Feature reinforcement with word embedding and parsing information in neural TTS
In this paper, we propose a feature reinforcement method under the sequence-to-sequence neural text-to-speech (TTS) synthesis framework. The proposed method utilizes the multiple input encoder to take three levels of text information, i.e., phoneme s…
Authors: Huaiping Ming, Lei He, Haohan Guo
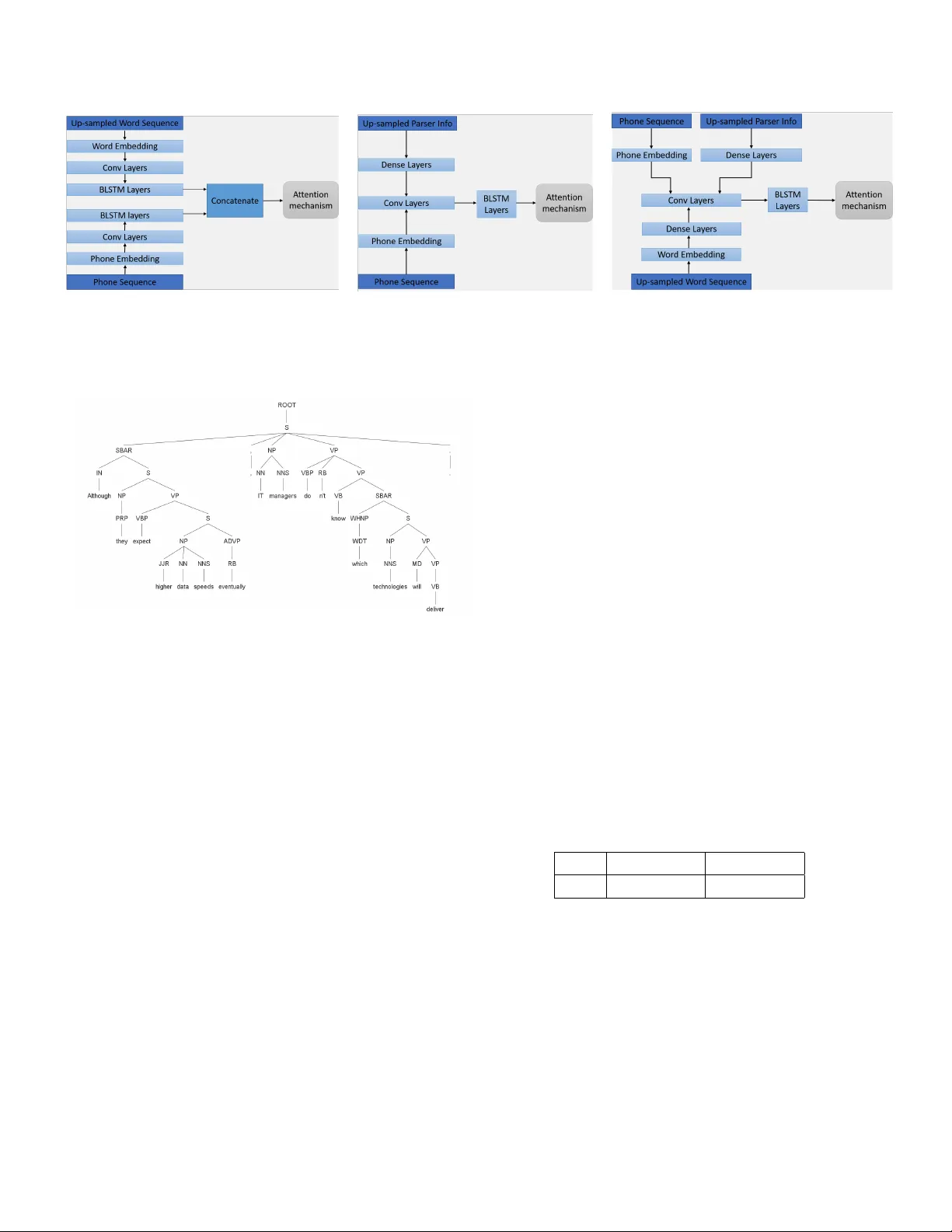
FEA TURE REINFORCEMENT WITH WORD EMBEDDING AND P ARSING INFORMA TION IN NEURAL TTS Huaiping Ming 1 , Lei He 1 , Haohan Guo 2 , F rank K. Soong 1 1 Microsoft China 2 School of Computer Science, Northwestern Polytechnical Uni versity , Xi’an, China ABSTRA CT In this paper , we propose a feature reinforcement method under the sequence-to-sequence neural text-to-speech (TTS) synthesis framework. The proposed method utilizes the mul- tiple input encoder to take three le vels of text information, i.e., phoneme sequence, pre-trained word embedding, and grammatical structure of sentence from parser as the input feature for the neural TTS system. The added word and sen- tence le vel information can be viewed as the feature based pre-training strategy , which clearly enhance the model gener - alization ability . The proposed method not only improv es the system robustness significantly but also improves the synthe- sized speech to near recording quality in our experiments for out-of-domain text. Index T erms — Neural TTS, feature reinforcement, word embedding, grammatical structure of sentences 1. INTR ODUCTION TTS aims at generating a speech wav eform from its corre- sponding text string. Neural TTS systems such as [1, 2, 3, 4, 5] ha ve achie ved impressi ve results in recent years. The dura- tion, which is a very important prosody feature for speech, is modeled separately from other prosody and spectral feature for traditional HMM and DNN based TTS pipelines [6, 7]. What’ s more, the duration is usually modeled in very small linguistic units such as in phone lev el. By contrast, neural TTS systems model all the prosody and spectral feature in sentence le vel with the help of attention mechanism. The joint optimizing of spectral and prosody feature results in more nat- ural synthesized speech. There are e xtensiv e studies on neural TTS in recent years. W enfu et al. [8] took the first step touching neural TTS with attention based sequence-to-sequence model. After that, some neural TTS model such as T acotron [1] and Char2W av [2] were proposed to synthesize speech directly from char- acters. T acotron2 [4] simplified the network structure of T acotron, and then uses the W a veNet [9] as a vocoder to synthesize high quality speech close to recordings. Further- more, there is a preliminary study of semi-supervised training which utilizing textual and acoustic kno wledge contained in large unpaired text and speech corpora to impro ve the data efficienc y [10]. Some other studies under the framework of attention based neural TTS system including DeepV oice [3], ClariNet [5], and V oiceLoop [11]. The neural TTS system can generate high quality speech, howe ver , there remain challenges too. The amount of high quality parallel < text, audio > paired data is quite limited compared with the av ailable data for natural language pro- cessing (NLP) tasks such as machine translation [12]. What’ s more, the training text is often sourced from very fe w do- mains, for instance, con versational text and news. Usually , the training data for TTS cannot cov er rich enough text con- text, and it’ s common to encounter the out-of-domain prob- lem. Generally , neural TTS systems hav e dif ficulties to cope with out-of-domain text, and they may lead to speech with strange prosody and ev en wrong pronunciation. W ord embedding [13] and parsing information [14] have been proved to be beneficial in traditional TTS pipelines. In this paper, instead of taking character or phone sequence as the only input, we propose to utilize information from pre-trained word embedding and grammatical structure of sentences to improv e the system performance. This can be viewed as feature based pre-training [15], which borrows knowledge from features generated by models trained with large data corpus. The word embedding is pre-trained with neural machine translation (NMT) task [12], which is based on a sequence-to-sequence encoder decoder model with an attention mechanism. The grammatical structure is extracted by the Stanford Parser tool [16, 17], which is a statistical parser using knowledge of language gained from hand-parsed sentences. Both w ord embedding and grammatical structure are con- text sensiti ve features from language related models. The model to generate word embedding and grammatical struc- ture information are trained with very large text data corpus, which means rich te xt context coverage. Such prior knowl- edge would help to solve the out-of-domain problem. The rest of this paper is or ganized as follo w: In section 2, we introduce the related work. The details of the proposed feature reinforcement method are described in Section 3. In Section 4, the experimental results are presented. Conclu- sions are drawn in Section 5. Fig. 1 . The baseline network structure of our end-to-end neu- ral TTS system. 2. RELA TED WORK V arious linguistic features extracted from text scripts have previously been considered for TTS in traditional HMM and DNN based TTS systems [14]. There are succsessful attempts which utilize word embedding and parsing information as part of the input feature for traditional TTS systems [13, 14]. Neural TTS represents the state-of-the-art for synthesized speech quality and naturalness. Currently , state-of-the-art neural TTS [4, 5] is based on a sequence-to-sequence en- coder decoder model with an attention mechanism. There are sev eral different network structures that have been proved to be effecti ve for neural TTS system. In this paper , we take a re-implemented version of T acotron 2 [4] as the baseline system. Different from the original implementation which takes character sequence as the input, we take phone sequence deriv ed from the normal- ized text as the input. The network structure of our baseline neural TTS system is illustrated in Fig. 1. In practice, each phone is mapped to its corresponding random initialized em- bedding vector . The embedding vectors will be randomly initialized with zero mean and unit v ariance Gaussian dis- tribution, and they will be jointly updated with the other network parameters during training. The output of the de- coder is mel-spectrogram, and it is used as the condition for the W av eNet v ocoder to generate corresponding speech wa veform. 3. FEA TURE REINFORCEMENT This paper utilizes multiple input encoder to combine infor- mation from phone lev el, word lev el, and sentence lev el. The information from different le vels of text are mixed together by the encoder and then share the same attention mechanism and decoder . Thus, we only illustrate the network structure of the encoder part for the proposed method as shown in Fig. 2. W ith dif ferent le vels of text information added as the input, we ha ve three dif ferent systems. There are many ways of c on- structing the multiple input encoder . W ith some comparison experiments, we propose to use dif ferent encoder structure for different systems described as follo ws. 3.1. Phone plus word input system The word embedding can be obtained from many NLP tasks. Our word embedding is obtained with the system described in [12], which achie ves human parity on automatic Chinese to English ne ws translation. This system is based on a sequence- to-sequence encoder decoder model with an attention mech- anism. The output of the NMT encoder is dumped out as the word embedding. Thus, the word embedding is trained with a similar framework as neural TTS, and we believ e this would benefit to the network con ver gence. The obtained w ord embedding contains both semantic information and semantic context information. W e expect this information would help to solv e the out-of-domain problem, and to enrich the prosody of generated speech. The encoder of the proposed phone plus word input sys- tem is illustrated in the left part of Fig. 2. The word sequence is up-sampled to align with the phone sequence. Specifically , we repeat a word multiple times corresponding to its num- ber of phones. Each word has its corresponding embedding vector pre-trained by NMT task. The word sequence and phone sequence use separate con volution layers followed by BLSTM layers structure. After that, the output of phone en- coder and word encoder are concatenated together and send to the attention mechanism. 3.2. Phone plus grammatical structur e input system In this system, the grammatical structure of a sentence will be analyzed first of all. W e choose the Stanford Parser tool [16, 17] for grammar parsing. It is a statistical parser using knowledge of language gained from hand-parsed sentences to try to produce the most likely analysis of new sentences. Here we hav e a parsing example of an English sentence shown in Fig. 3. The sentence is parsed into a tree structure according to its grammatical structure. Then we can e xtract information such as phrase type, phrase border and the relati ve position of the current word in the current phrase from the parsing re- sults. As the parsing results are extracted in word le vel, we also need to up-sample the parsing information to align with the phone. The obtained parser features contain from w ord lev el to sentence le vel conte xt-sensitiv e information. W e also expect this information would help to solve the out-of-domain problem, and to improve the prosody performance of gener- ated speech. The middle part of Fig. 2 illustrates the encoder of the phone plus grammatical structure input system. The up- sampled parsing information is passed to dense feed-forward layers to obtain a compressed representation. After that, we concatenate the output of dense layers and the phone Fig. 2 . The network structure of multiple input encoder for different systems. The left one is the encoder network structure for phone plus word input. The middle on is the encoder netw ork structure for phone plus parser input. The right one is the encoder network structure for phone plus word and parser input. Fig. 3 . An example of the grammatical structure of a sen- tence. The content of this sentence is: “ Although they expect higher data speeds e ventually , IT managers don’ t kno w which technologies will deliv er . ” embedding, and this mixed information will share the same con v olution layers and BLSTM layers to construct the multi- ple input encoder . 3.3. Phone plus word and grammatical structure input system In this system, we utilize both word embedding and parsing information addition to the phone input. The right part of Fig. 2 illustrates the encoder of the phone plus w ord and grammat- ical structure input system. The word embedding and parsing information are obtained e xactly the same as the above two systems. Both word embedding and parsing information are passed to their dense layers. Then the output of word and parsing dense layers are concatenated with the phone embed- ding to mix different le vel of text information together . After that, the mixed information will share the same con volution layers and BLSTM layers to construct the multiple input en- coder . 4. EXPERIMENTS 4.1. Data Set W e tested the proposed systems on a data set recorded by a professional US female speaker . The training data contains approximately 19 hours of speech. The text scripts are in the general domain, and the speech wa veform is mono, 16-bit, 16 kHz sampled. 4.2. Naturalness T est First of all, a subjectiv e mean option score (MOS) test is con- ducted for our baseline system. The testing set contains 38 randomly selected in domain texts that are not contained in the training set. Each speech sample is judged by 20 paid nativ e English speakers with a score from 1 to 5 in the test. The MOS test results are sho wn in T able 1. For in domain text, the o verall quality of synthesized speech is v ery close to recordings, and this result is similar to the results reported in [4]. T able 1 . The MOS of our baseline system, with 95% confi- dence lev el. In domain text scripts. Recordings Baseline MOS 4.51 ( ± 0.04) 4.41 ( ± 0.05) Then the o verall quality of the proposed method is ev al- uated by performing MOS tests on 30 out-of-domain texts. The content and style of the selected test text are quite dif fer- ent from the text in the training set, for e xample, news text which is v ery long (around 30 words). Each speech sample is also judged by 20 native English speakers with a score from 1 to 5 in this test. The test results of different systems are shown in T able 2. The MOS of the baseline system with phone input is 4.17, and the MOS of recordings is 4.44. The quality of synthesized speech has a clear gap to recordings for out-of-domain text. T able 2 . The MOS of dif ferent system and recordings, with 95% confidence lev el. Out-of-domain text scripts. Systems MOS phone input 4.17 ( ± 0.06) phone + word input 4.19 ( ± 0.06) phone + parser input 4.20 ( ± 0.06) phone + word + parser input 4.33 ( ± 0.06) Recordings 4.44 ( ± 0.09) W ith word embedding onboard, the MOS increased to 4.19. W ith parser information reinforcement, the MOS increased to 4.20. W e can see that adding word embedding and parser information separately will improve the system performance, but the impro vement is not significant. W ith both word embedding and parser onboard, the MOS increased to 4.33, which is very close to recordings. The added word and grammatical structure information are com- plementary , and the y together can improv e the ov erall quality of synthesized speech significantly . According to feedback from judges, speech samples synthesized by this system are better in tw o aspects. Firstly , the pauses between some words sound more appropriate. Secondly , the prosody sound more natural. As expected, the added word and grammatical struc- ture information are beneficial to neural TTS models. 4.3. Diagnostic Intelligibility T est As mentioned before, neural TTS may generate speech with strange prosody and wrong pronunciation with out-of-domain text. Different from semantically unpredictable sentences (SUS) test, we conduct a diagnostic intelligibility test to e v al- uate the performance of the proposed system on this problem. First of all, an automatic speech recognition (ASR) tool is utilized to select Grif fin-Lim [18] synthesized samples whi ch potentially hav e pronunciation probl ems. There are 308 cases selected from around 10000 sentences in different domains. During the test, the judges are requested to mark ev ery unin- telligible and unnatural word in the text script. There are two metrics for this test: case lev el intelligible rate, which is the proportion of the cases without any word marked as “Unin- telligible”, and case le vel natural rate, which is the proportion of the cases without any word marked as “Unintelligible” or “Unnatural”. Each sentence is mark ed by one judge, and each judge can marke up to 50 sentences. The judges can listen to the sentences more than once. The test results for dif ferent systems are shown in T able 3. The case level intelligible rate and natural rate are 88.64% and 86.36% respectively for the baseline system with phone input. W ith word embedding onboard, the intelligible rate and natural rate hav e 6.49% and 7.15% absolute improvement respectiv ely . This means the prior kno wledge contained in T able 3 . Diagnostic intelligibility and naturalness test results on 308 selected cases. Systems Intelligible rate Natural rate phone input 88.64% 86.36% phone + word input 95.13% 93.51% phone + parser input 96.10% 95.13% phone + word + parser input 96.10% 95.45% pre-trained word embedding do help to improv e the system robustness for out-of-domain te xt. W ith parser information reinforcement, the system im- prov ement is very clear , which is 7.46% and 8.77% for the intelligible rate and natural rate respectively . It’ s interesting that the improvement is bigger than the results of onboard word embedding. This implies that both word embedding and parser information contains conte xtual information which im- prov es system rob ustness, b ut the parser information contains more useful information. W ith both word embedding and parser information, the intelligible rate remains to be 96.10% compared with phone plus parser input system, b ut the natural rate increased slightly to 95.45%. The unchanged intelligible rate implies that most of the contextual information contained in word embedding and parser are nearly equiv alent. The increased natural rate further prov es that word embedding and parser are comple- mentary for naturalness improv ement. Overall, the proposed system has clear improvements on both intelligible rate (7.46% absolute impro vement) and natu- ral rate (9.09% absolute improvement) for the selected cases. W e can get the conclusion that the added word and grammati- cal structure information significantly impro ve the system ro- bustness for out-of-domain te xt. 5. CONCLUSION This paper proposes to utilize phoneme level information, word lev el information, and sentence level information as in- put features for neural TTS system. The experiments demon- strate that the added features will clearly enhance TTS model generalization ability . The speech naturalness test shows that the proposed method improv es the synthesized speech to near recording quality for out-of-domain text. The diagnostic in- telligibility test pro ves that the proposed method significantly improv es the system robustness for out-of-domain te xt. In the future work, we will continue to explore more features from the text, and add them to neural TTS system with dif ferent strategies. 6. REFERENCES [1] Y uxuan W ang, RJ Sk erry-Ryan, Daisy Stanton, Y onghui W u, Ron J W eiss, Navdeep Jaitly , Zongheng Y ang, Y ing Xiao, Zhifeng Chen, Samy Bengio, et al., “T acotron: T o wards end-to-end speech synthesis, ” INTERSPEECH , 2017. [2] Jose Sotelo, Soroush Mehri, Kundan Kumar , Joao Fe- lipe Santos, K yle Kastner , Aaron Courville, and Y oshua Bengio, “Char2Wav: End-to-end speech synthesis, ” ICLR workshop , 2017. [3] W ei Ping, Kainan Peng, Andre w Gibiansky , Sercan O Arik, Ajay Kannan, Sharan Narang, Jonathan Raiman, and John Miller , “Deep Voice 3: 2000-speaker neu- ral text-to-speech, ” arXiv preprint , 2017. [4] Jonathan Shen, Ruoming Pang, Ron J W eiss, Mike Schuster , Na vdeep Jaitly , Zongheng Y ang, Zhifeng Chen, Y u Zhang, Y uxuan W ang, Rj Skerrv-Ryan, et al., “Natural tts synthesis by conditioning wav enet on mel spectrogram predictions, ” in ICASSP , 2018, pp. 4779– 4783. [5] W ei Ping, Kainan Peng, and Jitong Chen, “ClariNet: Parallel wa ve generation in end-to-end text-to-speech, ” arXiv pr eprint arXiv:1807.07281 , 2018. [6] Heiga Zen, T akashi Nose, Junichi Y amagishi, Shinji Sako, T akashi Masuko, Alan W Black, and K eiichi T okuda, “The HMM-based speech synthesis system (HTS) version 2.0., ” in SSW . Citeseer , 2007, pp. 294– 299. [7] Zhizheng Wu, Oliv er W atts, and Simon King, “Merlin: An open source neural network speech synthesis sys- tem., ” in 9th ISCA Speech Synthesis W orkshop , 2016, pp. 202–207. [8] W enfu W ang, Shuang Xu, and Bo Xu, “First step to- wards end-to-end parametric TTS synthesis: Generating spectral parameters with neural attention, ” in INTER- SPEECH , 2016. [9] A ¨ aron V an Den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V inyals, Alex Graves, Nal Kalchbrenner , Andrew W Senior , and K oray Kavukcuoglu, “W a veNet: A generati ve model for raw audio, ” in arXiv pr eprint arXiv:1609.03499 , 2016. [10] Y u-An Chung, Y uxuan W ang, W ei-Ning Hsu, Y u Zhang, and RJ Skerry-Ryan, “Semi-supervised training for im- proving data ef ficiency in end-to-end speech synthesis, ” INTERSPEECH , 2018. [11] Y ani v T aigman, Lior W olf, Adam Polyak, and Eliya Nachmani, “V oiceLoop: V oice fitting and synthesis via a phonological loop, ” arXiv pr eprint arXiv:1707.06588 , 2018. [12] Hany Hassan, Anthon y Aue, Chang Chen, V ishal Chowdhary , Jonathan Clark, Christian Federmann, Xuedong Huang, Marcin Junczys-Dowmunt, W illiam Lewis, Mu Li, et al., “ Achie ving human parity on automatic chinese to english news translation, ” arXiv pr eprint arXiv:1803.05567 , 2018. [13] Peilu W ang, Y ao Qian, Frank K Soong, Lei He, and Hai Zhao, “W ord embedding for recurrent neural net- work based TTS synthesis, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2015, pp. 4879–4883. [14] Rasmus Dall, Kei Hashimoto, K eiichiro Oura, Y oshi- hiko Nankaku, and Keiichi T okuda, “Redefining the linguistic context feature set for HMM and DNN TTS through position and parsing, ” in INTERSPEECH , 2016, pp. 2851–2855. [15] Jacob Devlin, Ming-W ei Chang, Kenton Lee, and Kristina T outano v a, “Bert: Pre-training of deep bidirec- tional transformers for language understanding, ” arXiv pr eprint arXiv:1810.04805 , 2018. [16] Richard Socher, John Bauer , Christopher D Manning, et al., “Parsing with compositional vector grammars, ” in Pr oceedings of the 51st Annual Meeting of the Asso- ciation for Computational Linguistics (V olume 1: Long P apers) , 2013, v ol. 1, pp. 455–465. [17] Danqi Chen and Christopher Manning, “ A fast and ac- curate dependency parser using neural networks, ” in Pr oceedings of the confer ence on empirical methods in natural language pr ocessing (EMNLP) , 2014, pp. 740– 750. [18] Daniel Griffin and Jae Lim, “Signal estimation from modified short-time fourier transform, ” IEEE T ransac- tions on Acoustics, Speech, and Signal Pr ocessing , vol. 32, no. 2, pp. 236–243, 1984.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment