Exploring Architectures, Data and Units For Streaming End-to-End Speech Recognition with RNN-Transducer
We investigate training end-to-end speech recognition models with the recurrent neural network transducer (RNN-T): a streaming, all-neural, sequence-to-sequence architecture which jointly learns acoustic and language model components from transcribed…
Authors: Kanishka Rao, Hac{s}im Sak, Rohit Prabhavalkar
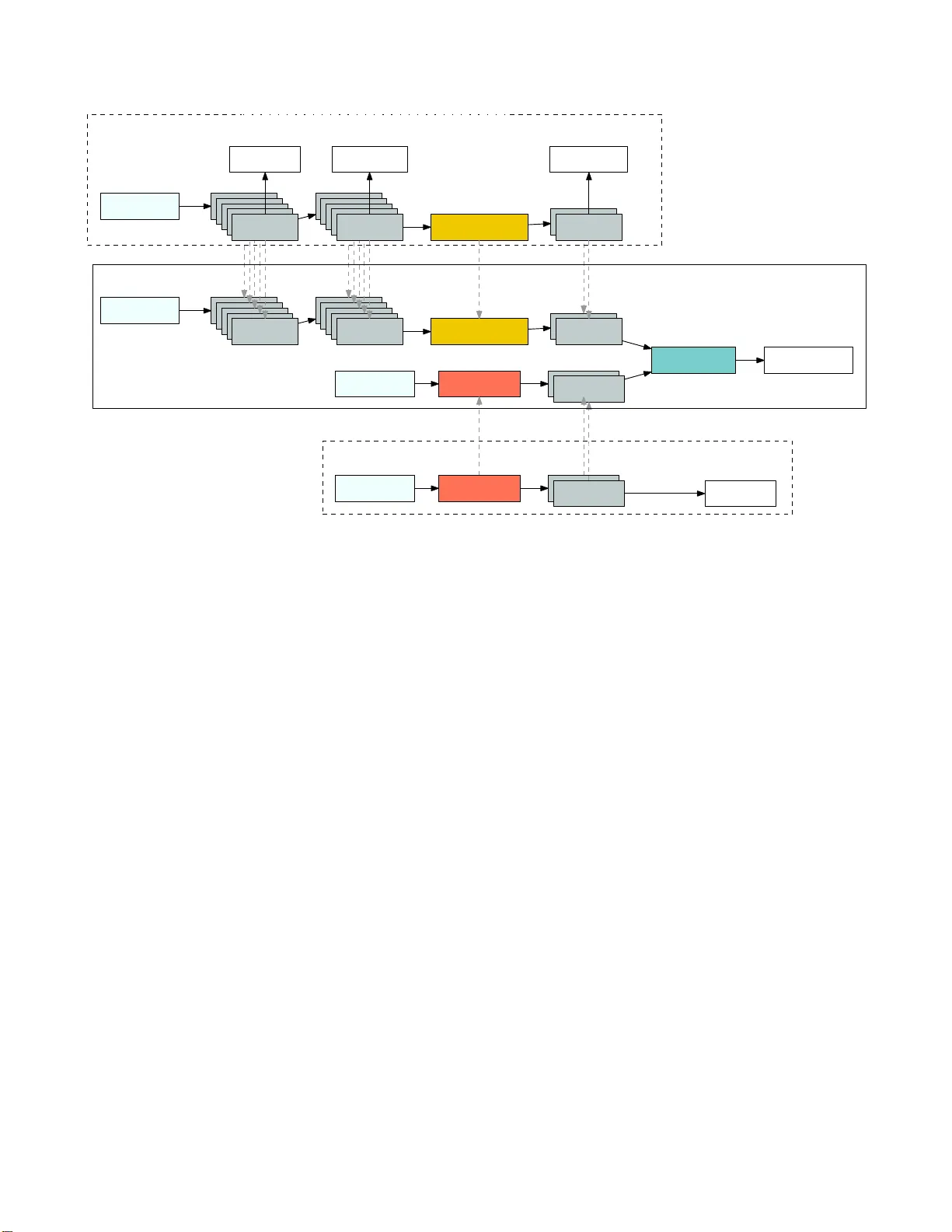
EXPLORING ARCHITECTURES, D A T A AND UNITS FOR ST REAMING END-TO-END SPEECH RECOGNITION WITH RNN-TRANSDUCER Kanishka Rao, Has ¸i m Sak, Rohit Prabhavalkar Google Inc., Mountain V iew , CA, U.S.A. { kanishkar ao,hasim,p rabhavalkar } @google.com ABSTRA CT W e in vestigate training end-to-end speech r ecognition models with the recur rent neural network tra n sducer (RNN- T): a streaming , all-neu ral, sequence- to-sequen ce architecture which jointly learns acoustic a n d language model components from transcribed acoustic data. W e explor e v arious model ar- chitectures and demonstrate how the model can be improved further if add itional text or pr onuncia tio n d ata are available. The model con sists of an ‘e n coder’ , which is initialized fr om a connection ist tempora l classification-ba sed (CTC) acou stic model, and a ‘d ecoder’ which is par tially initialized f r om a recurren t neural network languag e model trained on text data alone. The entir e n eural network is trained with the RNN-T lo ss an d d irectly o u tputs the reco gnized tran script as a sequence of graphemes, thus performing end-to-end speech recogn itio n. W e find that perfo rmance can be improved fur- ther throu gh the u se of sub-word units (‘wordpieces’) which capture longer context and sign ificantly r e d uce substitution errors. The best RNN-T system, a twelve-layer LSTM en - coder with a two-layer LSTM decoder tr ained with 30,00 0 wordpieces as ou tput targets achiev es a word er ror rate of 8.5% on voice-search and 5 .2% on voice-dictation tasks a nd is comp arable to a state-o f-the-art baseline at 8. 3 % on voice- search and 5.4% voice-dictation. Index T erms — ASR, end -to-end , sequen c e-to-seque nce models, recurren t neu ral networks transducer, wordpiece. 1. INTR ODUCTION The cur rent state-of -the-art autom atic speech r ecognitio n (ASR) systems break down the ASR pro blem into three main sub-pro blems: acoustic, pron unciation an d langu age model- ing. Speech r ecognition in volves d etermining the most likely word sequence, W = w 1 , ..., w n , given an acoustic input sequence, x = x 1 , ..., x T , where T represents the number of frames in the utterance: W ∗ = argmax W P ( W | x ) , (1) which is typ ically decomp osed into three separate models, as follows: W ∗ = argmax W X φ P ( x , φ | W ) P ( W ) (2) ≈ argmax W ,φ p ( x | φ ) P ( φ | W ) P ( W ) (3) The acoustic model, p ( x | φ ) , p redicts the likeliho od of the acoustic in put speech u tterance given a pho neme sequence, φ ; f or co nditional mo dels that d irectly p redict P ( φ | x ) , the likelihood is typically rep laced with a scaled likelihood ob- tained by dividing the p osterior with the prio r, P ( φ ) , in so- called hybr id models [1]. Deep re current neur al networks with long short-ter m m emory (LSTM) cells [2] have recently been shown to b e id eal for th is task [3, 4, 5]. T he pron u nci- ation mod el, P ( φ | W ) , is typica lly built fr om pronu nciation dictionaries cura te d by exper t hu man ling uists, with back-off to a grapheme- to-pho neme (G2P) model [6] f o r out of dictio- nary words. Finally , an N-g ram mod el trained o n text data may be used as a langua g e model, P ( W ) . Recently , ther e has been co nsiderable inter est in training end-to- end models f o r ASR [7 , 8, 9], which directly o utput word tr anscripts given the input aud io. 1 Thus, these models are much simpler than conventional ASR systems as a single neural network can be used to dir ectly recogniz e utteranc e s, without requiring separately-tr ained acoustic, pronu nciation and lan guage model compon ents. A particu lar class of ar- chitecures k nown as sequenc e-to-seque nce mod els [10] are particularly suited fo r end-to- end ASR as they include an en- coder network which corr esponds to the acou stic m odel of a conventional system and a decoder network which corre - sponds to the langua ge m odel. One drawback of typical enco der-decoder type arch i- tectures (e.g., [7, 9]) is that the entire in put seq uence is encoded b efore th e o utput seq uence m ay be decoded a n d thus these m odels cann ot be used f or real- tim e stream ing speech recogn itio n. Se veral strea ming encoder-decoder architecture s have been pro posed previously , includin g the neural trans- ducer [11], the recur rent neura l aligner (RNA) [12], and the 1 In t he c ontext of this work, we consid er models that are all-neu ral, and direct ly out put w ord transcrip ts from audi o u tterance s as being end-to-en d. recurren t neur al n etwork tr ansducer (RNN-T) [13, 14]. In particular, these architectures allow th e o utput to b e d e coded as soon as the fir st input is en c oded, without introdu cing ad - ditional laten cy incu rred when processing th e entire utteran ce at once. I n this work we on ly co nsider stream ing recog n ition architecture s, specifically the RNN-T model. Despite recent work on end-to- end ASR, co nventional systems still remain the state- of-the- a rt in terms o f word error rate (WER) perform a n ce. For exam ple, in our pr evi- ous work [15] we ev aluated a number of en d-to-e n d models including attention -based models [7] and RNN-T [13, 1 4] trained on ∼ 12, 5 00 ho u rs of tran scribed training data; al- though e n d-to-e n d appro aches were fo und to b e comp arable to a state-of -the-art context-dep endent phon e-based baseline on dictation test sets, these mod els we r e fou n d to be sig- nificantly worse than the baseline on voice-search test sets. End-to- end systems are typically tr a ined usin g transcrib e d acoustic data sets, which are relatively expensive to gen erate and thus much smaller than text-only data sets, which are used to train LMs in a traditional speech recog nizer . A d efi- ciency of end -to-end system s appears to be in their languag e modeling cap acity [15] which may be because large text-only data are not utilized in end-to -end s ystems. In this work we explor e a par ticular sequence- to-sequen ce architecure , RNN-T , and show how text and pro n unciation data may be included to improve end-to-e n d ASR perfor- mance. Ano ther contribution of this work is to in vestigate the use of wordpieces [16], which ha ve been e xplor ed pre viously in th e c ontext of machine translation, as a sub-word unit fo r end-to- end speec h recognitio n. The p aper is o rgan ized as f ollows: in Sectio n 2 we de - scribe the RNN-T and h ow it may be used fo r stre a ming recogn itio n. Section 3 d e scribes how th e RNN-T is train ed including the units, architectures and pre-tr aining p arts of the model. The experimental setup including the baseline system are detailed in Section 4. Section 5 compar es the word er ror rate perfor mance of various RNN-T models and the baseline to show relativ e im provement. W e find that the techniqu es introdu c ed in this work mostly im prove the languag e mo d- eling of the RNN-T , Section 6 shows som e select examples of su c h improved recognitio n. A conclud ing summ a ry and acknowledgements are in Sectio n 7 and Section 8. 2. RNN-TRANSDUCER The RNN-T was p roposed b y Graves [13] as a n extension to the connectio nist tem poral classification (CTC) [17] approach for sequ ence labe ling tasks where the alignment between the input sequen c e, x , and the output targets y is unknown. Th is is accom plished in the CTC formulation by intr o ducing a spe- cial label, called the blan k label, which models the probability of outpu ttin g no label corresp onding to a given in put frame. CTC has b e en widely used in p revious work s to train end-to- end ASR models [8, 18, 19]. Howe ver , a m ajor limitation of Fig. 1 . The RNN-T model. T he model consists of an encoder network, which maps input acoustic frames into a hig h er-le vel representatio n, and a prediction and joint network w h ich to- gether correspond to the decoder n e twork. The decoder is condition ed on the history of previous pr e dictions. CTC is its assumption that model o utputs at a gi ven frame are indepen d ent of pr evious o utput labels: y t ⊥ ⊥ y j | x , for t < j . The RNN-T mo del, d epicted in Figur e 1, co nsists o f an encoder (referr ed to as the tr anscription network in [ 13]), a prediction network and a joint network; as described in [15], the RNN-T model can b e compared to other encoder-decoder architecture s such as “listen, attend, and spell” [7], if we view the combinatio n of the pr ediction network an d the jo int net- work as a deco d er . The en coder is an RNN which co nverts the input acoustic fr ame x t into a higher-lev el representa- tion, h enc t , an d is analo gous to a CTC-based AM in a stan- dard speech recog nizer . Thus, as in CTC, the o utput o f the encoder network, h enc t , is conditioned o n the s eque nce of pre- vious acoustic frames x 0 , · · · , x t . h enc t = f enc ( x t ) , (4) The RNN-T rem oves th e conditio n al ind e penden ce as- sumption in CTC by introducin g a pr ediction network , an RNN that is explicitly con ditioned on the h istory of previous non-b lank targets p redicted by the mod el. Specifically , th e prediction n etwork receives as input the last non-bla nk label, y u − 1 , to prod uce as output h dec u . h dec u = f dec ( y u − 1 ) . (5) Finally , the joint n etwork , is a feed-fo rward network that combines the outputs of the pred ictio n n etwork and the en - coder to p rodu ce logits ( z t,u ) followed by a softmax layer to produ ce a distribution ov er the next ou tput symbol (either the blank symbol or one of the outp u t targets). z t,u = f joint ( h enc t , h dec u ) (6) W e use the sam e for m for f joint as descr ibed in [14]. Th e entire netw ork is trained jointly to optimize the RNN-T loss [13], which marginalize s over all alignments o f target labels with blanks as in CTC, an d is c o mputed u sing d ynamic progr amming. During each step of inf erence, the RNN-T model is fed the next acou stic f rame x t and the previously pr edicted la- bel y u − 1 , from which the mod e l produ c e s the next outpu t label prob abilities P ( y | t, u ) . If the pr e dicted label, y u , is non-b lank, then the pre diction network is up d ated with that label a s in put to gener a te the next ou tput label p robab ilities P ( y | t, u + 1 ) . Con versely , if a blank label is pred ic te d then the next acoustic fram e, x t +1 , is u sed to up date th e en c oder while retain the same p rediction network outp ut r esulting in P ( y | t + 1 , u ) . In this w ay the RNN-T can stream recognition results b y altern ating b etween updating the encoder and the prediction network based o n if the pred icted label is a blank or non-blan k . I nferenc e is term inated when blank is output at the last frame, T . During inf erence, the mo st likely label seq uence is com- puted u sing beam search as described in [ 1 3], with a minor alteration w h ich was fou n d to make the a lgorithm less co m - putationally intensive witho ut degradin g p erform ance: we skip summa tio n over pre fixes in pref ( y ) (see Algorith m 1 in [13]), unless multiple hypoth eses are identical. Note that un like other streamin g e ncoder-decod er arch i- tectures such as RN A [12] and NT [ 11], th e prediction net- work is not co nditioned o n the encod er output. This allows for th e th e pre- training of the decoder as a RNN language model on text-only data as described in Section 3. 3. UNITS, ARCHITECTURES AND TRAINING W e investi gate the use of grap h emes and su b -words (word- pieces) as ou tput lexical units in RNN- T mod els. F or th e graphe m es, we use letters ( a-z ), d ig its ( 0-9 ), special sym- bols ( &.’% /-: ) and a space symbol ( < spa ce > ). The space symb ol is used f or segmentin g re c ognized g rapheme sequences to word sequences. State-of-the- art large vocabulary speech recog nition sys- tems reco gnize million s of different words, inferenc e for RNN-T with that many o utput labels would be impractically slow . Th erefore , as su bword units, we use wordpiec e s as described in [16]. W e tr a in a statistical wordpiece mode l with word counts obtain ed fro m text da ta fo r segment- ing each word individually into subwords. An a dditional space symbol is inclu d ed in sub word units. An exam- ple segmentation for the sentence tortoi se and the hare is < tor > < to > < ise > < space > < and > < space > < the > < space > < ha > < re > . W or d- pieces have be shown to benefit end-to -end reco gnition [20] since they offer a balance with lo n ger co ntext th an grap hemes and a tunab le n umber of lab els. Since the word p iece mo del is based on word frequencies, more com mon w ords appear as a single label. A vocabulary of 1 ,000 gen erated wordpieces includes word s like ‘m all’, ‘rem ember’ and ‘doctor ’ while a vocab ulary of 30,00 0 wordpie c es also includ es less co mmon words like ‘mu ltimedia’, ‘tungsten’ and ‘49 er’. The word- piece mo dels may also outpu t any word th at th e grap heme model m ay; we find that all the graphemes ar e in cluded in the wordpiece v ocabularies. For the encoder networks in RNN-T m odels, we exper- imented with deep LSTM networks (5 to 12 laye r s). For the decoder networks, we used a stack of 2 laye r LSTM net- work, a feed-for ward layer and a softmax layer . In addition to training models with rand om initializatio n o f p arameters, we explored variations of initializin g en coder and decoder net- work parame te r s from p r e-trained mo d els. It has b een p re- viously shown that in itializing RNN-T encod er parameters from a m odel tra in ed with the CTC loss is be neficial for th e phone m e r e c ognition task [14]. W e experimented with ini- tializing encoder networks f rom m odels trained with th e CTC loss and with in itializing LSTM lay er parameters in predic- tion n etworks from LSTM language models tr a ined on text data. After initialization of encoder and predictio n network weights from sepa r ate pre-train e d m odels, th e en tire RNN-T model weights are trained with the RNN-T ob jectiv e. W e show one example arch itecture fo r th e RNN-T word- piece model in Figur e 2 . The figur e also shows the pre-tra in ed CTC LSTM acou stic model and LST M language model ar- chitectures used to initialize the enco d er and p rediction net- work weig hts. The dotted arro ws indicate the pre -trained lay- ers used to initialize specific layer s in the RNN-T m odel. The encoder networks in RNN-T models are pre- trained w ith the CTC loss using p honem es, g rapheme s and word pieces as out- put units. W e inves tigate encoder architectu res with mu lti- task tr a ining using h ierarchical- CTC [21] with various ’hi- erarchies’ of CTC losses at various depth s in the enco der network. W ith h ierarchica l- CTC the e ncoder n etworks ar e trained with multiple simu ltaneous CTC losses whic h was beneficial fo r grap heme r ecognitio n [22]. Afte r pre-tra ining all CTC losses and add itional weigh ts associated with g e n er- ating softmax p robabilities are discar d ed. For the wordpiece models which have longer dur ation than gr aphemes, we em- ploy an ad ditional ’time-conv olution ’ in th e encoder ne twork to reduc e the seq uence len gth of enco ded activations which is similar to the pyramidal sequenc e length redu ction in [7]. For these models, we used filters covering 3 non -overlapping consecutive activ ation vectors, thus reducin g th em to a sin- gle activ ation vector . The LSTM layers in d e coder networks are pre- trained as a langua g e model using the g rapheme s or wordpieces as lexical un its. Th e in put to the network is a label (g r apheme or wordpiece) in a segmented senten c e rep- resented as a one-hot vector . Th e target for the network is the next lab el in the sequen ce a nd the model is tr a ined with the cross-entro py loss. The weights in the sof tmax outpu t lay er are discarded after pre-tr aining and only the LSTM network weights are u sed to p artially initialize the RNN-T predictio n network. For wordpiece lan g uage mod els, we embed labels to a smaller d imension. These embed ding weights are also used to initialize the RNN-T wordpiece models. L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 LS TM 5x70 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 LS TM 5x70 0 Time Co nvo lutio n 3x L S T M 2 x 7 0 0 LS TM 2x70 0 Fee d For war d 700 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 LS TM 5x70 0 L S T M 5 x 7 0 0 CT C Pho neme L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 L S T M 5 x 7 0 0 LS TM 5x70 0 Time Co nvo lutio n 3x CT C Gra phe me L S T M 2 x 7 0 0 LS TM 2x70 0 CT C Wordp iece CE W ord piec e RN N-T W ord piec e Inp ut Embed din g L S T M 2 x 1 0 0 0 LS TM 2x10 00 Inp ut Embed din g L S T M 2 x 1 0 0 0 LS TM 2x10 00 Ac oust ic Fea ture Ac oust ic Fea ture Inp ut Wordp iece Inp ut Wordp iece RNN-T Training Enco der Hierarchical-C TC Pre-trainin g Decoder Lang uag e Model Pre-training Fig. 2 . The various stages of trainin g a wordpiece RNN-T . The en coder network is pre-train ed as a hierarch ical-CTC network simultaneou sly pred icting phon emes, graph emes and wordpie c e s at 5, 10 and 12 LSTM layers r espectively . A time conv olu- tional layer reduces the en coder time sequence len gth by a f actor of three. Th e decoder network is trained as a LSTM langauge model predicting wordpieces optimized with a cross-entropy loss . Finally , th e RNN-T network weights are initialized from the two pre-trained models, indicated by the dashed lines, and the entire network is optimized using the RNN-T loss. 4. EXPERIMENT AL SETUP W e com pare the RNN-T end-to -end recog nizer with a con- ventional A SR system con sisting of separate a coustic, pro - nunciation and languag e m odels. The acou stic mo del is a CTC trained L STM that predicts co ntext-depend ent (CD) phone m es first fine -tuned with sequence discrim in ativ e train- ing as described in [5] and fur ther imp roved with word-level edit-based minimu m Bayes r isk (EMBR) pr o posed recently by Shanno n [23]. Aco ustic mod els are trained on a set o f ∼ 22 million hand- transcribed anonym ized utterance s extracted from Goo gle US English voice traffic, which correspo nds to ∼ 18,0 00 hou r s of train ing data. These includ e voice-search as well as voice-dictation utteranc e s. W e use 80-dim ensional log me l filterbank e nergy f eatures co mputed every 10 ms stacked every 30ms to a sing le 24 0 -dimen sio n al acoustic feature vector . T o ac h iev e noise robustness aco ustic train- ing da ta is distorted as d escribed in [24]. The pr onun c iation model is a d ictionary containing hund r eds of th ousands of human expert transcribed US Eng lish word p ronu nciations. Additional word pronu nciations are learne d f rom a u dio data using pron unciation learnin g tec hniques [25]. For out-o f- dictionary word s a G2P model is trained using transcribed word pro nunciatio n s. A 5- gram lang uage mod el is tr a ined with a text sentenc e dataset wh ich include s untranscrib ed anonymized speech logs: 150 million sentences e a c h from voice-search an d voice-dictation queries, and anonymized typed logs inclu ding tens o f billion sen tences from Goo gle search from various sou rces. The langu age mo del is prune d to 100-m illion n-g rams with a target vocab ulary of 4 million and the various sources of text data are re-weigh ted using in- terpolation [26] f or the optimal word err or rate p e rforman ce. Single-pass d ecoding with a conventional WFST is carried out to generate recogn ition transcripts. The RNN-T is trained with the same d ata as th e baseline. The CTC enco der n etwork is pre- trained with a c oustic tran- scribed d a ta and as with the baseline a c oustic mod el the pro- nunciation model is used to generate phon eme transcriptio n s for the aco ustic d ata. The RNN-T decoder is p re-trained o n the text only data a s a LSTM langu age mo d el, r ough ly h alf a billion sen tences from th e text data a re sampled acco rd- ing to their count an d the data source interpolation we ight (as optimized in th e baseline). All RNN-T models are trained with LSTM networks in the te n sorflow [ 27] toolk it with asyn - chrono us stochastic gr adient descent. Models are evaluated using the RNN-T beam search algor ithm with a beam of 1 00 for grap h eme mo dels and 25 f or wordpiece models an d a tem- perature of 1.5 on the softmax. W or d e r ror r ate (WER) is re- ported o n a voice-search and a voice-dictation test set with rough ly 1 5,000 utterances each. 5. RESUL TS W e train and ev aluate various RNN-T and in c rementally show the WER impact with each improvement. A graph eme based RNN-T is trained from scratch (no pre- training) on the acoustic data with a 5-lay er LSTM en coder of 700 cells an d a 2-layer LSTM decod e r o f 700 cells. A fi- nal 700 unit feed-f orward layer and a softmax layer outp ut graphe m e labe l probab ilities. W e compare this model to a model with iden tical architectu re but with the encode r CTC pre-train e d. W e find CTC pre - training to b e helpfu l improv- ing WER 13. 9 % → 13.2% for voice-search and 8.4% → 8. 0% for voice-dictation. A model with a deep e r 8 -layer encoder is also trained with a mu lti-CTC loss at depth 5 and de p th 8 where b oth losses are optimized for the same g rapheme targets. W e foun d tr a in- ing 8-lay e r m odels withou t a m ulti-loss setup to be un sta- ble which we ackn owledge may b e addressed with recent ad- vancements in train ing deeper rec urrent mod els [2 8] but are not tested as par t of this work. T he deepe r 8 -layer en coder further imp roves WER 13.2% → 12 .0% fo r voice-search and 8.4% → 6.9 % fo r voice-dictation. T o in corpor ate th e knowledge of phone m es and specifi- cally th e p ronun ciation dictionary data we train a 8-layer e n - coder with hier archical-CTC with a phon eme target CTC at depth 5 an d a graph eme target CTC at depth 8. I n this way the network is for c ed to m odel ph onemes and is exposed to pronu nciation variants in the lab els where the s ame word (and thus sam e gr apheme sequ ence) m a y have different pron unci- ations (an d thus phon eme sequences). This appro ach does not ad d ress includ ing pron unciation s f or words that do not occur in the acoustic training d ata, w h ich we leave as f uture work. W e find that the pronu nciation da ta imp roves WER 12.0% → 11 .4% for voice-search but with little improvemen t for voice-dictation. Unlike voice-search the voice-dictation test set is com prised of mostly commo n words, we con jec- ture that it may b e sufficient to learn pron u nciations f or these words from the acou stic data alone an d thu s may not be nefit from additional human transcribed pronu nciations. Next, to include the te xt data we pre-train a 2-layer LSTM with 700 cells as a language model with grap heme targets. The mo del is train ed until word pe r plexity on a held -out set no longer improves, T able 2 sho ws the word preplexity a n d sizes of the various langua ge mod els that wer e trained. Addition of text d ata in this way impr oves WER 1 1.4% → 10 .8% for voice-search an d 6.8% → 6.4 % fo r voice-dictation. W e explo re mo d eling wordpieces, with 1 k, 10k an d 30k wordpieces, instead of graph emes a nd make sev eral c h anges to the arch itec tu re. The wordpiece enco der network is a 12- layer LSTM with 700 cells each , trained with hierar chical- CTC with phoneme targets at de p th 5, g raphem es at depth 10 and wordp ieces at depth 12 . Since wordpiece s are lo n ger units we include a time conv olution after depth 1 0 redu cing the sequen ce length by a factor o f 3. W e find that this time conv olution doe s not affect WER but drastically r e d uces train- ing and infer e nce time as there ar e 3 times fewer encod er fea- tures that need to b e p rocessed by the decod e r network. W or d- piece languag e mod els are trained similar to graphemes, since the numbers of labels are mu ch lar ger a n additional inp u t em - bedding of s ize 500 is used for w ordpie c e mo dels. Th e word- piece languag e m o dels perfor m m uch better in terms of word perplexity (T able 2 ) and th e RNN-T initialized f rom th em also see sign ificant WER improvements (T able 1). The b est en d - to-end R NN-T with 3 0k wordp ieces ach iev es a WER o f 8 .5% for voice-search and 5 .2% on voice-dictation which is o n par with the state-of-the-a r t ba seline speech recogn ition system. 6. ANAL YSIS W e o bserve that a large part of the improvements d escribed in this work are from a reduction in substitution errors. Using wordpieces instead of g raphem es results in an absolute 2 .3% word error rate improvement, o f this 1 . 5% is due to fixing substitution er rors. I nclusion of pro nunciatio n and text data improve voice-search word error rate by an absolute 0.6% and 0. 6% respectively , all of these are due to im provements in word su bstitution er rors. Many o f the cor rected substitution errors seem to b e f rom impr oved langu age modeling: words which may soun d similar but have d ifferent m eaning given the text con text. Some selected examples includ e impr ove- ments with prop er nouns: ‘ barbar a stanwic k ’ reco gnized by a g r apheme mo del is fixed when using wordpieces to the correct nam e ‘bar b ara stanwyck’ . Sim ilar improvements are found when includ in g p ronun ciation data: ‘seq u oia casino’ to ‘sycuan casino’, ‘w h ere is th ere’ to ‘ where is xur’ and also when including text data: ‘sold ier b oy’ to ‘soulja b oy’, ‘lorenzo llamas’ to ‘lor enzo lamas’. W e also fin d that word - pieces capture lo nger range language context than graphemes in improvements like ‘tortoise and the hair’ to ‘to r toise an d the hare’. 7. CONCLUSION W e train end -to-end speech recogn ition mod els using the RNN-T which pr e dicts g r aphemes or wordp ieces an d th us di- rectly ou tputs the transcript f rom audio . W e find pre - training the RNN-T encoder with CTC results in a 5% r elativ e WER improvement, an d using a deepe r 8-layer enco der instead of a 5-lay er en c oder fu r ther im proves WER by 10% rela- ti ve. W e in corpo r ate p ronun ciation data using a pre-trainin g hierarchica l-CTC loss which includes p honem e targets and find this improves the voice-search WER by 5% relati ve with little impact on the voice-dictation task. T o include text-on ly data we pre-train the recu rrent n etwork in the deco der as LSTM lang u age m odels resultin g in a overall 5% relative T able 1 . W or d error perfo rmance o n the voice-search and dictation tasks f or various RNN-T trained with g r aphemes an d wordpieces with v arious architectures and p re-trainin g. Also s hown for each mod e l is which types of train ing data are inclu ded: acoustic, p r onun c iation or te xt. The baseline is a s tate-of -the-art conv ention al spe e c h recog nition system with sep a rate acou stic, pronu nciation and lan guage models tra ined on all av ailable data. The par ameters for the b aseline system in c lu de 20 millio n weights from the acou stic model network, 0.2 millio n for each word in the pron unciation d ictionary and the 10 0 m illion n-gra m s in the language model. Layers Pre-trained T raining Data Used WER(%) Units Encoder Decoder Encod er Decoder Acoustic Pronunciation T ext Params VS IME RNN-T Grapheme s 5 x700 2x700 no no yes no no 21M 13.9 8.4 Grapheme s 5 x700 2x700 yes no yes no no 21M 13.2 8.0 Grapheme s 8 x700 2x700 yes no yes no no 33M 12.0 6.9 Grapheme s 8 x700 2x700 yes no yes yes no 33M 11.4 6.8 Grapheme s 8 x700 2x700 yes yes yes yes yes 33M 10.8 6.4 W or dpieces-1k 12x70 0 2x700 yes yes yes yes yes 55M 9 .9 6.0 W or dpieces-10 k 12x70 0 2x700 yes yes yes yes yes 66M 9 .1 5.3 W or dpieces-30 k 12x70 0 2x10 00 yes yes yes yes yes 96M 8 .5 5.2 Baseline - - - - - yes yes yes 120.2 M 8.3 5.4 T able 2 . The num ber of pa r ameters (in millions) and word perplexity for LSTM lan guage mod el trained with d ifferent units ev aluated on a held-out set. Units Params Perplexity Grapheme s 6M 185 W or dpieces-1k 10 M 138 W or dpieces-10 k 20M 130 W or dpieces-30 k 59M 119 improvement. W e train wordpiece RNN-Ts with 1k, 10k and 30k wordpiece s tar gets and find that th ey significantly outper- form the grap h eme-based RNN-T s. For co mparison we use a b aseline sp eech recognize r with individual acoustic, pro- nunciation and lang u age models with state-o f -the-art WERs of 8.3 % on voice-search and 5.4% on voice-dictation. W ith a 30 k wordpie c e RNN-T achieving WERs of 8.5% on voice- search an d 5 . 2% on voice-dictatio n we demonstrate th at a single end - to-end n eural model is capab le o f state-of- the-art streaming speech recognition . 8. A CKNOWL EDGEMENTS The au th ors would like to thank o ur co lleagues: Franc ¸ oise Beaufays, Alex Grav es and Leif Joh nson for help ful research discussions and Mike Schuster for help with wordpiece mod- els. 9. REFERENCES [1] N. Mo rgan and H. Bou r lard, “Continu ous speech r ecog- nition, ” IE E E Sign a l Pr o c e ssing Magazin e , vol. 12, n o. 3, pp. 24–42 , May 1 995. [2] S. Hochreiter and J. Schmidhub er , “L ong short-term memory , ” Neural Computatio n , v ol. 9, no. 8 , pp. 1735 – 1780, Nov 1997. [3] A. Graves and J. Schmidhu ber, “Framewise ph oneme classification w ith bidirectional lstm netw orks, ” in I E EE Internation al Joint Confer ence on Neural Networks , 2005, vol. 4. [4] H. Sak, A. W . Senior, an d F . Beaufays, “Long short- term mem o ry based recur r ent neural n etwork arch itec- tures for large vocabulary speec h recog nition, ” CoRR , vol. abs/1402.112 8, 2014 . [5] H. Sak, O. V inyals, G. Heigold , A. W . Senior, E. McDer- mott, R. Monga, and M. Mao, “Sequenc e d iscriminative distributed training of long short-te r m mem ory r ecurren t neural networks, ” in Interspeech , 2014. [6] K. Rao, F . Pen g, H. Sak, and F . Beaufays, “Graph eme- to-pho neme conversion u sing long short-term memo ry recurren t n e u ral networks, ” in ICASS P , 2015. [7] W . Chan, N. Jaitly , Q. V . L e , an d O. V inyals, “Listen, attend and spell, ” CoRR , vol. abs/1508.012 11, 201 5 . [8] D. Amo dei, R. Anubh ai, E. Battenb erg, C. Case, J. Casper, B. Catanza r o, J. Che n , M. Chrzan owski, A. Coates, an d G. Diamos et al, “De e p speech 2: E n d- to-end speech reco gnition in eng lish and mandarin , ” in ICML , 2016 . [9] D. Bahdan au, J. Chor owski, D. Serd y uk, P . Brakel, and Y . Beng io, “End-to -end attention -based large vocab u- lary speech rec o gnition, ” in ICASSP , 20 16, pp. 494 5– 4949. [10] I. Sutskever , O. V inyals, and Q. V . Le, “Sequence to sequence learning with ne ural networks, ” in NIP S , 20 14. [11] N. Jaitly , Q. V . Le, O. V inyals, I. Sutske ver , D . Sussillo, and S. Bengio, “ An online sequence-to-seque nce mo del using partial cond itioning, ” in NIPS , 2016 . [12] H. Sak, M. Shannon , K. Rao, and F . Beaufays, “Re- current neural align e r: An e n coder-decode r neu ral net- work mod el for seq uence-to -sequence mapping, ” in I n- terspeech , 2017. [13] A. Graves, “Sequence transduc tion with recu rrent neu- ral networks, ” in Pr oc. of I CAS SP , 2012. [14] A. Graves, A.-R. Mohamed, and G. E. Hinton, “Spe ech recogn itio n with deep recurrent neural network s, ” in In- ternational Con fe rence on Ma chin e Lea rning: Repre- sentation Learning W o rkshop , 2013. [15] R. Prabhav alkar, K. Rao, T . N. Sainath, B. Li, L. John - son, an d N. Jaitly , “ A co mparison of sequen ce-to- sequence mod e ls fo r speech recog nition, ” in I n ter- speech , 2017. [16] Y . W u, M. Schuster, Z. Chen, Q. V . Le, M. Norouzi, Q. Macherey , M. Krikun, Y . Cao, Q. Gao, and K. Macher ey et al., “Goo gle’ s neur a l mach ine tran sla- tion system: Bridging the gap between hum a n an d ma- chine translation, ” CoR R , vol. abs/1609.081 44, 201 6. [17] A. Graves, S. Fern ´ an dez, F . Go mez, and J. Schmidh u - ber, “Con n ectionist tempor al classification: Labeling unsegmented sequence data w ith recurre nt ne u ral net- works, ” in P r o c. of the I nternationa l Conference o n Ma- chine Learning (ICML) , 2006. [18] F . Ey ben, M. W ¨ ollmer, B. Schuller, an d A. Gr av es, “From speech to letters-using a novel neural network architecture for grap heme ba sed asr, ” in W o rkshop on Automatic Sp eech Recognition and Un derstanding (ASRU) . IE E E, 2009, pp. 376–38 0. [19] A. Graves an d N. Jaitly , “T ow ards en d-to-en d speech recogn itio n with r ecurren t neural networks, ” in ICML , 2014. [20] W . Chan, Y . Zhan g , L. Quoc, and N. Jaitly , “La te n t sequence decomp ositions, ” in ICLR , 201 7 . [21] S. Fern ´ andez, A. Grav es, and J. Sch midhub er , “Se- quence labelling in structured dom ains with hierarch i- cal recu rrent n eural network s., ” in Interna tional Joint Confer ence on Artificial Intelligence (IJCAI) , 2007. [22] K. Rao and H. Sak, “Mu lti-accent speech recogn ition with h ierarchical grapheme based mod els, ” in ICASSP , 2017. [23] M. Sha nnon, “Optimizing expected word erro r r ate via sampling for speech reco gnition, ” in Pr oc. of In ter - speech , 2017. [24] H. Sak, A. W . Senior, K. Rao, and F . Beaufays, “Fast and accu rate recu rrent neur al network aco ustic mod els for speech recogn ition, ” in INTERSPEECH , 2015. [25] A. Brugu ier , D. Gn anaprag asam, F . Beaufays, K. Rao, and L. Johnson , “ A more g eneral m ethod for pronu nci- ation learning, ” in In terspeech , 2 017. [26] C. Allauzen and M. Riley , “Bayesian lan guage model interpolatio n fo r mobile speech in put, ” in INTER- SPEECH , 2011. [27] M. Abadi, A. Aga r wal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrad o, A. Da vis, J. Dea n , and M. Devin et al., “T ensor flow: Large-scale mach ine learn ing on h eterogen eous distributed system s, ” CoRR , vol. abs/1603 .0446 7, 20 15. [28] J. G. Z illy , Sriv asta va R. K, J. Koutn´ ık, and J. Schm id- huber, “Recurrent highway networks, ” CoRR , vol. abs/1607 .0347 4, 20 16.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment