ c k +1 ( i ) =1 + c k ( i ) l ( f ( x ∗ k ( i ) , u ∗ k ( i )) , ¯ u ) l ( x ∗ k ( i ) , u ∗ k ( i )) , (19) where min a ∈ U l ( f ( x ∗ k ( i ) , u ∗ k ( i )) , a ) = l ( f ( x ∗ k ( i ) , u ∗ k ( i )) , ¯ u ) . Since ( x ∗ k ( i ) , u ∗ k ( i )) 6 = ( ¯ x, ¯ u ) , the last term on the right-hand side is strictly positive, which implies that c k ( i ) ∈ (0 , 1] ⇒ c k +1 ( i ) > 1 , and subsequently (18). It can be deduced that whene ver the algorithm is initialized with value c 0 ( i ) ∈ (0 , 1] , i = 0 , . . . , N − 1 , all subsequent coefficients are c k ( i ) > 1 , k ∈ N , if state and control satisfy ( x ∗ k ( i ) , u ∗ k ( i )) 6 = ( ¯ x, ¯ u ) . Remark 5: By the abo ve property of the coefficients tend- ing to ward higher magnitude and by definition of the Q- function being the infinite sum of stage cost, it is legitimate to directly impose a lower bound constraint c k ( i ) ≥ 1 , i ∈ { 0 , . . . , N − 1 } , for an y k ∈ N , on (13). Observe, when ( x ∗ k ( i ) , u ∗ k ( i )) = ( ¯ x, ¯ u ) , any c k ( i ) ∈ R > 0 is a feasible candidate to (12). Recalling from Proposition 1 that there exists an upper bound on the (first) parameter c k (0) ≤ ¯ c , the follo wing assumption regarding (19) is made: Assumption 4: For an y sequences { x k } ∞ k =0 { u k } ∞ k =0 , with x k ∈ X , u k ∈ U and ( x k , u k ) → ( ¯ x, ¯ u ) for k → ∞ , lim sup ( x k ,u k ) → ( ¯ x, ¯ u ) l ( f ( x k , u k ) , 0) l ( x k , u k ) < ∞ . (20) The abo ve Assumption 4 can be verified only using properties of the dynamic f and the stage cost l . Remark 6: Assumption 4 does not influence the func- tionality of the proposed algorithm but only provides a bound ¯ c regarding the suboptimality estimate established in Proposition 1. Furthermore, referring to (12) and (13) – for bounded, nonzero ( x ∗ k ( i ) , u ∗ k ( i )) and bounded 0 < c k ( i ) < ∞ – an infimum is attained for bounded c k +1 ( i ) < ∞ . Hence, dif ferent upper bounds ¯ c are obtained by Proposi- tion 3 and by the supremum of the right-hand side of Eq. (19) according to the value in Assumption 4. This implies that dif ferent performances may be achie ved with respect to the estimate (6), specifically regarding the dif ference between δ 0 and the sum o ver (∆ l ) k . B. Initialization Notice, that in (6), W ( x k ) relates to ˜ V ∞ ( x ∗ k , k ) whereas the applied control is giv en by µ ( x k ) = u ∗ k (0) . Since, if Assumption 2 holds, V ∞ ( x 0 ) ≤ ˜ V ∞ MPC ( x 0 ) for any x 0 ∈ X , inequality (6) can be extended to giv e an indirect comparison with the MPC cost. Denoting γ 0 := ˜ V ∞ MPC ( x 0 ) − V ∞ ( x 0 ) , it follows that under Assumption 2, γ 0 ≥ 0 and furthermore ∞ X k =0 l ( x ∗ k , u ∗ k (0)) ≤ ˜ V ∞ MPC ( x 0 ) − γ 0 + δ 0 − ∞ X k =0 (∆ l ) k | {z } :=∆ V N , (21) where x ∗ 0 = x 0 ∈ X . This implies that if γ 0 is large enough and the infinite sum ov er (∆ l ) k has a suf ficiently high (finite) value, ∆ V N can be made non-positi ve and thus ∞ X k =0 l ( x ∗ k , u ∗ k (0)) ≤ ˜ V ∞ MPC ( x 0 ) . This comparison, howe ver , is in so f ar indirect as it does not in v olve the actual infinite sum of stage costs under the control actions generated through (3) (with Assumption 2). Observe that this sum, by optimality , must be larger than V ∞ from (2) and thus from (6), ∞ X k =0 l ( x ∗ k , u ∗ k (0)) ≤ ∞ X k =0 l ( x MPC k , u MPC k (0)) + δ 0 − ∞ X k =0 (∆ l ) k , (22) with { x MPC k } ∞ k =0 and { u MPC k (0) } ∞ k =0 ∈ U ad the state and control trajectory , respecti vely , under (3). Here, only limited information about the relationship between V ∞ and the first term on the right-hand side of (22) is a v ailable though. Due to (in general) missing information about the solu- tion to the IHOCP (2), no specific allocation rule for the coefficients in (8) at k = 0 can be given. Therefore, starting the scheme (8) equiv alently to MPC (3), i. e., c 0 ( i ) = 1 , i = 0 , . . . , N − 1 , is reasonable. Y et, as elaborated in Proposition 4, the coef ficients may tend to a higher value, which suggests an initialization c 0 ( i ) > 1 . I V . S I M U L A T I O N S T UD Y Next, the time-v ariant stage cost approach (8) is compared to the standard MPC scheme (3) using two test systems. First, a linear mass spring damper system m ¨ x ( t ) + d ˙ x ( t ) + sx ( t ) = u (23) with specific m = 1 Kg, d = 0 . 2 Ns m and s = 1 N m is used under Euler discretization with sampling time ∆ t = 0 . 7 (exact discretization is not used for consistency with the second example). The stage cost and the horizon are set to l ( x, u ) = k x k 2 + u 2 and N = 10 , respectively . Secondly , the nonlinear system from [15] ˙ x 1 ( t ) = x 2 ( t ) ˙ x 2 ( t ) = − x 1 ( t ) π 2 + arctan(5 x 1 ( t )) − 5 x 2 1 ( t ) 2(1 + 25 x 2 1 ( t )) + 4 x 2 ( t ) + 3 u (24) is Euler discretized using ∆ t = 0 . 1 . The stage cost and the horizon are set to l ( x, u ) = x 2 2 + u 2 and N = 5 , respectively . Fig. 1. State space [ − 1 , 1] 2 of initial states x 0 for system (23). For certain areas of initial states, the infinite-horizon cost under (8) is lower than under (3) (blue), whereas elsewhere it may be higher (yellow). For linear and nonlinear system control, initial sets of coefficients c 0 ( i ) = 5 , i ∈ { 0 , . . . , 9 } and c 0 ( i ) = 20 , i ∈ { 0 , . . . , 4 } , are chosen assuming no further kno wledge about the optimal v alue function. Under variation of the Fig. 2. State space [ − 5 , 5] 2 of initial states x 0 for system (24). In particular , some symmetry can be detected in the performance under either control scheme. Whereas some state space segments mark better performance under MPC, adapting the coefficients appears to be beneficial for a larger partition of the space (dark blue). initial discrepancies − γ 0 + δ 0 in (21) by using other initial coefficients, the obtained simulation results may be different. The terminal costs (and a corresponding controller) are ob- tained by finding a local LQ control and by using the optimal (continuous time) value function gi ven in [15], respecti vely , for the two systems. The terminal set was obtained using lev el sets X f := { x ∈ X : F ( x ) ≤ 0 . 1 } . Reg arding (21), a comparison of MPC (3) and the proposed scheme (8) can be seen in Fig. 1 as well as in Fig. 2 for either system. The scale on the right side of the contour depicts the dif ference between the (quasi-) infinite sum of stage costs under either algorithm: positi ve v alues denote superiority of MPC and negati ve values indicate better performance under (8), using the presented initial coefficients. Though the performances are dependent on a, roughly speaking, suitable initialization of the coefficients, they may also vary with the specific coefficient update rule used, e. g., either by optimization or allocation. In the simulation, the algorithm presented in T able I is used. Additionally , for the nonlinear system, a lower bound on c k ( i ) ≥ 1 , for all i ∈ { 0 , . . . , 4 } , was imposed on the optimization in (13) according to Remark 5. It can be seen in the proposed approach may outperform MPC for certain initial states with the gi ven configuration, whereas elsewhere MPC appears superior . As pointed out in Sec. III-B, the initial coef ficients are, to this point, chosen arbitrarily , the performance under (8) is not guaranteed to be better with respect to the IHOCP . Howe ver , the results indicate the potential of cost reduction when the stage cost is weighted in the online optimization. This may be of special interest for short predicti ve horizon problems, as then the computational load is within limits (also regarding the additional optimization of the coef ficients). V . C O N C L U S I O N In this work, the rather general question of MPC per- formance with respect to a nonlinear IHOCP problem is addressed. In the frame work of stabilizing MPC, specif- ically that using a stabilizing terminal set constraint and terminal cost, some properties of a modified finite-horizon cost function with corresponding decay are presented and put in relation with the solution to the IHOCP . It is ar gued that an approximation of the IHOCP by the proposed finite- horizon scheme can induce a higher decay rate which could subsequently reduce the “degree of suboptimality”. Through introduction of coefficients to the standard MPC problem, this decay rate can be achie ved via an additional optimiza- tion problem while specific allocation can also be used to circumvent online optimization and guarantee stability . R E F E R E N C E S [1] D. P . Bertsekas. Dynamic Pr ogramming and Optimal Contr ol: Ap- pr oximate Dynamic Pr ogramming , volume II. Athena Scientific, 4th edition, 2012. [2] H. Chen and F . Allg ¨ ower . A quasi-infinite horizon nonlinear model predictiv e control scheme with guaranteed stability . Automatica , 34(10):1205–1217, 1998. [3] P . Dayan. The con ver gence of TD( λ ) for general λ . Machine Learning , 8(3-4):341–362, 1992. [4] F . A. C. C. Fontes. A general frame work to design stabilizing nonlinear model predictive controllers. Syst. Control Lett. , 42(2):127–143, 2001. [5] L. Gr ¨ une. Analysis and design of unconstrained nonlinear MPC schemes for finite and infinite dimensional systems. SIAM J. Contr ol Optimiz. , 48(2):1206–1228, 2009. [6] L. Gr ¨ une and A. Rantzer . On the infinite horizon performance of receding horizon controllers. IEEE T rans. Automat. Control , 53(9):2100–2111, 2008. [7] B. Hu and A. Linnemann. T oward infinite-horizon optimality in nonlinear model predictiv e control. IEEE T rans. Automat. Contr ol , 47(4):679–682, 2002. [8] A. Jadbabaie and J. Hauser . On the stability of receding horizon control with a general terminal cost. IEEE T rans. Automat. Contr ol , 50(5):674–678, 2005. [9] A. Jadbabaie, J. A. Primbs, and J. Hauser . Unconstrained receding horizon control with no terminal cost. In Pr oc. American Contr ol Confer ence , 2001. [10] H. Khalil. Nonlinear Systems . Prentice-Hall. 2nd edition, 1996. [11] F . L. Lewis and D. Vrabie. Reinforcement learning and adaptiv e dynamic programming for feedback control. IEEE Circuits Syst. Mag. , 9(3):32–50, 2009. [12] T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver, and D. W ierstra. Continuous control with deep reinforce- ment learning. A vailable at arXiv:1509.02971v5 [cs.LG], 2016. [13] D. Liu, D. W ang, D. Zhao, Q. W ei, and N. Jin. Neural-network-based optimal control for a class of unknown discrete-time nonlinear systems using globalized dual heuristic programming. IEEE Tr ans. Automat. Sc. and Eng. , 9(3):628–634, 2012. [14] D. Q. Mayne, J. B. Rawlings, C. V . Rao, and P . O. M. Scokaert. Con- strained model predicti ve control: Stability and optimality . Automatica , 36(6):789–814, 2000. [15] J. A. Primbs, V . Nevisti ´ c, and J. C. Doyle. Nonlinear optimal control: A control Lyapunov function and receding horizon perspective. Asian J. Contr ol , 1(1):14–24, 1999. [16] M. Reble and F . Allg ¨ ower . Unconstrained nonlinear model predictive control and suboptimality estimates for continuous-time systems. In Pr oc. 18th IF AC W orld Congr ess , 2011. [17] U. Rosolia and F . Borrelli. Learning Model Predictive Control for Iterativ e Tasks. A Data-Driven Control Framew ork. IEEE T rans. Automat. Control , 63(7):1883–1896, 2018. [18] G. A. Rummery and M. Niranjan. On-line Q-learning using connec- tionist systems , volume 37. Univ ersity of Cambridge, Department of Engineering Cambridge, England, 1994. [19] S. Singh, T . Jaakkola, M. L. Littman, and C. Szepesv ´ ari. Con- ver gence Results for Single-Step On-Policy Reinforcement-Learning Algorithms. Mac hine Learning , 38(3):287–308, Mar 2000. [20] R. S. Sutton. Learning to predict by the methods of temporal differences. Machine Learning , 3(1):9–44, 1988. [21] S. E. Tuna, M. J. Messina, and A. R. T eel. Shorter horizons for model predictiv e control. In Pr oc. American Control Conference , 2006. [22] C. W atkins and P . Dayan. Q-learning. Machine Learning , 8(3-4):279– 292, 1992. T echnical Note. [23] M. Zanon and S. Gros. Safe reinforcement learning using robust MPC. A vailable at arXiv:1906.04005v1 [cs.SY], 2019.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment