Multilingual End-to-End Speech Recognition with A Single Transformer on Low-Resource Languages
Sequence-to-sequence attention-based models integrate an acoustic, pronunciation and language model into a single neural network, which make them very suitable for multilingual automatic speech recognition (ASR). In this paper, we are concerned with …
Authors: Shiyu Zhou, Shuang Xu, Bo Xu
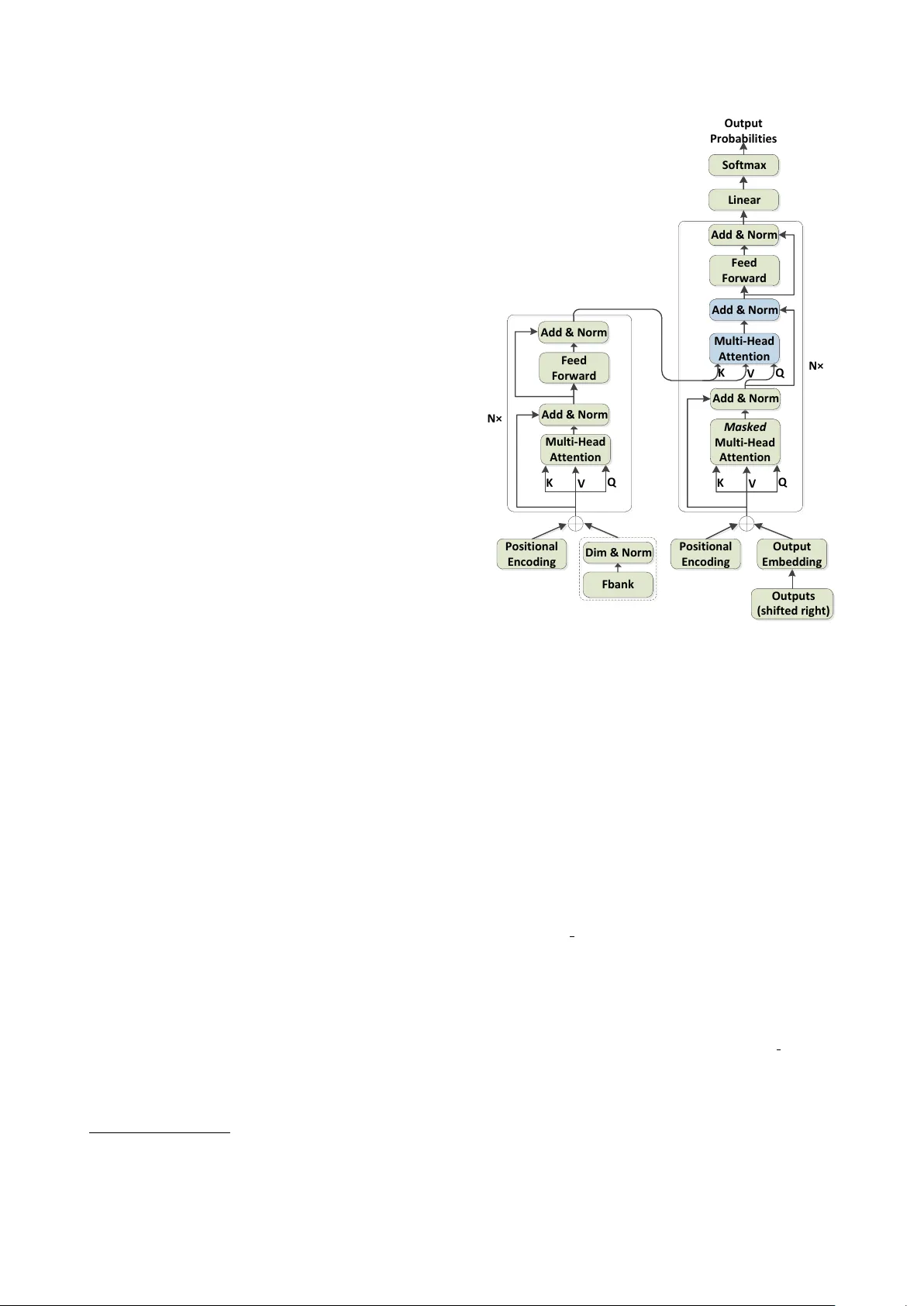
Multilingual End-to-End Speech Recognition with A Single T ransf ormer on Low-Resour ce Languages Shiyu Zhou 1 , 2 , Shuang Xu 1 , Bo Xu 1 1 Institute of Automation, Chinese Academy of Sciences 2 Uni versity of Chinese Academy of Sciences { zhoushiyu2013, shuang.xu, xubo } @ia.ac.cn Abstract Sequence-to-sequence attention-based models integrate an acoustic, pronunciation and language model into a single neural network, which make them very suitable for multilingual auto- matic speech recognition (ASR). In this paper , we are concerned with multilingual speech recognition on low-resource languages by a single Transformer , one of sequence-to-sequence attention- based models. Sub-words are employed as the multilingual modeling unit without using any pronunciation lexicon. First, we sho w that a single multilingual ASR Transformer performs well on low-resource languages despite of some language con- fusion. W e then look at incorporating language information into the model by inserting the language symbol at the begin- ning or at the end of the original sub-words sequence under the condition of language information being known during train- ing. Experiments on CALLHOME datasets demonstrate that the multilingual ASR T ransformer with the language symbol at the end performs better and can obtain relati vely 10.5% a verage word error rate (WER) reduction compared to SHL-MLSTM with residual learning. W e go on to show that, assuming the language information being known during training and testing, about relatively 12.4% a verage WER reduction can be observ ed compared to SHL-MLSTM with residual learning through giv- ing the language symbol as the sentence start token. Index T erms : ASR, speech recognition, multilingual, lo w- resource, sequence-to-sequence, T ransformer 1. Intr oduction Multilingual speech recognition has been in vestigated for many years [1, 2, 3, 4, 5]. Con ventional studies concentrate on the area of multilingual acoustic modeling by the context- dependent deep neural network hidden Markov models (CD- DNN-HMM) [6]. The hidden layers of DNN in CD-DNN- HMM can be thought of complicated feature transformation through multiple layers of nonlinearity , which can be used to ex- tract univ ersal feature transformation from multilingual datasets [1]. Among the CD-DNN-HMM based approaches, the ar- chitecture of SHL-MDNN [1], in which the hidden layers are shared across multiple languages while the softmax layers are language dependent, is a significant progress in the area of mul- tilingual ASR. These shared hidden layers and language depen- dent softmax layers of SHL-MDNN are optimized jointly by multilingual datasets. SHL-MLSTM [5] further explores long short-term memory (LSTM) [7] with residual learning as the shared hidden layer instead of DNN and achie ves better results than SHL-MDNN. Although these models achie ve encouraging results on mul- tilingual ASR tasks, a hand-designed language-specific pronun- ciation lexicon must be employed. This severely limits their application on low-resource languages, which may have not a well-designed pronunciation lexicon. Recent researches on sequence-to-sequence attention-based models try to remo ve this dependency on the pronunciation lexicon [8, 9, 10]. Chiu et al. shows that attention-based encoder-decoder architecture, namely listen, attend, and spell (LAS), achiev es a new state- of-the-art WER on a 12500 hour English voice search task us- ing the word piece models (WPM) [10]. Our pre vious work [9] demonstrates that the lexicon independent models can out- perform lexicon dependent models on Mandarin Chinese ASR tasks by the ASR Transformer and the character based model establishes a new state-of-the-art character error rate (CER) on HKUST datasets. Since the acoustic, pronunciation and language model are integrated into a single neural network by sequence-to-sequence attention-based models, it makes them very suitable for mul- tilingual ASR. In this paper , we concentrate on multilingual ASR on low-resource languages. Building on our work [9], we employ sub-words generated by byte pair encoding (BPE) [11] as the multilingual modeling unit, which do not need any pronunciation lexicon. The ASR Transformer is chosen to be the basic architecture of sequence-to-sequence attention-based model [9, 12]. T o alleviate the problem of few training data on low-resource languages, a well-trained ASR T ransformer from a high-resource language is adopted as the initial model rather than random initialization, whose softmax layer is replaced by the language-specific softmax layer . W e then look at incor- porating language information into the model by inserting the language symbol at the beginning or at the end of the original sub-words sequence [13] under the condition of language infor - mation being kno wn during training. A comparison with SHL- MLSTM [5] with residual learning is in vestig ated on CALL- HOME datasets with 6 languages. Experimental results rev eal that the multilingual ASR T ransformer with the language sym- bol at the end performs better and can obtain relatively 10.5% av erage WER reduction compared to SHL-MLSTM with resid- ual learning. W e go on to show that, assuming the language information being kno wn during training and testing, about rel- ativ ely 12.4% average WER reduction can be observed com- pared to SHL-MLSTM with residual learning through giving the language symbol as the sentence start token. The rest of the paper is organized as follows. After an ov erview of the related work in Section 2, Section 3 describes the proposed method in detail. W e then show experimental re- sults in Section 4 and conclude this work in Section 5. 2. Related work Although multilingual speech recognition has been studied [1, 2, 3, 4, 5] for a long time, these researches are commonly limited to making acoustic model (AM) multilingual, which require language-specific pronunciation model (PM) and lan- guage model (LM). Recently , sequence-to-sequence attention- based models, integrating the AM, PM and LM into a single network, have attracted a lot of attention on multilingual ASR [13, 14, 15, 16]. [14, 15] have presented a single sequence-to- sequence attention-based model can be capable of recognizing any of the languages seen in training. [13] explored the possi- bility of training a single model serve different English dialects and compared different methods incorporating dialect-specific information into the model. Howe ver , multilingual ASR on low-resource languages are few in vestigated by sequence-to- sequence attention-based models. Furthermore, we argue that the modeling unit of sub-words allows for a much stronger de- coder LM compared to graphemes [10], so sub-words encoded by BPE are employed as the multilingual modeling unit rather than graphemes [13, 14]. 3. System over view 3.1. ASR T ransformer model ar chitecture The ASR Transformer architecture used in this work is the same as our work [9, 12] which is shown in Figure 1. It stacks multi- head attention (MHA) [17] and position-wise, fully connected layers for both the encode and decoder . The encoder is com- posed of a stack of N identical layers. Each layer has two sub- layers. The first is a MHA, and the second is a position-wise fully connected feed-forward network. Residual connections are employed around each of the two sub-layers, follo wed by a layer normalization. The decoder is similar to the encoder except inserting a third sub-layer to perform a MHA over the output of the encoder stack. T o prevent leftward information flow and preserve the auto-regressi ve property in the decoder , the self-attention sub-layers in the decoder mask out all values corresponding to illegal connections. In addition, positional en- codings [17] are added to the input at the bottoms of these en- coder and decoder stacks, which inject some information about the relativ e or absolute position of the tokens in the sequence. The difference between the neural machine translation (NMT) T ransformer [17] and the ASR Transformer is the input of the encoder . W e add a linear transformation with a layer nor- malization to con vert the log-Mel filterbank feature to the model dimension d model for dimension matching, which is marked out by a dotted line in Figure 1. 3.2. Multilingual modeling unit Sub-words are employed as the multilingual modeling unit, which are generated by BPE 1 [11]. Firstly , the symbol vo- cabulary with the character vocab ulary is initialized, and each word is represented as a sequence of characters plus a special end-of-word symbol ‘@@’, which allows to restore the original tokenization. Then, all symbol pairs are counted iteratively and each occurrence of the most frequent pair (‘ A ’, ‘B’) are replaced with a new symbol ‘ AB’. Each merge operation produces a ne w symbol which represents a character n-gram. Frequent charac- ter n-grams (or whole words) are eventually merged into a sin- gle symbol. Then the final symbol vocab ulary size is equal to the size of the initial vocab ulary , plus the number of merg e op- erations α , which is the only hyper -parameter of this algorithm [11]. In our multilingual experiments, training transcripts in all languages are combined together to generate the multilingual 1 https://github .com/rsennrich/subword-nmt M u l t i - H e a d A t t e n t i o n K V Q P o s i t i o n a l E n c o d i n g F e e d F o r w a r d A d d & N o r m A d d & N o r m M a s k e d M u l t i - H e a d A t t e n t i o n K V Q P o s i t i o n a l E n c o d i n g O u t p u t E m b e d d i n g M u l t i - H e a d A t t e n t i o n A d d & N o r m A d d & N o r m O u t p u t s ( s h i f t e d r i g h t ) F e e d F o r w a r d A d d & N o r m K V Q L i n e a r O u t p u t P r o b a b i l i t i e s S o f t m a x N × N × F b a n k D i m & N o r m Figure 1: The arc hitectur e of the ASR T ransformer . symbol vocab ulary , instead of directly merging each language symbol vocabulary together . So same sub-words are shared among different languages automatically , which is very ben- eficial for languages belonging to the same language family . For example, for a German word of “univ ersit ¨ atsgeb ¨ au”, it is encoded into “univer@@ sit@@ ¨ a@@ ts@@ ge@@ b@@ ¨ a@@ u”; for an English word of “university”, it is encoded into “univer@@ sit@@ y”. T wo sub-words “univ er@@” and “sit@@” are shared in these two languages. 3.3. Language information as output tar gets Similar to [13, 18], we expand the symbol v ocabulary of the multilingual ASR Transformer to include a list of special sym- bols, each corresponding to a language. For example, we add the symbol < S EN > into the symbol v ocabulary when includ- ing English. If the language information of training data can only be known beforehand, two methods of adding the lan- guage symbol are explored, i.e. inserting at the beginning ( T ransformer-B ) or at the end ( T ransformer -E ) of the original sub-words sequence [13, 18]. What’ s more, if the language in- formation of both training and testing data can be known be- forehand, we directly take the language symbol < S Lang > as the sentence start token ( T ransformer-B2 ) rather than original sentence start token < S > . It can force the multilingual ASR T ransformer to decode a speech utterance into the pointed lan- guage, which is able to alleviate the language confusion greatly during testing. The difference between T ransformer -B and T ransformer - B2 is whether to utilize the language information during testing. The sentence start token is < S > in T ransformer -B . It first pre- dicts a language symbol by itself and then the following tokens are predicted as usual. Therefore, T ransformer-B do not need to kno w the language information beforehand during testing. In contrast, T ransformer -B2 employs < S Lang > as its sentence start token and predicts the following tokens as usual, which need to know the language information beforehand during test- ing. An example of adding the language symbol is shown in T able 1. T able 1: An example of adding the language symbol. Model Example Source amazing T ransformer < S > ama@@ z@@ ing < \ S > T ransformer-B < S > < S EN > ama@@ z@@ ing < \ S > T ransformer-E < S > ama@@ z@@ ing < S EN > < \ S > T ransformer-B2 < S EN > ama@@ z@@ ing < \ S > 4. Experiment 4.1. Data The datasets in the paper come from CALLHOME corpora col- lected by Linguistic Data Consortium (LDC). The follo wing six languages are used: Mandarin (MA), English (EN), Japanese (J A), Arabic (AR), German (GE) and Spanish (SP). W e follow the Kaldi [19] recipe to process CALLHOME datasets 2 . The detailed information is listed below in T able 2. W e train the ASR T ransformer with a gi ven number of epochs, so validation sets are not employed in this paper . All experiments are con- ducted using 80-dimensional log-Mel filterbank features, com- puted with a 25ms window and shifted e very 10ms. The fea- tures are normalized via mean subtraction and variance normal- ization on the speaker basis. Similar to [20, 21], at the current frame t , these features are stacked with 3 frames to the left and downsampled to a 30ms frame rate. W e generate more train- ing data by linearly scaling the audio lengths by factors of 0 . 9 and 1 . 1 [22], since it is always beneficial for training the ASR T ransformer [9]. T able 2: Multilingual dataset statistics. Language # training utts. # test utts. Mandarin (MA) 23915 3021 English (EN) 21194 2840 Japanese (J A) 27165 3381 Arabic (AR) 20828 2978 German (GE) 20027 5236 3 Spanish (SP) 17840 1982 T otal 130969 19438 4.2. Model and training details W e perform our experiments on the big model (D1024-H16) [9, 17] of the ASR T ransformer . T able 3 lists our experimental 2 the scripts of fisher callhome spanish in Kaldi are used to process all CALLHOME datasets with some tiny modifications. 3 W e employ devtest as evaltest in German since there is no ev altest from CALLHOME corpora. parameters. The Adam algorithm [23] with gradient clipping and warmup is used for optimization. During training, label smoothing of value ls = 0 . 1 is employed [24]. After trained, the last 20 checkpoints are averaged to make the performance more stable [17]. At the beginning we train the ASR Transformer on English data with a random initialization, b ut the result is poor although the CE loss looks good. W e propose that one reason for the poor performance could be the training data is too few but the param- eters of the ASR T ransformer are relativ ely lar ge which is about 230 M in this work. T o compensate the lack of training data on low-resource languages, a well-trained ASR Transformer with a CER of 26.64% on HKUST dataset, a corpus of Mandarin Chi- nese conv ersational telephone speech, is adopted from our work [9]. Its softmax layer is replaced by the language-specific soft- max layer which is initialized randomly . Through this initial- ization method, the ASR Transformer can con verge very well. All experiments in this paper are conducted by this initialization method. T able 3: Experimental parameters configuration. model N d model h d k d v war mup D1024-H16 6 1024 16 64 64 12000 steps 4.3. Number of merge operations First, we e valuate how the number of mer ge operations α in BPE affects the performance of the ASR T ransformer . When α is tiny , the number of sub-words is small. Otherwise the number of sub-words is large. Since the training data is quite few on low-resource languages, it means that the number of sub-words cannot be too large in order to make sure each sub-word has enough training samples. For each monolingual ASR T ransformer , we first experi- ment on English dataset for choosing an appropriate α . As shown in T able 4, the performance reaches the best when α = 500 and the number of sub-words is 548 on English dataset. Ap- pended with 4 extra tok ens, (i.e. an unkno wn token ( < UNK > ), a padding token ( < P AD > ), and sentence start and end tokens ( < S > / < \ S > )), the total number of sub-words is 552 . In this paper , we choose α = 500 in monolingual ASR T ransformer experiments. T able 4: WERs(%) of differ ent α on English dataset. α 50 100 500 1000 2000 # output. 106 156 552 1047 1997 WER 45 . 28 44 . 64 42.77 43 . 88 43 . 85 For the multilingual ASR T ransformer , all languages train- ing transcripts are combined together to generate the multi- lingual symbol v ocabulary by BPE. T able 6 sho ws that α do not affect the performance too much on average. W e choose α = 3000 in all multilingual ASR T ransformer experiments and the total number of sub-words is 8062 . 4.4. Results The baseline systems come from our pre vious work [5] and all results are summarized in T able 5. T able 5: Comparison of baseline systems and ASR T ransformer on CALLHOME datasets in WER/CER (%). Relative WER/CER r eduction is also shown between Multi-T ransformer -B2 and SHL-MLSTM-RESIDU AL. Model # params. MA EN J A AR GE SP A verage Mono-DNN [5] ≈ 21.0M 53 . 05 50 . 45 57 . 52 61 . 52 59 . 11 59 . 77 56 . 90 Mono-LSTM [5] ≈ 17.8M 50 . 53 48 . 16 55 . 14 59 . 21 56 . 61 57 . 71 54 . 56 SHL-MDNN [5] 38.0M 50 . 67 46 . 77 54 . 15 58 . 91 55 . 94 57 . 88 54 . 05 SHL-MLSTM-RESIDU AL [5] 22.0M 45.85 43.93 50.13 56.47 51.75 53.38 50.25 Mono-T ransformer ≈ 231M 39.62 42.77 39.55 50.78 48.94 54.42 46.01 Multi T ransformer 235M 40.28 42.35 39.29 50.87 47.82 53.26 45.65 T ransformer-B 235M 40.56 41.61 38.86 50.96 47.59 53.85 45.57 T ransformer-E 235M 40.49 40.63 38.67 50.16 47.24 52.58 44.96 T ransformer-B2 235M 37.62 40.36 38.13 48.82 46.22 53.07 44.03 Relativ e WER/CER Reduction − 17.9% 8.1% 23.9% 13.5% 10.7% 0.6% 12.4% T able 6: Multilingual r esults with dif fer ent α in WER/CER (%). α 1000 3000 5000 7000 9000 # output. 6084 8062 10025 11959 13883 MA 41.14 40.28 40.66 40.14 40.72 EN 42.76 42.35 42.49 42.73 42.76 J A 40.04 39.29 38.63 38.68 39.76 AR 51.04 50.87 51.32 51.15 51.80 GE 48.92 47.82 48.85 48.21 48.11 SP 54.34 53.26 53.07 53.37 53.73 A verage 46.37 45.65 45.84 45.71 46.15 T able 7: An English example of pr edictions fr om Multi- T ransformer-B2 with dif ferent < S Lang > . Correct T arget by any means < S MA > 八 月 零零 < S EN > by any means < S J A > バアエリミン < S AR > tayyib yacni min < S GE > war er nicht mit < S SP > vaya a dime mil First, we train six monolingual ASR Transformers ( Mono- T ransformer ) independently on each language data. As can be seen from T able 5, the monolingual ASR Transformer performs very well on each low-resource language and can obtain about relativ ely 15.7% WER reduction on av erage compared to mono- lingual LSTM ( Mono-LSTM ). Furthermore, we build a single multilingual ASR Trans- former ( Multi-T ransformer ) on all training data together with- out using any language information during training and testing. W e note that the Multi-T ransformer can achiev e slightly better performance than Mono-T ransformer on a verage, which repre- sents simply pooling the data together can give an acceptable recognition performance by a single multilingual ASR T rans- former . After analyzing recognition results from Multi- T ransformer , we find that some recognition results are completely wrong because of language confusion, especially when the speech utterance is short. F or example, sometimes an English word “um” is decoded into a German word “ja”, because they ha ve similar pronunciation. Since the language information of training data usually can be known beforehand, we go on to build two multilingual ASR T ransformers inte grating language information as depicted in Section 3.3 to alleviate the problem of language confusion. Here, the language information is just used during training and the model itself predicts the language symbol during testing. From T able 5, we can observe that inserting the language sym- bol at the end ( Multi-T ransformer -E ) is better than inserting it at the beginning ( Multi-T ransformer -B ). Compared to SHL- MLSTM-RESIDU AL, Multi-T ransformer-B can obtain about relativ ely 10.5% av erage WER reduction. If the language information of both training and testing data can be known beforehand, we directly take the language sym- bol < S Lang > as the sentence start token rather than original sentence start token < S > . It forces the multilingual ASR Trans- former to decode a speech utterance into the pointed language, which greatly alleviate the language confusion during testing. As can be seen from T able 5, Multi-T ransformer-B2 performs best and obtain relati ve 12.4% av erage WER reduction com- pared to SHL-MLSTM-RESIDU AL although the improv ement on Spanish is very little. What’ s more, an interesting observa- tion is that if we gi ve a wrong language symbol < S Lang > as the sentence start token, Multi-T ransformer -B2 is able to transliterate speech into the pointed language. An English ex- ample of predictions from Multi-T ransformer -B2 with different < S Lang > is sho wn in T able 7. W e can find that the prediction from wrong < S Lang > is an approximate pronunciation of the correct target. 5. Conclusions In this paper we inv estigated multilingual speech recognition on lo w-resource languages by a single multilingual ASR T rans- former . Sub-words are chosen as the multilingual modeling unit to remove the dependenc y on the pronunciation lexicon. A comparison with SHL-MLSTM with residual learning is in ves- tigated on CALLHOME datasets with 6 languages. Experimen- tal results re veal that a single multilingual ASR Transformer by inserting the language symbol at the end can obtain relativ ely 10.5% av erage WER reduction compared to SHL-MLSTM with residual learning if the language information of training data can be employed during training. W e go on to sho w that about relativ ely 12.4% a verage WER reduction can be observ ed com- pared to SHL-MLSTM with residual learning by giving the lan- guage symbol as the sentence start token assuming the language information being known during training and testing. 6. Refer ences [1] J.-T . Huang, J. Li, D. Y u, L. Deng, and Y . Gong, “Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers, ” in Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Confer ence on . IEEE, 2013, pp. 7304–7308. [2] N. T . V u, D. Imseng, D. Povey , P . Motlicek, T . Schultz, and H. Bourlard, “Multilingual deep neural network based acoustic modeling for rapid language adaptation, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE International Con- fer ence on . IEEE, 2014, pp. 7639–7643. [3] A. Mohan and R. Rose, “Multi-lingual speech recognition with low-rank multi-task deep neural networks, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Con- fer ence on . IEEE, 2015, pp. 4994–4998. [4] R. Sahraeian and D. V an Compernolle, “ A study of rank- constrained multilingual dnns for low-resource asr , ” in Acous- tics, Speech and Signal Processing (ICASSP), 2016 IEEE Inter- national Confer ence on . IEEE, 2016, pp. 5420–5424. [5] S. Zhou, Y . Zhao, S. Xu, and B. Xu, “Multilingual recurrent neural networks with residual learning for low-resource speech recogni- tion, ” Proc. Inter speech 2017 , pp. 704–708, 2017. [6] G. E. Dahl, D. Y u, L. Deng, and A. Acero, “Context-dependent pre-trained deep neural networks for large-v ocabulary speech recognition, ” IEEE T ransactions on audio, speech, and language pr ocessing , vol. 20, no. 1, pp. 30–42, 2012. [7] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural computation , v ol. 9, no. 8, pp. 1735–1780, 1997. [8] T . N. Sainath, R. Prabhav alkar , S. Kumar , S. Lee, A. Kannan, D. Rybach, V . Schogol, P . Nguyen, B. Li, Y . Wu et al. , “No need for a lexicon? evaluating the value of the pronunciation lexica in end-to-end models, ” arXiv preprint , 2017. [9] S. Zhou, L. Dong, S. Xu, and B. Xu, “ A comparison of modeling units in sequence-to-sequence speech recognition with the trans- former on mandarin chinese, ” arXiv preprint , 2018. [10] C.-C. Chiu, T . N. Sainath, Y . W u, R. Prabhav alkar, P . Nguyen, Z. Chen, A. Kannan, R. J. W eiss, K. Rao, K. Gonina et al. , “State- of-the-art speech recognition with sequence-to-sequence models, ” arXiv pr eprint arXiv:1712.01769 , 2017. [11] R. Sennrich, B. Haddow , and A. Birch, “Neural machine translation of rare words with subword units, ” arXiv preprint arXiv:1508.07909 , 2015. [12] S. Zhou, L. Dong, S. Xu, and B. Xu, “Syllable-based sequence- to-sequence speech recognition with the transformer in mandarin chinese, ” arXiv preprint , 2018. [13] B. Li, T . N. Sainath, K. C. Sim, M. Bacchiani, E. W einstein, P . Nguyen, Z. Chen, Y . W u, and K. Rao, “Multi-dialect speech recognition with a single sequence-to-sequence model, ” arXiv pr eprint arXiv:1712.01541 , 2017. [14] S. T oshniwal, T . N. Sainath, R. J. W eiss, B. Li, P . Moreno, E. W e- instein, and K. Rao, “Multilingual speech recognition with a sin- gle end-to-end model, ” arXiv preprint , 2017. [15] S. Kim and M. L. Seltzer , “T owards language-universal end-to- end speech recognition, ” arXiv preprint , 2017. [16] S. W atanabe, T . Hori, and J. R. Hershey , “Language indepen- dent end-to-end architecture for joint language identification and speech recognition, ” in Automatic Speech Recognition and Un- derstanding W orkshop (ASRU), 2017 IEEE . IEEE, 2017, pp. 265–271. [17] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “ Attention is all you need, ” in Advances in Neural Information Processing Systems , 2017, pp. 6000–6010. [18] M. Johnson, M. Schuster , Q. V . Le, M. Krikun, Y . Wu, Z. Chen, N. Thorat, F . V i ´ egas, M. W attenberg, G. Corrado et al. , “Google’ s multilingual neural machine translation system: enabling zero- shot translation, ” arXiv preprint , 2016. [19] D. Pov ey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and understanding , no. EPFL- CONF-192584. IEEE Signal Processing Society , 2011. [20] H. Sak, A. Senior , K. Rao, and F . Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recognition, ” arXiv pr eprint arXiv:1507.06947 , 2015. [21] A. Kannan, Y . W u, P . Nguyen, T . N. Sainath, Z. Chen, and R. Prabhavalkar , “ An analysis of incorporating an external lan- guage model into a sequence-to-sequence model, ” arXiv preprint arXiv:1712.01996 , 2017. [22] T . Hori, S. W atanabe, Y . Zhang, and W . Chan, “ Advances in joint ctc-attention based end-to-end speech recognition with a deep cnn encoder and rnn-lm, ” arXiv preprint , 2017. [23] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv preprint , 2014. [24] C. Szegedy , V . V anhoucke, S. Iof fe, J. Shlens, and Z. W ojna, “Re- thinking the inception architecture for computer vision, ” in Pr o- ceedings of the IEEE Conference on Computer V ision and P attern Recognition , 2016, pp. 2818–2826.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment