Adversarial Learning of Raw Speech Features for Domain Invariant Speech Recognition
Recent advances in neural network based acoustic modelling have shown significant improvements in automatic speech recognition (ASR) performance. In order for acoustic models to be able to handle large acoustic variability, large amounts of labeled d…
Authors: Aditay Tripathi, Aanchan Mohan, Saket An
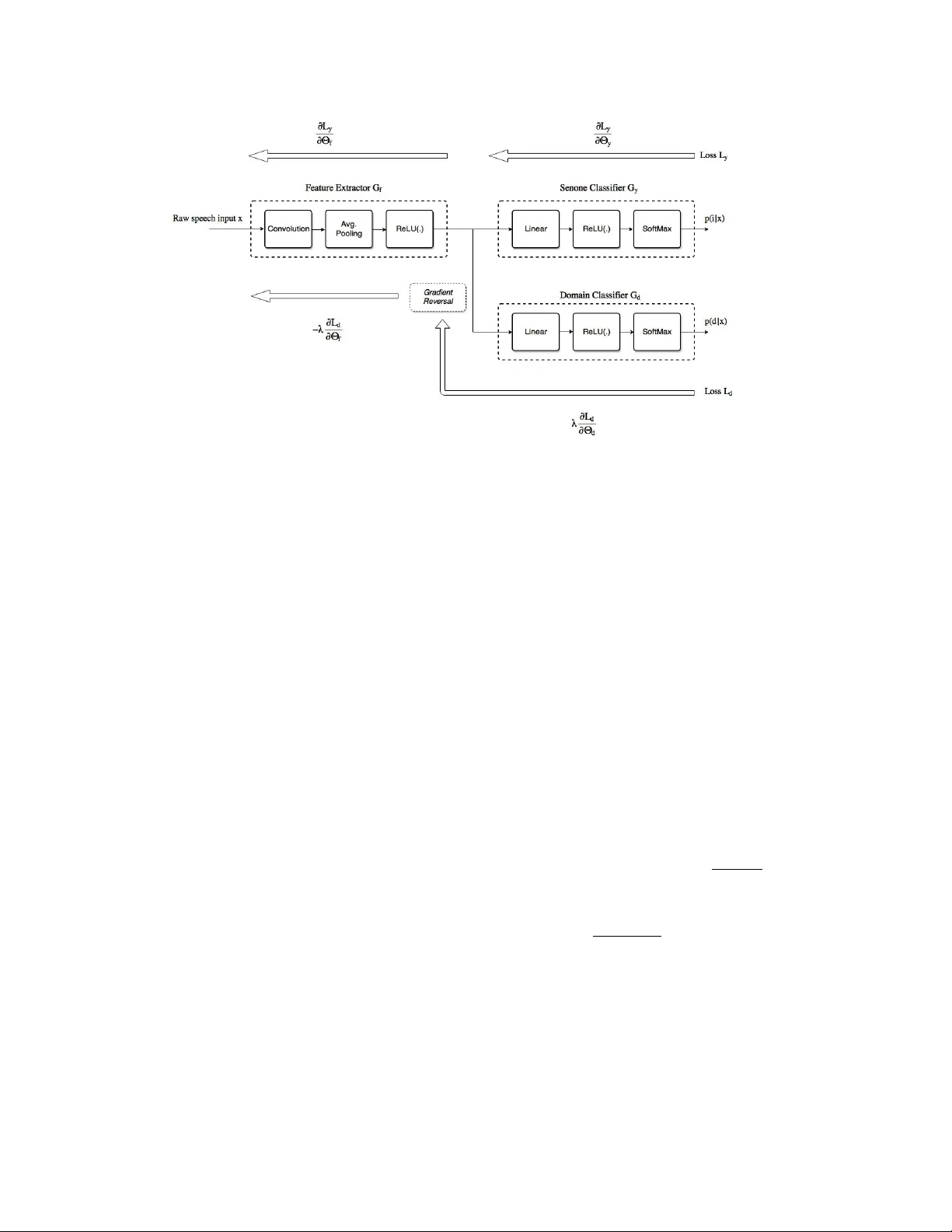
AD VERSARIAL LEARNING OF RA W SPEECH FEA TURES FOR DOMAIN INV ARIANT SPEECH RECOGNITION Aditay T ripathi ? ‡ Aanchan Mohan † Saket Anand ? Maneesh Singh ‡ ? Indraprastha Institute of Information T echnology , New Delhi, India. † Synaptitude Brain Health, V ancouver , Canada. ‡ V erisk Analytics, Jersey City , USA. ABSTRA CT Recent advances in neural network based acoustic modelling have shown significant improvements in automatic speech recognition (ASR) performance. In order for acoustic models to be able to handle large acoustic v ariability , large amounts of labeled data is necessary , which are often expensiv e to obtain. This paper ex- plores the application of adversarial training to learn features from raw speech that are inv ariant to acoustic variability . This acoustic variability is referred to as a domain shift in this paper . The ex- perimental study presented in this paper leverages the architecture of Domain Adversarial Neural Networks (D ANNs) [1] which uses data from two dif ferent domains. The DANN is a Y -shaped network that consists of a multi-layer CNN feature e xtractor module that is common to a label (senone) classifier and a so-called domain classifier . The utility of D ANNs is ev aluated on multiple datasets with domain shifts caused due to differences in gender and speaker accents. Promising empirical results indicate the strength of adver- sarial training for unsupervised domain adaptation in ASR, thereby emphasizing the ability of D ANNs to learn domain inv ariant features from raw speech. Index T erms — Unsupervised Domain Adaptation, Raw speech, ASR, Deep Learning, CNN 1. INTRODUCTION T raining neural network based acoustic models for Automatic Speech Recognition (ASR) gets challenging when limited amounts of supervised training data is av ailable. It is expensi ve to obtain labeled speech data that contains suf ficient v ariations of the different sources of acoustic variability such as speaker accent, speaker gen- der , speaking style, different types of background noise or the type of recording de vice [2]. T o mitigate the ef fects of acoustic variability that is inherent in the speech signal, domain adaptation techniques are often used in acoustic modelling. This paper in vestigates the use of Domain Adversarial Neural Networks (D ANNs) [1] for domain adaptation of the acoustic model from raw speech directly instead of relying on traditional log-mel features. Although MFCC or log- mel features are predominantly used in acoustic modeling, there has been significant recent interest to learn acoustic models using raw speech [3, 4, 5, 6]. For example, Sainath et.al. [7] sho wed that recognition performance on raw speech matches the performance on log-mel filters. Sev eral techniques hav e been proposed to mitigate the ef- fects of acoustic variability in the speech data at test time. Fea- ture space maximum lik elihood linear regression (fMLLR) [8], Maximum Likelihood Linear Regression [8], MAP [9], V ocal T ract Length Normalization (VL TN) [10] are well-known speaker adaptation techniques used in generativ e acoustic models. i- V ectors [11], LHUC [12] and KL-di vergence regularized DNN acoustic models[13] are the popular adaptation techniques used for discriminativ e acoustic models. All of these techniques require labeled data from the target domain to perform adaptation. The success of adversarial training using DANNs for unsuper- vised domain adaptation in computer vision [1] suggests promis- ing extensions to ASR applications as well. In a D ANN, domain adaptation is achieved by incorporating the additional task of do- main classification along with label classification. Both the domain- classifier and the label (senone) classifier share a common multi- layer CNN feature extraction module. The network is trained to minimize the cross-entropy loss of the label classifier and at the same time maximize that of the domain classifier . DANN has been used to learn domain-in variant feature representations, thus achie ving un- supervised domain adaptation for acoustic models trained on log- mel features [14, 15, 16]. V ariational Autoencoders (V AE) [17] hav e also been applied for unsupervised domain adaption. These techniques ha ve been studied for domain adaptation for discrimina- tiv e acoustic models trained on log filter-bank features. This paper presents an experimental study of unsupervised domain adaptation on discriminative acoustic models trained on raw speech by using D ANNs. Unsupervised domain adaptation is used to reduce acoustic variability due to (1) speaker gender and (2) speaker accent. T o study the impact of D ANN unsupervised domain adaptation on acoustic variability arising due to variations in speaker gender , experimental results are presented on the TIMIT data set. Furthermore, British and American accented data from the V oxforge corpus is used to study the impact of D ANN unsupervised domain adaptation on acoustic variability arising due to differing speaker accents. The experimen- tal study in this paper shows that domain inv ariant features can be learned directly from raw speech with significant improvement ov er the baseline acoustic models trained without domain adaptation. The remainder of the paper is organized as follows. Section 2 revie ws related work done in the area of domain-inv ariant feature learning using domain adversarial neural networks. Section 3 de- scribes the adversarial training for unsupervised domain adaptation for ASR trained on raw speech and Section 4 presents the experi- mental setup, description of input features and a description of the configuration of the acoustic model. Section 5 presents the exper - imental results obtained followed by a discussion in Section 6 and conclusion in Section 7. 2. RELA TION TO PRIOR WORK Domain adaptation using adversarial training was first introduced by Ganin et.al [1] for domain adaptation in computer vision. It has since been used for noise in variant feature learning in ASR using supervised labels and filter-bank features [14, 15]. Sun et.al. [16] used adversarial training for unsupervised domain adaptation for ro- bust speech recognition using filter bank features and used the WSJ and Librispeech speech corpora as data from different domains. All of these studies used filter-bank features to learn the domain in vari- ant features for ASR. In this study , domain inv ariant features are learned directly from raw speech to mitigate acoustic variabilities due to speaker gender and accent which often adversely affect ASR performance [18, 19]. 3. DOMAIN AD APT A TION USING RA W SPEECH FEA TURES This section explains unsupervised domain adaptation using adver- sarial training on raw speech features. Consider a classification prob- lem with the input feature v ector space X and Y = { 0 , 1 , 2 , ..., L − 1 } as the set of labels in the output space. Let S ( x, y ) and T ( x, y ) be unknown joint distributions defined ov er X × Y , referred to as the source and target distributions respectively . The unsupervised domain adaptation algorithm requires input as the labeled source do- main data , sampled from S ( x, y ) and unlabeled tar get domain data , sampled from the marginal distrib ution T ( x ) i.e. { ( x i , y i ) } n i =0 ∼ S ( x, y ); { ( x i ) } n + n 0 = N i = n +1 ∼ T ( x ) , where N = n + n 0 is the total number of input samples. As opposed to the class labels, which are assumed only for the source domain data, the binary domain labels ( d i = { 0 , 1 } ) are defined as d i = ( 0 for x i ∼ S ( x, y ) 1 for x i ∼ T ( x ) . (1) and are assumed to be known for each sample. The neural network architecture is as shown in Fig. 1 and comprises of three mod- ules: the feature extractor , label classifier and the domain classifier . The feature e xtractor is a multi-layer Con volutional Neural Network (CNN) that takes as input x i , while its output is a vailable to the label and domain classifiers, which predict the labels y i and d i respec- tiv ely . At training time, the label classifier’ s loss is only computed ov er labeled samples from S ( x, y ) , whereas the domain classifier’ s loss is computed ov er both, labeled samples from S ( x, y ) and unla- beled samples from T ( x ) . The feature extractor and the two classi- fier modules are described in detail in Sections 3.1 and 3.2. 3.1. Featur e Extractor The feature e xtractor, G f , sho wn in Fig. 1 is a multi-layer CNN and takes the raw speech input vector x i and generates a d -dimensional feature vector f i ∈ R d i.e., f i = G f ( x i ; Θ f ) , (2) where Θ f are the parameters of the feature extractor i.e. weights and biases of the con volutional layers. The input vector x i can be from the source distribution S ( x, y ) or the target distribution T ( x ) . The 1-d con volution operation in the con volutional layer in the network is defined as below f m,c, 1 i = σ ( m + k − 1 X j = m θ j − m,c, 1 f · x j i ) , (3) Eq. (3) gives feature vector output at index m from the first layer con volution operation on input feature v ector x i , θ c, 1 f denotes the k - dimensional vector of weights and biases of the first con volutional layer and c th con volutional filter . The function σ ( · ) is a non-linear activ ation function like the sigmoid or ReLU. 3.2. Label and Domain Classifiers The feature vector f i , which is extracted from G f , is mapped to class label y i = G y ( f i ; Θ y ) by the label classifier G y and to domain label d i = G d ( f i ; Θ d ) by a domain classifier G d as shown in Fig. 1. Both the label classifier as well as domain classifier are multi-layer feed-forward neural networks with parameters collecti vely denoted as Θ f and Θ d respectiv ely . The unsupervised domain adaptation is achieved by training the network to minimize the cross-entropy based label classification loss on the labeled source domain data and at the same time maximize the cross-entropy domain classification loss on the supervised source domain data and unsupervised target domain data. The classification losses is the cross-entropy costs. The total loss is giv en by E (Θ f , Θ y , Θ d ) = X i =1 ..N ,d i =0 L y ( G y ( G f ( x i ; Θ f ); Θ y ) , y i ) − λ X i =1 ..N L d ( G d ( G f ( x i ; Θ f ); Θ d ) , d i ) . (4) The parameter λ is a hyper-parameter that weighs the relativ e con- tribution of the two costs. T o simplify the abo ve equations, these are written in the compressed form as below E (Θ f , Θ y , Θ d ) = X i =1 ..N ,d i =0 L i y (Θ f , Θ y ) − λ X i =1 ..N L i d (Θ f , Θ d ) . (5) The label classifier tries to minimize the label classification loss L i y (Θ f , Θ y ) on the data from source distribution S ( x, y ) , therefore the parameters of both feature extractor (Θ f ) and label predictor (Θ y ) are optimized. This ensures that the features f i are discriminativ e enough to perform good prediction on samples from the source do- main. At the same time the extracted features should be inv ariant to the shift in domain. In order to obtain domain inv ariant features, the parameters of feature extractor Θ f are optimized to maximize the domain classification loss L y (Θ f , Θ d ) while at the same time domain classifier Θ d tries to classify the input features. In other words, the domain classifier of the trained network should not be able to correctly predict the domain labels of the features coming from the feature extractor . The desired parameters ˆ Θ f , ˆ Θ y , ˆ Θ d giv e the saddle point at the training and are estimated as: ( ˆ Θ f , ˆ Θ y ) = ar g min Θ f , Θ y E (Θ f , Θ y , ˆ Θ d ) (6) ˆ Θ d = ar g max Θ d E ( ˆ Θ f , ˆ Θ y , Θ d ) . (7) The model can be optimized by the standard stochastic gradient de- scent (SGD) based approaches. The parameter updates during the SGD becomes Θ f ← Θ f − µ n ∂ L i y ∂ Θ f − λ ∂ L i d ∂ Θ f o (8) Θ y ← Θ y − µ ∂ L i Y ∂ Θ y (9) Θ d ← Θ d − µ ∂ L i d ∂ Θ d . (10) where, µ is the learning rate. Eq. 8-10 can be implemented in some form of SGD by using a special Gradient Reversal Layer (GRL) at the end of feature extractor and at the be ginning of domain classifier as shown in fig. 1. During the backward propagation, GRL re verses Fig. 1 . The feature extractor extracts discriminati ve features directly from raw speech. It consists of sev eral stages of con volu- tion/pooling/ReLU. Senone classifier along with the feature extractor forms a standard architecture. Domain classifier is also connected to feature extractor through a gradient re versal. Reversal of gradient force the feature e xtractor to learn domain inv ariant features. the sign of gradients, multiply them with λ and pass it onto the sub- sequent layer , while in forward propagation GRL acts as an identity transform. At the test time, domain classifier and GRL are discarded. The data samples are passed through the feature extractor and label clas- sifier to get the predictions. 4. EXPERIMENT AL SETUP This section explains the setup used for domain adaptation experi- ments. Sec. 4.1 describes the dataset used for the experiments, sec. 4.2 details the input feature preparation and sec. 4.3 discusses the model architecture and training details. 4.1. Dataset Description TIMIT [20] and V oxforge [21] datasets are used to perform domain adaptation experiments. For TIMIT speech corpus domain adapta- tion is performed by taking male speech as source domain and fe- male speech corpus as target domain. For the V oxforge corpus do- main adaptation is performed by taking American accent and British accent as source domain and target domain respectively and vice- versa. For TIMIT speech corpus male and female speakers are sepa- rated into source domain and target domain datasets. TIMIT is a read speech corpus in which a speak er reads a prompt in front of the microphone. It consists of a total of 6300 sentences, 10 sentences spoken by each of the 630 speakers for 8 major dialect re gions of the United States of America. It consists a total of 3,696 training utter- ances sampled at 16kHz, excluding all SA utterances because they create a bias in the dataset. The training set consists of 438 male speakers and 192 female speakers. The core test set is used to report the results. It consists of 16 male speakers and 8 female speakers from all of the 8 dialect regions. For the V oxforge dataset American accent speech and British ac- cent speech are taken as two separate domains. V oxforge is a multi- accent speech dataset with 5 sec speech samples sampled at 16 KHz. Speech samples are recorded by users with their own microphones therefore quality varies significantly among samples. V oxforge cor- pus has 64 hrs of American accent speech and 13.5 hrs of British accent speech totaling to 83 hrs of speech. Results are reported on 400 utterances each for both the accents. Alignments are obtained by using HMM-GMM acoustic model trained using Kaldi [22]. 4.2. Input Featur es Raw speech features are obtained by using a rectangular window of size 10 ms on raw speech with a frame shift of 10 ms. A context of 31 frames is added to windowed speech features to get a total of 310 ms of context dependent raw speech features. These context dependent raw speech features are mean and v ariance normalized to obtain final features. 4.3. Model Description Feature extractor is a 2 layer con volutional neural network. The first con volutional layer has filter size of 64 with 256 feature maps along with the step size of 31. The second con volutional layer has filter size of 15 with 128 feature maps and step size of 1. After each con volutional layer a avg-pool layer is used with pooling size of 2 and a ReLU acti vation unit. Both the senone classifier and domain classifier are 4 layer and 6 layer fully connected neural networks with ReLU activation unit and hidden unit size of 1024 and 2048 for TIMIT and V oxforge respecti vely . The weights are initialized in Glorot [23] fashion. The model is trained with SGD with momentum [24]. Learning rate is selected during the training using formula µ p = µ 0 (1+ α ∗ p ) β , where p increases linearly from 0 to 1 as training progresses, µ 0 = 0 . 01 , α = 10 , and β = 0 . 75 . A momentum of 0 . 9 is also used. The adaptation param- eter λ is initialized at 0 and is gradually changed to 1 according to the formula λ p = 2 1+exp( − γ ∗ p ) − 1 , where γ is set to 10 as suggested in [1]. Domain labels are switched 10% of the times to stabilize the adversarial training. 5. RESUL TS This section presents the results of experiments performed to ev alu- ate the impact of adversarial training for unsupervised domain adap- tation. The experiments specifically study the acoustic v ariabilities like speaker gender and accent using TIMIT and V oxfor ge speech corpus respectively . Sec. 5.1 presents the domain adaptation exper - iments for speaker gender variability . Due to insufficient labeled fe- male speech data in TIMIT corpus domain adaptation, experiments Labeled source data Unlabeled target data T est data NN D ANN Male + Female Male 21.25 Male + Female Female 23.21 Male Female Male 24.63 25.37 Male Female Female 37.20 32.26 T able 1 . % PER for for acoustic model trained on supervised data from source domain and unsupervised data from tar get domain for TIMIT corpus taking male speech as source and female speech as target. are performed only for male speech as the source domain and fe- male speech as target domain. Sec. 5.2 discusses the experiments performed to mitigate speaker accent variability using American and British accent speech data in V oxfor ge. Experiments are performed by taking American accent as source domain and British accent as target domain and vice versa. Additional experiments are also per- formed by training the acoustic model on the labeled data from both the domains which work as the lower limit for the achiev able WER. In T able 1 and 2, DANN represents the domain adapted acoustic model using labeled data from the source domain and unlabeled data from the target domain and NN represents the acoustic model trained on the labeled data from the source domain only . W e also trained a fully connected DNN using MFCC features, with two layers for the feature extractor and three each for the senone and domain classi- fiers. Each fully connected layer comprised of 1024 nodes and the total number of parameters is similar to that of the model described in Sec. 4.3. 5.1. Domain adaptation for male and female speech domains in TIMIT corpus The first two rows in T able 1 list the PER results for the acoustic model trained on labeled data from both the domains with no do- main adaptation. This acoustic model gives the best results and is the lower limit for the PER. Rows 3 and 4 giv e the acoustic model trained on labeled data from the male speakers and adapted using unlabeled data from female speakers. Row 3 indicates the ef fect of domain adaptation on the performance on data from source domain which is male speech in this case. Ro w number 4 giv es the PER for the unadapted and adapted acoustic models for data from target domain which is female speech in this case. With male and female speech as source and target domains respectively , and using MFCC features as input, the PER dropped from 33.825% to 31.375% upon applying domain adaptation, indicating a higher absolute accuracy , but a poorer relati ve improv ement compared to raw speech. 5.2. Domain adaptation f or American and British accents do- mains in V oxforge corpus Rows 1 and 2 in T able 2 are the WER values for the acoustic model trained on labeled data from both the domains and without any do- main adaptation. These values correspond to lower limits for the WER for both the domains. Row number 3 and 4 represents the effect of domain adaptation on the performance of acoustic model on the data from source domain which is American and British re- spectiv ely . Rows number 5 and 6 gives the WER for target domain data on unadapted and adapted acoustic models. W ith American and British speech as source and tar get domains respectively , and using MFCC features, the WER dropped from 24.19% to 23.73% upon applying domain adaptation. These results indicate a poorer abso- lute accuracy as well as relative improv ement compared to the raw speech experiments reported in T able 2. Labeled source data Unlabeled target data T est data NN D ANN American + British American 10.87 American + British British 15.01 American British American 11.50 16.53 British American British 18.41 19.62 American. British Briti sh 28.11 23.10 British American American 23.37 23.16 T able 2 . % WER for acoustic models trained on supervised data from source domain and unsupervised data from tar get domain for V oxforge dataset taking American and British accents as two differ- ent acoustic domains. 6. DISCUSSION As can be seen from rows 3 and 4 of T able 1, the acoustic variabil- ity due to speaker gender results in a 12.57 % absolute increase in PER when the acoustic model (NN) trained on male speech (source domain) is tested on female speech (target domain). The effect of applying D ANN impro ves the absolute PER performance on the tar- get domain by nearly 5%. Similarly , domain shifts due to speaker accent cause the target domain performance deteriorate significantly . T able 2 reports an absolute de gradation of 16.61% when the acoustic model is trained on American speech (source domain) and tested on British speech (target domain). Upon applying D ANN using the un- labeled British speech, the absolute WER drops by nearly 5%. Gen- eral trends that appear from our experimental analysis point out that models undergoing adversarial training based unsupervised domain adaptation, impro ve in performance on the tar get domain data as op- posed to their unadapted counterparts. This improv ement howev er, comes at a cost of drop in source domain accuracy . This observa- tion is not unexpected as the feature extractor module perhaps learns to ignore some domain-specific features in the pursuit of learning in variant representations. 7. CONCLUSION The paper proposes unsupervised domain in v ariant features learning directly from raw speech using domain adversarial neural networks. The senone classification model is modified for domain adaptation by using an additional domain classifier and modifying the loss such that the network learns features from raw speech that are suf ficiently discriminativ e for the senone classifier and inv ariant enough to fool the domain classifier . This experimental study also shows that there is a significant acoustic variability present in the speech signal due to speaker gender and accent which adversely af fects the performance of models trained in a domain agnostic setting. The performance loss due to this v ariability can be alleviated by adversarial training based domain adaptation using unlabeled target domain data. Moreover , the analysis suggests that raw speech features along with a con volu- tional neural network based feature extractor may be more amenable to an advesarial approach to domain adaptation as opposed to hand- crafted features like MFCC, particularly when large amounts of data is available. The evaluation of the proposed approach is done using two benchmarking datasets: TIMIT for gender based domain shift and V oxforge corpus for using American and British accents for the domain shift. 8. A CKNO WLEDGMENT While the first author was at IIIT -Delhi, this work was partially sup- ported by the Infosys Center for Artificial Intelligence, IIIT -Delhi. 9. REFERENCES [1] Y aroslav Ganin, Evgeniya Ustino va, Hana Ajakan, P ascal Ger- main, Hugo Larochelle, Franc ¸ ois Laviolette, Mario Marchand, and V ictor Lempitsky , “Domain-adversarial training of neural networks, ” Journal of Machine Learning Research , vol. 17, no. 59, pp. 1–35, 2016. [2] Mohamed Benzeghiba, Renato De Mori, Olivier Deroo, Stephane Dupont, T eodora Erbes, Denis Jouvet, Luciano Fis- sore, Pietro Laface, Alfred Mertins, Christophe Ris, et al., “ Au- tomatic speech recognition and speech variability: A revie w , ” Speech communication , vol. 49, no. 10, pp. 763–786, 2007. [3] Dimitri Palaz, Ronan Collobert, et al., “ Analysis of CNN-based speech recognition system using raw speech as input, ” T ech. Rep., Idiap, 2015. [4] Dimitri Palaz, Mathew Magimai Doss, and Ronan Col- lobert, “Con volutional neural netw orks-based continuous speech recognition using raw speech signal, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE Interna- tional Confer ence on . IEEE, 2015, pp. 4295–4299. [5] Dimitri Palaz, Ronan Collobert, and Mathew Magimai-Doss, “Estimating phoneme class conditional probabilities from raw speech signal using conv olutional neural networks., ” in INTERSPEECH , Frdric Bimbot, Christophe Cerisara, Ccile Fougeron, Guillaume Gravier , Lori Lamel, Franois Pellegrino, and Pascal Perrier , Eds. 2013, pp. 1766–1770, ISCA. [6] Pegah Ghahremani, V imal Manohar, Daniel Pov ey , and San- jeev Khudanpur , “ Acoustic modelling from the signal domain using CNNs., ” in INTERSPEECH , 2016, pp. 3434–3438. [7] T ara N Sainath, Ron J W eiss, Andre w Senior , Ke vin W W ilson, and Oriol V inyals, “Learning the speech front-end with raw wa veform CLDNNs, ” in Sixteenth Annual Conference of the International Speech Communication Association , 2015. [8] Mark Gales and Steve Y oung, “The application of hidden Markov models in speech recognition, ” F oundations and tr ends in signal pr ocessing , vol. 1, no. 3, pp. 195–304, 2008. [9] Y oo Rhee Oh and Hong K ook Kim, “MLLR/MAP adapta- tion using pronunciation variation for non-native speech recog- nition, ” in Automatic Speech Recognition & Understanding, 2009. ASRU 2009. IEEE W orkshop on . IEEE, 2009, pp. 216– 221. [10] Puming Zhan and Alex W aibel, “V ocal tract length normal- ization for large vocab ulary continuous speech recognition, ” T ech. Rep., Carnegie-Mellon Univ Pittsburgh P A School Of Computer Science, 1997. [11] V ishwa Gupta, Patrick Kenn y , Pierre Ouellet, and Themos Stafylakis, “I-vector-based speaker adaptation of deep neural networks for french broadcast audio transcription, ” in Acous- tics, Speech and Signal Pr ocessing (ICASSP), 2014 IEEE In- ternational Confer ence on . IEEE, 2014, pp. 6334–6338. [12] Pawel Swietojanski and Stev e Renals, “Learning hidden unit contributions for unsupervised speaker adaptation of neural network acoustic models, ” in Spoken Language T echnology W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 171–176. [13] Dong Y u, Kaisheng Y ao, Hang Su, Gang Li, and Frank Seide, “KL-div ergence regularized deep neural network adaptation for improv ed large vocabulary speech recognition, ” in Acous- tics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE In- ternational Confer ence on . IEEE, 2013, pp. 7893–7897. [14] Y usuke Shinohara, “ Adversarial Multi-Task learning of deep neural networks for robust speech recognition., ” in INTER- SPEECH , 2016, pp. 2369–2372. [15] Dmitriy Serdyuk, Kartik Audhkhasi, Phil ´ emon Brakel, Bhu- vana Ramabhadran, Samuel Thomas, and Y oshua Bengio, “In- variant representations for noisy speech recognition, ” arXiv pr eprint arXiv:1612.01928 , 2016. [16] Sining Sun, Binbin Zhang, Lei Xie, and Y anning Zhang, “ An unsupervised deep domain adaptation approach for robust speech recognition, ” Neur ocomputing , 2017. [17] W ei-Ning Hsu, Y u Zhang, and James Glass, “Unsupervised domain adaptation for robust speech recognition via varia- tional autoencoder-based data augmentation, ” arXiv preprint arXiv:1707.06265 , 2017. [18] Chao Huang, T ao Chen, and Eric Chang, “ Accent issues in large v ocabulary continuous speech recognition, ” International Journal of Speech T echnology , vol. 7, no. 2, pp. 141–153, 2004. [19] Rachael T atman and Conner Kasten, “Effects of Talker Dialect, Gender & Race on Accuracy of Bing Speech and YouTube Automatic Captions, ” Pr oc. Interspeec h 2017 , pp. 934–938, 2017. [20] John S Garofolo, Lori F Lamel, William M Fisher , Jonathon G Fiscus, and David S Pallett, “DARPA TIMIT acoustic- phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1, ” NASA STI/Recon technical report n , vol. 93, 1993. [21] Ken MacLean, “V oxforge, ” K en MacLean.[Online]. A vailable: http://www . voxforge . org/home .[Acedido em 2012] . [22] Daniel Pov ey , Arnab Ghoshal, Gilles Boulianne, Lukas Bur- get, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, et al., “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on ASRU . IEEE Signal Processing Society , 2011, number EPFL-CONF- 192584. [23] Xavier Glorot and Y oshua Bengio, “Understanding the dif fi- culty of training deep feedforward neural networks., ” in Ais- tats , 2010, vol. 9, pp. 249–256. [24] Ilya Sutskev er, James Martens, George Dahl, and Geoffrey Hinton, “On the importance of initialization and momentum in deep learning, ” in International confer ence on machine learn- ing , 2013, pp. 1139–1147.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment