Software for Distributed Computation on Medical Databases: A Demonstration Project
Bringing together the information latent in distributed medical databases promises to personalize medical care by enabling reliable, stable modeling of outcomes with rich feature sets (including patient characteristics and treatments received). Howev…
Authors: Balasubramanian Narasimhan, Daniel L. Rubin, Samuel M. Gross
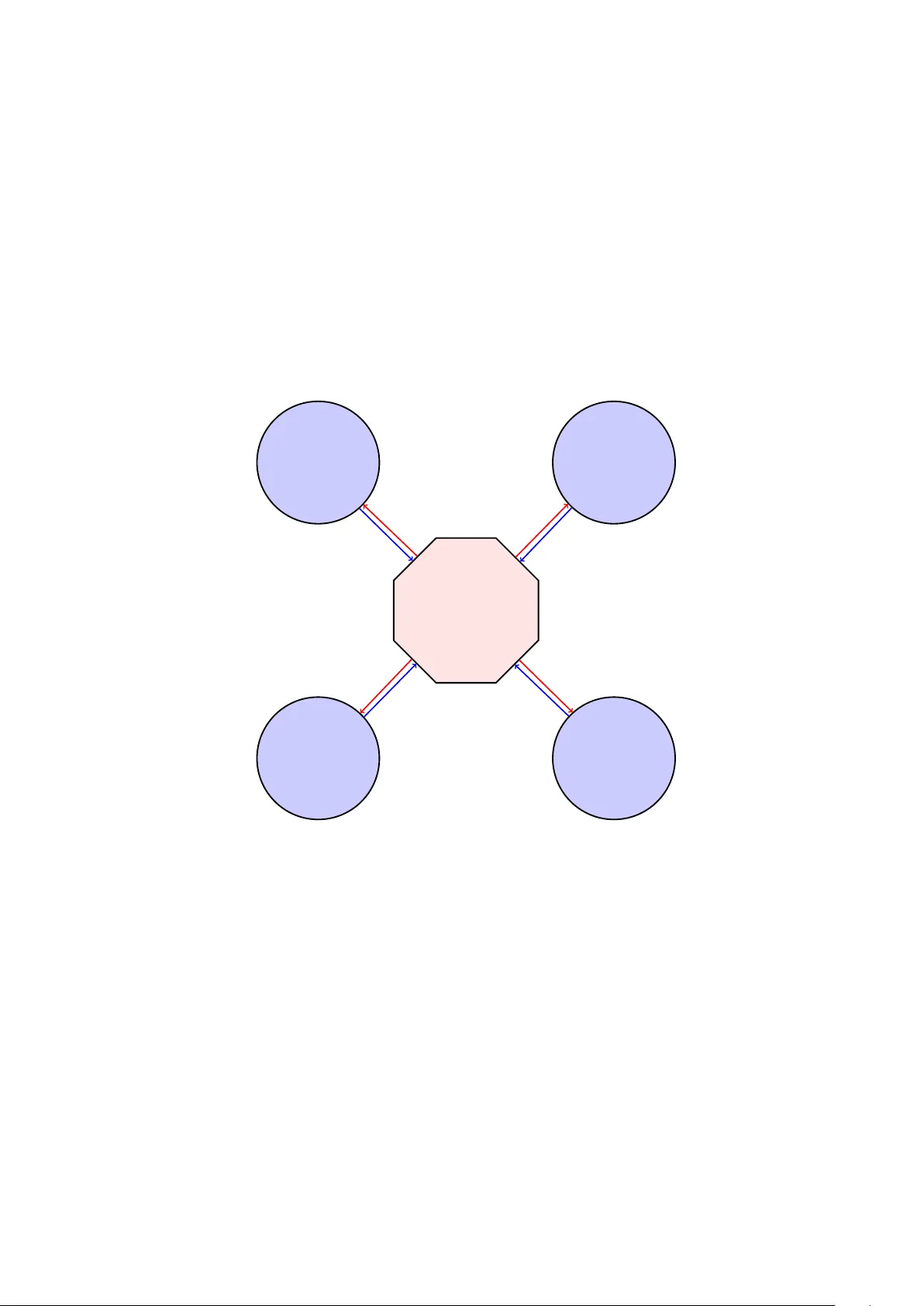
Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject B. Narasimhan Stanford Univ ersit y D. L. Rubin Stanford Univ ersit y S. M. Gross Stanford Univ ersit y M. Bendersky Stanford Univ ersit y P . W. La vori Stanford Univ ersit y Abstract Bringing together th e information laten t in distributed medical databases promises to personalize medical care b y enabling reliable, stable mo deling of outcomes with rich feature sets (including patient characteristics and treatmen ts received). Ho wev er, there are barriers to aggregation of medical data, due to lac k of standardization of on tologies, priv acy concerns, proprietary attitudes to ward data, and a reluctance to give up control o ver end use. Aggregation of data is not alw ays necessary for mo del fitting. In mo dels based on maximizing a lik eliho od, the computations can b e distributed, with aggregation limited to the interme diate results of calculations on lo cal data, rather than raw data. Distributed fitting is also p ossible for singular v alue decomp osition. There has been work on the technical asp ects of shared computation for particular applications, but little has b een published on the soft ware n eeded to support the “so cial net w orking” aspect of shared computing, to red uce the barriers to collaboration. W e describe a set of soft ware to ols that allo w the rapid assembly of a collab orativ e computational pro ject, based on the flexible and extensible R statistical soft ware and other op en source pac k ages, that can w ork across a heterogeneous collection of database environmen ts, with full transparency to allow lo cal officials concerned with priv acy protections to v alidate the safety of the metho d. W e describe the principles, architecture, and successful test results for the site-stratified Cox mo del and rank- k Singular V alue Decomp osition. Keywor ds : distributed computation, co x regression, singular v alue decomp osition, data ag- gregation, R . 1. In tro duction Bringing together the information laten t in distributed medical databases promises to p er- sonalize medical care by enabling reliable, stable mo deling of outcomes with rich feature sets (including patien t characteristics and treatments received). T o realize that promise, the Na- tional Institutes of Health (NIH) and oth er organizations support the aggregation of data from suc h databases, particularly the data developed by inv estigators on NIH-supp orted pro jects. These aggregated databases are made av ailable to qualified inv estigators to explore and ex- tract the useful information they contain. Ho w ev er, there are high (and growi ng) barriers to aggregation of medical data, some of them having to do with lack of standardization of on- 2 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject tologies, others o wing to priv acy concerns, and still others arising from a generally propriet ary attitude tow ard one’s own institution’s data, and a reluctance to giv e up control. In addition, the sheer size and complexit y of some databases has caused the NIH to think ab out splitting the storage of aggregated databases across several centers; see for example NIH ( 2015 ). It has long b een known that aggregation of data is not alwa ys necessary for mo del fitting. In man y circumstances, such as in fitting mo dels based on maximizing a likelihoo d, the compu- tations can be distributed, with aggregation limited to t he in termediate results of calculations on lo cal data, rather than ra w data; see Murtagh, Demir, Jenkings, W allace, Murtagh, Boniol, Bota, Laflamme, Boffetta, F erretti, and Burton ( 2012 ) for example. Indeed, sometimes distri- bution of the calculation among sites is necessary to share a heavy computational burden, as w ould b e the case for fitting the ADMM mo dels of Boyd, Parikh, Ch u, Peleato, and Eckstein ( 2011 ). It can ev en help attack the “conflicting ontologies” problem, by shifting the task of translation to the sites. There has b een work on the technical asp ects of shared computation for particular applica- tions: Jiang, Li, W ang, W u, Xue, Ohno-Machado, and Jiang ( 2013 ) and Lu, W ang, Ji, W u, Xiong, Jiang, and Ohno-Machado ( 2015 ) describ e distributed implemen tations of logistic re- gression and Cox regression respectively without sharing patient -lev el data using Java applets; W olfson, W allace, Masca, Row e, Sheehan, F erretti, LaFlamme, T obin, Macleo d, Little et al. ( 2010 ) describ e fitting generalized linear mo dels using R . Little has b een published on the soft w are needed to supp ort the “so cial netw orking” asp ect of shared computing, to reduce the barriers to collab oration. W e present a general set of softw are to ols that allow the rapid assem bly of a collab orativ e computational pro ject, based on the flexible and extensible ( R Core T eam 2014 ) statistical soft ware and other op en source pack ages, that can work across a heterogeneous collection of database environmen ts (RedCAP , i2b2, lo cal versions), with full transparency to allow lo cal officials concerned with priv acy protections to v alidate the safety of the metho d. Our work differs from the ab o v e in that it is far more general: Generalized Linear Mo del s, Co x Mo dels, Singular V alue Decomp osition computations all fit under the same infrastructure. It also has p oten tial for further extensibility since R already has a v ast arra y of statistical computations built into it; distributed implementations can b e easily con- structed by re-engineering existing co de for those computations. W olfson et al. ( 2010 ) comes closest in spirit to what we prop ose although the implemen tation is in a sp ecific cont ext, that of the OP AL system. Our softw are, examples, and do cumen tation can b e found on CRAN as w ell as GitHub, and it is freely mo difiable by users. The rationale, scienti fic uses, and further details of the so cial netw orking asp ects of the metho d are discussed elsewhere. In this article w e describ e the principles, archit ecture, and successful test results for tw o priv acy-preserving examples. The first is a nov el instance of fitting a site-stratified Cox Prop ortional Hazards Mo del and the second is a well-kno wn distributed v ersion of Rank- k Singular V alue Decom- p osition. These illustrate the c hallenges and solutions to implemen ting a shared computat ion. W e sho w ho w to tak e an y model fit that breaks up in a similar wa y and implemen t it as a distributed computation. W e describ e some p ossible use cases that may b e of interes t. 2. Managemen t of computations for a collab oration W e b egi n with an o verview of the pro cess and our softw are, with details in the implementation section following. As illustrated in Figure 1 , the setup of the softw are to manage computations for a collab oration b egins with a few steps that need only b e completed once at at a site, B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 3 Shiny App Computation T ype Exemplar Data Computation-specific Parameters Definition file ( defn.rds ) defineNewComputation() Requirements: R , distcomp package Stratified Cox Model Rank k SVD (a) Defining the computation. A computation ma y b e define on any machine where R and the distcomp pac k age are installed. The function defineNewComputati on() launc hes a shiny app that leads the user through the pro cess. The end result is an R data file unam biguously defining the computation instance for distcomp Shiny App OpenCPU URL Site Data Definition file ( defn.rds ) Site ready setupWorker() (b) Setting up the work er. This requires a one-time configuration of an op encpu server with the R pack age distcomp and a writable w orkspace. All in teraction is through a shin y app that configures the work er for the computation. Shiny App Full Path of defn.rds Worker Site URLS R script setupMaster() Full Path of Workspace (c) Setting up the master. The shiny app accepts the URLs of all work er sites, chec ks them and writes an R script for the computation. Figure 1: Inputs, outputs, and asso ciated R functions in pack age distcomp for each task. 4 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject and that will create an environmen t that will supp ort man y differen t collab orativ e efforts. The lo cal systems administrator mu st provide a computation serv er, install the application distcomp , and mak e the serv er URL av ailable to the site inv estigators. The administrator w ould also set up the required p ermissions. The other steps are taken by the site inv estigator for a given collab orativ e pro ject (a “com- putation” ). W e supp ose first that the inv estigator is the originator of a new computation and therefore, has access to a dataset that will b e used as that site’s contribution to the shared effort. The inv estigator runs a function from the distcomp pack age on his or her lo cal com- puter, whic h brings up a bro wser window with instructions for en tering the lo cation of the dataset, the names of its v ariables, and certain information ab out the format and v alues of the fields. The formula, in R format is en tered. Completing this task and surviving v arious c hec ks on data in tegrit y generates a unique computation-sp ecific identifier and a collection of metadata that define the computation and dataset. Then the inv estigator sets up the work er pro cess b y running another function in the distcomp pac k age. The result is that a copy of the local dataset and the metadata generated in the previous step is placed in t he computation serv er under the unique computation iden tifier. A t this p oin t the originating in ves tigator is ready to recruit other collab orators. They will ha v e to tak e the step of creating a computation server, as describ ed ab o ve, unless it has already b een done at that site. Then, they will run the same setup function locally , and en ter the computation definition (metadata) sent by the originating inv estigator. The function will return a URL (p oin ting to the computation serv er) that is to b e transmitted bac k to the originating in vestigator. Once the originating inv estigator has the URLs from the sites in hand, he or she runs the function for setting up a master site, and then finally another function that runs the compu- tation. The pro cess of setting up work er and master sites can b e rep eated for an y num b er of differen t computations and datasets. W e imagine that a group of collab orators in terested in a particular topic (say , prediction of outcome of therap y for a subtype of melanoma) would run (and subsequential ly up date) sev eral suc h computations, p erhaps v ariations of mo dels. The distributed computations of in terest to that group in vestigators might b e listed and managed on a w ebsite where a registry of active and proposed pro jects is maintai ned. Dep ending on the scop e of the collab orati on there may b e sev eral such websites. One may imagine a w ebsite providing the follo wing capabilities for a collab oration: Registration Registering users, providing credentials, b onafides etc. Av ailable Metho ds A mechanism for adding to a growing list of statistical computations that may b e implemen ted in the distcomp pro jects. The latest version of the pack age will automatically pro vide an up-to-date list. Pro ject Link ages Asso ciating users with pro jects so that they ma y participate in the col- lab oration. In order to prev en t malicious use and av oid inappropriate computational burdens on already established pro jects there are some chec ks and balances, such as requiring a new user to bring new data to the collab oration. Pro ject Examples/T emplates Pro viding some testable examples for p oten tial collab ora- tors so that there is a complete understanding of the requirements of each site. Some B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 5 canonical templates will b e provided. Users may run them on lo cal sites to completely examine the en tire pro cess. Pro ject Publishing Creation of pro jects and publishing them so that they mov e into place on a publicly visible w ebsite. A group of users or a single user will create a new collab- orativ e pro ject and lead it. T o ols Do wnloadable to ols, virtual machines and detailed to ol do cumen tation for enabling dryrun exp erimen ts lo cally . Do cumen tation Wikis for facilitating comm unication within the collab oration. There are man y op en source tools that can b e used for some of the tasks describ ed ab o ve. W e fo cus our atten tion on those tasks for whic h new to ols required developmen t. These are the to ols that allow rapid setup of a computation, at b oth master and work er sites, as describ ed ab o ve, with minimal ongoing burden once the initial steps are taken. The inten t is to lo w er the bar to collab oration to the p oin t where it is as easy to set up a distributed collab oration as it woul d b e to ev en b egin the discussion of data aggregation. 3. Illustration T o get a sense of what is b eing transmitted b et ween a master and work er sites, consider a setting where several distributed sites hav e data on patien t age and one wishes to compute the mean age of all patients. Assuming eac h site is willing to share the sum ¯ X i of the patien t ages at their site along with the num b er of patien ts n i , a master pro cess could calculate the ov erall mean b y requesting the pair ( ¯ X i , n i ) from each sit e and c omputing ¯ X = P i n i ¯ X i / P i n i . Only the summaries ( ¯ X i , n i ) are transmitted b y the sites to the master but not actual patien t level data. This sort of computation is also reminiscent of meta-analysis, where data from several studies gets p ooled to obtain meta-analytic estimates. The situation is only sligh tly more inv olv ed in mo del fitting. W e fo cus on surviv al data, where the num b er of cov ariates might be gathered on sub jects that are follo wed ov er time. The random quanti ty of interest is the time to “even t” T i for eac h sub ject i which may b e observ ed in some patients (in which case the observ ation is uncensored) or not (in whic h case it is censored). Th us, each sub ject i yields data ( T i , δ i ) where δ i = 1 if even t, 0 otherwise, indep enden t of T i in addition to cov ariates that may v ary o v er time. The Co x prop ortional hazards mo del assumes a hazard function of the form λ ( t ) = λ 0 ( t ) exp( X X X β ) , (1) where λ is an n × 1 vector , n b eing the num b er of sub jects, λ 0 , an unspecified baseline hazard, X X X the n × p vector of cov ariates and β a p × 1 v ector of co efficien ts. Mo del fitting and inference is accomplished by maximizing a partial lik eliho od function. The explicit form of this likelihoo d can b e written out using a counting pro cess formulation fol- lo wing T erry M. Therneau and P atricia M. Grambsc h ( 2000 ). F or each sub ject i , let N i ( t ) b e the num b er of observed eve nts in [0 , t ] and Y i ( t ), the indicator of whether the sub ject is in the “risk set” , that is, the sub ject ma y p oten tially contribut e an 6 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject ev en t at time t . Then the log of the partial likelihoo d function introduced by Cox ( 1972 ) has the form: l ( β | X X X ) = n X i =1 Z ∞ 0 Y i ( t ) X X X i ( t ) β − log X j Y j ( t ) r j ( β , t ) dN i ( t ) (2) where i indexes the sub ject, r i ( β , t ) = exp[ X X X i β ] is the risk score, X X X i ( t ) is the co v ariate ro w v ector. The score vector is given by: S ( β | X X X ) = n X i =1 Z ∞ 0 Z Z Z i ( β , s ) dN i ( s ) (3) where Z Z Z i ( β , s ) = X X X i ( s ) − x ( β , s ) (4) and x ( β , s ) = P Y i ( s ) r i ( β , s ) X X X i ( s ) P Y i ( s ) r i ( β , s ) . (5) The negativ e of the hessian is the Fisher information given by I I I ( β | X X X ) = n X i =1 Z ∞ 0 V ( β , s ) dN i ( s ) (6) where V ( β , s ) = P Y i ( s ) r i ( β , s ) Z Z Z > i ( β , s ) Z Z Z i ( β , s ) P Y i ( s ) r i ( β , s ) . (7) The solution ˆ β to the score Equation 3 and the inv erse of the information matrix I − 1 ( ˆ β ) are used as the estimate and the v ariance resp ectiv ely along with the fact that the estimate is asymptotically normally distributed. One can use a Newton-Raphson metho d to solve Equation 3 with an initial v alue for β , often just 0 0 0. The method is quite robust and in fact implemen ted in the p opular R survival pack age ( Therneau 2014 ). W e are intereste d in str atifie d Cox mo dels where the data is divided in to several strata, eac h with its o wn baseline hazard, y et use a common set of co efficien ts β . Sp ecifically , if there are K strata and one views the entir e n × p matrix X X X as a stacking of k sub-matrices X X X [ k ] eac h of dimension n k × p with n = P K k =1 n k , then sub ject i in stratum k incurs a hazard λ k ( t ) exp( X X X [ k ] i β ) . Suc h mo dels are particularly applicable in multicen ter studies and trials where the one needs to account for patien t mix at each institution, for example. In this case, the o v erall log-lik eliho od is a sum o v er the strata l ( β | X X X ) = K X k =1 l ( β , X X X [ k ] ) . (8) where each comp onen t of the sum is in fact giv en b y Equation 2 . It follo ws that the score function and the Fisher information also partition in to sums: S ( β | X X X ) = K X k =1 S ( β , X X X [ k ] ) (9) B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 7 Site 1 Data: X 1 Summaries: l 1 ( b )= l ( X 1 , b ) , S 1 ( b )= l 0 1 ( X 1 , b ) , I 1 ( b )= S 0 1 ( X 1 , b ) Site 2 Data: X 2 Summaries: l 2 ( b )= l ( X 2 , b ) , S 2 ( b )= l 0 2 ( X 2 , b ) , I 2 ( b )= S 0 2 ( X 2 , b ) Master Site b = 0 Iterate to con vergence: S = Â S k ( b ) I = Â I k ( b ) b i + 1 = b i + I 1 S Site 3 Data: X 3 Summaries: l 3 ( b )= l ( X 3 , b ) , S 3 ( b )= l 0 3 ( X 3 , b ) , I 3 ( b )= S 0 3 ( X 3 , b ) Site 4 Data: X 4 Summaries: l 4 ( b )= l ( X 4 , b ) , S 4 ( b )= l 0 4 ( X 4 , b ) , I 4 ( b )= S 0 4 ( X 4 , b ) b l 1 ( b ) , S 1 ( b ) , I 1 ( b ) b l 2 ( b ) , S 2 ( b ) , I 2 ( b ) b l 3 ( b ) , S 3 ( b ) , I 3 ( b ) b l 4 ( b ) , S 4 ( b ) , I 4 ( b ) Figure 2: Summary quan tities transmitted betw een master and work er sites in a stratified Co x mo del fit inv olving K = 4 sites. The red arrows show what the master sends to each site and the blue arro ws indicate what the sites return bac k. The summaries l , S and I are p er equations 8 , 9 , 10 resp ectiv ely . 8 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject and I ( β | X X X ) = K X k =1 I ( β , X X X [ k ] ) (10) where the comp onen ts in each sum ab o v e are given by Equations 3 and 6 . Note that in each stratum k , the computation of the likelihoo d, score and information for the site-stratified Cox prop ortional hazards mo del uses only stratum data X X X [ k ] . This feature of the site-stratified mo del enables distributed computation, since each site in a distributed optimization of the partial likelihoo d only need provide v alues of l ( β , X X X [ k ] ), U ( β | X X X [ k ] ), and I ( β | X X X [ k ] ) for a master pro cess to estimate β and its v ariance. This is illustrated in Figure 2 where four sites participate in a stratified Cox fit. 4. Implemen tation Our implementation is in the form of the distcomp R pack age which utilizes other R pack ages notably op encpu ( Ooms 2014 ) and shiny ( Chang, Cheng, Allaire, Xie, and McPherson 2015 ), to provide the infrastructure supp ort. (The pack age is on the Comprehensiv e R Arc hive Net w ork and may therefore b e installed like an y other.) W e use a master-work er mo del, where the master is the one in charge of the ov erall computation (the main iteration in an optimization for example) and the work ers merely compute functions on lo cal datasets and return the function result. Both the master and w ork er sites are expected to ha ve our pack age distcomp installed. In the course of a single fit, the master pro cess will mak e an unsp ecified n um b er of computation requests to the work er sites ov er secure http proto col. In what follo ws, we assume an op encpu server for distributed computations. W e describ e our implemen tation first in the contex t of a distributed stratified Cox Mo del fit discussed in Section 3 using the UIS dataset from Hosmer, Lemeshow, and Ma y ( 2008 ) on time un til return to drug use for patien ts enrolled in tw o different residen tial treatment programs. Assuming all data in one place, one w ould fit a stratified cox prop ortional hazard mo del using site (0 or 1) as a stratification v ariable as follo ws. R> uis <- readRDS("uis.RDS") R> coxOrig <- coxph(formula = Surv(time, censor) ~ age + + becktota + ndrugfp1 + ndrugfp2 + ivhx3 + race + + treat + strata(site), data = uis) R> summary(coxOrig) Call: coxph(formula = Surv(time, censor) ~ age + becktota + ndrugfp1 + ndrugfp2 + ivhx3 + race + treat + strata(site), data = uis) n= 575, number of events= 464 (53 observations deleted due to missingness) coef exp(coef) se(coef) z Pr(>|z|) age -0.028076 0.97 2315 0.008131 -3.453 0.000554 *** becktota 0.009146 1.009 187 0.004991 1.832 0.066914 . ndrugfp1 -0.521973 0.593349 0.124424 -4.195 2.73e-05 *** B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 9 ndrugfp2 -0.194178 0.823512 0.048252 -4.024 5.72e-05 *** ivhx3TRUE 0.263634 1.301652 0.108243 2.436 0.014868 * race -0.240021 0.786611 0.115632 -2.076 0.037920 * treat -0.212616 0.808466 0.093747 -2.268 0.023331 * --- Signif. codes: 0 ' *** ' 0.001 ' ** ' 0.01 ' * ' 0.05 ' . ' 0.1 ' ' 1 ... W e now aim to repro duce the same results using a distributed computation using op encpu . In order for the reader to repro duce our example, we use the same op encpu server on a single mac hine to sim ulate differen t sites; the pack age co de automatically detects such use to keep the site-sp ecific data separate. Some setup is inv olv ed b efore pro ceeding: an empt y directory has to b e set aside for the w orkspace for the op encpu server. The details and the structure of the workspace are further describ ed in App endix B . Define the computation W e define a computation definition ob ject ( c omp def for brevit y) that will enco de the characteristics of the computation. It con tains an iden tifier along with a formula (therefore, the v ariables) that will b e used in the mo del. Note that no data is stored in the definition, only the ch aracteristics of the computation. This c omp def serv es as an unam biguous definition of a computation task, whic h, in this case, happ ens to b e a particular instance of a stratified Cox mo del using the v ariables sp ecified in the formula. R> coxDef <- data.frame(compType = names(availableComput ations())[1], + formula = paste("Surv(time, censor) ~ age + becktota + ", + "ndrugfp1 + ndrugfp2 + ivhx3 + race + treat"), + id = "UIS", stringsAsFactors = FALSE) Set up w ork er pro cesses for the computation W e will split the data by site and set up w ork er processes using op encpu . Then we upload the c omp def along with the site- appropriate data to eac h work er. R> library("opencpu") R> siteData <- with(uis, split(x = uis, f = site)) R> nSites <- length(siteData) R> sites <- lapply(seq.int(nSites), + function(x) list(name = paste0("site", x), + url = opencpu$url())) R> ok <- Map(uploadNewComputation, sites, + lapply(seq.int(nSites), function(i) coxDef), siteData) R> stopifnot(all(as.logical(ok))) A t this p oin t, the tw o sites in this example eac h hav e access to their priv ate data and the computation definition. Since they eac h also ha ve the distcomp installed (b y default in this case), they also ha v e the co de required to engage in the computation. If either the data or the v ariables were incompatible, an error would hav e b een raised. 10 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject Build a master pro cess for the computation Once the sites are set up, the master ob- ject for the computation can b e constructed using the c omp def iden tifier and the for- m ula. Eac h site work er is represented by the op encpu web address and these are added to the master so that the master may use them in p erforming the computation. R> master <- CoxMaster$new(defnId = coxDef$id, + formula = coxDef$formula) R> for (site in sites) { + master$addSite(name = site$name, url = site$url) + } Fit the mo del A t this p oin t, the master is ready to p erform the computation, which in this case is maximizing the Cox partial lik eliho o d. Calling the run method of the master p erforms this optimization and the resulting summary can b e prin ted out. R> result <- master$run() R> print(master$summary(), digits = 5) coef exp(coef) se(coef) z p 1 -0.0280495 0.97234 0.0081301 -3.4501 5.6041e-04 2 0.0091441 1.00919 0.0049918 1.8318 6.6979e-02 3 -0.5219296 0.59337 0.1244240 -4.1948 2.7315e-05 4 -0.1941709 0.82352 0.0482507 -4.0242 5.7168e-05 5 0.2636376 1.30166 0.1082448 2.4356 1.4868e-02 6 -0.2400609 0.78658 0.1156319 -2.0761 3.7887e-02 7 -0.2125720 0.80850 0.0937466 -2.2675 2.3359e-02 As can b e seen, the results are similar to the original mo del fit. In the ab o ve example, the master p erforms an optimization of a multiv ariate likelihoo d func- tion that is the sum of the likelihoo ds at each site as sho wn in Equation 8 . Using a starting v alue for the parameter β = 0, it rep eatedly sends updated β v alues until a conv ergence criterion is reac hed. W e ha v e successfully tested other examples in a real three-site configuration, inv olving tw o US and one UK site. T ests inv olving real lo cally-originated data are underwa y . 5. A rank- k appro ximation example W e consider the problem of approx imating a matrix by another low-rank matrix. Assuming that the original matrix X X X is row-partioned into sub-matrices X X X j at j = 1 . . . , K sites, there is a well-kno wn iterativ e singular v alue decomp osition algorithm (see App endix A ) to obtain a lo w-rank appro ximation using the singular vectors, which is implemented in distcomp . The example b elo w assumes three sites. R> print(availableComputations()) $StratifiedCoxModel $StratifiedCoxModel$des c B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 11 [1] "Stratified Cox Model" ... $RankKSVD $RankKSVD$desc [1] "Rank K SVD" ... Using this information, we construct the c omp def for this computat ion where we will compute the first t w o singular v alues for a five-column matrix and use a generic identifier SVD . R> svdDef <- data.frame(compType = names(availableComput ations())[2], + rank = 2L, + ncol = 5L, + id = "SVD", + stringsAsFactors = FALSE) W e now generate random data for three sites, start the op encpu serve r, and set the URLs for the sites to b e the (same) lo cal op encpu URL. R> set.seed(12345) R> nSites <- 3 R> siteData <- lapply(seq.int(nSites) , + function(i) matrix(rnorm(100), nrow = 20)) R> library("opencpu") R> sites <- lapply(seq.int(nSites), + function(x) list(name = paste0("site", x), + url = opencpu$url())) Next, we upload the data to the three sites, ensuring that we use different names for the data files for eac h site. R> ok <- Map(uploadNewComputation, sites, + lapply(seq.int(nSites), function(i) svdDef), siteData) R> stopifnot(all(as.logical(ok))) A t this p oin t, the sites are instan tiated and ready to compute. So w e instantiate the master and add the three participating sites. R> master <- SVDMaster$new(defnId = svdDef$id, k = svdDef$rank) R> for (site in sites) { + master$addSite(name = site$name, url = site$url) + } All that remains is to call the run metho d of the master ob ject. R> result <- master$run() ... R> print(result) 12 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject $v [,1] [,2] [1,] 0.17947030 0.08275684 [2,] 0.78969198 0.34634459 [3,] -0.21294972 0.91875219 [4,] -0.54501407 0.16784298 [5,] 0.04229739 -0.03032954 $d [1] 9.707451 8.200043 This returns the appro ximate first t wo singular v alues and the asso ciated v ectors (up to a sign change). All five singular v ectors can b e obtained as show n b elo w. W e also compare the results to the SVD on the aggregated matrix. R> result <- master$run(k = 5) ... R> x <- do.call(rbind, siteData) R> print(result$d) [1] 9.707451 8.200043 7.982650 7.257355 6.235351 R> print(svd(x)$d) [1] 9.707537 8.199827 7.982888 7.257286 6.235182 R> print(result$v) [,1] [,2] [,3] [,4] [,5] [1,] 0.17947030 0.08275684 0.0165604 0.98008722 -0.008933396 [2,] 0.78969198 0.34634459 -0.3437723 -0.16504730 0.333181988 [3,] -0.21294972 0.91875219 0.2496210 -0.04479619 -0.214978886 [4,] -0.54501407 0.16784298 -0.5334277 0.10025749 0.616612820 [5,] 0.04229739 -0.03032954 0.7312254 -0.01140918 0.680060781 R> print(svd(x)$v) [,1] [,2] [,3] [,4] [,5] [1,] -0.17946375 0.08268613 -0.01644895 -0.98010572 -0.00883063 [2,] -0.78963831 0.34694371 0.34328503 0.16509457 0.33316749 [3,] 0.21305901 0.91839439 -0.25083926 0.04461477 -0.21505068 [4,] 0.54504905 0.16843629 0.53318714 -0.10009622 0.61663844 [5,] -0.04232602 -0.03120945 -0.73121540 0.01126215 0.68002329 As we can see, the distributed SVD is able to recov er the same factors (up to sign change) as the standard SVD algorithm. There is a slight loss of numerical precision in the alternating p o wer algorithm v ersus the standard LAP ACK implementation. The JSON serialization format emplo y ed here also loses precision. F uture implemen tations will use a more p ortable format suc h as Go ogle proto col buffers, as we note in Section 6 . 6. Priv acy con trol and confidence The motiv ating principles guiding the architecture of the distributed computation metho d w e hav e built include the preserv ation of data priv acy , retention of lo cal control and building B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 13 confidence in the safet y of the method b y using an op en platform. W e list sev eral features that serve that principle. Those features w ere chosen based on a particular threat mo del that deals with in ternal threats, since an anon ymous en tity is n ot a participan t in the collaborative mo del fitting. W e expand on these b elo w. Registering mac hines Only known machines are permitted to request computations. In our mo del, the master and w orkers are trusted; this comes ab out as a result of the initial pro cess in agreeing to collab orate on a computation. This trust also defines and limits the threat mo del for us, namely , that of a rogue inv estigator trying to p eek at in termediate results and trying to break the system, i.e., an internal threat. The audit to ols describ ed b elo w in analyzing logs will aid in limiting such a threat. Logging All requests for computation are logged by the lo cal computation server, providing accoun tabilit y . Site sp ecific dash b oards can b e developed (as shiny apps, for example) for analyzing these logs and flagging unusual requests. Single computation serv er A site could use a single computation server for all distributed collab oration s, or a small num b er, simplifying the ov ersight task. At an y site, it is t ypically an IT team that really handles access to the public facing web resources. In suc h a case, there is usually a single web URL (or ev en server, for that matter) serves as a gatew ay for all distcomp computations for a w ork er site. This gateke ep er usually has firew all rules installed so that only authorized masters can make computation queries. This simplicit y , how ever, creates a lo ophole. Our mo del relies on asso ciating a unique iden tifier with each c ompDef and asso ciated data at each site. Th us, if work er site A participates in tw o computations id1 and id2 with tw o different institutions B and C resp ectiv ely , there is the p ossibilit y that B ma y b e able to run a computation on data that was made av ailable to site C and vice-versa if B kno ws id2 . How ever, this is easily handled by means of an access rule that maps each master to a set of computations the master can access via a reverse pro xy ( Wikipedia 2015 ) application either in the gatek eep er or in front of the op encpu serv er ensuring prop er access. Con tingent participation A site agrees to or refuses a sp ecific computation, whic h it can insp ect, and can withdra w at an y time from any computation, so it retains complete con trol o v er the future use of its data. Limited computation The computation server can only resp ond to the sp ecific computa- tion request describ ed in the c omp def and also only those exp osed by distcomp . This can b e implemented by accepting requests for w eb addresses only of a particular form—a standard technique—at the the gatekeeper application thus prev ent ing other functions or scripts are from b eing executed. 7. Some p ossible use cases W e an ticipate that the main initial use will b e to make it p ossible for inv estigators who are already known to eac h other to quic kly p ool information by moun ting ” p op-up” collab ora- tions. Once the system is set up, understo od and has passed lo cal due diligence for priv acy protection, the additional cost and effort required to start a new computation among such a 14 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject w orking group should b e negligible. As use cases o ccur, a byp ro duct will b e a growing set of m utually understo od data fields, making future computations easier to set up. There are a few other use cases that we exp ect to see after some time. Preparation for aggregation. A group of sites who are considering the possibility of aggregating data for some purpose migh t start their collab oration with a few ” small wins” , to test their abilit y to rationalize their data dictionaries and see if there is sufficient v alue in aggregation. Com bining information when con trol ov er data use is imp ortan t. Owners of data, suc h as pharmaceutical companies, who are not willing to transfer them may b e willing to participate in collab oration s that make use of the distributed tec hnologies. In a single-work er configuration, information from a single source could b e used to fit a mo del prop osed by an outside party (acting as the master). This provides a wa y for organizations to allow others to access their data (for the purp ose of mo del fitting) in a controlled manner. Virtual aggregation. In a group of sites that often collaborate, a library of ” translated terms” and the asso ciated data fields could b e developed, creating a virtual data aggregation, whose information would b e accessed by distributed mo del building. If sufficien t trust has b een created, it is p ossible to mak e the setup of a new computation nearly transparent to the in v estigator. 8. Discussion The data aggregator must work in a highly restrictive regulatory regime that con trols and limits the exp ort of (iden tified) Protected Health Information (PHI) b ey ond the originating institution. Owners of data can b e reluctant to cede control o ver the use of their data, even when priv acy issues can b e resolv ed. It seems realistic to predict that regulatory concerns, priv acy issues, and reluctance to let raw data lea ve the lo cal source will contin ue to mak e it difficult to construct central rep ositories of data on biomarkers, treatment s, and clinical outcomes, despite ongoing efforts by the NIH to supp ort (and even mandate) such rep ositories. The barriers to access for such data do not seem to b e falling. This is of sp ecial concern for the aggregators of data (such as gene sequences) that are increasingly likely to emerge as part of the diagnostic and treatment pro cess, and therefore b ecome part of a system of medical records. Such data would b e regulated as PHI (under HIP AA) in the future if a consensus dev elops that they cannot b e irreversibly de-identified . The lac k of uniform standards for data managemen t, database on tologies, and the sp ecific con ten t and scope of databases mak es global aggregation of complex datsets laborious, exp en- siv e, and time-consuming. Reluctance to adopt common standards makes central repositories difficult to ac hiev e, and the effort is seldom funded by outside sources. Inv estigators might b e willing to pa y the mo dest price for standardizing the part of the data that is needed for a particular pro ject, and then to con tin ue to increase common ontological themes as they are rew arded with analyses. There are limitations to our curren t implementation. W e hav e not yet built metho ds b ey ond the t w o describ ed ab o ve. W e are working on others, including the lasso . Each new mo deling B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 15 tec hnique requires the creation of a definition that contains the relev an t parameters, asso ciated co de to compute the summary statistics at the w ork er sites, a matc hing master that mak es use of the facilities and registering it as an a v ailable computation in distcomp . This m ay seem lik e a v ast task giv en the v ariety of techniques and mo dels. How ever, these metho ds fall broadly in to a few categories: a large and useful group that aggregate likel iho ods and other statistics, a large group that optimize a criterion, ev en in a distributed manner like ADMM ( Boyd et al. 2011 ), etc. They all break up in a manner amenable to our approac h. The well- organized R soft w are is eminen tly suited to such implemen tations; often, new metho ds can b e implemen ted by mere re-engineering of already existing (op en) algorithms in R pac k ages to enable distributed computations. W e exp ect that the rep ertoire of mo dels will expand as others add their own features and make them av ailable. There is not y et an easy-to-use pro cedure for handling factor v ariables whose support v aries b y site. This and many other impro v emen ts in ease of use will require further effort. It is often the case that most data at sites is in databases such as Redcap or i2b2. Our examples ha ve used pure R structures for p ersistin g the data. A simple mo dification can enable the use of a system suc h as Redcap. In discussions with p ersonnel at some sites, this configuration seems most acceptable to the CIOs, enabling p eriodic up dates of the data. W e should mention, ho w eve r, that one imp ortan t adv antage is offered b y our use of op encpu whic h comes in tw o fla vors, a cloud server—the one that real sites will use—and a lo cal R pac k age—one that dev elop ers will use. This means that developers can prototype and debug distributed computations with v ery little effort on a laptop. How ever, a robust implementation of a distributed computation m ust deal with many modes of failure. More wor k remains to b e done on this, particularly in implemen ting a robust messaging system to deal with failures. An y distributed computation must address the p oten tial for race conditions. W e account for this in tw o w ays in our pac k age: (a) b y using instance ob jects so that even the same com- putation requests initiated at tw o differen t time p oin ts (regardless of origin) are guaranteed differen t instance ob jects and (b) using the master in a sequential iteration so that a new request is not sent until either the curren t request returns a result or times out. That said, there ma y be other race conditions that can o ccur at the op encpu level that ma y be disco vered o v er time. The curren t implemen tation mak es uses of the JSON serialization format, simply b ecause it is the b est supp orted format of op encpu . It would b e b etter to use a we ll-established p ortable and stable serialization format, such as Go ogle proto col buffers ( Go ogle 2012 ; Ed- delbuettel, Stok ely , and Ooms 2014 ; F rancois, Eddelbuettel, Stokely , and Ooms 2014 ). It is straigh tforward to adapt to this proto col once it is more widely supp orted in opencpu for example. These limitations of our first implementation notwithstanding, we hop e that low ering the barriers to shared statistical computation wil l accelerate the pace of collab oration and increase the accessibilit y of information that is now lo c ked up. 9. Ac kno wledgemen ts This work by supp orted in part by grants the Cancer Cente r Supp ort grant 1 P30 CA124435 from the National Cancer Center, the Clinical and T ranslational Science Award 1UL1 RR025744 for the Stanford Center for Clinical and T ranslational Education and Researc h (Sp ectrum) 16 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject from the National Cen ter for Research Resources, National Institutes of Health and aw ard LM07033 from the National Institutes of Health. References Anderson E, Bai Z, Bisc hof C, Blac kford S, Demmel J, Dongarra J, Du Croz J, Greenbaum A, Hammerling S, McKenney A, et al. (1999). LAP ACK Users’ guide , volume 9. Siam. Bo yd S, Parik h N, Chu E, Peleato B, Eckstein J (2011). “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers.” F ound. T r ends Mach. L e arn. , 3 (1), 1–122. ISSN 1935-8237. doi:10.1561/2200000016 . URL http: //dx.doi.org/10.1561/22 00000016 . Chang W, Cheng J, Allaire J, Xie Y, McPherson J (2015). shiny: Web Applic ation F r amework for R . R pack age version 0.11.1, URL http://CRAN.R- project.org/package=shi ny . Chen H, Martin B, Daimon CM, Maudsley S (2013). “Effective use of latent semantic index- ing and computational linguistics in biological and biomedical applications.” F r ontiers in physiolo gy , 4 . Co x DR (1972). “Regression Models and Lif e-T ables.” Journal of the R oyal Statistic al So ciety. Series B (Metho dolo gic al) , 34 (2), 187–220. URL http://links.jstor.org/sici?sici= 0035- 9246%281972%2934%3A2 %3C187%3ARMAL%3E2.0.CO%3B2- 6 . Eddelbuettel D, Stok ely M, Ooms J (2014). “RProtoBuf: Efficient Cross-Language Data Serialization in R.” Arxiv . . F rancois R, Eddelbuettel D, Stokely M, Ooms J (2014). RPr otoBuf: R Interfac e to the Pr oto c ol Buffers API. R p ackage version . . Go ogle (2012). Pr oto c ol Buffers: Develop er Guide . URL URLhttp://co de.google.com/ apis/protocolbuffers/do cs/overview.html . Hosmer D, Lemeshow S, May S (2008). Applie d Survival Analysis . John Wiley & Sons. ISBN-13: 0471754994, URL http://www.wiley.com/WileyCDA/Wil eyTitle/ productCd- 0471754994.html . Jiang W, Li P , W ang S, W u Y, Xue M, Ohno-Machado L, Jiang X (2013). “W ebGLORE: a w eb service for Grid LOgistic REgression.” Bioinformatics (Oxfor d, England) , 29 (24), 3238–3240. ISSN 1367-4811. doi:10.1093/bioinformatics/btt559 . PMID: 24072732 PMCID: PMC3842761. Leek JT, Storey JD (2007). “Capturing heterogeneity in gene expression studies b y surrogate v ariable analysis.” PL oS genetics , 3 (9), e161. Lu CL, W ang S, Ji Z, W u Y, Xiong L, Jiang X, Ohno-Machado L (2015). “W ebDISCO: A w eb service for distributed co x model learning without patient-lev el data sharing.” Journal of the A meric an Me dic al Informatics Asso ciation . ISSN 1067-5027. doi:10.1093/jamia/ocv083 . B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 17 Mazumder R, Hastie T, Tibshirani R (2010). “Spectral regularization algorithms for learning large incomplete matrices.” The Journal of Machine L e arning R ese ar ch , 11 , 2287–2322. Murtagh MJ, Demir I, Jenkings KN, W allace SE, Murtagh B, Boniol M, Bota M , Laflamme P , Boffetta P , F erretti V, Burton PR (2012). “Securing the data economy: translating priv acy and enacting securit y in the developmen t of DataSHIELD.” Public he alth genomics , 15 (5), 243–253. ISSN 1662-8063. doi:10.1159/000336673 . PMID: 22722688. NIH (2015). “NIH Collaboratory: Rethinking Clinical T rials.” Accessible at https://www. nihcollaboratory.org/Pa ges/distributed- research- network .aspx . No v em bre J, Johnson T, Bryc K, Kutalik Z, Bo yk o AR, Auton A, Indap A, King KS, Bergmann S, Nelson MR, et al. (2008). “Genes mirror geography within Europ e.” Na- tur e , 456 (7218), 98–101. Ooms J (2014). “The OpenCPU System: T ow ards a Univ ersal In terface for Scien tific Computing through Separation of Concerns.” A rxiv . . URL http://www.opencpu.org . R Core T eam (2014). R: A L anguage and Envir onment for Statistic al Computing . R F oun- dation for Statistical Computing, Vienna, Austria. URL http://www.R- project.org/ . T erry M Therneau, P atricia M Gramb sch (2000). Mo deling Survival Data: Extending the Cox Mo del . Springer-V erlag, New Y ork. ISBN 0-387-98784-3. Therneau TM (2014). A Package for Survival A nalysis in S . R pack age ver sion 2.37-7, URL http://CRAN.R- project.org /package=survival . Wikip edi a (2015). “Rev erse Proxy .” Accessible at https://en.wikipedia.org/wiki/ Reverse_proxy . W olfson M, W allace SE, Masca N, Row e G, Sheehan NA, F erretti V, LaFlamme P , T obin MD, Macleo d J, Little J, et al. (2010). “DataSHIELD : resolving a conflict in contemporary bioscience-performing a p ooled analysis of individual-lev el data without sharing the data.” International journal of epidemiolo gy , p. dyq111. A. Distributed rank- k singular v alue decomp ostion The singular v alue decomp osition (SVD) is a metho d for summarizing a dataset. The SVD of X X X , the n × p matrix of cov ariates, is formed by the matrices U U U , V V V , D D D such that X X X = U U U D D DV V V > , U U U > U U U = I , V V V > V V V = I , and D D D is diagonal with entries . (11) Additionally , we assume that the v alues of D D D is nonnegativ e and sorted, namely that D D D = diag( d 1 , d 2 , . . . , d min( n,p ) ) with d 1 ≥ d 2 , ≥ · · · ≥ 0. With these assumptions, the SVD of X X X is unique up to the signs of the columns of U U U and V V V . The SVD is a sort of factor mo del which decomp oses the v ariance of X X X into what are called principal comp onen ts. v 1 , the first column of V V V , is called the first principal comp onen t of X and is the maximizer of v ar( X X X v ). The v alues of u 1 can b e viewed as loading that tell 18 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject Data: X X X ∈ R n × p Result: u ∈ R n , v ∈ R p , and d > 0 u ← ( 1 √ n , 1 √ n , . . . , 1 √ n ); rep eat v ← X X X > u ; v ← v / k v k ; u ← X X X v ; d ← k u k ; u ← u/ k u k ; un til c onver genc e ; Algorithm 1: Alternating algorithm for rank-1 SVD. y ou ho w mu ch of the factor v 1 is presen t in each observ ation. d 2 1 / P j d 2 j is the prop ortion of the v ariance of X X X that can b e explained by v 1 , which means that the SVD also sorts the comp onen ts in order of their contribution to v ariance. When w e take a rank- k SVD we only k eep the k most imp ortan t factors, equiv alent to setting d k +1 = d k +2 = · · · = d min( n,p ) = 0. The SVD has man y uses in medical researc h. Often times, the results are themselves of int erest for examining a factor mo del. This is the case for metho ds like Latent Semantic Indexing ( Chen, Martin, Daimon, and Maudsley 2013 ). In a recen t example, Nov embr e, Johnson, Bryc, Kutalik, Bo yko, Auton, Indap, King, Bergmann, Nelson et al. ( 2008 ) reconstruct a map of europ e from the first tw o principal comp onen ts of SNP data. Additionally , SVDs are often used as a prepro cessing step b efore some further data analysis. There are many examples of this, including Principal Comp onen t Regression, SVD based imputation methods, and Surrogate V ariable Analysis – a technique based on trying to remov e unw anted v ariation from high dimensional data ( Mazumder, Hastie, and Tibshirani 2010 ; Leek and Storey 2007 ). Calculating an SVD can b e a challenging problem from a n umerical stabilit y standp oin t. F or this reason, it is relatively rare for p eople to implement their own v ersion of an SVD; R and MA TLAB b oth use the LAP ACK implemen tation of Anderson, Bai, Bisc hof, Blac kford, Dem- mel, Dongarra, Du Croz, Greenbaum, Hammerling, McKenney et al. ( 1999 ). Most of these metho ds in v olv e transforming the X X X matrix in a w ay that cannot b e done while main taining priv acy . That said, there is a relativ ely simple iterative pro cedure for calculating the rank-1 SVD that can b e mo dified to b e priv acy preserving. Algorithm 1 calculates ( u, v , d ), the rank-1 SVD of X X X . Since singular vectors can b e found successively b y remo ving the effect of the top singular vec- tor and then finding the rank-1 appro ximation again, w e can repeatedly apply the algorithm 1 in order to get a rank- k SVD. Com bining that idea with some mo difications to the previous algorithm in order to preserve priv acy , w e get algorithm 2 for rank- k priv acy protecting SVD. B. User in terface and further implemen tation details In order to make distcomp accessible to users who may not b e R programmers, shin y applets are pro vided to aid in the pro cess of defining a computation, setting up work er pro cesses and in generating co de for the master pro cess. B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 19 Data: each work er has priv ate data X X X i ∈ R n i × p Result: V ∈ R p × k , and d 1 ≥ . . . d k ≥ 0 V ← 0 , d ← 0 foreac h worker site j do U [ j ] = 0; transmit n j to master; end for i ← 1 to k do foreac h worker site j do u [ j ] ← (1 , 1 , . . . , 1) of length n j ; k u k ← q P j n j ; transmit k u k , V , and D to work ers; rep eat foreac h worker site j do u [ j ] ← u [ j ] / k u k ; calculate v [ j ] ← ( X X X [ j ] − U [ j ] D V > ) > u [ j ] ; transmit v [ j ] to master; end v ← P j v [ j ] ; v ← v / k v k ; transmit v to work ers; foreac h worker site j do calculate u [ j ] ← X X X [ j ] v ; transmit k u [ j ] k to master; end k u k ← P j k u [ j ] k ; transmit k u k to work ers; d i ← k u k ; un til c onver genc e ; V ← cbind ( V , v ); foreac h worker site j do U [ j ] ← cbind ( U [ j ] , u [ j ] ); end Algorithm 2: Priv acy preserving algorithm for rank- k SVD. 20 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject Figure 3: A part of defining a new computation. workspace defn defnId1 defn.rds data.rds defnId2 defn.rds data.rds . . . instances instance1.rds instance2.rds . . . Figure 4: Structure of workspace area. B.1. Define a computation The function defineNewComputation inv okes a shiny web application and Figure 1 gives an o v erview of what is exp ected by the application. A sample screen shot is sho wn in Figure 3 . Besides gathering some generic information such as a name and title for the computation, a form ula for the mo del and a starting dataset is also tak en as input. W e exp ect that the initial prop oser has actual data on sub jects from her site in some analyzable form (CSV assumed here) with meaningful names for the co v ariates. Other screens enable the user to choose from the av ailable computations, chec k data for conformability and execute a dry run. F or example, the pro vided form ula is c heck ed against the dataset to ensure the model can actually b e fit. The pro cess is not complete until the fit pro ceeds without error; the v arious buttons in the user in terface are articulated appropriately . The v ariables in the formu la then b ecome the v ariables that al l other participating sites will hav e to provide at a minimum. B. Narasimhan, D. L. Rubin, S. M. Gross, M. Bendersky , P . W. Lav ori 21 An identifier (for all practical purp oses unique) is generated and asso ciated with every com- putation definition. This ensures that a work er site (i.e., the asso ciated R computation en- gine) may participate in more than one computation; the identifier serv es to unambiguously distinguish v arious computations and asso ciate appropriate data and functions for that com- putation. The final result is a c omp def ob ject, containing all necessary metadata defining the compu- tation (but no individual patien t data), that is sav ed in an .rds file. B.2. Build work er pro cess for the computation Before a work er site can b e configured for a computation, an op encpu server needs to b e set up and its profile mo dified so that the distcomp pack age is loaded and configured with a workspace. The w orkspace configuration requires a one-time editing of a security policy (at least on the commonly used Ubuntu Lin ux servers) so that the op encpu serv er may write serialized ob jects into the area. The function setupWorker inv okes another shiny webapp that requires several inputs: the URL of the op encpu serv er, the c omp def (see Section B.1 ) and the site specific data. The shin y webapp p erforms sanity chec ks, ensures that the mo del can b e fit and if everything succeeds, it uploads information to the op encpu server so that the computation b ecomes accessible. The site is then ready to participate in a computation. B.3. Build master pro cess for the computation The function setupMaster in vok es a shiny webapp that creates a master pro cess R ob ject that can interact with work er pro cesses. Inputs to this application are the the c omp def generated in Section B.1 and URLs of sites participating in the computation. Once again some sanit y c hec ks are p erformed to ensure that sites are indeed addressable and finally , the R co de for running the computation is generated. The application up dates the user R profile with co de that ensures the instantiation of an ob ject with the correct iden tifier and v ariables and form ulae. No data is needed at this p oin t, but the master ob ject can do no real computation un til w ork er sites are added. B.4. W orkspace Details The pack age dis tcomp requires a w orkspace to do its work. The full structure of the wor kspace is shown in Figure 4 where R ob jects are p ersisted for computations. The defn folders store c omp def ob jects under v arious ident ifiers generated for the computations. The instances folders store the instan tiated ob jects used in the computations; these ma y be repeatedly sa v ed during iterations as they c hange state. A workspace is set up only once. It is b est done b y mo difying the user R profile to contain the follo wing t wo lines. library("distcomp") distcompSetup(workspace = "full path of workspace", ssl.verifyhost=FALSE, ssl.verifypeer=FALSE) 22 Soft w are for Distributed Computation on Medical Databases: A Demonstration Pro ject (On Unix and MacOS, the user’s .Rprofile file in the home directory will suffice, but on Windo ws, this needs to b e inserted into the site profile.) Thus every R inv o cation will hav e loaded the distcomp pac k age and know ab out the workspace. Affiliation: Balasubramanian Narasimhan Departmen t of Health Researc h and Policy , and Departmen t of Statistics Stanford Univ ersit y Stanford, CA 94305 E-mail: naras@stat.stanford.edu URL: http://statweb.stanford.ed u/~naras/ Daniel L. Rubin Departmen t of Radiology Stanford Univ ersit y Stanford, CA 94305 E-mail: dlrubin@stanford.edu URL: http://stanford.edu/~rubin / Sam uel M. Gross Departmen t of Statistics Stanford Univ ersit y Stanford, CA 94305 Marina Bendersky Departmen t of Radiology Stanford Univ ersit y Stanford, CA 94305 Philip W. La v ori Departmen t of Health Researc h and Policy Stanford Univ ersit y Stanford, CA 94305 E-mail: lavori@stanford.edu URL: https://med.stanford.edu/p rofiles/philip- lavori
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment