The Effect of Explicit Structure Encoding of Deep Neural Networks for Symbolic Music Generation
With recent breakthroughs in artificial neural networks, deep generative models have become one of the leading techniques for computational creativity. Despite very promising progress on image and short sequence generation, symbolic music generation …
Authors: Ke Chen, Weilin Zhang, Shlomo Dubnov
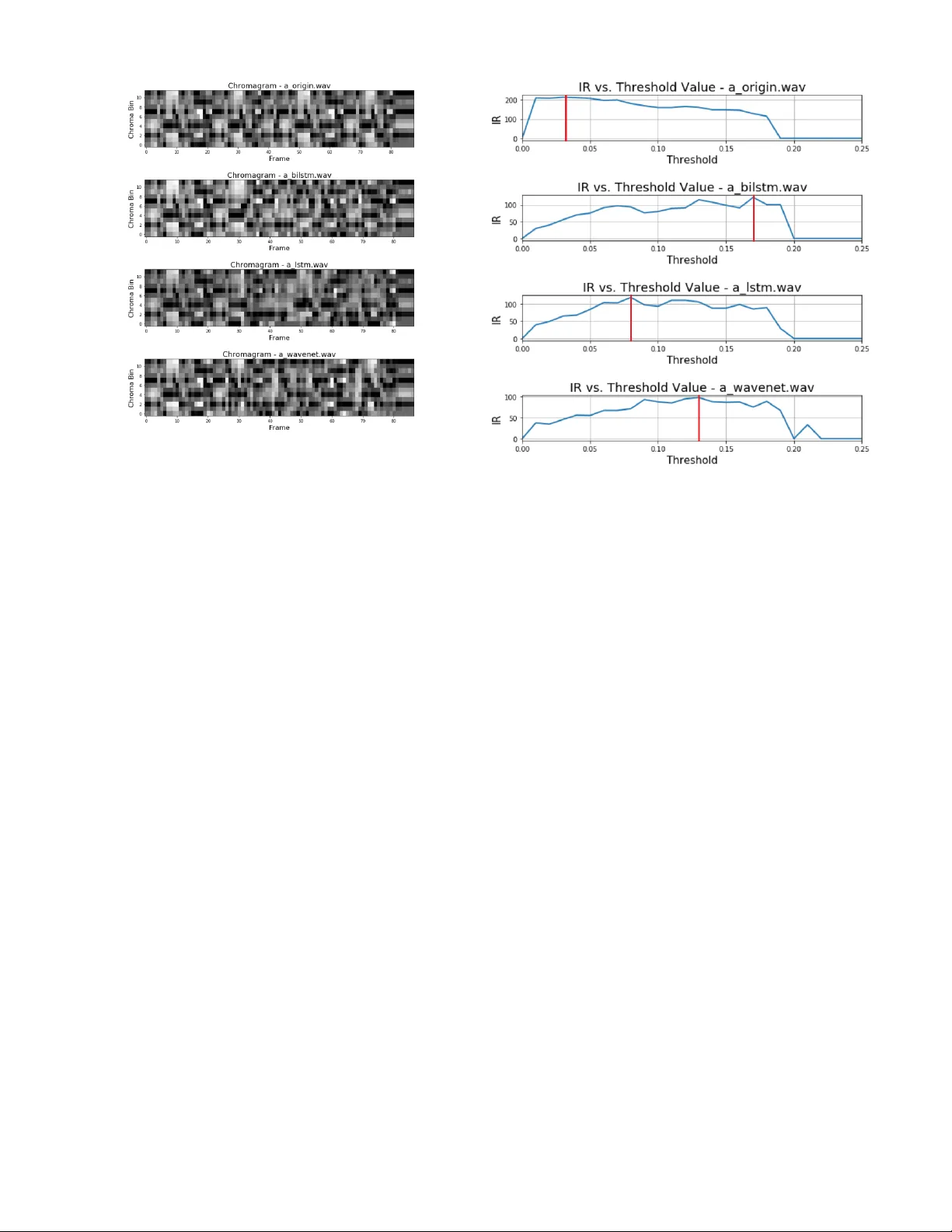
The Ef fect of Explicit Structure Encoding of Deep Neural Networks for Symbolic Music Generation K e Chen 1 4 , W eilin Zhang 2 4 , Shlomo Dubnov 3 , Gus Xia 4 and W ei Li 1 1 School of Computer Science, Fudan Uni versity , China 2 Department of Computer Science, Uni versity of Illinois Urbana-Champaign, USA 3 Department of Music, Uni versity of California San Die go, USA 4 Department of Computer Science, NYU Shanghai, China kchen15@fudan.edu.cn, weilinz2@illinois.edu, sdubnov@ucsd.edu, gxia@n yu.edu, weili-fudan@fudan.edu.cn Abstract —With recent breakthr oughs in artificial neural net- works, deep generative models ha ve become one of the leading techniques for computational creativity . Despite very promising progr ess on image and short sequence generation, symbolic music generation remains a challenging pr oblem since the structure of compositions ar e usually complicated. In this study , we attempt to solve the melody generation problem constrained by the given chord progression. In particular , we explore the effect of explicit architectural encoding of musical structure via comparing two sequential generative models: LSTM (a type of RNN) and W av eNet (dilated temporal-CNN). As far as we know , this is the first study of applying W aveNet to symbolic music generation, as well as the first systematic comparison between temporal- CNN and RNN for music generation. W e conduct a survey for evaluation in our generations and implemented V ariable Markov Oracle in music pattern discovery . Experimental r esults show that to encode structure more explicitly using a stack of dilated con volution lay ers improv ed the perf ormance significantly , and a global encoding of underlying chord progr ession into the generation procedure gains even more. Index T erms —symbolic music generation, artificial intelligence, deep generativ e model, machine learning and understanding of music, V ariable Markov Oracle, analysis of variance, music structure analysis I . I N T RO D U C T I O N Automated music generation has always been one of the principal targets of applying AI to music. W ith recent break- throughs in artificial neural networks, deep generative models hav e become one of the leading techniques for automated music generation [1], and many systems ha ve generated more con vincing results than traditional rule-based methods [2]. For the examples of re-generating J.S. Bach’ s work alone, we hav e seen [3] - [5]. Despite these promising progress, people still struggle to generate well-structured music. It is worth noting that most successful cases of automatic music compositions were limited to Bach, and at least for non-experts the structure of Bach’ s compositions is rather local and easy to percei ve compared to many other composers. In other words, automatic composition remains a challenging problem since music structures, for most compositions, are complicated and in volve long-term dependencies. T o solv e this problem, some studies imposed structural restrictions [6] - [8] on the final output. Ho wever , such post-processing restrictions usually conflict with the generating procedure and require tedious parameter tuning in order to make the algorithm con verge. It makes more sense to embed the notion of music structure into the model architecture and generati ve procedure. In this study , we chose the task in generating melody constrained by giv en chord progression. As discussed and practiced by [9], the generation of music by computers is considered as music computational creati vity . Solving this problem will show the importance of model choices and data representations in deep gener ative model . W e did a systematic comparison between two main-stream approaches of handling music structure representation using two sequential representa- tion generati ve models: LSTM (a type of RNN) and W av eNet (dilated temporal-CNN). The former encodes structure purely implicitly by the memory of hidden states, while the latter adds more explicit structured dependency via a lar ger recepti ve field of dilated con volutions. In terms of the dependencies between hidden variables, the relationship between LSTM and W a veNet is analogous to the one between a first-order autoregressi ve moving average (ARMA) model and a higher- order moving average (MA) model. From a signal processing perspectiv e, the output signals of LSTM and ARMA models depend on both history input and output signals, while the output signals of W av eNet and MA models solely depend on history inputs. T o our kno wledge, this is the first systematic comparison between temporal-CNN and RNN for symbolic music application. W e focus on symbolic music generation because music structure information is richer at the composition le vel than the performance and acoustic lev el [10]. As far as we know , this is the first attempt in applying W av eNet to symbolic music generation (The name of W aveNet implies its usage on audio applications, but in theory the temporal-CNN architecture can also be used for symbolic generation). Similarly to other studies [4] [11], we use chord progression as the global input for both models and turn the task into modeling the conditional distribution of music composition gi ven chords. W e present a no vel w ay of encoding chords and melody in a staggered representation. This ef fectively combines aspect of different time scales of chords and melody in music, learns simultane- ously temporal delayed dependencies between melody over past and next two bars, and also learns harmonic-melodic simultaneous relations within ev ery two bars of music. Such manipulation makes sense on a real composition scenario since in this context musicians rarely do purely-free improvisation (unconditioned generation) and almost always rely on a pre- defined guide (e.g. figured bass, chord progression, lead sheet, etc.) which encodes high-level music structure information. In order to ev aluate the performance of the neural model, we conducted a subjecti ve surv ey to e v aluate the quality of generated music. Human judgment takes into account, unconsciously , not only the local musical statistics, but also builds anticipations that keep track of long music structure, such as recognition of salient motifs and their patterns [12]. T o date, most of the ev aluation metrics for neural music models were done in terms of immediate prediction error, incapable of capturing longer terms salience structures. In order to be able to see how well the neurally generated music is able to learn such structure, we applied an Information Dynamics analysis dev eloped by [13] for music pattern discovery . W e applied this analysis to se veral musical music v ersus model- generated examples. Experimental results sho w that in terms of Information Dynamics ability for encoding of longer terms music structure, using dilated con volution layers improved the performance significantly . Moreover , we found that the results further improve when we incorporated the complete chord progression into the generation procedure rather than merely considering partial past chords. Our results show that repetition patterns will be found more clearly in the generation if we incorporate the global structure into our inputs. In the next section, we present related works. W e describe the methodology in Section III and show the experimental results in Section IV . W e discuss several important discoveries in Section V and finally come to the conclusion in Section VI. I I . R E L A T E D W O R K A. W aveNet for Sound Generation W av eNet [15] was first introduced by Google Deepmind as a generative model for raw audio. Since then, we ha ve seen many follow-up studies. Most works focus on tw o aspects: improving the speed of W aveNet, and applying W aveNet to audio-related applications. Parallel W av eNet [17] speeds up the generation process, and Fast W aveNet [18] reduces the time complexity . W av eNet was used in many aspects of raw audio generation as auto-encoder and audio synthesizer . Appli- cations include timbre style generator [19], v oice con version [20], speech synthesis [21] [22], speech enhancement [23], cello performance synthesizer [24], and speech denoising [25]. Most con vincing results were achie ved via adding conditions as an extra input. F or example, the neural audio synthesizer by W av eNet auto-encoders [19] add pitch conditioning during training. B. LSTM for Music Generation Many music generation works by deep neural networks start with unconditional (monophonic) symbolic melody genera- tion. The initial work [26] implemented the Back-Propagation Through T ime (BPTT) algorithm and used melody and dura- tion representation as the training input for generation. Since generation from single melody can be unstructured, follow up works usually includes conditions on chords or other musical features to guide the generation process. W ith Recurrent Neural Network (RNN) [27] and its ad- vanced versions (LSTM and GR U) [28] [29] came out, long- term dependency can be captured for music generation. The work by [30] demonstrated that RNNs is capable of revealing some higher-le vel information in melody generation. They tested the Blues impro visation performance of LSTM by inputting note slices in real time. The work by [31] defined sev eral measurements (T one di vision, Mode, Number of Oc- tav es, etc.) and create melody sequences by RNN by v aries inspirations. The unit selection method [32] took a series of measures in music as a unit and used a deep structured semantic model (DSSM) with LSTM to predict future units, instead of directly generate essential elements like notes. An important v ariation is the bidirectional architecture. DeepBach [4] introduced an innov ated bidirectional RNN for music harmonization. Ho wever , the main purpose of Deep- Bach is harmonization, not to use bidirectional neural networks for music generation. This work inspired us to use Bi-LSTM for conditioned melody generation. I I I . M E T H O D O L O G Y A. Pr oblem Definition For music piece of length T , given the melody until time point t ( t
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment