Learning Joint Acoustic-Phonetic Word Embeddings
Most speech recognition tasks pertain to mapping words across two modalities: acoustic and orthographic. In this work, we suggest learning encoders that map variable-length, acoustic or phonetic, sequences that represent words into fixed-dimensional …
Authors: Mohamed El-Geish
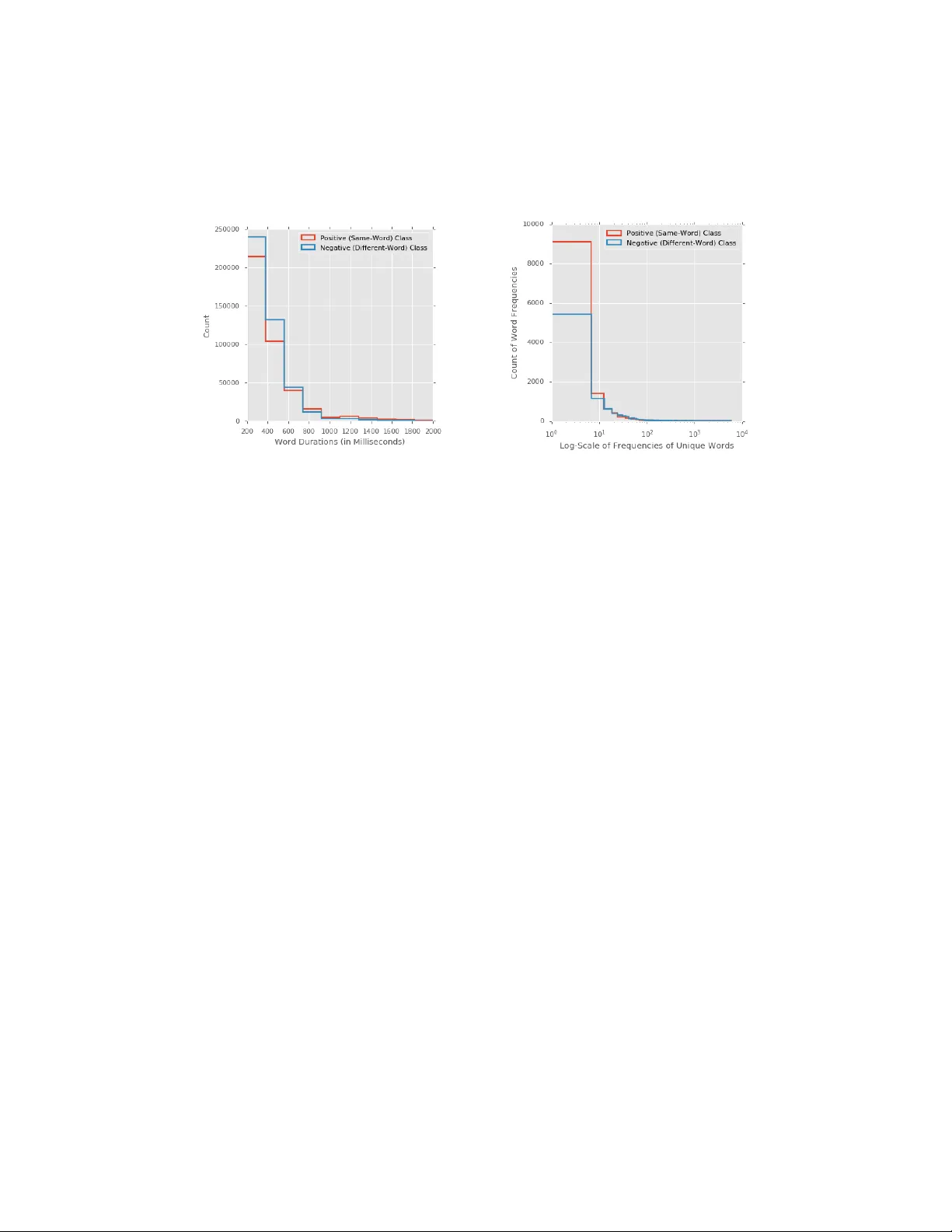
Lear ning J oint Acoustic-Phonetic W ord Embeddings Mohamed El-Geish V oicea geish@voicea.ai Abstract Most speech recognition tasks pertain to mapping words across two modalities: acoustic and orthographic. In this work, we suggest learning encoders that map variable-length — acoustic or phonetic — sequences that represent words into fixed-dimensional v ectors in a shared latent space; such that the distance between two word v ectors represents ho w closely the two w ords sound. Instead of directly learning the distances between word vectors, we emplo y weak supervision and model a binary classification task to predict whether two inputs, one of each modality , represent the same word gi ven a distance threshold. W e explore v arious deep-learning models, bimodal contrasti ve losses, and techniques for mining hard negati ve examples such as the semi-supervised technique of self-labeling. Our best model achiev es an F 1 score of 0.95 for the binary classification task. 1 Introduction The proliferation of voice-first applications and de vices generated unprecedented demand to impro ve a plethora of speech recognition tasks. In this w ork, we propose a b uilding block for speech recognition tasks like automatic speech recognition (ASR), keyword spotting, and query-by-e xample search. The outcome is an embedding model that maps variable-length — acoustic or phonetic — sequences that represent words into fixed-dimensional vectors in a shared latent space, which connects audio and phonetic modalities together , and encompasses a distributed representation of words, such that the distance between two w ord vectors represents ho w closely the two words sound: The more similar words sound, in either modality , the closer they end up in the shared vector space. Deep learning is befitting to learn pairwise relationships and joint embeddings, which hav e become the cornerstone of many machine learning applications [4, 38, 14, 26]. One of the applications we can reformulate is using the learned joint embeddings is ASR hypotheses reranking to reduce word error rate [2, 28]. The approach we took to learn distances between word embeddings in the vector space can be described as a weakly supervised task: Instead of training using ground-truth pairwise distances, we produced ground-truth data of word pairs labeled as either similar-sounding (distance of 0) or dif ferent-sounding (distance of 1) — making it a binary classification problem. At inference time, the model predicts real-valued distances that can be turned into labels gi ven a distance threshold. Despite the emergence of many successful embedding models, learning them is relatively poorly understood [46]. W e e xperimented with various techniques to mine hard examples for training. T raining using words picked at random from a corpus to be dissimilar to one another impedes learning; the model needs to be trained using hard examples of words that sound slightly different as examples of distant w ords [38, 47]. Another f acet of weak supervision is creating ground-truth data using heuristics applied to the results of ASR systems and unreliable, non-expert transcribers. 2 Related W ork Thanks to recent natural language processing (NLP) research [32, 37, 1], the use of word embeddings to represent the semantic relationships between words has been pre vailing. Similarly , in the field of speech recognition, the use of acoustic word embeddings has improv ed many tasks like keyword spotting [5], ASR systems [2], query-by-example search [25, 24, 41], and other word discrimination tasks [40, 21]; it also enabled attempts at unsupervised speech processing [20, 9] and representing semantic relationships between words [7, 8]. The aforementioned speech recognition research learned models from the acoustic representation of words — a single vie w , which requires side information to map that vie w into text. Infusing cross-modal (acoustic and orthographic) representations of words into the embedding model showed improvements in a plethora of applications; for example, [16] jointly learned to embed acoustic sequences and their respectiv e character sequences into a common vector space using deep bidirectional long short-term memory (LSTM) embedding models and multi- view contrastiv e losses. In [10], the model separately learns acoustic and orthographic embedding spaces, and then attempts to align them using adversarial training; it emplo ys a bidirectional LSTM encoder and a unidirectional LSTM decoder to perform the cross-modal alignment in an unsupervised fashion; the performance of such model is comparable to its supervised counterpart. One of the limitations of mapping acoustic representations to their corresponding character sequences is confusing homographs (words that share the same spelling but not the same pronunciation) — they may miss the subtle phonetic v ariations within words and/or across dialects. Multiple approaches attempted to mitigate such limitation. For e xample, [27] models phonetic information by training using both word- and frame- le vel criteria; ho we ver , it doesn’ t learn from phonetic labels so the learned embeddings cannot precisely represent the phonetic spelling of words. In [45], the objecti ve is to learn word embeddings from audio segments and use side information (phonetic labels) to train an acoustic model, which can be used for ASR systems — a desideratum similar to ours; it trains the model using a Siamese neural network and e xplores multiple loss functions. In [9], the objectiv e is to find vector representations that precisely describe represent the sequential phonetic structures of audio segments; in addition, [16] considers directly training using phonetic-spelling supervision as a future direction. It’ s worth mentioning that we discovered the latter after embarking on this endeavor , which validated our decision of using phonetic spelling instead of orthograph y . In [2, 40, 16], the models are trained using matched (similar-sounding) and mismatched (dif ferent- sounding) pairs of words; the mismatched words are drawn randomly , which makes minimizing losses lik e triplet and contrasti ve loss a challenge [47]. In [10], adversarial training is used to align the acoustic and orthographic vector spaces. W e use three different techniques, which we detail belo w , to mine for hard negati ve examples mining. 3 Dataset and Repr esentations The raw data consist of 25k short, single-channel recordings and their respectiv e transcripts. The recordings were captured at a sample rate of 16kHz and encoded using pulse-code modulation with 16-bit precision. T ranscripts do not include word alignments and may include errors. The dataset is proprietary and growing. T o obtain the phonetic spelling of words, we used the LibriSpeech lexicon [34]; it contains o ver 200k w ords and their pronunciations; out-of-v ocab ulary (OO V) words are excluded from the acoustic dataset as the y lack ground-truth phonetic labels. In order to obtain word alignments, we force-aligned each transcript in the raw dataset with recognition hypotheses generated by an ensemble of ASR systems. When the forced alignment failed due to an insertion or a deletion error , we considered the affected words too noisy to include. When the human-selected transcript for a w ord aligned successfully with an ASR hypothesis, we labeled the pair (the audio segment and its phonetic label) as similar-sounding (distance of 0). Using the set of positive pairs, we mined unique pairs of ASR hypotheses that substituted the human-selected transcript for the same audio segment and labeled them as hard negati ve e xamples (distance of 1). The restriction of starting from positi ve pairs reduced the ov erall number of e xamples; ho wever , it drastically increased the quality of the labels as we minimized the number of false neg ati ves. W e employed another technique to mine more of the hard negati ve examples: W e started from the hard negati ve examples we had created above and computed their phonetic-edit distance (between the human-selected transcript and the ASR’ s hypothesis for the same audio segment); then, we picked ones that scored below a maximum distance threshold (0.7 was satisfactory) and grouped them by their respecti ve human-selected transcripts; finally , we synthesized additional unique hard negati ve examples for ones that share the same human-selected transcript. The result of this process increased the number of neg ati ve examples from 73,845 to 439,679; it also helped balance the dataset, 2 which included 393,623 positi ve e xamples. W e remov ed stop words from the dataset as the y are not interesting for downstream tasks; w ords shorter than 0.2 seconds long were also removed as manual inspection deemed them mostly mislabeled. The processed dataset consisted of 654,224 e xamples that were split, with class-label stratification, into train/de v/test datasets of sizes 621,905/12,692/19,627 respectiv ely .The three sets contained 352,769/11,775/17,632 unique audio segments, respectiv ely . Figure 1: Distrib utions of word durations (left) and frequencies (right) in the dataset. The third technique we used to mine ev en more hard negati v e examples is a semi-supervised learning technique that’ s attributed to Scudder for his work circa 1965: self-labeling [39]. Every r epochs during training, we allow the dataset generator to augment the training dataset with newly minted hard negati ve examples. W e encode the phonetic spelling of the training set’ s lexicon and build a k -dimensional tree for the resultant phonetic embeddings. Then we sample, at random, from the unique audio se gments in the training set such that the sample’ s size is proportional to the number of epochs. Constraining the contributions of the less accurate models at early epochs reduces the chances of polluting the training set with easy-to-predict negati ve e xamples and hogging the memory . For each audio segment in the sample, we compute an embedding and find the closest phonetic neighbors within a maximum distance that reflects similarity (predicted a positiv e label). For each neighbor , we look up the true label of the word pair (audio segment and its phonetic label); if the model made a ne w mistake (the true label was ne gati ve and the pair is unique), we add the example to the training set as a hard ne gati ve. W e observed a health y gro wth in the training set’ s size thanks to self-labeling; it reached a 41% relativ e gro wth (to a total of 876,771 training e xamples) at one point. W e represented audio as mel-spectograms using standard parameters giv en a sample rate of 16KHz: 400 samples (25ms) for the length of the F ast F ourier Transform (FFT) windo w; a hop of 200 samples between successiv e frames, and 64 mel bands. The input audio signal was centered and padded with zeros (silence) to fit in a windo w of 2 seconds to fix the size of the model’ s input; the result is a tensor of size 64 × 161 × 1 (single channel). Audio e xamples were normalized individually using cepstral mean and v ariance normalization [44] and then normalized across e xamples to ha ve zero mean and unit variance for each mel band. W e represented phonetic spelling of words as a sequence of one-hot encoded vectors; the longest word in the LibriSpeech lexicon has 20 phones and there are 69 unique phones in the ARP Abet flav or used by the lexicon. W e indicate an empty phone using a sentinel value (making the length of the alphabet 70). The result is a matrix of size 70 × 20 . 4 Methods In this work, we follow an approach similar to [16] in the sense that we model the task at hand as a weakly supervised, bimodal binary classification task; and along the way , we learn acoustic and phonetic encoders that map words into a shared v ector space such that the distance between two word vectors represents ho w closely the two words sound. W e train a Siamese neural network [4] that feeds forward the acoustic and phonetic representations of a pair of words through a series of transformations to encode the two inputs into ` 2 -normalized vectors (embeddings), then outputs the distance between the two embeddings. Our objecti ve is to minimize the contrastiv e loss [13], which 3 allows us to learn encoders that map similar inputs to nearby points and dissimilar inputs to distant points in the shared vector space. T o describe the objecti ve formally , let ( x a , x p ) be the input word pair (acoustic and phonetic representations, respecti vely) and y be its true binary label such that y = 0 when the two representations, acoustic and phonetic, are of the same w ord; otherwise, y = 1 . The model learns two functions, f ( x a ) and g ( x p ) , that map the inputs into ` 2 -normalized embeddings; for each prediction, we compute the distance D ( f ( x a ) , g ( x p )) , or D for brevity , between the outputs of both functions using a distance function such as the Euclidean or cosine distance. Since the embeddings are ` 2 -normalized, we think of the two distance functions as mostly interchangeable. Giv en N training examples, we minimize the follo wing function: L = 1 N N X i (1 − y ( i ) ) ( D ( i ) ) 2 + y ( i ) max(0 , m − D ( i ) ) 2 where m > 0 is a mar gin parameter that controls when dissimilar pairs contribute to the loss function: only when D < m . Unless otherwise specified, we used m = 1 for the experiments below . 5 Experiments and Results Ev aluating embeddings depends hea vily on the do wnstream task; in this work, we picked F 1 score (the harmonic mean of precision and recall) as the metric of choice for the bimodal binary classification task. The binary labels at test time were calculated at a distance threshold of 0 . 5 , which approximates the observed break-e v en point when m = 1 in our experiments. In order to compute the break-even point for the test set, we generated all unique pairs of acoustic and phonetic inputs in the set — approximately , 192.6 million word pairs. The F 1 score of our best-performing model is 0 . 95 . (a) De velopment set loss before self-labeling to augment training data (red line) and after (gray line) — learning use to stagnate at much earlier epochs (x-axis). (b) Confusion matrix of our best-performing model. Projecting a sample of embeddings deri ved from the test set using a t-SNE [29] model results in a reasonable clustering of words. More interestingly , the model found phonetic analogies such as "cat" to "cool" is like "pat" to "pool", etc. W e also inspected a sample of 50 classification mistakes the model made. A fe w patterns emerged: the model failed to predict a distance that reflects similarity between the acoustic and phonetic embeddings when the audio was too noisy , too f aint (far field), or the speech was accented. Cross talk and re v erb were also problematic but not as common. Audio preprocessing to clean up the signal may be helpful in such cases. Also, training using n-grams and acquiring more data from speakers with accents and different acoustic en vironment may boost performance as we expect distrib utions of words to be non-IID (independent and identically distrib uted). W e experimented with and manually tuned v arious hyperparameter choices for input representations, architecture, contrasti ve losses, batch size, number of hidden units, number of epochs, embedding size, dimensions of filters in con volutional neural networks (CNN), single vs. bidirectional LSTM cells, Euclidean- vs. cosine- based distance functions, etc. The sparse representation of phonetic input led us to belie ve that the architecture for its encoder should be different from that of the acoustic one; howe ver , empirical e vidence suggests that mirroring the same architecture for both encoders, 4 T able 1: Summary of notable experiments and their results for training and testing, respecti vely . # Notable Experiment Details F 1 Scores 1 CNN ( 3 × 3 × 32 ); dense layer; 256-D embedding; batch size = 32 0 . 97 , 0 . 91 2 CNN ( 3 × 3 × 32 ) -> ( 3 × 3 × 64 ); dense layer; 256 -D embedding; batch size = 32 0 . 99 , 0 . 93 3 Same as #2 but for a dropout with a rate of 0 . 5 after the first hidden layer 0 . 99 , 0 . 94 4 Same as #3 but with another dropout of 0 . 5 after the second hidden layer 0 . 95 , 0 . 91 5 Same as #3 but with mar gin = the phonetic-edit distance for the pair 0 . 96 , 0 . 91 6 Same as #3 but with incoming weights constrained to a maximum norm of 3 0 . 99 , 0 . 94 7 2 unidirectional LSTM layers with 128 hidden units; dense layer; 256 -D embedding; batch size = 32 ; 24 epochs (in 99 hours) 0 . 91 , 0 . 87 8 2 Bidirectional LSTM layers with 512 hidden units and a dropout of 0 . 4 in between; a dropout of 0 . 2 for the acoustic input; 512 -D embedding; 28 epochs (in 47 hours) 0 . 95 , 0 . 91 9 CNN with 2 blocks [( 3 × 3 × 64 ) -> ( 2 × 2 ) max pooling]; two dense layers with 512 hidden units and a dropout of 0.4 in between; a dropout of 0.2 for the acoustic input; 512 -D embedding; cosine distance; batch size = 128 ; 64 epochs (in 4.8 hours) 0 . 99 , 0.95 10 Same as #9 but with additional dropout of 0 . 4 between conv olutional layers as well; trained for much longer (142 epochs in 19 hours) 0 . 96 , 0 . 93 with the exception of a dropout for the acoustic input layer, yields better results. T able 1 summarizes notable experiments and their results. W e use the ` 2 -normalized output of each encoder’ s last layer as the learned embedding hence we don’t use an acti v ation function to those layers. Unless otherwise specified, we constrained incoming weights to a maximum norm of 3 for layers with dropout re gularization to allo w for lar ge learning rates without the risk of the weights ballooning [43]. W e used the Adam optimizer [22] with initial learning rates tuned for dif ferent architectures ( 0 . 001 for CNN and 0 . 0001 for LSTM); we reduced the learning rate by a factor of 2 when learning stagnates for 2 epochs. Since the addition of self-labeling to our experiments, we observed a much steeper acceleration in learning in early epochs. T o balance the learning rate decay with the addition of new data on-the-fly during training, we increase the learning rate — by the same factor to a maximum of 0 . 001 — when new hard ne gati ve e xamples are mined to giv e the model a better chance at learning from the newly minted examples. For LSTM, we used tanh for activ ation; otherwise, we used rectified linear units (ReLU) [33], with the exception of the model’ s and the encoder’ s output layers. Network weight were initialized using He initialization [15] when ReLU was used; otherwise, we use the Xavier initialization method [12]. 6 Conclusion and Futur e W ork W e presented techniques for learning functions that map acoustic and phonetic representations of words into fix ed-dimensional vectors in a shared latent space, which are e xtremely useful in a plethora of speech recognition tasks. W e experimented with many modeling techniques, hyperparameters, and neural network architectures to learn the joint embeddings; our best model is a Siamese CNN that feeds forward acoustic and phonetic inputs and brings together , in the shared v ector space, similar-sounding w ords while keeping apart dif ferent-sounding ones. W e used binary classification as a surrogate task to learn the embeddings at the last layer of each encoder . The choice of training examples cannot be cannot be o verstated: we use three different techniques, including self-labeling, to mine hard negati ve examples for the contrastive loss function so that it can learn the subtleties requisite to discriminate between input words. One of the areas to explore in future work is training multiple models for multiple word duration buck ets to minimize e xtraneous padding. W e’ d also like to explore other loss functions detailed in [46, 16]. 5 Acknowledgments W e’ d like to thank Ahmad Abdulkader for his mentorship and guidance; and the authors of related work and software tools [6, 36, 31, 17, 23, 18, 30, 35, 3, 42, 19, 11] for allowing us to b uild on top of what they’ ve created. References [1] Ahmad Abdulkader, A Lakshmiratan, and J Zhang. “Introducing DeepT ext: Facebook’ s T ext Understanding Engine”. In: F acebook Code (2016). [2] Samy Bengio and Georg Heigold. “W ord Embeddings for Speech Recognition”. In: F ifteenth Annual Confer ence of the International Speec h Communication Association . 2014. [3] Stev en Bird, Ewan Klein, and Edward Loper. Natural Languag e Pr ocessing with Python . 1st. O’Reilly Media, Inc., 2009. I S B N : 9780596516499. [4] Jane Bromley et al. “Signature V erification Using a "Siamese" Time Delay Neural Netw ork”. In: Advances in neural information pr ocessing systems . 1994, pp. 737–744. [5] Guoguo Chen, Carolina Parada, and T ara N Sainath. “Query-by-Example K eyw ord Spotting Using Long Short-T erm Memory Networks”. In: 2015 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE. 2015, pp. 5236–5240. [6] François Chollet et al. K eras . https://keras.io . 2015. [7] Y u-An Chung and James Glass. “Learning W ord Embeddings from Speech”. In: (2017). [8] Y u-An Chung and James Glass. “Speech2vec: A Sequence-to-Sequence Framework for Learn- ing W ord Embeddings from Speech”. In: INTERSPEECH . 2018. [9] Y u-An Chung et al. “ Audio W ord2V ec: Unsupervised Learning of Audio Segment Representa- tions Using Sequence-to-Sequence Autoencoder”. In: (2016). [10] Y u-An Chung et al. “Unsupervised Cross-Modal Alignment of Speech and T ext Embedding Spaces”. In: Advances in Neur al Information Pr ocessing Systems 31 . Ed. by S. Bengio et al. Curran Associates, Inc., 2018, pp. 7354–7364. U R L : http : / / papers . nips . cc / paper / 7965 - unsupervised - cross - modal - alignment - of - speech - and - text - embedding - spaces.pdf . [11] FFmpe g . 2016. U R L : http://http://www.ffmpeg.org/ (visited on 12/16/2016). [12] Xavier Glorot and Y oshua Bengio. “Understanding the difficulty of training deep feedforward neural netw orks”. In: Pr oceedings of the thirteenth international confer ence on artificial intelligence and statistics . 2010, pp. 249–256. [13] Raia Hadsell, Sumit Chopra, and Y ann LeCun. “Dimensionality Reduction by Learning an In v ariant Mapping”. In: 2006 IEEE Computer Society Confer ence on Computer V ision and P attern Recognition (CVPR’06) . V ol. 2. IEEE. 2006, pp. 1735–1742. [14] David Harwath and James R Glass. “Learning W ord-Like Units from Joint Audio-V isual Analysis”. In: (2017). [15] Kaiming He et al. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification”. In: Pr oceedings of the IEEE international confer ence on computer vision . 2015, pp. 1026–1034. [16] W anjia He, W eiran W ang, and Karen Li vescu. “Multi-V iew Recurrent Neural Acoustic W ord Embeddings”. In: International Confer ence on Learning Repr esentations (2017). [17] John D Hunter. “Matplotlib: A 2D graphics environment”. In: Computing in science & engineering 9.3 (2007), p. 90. [18] Eric Jones, T ravis Oliphant, and Pearu Peterson. “ { SciPy } : Open source scientific tools for { Python } ”. In: (2014). [19] Kaldi ASR . 2016. U R L : http://kaldi- asr.org/ . [20] Herman Kamper, Aren Jansen, and Sharon Goldwater. “A Se gmental Frame work for Fully- Unsupervised Large-V ocab ulary Speech Recognition”. In: Computer Speech & Languag e 46 (2017), pp. 154–174. 6 [21] Herman Kamper, W eiran W ang, and Karen Li v escu. “Deep Con volutional Acoustic W ord Embeddings Using W ord-Pair Side Information”. In: Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE International Confer ence on . IEEE. 2016, pp. 4950–4954. [22] Diederik P Kingma and Jimmy Ba. “Adam: A method for stochastic optimization”. In: (2014). [23] Thomas Kluyver et al. “Jupyter Notebooks – a publishing format for reproducible computa- tional workflo ws”. In: P ositioning and P ower in Academic Publishing: Players, Agents and Agendas . Ed. by F . Loizides and B. Schmidt. IOS Press. 2016, pp. 87–90. [24] Keith Le vin, Aren Jansen, and Benjamin V an Durme. “Segmental Acoustic Inde xing for Zero Resource Ke yword Search”. In: 2015 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE. 2015, pp. 5828–5832. [25] Keith Le vin et al. “Fixed-Dimensional Acoustic Embeddings of V ariable-Length Segments in Low-Resource Settings”. In: A utomatic Speech Reco gnition and Understanding (ASR U), 2013 IEEE W orkshop on . IEEE. 2013, pp. 410–415. [26] Y ingming Li, Ming Y ang, and Zhongfei Mark Zhang. “A Surv e y of Multi-V ie w Representation Learning”. In: IEEE T ransactions on Knowledge and Data Engineering (2018). [27] Hyungjun Lim et al. “Learning Acoustic W ord Embeddings with Phonetically Associated T riplet Network”. In: (2018). [28] Y ukun Ma, Erik Cambria, and Benjamin Bigot. “ASR Hypothesis Reranking Using Prior- Informed Restricted Boltzmann Machine”. In: International Confer ence on Computational Linguistics and Intelligent T ext Pr ocessing . Springer. 2017, pp. 503–514. [29] Laurens van der Maaten and Geof fre y Hinton. “V isualizing data using t-SNE”. In: Journal of machine learning r esearc h 9.No v (2008), pp. 2579–2605. [30] Brian McFee et al. libr osa/librosa: 0.6.3 . Feb . 2019. D O I : 10.5281/zenodo.2564164 . U R L : https://doi.org/10.5281/zenodo.2564164 . [31] W es McKinney et al. “Data structures for statistical computing in python”. In: Pr oceedings of the 9th Python in Science Confer ence . V ol. 445. Austin, TX. 2010, pp. 51–56. [32] T omas Mikolov et al. “Distributed Representations of W ords and Phrases and Their Composi- tionality”. In: Advances in neural information pr ocessing systems . 2013, pp. 3111–3119. [33] V inod Nair and Geoffrey E Hinton. “Rectified linear units improv e restricted boltzmann machines”. In: Pr oceedings of the 27th international confer ence on machine learning (ICML- 10) . 2010, pp. 807–814. [34] V . Panayoto v et al. “Librispeech: An ASR Corpus Based on Public Domain Audio Books”. In: 2015 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . Apr . 2015, pp. 5206–5210. D O I : 10.1109/ICASSP.2015.7178964 . [35] Adam Paszke et al. “Automatic dif ferentiation in PyT orch”. In: (2017). [36] F . Pedregosa et al. “Scikit-learn: Machine Learning in Python”. In: Journal of Machine Learning Resear c h 12 (2011), pp. 2825–2830. [37] Jeffre y Pennington, Richard Socher, and Christopher Manning. “GloV e: Global V ectors for W ord Representation”. In: Pr oceedings of the 2014 confer ence on empirical methods in natur al language pr ocessing (EMNLP) . 2014, pp. 1532–1543. [38] Florian Schrof f, Dmitry Kalenichenko, and James Philbin. “Facenet: A Unified Embedding for Face Recognition and Clustering”. In: Pr oceedings of the IEEE conference on computer vision and pattern r ecognition . 2015, pp. 815–823. [39] H Scudder. “Probability of error of some adapti ve pattern-recognition machines”. In: IEEE T ransactions on Information Theory 11.3 (1965), pp. 363–371. [40] S. Settle and K. Li vescu. “Discriminative Acoustic W ord Embeddings: Recurrent Neural Network-Based Approaches”. In: 2016 IEEE Spoken Langua ge T echnolo gy W orkshop (SLT) . Dec. 2016, pp. 503–510. [41] Shane Settle et al. “Query-by-Example Search with Discriminati ve Neural Acoustic W ord Embeddings”. In: (2017). [42] SoX - Sound eXchange . 2015. U R L : http : / / sox . sourceforge . net/ (visited on 12/16/2016). 7 [43] Nitish Sri v astav a et al. “Dropout: a simple way to pre vent neural netw orks from o verfitting”. In: The Journal of Mac hine Learning Researc h 15.1 (2014), pp. 1929–1958. [44] Ole Morten Strand and Andreas Egeberg. “Cepstral Mean and V ariance Normalization in the Model Domain”. In: COST278 and ISCA T utorial and Researc h W orkshop (ITRW) on Robustness Issues in Con versational Interaction . 2004. [45] Gabriel Synnae ve, Thomas Schatz, and Emmanuel Dupoux. “Phonetics embedding learning with side information”. In: 2014 IEEE Spoken Langua ge T echnology W orkshop (SLT) . IEEE. 2014, pp. 106–111. [46] Evgeniya Ustinov a and V ictor Lempitsky. “Learning Deep Embeddings with Histogram Loss”. In: Advances in Neural Information Pr ocessing Systems 29 . Ed. by D. D. Lee et al. Curran Associates, Inc., 2016, pp. 4170–4178. [47] Chao-Y uan W u et al. “Sampling Matters in Deep Embedding Learning”. In: Pr oceedings of the IEEE International Confer ence on Computer V ision . 2017, pp. 2840–2848. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment