Non-Parallel Sequence-to-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations
This paper presents a method of sequence-to-sequence (seq2seq) voice conversion using non-parallel training data. In this method, disentangled linguistic and speaker representations are extracted from acoustic features, and voice conversion is achiev…
Authors: Jing-Xuan Zhang, Zhen-Hua Ling, Li-Rong Dai
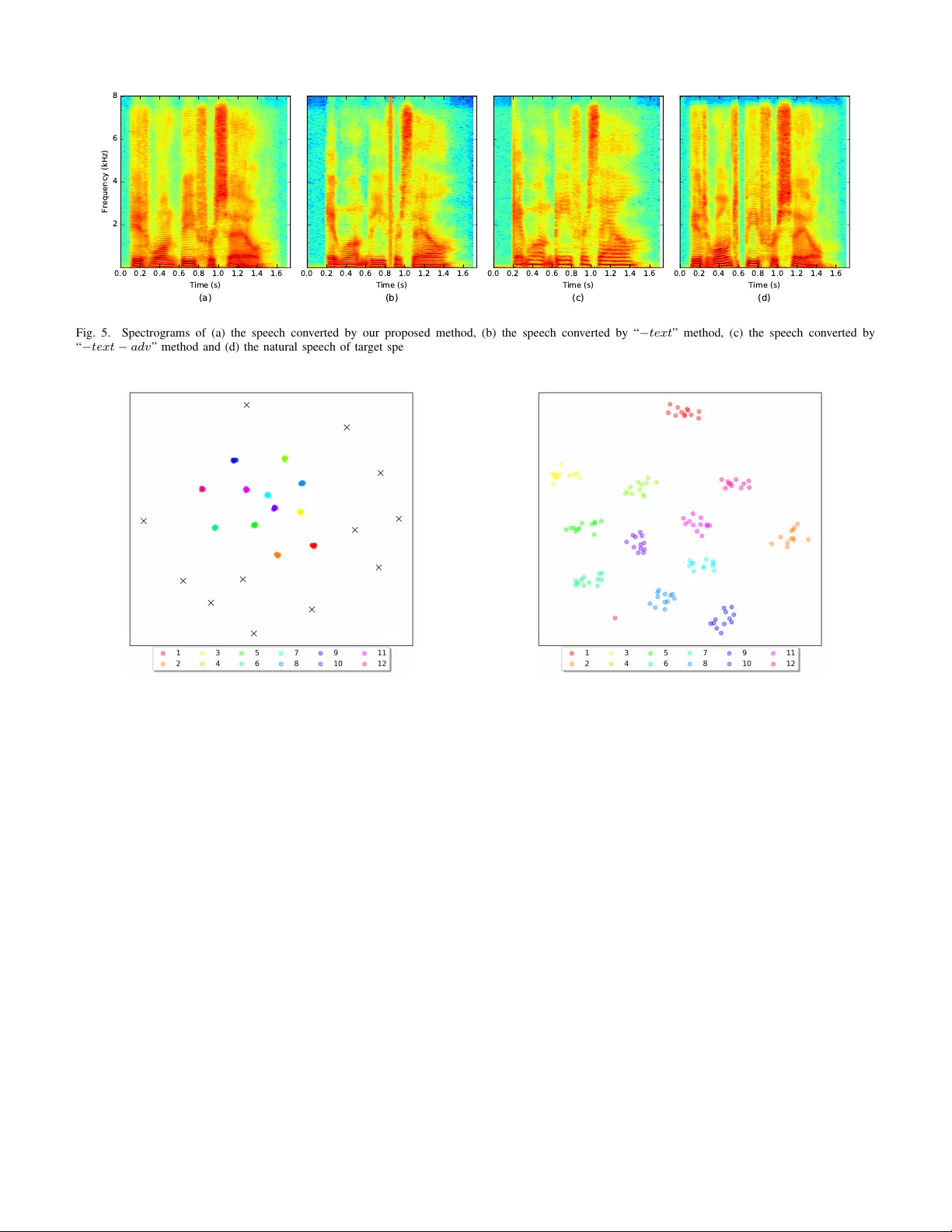
PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING c 2019 IEEE 1 Non-P arallel Sequence-to-Sequence V oice Con v ersion with Disentangled Linguistic and Speaker Representations Jing-Xuan Zhang, Zhen-Hua Ling, Senior Member , IEEE , and Li-Rong Dai Abstract —This paper presents a method of sequence-to- sequence (seq2seq) voice con v ersion using non-parallel train- ing data. In this method, disentangled linguistic and speaker repr esentations are extracted from acoustic features, and voice con version is achieved by preser ving the linguistic r epr esentations of source utterances while r eplacing the speaker r epresentations with the target ones. Our model is built under the framework of encoder -decoder neural networks. A recognition encoder is designed to learn the disentangled linguistic representations with two strategies. First, phoneme transcriptions of training data are introduced to pro vide the references for leaning linguistic repre- sentations of audio signals. Second, an adversarial training strat- egy is employed to further wipe out speaker information from the linguistic representations. Meanwhile, speaker repr esentations are extracted from audio signals by a speaker encoder . The model parameters are estimated by two-stage training, including a pr e- training stage using a multi-speaker dataset and a fine-tuning stage using the dataset of a specific conv ersion pair . Since both the recognition encoder and the decoder for reco vering acoustic features are seq2seq neural networks, there are no constrains of frame alignment and frame-by-frame conv ersion in our proposed method. Experimental results showed that our method obtained higher similarity and naturalness than the best non-parallel voice con version method in V oice Conversion Challenge 2018. Besides, the performance of our proposed method was closed to the state- of-the-art parallel seq2seq voice con version method. Index T erms —sequence-to-sequence, adversarial training, dis- entangle, voice con version I . I N T R O D U C T I O N V OICE con version (VC) aims at conv erting the input speeches of a source speaker to make it as if uttered by a target speaker without altering the linguistic content [1], [2]. V oice con version has wide applications such as personalized text-to-speech synthesis, entertainment, security attacking and so on [3]–[5]. The data conditions for VC can be divided into parallel and non-parallel ones [6]. Parallel VC methods are designed for the datasets with utterances of the same linguistic content but uttered by different persons. Thus, acoustic models that map the acoustic features of source speakers to those of target speakers can be learned directly when they are aligned. The This work was supported by National Key R&D Program of China (Grant No. 2019YFF0303001), the National Nature Science Foundation of China (Grant No. 61871358) and the Ke y Science and T echnology Project of Anhui Province (Grant No. 18030901016). J.-X. Zhang, Z.-H. Ling and L.-R. Dai are with the National Engineering Laboratory for Speech and Language Information Processing, Univ ersity of Science and T echnology of China, Hefei, 230027, China (e-mail: no- sisi@mail.ustc.edu.cn, zhling@ustc.edu.cn, lrdai@ustc.edu.cn). forms of the acoustic models for VC included joint density Gaussian mixture models (JD-GMMs) [3], [7], [8], deep neural networks (DNNs) [9]–[11], recurrent neural networks (RNNs) [12], [13], and so on. Recently , sequence-to-sequence (seq2seq) neural networks [14]–[17] hav e also been applied to VC, which achiev ed higher naturalness and similarity than con v entional frame-aligned con version [18]–[20]. Non-parallel VC is more challenging but more valuable in practice considering the dif ficulty of collecting parallel training data of different speakers. The methods for non-parallel VC can be roughly di vided into two categories. The methods of the first category handle non-parallel VC by first conv erting it into the parallel situation and then learning the mapping functions, such as generating parallel data through text-to- speech synthesis (TTS) [21], frame-selection [22], iterativ e combination of a nearest neighbor search step and a con version step alignment (INCA) [23], [24] and CycleGAN-based VC [25]–[27]. On the other hand, the methods of the second cate- gory factorize the linguistic and speaker related representations carried by acoustic features [28]–[36]. At the con version stage, the linguistic content of the source speaker is preserved while the speaker representation of the source speaker is transformed to that of the tar get speaker . In contrast, the parallel VC does not need to perform such factorization explicitly . For a pair of aligned frames, they carry the same linguistic content. Therefore, the mapping function between them can achie ve the transformation of speaker representations. One representativ e approach of the second category men- tioned abo ve is the recognition-synthesis approach to non- parallel VC [29]–[32]. T ypically , it concatenates an automatic speech recognition (ASR) model for extracting linguistic in- formation, such as the posterior probabilities or bottleneck features of phoneme classification, and a speaker-dependent synthesis model for generating voice of the target speaker . De- spite its success, con ventional recognition-synthesis methods hav e se veral deficiencies. First, an extra ASR model is required for extracting linguistic descriptions. This model is usually trained alone without joint optimization with the synthesis model. Second, the ASR model is usually trained with a phoneme classification loss and lacks explicit consideration on disentangling linguistic and speaker representations. Third, most of these methods follo w the framework of frame-by- frame con version and can not achiev e the adv antages of seq2seq modeling [18], such as duration modification. Therefore, a non-parallel seq2seq VC method with disen- tangled linguistic and speaker representations is presented in PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGU A GE PR OCESSING c 2019 IEEE 2 L i n g u i s t i c r e p r e s e n t a t i o n s Sp e a k e r r e p r e s e n t a t i o n s S eq 2 s eq d ec o d er S o u r c e u t t e r a n c e R ec o g n i t i o n en c o d er T a r g e t s p e a k e r C o n v e r t e d u t t e r a n c e ( b) P l ea s e c a l l S t el l a . L i n g u i s t i c r e p r e s e n t a t i o n s Sp e a k e r r e p r e s e n t a t i o n s S eq 2 s eq d ec o d er A c o u s t i c f e a t u r e s P h o n e m e t r a n s c r i p t i o n s ( a ) L i n g u i s t i c i n f o r m a t i o n Sp e a k e r i n f o r m a t i o n p iy z k ao l s t eh l ax T ex t en c o d er S p ea k er en c o d er R ec o g n i t i o n en c o d er D i s e n t a n g l e Fig. 1. (a) The overview of our model at the training stage and (b) the con version process of our proposed method. this paper . In this method, a seq2seq recognition encoder and a neural-network-based speaker encoder are constructed for transforming acoustic features into disentangled linguistic and speaker representations. A seq2seq decoder is built for recov ering acoustic features from the combination of them. Fig. 1 (a) depicts the overvie w of our model at the training stage and Fig. 1 (b) shows the con version process of our proposed method, where a W aveNet vocoder is adopted [37] for wa veform reconstruction. As shown in Fig. 1 (a), two strate gies are proposed to learn the speaker-irrele v ant linguistic representations. First, phoneme transcriptions of audio signals are sent into a text en- coder and the outputs are adopted as the references for learning linguistic representations from acoustic features. Second, an adversarial training strategy is further designed for eliminating speaker -related information from the linguistic representations. The model parameters are estimated by tw o-stage training, including pre-training using a multi-speaker dataset and fine- tuning on the dataset of a specific conv ersion pair . As shown in Fig. 1 (b), the con version stage includes first extracting linguistic representations from the source utterance and then reconstructing acoustic features from them together with the speaker representations of the target speaker . The text inputs are only used at training time and the con version process does not rely on any text inputs. Experiments have been conducted to compare our proposed method with state-of-the-art parallel and non-parallel VC methods objectiv ely and subjectiv ely . The results sho wed that our proposed method achieved higher similarity and natural- ness than the best non-parallel VC method in V oice Con version Challenge 2018 (VCC2018). Besides, its performance w as close to the state-of-the-art parallel seq2seq VC method. Some ablation tests have also been conducted to confirm the effecti veness of our proposed method. I I . R E L A T E D W O R K A. Recognition-synthesis appr oach to non-parallel VC Sun et al. [29] proposed to extract phonetic posterior- grams (PPGs) from source speech using an ASR model then feed them into a deep bidirectional long short-term mem- ory (BLSTM) model [38] for generating conv erted speech. Miyoshi et al. [30] proposed a seq2seq learning method for con v erting context posterior probabilities, which included a recognition model and a synthesis model. An any-to-any voice con v ersion framework was proposed based on a multi-speaker synthesis model conditioned on the i -vectors and the outputs of an ASR model [32]. In the study of Liu et al. [31], the ASR model was estimated using a large-scale training set and W aveNet vocoders were built with limited training data of target speakers for wa veform recovery . This method achiev ed the best performance of non-parallel VC in V oice Con version Challenge 2018. Compared with Miyoshi’ s method [30], the method pro- posed in this paper does not use a separate con version model for con verting linguistic representations. In contrast, we as- sume a uniform linguistic space across speakers. The recog- nition encoder compresses acoustic features into linguistic representations which ha ve equal lengths with phoneme tran- scriptions. Compared with other recognition-synthesis based VC methods [29], [31], [32], the recognition encoder and PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 3 the seq2seq decoder in our model are optimized jointly . Disentangled linguistic and speaker representations are also proactiv ely learned in our proposed method. B. Auto-encoder based voice con version The VC methods using auto-encoders (AEs) and variational auto-encoders (V AEs) [34], [35] hav e also been studied in recent years. Saito et al. [33] proposed to use PPGs for improving V AE-based VC. Se veral studies proposed AE-based VC with adversarial learning of hidden representations against speakers information [36], [39], [40]. Polyak et al. [39] tried to incorporate an attention module between the encoder and the decoder in a W aveNet-based AE. Howe ver , it degraded the mean opinion score (MOS) in ev aluation. Compared with the unsupervised learning of hidden repre- sentations in AE or V AE based VC, our method employs the supervision of corresponding phoneme transcriptions together with adversarial training to learn the recognition encoder . Furthermore, in contrast to the frame-le vel encoders and decoders in most previous studies, the joint training of the recognition encoder and the decoder in our proposed method can be vie wed as building a sequence-le vel auto-encoder . C. V oice cloning V oice cloning is a task that learns the v oice of unseen speak- ers from a few speech samples for text-to-speech synthesis [41]–[43]. V oice cloning takes texts as model inputs, which contain only linguistic information. In contrast, audio signals are used as the inputs of the VC task, which contain not only linguistic content but also speaker identity . Therefore, carefully disentangling acoustic features into linguistic and speaker representations is important for achieving high-quality VC in our proposed method. It is also possible to incorporate the techniques de v eloped for v oice cloning, such as the method of estimating speaker embeddings with limited data, into our proposed method for achieving the one-shot or few-shot learning of VC. I I I . P R O P O S E D M E T H O D A. Model ar chitectur e The proposed model contains fiv e components, including a text encoder E t , a recognition encoder E r , a speaker encoder E s , an auxiliary classifier C s , and a seq2seq decoder network D a . The overall architecture of the model is presented in Fig. 2 and functions of these components are described as follo ws. T ext encoder E t : T ext encoder transforms the text inputs into linguistic embeddings as H t = E t ( T ) , where T = [ t 1 , . . . , t N ] denotes the transcription sequence with one-hot encoding for each phoneme and H t = [ h t 1 , . . . , h t N ] denotes the sequence of embedding vectors. N represents the length of the phoneme sequence and the embedding sequence. The text encoder is built with stacks of con volutional layers followed by a BLSTM and a fully connected layer on the top. Recognition encoder E r : Recognition encoder accepts the acoustic feature sequence A = [ a 1 , . . . , a M ] as inputs and predicts the phoneme sequence T , where M represents the number of acoustic frames. The outputs of hidden units before the softmax layer are extracted as H r = E r ( A ) , where H r = [ h r 1 , . . . , h r N ] denotes the linguistic representations of audio signals. The recognition encoder E r is a seq2seq neural network which aligns the acoustic and phoneme sequences automatically . Its encoder is based on pyramid BLSTM [44] and its attention-based decoder is one-layer LSTM. Since one phoneme usually corresponds to tens of acoustic frames, we hav e M >> N and the encoding is a compr ession process. At the training stage, the output of the recognition encoder H r has the equal length to the phoneme sequence T regardless of the speaking rate of speakers. H r is expected to reside in the same linguistic space as H t and contains only information of linguistic content. Speaker encoder E s : The speaker encoder embeds the acoustic feature sequence into a vector as h s = E s ( A ) , which can discriminate speaker identities. The speaker embedding should contain only speaker-related information. Our speaker encoder is built with stacks of BLSTM followed by an average pooling and a fully connected layer . The speaker encoder is only employed at the pre-training stage which will be introduced in Section III-E. At the beginning of fine-tuning stage, a trainable speaker embedding is introduced for each speaker and is initialized by the h s extracted by the speaker encoder . A uxiliary classifier C s : The auxiliary classifier is em- ployed to predict the speaker identity from the linguistic representation of the audio input as ˆ P s = C s ( H r ) , where ˆ P s = [ ˆ p s 1 , . . . , ˆ p s N ] and each element ˆ p s n is the predicted probability distribution among speakers. C s is introduced for adversarial training in order to further eliminate speaker - related information remained within the linguistic represen- tation H r . In our implementation, C s is a DNN which makes prediction for each input embedding vector . Seq2seq decoder D a : The seq2seq decoder recovers the acoustic feature sequence from the combination of linguistic embeddings and speak er embeddings as ˆ A = D a ( h s , H t ) or ˆ A = D a ( h s , H r ) . ˆ A = [ ˆ a 1 , . . . , ˆ a M ] represents the reconstructed acoustic features and either H t or H r is fed into the decoder at each training step, in which condition a process of text-to-speech or auto-encoding of acoustic features is performed. It can be viewed as a decompr essing process in which the linguistic contents are transformed back into acous- tic features conditioned on the speaker identity information. Here, the structure of the seq2seq decoder is similar to the T acotron model [45], [46] for speech synthesis. B. Loss functions for disentangled linguistic repr esentations Three loss functions are designed for extracting the disen- tangled linguistic representations from audio signals and their details are as follows. 1) Phoneme sequence classification: The recognition en- coder is a seq2seq transducer that maps input acoustic feature sequences into the sequences of linguistic representations. The phoneme classification loss of the linguistic representation PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 4 𝐿 𝐶 𝑇 𝐄 𝑡 𝐄 𝑟 𝐄 𝑠 𝐿 𝑆 𝐶 𝐿 𝑆 𝐸 𝐿 𝑇 𝐶 𝑠 𝐿 𝐴 𝐷 𝑉 Sp e a ke r I D 𝑨 𝐂 𝑠 𝑻 P h o n e m e s t r a n s c r ip t io n s 𝐿 𝑅 𝐶 𝐿 𝐸 𝐷 𝐿 𝑅 𝐶 𝐿 𝐸 𝐷 A u t o - e n c o d in g T e x t - to - s p e e c h 𝐃 𝑎 𝐃 𝑎 𝑯 𝑡 𝑯 𝑟 𝒉 𝑠 𝑨 𝑨 L in g u is t ic s p a c e Sp e a ke r s p a c e S eq 2 s eq d ec o d er S eq 2 s eq d ec o d er S p ea ker e n c o d e r Rec o g n i t i o n en c o d er T ex t en c o d er 𝑷 𝑠 A c o u s t ic f e a t u r e s Fig. 2. The architecture of our proposed model and its forward propagation paths during training. The seq2seq decoder adopts the output of either recognition encoder or text encoder as input at each training step. H t , H r and h s represent the linguistic embedding from text, the linguistic embedding from audio and the speaker embedding respectiv ely . sequence H r is defined as L T C = 1 N N X n =1 CE ( t n , softmax ( W h r n ))) , (1) where CE ( · ) represents the cross entropy loss function, W is a trainable weight matrix of E r , h r n and t n denote the linguistic representation and the true label of the n -th phoneme respectiv ely . 2) Embedding similarity with text inputs: The linguis- tic representations extracted from audio signals and from phoneme sequences (i.e., H r and H t ) are expected to share the same linguistic space. Intuitiv ely , we would like the linguistic embeddings from both audio and text inputs to be similar with close distance. Inspired by pre vious studies on feature mapping [47], lip sync [48] and learning joint embed- ding space from audio and video inputs [49], the contrastiv e loss is adopted in this paper to increase the similarity between h r m and h t n if m = n and to reduce their similarity if m 6 = n . The loss function is defined as L C T = N ,N X m =1 ,n =1 I mn d mn + (1 − I mn ) max (1 − d mn , 0) . (2) I mn is the element of an indicator matrix where I mn = 1 if m = n and I mn = 0 otherwise. d mn is the distance between h r m and h t n which is defined as d mn = k h r m k h r m k 2 − h t n k h t n k 2 k 2 2 . (3) In our experiments, we found that the second term of the left part in Eq. (2) was necessary , which prevented the extracted representations from falling into the same vector . 3) Adversarial training against speaker classification: The auxiliary classifier C s is trained with a cross entropy loss L S C between the predicted speaker probabilities and the target labels as L S C = 1 N N X n =1 CE ( p s , ˆ p s n ) , (4) where p s is the one-hot speaker label of input audio signals. Meanwhile, the recognition encoder E r is optimized toward the opposite goal, i.e., fooling the auxiliary classifier to make a prediction of equal probabilities among speakers. Thus, an adversarial loss L ADV is designed for training E r as L ADV = 1 N N X n =1 k e − ˆ p s n k 2 2 . (5) where e = [1 /S, . . . , 1 /S ] > is an uniform distribution and S is the total number of speakers. When updating the parameters of the recognition encoder , C s is frozen. It is expected to reduce the speaker-related information carried by the linguistic representations of audio signals by minimizing L ADV . If the speaker representations are completely eliminated from linguistic hidden embeddings, the auxiliary classifier should achiev e the minimum loss and assign equal probability to each possible speaker . Similar loss functions have been used for disentangling person identity and word space of videos [49]. C. Loss functions for disentangled speaker repr esentations In parallel to producing linguistic representations, speaker embeddings are extracted from acoustic features by the speaker encoder E s . Speaker embeddings are expected to be discrim- inativ e to the speaker identity . Therefore, we introduce a speaker classification loss for the training of E s . The speaker classification loss of E s is calculated as L S E = CE ( p s , softmax ( V h s )) . (6) PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 5 where V is a trainable weight matrix of E s . Once the speaker representation h s for an input utterances is obtained, it is processed by L 2 normalization and fixed when passed through the decoder . In another word, the speaker encoder is only optimized by L S E and not influenced by further calculations using h s . Based on our experiments, this loss function can help to obtain consistent speaker embeddings from different utterances of the same speaker . Hence, we do not conduct adversarial training for extracting speaker embeddings. D. Loss functions for acoustic featur e prediction Acoustic features are eventually recovered from the linguis- tic representations H r or H t together with the speaker em- bedding h s via the seq2seq decoder . After L 2 normalization, the h s vector is concatenated with the linguistic representation of each phoneme. An L 1 loss is defined for the predicted acoustic features as L RC = 1 M M X i =1 k ˆ a i − a i k 1 , (7) where ˆ a i is the predicted acoustic feature vector at the i -th frame. In order to end the acoustic feature sequences generated by the seq2seq decoder at the con version stage, the hidden state of the seq2seq decoder at each frame is projected to a scalar followed by sigmoid acti v ation to predict whether current frame is the last frame in an utterance. Accordingly , a cross entropy loss L E D is defined for this prediction at the training stage. E. Model training In summary , there are totally 7 losses introduced above for training our proposed model. They are the loss for phoneme sequence classification L T C , the contrasti ve loss for embedding similarity with text inputs L C T , the losses for adversarial training L ADV and L S C , the loss for speaker representations L S E , and the losses for predicting acoustic features and utterance ends L RC and L E D . These losses are lev eraged through weighting factors to form the complete loss function. W eighting factors w adv , w ct , w sc are introduced for L ADV , L C T , L S C respectiv ely . For other losses, the weighting factors are set as 1 heuristically . The model parameters are estimated by two-stage training. At the first stage (i.e., the pre-training stage), the whole model is trained using a large multi-speaker dataset which contains triplets of text transcriptions, speech wav eforms and a speaker identity label for each utterance. Then, the model parameters are updated on a specific con version pair of source and target speakers at the second stage (i.e., the fine-tuning stage). It should be noticed that our model is capable of performing many-to-man y VC if we simply increase the number of speakers during fine-tuning. Ho we ver , we concentrate on the voice con version between a pair of speakers in this paper . The algorithm for pre-training is shown in Algorithm 1, where θ E t , θ E r , θ E s , θ C s and θ D a denote the parameters of the five model components respectively . The algorithm for Algorithm 1 Pre-training using a dataset of S speakers. Initialization: θ E t , θ E r , θ E s , θ C s , θ D a , iter ← 1 . Iteration: while not con veraged do Sample mini batch h A , T , p s i H t ← E t ( T ) , H r ← E r ( A ) , h s ← E s ( A ) ˆ P s ← C s ( H r ) if iter is ev en then ˆ A ← D a ( h s , H t ) else ˆ A ← D a ( h s , H r ) end if computing L T C , L C T , L ADV , L S C , L S E , L RC , L E D if iter is ev en then θ E t + ← − −∇ θ E t ( w ct L C T + L RC + L E D ) θ E r + ← − −∇ θ E r ( L T C + w ct L C T + w adv L ADV ) else θ E t + ← − −∇ θ E t w ct L C T θ E r + ← − −∇ θ E r ( L T C + w ct L C T + w adv L ADV + L RC + L E D ) end if θ E s + ← − −∇ θ E s L S E θ C s + ← − −∇ θ C s w sc L S C θ D a + ← − −∇ θ D a ( L RC + L E D ) iter + ← − 1 end while fine-tuning is almost the same as Algorithm 1. The multi- speaker dataset is replaced by the one containing the source speaker and the target speaker , and the number of speakers is reset as S = 2 . T wo trainable speaker embeddings are introduced for these two speakers. These two speaker embed- dings are initialized as the speaker encoder output h s av eraged across training utterances of these two speakers respecti vely . Then, the speaker encoder E s is discarded during fine-tuning. Besides, the softmax layer for multi-speaker classification in the auxiliary classifier is replaced by a sigmoid output layer for the binary speaker classification. I V . E X P E R I M E N T S A. Experiment conditions One female speaker (slt) and one male speaker (rms) in the CMU A CR TIC dataset [50] were used as the pair of speakers for conv ersion in our experiments. For each speaker , the ev aluation and test set both contained 66 utterances. The non- parallel training set for each speaker contained 500 utterances. For comparison with parallel VC, 500 parallel utterances were also selected for each speaker to form the parallel training set. The multi-speaker VCTK dataset [51] was utilized for model pre-training in our proposed method. Altogether 99 speakers were selected from the VCTK dataset. For each speaker , 10 and 20 utterances were used for validation and testing respectiv ely , and the remaining utterances were used as training samples. The total duration of training samples was about 30 hours. PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 6 T ABLE I D E T A I L S O F T H E M O D E L C ON FIG U R ATI O N S . E t Con v1D-5-512-BN-ReLU-Dropout(0.5) × 3 → 1 layer BLSTM, 256 cells each direction → FC-512-T anh → H t E r Encoder 2 layer Pyramid BLSTM [44], 256 cells each direction, i.e. reducing the sequence time resolution by factor 2. Decoder 1 layer LSTM, 512 cells with location-aware attention [52] → FC-512-T anh → H r E s 2 layer BLSTM, 128 cells each direction → av erage pooling → FC-128-T anh → h s C s FC-512-BN-LeakyReLU [53] × 3 → FC-99-Softmax → ˆ P s D a Encoder 1 layer BLSTM, 256 cells each direction PreNet FC-256-ReLU-Dropout(0.5) × 2 Decoder 2 layer LSTM, 512 cells with forward attention [54], 2 frames are predicted each decoder step PostNet Con v1D-5-512-BN-ReLU-Dropout(0.5) × 5 → Con v1D-5-80, with residual connection from the input to output “FC” represents fully connected layer . “BN” represents batch normal- ization. “Conv1D- k - n ” represents 1-D con volution with kernel size k and channel n . “ × N ” represents repeating the block for N times. D a follows the framework of the T acotron model [46]. The acoustic features were 80-dimensional Mel- spectrograms extracted e very 12.5 ms and the frame size for short-time Fourier transform (STFT) was 50 ms. The original Mel-spectrograms were then scaled to logarithmic domain. In order to obtain the inputs of the text encoder, we generated phoneme transcriptions using the grapheme-to- phoneme module of Festiv al 1 . Our model was implemented with PyT orch 2 . The Adam optimizer [55] was used and the training batch size was 32 and 8 at the pre-training and fine-tuning phases respectiv ely . The learning rate was fixed to 0.001 for the 80 epoches of pre-training and it was halved ev ery 7 epoches during fine-tuning. The weighting factors of loss functions were tuned on the v alidation set of the multi-speaker data and were determined as w ct = 30 and w sc = 0 . 1 . w adv was set as 20 and 0.2 during pre-training and fine-tuning respecti vely . The details of our model structures are summarized in T ABLE I 3 . A beam search with width of 10 was adopted for inference using the recognition encoder E r . The W av eNet vocoder predicted 10-bit wa veforms with µ -law companding. Its implementation follo wed our previous work [31]. 1 http://www.cstr.ed.ac.uk/projects/festival/ . 2 https://pytorch.org/ . 3 Implementation code is av ailable at https://github.com/ jxzhanggg/nonparaSeq2seqVC_code/ . B. Comparative methods Four VC methods were implemented for comparison with our proposed method 4 . T wo of them adopted parallel training and the rest adopted non-parallel training. The details of them are described as follows. DNN: Parallel VC method based on a DNN acoustic model. 41-dimensional Mel-cepstral coefficients (MCCs), 5- dimensional band aperiodicities (BAPs), 1-dimensional funda- mental frequency ( F 0 ), their delta and accelerate features were extracted as acoustic features. The Merlin open source toolkit 5 [56] was employed for implementation. The DNN contained 6 layers with 1024 units and tanh acti vations per layer . WORLD vocoder [57] was adopted for wav eform recov ery . Seq2seqVC: Parallel VC method based on a seq2seq model [18]. 80-dimensional Mel-spectrogram features were adopted as acoustic features together with bottleneck features, which were linguistic-related descriptions extracted by an ASR model trained on about 3000 hours of external speech data [18]. The W av eNet vocoder built in our proposed method was also used here for wa veform recovery . Previous study sho wed that this method achieved better performance than the best parallel VC method in VCC2018 [18]. CycleGAN: Non-parallel VC method based on CycleGAN [25]. An open source implementation of CycleGAN-based VC was adopted 6 . MCCs, B APs and F 0 were used as acoustic features. Only MCCs were con verted by CycleGAN and F 0 trajectories were conv erted by Gaussion mean normalization [58]. The BAP features were not con verted. WORLD vocoder was used for wav eform recovery . Actually , we hav e tried to adopt the W av eNet vocoder built in our proposed method. Howe ver , the reconstructed voice was noisy and the quality was not as good as that using WORLD vocoder . VCC2018: Non-parallel VC method based on con ventional recognition-synthesis approach [31]. The ASR model was the same as the one used by the Seq2seqVC method. Then, bottleneck features were extracted from the built recognition model as linguistic descriptions and were used as the inputs of speaker-dependent synthesis models. MCCs, BAPs and F 0 features were used as acoustic features and the W aveNet vocoder was adopted for wa veform recov ery . This method achiev ed the best performance on the non-parallel VC task of V oice Conv ersion Challenge 2018. C. Objective evaluations Mel-cepstrum distortion (MCD), root of mean square er- rors of F 0 ( F 0 RMSE), the error rate of voicing/un voicing flags (VUV) and the Pearson correlation factor of F 0 ( F 0 CORR) were used as the metrics for objecti ve ev aluation. In order to inv estigate the effects of duration modification, we also computed the average absolute dif ferences between the durations of the conv erted and target utterances (DDUR) as in our previous work [18]. When computing DDUR, the 4 Audio samples of our experiments are av ailable at https:// jxzhanggg.github.io/nonparaSeq2seqVC/ . 5 https://github.com/CSTR- Edinburgh/merlin/ . 6 https://github.com/leimao/Voice_Converter_ CycleGAN/ . PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 7 T ABLE II O B JE CT I V E E V A L U ATI O N R E S U L T S O F D I FF E R EN T M E TH O D S . Con version Pairs Methods MCD (dB) F 0 RMSE (Hz) VUV (%) F 0 CORR DDUR (s) rms-to-slt para DNN 4.134 16.651 9.205 0.585 0.481 Seq2seqVC 2.999 13.633 6.968 0.727 0.152 non-para CycleGAN 3.309 27.264 11.603 0.394 0.481 VCC2018 3.376 15.042 8.222 0.663 0.481 Proposed 3.088 16.043 7.898 0.624 0.261 slt-to-rms para DNN 3.747 16.484 11.750 0.526 0.481 Seq2seqVC 2.887 14.360 9.435 0.664 0.245 non-para CycleGAN 3.246 18.284 13.428 0.507 0.481 VCC2018 3.171 15.771 11.382 0.593 0.481 Proposed 2.974 16.080 10.327 0.581 0.264 Best results obtained among parallel and non-parallel VC methods for each metric are highlighted with bold fonts. “para” and “non-para” represent parallel VC and non-parallel VC respectively . T ABLE III M E AN O PI NI O N S C O R ES ( MO S ) W I T H 95% C ON FI D E NC E I N TE RV A L S O N NAT U R AL N E S S A N D S I MI L A R IT Y O F D IFF ER E N T M E T H O DS . Methods rms-to-slt slt-to-rms Naturalness Similarity Naturalness Similarlity para DNN 2 . 09 ± 0 . 09 2 . 03 ± 0 . 10 2 . 38 ± 0 . 10 2 . 42 ± 0 . 10 Seq2seqVC 4.20 ± 0 . 09 4.26 ± 0 . 09 4.18 ± 0 . 09 4.37 ± 0 . 09 non-para CycleGAN 1 . 48 ± 0 . 09 1 . 49 ± 0 . 08 1 . 81 ± 0 . 11 1 . 82 ± 0 . 11 VCC2018 3 . 53 ± 0 . 11 3 . 59 ± 0 . 14 3 . 76 ± 0 . 11 3 . 89 ± 0 . 12 Proposed 4.19 ± 0 . 09 4.24 ± 0 . 09 4.18 ± 0 . 09 4.26 ± 0 . 09 Highest scores among parallel and non-parallel VC methods for each metric are highlighted. silence segments at the beginning and the end of utterances were remov ed. Because Mel-spectrograms were adopted as acoustic fea- tures in the Seq2seqVC method and our proposed method, it’ s not straightforward to extract F 0 and MCCs features from the con v erted acoustic features. Therefore, the MCCs and F 0 were extracted from the waveform of conv erted utterances using STRAIGHT [59]. Then, they were aligned to the reference utterances by dynamic time wraping using MCCs features for calculating the metrics. The test set results of both rms-to-slt and slt-to-rms conv er - sions are reported in T ABLE II. As we can see from this table, among the parallel VC methods, Seq2seqVC achieved better performance than the DNN method. For non-parallel VC, our proposed method achie ved the best result on MCD, UVU and DDUR metrics. In terms of F 0 RMSE and F 0 CORR metrics, the VCC2018 method performed better than our proposed method. Although there were no parallel training utterances, our proposed method can still reduce the DDUR of the parallel and non-parallel methods following frame-by-frame con v ersion. The objecti ve performance of propose method was close to but still not as good as the parallel Seq2seqVC method in spectral and F 0 estimation. For durational con version, the Seq2seqVC method outperformed other methods by large margins. The reason is that the Seq2seqVC method made use of the supervision from paired utterances for learning the mapping function at utterance level. While our method can only obtain speaking rate information from the speaker embeddings. T o improv e the capability of speaker embeddings on describing speaking rates is worth further in vestig ation in the future. D. Subjective evaluations Subjectiv e ev aluations in term of both the naturalness and similarity of conv erted speech were conducted. 20 utterances in the test set of each speaker were randomly selected and con v erted using the five methods mentioned above. For each utterance, the con v erted samples were presented to listeners in random order, who were asked to gi ve a 5-scale opinion score (5: excellent, 4: good, 3: fair , 2: poor , 1: bad) on both naturalness and similarity of each sample. At least thirteen listeners participated in each ev aluation and they were asked to use headphones. The e v aluation results are presented in T ABLE III. As we can see from this table, the Seq2seqVC method and our proposed method achie v ed the best subjective performance among all parallel and non-parallel methods respectiv ely in both conv ersion directions. The DNN and CycleGAN methods obtained lo wer MOSs than other methods, which was consistent with the results of objectiv e ev aluations. Although the VCC2018 method adopted a much larger dataset than VCTK for training the recognition model, our method still achieved better performance than it. In rms- PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 8 Fig. 3. V isualization of speaker embeddings. Each point represents an utterance and the legend indicates different speakers. to-slt conv ersion, the p -v alues of t -tests between these two methods for naturalness and similarity were 7 . 3 × 10 − 22 and 3 . 3 × 10 − 19 respectiv ely . In slt-to-rms con version, the p -v alues for naturalness and similarity were 1 . 3 × 10 − 10 and 4 . 2 × 10 − 9 respectiv ely . W e can see that the superiority of our proposed method ov er the VCC2018 method was significant. Compared with the parallel Seq2seqVC method, our pro- posed method achieved close and slightly inferior perfor- mance. In rms-to-slt con v ersion, the p -v alues for naturalness and similarity were 0 . 94 and 0 . 73 respectiv ely . In slt-to- rms conv ersion, the p -values for naturalness and similarity were 0 . 94 and 0 . 03 respectively . Therefore, the superior of Seq2seqVC over proposed method is insignificant except the similarity in slt-to-rms conv ersion. In addition to using parallel training data, the Seq2seqVC method also benefitted from the bottleneck features extracted from an ASR model. Considering that the dataset for training the ASR model was much larger than the VCTK dataset used in our proposed method, it’ s possible to further improve our model by adopting a larger multi-speaker dataset for pre-training. E. V isualization of hidden r epresentations In order to demonstrate that our model can produce disen- tangled linguistic and speaker representations as we expected, the extracted linguistic and speaker representations were visu- alized by t-SNE [60]. 12 parallel utterances of 12 speakers in the test set of VCTK were selected and sent into the text encoder, the recognition encoder and the speaker encoder obtained by pre-training. The linguistic representations H t and H r giv en by the text encoder and the recognition encoder were averaged along the time axis to get single embedding vector for each utterance. Then, the speaker and linguistic embedding vectors of all utterances were projected into a 2- dimensional space by t-SNE and are shown in Fig. 3 and Fig. 4 respectiv ely . From Fig. 3, we can see the speaker embeddings from the same speaker were v ery similar with each other . The speaker embeddings of different speakers were also separable Fig. 4. V isualization of linguistic embeddings. The legend indicates different transcriptions. Each × symbol represents the linguistic embedding of a transcription given by the text encoder and each point represents the linguistic embedding of an utterance given by the recognition encoder . according to their genders. From Fig. 4, we can see that parallel utterances of different speakers had almost overlapped linguistic representations, which confirmed that the proposed model can generate speaker -in v ariant linguistic representations using the recognition encoder . The linguistic embeddings generated from te xt inputs were also located within the clusters of utterances with the same transcriptions, which indicated the effecti veness of the contrastive loss L C T . F . Evaluation on the amount of training data for fine-tuning In this experiment, we gradually reduced the number of training utterances used at the fine-tuning stage in order to ev aluate how the data amount affects the performance of our proposed method. Five configurations were compared which utilized 500, 400, 300, 200 and 100 training utterances for both source and target speakers respectively . Their objectiv e perfor- mances are summarized in T ABLE IV 7 . From T ABLE IV, we can see that the performance of our proposed method degraded slightly while reducing the number of utterances for fine-tuning. Even with only 100 non-parallel utterances, our method still achie ved lo wer MCD than the VCC2018 method in T ABLE II which used 500 training utterances. T wo ABX preference tests were conducted to compare our proposed method using 100 utterances for fine-tuning with the VCC2018 methods using 500 and 100 utterances respectiv ely . In each test comparing two methods, 20 test utterances were randomly selected for each speaker and were conv erted by both methods to the other speaker . Then conv erted utterances were presented to listeners in random order, who were asked to give their preferences in term of both similarity and natu- ralness. At least 13 listeners participated in each test and they were asked to use headphones. The av erage preference scores are shown in T ABLE V. From this table, we can see that there 7 Since this paper focuses on the acoustic models for voice con version, the same W aveNet vocoders trained with 500 utterances were used here for all configurations. PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 9 T ABLE IV O B JE CT I V E E V A L U ATI O N R E S U L T S O F O U R P R O P O S E D M E TH O D U S I N G D I FFE RE N T N U M B ER S O F N ON - PA R AL L E L U TT ER A N C ES F OR FI NE - T U N I NG . Con version Pairs # of Utt. MCD (dB) F 0 RMSE (Hz) VUV (%) F 0 CORR DDUR (s) rms-to-slt 500 3.088 16.043 7.898 0.624 0.261 400 3.095 15.544 8.423 0.649 0.263 300 3.114 15.950 8.037 0.636 0.270 200 3.126 15.194 7.923 0.670 0.286 100 3.171 16.368 8.410 0.622 0.290 slt-to-rms 500 2.974 16.080 10.327 0.581 0.264 400 3.007 16.591 10.391 0.563 0.257 300 3.009 16.507 10.336 0.572 0.265 200 3.036 16.852 10.401 0.570 0.283 100 3.062 16.312 10.566 0.567 0.300 T ABLE V R E SU L T S O F A B X P RE FE RE N C E T ES TS ( % ) B E TW EE N T H E P R O PO SE D M E TH O D U S I N G 1 0 0 T R A I NI N G U T T E RA NC E S A N D T H E V C C 2 01 8 M E T H O DS U S IN G 5 0 0 O R 1 0 0 T RA IN I N G U T T E R AN C E S . Con version Pairs Proposed (100) VCC2018 (500) VCC2018 (100) N/P p -value rms-to-slt Naturalness 37.31 42.31 - 20.38 0.367 Similarity 42.69 33.85 - 23.46 0.103 Naturalness 69.62 - 16.15 14.23 1 . 36 × 10 − 24 Similarity 75.38 - 13.85 10.77 6 . 52 × 10 − 33 slt-to-rms Naturalness 31.15 39.23 - 29.62 0.121 Similarity 43.08 36.92 - 20.00 0.268 Naturalness 34.61 - 27.69 37.70 0.158 Similarity 43.84 - 26.92 29.24 1 . 08 × 10 − 3 N/P denotes no preference. 100 or 500 indicates the number of non-parallel utterances from each speaker for model training. was no significant dif ference between our proposed method using 100 utterances and the VCC2018 method using 500 training utterances. Using the same 100 training utterances, our method achiev ed significantly better naturalness and similarity than the VCC2018 method, except the naturalness in slt-to- rms conv ersion. These results indicate the adv antage of our proposed method when the amount of training data is limited. G. Evaluation on mor e conver sion pairs In order to examine the generalization ability of our pro- posed method, experiments were conducted between more con v ersion pairs. In additional to the female (slt) and male (rms) speakers used in previous experiments, another female speaker (clb) and another male speaker (bdl) of the CMU ARCTIC dataset were adopted. The non-parallel datasets were constructed in the same way as the descriptions in Section IV -A. W e compared our proposed method with the VCC2018 baseline. The conv ersion models between two inter- gender speaker pairs and two intra-gender speaker pairs were built and e valuated objectiv ely . The results are presented in T ABLE VI. W e can see that the proposed method obtained consistently better MCD, UVU, DURR metrics than VCC2018 baseline. In terms of F 0 RMSE and F 0 CORR, the perfor- mance of proposed method was comparable with the baseline. These results demonstrate the effecti veness of our proposed method on various inter-gender and intra-gender con version pairs. H. Ablation studies In this section, ablation studies were conducted to v alidate the effecti veness of se veral strategies used in our proposed method, including the strategies of adversarial training, using text inputs and multi-speaker pre-training. For inv estigating the ef fects of adversarial training, we removed the component of C s , and the losses of L ADV and L S C (as indicated by “ − adv ” in T ABLE VII). For in vestigating the effects of using text inputs, the contrastive loss L C T was first remov ed (i.e., “ −L C T ”). Then we further remo ved the whole text inputs and the te xt encoder E t , making the model only learn from acoustic features (i.e., “ − text ”). For inv estigating the effects of pre- training, the model parameters were initialized randomly for fine-tuning (i.e., “ − pre - tr aining ”). T ABLE VII sho ws the objective ev aluation results of abla- tion studies, which confirmed the effecti veness all proposed strategies. In addition to the metrics used in Section IV -C, the phone error rate (PER) giv en by the recognition encoder was employed as shown at the last column of the table. W ithout adversarial training, the performance of proposed method degraded. After removing contrastive loss L C T , the objectiv e errors increased more seriously than removing adversarial PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 10 T ABLE VI O B JE CT I V E E V A L U ATI O N R E S U L T S O F V C C 2 0 18 B A SE LI NE A ND P RO P OS ED M ET HO D O N M OR E C O N V E RS I O N PA I R S . Methods Con version Pairs MCD (dB) F 0 RMSE (Hz) VUV (%) F 0 CORR DDUR (s) VCC2018 inter rms-to-slt 3.376 15.042 8.222 0.663 0.481 slt-to-rms 3.171 15.771 11.382 0.593 0.481 bdl-to-clb 3.669 15.723 6.930 0.667 0.496 clb-to-bdl 3.490 15.199 11.843 0.657 0.496 intra clb-to-slt 3.491 13.997 7.250 0.705 0.324 slt-to-clb 3.553 13.013 6.250 0.756 0.324 rms-to-bdl 3.312 15.030 11.893 0.656 0.668 bdl-to-rms 3.242 15.754 13.458 0.612 0.668 Proposed inter rms-to-slt 3.088 16.043 7.898 0.624 0.261 slt-to-rms 2.974 16.080 10.327 0.581 0.264 bdl-to-clb 3.150 15.692 6.162 0.672 0.165 clb-to-bdl 3.076 15.078 11.322 0.624 0.191 intra clb-to-slt 3.019 15.088 7.128 0.662 0.134 slt-to-clb 3.134 14.915 5.600 0.698 0.144 rms-to-bdl 3.157 15.192 11.855 0.581 0.344 bdl-to-rms 3.064 15.214 10.747 0.617 0.359 “inter” and “intra” represent inter-gender and intra-gender con versions respectively . “slt” and “clb” are female speakers. “rms” and “bdl” are male speakers. T ABLE VII O B JE CT I V E E V A L U ATI O N R E S U L T S O F A B L A T I ON S T U D I ES O N O U R P R O P OS E D M E T H OD . Con version Pairs Methods MCD (dB) F 0 RMSE (Hz) VUV (%) F 0 CORR DDUR (s) PER rms-to-slt Proposed 3.088 16.043 7.898 0.624 0.261 10.09 − adv 3.256 18.426 8.985 0.499 0.406 10.71 −L C T 3.235 17.065 8.747 0.586 0.368 11.41 − text 3.613 22.455 9.565 0.463 0.488 10.45 − text − adv 4.281 44.260 23.188 0.145 0.483 10.93 − pre - tr aining 3.200 16.961 8.126 0.619 0.593 14.81 slt-to-rms Proposed 2.974 16.080 10.327 0.581 0.264 8.84 − adv 3.127 21.227 11.903 0.319 0.374 9.76 −L C T 3.101 17.170 10.897 0.513 0.334 10.36 − text 3.438 20.852 13.197 0.220 0.424 9.25 − text − adv 4.222 82.042 12.090 0.464 0.406 9.21 − pre - tr aining 3.120 16.866 12.359 0.551 0.470 17.59 “ − adv ”, “ −L C T ” and “ − text ” represent the proposed method without using adversarial training, contrastiv e loss and text inputs respectively . “ − pr e - tr aining ” represents the proposed method without using pre-training strategy . training. Removing the text inputs and the text encoder caused further degradation. These results demonstrated that learning linguistic representations jointly with text inputs was crucial in our proposed method. The MCD and F 0 RMSE metrics in- creased dramatically if both adv ersarial training and te xt inputs were discarded. In this condition, the model was trained by naiv e sequence-le vel auto-encoding on acoustic features. An informal listening test showed obvious similarity degradation of conv erted speech. Without the pre-training stage, the PER of the proposed method increased dramatically . Larger PER means higher risk of mispronunciation in the conv erted speech. Our informal listening test indicated obvious naturalness and intelligibility degradations of con verted speech. Therefore, it is important to pre-train our model on a large multi-speaker dataset to increase its generalization ability and to improve the reliability of extracted linguistic representations. Fig. 5 shows the spectrograms of the speech con verted by the proposed, the “ − text ” and the “ − text − adv ” methods together with the spectrogram of natural target speech for a test utterance of slt-to-rms conv ersion. As presented in this figure, the proposed method generated the spectrogram which mostly resembled that of the target. As shown in Fig. 5 (b), the format patterns of the con verted speech without text inputs were inconsistent with those in the target speech. If the PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 11 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Time (s) 2 4 6 8 Frequency (kHz) (a) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Time (s) (b) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Time (s) (c) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 Time (s) (d) Fig. 5. Spectrograms of (a) the speech conv erted by our proposed method, (b) the speech con verted by “ − text ” method, (c) the speech conv erted by “ − text − adv ” method and (d) the natural speech of target speaker for a test utterance of slt-to-rms conv ersion. Fig. 6. V isualization of linguistic embeddings extracted by the model without the contrastiv e loss L C T . The legend indicates different transcriptions. Each × symbol represents the linguistic embedding of a transcription giv en by the text encoder and each point represents the linguistic embedding of an utterance giv en by the recognition encoder . adversarial training strategy was further discarded, there were serious spectrogram distortions between the con verted speech and the target one as sho wn in Fig. 5 (c), including a much higher overall pitch of the conv erted speech than that of the target speech. Fig. 6 presents the visualization of linguistic embeddings extracted by the proposed model without the contrastive loss L C T . W e can see that the linguistic embeddings extracted from texts scatter around and away from clusters of audio signals, ev en the same seq2seq decoder was used by text encoder and recognition encoder . The linguistic embeddings from the model without both text inputs and adversarial training are also visualized in Fig. 7. From this figure, we can see the similarities among the utterances of the same transcriptions from dif ferent speakers decreased comparing with those in Fig. 4. This result demonstrated the contributions of text inputs and adversarial training for obtaining disentangled linguistic and speaker representations. Fig. 7. V isualization of linguistic embeddings extracted by the model without both text inputs and adversarial training. The legend indicates different transcriptions. Each point represents the linguistic embedding of an utterance giv en by the recognition encoder . V . C O N C L U S I O N In this paper , a non-parallel sequence-to-sequence voice con v ersion method by learning disentangled linguistic and speaker representations is proposed. The whole model is built under the framework of encoder-decoder neural networks. The strategies of using text inputs and adversarial training are adopted for obtaining disentangled linguistic representations. The model parameters are pre-trained on a multi-speaker dataset and then fine-tuned on the data of a specific con version pair . Experimental results showed that our proposed method surpassed the non-parallel VC method which achieved the top rank in V oice Con version Challenge 2018. The performance of our proposed method was close to the state-of-the-art seq2seq- based parallel VC method. Ablation studies confirmed the ef- fectiv eness of adversarial training, using text inputs and model pre-training in our proposed method. In vestigating the methods of one-shot or few-shot voice con version by improving the prediction of speaker representations in our proposed method will be our work in future. PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 12 R E F E R E N C E S [1] D. G. Childers, B. Y egnanarayana, and K. W u, “V oice conversion: Factors responsible for quality , ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 1985, pp. 748–751. [2] D. G. Childers, K. Wu, D. M. Hicks, and B. Y egnanarayana, “V oice con version, ” Speec h Communication , vol. 8, no. 2, pp. 147–158, 1989. [3] A. Kain, “Spectral voice con version for text-to-speech synthesis, ” in IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP) , vol. 1, 1998, pp. 285–288. [4] L. M. Arslan, “Speaker transformation algorithm using segmental code- books (ST ASC), ” Speech Communication , vol. 28, no. 3, pp. 211–226, 1999. [5] C.-H. W u, C.-C. Hsia, T .-H. Liu, and J.-F . W ang, “V oice conv ersion using duration-embedded bi-HMMs for expressiv e speech synthesis, ” IEEE T ransactions on A udio, Speech, and Language Pr ocessing , vol. 14, no. 4, pp. 1109–1116, July 2006. [6] S. H. Mohammadi and A. Kain, “ An overvie w of voice con version systems, ” Speech Communication , vol. 88, pp. 65–82, 2017. [7] M. M ¨ uller , “Dynamic time warping, ” Information Retrieval for Music and Motion , pp. 69–84, 2007. [8] T . T oda, A. W . Black, and K. T okuda, “V oice conv ersion based on maximum-likelihood estimation of spectral parameter trajectory , ” IEEE T ransactions on Audio Speech and Language Processing , vol. 15, no. 8, pp. 2222–2235, 2007. [9] S. Desai, E. V . Raghavendra, B. Y egnanarayana, A. W . Black, and K. Prahallad, “V oice con version using artificial neural networks, ” in IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP) , 2009, pp. 3893–3896. [10] S. Desai, A. W . Black, B. Y egnanarayana, and K. Prahallad, “Spectral mapping using artificial neural networks for voice con version, ” IEEE T ransactions on Audio Speech and Language Processing , vol. 18, no. 5, pp. 954–964, 2010. [11] L.-H. Chen, Z.-H. Ling, L.-J. Liu, and L.-R. Dai, “V oice con ver - sion using deep neural networks with layer-wise generative training, ” IEEE/ACM Tr ansactions on Audio Speech and Language Pr ocessing , vol. 22, no. 12, pp. 1859–1872, 2014. [12] L. Sun, S. Kang, K. Li, and H. Meng, “V oice con version using deep bidirectional long short-term memory based recurrent neural networks, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2015, pp. 4869–4873. [13] T . Nakashika, T . T akiguchi, and Y . Ariki, “V oice conv ersion using RNN pre-trained by recurrent temporal restricted Boltzmann machines, ” IEEE T ransactions on Audio, Speech, and Langua ge Pr ocessing , vol. 23, no. 3, pp. 580–587, 2015. [14] I. Sutskev er , O. V inyals, and Q. V . Le, “Sequence to sequence learning with neural networks, ” in Advances in Neural Information Processing Systems , 2014, pp. 3104–3112. [15] K. Cho, B. V an Merrienboer, C. Gulcehre, D. Bahdanau, F . Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder–decoder for statistical machine translation, ” in Empirical Methods in Natural Language Processing , 2014, pp. 1724–1734. [16] D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate, ” in International Confer ence on Learning Repr esentations , 2015. [17] T . Luong, H. Pham, and C. D. Manning, “Ef fectiv e approaches to attention-based neural machine translation, ” in Empirical Methods in Natural Language Pr ocessing , 2015, pp. 1412–1421. [18] J.-X. Zhang, Z.-H. Ling, L.-J. Liu, Y . Jiang, and L.-R. Dai, “Sequence- to-sequence acoustic modeling for voice conv ersion, ” IEEE/ACM Tr ans- actions on Audio, Speech, and Language Processing , vol. 27, no. 3, pp. 631–644, 2019. [19] K. T anaka, H. Kameoka, T . Kaneko, and N. Hojo, “A TTS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms, ” in IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP) , 2019. [20] J.-X. Zhang, Z.-H. Ling, Y . Jiang, L.-J. Liu, C. Liang, and L.-R. Dai, “Improving sequence-to-sequence acoustic modeling by adding text- supervision, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2019, pp. 6785–6789. [21] H. Duxans, D. Erro, J. P ´ erez, F . Diego, A. Bonafonte, and A. Moreno, “V oice conversion of non-aligned data using unit selection, ” TC-ST AR W orkshop on Speec h-to-Speech Tr anslation , 2006. [22] D. Sundermann, H. Hoge, A. Bonafonte, H. Ney , A. Black, and S. Narayanan, “T ext-independent voice con version based on unit se- lection, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , vol. 1, 2006, pp. 81–84. [23] D. Erro and A. Moreno, “Frame alignment method for cross-lingual voice con version, ” in Annual Conference of the International Speech Communication Association (INTERSPEECH) , 2007, pp. 1969–1972. [24] D. Erro, A. Moreno, and A. Bonafonte, “INCA algorithm for training voice conv ersion systems from nonparallel corpora, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 18, no. 5, pp. 944– 953, 2010. [25] T . Kaneko and H. Kameoka, “CycleGAN-VC: Non-parallel voice con- version using cycle-consistent adversarial networks, ” in Eur opean Signal Pr ocessing Confer ence (EUSIPCO) , 2018, pp. 2114–2117. [26] F . Fang, J. Y amagishi, I. Echizen, and J. Lorenzo-Trueba, “High-quality nonparallel voice conversion based on cycle-consistent adversarial net- work, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2018, pp. 5279–5283. [27] T . Kaneko, H. Kameoka, K. T anaka, and N. Hojo, “CycleGAN- VC2:improved CycleGAN-based non-parallel voice conv ersion, ” in IEEE International Confer ence on Acoustics Speech and Signal Pro- cessing Pr oceedings , 2019, pp. 6820–6824. [28] T . Nakashika, T . T akiguchi, Y . Minami, T . Nakashika, T . T akiguchi, and Y . Minami, “Non-parallel training in v oice conversion using an adaptiv e restricted Boltzmann machine, ” IEEE/A CM T ransactions on Audio, Speech and Language Processing , vol. 24, no. 11, pp. 2032– 2045, 2016. [29] L. Sun, K. Li, H. W ang, S. Kang, and H. Meng, “Phonetic pos- teriorgrams for many-to-one voice con version without parallel data training, ” in 2016 IEEE International Conference on Multimedia and Expo (ICME) , 2016, pp. 1–6. [30] H. Miyoshi, Y . Saito, S. T akamichi, and H. Saruwatari, “V oice conv er- sion using sequence-to-sequence learning of context posterior probabili- ties, ” in Annual Conference of the International Speech Communication Association (INTERSPEECH) , 2017. [31] L.-J. Liu, Z.-H. Ling, Y . Jiang, M. Zhou, and L.-R. Dai, “W a veNet vocoder with limited training data for voice conv ersion, ” in Annual Confer ence of the International Speech Communication Association (INTERSPEECH) , 2018, pp. 1983–1987. [32] S. Liu, J. Zhong, L. Sun, X. W u, X. Liu, and H. Meng, “V oice con version across arbitrary speakers based on a single target-speaker utterance, ” in Annual Confer ence of the International Speech Communication Association (INTERSPEECH) , 2018, pp. 496–500. [33] Y . Saito, Y . Ijima, K. Nishida, and S. T akamichi, “Non-parallel voice con version using v ariational autoencoders conditioned by phonetic posteriorgrams and d-vectors, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2018, pp. 5274– 5278. [34] C.-C. Hsu, H.-T . Hwang, Y .-C. W u, Y . Tsao, and H.-M. W ang, “V oice con version from non-parallel corpora using variational auto-encoder, ” in 2016 Asia-P acific Signal and Information Pr ocessing Association Annual Summit and Confer ence (APSIP A) , 2016, pp. 1–6. [35] C.-C. Hsu, H.-T . Hwang, Y .-C. W u, Y . Tsao, and H.-M. W ang, “V oice con version from unaligned corpora using v ariational autoencoding W asserstein generati ve adversarial networks, ” in Annual Confer ence of the International Speech Communication Association (INTERSPEECH) , 2017, pp. 3364–3368. [36] J.-c. Chou, C.-c. Y eh, H.-y . Lee, and L.-s. Lee, “Multi-target voice con version without parallel data by adversarially learning disentangled audio representations, ” in Annual Confer ence of the International Speech Communication Association (INTERSPEECH) , 2018, pp. 501–505. [37] A. V . Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Graves, N. Kalchbrenner, A. W . Senior, and K. Kavukcuoglu, “W av eNet: A generativ e model for raw audio, ” in 9th ISCA Speech Synthesis W orkshop (SSW9) , 2016, pp. 125–125. [38] S. Hchreiter and J. Schmidhuber, “Long short-term memory , ” Neural Computation , vol. 9, no. 8, pp. 1735–1780, 1997. [39] A. Polyak and L. W olf, “ Attention-based W av eNet autoencoder for uni- versal voice con version, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2019. [40] O. Ocal, O. H. Elibol, G. Keskin, C. Stephenson, A. Thomas, and K. Ramchandran, “ Adversarially trained autoencoders for parallel-data- free voice con version, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2019. [41] S. O. Arik, J. Chen, K. Peng, W . Ping, and Y . Zhou, “Neural voice cloning with a few samples, ” in Advances in Neural Information Pr ocessing Systems , 2018, pp. 10 040–10 050. [42] Y . Jia, Y . Zhang, R. J. W eiss, Q. W ang, J. Shen, F . Ren, Z. Chen, P . Nguyen, R. Pang, I. L. Moreno et al. , “Transfer learning from speaker verification to multispeaker text-to-speech synthesis, ” in Advances in Neural Information Processing Systems , 2018, pp. 4485–4495. PREPRINT MANUSCRIPT OF IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH AND LANGUA GE PROCESSING c 2019 IEEE 13 [43] E. Nachmani, A. Polyak, Y . T aigman, and L. W olf, “Fitting new speak ers based on a short untranscribed sample, ” in International Conference on Machine Learning , 2018, pp. 3683–3691. [44] W . Chan, N. Jaitly , Q. Le, and O. V inyals, “Listen, attend and spell: A neural network for large vocabulary conv ersational speech recognition, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2016, pp. 4960–4964. [45] Y . W ang, R. J. Skerry-Ryan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio et al. , “T acotron: T owards end-to- end speech synthesis, ” in Annual Conference of the International Speech Communication Association (INTERSPEECH) , 2017, pp. 4006–4010. [46] J. Shen, R. Pang, R. J. W eiss, M. Schuster, N. Jaitly , Z. Y ang, Z. Chen, Y . Zhang, Y . W ang, R. J. Skerry-Ryan et al. , “Natural TTS synthesis by conditioning W aveNet on mel spectrogram predictions, ” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2018, pp. 4779–4783. [47] S. Chopra, R. Hadsell, and Y . LeCun, “Learning a similarity metric discriminativ ely , with application to face verification, ” in Computer V ision and P attern Recognition , 2005, pp. 539–546. [48] J. S. Chung and A. Zisserman, “Out of time: automated lip sync in the wild, ” in Asian Conference on Computer V ision , 2016, pp. 251–263. [49] H. Zhou, Y . Liu, Z. Liu, P . Luo, and X. W ang, “T alking face generation by adversarially disentangled audio-visual representation, ” in AAAI Confer ence on Artificial Intelligence (AAAI) , 2019. [50] J. K ominek and A. W . Black, “CMU ARCTIC databases for speech synthesis, ” http://festv ox.org/cmu arctic/index.html, 2003, Lang. T ech- nol. Inst., Carnegie Mellon Univ ., Pittsburgh, P A. [51] C. V eaux, J. Y amagishi, K. MacDonald et al. , “CSTR VCTK corpus: English multi-speaker corpus for cstr v oice cloning toolkit, ” University of Edinbur gh. The Centre for Speech T echnology Resear ch (CSTR) , 2017. [52] J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Bengio, “ Attention-based models for speech recognition, ” in Advances in Neural Information Pr ocessing Systems , 2015, pp. 577–585. [53] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep con volutional generativ e adversarial networks, ” in International Confer ence on Learning Representations , 2016. [54] J.-X. Zhang, Z.-H. Ling, and L.-R. Dai, “Forward attention in sequence- to-sequence acoustic modeling for speech synthesis, ” in IEEE In- ternational Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2018, pp. 4789–4793. [55] D. Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” Computer Science , 2014. [56] Z. Wu, O. W atts, and S. King, “Merlin: An open source neural network speech synthesis system, ” in 9th ISCA Speech Synthesis W orkshop (SSW9) , 2016. [57] M. Morise, F . Y okomori, and K. Ozawa, “WORLD: A vocoder-based high-quality speech synthesis system for real-time applications, ” IEICE T ransactions on Information and Systems , vol. 99, no. 7, pp. 1877–1884, 2016. [58] D. T . Chappell and J. H. L. Hansen, “Speaker-specific pitch contour modeling and modification, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , vol. 2, 1998, pp. 885–888. [59] H. Kawahara, I. Masuda-Katsuse, and A. D. Chev eign ´ e, “Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency based F0 extraction: Possible role of a repetitiv e structure in sounds, ” Speech Communication , vol. 27, no. 34, pp. 187–207, 1999. [60] L. v . d. Maaten and G. Hinton, “V isualizing data using t-SNE, ” Journal of Machine Learning Resear ch , vol. 9, no. Nov , pp. 2579–2605, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment