Unspeech: Unsupervised Speech Context Embeddings
We introduce "Unspeech" embeddings, which are based on unsupervised learning of context feature representations for spoken language. The embeddings were trained on up to 9500 hours of crawled English speech data without transcriptions or speaker info…
Authors: Benjamin Milde, Chris Biemann
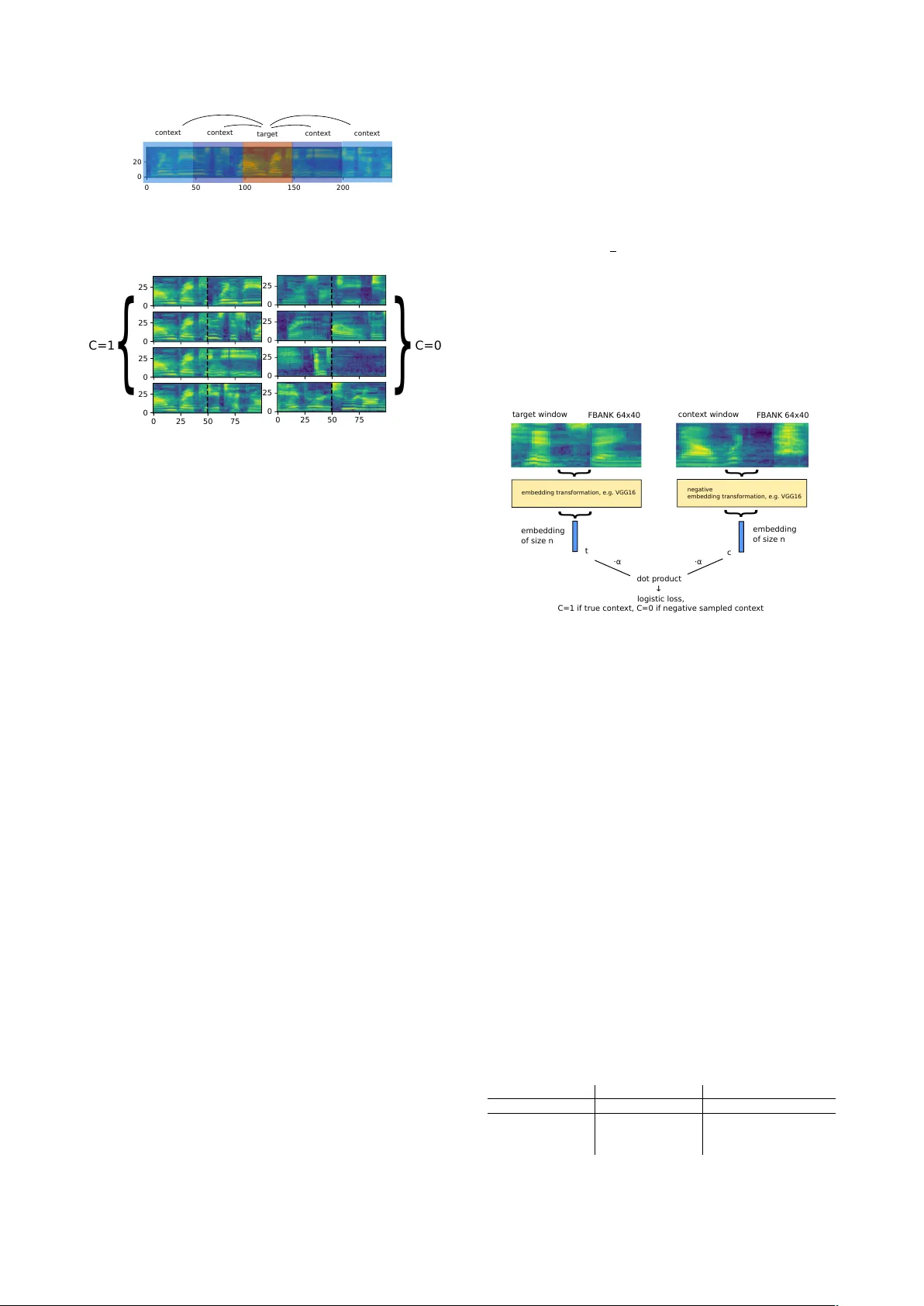
Unspeech: Unsupervised Speech Context Embeddings Benjamin Milde, Chris Biemann Language T echnology , Univ ersit ¨ at Hambur g { milde,biemann } @informatik.uni-hamburg.de Abstract W e introduce ”Unspeech” embeddings, which are based on unsupervised learning of context feature representations for spoken language. The embeddings were trained on up to 9500 hours of crawled English speech data without transcriptions or speaker information, by using a straightforward learning ob- jectiv e based on context and non-context discrimination with negati ve sampling. W e use a Siamese conv olutional neural net- work architecture to train Unspeech embeddings and ev aluate them on speaker comparison, utterance clustering and as a con- text feature in TDNN-HMM acoustic models trained on TED- LIUM, comparing it to i-vector baselines. Particularly decoding out-of-domain speech data from the recently released Common V oice corpus shows consistent WER reductions. W e release our source code and pre-trained Unspeech models under a permis- siv e open source license. Index T erms : Unsupervised learning, speech embeddings, con- text embeddings, speaker clustering 1. Introduction V ariance and variability in recordings of speech and its rep- resentations are a common problem in automatic speech pro- cessing tasks. E.g. speaker , en vironment characteristics and the type of microphone will cause large differences in typical speech representations (e.g. FB ANK, MFCC), making direct similarity comparisons difficult. W e can describe such factors of variance also as the context of an utterance; speech sounds that occur close in time share similar contexts. Based on this idea, we propose to learn representations of such contexts in an unsupervised way , without needing further speaker IDs, chan- nel information or transcriptions of the data. Recent acoustic models for automatic speech recognition (ASR) incorporate some form of (deep) neural network that can learn to deal with part of this variance by using supervised training data in combination with the ability to learn represen- tations as part of the model. A growing trend is to incorporate larger context views of the data explicitly into the neural net- work. In Deep Neural Network Hidden Markov Model (DNN- HMM) hybrids, fixed-length speaker embeddings like i-vectors are made av ailable for the neural network as additional input features [1]. T ypically , larger temporal windows than single speech frames are also used as input to the neural network to make context available to local predictions. This can e.g. be achiev ed by either stacking consecutive speech frames or by us- ing T ime-Delayed Neural Networks (TDNNs) [2, 3]. On the other hand, ”Unspeech” embedding models embed a window of speech into a fixed-length vector so that corre- sponding points are close, if they share similar contexts. Un- supervised training of the embedding function is inspired by negati ve sampling in word2vec [4] – where words that share a similar meaning are embedded in similar regions in a dense vector space. In this work, we demonstrate that the learned Un- speech context embeddings encode speaker characteristics and also can be used to cluster a speech corpus. As an additional context input feature, they can also improve supervised speech recognition tasks with TDNN-HMM acoustic models, in partic- ular when adaptation to out-of-domain data is needed. 2. Related W ork Speaker embeddings and phonetic embeddings are two major groups of proposed embeddings in speech: While speaker em- beddings seek to model utterances from the same speaker so that they share similar regions in a dense vector space, in phonetic embeddings, the same or similar phonetic content is close. I-vectors [5] are well-known, popular speaker vectors. Re- cently , supervised neural network-based speaker embeddings also succeeded to show good speaker discriminativ e properties [6, 7, 8], particularly on short utterances. Bengio and Heigold proposed supervised word embeddings for speech recognition [9], where words are nearby in the vector space if they sound alike. Kamper et al. [10] showed that auto-encoders can also be used in conjugntion with top-down information for unsuper - vised phonetic representation learning in speech. Chung et al. [11] proposed audio word2vec, based on sequence-to-sequence auto-encoders trained on a dictionary of isolated spoken w ords. By analogy of auto-encoders, P athak et al. introduced con- text encoders [12], a class of models that learn context embed- dings in images. There is also growing interest in representation learning on non-speech audio by using learning objectiv es di- rectly related to contexts. Jansen et al. [13] encoded the notion that (non-speech) sounds occurring in context are more related. Bromley et al. [14] introduced Siamese neural networks: two (time-delayed) neural networks that embed digital signa- tures and a learning objective based on discriminating between true and false signatures. This idea has recently been revisited in the context of joint phoneme and speaker embeddigs learn- ing in a weakly supervised setting, where speaker annotation, same word information and segmentation is av ailable [15, 16]. Gutmann et al. [17] introduced Noise-Contrastiv e Estimation (NCE), an estimator based on discriminating between observ ed data and some artificially generated noise. Jati et al. proposed Speaker2vec [18] for speaker segmentation, with unsupervised training using a neural encoder/decoder . V ery recently and in parallel to our efforts, Jati et al. also proposed (unsupervised) neural predictiv e coding to learn speaker characteristics [19]. In [20] unsupervised speaker clustering was proposed to yield labels for speaker adaptation in acoustic models, based on the idea that consecutive windows of speech are likely from the same speaker . Sev eral forms of conte xt/speaker embeddings hav e also been used for (speaker) adaptation in state-of-the-art speech recognition acoustic models: i-vector speaker embed- dings are by far the most popular [1, 21, 22]. V esely et al. proposed sequence summary neural netw orks for speaker adap- tation, where utterance context vectors are av eraged from the speech feature representation [23]. Gupta et al. [24] showed 0 50 100 150 200 0 20 tar get conte xt conte xt conte xt conte xt Figure 1: The initial sequence with unnormalized FBANK vec- tors: we choose one tar get window and two left and right con- texts. All windows ar e of the same size. 0 25 0 25 0 25 0 25 0 25 0 25 0 25 0 25 50 75 0 25 } } C=0 C=1 0 25 50 75 Figure 2: Sampling e xamples for two left contexts and two right contexts from the figur e above. P ositive e xample pairs ar e of class C = 1 , ne gative sampled pairs are C = 0 . In this exam- ple, each window has a size of 50 FBANK frames (0.5 seconds). that visual features, in the form of acti vations from a pre-trained Con vNet for object detection on videos can also be used as con- text v ectors in the acoustic model. 3. Proposed Models W e construct an artificial binary classification task with logistic regression, where two fixed sized windows are compared. One target window can have multiple context windows, depending on the number of left and right contexts. F or every left and right context, a pair with the target is created. Figure 1 illus- trates this with two right and left contexts, yielding four positive contexts and four randomly sampled negativ e contexts. For the target window we denote emb t as the target embedding trans- formation, taking a window of FBANK features and producing a fixed sized output vector , emb c as the embedding of a true context and emb neg as the embedding of a randomly sampled context. The pair of (embedded) speech windows is considered to be of class C = 1 if one window is the context of the other , or C = 0 if they are not. For C = 1 , we sample the pairs from consecutiv e windows, for C = 0 we use negativ e sampling to construct a pair of speech windo ws that are unrelated with high probability: W e uniformly sample a random utterance u and then uniformly a random position in u . 3.1. Objective Function W ith the scalar x as the output of the model for a particular data point, σ the sigmoid function and C its true class ∈ (0 , 1) , the logistic loss for a binary classification task is: loss ( x, C ) = C ( − log ( σ ( x ))) + (1 − C )( − l og (1 − σ ( x ))) (1) with x = emb T t emb c , the dot product o ver target and context embedding transformations if C = 1 and x = emb neg 1 T i emb neg 2 i , the dot product over two negati ve sam- pled embedding transformations if C = 0 , for k = number of negati ve samples we can thus obtain: N E G loss = − k · l og ( σ ( emb T t emb c )) − k X i =1 log (1 − σ ( emb T neg 1 i emb neg 2 i )) (2) Note that in the similar NCE loss formulation [17], P ( C = 1) = P ( C = 0) = 1 2 , i.e. the number of data points where C = 1 and C = 0 are the same, while we could have more negati ve than positive target/context embedding pairs, depend- ing on k . Instead, for C = 1 we multiply with k = the number of negati ve samples, to penalize errors on positiv e and negativ e context pairs equally . Another difference is that we sample two unrelated embedding windows instead of one. 3.2. Model Architectur e embedding tr ansfor mation, e.g. VGG16 } } embedding of size n embedding of size n dot pr oduct → logistic loss, C=1 if tr ue con te xt, C=0 if negative sa mpled conte xt negative embedding tr ansfor mation, e.g. VGG16 tar get window FBANK 64x40 FBANK 64x40 conte xt window t c · α · α } } Figure 3: Unspeech embeddings ar e trained using a Siamese neural network ar chitectur e combined with a dot pr oduct. W e use the VGG16A network as embedding transformation in the yellow boxes (a con volutional neural network with 16 layers). Figure 3 shows our architecture for FB ANK input features. W e project tw o dimensional input windo ws into two fixed sized embeddings, which are combined with a dot product. Since this is sensitive to the scaling of output embeddings, we multiply them with a single scalar parameter α , which is trained with the rest of the network. Direct normalization to unit length (mak- ing the dot product equiv alent to a cosine distance) did hamper con vergence of the loss and w as discarded early on. Many different architectures are possible for con v erting the input representation into a fixed sized embedding, but we mainly ev aluated with a VGG-style ConvNet architecture (Model A in [25]), as it is well established and it can exploit the two dimensional structure in the FBANK signal. W e share the weights of the con volutional layers of both embedding transfor- mations, but keep the fully connected layers separate. Dropout is used for fully connected layers (0.1) and L2 regularization is used on the weights (0.0001), for all experiments we optimize with AD AM [26]. W e make use of leaky ReLUs [27]. 4. Evaluation T able 1: Comparison of English speech data sets. hours speakers dataset train dev test train dev test TED-LIUM V2 211 2 1 1273+3 14+4 13+2 Common V oice V1 242 5 5 16677 2728 2768 TEDx (crawled) 9505 41520 talks T able 1 characterizes the datasets we used in our ev alua- tion. TED-LIUM V2 [28] has a comparatively small number of speakers, especially in the de velopment and test set of the corpus. TED-LIUM and Common V oice [29] are segmented at the utterance level, both are similar in the number of hours. In Common V oice, volunteers from all over the world recorded predefined prompts, in TED-LIUM utterances are segmented from and aligned to TED talks. In order to explore large-scale training, we also downloaded all TEDx talks from 01-01-2016 until 03-01-2018 from Y ouT ube, giving us 41520 talks (0.5 TB compressed audio data) with a total of 9505 hours of unanno- tated audio. While the majority of TEDx talks are in English, a very small number of them are in other languages or contain only music. W e did not segment or clean the TEDx data. 4.1. Same/different Speaker Experiment In the same/dif ferent speaker experiment, we evaluate a binary classification task: given two utterances, are they uttered from the same or different speakers? Our hypothesis is that Unspeech embeddings can be used for this task, because one strategy to discriminate samples of true contexts from negati ve sampled ones is modelling speaker traits. In T able 2 we show equal error rates (EER) 1 on same/different speaker comparisons of all utter - ance pairs, limiting the number of speakers to 100 in the train sets of TED-LIUM and Common V oice corpus in this experi- ment. The embedding dimension is 100 in all experiments, we train Unspeech models with different target window widths (32, 64, 128) and i-v ectors are trained/extracted with Kaldi [31]. For all e xperiments, we use two left and two right context windo ws. T able 2: Equal err or rates (EER) on TED-LIUM V2 – Unspeech embeddings corr elate with speaker embeddings. Embedding EER TED-LIUM: train dev test (1) i-vector 7.59% 0.46% 1.09% (2) i-vector -sp 7.57% 0.47% 0.93% (3) unspeech-32-sp 13.84% 5.56% 3.73% (4) unspeech-64 15.42% 5.35% 2.40% (5) unspeech-64-sp 13.92% 3.4% 3.31% (6) unspeech-64-tedx 19.56% 7.96% 4.96% (7) unspeech-128-tedx 20.32% 5.56% 5.45% The distance function d 1 ( a, b ) = σ ( emb t ( a ) T emb c ( b )) to compare two segments a and b correspond to the distance func- tion in the Unspeech training process. The cosine distance, or equally after normalization to unit length, the Euclidean dis- tance on vectors produced by emb t also produces good com- parison results, so that d 2 ( a, b ) = || emb t ( a ) − emb t ( b ) || can be used for comparing two Unspeech se gments. Sequences that are longer than the trained target windo w can be windo wed and av eraged to obtain a single v ector for the whole sequence, since vectors that are close in time share contexts and correlate highly . Howe ver , EER on i-vectors trained with supervised speaker la- bels compared with the cosine distance (results with d 2 ( a, b ) are identical after normalization) are lower than on Unspeech embeddings with d 2 ( a, b ) (1,2 vs 3,4,5). Training Unspeech on TEDx talks instead of TED-LIUM does also produce higher EER as a speaker embedding (6,7). ”-sp” denotes training on speed-perturbed data: adding copies of the raw training data at 0.9 and 1.1 playing speed, as recommended in [32]. 1 The error rate where the number of false positive and false nega- tiv es is the same, calculated using pyannote.metrics [30] 4.2. Clustering Utterances W e can also use the generated vectors to cluster a corpus of utterances to gain insight into what kind of utterances get clus- tered together . W e use HDBSCAN [33], a modern hierarchical density-based clustering algorithm for our experiments since it scales very well to a large number of utterances and the num- ber of clusters does not need to be known apriori. It uses an approximate nearest neighbor search if the comparison metric is Euclidean, making it significantly faster on a large number of utterances as compared to other speaker clustering methods that require distance computations of all utterance pairs (includ- ing greedy hierarchical clustering with BIC [34]). W e use Ad- justed Rand Index (ARI) [35] and Normalized Mutual Infor- mation (NMI) [36] to compare the clusters to the speaker IDs provided by the TED-LIUM corpus in T able 3. W e found that Unspeech embeddings and i-vectors giv e a sensible number of clusters, without much tweaking of HDBSCAN’ s two parame- ters (min. cluster size, min. samples) 2 . On the train set, Un- speech embeddings will provide slightly higher cluster scores, while i-vectors provide better scores for dev and test (that have a significantly smaller number of speakers). Unspeech-64 is slightly better than Unspeech-32 on the de v and test set. ARI is sensitiv e to the absolute number of outliers – we found NMI to be a better metric to compare the results on the train set. T aking a closer look at the clustered Unspeech embeddings, we observed that different speakers in the same talk tend to get clustered into distinct clusters (making the clustered output very often more accurate than the train speaker IDs provided in TED- LIUM), while the same speaker across different talks and also the same speaker in one talk with significantly different back- ground noises tends to be clustered into distinct clusters. This implies that Unspeech embeds more than just speaker traits. 4.3. Acoustic Models With Unspeech Cluster IDs W e can also train acoustic models with the cluster IDs provided and use them in lieu of speaker IDs for HMM-GMM speaker adaptation and online i-vector training for the TDNN-HMM model. W e use the TED-LIUM TDNN-HMM chain recipe (s5 r2) in Kaldi [37] and show WER before (plain) and af- ter rescoring with the standard 4-gram Cantab TED-LIUM LM (resc.). T able 4 shows WER on different speaker separation strategies on the train set, with one speaker per talk being the de- fault in the s5 r2 recipe. All models pre-trained online i-vectors based on the given speaker IDs and use those as additional input features. The standard recipe computes a fixed affine transform on the combined input features (40 dim hi-res MFCC + 100 dim i-vector), c.f. Appendix C.6 of [38]. GMM-HMM boot- strap models will perform about 15% worse and TDNN-HMM trained on them will perform about 10% worse if no speaker information is available. Using the cluster IDs from clustering Unspeech embeddings of all utterances, the baseline WER can not only be recovered, b ut ev en slightly improved upon. For all TDNN-HMM models we set the width of a layer to 1024. 4.4. Unspeech Context V ectors in TDNN-HMM models W e can also replace the i-vector representation used in training the TDNN-HMM with the Unspeech context vector . In T able 5, we selected the strongest baseline from T able 4 according to the dev set (Unspeech 64-sp clusters) and show WERs on the 2 W e use 5/3 for all experiments shown in T able 3, but other param- eters in the range 3-10 will giv e similar results. T able 3: Comparing clustered utter ances fr om TED-LIUM using i-vectors and (normalized) Unspeech embeddings with speaker labels fr om the corpus. ”-sp” denotes embeddings trained with speed-perturbed tr aining data. Embedding Num. clusters Outliers ARI NMI train dev test train de v test train dev test train dev test TED-LIUM IDs 1273 (1492) 14 13 3 4 2 1.0 1.0 1.0 1.0 1.0 1.0 i-vector 1630 12 10 8699 1 2 0.8713 0.9717 0.9792 0.9605 0.9804 0.9598 i-vector -sp 1623 12 10 9068 1 2 0.8641 0.9717 0.9792 0.9592 0.9804 0.9598 unspeech-32-sp 1686 16 12 3235 22 32 0.9313 0.9456 0.9178 0.9780 0.9536 0.9146 unspeech-64 1690 16 11 5690 14 21 0.8130 0.9537 0.9458 0.9636 0.9636 0.9493 unspeech-64-sp 1702 15 11 3705 23 25 0.9205 0.9517 0.9340 0.9730 0.9633 0.9366 T able 4: Comparing the ef fect of two speaker division baselines (One speaker per talk, one speaker per utterance) and cluster- ing with Unspeec h on WER with GMM-HMM and TDNN-HMM chain acoustic models tr ained on TED-LIUM. Acoustic model Spk. div . Dev WER T est WER plain resc. plain resc. GMM-HMM per talk 19.2 18.2 17.6 16.7 TDNN-HMM 8.6 7.8 8.8 8.2 GMM-HMM per utt. 19.6 18.7 20.1 19.2 TDNN-HMM 8.5 7.9 9.3 9.0 GMM-HMM Unspeech 18.4 17.4 17.5 16.5 TDNN-HMM 64 8.6 7.8 8.5 8.1 GMM-HMM Unspeech 18.4 17.5 17.2 16.4 TDNN-HMM 64-sp 8.3 7.5 8.6 8.2 T able 5: WER for TDNN-HMM chain models trained with Un- speech embeddings on TED-LIUM. Context vector Dev WER T est WER plain resc. plain resc. (1) none 9.1 8.5 9.5 9.1 (2) i-vector -sp-ted 8.3 7.5 8.6 8.2 (3) unspeech-64-sp-ted 9.1 8.3 9.6 9.0 (4) unspeech-64-sp-cv 9.1 8.3 9.5 9.1 (5) unspeech-64-sp-cv + (2) 8.4 7.6 8.5 8.1 (6) unspeech-64-tedx 9.0 8.2 9.4 8.7 (7) unspeech-128-tedx 8.9 8.2 9.4 8.9 TED-LIUM dev and test for different Unspeech context em- beddings. W e trained Unspeech models with different window sizes (64,128) on TED-LIUM (ted) and Common V oice V1 (cv) and computed them for e very 10 frames, lik e the online i-vector baseline. While Unspeech embeddings can slightly improve a baseline model trained without any context vectors, with best results obtained when training on the 9500 hours of TEDx data (6,7), using i-vectors (2) yields better WERs compared to Un- speech embeddings. Combining Unspeech embeddings trained on Common V oice and i-vectors in the input representation can yield slightly lower WERs than i-v ectors alone (5). In T able 6 we show WER on decoding utterances from the Common V oice V1 de v and test sets with TDNN-HMM acous- tic models trained on TED-LIUM. Utterances from Common V oice are much harder to recognize, since a lot more noise and variability is present in the recordings and the recording hav e perceiv ably a much lower signal-to-noise ratio. Since they also contain over 2700 speakers each using an egregious range of microphones, they provide an excellent dev/test to test ho w ro- bust the TDNN-HMM models are on out-of-domain data. Un- surprisingly , WERs are fairly high compared to the TED-LIUM test set with mostly clean and well pronounced speech. With T able 6: Decoding Common V oice V1 utterances. Mozilla’ s open sour ce dataset pr ovides a challenging test set, which is out-of-domain for an acoustic model trained on TED-LIUM. Context vector Dev WER T est WER plain resc. plain resc. (1) none 31.2 29.6 29.9 28.5 (2) i-vector -sp-ted 30.3 29.0 29.9 28.2 (3) unspeech-64-sp-cv 29.5 27.9 28.3 26.9 (4) unspeech-64-sp-cv + (2) 29.6 28.2 28.9 27.4 (5) unspeech-64-tedx 30.2 28.8 29.2 27.5 (6) unspeech-128-tedx 30.1 28.7 29.5 28.0 Common V oice we observed that acoustic models trained with Unspeech embeddings consistently resulted in better WERs compared to the baselines, helping the model to adapt. Par- ticularly pre-training Unspeech models on the Common V oice train data help a TDNN-HMM model trained on TED-LIUM to adapt to the style of Common V oice recordings. Embeddings from Unspeech models trained on TEDx will also perform bet- ter than the no context and i-v ector baseline models. In contrast to the results in T able 5, in this decoding task, i-vectors in the acoustic model do not provide much of an improv ement over the TDNN-HMM baseline model without context v ectors. 5. Conclusion Unspeech context embeddings contain and embed speaker char- acteristics, b ut supervised speaker embeddings like i-vectors would be better suited for tasks like speaker recognition or au- thentication. Howe ver , clustering utterances according to Un- speech contexts and using the cluster IDs for speaker adaptation in HMM-GMM/TDNN-HMM models is a viable alternativ e if no speaker information is a vailable. While using Unspeech con- text embeddings as additional input features did not yield sig- nificant WER improvements compared to an i-vector baseline on TED-LIUM dev and test, we observed consistent WER re- ductions with out-of-domain data from the Common V oice cor - pus when we add Unspeech embeddings. This is a compelling use case of Unspeech context embedding for the adaptation of TDNN-HMM models. Better scores on the same/different speaker similarity task was not indicativ e of WER reduction – our TEDx Unspeech models scored higher EERs, but were at the same time better context v ectors in the acous tic models. W e are currently also working on modifying the training objective to see if phonetic Unspeech embeddings can be trained using a similar unsupervised training procedure. Furthermore, we are releasing our source code and offer pre-trained models. 3 Acknowledgments. W e thank Michael Henretty from Mozilla for giving us access to Common V oice V1 speaker information. 3 See http://unspeech.net , license: Apache 2.0 6. References [1] G. Saon, H. Soltau, D. Nahamoo, and M. Picheny , “Speaker adaptation of neural network acoustic models using i-vectors. ” in ASR U , Olomouc, Czech Republic, 2013, pp. 55–59. [2] A. W aibel, T . Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural networks, ” in Readings in speech r ecognition , 1990, pp. 393–404. [3] V . Peddinti, D. Povey , and S. Khudanpur, “ A time delay neural network architecture for efficient modeling of long temporal con- texts, ” in Pr oc. Interspeech , Dresden, Germany , 2015, pp. 3214– 3218. [4] T . Mikolov , I. Sutskev er , K. Chen, G. Corrado, and J. Dean, “Dis- tributed Representations of W ords and Phrases and their Com- positionality , ” in Pr oc. NIPS , Lake T ahoe, NV , USA, 2013, pp. 3111–3119. [5] N. Dehak, P . J. Kenny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE Tr ans- actions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 4, pp. 788–798, 2011. [6] D. Snyder, P . Ghahremani, D. Povey , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur, “Deep neural network-based speaker embeddings for end-to-end speak er verification, ” in Pr oc. Spoken Language T echnolo gy W orkshop (SLT) , San Diego, CA, USA, 2016, pp. 165–170. [7] D. Snyder, D. Garcia-Romero, D. Povey , and S. Khudanpur , “Deep neural network embeddings for text-independent speaker verification, ” in Proc. Interspeech 2017 , Stockholm, Sweden, 2017, pp. 999–1003. [8] L. Li, Y . Chen, Y . Shi, Z. T ang, and D. W ang, “Deep speaker fea- ture learning for text-independent speaker verification, ” in Proc. Interspeech 2017 , Stockholm, Sweden, 2017, pp. 1542–1545. [9] S. Bengio and G. Heigold, “W ord embeddings for speech recog- nition, ” in Pr oc. Interspeec h , Singapore, 2014, pp. 1053–1057. [10] H. Kamper, M. Elsner, A. Jansen, and S. Goldwater , “Unsuper- vised neural network based feature extraction using weak top- down constraints, ” in Proc. Acoustics, Speech and Signal Process- ing (ICASSP) . South Brisbane, Queensland, Australia: IEEE, 2015, pp. 5818–5822. [11] Y .-A. Chung, C.-C. W u, C.-H. Shen, H.-Y . Lee, and L.-S. Lee, “ Audio word2v ec: Unsupervised learning of audio segment repre- sentations using sequence-to-sequence autoencoder, ” in Proc. In- terspeech , San Francisco, CA, USA, 2016, pp. 765–769. [12] D. Pathak, P . Krahenb uhl, J. Donahue, T . Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting, ” in Pr oceed- ings of Computer V ision and P attern Recognition (CVPR) , Cae- sars Palace, Ne vada, United States, 2016, pp. 2536–2544. [13] A. Jansen, M. Plakal, R. Pandya, D. P . Ellis, S. Hershey , J. Liu, R. C. Moore, and R. A. Saurous, “Unsupervised learning of se- mantic audio representations, ” arXiv pr eprint arXiv:1711.02209 , 2017. [14] J. Bromley , I. Guyon, Y . LeCun, E. S ¨ ackinger , and R. Shah, “Signature verification using a ”Siamese” time delay neural net- work, ” in Proc. Advances in Neural Information Pr ocessing Sys- tems (NIPS) , Den ver , CO, USA, 1994, pp. 737–744. [15] G. Synnaev e and E. Dupoux, “W eakly supervised multi- embeddings learning of acoustic models, ” arXiv pr eprint arXiv:1412.6645 , 2014. [16] N. Zeghidour , G. Synnaeve, N. Usunier , and E. Dupoux, “Joint learning of speaker and phonetic similarities with siamese net- works, ” in Proc. Interspeec h , San Francisco, CA, USA, 2016, pp. 1295–1299. [17] M. Gutmann and A. Hyv ¨ arinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models, ” in Proc. International Conference on Artificial Intelligence and Statistics , Sardinia, Italy , 2010, pp. 297–304. [18] A. Jati and P . Geor giou, “Speaker2vec: Unsupervised learning and adaptation of a speaker manifold using deep neural networks with an ev aluation on speaker segmentation, ” Proc. Interspeech 2017 , pp. 3567–3571, 2017. [19] ——, “Neural predictiv e coding using conv olutional neural net- works towards unsupervised learning of speaker characteristics, ” arXiv pr eprint arXiv:1802.07860 , 2018. [20] H. Jin, F . Kubala, and R. Schwartz, “ Automatic speaker cluster- ing, ” in Pr oceedings of the DARP A speech r ecognition workshop , 1997, pp. 108–111. [21] A. Senior and I. Lopez-Moreno, “Improving DNN speaker inde- pendence with i-vector inputs, ” in Proc. Acoustics, Speech and Signal Pr ocessing (ICASSP) , Florence, Italy , 2014, pp. 225–229. [22] Y . Miao, H. Zhang, and F . Metze, “Speaker adapti ve train- ing of deep neural network acoustic models using i-vectors, ” IEEE/ACM T ransactions on Audio, Speech and Language Pr o- cessing (T ASLP) , vol. 23, no. 11, pp. 1938–1949, 2015. [23] K. V esel ` y, S. W atanabe, K. ˇ Zmol ´ ıkov ´ a, M. Karafi ´ at, L. Burget, and J. H. ˇ Cernock ` y, “Sequence summarizing neural network for speaker adaptation, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP) , Lujiazui, Shanghai, China, 2016, pp. 5315–5319. [24] A. Gupta, Y . Miao, L. Nev es, and F . Metze, “Visual features for context-a ware speech recognition, ” in Pr oc. Acoustics, Speec h and Signal Pr ocessing (ICASSP) . IEEE, 2017, pp. 5020–5024. [25] K. Simonyan and A. Zisserman, “V ery deep convolutional networks for large-scale image recognition, ” arXiv preprint arXiv:1409.1556 , 2014. [26] D. P . Kingma and J. Ba, “Adam: A Method for Stochastic Opti- mization, ” CoRR , v ol. abs/1412.6, 2014. [27] A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier nonlinearities improve neural network acoustic models, ” in Pr oc. ICML , vol. 30, no. 1, Atlanta, GA, USA, 2013, p. 3. [28] A. Rousseau, P . Del ´ eglise, and Y . Est ` eve, “Enhancing the TED- LIUM corpus with selected data for language modeling and more TED talks, ” in Proc. LREC , Reykjavik, Iceland, 2014, pp. 3935– 3939. [29] Mozilla, Common V oice Corpus V1 , 2018. [Online]. A vailable: https://voice.mozilla.or g/en/data [30] H. Bredin, “pyannote.metrics: a toolkit for reproducible ev aluation, diagnostic, and error analysis of speaker diarization systems, ” in Pr oc. Interspeec h , Stockholm, Sweden, 2017. [Online]. A vailable: http://pyannote.github .io/pyannote- metrics [31] D. Pov ey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The Kaldi speech recognition toolkit, ” in Pr oc. ASRU , Atlanta, GA, USA, 2011. [32] T . K o, V . Peddinti, D. Povey , and S. Khudanpur , “ Audio augmen- tation for speech recognition, ” in Pr oc. Interspeec h , Dresden, Ger- many , 2015, pp. 3586–3589. [33] L. McInnes, J. Healy , and S. Astels, “hdbscan: Hierarchical den- sity based clustering, ” The Journal of Open Source Software , vol. 2, no. 11, p. 205, 2017. [34] B. Zhou and J. H. Hansen, “Unsupervised audio stream segmenta- tion and clustering via the bayesian information criterion, ” in In- ternational Conference on Spoken Language Pr ocessing (ICSLP) , Beijing, China, 2000, pp. 714–717. [35] L. Hubert and P . Arabie, “Comparing partitions, ” J ournal of clas- sification , vol. 2, no. 1, pp. 193–218, 1985. [36] A. Strehl, “Relationship-based clustering and cluster ensembles for high-dimensional data mining, ” Ph.D. dissertation, Univ ersity Of T e xas at Austin, 2002. [37] D. Povey , V . Peddinti, D. Galvez, P . Ghahremani, V . Manohar , X. Na, Y . W ang, and S. Khudanpur , “Purely sequence-trained neu- ral networks for ASR based on lattice-free MMI. ” in Proc. Inter- speech , San Fransisco, CA, USA, 2016, pp. 2751–2755. [38] D. Pove y , X. Zhang, and S. Khudanpur, “Parallel training of DNNs with natural gradient and parameter averaging, ” arXiv pr eprint arXiv:1410.7455 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment