Latent Sequence Decompositions
We present the Latent Sequence Decompositions (LSD) framework. LSD decomposes sequences with variable lengthed output units as a function of both the input sequence and the output sequence. We present a training algorithm which samples valid extensio…
Authors: William Chan, Yu Zhang, Quoc Le
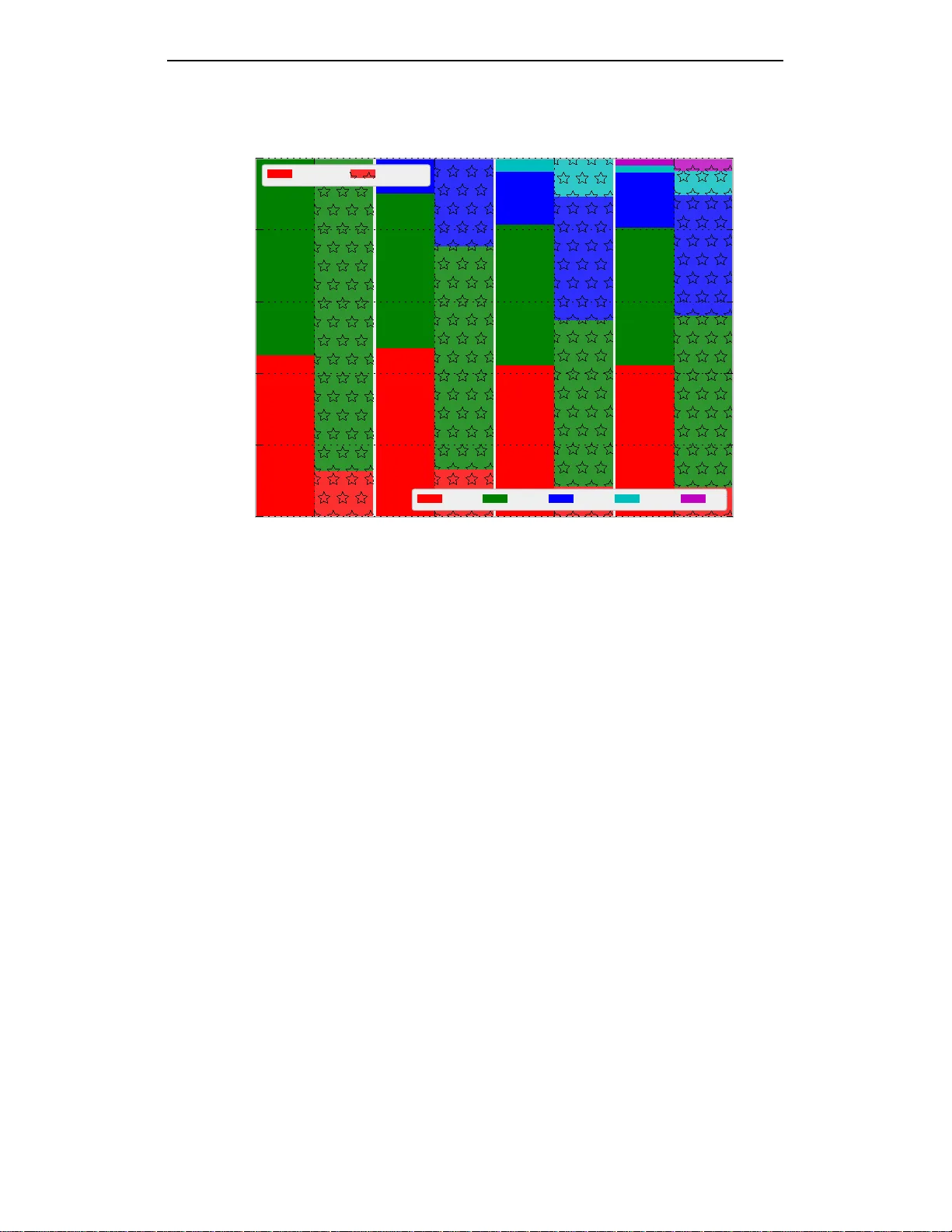
Published as a confer ence paper at ICLR 2017 L A T E N T S E Q U E N C E D E C O M P O S I T I O N S William Chan ∗ Carnegie Mellon Uni versity williamchan@ cmu.edu Y u Zhang ∗ Massachusetts Institute of T e chnolog y yzhang87@mit .edu Quoc V . Le, Navdeep J aitly Google Brain {qvl,ndjaitl y}@google.c om A B S T R A C T Sequence- to-sequen ce models rely on a fix ed decomposition of the tar get s e- quences into a sequ ence of to kens that may be words, word -pieces or ch aracters. The cho ice of these to kens and th e d ecompo sition of the target sequences into a sequence of tokens is often static, and independen t of the inp ut, output data do - mains. This can po tentially lead to a sub -optimal choic e of token dictio naries, as the decompo sition i s not inf ormed by the particular problem being solved. In th is paper we pr esent Latent Sequence Decomp ositions (LSD), a framework in which the d ecompo sition of sequences in to constituent to kens is learnt durin g the train- ing of the mo del. The decompo sition depends both on the input sequence and on the outp ut sequence. In L SD, durin g training, the m odel samples deco mpositions incrementa lly , from left to right by locally samp ling betwe en v alid extensions. W e experiment with the W all Street Journa l speech recognition task. Our LSD model achieves 12.9% WER com pared to a ch aracter baseline o f 14.8 % WER. When combined with a c on volutional network on the enc oder, we achieve a WER of 9.6%. 1 I N T RO D U C T I O N Sequence- to-sequen ce (seq2seq) models (Sutskev er et al., 2 014; Cho et al., 2 014) with atten tion (Bahdanau et al., 2 015) have been succ essfully applied to m any applicatio ns includ ing m achine translation (Lu ong et al., 2 015; Jean et al., 20 15), parsing (V inyals et al., 2015 a), imag e caption- ing (V inyals et al., 201 5b; Xu et al., 2015) and Au tomatic Speech Recogn ition (ASR) (Chan et al., 2016; Bahdanau et al., 2016 a ). Previous work h as assumed a fixed deterministic decompo sition for each ou tput seq uence. The output representatio n is usually a fixed sequence of words (Sutske ver et al., 2014; Cho et al., 2014), phone mes (Chorowski et al., 2015), characters (Chan et al., 2016; Bahdanau et al., 2016 a) or e ven a mixture of characters and words ( Luong & Manning, 2016). Howe ver, in all these cases, the models are trained tow ar ds one fixed decomposition for each output s equen ce. W e argue against using fixed determin istic d ecompo sitions o f a sequence that has been defined a priori. W ord segmented models (Luo ng et al., 2015; Jean et al., 2015) often have to deal with large softmax sizes, ra re words and Ou t-of-V ocab ulary (OO V) words. Chara cter models (Chan et al., 2016; Bahdanau et al., 2 016a) overcome the OO V pr oblem b y modelling the smallest output u nit, howe ver this typically results in lo ng d ecoder lengths and computationally expensive inference. An d ev en with mixed (b ut fixed) character-word mod els (Luong & Manning, 2016), it is unclear whether such a p redefined segmentation is optima l. In all these examp les, the outpu t decomp osition is on ly ∗ W ork done at Google Brain. 1 Published as a confer ence paper at ICLR 2017 a functio n o f the output sequence. This may be acceptab le f or problem s such as tran slations, but inappro priate for tasks such as speech recog nition, where segmentation should also be info rmed by the characteristics of the inputs, such as audio. W e want our model to have the capacity and flexibility to learn a distribution of seq uence d e- composition s. Additionally , the decomposition should be a sequen ce o f variable length tokens as deemed mo st pro bable. For example, lang uage may be more natur ally represented as word pieces (Schuster & Nakajima, 2012) rather than indi vidual characters. In many speech and language tasks, it is p robab ly more e fficient to model “q u” as o ne ou tput u nit r ather th an “q” + “u” as separate output units (since in English, “q” is almost alw a ys followed by “u”) . W ord piece models also naturally solve rare word and OO V pro blems similar to character models. The ou tput sequence deco mposition should be a function of both the input seque nce and the output sequence (rath er than output sequence alon e). For example, in spe ech, the c hoice of emitting “ing ” as one w ord piece or as separate tokens of “i” + “n” + “g” should be a function of the current output word as well as the audio signal (i.e., speaking style). W e present the Latent Sequence Decom positions (L SD) framework. LSD d oes not assume a fixed decomp osition fo r an output sequ ence, but rather learns to decompose sequences as f unction of both the input and the outp ut sequen ce. Each o utput sequence ca n be decomp osed to a set of laten t sequence d ecompo sitions using a dic tionary of variable length o utput tokens. Th e LSD fram ew ork produ ces a distrib ution over the latent sequence decomp ositions and m arginalizes ov er them during training. During test inference, we find the best decomposition and outpu t sequence, by using beam search to find the most likely output sequence from the model. 2 L A T E N T S E Q U E N C E D E C O M P O S I T I O N S In th is sectio n, we descr ibe LSD more f ormally . Let x b e ou r inp ut sequen ce, y b e ou r ou tput sequence an d z be a latent sequence decom position of y . The latent sequ ence decomp osition z consists of a sequence of z i ∈ Z wher e Z is the constructed token space. E ach token z i need n ot be the same length , but rather in o ur framework, we expect the to kens to have different leng ths. Specifically , Z ⊆ ∪ n i =1 C i where C is the set of singleton tokens and n is the length o f th e largest output to ken. In ASR , C would typically be the set of English character s, while Z would be word pieces (i.e., n -gram s of character s). T o give a co ncrete examp le, co nsider a set of tokens { “a” , “b” , “c” , “at” , “ca” , “cat” } . W ith this set of tokens, the word “cat” may be rep resented as the sequen ce “c”, “ a”, “t”, or the sequence “ca”, “t”, or alternativ ely as the sing le token “c at”. Since the approp riate deco mposition of th e w ord “cat” is not known a priori, the decomp osition its elf is latent. Note that the length | z a | of a decom position z a need not b e the same as the len gth of the output sequence, | y | (for example “ca”, “t” has a length of 2, whereas the seq uence is 3 chara cters long). Similarly , a different decomp osition z b (for examp le the 3-gram to ken “cat”) of the same sequence may be of a different length (in this case 1). Each decomp osition, collapses to the target outpu t sequence using a trivial collapsing function y = collapse( z ) . Clearly , the set of de composition s, { z : co llapse( z ) = y } , of a sequen ce, y , usin g a non-tr i vial token s et, Z , can be com binatorially lar ge. If there was a k nown, unique , co rrect segmentation z ∗ for a g iv en pair, ( x , y ) , one could simply train the mod el to output the fixed deterministic decompo sition z ∗ . Howe ver , in most prob lems, we do not know the best possible decomp osition z ∗ ; ind eed it may b e po ssible that the ou tput can be correctly decomp osed into multiple alternati ve but v alid segmentations. For example, in end-to-end ASR we typically use ch aracters as the o utput u nit of choice (Chan et al., 2016; Bahdanau et al., 2016a) but word p ieces may be better units as th ey mo re closely align with the acoustic entities su ch as syllables. Howe ver, the m ost app ropria te decomp osition z ∗ for a given is ( x , y ) pair is ofte n unknown. Giv en a particula r y , the best z ∗ could even cha nge dependin g on the input sequence x (i.e., speaking style). In LSD, we want to learn a probab ilistic segmentation mappin g from x → z → y . The model produ ces a distribution of deco mpositions, z , given an in put sequ ence x , an d the objective is to maximize the log-likeliho od of the grou nd truth sequence y . W e can accom plish this by factorizing 2 Published as a confer ence paper at ICLR 2017 and margina lizing over all possible z latent sequ ence decomp ositions und er o ur mo del p ( z | x ; θ ) with parameters θ : log p ( y | x ; θ ) = lo g X z p ( y , z | x ; θ ) (1) = log X z p ( y | z , x ) p ( z | x ; θ ) (2) = log X z p ( y | z ) p ( z | x ; θ ) (3) where p ( y | z ) = 1 (collapse( z ) = y ) captures path decom positions z that collapses to y . Du e to the exponential n umber of d ecompo sitions of y , exact inferenc e and sear ch is intrac table for any non- trivial token set Z an d s equen ce length | y | . W e describe a b eam s earch algorithm to do approxim ate inference decod ing in Section 4. Similarly , com puting the exact g radient is in tractable. However , we can d erive a gr adient estimator by differentiating w .r .t. to θ an d taking its expectation: ∂ ∂ θ log p ( y | x ; θ ) = 1 p ( y | x ; θ ) ∂ ∂ θ X z p ( y | x , z ) p ( z | x ; θ ) (4) = 1 p ( y | x ; θ ) X z p ( y | x , z ) ∇ θ p ( z | x ; θ ) (5) = 1 p ( y | x ; θ ) X z p ( y | x , z ) p ( z | x ; θ ) ∇ θ log p ( z | x ; θ ) (6) = E z ∼ p ( z | x , y ; θ ) [ ∇ θ log p ( z | x ; θ )] (7) Equation 6 u ses the ide ntity ∇ θ f θ ( x ) = f θ ( x ) ∇ θ log f θ ( x ) assuming f θ ( x ) 6 = 0 ∀ x . Equa- tion 7 gives us an u nbiased e stimator of ou r gradie nt. I t tells us to sam ple some latent sequence decomp osition z ∼ p ( z | y , x ; θ ) u nder o ur mod el’ s posterior, wh ere z is constraint to be a valid sequence th at co llapses to y , i.e. z ∈ { z ′ : collapse( z ′ ) = y } . T o train the model, we sample z ∼ p ( z | y , x ; θ ) and com pute the grad ient of ∇ θ log p ( z | x ; θ ) using b ackpro pagation . Howe ver, sampling z ∼ p ( z | y , x ; θ ) is difficult. D oing this exactly is computatio nally expensive, because it would require sampling co rrectly from the posterior – it would be possible to do this using a particle filtering lik e algorithm , but w o uld require a full forward pass through the outpu t sequ ence to do this. Instead, in our imp lementation we use a he uristic to sam ple z ∼ p ( z | y , x ; θ ) . At each outp ut time step t when pr oducing tokens z 1 , z 2 · · · z ( t − 1) , w e sample f rom z t ∼ p ( z t | x , y , z 2 ). W e found very minor differences in WER based on the vocab ulary size, fo r our n = { 2 , 3 } word piece exp eriments we used a vocab ulary size of 2 56 while our n = { 4 , 5 } word piece exp eriments used a vocab ulary size of 51 2. Additio nally , we r estrict h space i to b e a unigram token and not includ ed in any other word p ieces, this for ces the decomposition s to break o n word bound aries. T able 1 co mpares the effect of varying the n sized word piece vocabulary . Th e La tent Sequen ce Decompo sitions (LSD) mod els we re trained with the framework described in Section 2 and th e (Maximum Ex tension) MaxE xt decom position is a fixed decomp osition. Max Ext is gene rated in a left-to-righ t fashion, where at ea ch step the longest word piec e extension is selected fro m th e vocab ulary . The MaxExt decom position is not the shortest | z | po ssible sequenc e, howev er it is a determin istic decomp osition that c an be ea sily generated in linea r time on -the-fly . W e d ecoded these mod els with simple n-b est list be am search without any externa l d ictionary or L anguag e Mod el (LM). The b aseline model is simp ly the u nigram o r character mo del an d a chieves 14.76% WER. W e find the LSD n = 4 word piece vocabulary mod el to per form th e best at 12.8 8% WER or yieldin g a 12.7 % relative imp rovement over the baselin e character mo del. None o f our MaxEx t mo dels beat our chara cter model baseline, sugg esting the maximu m extension deco mposition to be a poo r decomp osition choice. Howev er , all our L SD models pe rform be tter th an the b aseline suggesting th e LSD framework is able to learn a decomp osition better than the baseline character decomp osition. W e also look at the distribution o f the characters covered based on the word piece leng ths d uring inference across different n sized word piece v o cabulary u sed in training. W e define the distribution of the characte rs covered as the per centage of ch aracters covered b y the set of word p ieces with the same leng th acr oss th e test set, and we exclude h space i in th is statistic. Figur e 1 plots the 5 Published as a confer ence paper at ICLR 2017 2 3 4 5 n -gram W or d Piece V o cab ulary 0 20 40 60 80 100 Distribution of the Cha racters Covered % Distribution of the Characters covered by the W ord Pieces for LSD and MaxExt Models LSD MaxExt 1 2 3 4 5 Figure 1: Distribution of the ch aracters covered by the n-gram s o f th e word piece m odels. W e train Latent Sequence Decompo sitions (LSD) and Maximu m Extension (MaxExt) models with n ∈ { 2 , 3 , 4 , 5 } sized word piece vocabulary an d measur e the distribution o f th e ch aracters covered by the word pieces. The bars with the so lid fill repr esents th e L SD models, and th e bars with th e star hatch fill represen ts the MaxEx t mo dels. Both the LSD and MaxE xt m odels prefer to use n ≥ 2 sized word p ieces to cover the m ajority o f the ch aracters. The MaxE xt mod els pref ers long er word pieces to cover characters compared to the LSD models. distribution of the { 1 , 2 , 3 , 4 , 5 } -n gram word pieces th e mod el decides to use to decomp ose th e sequences. When the mod el is trained to use the bigram word p iece vocabulary , we f ound the model to pr efer bigram s (55 % of th e ch aracters e mitted) over charac ters (45% of the char acters emitted) in the LSD d ecompo sition. Th is suggest tha t a ch aracter o nly vocabulary may not be the best vocab ulary to learn from. Our best model, LSD with n = 4 word piece vocabulary , covered the word charac ters with 42.16%, 3 9.35%, 14.83% and 3.66% of the time using 1, 2, 3, 4 sized word pieces respectively . In the n = 5 word piece vocabulary mo del, the LSD model uses the n = 5 sized word pieces t o cover ap proxim ately 2% of the characters. W e suspect if we used a larger dataset, we could extend the v o cabulary to co ver e ven larger n ≥ 5 . The MaxExt model were trained to greedily emit the longest possible word piece, consequen tly th is prior meant the m odel w ill pr efer to em it long word pieces over ch aracters. While this deco mposition results in the shorter | z | len gth, the WER is slightly worse than the cha racter baseline. This suggest the much sho rter decomposition s gen erated by the MaxEx t prior may not b e best decomp osition. This falls onto the principle that th e best z ∗ decomp osition is not only a fun ction of y ∗ but as a function of ( x , y ∗ ) . In the case of ASR, the segmentation is a fu nction of the a coustics as well as the text. T able 2 compare s our WSJ results with other published end-to-en d models. The be st CTC mod el achieved 27.3% WER with REINFORCE o ptimization o n WER (Graves & Jaitly, 2 014). The p re- viously best rep orted basic seq2seq model on WSJ WER a chieved 18.0% WER (Bahda nau et al., 2016b) with T ask Lo ss Estimation (TLE ). Our b aseline, also a seq2seq mod el, achiev ed 14.8 % WER. Main differences between o ur models is that we did no t use conv olu tional lo cational-ba sed 6 Published as a confer ence paper at ICLR 2017 T able 2: W all Stree t Jour nal test eval92 W ord Error Rate (WER) re sults acro ss Connectionist T em- poral Classification (CTC) and Seq uence-to -sequen ce (seq2seq) m odels. T he L atent Seq uence De - composition (L SD) mode ls use a n = 4 word p iece vocabulary (LSD4). T he Conv o lutional Neural Network ( CNN) model is with d eep residual co nnections, batch n ormalizatio n and conv olutions. The best end-to-en d model is seq2seq + LSD + CNN at 9.6% WER. Model WER Graves & Jaitly (2014) CTC 30.1 CTC + WER 27.3 Hannun et al. (2014) CTC 35.8 Bahdanau et al. (2016 a) seq2seq 18.6 Bahdanau et al. (2016 b) seq2seq + TLE 18.0 Zhang et al. (2017) seq2seq + CNN 2 11.8 Our W ork seq2seq 14.8 seq2seq + LSD4 12.9 seq2seq + LSD4 + CNN 9.6 priors and we used weigh t no ise d uring training . T he deep CNN model with residual con nections, batch norm alization and conv o lutions achie ved a WER of 11.8% (Zhang et al., 2017) 2 . Our LSD mod el u sing a n = 4 word piece vocabulary achieves a WER of 12.9% or 12.7 % relatively better over t he baselin e seq2seq model. If we combine our LSD model with th e CNN (Zhang et al., 2017) mod el, we a chieve a co mbined WER of 9.6% WER or 3 5.1% relativ ely b etter over the baseline seq2seq model. These numbers are all reported without the use of any languag e model. Please see Appendix A for th e decomp ositions gen erated b y our mod el. The LSD mo del learns multiple word piece decomposition s for the same word sequence. 6 R E L A T E D W O R K Singh et al. (2 002); McGraw et al. (2013); Lu et al. (2 013) built prob abilistic pronun ciation models for Hidd en Markov Model (HMM) b ased systems. Howe ver, s uch mo dels are still constrain t to th e condition al indepen dence and Marko vian assumptions of HMM-based systems. Connection ist T empor al Classification (CTC) (Graves et al., 2006; Graves & Jaitly, 2 014) based models assume conditio nal in depend ence, and can rely on dyna mic p rogram ming for exact infer- ence. Sim ilarly , Ling et al. (20 16) use latent codes to g enerate text, an d also assume cond itional indepen dence a nd leverage on dyn amic program ming f or exact max imum likelihood gra dients. Such mode ls can n ot lea rn the outpu t lang uage if the lang uage distribution is multimod al. Our seq2seq mo dels makes no such Ma rkovian assump tions and can lear n multim odal outpu t d istribu- tions. Collobert et al. (2016) and Zweig et al. (201 6) de velope d extensions of CTC where they used some word pieces. Howe ver, the word p ieces are only used in repeated character s an d the deco m- positions are fixed. W ord piece m odels with seq2 seq have a lso b een recently used i n machine tr anslation. Sennr ich et al. (2016) used word p ieces in rare word s, wh ile W u et al. (2 016) used word pieces for all the words, howe ver the decomp osition is fix ed and defined by heuristics o r another model. Th e decomp ositions in these models are also on ly a functio n of the ou tput sequence, while in LSD the decomposition is a 2 For our CNN architectures, we use and compare to the “(C (3 × 3) / 2) × 2 + NiN” architecture from T able 2 line 4. 7 Published as a confer ence paper at ICLR 2017 function of both th e in put and output seq uence. The LSD framework allows us to lear n a distribution of decomp ositions rather than learning just one decomp osition defined by a priori. V inyals et al. (2 016) used seq2 seq to o utputs sets, th e output sequence is u nord ered and used fixed length outpu t units; in our decompo sitions we maintain ord ering use variable lengthed output un its. Reinforceme nt learning (i.e. , REINFORCE an d other task loss estimators) (Sutton & Barto, 19 98; Graves & Jaitly, 2014 ; Ranzato et al., 2016) learn different ou tput sequences can yield different task losses. Ho wever , these methods don’t directly learn dif f erent decompositions of the same sequence. Future work should incorporate LSD with task loss optimization methods. 7 C O N C L U S I O N W e presented th e Latent Sequ ence Deco mposition s (LSD) fra mew ork. LSD allows u s to learn d e- composition s of sequences th at are a functio n of both the input an d outp ut sequence. W e presen ted a biased training algo rithm based on sampling valid extensions with an ǫ -greed y strategy , and a n approx imate decoding algorithm. On the W all Street Jour nal speech recognition task, the sequence- to-sequen ce character mo del baseline ac hieves 14.8% WER wh ile the LSD model ach iev es 12.9 %. Using a a deep conv o lutional neural network on the encoder with LSD, we achiev e 9.6% WER. A C K N OW L E D G M E N T S W e th ank Ashish Agarwal, Philip Bachman , Dzmitry Bahdanau , Eugen e Brevdo, Jan Chor owski, Jeff Dean, Chris Dy er , Gilbert Leung , Mohammad Norouzi, Noam Shazeer, Xin Pan, L uke V ilnis, Oriol V inyals and the Google Brain team for many insightful discussions and technical assistance. R E F E R E N C E S Martín Ab adi, Ashish Agarwal, Paul Bar ham, Eugen e Brevdo, Z hifeng Chen , Craig Citro, Greg S. Corrado, Andy Da vis, Jeffrey Dean , Matthieu Devin, San jay Ghemawat, I an Goodfellow , An drew Harp, Geof frey Irving, Michael Isard, Y a ngqing Jia, Rafal Jozefowicz, L ukasz Kaiser , Manjunath Kudlur , Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Mu rray , Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner , Ilya Sutskever , Kunal T alw a r , Paul T ucker , V in- cent V anhoucke, V ijay V asude van, Fer nanda V iégas, Oriol V inyals, Pete W arden, Martin W atten- berg, Martin W icke, Y uan Y u, and Xiao qiang Zheng. T ensorFlow: Large- scale machine learning on he terogene ous systems, 2015. URL http://tenso rflow.org/ . Software available fr om tensorflow .org. Dzmitry Bahd anau, K y ungh yun Cho, and Y oshua Bengio. Neural Mac hine Translation by Jointly Learning to Align an d T ra nslate. I n Internationa l Con fer en ce on Lea rning R epr esentations , 2015. Dzmitry Bah danau, Jan Cho rowski, Dmitriy Serdyuk , Philemon Brakel, a nd Y oshua Bengio. End - to-end Attention-based Large V ocabulary Speech Recognition. I n IEEE International Conference on Acoustics, Speech, and Signal Pr ocessing , 2016a . Dzmitry Bah danau, Dmitriy Serdyuk , Philemon Brakel, Nan Ro semary Ke, Jan Chorowski, Aar on Courville, a nd Y oshua Bengio. T ask Loss Estimatio n for Sequen ce Pred iction. In Internationa l Confer ence on Learning Repr esenta tions W orkshop , 2016b . W illiam Chan, Navdeep Jaitly , Quo c Le, an d Oriol V inyals. L isten, Attend an d Spell: A Neural Network f or L arge V oca bulary Con versational Speech Recognition. In IEEE Internatio nal Con- fer en ce on Acoustics, Speech, and Signal Pr ocessing , 2016. Kyunghyun Cho, Bart v an Merrienboer, Caglar Gulceh re, Dzmitry Bahdanau, F ethi Bougares, Hol- ger Schwen, and Y oshua Bengio. L earning Phrase Representations using RNN Encode r-Decoder for Statistical Mach ine Translation. I n Co nfer ence on Emp irical Metho ds in Natural Lan guage Pr ocessing , 20 14. Jan Chorowski, Dzmitry Bahdanau , Dmitriy Serdyu k, Kyunghyu n Ch o, and Y oshua Beng io. Attention-Based Models for Speech Recognitio n. In Neural In formation Pr ocessing Systems , 2015. 8 Published as a confer ence paper at ICLR 2017 Ronan Collob ert, Chr istian Puh rsch, and Gabriel Sy nnaeve. W av2Letter: an En d-to-E nd Con v Net- based Speech Recognition System. In arXiv:1 609.0 3193 , 2 016. Alex Graves. Practical V ariational In ference for N eural Network s. In Neural In formation Pr ocessing Systems , 2011. Alex Gr av es and Navdeep Jaitly . T ow a rds End -to-End Spee ch Recognition with Recur rent Neural Networks. In Interna tional Confer ence on Machine Learning , 2014. Alex Graves, Santiago Fernandez, F austino Gomez, and Jurgen Schmiduber . Connection ist T em po- ral Classification: Lab elling Unsegmented Sequence Data with Recur rent Neural Network s. In Internation al Confer ence on Machine Learning , 2006. Alex Gra ves, Na v deep Jaitly , and Abdel-r ahman Mohamed. Hybr id Speech Recognition with Bidi- rectional LSTM. In Automatic Speech Recognition and Understanding W orkshop , 2013. A wni Hannun, A ndrew Maas, Da niel Jur afsky , and Andrew Ng. First-Pass Large V ocab ulary Con - tinuous Speech Recognition using Bi-Directional Recurrent DNNs. In arXiv:1 408.2 873 , 2014. Salah Hihi and Y oshu a Bengio. Hierarchical Recurren t Neural Netw o rks for Long- T erm Depen den- cies. In Neural Information Pr ocessing Systems , 19 96. Sepp Hochreiter and Jurgen Sch midhub er . Lon g Sh ort-T erm M emory. Neural Co mputation , 9 (8): 1735– 1780 , November 1997. Sebastien Jean, Kyungh yun Cho, Roland Memisevic, an d Y oshua Bengio. On Usin g V ery Large T arget V ocabulary for Neural Machine Translation. In Association fo r Computationa l Linguistics , 2015. Diederik Kingm a a nd Jimmy Ba. Adam: A Method f or Stochastic Op timization. In Internationa l Confer ence on Learning Repr esenta tions , 2015. Jan Koutnik, Klaus Greff, Faustino G omez, and Jurgen Sch midhub er . A Clockwork RNN. In Internation al Confer ence on Machine Learning , 2014. W ang Ling , Edward Grefenstette, Karl Mor itz Hermann, T o mas K o cisky , Andrew Senior, FUmin W ang, and Phil Blunsom. La tent Predictor Networks for Cod e Generation. In Associa tion for Computation al Linguistics , 2016 . Liang Lu, Arna b Ghoshal, and Steve Renals. Acoustic d ata-driven pronu nciation lexicon for large vocab ulary speech r ecognition . In Automatic Speech Recognitio n and Und erstanding W orkshop , 2013. Minh-Th ang Lu ong and Christopher Manning. Achie ving Open V ocabulary Ne ural Machine T ran s- lation with Hybrid W ord-Ch aracter Models. I n Association for Computation al Linguistics , 2016 . Minh-Th ang Lu ong, Ilya Sutske ver , Quoc V . Le, O riol V inyals, and W ojciech Zaremba. Ad dress- ing the Rar e W o rd Prob lem in Neu ral Machin e Translation. In Association for Computatio nal Linguistics , 2015. Ian McGraw , Ibrah im Bad r , and James Gla ss. Learn ing Lexicons From Speech Using a Pronun - ciation Mixture Model. IE EE T ransactions on Audio, Speech, an d La nguage P r ocessing , 21 (2), 2013. Daniel Povey , Arnab Gh oshal, Gilles Bou lianne, Lukas Burget, Ondrej Glem bek, Nagendra Goel, Mirko Hannenma nn, Petr Motlicek, Y an min Qian, Petr Schwarz, Jan Silovsky , Georg Stemmer, and Karel V esely . Th e Kaldi Sp eech Recogn ition T oo lkit. In Automatic Speech Recognition and Understanding W orkshop , 2011. Marc’Aure lio Ranzato, Sumit Cho pra, Michae l Auli, and W ojciech Zarem ba. Sequence Level T rain- ing with Recurren t Neural Networks. In I nternation al Confer e nce o n Learnin g Representations , 2016. Mike Schuster and Kaisuke Nak ajima. Japan ese and Korean V oice Search. I n IEEE In ternationa l Confer ence on Acoustics, Speech and Signal Pr ocessing , 2012. 9 Published as a confer ence paper at ICLR 2017 Mike Schuster an d Kuldip Paliwal. Bidirectional Recur rent Neural Ne tworks. I EEE T ransactions on Signa l Pr o cessing , 45(11) , 1997. Rico Sennrich, Barry Hadd ow , and Alexandra Birch. Neural Machine T r anslation of Rare W o rds with Subword Units. In Association for Computation al Linguistics , 2016 . Rita Singh, Bhik sha Raj, and Richard Stern. Auto matic g eneration of subword un its for speech recogn ition s ystems. I EEE T ransactio ns on Speech and Audio Pr ocessing , 10(2 ), 2002. Ilya Sutsk ev er , Oriol V inyals, and Quoc Le. Sequ ence to Sequence Learning with Neural Networks. In Neural Information Pr ocessing Systems , 2014. Richard Sutton and Andrew B arto. Rein for cement Learning: An In tr oduc tion . MIT Press, 1998 . Oriol V inyals, Lu kasz Kaiser , T erry Koo, Slav Petrov , Ilya Sutskever , and Geo ffrey E. Hinton. Gram- mar as a foreign languag e. In Neural Information Pr ocessing Systems , 201 5a. Oriol V inyals, Alexande r T o shev , Sam y Bengio, an d Dumitru Erhan. Show and T e ll: A Neural Image Caption Gen erator. In IEEE Confer ence o n Compu ter V ision and P attern R ecognition , 2015b . Oriol V inyals, Samy Bengio, and Manjunath Kudlur . Order Matters: Sequen ce to sequence for sets . In Internation al C onference on Learning Repr esentations , 2016. Y onghui W u, Mik e Schuster, Zhifeng Chen, Quoc V . Le, Mohammad Noro uzi, W olfgan g Mache rey , Maxim Krikun , Y uan Cao, Qin Gao, Klau s Macherey , Jef f Klin gner, Apurva Shah, Melvin John- son, Xiaobing Liu, Lukasz Kaiser , Stephan Gouws, Y oshik iyo Kato, T aku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, W ei W ang, Cliff Y oung , Jason Smith, Jason Riesa, Alex Rudnick , Oriol V inyals, Gr eg Corrad o, Macduff Hughes, an d Jeffrey Dean. Google’ s Neu- ral Machine T ranslation System: Brid ging the Gap between Human and Machine Translation. In arXiv:160 9.081 44 , 201 6. Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyungh yun Cho, Aaron Courville, Ruslan Salakhu tdinov , Richard Zem el, a nd Y oshua Ben gio. Show , Attend and T ell: Neural Im age Caption Generation with V isual Attention. In Interna tional Confer ence on Machine Learning , 2015. Y u Zhan g, W illiam Chan , an d Navdeep Jaitly . V ery deep c onv olu tional networks for end-to -end speech recogn ition. In I EEE Internatio nal C onference on Acoustics, Speech and Signa l Pr ocess- ing , 2017 . Geoffrey Zweig, Chengzhu Y u, J asha Droppo, an d And reas Stolcke. Advances in All-Ne ural Spee ch Recognition . In arXiv:16 09.05 935 , 20 16. 10 Published as a confer ence paper at ICLR 2017 A L E A R N I N G T H E D E C O M P O S I T I O N S W e gi ve the top 8 hypoth esis gen erated b y a baseline seq2seq ch aracter model, a Latent Sequ ence Decompo sitions (LSD) word piece m odel and a Max imum Extension (M axExt) word piece model. W e note that “shamrock ’ s” is an out-o f-vocabulary word while “shamrock” is in-vocab ulary . Th e groun d truth is “shamrock ’ s pretax profit fr om the sale was o ne hund red twenty fiv e million dollar s a spokeswoman said”. Note how the LSD mo del generates multiple deco mpostion s for th e same word sequence, this does not happen with the MaxExt model. 11 Published as a confer ence paper at ICLR 2017 T able 3: T op hy pothesis comparsion between seq2seq character model, LSD word piece model and MaxEx t w ord piece mode l. n Hypothesis LogProb Reference - shamrock’ s pretax profit from the sale was one hundred twenty fiv e mil lion dollars a spokes woman said - Character seq2seq 1 c|h|a|m|r|o|c|k|’|s| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |a| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -1.373868 2 c|h|a|m|r|o|x| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |a| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -2.253581 3 c|h|a|m|r|o|c|k|s| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |a| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -3.482713 4 c|h|a|m|r|o|c|k|’|s| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |o|f| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -3.493957 5 c|h|a|m|r|o|d|’|s| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |a| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -3.885185 6 c|h|a|m|r|o|x| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |o|f| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -4.373687 6 c|h|a|m|r|o|c|’|s| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |a| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -5.148484 8 c|h|a|m|r|o|c|k|s| |p|r|e|t|a|x| |p|r|o|f|i|t| |f|r|o|m| |t|h|e| |s|a|l|e| |w|a|s| |o|n|e| |h|u|n|d|r|e|d| |t|w|e|n|t|y| |f|i|v|e| |m|i|l|l|i|o|n| |d|o|l|l|a|r|s| |o|f| |s|p|o|k|e|s|w|o|m|a|n| |s|a|i|d -5.602793 W ord Piece Model Maximum Extension 1 sh|am|ro|ck|’ s| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd|red| |tw|ent|y| |fiv e| |mil|lion| |doll|ars| |a| |sp|ok|es|w o|man| |said -1.155203 2 sh|am|ro|x| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd |red| |tw|ent|y| |fiv e| |mil|lion| |doll|ars| |a| |sp|ok|es|wo|man| |said -3.031330 3 sh|ar|ro|x| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd|red | |tw|ent|y| |fi ve| |mil|lion| |doll|ars| |a| |sp|ok|e s|wo|man| |said -3.074762 4 sh|e| |m| |ro|x| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd|red| |tw|ent|y| |fiv e| |mil|lion| |doll|ars| |a| |sp|ok|es|wo|man| |said -3.815662 5 sh|e| |mar|x| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd|red | |t w|ent|y| |fiv e| |mil|lion| |doll|ars| |a| |sp|ok|es|w o|man| |said -3.880760 6 sh|ar|ro|ck|s| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd |red| |tw|ent|y| |fiv e| |mil|li on| |doll|ars| |a| |sp|ok|e s|wo|man| |said -4.083274 7 sh|e| |m| |ro|ck|ed| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd |red| |tw|ent|y| |fi ve| |mil|lion| |doll|ars| |a| |sp|ok|e s|wo|man| |said -4.878025 8 sh|e| |m| |ro|ck|s| |pre|ta|x| |pro|fi|t| |from| |the| |sa|le| |was| |one| |hu|nd|red| |tw|ent|y| |fiv e| |mil |lion| |doll|ars| |a| |sp|ok|es|w o|man| |said -5.121490 W ord Piece Model Latent Sequence Decompositions 1 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|lio|n| |do ll|a|r|s| |a| |sp|ok|e|s|wo|ma|n| |said -28.111485 2 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|li|o|n| |do ll|ar|s| |a| |sp|ok|e|s|wo|ma|n| |said -28.172878 3 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|lio|n| |do ll|a|r|s| |a| |sp|ok|e|s|w|om|a|n| |said -28.453381 4 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|li|o|n| |do ll|a|r|s| |a| |sp|ok|e|s|w|om|a|n| |said -29.103184 5 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|lio|n| |do ll|a|r|s| |a| |sp|ok|e|s|w|om|a|n| |sa|id -29.159660 6 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|lio|n| |do ll|a|r|s| |a| |sp|o|k|e|s|w|o|ma|n| |said -29.164141 7 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|li|o|n| |do ll|a|r|s| |a| |sp|ok|e|s|w|om|a|n| |sai|d -29.169310 8 sh|a|m|ro|c|k|’ s| |pre|ta|x| |pro|fi|t| |fro|m| |t|h|e| |sa|l|e| |was| |on|e| |hu|n|dr|e|d| |t|we|nt|y| |fiv|e| |mil|li|o|n| |do ll|a|r|s| |a| |sp|ok|e|s|w|om|a|n| |sa|id -29.809937 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment