Computing Information Quantity as Similarity Measure for Music Classification Task
This paper proposes a novel method that can replace compression-based dissimilarity measure (CDM) in composer estimation task. The main features of the proposed method are clarity and scalability. First, since the proposed method is formalized by the…
Authors: Ayaka Takamoto, Mitsuo Yoshida, Kyoji Umemura
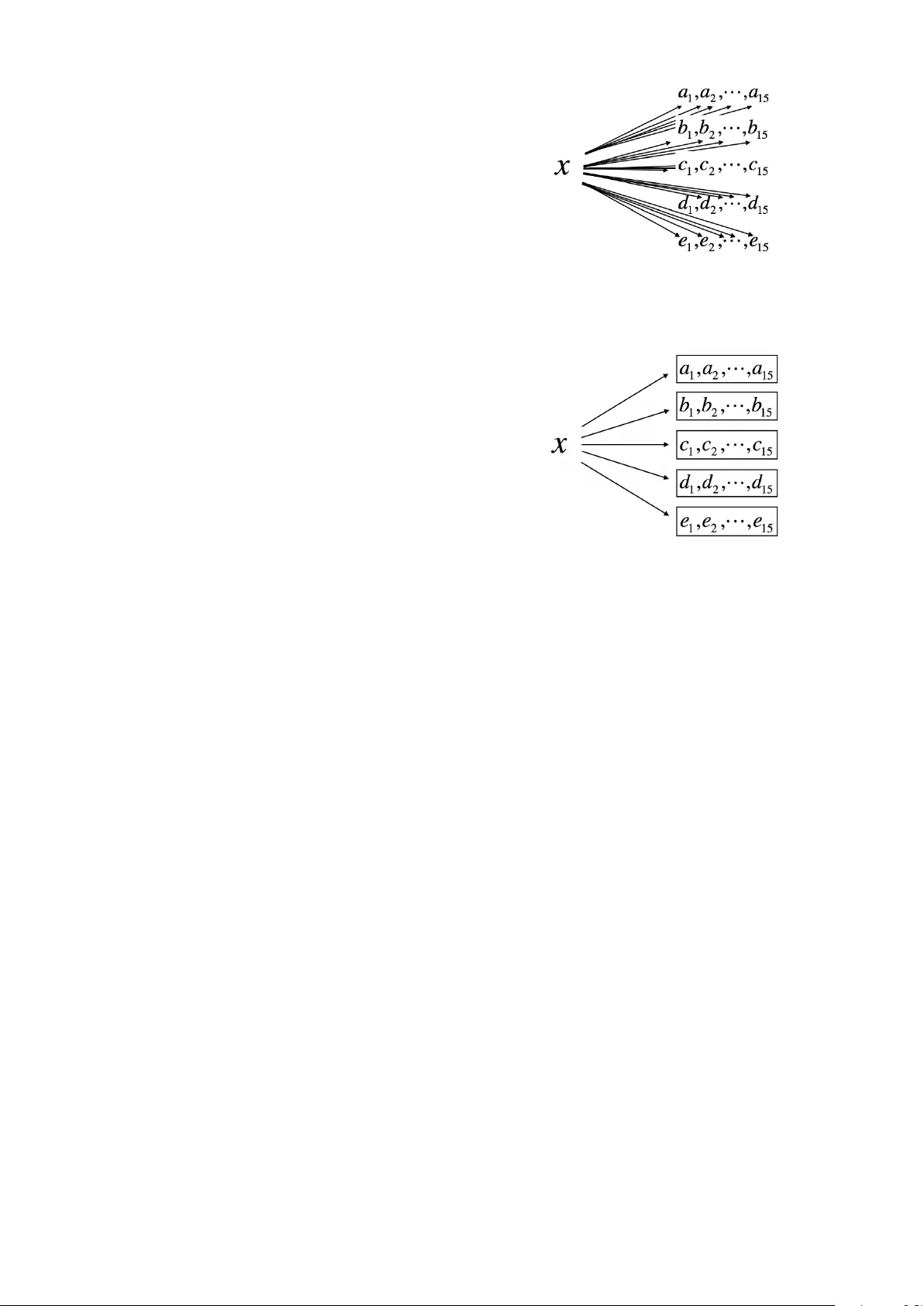
Computing Information Quantity as Similarity Measure for Music Classification T ask A yaka T akamoto, Mitsuo Y oshida, and K yoji Umemura Department of Computer Science and Engineering T oyohashi Univ ersity of T echnology T oyohashi, Aichi, Japan a153350@edu.tut.ac.jp, yoshida@cs.tut.ac.jp, umemura@tut.jp Y uk o Ichikaw a General Education Department, National Institute of T echnology , T okyo College Hachioji, T okyo, Japan yuko@tokyo-ct.ac.jp Abstract —This paper proposes a nov el method that can replace compression-based dissimilarity measure (CDM) in composer estimation task. The main features of the proposed method are clarity and scalability . First, since the proposed method is formalized by the information quantity , repr oduction of the result is easier compared with the CDM method, where the result depends on a particular compression program. Second, the proposed method has a lower computational complexity in terms of the number of learning data compared with the CDM method. The number of correct results was compared with that of the CDM for the composer estimation task of five composers of 75 piano musical scores. The proposed method performed better than the CDM method that uses the file size compressed by a particular program. Keyw ords —Music Component; Information Quantity; Classi- fication T ask I . I N T RO D U C T I O N When people listen to music, they can determine many features, such as genre and composer . The genre of music is easy to determine without previous knowledge, but not the composer , e ven if you hav e some knowledge. The difficulty depends on what should be estimated. There are some existing studies for such estimation, which are based on machine learning [1], [2]. The contribution of [2] implies that the feature that reflects the composer is short note sequence. Since the compres- sion program is a kind of program which captures frequent sequences of data, it may not be suprising if we use a compression program to estimate composer . Actually , there is an interesting research [3] that uses compression programs for composer estimation. They use the formular called NCD (Normalized Compression Distance). W e focus on a simi- lar but dif ferent similarity measure called compression-based dissimilarity measure (CDM) [4], which is tested in a wide range of data, not limited to music. Both CDM and NCD are based on the same plinciple. These principle are recently well presented in [5]. Although a compression program is easy to use, the result depends on the compression program and the behavior is difficult to analyze. Moreov er , since the compression is carried out with ev ery known musical score, there is a concern that the amount of calculation becomes enormous when we determine the degree of similarity for a new musical score. In this study , we propose a novel method that is well formalized. The proposed method realized the scalability of a large number of learning data by pre-processing the group of learning data. Finally , the precision of the proposed method was verified to be better than the method where the value of the CDM is determined by the compressed file size. I I . B A S E L I N E M E T H O D In this section, we will describe baseline CDM method [6] for estimating the composers. This work focuses on the improv ement of CDM. They conducted experiments on a very simple system with CDM, but it still performs well for composer estimation task, in order to make the analysis of improvments possible. W e have followed this work because we are also interesting in CDM, although we are aiming at replacing CDM with the proposed method, rather than simply improving the CDM. In baseline method, the musical scores are first con verted into string representation, where information for sound ’on’ or ’off ’ is expressed. The string representation is a long sequence of character ’0’ for ’of f ’ and character ’1’ for ’on’. The position of each character corresponds to a piano key number k ey and timing number time , where position = 88 × time + key . The number 88 is the number of keys on a piano. Second, it uses the CDM proposed by Keogh [4] for a pair of musical scores. The CDM is defined as follows: CDM( x, y ) = C ( xy ) C ( x ) + C ( y ) (1) where C ( x ) is the compressed file size of string x , and C ( xy ) is the compressed file size of the concatenation of x and y . The v alue of the CDM sho ws the dissimilarity between the two strings. The more the patterns shared by the two strings, the smaller the CDM value of the two strings. It is based on the principle that the string has more similar patterns, such as repetitions, if the compressed file size of its concatenated string is smaller based on the assumption that if specific phrases of the composer exist, then he/she used them in other 978-1-5386-3001-3/17/$31.00 c 2017 IEEE musical scores. The estimation of the composer is based on this concept. This method is based on the study in [6]. It is interesting that the CDM, which is a simple function of a compressed file size, can estimate the composer of musical scores. Howe ver , there is an issue of scalability in the CDM. Fig. 1 illustrates this issue, where x is the string representation of a musical score of unknown composer, and a 1 to a 15 are musical scores of a composer A . The CDM is defined as a measure between two musical scores. In a previous study of composer estimation, an unkno wn musical score was compared with all the known musical scores, then the k - nearest neighbor method ( k -NN) was applied [7] to the result. In general, when an application uses the relationship between two scores, an unknown musical score need to be compared with all the kno wn musical scores. The larger is the number of known scores, the more are the computation time required for one new musical score. This method cannot be scaled up to a large number of known musical scores. The study in [6] also argues that the compressed file size of string x is the approximation of the information quantity . The study in [6] also proposes to use offsetted compressed file size, where the value of the offset is obtained by observing the behavior of a specific compression program. This method was reported to improv e the number of correct estimation significantly . Howe ver , the problems of dependency on the compression program and scalability remained the same with the CDM method. I I I . P RO P O S E D M E T H O D In this study , we formed a group of musical scores of the same composer to address the scalability issue. Then, we computed the information quantity based on the probability of substrings of a large string. This lar ge string corresponds to the group. Fig. 2 shows how the groups were used. As is in Fig. 1, in Fig. 2, x is the string representation of a musical score of unknown composer , and a 1 to a 15 are musical scores of a composer A . The box sho ws that these scores form a group, and there is one long string representation for one group. The information quantity is then computed using the probability in a 1 , a 2 , ..., a 15 , and not the probability in x . Then, we computed the information quantity of an unkno wn musical score using the method described in the next session. The same process was carried out for the musical scores of the other four composers. W e computed the information quantity of the unknown musical score x with the group of each composer . W e obtained fiv e information quantities and determined that the composer of x is the one whose string had the least information quantity . Using the pre-processing, the computation time of infor- mation quantity of one music score does not depend on the number of music score in a group. It only depends on the length of music score to judge. Therefore, the number of computations for one unknown musical score is proportional to the number of composers, rather than the number of known musical scores. Fig. 1. Baseline system and other compression based approaches. When a method uses the relationship between two scores, an unknown musical score need to be compared with all the known musical scores. Fig. 2. Proposed system or scalable method. By pre-prosessing through all music score in a group. computation time of one music scores not depend the number of scores in group. I V . I N F O R M AT I O N Q U A N TI T Y In general, we calculate the information quantity of a string from the probabilities of characters in the string. Howe ver , we can make a good guess that specified substrings, such as words emerge repeatedly in the real strings. Therefore, in this study the calculation of the information quantity of a string was performed using the emergent probabilities of all substrings. First, we consider the information quantity of one character . In general, the information quantity of a certain ev ent depends on the occurring probability . Let the emergent probability of a certain character c be P ( c ) , then the information quantity of c is expressed using self-information [8] as follows: I c ( c ) = − log 2 P ( c ) (2) Let us consider the information quantity for the case where we treat the character sequence as a string. Let the i -th character of a string S with length N be c i . The character c i in S is independent of each other . The information quantity I c ( S ) of S based on the characters is expressed as (3). The expression in (3) indicates that the string information quantity is equal to the total sum of the information quantity of the characters. I c ( S ) = − log 2 ( N Y i =1 P ( c i )) = − N X i =1 log 2 P ( c i ) (3) For the case of the string representation of a musical score, specified substrings, such as motif may emerge repeatedly . Thus, if we assume that a string consists of some subse- quences, then the information quantity I s is expressed as (4). I s ( S ) = min π k ∈ π ( S ) − X t ∈ π k log 2 P ( t ) (4) where π ( S ) is the set of all possible w ays to di vide S , which includes 2 N − 1 ways, and t is a member of divided strings (a substring). More precisely , we divide the strings into finer substrings and calculate the information quantity as the sum of the information quantities of the new divided substrings. The information quantity varies depending on the partition. W e should take the minimum quantity because the more are the substrings considered, the less becomes the information quantity of the string. The number of partitions is 2 N − 1 , where N is the length of the string. Although this is a large number , the minimum value is easily obtained in O ( N 2 ) , when a dynamic programming is used. T o implement a program that obtains I s ( S ) , we require a module to compute P ( t ) , where t can be all substrings of the giv en large string. An efficient data structure, called suffix array , can be used to obtain the frequency of any substring [9]. Using this data structure, whose size is proportional to size of the large string, we can obtain the frequency of a substring t in the large string efficiently . W e used suffix array in the program implemented in this study . There is also a more efficient data structure called suffix tree [10]. Furthermore, there is a good algorithm that can construct suffix tree in O ( N ) time complexities, and O (1) time comple xities to obtain the frequency of a substring using the suffix tree. Maximum Likelihood Estimator (MLE) is usually used to estimate the probability from the frequency . W e use MLE but we use f r equency − 1 rather than f r equency in order to make the computed value stable. V . C O M P U TA T I O N A L C O M P L E X I T Y Let us examine by how much the computational complexity is reduced by the proposed method compared with the existing method. Let l be the average length of a string representation of a musical score. Let c be the number of composers. Let g be the average number of musical scores in one group. Let n be the number of unknown musical scores. First, the computational comple xity to compress a string representation of musical score is proportional to the length of the string. Thus: T compression = O ( l ) (5) T o estimate the composer of one musical score using CDM, we need to compute g × c compression: T C DM − O N E = O ( l × g × c )) (6) When there are many musical scores, we need to repeat the abov e operation for each n musical scores. T C DM = O ( n × l × g × c ) (7) T o compute one information quantity in Fig. 2, we need to compute two things: the pre-processing of the groups and to obtain the minimum of the considered partition. T inf ormation − q uantity = O ( g × l + l 2 ) (8) T o estimate the composer of one musical score using the proposed method, we need to compute the information quantity c times. T P roposed − O N E = O ( c × g × l + c × l 2 ) (9) When there are many musical scores, we only require one pre-processing operation. This is the reason why the proposed method is scalable. T P roposed = O ( c × g × l + n × c × l 2 ) (10) Both the complexity of T C DM and the T P roposed are pro- portional to c . There is no difference with respect to c . When n is large, the computational complexity of the proposed method is independent of g , while that of the CDM is multiplied by g . This means that when the number of musical scores for each composer increases, the computational complexity of the proposed method becomes smaller than CDM method. The proposed method has a complexity that is proportional to the square of the length of the unknown musical score, while that of the CDM method is proportional to the length. This is because the proposed method considers all substrings, while the compression program only considers some subsets of the substrings. As a result, the proposed method requires a large value of g when the l is large. V I . E V A L UAT I O N For the e valuation, the result can be much better than it should be if we include the same musical score as x in some of the kno wn musical scores. Therefore, we hav e to change our setting from Fig. 2 into Fig. 3 to measure the correctness of the methods. The musical score in question should be intentionally excluded from the set of kno wn musical scores. In the CDM method, the CDM between the same musical scores was not computed using the one-leave-out method. Fig. 3 corresponds Fig. 3. For the ev aluation, the result can be much better than it should be if we include the same musical score in some of the known musical scores. Therefore, the musical score in question should be intentionally excluded from the set of known musical scores for ev aluation. This corresponds to one-leav e-out method. T ABLE I S U MM A RY System Proposed CDM Offseted CDM Bach 9 10 11 Chopin 9 5 6 Group Debussy 14 11 12 Mozart 13 7 11 Satie 10 8 8 T otal 55 41 48 to this approach. In doing so, we need to pre-process many times, and this is only for the ev aluation, and not the actual estimation. In Fig. 3, A, B, C, D, and E indicate the composers and a 1 , · · · , a 15 denote the musical scores of composer A. When we need to estimate the composer of a 1 , we remove a 1 from the group of composer A, and create a new group data of the remaining musical scores. Then, we calculate the information quantities of a 1 with each of the fiv e grouping data. W e estimate that the composer of a 1 is the one whose string attains the least information quantity . Then, we determine the estimation from the information that the composer of a 1 is A. This information is used only for determining the correctness of the estimation. A summary of the total correct results is presented in T A- BLE I. In the estimations of 75 musical scores, the proposed method yielded 55 correct results. Since the task was to select one composer out of five composers, a random choice can achiev e 20% correct answers. Our method achiev ed more than 70% correct answers. This suggests that the proposed method can estimate the composer . Unlike the CDM, the proposed method is formalized as the estimation of information quantity , and is not dependent on a particular compression program. Therefore, reproduction of the result should be much easier than the CDM. As presented in T ABLE I, the proposed method yielded more correct results than previous methods. W e performed the McNemar’ s test of the proposed method with the original CDM and with of fsetted CDM [6]. As presented in table T ABLE II, the proposed method performed better than the CDM with a significance of α < 0 . 01 , although we could not T ABLE II M C N E M A R ’ S T E ST B E TW E E N P RO P O S ED M E TH O D A N D CD M W IT H O U T O FF SE T CDM Correct result Incorrect result T otal Proposed Correct result 38 17 55 Incorrect result 3 17 20 T otal 41 34 75 T ABLE III M C N E M A R ’ S T E ST B E TW E E N P RO P O S ED M E TH O D A N D CD M W IT H O FF SE T Offseted CDM Correct result Incorrect result T otal Proposed Correct result 43 12 55 Incorrect result 5 15 20 T otal 48 27 75 achiev e the statistical significance in T ABLE III. Since of fsetted CDM [6] aimed to obtain a more precise value of the information quantity rather than the compression, the behavior of the proposed method would be similar to offsetted CDM [6]. Howe ver , it can be seen that the proposed method is independent of the implementation of a particular compression program, while [6] depends on a compression program, bzip2. T ABLE IV to T ABLE VIII present the detailed results of applying the proposed method to 15 pieces for each fiv e composer: Bach, Chopin, Debussy , Mozart, and Satie. Each column below the label “Music”, contains the identifier starting with its composer and ending with the identification number . The column of the name of each composer contains information quantities using the group. The value is truncated to the nearest integer . The case where the information quantity of a gi ven score is the least, it is underlined. The corresponding composer of the underlined value is the estimation using the proposed method. The column “Result” indicates whether the estimation is correct or not, where “1” is correct, and “0” is incorrect. The column “CDM” is the result of using the baseline method, which follows the technique in [4], where C ( x ) is the file size of the compressed file using bzip2. The column “offset” is the result from a previous study [6], where C ( x ) is the offsetted size of the compressed file. V I I . D I S C U S S I O N Sometimes, the methods of smaller computational com- plexities may be slower in actual number of data when the data is not big enough. Currentlly , this is the case of the proposed method. Since the current group consists of 15 musical scores, the proposed method was slower than the CDM method in the current condition. There are several reasons for this inefficiency . The most important reason is that the proposed method requires a computation time that is proportional to the square of the length of the string, while the CDM (or compression program) requires a computational time that is proportional to the length. Furthermore, the string representation usually consists of more than 10000 characters. This length could be the reason for the inefficienc y . W e may improve the computation time by limiting the set of substring that is used to compute the information quantity and concentrate computation resources to the string that should be effecti ve. With respect to the ef ficiency of the compression program, the compression program may not consider all the strings. Thus, we need a heuristic technique that may be common to the compression program. There may be other viewpoints in terms of the contributions of this work. The application of the CDM is not limited to this task, but also applies to various types of tasks. W e may search an appropriate task where there are many samples in a class and the length of data to consider is small. There is a method to calculate information quantity for estimation similarities called normalized compression distance (NCD) [11]. Some studies ha ve applied this method in the field of biological information [12] and in the field of musical information [13], [14]. The order of computational complexity with this method is the same as in the CDM. It seems useful to select data patterns or subsequences that emer ged repeatedly from known data and improv e the compression program so that the information quantity of an unknown data is calculated with the selected data. Ho wev er , some compression programs hav e a limit in the number of words registered in their dictionary . Since our proposed method considers all the substrings of the giv en string, the method does not suffer this limitation, and we may state that it uses a larger dictionary compared with any other method. V I I I . C O N C L U S I O N W e proposed a no vel method that can replace the CDM method for the composer estimation task. The main feature of the proposed method is the pre-processing of the grouped data of each composer . W e showed that the computational complexity in terms of the number of known musical scores was smaller than in the CDM. This means that the proposed method is scalable. W e also verified that the number of correct estimations obtained was 55 out of 75 estimations. This result is better than the estimation result of the CDM method. Moreov er , the computational complexity to determine a new score was smaller than the CDM method. Based on the number of correct results and the order of computational complexity , we can conclude that computing the information quantity with grouping is effecti ve. R E F E R E N C E S [1] R. B. Dannenberg, B. Thom, and D. W atson, “ A machine learning approach to musical style recognition, ” in Pr oceedings of International Computer Music Conference , 1997, pp. 344–347. [2] T . Sawada and K. Satoh, “Composer classification based on patterns of short note sequences, ” in Pr oceedings of the AAAI-2000 W orkshop on AI and Music , 2000, pp. 24 – 27. [3] Y . Anan, K. Hatano, H. Bannai, M. T akeda, and K. Satoh, “Polyphonic music classification on symbolic data using dissimilarity functions. ” in ISMIR , 2012, pp. 229–234. T ABLE IV R E SU LT S O F B AC H ’ S M U SI C A L S C O RE S Music Bach Chopin Debussy Mozart Satie Result CDM Of fset Bach01 27451 24371 23512 25252 23938 0 0 0 Bach02 7444 6819 7004 6352 7574 0 0 0 Bach03 22101 18742 18379 19855 17964 0 0 0 Bach04 2711 3376 3509 2846 3464 1 1 1 Bach05 3093 3847 3827 3515 3908 1 1 1 Bach06 3128 3149 3491 2827 3420 0 0 1 Bach07 4796 6301 6487 5875 6740 1 1 1 Bach08 5278 5756 6017 5585 6018 1 1 1 Bach09 4068 4159 4239 4174 4468 1 1 1 Bach10 5817 6051 5717 5622 5977 0 0 0 Bach11 3411 4115 4171 3941 4380 1 1 1 Bach12 2847 3383 3444 3079 3592 1 1 1 Bach13 2577 3020 3163 2874 3221 1 1 1 Bach14 4736 5039 5185 4767 5173 1 1 1 Bach15 2943 3065 3170 2910 3197 0 1 1 T otal 9 10 11 [4] E. Keogh, S. Lonardi, and C. A. Ratanamahatana, “T o wards parameter- free data mining, ” in Proceedings of the T enth A CM SIGKDD Interna- tional Conference on Knowledge Discovery and Data Mining , ser. KDD ’04. New Y ork, NY , USA: A CM, 2004, pp. 206–215. [5] C. Louboutin and D. Meredith, “Using general-purpose compression algorithms for music analysis, ” Journal of New Music Research , 2016. [6] A. T akamoto, M. Umemura, M. Y oshida, and K. Umemura, “Impro ving compression based dissimilarity measure for music score analysis, ” in Pr oceedings of 2016 International Confer ence On Advanced Informat- ics: Concepts, Theory And Application (ICAICT A) , Aug 2016, pp. 1–5. [7] C. D. Manning, H. Sch ¨ utze et al. , F oundations of statistical natural language pr ocessing . MIT Press, 1999, vol. 999, pp. 604–606. [8] ——, F oundations of statistical natural language pr ocessing . MIT Press, 1999, vol. 999, pp. 61–63. [9] U. Manber and G. Myers, “Suf fix arrays: A new method for on-line string searches, ” SIAM Journal on Computing , vol. 22, no. 5, pp. 935– 948, 1993. [10] M. Crochemore and W . Rytter, Je wels of stringology: text algorithms . W orld Scientific, 2003, pp. 91–95. [11] R. Cilibrasi and P . M. B. V itanyi, “Clustering by compression, ” IEEE T ransactions on Information Theory , vol. 51, no. 4, pp. 1523–1545, April 2005. [12] M. Li, X. Chen, X. Li, B. Ma, and P . V it ´ anyi, “The similarity metric, ” in Proceedings of the F ourteenth Annual ACM-SIAM Symposium on Discr ete Algorithms , ser . SODA ’03. Philadelphia, P A, USA: Society for Industrial and Applied Mathematics, 2003, pp. 863–872. [13] R. Cilibrasi, P . V it ´ anyi, and R. De W olf, “ Algorithmic clustering of music based on string compression, ” Computer Music Journal , vol. 28, no. 4, pp. 49–67, 2004. [14] T . E. Ahonen, K. Lemstr ¨ om, and S. Linkola, “Compression-based similarity measures in symbolic, polyphonic music. ” in Pr oceesings of ISMIR2011 , 2011, pp. 91–96. T ABLE V R E SU LT S O F C H O P IN ’ S M U S I CA L S CO R E S Music Bach Chopin Debussy Mozart Satie Result CDM Offset Chopin01 19541 17771 17584 17969 18231 0 0 0 Chopin02 15815 15421 14967 14930 15409 0 0 0 Chopin03 9114 8287 8533 8891 8541 1 0 0 Chopin04 21942 21665 21541 23272 21159 0 0 1 Chopin05 9863 8631 9470 9094 9058 1 1 1 Chopin06 13492 13032 13408 13096 13624 1 0 0 Chopin07 65530 54654 58969 59320 58647 1 1 1 Chopin08 68263 61142 59976 67106 60229 0 0 0 Chopin09 14961 9395 13513 12461 12704 1 1 1 Chopin10 19985 13767 17612 17426 17165 1 1 1 Chopin11 20405 17357 19401 18954 17931 1 0 0 Chopin12 24312 20111 21933 22378 20811 1 0 1 Chopin13 18227 15593 15819 16123 15566 0 0 0 Chopin14 27187 23606 23634 23253 24323 0 0 0 Chopin15 10584 9210 9584 9619 9430 1 1 0 T otal 9 5 6 T ABLE VI R E SU LT S O F D E B US S Y ’ S M U S IC A L S C O R ES Music Bach Chopin Debussy Mozart Satie Result CDM Offset Debussy01 9354 7794 7112 9766 7236 1 1 1 Debussy02 26680 23481 22086 24583 24005 1 1 1 Debussy03 18945 17512 16432 18015 17533 1 1 1 Debussy04 8063 7009 6685 7759 6732 1 1 1 Debussy05 61477 58790 51872 68706 55066 1 0 0 Debussy06 10747 10289 8930 10398 9358 1 1 1 Debussy07 6248 5567 4876 5177 4946 1 0 1 Debussy08 37096 33933 30807 36659 34117 1 1 1 Debussy09 27645 25809 22510 28316 24011 1 1 1 Debussy10 24904 22108 20628 23234 21491 1 1 1 Debussy11 19554 18317 17215 19764 17722 1 1 1 Debussy12 26298 23519 20882 26313 23024 1 1 1 Debussy13 14808 14524 13286 13942 14126 1 1 1 Debussy14 12767 11919 10769 11536 11327 1 0 0 Debussy15 11136 11259 10988 10904 11387 0 0 0 T otal 14 11 12 T ABLE VII R E SU LT S O F M O Z A RT ’ S M US I C A L S C OR E S Music Bach Chopin Debussy Mozart Satie Result CDM Offset Mozart01 10249 8417 7873 9208 7992 0 0 0 Mozart02 14406 12283 13247 11508 12686 1 1 1 Mozart03 4010 3814 3954 3199 3801 1 0 1 Mozart04 7297 6862 7216 6730 7119 1 1 1 Mozart05 15086 12929 13605 11268 14960 1 1 1 Mozart06 36692 34726 35098 35133 37189 0 1 1 Mozart07 2011 1867 1987 1504 1917 1 0 0 Mozart08 4121 3982 3815 3541 4399 1 0 1 Mozart09 6537 6194 6392 5335 6679 1 0 0 Mozart10 2635 2506 1999 1883 2102 1 0 0 Mozart11 23620 19827 22406 19113 23005 1 1 1 Mozart12 8347 8277 8181 5915 6873 1 0 1 Mozart13 12219 12680 13134 11361 13393 1 0 1 Mozart14 11809 11318 11548 10456 11621 1 1 1 Mozart15 52876 46259 48003 43937 49226 1 1 1 T otal 13 7 11 T ABLE VIII R E SU LT S O F S ATI E ’ S M U S IC A L SC O R E S Music Bach Chopin Debussy Mozart Satie Result CDM Offset Satie01 2195 2062 2043 1631 2216 0 0 0 Satie02 23498 19024 19447 23665 18218 1 0 0 Satie03 17168 21461 18440 24132 4917 1 1 1 Satie04 7182 7522 7746 8586 4761 1 1 1 Satie05 12186 14146 11912 15434 4347 1 1 1 Satie06 42936 32240 32877 37414 24716 1 0 0 Satie07 43494 34264 36157 39355 28590 1 0 0 Satie08 13254 10550 8655 10950 9464 0 0 0 Satie09 4549 4489 4036 4420 4301 0 0 0 Satie10 17845 13940 13761 16366 9969 1 1 1 Satie11 1242 1233 1240 935 1071 0 0 0 Satie12 14957 14223 13550 15689 10827 1 1 1 Satie13 12061 11894 10876 12818 8932 1 1 1 Satie14 10464 10299 9578 11628 6917 1 1 1 Satie15 7030 6701 5432 8270 5845 0 1 1 T otal 10 8 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment