Toward domain-invariant speech recognition via large scale training
Current state-of-the-art automatic speech recognition systems are trained to work in specific `domains', defined based on factors like application, sampling rate and codec. When such recognizers are used in conditions that do not match the training d…
Authors: Arun Narayanan, Ananya Misra, Khe Chai Sim
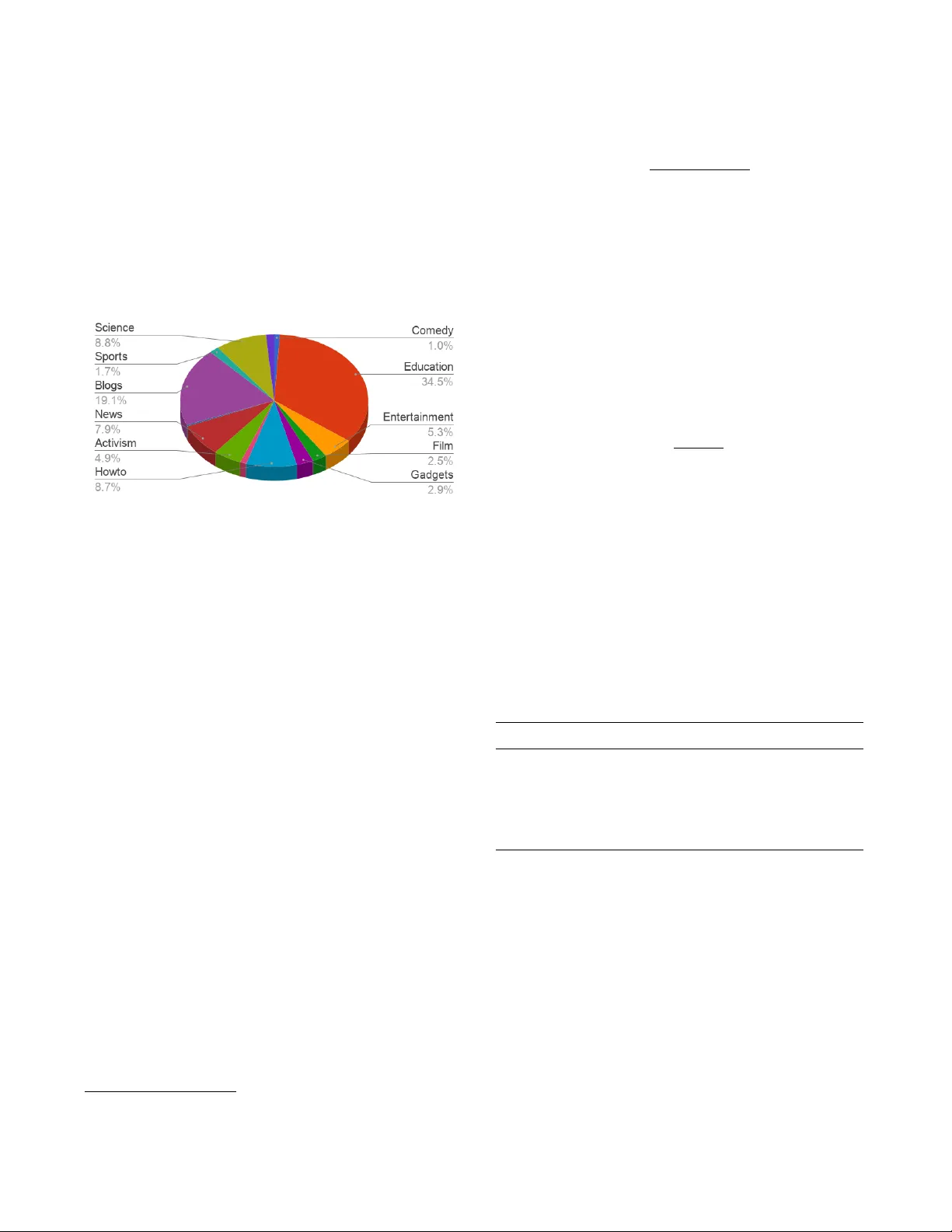
TO W ARD DOMAIN-INV ARIANT SPEECH RECOGNITION VIA LARGE SCALE TRAINING Arun Narayanan, Ananya Misr a, Khe Chai Sim, Golan Pundak, Anshuman T ripathi Mohamed Elfeky , P arisa Haghani, T r e vor Str ohman, Mic hiel Bacchiani Google, USA ABSTRA CT Current state-of-the-art automatic speech recognition sys- tems are trained to work in specific ‘domains’, defined based on factors like application, sampling rate and codec. When such recognizers are used in conditions that do not match the training domain, performance significantly drops. This work e xplores the idea of b uilding a single domain-in v ariant model for v aried use-cases by combining large scale training data from multiple application domains. Our final system is trained using 162,000 hours of speech. Additionally , each utterance is artificially distorted during training to simulate effects like background noise, codec distortion, and sam- pling rates. Our results show that, ev en at such a scale, a model thus trained works almost as well as those fine-tuned to specific subsets: A single model can be rob ust to multiple application domains, and variations like codecs and noise. More importantly , such models generalize better to unseen conditions and allow for rapid adaptation – we sho w that by using as little as 10 hours of data from a new domain, an adapted domain-inv ariant model can match performance of a domain-specific model trained from scratch using 70 times as much data. W e also highlight some of the limitations of such models and areas that need addressing in future work. Index T erms — speech recognition, multidomain model, domain robustness, noise rob ustness, codecs 1. INTRODUCTION Automatic speech recognition (ASR) has come a long way in the last few years, with state-of-the-art systems performing close to human performance [1, 2]. Even so, most ASR sys- tems are trained to work well in highly constrained settings, targeting specific use cases. Such systems perform poorly when used in conditions not seen during training. This mis- match problem has been widely studied in the context of ro- bustness to background noise and mixed bandwidths [3, 4, 5]. But there has not been a lot of work that addresses other forms of mismatch, e.g., application domains and codecs. In this work, we address domain robustness in a more general setting. W e broadly use the term ‘domain’ to mean a logical group of utterances that share some common char- acteristics. Examples include application domains like v oice search, video-captioning, call-center , etc., and sub-cate gories based on other forms of similarities like sample rate, noise, and the codec used to encode a wa veform. There is a lot of literature that addresses certain specific aspects of domain inv ariance. For robustness to noise, mul- ticondition training (MTR) using simulated noisy utterances has been sho wn to generalize well [3, 4]. In fact, the gains ov er MTR with specialized feature enhancement is usually minimal [6, 5]. Similarly , mixed bandwidth training has been shown to handle multiple sample rates simultaneously , with- out any need for explicit reconstruction of missing bands [5]. In the context of multiple application domains, training by pooling data was shown to work well for domains with lim- ited resources in [7]. Unlike existing studies that address only some form of domain rob ustness, like noise, the presented work scales it up to simultaneously address sev eral aspects of domain in v ari- ance: Robustness to a v ariety of application domains while operating at multiple sampling rates using multiple codecs for encoding input, and in the presence of background noise. T o build such a multidomain model, we pool training data from sev eral sources, and simulate conditions like background noise, codecs and sample rates. Since mixed-bandwidths and noise robustness ha ve receiv ed a lot of attention in the litera- ture, we will focus more on less explored areas of rob ustness like application domains and codecs. W e present results using, to the best of our knowledge, the largest speech database ever used to train a single model – 162,000 hours of speech before simulating additional con- ditions like noise, codec and sampling rates. After including simulated distortions, the probability that the model sees the same utterance in the same mixing condition twice dur- ing training is close to 0, which implies that the final size of speech material seen during training is 162,000 hours × the number of epochs during training. Surprisingly , even though the multidomain model is trained by combining di- verse datasets, it works almost as well as the domain-specific models. This is despite the fact we did not try to explicitly balance the amount of training data the model sees in each domain during training. It also generalizes better to unseen domains. Most interestingly , we sho w that such a model can be rapidly adapted to new conditions with v ery little data. On a previously unseen domain, we get large gains by adapting the multidomain model using as little as 10 hours of data, outperforming a model trained only on the new domain using 700 hours speech. Our results also sho w what domains, or combination of domains, are harder to model at this scale and warrant more research. The rest of the paper is organized as follows. Sec. 2 dis- cusses prior work. The models and training strategies used in this work are described in Sec. 3. Experimental settings and results are presented in Sec. 4. W e conclude in Sec. 5. 2. PRIOR WORK There hav e been a number of studies that address inv ariance to background noise. T raining on noisy data and using simu- lated noisy utterances to augment clean training are widely used [5, 3, 4, 8]. Specialized techniques like masking [9] and beamforming [10] (in the case of multi-microphone in- put) help in certain conditions. Adaptation has also been used to address noise. In [11], a model is adapted to a previously unseen f ar-field condition by learning a linear transform of an intermediate layer , where the noise or the domain information is best encoded. Paired clean and noisy unlabeled data and model-distillation were used in [12] to adapt a clean model to noisy conditions. Our work dif fers from these studies in that noise mismatch is only one of the dimensions we explore. Furthermore, our goal is to train a model that works well in multiple conditions, not just noise. Similar to noise, mixed bandwidth training helps general- ize to multiple sampling rates [5]. In [5], the authors train the acoustic model with data sampled at both 16 kHz and 8 kHz. When computing features for 8 kHz input, the high frequenc y logmel bands are set to zeros. While more sophisticated tech- niques like reconstructing high frequency bands hav e been proposed [13], the gains o ver mixed bandwidth training are often small. Multiple application domains have typically been studied in the context of transfer learning [14]. In [7], transfer learn- ing is used to adapt a model trained on switchboard [15] to improv e performance on domains with smaller training sets like WSJ [16] and AMI [17]. They also show that pooling data from multiple low-resource domains work better than transfer learning. Unlike [7], the current work studies do- main rob ustness in a much lar ger scale, where data sparsity is not necessarily a challenge. W e also study other forms of mismatch like codec, and consider many more applications domains. Domain adaptation has been widely studied in the ma- chine learning and vision literature. A typical formulation is to learn a model for a target domain with limited unla- beled data, using supervised data from a source domain. Do- main adversarial training and variants are widely used for this [18, 19]. 3. MODEL DESCRIPTION Feature extraction Application domains Simulations Noise simulation Mixed bandwidth simulation Codec simulation Random selection Feature frontend TensorFlow Queue ... Acoustic model trainer Training Fig. 1 : Bloc k diagram for multidomain tr aining. Fig. 1 shows a block diagram for the processing pathways. T o generate the training set, we pool data from multiple ap- plication domains. Utterances are chosen randomly from the pooled set during training. Giv en an utterance, we randomly apply zero or more simulated perturbations. This includes 1) noise simulation via a room simulator , 2) changing the sample rate, and 3) encoding and decoding using a lossy codec. The features e xtracted from the resulting utterance is pushed into a queue. The model reads from the queue during training. Fea- ture extraction and training happens asynchronously to pre- vent the feature computation ov erhead from slowing down training. The stages are described in more detail below . 3.1. Noise simulation For noise simulation, we use a setting similar to the one used in [3] that has been sho wn to work well for noisy and far - field voice search tasks. During training, a noise configu- ration, which defines mixing conditions like the size of the room, rev eberation time, position of the microphone, speech and noise sources, signal to noise ratio (SNR), etc., for each training utterance is randomly sampled from a collection of 3 million pre-generated configurations. A simulated room may contain 0 to 4 noise sources, which is mixed with speech at an SNR between 0 to 30 dB. The re verberation time is set to be between 0 and 900 msec, with a tar get to mic distance between 1 and 10 meters (see [3] for details). The noise snip- pets used for simulation come from a collection of Y ouT ube, cafeteria, and real-life noises. W e expect these snippets to cov er noise conditions encountered in typical use cases like voice-search on mobile phones. 3.2. Mixed bandwidth simulation W e only consider 8 kHz and 16 kHz sample rates in this work, since all the data we have use these rates. Note that for sample rates greater than 16 kHz, the input can be downsampled with- out an y loss of information since our feature frontend only uses frequencies up to 7.5 kHz. The majority of the data that we use for training is sampled at 16 kHz. T o balance the train- ing set, we randomly do wnsample an utterance to 8 kHz with a probability of 0.5. Our feature e xtraction frontend is config- ured to operate at 16 kHz, so the wa veform is then upsampled back to 16 kHz before feature extraction. Since we use log- mel features as input to the acoustic model (see Sec. 3.4), this is very similar to adding zeros to the high frequency logmel bands when the input is at 8 kHz [5]. 3.3. Codec simulation T o simulate a variety of audio encodings before transmis- sion to the recognition system, we encode and decode each wa veform with a randomly selected codec. W e train with the MPEG-2 Audio Layer 3 (MP3) and Adv anced Audio Cod- ing (AA C) codecs, both of which perform perceptual audio coding [20]. W e apply these at constant bit rate using the im- plementations in FFmpeg [21]. The set of 7 codec conditions sampled uniformly at random for training consists of: MP3 at bit rates of 128, 32 and 23 kbps, AA C at 128, 64 and 23 kbps, and no codec. Note that the training data we use may already be encoded in arbitrary ways before we obtain it, in which case it is decoded and then re-encoded and re-decoded with the selected codec. 3.4. Featur e extraction The acoustic models are trained using globally normalized logmel features. Input utterances are framed using a 32 msec window , with 10 msec o verlap between neighboring frames. 128 dimension logmel features are then extracted, spanning frequencies from 125 Hz to 7.5 kHz. Four contiguous frames are stacked to form a 512 dimensional feature that is used as input by the acoustic model. Input features are also subsam- pled by a factor of 3; the acoustic model operates at 33 Hz [22]. 3.5. Acoustic model W e use low frame rate (LFR) models [22] for acoustic modeling. The acoustic model (AM) predicts tied, context- dependent, single-state phones (CDPhones) e very 30 msec. W e use 8192 CDPhones; the tree used for state-tying is gen- erated using a subset of the application domains. The AM is a 5 layer unidirectional LSTM [23], with 1024 cells in the first 4 layers, and 768 cells in the last layer . The models are cross-entropy (CE) trained, using alignments generated using the original, unperturbed utterances. 3.6. Language model The focus of the current work is domain in variance of acoustic models, so we use the same language model (LM) in all e x- periments. The LM is a Bayesian interpolated 5-gram model trained from a variety of data sources lik e anon ymized and aggregated search queries and dictated texts [24]. It consists of around 100 million n-grams and a v ocabulary size of 4 mil- lion words. The LM is used for single pass decoding. 3.7. Large scale training One of the challenges in training at such a scale is the amount of resources needed, both in terms of disk space and com- pute. Since we use sev eral types of simulated perturbations, the amount of disk space needed to store features can quickly grow . T o deal with this, we only store the original wav e- forms and their corresponding alignments on disk. Feature are computed on-the-fly during training, after distorting the wa veforms based on zero or more perturbations. Some of the perturbations, like simulating a noise condition, can be computationally expensiv e. But we make use of the fact this can be done asynchronously with training and utilize the in- put queuing mechanism in T ensorFlow [25] to store the com- puted features. The trainer reads from the queue, and is not affected by the slo wness of feature computation process as long as there are enough jobs feeding the queue [26]. Fea- ture computation runs on CPUs; the models are trained on GPUs using asynchronous stochastic gradient descent. Using 32 GPU workers, each with Nvidia K80 GPUs, one epoch of CE training takes approximately 1.8 days for the multidomain training set. Training con ver ges within 15 – 20 epochs. It is possible to further speed up training using faster hardware like Nvidia P100 GPUs or TPUs [27]. 4. EXPERIMENTS AND RESUL TS 4.1. Datasets T able 1 : Data distribution for various application domains. Application Dataset size Domain (appr ox. hours) V oicesearch 16 k Dictation 18 k Other search 1 k Farfield 8 k Call-center 1 k Y ouT ube 117 k T otal 162 k W e experiment using a number of training sets that cover a variety of applications, all in English. This includes: V oic- esear ch , Dictation , Other sear ch , F arfield (Google Home), Y ouT ube (video-captioning), and Call-center . The amount of data a vailable for each of these application domains, sho wn in T ab. 1, is quite dif ferent, which is typical in an y large scale multidomain setting. As can be seen, the training set is domi- nated by Y ouT ube – around 70%. But the Y ouT ube set is quite div erse and includes multiple sub-domains. Fig. 2 shows the distribution of various application domains included in the Y ouT ube training set. Fig. 2 : Distrib ution of data in the Y ouT ube training set. The ev aluation sets come from similar domains as train- ing – V oicesearc h , Dictation , Call-center , and Y ouT ube – with additional variations to account for other forms of mismatch. Since voicesearch data originating from mobile phone is most likely to be corrupted by noise and codec 1 , we perturb the V oicesear ch test set with these distortions. The noisy sets are constructed using MTR configurations and noise segments not used in training. The Dictation set is downsampled to 8 kHz since that is another common use-case. A T elephony test set is used to ev aluate out-of-domain performance. It is acoustically most similar to Call-center , but is more con ver - sational. An analysis of the quantitativ e similarities of the different sets is presented in the follo wing section. All of the sets used for training and ev aluation are anonymized, and are representativ e of Google’ s voice search, captioning and cloud traffic. The Y ouT ube set was transcribed in a semi-supervised fashion [28, 29]; the rest of the datasets are hand-transcribed. 4.2. Dataset analysis T o understand the data landscape, we apply internal clustering metrics to gauge how well the data is clustered by domain and to estimate similarities between clusters. W e extract 32-dimensional i-vectors, which capture the acoustic characteristics of an utterance [30]. W e compute the 1 Data compression is used in low bandwidth conditions, which is typical for mobile phones not connected to broadband. silhouette coefficient [31] for each point as follo ws: s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } , (1) where s ( i ) is the silhouette for the i -th data point X i , a ( i ) is the mean Euclidean distance of X i to other points in the same cluster, and b ( i ) is the mean Euclidean distance of X i to the nearest neighboring cluster . The higher the silhouette score, the better the point sits within its designated cluster . The silhouette av eraged o ver a cluster thus suggests ho w well- defined the cluster is; over the entire data set, it quantifies how distinct the clusters are on average. T o understand how similar each application domain is to the held-out T elephony domain, we perform pairwise silhouette analysis. W e also compute a cluster similarity measure R ij [32]: R ij = S i + S j M ij , (2) where S i is a dispersion measure of cluster i and M ij is a dis- tance measure between clusters i and j . Here we define S i as the av erage Euclidean distance of points in cluster i to the cluster centroid, and M ij as the Euclidean distance between the centroids of clusters i and j . Results from 50 examples sampled from each application domain (T ab . 2) reinforce that T elephony is close to Call-center and suggest it is most dis- tinct from V oicesear ch . T able 2 : P airwise clustering metrics between each applica- tion domain and the T elephony domain. Lower silhouette scor es and higher cluster similarity indicate mor e overlap. Domain A verage silhouette Cluster similarity V oicesearch 0 . 0732 3 . 30 Dictation 0 . 0440 4 . 16 Farfield 0 . 0443 4 . 14 Call-center 0 . 0248 5 . 22 Y ouT ube 0 . 0321 4 . 81 4.3. Results W e first present results when using simulated perturbations. W e train on a subset of the application domains for ease of running experiments, and for e valuating the effect of each simulation technique before combining them. Finally , we present results when training with all of the domains and show generalization results to the unseen domain. Mixed band- width simulation is used in all e xperiments. Since training using multiple sample rates has already been shown to work well in prior work [5, 7], we did not explore it in detail in the current study . 4.3.1. Noise T o ev aluate noise simulation, we train using V oicesear ch , Dictation and Other searc h sets, with and without simulated background noise. Results are sho wn in T ab. 3. As sho wn, training with simulated noisy data using the MTR settings described in Sec. 3.1 does not affect performance in clean conditions. The word error rates (WERs) in clean condi- tions are almost identical when using models trained with and without noise. Unsurprisingly , training with noise sig- nificantly improves performance in noisy conditions. For the Dictation set, MTR training improv es WER by around 60% (relativ e). It is also interesting to note that MTR training only marginally af fects performance of the 8 kHz test set. T able 3 : Results using models trained w/ and w/o noise. T est set Sample W ord err or rate rate w/o Noise w/ Noise V oicesearch 16 kHz 10 . 5 10 . 4 + Noise 16 kHz 17 . 7 12 . 3 Dictation 16 kHz 7 . 7 7 . 8 + Noise 16 kHz 30 . 6 12 . 3 Dictation 8 kHz 8 . 2 8 . 4 4.3.2. Codecs T ab . 4 shows results when the models are trained with and without codec simulation. W e ev aluate on the V oicesear ch set under various codec conditions. MP3 at 64 kbps, Opus [33, 21] at 24 kbps, and SBC [34, 35] with a bitpool size of 24, 16 blocks and 8 subbands are unseen during training; the rest are seen. For the baseline model, performance worsens as the bitrate decreases since lower bitrates imply more lossy encoding. T raining with codecs mak es the performance under seen and unseen codecs close to not using any codec, even at low bitrates: For MP3 23k, training with codecs improves WER by almost 20%. T able 4 : Results using models tr ained with and without codec simulation. All of the r esults ar e on the V oicesear ch test set. T est set W ord err or rate w/o codec w/ codec No codec 10 . 5 10 . 0 AA C 23k 11 . 8 11 . 4 AA C 64k 10 . 6 10 . 0 MP3 23k 13 . 6 10 . 6 MP3 64k 10 . 5 10 . 2 OPUS 24k 10 . 8 10 . 2 SBC BLUEZ 10 . 7 10 . 2 4.3.3. Application domains Next, we look at performance of application domain specific models. Results are shown in T ab . 5. W e present results us- ing 3 domain-specific models trained on V oicesear ch and Dic- tation , Y ouT ube , and Call-Center data, respectiv ely . Unsur- prisingly , the models work well when the test domains match the model domains, and poorly when the domain changes. The Y ouT ube model, which is trained with the largest dataset among the 3 models, generalizes better . This is most likely because Y ouT ube training set includes data from a v aried set of sources. The results also highlight the issues of training using a sin- gle domain, as is typically done in ASR. For example, train- ing only on Call-center data results in poor performance for test sets that are sampled at 16 kHz. This is because Call- center data is at 8 kHz, and the model ne ver sees utterances at a higher sampling rate during training. The model per- forms much better on Dictation set when it is do wnsampled to 8 kHz. On the Call-center test set, the Y ouT ube model works as well as the domain-specific model. This is partly because the Call-center training set is smaller compared to the rest of the sets, thereby limiting the generalization ability of the model trained with it. It is also interesting to see that all models perform poorly on the T elephony test set, which is an unseen application domain for these models. As with the other test sets, the Y ouT ube model generalizes better and performs the best on this set. 4.3.4. Multidomain models In T ab . 6, we sho w results when the acoustic model is trained with all of the training data. Results are also shown with noise and codec simulation, in addition to multidomain training. Comparing these results with those in T ab. 5, we can see that the multidomain model works similar to or better than the domain-specific models in all cases. It also generalizes better: It has better performance on the T elephony set com- pared to the domain-specific models, and also on the noisy test sets compared to the baseline model trained without noise simulation. Finally , on the Call-center set, it outperforms the domain-specific model, which shows that multidomain train- ing partly addresses data sparsity issues. When doing noise simulation, we selectively add noise to only those domains for which the input data is relativ ely clean. Specifically , we add noise only to V oicesearc h , Dicta- tion , and Call-center . When the multidomain model is trained with noise simulation, it performs better on the noisy sets but degrades on the clean sets. Moreo ver , the performance in noisy conditions doesn’ t match those of the domain-specific model trained with noise (T ab . 3). This is likely because the model doesn’t see as much clean and noisy data as the domain-specific models because of the imbalance in train- ing data distribution. Adding noise also makes the underly- T able 5 : Results using domain-specific models. T est set Sample W ord err or rate rate V oicesearch- Call- Y ouT ube Dictation center V oicesearch 16 kHz 10 . 5 98 . 6 16 . 3 Dictation 16 kHz 7 . 7 97 . 8 13 . 9 Dictation 8 kHz 8 . 2 24 . 1 13 . 9 Call-center 8 kHz 25 . 4 20 . 5 20 . 4 Y ouT ube 16 kHz 54 . 9 97 . 2 15 . 9 T elephony 8 kHz 31 . 4 27 . 8 24 . 2 ing task harder since the model has to learn to normalize out variations in the training data along sev eral dimensions like application domain, noise and sample rate. It is interesting to see that ev en though large scale training works in some conditions, combinations of conditions makes it harder for the model to learn without any additional signal during train- ing. As with noise, the multidomain model with codec sim- ulation sho ws degradation on clean and noisy tests without codecs, as well as for the AA C 23k condition. It works better only on MP3 23k condition. In contrast, the domain-specific codec model performed better than its non-codec counterpart all around. 4.4. Adaptation using multidomain models One of the most important advantages of multidomain mod- eling is that it allo ws for easy and quicker adaptation to new conditions. T o demonstrate this, we use v arying amounts of in-domain data to improve performance on the T elephony do- main, which was not used to train the models in Sec. 4.3.4. W e e xperiment with 10 hours, 30 hours, 100 hours and 700 hours (approx.) of training data. For adaptation, we use the relati vely simpler fine-tuning approach. All layers of the model are tuned. A lower learning rate and early stopping is used to pre vent over -fitting. W e also train a separate model using the 700 hours training set, with model parameters ini- tialized from scratch. Results are shown in T ab . 7. As can be seen, ev en though the multidomain model gen- eralizes well compared to other domain specific models, it is still much worse than a model trained e xclusiv ely on T ele- phony training set. But the multidomain model fine-tuned on just 10 hours of T elephony speech works as well as a model trained on 700 hours from random initialization. Using more data for fine-tuning further impro ves performance. For ex- ample, the model fine-tuned using 100 hours of data outper - forms the randomly initialized model by 16% relative. And when using the entire 700 hours of data for fine-tuning, WER is better by 25% relati v e compared to the randomly initialized model. The table also shows results when the V oicesearc h- Dictation model is used for adaptation, instead of the mul- tidomain model. As shown, as more and more in-domain data is used for adaptation, the dif ference compared to using the multidomain model for initialization decreases. But even with 700 hours of in-domain data, using the multidomain model works better by about 8% relative. And with just 10 hours of data, adapting from the multidomain model is better by about 24% relati ve. The V oicesear ch-Dictation model needs around 100 hours of in-domain data to reach a similar lev el of performance as the T elephony model trained from scratch. The results clearly show that multidomain training allo ws for rapid adaptation. While fine-tuning to a particular subset this way comes at an expense of deteriorated WERs on the other subsets, we ha ve noticed, in experiments not reported here, that by merging the T elephony training set with mut- lidomain training data, as in Sec. 4.3.4, helps retain the best performance in the remaining subsets. It is also possible to introduce domain specific parameters, as in [36], to a void per- formance degradation when fine-tuning to a certain subset. 5. CONCLUSION W e presented a lar ge scale study on domain robustness, train- ing a single model by combining multiple application do- mains, sample rates, noise and codec conditions. Our results show that training at scale works well to address the domain mismatch problem: A model trained with data from multiple application domains work ed as well as the domain-specific models. The multidomain model also showed better general- ization properties, working better than domain-specific mod- els for unseen application domains and in noisy conditions. Our results also sho w that multidomain models can be used to rapidly adapt to previously unseen conditions. Multidomain training has sev eral practical applications when deploying recognizers in practice, especially when it is hard to predict ho w the system will get used in the end. Having a single system also impro ves ease of maintainability . The ability to adapt it with small amounts of data mak es it ideal to building task-specific models. One of the challenges going forw ard is the degradation in T able 6 : Results using multidomain models. T est set Sample W ord err or rate rate Multidomain Multidomain Multidomain + Noise + Codec V oicesearch 16 kHz 10 . 2 11 . 2 10 . 5 + AA C 23k 16 kHz 11 . 4 11 . 7 11 . 9 + MP3 23k 16 kHz 13 . 5 14 . 5 11 . 1 + Noise 16 kHz 15 . 6 13 . 9 15 . 8 Dictation 16 kHz 7 . 6 8 . 4 7 . 8 + Noise 16 kHz 24 . 5 15 . 5 24 . 3 Dictation 8 kHz 7 . 9 10 . 1 8 . 5 Call-center 8 kHz 16 . 4 17 . 5 17 . 6 Y ouT ube 16 kHz 16 . 3 16 . 3 16 . 6 T elephony 8 kHz 20 . 9 22 . 3 22 . 8 T able 7 : Results on the T elephony test set when adapting the multidomain model and the V oicesear ch-Dictation model us- ing in-domain data. Also shown are the corresponding base- lines from T ab . 6, and when using a model trained only on T elephony training data. T est set W ord err or rate Multidomain 20 . 9 + 10 hrs 13 . 2 + 30 hrs 12 . 2 + 100 hrs 11 . 3 + 700 hrs 10 . 1 V oicesearch- 31 . 4 Dictation + 10 hrs 16 . 3 + 30 hrs 14 . 6 + 100 hrs 13 . 0 + 700 hrs 10 . 9 700 hrs 13 . 5 performance when training the model with multiple simulated perturbation techniques. Future work will address this, by systematically dealing with the imbalance in training data dis- tribution, especially when using simulation techniques. W e also expect modeling strategies like domain adv ersarial train- ing [18] and better training techniques [37] to improve perfor - mance. It will also be interesting to understand how to choose right subsets of data to be transcribed to help the model gen- eralize better , and how to make use of unlabeled data that is av ailable in much larger amounts compared to the labeled sets used in this work. 6. REFERENCES [1] Andreas Stolck e and Jasha Droppo, “Comparing human and machine errors in con v ersational speech transcrip- tion, ” in Pr oc. INTERSPEECH , 2017, pp. 137–141. [2] George Saon, Gakuto Kurata, T om Sercu, Kartik Au- dhkhasi, Samuel Thomas, Dimitrios Dimitriadis, Xi- aodong Cui, Bhuv ana Ramabhadran, Michael Picheny , L ynn-Li Lim, Ber gul Roomi, and Phil Hall, “English con versational telephone speech recognition by humans and machines, ” in Pr oc. INTERSPEECH , 2017, pp. 132–136. [3] Chanwoo Kim, Ananya Misra, Kean Chin, Thad Hughes, Arun Narayanan, T ara Sainath, and Michiel Bacchiani, “Generation of lar ge-scale simulated utter - ances in virtual rooms to train deep-neural networks for far -field speech recognition in Google Home, ” in Pr oc. INTERSPEECH , 2017. [4] V ijayaditya Peddinti, V imal Manohar , Y iming W ang, Daniel Pove y , and Sanjeev Khudanpur, “Far -field ASR without parallel data., ” in Pr oc. INTERSPEECH , 2016, pp. 1996–2000. [5] D. Y u, M. L. Seltzer , J. Li, J.-T . Huang, and F . Seide, “Feature learning in deep neural networks - studies on speech recognition tasks, ” in Pr oceedings of the Interna- tional Confer ence on Learning Repr esentations , 2013. [6] A. Narayanan and D. L. W ang, “In vestigation of speech separation as a front-end for noise robust speech recog- nition, ” IEEE/A CM T ransactions on A udio, Speec h, and Language Pr ocessing , vol. 22, pp. 826–835, 2014. [7] P . Ghahremani, V . Manohar , H. Hadian, D. Pove y , and S. Khudanpur , “In vestigation of transfer learning for ASR using LF-MMI trained neural networks, ” in Pr oc. ASR U , 2017. [8] T ara N Sainath, Ron J W eiss, K evin W W ilson, Bo Li, Arun Narayanan, Ehsan V ariani, Michiel Bacchiani, Izhak Shafran, Andre w Senior , K ean Chin, et al., “Mul- tichannel signal processing with deep neural networks for automatic speech recognition, ” IEEE/A CM T ransac- tions on Audio, Speech, and Language Processing , vol. 25, no. 5, pp. 965–979, 2017. [9] A. Narayanan and D. L. W ang, “Ideal ratio mask es- timation using deep neural networks for robust speech recognition, ” in Pr oceedings of the IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocess- ing , 2013, pp. 7092–7096. [10] T akuya Y oshioka, Nobutaka Ito, Marc Delcroix, At- sunori Ogaw a, Keisuke Kinoshita, Masakiyo Fujimoto, Chengzhu Y u, W ojciech J Fabian, Miquel Espi, T akuya Higuchi, et al., “The NTT CHiME-3 system: Ad- vances in speech enhancement and recognition for mo- bile multi-microphone de vices, ” in Automatic Speech Recognition and Understanding (ASR U), 2015 IEEE W orkshop on . IEEE, 2015, pp. 436–443. [11] Seyedmahdad Mirsamadi and John HL Hansen, “On multi-domain training and adaptation of end-to-end rnn acoustic models for distant speech recognition, ” in Proc. INTERSPEECH , 2017, pp. 404–408. [12] Jinyu Li, Michael L. Seltzer, Xi W ang, Rui Zhao, and Y ifan Gong, “Large-scale domain adaptation via teacher-student learning, ” in Pr oc. INTERSPEECH , 2017, pp. 2386–2390. [13] Jianqing Gao, Jun Du, Changqing Kong, Huaifang Lu, Enhong Chen, and Chin-Hui Lee, “ An experimental study on joint modeling of mixed-bandwidth data via deep neural networks for robust speech recognition, ” in Neural Networks (IJCNN), 2016 International Joint Confer ence on . IEEE, 2016, pp. 588–594. [14] Y oshua Bengio, “Deep learning of representations for unsupervised and transfer learning, ” in Proceedings of ICML W orkshop on Unsupervised and T ransfer Learn- ing , 2012, pp. 17–36. [15] John J Godfrey , Edward C Holliman, and Jane Mc- Daniel, “Switchboard: T elephone speech corpus for research and development, ” in Acoustics, Speec h, and Signal Pr ocessing, 1992. ICASSP-92., 1992 IEEE Inter - national Conference on . IEEE, 1992, vol. 1, pp. 517– 520. [16] D. Paul and J. Baker , “The design of Wall street journal- based CSR corpus, ” in Pr oceedings of the International Confer ence on Spoken Language Processing , 1992, pp. 899–902. [17] Iain McCowan, Jean Carletta, W Kraaij, S Ashby , S Bourban, M Flynn, M Guillemot, T Hain, J Kadlec, V Karaiskos, et al., “The ami meeting corpus, ” in Pr oceedings of the 5th International Confer ence on Methods and T echniques in Behavioral Resear c h , 2005, vol. 88, p. 100. [18] Y aroslav Ganin, Evgeniya Ustinov a, Hana Ajakan, Pas- cal Germain, Hugo Larochelle, Franc ¸ ois Laviolette, Mario Marchand, and V ictor Lempitsky , “Domain- adversarial training of neural netw orks, ” The J ournal of Machine Learning Resear ch , vol. 17, no. 1, pp. 2096– 2030, 2016. [19] Eric Tzeng, Judy Hoffman, Kate Saenko, and T rev or Darrell, “ Adversarial discriminati ve domain adapta- tion, ” in Computer V ision and P attern Recognition (CVPR) , 2017, vol. 1, p. 4. [20] Karlheinz Brandenb urg, “MP3 and AA C explained, ” in A udio Engineering Society Confer ence: 17th Inter - national Confer ence: High-Quality Audio Coding , Sep 1999. [21] “FFmpeg, ” www .f fmpeg.or g . [22] Golan Pundak and T ara N Sainath, “Lower frame rate neural network acoustic models., ” in Pr oc. INTER- SPEECH , 2016, pp. 22–26. [23] H. Sak, A. Senior, and F . Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling, ” in Pr oc. INTERSPEECH , 2014. [24] Cyril Allauzen and Michael Riley , “Bayesian language model interpolation for mobile speech input, ” in Pr oc. Interspeech , 2011. [25] Mart ´ ın Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu De vin, San- jay Ghemaw at, Geoffre y Irving, Michael Isard, et al., “T ensorflow: a system for large-scale machine learn- ing., ” in OSDI , 2016, v ol. 16, pp. 265–283. [26] Ehsan V ariani, T om Bagby , Erik McDermott, and Michiel Bacchiani, “End-to-end training of acoustic models for large vocabulary continuous speech recog- nition with tensorflow , ” in Pr oc. Interspeech , 2017, pp. 1641–1645. [27] Norman P Jouppi, Cliff Y oung, Nishant Patil, Da vid Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al., “In-datacenter performance analysis of a tensor pro- cessing unit, ” in Computer Ar chitectur e (ISCA), 2017 A CM/IEEE 44th Annual International Symposium on . IEEE, 2017, pp. 1–12. [28] Hank Liao, Erik McDermott, and Andrew Senior, “Large scale deep neural network acoustic modeling with semi-supervised training data for youtube video transcription, ” in Automatic Speec h Recognition and Understanding (ASR U), 2013 IEEE W orkshop on . IEEE, 2013, pp. 368–373. [29] Hagen Soltau, Hank Liao, and Hasim Sak, “Neural speech recognizer: Acoustic-to-word LSTM model for large vocab ulary speech recognition, ” arXiv preprint arXiv:1610.09975 , 2016. [30] Andrew Senior and Ignacio Lopez-Moreno, “Improv- ing DNN speaker independence with i-vector inputs, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Confer ence on . IEEE, 2014, pp. 225–229. [31] Peter J. Rousseeuw , “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis, ” Com- putational and Applied Mathematics , v ol. 20, pp. 53–65, 1987. [32] David L. Davies and Donald W . Bouldin, “ A cluster sep- aration measure, ” IEEE T ransactions on P attern Analy- sis and Mac hine Intelligence , v ol. 1, pp. 224–227, April 1979. [33] JM. V alin, K. V os, and T . T erriberry , “Definition of the Opus Audio Codec, ” RFC 6716, RFC Editor, September 2012. [34] C. Hoene and M. Hyder, “Optimally using the bluetooth subband codec, ” in Proceedings of the IEEE 35th Con- fer ence on Local Computer Networks , 2010, pp. 356– 359. [35] “SBC library , ” Online: www .bluez.org. [36] Khe Chai Sim, Arun Narayanan, Ananya Misra, An- shuman T ripathi, Golan Pundak, T ara N. Sainath, Parisa Haghani, Bo Li, and Michiel Bacchiani, “Domain adap- tation using factorized hidden layer for robust automat- icspeech recognition, ” in Pr oc. INTERSPEECH , 2018. [37] S. Shankar , V . Piratla, S. Chakrabarti, S. Chaudhuri, P . Jyothi, and S. Sarawagi, “Generalizing across do- mains via cross-gradient training, ” in Pr oceedings of the International Conference on Learning Repr esentations , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment