Similarity Learning for High-Dimensional Sparse Data
A good measure of similarity between data points is crucial to many tasks in machine learning. Similarity and metric learning methods learn such measures automatically from data, but they do not scale well respect to the dimensionality of the data. I…
Authors: Kuan Liu, Aurelien Bellet, Fei Sha
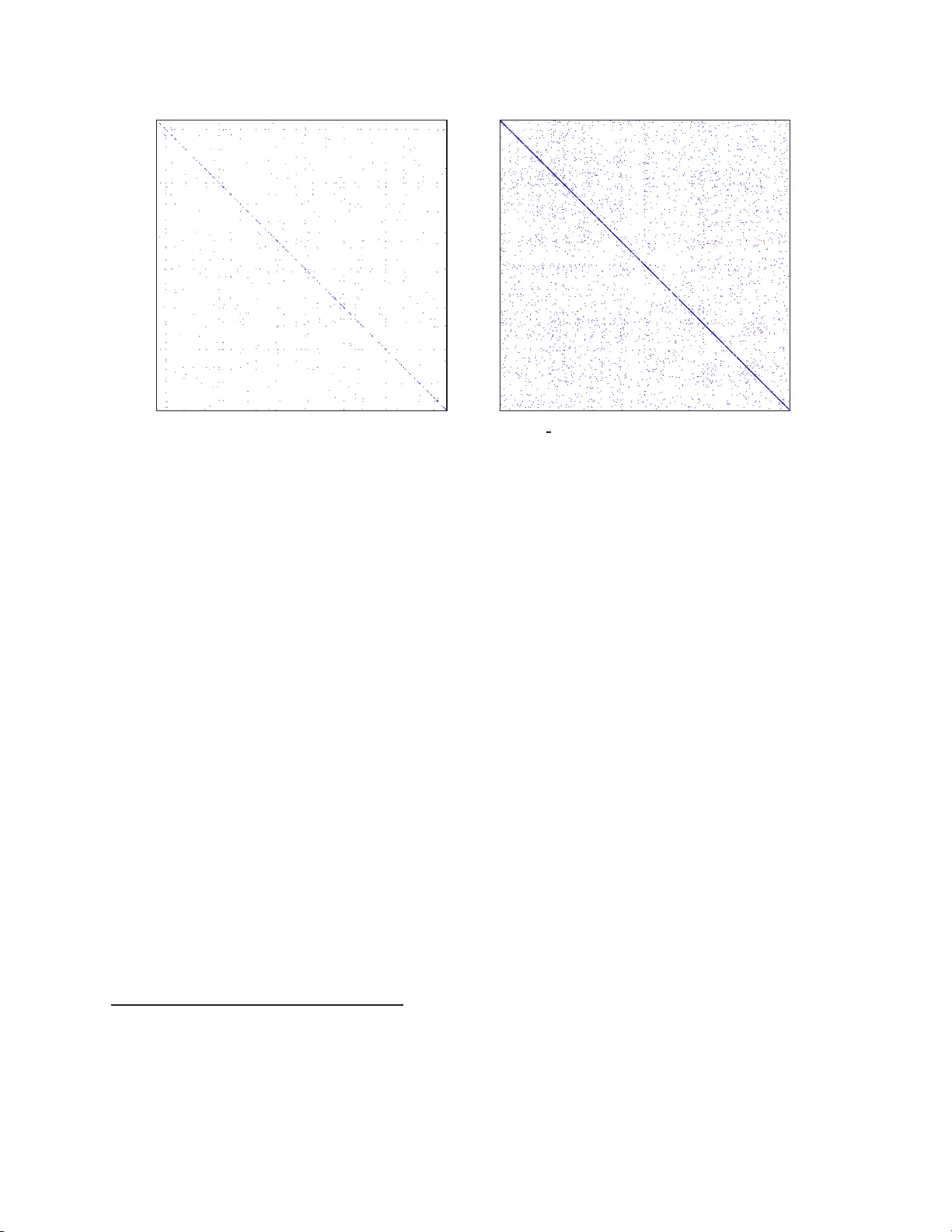
Similarity Learning for High-Dime nsional Sparse D ata Kuan Liu ∗ † , Au r ´ elien Bellet ∗ ‡ , Fei Sha † Abstract A good measure of similarity betwe e n data poin ts is crucial to m any tasks in machine learn ing. Similarity and metric learning method s learn such me asures a u tomatically fro m data, but they d o n ot scale well respect to th e d imensionality of the data . In this paper, we pr opose a metho d that can learn efficiently similarity measure from high -dimension al sparse data. The cor e idea is to p a rameterize the similarity measure as a conv ex combinatio n o f rank-o ne matrice s with specific sparsity structu res. The parameters are then optimized with an appr oximate Frank-W olfe proced ure to maxima lly satisfy relative similarity constrain ts on the training data. Our algorithm greedily incorpo rates one pair of features at a time in to the similarity measur e, providin g an ef ficient way to contro l the numb er of active features a nd thus r educe overfitting. It enjoys very appealing conver gence guar a ntees an d its time and memory com- plexity depends on the spar sity of the data in stead of the dimension of the f eature space. Our experimen ts on real-world high- dimensiona l d atasets dem onstrate its poten tial for classification, dim e nsionality re- duction and data exploration . 1 Introd uction In many applic ations , such as text proce ssing, computer vision or biology , data is represe nted as very high- dimensio nal but sparse vectors. T he ability to compute meaningful similarity scores between these objects is cruc ial to many tas ks, such as class ification, clustering or ranking . Ho wev er , handc rafting a rele v ant sim- ilarity measure for such data is challengin g because it is usually the case that only a small, often unkno wn subset of featur es is actually rele v ant to the task at hand. For instance, in drug discov ery , chemica l com- pound s can be represe nted as spa rse features describ ing their 3D propert ies, and only a few of them play an role in determining whether the compoun d will bind to a target recept or (G uyon et al., 2004). In te xt classi- fication, where each document is repre sented as a sparse bag of words, only a small subset of the words is genera lly sufficien t to discrimina te among documents of dif ferent topics. A princi pled way to obtain a similarity measure tailor ed to the proble m of interest is to learn it from data. This line of research, kno wn as similarity and distance metric learning , has been successful ly appli ed to many applicat ion domains (see Kulis, 2012; Bellet et al., 2013, for recent surv ey s). The basic idea is to learn the parameters of a similarity (or distance) function such that it satisfies proximity-base d constraints , requir ing for instan ce that some data instan ce x be more similar to y than to z according to the learned functi on. Ho we v er , similari ty learnin g typica lly requi res estimati ng a m atrix w ith O ( d 2 ) entrie s (w here d is the data dimensio n) to account for correlation between pairs of features . For high-di mension al data (say , d > 10 4 ), this is proble matic for at least three reasons: (i) trainin g the metric is computation ally ex pensi ve ∗ Equal contribution. † Department of Computer Science, Univ ersity of Southern C alifornia, { kuanl,feisha } @usc.edu . ‡ L TCI UMR 5141, T ´ el ´ ecom ParisT ech & CNRS, aurelien.bellet@te lecom-paristec h.fr . Most of the work in this paper was carried out while the author was af filiated with Department of Computer Science, Univ ersity of Southern California. 1 (quadr atic or cubic in d ), (ii) the matrix may not ev en fi t in memory , and (iii) learning so many parameters is lik ely to lead to se vere ove rfitting, espe cially for sparse data where some featu res are rarely observ ed. T o over come this difficult y , a common pract ice is to first project data into a low-dimen siona l space (using PCA or random projecti ons), and then learn a similarity function in the reduced space. Note that the projec tion intertwines useful features and irrele vant /noisy ones. Moreo ver , it is also dif ficult to inte rpret the reduce d featur e space, w hen we are intereste d in discov ering what features are more important than others for discri mination . In this paper , we propose a nov el method to learn a bilinear similarity function S M ( x , x ′ ) = x T M x ′ directl y in the original high-dimens ional spa ce while av oiding the above -mention ed pitf alls. The main idea combine s three ingredients : the sparsity of the data, the paramete rizatio n o f M as a con vex com- binati on of rank-one matrices with special sparsi ty structures, and an appro ximate Frank-W olfe procedure (Frank and W olfe, 1956; Clarkson, 2010; Jaggi, 2013) to learn the similarity parameters. The resulting algo- rithm iterati vely and greedily incorporate s one pair of features at a time into the learned similarity , provi ding an efficie nt way to ignore irrele v ant featur es as well as to guard against ove rfitting through early stopping. Our method has appealing appro ximation error guarant ees, time and memory complex ity indepen dent of d and outp uts extremel y sparse similarity functions that are f ast to compute and to interpret. The usefu lness of the propose d approa ch is e v aluate d on sev eral datasets with up to 100,000 featur es, some of which hav e a large proportion of irrelev ant features . T o the best of our kno wledge, this is the fi rst time that a full similarity or distance metric is learned directly on such high-dimen sional datasets without first reducing dimensionali ty . Our app roach signi ficantly outperforms both a diagonal similarity learn ed in the orig inal spac e and a full similari ty learne d in a reduced space (after PCA or random projection s). Furthermor e, our similarity func tions are extremely sparse (in the order of 0.0001% of nonz ero entries) , using a sparse subset of features and thus provi ding more economical analysis of the resulting model (for exa mple, examin ing the importanc e of the orig inal features and their pair wise interactio ns). The rest of this paper is orga nized as follo ws. S ection 2 briefly re vie ws some related work. Our approac h is desc ribed in Section 3. W e present our ex periment al results in Secti on 4 and conclu de in Section 5. 2 Related W ork Learning similarity and distance metric has attracted a lot of interests. In this section , we revi e w pre vio us ef forts that focus on ef ficient algorithms for high-dimen sional data – a comprehen si ve surve y of existi ng approa ches can be fou nd in (Bellet et al., 201 3). A m ajority of learning similarity has focused on learnin g either a Mahalanobis distance d M ( x , x ′ ) = ( x − x ′ ) T M ( x − x ′ ) where M is a symmetric positi v e semi-defini te (PSD) matrix , or a bilinear simi- larity S M ( x , x ′ ) = x T M x ′ where M is an arbitrary d × d matrix. In both cases, it requires estimating O ( d 2 ) paramet ers, w hich is undesirable in the high-dimensi onal setting. V irtually all ex isting methods thus resort to dimension ality reductio n (such as PC A or random projections) to preproce ss the data when it has more than a few hundre d dimensions, thereb y incurring a potent ial loss of performan ce and interpr etabilit y of the result ing function (see e.g., D a vis et al., 2007; W einber ger and Saul, 2009; G uillaumin et al., 2009; Y ing and Li, 2012; W ang et al., 2012; Lim et al., 2013; Qian et al. , 2014). There ha ve been a fe w solution s to this essential limitation. The most drastic strate gy is to learn a diagon al matrix M (Schultz and Joachims, 2003; Gao et al., 2014), w hich is very restricti ve as it amounts to a simple weighti ng of the fea tures. Instead, some approaches assume an explici t low-ran k decompos ition M = L T L and learn L ∈ R r × d in order to reduc e the number of parameters to learn (Goldbe r ger et al., 2004; W einber ger and Saul, 2009; Ked em et al., 2012). But this results in noncon ve x formulati ons with 2 many bad local op tima (Kulis, 2012) and requires to tune r carefully . Moreov er , the training complexi ty stil l depen ds on d and can thus remain quite lar ge. Another direction is to learn M as a combinat ion of rank- one matrices. In (Shen et al., 2012), the combinin g elements are selec ted greedily in a boosting manner b ut each iteration has an O ( d 2 ) complexit y . T o go around this limitation, Shi et al. (2014) generate a set of rank-o ne matrices before training and learn a sparse combinati on. Ho wev er , as the dimension increases, a lar ger dictionar y is needed and can be expensi ve to generate. Some work ha v e also gone into sparse and/or lo w-rank regu larizat ion to reduce overfittin g in high dimensions (Rosales and Fung, 2006; Qi et al., 2009; Y ing et al., 2009) b ut tho se do not reduc e the training comple xity of the algorit hm. T o the best of our kno wledge , DML-eig (Y ing and L i, 2012) and its extensio n DML- ρ (Cao et al., 2012 ) are the only prior attempts to use a Frank-W olfe procedu re for metric or similarity learning. Ho wev er , their formulat ion requires fi nding the large st eigen vector of the gradient m atrix at each iteration, which scales in O ( d 2 ) and is thus unsuitable for the high-dime nsiona l setting we con sider in this work . 3 Pr oposed A pproach This section intro duces H D S L (High-Dimensio nal Similarity L earnin g), the appro ach propos ed in this pa- per . W e fi rst describe our problem formulati on (Section 3.1), then deriv e an efficient algorithm to solve it (Section 3.2). 3.1 Pr oblem Formulation In this work, we propose to learn a similarity functio n for high -dimensi onal sparse data. W e assume the data points lie in some space X ⊆ R d , w here d is larg e ( d > 10 4 ), and are D -spars e on av erage ( D ≪ d ). Namely , the number of nonzero entries is typically much smaller than d . W e focus on learning a similarity functi on S M : X × X → R of the form S M ( x , x ′ ) = x T M x ′ , w here M ∈ R d × d . Note that for any M , S M can be co mputed in O ( D 2 ) time on a verage. Fea sible domain Our goa l is to deriv e an algorithm to learn a very spars e M wit h time and memory requir ements that depend on D but not on d . T o this end, giv en a scale parameter λ > 0 , w e will paramete rize M as a con v ex combin ation of 4-sp arse d × d bases: M ∈ D λ = con v( B λ ) , with B λ = [ ij n P ( ij ) λ , N ( ij ) λ o , where for an y pair of fea tures i, j ∈ { 1 , . . . , d } , i 6 = j , P ( ij ) λ = λ ( e i + e j )( e i + e j ) T = · · · · · · λ · λ · · · · · · · λ · λ · · · · · · , N ( ij ) λ = λ ( e i − e j )( e i − e j ) T = · · · · · · λ · − λ · · · · · · · − λ · λ · · · · · · . The use of such sparse matrices was suggested by Jaggi (2011). Besides the fact that they are instrumenta l to the effici ency of our algorith m (see Section 3.2), we giv e some additio nal moti v ation for their use in the conte xt of similari ty learning. First, any M ∈ D λ is a con vex combination of symmetric PSD matrices and is thus also symmetric PSD . Unlik e many metric learnin g algorithms, we thus av oid the O ( d 3 ) cost of projecting onto the PSD cone. Furthermor e, constr aining M to be symmetric PSD provid es useful regula rizatio n to pre ve nt ov erfitting 3 (Chechik et al., 2009) and allows the use of the square root of M to project the data into a new space where the dot pr oduct is equiv alent to S M . Because the bases in B λ are ran k-one, the dimensional ity of this projec tion space is at most the numbe r of bases composing M . Second, each basi s op erates on two features only . In parti cular , S P ( ij ) λ ( x , x ′ ) = λ ( x i x ′ i + x j x ′ j + x i x ′ j + x j x ′ i ) assigns a higher score when feature i appears jointly in x and x ′ (lik e wise for j ), as w ell as when feature i in x and feature j in y (and vice versa) co-occu r . Con versely , S N ( ij ) λ penali zes the co-occurre nce of feature s i and j . This will allo w us to easily control the number of activ e features and learn a very compact similarit y representat ion. Finally , notice that in the cont ext of text data represe nted as bags-of-wo rds (or other count data), the bases in B λ are quite natu ral: they can be intu iti ve ly though t of as enco ding the fact that a term i or j presen t in both documen ts make s them more similar , and that two terms i and j are associated with the same/dif ferent class or topi c. Optimization problem W e now describe the optimization problem to learn the similarity parameters . Fol- lo wing pre viou s work (se e for instance Schultz and Joa chims, 2003; W einber ger and Saul, 2009; Chechik et al., 2009), our tra ining data consist of side inf ormation in the form of tri plet constra ints: T = { x t should be m ore similar to y t than to z t } T t =1 . Such constraints can be bu ilt from a labeled training sample, provi ded directly by a domain exp ert, or obtain ed through implicit feedba ck such as clicks on sear ch engine result s. For notation al con venie nce, we write A t = x t ( y t − z t ) T ∈ R d × d for each constrain t t = 1 , . . . , T . W e want to define an objecti ve functi on that applie s a penalty w hen a constraint t is not satisfied with margin at least 1, i.e. whenev er h A t , M i = S M ( x t , y t ) − S M ( x t , z t ) < 1 . T o this end, we use the smoothed hinge loss ℓ : R → R + : ℓ h A t , M i = 0 if h A t , M i ≥ 1 1 2 − h A t , M i if h A t , M i ≤ 0 1 2 1 − h A t , M i 2 otherwis e , where h· , ·i denotes the Froben ius inner product. 1 Giv en λ > 0 , our similarity learning formula tion aims at fi nding the matrix M ∈ D λ that minimizes the a ver age penalty ove r the trip let constrain ts in T : min M ∈ R d × d f ( M ) = 1 T T X t =1 ℓ h A t , M i s.t. M ∈ D λ . (1) Due to the con vex ity of the smoothed hinge loss, Problem (1) in vol ves minimizin g a con vex function ov er the con v ex domain D λ . In the ne xt sectio n, we propose a greedy algorit hm to solve this prob lem. 3.2 Algorithm 3.2.1 Exact Frank-W olfe Algorithm W e propose to use a Frank-W olfe (FW) algorithm (Frank and W olfe, 1956; Clarkson, 2010; Jaggi , 2013) to learn the similarity . FW is a general proc edure to minimize a con vex and continu ously diffe rentiab le 1 In principle, any other conv e x and continuously differe ntiable loss function can be used in our frame work, such as the squared hinge loss, l ogistic loss or exponential loss. 4 Algorithm 1 Frank W olfe algorithm for pro blem (1) 1: initial ize M (0) to an arbi trary B ∈ B λ 2: f or k = 0 , 1 , 2 , . . . do 3: let B ( k ) F ∈ arg min B ∈B λ h B , ∇ f ( M ( k ) ) i and D ( k ) F = B ( k ) F − M ( k ) // comp ute forwar d dir ection 4: let B ( k ) A ∈ arg max B ∈S ( k ) h B , ∇ f ( M ( k ) ) i and D ( k ) A = M ( k ) − B ( k ) A // comp ute away direction 5: if h D ( k ) F , ∇ f ( M ( k ) ) i ≤ h D ( k ) A , ∇ f ( M ( k ) ) i then 6: D ( k ) = D ( k ) F and γ max = 1 // choose forward step 7: else 8: D ( k ) = D ( k ) A and γ max = α ( k ) B ( k ) A / (1 − α ( k ) B ( k ) A ) // choose away step 9: end if 10: let γ ( k ) ∈ arg min γ ∈ [0 ,γ max ] f ( M ( k ) + γ D ( k ) ) // perform line searc h 11: M ( k +1) = M ( k ) + γ ( k ) D ( k ) // up date iterate to war ds dir ection 12: end f or functi on ov er a compact and con vex set. At each iteratio n, it mov es to war ds a feasible point that minimizes a linearizati on of the objecti ve function at the current iterate. N ote that a minimizer of this linear function must be at a vert ex of the feasible domain. W e w ill exploi t the fact that in our formulati on (1 ), the vertice s of the fea sible domain D λ are the element s of B λ and ha v e special struc ture. The FW algorith m applied to (1) and enhance d with so-called away steps (Gu ´ elat and Marco tte, 1986) is described in details in Algorithm 1 . During the course of the algorit hm, we exp licitly maintain a repre- sentat ion of each iterate M ( k ) as a con ve x combinatio n of basi s elements: M ( k ) = X B ∈B λ α ( k ) B B , where X B ∈B λ α ( k ) B = 1 and α ( k ) B ≥ 0 . W e denote the set of acti ve basi s elements in M ( k ) as S ( k ) = { B ∈ B λ : α ( k ) B > 0 } . The algori thm goes as follo w s. W e initialize M (0) to a random basis element . Then, at each iterati on, we greedily choo se between movin g tow ards a (possibl y) ne w basis (forward step) or reducing the weight of an acti v e one (awa y step). The extent of the step is determined by line search. As a result, Algorithm 1 adds only one basis (at most 2 new features) at each iteration, which provid es a con venie nt way to control the number of activ e features and m aintain a compact repres entatio n of M ( k ) in O ( k ) memory cost. Furthermore, aw ay steps provid e a way to reduce the importance of a potentia lly “bad” basis element added at an earlier iteratio n (or ev en remov e it completely when γ ( k ) = γ max ). Note that throughou t the ex ecut ion of the algorithm, all iterates M ( k ) remain con v ex combinations of basis ele ments and are thus feasible. The followin g lemma sho ws that the iterat es of Algorithm 1 con ver ge to an opt imal solutio n of (1) with a rate of O (1 /k ) . Lemma 1. Let λ > 0 , M ∗ be an optimal solution to (1) and L = 1 T P T t =1 k A t k 2 F . At any iter ation k ≥ 1 of Algori thm 1, the iterate M ( k ) ∈ D λ satisfi es f ( M ( k ) ) − f ( M ∗ ) ≤ 16 Lλ 2 / ( k + 2) . Furthermor e, it has at most r ank k + 1 with 4( k + 1) nonzer o entries, and uses at most 2( k + 1) distinct featur es. Pr oof. The result follo ws from the analysis of the general FW algorithm (Jagg i, 2013), the fact that f has L -Lipschit z continuous gradient and observin g that diam k·k F ( D λ ) = √ 8 λ . Note that the optimality gap in Lemma 1 is indep endent from d . This means that Algorithm 1 is able to find a good approxi mate solut ion based on a small number of features , which is very appealin g in the high-d imension al setting. 5 V ar iant T ime complexity Memory comple xity Exact (Algorit hm 1) ˜ O ( T D 2 + T k ) ˜ O ( T D 2 + k ) Mini-bat ch ˜ O ( M D 2 + T k ) ˜ O ( T + M D 2 + k ) Mini-bat ch + heuri stic ˜ O ( M D + T k ) ˜ O ( T + M D + k ) T able 1: Complex ity of iterati on k (ignor ing logarithmic factors) for dif ferent varian ts of the algorith m. 3.2.2 Complexity Analysis W e no w analyz e the time and memory comple xity of Algorith m 1. O bserv e that the grad ient has the form: ∇ f ( M ) = 1 T T X t =1 G t , where G t = 0 if h A t , M i ≥ 1 − A t if h A t , M i ≤ 0 h A t , M i − 1 A t otherwis e . (2) The structu re of the algorit hm’ s updates is crucial to its efficienc y: since M ( k +1) is a con ve x combination of M ( k ) and a 4-sparse matrix B ( k ) , we can ef ficientl y compute most of the quant ities of interest through carefu l book-ke eping. In particular , storing M ( k ) at iteration k requires O ( k ) memory . W e can also recursi vely compute h A t , M ( k +1) i for all cons traints in only O ( T ) ti me and O ( T ) memory bas ed on h A t , M ( k ) i and h A t , B ( k ) i . This allo ws us, for instance, to efficien tly compute the objecti ve va lue as well identify the set of satisfied constr aints (those with h A t , M ( k ) i ≥ 1 ) and ignore them when computin g the gradien t. F inding the away directi on at iterat ion k can be done in O ( T k ) time. For the line search, we use a bisection algorithm to find a root of the gradien t of the 1-dimension al function of γ , which only depends on h A t , M ( k ) i and h A t , B ( k ) i , both of w hich are readily av ailable. Its time complex ity is O ( T log 1 ǫ ) where ǫ is the precisio n of the lin e-searc h, and requires consta nt memory . The bottleneck is to find the forwar d direct ion. Indeed, sequent ially considerin g each basis element is intract able as it tak es O ( T d 2 ) time. A more efficien t strate gy is to sequentiall y consid er each constrain t, which require s O ( T D 2 ) time and O ( T D 2 ) memory . The overal l itera tion compl exit y of Algorithm 1 is gi ve n in T able 1. 3.2.3 Appr oximate F orward Step Finding the forwa rd direction can be expens i ve when T and D are both lar ge. W e propose two strate gies to alle viat e this cost by finding an app roximatel y optimal basis (see T able 1 for iterat ion complex ity). Mini-Batch Appr oximatio n Instead of fi nding the forward and a way directions bas ed on the full gradi ent at each iteration, we estimate it on a mini-batch of M ≪ T constrain ts drawn uniformly at random (with- out replacement). T he complex ity of finding the forward direction is thus reduced to O ( M D 2 ) time and O ( M D 2 ) memory . U nder mild assumption s, concentr ation bounds such as Hoef fding ’ s inequali ty with- out replacemen t (Serfling, 1974) can be used to show that with high probab ility , the dev iation between the “utilit y” of an y basis ele ment B on the full set of constrain ts and its estimation on the mini-b atch, namely: 1 M M X t =1 h B , G t i − 1 T T X t =1 h B , G t i , 6 Datasets D imension Sparsity Tr aining si ze V alida tion size T est size dex ter 20,000 0.48% 300 300 2,000 doroth ea 100,000 0.91% 800 350 800 rcv1 2 47,236 0.16% 12,145 4,048 4,049 rcv1 4 29,992 0.26% 3,850 2,888 2,887 T able 2: Datasets used in the e xperimen ts decrea ses as O (1 / √ M ) . In other words, the mini-batc h vari ant of Algorithm 1 finds a forward direction which is approxi mately optimal. The FW algorithm is known to be rob ust to this setting, and con ver gen ce guaran tees similar to Lemma 1 can be ob tained follo wing (Jaggi, 2013; Freund and Grig as, 2013). Fas t H euristic T o a v oid the quadratic depende nce on D , we propose to use the follo wing heu ristic to find a goo d forwar d basis. W e fi rst pick a featur e i ∈ { 1 , . . . , d } unifo rmly at rand om, and solv e the linear proble m ov er the restricted set S j { P ( ij ) λ , N ( ij ) λ } . W e then fix j and solv e the problem again over the set S k { P ( kj ) λ , N ( kj ) λ } and use the resulting basis for the forward direction . This can be done in only O ( M D ) time and O ( M D ) memory and gi ve s good performan ce in prac tice, as we shall see in th e next sec tion. 4 Experiments In this section , w e present experiment s to study the performanc e of HDSL in classificat ion, dimensio nality reduct ion and data explorat ion against compe ting approache s. Our Matlab code is public ly av ailab le on GitHub und er GNU /GPL 3 license. 2 4.1 Experimental Setup Datasets W e report expe rimental results on se ver al real-world classifica tion datasets with up to 100,000 feature s. Dorothea and dext er come from the NIPS 2003 feature selection challenge (Guyon et al., 2004) and are res pecti vely pharmace utical and text dat a with pr edefined splitti ng into training , valida tion and test sets. They both contain a lar ge proportion of noisy/ir rele v ant fea tures. Reuters CV 1 is a popular text classification datase t with bag-of-w ords representati on. W e use the binary vers ion from the LIBS VM dataset collection 3 (with 60%/20%/20 % random splits) and the 4-classes ver sion (with 40%/30%/30% rando m splits ) intro- duced in (Cai and He, 20 12). Detailed information on the datase ts and splits is gi ven in T able 2. All datasets are normaliz ed such that each featur e takes va lues in [0 , 1] . Competing Methods W e compare the pr oposed approac h ( H D S L ) to sev eral metho ds: • I D E N T I T Y : The stand ard dot product as a baseli ne, which correspon ds to using M = I . • D I A G : Diagona l similari ty learning (i.e., a weighting of the feat ures), as don e in Gao et al. (2 014). W e obtain it by minimiz ing the same loss as in H D S L with ℓ 2 and ℓ 1 reg ulariza tion, i.e., min w ∈ R d f ( w ) = 1 T T X t =1 ℓ h A t , diag ( w ) i + λ Ω( w ) , 2 https://githu b.com/bellet/H DSL 3 http://www.cs ie.ntu.edu.tw/ ˜ cjlin/libsvmt ools/datasets/ 7 Datasets I D E N T I T Y R P + O A S I S PC A + O A S I S D I A G - ℓ 2 D I A G - ℓ 1 H D S L dex ter 20.1 24.0 [1000] 9.3 [50] 8.4 8.4 [773 ] 6.5 [183] doroth ea 9.3 11.4 [15 0] 9.9 [800] 6.8 6.6 [860] 6.5 [731] rcv1 2 6.9 7.0 [200 0] 4.5 [150 0] 3.5 3.7 [52 89] 3.4 [2126] rcv1 4 11.2 10.6 [1000 ] 6.1 [800] 6.2 7.2 [3878] 5.7 [188 8] T able 3: k -NN test error (%) of the similarities learned with each method. The number of feature s used by each similar ity (when smaller than d ) is gi v en in bra cke ts. Best accurac y on each datas et is sho wn in bold. where Ω( w ) ∈ {k w k 2 2 , k w k 1 } and λ is the regulariz ation parameter . Optimization is don e using (proxi mal) gradien t descent. • R P + O A S I S : S imilarity learning in random projected space. Giv en r ≪ d , let R ∈ R d × r be a matrix where each entry r ij is randomly drawn from N (0 , 1) . For each data instance x ∈ R d , w e generat e ˜ x = 1 √ r R T x ∈ R r and use this reduced data in O ASIS (Chechik et al., 2009 ), a fast onlin e method to learn a bi linear similarity from tripl et constrain ts. • P C A + O A S I S : Similarity learning in PCA space. Same as R P + O A S I S , except that PCA is used instead of random proj ection s to project the data into R r . • S V M : Support V ecto r Mach ines. W e use linear SVM, which is known to perform well for sparse hi gh- dimensio nal data (Caruana et al., 2008), with ℓ 2 and ℓ 1 reg ulariza tion. W e also use nonlinear SVM with the polynomial kern el (2nd and 3rd de gree) popu lar in tex t classifica tion (Chang et al., 2010). The SVM models ar e trained us ing liblinear (Fan et al., 2008) and libsvm (Chang and Lin, 2011) w ith 1vs1 paradi gm for multiclass. T raining Procedur e For all similarity learn ing algo rithms, we generate 15 training constraints for each instan ce by identifyin g its 3 targe t neigh bors (nearest neighbors with same label) and 5 impostors (nearest neighb ors with differ ent label ), follo wing W einber ger and Saul (2009). Due to the very small number of trainin g instan ces in dext er , we found that better performanc e is achie ve d using 20 constrain ts per instance x , each of them constructe d by randomly drawing a point from the class of x and a point from a diff erent class. All para meters are tuned using the accur acy on the valida tion set. For H D S L , we use the fa st heurist ic descri bed in Section 3.2.3 and tune the sca le parameter λ ∈ { 1 , 10 , . . . , 10 9 } . The reg ulariza tion parameters of D I AG and S V M are tuned in { 10 − 9 , . . . , 10 8 } and the “aggressi veness” parameter of OASIS is tuned in { 10 − 9 , . . . , 10 2 } . 4.2 Results Classificati on Perf ormance W e first in v estiga te the performance of each similarity learning approach in k -NN classificat ion ( k was set to 3 for all exper iments). F or R P + O A S I S and P C A + O A S I S , we choos e the dimensio n r of the reduce d space based on the accurac y of the learned similarity on the val idation set, limiting our searc h to r ≤ 2000 because O ASIS is extremely slo w beyond this point. 4 Similarly , we use the perfo rmance on v alidati on data to do early stop ping in H D S L , which also has the effe ct of restrict ing the number of feat ures used by the learn ed similarity . 4 Note that the number of P CA dimensions is at most the number of training examples. Therefore, for dexter and dorothea, r is at most 300 and 800 r espectively . 8 Datasets S V M -poly-2 S V M -poly-3 S V M -linear - ℓ 2 S V M -linear - ℓ 1 H D S L dex ter 9.4 9.2 8.9 8.9 [281] 6.5 [183 ] doroth ea 7 6.6 8.1 6.6 [366] 6.5 [731 ] rcv1 2 3 .4 3.3 3.5 4.0 [191 5] 3.4 [2126] rcv1 4 5 .7 5.7 5.1 5.7 [277 0] 5.7 [1888] T able 4: T est err or (%) of se v eral S VM varian ts compared to H D S L . As in T able 3, the nu mber of features is gi ve n in brack ets and best accur acies are sho wn in bold. 0 2000 4000 6000 8000 10000 0 50 100 150 200 250 iteration Number of Selected Features (a) dex ter dataset 0 2000 4000 6000 8000 0 500 1000 1500 2000 iteration Number of Selected Features (b) r cv1 4 dataset Figure 1: Number of act i ve feat ures learned by H D S L as a function of the iterat ion number . T able 3 shows the k -NN classificatio n performanc e. F irst, notice that R P + O A S I S often perfor ms worse than I D E N T I T Y , which is consist ent with pre vious observ ations that a lar ge number of rando m projections may be needed to obtain good performance (Fradkin and Madigan, 2003). P C A + O A S I S giv es much better results , but is generally outpe rformed by a simple diagonal similarity learned directly in the original high- dimensio nal space. H D S L , howe ver , outperfo rms all other algorithms on these data sets, including D I AG . This sho ws the good generaliz ation performa nce of the proposed approach , eve n thoug h the number of trainin g samples is sometimes very small compared to the number of feature s, as in dexter and dorothea. It also shows the relev ance of encodin g “second order” information (pairwise interactio ns between the original feature s) in the simil arity instead of simply con sideri ng a feature weightin g as in D I AG . T able 4 shows the compariso n with SV Ms. Interesti ngly , H D S L with k -NN outperfo rms all S VM v ariants on de xter and dorothe a, both of w hich hav e a lar ge proport ion of irrele vant features. Thi s sho ws that its greedy strate gy and early stopping mechanism achie v es better feature selection and generalizat ion than the ℓ 1 ver sion of linear SVM. On the other two datasets, H D S L is compet iti ve with SVM, althou gh it is outper formed slightly by one v arian t ( S V M -poly-3 on rcv1 2 and S V M -linear - ℓ 2 on rcv1 4), both of which rely on all features. Fea tur e S electio n and Sp arsity W e now focus on the ability of H D S L to perform feature selectio n and more genera lly to learn sparse similarity function s. T o better understand the beha vior of H D S L , we sho w in Figure 1 the number of selected features as a functio n of the iteration number for two of the datasets. Re- member that at most two new features can be add ed at each iteration. Figure 1 sho ws that H D S L incorpo rates many fea tures early on b ut tends to eve ntuall y con ver ge to a modest fraction of features (the same observ a- tion holds for the other two datasets) . This may ex plain why H D S L does not suf fer much from ov erfitting e ven w hen tra ining data is scarc e as in dexte r . 9 (a) dex ter ( 20 , 000 × 20 , 000 matrix, 712 nonzeros) (b) rcv1 4 ( 29 , 992 × 29 , 992 matrix, 5263 nonzeros) Figure 2: S parsity structur e of the matrix M learned by H D S L . Positiv e and negati v e entries are sho wn in blue and red , respecti vely (best seen in color). Another attrac ti ve characte ristic of H D S L is its ability to learn a matrix that is sparse not only on the diagon al but also of f-di agonal (the pro portion of nonzero entries is in the order of 0.0001% for all datasets). In other words, it only relies on a few relev ant pairwise interact ions between features. Figure 2 shows two exa mples, w here we can see that H D S L is able to exploit the product of two features as either a positi ve or neg ati ve contrib uti on to the similarity sc ore. This opens the door to an analysis of the impo rtance of pairs of feature s (for instanc e, word co-occurr ence) for the application at hand. Finally , the extreme sparsit y of the matrices allo w s very fast similarity computat ion. Finally , it is als o wort h noticin g that H D S L uses sig nificantly less fea tures than D I A G - ℓ 1 (see numbers in brack ets in T able 3 ). W e attrib ute this to the extra modeling capability brought by the non-di agonal similarity observ ed in Figure 2. 5 Dimension Redu ction W e now in vestigat e the potential of H D S L for dimen sional ity reduction. Recall that H D S L learns a seque nce of PSD matrices M ( k ) . W e can us e the square root of M ( k ) to pro ject the data into a new space where the dot product is equi v ale nt to S M ( k ) in the original space. The dimension of the projec tion space is equal to the rank of M ( k ) , which is upper bounded by k + 1 . A single run of H D S L can thus be seen as incremen tally buil ding projection spaces of increa sing dimensionali ty . T o assess the dimension ality reduction quality of H D S L (measured by k -NN classificati on error on the test set), we plot its performan ce at v arious iteratio ns durin g the runs that gav e the results in T able 3. W e compare it to two stand ard dimensio nality reduction techniques : random projectio n and PCA. W e also e v aluate R P + O A S I S and P C A + O A S I S , i.e., lea rn a similarity with OASIS on top of the RP and PC A features. 6 Note that OASIS was tuned sepa rately for each pro jectio n size, makin g the comp arison a bit un fair to H D S L . The results are shown in F igure 3. As observ ed earlier , rando m projection- based appro aches achie ve poor 5 Note that H D S L uses roughly the same number of features as S V M -linear- ℓ 1 (T able 4), but dra wing any con clusion is harder because t he objecti ve and training data for each method are dif ferent. Moreov er , 1-vs-1 SVM combines se veral binary models t o deal with the multiclass setting. 6 Again, we were not able to run OASIS beyond a certain dimension due to computational complexity . 10 10 1 10 2 10 3 10 4 5 10 15 20 25 30 35 40 45 50 projection space dimension Error rate HDSL RP RP+OASIS PCA PCA+OASI S Identit y (a) dex ter dataset 10 1 10 2 10 3 10 4 5 10 15 20 25 30 35 40 projection space dimension Error rate HDSL RP RP+OASIS PCA PCA+OASI S Identit y (b) dorothea dataset 10 1 10 2 10 3 10 4 5 10 15 20 25 30 35 40 projection space dimension Error rate HDSL RP RP+OASIS PCA PCA+OASI S Identit y (c) rcv1 2 dataset 10 1 10 2 10 3 10 4 5 10 15 20 25 30 35 40 projection space dimension Error rate HDSL RP RP+OASIS PCA PCA+OASI S Identit y (d) r cv1 4 dataset Figure 3: k -NN test error as a functio n of the dimensiona lity of the spac e (in log scale) . Best seen in color . perfor mance. When the feature s are not too noisy (as in rcv1 2 and rcv1 4), PCA-based methods are better than H D S L at compres sing the space into very few dimensions, b ut H D S L ev entual ly catch es up. On the other hand, PCA suf fers heavi ly from the presence of noise (dext er and dorothea), while H D S L is able to quickl y improv e upon the standard similarity in the original space. Finally , on all datasets, we observe that H D S L con v er ges to a station ary dimension without ove rfitting, unlike P C A + O A S I S which exhibit s signs of ov erfitting on dexter and rcv1 4 espe cially . 5 Conclusion In this work, we propos ed an efficien t approach to learn similarity functions from high-dimen sional sparse data. This is achie v ed by forming the similarit y as a combination of simple sparse basis elements that operat e on only two features and the use of an (approxi mate) F rank-W olfe algorith m. Experiments on real- world datasets confirmed the robu stness of the approach to noisy features and its usefulness for classificati on and dimensionali ty reduc tion. T ogether with the extr eme sparsity of the learned similarity , this makes our approa ch potentiall y useful in a v ariety of other conte xts, from data explorat ion to clustering and rankin g, and more gene rally as a way to preprocess the data before apply ing any learnin g algorithm. 11 Acknowledgments This work was in part supported by the Intelligence Adv anced Research Projects Ac- ti vity (IARP A) via Department of Defense U.S . Army Research Laboratory (DoD / A RL) contract num- ber W911NF-12-C-0012 , a NSF IIS-1065243 , an A lfred. P . Sloan Research Fello wship, D ARP A awar d D11AP00278, and an ARO YIP A ward (W911NF-12-1-0 241). The U.S. G ov ernmen t is authorized to re pro- duce and distrib ute reprints for G ov ernmen tal purpose s notwithsta nding an y copyrig ht annotation thereo n. The views an d conc lusions contain ed herein are thos e of the authors and sh ould not be interpre ted as neces- sarily rep resent ing the of ficial pol icies or endorse ments, either expre ssed or implied, of IARP A, DoD/ARL, or the U.S. Go vern ment. Refer ences Aur ´ elien Bellet , Amaury Habrard, and Marc Sebban. A Surve y on Metric Learn ing for F eature Vectors and Structure d Data. T echnical repo rt, arXiv:13 06.670 9, June 2013. Deng Cai and Xiaofei He. Manifold Adapti v e Experimental Design for Text Categor ization . TKDE , 24(4) : 707–7 19, 2012. Qiong Cao, Y iming Y ing, and P eng Li. Distance Metric L earning Rev isited. In EC ML/PKDD , pag es 283– 298, 2012 . Rich C aruana, Nikolaos Karampatziakis , and Ainur Y essenalin a. An empiric al e v aluat ion of superv ised learnin g in high dimensions. In ICML , pages 96–10 3, 2008. Chih-Chun g Chang and Chih-Jen Lin. LIBSVM : a library for support ve ctor machines. ACM T IST , 2(3): 27–27 , 2011. Y in-W en Chang, Cho-Jui Hsieh, Kai-W ei Chang, Michael Ringgaar d, and Chih-Jen Lin. Training and Testing Lo w-de gree Polynomial Data Mapp ings via Linear SVM. JMLR , 11:1471–14 90, 2010. Gal Chechik, Uri Shalit, V aru n Sharma, and Samy Bengio. A n online algorithm for larg e scale image similarit y learning. In NIPS , pages 306– 314, 2009. Ken neth L. Clark son. Coreset s, sparse greedy ap proximat ion, and the Frank- Wolfe algorithm. ACM T ran s- action s on Algorithms , 6(4):1– 30, 2010. Jason V . Dav is, Brian Kulis, Prateek Jain, Suvrit Sra, and Inderjit S . Dhillon. Informat ion-the oretic m etric learnin g. In ICML , pages 209–2 16, 2007. Rong-En Fan, Kai-W ei Chang, Cho-Jui Hsieh, Xiang-Rui W ang, and Chih-Jen Lin. LIBLIN E AR: A L ibrary for Lar ge Linear Classifica tion. JMLR , 9:1871 –1874 , 2008. Dmitriy Fradk in and Da vid Madigan. E xperimen ts with rand om projecti ons for machine learn ing. In KDD , pages 517–5 22, 2003. Mar guerit e Frank and Philip W olfe. An algori thm for quadrat ic programming. Nava l Resear c h Logis tics Quarterl y , 3(1-2):95–1 10, 1956. Robert M. Freund and Paul Grigas. Ne w Analysis and Results for the Conditiona l Gradient Method. T ech- nical repo rt, arXiv:1 307.087 3, 2013. 12 Xingyu Gao, S te ven C.H. Hoi, Y o ngdon g Z hang, Ji W an, and Jintao Li. SO M L: Sparse Online Metric Learning with Appli cation to Image Retrie v al. In A AAI , pages 12 06–12 12, 2014. Jacob Goldbe r ger , Sam Roweis, Geof f Hinton, and Ruslan Salakhu tdino v . Neighb ourhoo d Components Analysis . In NIPS , pages 513–5 20, 2004. Jacque s Gu ´ elat and Patrice Marco tte. Some comments on Wolf e’ s away step. Mathematical Pr og ramming , 35(1): 110–1 19, 1986 . Matthieu Guillaumin, Jakob J. V erb eek, and Cordelia Schmid. Is that you? Metric learning approaches for face identification. In ICCV , pages 498–5 05, 2009. Isabel le Guyon, Stev e R. Gunn, Asa Ben-Hur , and Gideon Dror . R esult Analysis of the NIPS 2003 Feature Selection Challen ge. In NIPS , 2004. Martin Jagg i. Sparse Con vex Optimizati on Methods for Machin e Learning . PhD thesis , ETH Zurich, 2011. Martin Jagg i. Revisit ing Frank-Wolfe: Projection-Fre e Sparse Con vex Optimiz ation. In ICML , 2013. Dor Kedem, Stephen T yree, Kilian W einber ger , F ei Sha, and Gert L anckriet. Non-lin ear Metric L earning. In NIPS , page s 2582–2 590, 2012. Brian Kulis. Metric Learning: A Surv ey . Found ations and Tr ends in Machine Learning , 5(4):287–3 64, 2012. Daryl K. Lim, Brian McFee, and Gert Lanckriet. Rob ust Structu ral Metric Learning. In ICML , 20 13. Guo-Jun Qi, Jinhu i T ang, Zheng-Jun Zha, T at-Seng C hua, and Hong-Jia ng Zhang. An E f ficient Sparse Metric Learning in High-Dimension al Space via l1-Penalized L og-Deter minant R egu larizat ion. In ICML , 2009. Qi Qian, Rong Jin, S hengh uo Zhu, and Y uanq ing Lin. An Inte grated Framewor k for High Dimensional Distance Metric Learning and Its Applicati on to Fine-Graine d V isual Categoriza tion. T echnical report, arXi v:140 2.0453, 2014. Romer Rosales and Glenn Fung. Learning Sparse Metrics via L inear Programming. In KDD , pages 367– 373, 2006 . Matthe w Schultz and T horsten Joac hims. Learning a Distance Metric from R elati ve Compari sons. In N IPS , 2003. Robert J. Serfling. Probability inequaliti es for the sum in sampling w ithout replacement. The Annals of Statis tics , 2(1):39–48, 1974. Chunhua Shen, Junae Kim, Lei W ang, and Anton van den Hengel. Positi v e Semidefinite Metric Learning Using Boostin g-lik e Algorithms. JMLR , 13:1 007–1 036, 2012. Y u an Shi, Aur ´ elien Bellet, and Fei Sha. Sparse Compositiona l Metric Learning. In AA AI , pages 20 78–20 84, 2014. Jun W ang, Adam W oznica, an d Ale xand ros Kalousis . Parametric Local Metric Learning for Nearest Neigh- bor Classificat ion. In NIPS , pages 1610 –1618 , 2012. 13 Kilian Q. W einber ger and Lawre nce K. Saul. Distance Metric Learnin g for Lar ge M ar gin Nearest Neighbor Classificati on. JMLR , 10:207–2 44, 2009. Y iming Y ing and Peng Li. Distan ce Metric Learning w ith Eigen value Optimizat ion. JMLR , 13 :1–26 , 2012. Y iming Y ing, Kaizhu H uang, and Colin Campbell. Sparse Metric Learning via Smooth Optimization . In NIPS , pag es 2214–222 2, 2009. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment