Linear Algebraic Structure of Word Senses, with Applications to Polysemy
Word embeddings are ubiquitous in NLP and information retrieval, but it is unclear what they represent when the word is polysemous. Here it is shown that multiple word senses reside in linear superposition within the word embedding and simple sparse …
Authors: Sanjeev Arora, Yuanzhi Li, Yingyu Liang
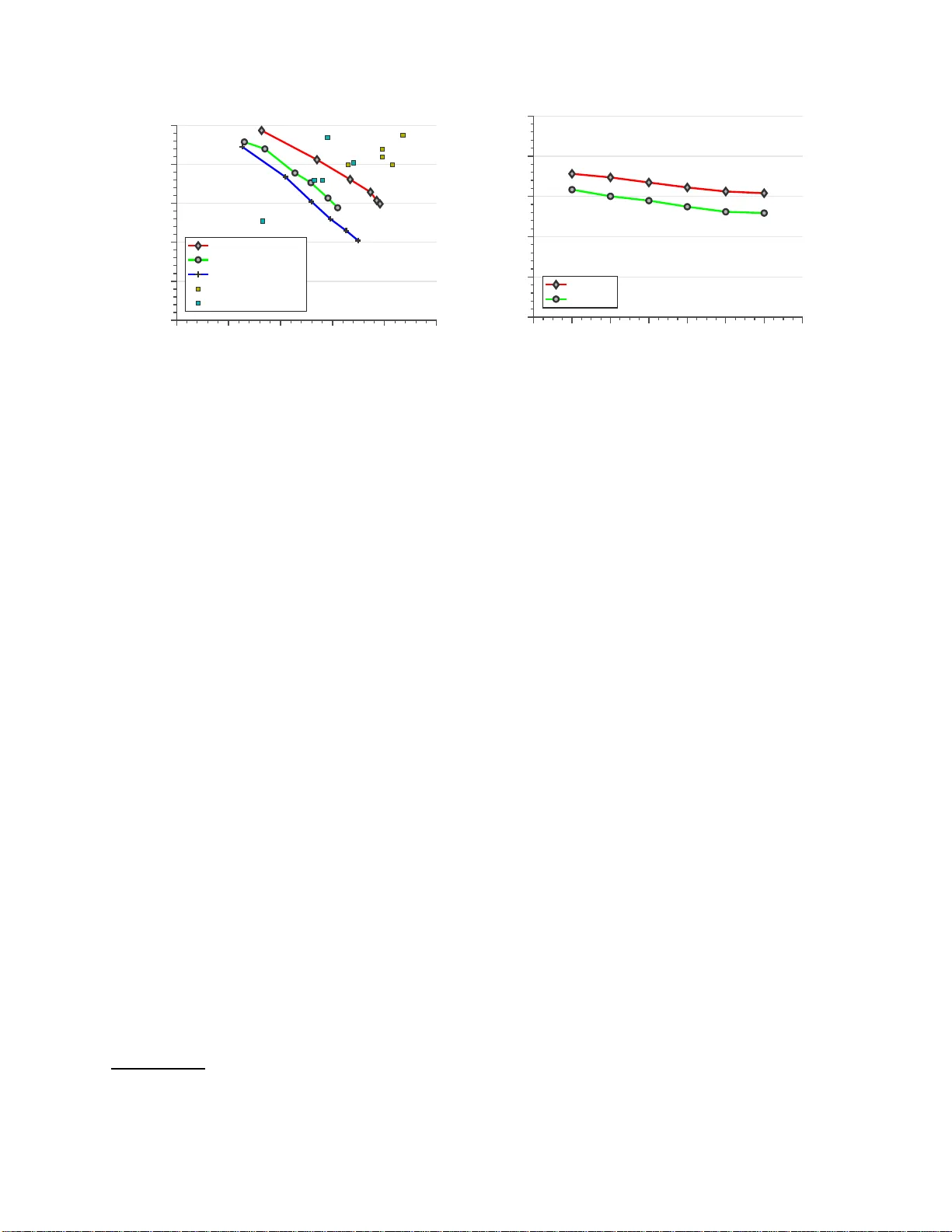
Linear Algebraic Structur e of W ord Senses, with A pplications to Polysemy Sanjee v Ar ora, Y uanzhi Li, Y ingyu Liang, T engyu Ma, Andr ej Risteski Computer Science Department, Princeton Unive rsity 35 Olden St, Princeton, NJ 085 4 0 { arora,yua nzhil,ying yul,tengyu ,risteski } @cs.princeton.edu Abstract W ord embed dings are ub iquitous in NLP a nd informa tio n retriev al, but it is un clear what they rep resent when the word is po lysemous. Here i t is shown that multiple word senses re - side in linear superpo sition within th e word embedd in g and simple sparse coding can re- cover vectors that appro ximately capture th e senses. The success of o ur appro ach, which applies to several embedd in g method s, is mathematically explained using a variant of the random walk on disco u rses m odel (Ar ora et al., 2016) . A novel aspect o f o ur tech- nique is that each extracted word sense is ac- compan ie d b y one of abou t 2000 “discour se atoms” that gives a succinct description of which oth er words co-occu r with that word sense. Discourse atoms can be of ind epen- dent interest, and m ake the method potentially more useful. Empirical tests are used to verify and support the theory . 1 Intr oduction W or d embeddi ngs are constru cted using F irth’ s hy- pothes is that a word’ s sense is captured by the distri- b ution of other words around it (Firth, 1957). Clas- sical vector space models (see the surv ey by Tu r- ney and Pantel (2010)) u se s imple l inear algebra on the matrix of word-word co-occurre nce counts, whereas recent neu ral n etwork and en erg y-based models suc h as wo rd2ve c use an objecti ve that in- v olves a nonco n v ex (thus, also nonlinear) funct ion of the word co-oc currence s (Bengio e t al., 2003; Mikol ov et al., 2013a; Miko lov et al., 2013b). This nonlineari ty makes it hard to discern ho w these modern embeddi ngs captur e the dif ferent senses of a polysemous word. The monolithi c vie w of embeddings, with the i nternal in formation e x- tracted only via inn er produc t, is felt to fail in cap- turing word senses (Grif fiths et al., 20 07; Reisinger and Moone y , 2010; Iacobacci et al., 2015). Re- search ers ha ve instead soug ht to capture polysemy using more complic ated represen tations, e.g., by in- ducing separate embeddi ngs for each sense (Mur phy et al., 2012; H uang et al., 2012). These embedding- per -sense represe ntations gro w natura lly out of classic W ord Sense Induction or WSI (Y arowsk y , 1995; S chutze, 1998; Reisinger and Mooney , 2010; Di Marco and Navigl i, 2013) techniq ues tha t per - form clustering on neigh boring words. The c urrent paper goe s beyon d this mono- lithic vie w , b y describing ho w multiple senses of a word actually reside in linear superposi- tion within th e standard word embe ddings (e.g., word2 vec (Miko lov et al ., 2013a) and GloV e (Pen- ningto n et al., 2014)). By thi s we mean th e fo llo w- ing: consider a polysemous word, say tie , which can refer to an article of clothing , or a dra wn match, or a physic al act. L et’ s take the usual vi ewpo int that tie is a singl e token that represents monosemous words tie1, tie2, ... . The theory and experi ments in this paper st rongly sugge st that word embeddings com- puted using modern techniq ues such as GloV e and word2 vec satisf y: v tie ≈ α 1 v tie1 + α 2 v tie2 + α 3 v tie3 + · · · (1) where coeffici ents α i ’ s are nonne gati ve and v tie 1 , v tie 2 , etc., are the hypothetica l embedding s of the diffe rent senses—th ose that woul d ha ve been induce d in th e thought e xperiment where all o c- curren ces of the dif ferent sen ses were hand-label ed in the co rpus. This L inearit y Assertion , w hereby linear struc ture appears out of a hi ghly nonlinear embeddi ng techni que, is explai ned theoreticall y in Section 2, and then empiric ally tested in a coup le of ways in Section 4. Section 3 uses the linearit y assertion to sho w how to do WSI vi a sparse cod ing, which can be seen as a linear algebr aic analog of the classic cluster ing- based approache s, albeit with overla pping clusters. On standar d tes tbeds it is competiti ve with earlier embeddi ng-for -each -sense approaches (Sectio n 6). A nove lty of our WSI method is that it automat- ically links differ ent senses of diffe rent words via our atoms of discours e (Sect ion 3). This can be seen as an answer to the suggestion in (Reisinger and Moone y , 2010) to enhanc e one-embeddi ng-per - sense methods so that they can automatica lly link togeth er sens es for dif ferent words, e.g., recogniz e that the “artic le of clothing” sense of tie is connected to shoe, jac ket, etc. This paper is inspire d by the solu tion of word analog ies via linear algebra ic methods (Mikolo v et al., 2013b) , and use of sparse coding on word em- beddin gs to get usef ul represe ntations for m any NLP tasks (Faruq ui et al., 2015). Our theory b uilds concep tually upon the r andom walk on disco urses model of A rora et al. (2016), although w e make a small but important change to explain empirical findings regardi ng polysemy . Our WSI procedure applie s (with minor variat ion in performance ) to canon ical embedding s such as word2v ec and GloV e as well as the older ve ctor space methods such as PMI (Church and Hanks, 199 0). This is not surpris- ing sinc e these embeddin gs are kno wn to be interre - lated (Levy and Goldber g, 2014; Arora et al., 2016 ). 2 Justification f or Linearity Assertion Since word embeddin gs are solutions to noncon ve x optimiza tion problems, at first sight it appears hop e- less to reason abou t their finer struc ture. B ut it be- comes possible to do so usi ng a gen erati ve model for langua ge (A rora et al., 2016) — a dynamic versi ons by the lo g-linear to pic mode l of (Mnih and Hinton , 2007) —which w e now recall. It posits that at ev ery point in the corp us there is a micro-topic (“what is being talke d about”) called discour se that is drawn from the con tinuum of unit v ectors in ℜ d . The pa- rameters of the model include a vector v w ∈ ℜ d for each word w . Each dis course c defines a distr ibu tion ov er words Pr[ w | c ] ∝ exp( c · v w ) . T he model as- sumes that the corpus is generat ed by the slow geo- metric random walk of c ov er the unit sphere in ℜ d : when the walk is at c , a few words are emitted by i.i.d. samples from the distr ibu tion (2), which, due to its log-lin ear form, strongly fav ors words close to c in cosine similarity . Estimate s for learnin g parame - ters v w using ML E and moment method s corre spond to standard embeddi ng methods su ch as GloV e and word2 vec (see the original pape r). T o study ho w word embeddin gs capture word senses , we’ll need to unders tand the relationshi p be- tween a word’ s embedding and those of words it co-occ urs with. In the next subsectio n, w e pro- pose a slight modification to the abov e model and sho ws how to infer the embedding of a word from the embeddin gs of other words that co-o ccur with it. This immediately leads to the Linearit y Assertion, as shown in Section 2.2. 2.1 Gaussian W alk Model As alluded to befor e, we modify the rando m walk model of (Arora et al., 2016) to the G aussia n ran- dom walk model . Again, the parameters of the mode l includ e a vect or v w ∈ ℜ d for each word w . The model assumes the corpus is generated as follo ws. First, a discours e vector c is drawn from a Gaussian with mean 0 and cov ariance Σ . Then , a windo w of n words w 1 , w 2 , . . . , w n are generated from c by: Pr[ w 1 , w 2 , . . . , w n | c ] = n Y i =1 Pr[ w i | c ] , (2) Pr[ w i | c ] = exp( c · v w i ) / Z c , (3) where Z c = P w exp( h v w , c i ) is the partition fun c- tion. W e also assume the partition functio n concen- trates in the sense that Z c ≈ Z exp ( k c k 2 ) for some consta nt Z . This is a direct extensi on o f (Arora et al., 2016, Lemma 2.1) to discourse vect ors with norm othe r than 1, and causes the addition al term exp( k c k 2 ) . 1 1 The formal proof of (Arora et al., 2016) still applies in this setting. The simplest way to informally justify t his assumption Theor em 1. Assume the above genera tive model, and let s denote the random variable of a window of n wor ds. Then, ther e is a linea r tr ansformati on A suc h that v w ≈ A E 1 n P w i ∈ s v w i | w ∈ s . Pr oof. Let c s be the disco urse ve ctor for the whole windo w s . By the law of total expect ation, we hav e E [ c s | w ∈ s ] = E [ E [ c s | s = w 1 . . . w j − 1 ww j +1 . . . w n ] | w ∈ s ] . (4) W e ev aluate the two sides of the equation. First, by Bayes’ rule and the assump tions on the distrib ution of c and the partit ion function, we ha ve: p ( c | w ) ∝ p ( w | c ) p ( c ) ∝ 1 Z c exp( h v w , c i ) · exp − 1 2 c ⊤ Σ − 1 c ≈ 1 Z exp h v w , c i − c ⊤ 1 2 Σ − 1 + I c . So c | w is a Gaussian dist rib ution with mean E [ c | w ] ≈ (Σ − 1 + 2 I ) − 1 v w . (5) Next, w e compute E [ c | w 1 , . . . , w n ] . Again using Bayes’ rule and the as sumptions on th e dis trib ution of c and the partition function, p ( c | w 1 , . . . , w n ) ∝ p ( w 1 , . . . , w n | c ) p ( c ) ∝ p ( c ) n Y i =1 p ( w i | c ) ≈ 1 Z n exp n X i =1 v ⊤ w i c − c ⊤ 1 2 Σ − 1 + nI c ! . So c | w 1 . . . w n is a Gaussian distri bu tion with mean E [ c | w 1 , . . . , w n ] ≈ Σ − 1 + 2 nI − 1 n X i =1 v w i . (6) No w pluggin g in equation (5) and (6) into equa- tion (4), we concl ude that (Σ − 1 + 2 I ) − 1 v w ≈ (Σ − 1 + 2 nI ) − 1 E " n X i =1 v w i | w ∈ s # . is t o assume v w are random vectors, and then Z c can be shown to concentrate around exp( k c k 2 ) . S uch a condition enforces the word vectors to be isotropic t o some extent, and makes the cov ari ance of the discourse identifiable. Re-arrang ing the equation completes the proof with A = n (Σ − 1 + 2 I )(Σ − 1 + 2 nI ) − 1 . Note: Interpr etati on. Theorem 1 sho ws that there exi sts a linear relation ship between the vector of a word and the vectors of the words in its conte xts. Consider the follo wing thought experimen t. First, choos e a word w . Then, for each windo w s contain- ing w , take the ave rage of the v ectors of the words in s and denote it as v s . No w , take the av erage of v s for al l the w indo ws s containin g w , and deno te the a verag e as u . Theorem 1 says that u can be mappe d to the word v ector v w by a linear transfor mation that does not depe nd on w . This linea r struct ure may als o ha ve co nnection s to some other phenomena related to linea rity , e.g., Gittens et al. (2017) and T ian et al. (2017 ). Exploring such conn ections is left for future work. The linear tran sformation is closely re lated to Σ , which describes the distrib ution of the discourse s. If we choose a coordin ate sys tem such that Σ is a diagonal matrix with diagonal entries λ i , then A will also be a diagona l matrix with diag onal en- tries ( n + 2 nλ i ) / (1 + 2 nλ i ) . This is smoothing the spectr um and essentially shrinks the dire ctions cor - respon ding to lar ge λ i relati v ely to the other direc- tions. Such directio ns are for common discours es and thus common words. Empirically , we indee d observ e that A shr inks the directi ons of common words . For example , its last right singular vect or has, as nearest neighbo rs, the vec tors for words like “with”, “as”, and “the. ” N ote that empirically , A is not a diagonal matrix since the word vectors are not in the coordina te system mention ed. Note: Implications fo r GloV e and word2vec . Repeatin g the calculation in Arora et al. (2016) for our ne w generati ve model, we can show that the solutio ns to GloV e and word2v ec training ob- jecti ve s solve for the follo wing vectors: ˆ v w = Σ − 1 + 4 I − 1 / 2 v w . Since these other embeddings are the same as v w ’ s up to linear transformati on, Theorem 1 (and the Linear ity Assertion ) still holds for them. Empirica lly , we find that Σ − 1 + 4 I − 1 / 2 is close to a scaled identity matrix (since k Σ − 1 k 2 is small), so ˆ v w ’ s can be used as a surrogate of v w ’ s. Experimental note: Using b etter sentence e m- beddings, SIF embeddings. Theorem 1 implic itly uses the av erage of the neighb oring word vectors as an estimate (MLE) for the discourse vecto r . This estimate is o f co urse als o a simple sentence em- beddin g , very popular in empirical NLP work and also reminiscent of word2v ec’ s t raining objec tiv e. In practice , this nai ve sente nce embedding can be impro ved by taking a weighted combinati on (ofte n tf-idf) of adjacent words. The paper (Arora et al., 2017) uses a simple twist to the genera tiv e model in (Arora et al., 2016) to pro vide a better estimate of the discourse c called SIF embeddi ng, whic h is bet- ter for do wnstream tasks and surpris ingly compet- iti ve with soph isticated LSTM-based sentenc e em- beddin gs. It is a wei ghted av erage of wo rd em- beddin gs in the windo w , with smaller weights for more frequent words (reminiscen t of tf-idf). This weighted av erage is the MLE estimate of c if abov e genera tiv e model is chan ged to: p ( w | c ) = αp ( w ) + (1 − α ) exp( v w · c ) Z c , where p ( w ) is the o verall prob ability of word w in the corpus and α > 0 is a constant (h yperpara meter). The theory in the current paper works with SIF embeddi ngs as an estimate of the discourse c ; in other words, in Theorem 1 we replace the av erage word vec tor with the SIF v ector of that windo w . Em- pirical ly we find that it lea ds to similar results in test- ing our the ory (Section 4) and better results in do wn- stream WSI ap plication s (Section 6). Therefore, SIF embeddi ngs are adopted in our experimen ts. 2.2 Pro of of L in earity Assert ion No w we use T heorem 1 to show ho w the Linear - ity A ssertio n follo ws. Recall the though t experimen t consid ered there. Sup pose wo rd w has two distinct senses s 1 and s 2 . Compute a wo rd embedding v w for w . T hen hand-repl ace each occurre nce of a sense of w by one of th e new tok ens s 1 , s 2 depen ding upon which one is being used. N ext, train sepa rate embe d- dings for s 1 , s 2 while k eeping the other embeddin gs fixed. (NB : the classic clusterin g-based sense indu c- tion (Schutze, 1998; Reisinger and Mooney , 2010 ) can be seen as an approxima tion to this thought ex- periment .) Theor em 2 (Main) . Assuming the model of Sec- tion 2.1, embeddin gs in the though t ex periment abo ve will satisfy k v w − ¯ v w k 2 → 0 as the corpus length tends to infinity , wher e ¯ v w ≈ αv s 1 + β v s 2 for α = f 1 f 1 + f 2 , β = f 2 f 1 + f 2 , wher e f 1 and f 2 ar e the numbers of occurr ence s of s 1 , s 2 in the corpus, r espec tively . Pr oof. Supp ose we pick a random sample of N win- do ws containing w in the corpus . For each w indo w , compute the a ver age of the word vectors and then apply the linear transfo rmation in Theorem 1. The transfo rmed vector s are i.i.d. estimates for v w , bu t with high probab ility about f 1 / ( f 1 + f 2 ) fraction of the occu rrences used sense s 1 and f 2 / ( f 1 + f 2 ) use d sense s 2 , an d the correspondi ng estimates for those two subpopu lations con ver ge to v s 1 and v s 2 respec - ti vely . Thus by constr uction, the estima te for v w is a linear combin ation of those for v s 1 and v s 2 . Note. Theorem 1 (and hence the Linearity A sser - tion) holds already for the origina l model in Arora et al. (2016) but with A = I , where I is the iden- tity tran sformation . In practi ce, we find ind ucing the word vect or re quires a non-identit y A , w hich is the reason for the mod ified model of Section 2.1. This also helps to addre ss a naggin g issue hiding in older cluste ring-base d approache s such as Reising er and Moone y (201 0) and Huang et al. (2012), which iden- tified senses of a polysemous word by clusterin g the senten ces tha t contain it. One imagines a good rep- resent ation of the sense of an indi vidual cluster is simply the cluste r center . T his turns ou t to be f alse — the closest words to the cluster center sometimes are not meaningfu l for the sense that is being cap- tured; see T able 1. Indeed, the authors of R eising er and Moone y (2010) seem aware of this because they mention “W e do not assume that cluster s corres pond to tradition al word senses . Rather , we only rely on clusters to capture meaningful v ariation in word usage. ” W e find that applying A to clust er centers makes them meaningfu l again. See also T able 1. 3 T owards WSI: Atoms of Discourse No w we consider how to do WSI using only word embeddi ngs and the L inearit y Assertion. Our ap- proach is fully unsu pervised , and tries to induce senses for all words in one go, togeth er with a vecto r repres entation for each sense. center 1 before and provide pro viding a after provid ing provide opportunities provision center 2 before and a to the after access accessible allowing prov ide T able 1: Four nearest word s for some cluster cen- ters that were computed for the word “access” by applyi ng 5 -means on the estimated discou rse vec- tors (see Section 2.1) of 1000 random windo w s from W ikip edia containing “access”. After applying the linear trans formation of Theor em 1 to the center , the neares t words become meanin gful. Giv en embeddings for al l words , it seems un- clear at first sight ho w to pin do wn the senses of tie us ing on ly (1) since v tie can be ex pressed in in- finitely many wa ys as such a combinat ion, and this is true ev en if α i ’ s were kno wn (and they aren’ t). T o pin down the senses w e will need to interre late the senses of dif ferent words, for example, relate the “articl e of clothing” sense tie1 w ith shoe, jack et, etc. T o do so we rely on the gener ati ve model of Sec- tion 2.1 according to which unit vector in the em- beddin g space correspo nds to a micro-top ic or dis- course . Empirically , discou rses c and c ′ tend to look similar to human s (in terms of nearby words) if their inner product is lar ger than 0 . 85 , and quite diffe rent if the inner produ ct is smaller tha n 0 . 5 . S o in the dis- cussio n belo w , a discourse sh ould really be thought of as a small re gion rathe r than a poin t. One imagines that the corpus has a “clot hing” dis- course that has a high proba bility of outputting the tie1 sense, and also of outputtin g related word s such as shoe , ja ck et, etc. B y (2) the prob ability of be- ing outp ut by a discour se is determined by the inner produ ct, so one expec ts that the v ector for “clo thing” discou rse has a hig h in ner prod uct with all of sho e, jac ket , ti e1, etc., and thus can stand as surrogate for v tie1 in (1)! Thus it m ay be suf ficient to conside r the follo wing globa l optimization: Given wor d vectors { v w } in ℜ d and two i nte- ger s k , m with k < m , find a set of unit vector s A 1 , A 2 , . . . , A m suc h that v w = m X j =1 α w, j A j + η w (7) wher e at most k of the coef ficients α w , 1 , . . . , α w ,m ar e nonzer o, and η w ’ s ar e err or vector s. Here k is the sparsity parameter , and m is the number of atoms, and the optimizatio n minimiz es the norms of η w ’ s (the ℓ 2 -recon struction error): X w v w − m X j =1 α w, j A j 2 2 . (8) Both A j ’ s and α w ,j ’ s are unkno wns, and the opti- mization is noncon vex. This is just spars e coding , useful in neuroscien ce (Olshausen an d Field , 199 7) and also in image proce ssing, computer vision, etc. This optimization is a surro gate for the de sired ex- pansio n of v tie as in (1), because one can hope that among A 1 , . . . , A m there will be direction s co rre- spond ing to clo thing , sports matches, etc ., that will ha ve hig h inner prod ucts with tie1 , ti e2, etc., re- specti vely . Furthermore, restrictin g m to be much smaller than the number of words ensures that the typica l A i needs to be reused to express multiple words . W e refer to A i ’ s, disco ver ed by this procedure, as atoms of dis cours e , since ex perimentat ion suggests that the actual discou rse in a typical place in text (namely , vector c in (2)) is a linear combina tion of a small number , around 3-4 , of suc h atoms. Implica- tions of this for text anal ysis are left for futu re work . Relationship to Clustering. Sparse coding is solv ed using alte rnating minimization to fi nd the A i ’ s that minimize (8). This objecti ve functio n re- vea ls sparse coding to be a linear algebrai c analogue of overl apping clustering , wher eby the A i ’ s act as cluste r center s and each v w is assigned in a soft way to at most k of them (using the coefficie nts α w ,j , of which at most k are nonzero). In fac t this clusteri ng vie wpoint is also the basi s of the alternating m ini- mization algo rithm. In the special case when k = 1 , each v w has to be assigned to a single cluster , which is the familiar geometric clu stering with squared ℓ 2 distan ce. Similar overla pping clustering in a traditional graph- theoretic setup —clustering w hile simultane- ously cross-r elating the senses of differe nt word s— seems more dif ficult but worth e xploring . 4 Experimental T ests of Theory 4.1 T est of Gaussian W alk Model: Induced Embeddings No w we test the pr ediction of the Gaussian walk model sugges ting a linear method to induce embed- #parag raphs 250k 500k 750k 1 million cos simila rity 0.94 0 .95 0.96 0.96 T able 2: Fitting the GloV e word v ectors with ave r- age discou rse vec tors using a lin ear transformatio n. The fi rst ro w is the number of paragrap hs used to compute the di scourse vectors, and the seco nd row is the ave rage cosine similaritie s between the fitted vec tors and the G loV e vec tors. dings from the context of a word. Start with th e GloV e embedding s; let v w denote the embedding for w . Randomly sampl e many para graphs from W ikip edia, and for each word w ′ and each occur - rence of w ′ compute the SIF embedding of te xt in the windo w of 20 words centered around w ′ . A ver - age the SIF embeddin gs for all occurren ces of w ′ to obtain vec tor u w ′ . The Gaussian walk model says that there is a line ar transfo rmation that maps u w ′ to v w ′ , so solve the regres sion: ar gmin A X w k Au w − v w k 2 2 . (9) W e call the vector s Au w the indu ced embedding s. W e can test this method of inducing embeddings by holdin g out 1/3 words randomly , doing the regres - sion (9) on th e rest, and computing th e cosin e sim- ilaritie s between Au w and v w on th e heldo ut set of words . T able 2 sho ws tha t the a ve rage cosine simil ar- ity between the induced embedding s and the GloV e vec tors is large . By contrast the av erage similar - ity between the av erage discourse vector s and the GloV e v ectors is much smaller (about 0.58), illus- trating the need for the line ar transfor mation. S im- ilar resu lts are observe d for the word2ve c and SN vec tors (Arora et al., 2016). 4.2 T est of Linearity Asserti on W e do two empir ical tests of the Lineari ty Assertion (Theorem 2). T est 1. The first test in vo lves the classi c artificial polyse mous words (also called pseud ow ords). First, pre-tra in a set W 1 of word vect ors on W ikipedia w ith exi sting embedd ing methods. The n, randomly pick m pairs of non-rep eated words, and for each pair , replac e each occurren ce of either of the two words m pairs 10 10 3 3 · 10 4 relati v e error SN 0.32 0.63 0.67 GloV e 0.29 0.32 0.51 cos similarity SN 0.90 0.72 0.75 GloV e 0.91 0.91 0.77 T able 3: The av erage relati v e errors and cosine sim- ilaritie s between the v ector s of pseu do words and those predicted by Theorem 2. m pairs of words are randomly selected and for each pair , all occur rences of the two wo rds in the corpu s is repl aced by a pse u- do word. Then train the vectors for the pseu do words on the ne w corpus. with a pseudo word. Third, train a set W 2 of vecto rs on the new co rpus, w hile holdin g fixed the vect ors of words that were not in vo lved in the pseudo word s. Construc tion ha s ensured that each pseudo word has two distinct “senses”, and w e also hav e in W 1 the “groun d truth” vecto rs for those senses. 2 Theorem 2 implies that the embedd ing of a pseu do word is a lin- ear combina tion of the sense vect ors, so we can com- pare this predicte d embedd ing to the one le arned in W 2 . 3 Suppose the trained vector for a pseudo word w is u w and the predicted vecto r is v w , then the comparis on criterion is the a verage relati ve error 1 | S | P w ∈ S k u w − v w k 2 2 k v w k 2 2 where S is the set of all the pseud ow ords. W e also report the av erage cosine similarit y between v w ’ s and u w ’ s. T able 3 sho ws the results for the GloV e and SN (Arora et al., 2016 ) vectors, av eraged ov er 5 runs. When m is small, the erro r is small and the co- sine similarit y is as lar ge as 0 . 9 . Even if m = 3 · 10 4 2 Note that this discussion assumes that the set of pseu- do words i s small, so that a typical neighborho od of a pseu- do word does not consist of other pseudo words. Otherwise the ground truth v ectors in W 1 become a bad approximation to the sense vectors. 3 Here W 2 is trained w hil e fi xing the v ectors of words not in volv ed in pseudow ords to be their pre-tr ai ned ve ctors i n W 1 . W e can also train all the v ectors in W 2 from random initializa- tion. Such W 2 will not be aligned wi th W 1 . Then we can learn a linear transformation fr om W 2 to W 1 using the ve ctors for the words not in volv ed in pseudo words, apply it on the v ectors for the pseudow ords, and compare the transformed vectors t o t he predicted ones. This is tested on word2v ec, resulting in r elat ive errors between 20% and 32% , and cosine similarities between 0 . 86 and 0 . 92 . These results again support our analysis. vec tor type GloV e skip-gr am SN cosine 0.72 0.73 0.76 T able 4: The av erage cosi ne of the angl es between the vectors of words an d the span of v ector rep resen- tation s of its senses . The words tested are thos e in the WSI task of SemEv al 201 0. (i.e., about 90 % of the words in the v ocab ulary are replac ed by pseud ow ords), the cosin e similarity re- mains abov e 0 . 7 , which is significant in the 300 di- mension al space. This provi des positi ve support for our anal ysis. T est 2. T he second test is a proxy for what would be a complete (b ut laborious ) test of the Linearity Assertion : repli cating the thought expe riment while hand-l abeling se nse usage for m any words in a cor- pus. The simpler prox y is as follows. For each word w , W ordNet (Fellbaum, 19 98) lists its va ri- ous senses by pro viding definit ion and exa mple sen- tences for each sense. T his is enough te xt (roughly a paragraph’ s wo rth) for our theory to allo w us to repres ent it by a v ector —specificall y , apply the S IF senten ce embedding follo w ed by the linear trans for - mation learned as in S ection 4.1. The text embed- ding for sense s should ap proximate the ground truth vec tor v s for it. T hen the Linearity Assertion pre- dicts that embedd ing v w lies close to the subspace spann ed by the sense vectors . (Note that this is a nontri vial ev ent: in 300 dimens ions a random vector will be quit e far from the subspace spanne d by some 3 other random vectors.) T able 4 checks this predic- tion using the polysemo us words appearing in the WSI task of SemEval 2010. W e tested three stan- dard word embed ding method s: GloV e, the skip- gram va riant of word2v ec, and SN (Arora et a l., 2016) . The resu lts show that the word vector s are quite close to the subspace spanned by the senses. 5 Experiments wi th Atoms of Discourse The experiments use 300 -dimens ional embeddings created using the SN objecti ve in (Arora et al., 2016) and a W ikipedia corp us of 3 billion token s (W ikime- dia, 2012), and the spar se coding is solved by stan- dard k -SVD algorithm (Damnjano vic et al., 2010). Experiment ation showed that the best sparsit y pa- rameter k (i.e., the maximum number of allo wed senses per word) is 5 , and the number of atoms m is about 2 000 . For the number of senses k , we tried plausible alt ernati ve s (based upon suggestio ns of many col leagues) that allow k to v ary fo r dif fer - ent words, for example to let k be correlat ed with the word frequen cy . But a fixed choice of k = 5 seems to produce just as good results. T o understand why , realize that this metho d retains no information about the corpus exce pt for the lo w dimens ional word em- beddin gs. S ince the sparse coding tend s to expr ess a word using fairly differe nt atoms, examining (7) sho ws that P j α 2 w ,j is bounde d by approximat ely k v w k 2 2 . So if too m any α w ,j ’ s are allo wed to be nonze ro, then some must nece ssarily ha ve small co- ef ficients, which makes the correspond ing compo- nents indistingu ishable from noise. In other words, raising k often picks not only ato ms correspo nding to additional senses, bu t also man y that don’t . The best number of atoms m wa s fou nd to be around 200 0 . This was estimated by re- running the spar se coding algo rithm multiple times with dif- ferent random initializa tions, whereupo n substantia l ov erlap was found between the two bases: a large fractio n of vectors in one basis were fou nd to hav e a very close vec tor in the other . Thus combining the bases while mer ging duplicates yielded a basis of about the same size. Around 100 atoms are used by a large number of words or ha ve no close-by words. They appear semanti cally meaningle ss and are ex- cluded by checking for this conditio n. 4 The con tent of each at om can be discerne d by lookin g at the nearby w ords in cosine simila rity . Some examp les are shown in T able 5. Each word is repres ented using at m ost five atoms, which usually captur e distinct senses (with some noise/mis takes ). The senses recove red for tie and spring are shown in T able 6. Similar results can be obtained by using other word embeddi ngs like word2 vec and GloV e. W e also observ e sparse coding proced ures as sign nonne gati v e val ues to most coe fficien ts α w ,j ’ s e v en if they are left unrestric ted. Probably this is becau se the appea rances of a word are best ex plained by what discou rse is being used to generate it, r ather than what discourses are not being used. 4 W e think semantically mean ingless atoms —i.e., unex- plained inner products—e xist because a simple language model such as ours canno t explain all observ ed co-occurrences due to grammar , stopwords, etc. It ends up needing smoothing t erms. Atom 1978 825 231 616 1638 149 330 drowning instagram stakes membran e slapping orchestra conf erences suicides twitter thorou ghbred mitochondria pulling philharmonic meetings overdose facebook guineas cytosol pluckin g philharmon ia seminars murder tum blr preakness cytoplasm squeezing cond uctor workshops poisoning vimeo filly memb r anes twisting sym phony exhibitions commits linkedin fillies organelles bowing orchestras organizes stabbing reddit epsom endop lasmic slamming toscan ini concerts strangulation myspace racecour se protein s tossing concertgeb o uw lectures gunsho t tweets sired vesicles grabbin g solti presentation s T able 5: Some discou rse atoms and their nearest 9 words. By Equation (2), words most likely to appear in a discourse are those neare st to it. tie spring trousers season scoreline wires operatic beginnin g dampe rs flower creek h umid blouse teams goalless cables soprano until brakes flowers b rook win ters waistcoat winning eq ualiser wiring m ezzo months susp ension flowering river summers skirt league clinching electrical contr alto earlier absorber s fragrant fork ppen slee ved finished scoreless wire b a ritone year wheels lilies piney warm pants ch ampionsh ip r e p lay cable coloratur a last dam per flowered elk tempera tures T able 6: Fi ve discourse atoms linked to the words tie and spring . Each atom is represen ted by its nearest 6 words . The algo rithm often makes a mistake in the last atom (or two), as happen ed here. Relationship to T opic Models. Atoms of disc ourse may be reminisce nt of results from other automated methods for obtaining a thematic underst anding of tex t, such as topic modelin g, described in the sur - ve y by B lei (2012). This is not sur prising si nce the model (2) us ed to compute the embeddings is re- lated to a log-linear top ic model by Mnih and H inton (2007 ). H o wev er , the discours es here are computed via sparse coding on word embeddin gs, which can be seen as a linear algebraic alternati ve, res ulting in fair ly fine-grained topics. Atoms are also reminis- cent of cohe rent “word clusters” detected in the past using B ro wn clustering, or e v en spar se coding (Mur - phy et al., 2012). The nove lty in this pape r is a clear interp retation of the sparse coding results as atoms of discourse, as well as its use to capture differ ent word senses. 6 T esti ng W SI in Applications While the main result of the paper is to re ve al the linear algebraic struc ture of word senses within ex- isting embedd ings, it is des irable to verify that this vie w can yield results competit iv e with earlier sense embeddi ng approaches. W e report some tests be- lo w . W e find that common word embeddin gs per- form simil arly with our metho d; for conc reteness we use induced embeddings describ ed in Section 4.1. They are e v aluated in three tasks: word sense induc- tion task in SemEval 2010 (Manan dhar et al., 2010), word similarity in context (Huang et al., 2012), and a new task we called poli ce lineup test . The results are compared to those of existin g embedd ing bas ed approa ches reporte d in related work (Huang et al., 2012; Neelak antan et al., 2014; Mu et al., 2017). 6.1 W ord Sense Induction In the WSI tas k in SemEval 2010, the algorit hm is gi ven a polysemous wo rd an d ab out 40 pieces of tex ts, each using it according to a single sense. T he algori thm has to clu ster the pieces of te xt so that those with the same sense are in the same cluster . The e v aluatio n cr iteria are F-score (Artiles et al., 2009) and V -Measure (Rosen ber g and Hirschber g, 2007) . The F-score tends to be highe r with a smaller number of clusters and the V -Measure tends to be higher with a lar ger number of cluste rs, and fair e v al- uation requires reporting both. Giv en a word and its ex ample texts, our alg orithm uses a Bayesia n analysis dictated by our theory to compute a vec tor u c for th e word in ea ch conte xt c and and then applies k -means on these vectors, w ith the small twist that sens e vectors ar e assigned to neares t centers based on inner produc ts rather than Euclidea n distances. T able 7 sho ws the resu lts. Computing v ector u c . For word w we star t by com- puting its e xpansion in terms of atoms of disco urse (see (8) in Section 3). In an ideal world the nonzero coef ficients would ex actly capture its sense s, and each text containi ng w would match to one of these nonze ro coef ficients. In the real world such deter - ministic su ccess is elusi ve and one m ust re ason us- ing Bayes’ rule. For each atom a , word w and text c there is a joint distrib ution p ( w, a, c ) describing the ev ent tha t atom a is the sense being used when word w was used in text c . Assuming that p ( w , c | a ) = p ( w | a ) p ( c | a ) (similar to Eqn (2)), the posterior distrib utio n is: p ( a | c, w ) ∝ p ( a | w ) p ( a | c ) /p ( a ) . (10) W e approximat e p ( a | w ) using Theorem 2, which sugge sts that the coef ficients in the expan sion of v w with res pect to atoms of discourse scale acco rding to probab ilities of usage. (This asserti on in volv es ig- noring the lo w-order terms in vo lving the logarith m in the theo rem statement.) Also, by th e rando m walk model, p ( a | c ) can be appro ximated by exp( h v a , v c i ) where v c is the S IF embedding of the contex t. Fi- nally , since p ( a ) = E c [ p ( a | c )] , it can be empirica lly estimated by randomly sampling c . The pos terior p ( a | c, w ) can be see n as a soft de- coding of te xt c to atom a . If te xts c 1 , c 2 both contain w , and the y were hard decoded to atoms a 1 , a 2 re- specti vely then th eir similarity would be h v a 1 , v a 2 i . W ith our soft decodi ng, the similarity can be defined by takin g the ex pectatio n over the full posterior: similarit y ( c 1 , c 2 ) = E a i ∼ p ( a | c i ,w ) ,i ∈{ 1 , 2 } h v a 1 , v a 2 i , (11) = * X a 1 p ( a 1 | c 1 , w ) v a 1 , X a 2 p ( a 2 | c 2 , w ) v a 2 + . At a high lev el this is ana logous to the Bayesian polyse my model of Reisinger and M oone y (2010 ) and Brody and Lapata (2009), except that they in- troduc ed separat e embedd ings for each sense clus- ter , while her e we are worki ng with structure already exi sting inside word embeddings . Method V -Measure F-Score (Huang et al., 2012 ) 10.60 38.05 (Neelaka ntan et al., 2014 ) 9.00 47.26 (Mu et al., 2017 ), k = 2 7.30 57.14 (Mu et al., 2017 ), k = 5 14.50 44.07 ours, k = 2 6.1 58.55 ours, k = 3 7.4 55.75 ours, k = 4 9.9 51.85 ours, k = 5 11.5 46.38 T able 7: Performance of dif ferent vectors in the WSI task of SemEv al 2010. The parameter k is the num- ber of cluste rs used in the methods . Rows are di- vided into two blocks, the first of which sho w s the results of the c ompetitors , and the second sho ws those of our algorit hm. Best results in each block are in boldfa ce. The last equation sug gests definin g the vecto r u c for the word w in the conte xt c as u c = X a p ( a | c, w ) v a , (12) which allo ws the similar ity of the word in the two conte xts to be express ed via thei r inner produc t. Results. The results are reported in T able 7. Our approa ch o utperfor ms the results by Huang et al. (2012 ) and N eelaka ntan et al. (2014) . When com- pared to Mu et al. (2017 ), for the case with 2 centers, we achie ved be tter V -measure b ut lower F-score, while for 5 cente rs, we achie ved lower V -measure b ut better F-score . 6.2 W ord Similarity in Context The dataset consists of around 2000 pairs of words, along with the cont exts the words occur in and the groun d-truth similarity score s. The ev aluatio n cri- terion is the correlatio n between the ground-tr uth scores and the predic ted ones. Our method computes the estimated sense vecto rs and then the similarity as in Section 6.1. W e compar e to the basel ines that sim- ply use the cosine similarity of the GloV e/skip-gra m vec tors, and also to the results of se veral existin g sense embedd ing methods. Results. T able 8 sho ws that our resul t is b etter than those of the baselines and Mu et al. (2017), b ut slightl y worse than tha t of Huang et al. (2012 ). Method Spearman coefficie nt GloV e 0.573 skip-g ram 0.622 (Huang et al., 2012 ) 0.657 (Neelaka ntan et al., 2014 ) 0.567 (Mu et al., 2017 ) 0.637 ours 0.652 T able 8: The results for dif feren t method s in the task of word similarity in context. The best result is in boldf ace. Our resul t is close to the best. Note that Huang et al. (2012) retraine d the vecto rs for the sen ses on the corpu s, while our method de- pends only on senses extra cted from th e of f-the-shelf vec tors. After all, our goal is to sho w word sen ses alread y reside within of f-the-s helf word vectors. 6.3 Pol ice Lineup Eva luating WSI systems can run into well- kno wn dif ficulties, as reflecte d in the changing metrics ov er the years (Navigl i and V annella, 2013). Inspired by word- intrusion tests for topic cohe rence (Chang et al., 2009), we pro posed a ne w simple test, which has the adva ntages of being easy to understand, and ca- pable of being administe red to humans. The testbed uses 200 poly semous words and their 704 senses according to W ordNet. Each sense is repres ented by 8 related w ords, which were col- lected from W ordNet and online dictio naries by col- leg e students , who were told to identify most rele- v ant other words occurring in the online definitions of this word sens e as well as in the accompan y- ing illustrati ve sentenc es. These are cons idered as groun d truth representati on of the word sense. T hese 8 words are typically not synon yms. For example, for the tool/ weapon sense of axe the y were “handle, harv est, cutting, split, tool, wood, battle, chop. ” The quantitati ve test is called police lineup . First, randomly pick one of these 200 polysemous words. Second, pick the true senses for the word and then add randomly pick ed senses from other words so that there ar e n senses in total, where each sen se is repres ented by 8 related words as mentioned. Fi- nally , the algorithm (or human) is gi ven the polyse- mous word and a set of n senses, and has to iden tify the true senses in this set. T able 9 gi ve s an example. word senses bat 1 navi gate nocturnal mouse wing cav e s onic fly dar k 2 used hitting ball gam e match crick et play baseball 3 wink brie fly shut eyes wink bate quickl y action 4 whereby le gal court la w lawyer suit bill judg e 5 loose ends tw o loops shoelace s tie rope s tring 6 horny proj ecting bird oral nest horn hard food T able 9: An example of the police lineup test with n = 6 . The algorithm (or human subject) is giv en the polysemou s word “bat” and n = 6 senses each of which is represen ted as a list of words, and is aske d to identify the true senses belonging to “bat” (high- lighte d in boldfac e for demonstratio n). Algorithm 1 Our method for the police lineu p test Input: W o rd w , list S o f senses (each has 8 words) Output: t senses out of S 1: Heur istically fin d inflectional forms of w . 2: Find 5 atoms for w and each inflectional form . Let U denote the union of all these atoms. 3: Initialize the set of cand idate senses C w ← ∅ , and the score for each sense L to score ( L ) ← −∞ 4: for each atom a ∈ U d o 5: Rank senses L ∈ S by score ( a, L ) = s ( a, L ) − s L A + s ( w , L ) − s L V 6: Add the two senses L with h ighest score ( a, L ) to C w , and update their scores score ( L ) ← max { scor e ( L ) , sco re ( a, L ) } 7: Return the t senses L ∈ C s with highest score ( L ) Our method (Alg orithm 1) uses the simila rities between any word (or atom) x and a set of words Y , defined as s ( x, Y ) = h v x , v Y i where v Y is the SIF embedding of Y . It als o us es the a verage simi- laritie s: s Y A = P a ∈ A s ( a, Y ) | A | , s Y V = P w ∈ V s ( w , Y ) | V | where A are all the atoms, and V are all the words. W e note two important practic al details. First, while we hav e been using atoms of discourse as a proxy for word sense, these are too coar se-graine d: the to- tal number of senses (e.g., W ordNet synsets) is far greate r than 2000 . T hus the score( · ) func tion uses both the atom and the word vector . Second, some words are more pop ular than the others—i.e., hav e lar ge components along many atoms and words — which seems to be an i nstance of the smoothing 0 0.2 0.4 0.6 0.8 1 Recall 0 0.2 0.4 0.6 0.8 1 Precision Our method Mu et al, 2017 word2vec Native speaker Non-native speaker 10 20 30 40 50 60 70 80 Number of meanings m 0 0.2 0.4 0.6 0.8 1 Recall Precision A B Figure 1: Precision and recal l in the pol ice line up test. ( A ) For each poly semous wor d, a set of n = 20 senses contai ning the grou nd truth sense s of the wor d are presente d. H uman subj ects are told that on a verag e each word has 3.5 senses and were asked to choose the sen ses the y thou ght were true. The algorithms select t senses for t = 1 , 2 , . . . , 6 . For each t , each algorithm was run 5 times (stand ard deviat ions over the runs are too small to plot). ( B ) The perfor mance of our method for t = 4 and n = 20 , 30 , . . . , 70 . pheno menon alluded to in Footno te 4. The penalty terms s L A and s L V lo wer the scores of senses L con- tainin g suc h w ords. Finally , our algorit hm retu rns t senses w here t can be v aried . Results. The precision and recall for dif ferent n and t (numbe r of senses the algorithm returns) are pre- sented in Figure 1. Our algorithm outperfo rms the two selecte d compet itors. For n = 20 and t = 4 , our algo rithm succee ds with pre cision 65% an d re- call 75% , and performance remains reaso nable for n = 50 . Giving the same test to humans 5 for n = 20 (see the left figure) suggests that our method per- forms similar ly to non-n ati ve speake rs. Other word embedding s can also be used in the test and achie ved slig htly lower performance. For n = 20 and t = 4 , the precisi on/recall are lower by the follo wing amounts: GloV e 2 . 3% / 5 . 76% , NNS E (matrix fac torizatio n on PMI to rank 300 by Murphy et al. (2012)) 25% / 28% . 7 Conclusions Dif ferent s enses of polysemous word s ha ve been sho wn to lie in linear superp osition inside standard word embedding s like word2 vec and GloV e. This has also been sho wn theoret ically b uilding upon 5 Human subjects are graduate students from science or engi- neering majors at major U.S. uni ve rsities. Non-nativ e speake rs hav e 7 to 10 years of English language use/learning. pre vious genera tiv e models, and empirical tests of this theory were presen ted. A priori, one imagines that sho wing such theoretical results about the in- ner structure of modern word embedding s would be ho peless since they are solutio ns to complic ated nonco n v ex optimization . A new WSI method is also propose d based upon these insights that uses only the word embedding s and sparse coding, and shown to prov ide very com- petiti ve performan ce on some WSI benchmarks . One novel aspect of our approach is that the word senses are in terrelate d using one of about 20 00 dis- course vect ors that g iv e a succin ct desc ription of which other words appear in the neighborh ood with that sense. Our method based on sparse coding can be seen as a linear algebraic analog of the cluster - ing approa ches, and also gi ves fine-g rained thematic structu re reminisc ent of topic models. A no vel pol ice lineup test was al so proposed for testing such WSI metho ds, where the algorithm is gi ven a word w and word clusters, some of which belong to senses of w and the others are distrac tors belong ing to senses of oth er words. The algor ithm has to identify the ones belonging to w . W e con- jecture this police lineup test with distracto rs will challe nge some exi sting WSI methods, whereas our method wa s foun d to achie v e performance similar to non-n ativ e speaker s. Acknowledgeme nts W e thank the re vie wers and the Action E ditors of T A CL for helpful feedbac ks an d thank the editors for grantin g a special relaxation of the page limit for our paper . T his work was support ed in part by NSF grants CCF -15273 71, D MS-131730 8, Simons In- ves tigator A ward, Simons Collaboration Grant, an d ONR-N00014-16 -1-2329 . T engyu Ma was additi on- ally sup ported by the Simons A ward in Theoreti cal Computer Science and by the IBM Ph.D. Fellow- ship. Refer ences Arora et al. (201 6 Sanjee v Arora , Y uanzh i Li, Y ing yu Liang, T e ngyu Ma, and Andrej Risteski. 2016. A la- tent variable mo del appro a ch to PMI- based word em- bedding s. T ransaction o f Association fo r Compu ta- tional Linguistics , pages 385–3 99. Arora et al. (201 7 Sanjee v Arora, Y ingy u Liang, an d T engyu Ma. 2017. A simple but toug h-to-b eat base- line fo r sentence embeddin gs. In In Pr oceedin g s of In- ternational Confer ence on Learning Repr esentation s . Artiles et al. (200 9 Javier Artiles, Enriq ue Amig ´ o, and Julio Gonzalo. 200 9. The role of named entities in web p eople searc h. I n P r o ceedings o f the 2 009 Co n - fer ence o n E mpirical Methods in Natural Language Pr o cessing , pages 534–54 2. Bengio et al. (200 3 Y osh u a Bengio, R ´ ejean Duchar me, Pascal V in cent, and Christian Jauvin. 2 0 03. A neu- ral probab ilistic language model. J ournal of Machine Learning Resear ch , p ages 1137– 1155 . Blei (20 12 Da vid M. Blei. 2012 . Probabilistic topic mo d- els. Commu n ication of the Association for Computin g Machinery , pages 77–84. Brody and Lapata (200 9 Samuel Brody and Mirella La- pata. 2009 . B ayesian word sense induction. In Pr o ceedings of the 12th Confer en ce of the Eu r o p ean Chapter of the Association for Computational Lin guis- tics , pages 103– 111. Chang et al. (200 9 Jonathan Chang , Sean Gerrish, Chong W ang , Jordan L. Boyd-Gr aber, and David M. Blei. 2009. Reading tea lea ves: How humans interpret top ic models. In Advan ces in Neural Informa tion Pr ocess- ing Systems , pages 288– 2 96. Church and Hanks (199 0 K enneth W ard Church and Patrick Hank s. 1990. W ord association no rms, mutual informatio n , and lexicography . Comp utationa l linguistics , pages 22–2 9. Damnjanovic et al. (2010 Ivan Dam njanovic, Matthew Davies, and Mark Plumbley . 2 010. SMALLbox – an ev aluation framework for sp a r se representations and dictionary learnin g alg orithms. In Internation al Co n - fer ence on Latent V ariable An a lysis and S ignal Sepa - ration , pages 418–425 . Di Marco and Navigli (2013 Antonio Di Marco and Roberto Navigli. 2013. Clustering an d diversi- fying web search results with g raph- b ased word sense induction. Comp utationa l Linguistics , pages 709–7 54. Faruqui et al. (2015 Manaal Faruqui, Y ulia T svetkov , Dani Y ogatama, Chris Dy er , an d Noah A. Smith. 2015. Sparse overcomplete word vector r e presenta- tions. In Pr oceedings of Associa tion for Comp uta- tional Linguistics , pages 1491– 1500. Fellbaum (199 8 Christiane Fellbaum. 1998. W or dNet: An Electr onic Le xical Databa se . MIT Press. Firth (19 5 7 John Rup ert Firth. 195 7. A syno psis of lin- guistic th eory , 1930-19 55. Studie s in Ling uistic An al- ysis . Gittens et al. (201 7 Alex Gitten s, Dimitris Achlioptas, and Mich ael W Mah oney . 2017 . Skip-gra m – Zipf + Uniform = V ector Additi vity . In Pr oceedings of the 55th An nual Meeting of th e Associa tion for Computa- tional Lin guistics (V o lume 1: Long P a pers) , volume 1, pages 69–7 6. Griffiths et al. (2007 Thomas L . Griffiths, Ma r k Steyvers, and Joshua B. T enenbaum. 2007. T o pics in seman tic representatio n. P sychologica l r eview , p a ges 211–2 4 4. Huang et al. (20 12 Eric H. Huang, Richard Socher , Christopher D. Mann ing, and And rew Y . Ng. 201 2. Improving word representations via global context and multiple word prototy pes. In Pr ocee d ings of the 50th Annua l Meeting of the Associatio n for Computatio n al Linguistics , pages 873– 882. Iacobacci et al. (2015 I gnacio Iaco bacci, Mo h am- mad T aher Pilehvar , and Roberto Navigli. 201 5. SensEmbed: Lear n ing sense embe ddings for word an d relational similarity . In Pr oce e d ings of Association for Computatio nal Lin g uistics , pages 95–105. Levy and Go ldberg (2 014 Omer Levy and Y oav Gold- berg. 201 4. Neural word embedd in g as implicit ma- trix factorization . In Adva nces in Neural Informatio n Pr o cessing Systems , pages 2177– 2185 . Manandh ar et al. (2 010 Suresh Manandh ar , Io annis P Klapaftis, Dm itriy Dligach , and Sameer S Pradhan . 2010. Sem E val 2 010: Task 1 4: Word sen se ind uc- tion & d isam biguation . In Pr oceedings o f the 5th In- ternational W orksho p o n S emantic Eva luation , p ages 63–68 . Mikolov et al. (2013a T om as Mikolov , Ilya Sutskever , Kai Chen, Greg S. Corrado , an d Jeff Dea n. 201 3 a. Distributed re presentation s of words an d p h rases and their compositionality . In Advances in Neur al Infor- mation Pr oc essing Systems , pages 3111– 3 119. Mikolov et al. (2013b T o mas Mikolov , W e n -tau Y ih, a nd Geoffrey Zwe ig . 2013b. Linguistic r egu larities in continuo us space word rep resentations. In Pr oceed- ings of the Conference of the North American Chapter of the Association for Computation al Lingu istics: Hu- man Langu age T echnologies , pag es 746–75 1. Mnih and Hinton (200 7 Andriy Mnih and Geoffrey Hin - ton. 2007. Thre e new gr aphical mo dels for statistical languag e mo delling. In Pr oceedin gs of the 24 th In- ternational Confer ence on Machine Learning , p a ges 641–6 48. Mu et al. (20 17 Jiaqi Mu, Sum a Bhat, an d Pramod V iswanath. 2017. Geometry of p olysemy . In Pr o ceedings of Internation a l Confer ence on Learning Repr esentation s . Murphy et al. (2012 Brian Murphy , Partha Pratim T aluk - dar, an d T om M. Mitchell. 2012. Learn in g e ffective and interpretable semantic mo dels usin g n on-negative sparse embed ding. In Pr oceedings of th e 24th In- ternational Confer ence on Compu tational Linguistics , pages 1933 –1950 . Navigli and V ann ella (2013 Roberto Navigli an d Da n iele V annella. 2013 . SemEval 2 013: T a sk 11: Word sense induction and disamb ig uation with in an en d -user ap - plication. In Second Joint Co n fer ence on Lexical an d Computation al Sem a ntics , pages 193–20 1. Neelakantan et al. (201 4 Ar vind Neelak a n tan, Jeev an Shankar, Re Passos, an d An drew Mcc a llum. 201 4 . Efficient nonp arametric estimation of multiple em- bedding s per word in vector space. In Pr oceedin gs of Conference o n Empirical Methods in Natural Language Pr ocessing , pag es 1059–1 069. Olshausen and Field (199 7 Bruno Olshausen and David Field. 199 7 . Sp arse coding with an overcomplete ba- sis set: A strategy e mployed by V1? V ision Resear ch , pages 3311 –3325 . Penningto n et al. (2014 Jeffrey Penning ton, Richard Socher, and Christopher D. Manning. 201 4. GloVe: Global V ectors for w ord representation. In P r o ceed- ings of the Emp iricial Methods in Natural Language Pr o cessing , pages 1532–1 543. Reisinger and Moon ey (2010 Joseph Reisinger and Ray- mond Moo ney . 2010. Multi-pr ototype vector-space models of word mean ing. In P r oceed in gs of the Con- fer ence of the North American Chap ter of the Associa- tion for Computationa l Lingu istics: Human Lang u age T echnologies , p ages 107–1 17. Rosenberg and Hirschberg (2 007 Andrew Rosenbe rg and Julia Hirsch b erg. 20 07. V -m easure: A conditio nal entropy-b ased external clu ster e valuation measure . In Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing and Confer ence on Computationa l Natural Language Learning , pages 410–420 . Schutze (199 8 Hinrich Schutze. 1998. Autom atic word sense discriminatio n. Co m p utationa l Linguistics , pages 97–1 23. T ian et al. (20 17 Ran T ian, Naoaki Ok azaki, and Kentaro Inui. 2017. Th e mechan ism of additive com position. Machine Learning , 106(7):10 83–1 130. T urney a n d Pantel (2010 Peter D. Turney an d Patrick Pan- tel. 2010. From frequ ency to meaning : V ector space models of semantics. Journal of Artificial Intelligence Resear ch , pages 141–188 . W ikimedia (201 2 W ikimedia. 2 012. E nglish W ikiped ia dump. Accessed March 2015. Y arowsky (19 95 Da vid Y arowsky . 1995. Un supervised word sense disambig uation r iv aling sup ervised meth- ods. In Pr o ceedings of the 33r d An nual Meetin g on As- sociation fo r Compu tational Linguistics , pages 1 8 9– 196.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment