A Survey of Voice Translation Methodologies - Acoustic Dialect Decoder
Speech Translation has always been about giving source text or audio input and waiting for system to give translated output in desired form. In this paper, we present the Acoustic Dialect Decoder (ADD) - a voice to voice ear-piece translation device.…
Authors: Hans Krupakar, Keerthika Rajvel, Bharathi B
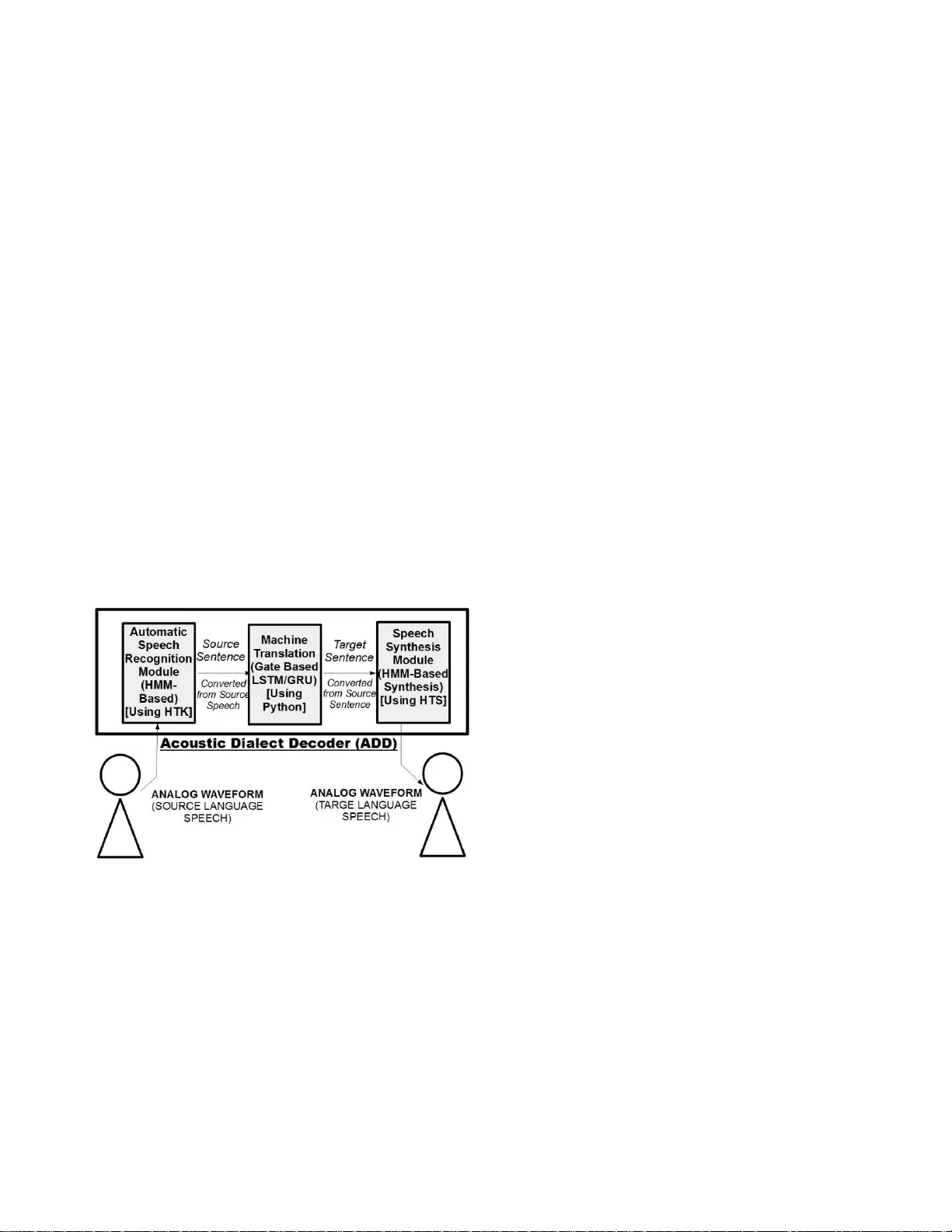
International Confere nce On Information Co mmunication & Embedded Systems (IC IC ES -2016) A SURVEY OF VOICE TRANSLATI ON METHODOL OGIES - ACOUSTIC DIA LECT DECODE R Hans Krupakar Keerthika Rajvel Dept. of Computer Science a nd Engineering Dept. of Computer Science and Engineeri ng SSN College Of Engineering SSN College of Engineering E-mail: hans13033@cse.ssn.edu.i n E-m ail: keerthi ka13049@cse.ssn.ed u.in Bharathi B Angel Deborah S Vallidevi Krishnamurthy Dept. of Computer Science Dep t. of Computer Science Dept. of Computer Science and Engineering and Engineering and Engineering SSN College Of Engi neering SSN College Of Engineeri ng SSN College Of Engineerin g E-mail: bharathib@ss n.edu.in E-mail: angeldeborahs @ssn.edu.in E-mail: vallidevi k@ssn.edu.in Abstract — S peech Translation has alw ays been about giving source text/audio input and w aiting for system to give translated output in desired form. In this paper, we present the Acoustic Dialect Decoder ( ADD) – a voice to vo ice ear -piece translation device. We introduce and survey the recent advances made i n th e fiel d of S peech E ngineering, to employ in the ADD, particularly focusing on the three ma jor processing steps of Recognition, T ranslation a nd Synthesis. We ta ckle the problem of machine understanding of natural language by designing a recognition unit for source audio to text, a translation unit for source la nguage text to target la nguage text, and a synthesis unit for tar get language text to target language speech. Speech from t he surroundings w ill be recorded by the recognition unit present on the ear- piece and translation will start a s soon as one sentenc e is successfully read. This w ay, w e hope to give translated output as and w hen input is being read. The recognition unit will use Hidden Markov Models (HMM s) Based Tool-Kit (HTK), hybrid RNN systems w ith gated memory cells, and the synt hesis unit, HMM based speech synthesis system HTS. This syste m will initially be built as an English to Tamil transla tion device. Keywords — Voice Translator, Speech Recognition, Machine Translation, Speech Synthesis, De ep learn ing, RNN, LSTM , HTK, HTS, HMMs. 1. INTRODUCTION Language is t he one thing i n the world that can b oth enable, and at the same time, completely shut out human communication. If it's a lan guage known to us, we take hardly second s to understand i t. B ut if it 's a la nguage that we don't understand, it just cannot be understood without using dictionaries, manual par sers, tr anslators and/o r various applications ava ilable for translation. All of t hese so lutions disrupt the flow of any conversation that someone could have with another per son o f a different dialec t, because o f the p ause required to r equest f or translation and time it takes for the actual translation pro cess. Automated simultaneous translatio n of natural language should have been a nat ural result in our multilingual world in order to make the process of communication amo ngst humans better, easier an d efficient. Ho wever, the existing methods, incl uding Goog le voice tran slators, t ypically handle the pro cess of tra nslation i n a non -automated manner. This makes the process o f tr anslation o f word( s) and/o r sentences from one la nguage to another, slower and more tedious. We wish to make that pro cess auto matic – have a device do what a human translator d oes, inside our ears. 1.1 MOTIVATION Speech T ranslation is the pr ocess b y which conversationa l spoken word(s) and/or phrase ar e translated and the result is obtained either in the for m of words displayed on a screen or output bein g spoken aloud in the seco nd lan guage. The key to make this technolo gy hi ghly efficie nt is to auto mate thi s process and make it a n inter -audio conversion so that it produces simultaneous results without ha ving to physically start the process o f translation. This enables peop le to simpl y wear the device and h ear native spee ch in their o wn languages. When e veryone in the world is equip ped with one of these devices, there would b e total understanding and harmony. T his tec hnolog y is o f tre mendous i mportance as it enables speakers of different langua ges to co mmunicate and ad ds value to humanki nd in t erms of Wo rld P eace, Science and Commerce, Cross -Cultural exchange, World P olitics and Global Business. 2. RECOGNITION Automatic speec h recognition (ASR) can be d efined as the independent, computer driven transcr iption of spoken language into rea dable text in rea l time [1] . 2.1 IMPLEM ENTATION Initially, the a udio is input into the system. This audio is subjected to the process of Feature Extraction wherein nois e and surrou nding dist urbances are r emoved to prod uce a feature vector. Grammar files for the inpu t sentence ar e generated in E xtended B ackus Naur For m (EBNF) . The vector is then trained using these gra mmar files to generat e the audio inp ut's co rresponding text ual se ntence. This process is explained i n a modular fa shion in Figure 1 . FIG. 1 – SCHEMA TIC OF HMM-B ASED RECOGNITI ON [2] 2.2 SURVEY OF AVAI LABLE METHODS There are a lot of methods used for ASR including HMM s, DTW, neural net works and d eep neural net works[3 ]. HMM s are used in speech reco gnition b ecause a speec h si gnal ca n be visualised as a piecewise stationar y s ignal or a short -time stationary si gnal. In a s hort time -scale (1 0ms), speec h can be approximated as a statio nary pro cess. Speech can be tho ught of as a Markov model for many stoc hastic purposes. Another reason why HM Ms are p opular is beca use the y can be trained automaticall y and are simple and co mputationally feasible to use[4] . D ynamic ti me warping was used befor e HMMs in SR but has long b een d eclared less successful and isn't u sed[5] . Neural networks ca n be used efficiently in SR but are rarely successful f or continuous recognition tasks because o f t heir lack of ability to model te mporal dependencies [ 6].Deep neural net works ha ve bee n sho wn to succeed in SR but bec ause it is a s ystem o f 3 co mponents, recognition, translation and synthesis, we have used HMMs with the least time co mplexity. SR can be further divided into word-ba sed, phrase -based a nd phoneme-based mechanis ms. While there i s excellent performance in isolated word recognition with word -based models, they fail when it co mes to continuous SR becau se of complexity. Phoneme -based is the best ap proach and is employed in t his system because of its abilit y to i ncorporate and w ork with large corpus and ease of addition o f new words into the vocabular y [7]. 2.3 SURVEY OF F EATURE EXTRACTION METHODS The main co mponent of ASR is Feature E xtraction. It uses maximum rele vant infor mation about the speech signal and helps distingui sh bet ween different linguistic units and removes external noise, disturb ances and emotions [ 2]. Commonly used feature extr action techniques are MFCC s (Mel Frequency Cepstral Coefficients), LPCs (Linea r Prediction Coefficients) and LPCCs (Linear Predi ction Cepstral Coefficie nts) [8]. M FCCs feature s hall be used for this process and t he reason is stated as follows. MFCC s have been ascertained as the state - of -the-art for feature ex traction especially since i t is based on actual human auditory syste m and has a p erceptual frequency scale called Mel - frequency scale . It com bines the advantage of the C epstral analysis with a perceptual frequency s cale b ased o n critical bands making use o f logarit hmically spaced filter banks [9] . Prior to the introduction of MFCCs, LPCs and LPCCs were used for the feature ext raction pro cess. These ha ve been stated as obsolete since both have a linear computation nature and lack p erceptual frequency scales even tho ugh they are ef ficient in tuning o ut e nviro nmental noise and other disturbances fro m the sampled speech signal [ 10]. Further, several researches based on feature extraction for various languages like E nglish, C hinese, Japanese and eve n India n lan guages like Hindi have proved experimentally that MFCCs p roduce at least 80 percent efficiency as opposed to just 6 0 per cent by LPCs a nd LPCC s [11] . 2.4 SURVEY OF TOO LS FOR A SR There are numerous to ols develo ped for ASR such a s HT K, JULIUS, SPHINX, KALDI , iATROS, AUDACIT Y, PRAAT, SCARF, RWT H ASR and CSL. Out of all the available, the 2 fairly popular and widely accepted frameworks are HTK and SPHI NX. B oth of the se are b ased o n Hidd en Marko v Model( HMM) and are open source. Both framewor ks can be used to develop, train, and test a speech model from e xisting corpus sp eech utterance data by usi ng Hidden Mar kov modeling techniq ues [12]. Figure 2 shows the r esults th at were achieved decoding t he test data from AN4 co rpus. These were ac hieved on a PC running Wi ndows a nd Cygwin, with a 2.6GHz Pentium 4 processor with 2 GB System R AM [12] . Metric Sphinx3 HTK Peak Memory Usage (MB ) 8.2 5.9 Time to Completion (sec) 63 93 Sentence Error Rate ( %) 59.2 69.0 Word Error Rate (%) 21.3 9.0 Word Substitution Errors 92 92 Word Insertion Errors 71 154 Word Deletio n Errors 2 0 FIG. 2 – RESULTS FROM AN 4 CORPUS HTK deco der did not make an y deletio ns, which gave it a slight advantage on the overall word error r ate. Also, while HVite uses less m emory during d ecoding, the time difference in running the test set is significant at 30 second s [12], [13] . In ad dition to thi s HT K supports HCop y too ls which provide a wealth o f input/output co mbinat ions of model data and fron t-end features couple o f which are not present in SPHINX but certain compatibility is provided. However, the ef ficiency of compatibilit y i s debatab le [14] . Other sli ght advantages of HT K over SPHINX are that HT K is supported on m ultiple OS while SPHINX is largel y supported on LINUX platforms only. Also, HT K uses C Programming la nguage while SP HINX uses t he Java Programming language [15] . 3. TRANSLATION Machine Translation (MT) i s the process of convertin g a source sentence sequence i nto the target sente nce sequenc e of same/different le ngth. Even though MT has co me a long way fro m where it was with i ts initial models, it is no where near being completel y efficient. Machine translation has been worked o n for dec ades now and t he recent advancements of using neural networks have prop elled the field to a new height. MT can be dir ect, rule -based or data - driven. 3.1 HISTORY Machine tra nslation has b een i mplemented i n multit udes o f methodologies ranging over decad es of resear ch. Ma chine Translation saw its ad vent with the dire ct tran slation system , and then m ore ways were introduced like rule-based and Example-Based Machine T ranslation (EBMT ) systems. Direct tran slation is the process conditional transcr iption o f source and target words. R ule-based systems operated on rules to translate sentences while the example -based system mapped via exa mples. The prob lems with t hese appr oaches are th e lac k of interlingua database and scalability, naive nature of translations etc [15] . Statistical Machine Tr anslation is one where the so urce sentence is encod ed into a representation which is tran slated into target language by ma ximising the pro bability of the closeness of the target sentence b y using Ba yes r ule. It i s faster t han any of the syste ms used before it because of it s parallel processing of various modules or subsyste ms. It is not scalab le to lar ge scale MT bec ause o f mem ory and performance bottlenecks [16] . 3.2 RNNs IN M T - ENCODER DE CODER APPROA CH While SMT is better than the p reviousl y used M T techniques, there was still an inherent co mplexity issue. More importantly, SMT systems took up a lo t o f space even for a translatio n engine with ver y small vocabularie s. The advent o f Recurrent Neural Net works (R NNs) into Natur al Language P rocessing saw the field take a turn to an unexpected ad vancement. RNNs can b e defi ned by means of: < > = < 1> , < > < > = < > where f is a s mooth bo unded function, h t refer s to the hidden layer f unction at time epoch t, x t refers to the input recei ved by RNN at ti me t, y t the o utput at ti me t, and g kno wn as t he output function. Usually, the input to RNNs is encoded in the hidden la yer usi ng func tions that map the input onto the continuous space like tanh, sigmoid functio n etc. The output function is a n activation function and the most co mmon ones are the So ftMax activation function, sigmoid functions, tan h etc [17] . The first RNN syste ms used in MT involved one RNN that takes in the source sentence as i nput, word b y word, mutating the inpu t using the hidden la yer where t he output function m apped th e e ncoded form of the input from th e hidden layer bac k into a form that ca n be used to arrive at the target sentence using language a nd tra nslation modelling functions. I n t he b eginning, ther e was o nly o ne hidd en layer used and this type o f RNN s ar e known as shallow RNNs. Later, more la yers of hidd en functions were used in stead of just one or t wo and t his s ystem is known as Deep RNN (DRNNs). DRNN s were found to be much better at encoding the source sentence into the target sentence and thus quic kly replaced shallow RNNs in MT . T he ap proach of using a single RNN for MT is widely known as t he phrase-based appr oach [18] . One o f the more recent methods in MT is the encod er - decoder ap proach. This metho d, shown in fi gure 3, involves two RNNs, one for encoding a nd the o ther for decoding. T he encoder RNN takes the source sentence, word b y word, and transforms it i nto a vector tha t co ntains all the proper ties of the sentence as the hidd en layer functio n i s recursi ve on its previous function. T he d ecoder RNN then takes t his vector and maps it to the target se ntence [ 19], [20] . FIG. 3 – ENCOD ER DECODER A PPROACH [19 ] While t his syste m, t heoretically, is perfect i n retaining lo ng range dependencies across th e input sentence, in p ractice, it falls short because the s ystem is unable to maintain the se dependencies without me mory units. T his made it impossible for this syste m to translate sentences of a bigger sentence length. T his is popularl y known as the vanishing gradient proble m. To get rid of t his problem, there ha ve been various methods i mplemented [20] . 3.3 AUTOM ATIC SEGMENTA TION Automatic Segmentation was o ne o f the first such met hods where meaningful phrases were tra nslated together a fter successful seg mentation. The issue o f sentence length occurs because the Neural Net work fails to recognize some of the initial words of t he inp ut sentence fro m t he vecto r that the sentence is transcribed to. The input sentence is seg mented into cohesive ph rases t hat can be translated easily b y the NN. After every segment of the source se ntence i s tr ansla ted into the target sentence, t he tar get phrases are co ncatenated together to produce o utput. While this gets rid of the vanishing g radient p roblem, it poses a few new di fficulties. Because the neural net work can only work with eas y to translate (cohes ive) cla uses, there is a clause division problem because the system cannot decide the b est co hesive phrases to translate i nto target lang uage easily. Also, computational c omplexity increases because of the par allel processin g req uired in readin g input word s a nd translating previously r ead phrase at the same time. Also, this method of concatenati ng translated phra ses on ly works with languages that don't have long range dependencie s between the words of a sente nce and only with source target language pairs with semanticall y similar grammar structures.[21] . 3.4 BIDIRECTIONAL R NNs : One of t he mai n proble ms of RNN s is the inabili ty of the system to maintain lo ng ra nge d ependencies for sente nces with a lot of w ords. One o f the main reasons for this is that the input sequence is on ly scanned in o ne direction, normally from the be ginning of the se ntence to t he end. To simultaneously model both past and future r eferences, bidirectional RNNs should be used [22] . T he RNN system is composed of two independent rec urrent layers: one la yer processes the input sentence in forward ti me steps 1 to T (first word through to last word), while the other la yer processes the inpu t se ntence in b ackward time step s from T to 1 (last word to first wo rd). Bidirectional RNNs are defined by an output function y, 2 hidden states, h f for forward time steps and h r for the back ward time steps as: < > = < 1> , < > < > = < 1> , < > < > = < 1> f , < 1 > , < > The hidd en state function s ca n be a si mple sigmoid function or a complex LSTM network [7]. The use of BRNNs in phrase-based SMT is imple mented with the help of n -best lists as the s ystems are co mple mentary. While the translatio n quality was significantly b et ter than using unidirectio nal RNNs, this particular BRNN MT system d id not come close to the current best transla tion quality. BRNNs were also later used in many Encoder Decoder models, one of whic h had a B i-Directional Decoder RN N used to model eac h wo rd to summarize b oth the preceding and s ucceeding words. T his m ethod aligned an d simultaneously translated input [2 3], [24] . 3.5 LSTM Because reg ular RNN hi dden la yers are unable to successfully store infor mation about the se ntence word s in them, t he hidden la yers are b uilt along with a gate -operated memory unit that is capable o f retaining the encod ing don e in the state for a lon g ti me. This solves the p roblem of lac k of lo ng range dependenc ies in the s ystem. To ensure that t he system do esn't have erro rs, an al gorithm li ke b ack propagation, Stochastic Grad ient De scent (SGD), Linear Gradient Descent etc. is used to normalise the values. T he main problem with regular RNN s ystems is that it doesn't retain the values for these algorithms to b e applied. An LSTM neuron is defined as: < > = < > + < 1 > + < 1> + < > = < > + < 1 > + < 1> + < > = < > < 1> + < > < > + < 1> + < > = < > + < 1 > + < 1> + < > = < > < > < > = < > where i, f, c, and o are the input, forget, cell a nd o utput gate s respectively. T he hidd en la yer depends on t he outp ut and the cell gates. T he output of each hidden la yer is a function of the hidden layer at that ti me epoch t. is the logistic s igmoid function and Wij refers to the weight of the edge fro m i to j gates. This is explai ned in figure 4 [25], [26]. FIG. 4 – LSTM NETWORK SCH EMA [28] There were si gnificant impro vements in perfor mance of the system when compared to traditional RNNs. Interestin gly, it was fo und that the perfor mance increased when t he sentence was input in reverse order bec ause o f the struct ural similarities in t he languages of English and Frenc h t hat this system was imple mented in [27 ]. 3.6 GRU Gated Recurrent U nits (GRU s) are a variat ion of t he well known LSTM approach where the neuron has gated mechanisms t hat e nable it to remember e ncodings l ike LSTMs but unlike the LST M, it has no memory unit o f i ts own. GRUs, shown i n figure 5, are defined by: < > = 1 < > < 1> + < > < > < > = + 1 h < > = + < > < 1> < > = < > + < 1> < > = < > where is element wise multiplicatio n oper ator, y is t he output function, h is t he hidden state function, z is the updat e gate, r is the reset gate and is th e can didate activation function of the Gated Recurrent Unit, is the sig moid function. FIG. 5 – GRU N ETWORK SCHEM A [29] GRUs have pro ven to be really close i n terms of performance w ith the LSTM networks an d there is really nothing that ca n sa y tha t one is clearly o ne that is better tha n the other. B oth s ystems have been interchan geably used i n MT with similar resulting tran slations [30] . 3.7 LARGE VOCAB ULARY PRO BLEM: The m ethods of machine translation described b y va riou s RNN appr oaches fail to ac knowledge the proble m of a targe t vocabulary. The pr esence of a ver y big target vocabulary makes it co mputationally infe asible i f the n umber o f words in the target language known to the system exceeds a threshold a mount. T o ad dress this problem, a h ybrid enco der decoder system with an attentio n mechanism has bee n used [23] . The algorith m proposed s uccessfully ma nages to kee p the co mputational co mplexity to onl y a par t of the vocabulary. In the system p roposed, a Bi -Directional RNN with a Gate d Recurrent Unit (GRU) i s used as the e ncoder to ensure that the encoding process is ver y efficient and at the same time, faster than conventio nal BRNNs b ecause the gated unit skips over time epochs. The deco der computes the context vecto r c as a co nvex sum o f t he hidden state s (h 1 , . . . , h T ) with the coefficients α 1 , . . . , α T computed by < > = exp ( < > , < 1> ) exp ( < > , < 1> k where a is a feed for ward NN with a si ngle hidden la yer z. One o f the major hurdles in this system is the scaling of complexity o f accessi ng a large target vocabulary. There are 2 app roaches to deal with the prob lem o f co mplexity due t o a large vocabulary: Stochastic Appr oximation of P robability: In t his method, the target word is best esti mated using a noise contrastive estimation. Hierarchy Classes: I n this ap proach, the target words are clustered hierarchicall y in to multiple classes suc h t hat the target pr obabi lity is based o n the class probabilit y and the inter-class probab ility. The Rare words model is a tr anslation -specific sol ution for this proble m. In t his appro ach, only a small subset of the target vocab ulary i s used to co mpute the normalization constant d uring training, making co mplexity constant with respect to the target vocab ulary. Also, after eac h update, the complexity is brought do wn [3 1] . The easiest wa y to select a p art of the vocab ulary i s to select top N most frequent target words but this would ruin the point of having a large vocab ulary. T his model creates a dictionary based on source and target word alignment. Using this d ictionar y, K best c hoice s are chosen and this i s further scrutinized for the final output. Also, it obtained a B LEU score of 37 .2 for English to French translation which is j ust 0.3 behind the current bes t. A lso, it was able to perfor m really efficie ntly eve n though it had a large targe t vocabulary[32] . 4. SYNTHESIS Speech synthe sis is the process of generating co mputer simulation o f human speech. It is used to translate written information/text into aural information. It h as been the counterpart of speech r ecognition . 4.1 IMPLEM ENTATION The text ual input sente nce is fir st pre -proce ssed b y a proces s called Normalization where things like special character s, date and time, n umbers, and abbreviations are t urned i nto words. Next, a list o f phon emes, taken from the list of database of phoneme s used in the language, is used for prosody generation o f t he spe ech so unds of the target speech sentences [3 3]. The phonemes ar e chose n based o n the spectral parameter, the i ntonation based o n the e xcitation parameter, a nd the d uration, based on the duration parameter. This system i s shown in figure 6. FIG. 6 – SCHEMA TIC OF HMM- BASED SYNTHESIS 4.2 IMPO RTANCE OF PROSODY [33] , [34] The most important qualitie s of a speech synthesis system are naturalness- how closel y output sounds like hu man speech and intelligibilit y- t he ease with which the o utput is understood. Appropriate Prosody model is e ssential to ensure naturalness a nd intelligibility as it serves as the backbone of TT S system. Proso dy means the character istics that are o btained from the spe ech like accent, inton ation and rhythm. These para meters have information o f d uration, pitch and intensit y. Earlier r ule -based appr oach was used for deriving the p rosody modelling for co ncatenative synthesis. Today, statistical approaches are popularly adopted. Also cues are provided by the pr osody to the listener to help t hem interpret the speec h cor rectly. Factors like wa y of speaking, regional e ffect and various other phonological factors affect the prosody. 4.3 SYNTHESIS TECHNO LOGIES There are three main approaches to spee ch synthe sis: Formant synthesis, Articulator y synthesis, and Concatenative synthe sis. 4.3.1 FORMANT SYNTH ESIS Formants are a s et of resonance frequencies o f t he v ocal tract. Formant synthesis models the frequencies of speech signal. I t does not u se huma n speech samples in stead create s an artificial speech using parameters such as fundamental frequency, voicin g, and noise levels are varied over time t o create a wavefor m of artificial speech [35]. It res ults in robotic sounding speech. 4.3.2 ARTICULATORY SYNTHESIS Articulatory s ynthesis tries to model the human sp eech production s ystem and ar ticulator y processes d irectly. However, it is the most di fficult method to i mplement due t o lack of knowledge of the complex h uman artic ulation organs[35] . 4.3.3 CO NCATENATIVE SYNTHE SIS Concatenative synthesis is b ased on the concatenat ion of segments o f r ecorded speech. It produces the most natural sounding synthesized speech. Ho wever, it has serious drawbacks li ke audib le glitches in the outp ut so metimes and the memor y requirement is la rge to stor e a la r ge amount of speech corpus [3 6] . 4.3.4 HMM B ASED SYNTHESIS It is a statistical par ametric synthe sis tec hnique. It is used easily for implementing prosody and vario us voice characteristics on the basi s of probab ilities without having large datab ases. In this syste m, the freq uency spectrum, fundamental frequenc y, and pro sody of speech are modeled simultaneously by HMM s [3 7] . Speech waveforms are generated from HMMs on the basis o f maximum li kelihood criterion. In this appro ach speech utterance s are used to extract spectral (Mel -Cepstral Coefficients.), excitation parameters and m odel cont ext dependent p hone model s which are, in turn, concate nated and used to synthesize speech w avefor m corr esponding to the text input [35], [36].HT S technology is preferred because it overco mes the drawbacks of For mant and Articulator y synthesis as H MM based is a statistical ap proach. 5. USE OF 3 INDEPEN DENT M ODULES: Spontaneous speec h poses a very i mportant prob lem in the process of translatio n. This occurs mainly because the variation is speech patter ns, ac cents, intonations etc. make it impossible to detect eve n the right sentence let a lone the errors present in the 3 modules employed. Most of the se errors are ca used by the lack of accuracy of the reco gnition. As a result, the input sente nce is not well formed. Even without recognition erro rs, speech translation ca nnot rely on conventional grammar models and structures b ecause they differ from those o f written language b ecause of the nature of speech. Recently, SMT has shown pr omise in voice tr anslation. SMTs do n't ha ve the need to m ake syntactic assu mptions because of the sta tistical nature of the s ystem. A target sentence is guaranteed to be output b y the system re gardless of the nature of input. T his e nsures that even if there i s no syntactic and structural accurac y in tra nslation, at least th e same meaning is retained in the transla tion. Having sa id that, the SMT structure of recognitio n follo wed by translatio n and synthesis lac ks co herent a w orking style b ecause o f t he ver y independent ap proach of eac h of the se modules. Also, there are a lo t of models like n -best list s, n-gra m model, bag of words model etc. that ca n be used alon g with the SM T system to increa se the p erformance of the system q uite drastically [38], [39]. 6. PROPOSED SYSTEM The proposed system i s composed of three processes - recognition, tr anslation and s ynthesis. Fig. 1 describes t he processes involved . Section 2 begins b y describing t he working of HMM -Based R ecognition and supp orts the decision for choosing that m ethodolo gy by surveying the other tools and methods availab le to perfor m S R. Section 3 contains the surve y of the vario us translation methodologies and with focu s on the adaptation of LSTM and GRU, and then add ressing the targe t vocabulary prob lem. This help s make the choice to u se gated memory ne tworks and tr y o ut several variations to see opti mality in outpu t. Section 4 explains the HM M-Based synthesis process and supp orts the decision with surve y of the other available methodologies, thus making it the perfect met hodo logy for the task. Further, Section 5 m entions the drawbacks of u sing three independent modules in voice translation . It also talks abou t complementary lang uage models t hat can be u sed to enhance performance. T he survey concludes by stating the requirements a nd e xpectations o f the model. T he scope for extension of the ser vices pro vided b y ADD is described in Section 8. FIG. 7 - THE PROPO SED SYSTEM This Acoustic Dialect Deco der is a p roject undertaki ng funded by SSN College O f Engineering for R s. 20,00 0. 7. CONCLUSION We have found that HMM based Speech Recognition, hybrid RNN b ased Mac hine T ranslation based on gated units and other ap proaches, and H MM based Speech S ynthesis to be the b est approaches in the respecti ve paradigms. Therefore, th e obj ective is to build a continuous speaker - independent English - T amil Voice Translation system using HMM based speech recognition in HTK, hybrid RNN system with at least one LSTM or GRU based Machine Translation s ystem i n Python, and HMM based speech synthesis o n HT S. T he id ea is to work with medium to fairly large vocab ulary size and imp rove efficiency and accuracy of the system. 8. FUTURE WORK ADD has huge scop e for i mprovement and extensio n. It ca n be made to tran slate multiple languages using the same input structures. It can be made much more e fficient using vario us efficiency e nhancing algorithms like the r are words model and many ot hers. It can also be improved to m ake the target speech sound exactly like the source speaker to en hance the comfort of using the device. T his system ca n al so b e incorporated into a hearing aid to enable the sa me service for people who are dea f as well. 9. REFERENCE S [1] S. K. Mukundan, “’ Shreshta Bhasha ’ Mala yalam Speech Recognition usi ng HTK,” vol. 1, no. 1, pp. 1 – 5, 2014. [2] J. S. Pokhariya and S. Ma thur, “Sanskrit Speech Recognition using Hidden Ma rkov Model T oolkit,” vol. 3, no. 10, pp. 93 – 98 , 2014. [3] L. Rabiner and B. -H. Juang, Fun damentals of Speech Recog nition . Upp er Saddle River, NJ, USA: Prentice-Hall, Inc., 199 3. [4] X. Yao, P . Bhutada, K. Georgila, K. Sagae, R. Artstein, and D. T raum, “Practical Eval uation of Speech Recognizers for Virtual Human Dialog ue Systems,” 2008 . [5] N. U. Nair and T . V Sreenivas, “Multi Pattern Dynamic Time Warpin g for automatic speech recognition,” in TE NCON 2008 - 2008 IEEE Region 10 Conference , 2008, pp. 1 – 6. [6] A. Graves, A. Mo hamed, and G. Hinton, “Speech Recognition With Deep Rec urrent Neural Networks,” Icassp , no. 3, pp. 66 45 – 6 649, 2013. [7] J. Dines and M. Magimai Dos s, “A study of phoneme and grapheme based context -dependent ASR systems,” Lect. No tes Comp ut. Sci. (inc luding Subser. Lect. Notes Artif. I ntell. Lect. No tes Bioinformatics) , vol. 48 92 LNCS, pp . 215 – 226, 2008. [8] W. Han, C.-F. Cha n, C.-S. Choy, and K. -P. P un, “An efficient MFCC extractio n method in speec h recognition,” in Circu its and Systems, 20 06. IS CAS 2006. Proceed ings. 2006 IEEE Interna tional Symposium o n , 2006, p. 4 pp. – . [9] S. E. Bou- Ghazale a nd J. H. L. Hansen, “A Comparative Study of T raditional and Ne wly Proposed Features for Reco gnition of Speec h under Stress,” IEEE Trans. S peech Audio P rocess. , vol. 8, no. 4, pp. 429 – 442, 2000. [10] D. A. Reynolds, “Experi mental evaluation of features for robust spea ker identification,” Sp eech Audio Process. I EEE Trans. , vol. 2, no. 4, pp. 639 – 643, Oct. 1994. [11] D. -S. Ki m, S.- Y. Lee, a nd R. M. Kil, “Auditor y pr ocessing of speech signals fo r robust speech recognition in real - world noisy environ ments,” Speech Audio Process. IEEE Trans. , vol. 7, no. 1, pp. 55 – 69, Jan. 1 999. [12] H. M. Dinhz, T. D. Nguyen, and T. D. Pham, “Comparative Analysis o f HTK and Sphinx in V ietnamese Speech Reco gnition,” Ijarcce , vol. 4, no. 5, pp. 739 – 741, 2015. [13] G. Ma, W. Zhou, J. Zheng, X. Yo u, and W. Ye, “A Comparison between HT K and SP HINX on Chinese Mandarin,” in Artificial I ntelligen ce, 2009. JCAI ’09. International J oint Conferenc e on , 2009, pp. 394 – 397. [14] K. Vertanen, “Baseline WSJ acoustic models for HTK and Sphinx: T raining recipes and reco gnition experiments,” Cave ndish Lab. Univ. Cambridge , 2006. [15] A. T rujillo, Tran slation Engines: Techn iques for Machine Translatio n . Spr inger London, 2012. [16] P . Koehn, Statistical Ma chine Translation . Cambridge University P ress, 2010. [17] S. Hir egoudar, K. Manjunath, and K. S. P atil, “a Survey : Research Su mmary on Neural Net works,” pp. 385 – 38 9, 2014. [18] P . Koehn, F. J. Och, and D. M arcu, “Statistical phrase- based translatio n,” Proc. 2 003 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. - NAACL ’03 , vol. 1, no. June, pp. 48 – 54, 2003. [19] K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Sc hwenk, and Y. Bengio, “Learning Phrase Representations usi ng RNN Encoder-Decoder for Statistical Mac hine Translation,” 201 4. [20] K. Cho, B. van Merrienboer, D. Bahdanau, and Y. Bengio, “On the Pro perties of Neural Machine Translation: Encoder -Decoder Ap p roaches,” 2014 . [21] J . Pouget-Abadie, D. B ahdanau, B. van Merrienboer , K. Cho, and Y. Bengio, “Overcoming the Curse of Sentence Length for Neural M achine Translatio n using Automatic Seg mentation,” 20 14. [22] M. Sundermeyer, T. Alkhouli, J. W uebker, and H . Ney, “Translation Mod eling with Bidirectio nal Recurrent Neural Networ ks Human Langua ge Technology and P attern Recognition Group,” pp . 14 – 25, 2014. [23] D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation b y Jointly Learning to Alig n and Trans late,” Iclr 2015 , pp. 1 – 15, 2014. [24] M. Schuster and K. K. P aliwal, “Bidirectional recurrent neural net works,” IEEE Trans. Signal Process. , vol. 45, no. 11, pp. 2673 – 2681, 199 7. [25] Z. C. Lipton, “A Critical Re view of Recurrent Neural Networks for Seque nce Learning,” pp. 1 – 35, 2015. [26] A. Grave s, “Generating seque nces with recurrent neural networks,” arXiv Prepr. arXiv1308.0850 , pp. 1 – 43, 2013. [27] I. Sutskever, O. Vinyals, and Q. V Le, “Sequence to sequence learning with neural networks,” Adv. Neural Inf. Proce ss. Syst. , pp . 3104 – 3112 , 2014. [28] S. Ho chreiter, S. Hochreiter , J. Schmidhuber, and J . Schmidhuber, “Long short - term memory.,” Neura l Comput. , vol. 9 , no. 8, pp. 1735 – 80, 1997. [29] J . Chung, Ç. Gülçehre, K. Cho , and Y. Bengio, “Empirical Eva luation o f Gated Recurrent Ne ural Networks on Sequence Mod eling,” CoRR , vol. abs/1412.3555, 2014. [30] J . Chung, C. Gulcehre, K. Cho , and Y. Bengio, “Empirical Evaluation o f Gated Recurrent Ne ural Networks on Sequence Mod eling,” pp. 1 – 9, 2014. [31] M. -T . Luong, I. Sutskever, Q. V. Le, O. Vinyals, and W. Zaremba, “Addressin g the Rare Word Problem in Neural Machine T ranslation,” Arxiv , pp. 1 – 11, 2014. [32] S. J ean, K. Cho, R. Me misevic, and Y. B engio, “On Using Very Large T arget Vocabular y for Neural Machine Tr anslation,” vol. 000, 2 014. [33] M. C. Anil and S. D. Shirbaha durkar, “Speech modification for prosod y conversion in expressive Marathi text- to - speec h synthesis,” i n Signa l Processing and Integrated Networks (SPIN), 20 14 Internationa l Conference on , 2014 , pp. 56 – 58. [34] J . Yamagishi, T. Ko bayashi, Y. Nakano, K. Oga ta, and J. Isogai, “Anal ysis of speaker adaptation algorithms for HMM -based speech s ynthesis and a constrained SMAP LR adaptation algorithm,” IEEE Trans. Audio, Speech Lang. Process. , vol. 17, no. 1, pp. 66 – 83, 2009. [35] Y. Tabet and M. B oughazi, “Speech synthesis techniques. A surve y,” Int. Wo rk. Syst. Sign al Process. their Appl. WOSSPA , p p. 67 – 70, 2011. [36] S. I . Conference and A. Co mputing, “A Novel Intonation Model to Improve the Quality of T amil Text- to - Speech S ynthesis Syste m,” pp. 335 – 340, 2014. [37] K. Tokuda, Y. Nankaku, T . Toda, H. Zen, J. Yamagishi, and K. O ura, “Speech Synthesis Based on Hidden Markov Models,” Proc. IEEE , vol. 101, no. 5, pp. 1234 – 1252, 2013 . [38] F. J . Och and H. Ne y, “Improved Statistical Alignment Models,” in Proceed ings of the 38 th Annual Meetin g on Association for Comp utational Linguistics , 200 0, pp. 440 – 447. [39] V. H. Quan, M. Federico, and M. Cettolo, “Integrated N -best Re -ranking for Spoken Language Translati on,” In terspeech , p p. 3181 – 3 184, 2005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment