Synthesizing Images from Spatio-Temporal Representations using Spike-based Backpropagation
Spiking neural networks (SNNs) offer a promising alternative to current artificial neural networks to enable low-power event-driven neuromorphic hardware. Spike-based neuromorphic applications require processing and extracting meaningful information …
Authors: Deboleena Roy, Priyadarshini P, a
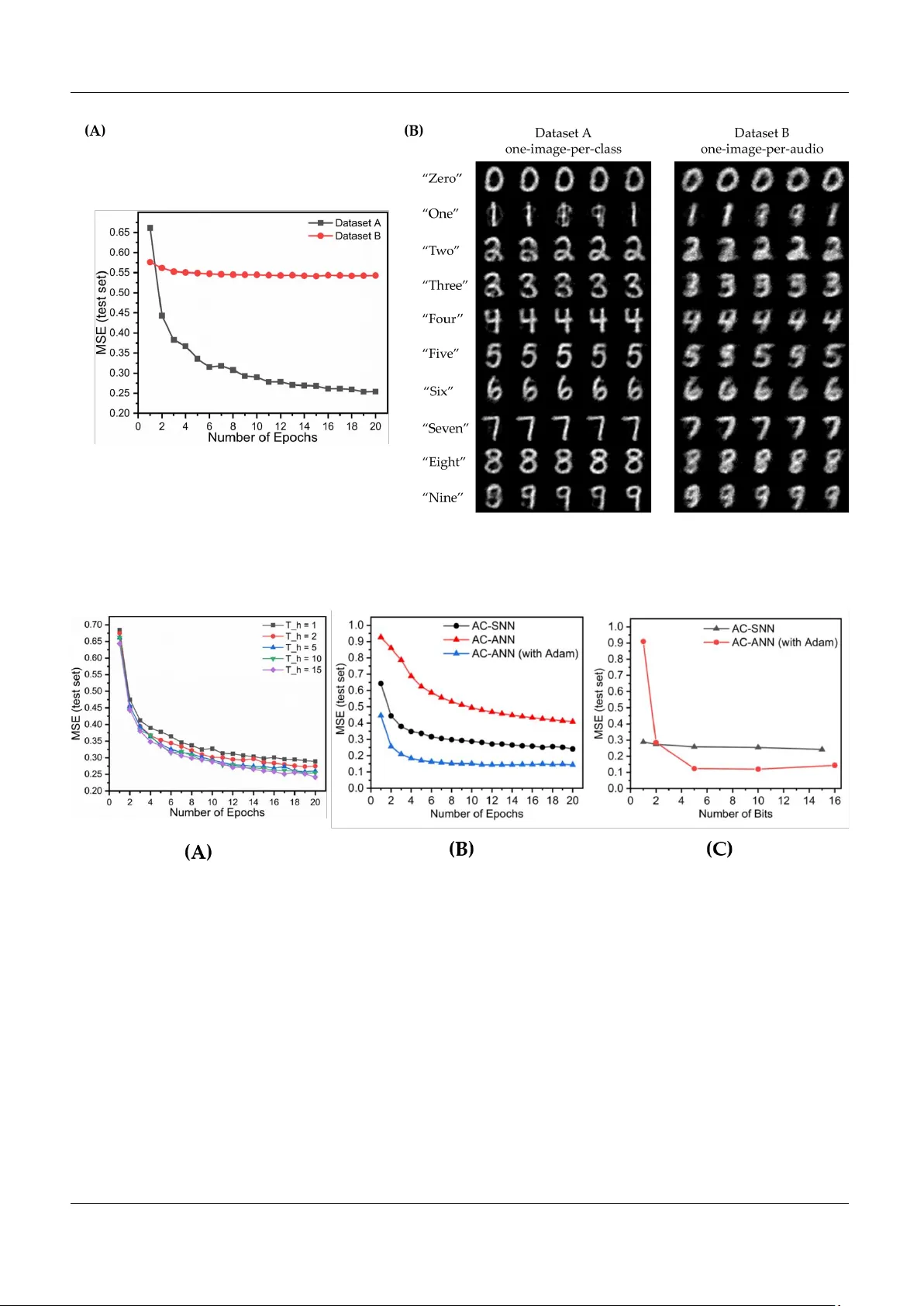
Synthesizing Images fr om Spatio-T emporal Representations using Spike-based Bac kpr opagation Deboleena Roy ∗ , Priy adarshini P anda and Kaushik Ro y Depar tment of Electrical and Computer Engineer ing, Purdue Univ ersity , W est Laf a yette , IN, USA Correspondence*: Mailbo x 312, EE Building, 450 Nor thwestern A ven ue, W est Laf a yette 47907, IN, USA ro y77@purdue.edu ABSTRA CT Spiking neural networks (SNNs) off er a promising alter nativ e to current ar tificial neural netw or ks to enable lo w-pow er ev ent-driven neuromorphic hardware. Spik e-based neuromor phic applications require processing and extr acting meaningful information from spatio-temporal data, represented as series of spike trains o ver time. In this paper , we propose a method to synthesize images from multiple modalities in a spike-based en vironment. W e use spiking auto-encoders to con v er t image and audio inputs into compact spatio-tempor al representations that is then decoded f or image synthesis . For this, w e use a direct tr aining algorithm that computes loss on the membrane potential of the output lay er and back-propagates it by using a sigmoid appro ximation of the neuron’ s activ ation function to enab le diff erentiability . The spiking autoencoders are benchmarked on MNIST and F ashion-MNIST and achie v e v er y low reconstruction loss , comparab le to ANNs. Then, spiking autoencoders are trained to lear n meaningful spatio-temporal representations of the data, across the two modalities - audio and visual. W e synthesize images from audio in a spike-based environment by first generating, and then utilizing such shared multi-modal spatio-temporal representations. Our audio to image synthesis model is tested on the task of conv er ting TI-46 digits audio samples to MNIST images . We are ab le to synthesize images with high fidelity and the model achie v es competitive perf or mance against ANNs. 1 INTR ODUCTION In recent years, Artificial Neural Networks (ANNs) hav e become powerful computation tools for complex tasks such as pattern recognition, classification and function estimation problems (LeCun et al., 2015). They ha ve an “acti v ation” function in their compute unit, also kno w as a neuron. These functions are mostly sigmoid , tanh , or ReLU (Nair and Hinton, 2010) and are very dif ferent from a biological neuron. Spiking neural networks (SNNs), on the other hand, are recognized as the “third generation of neural networks” (Maass, 1997), with their “spiking” neuron model much closely mimicking a biological neuron. They hav e a more biologically plausible architecture that can potentially achiev e high computational power and ef ficient neural implementation (Ghosh-Dastidar and Adeli, 2009; Maass, 2015). 1 Roy et al. Synthesizing Images from Spatio-T emporal Representations For any neural network, the first step of learning is the ability to encode the input into meaningful representations. Autoencoders are a class of neural networks that can learn ef ficient data encodings in an unsupervised manner (V incent et al., 2008). Their two-layer structure mak es them easy to train as well. Also, multiple autoencoders can be trained separately and then stack ed to enhance functionality (Masci et al., 2011). In the domain of SNNs as well, autoencoders provide an e xciting opportunity for implementing unsupervised feature learning (Panda and Roy, 2016). Hence, we use autoencoders to in vestigate ho w input spike trains can be processed and encoded into meaningful hidden representations in a spatio-temporal format of output spike trains which can be used to recognize and regenerate the original input. Generally , autoencoders are used to learn the hidden representations of data belonging to one modality only . Ho we ver , the information surrounding us presents itself in multiple modalities - vision, audio, and touch. W e learn to associate sounds, visuals and other sensory stimuli to one another . For example, an “apple” when sho wn as an image, or as text, or heard as an audio, holds the same meaning for us. A better learning system is one that is capable of learning shared representation of multimodal data (Sri vasta va and Salakhutdinov, 2012). W ysoski et al. (2010) proposed a bimodal SNN model that performs person authentication using speech and visual (face) signals. STDP-trained networks on bimodal data have exhibited better performance (Rathi and Roy, 2018). In this work, we e xplore the possibility of tw o sensory inputs - audio and visual, of the same object, learning a shared representation using multiple autoencoders, and then use this shared representation to synthesize images from audio samples. T o enable the abov e discussed functionalities, we must look at a way to train these spiking autoencoders. While sev eral prior works exist in training these networks, each comes with its own advantages and drawbacks. One w ay to train spiking autoencoders is by using Spike T iming Dependent Plasticity (STDP) (Sj ¨ ostr ¨ om and Gerstner, 2010), an unsupervised local learning rule based on spik e timings, such as Burbank (2015) and T av anaei et al. (2018). Howe ver , STDP , being unsupervised and localized, still fails to train SNNs to perform at par with ANNs. Another approach is deriv ed from ANN backpropagation; the av erage firing rate of the output neurons is used to compute the global loss (Bohte et al., 2002; Lee et al., 2016). Rate-coded loss fails to include spatio-temporal information of the network, as the network response is accumulated ov er time to compute the loss. W u et al. (2018b) applied backpropagation through time (BPTT) (W erbos, 1990), while Jin et al. (2018) proposed a hybrid backpropagation technique to incorporate the temporal ef fects. V ery recently W u et al. (2018a) demonstrated direct training of deep SNNs in a Pytorch based implementation frame work. Ho wev er , it continues to be a challenge to accurately map the time-dependent neuronal behavior with a time-a veraged rate coded loss function. In a network trained for classification, an output layer neuron competes with its neighbors for the highest firing rate, which translates into the class label, thus making rate-coded loss a requirement. Ho we ver , the target for an autoencoder is very dif ferent. The output neurons are trained to re generate the input neuron patterns. Hence, the y pro vide us with an interesting opportunity where one can choose not to use rate-coded loss. Spiking neurons ha ve an internal state, referred to as the membrane potential ( V mem ), that regulates the firing rate of the neuron. The V mem changes ov er time depending on the input to the neuron, and whene ver it exceeds a threshold, the neuron generates a spike. Panda and Roy (2016) first presented a backpropagation algorithm for spiking autoencoders that uses V mem of the output neurons to compute the loss of the network. They proposed an approximate gradient descent based algorithm to learn hierarchical representations in stacked con volutional autoencoders. For training the autoencoders in this work, we compute the loss of the network using V mem of the output neurons, and we incorporate BPTT (W erbos, 1990) by unrolling the network o ver time to compute the gradients. This is a provisional file , not the final typeset ar ticle 2 Roy et al. Synthesizing Images from Spatio-T emporal Representations In this work, we demonstrate that in a spike-based en vironment, inputs can be transformed into compressed spatio-temporal spike maps, which can be then be utilized to reconstruct the input later , or can be transferred across network models, and data modalities. W e train and test spiking autoencoders on MNIST and Fashion-MNIST dataset. W e also present an audio-to-image synthesis framework, composed of multi-layered fully-connected spiking neural networks. A spiking autoencoder is used to generate compressed spatio-temporal spike maps of images (MNIST). A spiking audiocoder then learns to map audio samples to these compressed spike map representations, which are then con verted back to images with high fidelity using the spiking autoencoder . T o the best of our knowledge, this is the first work to perform audio to image synthesis in a spike-based en vironment. The paper is or ganized in the follo wing manner: In Section 2, the neuron model, the netw ork structure and notations are introduced. The backpropagation algorithm is e xplained in detail. This is follo wed by Section 3 where the performance of these spiking autoencoders is e valuated on MNIST (LeCun et al., 1998) and Fashion-MNIST (Xiao et al., 2017) datasets. W e then setup our Audio to Image synthesis model and e valuate it for con verting TI-46 digits audio samples to MNIST images. Finally , in Section 4, we conclude the paper with discussion on this work and its future prospects. 2 LEARNING SP A TIO-TEMPORAL REPRESENT A TIONS USING SPIKING A UT OENCODERS In this section, we understand the spiking dynamics of the autoencoder network and mathematically deriv e the proposed training algorithm, a membrane-potential based backpropagation. 2.1 Input Encoding and Neuron Model A spiking neural network dif fers from a con ventional ANN in tw o main aspects - inputs and acti v ation functions. For an image classification task, for example, an ANN would typically take the raw pix el values as input. Ho wev er , in SNNs, inputs are binary spike ev ents that happen ov er time. There are se veral methods for input encoding in SNNs currently in use, such as rate encoding, rank order coding and temporal coding (W u et al., 2007). One of the most common methods is rate encoding, where each pixel is mapped to a neuron that produces a Poisson spike train, and its firing rate is proportional to the pix el v alue. In this work, e very pixel v alue of 0 − 255 is scaled to a v alue between [0 , 1] and a corresponding Poisson spike train of fixed duration, with a pre-set maximum firing rate, is generated (Fig.1). Figure 1. The input image is con verted into a spike map o ver time. At each time step neurons spike with a probability proportional to the corresponding pix el v alue at their location. These spik e maps, when summed ov er se veral time steps, reconstruct the original input Frontier s 3 Roy et al. Synthesizing Images from Spatio-T emporal Representations The neuron model is that of a leak y integrate-and-fire (LIF) neuron. The membrane potential ( V mem ) is the internal state of the neuron that gets updated at each time step based on the input of the neuron, Z [ t ] (eq. 1).The output activ ation ( A [ t ] ) of the neuron depends on whether V mem reaches a threshold ( V th ) or not. At any time instant, the output of the neuron is 0 unless the follo wing condition is fulfilled, V mem ≥ V th (eq. 2). The leak factor is determined by a constant α . After a neuron spikes, it’ s membrane potential is reset to 0. Fig. 2B illustrates a typical neuron’ s behavior o ver time. V [ t ] mem = (1 − α ) V [ t − 1] mem + Z [ t ] (1) A [ t ] = ( 0 , V [ t ] mem < V th 1 , V [ t ] mem ≥ V th (2) The acti vation function (eq. 2), which is a clip function, is non-dif ferentiable with respect to V mem , and hence we cannot take its deriv ativ e during backpropagation. Se veral w orks use various approximate pseudo-deri vati ves, such as piece-wise linear (Esser et al., 2015), and exponential deri v ati ve (Shrestha and Orchard, 2018). As mentioned in (Shrestha and Orchard, 2018), the probability density function of the switching activity of the neuron with respect to its membrane potential can be used to approximate the clip function. It has been observ ed that biological neurons are noisy and exhibit a probabilistic switching behaviour (Nessler et al., 2013; Benayoun et al., 2010), which can be modeled as ha ving a sigmoid-like characterstic (Sengupta et al., 2016). Thus, for backpropagation, we approximate the clip function (eq. 2) with a sigmoid which is centered around V th , and thereby , the deri vati ve of A [ t ] is approximated as the deri vati ve of the sigmoid, ( A [ t ] apx ) (eq. 3, 4). A [ t ] apx = 1 1 + exp( − ( V [ t ] mem − V th )) (3) ∂ A [ t ] ∂ V [ t ] mem ≈ ∂ A [ t ] apx ∂ V [ t ] mem = exp( − ( V [ t ] mem − V th )) (1 + exp( − ( V [ t ] mem − V th ))) 2 (4) 2.2 Network Model W e define the autoencoder as a tw o layer fully connected feed-forward network. T o e v aluate our proposed training algorithm, we ha ve used tw o datasets - MNIST (LeCun et al., 1998) and Fashion MNIST (Xiao et al., 2017). The two datasets ha ve the same input size, a 28 × 28 gray-scale image. Hence, the input and the output layers of their networks hav e 784 neurons each. The number of l ayer (1) neurons is different for the two datasets. The input neurons ( l ayer (0) ) are mapped to the image pixels in a one-to-one manner and generate the Poisson spike trains. The autoencoder trained on MNIST later used as one of the building blocks of the audio-to-image synthesis network. The description of the network and the notation used throughout the paper is gi ven in Fig. 2A. 2.3 Backpr opagation using Membrane P otential In this work, loss is computed using the membrane potential of output neurons at ev ery time step and then it’ s gradient with respect to weights is backpropagated for weight update. The input image is provided to the network as 784 × 1 binary vector over T time steps, represented as X ( t ) spik e . At each time step the desired membrane potential of the output layer is calculated (eq. 5). The loss is the dif ference between This is a provisional file , not the final typeset ar ticle 4 Roy et al. Synthesizing Images from Spatio-T emporal Representations Figure 2. The dynamics of a spiking neural network (SNN): (A) A two layer feed-forw ard SNN at any gi ven arbitrary time instant. The input vector is mapped one-to-one to the input neurons ( l ayer (0) ). The input v alue gov erns the firing rate of the neuron, i.e. number of times the neuron output is 1 in a gi ven duration. (B) A leak y integrate and fire (LIF) neuron model with 3 synapses/weights at its input. The membrane potential of the neuron inte grates ov er time (with leak). As soon as it crosses V th , the neuron output changes to 1, and V mem is reset to 0. For taking deri vati ve during backpropagation, a sigmoid approximation is used for the neuron acti vation the desired membrane potential and the actual membrane potential of the output neurons. Additionally a masking function is used that helps us focus on specific neurons at a time. The mask used here is bitwise XOR between expected spik es ( X [ t ] spik e ) and output spikes ( A (2)[ t ] ) at a gi ven time instant. The mask only preserves the error of those neurons that either were supposed to spike but did not spike, or were not supposed to spike, b ut spiked. It sets the loss to be zero for all other neurons. W e observed that masking is essential for training in spiking autoencoder as sho wn in Fig. 4A O [ t ] = V th . ∗ X [ t ] spik e (5) mask = bitX O R ( X [ t ] spik e , A (2)[ t ] ) (6) E r r or = E = mask . ∗ ( O [ t ] − V (2)[ t ] mem ) (7) Loss = L = 1 2 | E | 2 (8) The weight gradients, ∂ L ∂ W , are computed by back-propagating loss in the two layer network as depicted in Fig. 2A. W e derive the weight gradients belo w . ∂ L ∂ V (2)[ t ] mem = − E (9) Frontier s 5 Roy et al. Synthesizing Images from Spatio-T emporal Representations From eq. 1, ∂ V (2)[ t ] mem ∂ W (2) = (1 − α ) ∂ V (2)[ t − 1] mem ∂ W (2) + A (1)[ t ] T . (10) The deri vati ve is dependent not only on the current input ( A (1)[ t ] ), but also on the state from pre vious time step ( V (2)[ t − 1] mem ). Next we apply chain rule on eq. 9 - 10, ∂ L ∂ W (2) = ∂ L ∂ V (2)[ t ] mem ∂ V (2)[ t ] mem ∂ W (2) = − E (1 − α ) ∂ V (2)[ t − 1] mem ∂ W (2) + A (1)[ t ] T , (11) from eq. 1, ∂ V (2)[ t ] mem ∂ Z (2)[ t ] = I , (12) from 9 and 12, we obtain the local error of l ayer (2) with respect to the ov erall loss which is backpropagated to l ayer (1) , δ 2 = ∂ L ∂ Z (2)[ t ] = I ( − E ) = − E , (13) next, the gradients for lay er (1) are calculated, ∂ Z (2)[ t ] ∂ A (1)[ t ] = W (2) , (14) from eq. 3 - 4, ∂ A (1)[ t ] ∂ V (1)[ t ] mem ≈ ∂ A (1)[ t ] apx ∂ V (1)[ t ] mem = exp( − ( V (1)[ t ] mem − V th )) (1 + exp( − ( V (1)[ t ] mem − V th ))) 2 , (15) from eq. 1, ∂ V (1)[ t ] mem ∂ W (1) = (1 − α ) ∂ V (1)[ t − 1] mem ∂ W (1) + X [ t ] spik e T , (16) from 13 - 16, ∂ L ∂ W (1) = ∂ L ∂ V (1)[ t ] mem ∂ V (1)[ t ] mem ∂ W (1) = W (2) T δ 2 ◦ ∂ A (1)[ t ] ∂ V (1)[ t ] mem (1 − α ) ∂ V (1)[ t − 1] mem ∂ W (1) + X [ t ] spik e T . (17) Thus, equations 11 and 17 sho w how gradients of the loss function with respect to weights are calculated. For weight update, we use mini-batch gradient descent and a weight decay v alue of 1e-5. W e implement Adam optimization (Kingma and Ba, 2014), b ut the first and second moments of the weight gradients are a veraged over time steps per batch (and not a veraged over batches). W e store ∂ V ( l )[ t ] mem ∂ W ( l ) of the current time step for use in next time step. The initial condition is, ∂ V ( l )[0] mem ∂ W ( l ) = 0 . If a neuron spikes, it’ s membrane potential is reset and therefore we reset ∂ V ( l,m )[ t ] mem ∂ W ( l ) to 0 as well, where l is the layer number and m is the neuron number . This is a provisional file , not the final typeset ar ticle 6 Roy et al. Synthesizing Images from Spatio-T emporal Representations 3 EXPERIMENTS 3.1 Regenerative Learning with Spiking Autoencoder s (A) (B) Figure 3. The AE-SNN (784-196-784) is trained over MNIST (60,000 training samples, batch size = 100) for dif ferent leak coefficients ( α ). (A) spike-based MSE (Mean Square Error) Reconstruction Loss per batch during training. (B) A v erage MSE ov er entire dataset after training (A) (B) Figure 4. The AE-SNN (784-196-784) is trained over MNIST (60,000 training samples, batch size = 100) and we study the impact of (A) mask, and (B) input spike train duration on the Mean Square Error (MSE) Reconstruction Loss For MNIST , a 784-196-784 fully connected network is used. The spiking autoencoder (AE-SNN) is trained for 1 epoch with a batch size of 100, learning rate 5e-4, and a weight decay of 1e-4. The threshold Frontier s 7 Roy et al. Synthesizing Images from Spatio-T emporal Representations Figure 5. AE-SNN trained on MNIST (training examples = 60,000, batch size = 100). (A) Spiking autoencoder (AE-SNN) versus AE-ANNs (trained with/without Adam). (B) Regenerated images from test set for AE-SNN (input spike duration = 15, leak = 0.1) Figure 6. AE-SNN trained on F ashion-MNIST (training examples = 60,000, batch size = 100) (A) AE- SNN (784 × (512/1024) × 784) versus AE-ANNs (trained with/without Adam, lr = 5e-3) (B) Regenerated images from test set for AE-SNN-1024 ( V th ) is set to 1. W e define two metrics for network performance, Spike-MSE and MSE. Spike-MSE is the mean square error between the input spike map and the output spike map, both summed over the entire duration. MSE is the mean square error between the input image and output spik e map summed ov er the entire duration. Both, input image and output map, are normalized, zero mean and unit variance, and then the mean square error is computed. The duration of inference is k ept the same as the training duration of the network. It is observed in Fig. 3 that the leak coefficient plays an important role in the performance of the network. While a small leak coef ficient improves performance, too high of a leak degrades it greatly . W e use Spike-MSE as the comparison metric during training in Fig. 3A, to observe ho w well the autoencoder can recreate the input spike train. In Fig. 3B, we report two dif ferent MSEs, one computed against input spike map (spikes) and the other compared firing rate to pixel v alues (pixels), after normalizing both. F or ’IF’ This is a provisional file , not the final typeset ar ticle 8 Roy et al. Synthesizing Images from Spatio-T emporal Representations Figure 7. (A) AE-SNN (784 × H × 784) trained on MNIST (training examples = 60,000, batch size = 100) for dif ferent hidden layer sizes = 64, 196, 400 (B) AE-ANN (784 × 1024 × 784) trained on Fashion-MNIST (training examples = 60,000, batch size = 100) with Adam optimization for various learning rates (lr). Baseline: AE-SNN trained with input spik e train duration of 60 time steps. (C) AE-SNN (784 × 1024 × 784) trained on Fashion-MNIST (training e xamples = 60,000, batch size = 100) for varying input time steps, T = 15, 30, 60. Baseline: AE-ANN trained using Adam with lr = 5e-3 neuron ( α = 0 ), the train data performs worse than test data, implying underfitting. At α set to 0 . 01 we find the network ha ving comparable performance between test and train datasets, indicating a good fit. At α = 0 . 1 , the Spike-MSE is lowest for both test and train data, ho wev er the MSE is higher . While the network is able to faithfully reconstruct the input spike pattern, the difference between Spike-MSE and regular MSE is because of the dif ference in actual pixel intensity and the con verted spik e maps generated by the poisson generator at the input. On further increasing the leak, there is an overall performance degradation on both test and train data. Thus, we observ e that leak coef ficient needs to be fine-tuned for optimal performance. Going forth, we set the leak coef ficient at 0.1 for all subsequent simulations, as it ga ve the lo west train and test data MSE on direct comparison with input spike maps. Fig. 4A sho ws that using a mask function is essential for training this type of network. W ithout a masking function the training loss does not con verge. This is because all of the 784 output neurons are being forced to ha ve membrane potential of 0 or V th , resulting in a highly constrained optimization space, and the network e ventually f ails to learn any meaningful representations. In the absence of an y masking function, the sparsity of the error vector E was less than 5%, whereas, with the mask, the a verage sparsity was close to 85%. This allows the optimizer to train the critical neurons and synapses of the network. The weight update mechanism learns to focus on correcting the neurons that do not fire correctly , which ef fectively reduces the number of learning v ariables, and results in better optimization. Another interesting observ ation was that increasing the duration of the input spike train improv es the performance as sho wn in Fig.4B. Ho we ver , it comes at the cost of increased training time as backpropagation is done at each time step, as well as increased inference time. W e settle for an input time duration of 15 as a trade-of f between MSE and time taken to train and infer for the next set of simulations. W e also study the impact of hidden layer size for the reconstruction properties of the autoencoder . As sho wn in Fig. 7A, as we increase the size of the network, the performance improves. Ho wev er , this comes at the cost of increased network size, longer training time and slower inference. While one gets a good improv ement when increasing hidden layer size from 64 to 196, the benefit diminishes as we increase the hidden layer size to 400 neurons. Thus for our comparison with ANNs, we use the 784 × 196 × 784 network. Frontier s 9 Roy et al. Synthesizing Images from Spatio-T emporal Representations For comparison with ANNs, a network (AE-ANN) of same size (784 × 196 × 784) is trained with SGD, both with and without Adam optimizer (Kingma and Ba, 2014) on MNIST for 1 epoch with a learning rate of 0.1, batch size of 100, and weight decay of 1e-4. When training the AE-SNN, the first and second moments of the gradients are computed over sequential time steps within a batch (and not across batches). Thus it is not analogous to the AE-ANN trained with Adam, where the moments are computed o ver batches. Hence, we compare our network with both variants of the AE-ANNs, trained with and without Adam. The AE-SNN achie ves better performance than the AE-ANN trained without Adam; ho wev er it lags behind the AE-ANN optimized with Adam as sho wn in Fig. 5A. Some of the reconstructed MNIST images are depicted in Fig. 5B. One important thing to note is that the AE-SNN is trained at ev ery time step, hence there are 15 × more backpropagation steps as compared to an AE-ANN. Ho we ver at ev ery backpropagation step, the AE-SNN only backpropag ates the error vector of a single spike map, which is very sparse, and carries less information than the error vector of the AE-ANN. Next, the spiking autoencoder is e v aluated on the Fashion-MNIST dataset (Xiao et al., 2017). It is similar to MNIST , and comprises of 28 × 28 gray-scale images (60,000 training, 10,000 testing) of clothing items belonging to 10 distinct classes. W e test our algorithm on two network sizes: 784-512-784 (AE-SNN-512) and 784-1024-784 (AE-SNN-1024). The AE-SNNs are compared against AE-ANNs of the same sizes (AE-ANN-512, AE-ANN-1024) in Fig. 6A. For the AE-SNNs, the duration of input spike train is 60, leak coef ficient is 0.1, and learning rate is set at 5e-4. The networks are trained for 1 epoch, with a batch size of 100. The longer the spike duration, the better would be the spike image resolution. For a duration of 60 time steps, a neuron can spike an ywhere between zero to 60 times, thus allo wing 61 gray-scale le vels. Some of the generated images by AE-SNN-1024 are displayed in Fig. 6B. The AE-ANNs are trained for 1 epoch, batch size 100, learning rate 5e-3 and weight decay 1e-4. For F ashion-MNIST , the AE-SNNs exhibited better performance than AE-ANNs as sho wn in Fig. 6A. W e varied the learning rate for AE-ANN, and the AE-SNN still outperformed it’ s ANN counterpart (Fig. 7B). This is an interesting observ ation, where the better performance comes at the increased ef fort of per-batch training. Also it exhibits such behavior on only this dataset, and not on MNIST (Fig.5A). The spatio-temporal nature of training ov er each time step could possibly train the network to learn the details in an image better . Spiking Neural Networks hav e an inherent sparsity in them which could possibly acts like a dropout re gularizer (Sriv astav a et al., 2014). Also, in case of AE-SNN, the update is made at e very time step (60 updates per batch), in contrast to ANN where there is one update for one batch. W e ev aluated AE-SNN for shorter time steps, and observe that for smaller time steps (T = 5, 10), AE-SNN performs worse than AE-ANN (Fig. 7C). The impact of time steps is greater for F ashion-MNIST , as compared to MNIST (Fig. 4B), as F ashion-MNIST data has more grayscale le vels than the near-binary MNIST data. W e also observed that, for both datasets, MNIST and Fashion-MNIST , the AE-SNN conv erges f aster than AE-ANNs trained without Adam, and con ver ges at almost the same time as an AE-ANN trained with Adam. The proposed spike-based backpropagation algorithm is able to bring the AE-SNN performance at par , and at times ev en better , than AE-ANNs. 3.2 A udio to Image Synthesis using Spiking A uto-Encoders 3.2.1 Dataset For the audio to image con version task, we use tw o standard datasets, the 0-9 digits subset of TI-46 speech corpus (Liberman et al., 1993) for audio samples, and MNIST dataset (LeCun et al., 1998) for images. The audio dataset has read utterances of 16 speakers for the 10 digits, with a total 4136 audio samples. W e di vide the audio samples into 3500 train samples and 636 test samples, maintaining an 85%/15% train/test This is a provisional file , not the final typeset ar ticle 10 Roy et al. Synthesizing Images from Spatio-T emporal Representations ratio. For training, we pair each audio sample with an image. W e chose two ways of preparing these pairs, as described belo w: 1. Dataset A : 10 unique images of the 10 digits is manually selected ( 1 image per class) and audio samples are paired with the image belonging to their respecti ve classes (one-image-per -audio-class). All audio samples of a class are paired with the identical image of a digit belonging to that class. 2. Dataset B : Each audio sample of the training set is paired with a randomly selected image (of the same label) from the MNIST dataset (one-image-per -audio-sample). Every audio sample is paired with a unique image of the same class. The testing set is same for both Dataset A and B, comprising of 636 audio samples. All the audio clips were preprocessed using Auditory T oolbox (Slaney, 1998). The y were con verted to spectrograms ha ving 39 frequency channels o ver 1500 time steps. The spectrogram is then con verted into a 58500 × 1 vector of length 58500. This vector is then mapped to the input neurons ( l ayer (0) ) of the audiocoder, which then generate Poisson spike trains o ver the gi ven training interv al. 3.2.2 Network Model Figure 8. Audio to Image synthesis model using an Autoencoder trained on MNIST images, and an Audiocoder trained to con vert TI-46 digits audio samples into corresponding hidden state of the MNIST images. The principle of stacked autoencoders is used to perform audio-to-image synthesis. An autoencoder is built of tw o sets of weights; the l ayer (1) weights ( W (1) ) encodes the information into a “hidden state” of a dif ferent dimension, and the second layer ( W (2) ) decodes it back to it’ s original representation. W e first Frontier s 11 Roy et al. Synthesizing Images from Spatio-T emporal Representations train a spiking autoencoder on MNIST dataset. W e use the AE-SNN as trained in Fig. 5A. Using l ayer (1) weights ( W [1] ) of this AE-SNN, we generate “hidden-state” representations of the images belonging to the training set of the multimodal dataset. These hidden-state representations are spike trains of a fixed duration. Then we construct an audiocoder: a two layer spiking network that con verts spectrograms to this hidden state representation. The audiocoder is trained with membrane potential based backpropagation as described in Section 2.3. The generated representation, when fed to the “decoder” part of the autoencoder , gi ves us the corresponding image. The network model is illustrated in Fig. 8 3.2.3 Results The MNIST autoencoder (AE-SNN) used for audio-to-image synthesis task is trained using the following parameters: batch size of 100, learning rate 5e-4, leak coef ficient 0.1, weight decay 1e-4, input spike train duration 15, and number of epochs 1, as used in section 3.1. W e use Dataset A and Dataset B (as described in section 3.2.1) to train and e valuate our audio-to-image synthesis model. The images that were paired with the training audio samples are con verted to Poisson spike trains (duration 15 time steps) and fed to the AE-SNN, which generates a 196 × 15 corresponding bitmap as the output of l ayer (1) (Fig. 2A). This spatio temporal representation is then stored. Instead of storing the entire duration of 15 time steps, one can choose to store a subset, such as first 5 or 10 time steps. W e use T h to denote the sav ed hidden state’ s duration. This stored spike map serves as the target spike map for training the audiocoder (A C-SNN), which is a 58500 × 2048 × 196 fully connected network. The spectrogram (39 × 1500) of each audio sample was con verted to 58500 × 1 vector which is mapped one-to-one to the input neurons( l ayer (0) ). These input neurons then generate Poisson spike trains for 60 time steps. The target map, of T h time steps, was sho wn repeatedly ov er this duration. The audiocoder (AC-SNN) is trained o ver 20 epochs, with a learning rate of 5e-5 and a leak coef ficient of 0.1. W eight decay is set at 1e-4 and the batch size is 50. Once trained, the audiocoder is then merged with W (2) of AE-SNN to create the audio-to-image synthesis model (Fig. 8). For Dataset A, we compare the images generated by audio samples of a class ag ainst the MNIST image of that class to compute the MSE. In case of Dataset B, each audio sample of the train set is paired with an unique image. F or calculating training set MSE, we compare the paired image and the generated image. For testing set, the generated image of an audio sample is compared with all the trai ning images having the same label in the dataset, and the lowest MSE is recorded. The output spike map is normalized and compared with the normalized MNIST images, as was done pre viously . Our model gi ves lo wer MSE for Dataset A compared to Dataset B (Fig 9A), as it is easier to learn just one representativ e image for a class, than unique images for e very audio sample. The network trained with Dataset A generates very good identical images for audio samples belonging to a class. In comparison the netw ork trained on Dataset B generates a blurry image, thus indicating that it has learned to associate the underlying shape and structure of the digits, but has not been able to learn finer details better . This is because the network is trained ov er multiple dif ferent images of the same class, and it learns what is common among them all. Fig. 9B displays the generated output spike map for the two models trained ov er Dataset A and B for 50 dif ferent test audio samples (5 of each class). The duration ( T h ) of stored “hidden state” spike train was varied from 15 to 10, 5, 2, and 1. A spike map at a single time step is a 1-bit representation. The AE-SNN compresses an 784 × 8 bit representation into 196 × T h -bit representation. For T h = 15, 10, 5, 2, and 1, the compression is 2.1 × , 3.2 × , 6.4 × , 16 × and 32 × respecti vely . In Fig. 10A we observe the reconstruction loss (test set) o ver epochs for training using This is a provisional file , not the final typeset ar ticle 12 Roy et al. Synthesizing Images from Spatio-T emporal Representations Figure 9. The performance of the Audio to Image synthesis model on the tw o datasets - A and B ( T h = 10)) (A) Mean square error loss (test set) (B) Images synthesized from dif ferent test audio samples (5 per class) for the two datasets A, and B Figure 10. The audiocoder (A C-SNN/A C-ANN) is trained o ver Dataset A, while the autoencoder (AE- SNN/AE-ANN) is fixed. MSE is reported on the ov erall audio-to-image synthesis model composed of A C-SNN/ANN and AE-SNN/ANN. (A) Reconstruction loss of the audio-to-image synthesis model for v arying T h (B) Audiocoder performance A C-SNN ( T h = 15 ) vs A C-ANN (16 bit full precision) (C) Ef fect of training with reduced hidden state representation on A C-SNN and A C-ANN models dif ferent lengths of hidden state. Ev en when the A C-SNN is trained with a much smaller “hidden state”, the AE-SNN is able to reconstruct the images without much loss. For comparison, we initialize an ANN audiocoder (A C-ANN) of size 58500 × 2048 × 196. The AE-ANN trained ov er MNIST in section 3.1 is used to con vert the images of the multimodal dataset (A/B) to 196 × 1 “hidden state” vectors. Each element of this vector is 16 bit full precision number . In case of AE-SNN, the “hidden state” is represented as a 196 × T h bit map. F or comparison, we quantize the equiv alent hidden Frontier s 13 Roy et al. Synthesizing Images from Spatio-T emporal Representations state vector into 2 T h le vels. The AC-ANN is trained using these quantized hidden state representations with the follo wing learning parameters: learning rate 1e-4, weight decay 1e-4, batch size 50, epochs 20. Once trained, the ANN audio-to-image synthesis model is built by combining A C-ANN and l ayer (2) weights ( W (2) ) of AE-ANN. The A C-ANN is trained with/without Adam optimizer , and is paired with the AE-ANN trained with/without Adam optimizer respecti vely . In Fig. 10B, we see that our spiking model achie ves a performance in between the two ANN models, a trend we ha ve observ ed earlier while training autoencoders on MNIST . In this case, the A C-SNN is trained with T h as 15, while A C-ANNs are trained without any output quantization; both are trained on Dataset A. In Fig. 10C, we observe the impact of quantization for the ANN model and the corresponding impact of lower T h for SNN. F or higher hidden state bit precision, the ANN model outperforms the SNN one. Ho we ver for extreme quantization case, number of bits = 2, and 1, the SNN performs better . This could possibly be attrib uted to the temporal nature of SNN, where the computation is e vent-dri ven and spread out o ver se veral time steps. Note, all simulations were performed using MA TLAB, which is a high lev el simulation en vironment. The algorithm, ho wev er , is agnostic of implementation en vironment from a functional point of vie w and can be easily ported to more traditional ML frame works such as PyT orch or T ensorFlow . T able 1. Summary of results obtained for the 3 tasks - Autoencoder on MNIST , Autoencoder on Fashion- MNIST , and Audio to Image con version (T = input duration for SNN) Dataset Network Size Epochs T Loss (MSE) (test) SNN ANN ANN (with Adam) MNIST 784-196-784 1 15 0.357 0.226 0.122 Fashion-MNIST 784-512-784 1 60 0.178 0.416 0.300 784-1024-784 1 60 0.140 0.418 0.387 Audio-to-Image A 58500-2048-196/196-784 20 30 0.254 0.408 0.144 Audio-to-Image B 58500-2048-196/196-784 20 30 0.543 0.611 0.556 4 DISCUSSION AND CONCLUSION In this work, we propose a method to synthesize images in spike-based environment. In T able 1, we hav e summarized the results of training autoencoders and audiocoders using our o wn V mem -based backpropagation method 1 2 . The proposed algorithm brings SNN performance at par with ANNs for the given tasks, thus depicting the effecti veness of the training algorithm. W e demonstrate that spiking autoencoders can be used to generate reduced-duration spike maps (“hidden state”) of an input spike train, which are a highly compressed v ersion of the input, and they can be utilized across applications. This is also the first w ork to demonstrate audio to image synthesis in spiking domain. While training these autoencoders, we made a few important and interesting observ ations; the first one is the importance of bit masking of the output layer . Trying to steer the membrane potentials of all the neurons is extremely hard to optimize, and selecti vely correcting only incorrectly spik ed neurons makes training easier . This could be applicable to any spiking neural network with a lar ge output layer . Second, while the AE-SNN is trained with spike durations of 15 time steps, we can use hidden state representations of much lower duration to train our audiocoder with negligible loss in reconstruction of images for the audio-to-image synthesis task. In this task, the ANN model trained with Adam outperformed the SNN one when trained with full precision 1 T able 1: Audio-to-Image A: SNN: T h = 15 , ANN : no quantization for hidden state 2 T able 1: Audio-to-Image B: SNN: T h = 10 , ANN : no quantization for hidden state This is a provisional file , not the final typeset ar ticle 14 Roy et al. Synthesizing Images from Spatio-T emporal Representations “hidden state”. Ho wev er , at ultra-lo w precision, the hidden state loses it’ s meaning in ANN domain, b ut in SNN domain, the network can still learn from it. This observation raises important questions on the ability of SNNs to possibly compute with less data. While sparsity during inference has always been an important aspect of SNNs, this work suggests that sparsity during training can also be potentially exploited by SNNs. W e explored ho w SNNs can be used to compress information into compact spatio-temporal representations and then reconstruct that information back from it. Another interesting observation is that we can potentially train autoencoders and stack them to create deeper spiking netw orks with greater functionalities. This could be an alternativ e approach to training deep spiking networks. Thus, this work sheds light on the interesting behavior of spiking neural networks, their ability to generate compact spatio-temporal representations of data, and of fers a new training paradigm for learning meaningful representations of comple x data. CONFLICT OF INTEREST ST A TEMENT The authors declare that the research was conducted in the absence of an y commercial or financial relationships that could be construed as a potential conflict of interest. A UTHOR CONTRIBUTIONS DR, PP , and KR concei ved the idea. DR formulated the problem and performed the simulations. DR, PP , and KR analyzed the results. DR wrote the paper . A CKNO WLEDGMENTS This work was supported in part by the Center for Brain Inspired Computing (C-BRIC), one of the six centers in JUMP , a Semiconductor Research Corporation (SRC) program sponsored by D ARP A, the National Science Foundation, Intel Corporation, the DoD V anne var Bush Fello wship, and by the U.S. Army Research Laboratory and the U.K. Ministry of Defense under Agreement Number W911NF-16-3-0001. D A T A A V AILABILITY ST A TEMENT The datasets analyzed for this study can be found at the follo wing links: • MNIST http://yann.lecun.com/exdb/mnist/ • Fashion MNIST https://github .com/zalandoresearch/fashion-mnist • TI-46 audio dataset https://catalog.ldc.upenn.edu/LDC93S9 REFERENCES Benayoun, M., Co wan, J. D., van Drongelen, W ., and W allace, E. (2010). A v alanches in a stochastic model of spiking neurons. PLoS computational biology 6, e1000846 Bohte, S. M., K ok, J. N., and La Poutre, H. (2002). Error-backpropag ation in temporally encoded netw orks of spiking neurons. Neur ocomputing 48, 17–37 Burbank, K. S. (2015). Mirrored stdp implements autoencoder learning in a network of spiking neurons. PLoS computational biology 11, e1004566 Esser , S. K., Appuswamy , R., Merolla, P ., Arthur , J. V ., and Modha, D. S. (2015). Backpropagation for energy-ef ficient neuromorphic computing. In Advances in Neural Information Pr ocessing Systems . 1117–1125 Frontier s 15 Roy et al. Synthesizing Images from Spatio-T emporal Representations Ghosh-Dastidar , S. and Adeli, H. (2009). Spiking neural networks. International journal of neural systems 19, 295–308 Jin, Y ., Li, P ., and Zhang, W . (2018). Hybrid macro/micro le vel backpropagation for training deep spiking neural networks. arXiv pr eprint Kingma, D. P . and Ba, J. (2014). Adam: A method for stochastic optimization. arXiv pr eprint LeCun, Y ., Bengio, Y ., and Hinton, G. (2015). Deep learning. natur e 521, 436 LeCun, Y ., Bottou, L., Bengio, Y ., and Haf fner , P . (1998). Gradient-based learning applied to document recognition. Pr oceedings of the IEEE 86, 2278–2324 Lee, J. H., Delbruck, T ., and Pfeiffer , M. (2016). T raining deep spiking neural networks using backpropagation. F r ontiers in neur oscience 10, 508 Liberman, M., Amsler , R., Church, K., Fox, E., Hafner , C., Klav ans, J., et al. (1993). T i 46-word. Philadelphia (P ennsylvania): Linguistic Data Consortium Maass, W . (1997). Networks of spiking neurons: the third generation of neural network models. Neural networks 10, 1659–1671 Maass, W . (2015). T o spike or not to spike: that is the question. Pr oceedings of the IEEE 103, 2219–2224 Masci, J., Meier , U., Cire s ¸ an, D., and Schmidhuber , J. (2011). Stacked con volutional auto-encoders for hierarchical feature e xtraction. In International Confer ence on Artificial Neur al Networks (Springer), 52–59 Nair , V . and Hinton, G. E. (2010). Rectified linear units improv e restricted boltzmann machines. In Pr oceedings of the 27th international confer ence on machine learning (ICML-10) . 807–814 Nessler , B., Pfeiffer , M., Buesing, L., and Maass, W . (2013). Bayesian computation emer ges in generic cortical microcircuits through spike-timing-dependent plasticity . PLoS computational biology 9, e1003037 Panda, P . and Roy , K. (2016). Unsupervised regenerati ve learning of hierarchical features in spiking deep networks for object recognition. In Neural Networks (IJCNN), 2016 International J oint Conference on (IEEE), 299–306 Rathi, N. and Roy , K. (2018). Stdp-based unsupervised multimodal learning with cross-modal processing in spiking neural network. IEEE T ransactions on Emer ging T opics in Computational Intelligence Sengupta, A., Parsa, M., Han, B., and Roy , K. (2016). Probabilistic deep spiking neural systems enabled by magnetic tunnel junction. IEEE T ransactions on Electr on Devices 63, 2963–2970 Shrestha, S. B. and Orchard, G. (2018). Slayer: Spike layer error reassignment in time. In Advances in Neural Information Pr ocessing Systems . 1419–1428 Sj ¨ ostr ¨ om, J. and Gerstner , W . (2010). Spike-timing dependent plasticity . Spike-timing dependent plasticity 35, 0–0 Slaney , M. (1998). Auditory toolbox. Interval Researc h Corporation, T ech. Rep 10, 1998 Sri vasta v a, N., Hinton, G., Krizhevsky , A., Sutsk ev er , I., and Salakhutdinov , R. (2014). Dropout: a simple way to pre vent neural networks from ov erfitting. The Journal of Machine Learning Resear ch 15, 1929–1958 Sri vasta v a, N. and Salakhutdino v , R. (2012). Learning representations for multimodal data with deep belief nets. In International confer ence on machine learning workshop . v ol. 79 T a vanaei, A., Masquelier , T ., and Maida, A. (2018). Representation learning using e vent-based stdp. Neural Networks This is a provisional file , not the final typeset ar ticle 16 Roy et al. Synthesizing Images from Spatio-T emporal Representations V incent, P ., Larochelle, H., Bengio, Y ., and Manzagol, P .-A. (2008). Extracting and composing robust features with denoising autoencoders. In Pr oceedings of the 25th international conference on Mac hine learning (A CM), 1096–1103 W erbos, P . J. (1990). Backpropagation through time: what it does and ho w to do it. Pr oceedings of the IEEE 78, 1550–1560 W u, Q., McGinnity , M., Maguire, L., Glackin, B., and Belatreche, A. (2007). Learning mechanisms in networks of spiking neurons. In T r ends in Neural Computation (Springer). 171–197 W u, Y ., Deng, L., Li, G., Zhu, J., and Shi, L. (2018a). Direct training for spiking neural networks: F aster , larger , better . arXiv pr eprint W u, Y ., Deng, L., Li, G., Zhu, J., and Shi, L. (2018b). Spatio-temporal backpropagation for training high-performance spiking neural networks. F r ontiers in neur oscience 12 W ysoski, S. G., Benusko va, L., and Kasabo v , N. (2010). Evolving spiking neural networks for audiovisual information processing. Neural Networks 23, 819–835 Xiao, H., Rasul, K., and V ollgraf, R. (2017). Fashion-mnist: a no vel image dataset for benchmarking machine learning algorithms. arXiv pr eprint Frontier s 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment