Collage Inference: Achieving low tail latency during distributed image classification using coded redundancy models
Reducing the latency variance in machine learning inference is a key requirement in many applications. Variance is harder to control in a cloud deployment in the presence of stragglers. In spite of this challenge, inference is increasingly being done…
Authors: Krishna Narra, Zhifeng Lin, Ganesh Ananthanarayanan
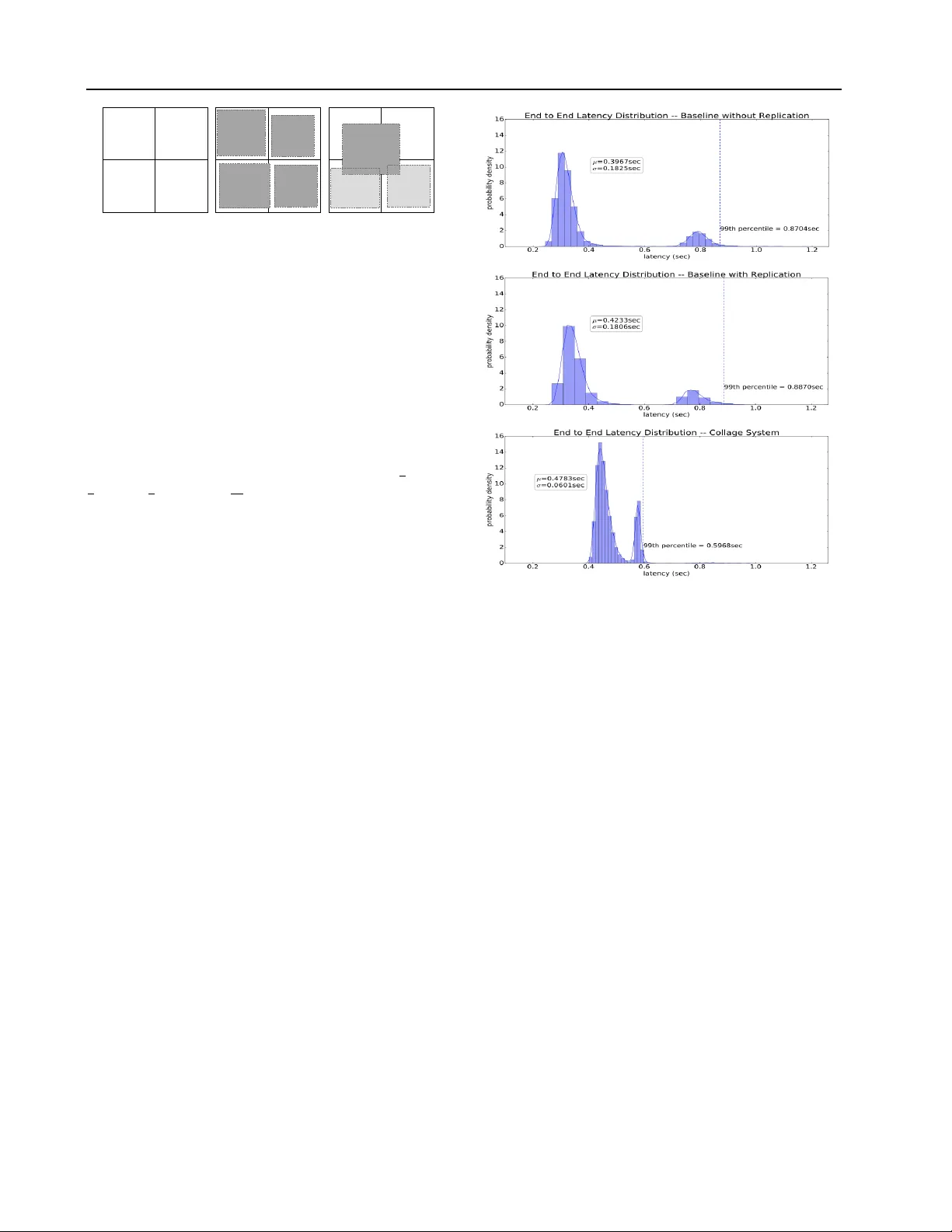
Collage Infer ence: Achieving lo w tail latency during distrib uted image classification using coded r edundancy models Krishna Giri Narra 1 Zhifeng Lin 1 Ganesh Ananthanarayanan 2 Salman A vestimehr 1 Murali Annav aram 1 Abstract Reducing the latency v ariance in machine learn- ing inference is a ke y requirement in many appli- cations. V ariance is harder to control in a cloud deployment in the presence of stragglers. In spite of this challenge, inference is increasingly being done in the cloud, due to the advent of afford- able machine learning as a service (MLaaS) plat- forms. Existing approaches to reduce variance rely on replication which is expensi v e and par- tially negates the af fordability of MLaaS. In this work, we ar gue that MLaaS platforms also pro- vide unique opportunities to cut the cost of redun- dancy . In MLaaS platforms, multiple inference requests are concurrently recei ved by a load bal- ancer which can then create a more cost-efficient redundancy coding across a larger collection of images. W e propose a no v el con volutional neu- ral network model, Collage-CNN, to provide a lo w-cost redundanc y frame work. A Collage-CNN model takes a collage formed by combining mul- tiple images and performs multi-image classifica- tion in one shot, albeit at slightly lo wer accuracy . W e then augment a collection of traditional single image classifiers with a single Collage-CNN clas- sifier which acts as a lo w-cost redundant backup. Collage-CNN then provides backup classification results if a single image classification straggles. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile tail la- tency of inference can be reduced by 1.47X com- pared to replication based approaches while pro- viding high accuracy . Also, v ariation in inference latency can be reduced by 9X with a slight in- crease in av erage inference latency . 1 EE Department, Uni versity Of Southern Californi a, Los Ange- les, California, USA 2 Microsoft Research, Redmond, W ashington, USA. Correspondence to: Krishna Giri Narra < narra@usc.edu > . CodML workshop at 36th International Conference on Machine Learning (ICML 2019). cheetah camel deer 1 2 3 4 tiger , camel deer , frog 5 frog Figure 1. Collage Inference illustration 1. Introduction Low latency and lo w variance machine learning inference is critical in man y control systems applications, such as robotics. Machine learning as a service (MLaaS) platforms are attracti ve for scaling inference traf fic. The inference is performed by deploying the trained models on the MLaaS platforms. T o achieve scalability of the inference service, incoming queries are distributed across multiple replicas of the ML model. As the inference demands gro w an enterprise can simply increase the cloud instances to meet the demand. Howe ver , virtualized services are prone to straggler prob- lems, which lead to the high variability and long tail in the inference latency . Straggler incidence is more acute in cloud-based deployments because of the widespread shar - ing of compute, memory and network resources ( Dean and Barroso , 2013 ). Existing techniques to lower tail latency can be broadly classified into two cate gories: replication (e.g., ( Dean and Barroso , 2013 ; Ananthanarayanan et al . , 2010 ; W ang et al . , 2014 )), coded computing (e.g.,( Lee et al . , 2016 ; Li et al . , 2016 ; Dutta et al . , 2016 ; Y u et al . , 2017 )). In replication based techniques, additional resources are used to add re- dundancy during e xecution: either a task is replicated at its launch, or a task is replicated on detection of a straggler node. Replicating e very request pro-activ ely as a straggler mitigation strategy could lead to a significant increase in resource costs. Replicating a request reactively on the de- tection of a straggler can increase latency . While MLaaS platforms are more prone to stragglers, in this work we ar- gue that the y are also more amenable to low cost redundancy Collage Inference 7 Compute Node 1 Node 10 Node 9 2 8 3 4 5 6 7 predicted class predicted predicted class classes Decode 4 7 8 5 2 3 6 7 Request 1 Request 9 Request Request Request Request Request Request Request co l l a g e cr e a t i o n 1 9 Load Balancer/Encoder 8 collage image 1 image 9 S- CNN Collage - CNN S- CNN Load Balancer/Decoder Final Decode Process image Respon se 1 Respon se 2 Respon se 3 Respon se 4 Respon se 5 Respon se 6 Respon se 7 Respon se 8 Respon se 9 Figure 2. Collage Inference T echnique schemes. MLaaS platforms deploy a front-end load balancer that receiv es requests from multiple users and submits them to the back-end cloud instances. In this setting, the load balancer has the unique advantage of treating multiple re- quests as a single collective and create a more cost effecti ve redundancy strate gy . W e propose the Collage Inference technique as a cost effec- tiv e redundanc y strategy to deal with v ariance in inference latency . Collage Inference uses a unique con volutional neu- ral netw ork (CNN) based coded redundanc y model, referred to as a Collage-CNN, that can perform multiple predictions in one shot, albeit at a slight reduction in prediction accuracy . Collage-CNN is like a parity model where the input encod- ing is the collection of images that are spatially arranged into a collage. Its output is decoded to get the missing predictions of images that are assigned to straggler nodes. This coded redundancy model is run concurrently as a single backup service for a collection of indi vidual image inference models. An indi vidual image inference model is referred to as an S-CNN. Figure 1 sho ws a service comprising of four S-CNN models and one Collage-CNN model. When predic- tion from model 4 is missing, the corresponding prediction from Collage-CNN is used in its place. 2. Collage Inference T echnique The Collage-CNN model is a novel multi-object classifi- cation model. The critical insight behind collage infer- ence is that the spatial information within an input im- age is critical, for CNNs to achiev e high accuracy , and it should be maintained. So, we use the collage image composed of all the images as the encoding. The Collage- CNN model takes a collage encoded from the images [ I mag e 1 , .., I mag e i , .., I mag e N ] , where each image is in- put to one of the N single image classifiers. The Collage- CNN provides the predictions for all the objects in the col- lage along with the locations of each object in the collage. The predicted locations are in the form of rectangular bound- ing boxes. By smartly encoding the individual images into a collage and using location information from the Collage- CNN predictions, the collage inference technique can re- place the missing predictions from any straggler nodes. The encoding of individual images into a single collage image happens as follo ws. Let a Collage-CNN be pro viding backup for N S-CNN model replicas that are each running on a compute node. T o encode the N images into a collage we first create a square grid consisting of [ √ N , √ N ] boxes. Each image that is assigned to an S-CNN model running on compute node i is placed in a predefined square box within the collage. Specifically , in the collage, each compute node i is assigned the box location i . This encoding information is used while decoding outputs of the Collage-CNN. From the outputs of the Collage-CNN, class prediction corresponding to each bounding box i is extracted, and this prediction corresponds to the node i . Our Collage-CNN model takes collage with 416x416 resolution as input. As the size of N grows, more images must be packed into the collage, which reduces the resolution of each image. It can lo wer the accuracy of predictions. Figure 2 sho ws the collage inference technique for ten nodes with one of the nodes providing redundancy for the remain- ing N = 9 nodes. Each of the nine nodes running S-CNN model takes an individual image as input. The 10 th node takes the collage image as input. Inside the load balancer, each of the nine input images is lo wered in resolution and inserted into a specific location to form the collage image. The input image to node i goes into location i in the collage image. This collage image is provided as input to node 10. The predictions from the Collage-CNN are processed using the collage decoding algorithm. The output predictions from all the ten nodes go to the final decode process in the load balancer . This decode process uses the predictions from the Collage-CNN model to fill in any missing predictions from the nine nodes and return the final prediction responses to the user . The collage decoding algorithm extracts the best possible class predictions for the N images from all the Collage- CNN predictions. The decoding algorithm calculates the Jaccard similarity coefficient of each predicted bounding box with each of the N ground truth bounding boxes that are used in creating the collages. Let area of ground truth bounding box be A g t , area of predicted bounding box be A pred and area of intersection between both the boxes be A i . Then Jaccard similarity coef ficient can be computed using the formula: A i A gt + A pred − A i . The ground truth bounding box with the largest similarity coefficient is assigned the class label of the predicted bounding box. As a result, the image present in this ground truth bounding box is predicted as ha ving an object belonging to this class label. This is repeated for all the object predictions. T o illustrate the algorithm, consider example scenarios shown in figure 3 . The ground truth input collage is a 2x2 collage that is formed Collage Inference Class A Class B Class C Class D G1 G2 G3 G4 (a) Ground T ruth Class A Class E Class C Class D P1 P2 P3 P4 (b) Scenario 1 Class A P1 Class C P3 Class D P4 (c) Scenario 2 Figure 3. Fe w Collage Prediction scenarios from four images. It has four bounding boxes G1, G2, G3, and G4 which contain objects belonging to classes A, B, C, and D respectiv ely . In scenario 1, the collage model predicts four bounding box es P1, P2, P3 and P4. In this scenario: P1 would ha ve lar gest similarity v alue with G1, P2 with G2, P3 with G3 and P4 with G4. So, the decoding algorithm predicts class A in G1, class E in G2, class C in G3, class D in G4. In scenario 2, three bounding boxes are predicted by the model. Predicted box P1 is spread ov er G1, G2, G3 and G4. Jaccard similarity v alue of P1 with box G1 is: 1 3 , G2 is: 1 7 , G3 is: 1 7 and G4 is: 1 17 . So, the algorithm predicts class A in G1, empty prediction in G2, class C in G3, class D in G4. 3. Experimental Results W e trained and measured the top-1 accuracy of Collage- CNN and S-CNN models using images from 100 classes of the Imagenet-1k (ILSVRC 2012) dataset. Resnet-34 is used as the S-CNN model, and its accuracy is 80.72%. Accurac y of Collage-CNN is 76.9% when there are nine images per collage. Hence, Collage-CNN essentially tradesof f a small accuracy degradation to impro ve the cost of redundancy through collage coding. W e implemented an online image classification system and deployed it on the Digital Ocean cloud. This system is sim- ilar to the one described in figure 2 where a load balancer receiv es requests from multiple clients concurrently . The load balancer is responsible for creating an appropriate col- lage image with the incoming images. W e performed exper- iments with nine S-CNN compute nodes and one Collage- CNN compute node. V alidation images from Imagenet dataset are used to generate inference requests. T wo base- lines are used for comparison. First is the no replication baseline, where no straggling request is replicated. Sec- ond is the replication baseline, where straggling requests are replicated based on a fixed timeout. W e measured the end-to-end latency for each request from the time it is sent to the time predictions for it are received. For requests to Collage-CNN model, the end-to-end latency also includes time spent in creating the collage image. The end to end latenc y distribution observed when the image classification system consists of nine S-CNN models with no Figure 4. Inference latenc y comparison request replication is sho wn in the top sub-figure of figure 4 . The middle sub-figure corresponds to the system consisting of nine S-CNN models with request replication. The bottom sub-figure corresponds to system consisting of nine S-CNN models and one Collage-CNN model. The x-axis sho ws the latency in seconds. The histograms along y-axis are the probability density v alues for the latenc y distrib ution. The blue curve line sho ws the estimated probability density func- tion. Collage inference has a slightly higher mean latenc y due to the collage creation time. Using Collage-CNN model reduces the standard deviation in latency by 3X and v ariance by 9X. The 99-th percentile latency of Collage inference is 1.47X lower than both No replication and Replication meth- ods. When the Collage-CNN predictions are used by the final decoder to fill in the missing predictions, the accuracy of these predictions is 87.86%. It is significantly better than the top-1 accuracy (76.9%) because, when using Collage- CNN, only a subset of its predictions corresponding to the straggler nodes need to be accurate. 4. Conclusion and Future W ork In this paper we described a nov el coded redundancy model and demonstrated that it reduces inference tail latenc y . Fu- ture work includes improving the Collage-CNN model and reducing the ov erhead of creating the collage image. Collage Inference References Ganesh Ananthanarayanan, Srikanth Kandula, Albert G Greenberg, Ion Stoica, Y i Lu, Bikas Saha, and Edward Harris. 2010. Reining in the Outliers in Map-Reduce Clusters using Mantri.. In OSDI , V ol. 10. 24. Jeffre y Dean and Luiz Andr Barroso. 2013. The T ail at Scale. Commun. A CM 56 (2013), 74– 80. http://cacm.acm.org/magazines/2013/ 2/160173- the- tail- at- scale/fulltext Sanghamitra Dutta, V iveck Cadambe, and Pulkit Grover . 2016. Short-Dot: Computing Large Linear Transforms Distributedly Using Coded Short Dot Products. In Ad- vances In Neural Information Pr ocessing Systems . 2092– 2100. Kangwook Lee, Maximilian Lam, Ramtin Pedarsani, Dim- itris Papailiopoulos, and Kannan Ramchandran. 2016. Speeding up distributed machine learning using codes. In 2016 IEEE International Symposium on Information Theory (ISIT) . 1143–1147. https://doi.org/10. 1109/ISIT.2016.7541478 S. Li, M. A. Maddah-Ali, and A. S. A vestimehr . 2016. A Unified Coding Framework for Distributed Computing with Straggling Servers. In 2016 IEEE Globecom W ork- shops (GC Wkshps) . 1–6. https://doi.org/10. 1109/GLOCOMW.2016.7848828 Da W ang, Gauri Joshi, and Gregory W ornell. 2014. Effi- cient T ask Replication for Fast Response Times in Par- allel Computation. SIGMETRICS P erform. Eval. Rev . 42, 1 (June 2014), 599–600. https://doi.org/10. 1145/2637364.2592042 Qian Y u, Mohammad Maddah-Ali, and Salman A vestimehr . 2017. Polynomial codes: an optimal design for high- dimensional coded matrix multiplication. In Advances in Neural Information Pr ocessing Systems . 4403–4413.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment