A Greedy Approach to Adapting the Trace Parameter for Temporal Difference Learning
One of the main obstacles to broad application of reinforcement learning methods is the parameter sensitivity of our core learning algorithms. In many large-scale applications, online computation and function approximation represent key strategies in…
Authors: Martha White, Adam White
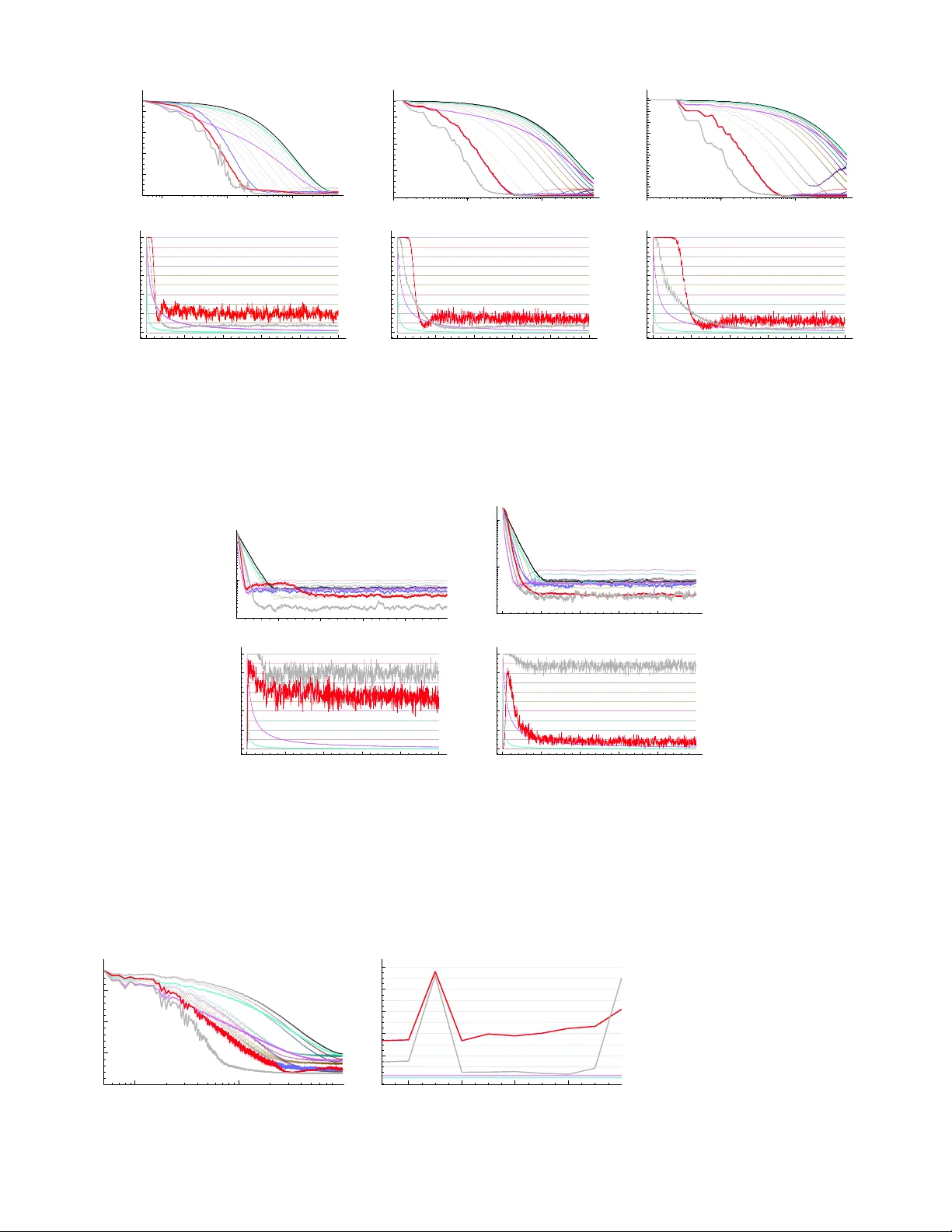
A Greed y Appr oac h to Adapting the T race P arameter f or T emporal Difference Learning Mar tha White Depar tment of Computer Science Indiana University Bloomington, IN 47405, USA mar tha@indiana.edu Adam White Depar tment of Computer Science Indiana University Bloomington, IN 47405, USA adamw@indiana.edu ABSTRA CT One of the main obstacles to broad application of reinforce- men t learning methods is the parameter sensitivity of our core learning algorithms. In many large-scale applications, online computation and function appro ximation represent k ey strategies in scaling up reinforcemen t learning algorithms. In this setting, w e ha ve effectiv e and reasonably w ell un- derstoo d algorithms for adapting the learning-rate parame- ter, online during learning. Such meta-learning approach es can impro ve rob ustness of lea rning and enable specialization to curren t task, improving learning speed. F or temp oral- difference learning algorithms which w e study here, there is yet another parameter, λ , that similarly impacts learn- ing speed and stability in practice. Unfortunately , unlike the learning-rate parameter, λ parametrizes the ob jective function that temporal-difference methods optimize. Differ- en t cho ices of λ pro duce different fixed-point solutions, and th us adapting λ online and characterizing the optimization is substantially more complex than adapting the learning- rate parameter. There are no meta-learning metho d for λ that can achiev e (1) incremental updating, (2) compatibil- it y with function approximatio n, and (3) maintain stability of learning under b oth on and off-p olicy sampling. In this paper we contribute a nov el ob jective function for optimiz- ing λ as a function of state rather than time. W e derive a new incremental, linear complexit y λ -adaption algorithm that do es not require offline batch up dating or access to a model of the w orld, and presen t a suite of exp erimen ts il- lustrating the practicality of our new algorithm in three dif- feren t settings. T aken together, our con tributions represent a concrete step tow ards blac k-box application of temp oral- difference learning methods in real world problems. K eywords Reinforcemen t learning; temporal difference learning; off- policy learning 1. INTR ODUCTION In reinforcement learning, the training data is pro duced b y an adaptive learning agent’s in teraction with its environ- men t, whic h mak es tuning the parameters of the learning App ears in: Pr o ce e dings of the 15th International Confer enc e on Autonomous Agents and Multiagent Systems (AAMAS 2016), J. Thangar ajah, K. T uyls, C. Jonker, S. Marsel la (e ds.), May 9–13, 2016, Singap or e. Copyright c 2016, International Foundation for Autonomous Agents and Multiagent Systems (www .ifaamas.org). All rights reserved. process both c hallenging and essen tial for goo d p erformance. In the online setting we study here, the agent-en vironment in teraction pro duces an unending stream of temp orally cor- related data. In this setting there is no testing-training split, and thu s the agent’s learning pro cess must be robust and adapt to new situations not considered by the human de- signer. Robustness is often critically related to the v alues of a small set parameters that con trol the learning pro cess (e.g., the step-size parameter). In real-world applications, ho w ever, we cannot exp ect to test a large range of theses parameter v alues, in all the situations the agent may face, to ensure go od p erformance—com mon practice in empiri- cal studies. Unfortunately , safe v alues of these parameters are usually problem dep enden t. F or example, in off-p olicy learning (e.g., learning from demonstrations), large imp or- tance sampling ratios can destabilize pro v ably conv ergent gradien t temporal difference learning metho ds, when the pa- rameters are not set in a very particular wa y ( λ = 0) [ 33 ]. In suc h situations, we turn to meta-learning algorithms tha t can adapt the parameters of the agent contin uously , based on the stream of exp erience and some notion of the agent’s o wn learning progress. These meta-learning approac hes can potentially improv e robustness, and also help the agent spe- cialize to the current task, and thus improv e learning sp eed. T emp oral difference learning metho ds make use of tw o im- portant parameters: the step-size parameter and the trace- deca y parameter. The step-size parameter is the same as those used in sto c hastic gradien t descen t, and there are algo- rithms av ailable for adjusting this parameter online, in rein- forcemen t learning [ 2 ]. F or the trace decay parameter, on the other hand, we hav e no generally applicable meta-learning algorithms that are compatible with function approxima- tion, incremen tal pro cessing, and off-policy sampling. The difficult y in adapting the trace decay parameter, λ , mainly arises from the fact that it has seemingly multi- ple roles and also influences the fixed-p oin t solution. This parameter w as in tro duc ed in Samuel ’s chec ker play er [ 16 ], and later described as interpolation parameter b et ween of- fline TD(0) and Monte-Carlo sampling (TD( λ = 1) by Sut- ton[ 21 ]. It has b een empirically demonstrated that v alues of λ b et w een zero and one often p erform the b est in practice [ 21 , 23 , 32 ]. This trace parameter can also b e viewed as a bias-v ariance trade-off parameter: λ closer to one is less biased but lik ely to hav e higher v ariance, where λ closer to zero is more biased, but lik ely has low er v ariance. How ever, it has also b een describ ed as a credit-assignmen t parameter [ 19 ], as a method to enco de probability of transitions [ 25 ], a w ay to incorp orate the agent’s confidence in its v alue func- tion estimates [ 23 , 29 ], and as an a veraging of n-step returns [ 23 ]. Selecting λ is further complicated b y the fact that λ is a part of the problem defin ition: the solution to the Bellman fixed point equation is dependent on the ch oice of λ (unlike the step-size parameter). There are few approaches for setting λ , and most exist- ing work is limited to special cases. F or instance, several approac hes hav e analyzed setting λ for v ariants of TD that w ere introduced to simplify the analysis, including phased TD [ 5 ] and TD ∗ ( λ ) [ 17 ]. Though b oth pro vide v aluable in- sigh ts in to the role of λ , the analysis do es not easily extend to con ven tional TD algorithms. Sutton and Singh [ 25 ] in ves- tigated tuning b oth the learning rate parameter and λ , and proposed t w o meta-learning algorithms. The first assumes the problem can b e mo deled by an acyclic MDP , and the other requires access to the transition mo del of the MDP . Singh and Da yan [ 18 ] and Kearns and Singh [ 5 ] contributed extensiv e simulat ion studies of the interaction betw een λ and other agen t parameters on a chain MDP , but again relied on access to the mo del and offline computation. The most re- cen t study [ 3 ] explores a Bay esian v ariant of TD learning, but requires a batch of sample s and can only b e used off-line. Finally , Konidaris et al. [ 6 ] in tro duce TD γ as a method to re- mo v e the λ parameter altogether. Their approach, how ever, has not been extended to the off-p olicy setting and their full algorithm is to o computationally exp ensiv e for incremen tal estimation, while their incremen tal v ariant introduces a sen- sitiv e meta-parameter. Although this long-history of prior w ork has help ed develop our in tuitions a b out λ , the av ailable solutions are still far from the use cases outlined ab o v e. This pap er introduces an new ob jective based on lo cally optimizing bias-v ariance, which we use to dev elop an effi- cien t, incremen tal algorithm for learning state-based λ . W e use a forw ard-bac kward analysis [ 23 ] to deriv e an incremen- tal algorithm to estimate the v ariance of the return. Using this estimate, we obtain a closed-form estimate of λ on each time-step. Finally , we empirically demonstrate the general- it y of the approach with a suite of on-p olicy and off-p olicy experiments. Our results show that our new algorithm, λ - greedy , is consistently amongst the b est p erformin g, adapt- ing as the problem chan ges, whereas an y fixed approach w orks we ll in some settings and po orly in anothers. 2. B A CKGR OUND W e mo del the agen t’s interaction with an unkno wn envi- ronmen t as a discrete time Marko v Decision Process (MDP). A MDP is characterized by a finite set of states S , set of ac- tions A , a reward function r : S × S → R , and generalized state-based discount γ : S ∈ [0 , 1], whic h enco des the level of discounting p er-state (e.g., a common setting is a con- stan t discoun t for all states). On each of a discrete n umber of timesteps, t = 1 , 2 , 3 , . . . , the agent observes the current state S t , selects an action A t , according to its target p olicy π : S × A → [0 , 1], and the environmen t transitions to a new state S t +1 and emits a reward R t +1 . The state transitions are go v erned b y the transition function P : S ×A×S → [0 , 1], where P ( S t , A t , S t +1 ) denotes the probability of transition- ing from S t to S t +1 , due to action A t . A t timestep t , the future rewards are summarized by the Monte Carlo (MC) return G t ∈ R defined by the infinite discoun ted sum G t def = R t +1 + γ t +1 R t +2 + γ t +1 γ t +2 R t +3 + . . . γ t = γ ( S t ) = R t +1 + γ t +1 G t +1 . The agen t’s ob jectiv e is to estimate the exp ected return or v alue function , v π : S → R , defined as v π ( s ) def = E [ G t | S t = s, A t ∼ π ]. W e estimate the v alue function using the stan- dard framework of linear function approximation. W e as- sume the state of the environmen t at time t can b e c har- acterized by a fixed-length feature v ector x t ∈ R n , where n |S | ; implicitly , x t is a function of the random v ari- able S t . The agent uses a linear estimate of the v alue of S t : the inner pro duct of x t and a mo difiable set of weigh ts w ∈ R n , ˆ v ( S t , w ) def = x > t w , with mean-squared error (MSE) = P s ∈S d ( s )( v ( s ) − ˆ v ( s, w )) 2 , where d : S → [0 , 1] enco des the distribution o v er states induced by the agen t’s b eha vior in the MDP . Instead of estimating the exp ected v alue of G t , we can estimate a λ -return that is expected to hav e low er v ariance G λ t def = R t +1 + γ t +1 [(1 − λ t +1 ) x > t +1 w + λ t +1 G λ t +1 ] , where the tr ac e de c ay function λ : S → [0 , 1] sp ecifies the trace parameter as a function of state. The trace parameter λ t +1 = λ ( s t +1 ) av erages the estimate of the return, x > t +1 w , and the λ -return starting on the next step, G λ t +1 . When λ = 1, G λ t becomes the MC return G t , and the v alue func- tion can b e estimated by av eraging rollouts from each state. When λ = 0, G λ t becomes equal to the one-step λ -r eturn , R t +1 + γ t +1 x > t +1 w , and the v alue function can be estimated b y the linear TD(0) algo rithm. The λ -return when λ ∈ (0 , 1) is often easier to estimate than MC, and yields more accu- rate predictions than using the one-step return. The intu - ition, is that the for large λ , the estimate is high-v ariance due to a veraging p ossibly long tra jectories of noisy rewards, but less bias b ecause the initial biased estimates of the v alue function participate less in the computation of the return. In the case of low λ , the estimate has low er-v ariance be- cause fewer p oten tially noisy rewards participate in G λ t , but there is more bias d ue to the increase role of the initial v alue function estimates. W e further discuss the in tuition for this parameter in the next section. The generalization to state-based γ and λ ha ve not yet been widely considered, though the concept w as introduced more than a decade ago [ 22 , 27 ] and the generalization shown to b e useful [ 22 , 10 , 14 , 26 ]. The Bellman operator can b e generalized to include state-based γ and λ (see [ 26 , Equa- tion 29]), where the c hoice of λ per-state influences the fixed point. Time-based λ , on the other hand, w ould not result in a well-defined fixed p oin t. Therefore, to ensure a well- defined fixed p oin t, we will design an ob jective and algo- rithm to learn a state-based λ . This pap er considers b oth on- and off-p olicy p olicy ev al- uation. In the more con ven tional on-policy learning set- ting, we estimate v π ( s ) based on samples generated while selecting actions according to the target p olicy π . In the off-policy case, we estimate v π ( s ) based on samples gener- ated while selecting actions according to the b eha vior p olicy µ : S × A → [0 , 1], and π 6 = µ . In order to learn ˆ v in b oth these settings w e use the GTD( λ ) algorithm [ 9 ] sp ecified by the follo wing update equations: ρ t def = π ( S t , A t ) µ ( S t , A t ) importance sampling ratio e t def = ρ t ( γ t λ t e t − 1 + x t ) eligibilit y trace δ t def = R t +1 + γ t x > t +1 w t − x > t w t TD error w t +1 ← w t + α ( δ t e t − γ t (1 − λ t +1 ) e > t h t x t +1 ) h t +1 ← h t + α h ( δ t e t − x > t h t ) x t auxiliary w eights with step-sizes α, α h ∈ R + and an arbitrary initial w 0 , h 0 (e.g., the zero vector). The imp ortance sampling ratio ρ t ∈ R + facilitates learning ab out rewards as if they were gen- erated by following π , instead of µ . This ratio can b e very large if µ ( S t , A t ) is small, which can comp ound and desta- bilize learning. 3. OBJECTIVE FOR TRA CE AD APT A TION T o obtain an ob jective for selecting λ , w e need to clarify its role. Although λ was not introduced with the goal of trading off bias and v ariance [ 21 ], several algorithms and significant theory ha ve developed its role as such [ 5 , 17 ]. Other roles ha v e b een suggested; how ever, as we discuss b elo w, eac h of them can still be thought of as a bias-v ariance trade-off. The λ parameter has b een describ ed as a credit assign- men t parameter, which allows TD( λ ) to p erform multi-step updates on each time step. On each up date, λ t con trols the amoun t of credit assigned to previous transitions, using the eligibilit y trace e . F or λ t close to 1, TD( λ ) assigns more credit for the curren t reward to previous transitions, result- ing in up dates to man y states along the curren t tra jectory . Con v ersely , for λ t = 0, the eligibility trace is cleared and no credit is assigned bac k in time, p erforming a single-step TD(0) update. In fact, this intuit ion can still b e thought of as a bias-v ariance trade-off. In terms of credit assignment, w e ideally alwa ys wan t to send maximal credit λ = 1, but deca y ed b y γ , for the curren t reward, whic h is also un biased. In practice, how ever, this often leads to high v ariance, and th us we mitigate the v ariance by choosing λ less than one and speed learning ov erall, but introduce bias. Another interpretation is that λ should be set to reflect confidence in v alue function estimates [ 29 , 23 ]. If your con- fidence in the v alue estimate of state s is high, then λ ( s ) should b e close to 0, meaning we trust the estimates pro- vided by ˆ v . If y our confidence is low, susp ecting that ˆ v may be inaccurate, then λ ( s ) should b e close to 1, meaning we trust observ ed rewards more. F or example in states that are indistinguishable with function approximation (i.e., aliased states), we should not trust the ˆ v as m uc h. This intuition similarly translates to bias-v ariance. If ˆ v is accurate, then decreasing λ ( s ) do es not incur (m uc h) bias, but can signifi- can tly decrease the v ariance since ˆ v gives the correct v alue. If ˆ v is inaccurate, then the increased bias is not worth the reduced v ariance, so λ ( s ) should b e closer to 1 to use actual (potentially high-v ariance) samples. Finally , a less commonly discussed interpretation is that λ acts as parameter that simulates a form of exp erience re- pla y (or mo del-based simulation of tra jectories). One can imagine that sending back information in eligibility traces is like simulating experience from a mo del, where the mo del could be a set of tra jectories, as in experience replay [ 8 ]. If λ = 1, the traces are longer and each update gets more tra jectory information, or experience replay . If a tra jectory from a point, how ever, was unlikely (e.g., a rare transition), w e ma y not wan t to use that information. Such an approach w as taken b y Sutton and Singh [ 25 ], where λ w as set to the transition probabilities. Ev en in this model-based in ter- pretation, the goal in setting λ b ecomes one of mitigating v ariance, without incurring too muc h bias. Optimizing this bias-v ariance trade-off, how ever, is dif- ficult b ecause λ affects the return w e are appro ximating. Join tly optimizing for λ across all time-steps is generally not feasible. One strategy is to take a batch approach, where the optimal λ is determined after seeing all the data [ 3 ]. Our goal, how ever, is to develop approac hes for the online set- ting, where future states, actions, rew ards and the influence of λ ha ve yet to b e observ ed. W e prop ose to tak e a greedy approac h: on eac h time step select λ t +1 to optimize the bias-v ariance trade-off for only this step . This greedy ob jective corresp onds to minimizing the mean-squared error betw een the unbiased λ = 1 return G t and the estimate ˆ G t with λ t +1 ∈ [0 , 1] with λ = 1 into the future after t + 1 ˆ G t def = ρ t ( R t +1 + γ t +1 [(1 − λ t +1 ) x > t +1 w t + λ t +1 G t +1 | {z } Monte Carlo ]) . Notice that ˆ G t in terpolates b et ween the curren t v alue es- timate and the unbiased λ = 1 MC return, and so is not recursiv e. Pic king λ t +1 = 1 gives an unbiased estimate, since then we would be estimating ˆ G t = G t . W e greed- ily decide how λ t +1 should be set on this step to lo cal ly optimize the mean-squared error (i.e., bias-v ariance). This greedy decision is made give n b oth x t and x t +1 , which are both av ailable when choosing λ t +1 . T o simplify notation in this section, we assume that x t and x t +1 are b oth given in the below expectations. T o minimize the mean-squared error in terms of λ t +1 MSE( λ t +1 ) def = E h ( ˆ G t − E [ G t ]) 2 i w e will consider the tw o terms that comp ose the mean- squared error: the squared bias term and the v ariance term. Bias( λ t +1 ) def = E [ ˆ G t ] − E [ G t ] V ariance( λ t +1 ) def = V ar[ ˆ G t ] MSE( λ t +1 ) = Bias( λ t +1 ) 2 + V ariance( λ t +1 ) . Let us b egin b y rewriting the bias. Since we are giv en x t , ρ t , x t +1 and γ t +1 when c hoosing λ t +1 , E [ ˆ G t ] = ρ t E h R t +1 + γ t +1 (1 − λ t +1 ) x > t +1 w t + λ t +1 G t +1 i = ρ t E [ R t +1 ] + ρ t γ t +1 (1 − λ t +1 ) x > t +1 w t + λ t +1 E [ G t +1 ] F or conv enience, define err( w , x t +1 ) def = E [ G t +1 ] − x > t +1 w (1) as the difference b et ween the λ = 1 return and the curren t appro ximate v alue from state x t +1 using weigh ts w t . Using this definition, w e can rewrite (1 − λ t +1 ) x > t +1 w t + λ t +1 E [ G t +1 ] = (1 − λ t +1 )( E [ G t +1 ] − err( w t , x t +1 )) + λ t +1 E [ G t +1 ] = E [ G t +1 ] − (1 − λ t +1 )err( w t , x t +1 ) giving E [ ˆ G t ] = ρ t ( E [ R t +1 ] + γ t +1 E [ G t +1 ]) − ρ t γ t +1 (1 − λ t +1 )err( w t , x t +1 ) = E [ G t ] − ρ t γ t +1 (1 − λ t +1 )err( w t , x t +1 ) = ⇒ Bias 2 ( λ t +1 ) = E [ G t ] − E [ ˆ G t ] 2 = ρ 2 t γ 2 t +1 (1 − λ t +1 ) 2 err 2 ( w t , x t +1 ) . F or the v ariance term, we will assume that the noise in the rew ard R t +1 giv en x t and x t +1 is indep enden t of the other dynamics [ 12 ], with v ariance σ r ( x t , x t +1 ). Again since we are giv en x t , ρ t , x t +1 and γ t +1 V ar[ ˆ G t ] = ρ 2 t V ar[ R t +1 + γ t +1 (1 − λ t +1 ) x > t +1 w t | {z } constant given ρ t , x t +1 , γ t +1 + γ t +1 λ t +1 G t +1 ] = ρ 2 t V ar[ R t +1 ] + ρ 2 t γ 2 t +1 λ 2 t +1 V ar[ G t +1 ] | {z } independent given x t , x t +1 = ρ 2 t σ r ( x t , x t +1 ) + ρ 2 t γ 2 t +1 λ 2 t +1 V ar[ G t +1 ] = ⇒ V ariance( λ t +1 ) = ρ 2 t γ 2 t +1 λ 2 t +1 V ar[ G t +1 ] + ρ 2 t σ r ( x t , x t +1 ) Finally , we can drop the constan t ρ 2 t σ r ( x t , x t +1 ) in the ob- jectiv e, and drop the ρ 2 t γ 2 t +1 in b oth the bias and v ariance terms as it only scales the ob jective, giving the optimization min λ t +1 ∈ [0 , 1] Bias 2 ( λ t +1 ) + V ariance( λ t +1 ) ≡ min λ t +1 ∈ [0 , 1] (1 − λ t +1 ) 2 err 2 t +1 ( w t ) + λ 2 t +1 V ar[ G t +1 ] . W e can tak e the gradien t of this optimization to find a closed form solution − 2(1 − λ t +1 )err 2 t +1 ( w t ) + 2 λ t +1 V ar[ G t +1 ] = 0 = ⇒ V ar[ G t +1 ] + err 2 t +1 ( w t ) λ t +1 − err 2 t +1 ( w t ) = 0 = ⇒ λ t +1 = err 2 t +1 ( w t ) V ar[ G t +1 ] + err 2 t +1 ( w t ) (2) whic h is alwa ys feasible, unless b oth the v ariance and error are zero (in which case, an y choice of λ t +1 is equiv alent). Though the importance sampling ratio ρ t does not affect the choice of λ on the current time step, it can ha v e a dra- matic effect on V ar[ G t +1 ] into the future via the eligibility trace. F or example, when the target and b eha vior p olicy are strongly mis-matched, ρ t can b e large, which mult iplies into the eligibility trace e t . If several steps ha v e large ρ t , then e t can get very large. In this case, the equation in ( 2 ) would select a small λ t +1 , significan tly decreasing v ariance. 4. TRA CE AD APT A TION ALGORITHM T o appro ximate the solution to our prop osed optimiza- tion, we need a w ay to appro ximate the error and the v ari- ance terms in equation ( 2 ). T o estimate the error, we need an estimate of the exp ected return from eac h state, E [ G t ]. T o estimate the v ariance, we need to obtain an estimate of E [ G 2 t ], and then can use V ar[ G t ] = E [ G 2 t ] − E [ G t ] 2 . The esti- mation of the exp ected return is in fact the problem tackled b y this pap er, and one could use a TD algorithm, learning w eigh t vector w err to obtain approximation x > t w err to E [ G t ]. This approach may seem problematic, as this sub-step ap- pears to b e solving the same problem we originally aimed to solve. How ever, as in many meta-parameter optimization approac hes, this approximation can b e inaccurate and still adequately guide selection of λ . W e discuss this further in the experimental results section. Similarly , we would like to estimate E [ G 2 t ] with w sq x > t b y learning w sq ; estimating the v ariance or the second moment Algorithm 1: Policy ev aluation with λ -greedy w t ← 0 // Main w eights h t ← 0 // Auxiliary w eights for off-policy learning e t ← 0 // Main trace parameters x t ← the initial observ ation w err ← Rmax 1 − γ × 1 , w sq ← 0 . 0 × 1 // Aux. w eights for λ ¯ e t ← 0 , ¯ z t ← 0 // Aux. traces rep eat T ake action accord. to π , observe x t +1 , rew ard r t +1 ρ t = π ( s t , a t ) /µ ( s t , a t ) // In on-policy , ρ t = 1 λ t +1 ← λ -greedy( w err , w sq , w t , x t , x t +1 , r t +1 , ρ t ) // No w can use an y algorithm, e.g., GTD δ t = r t +1 + γ t +1 w > t x t +1 − w > t x t e t = ρ t ( γ t λ t e t − 1 + x t ) w t +1 = w t + α ( δ t e t − γ t +1 (1 − λ t +1 ) x t +1 )( e > t h t )) h t +1 = h t + α h ( δ t e t − ( h > t x t ) x t ) un til agent done in teraction with environmen t Algorithm 2: λ -greedy( w err , w sq , w t , x t , x t +1 , r t +1 , ρ t ) // Use GTD to update w err ¯ g t +1 ← x > t +1 w err δ t ← r t +1 + γ t +1 ¯ g t +1 − x > t w err ¯ e t = ρ t ( γ t ¯ e t − 1 + x t ) w err = w err + αδ t ¯ e t // Use VTD to update w sq ¯ r t +1 ← ρ 2 t r 2 t +1 + 2 ρ 2 t γ t +1 r t +1 ¯ g t +1 ¯ γ t +1 ← ρ 2 t γ 2 t +1 ¯ δ t ← ¯ r t +1 + ¯ γ t +1 x > t +1 w sq − x > t w sq ¯ z t = ¯ γ t ¯ z t − 1 + x t w sq = w sq + α ¯ δ t ¯ z t // Compute λ estimate errsq = ( ¯ g t +1 − x > t +1 w t ) 2 v arg = max(0 , x > t +1 w sq − ( ¯ g t +1 ) 2 ) λ t +1 = errsq / (v arg + errsq) return λ t +1 of the return, ho wev er, has not b een extensiv ely studied. Sobel [ 20 ] provides a Bellman equation for the v ariance of the λ -return, when λ = 0. There is also an extensive litera- ture on risk-av erse MDP learning, where the v ariance of the return is often used as a measure [ 15 , 13 , 1 , 28 ]; how ever, an explicit wa y to estimate the v ariance of the return for λ > 0 is not given. There has also b een some w ork on estimat- ing the v ariance of the value function [ 12 , 35 ], for general λ ; though related, this is differen t than estimating the v ariance of the λ -r eturn . In the next section, w e pro vide a deriv ation for a new algo- rithm called v ariance temp oral difference learning (VTD), to appro ximate the second moment of the return for any state- based λ . The general VTD up dates are given at the end of Section 5.2 . F or λ -greedy , w e use VTD to estimate the v ari- ance, with the complete algorithm summarized in Algorithm 1 . W e opt for simple meta-parameter settings, so that no additional parameters are in troduced. W e use the same step- size α that is used for the main w eights to up date w err and w sq . In addition, we set the weigh ts w err and w sq to reflect a priori estimates of error and v ariance. As a reasonable rule-of-th umb, w err should b e set larger than w sq , to reflect that initial v alue estimates are inaccurate. This results in an estimate of v ariance V ar[ G t +1 ] ≈ x > t +1 w sq − ( x > t +1 w err ) 2 that is capp ed at zero un til x > t +1 w sq becomes larger than ( x > t +1 w err ) 2 . 5. APPR O XIMA TING THE SECOND MO- MENT OF THE RETURN In this section, we derive the general VTD algorithm to appro ximate the second momen t of the λ -return. Though we will set λ t +1 = 1 in our algorithm, w e nonetheless provide the more general algorithm as the only mo del-free v ariance estimation approac h for general λ -returns. The k ey nov elty is in determining a Bellman op erator for the squared return, which then defines a fixed-p oin t ob jec- tiv e, called the V ar-MSPBE. With this Bellman op erator and recursive form for the squared return, w e derive a gra- dien t TD algorithm, called VTD, for estimating the second momen t. T o av oid confusion with parameters for the main algorithm, as a general rule throughout the do cumen t, the additional parameters used to estimate the second moment ha v e a bar. F or example, γ t +1 is the discount for the main problem, and ¯ γ t +1 is the discoun t for the second moment. 5.1 Bellman operator for squared r eturn The recursiv e form for the squared-return is ( G λ t ) 2 = ρ 2 t ( ¯ G 2 t + 2 γ t +1 λ t +1 ¯ G t G λ t +1 + γ 2 t +1 λ 2 t +1 ( G λ t +1 ) 2 ) = ¯ r t +1 + ¯ γ t +1 ( G λ t +1 ) 2 where for a giv en λ : S → [0 , 1] and w , ¯ G t def = R t +1 + γ t +1 (1 − λ t +1 ) x > t +1 w ¯ r t +1 def = ρ 2 t ¯ G 2 t + 2 ρ 2 t γ t +1 λ t +1 ¯ G t G λ t +1 ¯ γ def = ρ 2 t γ 2 t +1 λ 2 t +1 . The w are the w eights for the λ -return, and not the w eights w sq w e will learn for appro ximating t he second momen t. F or further generalit y , w e int ro duce a meta-parameter ¯ λ t ¯ V ¯ λ t def = ¯ r t +1 + ¯ γ t +1 (1 − ¯ λ t +1 ) x > t +1 w sq + ¯ λ t +1 ¯ V ¯ λ t +1 to get a ¯ λ -squared-return where for ¯ λ t +1 = 1, ¯ V ¯ λ t = ( G λ t ) 2 . This meta-parameter ¯ λ plays the same role for estimating ( G λ t ) 2 as λ for estimating G t . W e can define a generalized Bellman op erator ¯ T for the squared-return, using this abov e recursiv e form. The goal is to obtain the fixed p oin t ¯ T¯ v = ¯ v , where a fixed p oin t exists if the op erat or is a c ontr action . F or the first moment , the Bellman op erator is known to b e a contractio n [ 30 ]. This result, ho w ev er, do es not immediately extend here b ecause, though t ¯ r t +1 is a v alid finite reward, ¯ γ t +1 does not satisfy ¯ γ t +1 ≤ 1, b ecause ρ 2 t can be large. W e can nonetheless define such a Bellman operator for the ¯ λ -squared-return and determine if a fixed p oin t exists. In terestingly , ¯ γ t +1 can in fact b e larger than 1, and we can still obtain a contraction. T o define the Bellman op erator, w e use a recent generalization that enables the discount to be defined as a function of ( s, a, s 0 ) [ 34 ], rather than just as a function of s 0 . W e first define ¯ v , the exp ected ¯ λ -squared- return ¯ v def = ∞ X t =0 ( ¯ P π,γ ) t ¯ r , where ¯ P π,γ ( s, s 0 ) def = X s,a,s 0 P ( s, a, s 0 ) µ ( s, a ) ρ ( s, a ) 2 γ ( s 0 ) 2 λ ( s 0 ) 2 (3) ¯ r def = X s,a,s 0 P ( s, a, s 0 ) µ ( s, a ) ¯ r ( s, s 0 ) . Using similar equations to the generalized Bellman op erator [ 34 ], w e can define ¯ T¯ v = ∞ X t =0 ( ¯ P π,γ Λ ) t ¯ r + ¯ P π,γ ( I − ¯ Λ ) ¯ v where ¯ Λ ∈ R |S |×|S | is a matrix with ¯ λ ( s ) on the diagonal, for all s ∈ S . The infinite sum is conv ergent if the maxi- m um singular v alue of ¯ P π,γ ¯ Λ is less than 1, giving solution P ∞ t =0 ( ¯ P π,γ ¯ Λ ) t = ( I − ¯ P π,γ ¯ Λ ) − 1 . Otherwise, how ever, the v alue is infinite and one can see that in fact the v ariance of the return is infinite! W e can naturally inv estigate when the second moment of the return is guaranteed to b e finite. This condition on ¯ P π,γ ¯ Λ should facilitate identify ing theoretical conditions on the target and behavior p olicies that enable finite v ariance of the return. This theoretical c haracterization is outside of the scop e of this work, but we can reason ab out differ- en t settings that provid e a well-defined, finite fixed p oin t. First, clearly setting λ t +1 = 0 for every state ensures a finite second moment, given a finite ¯ v , regardless of pol- icy mis-match. F or the on-p olicy setting, where ρ t = 1, ¯ γ t +1 ≤ γ t +1 and so a well-defined fixed point exists, under standard assumptions (see [ 34 ]). F or the off-p olicy setting, if ¯ γ t +1 = λ 2 t +1 γ 2 t +1 ρ 2 t < 1, this is similarly the case. Other- wise, a solution ma y still exist, b y ensuring that the maxi- m um singular v alue of ¯ P π,γ is less than one; w e h yp othesize that this prop ert y is unlikely if there is a large mis-matc h betw een the target and b eha vior policy , causing many large ρ t . An imp ortan t future a ven ue is to understand the re- quired similarit y betw een π and µ to enable finite v ariance of the return, for any giv en λ . Interestingly , the λ -greedy algorithm should adapt to such infinite v ariance settings, where ( 2 ) will set λ t +1 = 0. 5.2 VTD deriv ation In this section, we prop ose V ar-MSPBE, the mean-squared pro jected Bellman error (MSPBE) ob jective for the ¯ λ -squared- return, and derive VTD to optimize this ob jective. Given the definition of the generalized Bellman operator ¯ T , the deriv ation parallels GTD( λ ) for the first moment [ 9 ]. The main difference is in obtaining unbiased estimates of parts of the ob jective; we will therefore fo cus the results on this no v el aspect, summarized in the below tw o theorems and corollary . Define the error of the estimate x > t w sq to the future ¯ λ - squared-return ¯ δ ¯ λ t def = ¯ V ¯ λ t − x > t w sq and, as in previous work [ 24 , 9 ], w e define the MSPBE that corresponds to ¯ T V ar-MSPBE( w sq ) def = E [ ¯ δ ¯ λ t x t ] > E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ] . T o obtain the gradient of the ob jectiv e, we pro ve that w e can obtain an unbiased sample of ¯ δ ¯ λ t x t (a forward view) using a trace of the past (a backw ard view). The equiv alence is simpler if we assume that we hav e access to an estimate of the first moment of the λ -return. F or our setting, we do in fact hav e such an estimate, b ecause w e simultaneously learn w err . W e include the more general exp ectation equiv alence in Theorem 2 , with all proofs in the app endix. Theorem 1. F or a given unbiase d estimate ¯ g t +1 of E [ G λ t +1 | S t +1 ] , define ¯ δ t def = ( ρ 2 t ¯ G 2 t + 2 ρ 2 t γ t +1 λ t +1 ¯ G t ¯ g t +1 ) + ¯ γ t +1 x > t +1 w sq t − x > t w sq t ¯ z t def = x t + ¯ γ t +1 ¯ λ t +1 ¯ z t − 1 Then E [ ¯ δ ¯ λ t x t ] = E [ ¯ δ t ¯ z t ] Theorem 2. E [ ¯ r t +1 ¯ z t ] = E [ ρ 2 t +1 ¯ G 2 t ¯ z t ] + 2 E [ ρ 2 t +1 ¯ G t ( ¯ a t + ¯ B t w t )] wher e ¯ a t def = ρ t γ t λ t ( R t ¯ z t − 1 + ¯ a t − 1 ) ¯ B t def = ρ t γ t λ t ( γ t (1 − λ t ) ¯ z t − 1 x > t + ¯ B t − 1 ) Corollar y 1. F or λ t = 1 for al l t , E [ ¯ r t +1 ¯ z t ] = E [ ρ 2 t R 2 t +1 ¯ z t ] + 2 E [ R t +1 ¯ a t ] wher e ¯ z t = x t + ρ 2 t − 1 γ 2 t ¯ z t − 1 ¯ a t = ρ t γ t ( R t ¯ z t − 1 + ¯ a t − 1 ) . T o derive the VTD algorithm, we take the gradient of the V ar-MSPBE. As this again parallels GTD( λ ), w e include the deriv ation in the app endix for completeness and provide only the final result here. − 1 2 ∇ V ar-MSPBE( w sq ) = E [ ¯ δ ¯ λ t x t ] − E [ ¯ γ t +1 (1 − ¯ λ t +1 ) x t +1 ¯ z > t ] E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ] . As with previous gradient TD algorithms, we will learn an auxiliary set of weigh ts w sq to estimate a part of this ob- jectiv e: E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ]. T o obtain such an estimate, no- tice that h sq = E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ] corresponds to an LMS solution, where the goal is to obtain x > t h sq that estimates E [ ¯ δ ¯ λ t | x t ]. Therefore, we can use an LMS up dat e for h sq , giving the final set of update equations for VTD: ¯ g t +1 ← x > t +1 w err ¯ r t +1 ← ρ 2 t ¯ G 2 t + 2 ρ 2 t γ t +1 λ t +1 ¯ G t ¯ g t +1 ¯ γ t +1 ← ρ 2 t γ 2 t +1 λ 2 t +1 ¯ δ t ← ¯ r t +1 + ¯ γ t +1 x > t +1 w sq t − x > t w sq t w sq t +1 ← w sq t + ¯ α h ¯ δ t ¯ z t − ¯ α h ¯ γ t +1 (1 − ¯ λ t +1 ) x t +1 ¯ z > t h sq t h sq t +1 ← h sq t + ¯ α h ¯ δ t ¯ z t − ¯ α h x > t h sq t x t . F or λ -greedy , we set ¯ λ t +1 = 1, causing the term with the auxiliary weigh ts to b e multiplied by 1 − ¯ λ t +1 , and so re- mo ving the need to appro ximate h sq . 6. RELA TED WORK There has b een a significan t effort to empirically inv esti- gate λ , t ypically using batc h off-line computing and mo del- based techniques. Sutton and Singh [ 25 ] in v estigated tun- ing b oth α and λ . They prop osed three algorithms, the first tw o assume the underlying MDP has no cycles, and the third mak es use of an estimate of the transition probabilities and is thus of most interest in tabular domains. Singh and Da ya n [ 18 ] provided analytical expression for bias and v ari- ance, given the mo del. They suggest that there is a largest feasible step-size α , below whic h bias conv erges to zero and v ariance conv erges to a non-zero v alue, and ab o ve which bias and/or v ariance may diverge. Downey and Sanner [ 3 ] used a Ba y esian v arian t of TD learning, requiring a batc h of sam- ples and off-line computation, but did provide an empirical demonstration off optimally setting λ after obtaining all the samples. Kearns and Singh[ 5 ] compute a bias-v ariance error bound for a mo dification of TD called phased TD. In each discrete phase the algorithm is giv en n tra jectories from each state. Because w e ha v e n tra jectories in eac h state the effec- tiv e learnin g rate is 1 /n removing the complexities of sample a ve raging in the conv entional online TD-up date. The error bounds are useful for, among other things, computing a new λ v alue for each phase which outp erforms any fixed λ v alue, empirically demonstrating the utility of c hanging λ . There has also been a significan t effort to theoretically c haracterizing λ . Most notably , the work of Schapire and W armuth [ 17 ] contributed a finite sample analysis of incre- men tal TD-style algorithms. They analyze a v arian t of TD called TD ? ( λ ), which although still linear and incremen tal, computes v alue estimates quite differen tly . The resulting fi- nite sample bound is particularly interesting, as it do es not rely on mo del assumptions, using only access to a sequence of feature vectors, rewards and returns. Unfortunately , the bound cannot b e analytically minimized to pro duce an op- timal λ v alue. They did simulate their b ound, further veri- fying the in tuition that λ should b e larger if the b est linear predictor is inaccurate, small if accurate and an interme- diate v alue otherwise. Li [ 7 ] later derived similar bounds for another gradient descent algorithm, called residual gra- dien t. This algorithm, how ever, do es not utilize eligibility traces and conv erges to a differen t solution than TD meth- ods when function approximation is used [ 24 ]. Another approach inv olves remo ving the λ parameter al- together, in an effort to impro ve robustness. Konidaris et al. [ 6 ] in tro duced a new TD method called TD γ . Their w ork defines a plausible set of assumptions implicitly made when constructing the λ -returns, and then relaxes one of those assumptions. They deriv e an exact (but computa- tionally exp ensiv e) algorithm, TD γ , that no longer depends on a choice of λ and p erforms well empirically in a v ariety of policy learning b enc hmarks. The incremental appro xi- mation to TD γ also p erforms reasonably well, but app ears to b e somewhat sensitive to the choice of meta parameter C , and often requires large C v alues to obtain go od p erfor- mance. This can b e problematic, as the complexit y gro ws as O ( C n ), where n is the length of the tra jectories—not linearly in the feature vector size. Nonetheless, TD γ con- stitutes a reasonable w ay to reduce parameter sensitivit y in the on-p olicy setting. Garcia and Serre[ 4 ] prop osed a v ari- an t of Q-learning, for which the optimal v alue of λ can b e computed online. Their analysis, how ev er, w as restricted to the tabular case. Finally , Mahmoo d et al. [ 11 ] in tro- duced weigh ted imp ortance sampling for off-p olicy learning; though indirect, this is a strategy for enabling larger λ to b e selected, without destabilizing off-p olicy learning. This related work has help ed shap e our intuition on the role of λ , and, in sp ecial cases, pro vided effective strate- gies for adapting λ . In the next section, we add to existing w ork with an empirical demonstration of λ -greedy , the first λ -adaptation algorithm for off-p olicy , incremental learning, dev eloped from a well-defined, greedy ob jectiv e. 7. EXPERIMENTS W e inv estigate λ -greedy in a ring-worl d, under b oth on and off-p olicy sampling. This ring-w orld was previously in- troduced as a suitable domain for inv estigating λ [ 5 ]. W e v aried the length of the ring-w orld from N = 10 , 25 , 50. The rew ard is zero in every state, except for tw o adjoining states that hav e +1 and -1 reward, and are terminal states. The agen t is teleported back to the middle of the ring-w orld up on termination. The target p olicy is to take action “righ t” with 95% probabilit y , and action “left” with 5% probabilit y . The feature representation is a tabular enco ding of states with binary identit y vectors, but we also examine the effects of aliasing state v alues to simulate p oor generalization: a com- mon case where the true v alue function cannot b e repre- sen ted. The length of the exp erimen t is a function of the problem size, N × 100, proportionally scaling the n umber of samples for longer problem instances. W e compared to fixed v alues of λ = 0 , 0 . 1 , . . . , 0 . 9 , 1 . 0 and to tw o time-decay sc hedules, λ t = 10 / (10 + t ) , λ t = 100 / (100 + t ), whic h work ed well compared to sev eral other tested settings. The discoun t factor is γ = 0 . 99 for the on- policy chai ns and 0.95 for the off-p olicy chains. W e include the optimal λ -greedy , whic h computes w sq and w sq using closed form solutions, defined by their resp ectiv e Bellman operators. F or λ -greedy , the initialization was w sq = 0 . 0 and w err = Rmax 1 − γ × 1 for on-p olicy , to match the rule-of- th um b of ini tializing with high lam b das, and t he opp osite for off-policy , to match the rule-of-th umb of more caution in off- policy domains. This max return v alue is a common c hoice for optimistic initialization, and preven ted inadv ertent ev al- uator bias by ov erly tuning this parameter. W e fixed the learning-rate parameter for λ -greedy to b e equal to equal to α used in learning the v alue function ( w ), again to demon- strate p erformance in less than ideal settings. Sw eeping the step-size for λ -greedy w ould improv e p erformance. The performance results in on and off-p olicy are sum- marized in Figure 1 and 2 . W e rep ort the absolute v alue error compared to the true v alue function, which is com- putable in this domain for eac h of the settings. W e av erage o ver 100 runs, and rep ort the results for the b est param- eter settings for eac h of the algorithms with 12 v alues of α ∈ { 0 . 1 × 2 j | j = − 6 , − 6 , ..., 5 , 6 } , 11 v alues of η ∈ { 2 j | j = − 16 , − 8 , − 4 , . . . , 4 , 8 , 16 } ( α h = αη ). In general, w e find that λ -greedy works well across set- tings. The optimal λ -greedy consisten tly performs the b est, indicating the merit of the ob jective. Estimating w sq and w sq t ypically cause λ -greedy to p erform more p oorly , indi- cating an opp ortun ity to impro ve these algorithms to matc h the performance of the optimal, idealistic version. In partic- ular, we did not optimize the meta-parameters in λ -greedy . F or the fixed v alues of λ and decay schedules, we find that they can b e effective for sp ecific instances, but do not p er- form well across problem settings. In particular, the fixed deca y schedules settings appear to be un-robust to an in- creasing chain length and the fixed λ are not robust to the c hange from on-policy to off-p olicy . W e also examined the λ v alue selected b y our λ -greedy al- gorithm plotted ag ainst time. F or tabular features, λ should con v erge to zero ov er-time, since the v alue function can b e appro ximated and so, at some p oin t, no bias is int ro duced b y using λ t = 0, but v ariance is reduced. The algorithm does conv erge to a state-based λ ( λ ( s ) ≈ 0 for all states), whic h was one of our goals to ensure we hav e a w ell-defined fixed p oin t. Second, for aliased features, we exp ect that the final p er-state λ should b e larger for the states that ha ve been aliased. The in tuition is that one should not b oot- strap on the v alues of these states, as that introduces bias. W e demonstrate that this does indeed o ccur, in Figure 3 . As exp ected, the λ -greedy is more robust to state aliasing, compared to the fixed strategies. State aliasing pro vides a concrete example of when we hav e less confidence in ˆ v in specific states, and an effective strategy to mitigate this sit- uation is to set λ high in those states. 8. CONCLUSION AND DISCUSSION In this pap er, w e ha ve prop osed the first linear-complexity λ adaptation algorithm for incremental, off-p olicy reinforce- men t learning. W e proposed an ob jectiv e to greedily trade- off bias and v ariance, and derived an efficien t algorithm to obtain the solution to this ob jectiv e. W e demonstrate the ef- ficacy of the approach in an on-p olicy and off-policy setting, v ersus fixed v alues of λ and time-deca y heuristics. This work op ens up many av enues for efficiently selecting λ , by providing a concrete greedy ob jectiv e. One imp ortan t direction is to extend the ab o ve analysis to use the recently in troduced true-online traces [ 32 ]; here w e focused on the more well-understood λ -return, but the proposed ob jective is not restricted to that setting. There are also numerous future directions for improving optimization of this ob jec- tiv e. W e used GTD( λ = 1) to learn the second moment of the λ -return inside λ -greedy . Another p ossible direction is to simply explore using λ < 1 or even least-squares methods to impro v e estimation inside λ -greedy . There are also opportunities to mo dify the ob jectiv e to consider v ariance into the future differently . The curren t ob jectiv e is highly cautious, in that it assumes that only λ t +1 can b e mo dified, and assumes the agen t will b e forced to use the un biased λ t + i = 1 for all future time steps. As a consequence, the algorithm will often prefer to set λ t +1 small, as future v ariance can only b e controlled b y the set- ting of λ t +1 . A natural relaxation of this strictly greedy setting is to recognize that the agen t, in fact, has cont rol o ve r all future λ t + i , i > 1. The agen t could remain cautious for some num b er of steps, assuming λ t + i will likely b e high for 1 < i ≤ k for some horizon k . Ho wev er, we can assume that after k steps, λ t + i w e b e reduced to a small v alue, cut- ting off the traces and mitigating the v ariance. The horizon k could b e encoded with an aggressive discoun t; m ultiplying the curren t discoun t ¯ γ t +1 b y a v alue less than 1. Com- monly , a multiplicativ e factor less than 1 indicates a horizon of 1 1 − factor ; for example, 1 1 − 0 . 8 = 5 gives a horizon of k = 5. The v ariance term in the ob jectiv e in ( 2 ) could b e mo dified to include this horizon, providing a metho d to incorp orate the lev el of caution. Ov erall, this w ork tak es a small step tow ard the goal of au- tomatically selecting the trace parameter, and thus one step closer tow ard parameter-free black-bo x application of rein- forcemen t learning with man y av enues for future researc h. Ac kno wledgements W e would lik e to thank David Silver for helpful discussions and the reviewers for helpful comments. Error 10 100 1000 0 2 4 6 8 λ -greedy optimal λ -greedy λ =0 λ =1 λ =100/(100+t) λ =10/(10+t) 10 100 1000 0 1 2 3 10 100 1000 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 λ v alue 0 1000 2000 3000 4000 5000 0 0.2 0.4 0.6 0.8 1 0 1000 2000 3000 4000 5000 0 0.2 0.4 0.6 0.8 1 0 1000 2000 3000 4000 5000 0 0.2 0.4 0.6 0.8 1 Chain 10 Chain 25 Chain 50 Figure 1: On-policy learning p erformance of GTD( λ ) with different methods of adapting λ , for three sizes in the ringw orld domain. The first row of results plots the mean squared v alue error v erses time for several approaches to adapting λ : the optimal λ -greedy algorithm, our appro ximation algorithm, sev eral fixed v alues of λ , and tw o fixed deca y schedule s. The second ro w of results plots the λ v alues o ver-time used by each algorithm. W e highligh t early learning by taking the log of y axis, as the algorithms should b e able to exploit the lo w v ariance to learn quickly . F or off-p olicy learning, there is more v ariance due to imp ortance sampling and so w e prefer long-term stability . W e therefore highlight later learning using the log of the x-axis. Error 1000 2000 3000 4000 0.01 0.1 1 0 1000 2000 3000 4000 0.01 0.1 1 λ v alue 0 1000 2000 3000 4000 5000 0 0.2 0.4 0.6 0.8 1 0 1000 2000 3000 4000 0 0.2 0.4 0.6 0.8 1 π ( s, righ t) = 0 . 95 , µ ( s, righ t) = 0 . 85 π ( s, righ t) = 0 . 95 , µ ( s, righ t) = 0 . 75 Figure 2: Off-p olicy learning p erformanc e of GTD( λ ) with differen t methods of adapting λ , for tw o different configurations of π and µ in the size 10 ringw orld domain. The first row of results plots the mean squared v alue error verses time for sev eral approac hes to adapting λ . In off-p olicy learning, there is more v ariance due to importance sampling and so we prefer long-term stability . W e therefore highligh t later learning using the log of the x-axis. The second row of results plots the λ v alues o ver- time used b y eac h algorithm. 10 100 0 0.5 1 1.5 2 4 6 8 0 0.2 0.4 0.6 0.8 1 Figure 3: A closer examina- tion of the effects of state alias- ing on the choice of state-based λ , for the length 10 chain with γ = 0 . 95, under on-p olicy sam- pling. State three is aliased with the last state. The left graph shows the learning curv es o ve r 5000 steps, and the righ t graph shows the learned λ func- tion in each state at the end of the run. REFERENCES [1] P . L. A and M. Ghav amzadeh. Actor-Critic algorithms for risk-sensitiv e MDPs. In A dvanc es in Neura l Information Pr oc essing Systems , 2013. [2] W. Dabney and A. G. Barto. Adaptive step-size for online temporal difference learning. In AAAI , 2012. [3] C. Downey and S. Sanner. T emporal difference Ba y esian model av eraging: A Bay esian p erspective on adapting lam b da. In International Confer enc e on Machine L e arning , 2010. [4] F. Garcia and F. Serre. F rom Q(lambda) to Average Q-learning: Efficient Implementation of an Asymptotic Appro ximation. In International Joint Confer enc e on Artificial Intel ligenc e , 2001. [5] M. J. Kearns and S. P . Singh. Bias-V ariance error bounds for temp oral difference updates. In Annual Confer enc e on L e arning The ory , 2000. [6] G. Konidaris, S. Niekum, and P . S. Thomas. TDgamma: Re-ev aluating Complex Backups in T emp oral Difference Learning. In NIPS , 2011. [7] L. Li. A worst-case comparison b et ween temporal difference and residual gradien t with linear function appro ximation. In International Confer enc e on Machine L e arning , 2008. [8] L.-J. Lin. Self-Improving Reactive Agen ts Based On Reinforcemen t Learning, Planning and T eaching. Machine L e arning , 1992. [9] H. Maei. Gr adient T emp or al-Differ enc e L ear ning Algo rithms . PhD thesis, Univ ersity of Alberta, 2011. [10] H. Maei and R. Sutton. GQ ( λ ): A general gradient algorithm for temporal-difference prediction learning with eligibilit y traces. In AGI , 2010. [11] A. R. Mahmo od, H. P . v an Hasselt, and R. S. Sutton. W eighted imp ortance sampling for off-p olicy learning with linear function appro ximation. In A dvanc es in Neur al Information Pr oc essing Systems , 2014. [12] S. Mannor, D. Simester, P . Sun, and J. N. Tsitsiklis. Bias and v ariance in v alue function estimation. In International Confer enc e on Machine L e arning , 2004. [13] S. Mannor and J. N. Tsitsiklis. Mean-V ariance pptimization in Mark ov Decision Processes. In ICML , 2011. [14] J. Mo da yil, A. White, and R. S. Sutton. Multi-timescale nexting in a reinforcemen t learning robot. A daptive Behavior - Animals, Animats, Softwar e A gents, R ob ots, A daptive Systems , 2014. [15] T. Morimura, M. Sugiyama, H. Kashima, H. Hac hiya, and T. T anak a. Parame tric return densit y estimation for reinforcemen t learning. In Confer ence on Unc ertainty in Artificial Intel ligenc e , 2010. [16] A. L. Samuel. Some studies in machine learning using the game of c hec k ers. IBM Journal of R ese ar ch and Development () , 1959. [17] R. E. Schapire and M. K. W arm uth. On the w orst-case analysis of temporal-difference learning algorithms. Machine L ea rning , 1996. [18] S. P . Singh and P . Day an. Analytical mean squared error curv es in temporal difference learning. In A dvanc es in Neur al Information Pr o c essing Systems , 1996. [19] S. P . Singh and R. S. Sutton. Reinforcement learning with replacing eligibilit y traces. Machine L e arning , 1996. [20] M. J. Sob el. The v ariance of discounted Marko v Decision Processes. Journal of Applie d Pr ob ability , 1982. [21] R. Sutton. Learning to predict by the metho ds of temporal differences. Machine L e arning , 1988. [22] R. Sutton. TD mo dels: Mo deling the world at a mixture of time scales. In International Confer enc e on Machine L e arning , 1995. [23] R. Sutton and A. G. Barto. Intr o duction to r einfor c ement le arning . MIT Press, 1998. [24] R. Sutton, H. Maei, D. Precup, and S. Bhatnagar. F ast gradien t-descen t methods for temp oral-difference learning with linear function appro ximation. International Confer enc e on Machine L e arning , 2009. [25] R. Sutton and S. P . Singh. On step-size and bias in temporal-difference learning. In Pr o ce e dings of the Eighth Y ale Workshop on A daptive and L e arning Systems , 1994. [26] R. S. Sutton, A. R. Mahmo od, and M. White. An emphatic approac h to the problem of off-p olicy temporal-difference learning. The Journal of Machine L e arning R ese ar ch , 2015. [27] R. S. Sutton, D. Precup, and S. Singh. Bet ween MDPs and semi-MDPs: A framework for temp oral abstraction in reinforcemen t learning. Artificial intel ligenc e , 1999. [28] A. T amar, D. Di Castro, and S. Mannor. T emp oral difference methods for the v ariance of the reward to go. In International Confer enc e on Machine L e arning , 2013. [29] G. T esauro. Practical issues in temp oral difference learning. Machine L ear ning , 1992. [30] J. N. Tsitsiklis and B. V an Roy . An analysis of temporal-difference learning with function appro ximation. A utomatic Contr ol, IEEE T r ansactions on , 42(5):674–690, 1997. [31] H. v an Hasselt, A. R. Mahmo od, and R. Sutton. Off-policy TD ( λ ) with a true online equiv alence. In Confer enc e on Unc ertainty in A rtificial Intel ligenc e , 2014. [32] H. v an Seijen and R. Sutton. T rue online TD(lambda). In International Confer enc e on Machine L e arning , 2014. [33] A. White. Developing a pr e dictive appr o ach to know le dge . PhD thesis, Univ ersit y of Alberta, 2015. [34] M. White. T ransition-based discounting in Marko v decision processes. In pr ep ar ation , 2016. [35] M. White and A. White. Interv al estimation for reinforcemen t-learning algorithms in contin uous-state domains. In A dvanc es in Neura l Information Pr o c essing Systems , 2010. APPENDIX Recall that for squared return ( G λ t ) 2 , we use ¯ V ¯ λ t to indicate the ¯ λ -squared-return. ¯ V ¯ λ t def = ¯ r t +1 + ¯ γ t +1 (1 − ¯ λ t +1 ) x > t +1 w sq + ¯ λ t +1 ¯ V ¯ λ t +1 ¯ δ ¯ λ t def = ¯ V ¯ λ t − x > t w sq ¯ δ t def = ¯ r t +1 + ¯ γ t +1 x > t +1 w sq − x > t w sq ¯ r t +1 def = ρ 2 t ¯ G 2 t + 2 ρ 2 t γ t +1 λ t +1 ¯ G t G λ t +1 ¯ γ t +1 def = ρ 2 t γ 2 t +1 λ 2 t +1 ¯ G t def = R t +1 + γ t +1 (1 − λ t +1 ) x > t +1 w . If ¯ λ = 1, then ¯ V ¯ λ t = ( G λ t ) 2 . Note that the weigh ts w in ¯ G t are the weigh ts for the main estimator that defines the λ -return, not the weigh ts w sq that estimate the second mo- men t of the λ -return. Theorem 1 F or a given ¯ λ : S → [0 , 1], E [ ¯ δ ¯ λ t x t ] = E [ ¯ δ t ¯ z t ] where ¯ z t def = x t + ¯ γ t ¯ λ t ¯ z t − 1 Pro of: As in other TD a lgorithms [ 9 ], w e use index shifting to obtain an unbiased estimate of future v alues using traces. ¯ V ¯ λ t = ¯ r t +1 + ¯ γ t +1 (1 − ¯ λ t +1 ) x > t +1 w sq + ¯ λ t +1 ¯ V ¯ λ t +1 = ¯ r t +1 + ¯ γ t +1 x > t +1 w sq − ¯ γ t +1 ¯ λ t +1 x > t +1 w sq + ¯ γ t +1 ¯ λ t +1 ¯ V ¯ λ t +1 = ¯ r t +1 + ¯ γ t +1 x > t +1 w sq + ¯ γ t +1 ¯ λ t +1 ¯ δ ¯ λ t +1 = ¯ r t +1 + ¯ γ t +1 x > t +1 w sq + ¯ γ t +1 ¯ λ t +1 ¯ δ ¯ λ t +1 Therefore, for ¯ δ t = ¯ r t +1 + ¯ γ t +1 x > t +1 w sq − x > t w sq , E [ ¯ δ ¯ λ t x t ] = E [( ¯ V ¯ λ t − x > t w sq ) x t ] = E [( ¯ δ t + ¯ γ t +1 ¯ λ t +1 ¯ δ ¯ λ t +1 ) x t ] = E [ ¯ δ t x t ] + E [ ¯ γ t ¯ λ t ¯ δ ¯ λ t x t − 1 ] = E [ ¯ δ t x t ] + E [ ¯ γ t ¯ λ t ( ¯ δ t + ¯ γ t +1 ¯ λ t +1 ¯ δ ¯ λ t +1 ) x t − 1 ] = E [ ¯ δ t ( x t + ¯ γ t ¯ λ t x t − 1 )] + E [ ¯ γ t ¯ λ t ¯ γ t +1 ¯ λ t +1 ¯ δ ¯ λ t +1 x t − 1 ] = E [ ¯ δ t ( x t + ¯ γ t ¯ λ t x t − 1 )] + E [ ¯ γ t − 1 ¯ λ t − 1 ¯ γ t ¯ λ t ¯ δ ¯ λ t x t − 2 ] = . . . = E [ ¯ δ t ¯ z t ] T o enable the abov e recursive form, we need to ensure that ¯ r t +1 is computable on each step, given S t , S t +1 . W e c haracterize the expectation of ¯ r t +1 , using the current un- biased estimate x > t w err of E [ G λ t +1 | S t +1 ], providing a wa y to obtain an un biased sample of ¯ r t +1 on eac h step. Proposition 1. E [ ¯ r t +1 | S t , S t +1 ] = E [ ρ 2 t ¯ G 2 t | S t , S t +1 ] + 2 E [ ρ 2 t γ t +1 λ t +1 ¯ G t | S t , S t +1 ] E [ G λ t +1 | S t +1 ] Pro of: E [ ¯ r t +1 | S t , S t +1 ] = E [ ρ 2 t ¯ G 2 t + 2 ρ 2 t γ t +1 λ t +1 ¯ G t G λ t +1 | S t , S t +1 ] = E [ ρ 2 t ¯ G 2 t | S t , S t +1 ] + 2 E [ ρ 2 t γ t +1 λ t +1 | S t , S t +1 ] E [ ¯ G t G λ t +1 | S t , S t +1 ] No w b ecause we assumed indep enden t, zero-mean noise in the reward, i.e. R t +1 = E [ R t +1 | S t , S t +1 ] + t +1 for indep en- den t zero-mean noise t +1 , b ecause we assume that x t +1 is completely determined b y S t +1 and because E [ G λ t +1 | S t , S t +1 ] = E [ G λ t +1 | S t +1 ], w e obtain E [ ¯ G t G λ t +1 | S t +1 ] = E [( R t +1 + γ t +1 (1 − λ t +1 ) x > t +1 w ) G λ t +1 | S t , S t +1 ] = E [ R t +1 | S t , S t +1 ] E [ G λ t +1 | S t +1 ] + E [ γ t +1 (1 − λ t +1 ) x > t +1 w | S t , S t +1 ] E [ G λ t +1 | S t +1 ] completing the proof. This previous result requires that ¯ r t +1 can be given to the algorithm on each step. The result in Theorem 1 requires an an estimate of E [ G λ t +1 | S t +1 ], to define the rew ard; such an estimate, how ever, may not alwa ys b e av ailable. W e char- acterize the exp ectation E [ ¯ δ ¯ λ t x t ] in the next theorem, when suc h an estimate is not pro vided. F or general trace functions λ , this estimate requires a matrix to b e stored and up dated; ho w ever, for λ = 1 as addressed in this work, Corollary ?? indicates that this simplifies to a linear-space and time al- gorithm. Theorem 2 E [ ¯ r t +1 ¯ z t ] = E [ ρ 2 t +1 ¯ G 2 t ¯ z t ] + 2 E [ ρ 2 t +1 ¯ G t ( ¯ a t + ¯ B t w t )] where ¯ a t def = ρ t γ t λ t ( R t ¯ z t − 1 + ¯ a t − 1 ) ¯ B t def = ρ t γ t λ t ( γ t (1 − λ t ) ¯ z t − 1 x > t + ¯ B t − 1 ) Pro of: E [ ¯ r t +1 ¯ z t ] = E [ ρ 2 t ¯ G 2 t ¯ z t ] + 2 E [ ρ 2 t γ t +1 λ t +1 ¯ G t G λ t +1 ¯ z t ] No w let us lo ok at this second term which still contains G λ t . E [ γ t λ t G λ t ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 ] = E [ ρ t γ t λ t ( ¯ G t + γ t +1 λ t +1 G λ t +1 ) ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 ] = E [ ρ t γ t λ t ¯ G t ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 ] + E [ ρ t − 1 γ t − 1 λ t − 1 γ t λ t G λ t ¯ G t − 2 ρ 2 t − 2 ¯ z t − 2 ] = E [ ρ t γ t λ t ¯ G t ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 ] + E [ ρ t γ t λ t ρ t − 1 γ t − 1 λ t − 1 ( ¯ G t + γ t +1 λ t +1 G λ t +1 ) ¯ G t − 2 ρ 2 t − 2 ¯ z t − 2 ] = E [ ρ t γ t λ t ¯ G t ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 ] + E [ ρ t γ t λ t ρ t − 1 γ t − 1 λ t − 1 ¯ G t ¯ G t − 2 ρ 2 t − 2 ¯ z t − 2 ] + E [ ρ t − 1 γ t − 1 λ t − 1 ρ t − 2 γ t − 2 λ t − 2 γ t λ t G λ t ¯ G t − 3 ρ 2 t − 3 ¯ z t − 3 ] = . . . = E [ ρ t γ t λ t ¯ G t ( ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 + ρ t − 1 γ t − 1 λ t − 1 ¯ G t − 2 ρ 2 t − 2 ¯ z t − 2 + . . . )] . Eac h ¯ G t − i in to the past should use the current (given) weigh t v ector w , to get the current v alue estimates in the return. Therefore, instead of keeping a trace of ¯ G t − i = r t − i +1 + γ t − i +1 (1 − λ t − i +1 ) x > t − i +1 w t − i +1 , we will keep a trace of fea- ture v ectors and a trace of the rew ard ¯ a t = ρ t γ t λ t ( r t ρ 2 t − 1 ¯ z t − 1 + ¯ a t − 1 ) ¯ B t = ρ t γ t λ t ( γ t (1 − λ t ) ρ 2 t − 1 ¯ z t − 1 x > t + ¯ B t − 1 ) . Because ¯ B t w = ρ t γ t λ t ( γ t (1 − λ t ) ¯ z t − 1 x > t w + ¯ B t − 1 w ) w e get ¯ a t + ¯ B t w = ρ t γ t λ t ( ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 + ρ t − 1 γ t − 1 λ t − 1 ¯ G t − 2 ρ 2 t − 2 ¯ z t − 2 + . . . ) giving E [ γ t λ t G λ t ¯ G t − 1 ρ 2 t − 1 ¯ z t − 1 ] = E [ ¯ G t ( ¯ a t + ¯ B t w )] . Finally , we can put this all together to get E [ ¯ r t +1 ¯ z t ] = E [ ρ 2 t ¯ G 2 t ¯ z t ] + 2 E [ ρ 2 t γ t +1 λ t +1 ¯ G t G λ t +1 ¯ z t ] = E [ ρ 2 t ¯ G 2 t ¯ z t ] + 2 E [ ρ 2 t − 1 γ t λ t ¯ G t − 1 G λ t ¯ z t − 1 ] = E [ ρ 2 t ¯ G 2 t ¯ z t ] + 2 E [ ¯ G t ( ¯ a t + ¯ B t w )] Remark: One can derive that E [( G λ t ) 2 x t ] = E [ ¯ r t +1 ¯ z t ]; this pro vides a w a y to use an LMS update rule for the ab o v e, without b ootstrapping and corresp onds to minimizing the mean-squared error using samples of returns. How ever, as has previously b een observ ed, we found this performed more po orly than using bo otstrapping. Deriv ation of the gradient of VTD 1 2 ∇ V ar-MSPBE( w sq ) = 1 2 ∇ ( E [ ¯ δ ¯ λ t x t ] > E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ]) = ∇ E [ ¯ δ ¯ λ t x t ] > ( E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ]) . First w e c haracterize this gradien t ∇ E [ ¯ δ ¯ λ t x t ] > . ∇ E [ ¯ δ ¯ λ t x t ] > = ∇ E [ ¯ δ t ¯ z t ] = E [( ¯ γ t +1 x t +1 − x t ) ¯ z > t ] . This product can b e simplified using E [ x t ¯ z > t ] = E [ x t ( x t + ¯ γ t ¯ λ t ¯ z t − 1 ) > ] = E [ x t x > t ] + E [ x t +1 ¯ γ t +1 ¯ λ t +1 ¯ z > t ] = E [ x t x > t ] + E [ ¯ γ t +1 ¯ λ t +1 x t +1 ¯ z > t ] giving ∇ E [ ¯ δ ¯ λ t x t ] > = E [ ¯ γ t +1 (1 − ¯ λ t +1 ) x t +1 ¯ z > t ] − E [ x t x > t ] . Therefore, the gradien t reduces to − 1 2 ∇ V ar-MSPBE( w sq ) = ( E [ x t x > t ] − E [ ¯ γ t +1 (1 − ¯ λ t +1 ) x t +1 ¯ z > t ])( E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ]) = E [ ¯ δ ¯ λ t x t ] − E [ ¯ γ t +1 (1 − ¯ λ t +1 ) x t +1 ¯ z > t ] E [ x t x t ] − 1 E [ ¯ δ ¯ λ t x t ] .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment