CNN Architectures for Large-Scale Audio Classification
Convolutional Neural Networks (CNNs) have proven very effective in image classification and show promise for audio. We use various CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 vide…
Authors: Shawn Hershey, Sourish Chaudhuri, Daniel P. W. Ellis
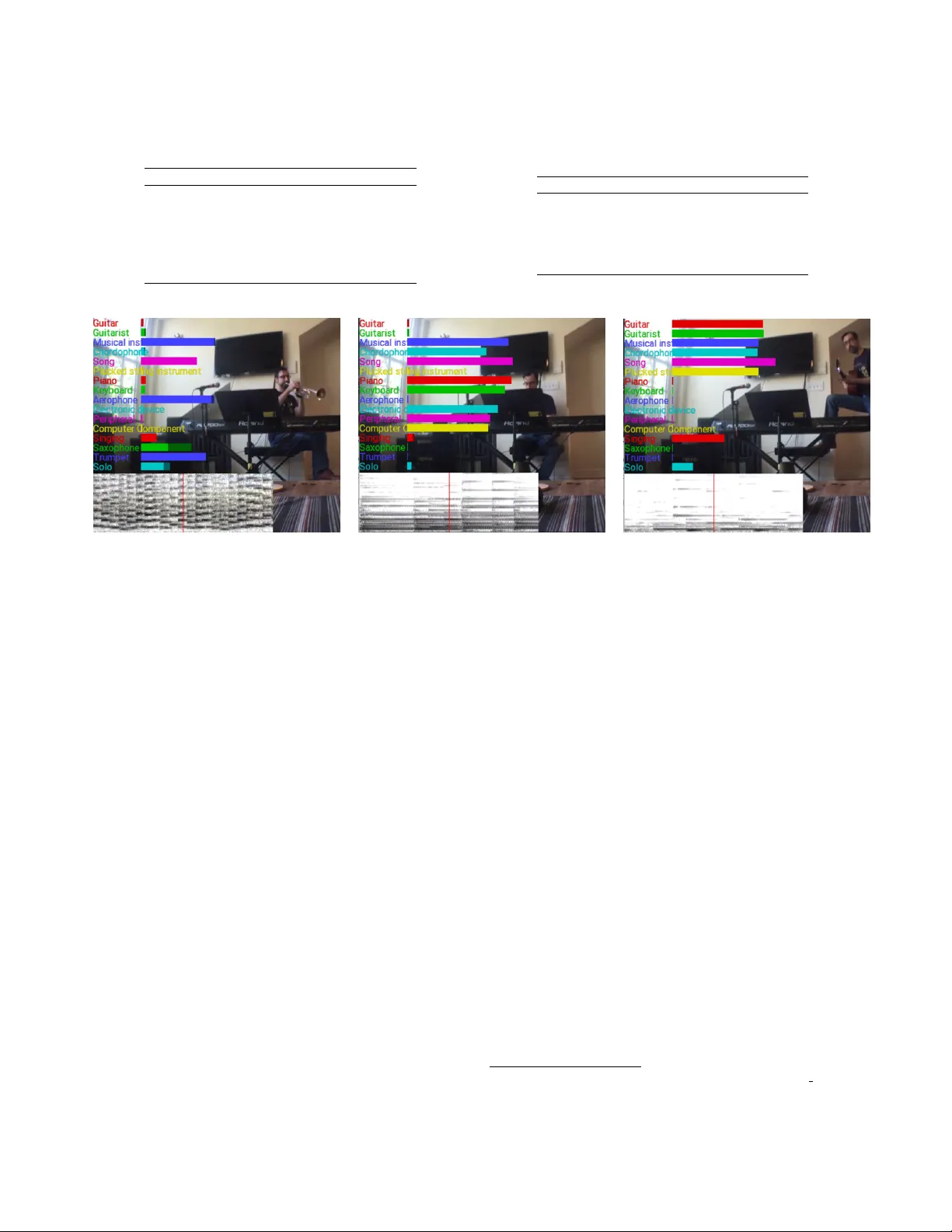
CNN ARCHITECTURES FOR LARGE-SCALE A UDIO CLASSIFICA TION Shawn Hershe y , Sourish Chaudhuri, Daniel P . W . Ellis, J ort F . Gemmeke , Ar en J ansen, R. Channing Moor e, Manoj Plakal, Devin Platt, Rif A. Saur ous, Bryan Se ybold, Malcolm Slaney , Ron J. W eiss, K evin W ilson Google, Inc., Ne w Y ork, NY , and Mountain V iew , CA, USA shershey@google.com ABSTRA CT Con volutional Neural Networks (CNNs) hav e prov en very effecti ve in image classification and show promise for audio. W e use v ar - ious CNN architectures to classify the soundtracks of a dataset of 70M training videos (5.24 million hours) with 30,871 video-lev el la- bels. W e examine fully connected Deep Neural Networks (DNNs), AlexNet [1], V GG [2], Inception [3], and ResNet [4]. W e in vestigate varying the size of both training set and label v ocabulary , finding that analogs of the CNNs used in image classification do well on our au- dio classification task, and larger training and label sets help up to a point. A model using embeddings from these classifiers does much better than raw features on the Audio Set [5] Acoustic Event Detec- tion (AED) classification task. Index T erms — Acoustic Event Detection, Acoustic Scene Clas- sification, Conv olutional Neural Networks, Deep Neural Networks, V ideo Classification 1. INTR ODUCTION Image classification performance has improv ed greatly with the ad- vent of large datasets such as ImageNet [6] using Con volutional Neural Netw ork (CNN) architectures such as AlexNet [1], VGG [2], Inception [3], and ResNet [4]. W e are curious to see if similarly lar ge datasets and CNNs can yield good performance on audio classifica- tion problems. Our dataset consists of 70 million (henceforth 70M) training videos totalling 5.24 million hours, each tagged from a set of 30,871 (henceforth 30K) labels. W e call this dataset Y ouT ube-100M. Our primary task is to predict the video-lev el labels using audio in- formation (i.e., soundtrack classification). Per L yon [7], teaching machines to hear and understand video can improve our ability to “categorize, or ganize, and index them”. In this paper , we use the Y ouT ube-100M dataset to inv estigate: how popular Deep Neural Network (DNN) architectures compare on video soundtrack classification; how performance v aries with differ - ent training set and label v ocabulary sizes; and whether our trained models can also be useful for AED. Historically , AED has been addressed with features such as MFCCs and classifiers based on GMMs, HMMs, NMF , or SVMs [8, 9, 10, 11]. More recent approaches use some form of DNN, including CNNs [12] and RNNs [13]. Prior work has been reported on datasets such as TRECV id [14], Acti vityNet [15], Sports1M [16], and TUT/DCASE Acoustic scenes 2016 [17] which are much smaller than Y ouTube-100M. Our large dataset puts us in a good position to ev aluate models with large model capacity . RNNs and CNNs hav e been used in Large V ocabulary Continu- ous Speech Recognition (L VCSR) [18]. Unlike that task, our labels apply to entire videos without any changes in time, so we ha ve yet to try such recurrent models. Eghbal-Zadeh et al. [19] recently won the DCASE 2016 Acous- tic Scene Classification (ASC) task, which, lik e soundtrack classi- fication, inv olves assigning a single label to an audio clip contain- ing many ev ents. Their system used spectrogram features feeding a VGG classifier , similar to one of the classifiers in our work. This paper , ho wev er, compares the performance of sev eral different ar- chitectures. T o our knowledge, we are the first to publish results of Inception and ResNet networks applied to audio. W e aggregate local classifications to whole-soundtrack deci- sions by imitating the visual-based video classification of Ng et al. [20]. After in vestigating se veral more complex models for com- bining information across time, they found simple averaging of single-frame CNN classification outputs performed nearly as well. By analogy , we apply a classifier to a series of non-overlapping segments, then a verage all the sets of classifier outputs. Kumar et al. [21] consider AED in a dataset with video-level la- bels as a Multiple Instance Learning (MIL) problem, but remark that scaling such approaches remains an open problem. By contrast, we are in vestigating the limits of training with weak labels for v ery large datasets. While many of the indi vidual segments will be uninforma- tiv e about the labels inherited from the parent video, we hope that, giv en enough training, the net can learn to spot useful cues. W e are not able to quantify ho w “weak” the labels are (i.e., what proportion of the segments are uninformativ e), and for the majority of classes (e.g., “Computer Hardware”, “Boeing 757”, “Ollie”), it’ s not clear how to decide relev ance. Note that for some classes (e.g. “Beach”), background ambiance is itself informativ e. Our dataset size allo ws us to examine networks with lar ge model capacity , fully exploiting ideas from the image classification liter- ature. By computing log-mel spectrograms of multiple frames, we create 2D image-like patches to present to the classifiers. Although the distinct meanings of time and frequency axes might argue for audio-specific architectures, this work employs minimally-altered image classification networks such as Inception-V3 and ResNet-50. W e train with subsets of Y ouTube-100M spanning 23K to 70M videos to ev aluate the impact of training set size on performance, and we in vestigate the effects of label set size on generalization by training models with subsets of labels, spanning 400 to 30K, which are then e v aluated on a single common subset of labels. W e additionally examine the usefulness of our networks for AED by examining the performance of a model trained with embeddings from one of our networks on the A udio Set [5] dataset. 2. D A T ASET The Y ouT ube-100M data set consists of 100 million Y ouT ube videos: 70M training videos, 10M e valuation videos, and a pool of 20M videos that we use for validation. V ideos average 4.6 min- utes each for a total of 5.4M training hours. Each of these videos T able 1 : Example labels from the 30K set. Label prior Example Labels 0 . 1 . . . 0 . 2 Song, Music, Game, Sports, Performance 0 . 01 . . . 0 . 1 Singing, Car , Chordophone, Speech ∼ 10 − 5 Custom Motorcycle, Retaining W all ∼ 10 − 6 Cormorant, Lecturer is labeled with 1 or more topic identifiers (from Knowledge Graph [22]) from a set of 30,871 labels. There are an av erage of around 5 labels per video. The labels are assigned automatically based on a combination of metadata (title, description, comments, etc.), con- text, and image content for each video. The labels apply to the entire video and range from very generic (e.g. “Song”) to very specific (e.g. “Cormorant”). T able 1 sho ws a fe w examples. Being machine generated, the labels are not 100% accurate and of the 30K labels, some are clearly acoustically rele vant (“Trumpet”) and others are less so (“W eb Page”). V ideos often bear annotations with multiple degrees of specificity . For example, videos labeled with “Trumpet” are often labeled “Entertainment” as well, although no hierarchy is enforced. 3. EXPERIMENT AL FRAMEWORK 3.1. T raining The audio is divided into non-ov erlapping 960 ms frames. This gav e approximately 20 billion examples from the 70M videos. Each frame inherits all the labels of its parent video. The 960 ms frames are decomposed with a short-time Fourier transform applying 25 ms windows every 10 ms. The resulting spectrogram is integrated into 64 mel-spaced frequenc y bins, and the magnitude of each bin is log- transformed after adding a small of fset to avoid numerical issues. This gi ves log-mel spectrogram patches of 96 × 64 bins that form the input to all classifiers. During training we fetch mini-batches of 128 input examples by randomly sampling from all patches. All experiments used T ensorFlow [23] and were trained asyn- chronously on multiple GPUs using the Adam [24] optimizer . W e performed grid searches ov er learning rates, batch sizes, number of GPUs, and parameter serv ers. Batch normalization [25] w as applied after all con volutional layers. All models used a final sigmoid layer rather than a softmax layer since each example can have multiple labels. Cross-entropy was the loss function. In view of the lar ge training set size, we did not use dropout [26], weight decay , or other common regularization techniques. For the models trained on 7M or more examples, we saw no e vidence of overfitting. During train- ing, we monitored progress via 1-best accuracy and mean A verage Precision (mAP) ov er a validation subset. 3.2. Evaluation From the pool of 10M ev aluation videos we created three balanced ev aluation sets, each with roughly 33 examples per class: 1M videos for the 30K labels, 100K videos for the 3087 (henceforth 3K) most frequent labels, and 12K videos for the 400 most frequent labels. W e passed each 960 ms frame from each e valuation video through the classifier . W e then av eraged the classifier output scores across all segments in a video. For our metrics, we calculated the balanced a verage across all classes of A UC (also reported as the equi valent d-prime class sepa- ration), and mean A verage Precision (mAP). A UC is the area under the Receiver Operating Characteristic (R OC) curve [27], that is, the probability of correctly classifying a positi ve example (correct ac- cept rate) as a function of the probability of incorrectly classifying a negativ e example as positive (false accept rate); perfect classifica- tion achie ves A UC of 1.0 (corresponding to an infinite d-prime), and random guessing gives an A UC of 0.5 (d-prime of zero). 1 mAP is the mean across classes of the A verage Precision (AP), which is the proportion of positiv e items in a ranked list of trials (i.e., Precision) av eraged across lists just long enough to include each individual pos- itiv e trial [28]. AP is widely used as an indicator of precision that does not require a particular retriev al list length, but, unlike A UC, it is directly correlated with the prior probability of the class. Be- cause most of our classes hav e very lo w priors ( < 10 − 4 ), the mAPs we report are typically small, even though the false alarm rates are good. 3.3. Architectur es Our baseline is a fully connected DNN, which we compared to sev- eral networks closely modeled on successful image classifiers. For our baseline experiments, we trained and evaluated using only the 10% most frequent labels of the original 30K (i.e, 3K labels). For each e xperiment, we coarsely optimized number of GPUs and learn- ing rate for the frame le vel classification accuracy . The optimal num- ber of GPUs represents a compromise between ov erall computing power and communication o verhead, and varies by architecture. 3.3.1. Fully Connected Our baseline network is a fully connected model with RELU ac- tiv ations [29], N layers, and M units per layer . W e swept ov er N = [2 , 3 , 4 , 5 , 6] and M = [500 , 1000 , 2000 , 3000 , 4000] . Our best performing model had N = 3 layers, M = 1000 units, learn- ing rate of 3 × 10 − 5 , 10 GPUs and 5 parameter servers. This netw ork has approximately 11.2M weights and 11.2M multiplies. 3.3.2. AlexNet The original AlexNet [1] architectures was designed for a 224 × 224 × 3 input with an initial 11 × 11 con volutional layer with a stride of 4. Because our inputs are 96 × 64 , we use a stride of 2 × 1 so that the number of acti vations are similar after the initial layer . W e also use batch normalization after each con volutional layer instead of local response normalization (LRN) and replace the final 1000 unit layer with a 3087 unit layer . While the original AlexNet has approximately 62.4M weights and 1.1G multiplies, our version has 37.3M weights and 767M multiplies. Also, for simplicity , unlike the original AlexNet, we do not split filters across multiple de vices. W e trained with 20 GPUs and 10 parameter servers. 3.3.3. VGG The only changes we made to VGG (configuration E) [2] were to the final layer (3087 units with a sigmoid) as well as the use of batch normalization instead of LRN. While the original network had 144M weights and 20B multiplies, the audio variant uses 62M weights and 2.4B multiplies. W e tried another variant that reduced the initial strides (as we did with AlexNet), but found that not modifying the strides resulted in faster training and better performance. W ith our setup, parallelizing beyond 10 GPUs did not help significantly , so we trained with 10 GPUs and 5 parameter servers. 1 d 0 = √ 2 F − 1 ( A UC ) where F − 1 is the inverse cumulati ve distribution function for a unit Gaussian. T able 2 : Comparison of performance of several DNN architectures trained on 70M videos, each tagged with labels from a set of 3K. The last ro w contains results for a model that was trained much longer than the others, with a reduction in learning rate after 13 million steps. Architectures Steps T ime A UC d-prime mAP Fully Connected 5M 35h 0.851 1.471 0.058 AlexNet 5M 82h 0.894 1.764 0.115 VGG 5M 184h 0.911 1.909 0.161 Inception V3 5M 137h 0.918 1.969 0.181 ResNet-50 5M 119h 0.916 1.952 0.182 ResNet-50 17M 356h 0.926 2.041 0.212 3.3.4. Inception V3 W e modified the inception V3 [3] network by removing the first four layers of the stem, up to and including the MaxPool, as well as re- moving the auxiliary netw ork. W e changed the A verage Pool size to 10 × 6 to reflect the change in activ ations. W e tried including the stem and removing the first stride of 2 and MaxPool but found that it performed worse than the variant with the truncated stem. The orig- inal network has 27M weights with 5.6B multiplies, and the audio variant has 28M weights and 4.7B multiplies. W e trained with 40 GPUs and 20 parameter servers. 3.3.5. ResNet-50 W e modified ResNet-50 [4] by removing the stride of 2 from the first 7 × 7 con v olution so that the number of activ ations was not too dif fer- ent in the audio v ersion. W e changed the A verage Pool size to 6 × 4 to reflect the change in activ ations. The original network has 26M weights and 3.8B multiplies. The audio v ariant has 30M weights and 1.9B multiplies. W e trained with 20 GPUs and 10 parameter servers. 4. EXPERIMENTS 4.1. Architectur e Comparison For all network architectures we trained with 3K labels and 70M videos and compared after 5 million mini-batches of 128 inputs. Be- cause some networks trained faster than others, comparing after a fixed wall-clock time w ould giv e slightly different results but would not change the relative ordering of the architectures’ performance. W e include numbers for ResNet after training for 17 million mini- batches (405 hours) to sho w that performance continues to impro ve. W e reduced the learning rate by a factor of 10 after 13 million mini- batches. T able 2 shows the ev aluation results calculated over the 100K balanced videos. All CNNs beat the fully-connected baseline. In- ception and ResNet achieve the best performance; they provide high model capacity and their conv olutional units can efficiently capture common structures that may occur in different areas of the input ar- ray for both images, and, we infer , our audio representation. T o in vestigate how the prior likelihood of each label affects its performance, Fig. 1 sho ws a scatter plot of the 30K classes with label frequency on the x axis and ResNet-50’ s d-prime on the y axis. d- prime seems to stay centered around 2.0 across label prior , although the variance of d-prime increases for less-common classes. This is contrary to the usual result where classifier performance improves with increased training data, particularly o ver the 5 orders of magni- tude illustrated in the plot. Fig. 1 : Scatter plot of ResNet-50’ s per -class d-prime versus log prior probability . Each point is a separate class from a random 20% subset of the 30K set. Color reflects the class AP . 4.2. Label Set Size Using a 400 label subset of the 30K labels, we inv estigated how training with different subsets of classes can af fect performance, per- haps by encouraging intermediate representations that better gener- alize to unseen e xamples e ven for the e v aluation classes. In addition to examining three label set sizes (30K, 3K, and 400), we compared models with and without a bottleneck layer of 128 units placed right before the final output layer. W e introduced the bottleneck layer to speed up the training of the model trained with 30K labels. Without a bottleneck, the lar ger output layer increased the number of weights from 30M to 80M and significantly reduced training speed. W e do not report metrics on the 30K label model without the bottleneck because it would have taken sev eral months to train. For all label set size experiments, we used the ResNet-50 model and trained for 5 million mini-batches of 128 inputs (about 120 hours) on 70M videos. T ables 3 shows the results. When comparing models with the bottleneck, we see that performance does indeed impro ve slightly as we increase the number of labels we trained on, although net- works without the bottleneck have higher performance overall. The bottleneck layer is relati vely small compared to the 2048 activ ations coming out of ResNet-50’ s A verage Pool layer and so it is effecting a substantial reduction in information. These results provide weak support to the notion that training with a broader set of categories can help to regularize e ven the 400 class subset. 4.3. T raining Set Size Having a very large training set av ailable allo ws us to inv estigate how training set size affects performance. W ith 70M videos and an av erage of 4.6 minutes per video, we have around 20 billion 960 ms training examples. Giv en ResNet-50’ s training speed of 11 mini- batches per second with 20 GPUs, it would take 23 weeks for the network to see each pattern once (one epoch). Howe ver , if all videos were equal length and fully randomized, we expect to see at least one frame from each video in only 14 hours. W e hypothesize that, even T able 3 : Results of v arying label set size, ev aluated ov er 400 labels. All models are variants of ResNet-50 trained on 70M videos. The bottleneck, if present, is 128 dimensions. Bneck Labels A UC d-prime mAP no 30K — — — no 3K 0.930 2.087 0.381 no 400 0.928 2.067 0.376 yes 30K 0.925 2.035 0.369 yes 3K 0.919 1.982 0.347 yes 400 0.924 2.026 0.365 T able 4 : Results of training with different amounts of data. All rows used the same ResNet-50 architecture trained on videos tagged with labels from a set of 3K. T raining V ideos A UC d-prime mAP 70M 0.923 2.019 0.206 7M 0.922 2.006 0.202 700K 0.921 1.997 0.203 70K 0.909 1.883 0.162 23K 0.868 1.581 0.118 T rumpet Piano Guitar Fig. 2 : Three example excerpts from a video classified by ResNet-50 with instantaneous model outputs overlaid. The 16 classifier outputs with the greatest peak values across the entire video were chosen from the 30K set for display . if we cannot get through an entire epoch, 70M videos will provide an adv antage over 7M by virtue of the greater div ersity of videos underlying the limited number of training patterns consumed. W e trained a ResNet-50 model for 16 million mini-batches of 128 inputs (about 380 hours) on the 3K label set with 70M, 7M, 700K, 70K, and 23K videos. The video lev el results are shown in T able 4. The 70K and 23K models show worse performance but the v alidation plots (not included) showed that they likely suf fered from ov erfitting. Regu- larization techniques (or data augmentation) might hav e boosted the numbers on these smaller training sets. The 700K, 7M, and 70M models are mostly very close in performance although the 700K model is slightly inferior . 4.4. AED with the A udio Set Dataset Audio Set [5] is a dataset of o ver 1 million 10 second excerpts la- beled with a vocab ulary of acoustic events (whereas not all of the Y ouT ube-100M 30K labels pertain to acoustic e vents). This comes to about 3000 hours – still only ≈ 0 . 05% of Y ouT ube-100M. W e train two fully-connected models to predict labels for Audio Set . The first model uses 64 × 20 log-mel patches and the second uses the out- put of the penultimate “embedding” layer of our best ResNet model as inputs. The log-mel baseline achie ves a balanced mAP of 0.137 and A UC of 0.904 (equiv alent to d-prime of 1.846). The model trained on embeddings achie ves mAP / A UC / d-prime of 0.314 / 0.959 / 2.452. This jump in performance reflects the benefit of the larger Y ouT ube-100M training set embodied in the ResNet classifier outputs. 5. CONCLUSIONS The results in Section 4.1 sho w that state-of-the-art image networks are capable of excellent results on audio classification when com- pared to a simple fully connected network or earlier image classifica- tion architectures. In Section 4.2 we saw results showing that train- ing on larger label set vocabularies can improv e performance, albeit modestly , when evaluating on smaller label sets. In Section 4.3 we saw that increasing the number of videos up to 7M improves per- formance for the best-performing ResNet-50 architecture. W e note that regularization could have reduced the gap between the models trained on smaller datasets and the 7M and 70M datasets. In Section 4.4 we see a significant increase over our baseline when training a model for AED with ResNet embeddings on the Audio Set dataset. In addition to these quantified results, we can subjectiv ely e xam- ine the performance of the model on segments of video. Fig. 2 shows the results of running our best classifier over a video and overlaying the frame-by-frame results of the 16 classifier outputs with the great- est peak values across the entire video. The different sound sources present at different points in the video are clearly distinguished. 2 6. A CKNO WLEDGEMENTS The authors would like to thank George T oderici and Marvin Ritter , both with Google, for their very v aluable feedback. 2 A similar video is av ailable online at https://youtu.be/oAAo r7ZT8U. 7. REFERENCES [1] A. Krizhevsky , I. Sutske ver , and G. E. Hinton, “Imagenet clas- sification with deep conv olutional neural networks, ” in Ad- vances in neural information pr ocessing systems , 2012, pp. 1097–1105. [2] K. Simonyan and A. Zisserman, “V ery deep conv olutional networks for large-scale image recognition, ” arXiv pr eprint arXiv:1409.1556 , 2014. [3] C. Szegedy , V . V anhoucke, S. Ioffe, J. Shlens, and Z. W ojna, “Rethinking the inception architecture for computer vision, ” arXiv pr eprint arXiv:1512.00567 , 2015. [4] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learn- ing for image recognition, ” arXiv preprint , 2015. [5] J. F . Gemmeke, D. P . W . Ellis, D. Freedman, A. Jansen, W . La wrence, R. C. Moore, M. Plakal, and M. Ritter , “ Au- dio Set: An ontology and human-labeled dartaset for audio ev ents, ” in IEEE ICASSP 2017 , New Orleans, 2017. [6] J. Deng, W . Dong, R. Socher , L.-J. Li, K. Li, and L. Fei- Fei, “Imagenet: A large-scale hierarchical image database, ” in Computer V ision and P attern Recognition, 2009. CVPR 2009. IEEE Confer ence on . IEEE, 2009, pp. 248–255. [7] R. F . L yon, “Machine hearing: An emerging field [exploratory dsp], ” Ieee signal pr ocessing ma gazine , vol. 27, no. 5, pp. 131– 139, 2010. [8] A. Mesaros, T . Heittola, A. Eronen, and T . V irtanen, “ Acoustic ev ent detection in real life recordings, ” in Signal Pr ocessing Confer ence, 2010 18th Eur opean . IEEE, 2010, pp. 1267–1271. [9] X. Zhuang, X. Zhou, M. A. Hasegaw a-Johnson, and T . S. Huang, “Real-world acoustic ev ent detection, ” P attern Recog- nition Letters , v ol. 31, no. 12, pp. 1543–1551, 2010. [10] J. F . Gemmeke, L. V uegen, P . Karsmakers, B. V anrumste, et al., “ An exemplar -based nmf approach to audio ev ent detection, ” in 2013 IEEE W orkshop on Applications of Signal Pr ocessing to Audio and Acoustics . IEEE, 2013, pp. 1–4. [11] A. T emko, R. Malkin, C. Zieger , D. Macho, C. Nadeu, and M. Omologo, “Clear ev aluation of acoustic ev ent detection and classification systems, ” in International Evaluation W ork- shop on Classification of Events, Activities and Relationships . Springer , 2006, pp. 311–322. [12] N. T akahashi, M. Gygli, B. Pfister , and L. V an Gool, “Deep con volutional neural networks and data augmentation for acoustic e vent detection, ” arXiv pr eprint arXiv:1604.07160 , 2016. [13] G. Parascandolo, H. Huttunen, and T . V irtanen, “Recurrent neural networks for polyphonic sound ev ent detection in real life recordings, ” in 2016 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2016, pp. 6440–6444. [14] G. A wad, J. Fiscus, M. Michel, D. Joy , W . Kraaij, A. F . Smeaton, G. Quenot, M. Eskevich, R. Aly , and R. Ordelman, “T recvid 2016: Evaluating video search, video ev ent detection, localization, and hyperlinking, ” in Pr oceedings of TRECVID 2016 . NIST , USA, 2016. [15] B. G. Fabian Caba Heilbron, V ictor Escorcia and J. C. Niebles, “ Activitynet: A large-scale video benchmark for human activ- ity understanding, ” in Pr oceedings of the IEEE Conference on Computer V ision and P attern Recognition , 2015, pp. 961–970. [16] A. Karpathy , G. T oderici, S. Shetty , T . Leung, R. Sukthankar, and L. Fei-Fei, “Large-scale video classification with con volu- tional neural networks, ” in CVPR , 2014. [17] A. Mesaros, T . Heittola, and T . V irtanen, “TUT database for acoustic scene classification and sound event detection, ” in 24th Eur opean Signal Pr ocessing Confer ence 2016 (EUSIPCO 2016) , Budapest, Hungary , 2016, http://www.cs.tut. fi/sgn/arg/dcase2016/ . [18] T . N. Sainath, O. V inyals, A. Senior , and H. Sak, “Con volu- tional, long short-term memory , fully connected deep neural networks, ” in 2015 IEEE International Conference on Acous- tics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2015, pp. 4580–4584. [19] H. Eghbal-Zadeh, B. Lehner, M. Dorfer , and G. W idmer , “Cp- jku submissions for dcase-2016: A hybrid approach using bin- aural i-vectors and deep con volutional neural networks, ” . [20] J. Y ue-Hei Ng, M. Hausknecht, S. V ijayanarasimhan, O. V inyals, R. Monga, and G. T oderici, “Beyond short snip- pets: Deep networks for video classification, ” in Proceed- ings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2015, pp. 4694–4702. [21] A. Kumar and B. Raj, “ Audio e vent detection using weakly labeled data, ” arXiv pr eprint arXiv:1605.02401 , 2016. [22] A. Singhal, “Introducing the knowledge graph: things, not strings, ” 2012, Official Google blog, https://googleblog.blogspot.com/2012/05/ introducing- knowledge- graph- things- not. html . [23] M. Abadi et al., “T ensorFlow: Large-scale machine learning on heterogeneous systems, ” 2015, Software av ailable from ten- sorflow .org. [24] D. Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [25] S. Ioffe and C. Szegedy , “Batch normalization: Accelerat- ing deep network training by reducing internal covariate shift, ” arXiv pr eprint arXiv:1502.03167 , 2015. [26] N. Srivasta va, G. E. Hinton, A. Krizhevsk y , I. Sutske ver , and R. Salakhutdinov , “Dropout: a simple way to prevent neural networks from overfitting., ” Journal of Machine Learning Re- sear ch , v ol. 15, no. 1, pp. 1929–1958, 2014. [27] T . Fawcett, “Roc graphs: Notes and practical considerations for researchers, ” Machine learning , vol. 31, no. 1, pp. 1–38, 2004. [28] C. Buckley and E. M. V oorhees, “Retriev al ev aluation with incomplete information, ” in Pr oceedings of the 27th annual international A CM SIGIR confer ence on Resear ch and devel- opment in information r etrieval . A CM, 2004, pp. 25–32. [29] V . Nair and G. E. Hinton, “Rectified linear units improve re- stricted boltzmann machines, ” in Pr oceedings of the 27th Inter - national Confer ence on Machine Learning (ICML-10) , 2010, pp. 807–814.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment