Representation Mixing for TTS Synthesis
Recent character and phoneme-based parametric TTS systems using deep learning have shown strong performance in natural speech generation. However, the choice between character or phoneme input can create serious limitations for practical deployment, …
Authors: Kyle Kastner, Jo~ao Felipe Santos, Yoshua Bengio
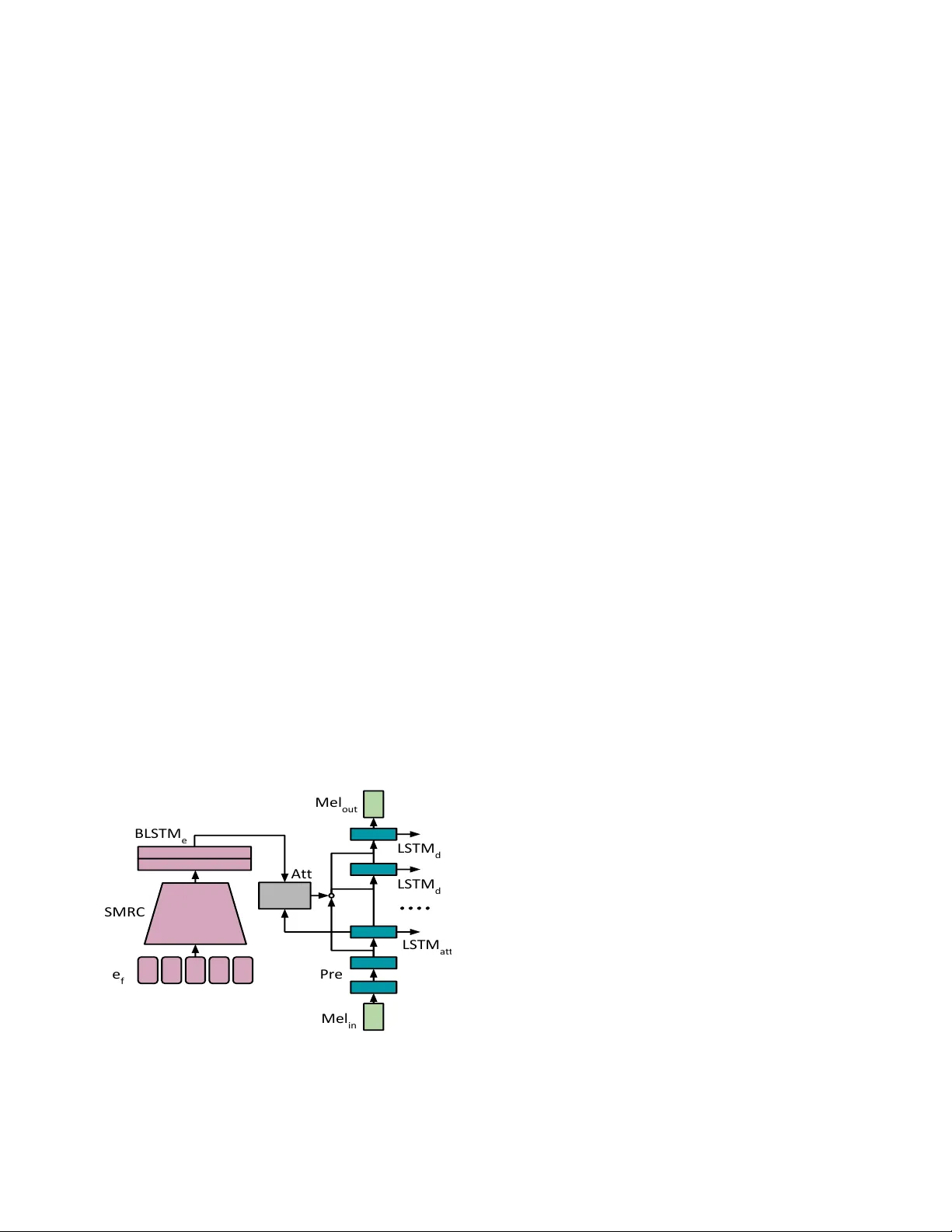
REPRESENT A TION MIXING FOR TTS SYNTHESIS K yle Kastner , J o ˜ ao F elipe Santos, Y oshua Bengio † , Aar on Courville ? MILA Uni versit ´ e de Montr ´ eal Montr ´ eal, Canada ABSTRA CT Recent character and phoneme-based parametric TTS sys- tems using deep learning hav e sho wn strong performance in natural speech generation. Howe ver , the choice between character or phoneme input can create serious limitations for practical deployment, as direct control of pronunciation is crucial in certain cases. W e demonstrate a simple method for combining multiple types of linguistic information in a sin- gle encoder , named r epresentation mixing , enabling flexible choice between character , phoneme, or mixed representations during inference. Experiments and user studies on a public audiobook corpus show the ef ficacy of our approach. Index T erms — T ext-to-speech, deep learning, recurrent neural network, attention, sequence-to-sequence learning. 1. INTR ODUCTION TTS synthesis [1] focuses on building systems which can gen- erate speech (often in the form of an audio feature sequence a ), giv en a set of linguistic sequences, l . These sequences, l and a , are of different length and dimensionality thus it is necessary to find the alignment between the linguistic infor- mation and the desired audio. W e approach the alignment problem by jointly learning to align these two types of in- formation [2], effecti vely translating the information in the linguistic sequence(s) into audio through learned transforma- tions for effecti ve TTS synthesis [3, 4, 5, 6, 7]. 1.1. Data Representation W e employ log mel spectr ograms as the audio feature rep- resentation, a well-studied time-frequency representation [8] for audio sequence a . V arious settings used for this transfor - mation can be seen in T able 2. Linguistic information, l , can be gi ven at the abstract level as graphemes (also known as characters when using English) or at a more detailed level which may include pronunciation information, such as phonemes. Practically , character-le vel information is widely av ailable in open data sets though this representation allows ambiguity in pronunciation [9]. † CIF AR Senior Fellow ? CIF AR Fellow 1.2. Moti vating Representation Mixing In some cases, it may be impossible to fully realize the desired audio without being given direct kno wledge of pronunciation. T ake as a particular example the sentence ”All traveler s wer e exhausted by the wind down the river” . The word ”wind” in this sentence can be either noun form such as ”The wind blew swiftly on the plains” , or v erb form for tra veling such as ”... and as we wind on down the r oad” , both of which hav e different pronunciation. W ithout external knowledge (such as additional context, or an accompanying video) of which pronunciation to use for the word, a TTS system which operates on character input will always hav e ambiguity in this situation. Alternate ap- proaches such as grapheme to phoneme methods [10] will also be unable to resolve this problem. Such cases are well- known in both TTS and linguistics [11, 12], motiv ating our desire to flexibly combine grapheme and phoneme inputs in a single encoder . Our method allows per example control of pronunciation during inference without requiring this infor- mation for all desired inputs, and similar methods have also been important for other systems [13]. e c e p e m m e j e f l p l c Fig. 1 . V isualization of embedding computation 2. REPRESENT A TION MIXING DESCRIPTION The input to the system consists of one data sequence, l j , and one mask sequence, m . The data sequence, l j , consists of a mixture between a character sequence, l c , and a phonetic sequence, l p . The mask sequence describes which respective sequence the symbol came from with an inte ger ( 0 or 1 ). Each time a training sequence is encountered, it is randomly mixed at the word level and we assign all spaces and punctuation as characters. For example, a pair ” the cat ”, ” @ d @ ah @ k @ ah @ t ” (where @ is not a used symbol and serves only as an identi- fier to mark phoneme boundaries) can be resampled as ” the @ k @ ah @ t ”, with a corresponding mask of [0 , 0 , 0 , 0 , 1 , 1 , 1] . On the next occurrence, it may be resampled as ” @ d @ ah cat ”, with mask [1 , 1 , 0 , 0 , 0 , 0] . This resampling procedure can be seen as data augmentation, as well as training the model to smoothly process both character and phoneme in- formation without ov er-reliance on either representation. W e demonstrate the importance of each aspect in Section 4. 2.1. Combining Embeddings The full mixed sequence, l j , separately passes through two embedding matrices, e c and e p , and is then combined using the mask sequence to form a joint mixed embedding, e j . For con venience, e c and e p , are set to a vocab ulary size that is the max of the character and phoneme vocabulary sizes. This mixed embedding is further combined with an embedding of the mask sequence itself, e m , for a final combined embed- ding, e f . This embedding, e f , is treated as the standard input for the rest of the network. A diagram describing this process is shown in Figure 1. e j = (1 − m ) ∗ e c + m ∗ e p (1) e f = e m + e j (2) 2.2. Stack ed Multi-scale Residual Con volution In the next sections, we describe the network architecture for transforming the mix ed representation into a spectrogram and then an audio w aveform. A full system diagram of our neural network architecture can be seen in Figure 2. e f SMRC BLSTM e Att Pre Mel in Mel out LSTM att LSTM d LSTM d Fig. 2 . Encoding, attention, and one step of mel decoder The final embedding, e f , from the previous section is used as input to a stacked multi-scale residual conv olutional sub- network (SMRC). The SMRC consists of several layers of multi-scale con volutions, where each multi-scale layer is in turn a concatenation of 1 × 1 , 3 × 3 , and 5 × 5 layers concate- nated across the channel dimension. The layers are connected using residual bypass connections [14] and batch normaliza- tion [15] is used throughout. After the conv olutional stage, the resulting activ ations are input to a bidirectional LSTM layer [16, 17]. This ends the encoding part of the network. 2.3. The Importance of Noisy T eacher Forcing All audio information in the network passes through a mul- tilayer pre-net with dropout [18, 4, 5], in both training and ev aluation. W e found that using pre-net corrupted audio in ev ery layer (including the attention layer) greatly improves the robustness of the model at ev aluation, while corruption of linguistic information made the generated audio sound less natural. 2.4. Attention-based RNN Decoder The encoding activ ations are attended using a Gaussian mix- ture (GM) attention [19] driven by an LSTM network (condi- tioned on both the text and pre-net activ ations), with a softplus activ ation for the step of the Gaussian mean as opposed to the more typical exponential activ ation. W e find that a softplus step substantially reduces instability during training. This is likely due to the relati ve length differences between linguistic input sequences and audio output. Subsequent LSTM decode layers are conditioned on pre- net activ ations, attention activ ations, and the hidden state of the layer before, forming a series of skip connections [19, 20]. LSTM decode layers utilize cell dropout regularization [21]. The final hidden state is projected to match the dimension- ality of the audio frames and a mean squared error loss is calculated between the predicted and true next frames. 2.5. T runcated Backpropagation Through Time (TBPTT) The network uses truncated backpropag ation through time (TBPTT) [17] in the decoder, only processing a subsection of the relev ant audio sequence while reusing the linguistic sequence until the end of the associated audio sequence. TBPTT training allows for a particular iterator packing scheme not av ailable with full sequence training, which con- tinuously packs subsequences resetting only the particular elements of the sequence minibatches (and the associated RNN state) when reaching the end of an audio sequence. A simplified diagram of this approach can be seen in Figure 3. 2.6. Con verting Features Into W a veforms After predicting a log mel spectrogram sequence from lin- guistic input, further transformation must be applied to get an audible wav eform. A variety of methods have been proposed Single minibatch T runcated minibatches with resets Fig. 3 . Comparison of standard minibatching versus truncation. for this inv ersion such as the Griffin-Lim transform [22], and modified variants [23]. Neural decoders such as the condi- tional W av eNet decoder [24, 5] or conditional SampleRNN [25] can also act effecti vely as an in version procedure to trans- form log mel spectrograms into audible wa veforms. Optimization methods also w ork for inv ersion and we uti- lize an L-BFGS based routine. This process optimizes ran- domly initialized parameters (representing the desired wav e- form) passed through a log mel spectrogram transform, to make the transform of these parameters match a giv en log mel spectrogram [26]. This results in a set of parameters (which we now treat as a fixed wav eform) with a lossy transform that closely matches the gi ven log mel spectrogram. The ov erall procedure closely resembles effecti ve techniques in other generative modeling settings [27]. In version Method Seconds per Sample STRTF 100 L-BFGS 1.49E-4 3.285 1000 L-BFGS 1.32E-3 29.08 Modified Griffin-Lim 2.81E-4 6.206 100 L + GL 4.11E-4 9.063 1000 L + GL 1.6E-3 35.28 W av eNet 7.9E-3 174.7 100 L + GL + WN 8.3E-3 183.7 1000 L + GL + WN 9.5E-3 210.0 T able 1 . Comparison of various log mel spectrogram to waveform con version techniques. STR TF stands for ”slo wer than real time f ac- tor” (calculated assuming output sample rate of 22 . 05 kHz), where 1 . 0 would be real-time generation for a single example. 2.7. In version Pipeline This work uses a combined pipeline of L-BFGS based in ver - sion, follo wed by modified Griffin-Lim for wav eform estima- tion [23]. The resulting wav eform is of moderate quality , and usable for certain applications including speech recognition. Using either L-BFGS or Griffin-Lim in isolation did not yield usable audio in our experiments. W e also found that this or- dering (L-BFGS then Griffin-Lim) in our two-stage pipeline works much better than the re verse setting. T o achiev e the highest quality output, we then use the moderate quality wa veform output from the two stage pipeline, con verted back to log mel spectrograms, for conditional W av eNet synthesis. Though other work [5] clearly shows that log mel spectrogram conditioned W aveNet can be used directly , we find the two stage pipeline allows for quicker quality checking during development, as well as slightly higher quality in the resulting audio after W av eNet sampling. W e suspect this is because the pre-trained W aveNet [28] that we use is trained on ground-truth log mel spectrograms rather than predicted outputs. The synthesis speed of each setting is shown in T able 1. 3. RELA TED WORK Representation mixing is closely related to the ”mixed- character-and-phoneme” setting described in Deep V oice 3 [13], with the primary difference being our addition of the mask embedding e m . W e found utilizing a mask embedding alongside the character and phoneme embeddings further im- prov ed quality , and was an important piece in the text portion of the network. The focused user study in this paper also highlights the adv antages of this kind of mixing independent of high-level architecture choices, since our larger system is markedly dif ferent from that used in Deep V oice 3. The SMRC subnetwork is closely related to the CBHG encoder [4], differing in the number and size of con volutional scales used, no max-pooling, use of residual connections, and multiple stacks of multi-scale layers. W e use a Gaussian mix- ture attention, first described by Graves [19] and used in sev- eral speech related papers [3, 29, 30], though we utilize soft- plus activ ation for the mean-step parameter finding that it im- prov ed stability in early training. Our decoder LSTMs utilize cell dropout [21] as seen in prior work [31, 32]. Unlike T acotron [4], we do not use multi-step prediction, conv olutional layers in the mel- decoding stage, or Griffin-Lim inside the learning pathway . Audio processing closely resembles T acotron 2 [5] overall, though we precede conditional W aveNet with a computation- ally ef ficient two stage L-BFGS and Griffin-Lim inference pipeline for quality control, and as an alternativ e to neural in version. 4. EXPERIMENTS The model is trained on LJSpeech [33], a curated subset of the LibriV ox corpus [9]. LJSpeech consists of 13 , 100 audio files (comprising a total time of approximately 24 hours) of read English speech, spoken by Linda Johnson. The content of these recordings is drawn from scientific, instructional, and political te xts published between 1893 and 1964 . The record- ings are stored as 22 . 05 kHz, 16 bit W A V files, though these are con versions from the original 128 kbps MP3 format. Character lev el information is extracted from audio tran- scriptions after a normalization and cleaning pipeline. This step includes con verting all text to lowercase along with ex- panding acronyms and numerical values to their spelled-out equiv alents. Phonemes are then extracted from the paired audio and character samples, using a forced alignment tool such as Gentle [34]. This results in character and phoneme information aligned along word le vel boundaries, so that ran- domly mixed linguistic sequences can be sampled repeatedly throughout training. When using representation mixing for training, we choose between characters and phonemes with probability . 5 for each word in all experiments. Audio Processing 22 . 05 kHz 16 bit input, scale between ( − 1 , 1) , log mel spectrogram 80 mel bands, window size 512 , step 128 , lower edge 125 Hz, upper edge 7 . 8 kHz, mean and std dev normalized per feature dimension after log mel calculation. Embeddings vocab ulary size (v) 49 , 49 , 2 , embedding dim 15 , truncated normal 1 √ v SMRC 3 stacks, stack scales 1 × 1 , 3 × 3 , 5 × 5 , 128 channels each, batch norm, residual connections, ReLU activ ations, orthonormal init Enc Bidir LSTM hidden dim 1024 (128 × 4 × 2) , truncated normal init scale 0 . 075 Pre-net 2 layers, hidden dim 128 , dropout keep prob 0 . 5 , linear activ ations, orthonormal init Attention LSTM num mixes 10 , softplus step activation, hidden dim 2048 (512 × 4) , trunc norm init scale 0 . 075 Decoder LSTMs 2 layers, cell dropout keep prob 0 . 925 , truncated normal init scale 0 . 075 Optimizer mse, no output masking, Adam optimizer, learn- ing rate 1 E − 4 , global norm clip scale 10 Other TBPTT length 256 , batch size 64 , training steps 500 k, 1 T itanX Pascal GPU, training time 7 days T able 2 . Architecture hyperparameter settings 4.1. Log Mel Spectrogram In version Experiments W e use a high quality implementation of W aveNet, including a pre-trained model directly from Y amamoto et. al. [28]. This model was also trained on LJSpeech, allowing us to directly use it as a neural in verse to the log mel spectrograms pre- dicted by the attention-based RNN model, or as an inv erse to log mel spectrograms extracted from the network predictions after further processing. Ultimately combining the two stage L-BFGS and modified Griffin-Lim pipeline with a final condi- tional W aveNet sampling pass demonstrated the best quality , and is what we used for the user study shown in T able 3. 4.2. Prefer ence T esting Giv en the ov erall system architecture, we pose three primary questions (referenced in column Q in T able 3) as a user study: 1) Does representation mixing (RM) improve character- based inference over a baseline which was trained only on characters? 2) Does RM improve phoneme with character backof f for unknown word (PWCB) inference ov er a baseline trained on fixed PWCB? 3) Does PWCB inference improve over character-based inference in a model trained with representation mixing? T o answer these questions, we pose each as a preference test by presenting study participants with 20 paired choices. Each user was instructed to choose the sample they preferred 1 . The 20 tests were chosen randomly in a pool of 123 possible tests covering all three question types, from 41 possible sen- tences. Presentation order was randomized for each question and ev ery user . The overall study consisted of 22 users and 429 responses across all categories (some users didn’t select any preference for some questions). Q Model A Model B C. A T otal % A 1 RM (char) Char 101 137 73.7% 2 RM (PWCB) PWCB 106 145 73.1% 3 RM (PWCB) RM (char) 86 147 58.5% T able 3 . A / B user preference study results. RM uses approach in parenthesis at inference time. Columns ” C. A ” and ” % A ” indicate the number and percentage of users which preferred Model A . W e see that users clearly prefer models trained with repre- sentation mixing, ev en when using identical information for inference. This highlights the data augmentation aspects of representation mixing, as regardless of information type rep- resentation mixing (RM) gives clearly preferable results com- pared to static representations (Char , PWCB). The preference of representation mixing over static PWCB also means that introducing phoneme and character information without mix- ing is less beneficial than full representation mixing. It is also clear that for representation mixing models, pro- nunciation information (PWCB) at inference giv es preferable samples compared to character information. This is not sur- prising, but further reinforces the importance of using pronun- ciation information where possible. Representation mixing enables choice in input format, allo wing the possibility to use many dif ferent inference representations for a given sentence with a single trained model. 5. CONCLUSION This paper shows the benefit of r epr esentation mixing , a sim- ple method for combining multiple types of linguistic infor- mation for TTS synthesis. Representation mixing enables in- ference conditioning to be controlled independently of train- ing representation, and also results in improv ed quality over strong character and phoneme baselines trained on a publi- cally av ailable audiobook corpus. 1 https://s3.amazonaws.com/representation- mixing- site/index.html 6. REFERENCES [1] A. J. Hunt and A. W . Black, “Unit selection in a concatena- tiv e speech synthesis system using a large speech database, ” in Acoustics, Speech, and Signal Pr ocessing, 1996. ICASSP- 96. Confer ence Pr oceedings., 1996 IEEE International Con- fer ence on . IEEE, 1996, vol. 1, pp. 373–376. [2] D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine transla- tion by jointly learning to align and translate, ” in International Confer ence on Learning Representations (ICLR 2015) , 2015. [3] J. Sotelo, S. Mehri, K. Kumar , J. F . Santos, K. Kastner, A. Courville, and Y . Bengio, “Char2wav: End-to-end speech synthesis, ” 2017. [4] Y . W ang, R. Skerry-Ryan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio, et al., “T acotron: A fully end-to-end text-to-speech synthesis model, ” arXiv preprint , 2017. [5] J. Shen, R. Pang, R. J. W eiss, M. Schuster, N. Jaitly , Z. Y ang, Z. Chen, Y . Zhang, Y . W ang, R. Skerry-Ryan, et al., “Natu- ral tts synthesis by conditioning wav enet on mel spectrogram predictions, ” arXiv pr eprint arXiv:1712.05884 , 2017. [6] H. T achibana, K. Uenoyama, and S. Aihara, “Efficiently train- able text-to-speech system based on deep con volutional net- works with guided attention, ” in ICASSP , 2018. [7] W . Ping, K. Peng, and J. Chen, “ClariNet: Parallel W ave Gen- eration in End-to-End T ext-to-Speech, ” ArXiv e-prints , July 2018. [8] J. O. Smith, Spectral Audio Signal Pr ocessing , online book, 2011 edition. [9] “Libriv ox, ” http://libriv ox.org/. [10] K. Rao, F . Peng, H. Sak, and F . Beaufays, “Grapheme-to- phoneme con version using long short-term memory recurrent neural networks, ” in ICASSP , 2015. [11] A. W . Black, K. Lenzo, and V . Pagel, “Issues in building gen- eral letter to sound rules, ” 1998. [12] C. M. Eddington and N. T okowicz, “How meaning similarity influences ambiguous word processing: The current state of the literature, ” Psychonomic bulletin & r eview , vol. 22, no. 1, pp. 13–37, 2015. [13] W . Ping, K. Peng, A. Gibiansky , S. O. Arik, A. Kannan, S. Narang, J. Raiman, and J. Miller, “Deep voice 3: Scal- ing text-to-speech with con volutional sequence learning, ” in International Conference on Learning Repr esentations (ICLR 2018) , 2018. [14] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oceedings of the IEEE confer ence on Computer V ision and P attern Recognition , 2016. [15] S. Ioffe and C. Szegedy , “Batch normalization: Accelerat- ing deep network training by reducing internal covariate shift, ” 2015. [16] M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural networks, ” IEEE T ransactions on Signal Processing , vol. 45, no. 11, pp. 2673–2681, 1997. [17] S. Hochreiter and J. Schmidhuber, “Long short-term memory , ” Neural Computation , vol. 9, no. 8, pp. 1735–1780, 1997. [18] N. Sriv astav a, G. Hinton, A. Krizhevsky , I. Sutske ver , and R. Salakhutdinov , “Dropout: A simple way to prev ent neural networks from ov erfitting, ” The Journal of Machine Learning Resear ch , vol. 15, no. 1, pp. 1929–1958, 2014. [19] A. Graves, “Generating sequences with recurrent neural net- works, ” arXiv: 1308.0850 [cs.NE] , Aug. 2013. [20] S. Zhang, Y . W u, T . Che, Z. Lin, R. Memisevic, R. R. Salakhut- dinov , and Y . Bengio, “ Architectural complexity measures of recurrent neural networks, ” in Advances in Neural Information Pr ocessing Systems , 2016, pp. 1822–1830. [21] S. Semeniuta, A. Sev eryn, and E. Barth, “Recurrent dropout without memory loss, ” in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: T echnical P apers , 2016, pp. 1757–1766. [22] D. Griffin and J. Lim, “Signal estimation from modified short- time fourier transform, ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , vol. 32, no. 2, pp. 236–243, 1984. [23] M. Slaney , D. Naar , and R. L yon, “ Auditory model in version for sound separation, ” in Acoustics, Speech, and Signal Pr o- cessing, 1994. ICASSP-94., 1994 IEEE International Confer- ence on . IEEE, 1994, vol. 2, pp. II–77. [24] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Grav es, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “W av eNet: A Generative Model for Raw Audio, ” ArXiv e-prints , Sept. 2016. [25] S. Mehri, K. Kumar , I. Gulrajani, R. Kumar , S. Jain, J. Sotelo, A. Courville, and Y . Bengio, “Samplernn: An unconditional end-to-end neural audio generation model, ” arXiv pr eprint arXiv:1612.07837 , 2016. [26] C. Thom ´ e, “Personal communication, ” 2018. [27] L. A. Gatys, A. S. Ecker , and M. Bethge, “Image style trans- fer using con volutional neural networks, ” in CVPR , 2016, pp. 2414–2423. [28] R. Y amamoto, M. Andre ws, M. Petrochuk, W . Hy , cbrom, O. V ishnepolski, M. Cooper, K. Chen, and A. Pielikis, “r9y9/wavenet vocoder: v0.1.1 release, ” Oct. 2018, https://github .com/r9y9/wav enet vocoder . [29] R. Skerry-Ryan, E. Battenberg, Y . Xiao, Y . W ang, D. Stan- ton, J. Shor, R. J. W eiss, R. Clark, and R. A. Saurous, “T o- wards end-to-end prosody transfer for expressi ve speech syn- thesis with tacotron, ” arXiv pr eprint arXiv:1803.09047 , 2018. [30] Y . T aigman, L. W olf, A. Polyak, and E. Nachmani, “V oice syn- thesis for in-the-wild speakers via a phonological loop, ” arXiv pr eprint arXiv:1707.06588 , 2017. [31] D. Ha, A. Dai, and Q. V . Le, “Hypernetworks, ” arXiv pr eprint arXiv:1609.09106 , 2016. [32] D. Ha and D. Eck, “ A neural representation of sketch draw- ings, ” arXiv pr eprint arXiv:1704.03477 , 2017. [33] K. Ito, “The lj speech dataset, ” https://keithito.com/ LJ- Speech- Dataset/ , 2017. [34] R. M. Ochshorn and M. Hawkins, “Gentle forced aligner [com- puter software], ” 2017, https://github.com/lo werquality/gentle.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment