Continual Learning of New Sound Classes using Generative Replay
Continual learning consists in incrementally training a model on a sequence of datasets and testing on the union of all datasets. In this paper, we examine continual learning for the problem of sound classification, in which we wish to refine already…
Authors: Zhepei Wang, Cem Subakan, Efthymios Tzinis
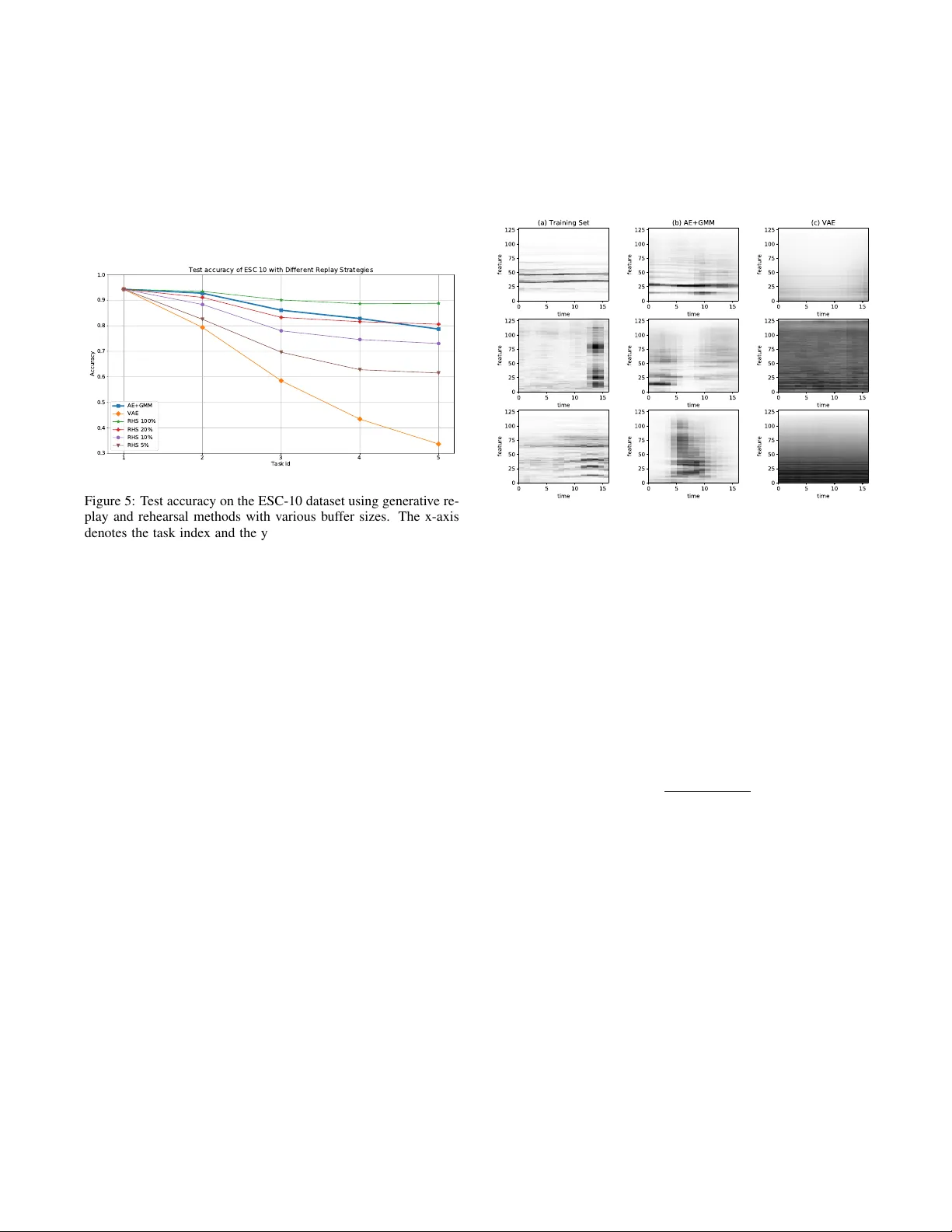
CONTINU AL LEARNING OF NEW SOUND CLASSES USING GENERA TIVE REPLA Y Zhepei W ang ] , Cem Subakan [ , Efthymios Tzinis ] , P aris Smaragdis ] \ , Laur ent Charlin [ ♦ ] Uni versity of Illinois at Urbana-Champaign, Department of Computer Science [ Mila–Quebec Artificial Intelligence Institute ♦ HEC Montr ´ eal, Canada CIF AR AI Chair \ Adobe Research ABSTRA CT Continual learning consists in incrementally training a model on a sequence of datasets and testing on the union of all datasets. In this paper , we examine continual learning for the problem of sound classification, in which we wish to refine already trained models to learn new sound classes. In practice one does not want to maintain all past training data and retrain from scratch, but naively updat- ing a model with new data(sets) results in a degradation of already learned tasks, which is referred to as “catastrophic forgetting. ” W e dev elop a g enerative r eplay procedure for generating training audio spectrogram data, in place of keeping older training datasets. W e show that by incrementally refining a classifier with generati ve re- play a generator that is 4% of the size of all previous training data matches the performance of refining the classifier keeping 20% of all previous training data. W e thus conclude that we can extend a trained sound classifier to learn new classes without having to keep previously used datasets. Index T erms — Sound classification, neural networks, contin- ual learning, generativ e replay 1. INTR ODUCTION Standard supervised machine learning setup posits that the full training dataset is av ailable to the model at once. This is a sim- plistic assumption. In the wild, the training data may arriv e in (non- iid) batches and new classes may appear throughout the learning process. This is typical of human learning where new concepts (classes) are learned throughout life. Continual learning proposes a more realistic sequential learn- ing paradigm composed of training episodes [1, 2, 3]. At each episode, the model is only trained on data from a single new task and does not hav e access to data from earlier tasks. Continual learn- ing is also useful for de vices with constrained access to data (either due to storage limitations, or priv acy constraints). In such cases classifiers need to be continually trained to learn ne w classes while minimizing storage. This limits the amount of possible retraining on previous tasks. Continual learning is particularly challenging for neural net- works because of catastrophic for getting : at each episode the net- work will “for get” the kno wledge it has learned in earlier tasks [4, 5]. While a flurry of methods hav e been recently proposed for continual learning [6, 7, 8, 9, 10], much work remains before con- tinual learning becomes a practical technique. In this paper , we explore a continual learning setup for training a classifier on en vironmental sound classes. This is a challenging This work is supported by NSF grant #1453104. task because it necessitates learning a classifier on time-series data, as opposed to typical applications in the continual learning literature that focus on static data (e.g., images) [7]. T o alleviate catastrophic forgetting, we utilize the generative replay technique [8], which provides very competitive continually- learned classifiers. A generator is trained simultaneously with the classifier . For each task, the generator is used to simulate earlier- task examples for the classifier . Further , we propose a con volutional autoencoder architecture to embed time-series data, and we make use of the two-step learning framew ork introduced in [11] to learn the generativ e model to replay earlier tasks. W e experiment with the ESC-10 (En vironmental Sound Classi- fication) dataset [12]. Namely , we compare our proposed genera- tiv e replay based method with r ehearsal which consists in storing a fixed percentage of the data associated with earlier tasks to combat forgetting. Stored data is used as training data in each of the sub- sequent episodes. This method has been shown to be a v ery strong baseline [13]. W e sho w that by using a generativ e model with size approximately equal to 4% of the whole training set, we are able to match the classification accuracy obtained with a rehearsal method which stores 20% of the training dataset. 2. METHODOLOGY FOR CONTINU AL LEARNING 2.1. Definition of Continual Learning In continual learning [1, 2, 3], the goal is to train a model on a sequence of datasets {D 1 , D 2 , . . . , D T } , where each dataset corre- sponds to a (new) task . According to the standard continual learn- ing setup, when training the model for task t , the data of past tasks and future tasks are not a vailable. That is, when training for task t , we are only allo wed to use the dataset D t . The objectiv e is to learn a single model which is able to predict well on data from all tasks 1 , . . . , T , despite training in a sequential manner . This is challenging in neural network models as training on the current task without incorporating data from earlier tasks typically results in for getting the e xisting knowledge. This phenomenon is referred to as Catastr ophic F or getting [4, 5]. Namely , when training for task t , the model forgets the kno wledge related to tasks with index < t , if no measures are taken to mitigate forgetting. In the follo wing two subsections, we describe two strategies to combat catastrophic forgetting. 1 1 In addition to avoiding catastrophic forgetting, another goal of contin- ual learning is to improve/speed-up learning on future and past tasks. This is referred to as forward transfer and positive backwar d transfer [6]. This is a very interesting research direction for continual learning, but in this paper we focus more on combating catastrophic forgetting. 2.2. Naive Rehearsal A simple method to combat catastrophic forgetting is to keep a buf fer of random samples to remember the past tasks. The buf fer contains e xamples from earlier tasks to reinforce the kno wledge from earlier tasks, when training on the current task. This method is referred to as naive rehearsal or simply r ehearsal , as we do in the rest of this paper . Although simple, this method is surpris- ingly effecti ve, and has been shown to perform very comparable to state-of-the-art continual learning methods on various standard continual learning experiments [13]. For this reason we use re- hearsal as a baseline method. When training for t , we keep a buf fer M = S t − 1 k =1 M k , where M k contains randomly selected e xamples from task k , such that k ≤ t − 1 . The cost function associated with rehearsal is: L t naivereplay = 1 |D t | X ( x,y ) ∈D t cost ( y , f θ ( x ))+ t − 1 X k =1 1 |M k | X ( x 0 ,y 0 ) ∈M k cost ( y 0 , f θ ( x 0 )) , (1) where the first term accounts for the loss on the current task (current loss), and the second term accounts for the rehearsal loss. The input features are denoted with x , the tar get values are denoted with y , the continually trained classifier is denoted with f θ ( . ) , and cost ( . ) denotes a classification loss, which is typically chosen as the cross- entropy loss. In Figure 1 we illustrate the schematics of the loss function. f t X t ˆ Y t current loss X 1: t − 1 buf fer ˆ Y 1: t − 1 rh. loss Y t Y 1: t − 1 buf fer Figure 1: The diagram for the loss computation in the naive re- hearsal method at task t . W e separately compute two losses for the current tasks, and a rehearsal (rh.) loss on the stored buf fer . Even though rehearsal combats forgetting, it requires the stor- age of data in form of a rehearsal buf fer . In the next section, we introduce another method which mitigates forgetting by continually learning a generativ e model, which does not require storage of past data items. 2.3. Generative Replay An effectiv e alternati ve to rehearsal is generative replay [8]. This method continually trains a generati ve model in addition to the clas- sifier to r eplay the data from earlier tasks. By the virtue of having a generative model, in lieu of storing examples from earlier tasks, we generate data, and use this generated data to av oid for getting (by using it as training data). The cost function for continual classifier training is therefore written as follows: L t genreplay = X ( x,y ) ∈D t cost ( f t ( x ) , y ) + X x g ∈D g cost ( f t ( x g ) , f t − 1 ( x g )) , (2) where, the first term is the loss associated with the current task, and the second term is the loss associated with the rehearsal, where D g is data simulated from the generativ e model model after being done with training it until task t − 1 , which is used to rehearse the datasets {D 1 , . . . , D t − 1 } . The schematic illustration of this loss function is sho wn in Figure 3. Similarly , the generator G t is trained by using the examples from the current dataset D t and the simulated examples from the generator G t − 1 : L t gen = X x ∈D t gencost ( x ) + X x g ∈D g gencost ( x g ) , (3) where again the loss function is composed of the current loss term (the first term) and the rehearsal loss (the second term). W e illustrate the workflo w of the method in Figure 2. G t − 1 X 1: t − 1 replay G t replay loss X t current loss Figure 2: Diagram for continually training a generativ e model using generativ e replay: At task t , the data is r eplayed from the genera- tiv e model G t − 1 , and its likelihood is ev aluated on the generative model G t that we currently train. The dashed blocks means that the parameters are frozen, and not being updated, and solid blocks mean that the block parameters are optimized. X 1: t − 1 replay f t − 1 Y 1: t − 1 target replay loss f t ˆ Y 1: t − 1 G t − 1 X t ˆ Y t current loss Y t Figure 3: Training the classifier using the generative replay at task t : The data for the earlier tasks is generated from G t − 1 . The outputs of the current classifier f t and the earlier classifier f t − 1 are matched to compute a replay loss. Note that in our application the generator G generates of spectra segments as our goal to classify segments of audio data. Next, we describe the details of the architecture of the generator G . 2.4. The Generative Model Ar chitecture In this paper , we use maximum-likelihood based generati ve model- ing as opposed to Generati ve Adversarial Networks (GANs) [14] as the former is significantly easier to train [15]. In our generative models, we use a con volutional autoencoder to compute embeddings for spectrogram sequences. The architec- ture of our autoencoder is sho wn in Figure 4, which consists of us- ing con volutional layers across the time axis to model the temporal structure, and then reducing and increasing the feature dimension- ality using fully connected layers. After learning the embeddings h , we learn the generative model by fitting a Gaussian mixture model (GMM) on the latent embeddings, as described in the 2-step learn- ing method in [11]. Adv antages of using GMMs in the latent space is adv ocated by multiple papers in the literature [16, 11, 17, 18, 19]. In our experiments we ha ve observed that separating the learning of parameters of the prior distribution on the latent variables from the learning of autoencoder resulted in the accurate learning of the generativ e model (which we refer to as 2-step training). W e have observed that the joint training of GMM and the autoencoder of- ten resulted in slightly worse results than that of the 2-step learning approach, and therefore we hav e chosen to use the 2-step training rather than jointly training the prior and the autoencoder . W e also compare the proposed generative modeling scheme with V AEs with standard Gaussian prior [20], and observe that the proposed gen- erativ e modeling scheme yields much superior generations, which results in better classification. Fully Connected Fully Connected Encoder Conv 1D Conv 1D Conv 1D Decoder Transpose Conv 1D Transpose Conv 1D Transpose Conv 1D h Autoencoder Architecture Figure 4: The autoencoder architecture used to model the spec- tra. The con volutional encoder maps the spectra into latent space h , which is then transformed by the decoder into reconstructed rep- resentation. W e apply ReLU after each of the first two conv olutional layers in both the encoder and the decoder . 3. EXPERIMENT AL SETUP In this section we introduce our continual learning setup for audio classification. The e xperiments simulate scenarios where the model incrementally learns new sound classes without having full access to the previously-encountered sound classes. The model observes ten sound classes in a sequence of five tasks, where in each task two new classes are presented. This is similar to similar to the setup in [21]. 3.1. Data W e select the publicly a vailable ESC-10 [12] dataset for our exper - iments. The ESC-10 dataset consists of 400 fiv e-seconds record- ings sampled at 44kHz of acoustic events from 10 classes, namely: chainsaw , clock ticking , crackling fir e , crying baby , dog barking , helicopter , rain , r ooster , seawaves , and sneezing . For each recording we extract a T ime-Frequency (TF) spectro- gram representation using a 2048 samples window and a 512 sam- ples hop size. Next, we compute the square root of the mel-scaled spectrogram using 128 mel-features for each spectrogram. W e fur - ther segment our data to snippets that correspond to ≈ 220 ms so that each input data sample has a size of 128 × 16 . W e ignore low- energy spectra whose Frobenius norm is less than 1e-4. Finally , we normalize each spectrogram by the maximum ener gy from each mel-spectrogram so that each v alue lies in [0 , 1] . Our initial exper- imental results demonstrate that normalized mel-spectrograms are more discriminativ e under the chosen classifier architecture and can be easily reconstructed from the generator . In total there are 9500 mel-spectrograms that we further split into training, validation and test set with a ratio of 7 : 2 : 1 . T o setup the e xperiment in the setting of continual learning, we partition the dataset into fi ve subsets/tasks where all classes are mu- tually exclusi ve. W e group the classes based on the their label in- dices so the two sound classes from the same group are more similar to each other compared to classes from the other groups. 3.2. Generative Replay Setup W e next discuss the setup for generati ve replay including the archi- tecture of the classifier and the generator . 3.2.1. Classifier Ar chitectur e The classifier contains two 1-D con volutional layers with 64 and 128 filters, respectiv ely , one average pooling layer and two fully- connected layers with 50 and 10 hidden nodes each. For the con vo- lutional layers, we use a filter of length 3 and perform same-padding to the input. W e use a rectified linear unit (ReLU) as a nonlinear- ity after each con volutional layer and the first fully-connected layer . The output of the second fully-connected layer is passed into a soft- max layer for a 10 -class classification. 3.2.2. Generator Ar chitectur e W e experiment with both the autoencoder and the variational au- toencoder architectures as the generator . The encoder consists of three 1-D con volutional layers followed by a fully-connected layer with 50 hidden units. Each of the conv olutional layers uses 128 fil- ters of lengths 6 , 4 , and 3 and strides of 1 , 2 , and 2 , respecti vely . The decoder consists of three 1-D transposed con volutional layers, each with 128 filters of length 4 , 4 , and 7 and stride of 2 , 2 , and 1 , respec- tiv ely . W e do not perform zero-padding and we apply ReLU after each one of the first two con volutional layers in both the encoder and the decoder as shown in Figure 4. The variational autoencoder architecture contains an additional linear layer on top of the con vo- lutional encoder with 50 dimensions with a reparameterization trick for being able to sample from the latent space. 3.3. Rehearsal Setup W e compare the proposed generati ve replay mechanism with re- hearsal based methods. W e set up the rehearsal data by storing p % of the training data at each task into a b uffer . This buffer is a vail- able to the models throughout all tasks. In our setting, the size of the buf fer increases linearly with the number of tasks. W e adjust the percentage of the rehearsal data such that the the data from each task have equal probability to be dra wn. The parameter of the per- centage p of the rehearsal data lies in p ∈ { 5 , 10 , 20 , 100 } . 3.4. T raining Setup For all experiments, we optimize our models using Adam[22]. The batch size is set to 100 , and there are 10 - 15 batches per epoch for each task. T o train the classifier, we use an initial learning rate equal to 5e-4 and we train it for 300 epochs by minimizing the cross- entropy loss for each task. Moreover , in order to train the generator , we use an initial learning rate of 1e-3 and train it for 1700 epochs for each task. The autoencoder loss is the binary cross-entropy for each time-frequency bin between the original spectrogram and the reconstruction. The loss for the variational autoencoder is the sum of binary cross-entropy and KL-Diver gence between the modeled distribution and unit Gaussian. 4. RESUL TS AND DISCUSSIONS W e report the performance of various replay strategies under the sound classification setup. For each experiment we report the per- formance obtained by the models using fiv e dif ferent permutations of the order of tasks. In each task, we report the mean accuracy on the test set, which contains all sound classes that the model has seen up until the current task. 1 2 3 4 5 Task id 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Accuracy Test accuracy of ESC 10 with Different Replay Strategies AE+GMM VAE RHS 100% RHS 20% RHS 10% RHS 5% Figure 5: T est accurac y on the ESC-10 dataset using generativ e re- play and rehearsal methods with v arious buffer sizes. The x-axis denotes the task index and the y-axis refers to the accuracy of the model’ s prediction. Each point represents the mean of the accuracy after fiv e runs using different permutations for the tasks. 4.1. Overall Results Figure 5 shows the test accuracy of different generativ e re- play strategies and rehearsal methods for various buf fer sizes. “ AE+GMM” refers to the proposed generative replay setting with an autoencoder and a Gaussian mixture learned in two steps as de- scribed in Section 2.4. “V AE” corresponds to the v ariational autoen- coder mentioned in Section 3.2.2. “RHS X%” denotes a rehearsal based method with X% training data stored into the buf fer . “RHS 100 %” is used as an upper -bound estimation of the performance of any replay strategy since it corresponds to the ideal case where all the training data is av ailable in all future stages. Overall, RHS 100 % has the highest mean accuracy and it fits the expectation as an upper-bound estimation of any replay strat- egy . The performance of rehearsal methods increases as the pro- portion of the data stored in buf fer increases. W e also notice that for all methods the v ariance of the test accuracy tends to decrease as the number of tasks increases. Initially , the variance is large be- cause a random binary classification task might deviate too much in terms of dif ficulty from another . Howe ver , towards the end, the models ha ve seen all sound classes regardless of the permutation, and therefore the mean accuracy tends to stabilize. 4.2. Comparison Between AE+GMM and V AE AE+GMM significantly outperforms V AE as a replay strategy . The mean accuracy of AE+GMM is similar to RHS 20%, while V AE performs significantly worse than 5%. W e analyze such notable difference by looking at the samples generated by both models as illustrated in Figure 6. W e show three examples from the train- ing set and the respectiv e generations using AE+GMM and V AE. Note that V AE smooths out the temporal structure of the generated mel-spectrograms and lacks div ersity between classes. On the other hand, AE+GMM generates mel-spectrograms with much more di- verse temporal structure, exhibiting much closer resemblance to the examples from the training set. Figure 6: Mel-spectrograms from the training set (column a), gen- erated by AE-GMM (column b) and generated by a V AE (column c). Notice ho w the V AE generated data do not reproduce salient class features, whereas the proposed AE+GMM generator does so better . 4.3. Comparison Between AE+GMM and Rehearsal Based Methods W e observe that AE+GMM performs significantly better than re- hearsal schemes with buf fer proportion p = 5% , 10% . The accu- racy of AE+GMM is almost identical to RHS 20% at the last task and marginally higher in all previous tasks. The total number of trainable parameters in AE+GMM is less than 480 , 000 . The size of the network is equi valent to 480000 / (128 × 16) 9500 × 0 . 7 ≈ 3 . 5% of the train- ing data. In other words, using a generator whose size is less than 4 % of the training data, we are capable of reaching the accuracy comparable to storing 20 % of the data. The result demonstrates the effecti veness of AE+GMM generativ e replay strategy when limited storage space is av ailable. 5. CONCLUSION W e showed that generativ e replay is an effecti ve continual learn- ing method for audio classification tasks. Using a generati ve model whose size is less than 4 % of the size of the training data, we ob- tain a test accurac y comparable to a b uffer -based rehearsal scheme which needs to store 20 % of all used training data. These results highlight the potential of using generative models instead of keep- ing previously seen training data when there are storage constraints. W e see these aspects being crucial to sound recognition systems for which keeping prior training data is prohibitiv e, but often need (to learn) to perform new tasks on the fly . 6. REFERENCES [1] J. C. Schlimmer and D. Fisher , “ A case study of incremental concept induction, ” in AAAI , vol. 86, 1986, pp. 496–501. [2] R. S. Sutton, S. D. Whitehead, et al. , “Online learning with random representations, ” in Pr oceedings of the T enth Interna- tional Confer ence on Machine Learning , 1993, pp. 314–321. [3] M. B. Ring, “Child: A first step towards continual learning, ” Machine Learning , v ol. 28, no. 1, pp. 77–104, 1997. [4] S. Thrun and T . M. Mitchell, “Lifelong robot learning, ” Robotics and Autonomous Systems , v ol. 15, pp. 25–46, 1995. [5] R. French, “Catastrophic forgetting in connectionist net- works, ” T rends in Cognitive Sciences , no. 4, 1999. [6] D. Lopez-Paz and M. Ranzato, “Gradient episodic memory for continual learning, ” in Pr oceedings of the 31st Interna- tional Confer ence on Neur al Information Pr ocessing Systems . Curran Associates Inc., 2017, pp. 6470–6479. [7] S.-A. Rebuf fi, A. K olesnikov , G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning, ” in Pr oc. CVPR , 2017. [8] H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay , ” in Advances in Neural Informa- tion Pr ocessing Systems , 2017, pp. 2990–2999. [9] Z. Li and D. Hoiem, “Learning without forgetting, ” IEEE T ransactions on P attern Analysis and Machine Intelligence , vol. 40, no. 12, pp. 2935–2947, 2018. [10] G. I. Parisi, R. Kemker , J. L. Part, C. Kanan, and S. W ermter, “Continual lifelong learning with neural networks: A revie w , ” arXiv pr eprint arXiv:1802.07569 , 2018. [11] C. Subakan, O. K oyejo, and P . Smaragdis, “Learning the Base Distribution in Implicit Generativ e Models, ” ArXiv e-prints , Mar . 2018. [12] K. J. Piczak, “ESC: Dataset for En vironmental Sound Classification, ” in Proceedings of the 23rd Annual ACM Confer ence on Multimedia . A CM Press, 2015, pp. 1015– 1018. [Online]. A vailable: http://dl.acm.org/citation.cfm? doid=2733373.2806390 [13] Y . Hsu, Y . Liu, and Z. Kira, “Re-ev aluating continual learning scenarios: A categorization and case for strong baselines, ” CoRR , vol. abs/1810.12488, 2018. [Online]. A vailable: http://arxi v .org/abs/1810.12488 [14] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farle y , S. Ozair , A. Courville, and Y . Bengio, “Generative adversarial nets, ” in Advances in Neural Information Pr o- cessing Systems 27 , Z. Ghahramani, M. W elling, C. Cortes, N. D. Lawrence, and K. Q. W einberger , Eds. Curran Asso- ciates, Inc., 2014, pp. 2672–2680. [Online]. A vailable: http: //papers.nips.cc/paper/5423- generativ e- adversarial- nets.pdf [15] M. Lucic, K. Kurach, M. Michalski, O. Bousquet, and S. Gelly , “ Are gans created equal? a lar ge-scale study , ” in Pr oceedings of the 32Nd International Conference on Neural Information Pr ocessing Systems , ser . NIPS’18. USA: Curran Associates Inc., 2018, pp. 698–707. [Online]. A vailable: http://dl.acm.org/citation.cfm?id=3326943.3327008 [16] M. D.Hoffman and M. J. Johnson, “ELBO surgery: yet an- other way to carve up the variational e vidence lower bound, ” in NIPS workshop for approximate Bayesian infer ence , Dec. 2016. [17] Z. Jiang, Y . Zheng, H. T an, B. T ang, and H. Zhou, “V ariational deep embedding: an unsupervised and generativ e approach to clustering, ” in Proceedings of the 26th International Joint Confer ence on Artificial Intellig ence . AAAI Press, 2017, pp. 1965–1972. [18] N. Dilokthanakul, P . A. M. Mediano, M. Garnelo, M. C. H. Lee, H. Salimbeni, K. Arulkumaran, and M. Shanahan, “Deep unsupervised clustering with gaussian mixture variational autoencoders, ” CoRR , v ol. abs/1611.02648, 2016. [Online]. A vailable: http://arxi v .org/abs/1611.02648 [19] J. T omczak and M. W elling, “V ae with a vampprior , ” in Inter- national Confer ence on Artificial Intelligence and Statistics , 2018, pp. 1214–1223. [20] D. P . Kingma and M. W elling, “Auto-Encoding V ariational Bayes, ” arXiv e-prints , Dec. 2013. [21] A. Rios and L. Itti, “Closed-loop GAN for continual learning, ” CoRR , vol. abs/1811.01146, 2018. [Online]. A vailable: http://arxi v .org/abs/1811.01146 [22] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” CoRR , vol. abs/1412.6980, 2014. [Online]. A vailable: http://arxi v .org/abs/1412.6980
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment