Cycle-consistency training for end-to-end speech recognition
This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end-to-end approach can eliminate the need for expert knowledge such as pronunciation dictionaries to build ASR systems, it s…
Authors: Takaaki Hori, Ramon Astudillo, Tomoki Hayashi
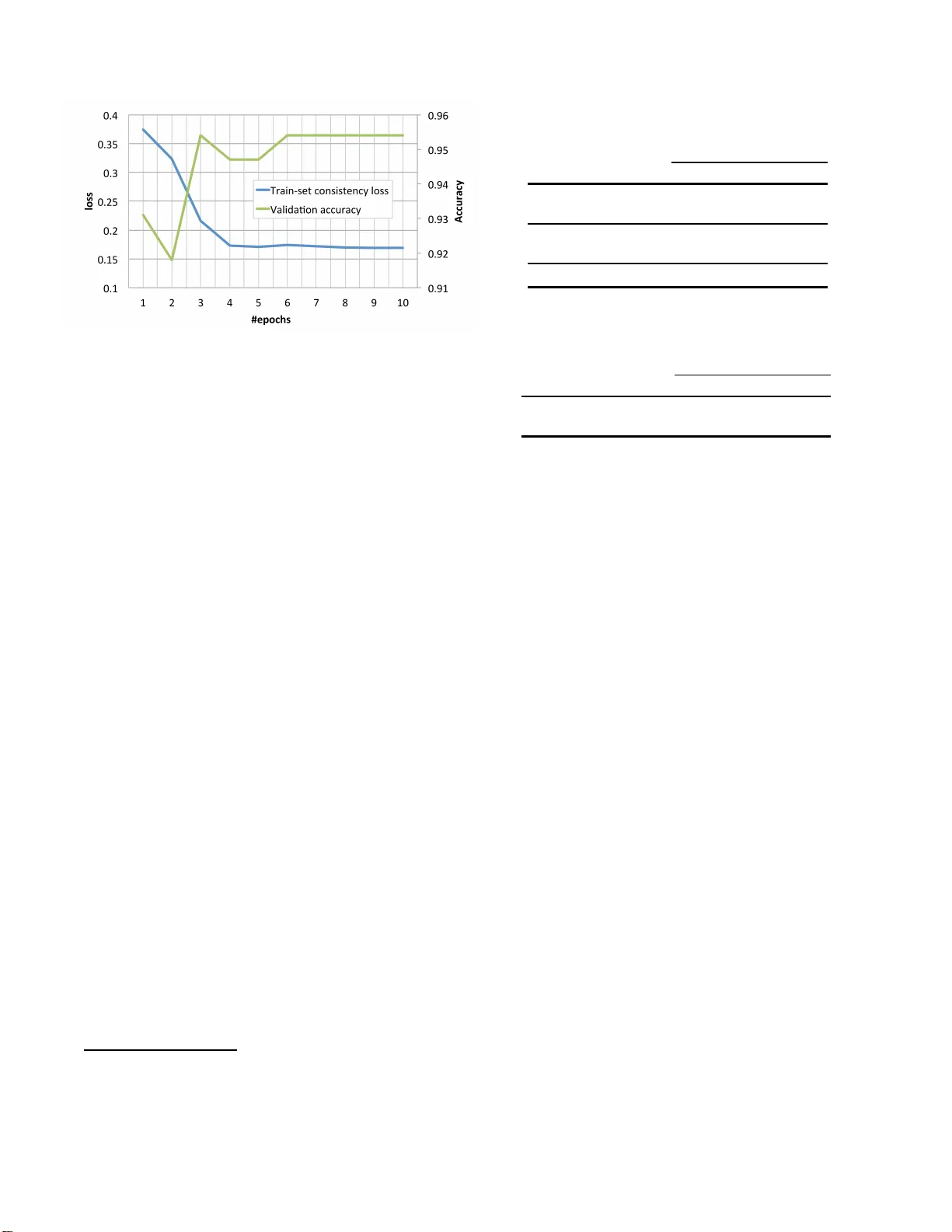
CYCLE-CONSISTENCY TRAINING FOR END-T O-END SPEECH RECOGNITION T akaaki Hori 1 , Ramon Astudillo 2 , T omoki Hayashi 3 , Y u Zhang 4 , Shinji W atanabe 5 , Jonathan Le Roux 1 1 Mitsubis hi Electric Research L abo ratories (ME RL), 2 Spoken Language Systems Lab, INESC-ID, 3 Nagoya University , 4 Google, Inc., 5 Center for Language and Speech Processing, John s Hopkins Univ ersity { thori, leroux } @merl.com, ramon@astud illo.com, hayashi.tomok i@g.sp.m.is.n agoya-u.ac.jp , ngyuzh@google .com, shinjiw@jhu.edu ABSTRA CT This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end- to-end approach can eliminate the need for expert kno wledge such as p ronunciation dictionaries to build ASR systems, it still requires a large amount of paired data, i.e., speec h utt erances and t heir tran- scriptions. Cycle-consistenc y losses hav e been recently propose d as a way to mitigate the problem of limited paired data. These ap- proaches compo se a rev erse operation with a given tr ansformation, e.g., text-to-speech (TTS) with ASR, to b uild a loss that only requ ires unsupervised data, speech in this example. Applying cycle consis- tency to ASR models is not trivial since fundamental information, such as spe aker traits, are lost in t he intermediate te xt bottleneck. T o solve this problem, this work presents a loss t hat is based on the speech enco der state sequence instead of the raw speech signal. This is achie v ed by t r ai ning a T e xt-T o-Encoder model and defining a loss based on the encoder reconstruction error . Experimental r esults on the L ibriSpeech corpus sho w that the proposed cycle-co nsistency training r educed the word error rate by 14.7% from an initial model trained with 100-h our paired data, using an addition al 360 hours of audio data wit hout transcriptions. W e also in ve stigate t he use of text- only data mainly for languag e modeling to further improve the per- formance in the unpaired data training scenario. Index T erms — speech recognition, end-to-end, unpaired data, cycle consistenc y 1. INTRODUCTION In r ecent years, automatic sp eech recognition (ASR ) technology has been widely used as an effec tiv e user interface for various de vices such as car navigation systems, smart pho nes, and smart speak ers. The recognition accuracy has dramatically impro ved with the help o f de ep learning techniques [1], and reliability of speech interfaces has been greatly enhanced. Ho wev er , b uilding ASR systems i s very costly and time consuming. Current systems typically hav e a mo dule-based architecture in cluding an acoustic model, a pronunciation dicti onary , and a language model, which rely on phonetically-designed phone units and word-lev el pronunci- ations using linguistic assumptions. T o build a l anguage model, t ext The work reported here was conducte d at the 2018 Frederick Jelinek Memorial Summer W orkshop on Speech and Language T echnologi es, and supported by Johns Hopkins Univ ersity with unrestricted gifts from Ama- zon, Face book, Google, Microsoft and Mitsub ishi E lectri c. W ork by Ram ´ on Astudillo wa s supported by the Portugue se Foundation for Science and T ech- nology (FCT ) grant number UID/CEC/ 50021/2019. preprocessing such as tokenization for some l anguages that do not explicitly have word boundaries i s also required. Consequently , it is not easy for non-e xperts to dev elop ASR systems, especially for underresource d languages. End-to-end ASR has the goal of simplifying the module-based architecture into a single-network architecture wi t hin a deep learning frame work, in order to address these issues [2–6]. End-to-end ASR methods typically rely only on paired acoustic and langu age data, without the need for extra linguistic kno wledge, and train the model with a single algorithm. T herefore, this approach makes i t feasible to build AS R systems without expert knowled ge. Howe ver , i n the end- to-end ASR frame work a large amount of training data is crucial to assure high recog nition accurac y . Paired acoustic (speec h) and lan- guage (transcription) realizations spok en by multiple spe akers are needed [7]. Nowa days, it is easy to collect audio and text data inde- pendently from the world wide web, but difficu lt to find paired data in differen t languages. T ranscribing existing audio data or recording texts spok en by suf fi cient speakers are also very exp ensiv e. There are se veral approaches that tackle the problem of limited paired data in the l iterature [8–1 2]. In particular , cycle consistenc y has recently been introduced in machine translation (MT) [13] and image transformation [14], and enables one to optimize deep net- works using unpaired data. The basic underlying assumption is t hat, gi ven a model that con verts input data to output data an d ano ther model that reconstructs the input data from the outpu t data, input data and i ts reconstruction sho uld be close to each other . For ex- ample, suppose an English-to-French MT system translates an En- glish sentence to a French sentence, and t hen a French-to-English MT system back-translates the French sentence to an English sen- tence. In this case, we can train the English-to-French system so t hat the difference between the E nglish sentence and its back-translation becomes small er, for which we only need English sentences. The French-to-English MT system can also be trained in the same man- ner using only French sentences. Applying the concept of cycle consistenc y to ASR is quite chal- lenging. As is the case in MT , the output of ASR is a discrete distri- bution over the set of all possible sentences. It is therefore not pos- sible to build an end-to-e nd differentiable loss that back-p ropagates error through the most probable sentence in this step. Since the set of possible sentences is exp onentially large in the size of the sentence, it i s not po ssible to exactly average ov er all possible sentences ei- ther . Furthermore, unlike in MT and image transformation, in AS R , the input and output domains are very different and do not contain the same information. The outpu t text does not include speaker and prosody information, which i s eliminated through feature extraction and decoding. Hence, the speech reconstructed by t he TTS system does not have the original speaker and prosody information and can result in a strong mismatch. Previo us approaches related to cycle consistency in end-to- end AS R [9, 12] circumvent these problems by av oiding back- propagating the error bey ond the discrete steps and adding a speaker network to t ransfer the information not present in the text. There- fore, these methods are not strictly cycle-consistenc y tr aining, as used in MT and i mage tr ansformation. Gradients are not cycled both through ASR and TTS simultaneou sly and only the second step on a ASR-TTS or TTS-AS R chain can be updated. In this work, we propose an alternati ve approach that uses an end-to-end differentiable loss in the cycle-consistenc y manner . This idea rests on the t wo follo wing principles. 1. Enco der-state-le vel cycle consistenc y: W e use ASR encoder state sequences for computing the cycle consistency instead of wa veform or spectral features. This uses a normal T TS T acotron2 end-to-end model [15] modified to reconstruct the encoder state sequence i nstead of speech. W e call this a text-to-encoder (TT E) model [8], which we introduced in our prior work on data augmen tation. This approach reduces the mismatch between the original and the recon struction by av oiding the problem of missing para-linguistic information. 2. Expe cted end-to-end loss: W e use an expected loss approximated with a sampling-based method. In other words, we sample multiple sentences from the ASR model, generate an encoder state sequence for each, and compute the consistency loss for each senten ce by com- paring each encoder state sequence with the original. Then, the mean loss can be used to backpropagate the error to the ASR model via the RE INFORCE algorithm [16]. This al- lo ws us to update the ASR system when the TTE is used to compute the loss, unlike [9]. The proposed approach allo ws therefore training with unpaired data, e ven if only speech is ava ilable. Furthermore, since error is backpropa gated into the AS R system from a TTS-based l oss, addi- tional unsupervised losses can be used, such as l anguage models. W e demonstrate the efficac y of t he proposed method in a semi- supervised training condition on the LibriSpeech corpus. 2. CYCLE-CONSISTENCY TRAINING FOR ASR 2.1. Basic concept The proposed method consists of an A S R encoder-dec oder , a TTE encoder -decoder , and consistency loss computation as shown in Fig. 1. In this framew ork, we need only audio data for back propa- gation. In a first step, the ASR system t ranscribes the input audio feature sequence into a sequence of characters. In addition to this, a encod er st at e sequence is obtained. In a second step, the TTE system reconstructs the ASR encod er state sequence fro the char- acter sequence. F inally , the cycle-consisten cy loss is computed by comparing the original stat e sequence and t he r econstructed one. Backpropaga tion is performed wi th respect to this loss to update t he ASR parameters. 2.2. Attenti on-based ASR model The AS R model used i s the well kno wn attention-based encoder - decoder [17]. This model directly estimates the posterior p asr ( C | X ) , where X = { x 1 , x 2 , . . . , x T | x t ∈ R D } is a sequence of input D - dimensional feature vectors, and C = { c 1 , c 2 , . . . , c L | c l ∈ U } is Fig. 1 : Cycle-consistency training for ASR. a sequence of output cha racters in the label set U . The posterior p asr ( C | X ) is factorized the probability chain rule as follows: p asr ( C | X ) = L Y l =1 p asr ( c l | c 1: l − 1 , X ) , (1) where c 1: l − 1 represents the subsequen ce { c 1 , c 2 , . . . c l − 1 } , and p asr ( c l | c 1: l − 1 , X ) is calculated as follows: h asr t = Encoder asr ( X ) , (2) a asr lt = A tt entio n asr ( q asr l − 1 , h asr t , a asr l − 1 ) , (3) r asr l = Σ T t =1 a asr lt h asr t , (4) q asr l = Decoder asr ( r asr l , q asr l − 1 , c l − 1 ) , (5) p asr ( c l | c 1: l − 1 , X ) = Softmax(LinB( q asr l )) , (6) where a asr lt represents an attention weight, a asr l the corresponding attention wei ght vector , h asr t and q asr l the hidden states of the en- coder and decoder networks, respectiv ely , r asr l a character-wise hid- den vector , which i s a weighted summarization of the hidden v ectors h asr t using the attention weight v ector a asr l , and LinB( · ) represents a linear layer with a trainable matrix and bias parameters. All of the above networks are optimized using back-propagation to minimize the following objecti ve function: L asr = − log p asr ( C | X ) = − Σ L l =1 log p asr ( c asr l | c asr 1: l − 1 , X ) , (7) where c asr 1: l − 1 = { c asr 1 , c asr 2 , . . . , c asr l − 1 } represents the ground truth for the prev ious characters, i .e. teacher-forcing is used in training. In the inference stage, the character sequence ˆ C is predicted as ˆ C = argmax C ∈U + log p asr ( C | X ) . (8) where U + is the set of all sentences formed from the original char- acter vocab ulary U . 2.3. T acotro n2-based TTE model For the TTE model, we use the T acotron2 architecture, which has demonstrated superior performance in the field of text-to-speech synthesis [15]. In our frame work, the network predicts the AS R encoder state h asr t and the end-of-sequence probability s t at each frame t from a sequen ce of input characters C = { c 1 , c 2 , . . . , c L } as follows: h tte l = Encoder tte ( C ) , (9) a tte tl = A tt entio n tte ( q tte t − 1 , h tte l , a tte t − 1 ) , (10) r tte t = Σ L l =1 a tte tl h tte l , (11) v t − 1 = Prenet( h asr t − 1 ) , (12) q tte t = Decod er tte ( r tte t , q tte t − 1 , v t − 1 ) , (13) ˆ h b, asr t = tanh(LinB( q tte t )) , (14) d t = P ostnet( q tte l ) , (15) ˆ h a, asr t = tanh(LinB( q tte l ) + d t ) , (16) ˆ s t = Sigmoid(LinB( q tte t )) , (17) where Prenet( · ) is a shallow feed-forw ard network to con vert the network outputs before feedback t o the decoder , Po stnet( · ) is a con- volution al neural network to refine the network outputs, and ˆ h b, asr t and ˆ h a, asr t represent predicted hidden states of the AS R encoder be- fore and after refinement by Postnet. Note that t he indices t and l of the encoder and decoder states are re versed compared to the AS R formulation in Eqs. (2)-(6), and that we use an additional activ ation function tanh( · ) in Eqs. (14) and (16) to avoid range mismatch in the outputs, i n contrast to the original T acotron2 [15]. All of the networks are jointly optimized to minimize the fol- lo wing objectiv e function: L tte = MSE( ˆ h a, asr t , h asr t ) + MSE( ˆ h b, asr t , h asr t ) + L1( ˆ h a, asr t , h asr t ) + L1 ( ˆ h b, asr t , h asr t ) + 1 T Σ T t =1 ( s t ln ˆ s t + (1 − s t ) ln(1 − ˆ s t )) , (18) where MSE( · ) represents mean square error , L1( · ) represent an L1 norm, and the last two terms represent the binary cross entrop y for the end-of-sequence probability . 2.4. Cycle-consistency training In this work, we use the TT E r econstruction loss L tte in Eq. (18) to measure t he cycle consistency . The l oss compares the ASR en- coder state sequenc e with the encod er sequence reconstructed from the ASR output by the TTE. Ho wev er, the argma x function in Eq. (8) to output the character sequence is not differen tiable, and the consis- tency loss cannot be propagated through TT E to ASR directly . T o solve this problem, we introduce the expected loss L ette = E C | X h L tte ( ˆ H asr ( C ) , H asr ( X )) i , (19) where ˆ H asr ( C ) denotes the state seq uence { ˆ h a, asr t , ˆ h b, asr t , ˆ s t | t = 1 , . . . , T } predicted by the TTE model for a given character sequence C , and H asr ( X ) denotes the original st at e sequen ce { h asr t , s t | t = 1 , . . . , T } gi ven by the ASR encoder for t he input feature sequence X . T o compute the gradients with respect to the expe ctation in Eq. 19, we utilize the REINFOR CE algorithm [16]. This yields the follo wing expression for the gradient ∇L ette ≈ 1 N X C n ∼ p asr ( ·| X ) , n =1 ,...,N T ( C n , X ) ∇ log p asr ( C n | X ) , (20) where the weight for each sample C n is defined as T ( C n , X ) = L tte ( ˆ H asr ( C n ) , H asr ( X )) − B ( X , C n ) (21) and B ( X , C n ) is a baseline value used to reduce the estimate v ari- ance [16]. W e used the mean value of H asr ( C n ) ove r N samples for B ( X , C n ) in this work. 3. RELA TE D WORK The algorithm introduced in this paper is related to existing works on data augmentation and chain-based training. Our prior work [ 8] introduced t he T TE model but used the synthesized encoder state se- quences to train the ASR decoder from text data only . This i s equi v- alent to back-tran slation in MT [18] and builds a non-differentiable TTE-ASR chain as opposed to the end-to-end differentiable ASR- TTE chain proposed here. The work in [11] introduces a model consisting of a text-to- text auto-encoder and a speech-to-te xt encoder -decoder sharing the speech and t ext encodings. This model can also be trained jointly us- ing paired and unpaired data but uses a simpler text encoder . Further- more speech-only data is used to enhance the speech encoding s, but not used to r educe recognition errors unlike our cycle-consistenc y approach. Finally , the text encoder is much simpler than our T TE model. In our work, the TTE model can hopefully generate better speech encodings to compute the consistency loss. The speech chain model [9] is the most similar architecture to ours. As described in Section 1, the ASR model is tr ai ned with syn- thesized speech and the TTS model is trained with ASR hypotheses for unpaired data. Therefore, the models are not tightly connected with each other , i.e. , one model cannot be upd ated directly with the help of the other model t o reduce the recognition or synthesis errors. Our approach utilizes an end-to-end differentiable loss that allows TTS or other loss to be used after ASR for unsupervised training. W e introduce as well the TTE model, which benefits from the reduc- tion of speak er variations in the loss function and of compu tational complex ity . W ith reg ard to cycle-consistency approaches i n other disciplines, our approach is most similar to the dual learning ap- proach in MT [13 ]. This paper combines alternating losses as in [9] using REINFORCE t o compute expected translation losses. 4. EXPERIMENTS 4.1. Conditions W e conducted sev eral experiments using the LibriSpeech cor- pus [19], consisting of two sets of clean speech data (100 hours + 360 hours), and other (noisy) speech data (500 hours) for training. W e used 100 hours of the clean speech data to train the initi al ASR and TT E models, and the audio of 360 hours set for unsupervised re-training of the ASR model with the cycle-consistenc y loss. W e used fiv e hours of clean de velopment data as a validation set, and fiv e hours of clean test data as an ev aluation set. The open source speech recognition toolkit Kaldi [20] was used to extract 80-dimensional log mel-filter bank acoustic vectors with three-dimensional pitch features. The ASR encoder had an ei ght- layered bidirectional long short-term memory w i th 320 cells includ- ing projection layers [21] (BLS T MP), and the ASR decoder had a one-layered LSTM with 300 cells. In the second and third layers from the bottom of the ASR encoder , sub-sampling was performed to reduce the utterance length f r om T do wn to T / 4 . The ASR at- tention network used location-aware attention [4]. For decoding, we used a beam search algorithm with beam size of 20. W e set the max- imum and minimum lengths of the output sequence t o 0.2 and 0.8 times the length of the subsampled input sequence, respectiv ely . The architecture of the TTE model followed the original T acotron2 [15]. It use 512-dimensional character embeddings, the TTE encoder con sisted of a three-layered 1D con volutional neural network (CNN) containing 512 filters with size 5, a batch normal- ization, and rectified linear unit (ReLU) activ ation function, and Fig. 2 : Learning curve . a one-layered BLSTM with 512 units (256 units for forward pro- cessing, the rest for backward processing). Although the attention mechanism of the TTE model was based on location-a ware atten- tion [4], we additionally accumulated the attention weight feedback to the next step to accelerate attention learning. The TTE decoder consisted of a two-layered L STM with 1024 units. Prenet was a two- layered feed forward network wit h 256 units and ReLU activ ation. Postnet was a fiv e-l ayered CNN containing 512 filters with the shape 5, a batch normalization, and tanh acti vation f unction ex cept in the final layer . Dropo ut [22] with a probability of 0.5 wa s applied to all of the con volution and Prenet layers. Zoneout [23] with a probab il- ity of 0.1 was applied to the decoder L S TM. During gene ration, we applied dropout to Prenet in the same manner as in [15], and set the threshold v alue of the end-of-sequence probability at 0.75 to pre vent from cutting of f the end of the input sequence. In cycle-consistenc y training, fiv e sequences of characters were drawn from the ASR model for each utterance, where each character was drawn repeatedly from the S oftmax distribution of ASR un til it enco untered the end-of-sequence label ‘ ’. During train- ing, we also used the 100-hour paired data to regularize the model parameters in a teacher-forcing manner , i. e., t he parameters were updated alternately by cross-entropy loss with paired data an d the cycle-con sistency loss with unpaired data. All models were trained using the end-to-end speech processing toolkit ESPnet [24 ] on a single GPU (Titan Xp). Character error rate (CER) and word error rate (WER) were used as ev aluation metrics. 4.2. Results First, we sho w the changes of the consistency loss for training data and the validation accuracy for dev elopment data in Fig. 2, where the accurac y was computed based on the prediction with ground truth history . The consistenc y loss succe ssfully decreased as the number of epochs increased. Although t he v alidation accuracy did not im- prov e smoothly , it reached a better value than that for the fir st epoch. W e chose the 6th-epoch model for the following ASR experiments. T able 1 shows the ASR performance using different training methods. C ompared with the baseline result giv en by the initial ASR model, we can confirm that our proposed c ycle-consistency train- ing reduced t he wo rd error rate from 25.2% to 21.5%, a relati ve re- duction of 14.7% . Thus, the results demonstrate that the proposed Our basel ine WER is m uch worse than that reported in [19] for the 100- hour traini ng setup. T his is beca use we did not use any pronu nciati on lexicon or word-based language model for end-to-en d ASR. Such end-t o-end systems typica lly unde rperform conv entional DNN/HMM systems with n-gram lan- guage m odel when using this s ize of training data. T able 1 : ASR performance using differe nt t r aining methods. CER / WE R [%] V alidation Eva luation Baseline 11.2 / 24.9 11.1 / 25.2 Cycle-consistenc y loss 9.5 / 21.5 9.4 / 21.5 CE loss (1 best) 47.8 / 86.8 48.8 / 89.3 CE loss (5 samples) 13.3 / 28.2 12.3 / 27.7 Oracle 4.7 / 11.4 4.6 / 11.8 T able 2 : ASR performance w i th LM shallow fusion. CER / WER [%] V alidation Eva luation Baseline + LM 11.9 / 22.6 11.9 / 22.9 Cycle consistency + L M 10 .2 / 19.6 9.9 / 19.5 method works for AS R t raining wi t h unpaired data. T o verify the effe ctiv eness of our approach, we further examined more straight- forward methods, in which we simply used cross-entropy (CE) loss for unpaired data, w here the target was chosen as the one best A S R hypothesis or sampled in the same manner as the cycle-consistency training. T o alleviate the impact of the ASR errors, we weighted the CE loss by 0.1 for unpaired data while we did not down-weigh t the paired data. Howe ver , the error rates increased significantly in the 1- best condition. Even in the 5-sample condition, we could not obtain better performance than the baseline. W e also cond ucted additiona l experimen ts under an oracle condition, where the 360-hour paired data were used together wi th the 100-hour data using the st andard CE loss. The error rates can be considered the upper bound of this frame work. W e can see that there is still a big gap to the upper bound and further challenges need to be overcome to reach this goal. Finally , we combined the ASR model with a character-bas ed language model (LM) in a shallo w fusion technique [25]. An LS TM- based LM was trained using text-only data from the 500-hour noisy set excluding audio data, and used for decoding. A s shown in T a- ble 2, the use of tex t-only data yielded further improveme nt reaching 19.5% W ER (an 8% error reduction ), which is the best number we hav e achie ved so far for this unpaired data setup. 5. CONCLUSION In this paper , we proposed a nov el method to train end-to-end au- tomatic speech recognition (ASR) models using unpaired data. The method emplo ys an attention-based AS R mode l and a T acotron2- based text-to-encoder (TTE) model to compu te a cycle-consistenc y loss using audio data only . Experimental results on the LibriSpeech corpus demonstrated that the proposed cycle-consistenc y training re- duced the wo rd error rate by 14.7% from an i nitial model trained with 100-hou r paired data, using an additional 360 hours of audio- only data without transcriptions. W e also in vestigated the use of text-only data from 500-hour utterances for language modeling, and obtained a further error reduction of 8%. Accordingly , we achiev ed 22.7% error reduction in total for this unpaired data setup. Future work includes joint training of ASR and TTE model using both sides of the cyc le-consistency loss, and the use of additional loss functions to make the training better . 6. REFERENCES [1] Geof frey Hinton, Li Deng, Dong Y u, George E Dahl, Abdel- rahman Mohamed, Navdeep Jaitly , Andre w S enior, V incent V anhoucke, Patrick Nguyen, T ara N Sainath, et al., “Deep neu- ral networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Pr ocessing Maga zine , vol. 29, no. 6, pp. 82–97, 2012. [2] Alex Graves and Navdeep Jaitly , “T owards end-to-end speech recognition wi t h recurrent neural netwo rks, ” in Pr oc. Inter- national Conferen ce on Mac hine Learning (I CML) , 2014, pp. 1764–1 772. [3] Alex Graves, Abdel-rahman Mohamed, and Geoffre y Hinton, “Speech recognition with deep recurrent neural network s, ” in Pr oc. IEEE International C onfer ence on Acoustics, spe ech and signal pr ocessing (ICASSP) , 2013, pp. 6645–6649. [4] Jan K Choro wski, Dzmitry Bahdanau, Dmitriy S erdyuk, Ky unghyun Cho, and Y oshua Bengio, “ Attention-based mod- els for speech recognition, ” in Advances i n Ne ural Information Pr ocessing Systems (NIPS) , 2015, pp. 577–585. [5] Suyoun Kim, T akaaki Hori, and Shinji W atanabe, “Joint CTC- attention based end-to-end speech recognition using multi-task learning, ” in Proc. IE EE International Confer ence on Acous- tics, speech and signal pro cessing (ICASSP) , 2017, pp. 4835– 4839. [6] T akaaki Hori, Shinji W atanabe, and John R. Hershey , “Joint CTC/attention decoding for end-to-end speech recognition, ” in Pr oc. Annual Meeting of the A ssociation for Computational Linguistics (A CL) , 2017. [7] Dario Amodei, Rishita Anubhai, Eric Batt enberg , Carl Case, Jared Casper , Bryan Catanzaro, Jingdong Chen, Mike Chrzano wski, Adam Coates, Greg Diamos, et al., “Deep speech 2: End-to-end speech recognition in english and man- darin, ” arXiv pr eprint arXiv:1512.02595 , 2015. [8] T omoki Hayashi, Shinji W atanabe, Y u Z hang, T omoki T oda, T akaaki Hori, Ramon Astudillo, and Kazuya T akeda, “Back- translation-style data augmen tation for end-to-end asr , ” arXiv pr eprint arXiv:1807.10893 , 2018. [9] Andros T jandra, Sakriani Sakti, and S atoshi Nakamu ra, “Li s- tening while speakin g: Speech chain by deep learning, ” in Pr oc. IEEE Automatic Speech Reco gnition and Under standing W orkshop (ASR U) , 2017, pp. 301–30 8. [10] Adithya Renduchintala, Shuoyang Ding, Matthe w Wiesner , and Shinji W atanabe, “Multi-modal data augmentation for end- to-end ASR, ” in Pr oc. Inter speech , 2018, pp. 2394–2398 . [11] Shigeki Karita, Shinji W atanabe, T omoharu Iwata, Atsunori Ogaw a, and Marc Delcroix, “Semi-supervised end-to-end speech recognition, ” Pro c. Interspeec h , pp. 2–6, 2018. [12] Andros Tjandra, Sakriani Sakti, and Satoshi Nakamura, “Ma- chine speech chain with one-shot speaker adaptation, ” i n Pr oc. Interspeec h 2018 , 2018, pp. 887–89 1. [13] Di He, Y ingce Xia, T ao Qin, Li wei W ang, Nenghai Y u, Tiey an Liu, and W ei-Y ing Ma, “Dual learning for machine transla- tion, ” in Advances i n Neural Information Processin g Systems 29 , D. D. Lee, M. Sugiyama, U. V . Luxb urg, I. Guyon, and R. Garnett, Eds., pp. 820–828. 2016. [14] Jun-Y an Zhu, T aesung Park, Phil l ip Isola, and Alexei A Efros, “Unpaired image-to-image translation using cycle-consistent adversa rial networks, ” arXiv pr eprint arXiv:1703.10593 , 2017 . [15] Jonath an Shen, Ruom ing Pang, Ron J W eiss, Mike Schuster , Navdee p Jaitly , Zongheng Y ang, Zhifeng C hen, Y u Zhang, Y uxuan W ang, RJ Skerry-Ryan, et al., “Natural TT S synthe- sis by conditioning wavene t on mel spectrogram predictions , ” arXiv pr eprint arXiv:1712.05884 , 2017. [16] Ronald J W illiams, “Simple statistical gradient-following al- gorithms for connectionist reinforcement learning, ” Machine learning , vol. 8, no. 3-4, pp. 229–256, 1992. [17] W illiam Chan, Navdeep Jaitly , Quoc V Le, and Oriol V inyals, “Listen, attend and spell: A neural network for large vocab u- lary con versational speec h recognition, ” in Proc. IEE E Inter - national Confer ence on A coustics, speech and signal pro cess- ing (ICASSP) , 2015. [18] Rico Sennrich, Barry Haddo w , and Alex andra Birch, “Improv - ing neural machine translation models wi th monoling ual data, ” arXiv pr eprint arXiv:1511.06709 , 2015. [19] V assil Panayotov , Guoguo Chen, Daniel Pov ey , and Sanjee v Khudanpu r , “Librispeech: an asr corpus based on public do- main audio books, ” in Proc . IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2015, pp. 5206–5 210. [20] Daniel Pov ey , Arnab Ghoshal, Gilles Boulianne, Lukas Bur- get, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, Jan Silovsk y , Georg Stemmer , and Karel V esely , “The Kaldi speech recog nition toolkit, ” in IEEE W orkshop on Automatic Speec h Recognition and Understan ding (A SR U) , Dec. 2011. [21] Has ¸i m Sak, Andre w Senior, and Franc ¸ oise Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling, ” in Pr oc. Intersp eech , 2014. [22] Nitish Sriv astav a, Geoffre y Hinton, Alex Krizhe vsky , Ilya Sutske ver , and Ruslan Salakhutdino v , “Dropout: a simple way to prev ent neural networks from ov erfitting, ” The Jo urnal of Mach ine Learning Resear ch , vol. 15, no. 1, pp. 192 9–1958, 2014. [23] Da vid Krueger , T egan Maharaj, J ´ anos Kr am ´ ar , Mohammad Pezeshki, Nicolas Ballas, Nan Rosemary Ke, Anirudh Goyal, Y oshua Bengio, Aaron Courville, and Chris Pal, “Zoneout: Regularizing rnns by randomly preserving hidden activ ations, ” arXiv pr eprint arXiv:1606.01305 , 2016. [24] Shinji W atanabe, T akaaki Hori, Shigeki Karita, T omoki Hayashi, Jiro Nishitoba, Y uya Unno, Nelson E nrique Y alta Soplin, Jahn Heymann , Matthew Wiesner , Nanxin Chen, et al., “ESPnet: End-to-end speech processing toolkit, ” arXiv pr eprint arXiv:1804.00015 , 2018. [25] T akaaki Hori, Shinji W atanabe, Y u Zhang, and William Chan, “ Advan ces in joint CT C -attention based end-to-end speech recognition with a deep CNN encoder and RNN-LM, ” in Proc . Interspeec h , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment