Competitive Multi-Agent Deep Reinforcement Learning with Counterfactual Thinking
Counterfactual thinking describes a psychological phenomenon that people re-infer the possible results with different solutions about things that have already happened. It helps people to gain more experience from mistakes and thus to perform better …
Authors: Yue Wang, Yao Wan, Chenwei Zhang
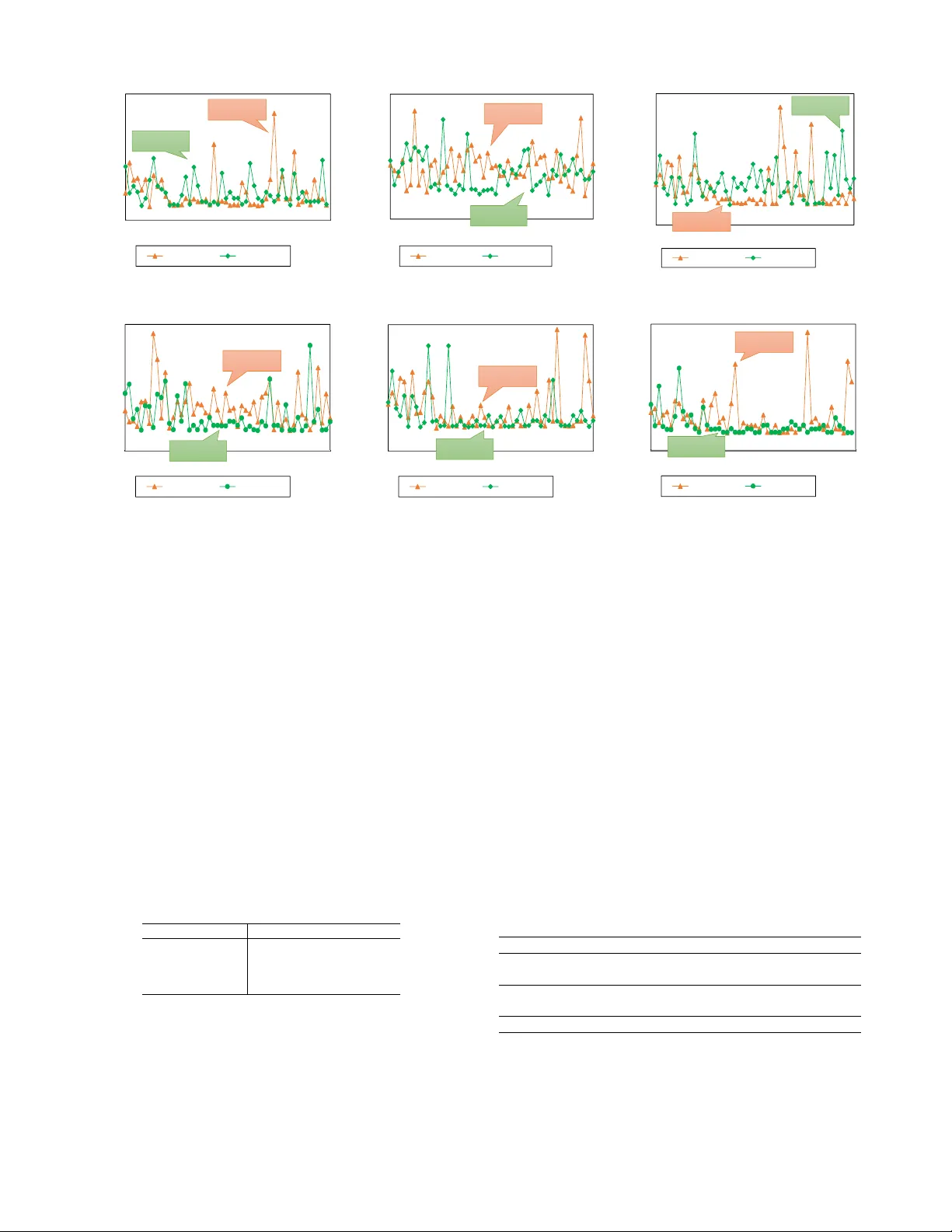
Competiti v e Multi-Agent Deep Reinforcement Learning with Counterfactual Thinking Y ue W ang 1 , 2 , Y ao W an 3 , Chenwei Zhang 4 ∗ , Lixin Cui 1 , 2 , Lu Bai 1 , 2 † , Philip S Y u 5 1 School of Information, Central Univ ersity of Finance and Economics, Beijing, P . R. China Email: { wangyuecs,bailucs,cuilixin } @cufe.edu.cn 2 State Ke y Laboratory of Cognitive Intelligence, iFL YTEK, Hefei, P . R. China 3 Department of Computer Science, Zhejiang Univ ersity , Hangzhou, P . R. China Email: wanyao@zju.edu.cn 4 Amazon, Seattle, USA Email: cwzhang@amazon.com 5 Department of Computer Science, Univ ersity of Illinois at Chicago, Chicago, USA Email: psyu@uic.edu Abstract —Counterfactual thinking describes a psychological phenomenon that people re-infer the possible r esults with dif- ferent solutions about things that hav e already happened. It helps people to gain more experience from mistakes and thus to perform better in similar future tasks. This paper in ves- tigates the counterfactual thinking f or agents to find optimal decision-making strategies in multi-agent reinf orcement learning en vironments. In particular , we pr opose a multi-agent deep reinf orcement learning model with a structur e which mimics the human-psychological counterfactual thinking pr ocess to impro ve the competitive abilities for agents. T o this end, our model generates se veral possible actions (intent actions) with a par- allel policy structure and estimates the rewards and regrets for these intent actions based on its current understanding of the en vironment. Our model incorporates a scenario-based framework to link the estimated regrets with its inner policies. During the iterations, our model updates the parallel policies and the corresponding scenario-based regr ets for agents simul- taneously . T o v erify the effectiveness of our pr oposed model, we conduct extensiv e experiments on two different en vironments with real-world applications. Experimental results show that counterfactual thinking can actually benefit the agents to obtain more accumulative rewards from the en vironments with fair information by comparing to their opponents while keeping high performing efficiency . Index T erms —Multi-agent, reinf orcement lear ning, counterfac- tual thinking, competiti ve game I . I N T R O D U C T I O N Discov ering optimized policies for indi viduals in complex en vironments is a pre valent and important task in the real world. For example, (a) traders demand to explore competiti ve pricing strategies in order to get maximum re venue from markets when competing with other traders [1]; (b) network switches need optimized switching logic to improve their com- munication ef ficiency with limited bandwidth by considering other switches [2]; (c) self-dri ving cars require reasonable and robust driving controls in complex traf fic en vironments with other cars [3]. ∗ W ork done while at Univ ersity of Illinois at Chicago † Lu Bai is corresponding author (email: bailucs@cufe.edu.cn). Environmen t Agent a sr a=μ(s) Customers Senseandavoidcollision Competeformor emarketshar e RL process Fig. 1: Explore and exploit the environments as RL processes. The core challenge raised in aforementioned scenarios is to find the optimized action policies for AI agents with lim- ited kno wledge about en vironments. Currently , many existing works learn the policies via the process of “exploration- exploitation” [4] which exploits optimized actions from the known en vironment as well as explores more potential ac- tions on the unknown en vironment. From the perspectiv e of data mining, this “e xploration-exploitation” process can be considered as discov ering the “action-state-rew ard” patterns that maximize total re wards from a huge exploring-dataset generated by agents. There is a more complex situation that the en vironment may consist of multiple agents and each of them needs to compete with the others. In this scenario, it is imperativ e for each agent to find optimal action strategies in order to get more rewards than its competitors. An intuitive solution is to model this process as a Marko v decision process (MDP) [5] and try to approach the problem by single-agent reinforcement learning, without considering the actions of other agents [6]. Figure 1 shows a schema of the process of reinforcement learning on two specific tasks, i.e., self-driving and marketing. Reinforcement learning aims to train agents to find policies which lead them to solve the tasks they do not have complete prior knowledge. Under the RL frame work, an agent policy (i.e., µ ( s ) in Figure 1) is a probabilistic distribution of actions for the agent which is related to its observation or state for an en vironment. When an agent (i.e., car or trader) observes a new en vironment state, it performs an action and obtains a rew ard. The RL training for agents is a greedy iterativ e process and it usually starts with a randomized exploration which is implemented by initializing a totally stochastic policy and then re vising the policy by the receiv ed rew ards at each iteration. The RL explores the policy space and fav ors those policies that better approximate to the globally optimal policy . Therefore, theoretically , by accumulativ ely exploring more policy subspaces at each iteration, the probability to get a better policy of an agent is increasing. Challenges. Howe ver , the traditional single-agent reinforce- ment learning approaches ignore the interactions and the decision strategies of other competitors. There are mainly two challenges to extend the reinforcement learning from single- agent to multi-agent scenarios. (a) Optimize action policy among competitors. Generally , the single-agent reinforcement learning method (SRL) only optimizes the action policy for a specific agent. SRL does not model the interactions between multiple agents. Consequently , it challenges a lot when using SRL to optimize the action policy for a specific agent among a group of competitors simultaneously . (b) Learn action pol- icy based on sparse feedbacks. Since history nev er repeats itself, historical data only record feedbacks sparsely under the actions which hav e already happened, it challenges a lot to effecti vely learn optimized policies from historical data with sparse “action-state-re ward” tuples. (c) Infer the counterfactual feedbacks. One solution to the sparse feedbacks issue is to infer the counterfactual feedbacks for those historical non- chosen optional actions which have the potential to improve the learning efficienc y for agent action policies. Howe ver , it still remains a challenge to counterfactually infer the possible feedbacks from an en vironment when an agent performs different optional actions at the same historical moment. Currently , many existing works hav e applied the multi- agent deep reinforcement learning framew ork to mitigate the issues in en vironments with sev eral agents. Howe ver , most of them [7] [8] [9] still do not incorporate the counterf actual information contained in the history observation data which could further improv e the learning efficienc y for agents. Our Solutions and Contributions. T o address the aforemen- tioned challenges, in this paper , we formalize our problem as the competitiv e multi-agent deep reinforcement learning with a centralized critic [8] and improv e the learning ef- ficiency of agents by estimating the possible rew ards for agents based on the historical observation. T o this end, we propose a CounterFactual Thinking agent (CFT) with the off-polic y actor-critic framework by mimicking the human- psychological acti vities. The CFT agent w orks in the follo wing process: when it observes a new en vironment state, it uses sev eral parallel policies to develop action options or intents, for agents and estimates returns for the intents by its current understanding for the environment through regrets created by previous iterations. This is a similar process as the psycholog- ical activity that people reactiv e choices resulting from one’ s own e xperience and en vironment [10]. W ith the estimated returns, the CFT agent chooses one of the policies to generate its practical actions and recei ves new regrets for those non- chosen policies by measuring the loss between the estimated returns and practical rew ards. This also mimics the human- psychological acti vities that people suffer regrets after making decisions by observing the gap between ideal and reality . Then the receiv ed regrets help the CFT agent to choose the policies in the next iteration. It is worth mentioning that the proposed CFT agent is also more ef fectiv e than existing multi-agent deep reinforcement learning methods during the training process since the parallel policy structure helps CFT agents to search from a wider range of policy subspaces at each iteration. Therefore, it could also be more informative than other related methods in multi-agent en vironments. W e apply the CFT agent to sev eral competitive multi-agent reinforcement learning tasks (waterworld, pursuit- ev asion [11]) and real-world applications. The experimental result shows the CFT agents could learn more competiti ve action policy than other alternativ es. In summary , the main contributions of this paper can be summarized as follows: • W e study the problem of competing with each other in a multi-agent en vironment with a competitive multi- agent deep reinforcement learning frame work. W ithin this framew ork, we define the competitiv e ability of an agent as the ability to explore more policy subspaces. • W e propose the counterfactual thinking agent (CFT) to enhance the competiti ve ability of agents in multi-agent en vironments. CFT generates several potential intents through parallel polic y structure and learns the corre- sponding regrets through the difference between esti- mated returns and practical re wards. The intent generation and regret learning process supervise each other with a max-min process. • W e demonstrate that CFT agents are more effecti ve than their opponents both in simulated and real-world en vironments while k eeping high performing ef ficiency . This sho ws that counterfactual thinking mechanism helps agents explore more policy subspaces with the same iterations than other alternativ es. Organization. The remainder of this paper is or ganized as follows. In Section II, we introduce some background knowl- edge on multi-agent reinforcement learning. In Section III, we first gi ve an overvie w of our proposed frame work and then present each module of our proposed framew ork in detail. Section IV describes the datasets and en vironments used in our experiment and shows the experimental results and analysis. Section V highlights some works related to this paper . Finally , we conclude this paper and gi ve some future research directions in Section VI. I I . P R E L I M I N A R I E S When an agent tries to maximize its interests from an en vironment, it must consider both the reward it receives after each action and feedbacks from the en vironment. This could be simplified as a Marko v decision process (MDP) and use reinforcement learning methods to search the optimal action policy [12]. In our scenario, since our problem relates to the interaction between sev eral agents, a natural way to explore this problem is to use an N -agents MDP [11]. In this section, we first introduce some background knowledge about multi-agent reinforcement learning and then mathematically formularized the problem studied in this paper . A. Multi-Agent Reinfor cement Learning F rame work In this paper , we consider a multi-agent extension of MDP named partially observable Markov games [13]. A Markov game for N agents is defined by a set of states S describing the possible configurations of all agents, a set of actions, A 1 , A 2 , . . . , A N , a set of states S which represents the ob- served environment settings of all agents and a state transition function T . T : S × A 1 × A 2 × . . . × A N 7→ S , (1) where each agent i ( i = 1 , 2 , 3 , . . . , N ) gets rewards as a function of the state and its action r i : r i : S × A i 7→ R . (2) The policy for each agent i is a probabilistic distribution which is defined as: π i ( a, s | θ ) 7→ [0 , 1] , (3) where for ∀ a ∈ A i and ∀ s ∈ S . The target for each agent i is to maximize its own accumulated expectation reward R i : R i = ∞ X t =0 γ t r t i , (4) where 0 < γ < 1 is a discount factor . W e adjust our setting by omitting the mapping from states to agent observations. This allows us to compare the competitiv e abilities of agents with dif ferent action policies under the same state information simultaneously . B. T emporal Differ ence Learning Many MDP problems are often solved by multi-agent re- inforcement learning (MARL) [14]. Since a real-world ap- plication contains more factors than agents could observe, we discuss our problem in the stochastic en vironment [15] with model-free methods. Monte Carlo and temporal differ - ence learning (TD) are often used model-free methods to deal with reinforcement learning (RL) problems. Furthermore, since real-world applications are usually continuous without terminate states, we use TD methods to study the MARL problem in this paper . The mainstream TD methods to learn the optimal policies for RL problems are categorized into value-based, policy- based [16] and combined methods (consider both the value and policy optimization). The representativ e methods include Q-learning [17], policy gradient algorithms (PG) [18], and actor-critic algorithms [19]. All these methods relates to two important notations: the value (V) function and action-value (Q) function [20]. If we let the agent optimize its policy independently , the V and Q function for agent i are denoted as follows. V π i ( s ) = E [ R 1 i | s 1 = s ; π ] , (5) Q π i ( s, a ) = E [ R 1 i | s 1 = s, A 1 i = a ; π ] , (6) where R t i can be obtained by: R t i = γ 0 r i ( s t , a ) + γ 1 r i ( s t +1 , a ) + γ 2 r i ( s t +3 , a ) + .... (7) It is the total discounted reward from time-step t for agent i . Intuitionally , V π i ( s ) refers to the re ward expectation of agent i for state s and Q π i ( s, a ) represents the rew ard expectation of agent i when it taking action a at state s . C. Appr oximate Q and V with Deep Neural Networks In order to solve the combinatorial explosion problem [21] in ev aluating policies under high state or action dimensions, recent methods apply deep neural networks to estimate V and Q functions. This lead to the flourishing of deep reinforcement learning methods (DRL). The current popular DRL methods include Deep Q-Network (DQN) [22] and Deep Deterministic Policy Gradient (DDPG) [23]. DQN is the deep learning e xtension of Q-learning. It follo ws the v alue-based way and learns the Q-function with deep neural networks. Since DQN usually needs discrete candidate actions, and it may suf fer non-stationary problems under multi- agent settings [8], it is rare to use DQN in problems with continuous action spaces. DDPG is a deep reinforcement learning method which combines a policy estimation and a value computation process together . It originates from PG [18] which models the perfor- mance of policy for agent i as J ( θ i ) = E s ∼ ρ π i ,a ∼ π i ( R i ) . Then the gradient of the policy for agent i is obtained by: ∇ J ( θ i ) = E s ∼ ρ π i ,a ∼ π θ i i [ ∇ θ i log π i ( a, s | θ i ) Q i ( s, a | θ i )] , (8) where ρ π i is the state distribution for agent i by exploring the policy space with policy π i . Since computing PG requires to integrate ov er both state and action spaces, PG suffers from the high variance problem [8] and needs more samples for training. Deterministic policy gradient (DPG) [20] alleviates this problem by providing a continuous policy function a = µ ( s | θ i ) for agent i . This change av oids the integral over the action space. With function µ ( s | θ i ) , the gradient of DPG for agent i can be written as: ∇ J ( µ θ i ) = E s ∼ ρ µ [ ∇ θ i µ ( s | θ i ) ∇ a Q i ( s, a | θ i ) | a = µ ( s | θ i ) ] . (9) Since DPG only integrates ov er the state space, it can be estimated more efficiently than stochastic polic y gradient algorithms [20] . As a deep learning extension of DPG, by applying the off- policy actor-critic framew ork, DDPG [23] uses a stochastic behavior policy β with noise in Gauss distribution to explore the state space ρ β and a deterministic target policy to approxi- mate the critic policy . By learning the Q-values through neural networks, the gradient of agent i in DDPG then becomes: ∇ J ( θ µ i ) = E s t ∼ ρ β i [ ∇ θ µ i µ ( s t | θ µ i ) ∇ a Q i ( s, a | θ Q i ) | a = µ ( s t | θ µ i ) ] , (10) where θ Q i and θ µ i are parameters for the target and current policy neural network respectiv ely . During the training pro- cess, DDPG uses a replay buf fer D to record the “state-action- rew ard” tuples obtained by the exploration policy β and then optimizes the parameters for the current neural network by drawing sample batches from D . W ith a trained current policy neural network, it updates the target policy neural network by a soft-updating method. This frame work stabilizes the learning process and av oids the large variance problem in the original policy gradient methods and its deterministic action outputs are useful in continuous control RL problems. Therefore, DDPG has successfully applied in the MARL [8] problems and our model follo ws the similar off-polic y actor-critic frame work as DDPG. D. Compete in N -Agent MDP In this paper , we aim to extend the reinforcement learning from single-agent to multi-agent settings in a competitiv e en vironment. In order to mak e all agents compete with each other in an en vironment, we redefine the Q-values for all agents as the following equation. Q π i ( s t , a ) = γ Q π i ( s t +1 , a ) + r 0 i ( s t , a ) , ( i = 1 , 2 , ..., N ) , (11) where r 0 i ( s t , a ) is a revised rew ards which is denoted as: r 0 i ( s t , a ) = (1 − α ) r i ( s t , a ) + α − r ˆ i ( s t , a ) N − 1 . (12) In Equation 12, r ˆ i ( s t , a ) is the total rew ards of all other agents than i ; The weight α ( 0 ≤ α < 1 ) decides the ratio to consider the rewards of others for agent i . Therefore, the weight of α controls the degree of competition among all agents. e.g. when α > 0 . 5 , the related agents care its own future re wards more than other the re wards of its other competitors. W ith all agents maximizing the Q-values computed by Equation 11, a multi-agent en vironment becomes a more competitiv e environment than it is used to be. I I I . C O U N T E R FAC T U A L T H I N K I N G A G E N T I N M U LT I - A G E N T R E I N F O R C E M E N T L E A R N I N G Inspired by a psychological phenomenon, named counter- factual thinking, that people re-infer the possible results with different solutions about something that has already happened, this paper proposes to introduce a counterfactual thinking mechanism for an agent in a multi-agent environment. W e argue that it may help people to gain more experience from mistakes and thus to perform better in similar future tasks [24]. A. An Overview As shown in Figure 2, our counterfactual thinking agent consists of a counterfactual thinking actor and a counterfac- tual thinking critic. Different from the previous actor-critic works [8], our CFT agent generates sev eral candidate actions by following its parallel policies when encountering a new state. Then, it chooses one of the candidate actions with its experience (historical regrets for parallel policies) to the en vironment. This mimics the beha vior when a human seeking additional options before making decisions [25]. Finally , the CFT agent re vises its polices and the related re grets by e valuat- ing the candidate actions with its current critic simultaneously . The experiment results show that this mechanism could bring more accumulative re ward within the same episode for agents and thus make the related agents more competitiv e than their competitors. W e will elaborate each module in detail in the following subsections. B. Counterfactual Thinking Actor A counterfactual thinking actor runs in the follo wing pro- cess. It first matches the current encountered state into a specific scenario which belongs to the results of a state clus- tering process. Then it dev elops a few intents from K parallel policies according to the matched scenario. Finally , it outputs both the minimum-regret action and all candidate actions to the en vironment and critic. W ith the Q-value estimated by the critic, the actor updates its re grets about the candidate policies. Concretely , we define the related notations for a counterfactual thinking actor as the followings. Counterfactual Thinking Actor . A counterfactual thinking (CFT) actor has K parallel policies µ i ( i = 1 , 2 , ..., K ), where each policy associates to a regret m k,l ( m k,l ∈ [0 , 1] ) under the l -th scenario. A counterfactual thinking actor generates K intents µ i ( s ) . T o reduce the variance of the actions which are generated by counterfactual thinking actor , we combine a clustering process to the forward computation of the counterfactual thinking actor . As it is shown in Figure 2 (b), we use a clustering method to divide the encountered states of a counterfactual thinking actor to sev eral clusters (named “scenarios”). And then, every time our actor encounters a new state, it will check the clustering results to find the most related scenario and associates its policies with the corresponding regrets τ i s for that scenario. In order to implement the parallel policy structure for coun- terfactual thinking actors, we propose the K -parallel policy layer in our actor which generates se veral intent actions with a giv en state. K -Parallel P olicy Layer . A K -parallel policy layer contains a R K ×| g ( s ) |×| a | tensor C = { C 1 , C 2 , ..., C K } where C k is a R | g ( s ) |×| a | matrix ( k = 1 , 2 , ..., K ). The input for a K -parallel policy layer is a R | g ( s ) | vector which represents an observed state. Its output includes K vectors which represents K intent actions or linear transformation of the intent actions. They can be computed as follows: I k = g ( s ) × C k , for k = 0 , 1 , 2 , 3 , . . . , K. (13) K -parallel policy layer generates K intent actions where I k is the k -th intent action; s is the current state; g ( s ) is a function which can be extended to several linear transformations or other neural layers. After obtaining K intent actions, we utilize a data structure named scenario-regret matrix to e valuate the parallel policies. Envir onment CFT Actor 1 CFTCritic 1 Actor 2 Critic 2 a 1 s a 2 s a 1, I 1 ,…,I K a 2 a 2 a 1 Q 1 Q 2 m :,l s s r 1 r 2 Counterfactualagen t Normalagent (a) Framework. Linear Linear s t Clustering [ s 1 ,s 2 ,s 3 …s m ] T Scenario matcher Counterfa ctual decisionmaker K ‐parallelpolicy Inten tactions I 1 ,I 2 ,…I K a i Linear …… Reg ret s m :,l Scenario l (b) Counterfactual thinking actor . s,a 1 ,a 2 ,…,a i ,… a n Hypothesis inferring Intentactions I 1 ,I 2 ,…I K Max‐based evaluating Q(s,a 1 ,…,a i ,… a n ) Regre ts m :,l (c) Counterfactual thinking critic. Fig. 2: The framew ork counterfactual actor-critic reinforcement learning, where a i is the action of the i -th agent (the i -th agent is a counterfactual thinking agent) and m : ,l is the regret distribution for the l -th scenario. Scenario-Regret Matrix. A scenario-regret matrix M = { m k,l } K × L is a R K × L matrix which records the regret values for K policies under L dif ferent scenarios. m k,l refers to the prior regret value for the k -th policy under the l -th scenario. W e get the scenarios through the aforementioned clustering process toward all encountered states by the actor . During the forward computation of the counterfactual thinking agent, ev ery time a new state is observed, the actor first matches the state to a scenario (with the scenario matcher in Figure 2 (b)) and then outputs the intent with the minimum regret as the final action. The scenario matcher can be implemented by an y kind of similarity computation. The scenario-regret matrix is randomly initialized at first and then learned by receiving the regrets updated by the critic. The final output of a counterfactual thinking actor can be obtained through Algorithm 1. The SOFTMIN function [26] Algorithm 1: Forward computing for a CFT actor Data: state s , random degree Result: action a 1 begin 2 Initialize the scenario-regret matrix M randomly . 3 Generate a set of K intent actions I with a K -parallel policy layer . 4 Match the state s to the l -the scenario. 5 W ith probability : 6 Output one of intent in I as a with the probabilistic distribution of SOFTMIN( M ). 7 W ith probability (1 − ) : 8 Output a = P k ∈ [1 ,K ] m k,l I k . 9 end in Algorithm 1 is an opposite operation to SOFTMAX which giv es the policy with the minimum regret with the biggest weight. The random degree controls the ratio of Algorithm 1 to generate an action based on random sampling. Line 5-8 is the implementation for the “counterfactual decision maker” in Figure 2 (b). The counterfactual thinking actor is trained by the objectiv e function. arg max θ µ i q i , (14) where q i is computed by the current critic neural network with the state s and the outputted a from the CFT actor . θ µ i is the parameters for the neural network of a CFT actor . Intuitiv ely , this process revises the parameter θ µ i for CFT actor to get the maximized q i at each iteration. C. Counterfactual Thinking Critic The critic in our model has two simultaneous tasks during the forward process: compute the Q-v alue and update the scenario-regret matrix for the counterfactual thinking actor . W e discuss how this is implemented in this section. Counterfactual thinking critic. A counterfactual thinking critic computes the Q-values for all K intent actions gen- erated by the counterfactual thinking actor . By computing the maximum Q-value for all K actions, it calculates the regret value for each intent actions. Since the counterfactual thinking critic is a centralized critic, it also uses actions of all agents to ev aluate Q-values. T o compute maximum Q-value by considering all intent actions for an agent, we define the following notation. Counterfactual Q-value. In a multi-agent Markov game, if the i -the agent applies the counterfactual thinking mechanism (which means it uses the counterfactual thinking actor and critic), s is the current state. The counterfactual Q-value q i k can be obtained by Equation 6 with the current Q network. q k i = Q ( s, a 1 , a 2 , ..., I k i , ..., a N ) , (15) where a 1 , a 2 , ..., a i − 1 , a i +1 , ..., a N are the actions of other N − 1 agents in a multi-agent environment at this iteration. In Equation 15, the action for the i -th agent is replaced by ev ery intent action of the K intent actions obtained by its counterfactual thinking actor . For each iteration, our critic outputs the maximum coun- terfactual Q-value max( q i ) of all q k s ( k = 1 , 2 , ..., K ) for the i -th agent. W ith max( q i ) , the posterior regrets for the i -th agent under the l -th scenario are computed by the follo wing equation. m ∗ k,l = max( q i ) − q k i , (16) where k = 1 , 2 , ..., K . Then the objectiv e function for a counterfactual thinking critic of the i -th agent is: arg min θ q i ,m : ,l ( λ | q t − 1 i − q t i | 2 n + (1 − λ ) K L ( m : ,l , m ∗ : ,l )) , (17) where q t − 1 i is the current Q-value computed by Algorithm 2 and q t i is the target Q-value which can be computed by Equation 11. The KL function is the KL-div ergence which compares the dif ference between the prior and posterior regret distribution m : ,l and m ∗ : ,l for all K intent action of the i -th agent. Algorithm 2: Forward computing for a CFT critic Data: state s , practical action a , an intent actions set I Result: q i t − 1 and m ∗ : ,l 1 begin 2 Compute the q i t − 1 by the current Q-neural-network with s and a . 3 Compute the q k i for each intent I k generated by CFT actor . 4 Find the maximum Q-value max( q i ) of all q k i s. 5 Compute regrets m ∗ : ,l for all intents by Eq. (15) under the l -th scenario. 6 Output q i t − 1 and m ∗ : ,l . 7 end In Algorithm 2, Line 3 corresponds to the “Hypothesis infer - ring” and Line 4-5 corresponds to the “Max-based ev aluating” in Figure 2 (c) respectiv ely . D. End-to-End T raining Our CFT agent consists of a counterfactual thinking actor and a counterfactual thinking critic. Since both the forward processes of them are differentiable, we train this model with the back-propagation methods with an Adam [27] optimizer . The training for CFT agents is a max-min process [28] which maximizes the Q-value for the actor with current critic and minimizes the difference between the current and tar get critics. Since the CFT actor and critic are linked by a scenario-regret matrix, during the training process, the actions outputted by the CFT actor are weighted by the scenario-regret matrix learned by last iteration and the CFT critic revises the scenario-regret matrix with its forward process. I V . E X P E R I M E N T S A N D A NA LY S I S T o v erify the ef fectiv eness of our proposed CFT , we con- duct experiments on two standard multi-agent en vironments with real-world applications. Overall the empirical results demonstrate that the CFT e xcels on competiti ve multi-agent reinforcement learning, consistently outperforming all other approaches. A. Compar ed Baselines The comparison methods of this work are MADDPG [8], CMPG [9] and our counterfactual thinking agent (CFT). • MADDPG is the state-of-the-art method about the multi- agent deep reinforcement learning. Since our model is based on the similar off-polic y actor-critic frame work as MADDPG, the comparison of MADDPG and our model can directly tell us whether the proposed counterfactual mechanism improves the competitiv e ability for an agent. • CMPG uses historical actions of agents as the estimated intents to enhance the stability of the learning process for the actor-critic framew ork. Since CMPG is the latest methods which improv e the learning ef ficiency for RL problems with a counterfactual style method, we also compare our model with it. B. En vir onment 1: Multi-Agent W ater-W orld (MA WW) Problem Background. This is a multi-agent version pursuer and e vader game in a simulated underwater en vironment which is provided in MADRL [29]. Sev eral pursuers are co-existing to purchase some ev aders in an en vironment with floating poison objects and obstacles. Ev ery time a pursuer captures an e vader , it recei ves +10 reward. What’ s more, the pursuer receiv es -1 rew ard when it encounters a poisoned object. This en vironment can be used to research the mix ed cooperati ve- competitiv e behaviors between agents. T raining Setup. W e set the scenario number to 16 and the number of intent actions K to 4. Furthermore, since our method is based on the off-policy actor-critic framework, we set the exploration episode to 10 for each testing belo w . This means that the policies for all agents are optimized after the 10 th episode. Results. In this experiment, we add two pursuers to compete in a water world environment with 50 ev aders and 50 poison objects. T o compare the competiti ve ability for each mentioned method, we set one of the pursuers as a CFT or CMPG agent, the others as DDPG agents. Furthermore, we also compare the competitive abilities of CFT and CMPG. As it is sho wn in Figure 3 (a), the rewards for two same DDPG agents are almost the same. This means that there is no difference between the competitive abilities of two DDPG agents. W e further analyze the results in Figure 3 (b) and (c) and discover that the CFT agent recei ves significant more rewards than its DDPG based competitors. Figure 3 (d) and (e) present that CMPG can also improve the competitiv e abilities for an agent in this task. Figure 3 (f) compares the competiti ve abilities for CFT and CMPG agent directly , the result shows that CFT agent can be more competitiv e than the CMPG agent. In addition, we analyze the means and standard deviations of rew ards in all cases in Figure 2. The results are listed in T able 2, where the last row (corresponding to Figure 3 (f)) compares the competitive abilities of a CFT agent (pursuer 0) and a CMPG agent (pursuer 1). The star -marked pursuers in T able 2 apply CFT or CMPG and the none-star-marked pursuers apply DDPG. In all, the results in this section confirm that Nocounterfa ctual agents ‐50 0 50 100 150 200 250 300 350 0 1 02 03 04 05 0 Reward Episode Pursuer0 Pursuer1 Pursuer0 Pursuer1 (a) Both pursuer 0 and 1 are DDPG agents (MADDPG). Counterfactualagent=0 ‐5 0 0 50 100 150 200 250 0 1 02 03 04 05 0 Re wa rd Episode Pursuer0 Pursuer1 ‐50 0 50 100 150 200 0 1 02 03 04 05 0 Reward Episode Pursuer0 Pursuer1 Pursuer1 Pursuer0 (b) Pursuer 0 is a CFT agent, pursuer 1 is a DDPG agent. Counterfactualagent=1 ‐50 0 50 100 150 200 250 0 1 02 03 04 05 0 Reward Episode Pursuer0 Pursuer1 Pursuer1 Pursuer0 (c) Pursuer 1 is a CFT agent, pursuer 0 is a DDPG agent. Coma=0 ‐50 0 50 100 150 200 250 0 1 02 03 04 05 0 Reward Episode Pursuer0 Pursuer1 Pursuer0 Pursuer1 (d) Pursuer 0 is a CMPG agent, pursuer 1 is a DDPG agent. Coma=1 ‐50 0 50 100 150 200 0 1 02 03 04 05 0 Reward Episode Pursuer0 Pursuer1 Pursuer0 Pursuer1 (e) Pursuer 1 is a CMPG agent, pursuer 0 is a DDPG agent. Co unterfact u a lvsCOMA (0cft,1 co ma ) ‐50 0 50 100 150 200 250 300 0 1 02 03 04 05 0 Reward Episode Pursuer0 Pursuer1 Pursuer0 Pursuer1 (f) CFT V .S. CMPG. Pursuer 0 is a CFT agent and pursuer 1 is a CMPG agent. Fig. 3: Comparison of accumulati ve rewards obtained by agents on MA WW en vironment. (a) directly use the frame work of MADDPG and it is shown no significant difference between the competitive abilities of two related agents; (b) and (c) compares the competitive abilities between a pre-set counterfactual agent and an agent applying DDPG. (d) and (e) shows that CMPG can also improv e the competitiv e abilities for agents to wards DDPG based competitors; (f) shows that a CFT agent is more competitiv e than a CMPG agent. our counterfactual mechanism (CFT) indeed helps an agent to compete in the multi-agent en vironments. C. En vir onment 2: Multi-Seller Marketing (MSM) Problem Background. In the Multi-Seller Marketing (MSM) en vironment, a market contains multiple sellers is a perfect en vironment to fit the multi-agent Marko v game framework. T o study the dynamic process between sellers in a multi-seller market, we conduct experiments on two real-world datasets (i.e. RET AIL 1 and HOTEL 2 ) of the MSM en vironment. T able I shows the statistics of these two datasets. W e use the first 100,000 rows of RET AIL and all ro ws of HO TEL in this experiment. RET AIL HO TEL Rows 100,000 276,592 Start 2012-03-02 2012-11-01 End 2013-07-23 2013-06-30 Competitor num. 2,606 57,646 T ABLE I: Dataset statistics Those datasets (i.e., RET AIL and THO TEL) contain the instant price as well as the volume of products (or hotel 1 https://www .kaggle.com/c/acquire-valued-shoppers-challenge/data 2 https://www .kaggle.com/c/expedia-personalized-sort/data booking count), for different brands. W e treat the instant prices as the actions and the corresponding sales volume as the re ward for the corresponding brand sellers. Since our model needs a centralized critic, the state for each agent is the same with others which consists of instant sales volumes for all sellers. T o predict the feedbacks of a market, we use a recurrent neural network model (RNN) [30] to learn the relationship between the instant prices and rewards (by modeling the prediction as a sequence-to-sequence learning problem). T raining Setup. W e set the scenario number to 16 and the number of intent actions K to 6. Moreover , we also set the exploration episode to 10 for each testing as in Section IV -B. Methods MADDPG CFT CMPG Pursuer0 ∗ 38.2 ± 57.13 61.0 ± 33.62 54.2 ± 47.32 Pursuer1 37.9 ± 42.04 22.2 ± 31.17 48.3 ± 47.51 Pursuer0 38.2 ± 57.13 32.9 ± 48.39 31.9 ± 43.59 Pursuer1 ∗ 37.9 ± 42.04 44.3 ± 38.31 19.5 ± 36.09 CFT vs CMPG - 43.4 ± 55.83 19.7 ± 32.89 T ABLE II: Comparison of accumulativ e rew ards. The star marked pursuer is applying the competitive models. Results on RET AIL dataset in the MSM en vironment. Figure 4 lists the comparison results between CFT and DDPG agents on MSM with retail datasets. In this section, we extract the price timeseries and sales volumes for top-7 sellers of the best- seller product from RET AIL dataset. As introduced in 4.1, we trained RNN with the extracted results. Based on Figure 4 (a), we analyze whether the RNN prediction model captures the real-world rules. In order to ease the observation about the difference of seller behaviors with the dif ferent market occupation, we rank all sellers according to their accumulative sales volumes and named them as “Seller 0” to “Seller 6”. T o further analyze the effecti ve for counterfactual thinking mechanism, we let seller 3 or 6 as the CFT agents respectively . The result is shown in Figure 3 (b) and (c). W e observe that the ranks of seller 3 and 6 are highly improv ed after using the CFT method in Figure 3 (b) and (c). Results on HOTEL dataset in the MSM en vironment. Figure 5 compares the competitiv e abilities of agents on MSM with HO TEL dataset. In this section, we extract the price timeseries and sales volumes for top-5 brands of the most popular hotels from HO TEL dataset. In a similar way of the last section, we rank all hotel brands according to their accumulativ e sales volumes and named them as “Hotel 0” to “Hotel 9”. In this testing phase, we let hotel 0 or 1 to learn policies with counterfactual mechanism respectively since they are the two least competitive agents in Figure 4 (a). From Figure 4 (b) and (c), we can observ e that the accumulati ve rew ards of a CFT agent are significantly increased under the same en vironment by competing with other DDPG based competitors (hotels). In summary , both the results in Figure 3, 4 and 5 show that our counterfactual mechanism indeed helps an agent to become more competitiv e than it before in a multi-agent Markov game en vironment. D. Scalability W e also compare the scalability for all related methods under MA WW in this section. T o make a fair comparison, we set this en vironment with 2 same agents of each type (MADDPG, CFT , and CMPG) and all scalability experiments are completed on a workstation with E3 CPU, 64 GB RAM, and Nvidia P5000 GPU. Besides, we set the steps to explore in each episode to 100, the batch size for sampling to 100 and the exploration episode to 10 for all agents. For every CFT agent in this experiment, its scenario number L = 16 and the parallel policy number K = 4 (which is the same settings as in IV .B). The result is shown in Figure 6. As it is shown in Figure 6, the computation efficiency of CFT is linear to the number of agents. W e can observe that from Figure 6 (a), since the CMPG method needs to compute a normalized Q-value based on all pre vious actions in the replay buf fer , it has the worst ef ficiency of all related methods. Furthermore, since MADDPG only uses a one-way agent to generate one exploration action and learns to update the action based on a single current Q-v alue from an ordinary critic, it is the most efficient method of all mentioned methods. Our CFT method uses a parallel structure to search several policy sub-spaces simultaneously , therefore, it is less efficient than MADDPG. Howe ver , it is still a more efficient method by comparing to CMPG. Figure 6 (b) shows the scalability of the CFT agent tow ards numbers of intent actions. W e observe that the CFT agents are very efficient with the parallel policy number K (from 2 to 10) and the computation time of CFT agents is linear to the intended action number . Therefore, CFT has the potential to be applied to large scale multi-agent reinforcement learning problems. V . R E L A T E D W O R K Counterfactuals refer to the hypothetical states which are opposite to the f acts [31]. In studies about the complex systems which can hardly be accurately recreated, scientists usually use this idea to infer the consequences for unobserved conditions. e.g. medical scientists apply counterfactuals to discov er the reasons to cause a certain disease [32]; psychologists use counterfactual thinking to predict future decisions of people in similar tasks [24]; historians infer the causal importance of some special ev ents via counterfactual thinking [33]. Reinforcement learning (RL) is an area of machine learning to train agents to take ideal actions in a dynamic en vironment in order to receive maximum accumulativ e rewards. Multi- agent deep reinforcement learning (MADRL) is the recent extension of RL to deal with the similar problems in high- dimensional en vironments [34]. The hot topics for MADRL include learning to communicate between agents [7], exploring the competitiv e or cooperativ e behavior patterns for agents [8], etc. The main challenge to effecti vely train MADRL models is to e xplore as much as policy subspaces with limit observ ations. One reason for this problem is that it is dif ficult to completely recreate a high-dimensional multi-agent environment in which ev ery agent beha ves exactly the same as itself in history . Therefore, the observed action-re ward tuples from the running en vironment are usually sparse and this sparse observation hinders the con vergence rate for MADRL models. Counter- factual thinking shed a light on this issue by maximizing the utilization of observations to improv e the learning efficienc y . Concretely , to incorporate the counterfactual information into the process of reinforcement learning. W olpert et al. [35] proposed the difference reward to revise the original rewards of an agent by the re wards under a default action during the simulation process. Jakob N. Foerster et al. [9] applies the av erage of all historical actions of an agent as the estimation for Q-values under counterfactual actions. This method use a regularized re ward as the estimation for the real reward to compute the current Q-value for critics. All previous methods improv e the performance of agents under multi-agent settings. Howe ver , the y still do not directly address the problem to increase the efficienc y for exploring the policy subspaces. T o enlarge the exploration coverage of policy subspaces for agents at each iteration, our method implements the coun- terfactual thinking by mimicking the human psychobiological process [24] with intent generating and ev aluating with current experience. The e xperimental results show that this indeed Nocounterfa ctual agent ‐500 0 500 1000 1500 2000 0 1 02 03 04 05 0 Reward Episode Seller0 Seller1 Seller2 Seller3 Seller4 Seller5 Seller6 Seller 3 Seller6 (a) All sellers are DDPG agents, which is the default MADDPG. Cfagent =3 ‐1000 ‐500 0 500 1000 1500 2000 2500 0 1 02 03 04 05 0 Reward Episode Seller0 Seller1 Seller2 Seller3 Seller4 Seller5 Seller6 Seller 3 (b) Seller 3 is a CFT agent, others are DDPG agents Cfagent=6 ‐1000 ‐500 0 500 1000 1500 2000 0 1 02 03 04 05 0 Reward Episode Seller0 Seller1 Seller2 Seller3 Seller4 Seller5 Seller6 Seller6 (c) Seller 6 is a CFT agent, others are DDPG agents Fig. 4: Comparison of different actors thinking with counterfactual actor-critic reinforcement learning on MSM with RET AIL dataset. ‐50 0 50 100 150 200 250 300 350 400 0 1 02 03 04 05 0 Reward Episode Hotel0 Hotel1 Hotel2 Hotel3 Hotel4 Hotel0 Hotel1 (a) All hotels are DDPG agents, which is the default MADDPG. Counterfactu a lagent=0 ‐400 ‐300 ‐200 ‐100 0 100 200 300 400 500 0 1 02 03 04 05 0 Reward Episode Hotel0 Hotel1 Hotel2 Hotel3 Hotel4 Hotel1 Hotel0 (b) Hotel 0 is a CFT agent, others are DDPG agents Cf_agent=1 ‐300 ‐200 ‐100 0 100 200 300 400 500 0 1 02 03 04 05 0 Reward Episode Hotel0 Hotel1 Hotel2 Hotel3 Hotel4 Hotel1 Hotel0 (c) Hotel 1 is a CFT agent, others are DDPG agents Fig. 5: Comparison of different actors thinking with counterfactual actor-critic reinforcement learning on MSM with HO TEL dataset. improv es the learning ef ficiency for an agent in the multi- agent en vironment and make it more competitiv e. V I . C O N C L U S I O N In the multi-agent environment, it is difficult to completely recreate a historical moment for an en vironment since this needs to replay all actions for the related agents in the same order historically . Therefore, if an agent has choices at a spe- cial moment in a multi-agent en vironment, it challenges a lot to compute the accurate results for actions other than the practical chosen one. In order to estimate the possible returns for those non-chosen options, we propose the counterfactual thinking multi-agent deep reinforcement learning model (CFT). This model generates several intent actions which mimic the human psychological process and then learns the regrets for the non- chosen actions with its estimated Q-values at that moment simultaneously . The estimated Q-values and policies of an agent supervise each other during the training process to generate more ef fectiv e policies. Since this frame work can explore the policy subspace parallelly , CFT could conv erge to the optimal faster than other e xisting methods. W e test CFT on standard multi-agent deep reinforcement learning platforms and real-world problems. The results sho w that CFT signif- icantly improves the competitive ability of a specific agent by receiving more accumulati ve rew ards than others in multi- agent en vironments. This also verifies that the counterfactual thinking mechanism is useful in training agent to solve the multi-agent deep reinforcement learning problems. V I I . A C K N OW L E D G E M E N T S This work is supported by the National Natural Science Foundation of China (Grant No. 61602535,61503422), Pro- gram for Innovation Research in Central Uni versity of Finance and Economics, Beijing Social Science Foundation (Grant No. 15JGC150), and the Foundation of State Ke y Laboratory of Cognitiv e Intelligence (Grant No. COGOSC-20190002), iFL YTEK, P .R. China. This work is also supported in part by NSF under grants III-1526499, III-1763325, III-1909323, SaTC-1930941, and CNS-1626432 . R E F E R E N C E S [1] Learning competitiv e pricing strategies by multi-agent reinforcement learning. Journal of Economic Dynamics and Contr ol , 27(11):2207 – 2218, 2003. Computing in economics and finance. [2] P . J. ’t Hoen and J. A. La Poutr ´ e. A decommitment strategy in a competitive multi-agent transportation setting. In Peyman Faratin, David C. Parkes, Juan A. Rodr ´ ıguez-Aguilar , and W illiam E. W alsh, editors, Agent-Mediated Electr onic Commerce V . Designing Mechanisms and Systems , pages 56–72, Berlin, Heidelberg, 2004. Springer Berlin Heidelberg. [3] Ahmad El Sallab, Mohammed Abdou, Etienne Perot, and Senthil Y oga- mani. Deep reinforcement learning frame work for autonomous dri ving. CoRR , abs/1704.02532, 2017. [4] Michael Castronovo, Francis Maes, Raphael Fonteneau, and Damien Ernst. Learning exploration/exploitation strategies for single trajectory reinforcement learning. In Pr oceedings of the T enth European W orkshop on Reinfor cement Learning, EWRL 2012, Edinbur gh, Scotland, UK, J une, 2012 , pages 1–10, 2012. 0 500 1000 1500 2000 2500 3000 3500 0 1 02 03 04 0 Time(Seconds) Episode MADDPG CFT CMPG Updatetarget neuralnetwork fromhere (a) MADDPG v .s. CFT v .s. CMPG. 0 100 200 300 400 500 600 700 0 1 02 03 04 0 Time(Seconds) Episode K=2 K=4 K=6 K=8 K=8 Updatetarget neuralnetwork fromhere (b) Comparison of CFTs with dif ferent intent policy number K . Fig. 6: Comparison of scalability for all methods. [5] Christos H. Papadimitriou and John N. Tsitsiklis. The complexity of markov decision processes. Mathematics of Operations Resear ch , 12(3):441–450, 1987. [6] Leslie Pack Kaelbling, Michael L. Littman, and Andrew W . Moore. Reinforcement learning: A survey . J. Artif. Intell. Res. , 4:237–285, 1996. [7] Jakob N. Foerster , Y annis M. Assael, Nando de Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforce- ment learning. In Advances in Neural Information Pr ocessing Systems 29: Annual Conference on Neural Information Pr ocessing Systems 2016, December 5-10, 2016, Bar celona, Spain , pages 2137–2145, 2016. [8] Ryan Lowe, Y i W u, A viv T amar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperativ e-competitive en vironments. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Pr ocessing Systems 2017, 4-9 December 2017, Long Beach, CA, USA , pages 6382–6393, 2017. [9] Jakob N. Foerster , Gregory Farquhar , Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, F ebruary 2-7, 2018 , pages 2974–2982, 2018. [10] Andrew Forne y , Judea Pearl, and Elias Bareinboim. Counterfactual data- fusion for online reinforcement learners. In Proceedings of the 34th International Confer ence on Machine Learning, ICML 2017, Sydney , NSW , Austr alia, 6-11 August 2017 , pages 1156–1164, 2017. [11] Jayesh K. Gupta, Maxim Egorov , and Mykel J. K ochenderfer . Co- operativ e multi-agent control using deep reinforcement learning. In Autonomous Agents and Multiagent Systems - AAMAS 2017 W orkshops, Best P apers, S ˜ ao P aulo, Brazil, May 8-12, 2017, Revised Selected P apers , pages 66–83, 2017. [12] Martijn van Otterlo and Marco W iering. Reinforcement Learning and Markov Decision Processes , pages 3–42. Springer Berlin Heidelberg, Berlin, Heidelberg, 2012. [13] Matthew J. Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. In 2015 AAAI F all Symposia, Arlington, V ir ginia, USA, November 12-14, 2015 , pages 29–37, 2015. [14] Xiaofeng W ang and T uomas Sandholm. Reinforcement learning to play an optimal nash equilibrium in team markov games. In Advances in Neural Information Pr ocessing Systems 15 [Neural Information Pro- cessing Systems, NIPS 2002, December 9-14, 2002, V ancouver , British Columbia, Canada] , pages 1571–1578, 2002. [15] Martin Lauer and Martin Riedmiller . An algorithm for distributed reinforcement learning in cooperati ve multi-agent systems. In In Pr oceedings of the Seventeenth International Confer ence on Machine Learning , pages 535–542. Morgan Kaufmann, 2000. [16] de Schutter B Busoniu L, Babuka R and Ernst D. Reinfor cement Learning and Dynamic Pr ogramming Using Function Appr oximators . FL: CRC Pressp, Boca Ratone, 2010. [17] Christopher J. C. H. W atkins and Peter Dayan. T echnical note q-learning. Machine Learning , 8:279–292, 1992. [18] Richard S. Sutton, David A. McAllester , Satinder P . Singh, and Yishay Mansour . Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Pr ocessing Systems 12, [NIPS Conference, Denver , Colorado, USA, November 29 - December 4, 1999] , pages 1057–1063, 1999. [19] H. J. Kushner and G. Y in. Stochastic approximation and recursive algorithms and applications . Springer , 2003. [20] David Silver , Guy Lever , Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin A. Riedmiller . Deterministic policy gradient algorithms. In Pr oceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 J une 2014 , pages 387–395, 2014. [21] Alain Dutech, Olivier Buffet, and Franc ¸ ois Charpillet. Multi-agent sys- tems by incremental gradient reinforcement learning. In Proceedings of the Seventeenth International Joint Conference on Artificial Intelligence, IJCAI 2001, Seattle, W ashington, USA, August 4-10, 2001 , pages 833– 838, 2001. [22] V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan W ierstra, and Martin A. Riedmiller. Playing atari with deep reinforcement learning. CoRR , abs/1312.5602, 2013. [23] Timothy P . Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, T om Erez, Y uval T assa, David Silver , and Daan W ierstra. Continuous control with deep reinforcement learning. In 4th International Confer- ence on Learning Repr esentations, ICLR 2016, San J uan, Puerto Rico, May 2-4, 2016, Confer ence Tr ack Pr oceedings , 2016. [24] Marian Gomez Beldarrain, J. Carlos Garcia-Monco, Elena Astigarraga, Ainara Gonzalez, and Jordan Grafman. Only spontaneous counterfactual thinking is impaired in patients with prefrontal cortex lesions. Cognitive Brain Researc h , 24(3):723–726, 8 2005. [25] R. Polikar. Ensemble based systems in decision making. IEEE Circuits and Systems Magazine , 6(3):21–45, Third 2006. [26] Lotfi Ben Romdhane. A softmin-based neural model for causal reason- ing. IEEE T rans. Neural Networks , 17(3):732–744, 2006. [27] Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In 3r d International Confer ence on Learning Represen- tations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference T rack Proceedings , 2015. [28] Edward Choi, Siddharth Biswal, Bradley Malin, Jon Duke, W alter F . Stew art, and Jimeng Sun. Generating multi-label discrete patient records using generative adversarial networks. In Pr oceedings of the Machine Learning for Health Care Conference, MLHC 2017, Boston, Massachusetts, USA, 18-19 August 2017 , pages 286–305, 2017. [29] Jayesh K Gupta, Maxim Egorov , and Mykel Kochenderfer . Cooperative multi-agent control using deep reinforcement learning. In International Confer ence on Autonomous Agents and Multiagent Systems , pages 66– 83. Springer, 2017. [30] Ilya Sutskev er, Oriol V inyals, and Quoc V . Le. Sequence to sequence learning with neural networks. In Advances in Neural Information Pr ocessing Systems 27: Annual Confer ence on Neural Information Pr ocessing Systems 2014, December 8-13 2014, Montr eal, Quebec, Canada , pages 3104–3112, 2014. [31] Judea Pearl. Causal inference in statistics: An ov erview . Statist. Surv . , 3:96–146, 2009. [32] Hfler M. Causal inference based on counterfactuals. BMC Med Res Methodol , 28, 5 2005. [33] Jack S. Le vy . Counterfactuals, causal inference, and historical analysis. Security Studies , 24, 07 2015. [34] Thanh Thi Nguyen, Ngoc Duy Nguyen, and Saeid Nahav andi. Deep reinforcement learning for multi-agent systems: A revie w of challenges, solutions and applications. CoRR , abs/1812.11794, 2018. [35] DA VID H. W OLPER T and KA GAN TUMER. Optimal P ayoff Functions for Members of Collectives , pages 355–369.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment