Simultaneous Learning of Trees and Representations for Extreme Classification and Density Estimation
We consider multi-class classification where the predictor has a hierarchical structure that allows for a very large number of labels both at train and test time. The predictive power of such models can heavily depend on the structure of the tree, an…
Authors: Yacine Jernite, Anna Choromanska, David Sontag
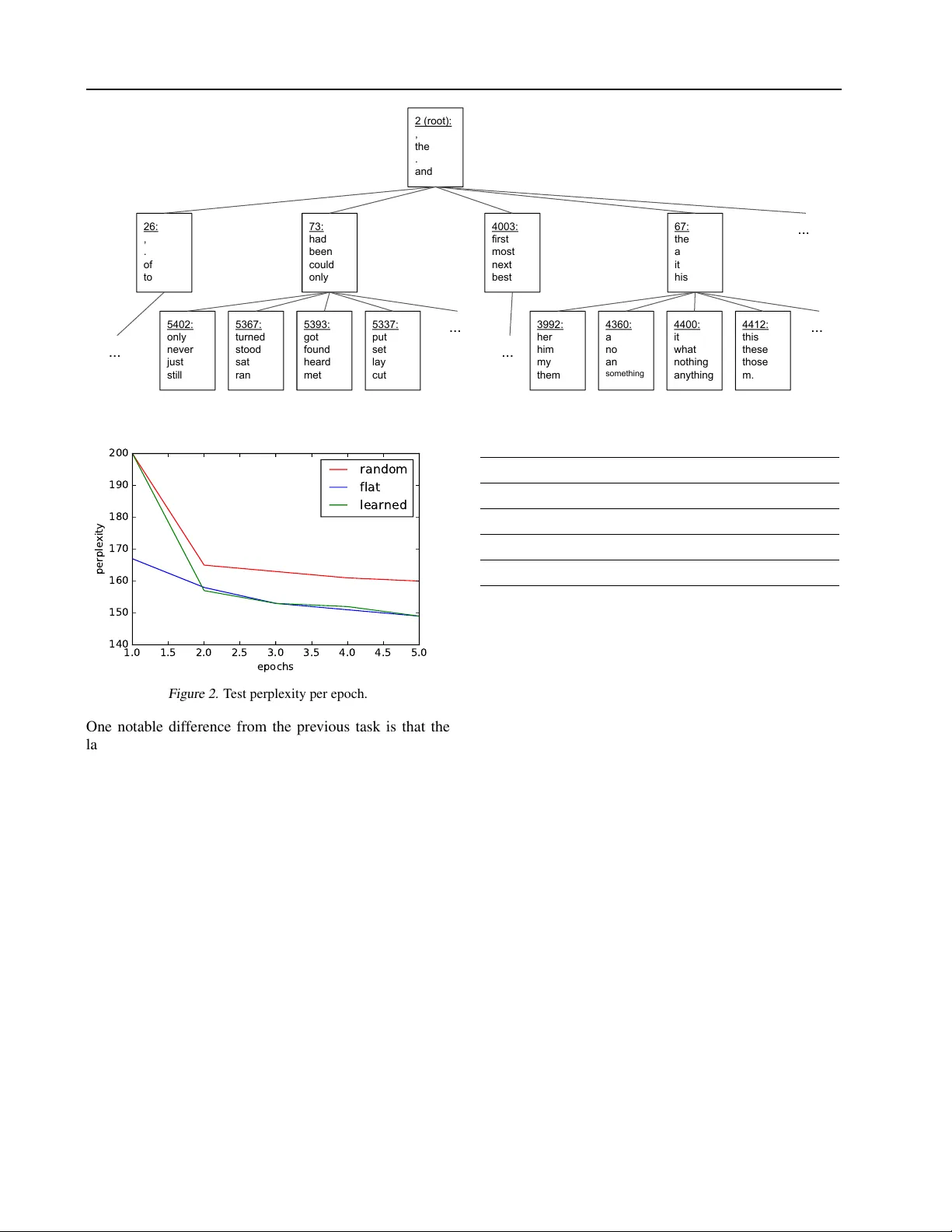
Simultaneous Lear ning of T r ees and Repr esentations f or Extr eme Classification and Density Estimation Y acine Jer nite 1 Anna Choromanska 1 David Sontag 2 Abstract W e consider multi-class classification where the predictor has a hierarchical structure that allows for a very lar ge number of labels both at train and test time. The predictiv e power of such models can heavily depend on the structure of the tree, and although past work sho wed ho w to learn the tree structure, it expected that the feature vectors remained static. W e provide a no vel algorithm to simultaneously perform representation learning for the input data and learning of the hierarchi- cal predictor . Our approach optimizes an objec- tiv e function which fav ors balanced and easily- separable multi-w ay node partitions. W e theoret- ically analyze this objective, showing that it gives rise to a boosting style property and a bound on classification error . W e next show how to extend the algorithm to conditional density estimation. W e empirically validate both variants of the al- gorithm on te xt classification and language mod- eling, respectiv ely , and show that they compare fa vorably to common baselines in terms of accu- racy and running time. 1. Introduction Sev eral machine learning settings are concerned with per- forming predictions in a very large discrete label space. From extreme multi-class classification to language model- ing, one commonly used approach to this problem reduces it to a series of choices in a tree-structured model, where the leaves typically correspond to labels. While this al- lows for faster prediction, and is in many cases necessary to make the models tractable, the performance of the sys- tem can depend significantly on the structure of the tree used, e.g. (Mnih & Hinton, 2009). Instead of relying on possibly costly heuristics (Mnih & Hinton, 2009), extrinsic hierarchies (Morin & Bengio, 2005) which can badly generalize across different data 1 New Y ork Univ ersity , New Y ork, New Y ork, USA 2 Massachussets Institute of T echnology , Cambridge, Mas- sachussets, USA. Correspondence to: Y acine Jernite < jer- nite@cs.nyu.edu > , Anna Choromanska < ac5455@nyu.edu > , David Sontag < dsontag@mit.edu > . sets, or purely random trees, we provide an ef ficient data- dependent algorithm for tree construction and training. In- spired by the LOM tree algorithm (Choromanska & Lang- ford, 2015) for binary trees, we present an objective func- tion which fav ors high-quality node splits, i.e. balanced and easily separable. In contrast to previous work, our ob- jectiv e applies to trees of arbitrary width and leads to guar- antees on model accuracy . Furthermore, we show how to successfully optimize it in the setting when the data repre- sentation needs to be learned simultaneously with the clas- sification tree. Finally , the multi-class classification problem is closely related to that of conditional density estimation (Ram & Gray, 2011; Bishop, 2006) since both need to consider all labels (at least implicitly) during learning and at prediction time. Both problems present similar dif ficulties when deal- ing with very large label spaces, and the techniques that we present in this work can be applied indiscriminately to either . Indeed, we sho w how to adapt our algorithm to ef- ficiently solve the conditional density estimation problem of learning a language model which uses a tree structured objectiv e. This paper is organized as follo ws: Section 2 discusses re- lated work, Section 3 outlines the necessary background and defines the flat and tree-structured objectiv es for multi-class classification and density estimation, Section 4 presents the objecti ve and the optimization algorithm, Sec- tion 5 contains theoretical results, Section 6 adapts the al- gorithm to the problem of language modeling, Section 7 re- ports empirical results on the Flickr tag prediction dataset and Gutenber g text corpus, and finally Section 8 concludes the paper . Supplementary material contains additional ma- terial and proofs of theoretical statements of the paper . W e also release the C++ implementation of our algorithm. 2. Related W ork The multi-class classification problem has been addressed in the literature in a variety of ways. Some examples in- clude i) clustering methods (Bengio et al., 2010; Madzarov et al., 2009; W eston et al., 2013) ((Bengio et al., 2010) was later improved in (Deng et al., 2011)), ii) sparse out- put coding (Zhao & Xing, 2013), iii) variants of error cor - recting output codes (Hsu et al., 2009), iv) variants of it- Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation erativ e least-squares (Agarwal et al., 2014), v) a method based on guess-averse loss functions (Beijbom et al., 2014), and vi) classification trees (Beygelzimer et al., 2009b; Choromanska & Langford, 2015; Daume et al., 2016) (that includes the Conditional Probability T rees (Beygelzimer et al., 2009a) when extended to the classification setting). The recently proposed LOM tree algorithm (Choro- manska & Langford, 2015) dif fers significantly from other similar hierarchical approaches, lik e for exam- ple Filter Trees (Beygelzimer et al., 2009b) or random trees (Breiman, 2001), in that it addresses the problem of learning good-quality binary node partitions. The method results in lo w-entropy trees and instead of using an ineffi- cient enumerate-and-test approach, see e.g: (Breiman et al., 1984), to find a good partition or e xpensiv e brute-force op- timization (Agarwal et al., 2013), it searches the space of all possible partitions with SGD (Bottou, 1998). Another work (Daume et al., 2016) uses a binary tree to map an ex- ample to a small subset of candidate labels and makes a final prediction via a more tractable one-against-all classi- fier , where this subset is identified with the proposed Recall T ree. A notable approach based on decision trees also in- clude FastXML (Prabhu & V arma, 2014) (and its slower and less accurate at prediction predecessor (Agarwal et al., 2013)). It is based on optimizing the rank-sensitiv e loss function and shows an adv antage o ver some other rank- ing and NLP-based techniques in the conte xt of multi-label classification. Other related approaches include the SLEEC classifier (Bhatia et al., 2015) for extreme multi-label clas- sification that learns embeddings which preserve pairwise distances between only the nearest label vectors and rank- ing approaches based on negativ e sampling (W eston et al., 2011). Another tree approach (K ontschieder et al., 2015) shows no computational speed up but leads to significant improv ements in prediction accuracy . Conditional density estimation can also be challenging in settings where the label space is large. The underlying problem here consists in learning a probability distribution ov er a set of random v ariables giv en some context. For example, in the language modeling setting one can learn the probability of a word giv en the previous te xt, either by making a Marko v assumption and approximating the left context by the last few words seen (n-grams e.g. (Je- linek & Mercer, 1980; Katz, 1987), feed-forward neural language models (Mnih & T eh, 2012; Mikolov et al., 2011; Schwenk & Gauvain, 2002)), or by attempting to learn a lo w-dimensional representation of the full history (RNNs (Mikolo v et al., 2010; Mirowski & Vlachos, 2015; T ai et al., 2015; Kumar et al., 2015)). Both the recurrent and feed-forward Neural Probabilistic Language Models (NPLM) (Bengio et al., 2003) simultaneously learn a dis- tributed representation for words and the probability func- tion for word sequences, expressed in terms of these repre- sentations. The major drawback of these models is that they can be slo w to train, as the y gro w linearly with the v ocab u- lary size (an ywhere between 10,000 and 1M w ords), which can make them dif ficult to apply (Mnih & T eh, 2012). A number of methods hav e been proposed to overcome this difficulty . W orks such as LBL (Mnih & Hinton, 2007) or W ord2V ec (Mikolo v et al., 2013) reduce the model to its barest bones, with only one hidden layer and no non- linearities. Another proposed approach has been to only compute the NPLM probabilities for a reduced vocab u- lary size, and use hybrid neural- n -gram model (Schwenk & Gauv ain, 2005) at prediction time. Other a venues to reduce the cost of computing gradients for large vocab u- laries include using different sampling techniques to ap- proximate it (Bengio & S ´ en ´ ecal, 2003; Bengio & Senecal, 2008; Mnih & T eh, 2012), replacing the likelihood objec- tiv e by a contrastive one (Gutmann & Hyv ¨ arinen, 2012) or spherical loss (de Br ´ ebisson & V incent, 2016), relying on self-normalizing models (Andreas & Klein, 2015), taking advantage of data sparsity (V incent et al., 2015), or using clustering-based methods (Grav e et al., 2016). It should be noted howe v er that most of these techniques (to the excep- tion of (Grav e et al., 2016)) do not provide an y speed up at test time. Similarly to the classification case, there have also been a significant number of works that use tree structured mod- els to accelerate computation of the likelihood and gra- dients (Morin & Bengio, 2005; Mnih & Hinton, 2009; Djuric et al., 2015; Mikolov et al., 2013). These use var- ious heuristics to build a hierarchy , from using ontolo- gies (Morin & Bengio, 2005) to Huffman coding (Mikolov et al., 2013). One algorithm which endeav ors to learn a binary tree structure along with the representation is pre- sented in (Mnih & Hinton, 2009). They iterativ ely learn word representations given a fixed tree structure, and use a criterion that trades off between making a balanced tree and clustering the words based on their current embedding. The application we present in the second part of our paper is most closely related to the latter work, and uses a similar embedding of the context. Ho we ver , where their setting is limited to binary trees, we work with arbitrary width, and provide a tree b uilding objecti v e which is both less compu- tationally costly and comes with theoretical guarantees. 3. Background In this section, we define the classification and log- likelihood objectiv es we wish to maximize. Let X be an input space, and V a label space. Let P be a joint distri- bution ov er samples in ( X , V ) , and let f Θ : X → R d r be a function mapping ev ery input x ∈ X to a representation r ∈ R d r , and parametrized by Θ (e.g. as a neural network). W e consider two objectiv es. Let g be a function that takes an input representation r ∈ R d r , and predicts for it a la- bel g ( r ) ∈ V . The classification objectiv e is defined as the expected proportion of correctly classified e xamples: O class (Θ , g ) = E ( x,y ) ∼P h 1 [ g ◦ f Θ ( x ) = y ] i (1) Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Now , let p θ ( ·| r ) define a conditional probability distribu- tion (parametrized by θ ) over V for any r ∈ R d r . The den- sity estimation task consists in maximizing the expected log-likelihood of samples from ( X , V ) : O ll (Θ , θ ) = E ( x,y ) ∼P h log p θ ( y | f Θ ( x )) i (2) T ree-Structured Classification and Density Estimation Let us now show how to express the objectives in Equa- tions 1 and 2 when using tree-structured prediction func- tions (with fixed structure) as illustrated in Figure 1. 1 2 " a " " b " " c " " d " V = {"a","b","c","d","e","f","g","h","i"} 4 c i = (( 1 ,3),( 4 ,3)) 3 " e " "f " " g " " h " " i " Figure 1. Hierarchical predictor: in order to predict label “ i ”, the system needs to choose the third child of node 1 , then the third child of node 4 . Consider a tree T of depth D and arity M with K = |V | leaf nodes and N internal nodes. Each leaf l corresponds to a label, and can be identified with the path c l from the root to the leaf. In the rest of the paper, we will use the following notations: c l = (( c l 1 , 1 , c l 1 , 2 ) , . . . , ( c l d, 1 , c l d, 2 ) , . . . , ( c l D, 1 , c l D, 2 )) , (3) where c l d, 1 ∈ [1 , N ] correspond to the node index at depth d , and c l d, 2 ∈ [1 , M ] indicates which child of c l d, 1 is next in the path. In that case, our classification and density esti- mation problems are reduced to choosing the right child of a node or defining a probability distribution over children giv en x ∈ X respectively . W e then need to replace g and p θ with node decision functions ( g n ) N n =1 and conditional probability distrib utions ( p θ n ) N n =1 respectiv ely . Given such a tree and representation function, our objectiv e functions then become: O class (Θ , g ) = E ( x,y ) ∼P h D Y d =1 1 [ g c l d, 1 ◦ f Θ ( x ) = c l d, 2 ] i (4) O ll (Θ , θ ) = E ( x,y ) ∼P h D X d =1 log p θ c l d, 1 ( c l d, 2 | f Θ ( x )) i (5) The tree objecti ves defined in Equations 4 and 5 can be optimized in the space of parameters of the representation and node functions using standard gradient ascent methods. Howe v er , they also implicitly depend on the tree structure T . In the rest of the paper , we provide a surrog ate objectiv e function which determines the structure of the tree and, as we show theoretically (Section 5), maximizes the criterion in Equation 4 and, as we show empirically (Sections 6 and 7), maximizes the criterion in Equation 5. 4. Learning T ree-Structured Objecti ves In this section, we introduce a per -node objecti ve J n which leads to good quality trees when maximized, and provide an algorithm to optimize it. 4.1. Objective function W e define the node objectiv e J n for node n as: J n = 2 M K X i =1 q ( n ) i M X j =1 | p ( n ) j − p ( n ) j | i | , (6) where q ( n ) i denotes the proportion of nodes reaching node n that are of class i , p ( n ) j | i is the probability that an example of class i reaching n will be sent to its j th child, and p ( n ) j is the probability that an example of an y class reaching n will be sent to its j th child. Note that we have: ∀ j ∈ [1 , M ] , p ( n ) j = K X i =1 q ( n ) i p ( n ) j | i . (7) The objectiv e in Equation 6 reduces to the LOM tree ob- jectiv e in the case of M = 2 . At a high lev el, maximizing the objective encourages the conditional distribution for each class to be as dif ferent as possible from the global one; so the node decision function needs to be able to discriminate between examples of the different classes. The objectiv e thus fa vors balanced and pure node splits. T o wit, we call a split at node n perfectly balanced when the global distribution p ( n ) · is uniform, and perfectly pur e when each p ( n ) ·| i takes value either 0 or 1 , as all data points from the same class reaching node n are sent to the same child. In Section 5 we discuss the theoretical properties of this objectiv e in details. W e sho w that maximizing it leads to perfectly balanced and perfectly pure splits. W e also de- riv e the boosting theorem that sho ws the number of internal nodes that the tree needs to hav e to reduce the classification error belo w any arbitrary threshold, under the assumption that the objective is “weakly” optimized in each node of the tree. Remark 1. In the r est of the paper , we use node functions g n which take as input a data repr esentation r ∈ R d r and output a distribution over childr en of n (for example using a soft-max function). When used in the classification set- ting, g n sends the data point to the child with the highest pr edicted pr obability . W ith this notation, and repr esenta- Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Algorithm 1 T ree Learning Algorithm Input Input representation function: f with parameters Θ f . Node decisions functions ( g n ) K n =1 with parameters (Θ n ) K n =1 . Gradient step size . Ouput Learned M -ary tree, parameters Θ f and (Θ n ) K n =1 . procedur e InitializeNodeStats () for n = 1 to N do for i = 1 to K do SumProbas n,i ← 0 Counts n,i ← 0 procedur e NodeCompute ( w , n , i , target) p ← g n ( w ) SumProbas n,i ← SumProbas n,i + p Counts n,i ← Counts n,i + 1 // Gradient step in the node parameters Θ n ← Θ n + ∂ p target ∂ Θ n retur n ∂ p target ∂ w InitializeNodeStats () for Each batch b do // AssignLabels () re-b uilds the tree based on the // current statistics AssignLabels ( { 1 , . . . , K } , root) for each e xample ( x , i ) in b do Compute input representation w = f ( x ) ∆ w ← 0 for d = 1 to D do Set node id and target: ( n, j ) ← c i d ∆ w ← ∆ w + NodeCompute ( w , n, i, j) // Gradient step in the parameters of f Θ f ← Θ f + ∂ f ∂ Θ f ∆ w tion function f Θ , we can write: p ( n ) j : = E ( x,y ) ∼P [ g n ◦ f Θ ( x )] (8) and p ( n ) j | i : = E ( x,y ) ∼P [ g n ◦ f Θ ( x ) | y = i ] . (9) An intuitive geometric interpr etation of pr obabilities p ( n ) j and p ( n ) j | i can be found in the Supplementary material. 4.2. Algorithm In this section we present an algorithm for simultaneously building the classification tree and learning the data repre- sentation. W e aim at maximizing the accuracy of the tree as defined in Equation 4 by maximizing the objecti ve J n of Equation 6 at each node of the tree (the boosting theorem that will be presented in Section 5 shows the connection between the two). Algorithm 2 Label Assignment Algorithm Input labels currently reaching the node node ID n Ouput Lists of labels now assigned to the node’ s children procedur e CheckFull (full, assigned, count, j ) if | assigned j | ≡ 2 mod ( M − 1) then count ← count − ( M − 1) if count = 0 then full ← full ∪ { j } if count = 1 then count ← 0 for j 0 s.t. | assigned j 0 | ≡ 1 mod ( M − 1) do full ← full ∪ { j 0 } procedur e AssignLabels (labels, n ) // first, compute p ( n ) j and p ( n ) j | i . p av g 0 ← 0 count ← 0 for i in labels do p av g 0 ← p av g 0 + SumProbas n,i count ← count + Counts n,i p av g i ← SumProbas n,i / Counts n,i p av g 0 ← p av g 0 / count // then, assign each label to a child of n unassigned ← labels full ← ∅ count ← ( | unassigned | − ( M − 1)) for j = 1 to M do assigned j ← ∅ while unassigned 6 = ∅ do . . ∂ J n ∂ p ( n ) j | i is giv en in Equation 10 ( i ∗ , j ∗ ) ← argmax i ∈ unassigned ,j 6∈ full ∂ J n ∂ p ( n ) j | i if n = root then c i ∗ ← ( n, j ∗ ) else c i ∗ ← ( c i ∗ , ( n, j ∗ )) assigned j ∗ ← assigned j ∗ ∪ { i ∗ } unassigned ← unassigned \ { i ∗ } CheckFull (full, assigned, count, j ∗ ) for j = 1 to M do AssignLabels (assigned j , child n,j , d + 1 ) retur n assigned Let us now sho w how we can efficiently optimize J n . The gradient of J n with respect to the conditional probability distributions is (see proof of Lemma 1 in the Supplement): ∂ J n ∂ p ( n ) j | i = 2 M q ( n ) i (1 − q ( n ) i ) sign( p ( n ) j | i − p ( n ) j ) . (10) Then, according to Equation 10, increasing the likelihood of sending label i to any child j of n such that p ( n ) j | i > p ( n ) j Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation increases the objectiv e J n . Note that we only need to con- sider the labels i for which q ( n ) i > 0 , that is, labels i which reach node n in the current tree. W e also want to mak e sure that we ha ve a well-formed M - ary tree at each step, which means that the number of la- bels assigned to any node is always congruent to 1 modulo ( M − 1) . Algorithm 2 pro vides such an assignment by greedily choosing the label-child pair ( i, j ) such that j still has room for labels with the highest value of ∂ J n ∂ p ( n ) j | i . The global procedure, described in Algorithm 1, is then the following. • At the start of each batch, re-assign targets for each node prediction function, starting from the root and going do wn the tree. At each node, each label is more likely to be re-assigned to the child it has had most affinity with in the past (Algorithm 2). This can be seen as a form of hierarchical on-line clustering. • Every example no w has a unique path depending on its label. For each sample, we then take a gradient step at each node along the assigned path (see Algorithm 1). Lemma 1. Algorithm 2 finds the assignment of nodes to childr en for a fixed depth tr ee which most incr eases J n un- der well-formedness constraints. Remark 2. An interesting featur e of the algorithm, is that since the repr esentation of examples fr om differ ent classes ar e learned together , there is intuitively less of a risk of getting stuck in a specific tree configuration. Mor e specifi- cally , if two similar classes are initially assigned to differ- ent childr en of a node, the algorithm is less likely to keep this initial decision since the repr esentations for examples of both classes will be pulled together in other nodes. Next, we provide a theoretical analysis of the objectiv e in- troduced in Equation 6. Proofs are deferred to the Supple- mentary material. 5. Theoretical Results In this section, we first analyze theoretical properties of the objectiv e J n as regards node quality , then prov e a boosting statement for the global tree accuracy . 5.1. Properties of the objecti ve function W e start by showing that maximizing J n in ev ery node of the tree leads to high-quality nodes, i.e. perfectly balanced and perfectly pure node splits. Let us first introduce some formal definitions. Definition 1 (Balancedness factor) . The split in node n of the tr ee is β ( n ) -balanced if β ( n ) ≤ min j = { 1 , 2 ,...,M } p ( n ) j , wher e β ( n ) ∈ (0 , 1 M ] is a balancedness factor . A split is perfectly balanced if and only if β ( n ) = 1 M . Definition 2 (Purity factor) . The split in node n of the tree is α ( n ) -pur e if 1 M M X j =1 K X i =1 q ( n ) i min p ( n ) j | i , 1 − p ( n ) j | i ≤ α ( n ) , wher e α ( n ) ∈ [0 , 1 M ) is a purity factor . A split is perfectly pure if and only if α ( n ) = 0 . The following lemmas characterize the range of the objec- tiv e J n and link it to the notions of balancedness and purity of the split. Lemma 2. The objective function J n lies in the interval 0 , 4 M 1 − 1 M . Let J ∗ denotes the highest possible value of J n , i.e. J ∗ = 4 M 1 − 1 M . Lemma 3. The objective function J n admits the highest value, i.e. J n = J ∗ , if and only if the split in node n is perfectly balanced, i.e. β ( n ) = 1 M , and perfectly pure , i.e. α ( n ) = 0 . W e next show Lemmas 4 and 5 which analyze balancedness and purity of a node split in isolation, i.e. we analyze resp. balancedness and purity of a node split when resp. purity and balancedness is fixed and perfect. W e show that in such isolated setting increasing J n leads to a more balanced and more pure split. Lemma 4. If a split in node n is perfectly pur e, then β ( n ) ∈ " 1 M − p M ( J ∗ − J n ) 2 , 1 M # . Lemma 5. If a split in node n is perfectly balanced, then α ( n ) ≤ ( J ∗ − J n ) / 2 . Next we provide a bound on the classification error for the tree. In particular , we show that if the objectiv e is “weakly” optimized in each node of the tree, where this weak advan- tage is captured in a form of the W eak Hypothesis Assump- tion , then our algorithm will amplify this weak advantage to build a tree achie ving an y desired lev el of accuracy . 5.2. Error bound Denote y ( x ) to be a fixed target function with do- main X , which assigns the data point x to its label, and let P be a fixed target distrib ution ov er X . T o- gether y and P induce a distribution on labeled pairs ( x, y ( x )) . Let t ( x ) be the label assigned to data point x by the tree. W e denote as ( T ) the error of tree T , i.e. ( T ) : = E x ∼P h P K i =1 1 [ t ( x ) = i, y ( x ) 6 = i ] i ( 1 − ( T ) refers to the accuracy as giv en by Equation 4). Then the following theorem holds Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Theorem 1. The W eak Hypothesis Assumption says that for any distribution P over the data, at each node n of the tr ee T ther e exists a partition such that J n ≥ γ , wher e γ ∈ M 2 min j =1 , 2 ,...,M p j , 1 − M 2 min j =1 , 2 ,...,M p j . Under the W eak Hypothesis Assumption, for any κ ∈ [0 , 1] , to obtain ( T ) ≤ κ it suffices to have a tr ee with N ≥ 1 κ 16[ M (1 − 2 γ )+2 γ ]( M − 1) log 2 eM 2 γ 2 ln K internal nodes . The above theorem shows the number of splits that suffice to reduce the multi-class classification error of the tree be- low an arbitrary threshold κ . As shown in the proof of the abov e theorem, the W eak Hypothesis Assumption implies that all p j s satisfy: p j ∈ [ 2 γ M , M (1 − 2 γ )+2 γ M ] . Below we show a tighter version of this bound when assuming that each node induces balanced split. Corollary 1. The W eak Hypothesis Assumption says that for any distribution P over the data, at each node n of the tr ee T ther e exists a partition such that J n ≥ γ , wher e γ ∈ R + . Under the W eak Hypothesis Assumption and when all nodes make perfectly balanced splits, for any κ ∈ [0 , 1] , to obtain ( T ) ≤ κ it suffices to have a tr ee with N ≥ 1 κ 16( M − 1) log 2 eM 2 γ 2 ln K internal nodes . 6. Extension to Density Estimation W e no w show how to adapt the algorithm presented in Sec- tion 4 for conditional density estimation, using the example of language modeling. Hierarchical Log Bi-Linear Language Model (HLBL) W e take the same approach to language modeling as (Mnih & Hinton, 2009). First, using the chain rule and an order T Markov assumption we model the probability of a sentence w = ( w 1 , w 2 , . . . , w n ) as: p ( w 1 , w 2 , . . . , w n ) = n Y t =1 p ( w t | w t − T ,...,t − 1 ) Similarly to their work, we also use a low dimensional representation of the context ( w t − T ,...,t − 1 ) . In this set- ting, each word w in the vocab ulary V has an embedding U w ∈ R d r . A giv en context x = ( w t − T , . . . , w t − 1 ) cor- responding to position t is then represented by a context embedding vector r x such that r x = T X k =1 R k U w t − k , where U ∈ R |V |× d r is the embedding matrix, and R k ∈ R d r × d r is the transition matrix associated with the k th con- text word. The most straight-forward way to define a probability func- tion is then to define the distribution over the next word giv en the context representation as a soft-max, as done in (Mnih & Hinton, 2007). That is: p ( w t = i | x ) = σ i ( r > x U + b ) = exp( r > x U i + b i ) P w ∈V exp( r > x U w + b w ) , where b w is the bias for word w . Howe v er , the complexity of computing this probability distribution in this setting is O ( | V | × d r ) , which can be prohibiti v e for large corpora and vocab ularies. Instead, (Mnih & Hinton, 2009) takes a hierarchical ap- proach to the problem. They construct a binary tree, where each word w ∈ V corresponds to some leaf of the tree, and can thus be identified with the path from the root to the corresponding leaf by making a sequence of choices of going left versus right. This corresponds to the tree- structured log-likelihood objecti ve presented in Equation 5 for the case where M = 2 , and f Θ ( x ) = r x . Thus, if c i is the path to word i as defined in Expression 3, then: log p ( w t = i | x ) = D X d =1 log σ c i d, 2 (( r > x U c i d, 1 + b c i d, 1 ) (11) In this binary case, σ is the sigmoid function, and for all non-leaf nodes n ∈ { 1 , 2 , . . . , N } , we have U n ∈ R d r and b n ∈ R d r . The cost of computing the likelihood of word w is then reduced to O (log( |V | ) × d r ) . In their work, the authors start the training procedure by using a random tree, then alternate parameter learning with using a clustering- based heuristic to rebuild their hierarchy . W e expand upon their method by providing an algorithm which allows for using hierarchies of arbitrary width, and jointly learns the tree structure and the model parameters. Using our Algorithm W e may use Algorithm 1 as is to learn a good tree structure for classification: that is, a model that often predicts w t to be the most likely word after seeing the context ( w t − T , . . . , w t − 1 ) . Howev er , while this could certainly learn interesting representations and tree struc- ture, there is no guarantee that such a model would achie ve a good av erage log-likelihood. Intuitively , there are often sev eral valid possibilities for a word given its immediate left context, which a classification objective does not nec- essarily take into account. Y et another option would be to learn a tree structure that maximizes the classification objectiv e, then fine-tune the model parameters using the log-likelihood objecti ve. W e tried this method, but initial tests of this approach did not do much better than the use of random trees. Instead, we present here a small modifi- cation of Algorithm 1 which is equi v alent to log-likelihood training when restricted to the fixed tree setting, and can be sho wn to increase the value of the node objectiv es J n : by replacing the gradients with respect to p targ et by those Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation with respect to log p targ et . Then, for a given tree struc- ture, the algorithm takes a gradient step with respect to the log-likelihood of the samples: ∂ J n ∂ log p ( n ) j | i = 2 M q ( n ) i (1 − q ( n ) i ) sign( p ( n ) j | i − p ( n ) j ) p ( n ) j | i . (12) Lemma 1 extends to the ne w version of the algorithm. 7. Experiments W e ran experiments to ev aluate both the classification and density estimation version of our algorithm. For classifi- cation, we used the YFCC100M dataset (Thomee et al., 2016), which consists of a set of a hundred million Flickr pictures along with captions and tag sets split into 91M training, 930K validation and 543K test examples. W e focus here on the problem of predicting a picture’ s tags giv en its caption. For density estimation, we learned a log- bilinear language model on the Gutenberg novels corpus, and compared the perplexity to that obtained with other flat and hierarchical losses. Experimental settings are de- scribed in greater detail in the Supplementary material. 7.1. Classification W e follow the setting of (Joulin et al., 2016) for the YFCC100M tag prediction task: we only keep the tags which appear at least a hundred times, which leaves us with a label space of size 312K. W e compare our results to those obtained with the FastT ext software (Joulin et al., 2016), which uses a binary hierarchical softmax objec- tiv e based on Huf fman coding (Huf fman trees are designed to minimize the expected depth of their leav es weighed by frequencies and ha ve been sho wn to work well with word embedding systems (Mikolov et al., 2013)), and to the T agspace system (W eston et al., 2014), which uses a sampling-based margin loss (this allows for training in tractable time, b ut does not help at test time, hence the long times reported). W e also extend the FastT ext software to use Huffman trees of arbitrary width. All models use a bag- of-word embedding representation of the caption text; the parameters of the input representation function f Θ which we learn are the word embeddings U w ∈ R d (as in Section 6) and a caption representation is obtained by summing the embeddings of its words. W e experimented with embed- dings of dimension d = 50 and d = 200 . W e predict one tag for each caption, and report the precision as well as the training and test times in T able 1. Our implementation is based on the FastT ext open source version 1 , to which we added M -ary Huf fman and learned tree objectives. T able 1 reports the best accuracy we ob- tained with a hyper-parameter search using this version on our system so as to provide the most meaningful compari- son, even though the accuracy is less than that reported in 1 https://github .com/facebookresearch/fastT ext d Model Arity P@1 T rain T est 50 T agSpace 1 - 30.1 3h8 6h FastT ext 2 2 27.2 8m 1m M -ary Huffman T ree 5 28.3 8m 1m 20 29.9 10m 3m Learned T ree 5 31.6 18m 1m 20 32.1 30m 3m 200 T agSpace 1 35.6 5h32 15h FastT ext 2 2 35.2 12m 1m M -ary Huffman T ree 5 35.8 13m 2m 20 36.4 18m 3m Learned T ree 5 36.1 35m 3m 20 36.6 45m 8m T able 1. Classification performance on the YFCC100M dataset. 1 (W eston et al., 2014). 2 (Joulin et al., 2016). M -ary Huffman T ree modifies FastT ext by adding an M -ary hierarchical softmax objectiv e. (Joulin et al., 2016). W e gain a few different insights from T able 1. First, al- though wider trees are theoretically slower (remember that the theoretical complexity is O ( M log M ( N )) for an M -ary tree with N labels), they run incomparable time in practice and always perform better . Using our algorithm to learn the structure of the tree also always leads to more accu- rate models, with a gain of up to 3.3 precision points in the smaller 5-ary setting. Further , both the importance of having wider trees and learning the structure seems to be less when the node prediction functions become more ex- pressiv e. At a high lev el, one could imagine that in that setting, the model can learn to use different dimensions of the input representation for different nodes, which would minimize the negati ve impact of having to learn a repre- sentation which is suited to more nodes. Another thing to notice is that since prediction time only depends on the expected depth of a label, our models which learned balanced trees are nearly as fast as Huf fman coding which is optimal in that respect (except for the dimension 200, 20-ary tree, but the tree structure had not stabilized yet in that setting). Giv en all of the abov e remarks, our al- gorithm especially shines in settings where computational complexity and prediction time are highly constrained at test time, such as mobile devices or embedded systems. 7.2. Density Estimation W e also ran language modeling experiments on the Guten- berg no vel corpus 2 , which has about 50M tokens and a vo- cabulary of 250,000 w ords. 2 http://www .gutenberg.or g/ Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation 5402: only never just still 5367: turned stood sat ran 5393: got found heard met 5337: put set lay cut 3992: her him my them 4360: a no an something 4400: it what nothing anything 4412: this these those m. 26: , . of to 73: had been could only 4003: first most next best 67: the a it his 2 (root): , the . and ... ... ... ... ... Figure 3. Tree learned from the Gutenberg corpus, sho wing the four most common words assigned to each node. 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 epochs 140 150 160 170 180 190 200 perplexity random flat learned Figure 2. T est perplexity per epoch. One notable difference from the previous task is that the language modeling setting can drastically benefit from the use of GPU computing, which can make using a flat soft- max tractable (if not fast). While our algorithm requires more flexibility and thus does not benefit as much from the use of GPUs, a small modification of Algorithm 2 (de- scribed in the Supplementary material) allows it to run un- der a maximum depth constraint and remain competitiv e. The results presented in this section are obtained using this modified version, which learns 65-ary trees of depth 3. T able 2 presents perplexity results for different loss func- tions, along with the time spent on computing and learning the objective (softmax parameters for the flat version, hi- erarchical softmax node parameters for the fixed tree, and hierarchical softmax structure and parameters for our algo- rithm). The learned tree model is nearly three and sev en times as fast at train and test time respectively as the flat objectiv e without losing any points of perplexity . Huffman coding does not apply to trees where all of the leav es are at the same depth. Instead, we use the follow- ing heuristic as a baseline, inspired by (Mnih & Hinton, Model perp. train ms/batch test ms/batch Clustering T ree 212 2.0 1.0 Random T ree 160 1.9 0.9 Flat soft-max 149 12.5 6.9 Learned T ree 148 4.5 0.9 T able 2. Comparison of a flat soft-max to a 65-ary hierarchical soft-max (learned, random and heuristic-based tree). 2009): we learn word embeddings using FastT ext, perform a hierarchical clustering of the v ocabulary based on these, then use the resulting tree to learn a new language model. W e call this approach “Clustering Tree”. Howe ver , for all hyper-parameter settings, this tree structure did worse than a random one. W e conjecture that its poor performance is because such a tree structure means that the deepest node decisions can be quite difficult. Figure 2 shows the e volution of the test perplexity for a few epochs. It appears that most of the relev ant tree structure can be learned in one epoch: from the second epoch on, the learned hierarchical soft-max performs similarly to the flat one. Figure 3 sho ws a part of the tree learned on the Gutenberg dataset, which appears to make semantic and syntactic sense. 8. Conclusion In this paper , we introduced a prov ably accurate algo- rithm for jointly learning tree structure and data represen- tation for hierarchical prediction. W e applied it to a multi- class classification and a density estimation problem, and showed our models’ ability to achie ve fa vorable accuracy in competitiv e times in both settings. Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation References Agarwal, A., Kakade, S. M., Karampatziakis, N., Song, L., and V aliant, G. Least squares re visited: Scalable ap- proaches for multi-class prediction. In ICML , 2014. Agarwal, R., Gupta, A., Prabhu, Y ., and V arma, M. Multi- label learning with millions of labels: Recommending advertiser bid phrases for web pages. In WWW , 2013. Andreas, J. and Klein, D. When and why are log-linear models self-normalizing? In N AA CL HLT , 2015. Azocar , A., Gimenez, J., Nikodem, K., and Sanchez, J. L. On strongly midcon vex functions. Opuscula Math. , 31 (1):15–26, 2011. Beijbom, O., Saberian, M., Kriegman, D., and V asconce- los, N. Guess-av erse loss functions for cost-sensitiv e multiclass boosting. In ICML , 2014. Bengio, S., W eston, J., and Grangier, D. Label embedding trees for large multi-class tasks. In NIPS , 2010. Bengio, Y . and S ´ en ´ ecal, J.-S. Quick training of probabilis- tic neural nets by importance sampling. In AIST ATS , 2003. Bengio, Y . and Senecal, J.-S. Adaptiv e importance sam- pling to accelerate training of a neural probabilistic lan- guage model. IEEE T rans. Neural Networks , 19:713– 722, 2008. Bengio, Y ., Ducharme, R., V ., Pascal, and Jan vin, C. A neural probabilistic language model. J. Mach. Learn. Res. , 3:1137–1155, 2003. Beygelzimer , A., Langford, J., Lifshits, Y ., Sorkin, G. B., and Strehl, A. L. Conditional probability tree estimation analysis and algorithms. In U AI , 2009a. Beygelzimer , A., Langford, J., and Ra vikumar, P . D. Error- correcting tournaments. In ALT , 2009b. Bhatia, K., Jain, H., Kar , P ., V arma, M., and Jain, P . Sparse local embeddings for e xtreme multi-label classification. In NIPS . 2015. Bishop, C. M. P attern Reco gnition and Machine Learning . Springer , 2006. Bottou, L. Online algorithms and stochastic approxima- tions. In Online Learning and Neural Networks . Cam- bridge Univ ersity Press, 1998. Breiman, L. Random forests. Mac h. Learn. , 45:5–32, 2001. Breiman, L., Friedman, J. H., Olshen, R. A., and Stone, C. J. Classification and Regr ession T r ees . CRC Press LLC, Boca Raton, Florida, 1984. Choromanska, A. and Langford, J. Logarithmic time online multiclass prediction. In NIPS . 2015. Choromanska, A., Choromanski, K., and Bojarski, M. On the boosting ability of top-do wn decision tree learn- ing algorithm for multiclass classification. CoRR , abs/1605.05223, 2016. Daume, H., Karampatziakis, N., Langford, J., and Mineiro, P . Logarithmic time one-against-some. CoRR , abs/1606.04988, 2016. de Br ´ ebisson, A. and V incent, P . An e xploration of softmax alternativ es belonging to the spherical loss family . In ICLR , 2016. Deng, J., Satheesh, S., Berg, A. C., and Fei-Fei, L. Fast and balanced: Efficient label tree learning for lar ge scale object recognition. In NIPS , 2011. Djuric, N., W u, H., Radosavljevic, V ., Grbovic, M., and Bhamidipati, N. Hierarchical neural language models for joint representation of streaming documents and their content. In WWW , 2015. Grav e, E., Joulin, A., Ciss ´ e, M., Grangier, D., and J ´ egou, H. Ef ficient softmax approximation for gpus. CoRR , abs/1609.04309, 2016. Gutmann, M. U. and Hyv ¨ arinen, A. Noise-contrastive es- timation of unnormalized statistical models, with appli- cations to natural image statistics. J . Mach. Learn. Res. , 13(1):307–361, 2012. Hsu, D., Kakade, S., Langford, J., and Zhang, T . Multi- label prediction via compressed sensing. In NIPS , 2009. Jelinek, F . and Mercer , R. L. Interpolated estimation of Markov source parameters from sparse data. In Pr oceed- ings, W orkshop on P attern Recognition in Practice , pp. 381–397. North Holland, 1980. Joulin, Armand, Gra ve, Edouard, Bojanowski, Piotr , and Mikolov , T omas. Bag of tricks for efficient text classifi- cation. CoRR , abs/1607.01759, 2016. Katz, S. M. Estimation of probabilities from sparse data for the language model component of a speech recognizer . In IEEE T rans. on Acoustics, Speech and Singal pr oc. , volume ASSP-35, pp. 400–401, 1987. K ontschieder, P ., Fiterau, M., Criminisi, A., and Bulo’, S. Rota. Deep Neural Decision Forests. In ICCV , 2015. Kumar , A., Irsoy , O., Su, J., Bradbury , J., English, R., Pierce, B., Ondruska, P ., Gulrajani, I., and Socher, R. Ask me anything: Dynamic memory networks for natu- ral language processing. CoRR , abs/1506.07285, 2015. Madzarov , G., Gjorgje vikj, D., and Chorbev , I. A multi- class svm classifier utilizing binary decision tree. Infor- matica , 33(2):225–233, 2009. Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Mikolov , T ., Karafit, M., Burget, L., Cernock, J., and Khu- danpur , S. Recurrent neural network based language model. In INTERSPEECH , 2010. Mikolov , T ., Deoras, A., K ombrink, S., Burget, L., and Cer- nocky , J. Honza. Empirical e valuation and combination of advanced language modeling techniques. In INTER- SPEECH , 2011. Mikolov , T ., Sutskev er , I., Chen, K., Corrado, G. S., and Dean, J. Distributed representations of words and phrases and their compositionality . In NIPS , 2013. Mirowski, P . and Vlachos, A. Dependency recurrent neu- ral language models for sentence completion. CoRR , abs/1507.01193, 2015. Mnih, A. and Hinton, G. Three new graphical models for statistical language modelling. In ICML , 2007. Mnih, A. and Hinton, G. E. A scalable hierarchical dis- tributed language model. In NIPS . 2009. Mnih, A. and T eh, Y . W . A fast and simple algorithm for training neural probabilistic language models. In ICML , 2012. Morin, F . and Bengio, Y . Hierarchical probabilistic neural network language model. In AIST A TS , 2005. Prabhu, Y . and V arma, M. Fastxml: A fast, accurate and stable tree-classifier for extreme multi-label learning. In A CM SIGKDD , 2014. Ram, P . and Gray , A. G. Density estimation trees. In KDD , 2011. Schwenk, H. and Gauvain, J.-L. Connectionist language modeling for large v ocabulary continuous speech recog- nition. In ICASSP , 2002. Schwenk, H. and Gauvain, J.-L. Training neural network language models on very lar ge corpora. In HLT , 2005. Shalev-Shw artz, S. Online learning and online con vex op- timization. F ound. T rends Mach. Learn. , 4(2):107–194, 2012. T ai, K. S., Socher , R., and Manning, C. D. Improved se- mantic representations from tree-structured long short- term memory networks. CoRR , abs/1503.00075, 2015. Thomee, Bart, Shamma, David A., Friedland, Gerald, Elizalde, Benjamin, Ni, Karl, Poland, Douglas, Borth, Damian, and Li, Li-Jia. YFCC100M: the new data in multimedia research. Commun. A CM , 59(2):64–73, 2016. V incent, P ., de Br ´ ebisson, A., and Bouthillier , X. Efficient exact gradient update for training deep netw orks with very lar ge sparse targets. In NIPS , 2015. W eston, J., Bengio, S., and Usunier , N. Wsabie: Scaling up to large v ocabulary image annotation. In IJCAI , 2011. W eston, J., Makadia, A., and Y ee, H. Label partitioning for sublinear ranking. In ICML , 2013. W eston, Jason, Chopra, Sumit, and Adams, Keith. #tagspace: Semantic embeddings from hashtags. In Pr o- ceedings of the 2014 Confer ence on Empirical Methods in Natural Language Pr ocessing, EMNLP 2014, Octo- ber 25-29, 2014, Doha, Qatar , A meeting of SIGD AT , a Special Interest Gr oup of the ACL , pp. 1822–1827, 2014. Zhao, B. and Xing, E. P . Sparse output coding for large- scale visual recognition. In CVPR , 2013. Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Simultaneous Lear ning of T r ees and Repr esentations f or Extr eme Classification with A pplication to Language Modeling (Supplementary material) 9. Geometric interpr etation of probabilities p ( n ) j and p ( n ) j | i K 1 K 2 K 3 K 4 100 100 70 100 100 70 70 70 100 100 100 100 h Discrete: p ( n ) 1 = 6 12 = 0 . 5 p ( n ) 1 | 1 = 3 3 = 1 , p ( n ) 1 | 2 = 3 3 = 1 , p ( n ) 1 | 3 = 0 3 = 0 , p ( n ) 1 | 4 = 0 3 = 0 Continuous: p ( n ) 1 = 1 12 ( σ (100) + σ (70) + . . . + σ ( − 70) + σ ( − 100)) ≈ 0 . 5 p ( n ) 1 | 1 = 1 3 ( σ (100) + σ (70) + σ (100)) ≈ 1 p ( n ) 1 | 2 = 1 3 ( σ (100) + σ (70) + σ (100)) ≈ 1 p ( n ) 1 | 3 = 1 3 ( σ ( − 100) + σ ( − 70) + σ ( − 100)) ≈ 0 p ( n ) 1 | 4 = 1 3 ( σ ( − 100) + σ ( − 70) + σ ( − 100)) ≈ 0 Figure 3. The comparison of discrete and continuous definitions of probabilities p ( n ) j and p ( n ) j | i on a simple example with K = 4 classes and binary tree ( M = 2 ). n is an ex emplary node, e.g. root. σ denotes sigmoid function. Color circles denote data points. Remark 3. One could define p ( n ) j as the ratio of the number of examples that r each node n and are sent to its j th child to the total the number of examples that r each node n and p ( n ) j | i as the ratio of the number of examples that r each node n , corr espond to label i , and ar e sent to the j th child of node n to the total the number of examples that reac h node n and corr espond to label i . W e instead look at the continuous counter-parts of these discr ete definitions as given by Equations 8 and 9 and illustrated in F igure 3 (note that continuous definitions have ele gant geometric interpretation based on margins), which simplifies the optimization pr oblem. 10. Theoretical pr oofs Pr oof of Lemma 1. Recall the form of the objecti ve defined in 6: J n = 2 M K X i =1 q ( n ) i M X j =1 | p ( n ) j − p ( n ) j | i | = 2 M E i ∼ q ( n ) h f J n ( i, p ( n ) ·|· , q ( n ) ) i Where: f J n ( i, p ( n ) ·|· , q ( n ) ) = M X j =1 p ( n ) j − p ( n ) j | i = M X j =1 p ( n ) j | i − K X i 0 =1 q ( n ) i 0 p ( n ) j | i 0 = M X j =1 K X i 0 =1 ( 1 i = i 0 − q ( n ) i 0 ) p ( n ) j | i 0 Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Hence: ∂ f J n ( i, p ( n ) ·|· , q ( n ) ) ∂ p ( n ) j | i = (1 − q ( n ) i ) sign( p ( n ) j | i − p ( n ) j ) And: ∂ f J n ( i, p ( n ) ·|· , q ( n ) ) ∂ log p ( n ) j | i = (1 − q ( n ) i ) sign( p ( n ) j | i − p ( n ) j ) ∂ p ( n ) j | i ∂ log p ( n ) j | i = (1 − q ( n ) i ) sign( p ( n ) j | i − p ( n ) j ) p ( n ) j | i By assigning each label j to a specific child i under the constraint that no child has more than L labels, we take a step in the direction ∂ E ∈ { 0 , 1 } M × K , where: ∀ i ∈ [1 , K ] , P M j =1 ∂ E j,i = 1 and ∀ j ∈ [1 , M ] , P K i =1 ∂ E j,i ≤ L Thus: ∂ J n ∂ p ( n ) ·|· ∂ E = 2 M E i ∼ q ( n ) h f J n ( i, p ( n ) ·|· , q ( n ) ) i ∂ p ( n ) ·|· ∂ E = 2 M K X i =1 q ( n ) i (1 − q ( n ) i ) M X j =1 sign( p ( n ) j | i − p ( n ) j ) ∂ E j,i (13) And: ∂ J n ∂ log p ( n ) ·|· ∂ E = 2 M K X i =1 q ( n ) i (1 − q ( n ) i ) M X j =1 sign( p ( n ) j | i − p ( n ) j ) p ( n ) j | i ∂ E j,i (14) If there exists such an assignment for which 13 is positiv e, then the greedy method proposed in 2 finds it. Indeed, suppose that Algorithm 2 assigns label i to child j and i 0 to j 0 . Suppose now that another assignment ∂ E 0 sends i to j 0 and i to j 0 . Then: ∂ J n ∂ p ( n ) ·|· ∂ E − ∂ E 0 = ∂ J n ∂ p ( n ) j | i + ∂ J n ∂ p ( n ) j 0 | i 0 − ∂ J n ∂ p ( n ) j | i 0 + ∂ J n ∂ p ( n ) j 0 | i (15) Since the algorithm assigns children by descending order of ∂ J n ∂ p ( n ) j | i until a child j is full, we have: ∂ J n ∂ p ( n ) j | i ≥ ∂ J n ∂ p ( n ) j | i 0 and ∂ J n ∂ p ( n ) 0 j | i 0 ≥ ∂ J n ∂ p ( n ) j 0 | i Hence: ∂ J n ∂ p ( n ) ·|· ∂ E − ∂ E 0 ≥ 0 Thus, the greedy algorithm finds the assignment that most increases J n most under the children size constraints. Moreov er , ∂ J n ∂ p ( n ) ·|· is always positi ve for L ≤ M or L ≥ 2 M ( M − 2) . Pr oof of Lemma 2. Both J n and J T are defined as the sum of non-negati ve values which gi ves the lower-bound. W e next deriv e the upper-bound on J n . Recall: J n = 2 M M X j =1 K X i =1 q ( n ) i | p ( n ) j − p ( n ) j | i | = 2 M M X j =1 K X i =1 q ( n ) i K X l =1 q ( n ) l p ( n ) j | l − p ( n ) j | i Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation since p ( n ) j = P K l =1 q ( n ) l p ( n ) j | l . The objectiv e J n is maximized on the extremes of the [0 , 1] interval. Thus, define the following tw o sets of indices: O j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 1 } and Z j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 0 } . W e omit indexing these sets with n for the ease of notation. W e continue as follows J n ≤ 2 M M X j =1 X i ∈ O j q ( n ) i 1 − X l ∈ O j q ( n ) l + X i ∈ Z j q ( n ) i X l ∈ O j q ( n ) l = 4 M M X j =1 X i ∈ O j q ( n ) i − X i ∈ O j q ( n ) i 2 = 4 M 1 − M X j =1 X i ∈ O j q ( n ) i 2 , where the last inequality is the consequence of the following: P M j =1 p ( n ) j = 1 and p ( n ) j = P K l =1 q ( n ) l p ( n ) j | l = P i ∈ O j q ( n ) i , thus P M j =1 P i ∈ O j q ( n ) i = 1 . Apllying Jensen’ s ineqality to the last inequality obtained giv es J n ≤ 4 M − 4 M X j =1 1 M X i ∈ O j q ( n ) i 2 = 4 M 1 − 1 M That ends the proof. Pr oof of Lemma 3. W e start from proving that if the split in node n is perfectly balanced, i.e. ∀ j = { 1 , 2 ,...,M } p ( n ) j = 1 M , and perfectly pure, i.e. ∀ j = { 1 , 2 ,...,M } i = { 1 , 2 ,...,K } min( p ( n ) j | i , 1 − p ( n ) j | i ) = 0 , then J n admits the highest v alue J n = 4 M 1 − 1 M . Since the split is maximally balanced we write: J n = 2 M M X j =1 K X i =1 q ( n ) i 1 M − p ( n ) j | i . Since the split is maximally pure, each p ( n ) j | i can only take value 0 or 1 . As in the proof of previous lemma, define two sets of indices: O j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 1 } and Z j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 0 } . W e omit indexing these sets with n for the ease of notation. Thus J n = 2 M M X j =1 X i ∈ O j q ( n ) i 1 − 1 M + X i ∈ Z j q ( n ) i 1 M = 2 M M X j =1 X i ∈ O j q ( n ) i 1 − 1 M + 1 M 1 − X i ∈ O j q ( n ) i = 2 M 1 − 2 M M X j =1 X i ∈ O j q ( n ) i + 2 M = 4 M 1 − 1 M , Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation where the last equality comes from the fact that P M j =1 p ( n ) j = 1 and p ( n ) j = P K l =1 q ( n ) l p ( n ) j | l = P i ∈ O j q ( n ) i , thus P M j =1 P i ∈ O j q ( n ) i = 1 . Thus we are done with proving one induction direction. Next we prov e that if J n admits the highest value J n = 4 M 1 − 1 M , then the split in node n is perfectly balanced, i.e. ∀ j = { 1 , 2 ,...,M } p ( n ) j = 1 M , and perfectly pure, i.e. ∀ j = { 1 , 2 ,...,M } i = { 1 , 2 ,...,K } min( p ( n ) j | i , 1 − p ( n ) j | i ) = 0 . W ithout loss of generality assume each q ( n ) i ∈ (0 , 1) . The objective J n is certainly maximized in the extremes of the interval [0 , 1] , where each p ( n ) j | i is either 0 or 1 . Also, at maximum it cannot be that for any given j , all p ( n ) j | i ’ s are 0 or all p ( n ) j | i ’ s are 1 . The function J ( h ) is differentiable in these extremes. Next, define three sets of indices: A j = { i : K X l =1 q ( n ) i p ( n ) j | l ≥ p ( n ) j | i } and B j = { i : K X l =1 q ( n ) i p ( n ) j | l < p ( n ) j | i } and C j = { i : K X l =1 q ( n ) i p ( n ) j | l > p ( n ) j | i } . W e omit indexing these sets with n for the ease of notation. Objectiv e J n can then be re-written as J n = 2 M M X j =1 X i ∈A j q ( n ) i K X l =1 q ( n ) i p ( n ) j | l − p ( n ) j | i ! + 2 X i ∈B j q ( n ) i p ( n ) j | i − K X l =1 q ( n ) i p ( n ) j | l ! , W e next compute the deriv atives of J n with respect to p ( n ) j | z , where z = { 1 , 2 , . . . , K } , ev erywhere where the function is differentiable and obtain ∂ J n ∂ p ( n ) j | z = ( 2 q ( n ) z ( P i ∈C j q ( n ) i − 1) if z ∈ C j 2 q ( n ) z (1 − P i ∈B j q ( n ) i ) if z ∈ B j , Note that in the extremes of the interv al [0 , 1] where J n is maximized, it cannot be that P i ∈C j q ( n ) i = 1 or P i ∈B j q ( n ) i = 1 thus the gradient is non-zero. This fact and the fact that J n is con vex imply that J n can only be maximized at the extremes of the [0 , 1] interv al. Thus if J n admits the highest value, then the node split is perfectly pure. W e still need to show that if J n admits the highest v alue, then the node split is also perfectly balanced. W e gi ve a proof by contradiction, thus we assume that at least for one v alue of j , p ( n ) j 6 = 1 M , or in other words if we decompose each p ( n ) j as p ( n ) j = 1 M + x j , then at least for one value of j , x j 6 = 0 . Lets once again define two sets of indices (we omit indexing x j and these sets with n for the ease of notation): O j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 1 } and Z j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 0 } , Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation and recall that p ( n ) j = P K l =1 q ( n ) l p ( n ) j | l = P i ∈ O j q ( n ) i . W e proceed as follows 4 M 1 − 1 M = J n = 2 M M X j =1 X i ∈ O j q ( n ) i (1 − p ( n ) j ) + X i ∈ Z j q ( n ) i p ( n ) j = 2 M M X j =1 h p ( n ) j (1 − p ( n ) j ) + p ( n ) j (1 − p ( n ) j ) i = 4 M M X j =1 h p ( n ) j − ( p ( n ) j ) 2 i = 4 M 1 − M X j =1 ( p ( n ) j ) 2 = 4 M 1 − M X j =1 1 M + x j 2 = 4 M 1 − 1 M − 2 M M X j =1 x j − M X j =1 x 2 j < 4 M 1 − 1 M Thus we obtain the contradiction which ends the proof. Pr oof of Lemma 4. Since we node that the split is perfectly pure, then each p ( n ) j | i is either 0 or 1 . Thus we define two sets O j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 1 } and Z j = { i : i ∈ { 1 , 2 , . . . , K } , p ( n ) j | i = 0 } . and thus J n = 2 M M X j =1 X i ∈ O j q ( n ) i (1 − p j ) + X i ∈ Z j q ( n ) i p j Note that p j = P i ∈ O j q ( n ) i . Then J n = 2 M M X j =1 [ p j (1 − p j ) + (1 − p j ) p j ] = 4 M M X j =1 p j (1 − p j ) = 4 M 1 − M X j =1 p 2 j and thus M X j =1 p 2 j = 1 − M J n 4 . (16) Lets express p j as p j = 1 M + j , where j ∈ [ − 1 M , 1 − 1 M ] . Then M X j =1 p 2 j = M X j =1 1 M + j 2 = 1 M + 2 M M X j =1 j + M X j =1 2 j = 1 M + M X j =1 2 j , (17) since 2 M P M j =1 j = 0 . Thus combining Equation 16 and 17 1 M + M X j =1 2 j = 1 − M J n 4 Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation and thus M X j =1 2 j = 1 − 1 M − M J n 4 . The last statement implies that max j =1 , 2 ,...,M j ≤ r 1 − 1 M − M J n 4 , which is equiv alent to min j =1 , 2 ,...,M p j = 1 M − max j j ≥ 1 M − r 1 − 1 M − M J n 4 = 1 M − p M ( J ∗ − J n ) 2 . Pr oof of Lemma 5. Since the split is perfectly balanced we ha ve the follo wing: J n = 2 M M X j =1 K X i =1 q ( n ) i 1 M − p ( n ) j | i = 2 M K X i =1 M X j =1 q ( n ) i 1 M − p ( n ) j | i Define two sets A i = { j : j ∈ { 1 , 2 , . . . , K } , p ( n ) j | i < 1 M } and B i = { j : j ∈ { 1 , 2 , . . . , K } , p ( n ) j | i ≥ 1 M } . Then J n = 2 M K X i =1 X j ∈A i q ( n ) i 1 M − p ( n ) j | i + X j ∈B i q ( n ) i p ( n ) j | i − 1 M = 2 M K X i =1 q ( n ) i X j ∈A i 1 M − p ( n ) j | i + X j ∈B i p ( n ) j | i − 1 M = 2 M K X i =1 q ( n ) i X j ∈A i 1 M − p ( n ) j | i + X j ∈B i (1 − 1 M ) − (1 − p ( n ) j | i ) Recall that the optimal value of J n is: J ∗ = 4 M 1 − 1 M = 2 M N X i =1 q ( n ) i ( M − 1) 1 M + 1 − 1 M = 2 M N X i =1 q ( n ) i X j ∈A i ∪B i 1 M − 1 M + 1 − 1 M Note A i can hav e at most M − 1 elements. Furthermore, ∀ j ∈ A i , p ( n ) j | i < 1 − p ( n ) j | i . Then, we have: J ∗ − J n = 2 M K X i =1 q ( n ) i X j ∈A i p ( n ) j | i + X j ∈B i (1 − p ( n ) j | i ) + 1 M − (1 − 1 M ) − 1 M + 1 − 1 M Hence, since B i has at least one element: J ∗ − J n ≥ 2 M K X i =1 q ( n ) i X j ∈A i p ( n ) j | i + X j ∈B i 1 − p ( n ) j | i ≥ 2 M K X i =1 q ( n ) i M X j =1 min( p ( n ) j | i , 1 − p ( n ) j | i ) ≥ 2 α Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Pr oof of Theorem 1. Let the weight of the tree leaf be defined as the probability that a randomly chosen data point x drawn from some fixed target distribution P reaches this leaf. Suppose at time step t , n is the heaviest leaf and has weight w . Consider splitting this leaf to M children n 1 , n 2 , . . . , n M . Let the weight of the j th child be denoted as w j . Also for the ease of notation let p j refer to p ( n ) j (recall that P m j =1 p j = 1 ) and p j | i refer to p ( n ) j | i , and furthermore let q i be the shorthand for q ( n ) i . Recall that p j = P K i =1 q i p j | i and P K i =1 q i = 1 . Notice that for any j = { 1 , 2 , . . . , M } , w j = w p j . Let q be the k -element vector with i th entry equal to q i . Define the following function: ˜ G e ( q ) = P K i =1 q i ln 1 q i . Recall the expression for the entropy of tree leav es: G e = P l ∈L w l P K i =1 q ( l ) i ln 1 q ( l ) i , where L is a set of all tree leaves. Before the split the contribution of node n to G e was equal to w ˜ G e ( q ) . Note that for any j = { 1 , 2 , . . . , M } , q ( n j ) i = q i p j | i p j is the probability that a randomly chosen x drawn from P has label i given that x reaches node n j . For bre vity , let q n j i be denoted as q j,i . Let q j be the k -element vector with i th entry equal to q j,i . Notice that q = P M j =1 p j q j . After the split the contribution of the same, no w internal, node n changes to w P M j =1 p j ˜ G e ( q j ) . W e denote the difference between the contribution of node n to the value of the entropy-based objecti ves in times t and t + 1 as ∆ e t := G e t − G e t +1 = w ˜ G e ( q ) − M X j =1 p j ˜ G e ( q j ) . (18) The entropy function ˜ G e is strongly concave with respect to l 1 -norm with modulus 1 , thus we extend the inequality giv en by Equation 7 in (Choromanska et al., 2016) by applying Theorem 5.2. from (Azocar et al., 2011) and obtain the follo wing bound ∆ e t = w ˜ G e ( q ) − M X j =1 p j ˜ G e ( q j ) ≥ w 1 2 M X j =1 p j k q j − M X l =1 p l q l k 2 1 = w 1 2 M X j =1 p j K X i =1 q i p j | i p j − M X l =1 p l q i p l | i p l ! 2 = w 1 2 M X j =1 p j K X i =1 q i p j | i p j − M X l =1 p l | i ! 2 = w 1 2 M X j =1 p j K X i =1 q i p j | i p j − 1 ! 2 = w 1 2 M X j =1 1 p j K X i =1 q i p j | i − p j ! 2 . Before proceeding, we will bound each p j . Note that by the W eak Hypothesis Assumption we have γ ∈ M 2 min j =1 , 2 ,...,M p j , 1 − M 2 min j =1 , 2 ,...,M p j , thus min j =1 , 2 ,...,M p j ≥ 2 γ M , thus all p j s are such that p j ≥ 2 γ M . Thus max j =1 , 2 ,...,M p j ≤ 1 − 2 γ M ( M − 1) = M (1 − 2 γ ) + 2 γ M . Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Thus all p j s are such that p j ≤ M (1 − 2 γ )+2 γ M . ∆ e t ≥ w M 2 2[( M (1 − 2 γ ) + 2 γ ] M X j =1 1 M K X i =1 q i p j | i − p j ! 2 ≥ w M 2 2[( M (1 − 2 γ ) + 2 γ ] M X j =1 1 M K X i =1 q i p j | i − p j 2 = w M 2 8[( M (1 − 2 γ ) + 2 γ ] 2 M M X j =1 K X i =1 q i p j | i − p j 2 = M 2 [( M (1 − 2 γ ) + 2 γ ] w J 2 n 8 , where the last inequality is a consequence of Jensen’ s inequality . w can further be lower -bounded by noticing the following G e t = X l ∈L w l K X i =1 q ( l ) i ln 1 q ( l ) i ! ≤ X l ∈L w l ln K ≤ w ln K X l ∈L 1 = [ t ( M − 1) + 1] w ln K ≤ ( t + 1)( M − 1) w ln K, where the first inequality results from the fact that uniform distrib ution maximizes the entropy . This giv es the lower -bound on ∆ e t of the following form: ∆ e t ≥ M 2 G e t J 2 n 8( t + 1)[ M (1 − 2 γ ) + 2 γ ]( M − 1) ln K , and by using W eak Hypothesis Assumption we get ∆ e t ≥≥ M 2 G e t γ 2 8( t + 1)[ M (1 − 2 γ ) + 2 γ ]( M − 1) ln K Follo wing the recursion of the proof in Section 3.2 in (Choromanska et al., 2016) (note that in our case G e 1 ≤ 2( M − 1) ln K ), we obtain that under the W eak Hypothesis Assumption , for any κ ∈ [0 , 2( M − 1) ln K ] , to obtain G e t ≤ κ it suffices to mak e t ≥ 2( M − 1) ln K κ 16[ M (1 − 2 γ )+2 γ ]( M − 1) ln K M 2 log 2 eγ 2 splits. W e next proceed to directly proving the error bound. Denote w ( l ) to be the probability that a data point x reached leaf l . Recall that q ( l ) i is the probability that the data point x corresponds to label i gi ven that x reached l , i.e. q ( l ) i = P ( y ( x ) = i | x reached l ) . Let the label assigned to the leaf be the majority label and thus lets assume that the leaf is assigned to label i if and only if the follo wing is true ∀ z = { 1 , 2 ,...,k } z 6 = i q ( l ) i ≥ q ( l ) z . Therefore we can write that ( T ) = K X i =1 P ( t ( x ) = i, y ( x ) 6 = i ) (19) = X l ∈L w ( l ) K X i =1 P ( t ( x ) = i, y ( x ) 6 = i | x reached l ) = X l ∈L w ( l ) K X i =1 P ( y ( x ) 6 = i | t ( x ) = i, x reached l ) P ( t ( x ) = i | x reached l ) = X l ∈L w ( l )(1 − max( q ( l ) 1 , q ( l ) 2 , . . . , q ( l ) K )) K X i =1 P ( t ( x ) = i | x reached l ) = X l ∈L w ( l )(1 − max( q ( l ) 1 , q ( l ) 2 , . . . , q ( l ) K )) (20) Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Consider again the Shannon entropy G ( T ) of the leav es of tree T that is defined as G e ( T ) = X l ∈L w ( l ) K X i =1 q ( l ) i log 2 1 q ( l ) i . (21) Let i l = arg max i = { 1 , 2 ,...,K } q ( l ) i . Note that G e ( T ) = X l ∈L w ( l ) K X i =1 q ( l ) i log 2 1 q ( l ) i ≥ X l ∈L w ( l ) K X i =1 i 6 = i l q ( l ) i log 2 1 q ( l ) i ≥ X l ∈L w ( l ) K X i =1 i 6 = i l q ( l ) i = X l ∈L w ( l )(1 − max( q ( l ) 1 , q ( l ) 2 , . . . , q ( l ) K )) = ( T ) , (22) where the last inequality comes from the f act that ∀ i = { 1 , 2 ,...,K } i 6 = i l q ( l ) i ≤ 0 . 5 and thus ∀ i = { 1 , 2 ,...,K } i 6 = i l 1 q ( l ) i ∈ [2; + ∞ ] and consequently ∀ i = { 1 , 2 ,...,K } i 6 = i l log 2 1 q ( l ) i ∈ [1; + ∞ ] . W e next use the proof of Theorem 6 in (Choromanska et al., 2016). The proof modifies only slightly for our purposes and thus we only list these modifications below . • Since we define the Shannon entropy through logarithm with base 2 instead of the natural logarithm, the right hand side of inequality (2.6) in (Shalev-Shw artz, 2012) should hav e an additional multiplicative factor equal to 1 ln 2 and thus the right-hand side of the inequality stated in Lemma 14 has to hav e the same multiplicative f actor . • For the same reason as abov e, the right-hand side of the inequality in Lemma 9 should take logarithm with base 2 of k instead of the natural logarithm of k . Propagating these changes in the proof of Theorem 6 results in the statement of Theorem 1. Pr oof of Cor ollary 1. Note that the lower -bound on ∆ e t from the previous pro ve could be made tighter as follows: ∆ e t ≥ w 1 2 M X j =1 1 p j K X i =1 q i p j | i − p j ! 2 = w M 2 2 M X j =1 1 M K X i =1 q i p j | i − p j ! 2 ≥ w M 2 2 M X j =1 1 M K X i =1 q i p j | i − p j 2 = w M 2 8 2 M M X j =1 K X i =1 q i p j | i − p j 2 = M 2 w J 2 n 8 , Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation d Model Arity Prec Rec T rain T est 50 T agSpace - 30.1 - 3h8 6h FastT ext 2 27.2 4.17 8m 1m Huffman T ree 5 28.3 4.33 8m 1m 20 29.9 4.58 10m 3m Learned T ree 5 31.6 4.85 18m 1m 20 32.1 4.92 30m 3m 200 T agSpace - 35.6 - 5h32 15h FastT ext 2 35.2 5.4 12m 1m Huffman T ree 5 35.8 5.5 13m 2m 20 36.4 5.59 18m 3m Learned T ree 5 36.1 5.53 35m 3m 20 36.6 5.61 45m 8m T able 3. Classification performance on the YFCC100M dataset. where the first inequality was taken from the proof of Theorem 1 and the follo wing equality follo ws from the fact that each node is balanced. By next following exactly the same steps as shown in the proof of Theorem 1 we obtain the corollary . 11. Experimental Setting 11.1. Classification For the YFCC100M e xperiments, we learned our models with SGD with a linearly decreasing rate for fiv e epochs. W e run a hyper-parameter search on the learning rate (in { 0 . 01 , 0 . 02 , 0 . 05 , 0 . 1 , 0 . 25 , 0 . 5 } ). In the learned tree settings, the learning rate stays constant for the first half of training, during which the AssignLabels() routine is called 50 times. W e run the experiments in a Hogwild data-parallel setting using 12 threads on an Intel Xeon E5-2690v4 2.6GHz CPU. At prediction time, we perform a truncated depth first search to find the most likely label (using the same idea as in a branch-and-bound algorithm: if a node score is less than that of the best current label, then all of its descendants are out). 11.2. Density Estimation In our experiments, we use a context window size of 4. W e optimize the objecti ves with Adagrad, run a hyper-parameter search on the batch size (in { 32 , 64 , 128 } ) and learning rate (in { 0 . 01 , 0 . 02 , 0 . 05 , 0 . 1 , 0 . 25 , 0 . 5 } ). The hidden represen- tation dimension is 200 . In the learned tree settings, the AssignLabels() routine is called 50 times per epoch. W e used a 12GB NVIDIA GeForce GTX TIT AN GPU and all tree-based models are 65-ary . For the Cluster T ree, we learn dimension 50 word embeddings with FastT ree for 5 epochs using a hierarchical softmax loss, then obtain 45 = 65 2 centroids using the ScikitLearn implementation of MiniBatchKmeans, and greedily assign words to clusters until full (when a cluster has 65 words). Simultaneous Learning of T rees and Repr esentations for Extr eme Classification and Density Estimation Algorithm 3 Label Assignment Algorithm under Depth Constraint Input Node statistics, max depth D Paths from root to labels: P = ( c i ) K i =1 node ID n and depth d List of labels currently reaching the node Ouput Updated paths Lists of labels now assigned to each of n ’ s children under depth constraints procedur e AssignLabels (labels, n , d ) // first, compute p ( n ) j and p ( n ) j | i . is the element-wise // multiplication p av g 0 ← 0 count ← 0 for i in labels do p av g 0 ← p av g 0 + SumProbas n,i count ← count + Counts n,i p av g i ← SumProbas n,i / Counts n,i p av g 0 ← p av g 0 / count // then, assign each label to a child of n under depth // constraints unassigned ← labels full ← ∅ for j = 1 to M do assigned j ← ∅ while unassigned 6 = ∅ do . . ∂ J n ∂ p ( n ) j | i is giv en in Equation 10 ( i ∗ , j ∗ ) ← argmax i ∈ unassigned ,j 6∈ full ∂ J n ∂ p ( n ) j | i c i ∗ d ← ( n, j ∗ ) assigned j ∗ ← assigned j ∗ ∪ { i ∗ } unassigned ← unassigned \ { i ∗ } if | assigned j ∗ | = M D − d then full ← full ∪ { j ∗ } for j = 1 to M do AssignLabels (assigned j , child n,j , d + 1 ) retur n assigned Leaf 229 Leaf 230 Leaf 300 Leaf 231 suggested vegas payments operates watched & buy-outs includes created calif. swings intends violated park gains makes introduced n.j. taxes means discov ered conn. operations helps carried pa. profits seeks described pa. penalties reduces accepted ii relations continues listed d. liabilities fails . . . . . . . . . . . . T able 4. Example of labels reaching leaf nodes in the final tree. W e can identify a leaf for 3rd person verbs, one for past participates, one for plural nouns, and one (loosely) for places.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment