Single-Channel Multi-talker Speech Recognition with Permutation Invariant Training
Although great progresses have been made in automatic speech recognition (ASR), significant performance degradation is still observed when recognizing multi-talker mixed speech. In this paper, we propose and evaluate several architectures to address …
Authors: Yanmin Qian, Xuankai Chang, Dong Yu
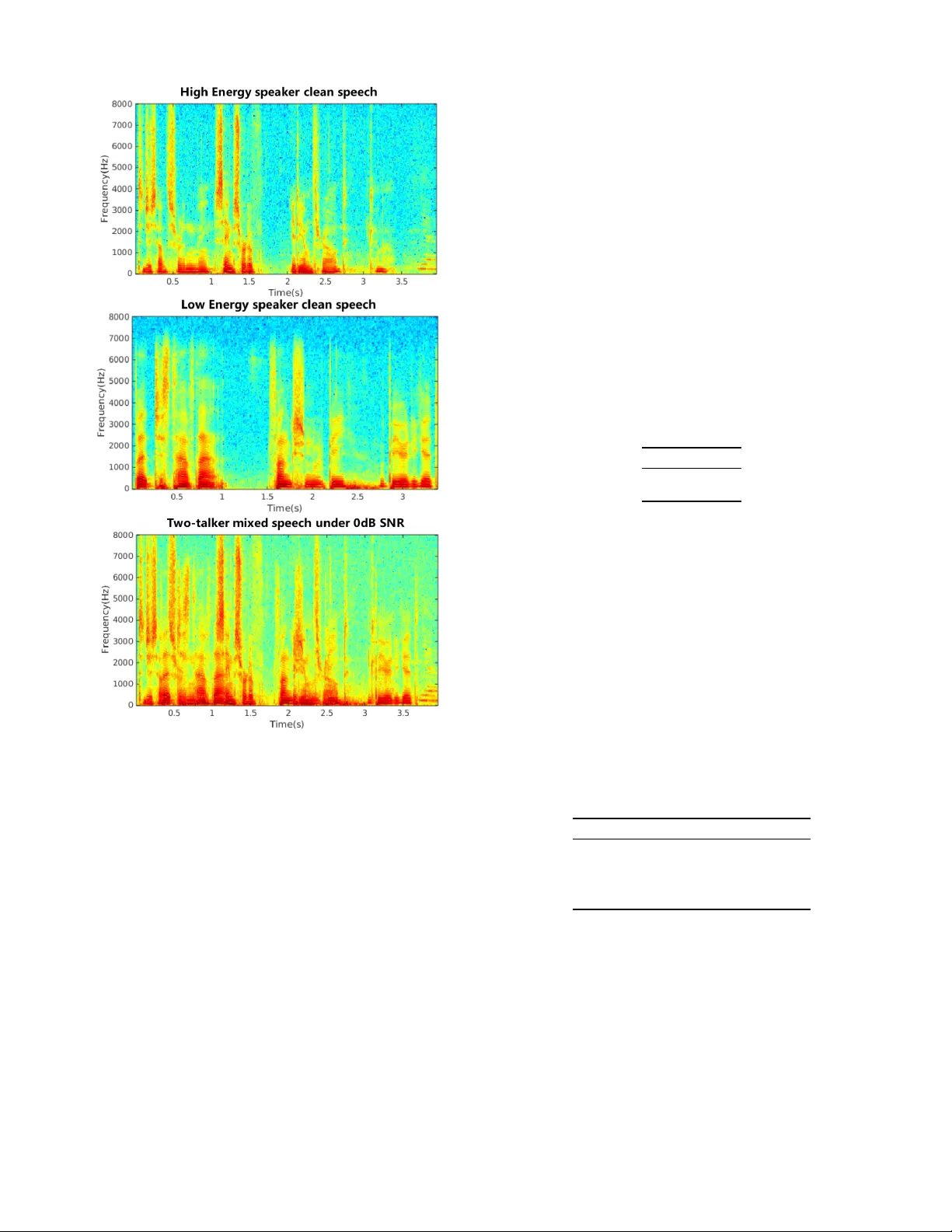
IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGU A GE PR OCESSING 1 Single-Channel Multi-talker Speech Recognition with Permutation In v ariant T raining Y anmin Qian, Member , IEEE, Xuankai Chang, Student Member , IEEE, and Dong Y u, Senior Member , IEEE Abstract —Although great pr ogresses ha ve been made in auto- matic speech r ecognition (ASR), significant perf ormance degrada- tion is still observed when recognizing multi-talker mixed speech. In this paper , we propose and evaluate several architectures to address this problem under the assumption that only a single channel of mixed signal is av ailable. Our technique extends permutation inv ariant training (PIT) by introducing the front- end feature separation module with the minimum mean square error (MSE) criterion and the back-end recognition module with the minimum cross entr opy (CE) criterion. More specifically , during training we compute the average MSE or CE over the whole utterance for each possible utterance-lev el output-target assignment, pick the one with the minimum MSE or CE, and optimize for that assignment. This strategy elegantly solves the label permutation problem observed in the deep learning based multi-talker mixed speech separation and recognition systems. The proposed architectures are ev aluated and compared on an artificially mixed AMI dataset with both two- and three- talker mixed speech. The experimental results indicate that our proposed architectur es can cut the word error rate (WER) by 45.0% and 25.0% relatively against the state-of-the-art single- talker speech recognition system across all speakers when their energies are comparable, for two- and three-talk er mixed speech, respecti vely . T o our knowledge, this is the first work on the multi-talker mixed speech recognition on the challenging speaker- independent spontaneous large vocabulary continuous speech task. Keyw ords — permutation invariant training, multi-talker mixed speech recognition, feature separation, joint-optimization I . I N T RO D U C T I O N Thanks to the significant progresses made in the recent years [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15], [16], [17], [18], [19], [20], the ASR systems now surpassed the threshold for adoption in many real-world scenarios and enabled services such as Microsoft Cortana, Apple’ s Siri and Google Now , where close-talk microphones are commonly used. Howe ver , the current ASR systems still perform poorly when far -field microphones are used. This is because many difficulties hidden by close-talk microphones now surface under distant recognition scenarios. For example, the signal to noise ratio (SNR) between the target speaker and the interfering noises is much lower than that when close-talk microphones are used. As a result, the interfering signals, such Y anmin Qian and Xuankai Chang are with Computer Science and Engi- neering Department, Shanghai Jiao T ong Univ ersity , Shanghai, 200240 P . R. China ( { yanminqian,xuank } @sjtu.edu.cn). Dong Y u is with T encent AI Lab, Seattle, USA (dyu@tencent.com). as background noise, rev erberation, and speech from other talkers, become so distinct that they can no longer be ignored. In this paper , we aims at solving the speech recognition problem when multiple talkers speak at the same time and only a single channel of mixed speech is a v ailable. Many attempts hav e been made to attack this problem. Before the deep learning era, the most famous and ef fecti ve model is the factorial GMM-HMM [21], which outperformed human in the 2006 monaural speech separation and recognition challenge [22]. The factorial GMM-HMM, howe ver , requires the test speakers to be seen during training so that the interactions between them can be properly modeled. Recently , sev eral deep learning based techniques have been proposed to solve this problem [19], [20], [23], [24], [25], [26]. The core issue that these techniques try to address is the label ambiguity or permutation problem (refer to Section III for details). In W eng et al. [23] a deep learning model was de veloped to recognize the mix ed speech directly . T o solv e the label ambiguity problem, W eng et al. assigned the senone labels of the talker with higher instantaneous energy to output one and the other to output two. This, although addresses the label ambiguity problem, causes frequent speak er switch across frames. T o deal with the speaker switch problem, a tw o-speaker joint-decoder with a speaker switching penalty was used to trace speakers. This approach has two limitations. First, energy , which is manually picked, may not be the best information to assign labels under all conditions. Second, the frame switching problem introduces burden to the decoder . In Hershey et al. [24], [25] the multi-talker mixed speech is first separated into multiple streams. An ASR engine is then applied to these streams independently to recognize speech. T o separate the speech streams, they proposed a technique called deep clustering (DPCL). They assume that each time- frequency bin belongs to only one speaker and can be mapped into a shared embedding space. The model is optimized so that in the embedding space the time-frequency bins belong to the same speaker are closer and those of different speakers are farther away . During ev aluation, a clustering algorithm is used upon embeddings to generate a partition of the time-frequency bins first, separated audio streams are then reconstructed based on the partition. In this approach, the speech separation and recognition are usually two separate components. Chen et al. [26] proposed a similar technique called deep attractor network (DANet). Follo wing DPCL, their approach also learns a high-dimensional embedding of the acoustic signals. Dif ferent from DPCL, howe ver , it creates cluster centers, called attractor points, in the embedding space to pull together the time-frequency bins corresponding to the same source. The main limitation of D ANet is the requirement to IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 2 estimate attractor points during ev aluation time and to form frequency-bin clusters based on these points. In Y u et al. [19] and K olbak et al.[20], a simpler yet equally effecti ve technique named permutation in v ariant train- ing (PIT) 1 was proposed to attack the speaker independent multi-talker speech separation problem. In PIT , the source targets are treated as a set (i.e., order is irrelev ant). During training, PIT first determines the output-target assignment with the minimum error at the utterance lev el based on the forward- pass result. It then minimizes the error giv en the assign- ment. This strategy ele gantly solved the label permutation problem. Howe ver , in these original works PIT was used to separate speech streams from mixed speech. For this reason, a frequenc y-bin mask was first estimated and then used to reconstruct each stream. The minimum mean square error (MMSE) between the true and reconstructed speech streams was used as the criterion to optimize model parameters. Moreov er , most of previous works on multi-talker speech still focus on speech separation [19], [20], [24], [25], [26]. In contrast, the multi-talker speech recognition is much harder and the related work is less. There has been some attempts, but the related tasks are relativ ely simple. For example, the 2006 monaural speech separation and recognition challenge [21], [22], [23], [27], [28] was defined on a speaker -dependent, small vocab ulary , constrained language model setup, while in [25] a small vocabulary reading style corpus was used. W e are not aware of any extensiv e research work on the more real, speaker -independent, spontaneous large vocab ulary continuous speech recognition (L VCSR) on multi-talker mixed speech before our work. In this paper, we attack the multi-talker mix ed speech recognition problem with a focus on the speaker-independent setup gi ven just a single-channel of the mixed speech. Different from [19], [20], here we extend and redefine PIT over log filter bank features and/or senone posteriors. In some architectures PIT is defined upon the minimum mean square error (MSE) between the true and estimated individual speaker features to separate speech at the feature lev el (called PIT -MSE from now on). In some other architectures, PIT is defined upon the cross entropy (CE) between the true and estimated senone posterior probabilities to recognize multiple streams of speech directly (called PIT -CE from now on). Moreov er , the PIT -MSE based front-end feature separation can be combined with the PIT -CE based back-end recognition in a joint optimization architecture. W e e v aluate our architectures on the artificially generated AMI data with both two- and three-talker mixed speech. The exper - imental results demonstrate that our proposed architectures are very promising. The rest of the paper is organized as follows. In Section II we describe the speaker independent multi-talk er mixed speech recognition problem. In Section III we propose several PIT - based architectures to recognize multi-streams of speech. W e report experimental results in Section IV and conclude the paper in Section V. 1 In [24], a similar permutation free technique, which is equivalent to PIT when there are exactly two-speakers, was e valuated with neg ativ e results and conclusion. I I . S I N G L E - C H A N N E L M U LT I - T A L K E R S P E E C H R E C O G N I T I O N In this paper , we assume that a linearly mixed single- microphone signal y [ n ] = P S s =1 x s [ n ] is kno wn, where x s [ n ] , s = 1 , · · · , S are S streams of speech sources from different speakers. Our goal is to separate these streams and recognize every single one of them. In other words, the model needs to generate S output streams, one for each source, at ev ery time step. Howev er, giv en only the mixed speech y [ n ] , the problem of recognizing all streams is under-determined because there are an infinite number of possible x s [ n ] (and thus recognition results) combinations that lead to the same y [ n ] . Fortunately , speech is not random signal. It has patterns that we may learn from a training set of pairs y and ` s , s = 1 , · · · , S , where ` s is the senone label sequence for stream s . In the single speaker case, i.e., S = 1 , the learning problem is significantly simplified because there is only one possible recognition result, thus it can be casted as a simple supervised optimization problem. Gi ven the input to the model, which is some feature representation of y , the output is simply the senone posterior probability conditioned on the input. As in most classification problems, the model can be optimized by minimizing the cross entropy between the senone label and the estimated posterior probability . When S is greater than 1 , howe ver , it is no longer as simple and direct as in the single-talker case and the label ambiguity or permutation becomes a problem in training. In the case of two speakers, because speech sources are symmetric giv en the mixture (i.e., x 1 + x 2 equals to x 2 + x 1 and both x 1 and x 2 hav e the same characteristics), there is no predetermined way to assign the correct target to the corresponding output layer . Interested readers can find additional information in [19], [20] on ho w training progresses to nowhere when the con ventional supervised approach is used for the multi-talker speech separation. I I I . P E R M U T A T I O N I N V A R I A N T T R A I N I N G F O R M U LTI - T A L K E R S P E E C H R E C O G N I T I O N T o address the label ambiguity problem, we propose several architectures based on the permutation inv ariant training (PIT) [19], [20] for multi-talker mixed speech recognition. For simplicity and without losing the generality , we always assume there are two-talkers in the mixed speech when describing our architectures in this section. Note that, DPCL [24], [25] and DANet [26] are alterna- tiv e solutions to the label ambiguity problem when the goal is speech source separation. Howe ver , these two techniques cannot be easily applied to direct recognition (i.e., without first separating speech) of multiple streams of speech because of the clustering step required during separation, and the assumption that each time-frequency bin belongs to only one speaker (which is false when the CE criterion is used). A. F eatur e Separation with Dir ect Supervision T o recognize the multi-talker mixed speech, one straight- forward approach is to estimate the features of each speech IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 3 (a) Arch#1: Feature separation with the fixed reference assignment (b) Arch#2: Feature separation with permutation in variant training Fig. 1: Feature separation architectures for multi-talker mixed speech recognition source gi ven the mixed speech feature and recognize them one by one using a normal single-talker L VCSR system. This idea is depicted in Figure 1 where we learn a model to recov er the filter bank (FB ANK) features from the mixed FB ANK features and then feed each stream of the recovered FBANK features to a con ventional L VCSR system for recognition. In the simplest architecture, which is denoted as Arch#1 and illustrated in Figure 1(a), feature separation can be considered as a multi-class regression problem, similar to many previous works [29], [30], [31], [32], [33], [34]. In this architecture, Y , the feature of mixed speech, are used as the input to some deep learning models, such as deep neural networks (DNNs), con volutional neural networks (CNNs), and long short-term memory (LSTM) recurrent neural networks (RNNs), to esti- mate feature representation of each individual talker . If we use the bidirectional LSTM-RNN model, the model will compute H 0 = Y (1) H f i = RN N f i ( H i − 1 ) , i = 1 , · · · , N (2) H b i = RN N b i ( H i − 1 ) , i = 1 , · · · , N (3) H i = S tack ( H f i , H b i ) , i = 1 , · · · , N (4) ˆ X s = Linear ( H N ) , s = 1 , · · · , S (5) where H 0 is the input, N is the number of hidden layers, H i is the i -th hidden layer , RN N f i and R N N b i are the forward and backward RNNs at hidden layer i , respectiv ely , ˆ X s , s = 1 , · · · , S is the estimated separated features from the output layers for each speech stream s . During training, we need to provide the correct reference (or target) features X s , s = 1 , · · · , S for all speakers in the mixed speech to the corresponding output layers for supervision. The model parameters can be optimized to minimize the mean square error (MSE) between the estimated separated feature ˆ X s and the original reference feature X s , J = 1 S min S X s =1 X t || X s t − ˆ X s t || 2 (6) where S is the number of mixed speakers. In this architecture, it is assumed that the reference features are organized in a given order and assigned to the output layer segments accordingly . Once trained, this feature separation module can be used as the front-end to process the mixed speech. The separated feature streams are then fed into a normal single- speaker L VCSR system for decoding. B. F eatur e Separation with P ermutation In variant T raining The architecture depicted in Figure 1(a) is easy to implement but with obvious dra wbacks. Since the model has multiple output layer segments (one for each stream), and they depend on the same input mixture, assigning reference is actually difficult. The fixed reference order used in this architecture is not quite right since the source speech streams are symmetric and there is no clear clue on how to order them in advance. This is referred to as the label ambiguity (or label permutation) problem in [19], [23], [24]. As a result, this architecture may work well on the speaker-dependent setup where the target speaker is known (and thus can be assigned to a specific output segment) during training, b ut cannot generalize well to the speaker -independent case. The label ambiguity problem in the multi-talker mixed speech recognition was addressed with limited success in [23] where W eng et al. assigned reference features depending on IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 4 the ener gy le vel of each speech source. In the architecture illus- trated in Figure 1(b), named as Arch#2 , permutation inv ariant training (PIT) [19], [20] is utilized to estimate individual feature streams. In this architecture, The reference feature sources are gi ven as a set instead of an ordered list. The output- reference assignment is determined dynamically based on the current model. More specifically , it first computes the MSE for each possible assignment between the reference X s 0 and the estimated source ˆ X s , and picks the one with minimum MSE. In other words, the training criterion is J = 1 S min s 0 ∈ permu ( S ) X s X t || X s 0 t − ˆ X s t || 2 , s = 1 , · · · , S (7) where permu ( S ) is a permutation of 1 , · · · , S . W e note two important ingredients in this objectiv e function. First, it automatically finds the appropriate assignment no matter how the labels are ordered. Second, the MSE is computed over the whole sequence for each assignment. This forces all the frames of the same speaker to be aligned with the same output segment, which can be re garded as performing the feature-le vel tracing implicitly . With this ne w objectiv e function, W e can simultaneously perform label assignment and error ev aluation on the feature lev el. It is expected that the feature streams separated with PIT (Figure 1(b)) has higher quality than that separated with fixed reference order (Figure 1(a)). As a result, the recognition errors on these feature streams should also be lo wer . Note that the computational cost associated with permutation is negligible compared to the network forward computation during training, and no permutation (and thus no cost) is needed during ev aluation. C. Direct Multi-T alker Mixed Speech Recognition with PIT In the previous two architectures mixed speech features are first separated e xplicitly and then recognized independently with a con ventional single-talk er L VCSR system. Since the feature separation is not perfect, there is mismatch between the separated features and the normal features used to train the con ventional L VCSR system. In addition, the objectiv e function of minimizing the MSE between the estimated and reference features is not directly related to the recognition performance. In this section, we propose an end-to-end ar- chitecture that directly recognizes mixed speech of multiple speakers. In this architecture, denoted as Arch#3 , we apply PIT to the CE between the reference and estimated senone posterior probability distributions as shown in Figure 2(a). Gi ven some feature representation Y of the mixed speech y , this model will compute H 0 = Y (8) H f i = RN N f i ( H i − 1 ) , i = 1 , · · · , N (9) H b i = RN N b i ( H i − 1 ) , i = 1 , · · · , N (10) H i = S tack ( H f i , H b i ) , i = 1 , · · · , N (11) H s o = Linear ( H N ) , s = 1 , · · · , S (12) O s = S of tmax ( H s o ) , s = 1 , · · · , S (13) using a deep bidirectional RNN, where Equations (8) ∼ (11) are similar to Equations (1) ∼ (4). H s o , s = 1 , · · · , S is the excitation at output layer for each speech stream s , and O s , s = 1 , · · · , S is the output segment for stream s . Different from architectures discussed in pre vious sections, in this archi- tecture each output segment represents the estimated senone posterior probability for a speech stream. No additional feature separation, clustering or speaker tracing is needed. Although various neural network structures can be used, in this study we focus on bidirectional LSTM-RNNs. In this direct multi-talker mixed speech recognition archi- tecture, we minimize the objectiv e function J = 1 S min s 0 ∈ permu ( S ) X s X t C E ( ` s 0 t , O s t ) , s = 1 , · · · , S (14) In other words, we minimize the minimum average CE of ev ery possible output-label assignment. All the frames of the same speaker are forced to be aligned with the same output segment by computing the CE over the whole sequence for each assignment. This strategy allows for the direct multi- talker mixed speech recognition without e xplicit separation. It is a simpler and more compact architecture for multi-talker speech recognition. D. Joint Optimization of PIT -based F eatur e Separation and Recognition As mentioned abov e, the main dra wback of the feature separation architectures is the mismatch between the distorted separation result and the features used to train the single- talker L VCSR system. The direct multi-talker mixed speech recognition with PIT , which bypassed the feature separation step, is one solution to this problem. Here we propose another architecture named joint optimization of PIT -based feature separation and recognition, and it is denoted as Arch#4 and shown in Figure 2(b). This architecture contains two PIT -components, the front- end feature separation module with PIT -MSE and the back-end recognition module with PIT -CE. Different from the architec- ture in Figure 1(b), in this architecture a new L VCSR system is trained upon the output of the feature separation module with PIT -CE. The whole model is trained progressiv ely: the front- end feature separation module is firstly optimized with PIT - MSE; Then the parameters in the back-end recognition module are optimized with PIT -CE while keeping the parameters in the feature separation module fixed. Finally parameters in both modules are jointly refined with PIT -CE using a small learning rate. Note that the reference assignment in the recognition (PIT -CE) step is the same as that in the separation (PIT -MSE) step. J 1 = 1 S min s 0 ∈ permu ( S ) X s X t || X s 0 t − ˆ X s t || 2 , s = 1 , · · · , S (15) J 2 = 1 S min s 0 ∈ permu ( S ) X s X t C E ( ` s 0 t , O s t ) , s = 1 , · · · , S (16) IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 5 (a) Arch#3: Direct multi-talker mixed speech recognition with PIT (b) Arch#4: Joint optimization of PIT -based feature separation and recognition Fig. 2: Advanced architectures for multi-talker mixed speech recognition During decoding, the mixed speech features are fed into this architecture, and the final posterior streams are used for decoding as normal. I V . E X P E R I M E N TA L R E S U L T S T o ev aluate the performance of the proposed architectures, we conducted a series of experiments on an artificially gener- ated two- and three-talker mixed speech dataset based on the AMI corpus [35]. There are four reasons for us to use AMI: 1) AMI is a speaker -independent spontaneous L VCSR corpora. Compared to small vocabulary , speaker-dependent, read English datasets used in most of the previous studies [22], [23], [27], [28], observations made and conclusions drawn from AMI are more likely generalized to other real-world scenarios; 2) AMI is a re- ally hard task with different kinds of noises, truly spontaneous meeting style speech, and strong accents. It reflects the true ability of L VCSR when the training set size is around 100hr . The state-of-the-art word error rate (WER) on AMI is around 25.0% for the close-talk condition [36] and more than 45.0% for the far-field condition with single-microphone [36], [37]. These WERs are much higher than that on other corpora, such as Switchboard [38] on which the WER is no w below 10.0% [18], [36], [39], [40]; 3) Although the close-talk data (AMI IHM) was used to generate mixed speech in this work, the existence of parallel far -field data (AMI SDM/MDM) allows us to ev aluate our architectures based on the f ar-field data in the future; 4) AMI is a public corpora, using AMI allo ws interested readers to reproduce our results more easily . The AMI IHM (close-talk) dataset contains about 80hr and 8hr speech in training and ev aluation sets, respectiv ely [35], [41]. Using AMI IHM, we generated a two-talk er (IHM-2mix) and a three-talker (IHM-3mix) mixed speech dataset. T o artificially synthesize IHM-2mix, we randomly select two speakers and then randomly select an utterance for each speaker to form a mixed-speech utterance. For easier explana- tion, the high energy (High E) speaker in the mixed speech is al ways chosen as the target speak er and the lo w ener gy (Low E) speaker is considered as interference speaker . W e synthesized mixed speech for five different SNR conditions (i.e. 0dB, 5dB, 10dB, 15dB, 20dB) based on the energy ratio of the two-talkers. T o eliminate easy cases we force the lengths of the selected source utterances comparable so that at least half of the mixed speech contains overlapping speech. When the two source utterances have different lengths, the shorter one is padded with small noise at the front and end. The same procedure is used for preparing both the training and testing data. W e generated in total 400hr two-talker mixed speech, 80hr per SNR condition, as the training set. A subset of 80hr speech from this 400hr training set was used for fast model training and ev aluation. For ev aluation, total 40hr two-talker mixed speech, 8hr per SNR condition, is generated and used. The IHM-3mix dataset was generated similarly . The relativ e energy of the three speakers in each mixed utterance varies randomly in the training set. Different from the training set, all the speakers in the same mixed utterance hav e equal energy in the testing set. W e generated in total 400hr and 8hr three-talker mixed speech as the training and testing set, respectively . Figure 3 compares the spectrogram of a single-talker clean utterance and the corresponding 0db two-talker mixed utter- ance in the IHM-2mix dataset. Obviously it is really hard to separate the spectrogram and reconstruct the source utterances by visually examining it. IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 6 Fig. 3: Spectrogram comparison between the original single- talker clean speech and the 0db two-talk er mixed-speech in the IHM-2mix dataset A. Single-speak er Recognition Baseline In this work, all the neural networks were built using the lat- est Microsoft Cognitive T oolkit (CNTK) [42] and the decoding systems were built based on Kaldi [43]. W e first followed the officially released kaldi recipe to build an LD A-MLL T -SA T GMM-HMM model. This model uses 39-dim MFCC feature and has roughly 4K tied-states and 80K Gaussians. W e then used this acoustic model to generate the senone alignment for neural network training. W e trained the DNN and BLSTM- RNN baseline systems with the original AMI IHM data. 80- dimensional log filter bank (LFBK) features with CMVN were used to train the baselines. The DNN has 6 hidden layers each of which contains 2048 Sigmoid neurons. The input feature for DNN contains a windo w of 11 frames. The BLSTM-RNN has 3 bidirectional LSTM layers which are followed by the softmax layer . Each BLSTM layer has 512 memory cells. The input to the BLSTM-RNN is a single acoustic frame. All the models explored here are optimized with cross-entropy criterion. The DNN is optimized using SGD method with 256 minibatch size, and the BLSTM-RNN is trained using SGD with 4 full-length utterances in each minibatch. For decoding, we used a 50K-word dictionary and a trigram language model interpolated from the ones created using the AMI transcripts and the Fisher English corpus. The perfor- mance of these two baselines on the original single-speaker AMI corpus are presented in T able I. These results are com- parable with that reported by others [41] even though we did not use adapted fMLLR feature. It is noted that adding more BLSTM layers did not show meaningful WER reduction in the baseline. T ABLE I: WER (%) of the baseline systems on original AMI IHM single-talker corpus Model WER DNN 28.0 BLSTM 26.6 T o test the normal single-speaker model on the two-talker mixed speech, the above baseline BLSTM-RNN model is utilized to decode the mixed speech directly . During scoring we compare the decoding output (only one output) with the reference of each source utterance to obtain the WER for the corresponding source utterance. T able II summarizes the recognition results. It is clear , from the table, that the single- speaker model performs very poorly on the multi-talker mixed speech as indicated by the huge WER degradation of the high- energy speaker when SNR decreases. Further more, in all the conditions, the WERs for the low energy speaker are all above 100.0%. These results demonstrate the great challenge in the multi-talker mixed speech recognition. T ABLE II: WER (%) of the baseline BLSTM-RNN single- speaker system on the IHM-2mix dataset SNR Condition High E Spk Lo w E Spk 0db 85.0 100.5 5db 68.8 110.2 10db 51.9 114.9 15db 39.3 117.6 20db 32.1 118.7 B. Evaluation of T wo-talker Speech Recognition Ar chitectur es The proposed four architectures for two-taker speech recog- nition are evaluated here. For the first two approaches (Arch#1 and Arch#2) that contain an explicit feature separation stage (with and without PIT -MSE), a 3-layer BLSTM is used in the feature separation module. The separated feature streams are fed into a normal 3-layer BLSTM L VCSR system, trained with IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 7 single-talker speech, for decoding. The whole system contains in total six BLSTM layers. For the other two approaches (Arch#3 and Arch#4), in which PIT -CE is used, 6-layer BLSTM models are used so that the number of parameters is comparable to the other two architectures. In all these architectures the input is the 40-dimensional LFBK feature and each layer contains 768 memory cells. T o train the latter two architectures that exploit PIT -CE we need to prepare the alignments for the mixed speech. The senone alignments for the two-talkers in each mixed speech utterance are from the single-speaker baseline alignment. The alignment of the shorter utterance within the mixed speech is padded with the silence state at the front and the end. All the models were trained with a minibatch of 8 utterances. The gradient was clipped to 0.0003 to guarantee the training stability . T o obtain the results reported in this section we used the 80hr mixed speech training subset. The recognition results on both speakers are ev aluated. For scoring, we e v aluated the two hypotheses, obtained from two output sections, against the two references and pick the assignment with better WER to compute the final WER. The results on the 0db SNR condition are shown in T able III. Compared to the 0dB condition in T able II, all the proposed multi-talker speech recognition architectures obtain obvious improv ement on both speakers. W ithin the two architectures with the explicit feature separation stage, the architecture with PIT -MSE is significantly better than the baseline feature separation architecture. These results confirmed that the label permutation problem can be well alle viated by the PIT -MSE at the feature lev el. W e can also observe that applying PIT - CE on the recognition module (Arch#3 & Arch#4) can further reduce WER by 10.0% absolute. This is because these two architectures can significantly reduce the mismatch between the separated feature and the feature used to train the L VCSR model. It is also because cross-entropy is more directly related to the recognition accuracy . Comparing Arch#3 and Arch#4, we can see that the architecture with joint optimization on PIT - based feature separation and recognition slightly outperforms the direct PIT -CE based model. Since Arch#3 and Arch#4 achiev e comparable results, and the model architecture and training process of Arch#3 is much simpler than that of Arch#4, our further ev aluations reported in the following sections are based on Arch#3. F or clarity , Arch#3 is named direct PIT -CE-ASR from no w on. T ABLE III: WER (%) of the proposed multi-talk er mixed speech recognition architectures on the IHM-2mix dataset under 0db SNR condition (using 80hr training subset). Arch#1- #4 indicate the proposed architectures described in Section III.A-D, respectiv ely Arch Front-end Back-end High E WER Lo w E WER #1 Feat-Sep-baseline Single-Spk-ASR 72.58 79.61 #2 Feat-Sep-PIT -MSE Single-Spk-ASR 68.88 75.62 #3 × PIT -CE 59.72 66.96 #4 Feat-Sep-PIT -MSE PIT -CE 58.68 66.25 C. Evaluation of the Dir ect PIT -CE-ASR Model on Larg e Dataset W e e v aluated the direct PIT -CE-ASR architecture on the full IHM-2mix corpus. All the 400hr mixed data under different SNR conditions are pooled together for training. The direct PIT -CE-ASR model is still composed of 6 BLSTM layers with 768 memory cells in each layer . All other configurations are also the same as the experiments conducted on the subset. The results under dif ferent SNR conditions are sho wn in T able IV. The direct PIT -CE-ASR model achieved significant improv ements on both talkers compared to baseline results in T able II for all SNR conditions. Comparing to the results in T able III, achiev ed with 80hr training subset, we observe that additional absolute 10.0% WER improvement on both speakers can be obtained using the large training set. W e also observe that the WER increases slowly when the SNR becomes smaller for the high energy speaker , and the WER improv ement is v ery significant for the lo w ener gy speaker across all conditions. In the 0dB SNR scenario, the WERs on two speakers are very close and are 45.0% less than that achiev ed with the single-talker ASR system for both high and low energy speakers. At 20dB SNR, the WER of the high energy speaker is still significantly better than the baseline, and approaches the single-talker recognition result reported in T able I. T ABLE IV: WER (%) of the proposed direct PIT -CE-ASR model on the IHM-2mix dataset with full training set SNR Condition High E WER Lo w E WER 0db 47.77 54.89 5db 39.25 59.24 10db 33.83 64.14 15db 30.54 71.75 20db 28.75 79.88 D. P ermutation In variant T raining with Alternative Deep Learning Models W e in vestigated the direct PIT -CE-ASR model with alterna- tiv e deep learning models. The first model we e valuated is a 6-layer feed-forward DNN in which each layer contains 2048 Sigmoid units. The input to the DNN is a window of 11 frames each with a 40-dimensional LFBK feature. The results of DNN-based PIT -CE-ASR model is reported at the top of T able V. Although it still gets ob vious im- prov ement over the baseline single-speaker model, the gain is much smaller with near 20.0% WER difference in ev ery condition than that from BLSTM-based PIT -CE-ASR model. The difference between DNN and BLSTM models partially attribute to the stronger modeling power of BLSTM models and partially attribute to the better tracing ability of RNNs. W e also compared the BLSTM models with 4, 6, and 8 layers as shown in T able V. It is observed that deeper BLSTM models perform better . This is different from the single speaker ASR model whose performance peaks at 4 BLSTM layers [37]. This is because the direct PIT -CE-ASR architecture needs IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 8 Fig. 4: Decoding results of baseline single speaker BLSTM-RNN system on 0db two-talker mixed speech sample Fig. 5: Decoding results of the proposed direct PIT -CE-ASR model on 0db two-talker mixed speech sample to conduct two tasks - separation and recognition, and thus requires additional modeling power . T ABLE V: WER (%) of the direct PIT -CE-ASR model using different deep learning models on the IHM-2mix dataset Models SNR Condition High E WER Low E WER 6L-DNN 0db 72.95 80.29 5db 65.42 84.44 10db 55.27 86.55 15db 47.12 89.21 20db 40.31 92.45 4L-BLSTM 0db 49.74 56.88 5db 40.31 60.31 10db 34.38 65.52 15db 31.24 73.04 20db 29.68 80.83 6L-BLSTM 0db 47.77 54.89 5db 39.25 59.24 10db 33.83 64.14 15db 30.54 71.75 20db 28.75 79.88 8L-BLSTM 0db 46.91 53.89 5db 39.14 59.00 10db 33.47 63.91 15db 30.09 71.14 20db 28.61 79.34 E. Analysis on Multi-T alker Speech Recognition Results T o better understand the results on multi-talker speech recognition, we computed the WER separately for the speech mixed with same and opposite genders. The results are shown in T able VI. It is observed that the same-gender mixed speech is much more difficult to recognize than the opposite-gender mixed speech, and the gap is ev en larger when the energy ratio of the two speakers is closer to 1. It is also observed that the mixed speech of two male speakers is hard to recognize than that of tw o female speakers. These results suggest that effecti ve exploitation of gender information may help to further improve the multi-talker speech recognition system. W e will explore this in our future work. T ABLE VI: WER (%) comparison of the 6-layer-BLSTM direct PIT -CE-ASR model on the mix ed speech generated from two male speakers ( M + M ), two female speakers ( F + F ) and a male and a female speaker ( M + F ) Genders SNR Condition High E WER Low E WER M + M 0db 52.18 59.32 5db 42.64 61.77 10db 36.10 63.94 F + F 0db 49.90 57.59 5db 40.02 60.92 10db 32.47 65.15 M + F 0db 44.89 51.72 5db 37.34 57.43 10db 33.22 63.86 T o further understand our model, we examined the recog- nition results with and without using the direct PIT -CE-ASR. An example of these results on a 0db two-talker mixed speech utterance is shown in Figure 4 (using the single-speaker baseline system) and 5 (with direct PIT -CE-ASR). It is clearly seen that the results are erroneous when the single-speaker baseline system is used to recognize the two-talker mixed speech. In contrast, much more words are recognized correctly with the proposed direct PIT -CE-ASR model. F . Thr ee-T alker Speech Recognition with Dir ect PIT -CE-ASR In this subsection, we further extend and ev aluate the proposed direct PIT -CE-ASR model on the three-talker mixed speech using the IHM-3mix dataset. The three-talker direct PIT -CE-ASR model is also a 6-layer BLSTM model. The training and testing configurations are the same as those for two-talker speech recognition. The direct IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 9 0 1 2 3 4 5 6 7 8 9 0 10 20 30 40 50 60 70 80 90 100 Cros s En tropy Epochs 6L - BLS TM - 2SPK - Train 6L - BLS TM - 2SPK - Val 6L - BLS TM - 3SPK - Train 6L - BLS TM - 3SPK - Val Fig. 6: CE values over epochs on both the IHM-2mix and IHM-3mix training and validation sets with the proposed direct PIT -CE-ASR model PIT -CE-ASR training processes as measured by CE on both two- and three-talk er mixed speech training and v alidation sets are illustrated in Figure 6. It is observed that the direct PIT -CE-ASR model with this specific configuration conv erges slowly , and the CE improv ement progress on the training and validation sets is almost the same. The training progress on three-talker mix ed speech is similar to that on two-talker mixed speech, but with an obviously higher CE value. This indicates the huge challenge when recognizing speech mixed with more than two talk ers. Note that, in this set of experiments we used the same model configuration as that used in two-talker mixed speech recognition. Since three-talk er mix ed speech recognition is much harder , using deeper and wider models may help to improve performance. Due to resource limitation, we did not search for the best configuration for the task. The three-talk er mix ed speech recognition WERs are re- ported in T able VII. The WERs on dif ferent gender com- binations are also provided. The WERs achie ved with the single-speaker model are listed at the first line in T able VII. Compared to the results on IHM-2mix, the results on IHM- 3mix are significantly worse using the conv entional single speaker model. Under this extremely hard setup, the pro- posed direct PIT -CE-ASR architecture still demonstrated its powerful ability on separating/tracing/recognizing the mixed speech, and achie ved 25.0% relati ve WER reduction across all three speakers. Although the performance gap from two- talker to three-talker is obvious, it is still very promising under this speaker-independent three-talker L VCSR task. Not surprisingly , the mixed speech of different genders is relati vely easier to recognize than that of same gender . Moreov er , we conducted another interesting experiment. W e used the three-talker PIT -CE-ASR model to recognize the two- talker mixed speech. The results are sho wn in T able VIII. Surprisingly , the results are almost identical to that obtained using the 6-layer BLSTM based two-talker model (shown in T ABLE VII: WER (%) comparison of the baseline single- speaker BLSTM-RNN system and the proposed direct PIT - CE-ASR model on the IHM-3mix dataset. Diff indicates the mixed speech is from different genders, and Same indicates the mixed speech is from same gender Genders Model Speaker1 Speaker2 Speaker3 All BLSTM-RNN 91.0 90.5 90.8 All direct PIT -CE-ASR 69.54 67.35 66.01 Different 69.36 65.84 64.80 Same 72.21 70.11 69.78 T able IV). This demonstrates the good generalization ability of our proposed direct PIT -CE-ASR model over variable number of mix ed speakers. This suggests that a single PIT model may be able to recognize mixed speech of different number of speakers without knowing or estimating the number of speakers. T ABLE VIII: WER (%) of using three-talker direct PIT -CE- ASR model to recognize two-talker mixed IHM-2mix speech Model SNR Condition High E WER Low E WER Three-T alker PIT -CE-ASR 0db 46.63 54.59 5db 39.47 59.78 10db 34.50 64.55 15db 32.03 72.88 20db 30.66 81.63 V . C O N C L U S I O N In this paper , we proposed sev eral architectures for recog- nizing multi-talker mixed speech giv en only a single channel of the mixed signal. Our technique is based on permutation in variant training, which was originally developed for separa- tion of multiple speech streams. PIT can be performed on the front-end feature separation module to obtain better separated feature streams or be extended on the back-end recognition module to predict the separated senone posterior probabilities directly . Moreover , PIT can be implemented on both front- end and back-end with a joint-optimization architecture. When using PIT to optimize a model, the criterion is computed over all frames in the whole utterance for each possible output- target assignment, and the one with the minimum loss is picked for parameter optimization. Thus PIT can address the label per - mutation problem well, and conduct the speaker separation and tracing in one shot. Particularly for the proposed architecture with the direct PIT -CE based recognition model, multi-talker mixed speech recognition can be directly conducted without an explicit separation stage. The proposed architectures were e v aluated and compared on an artificially mixed AMI dataset with both two- and three- talker mixed speech. The experimental results indicate that the proposed architectures are v ery promising. Our models can obtain relati ve 45.0% and 25.0% WER reduction against the state-of-the-art single-talker speech recognition system across IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 10 all speakers when their energies are comparable, for two- and three-talker mix ed speech, respecti vely . Another interesting observation is that there is e ven no degradation when using proposed three-talker model to recognize the two-talker mixed speech directly . This suggests that we can construct one model to recognize speech mixed with variable number of speakers without knowing or estimating the number of speakers in the mixed speech. T o our kno wledge, this is the first work on the multi-talker mixed speech recognition on the challenging speaker -independent spontaneous L VCSR task. A C K N O W L E D G M E N T This work was supported by the Shanghai Sailing Program No. 16YF1405300, the China NSFC projects (No. 61573241 and No. 61603252), the Interdisciplinary Program (14JCZ03) of Shanghai Jiao T ong University in China, and the T encent- Shanghai Jiao T ong Univ ersity joint project. Experiments ha ve been carried out on the PI supercomputer at Shanghai Jiao T ong University . R E F E R E N C E S [1] D. Y u and L. Deng, A utomatic Speech Reco gnition: A Deep Learning Appr oach , ser . Signals and Communication T echnology . Springer London, 2014. [Online]. A vailable: https://books.google.com/books?id=rUBTBQAA QBAJ [2] D. Y u, L. Deng, and G. E. Dahl, “Roles of pre-training and fine-tuning in context-dependent DBN-HMMs for real-world speech recognition, ” in NIPS W orkshop on Deep Learning and Unsupervised F eature Learning , 2010. [3] G. E. Dahl, D. Y u, L. Deng, and A. Acero, “Context-dependent pre- trained deep neural networks for large-v ocabulary speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing (T ASLP) , vol. 20, pp. 30–42, 2012. [4] F . Seide, G. Li, and D. Y u, “Con versational speech transcription using context-dependent deep neural networks. ” in Annual Conference of International Speech Communication Association (INTERSPEECH) , 2011, pp. 437–440. [5] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A.-r . Mohamed, N. Jaitly , A. Senior , V . V anhoucke, P . Nguyen, T . N. Sainath et al. , “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal Processing Magazine (SPM) , vol. 29, pp. 82–97, 2012. [6] O. Abdel-Hamid, A.-r. Mohamed, H. Jiang, and G. Penn, “ Applying con volutional neural networks concepts to hybrid NN-HMM model for speech recognition, ” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2012, pp. 4277–4280. [7] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, L. Deng, G. Penn, and D. Y u, “Conv olutional neural networks for speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing (T ASLP) , vol. 22, pp. 1533–1545, 2014. [8] T . N. Sainath, O. V inyals, A. Senior , and H. Sak, “Con volutional, long short-term memory , fully connected deep neural networks, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2015, pp. 4580–4584. [9] M. Bi, Y . Qian, and K. Y u, “V ery deep con volutional neural networks for L VCSR, ” in Annual Confer ence of International Speech Communication Association (INTERSPEECH) , 2015, pp. 3259–3263. [10] Y . Qian, M. Bi, T . T an, and K. Y u, “V ery deep conv olutional neural networks for noise robust speech recognition, ” IEEE/ACM T ransactions on A udio, Speech, and Language Processing (T ASLP) , v ol. 24, no. 12, pp. 2263–2276, 2016. [11] Y . Qian and P . C. W oodland, “V ery deep conv olutional neural networks for robust speech recognition, ” in IEEE Spoken Language T echnology W orkshop (SLT) , 2016, pp. 481–488. [12] V . Mitra and H. Franco, “Time-frequency con volutional networks for robust speech recognition, ” in IEEE W orkshop on Automatic Speech Recognition and Understanding (ASRU) , 2015, pp. 317–323. [13] V . Peddinti, D. Povey , and S. Khudanpur, “ A time delay neural network architecture for efficient modeling of long temporal contexts, ” in An- nual Conference of International Speech Communication Association (INTERSPEECH) , 2015, pp. 3214–3218. [14] T . Sercu, C. Puhrsch, B. Kingsbury , and Y . LeCun, “V ery deep multilin- gual con volutional neural networks for L VCSR, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2016, pp. 4955–4959. [15] D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper , B. Catan- zaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos et al. , “Deep speech 2: End-to-end speech recognition in English and Mandarin, ” in International Confer ence on Machine Learning (ICML) , 2016. [16] S. Zhang, H. Jiang, S. Xiong, S. W ei, and L. Dai, “Compact feedforward sequential memory networks for large vocabulary continuous speech recognition, ” in Annual Confer ence of International Speech Communi- cation Association (INTERSPEECH) , 2016, pp. 3389–3393. [17] D. Y u, W . Xiong, J. Droppo, A. Stolcke, G. Y e, J. Li, and G. Zweig, “Deep conv olutional neural networks with layer-wise context expansion and attention. ” in Annual Confer ence of International Speech Commu- nication Association (INTERSPEECH) , 2016, pp. 17–21. [18] W . Xiong, J. Droppo, X. Huang, F . Seide, M. Seltzer, A. Stolcke, D. Y u, and G. Zweig, “The Microsoft 2016 conv ersational speech recognition system, ” in IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2017, pp. 5255–5259. [19] D. Y u, M. Kolbk, Z.-H. T an, and J. Jensen, “Permutation inv ariant training of deep models for speaker -independent multi-talker speech separation, ” in IEEE International Confer ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , 2017, pp. 241–245. [20] M. Kolbk, D. Y u, Z.-H. T an, and J. Jensen, “Multi-talker speech separation with utterance-lev el permutation in variant training of deep recurrent neural networks, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing (T ASLP) , accepted, 2017. [21] Z. Ghahramani and M. I. Jordan, “Factorial hidden Markov models, ” Machine learning (MLJ) , vol. 29, no. 2-3, pp. 245–273, 1997. [22] M. Cooke, J. R. Hershey , and S. J. Rennie, “Monaural speech separation and recognition challenge, ” Computer Speech and Language (CSL) , vol. 24, pp. 1–15, 2010. [23] C. W eng, D. Y u, M. L. Seltzer , and J. Droppo, “Deep neural networks for single-channel multi-talker speech recognition, ” IEEE/ACM T rans- actions on Audio, Speech, and Language Pr ocessing (T ASLP) , vol. 23, no. 10, pp. 1670–1679, 2015. [24] J. R. Hershey , Z. Chen, J. L. Roux, and S. W atanabe, “Deep clustering: Discriminativ e embeddings for segmentation and separation, ” in IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2016, pp. 31–35. [25] Y . Isik, J. L. Roux, Z. Chen, S. W atanabe, and J. R. Hershey , “Single- channel multi-speaker separation using deep clustering, ” in Annual Confer ence of International Speech Communication Association (IN- TERSPEECH) , 2016, pp. 545–549. [26] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single- microphone speaker separation, ” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2017, pp. 246–250. [27] J. R. Hershey , S. J. Rennie, P . A. Olsen, and T . T . Kristjansson, “Super-human multi-talker speech recognition: A graphical modeling approach, ” Computer Speech and Language (CSL) , vol. 24, pp. 45 – 66, 2010. [28] S. J. Rennie, J. R. Hershey , and P . A. Olsen, “Single-channel multitalker speech recognition, ” IEEE Signal Pr ocessing Magazine (SPM) , vol. 27, pp. 66–80, 2010. IEEE/A CM TRANSA CTIONS ON A UDIO, SPEECH, AND LANGUA GE PROCESSING 11 [29] P .-S. Huang, M. Kim, M. Haseg awa-Johnson, and P . Smaragdis, “Deep learning for monaural speech separation, ” in IEEE International Con- fer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2014, pp. 1562–1566. [30] F . W eninger, H. Erdogan, S. W atanabe, E. V incent, J. Roux, J. R. Hershey , and B. Schuller , “Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR, ” in Interna- tional Conference on Latent V ariable Analysis and Signal Separation (L V A/ICA) . Springer-V erlag New Y ork, Inc., 2015, pp. 91–99. [31] Y . W ang, A. Narayanan, and D. W ang, “On training targets for super- vised speech separation, ” IEEE/ACM T ransactions on Audio, Speech and Language Processing (T ASLP) , vol. 22, pp. 1849–1858, 2014. [32] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “ An experimental study on speech enhancement based on deep neural networks, ” IEEE Signal Pr ocessing Letters (SPL) , vol. 21, pp. 65–68, 2014. [33] P . S. Huang, M. Kim, M. Hasegaw a-Johnson, and P . Smaragdis, “Joint optimization of masks and deep recurrent neural networks for monaural source separation, ” IEEE/ACM T ransactions on Audio, Speech, and Language Processing (TASLP) , vol. 23, pp. 2136–2147, Dec 2015. [34] J. Du, Y . T u, L. R. Dai, and C. H. Lee, “ A regression approach to single- channel speech separation via high-resolution deep neural networks, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing (T ASLP) , vol. 24, pp. 1424–1437, Aug 2016. [35] T . Hain, L. Burget, J. Dines, P . N. Garner, F . Gr ´ ezl, A. E. Hannani, M. Huijbregts, M. Karafiat, M. Lincoln, and V . W an, “Transcribing meetings with the AMID A systems, ” IEEE/A CM Tr ansactions on A udio, Speech, and Language Pr ocessing (T ASLP) , vol. 20, no. 2, pp. 486–498, 2012. [36] D. Pove y , V . Peddinti, D. Galvez, P . Ghahremani, V . Manohar, X. Na, Y . W ang, and S. Khudanpur , “Purely sequence-trained neural networks for ASR based on lattice-free MMI, ” in Annual Conference of Interna- tional Speech Communication Association (INTERSPEECH) , 2016, pp. 2751–2755. [37] Y . Zhang, G. Chen, D. Y u, K. Y ao, S. Khudanpur, and J. Glass, “Highway long short-term memory RNNs for distant speech recogni- tion, ” IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pp. 5755–5759, 2016. [38] J. J. Godfrey and E. Holliman, “Switchboard-1 release 2, ” Linguistic Data Consortium, Philadelphia , 1997. [39] T . Sercu and V . Goel, “Dense prediction on sequences with time-dilated con volutions for speech recognition, ” arXiv preprint , 2016. [40] G. Saon, T . Sercu, S. Rennie, and H.-K. J. Kuo, “The IBM 2016 english con versational telephone speech recognition system, ” in An- nual Conference of International Speech Communication Association (INTERSPEECH) , 2016, pp. 7–11. [41] P . Swietojanski, A. Ghoshal, and S. Renals, “Hybrid acoustic models for distant and multichannel large vocab ulary speech recognition, ” in IEEE W orkshop on Automatic Speech Recognition and Understanding (ASR U) , 2013, pp. 285–290. [42] D. Y u, A. Eversole, M. Seltzer, K. Y ao, Z. Huang, B. Guenter, O. Kuchaiev , Y . Zhang, F . Seide, H. W ang et al. , “ An introduction to computational networks and the computational network toolkit, ” Micr osoft T echnical Report MSR-TR-2014–112 , 2014. [43] D. Povey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE W orkshop on Automatic Speech Recognition and Understanding (ASR U) , no. EPFL-CONF-192584, 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment