Performing Deep Recurrent Double Q-Learning for Atari Games
Currently, many applications in Machine Learning are based on define new models to extract more information about data, In this case Deep Reinforcement Learning with the most common application in video games like Atari, Mario, and others causes an i…
Authors: Felipe Moreno-Vera
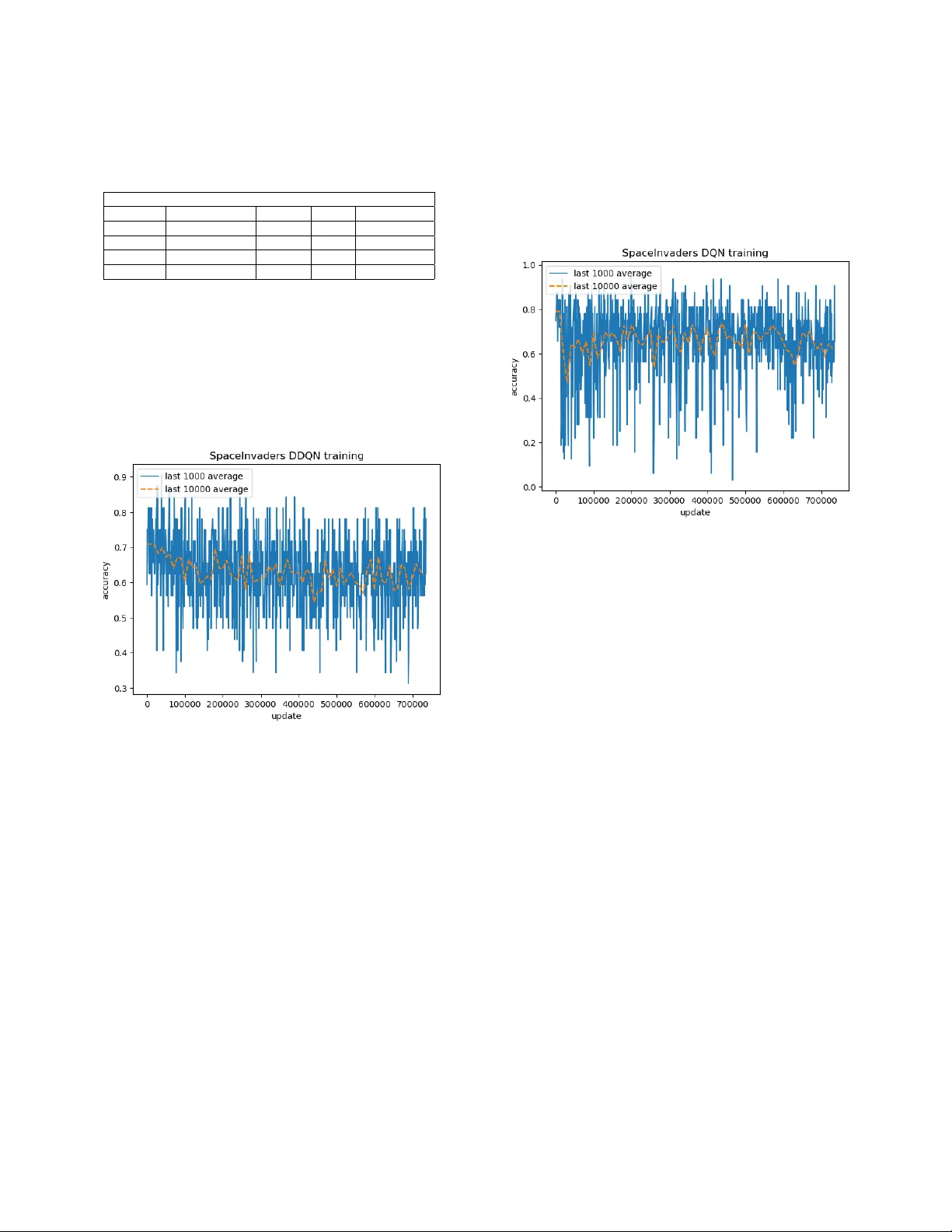
Performing Deep Recurrent Double Q-Learning for Atari Games Felipe Moreno-V era Universidad Cat ´ olica San P ablo Arequipa, Per ´ u felipe.moreno@ucsp.edu.pe Abstract —Currently , many applications in Machine Learning are based on defining new models to extract more information about data, In this case Deep Reinf orcement Learning with the most common application in video games like Atari, Mario, and others causes an impact in how to computers can learning by himself with only inf ormation called rewards obtained fr om any action. There is a lot of algorithms modeled and implemented based on Deep Recurrent Q-Learning proposed by DeepMind used in AlphaZero and Go. In this document, we pr oposed deep recurr ent double Q-learning that is an impr ovement of the algorithms Double Q-Learning algorithms and Recurrent Networks like LSTM and DRQN. Index T erms —Deep Reinf orcement Learning, Double Q- Learning, Recurrent Q-Learning, Reinforcement Learning, Atari Games, DQN, DRQN, DDQN I . I N T R O D U C T I O N Currently , there is an increase in the number in of appli- cations in Reinforcement Learning. One recently application of Deep Reinforcement Learning (DRL) is self-driving cars [1], [2], another one is in games like AlphaZero (Go, Chess, etc) and video games like Mario, T op racer, Atari, etc. Deep Reinforcement Learning is considered as a third model in Ma- chine Learning (with Supervised Learning and Unsupervised Learning) with a dif ferent learning model and architecture. There are sev eral methods of implementing these learning processes, where Q-Learning is a prominent algorithm, the Q value of a pair (state, action) contains the sum of all these possible re wards. The problem is that this sum could be infinite in case there is no terminal state to reach and, in addition, we may not want to give the same weight to immediate re wards as to future rewards, in which case use is made of what is called an accumulated reinforcement with discount: future rew ards are multiplied by a factor γ [0, 1] so that the higher this factor , the more influence future rew ards have on the Q value of the pair analyzed. I I . B AC K G RO U N D Sutton et al. [3], [4] define various models to describe Reinforcement Learning and how to understand it. DeepMind was the first to achiev e this Deep Learning with AlphaZero and Go game using Reinforcement Learning with Deep Q- Learning (DQN) [5] and Deep Recurrent Q-Leaning (DRQN) [6], follow up by OpenAI who recently surpassed professional players in StarCraft 2 (Gramve created by Blizzard) and 978-1-7281-5666-8/19/$31.00 2019 IEEE previously in Dota 2 de veloped by V alve. Chen et al. [7] proposed a CNN based on DRQN using Recurrent Netw orks (a little variance of DRQN model using LSTM, the first neural network architecture that introduces the concept of memory cell [8], on agents actions to extract more information from frames. A. Deep Q-Learning (DQN) The first algorithm proposed by DeepMind was Deep Q- Learning, based on Q-Learning with experience replay [5], with this technique they save the last N experience tuples in replay memory . This approach is in some respects limited since the memory buf fer does not differentiate important transitions and always ov erwrites with recent transitions due to the finite memory size N. Fig. 1. Deep Mind DQN algorithm with experience replay [5]. B. Deep Double Q-Learning (DDQN) Hado et al. [5] propose the idea of Double Q-learning is to reduce overestimation by decomposing the max operation in the target into action selection and action e valuation. • DQN Model : Y t = R t +1 + γ maxQ ( S t +1 ; a t ; θ t ) • DDQN Model : Y t = R t +1 + γ Q ( S t +1 ; ar gmaxQ ( S t +1 ; a t ; θ t ); θ 1 t ) Where: • • a t represents the agent. • • θ t are the parameters of the network. • • Q is the vector of action values. • • Y t is the target updated resembles stochastic gradient descent. • • γ is the discount factor that trades of f the importance of immediate and later rewards. • • S t is the vector of states. • • R t +1 is the reward obtained after each action. C. Deep Recurrent Q-Learning (DRQN) Mathew et al. [6] have been shown to be capable of learning human-lev el control policies on a variety of different Atari 2600 games. So they propose a DRQN algorithm which con volves three times over a single-channel image of the game screen. The resulting activ ation functions are processed through time by an LSTM layer (see Fig.2. Fig. 2. Deep Q-Learning with Recurrent Neural Networks model Deep Recurrent Q-Learning model (DQRN) [6] D. Deep Q-Learning with Recurr ent Neural Networks (DQRNN) Chen et al. [7] say DQN is limited, so the y try to impro ve the beha vior of the network using Recurrent networks (DRQN) using LSTM in the networks to take better advantage of the experience generated in each action (see Fig.3). I I I . P R O P O S E D M O D E L W e implement the CNN proposed by Chen et al. [7] with some variations in the last layers and using AD AM error . The first attempt was a simple CNN with 3 Conv 2D layers, with the Q-Learning algorithm, we obtain a slow learning process for easy games like SpaceIn vaders or Pong and very low accuracy in complicated games like Beam Rider or Enduro. Then, we try modifying using Dense 512 and 128 networks at the last layer with linear acti vation and relu, adding an LSTM layer with activ ation tanh. Fig. 3. Deep Q-Learning with Recurrent Neural Networks model (DQRN) [7]. In table II we present our Hyperparameters using in our models, we denote this list of hyperparameters as the better set (in our case). W e run models over an NVIDIA GeForce GTX 950 with Memory 1954MiB using T ensorflow , Keras and GYM (Atari library) for python. W e implement DDQN, DRQN, DQN and our proposed to combine DRQN with Double Q-Learning [9] algorithm using LSTM. Conv 2D, 32 (8x8), stride = 4 Conv 2D, 64 (4x4), stride = 2 Dense(512, relu) Dense(actions, linear) Conv 2D, 64 (3x3), stride = 1 Convolutional Network Conv 2D, 32 (8x8), stride = 4 Conv 2D, 64 (4x4), stride = 2 Conv 2D, 64 (3x3), stride = 1 LSTM(512, tanh) Dense(128, relu) Dense(actions, linear) Recurrent Convolutional Network Fig. 4. Conv olutional Networks proposed in our models. I V . E X P E R I M E N T S A N D R E S U LT S Our experiments are built ov er Atari Learning Environment (ALE) [10] which serves us as an ev aluation platform for our algorithm in the games SpaceInv aders, Enduro, Beam Rider , and Pong and allow us to compare with DQN (Double Q- Learning), DDQN (Deep Double Q-Learning), and DRQN (Deep Recurrent Q-Learning). After to run our algorithms using 10M (10 million) episodes, we obtain results for each model in each respective game. W e get the best scores for the 4 games mentioned above (See T able I). T ABLE I R E SU LT S S C OR E S O F S P AC E I NVAD E R S , E N D UR O , P O N G A N D B E A M R I DE R . Models and respective Scores Model SpaceIn vaders Enduro Pong Beam Rider DQN 1450 1095 65 349 DRQN 1680 885 39 594 DDQN 2230 1283 44 167 DRDQN 2450 1698 74 876 W e compare with V olodymyr et al. [11] Letter about best scores form games obtained by DQN agents and professionals gamers (humans) to verify correct behavior of learning pro- cess, we measure accuracy based on Q-tables from the agent and DL algorithm (Double Q-Learning) extracting information from frames with the Con volutional Neural Networks (See Fig. 5, and Fig.6). Fig. 5. DDQN Accuracy . C O N C L U S I O N S W e present a model based on DRQN and Double Q- Learning combined to get a better performance in some games, using LSTM and CNN to analyze frames. W e notice that each method could be good for a set of specific Atari games and other similar games but not for all. Some kind of sets of games can be improved using different CNN and get more information from the frames in each batch iteration. In this work, we determine which one can be improved with the techniques of Deep Recurrent Double Q-Learning and which can be group based on which learning algorithm improv e their scores. F U T U R E W O R K S W ith these results, we notice that every game in atari has a similar behavior to others different games, but because of technical details and our equipment, we could not determine which games hav es similar behavior but we encourage to do it and get all set of similar behaviors and verify which methods should help to impro ve the learning process per each game. A C K N O W L E D G M E N T This work was supported by grant 234-2015-FONDECYT (Master Program) from CienciActiv a of the National Coun- cil for Science,T echnology and T echnological Inno vation (CONCYTEC-PER U). Fig. 6. DRDQN Accuracy . R E F E R E N C E S [1] Leon-V era, Leonardo and Moreno-V era, Felipe, Car Monitoring System in Apartments Garages by Small Autonomous Car Using Deep Learning, Annual International Symposium on Information Management and Big Data, Springer , 2018. [2] Leon-V era, Leonardo and Moreno-V era, Felipe, Sistema de Monitoreo de Autos por Mini-Robot inteligente utilizando T ecnicas de V ision Computacional en Garaje Subterraneo, LACCEI, 2018. [3] Richard S. Sutton, ”Reinforcement Learning Architectures”. [4] Richard Sutton and Andrew Barto. Reinforcement Learning: An Intro- duction. MIT Press, 1998. [5] V olodymyr Mnih, Koray Kavukcuoglu, Da vid Silver , Daan W ierstra, Alex Grav es, Ioannis Antonoglou, Martin Riedmiller, ”Playing Atari with Deep Reinforcement Learning”, In NIPS Deep Learning W orkshop 2013. [6] Matthew Hausknecht and Peter Stone, ”Deep Recurrent Q-Learning for Partially Observable MDPs”, In AAAI Fall Symposium Series 2015. [7] Clare Chen, V incent Y ing, Dillon Laird, ”Deep Q-Learning with Recur- rent Neural Networks”. [8] Hochreiter and Schmidhuber . Long short-term memory. Neural Comput. 9(8):1735-1780. [9] Hado v an Hasselt, Arthur Guez and David Silver, ”Deep Reinforcement Learning with Double Q-learning”. [10] M. Bellemare, Y . Naddaf, J. V eness and M. Bo wling, The arcade learning en viroment. An ev aluation platform for general agents. In Journal of Artificial Intelligence Research, 47:253-279, 2013 [11] V olodymyr Mnih, K oray Kavukcuoglu, David Silver , Andrei A. Rusu, Joel V eness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan W ierstra, Shane Legg & Demis Hassabis, ”Human-lev el control through deep reinforcement learning”. T ABLE II H Y PE R PAR A M E TE R S U S E D I N M OD E L S List of Hyperparameters Iterations 10 000000 number of batch iterations to the learning process miniBatch size 32 number of experiences for SGD update Memory buf fer size 900000 SGD update are sampled from this number of most recent frames Learning Rate 0.00025 learning rate used by RMS Propagation T raining Frequency 4 Repeat each action selected by the agent this many times Y Update Frequency 40000 number of parameter updates after which the target network updates Update Frequency 10000 number of actions by agent between successiv e SGD updates Replay start size 50000 The number of Replay Memory in experience Exploration max 1.0 Max value in exploration Exploration min 0.1 Min value in exploration Exploration Steps 850000 The number of frames over which the initial value of e reaches final value Discount Factor 0.99 Discount factor γ used in the Q-learning update
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment