Non-linear Label Ranking for Large-scale Prediction of Long-Term User Interests
We consider the problem of personalization of online services from the viewpoint of ad targeting, where we seek to find the best ad categories to be shown to each user, resulting in improved user experience and increased advertisers' revenue. We prop…
Authors: Nemanja Djuric, Mihajlo Grbovic, Vladan Radosavljevic
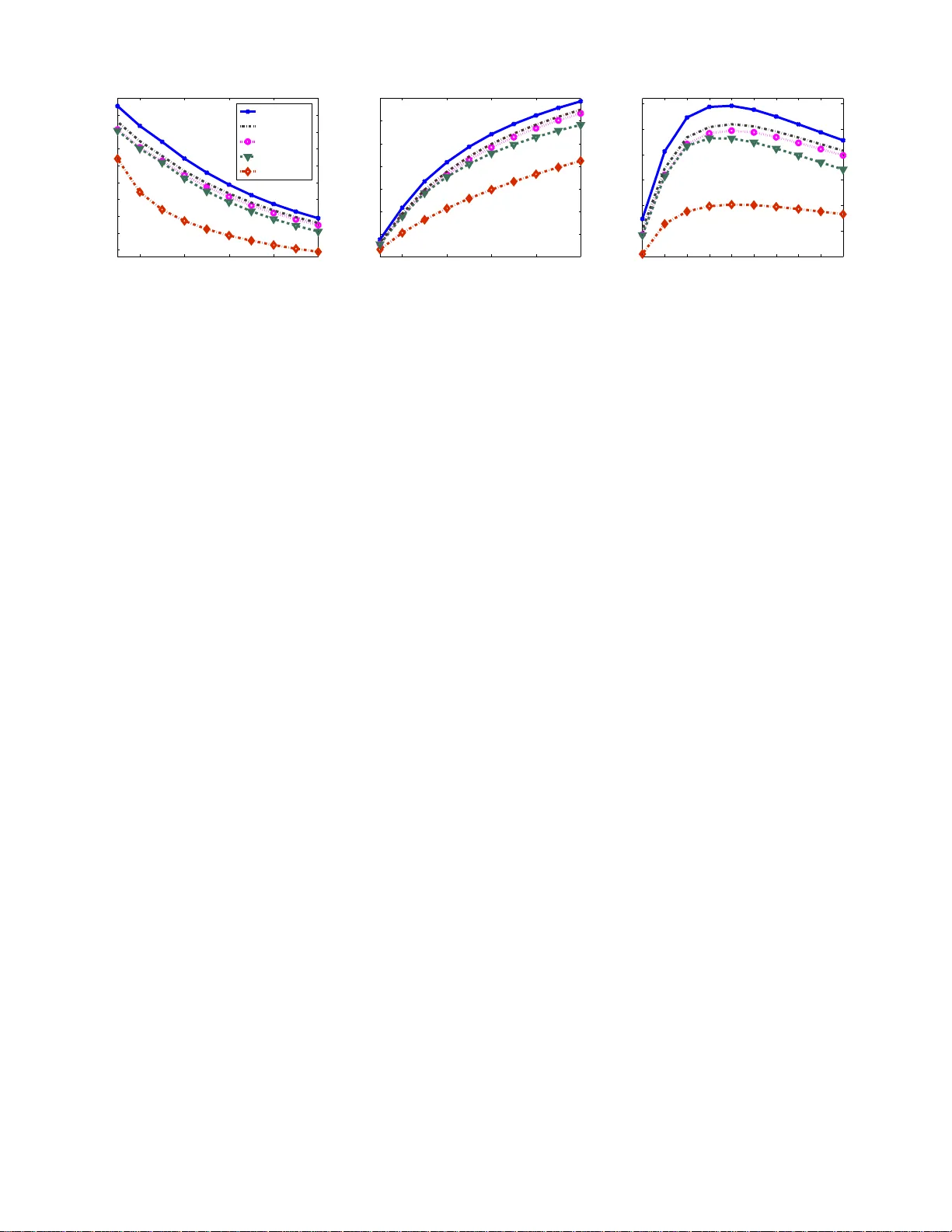
Non-linear Label Ranking f or Large-scale Pr ediction of Long-T erm User Inter ests Nemanja Djuric † , Mihajlo Grbovic † , Vladan Radosavlje vic † , Narayan Bhamidipati † , Slobodan V ucetic ‡ † Y ahoo! Labs, Sunnyvale, CA, USA, { nem anja, mihajlo, vladan, narayanb } @yaho o-inc.c om ‡ T emple Uni versity , Philadelphia, P A, USA, vucetic@temple.e du Abstract W e c onsider the problem of p ersonalization of o nline services from the vie wpoint of ad targeting, where we seek to find the best ad categories t o be shown to each user , resulting in improv ed use r e xperience an d increased advertisers’ re v enue. W e propose to address this pro blem as a task of ranking the ad categ ories de pending on a user’ s preferenc e, and introduce a nov el label ranking approach capable of ef ficiently learn- ing non -linear , highly accurate models in large-scale settings. Experiments o n a real-world advertising da ta set with more than 3 . 2 million users show that the propose d algorithm out- performs the e xisting solutions in t erms of bo th rank loss and top- K retrie va l performance, strong ly suggesting the benefit of using the proposed model on lar ge-scale ranking pro blems. Intr oduction Personalization of online con tent has become an impor- tant topic in the recent years. It has been defined as ”the ability to p roactively tailor produ cts an d produ ct purcha sing experiences to tastes o f individual consu mers based u pon their person al and p referenc e informatio n” (Chellappa and Sin 2005), which may l ead to improved user experience and directly tran slate in to finan cial gains for online businesses (Riecken 2000). In ad dition, persona l- ization fosters stron ger bond between users and com pa- nies, and can h elp in increasing user loyalty and retention (Alba et al. 1997). For these reasons it has been reco gnized as an impo rtant strategic goal of major inter net companies (Manber, Patel, and Robison 2000; Das et al. 2007), and is a foc us o f significant resear ch efforts. Perso nalized con- tent has already becom e an integral part of many popu- lar online ser vices, a tr end likely to continue in the futu re (T uzhilin 2009). W e consider co ntent personalization fr om the viewpoint of targeted advertising (Essex 20 09), an increasingly imp or- tant aspect of o nline businesses. Here, for each in dividual user t he task is to find the best matching ads to be displayed , which improves user’ s on line experience (as only relev ant and interesting ads are shown to the user) and can lead to in- creased revenue for the advertisers (as users ar e more likely to click on the ad and make a purcha se). Due to its large im- pact and many open research questions, tar geted advertising Copyrigh t c 2021, Association for the Adv ancement of Artificial Intelligence (www .aaai.org). All rights reserved. has garnered significant interest from the machine lea rning commun ity , as witne ssed by a large numbe r of recent work- shops an d publicatio ns (Broder 2008; Pandey et al. 2 011; Majumder and Shriv asta va 2013). One of the most po pular approach es in pr esent-day target- ing, par ticularly in bra nd awareness campaign s, is to assign categories to the display ad s, such a s ”sports” o r ”finan ce”, and t hen separately lear n to p redict user interest in each of these categories using historical recor ds (Ah med et al. 2011; Pandey et al. 2011; T yler et al. 20 11). T ypic ally , a taxo nomy is used to decide on the c ategories, and depending on how detailed it is hund reds of sep arate categor y qualification tasks may need to be solved. Thu s, fo r each ad category , a separate p redictive m odel is train ed, able to estimate the probab ility of an ad click for the entire user p opulation . Then, for each category , N users with the high est click p rob- ability are selected for ad expo sure. Known issues with the approa ch include overexposure, wh ere a single user may b e among the to p N users fo r many categor ies, and starvation, where some users do not qualify for any of the cate gories. An alternative a venue, k nown in the indu stry as a user- interest model, is to sort for each user outputs of the p re- dictiv e models, and qualify users based on their top K cate- gories. The appro ach guarantees tha t a user is qualified into se veral cate gories, eliminating o verexposure and starvation issues. Ho we ver , this method may still be sub optimal, as the predictive models are trained in isolation and do no t c onsider relationships b etween d ifferent categories. In this pa per we explore metho ds capable of capturing more c omplex class depend encies, and consider the u ser-interest model fr om a label r anking standpoin t (V embu and G ¨ artner 201 1). How- ev er , the sheer scale of ad targeting problems, with data sets comprising millions o f users an d features an d hund reds of categories, rend ers many e xisting label rank ing a pproac hes intractable, presenting new challen ges to the researchers. T o ad dress th is issue, we prop ose a n ovel label ran k- ing algorithm suitable for large-scale settings. The metho d lends ideas from the state-of-the- art AMM classifiers (W ang et al. 20 11), ef ficiently learning accur ate, non-linear models on limited r esources. Empirica l ev aluation was per- formed in a real-world ad targeting setting, using, to the best of our kno wledge, th e largest dataset considered th us far in the label r anking lit erature. The results sh ow that the algo- rithm significantly outperfor med the existing methods, indi- cating the benefits of the proposed appr oach to label ranking tasks. Backgr ound In this section we present works a nd ideas that led to the pro- posed algo rithm. W e first discuss label r anking setting, and then descr ibe Adaptive Multi-hyper plane Machine (AMM), a non-lin ear , multi-class mod el used to d evelop a novel large-scale label ranking approach introduced in this paper . Label ranking Unlike standard machine learnin g problems such as m ulti- class or m ulti-label classification, label ra nking is a rela- ti vely n ovel to pic wh ich inv olves a complex task of label preferen ce learning . More specifically , rather th an pr edicting one or m ore class labels for a ne wly observed example, we seek to find a strict rankin g of classes by their importance or relev ance to the giv en e xample. F or instance, let us con sider targeted ad vertising domain , an d assume that the e xamples are in ternet users and class labels are u ser pr eference s from the set Y = { ”spo rts”, ”travel”, ”finance” } . Then , instead of simply in ferring tha t the u ser is a ”spo rts” per son, which would result in user being shown o nly spor ts-related ads, it is more inform ativ e to know that the user prefer s sports ov er finance over travel, resulting in more div erse an d more effec- ti ve ad tar geting. Note that the label ranking pr oblem dif fers from the learnin g-to-ran k setup (Cao et al. 2007), wher e the task is to rank the exam ples and not labels, an d can also be seen as a generalization of class ification and multi-label problem s (Dekel, Mannin g, and Singer 2003). More formally , in the lab el ranking scenario th e input is defined by a feature vector x ∈ X ⊂ R d , and the o utput is d efined by a ranking π ∈ Π of class lab els. Here, the la- bels originate from a predefin ed set Y = { 1 , 2 , . . . , L } (e.g. , π = [3 , 1 , 4 , 2] for L = 4 ), and Π is a set of all label permu- tations. Let u s denote by π i a class label at the i th position in the label ranking π , and by π − 1 i a p osition (or rank) of label i in the ranking π . For instance, in the above example we would have π 1 = 3 and π − 1 1 = 2 . Then , fo r any i and j , wh ere 0 ≤ i < j ≤ L , we say that label π i is p r eferr ed over label π j , or equ iv alently π i ≻ π j . Mor eover , in th e case of an inco mplete or der π , we say that any lab el i ∈ π is p referred over the missing ones. Further, let us assume that we are given a samp le fr om the u nderlyin g distribution D = { ( x t , π t ) , t = 1 , ..., T } , wh ere π t is a vecto r contain - ing either a total or a p artial ord er of class labels Y . Th e learning go al is to find a mo del f th at map s inp ut examples x into a total order ing of labels, f : X → Π . In the recent year s the p roblem ha s seen increased attention by the machine learning commun ity (e. g., see recent workshops and tutoria ls at ICML, NIPS, and other venues), and many effecti ve alg orithms have been proposed in the literatur e (Har -Peled, Roth, and Zimak 2003; Dekel, Manning, and Singer 2003; Kamishima and Akaho 2006; Cheng, H ¨ uhn, and H ¨ ullermeier 2009; Grbovic, Djuric, and V ucetic 2013); for an e x- cellent revie w s ee (V embu and G ¨ artn er 2011). In (Cheng, H ¨ uhn, and H ¨ ullermeier 2009; Cheng, Dembczy ´ nski, and H ¨ ullermeier 2010) authors propo se instance-based methods for label rank ing, where train ing examples are first clustered ac cording to their feature vectors, and then centro id and m ean ranking are fou nd for each c luster and u sed for infer- ence. Th is idea was extend ed in (Grb ovic et al. 201 3; Grbovic, Djuric, an d V u cetic 2013), wher e authors use f ea- ture vectors to supervise clu stering, resu lting in imp roved perfor mance. Apart f rom the p rototyp e-based meth ods, often con sidered appro aches includ e learning a scorin g func- tion g i for each class, i = 1 , . . . , L , and sor ting their output in order to infer labe l r anking ( Elisseeff and W eston 2001; Dekel, Manning, and Singer 2003; Har-Peled, R oth, and Zimak 2003), or training a number of binary classification models to predict pairwise label preferen ces and aggregating their output into a total ord er (H ¨ ullermeier et al. 2008; H ¨ ullermeier and V anderlo oy 20 10). Adaptiv e Multi-hyper plane Machine The AMM algorithm is a budgeted, multi-class method suitable for large-scale problem s (W ang et al. 2011; Djuric et al. 2014). It is an SVM-like algor ithm that for- mulates a non-linear model by assigning a numb er of linear hyper planes to each class in ord er to captur e data non-lin earity . Gi ven a d -dimen sional example x an d a set Y of L possible classes, AMM has the following fo rm, f ( x ) = arg ma x i ∈Y g ( i, x ) , (1) where the scoring function g ( i, x ) fo r the i th class, g ( i, x ) = max j w T i,j x , (2) is parameterize d by a weigh t matrix W written as W = w 1 , 1 . . . w 1 ,b 1 | w 2 , 1 . . . w 2 ,b 2 | . . . | w L, 1 . . . w L,b L , (3) where b 1 , . . . , b L are the numbers of weig hts (i.e., hyp er- planes) assigned to each of the L classes, and each block in (3) is a set o f class-spec ific weights. Thu s, fro m ( 1) we can see that the pred icted la bel of the examp le x is th e class of the weight vector tha t achieves the maximum value g ( i, x ) . AMM is tr ained by m inimizing the following conve x problem at each t th training iteration, L ( t ) ( W | z ) ≡ λ 2 || W || 2 F + l ( W ; ( x t , y t ); z t ) , (4) where λ is the r egularization p arameter, an d the instanta - neous loss l ( · ) is computed as l ( W ; ( x t , y t ); z t ) = max 0 , 1 + max i ∈Y \ y t g ( i, x t ) − w T y t ,z t x t . (5) Element z t of vector z = [ z 1 . . . z T ] d etermines wh ich weight belong ing to the true class of th e t th example is used to calculate (5), an d can be fixed prior to the start of a train- ing epoch o r , as done in th is pap er , can be compute d on- the-fly as an index of a true-class weight th at p rovides th e highest score (W ang et al. 20 11). AMM uses Stocha stic Gr adient Descent (SGD) to solve (4). The SGD is initialized with the ze ro-matrix (i.e., W (0) = 0 ), which comp rises in finite nu mber of zero - vectors for each class. This is followed by an i terative proce- dure, wh ere trainin g examples ar e ob served one by on e and the weight matr ix is m odified accordin gly . Upo n receiving example ( x t , y t ) ∈ D at the t th round , w ( t ) ij is updated as w ( t +1) ij = w ( t ) ij − η ( t ) ∇ ( t ) ij , (6) where η ( t ) = 1 / ( λt ) is a learning rate, and ∇ ( t ) ij is the sub- gradient of (4) with respect to w ( t ) i,j , ∇ ( t ) i,j = λ w ( t ) i,j + x t , if i = i t , j = j t , λ w ( t ) i,j − x t , if i = y t , j = z t , λ w ( t ) i,j , otherwise, (7) with i t = arg ma x k ∈Y \ y t g ( k , x ) and j t = arg max k ( w ( t ) i t ,k ) T x t . ( 8) If the loss (5) at the t th iteration is positiv e, class weigh t f rom the true class y t indexed by z t is moved towards x t during the update, while the class weight w ( t ) i t ,j t with the maximu m prediction from the remaining classes is pushed a way . If the updated weight is a zero-we ight then it bec omes n on-zero , thus increasing the weigh t count b i for that class by on e. I n this way , complexity o f the m odel a dapts to comp lexity of the data, and b i , i = 1 , . . . , L , are learned during training. Methodology It has been shown th at the existing lab el ranking method s achieve go od perf orman ce on many tasks, however , in the large-scale setting co nsidered in this paper, they mig ht not be as effecti ve. When faced wit h non-lin ear problems comp ris- ing millions of examples an d features, the prop osed meth ods are either too costly to train and use, or may not b e expres- si ve en ough to learn co mplex prob lems. T o address this is- sue, in this section we present a novel rank ing algorith m, called AMM-ran k, that extend s the id ea o f adaptab ility an d online learning fro m AMM to label rank ing setting, allow- ing large-scale training of accurate ranking models. AMM-rank algor ithm Before detailing the training pro cedure o f AMM-rank, we first conside r its predictive label ran king m odel. As dis- cussed previously , we assume that the t th training examp le x t is associated with (p ossibly) incomp lete label ranking π t of leng th L t ≤ L . Giv en a train ed AMM-rank mode l (3) and a test example x , a score f or each class is f ound using equation (2), an d the pre dicted label rank ing is obtain ed by sorting the scores in the descending order, ˆ π = sor t([ g (1 , x ) , g (2 , x ) , . . . , g ( L , x )]) , (9) where the sort function returns indices of the sorted scores. T raining of AMM-rank re sembles the training o f AMM multi-class mode l described in the p revious section. Learn - ing is initialized with a zero-matr ix compr ising an infinite number of zero- vectors fo r each class, f ollowed by itera- ti vely observ ing examples on e by one a nd m odifyin g th e weight matrix . At each t th training iteration we minimize the following regularize d instan teneous rank loss, L ( t ) r ank ( W | z ) ≡ λ 2 k W k 2 F + l r ank ( W ; ( x t , y t ); z t ) . (10) The ranking loss l r ank ( · ) is defined as l r ank ( W ; ( x t , y t ); z t ) = L t X i =1 ν ( i ) L X j =1 I ( π i ≻ j ) max (0 , 1 + g ( j, x t ) − w T π i ,z ti x t ) , (11) where ν ( i ) is a pred efined impor tance assigned to the i th rank, and function I ( arg ) return s 1 if arg ev aluates to tru e, and 0 other wise. As in label ran king setting we need to keep track o f pr edicted scores of all L classes and not only the top one, note that we intro duced vector z t instead of a scalar z t as in (4), whose elemen t z ti determines which weight be- longing to label i is used to compute (10) for the t th example. Dependin g on the problem at hand , u sing the fu nction ν ( i ) a modeler c an emp hasize the importan ce of some ranks over th e others. For example, let us assum e ν ( i ) = 1 /i . Th en, in the ran king loss defined in (11), the fac- tor i − 1 enforce s high er penalty for misrankin g of top - ranked topics, while the mistakes made fo r lower -ranked topics incur pro gressively smaller costs. This appr oach has been explored previously in inf ormation retriev al setting (W eston et al. 201 2). Howe ver , it is also applicable in the context of targeted advertising, wher e lower-ranked classes have prog ressi vely lower relevance to an ad publishe r than the hig her-ranked ones. Furtherm ore, p enalty is incurr ed whenever the lower -ranked label was either predicted to b e preferr ed over the hig her-ranked o ne, or t he score o f the pr e- ferred label was higher with a margin smaller than 1 . W e use SGD at each training iteration to minimize the ob- jectiv e fu nction ( 10). Su bgradie nt of the instantaneou s rank loss with respect to the weights can be computed as ∇ ( t ) i,j = λ w ( t ) i,j − x t I ( j = z ti ) ν ( π − 1 i ) L X k =1 I i ≻ k ) · I (1 + g ( k , x t ) > ( w ( t ) ij ) T x t + x t I ( j = z ti ) · L X k =1 ν ( k ) I ( k ≻ i ) I 1 + ( w ( t ) ij ) T x t > ( w ( t ) kz tk ) T x t . (12) An SGD update step (12) can be summarized as follows. At ev ery training round all m odel weights a re r educed towards zero by m ultiplying them with (1 − 1 /t ) (th e first ter m on the RHS). In add ition, if the j th weight of th e i th class was used to compu te the score fo r the t th label (i.e., I ( j = z ti ) equals 1 ), it is pushed fu rther tow ards x t whenever the i th label was e ither wrongly pr edicted to be less pr eferred or correctly p redicted with margin smaller than 1 (th e secon d term on the RHS). Moreover , the weight is pushed fu rther away from x t whenever the s core of the class preferr ed over the i th class w as either lower or higher with margin les s than 1 (th e third term on the RHS). Similarly to the AMM model, the comp lexity of AMM-rank rankin g mod el is a utomati- cally lear ned d uring trainin g, and adapts to the complexity of the considered label rankin g pr oblem. Experiments In this section we describe the problem setting and present a large-scale, real-world data set that was used for e valuation, followed by description and an alysis of empirical results. Dataset W e are ad dressing a problem from display advertising domain which c onsists of several key play ers: 1) adver- tisers, compan ies that want to advertise their p rodu cts; 2) publishers, web sites that host the advertisements (such as Y ahoo o r Go ogle); an d 3 ) o nline user s. The web envi- ronmen t provides pub lishers with the means to track user behavior in much greater de tail th an in the offline setting, including captu ring user ’ s registered infor mation ( e.g., demogr aphics, location ) and activity lo gs th at comprise search queries, page views, email acti vity , ad clicks, and purcha ses. This b rings the ab ility to target users based on their past behavior, which is typically re ferred to as ad targeting (Ahmed et al. 2011; Pandey et al. 201 1; T yler et al. 20 11; Agarwal, P andey , and Josifovski 2 012; Aly et al. 2012). Having this in min d, the main motiv ation for the f ollowing expe rimental setup was the task of esti- mating user’ s a d click intere sts using their past acti vities. The idea is that, if we sor t the interests in descen ding ord er of p referenc e and a ttempt to p redict this rankin g, this task can be formulate d as a lab el ranking problem. The data set that was used in the empirical e valuation w as generated using th e infor mation abo ut users’ onlin e activ- ities collected at Y aho o servers. The activities are tempo - ral sequence s of raw events that were extracted fr om server logs an d are repre sented as tuples ( u i , e i , t i ) , i = 1 , . . . , N , where u i is ID of a user that generated the i th tuple, e i is an event type, t i is a timestamp , and N is a to tal nu mber of recorde d tuples. F or each user we considered events belong- ing to one of the following six gr oups: • pag e views (”pv ”) - website pages that the user visited; • search q ueries (”sq”) - user -gener ated s earch quer ies; • search link click s (”slc”) - user clicks on search links; • spo nsored link clicks (”olc” ) - user clicks o n searc h- advertising links that appear next to actu al search links; • ad views (”adv”) - display ads that the user vie wed; • ad clicks ( ”adc”) - display ads that the user clicked on. Events from the se six group s are all categor ized into an in- house hierarchical taxono my by an au tomatic categoriza- tion sy stem and h uman ed itors. Each ev ent is assigned to a category f rom a le af of the taxonom y , and then propa- gated up wards toward parent categories. Considering that the server logs for each user are retained for se veral mo nths, the rec orded e ven ts can be used to capture users’ interests in categories ov er l ong per iods of time. Follo wing the ad categorizatio n step, we can com pute in- tensity an d recency mea sures for each of L conside red cat- egories in each o f the six group s. Let D ugct denote a set of all tuples that were gener ated b y user u , wh ere e i belongs to gr oup g and is lab eled with category c , with timestamp t i ≤ t . Then, intensity and recency are defined as follows, • intensity is an exponen tially time-d ecayed co unt of a ll tuples in D ugct , computed as intensity ( u, g , c, t ) = X ( u i ,e i ,t i ) ∈D ugct α t − t i , (13) where α is a fixed deca y factor , with 0 < α < 1 (we omit the exact value as it represents sensiti ve information) . • recency is a difference between tim estamp t and a time- stamp of the most recent ev ent from D ugct , computed as rec e ncy ( u, g , c, t ) = min ( u i ,e i ,t i ) ∈D ugct ( t − t i ) . (14 ) The intensity and recency m easures were u sed to g enerate both the fe atures an d the lab el ranks fo r each user . In par- ticular , we fir st ch ose two timestamps that w ere o ne mo nth apart, T f eatur es and T labels , where T f eatur es < T labels . Then, at timestamp T f eatur es we used (13) and (14) to com- pute in tensity and r ecency of L c ategories in each of ”pv”, ”sq”, ”slc”, an d ”olc” grou ps separately , which, together with user’ s age (split into 9 buckets and represented as 9 b i- nary fe atures) and gend er (represented as 2 bina ry featu res) was u sed as a feature vector x , resulting in inp ut space di- mensionality d o f (2 · 4 · L + 9 + 2) . In addition, in order to ev aluate the influenc e of user ad vie ws to their ad clicks, we also con sidered the case where intensity and recency of L categories in th e ”ad v” g roup were appen ded to the feature vector , incr easing the dimensionality by 2 L . Furthermo re, to quan tify user interests and g enerate groun d-truth ranks π , we considered on ly ”adc” events be- tween T f eatur es and T labels , and co mputed intensity o f L categories at timestamp T labels . W e consider level of interest of user u in c ategory c to b e eq ual to intensity of c in ”adc ” group , and preference ran king of categories is obtained sim- ply by sorting th eir in tensities. Note that th e gr ound- truth ranking is in most cases incomp lete, as users u sually do not interact with all categories fr om the taxonom y . W e considered L = 50 second-level categories of th e taxonom y (e .g., ”finan ce/loans”, ”retail/ap parel”), and col- lected data comprising 3 , 289 , 229 anonymou s users th at clicked on more than 2 ca tegories. Category d istribution in the gr ound -truth ran ks is gi ven in Fi g. 1, where we see tha t a large fraction of ad clicks w ould be missed if users were tar- geted on ly with the most clicked categories, wh ich directly results in lost re venue for both publishers and advertisers. Results W e comp ared AMM-rank to follo wing ap proach es: a) multi- class AM M (W ang et al. 20 11), wh ere the top-r anked cat- 10 20 30 40 50 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Category ID Number of ad click events Figure 1: Number of ad click ev ents per category egory was used as a tr ue class and the ou tput scores for all categorie s were sorted to obtain ranking , used as a na¨ ıve baseline; b) Central-Mal, which always pred icts ce n- tral r anking of th e training set co mputed using th e Mal- lows m odel (M allows 19 57); c) AG-Mal, which comp utes Central-Mal ov er all users gr ouped in different ag e (”1 3- 17”, ”18-20”, ”21 -24”, ”25-29”, ”30 -34”, ”35-44”, ”45-54 ”, ”55-64 ”, ”6 5+”) and gend er (male/fem ale) buckets; d) IB- Mal, which comp utes Central-Mal over k nearest neigh- bors (Cheng, H ¨ uhn, and H ¨ ullermeier 2009); e) log istic re- gression (LR), where L binar y mod els wer e trained and we sor ted th eir ou tputs to ob tain a rankin g; and f) pair- wise approa ch (H ¨ ullermeier et al. 2008), where L ( L − 1) / 2 binary LR models were trained and we sorte d the sum of their so ft votes towards each label to obtain a r anking (PW - LR). AMM- rank and P W -LR ha ve O ( N L 2 ) an d IB-Mal has O ( N 2 L ) time complexity , while the remaining methods are O ( N L ) app roaches. Central-Mal is a very simple and ef ficient baseline, and is an often- used metho d for basic con tent p ersonalization . As the m ethod simply p redicts po pulation’ s mea n rank ing, to improve its perf orman ce we co nsidered A G-Mal, a meth od common ly used in practice, where we first compute mean rank fo r each age- gender grou p, and then use the grou p’ s mean ra nk as a p rediction fo r qualified users. Fur ther, IB-Mal is an instance-b ased metho d whic h is extrem ely competitive to the other state-of -the-art app roaches (e.g ., see Grbovic, Djur ic, and V u cetic 2013) , where we first find k nearest neig hbors b y co nsidering feature vectors x and then predict Mallows mean ranking over the neigh- bors ( due to large time cost, for each user we searc h fo r nearest neighbor s in a subsampled set of 1 00 , 000 users). Lastly , we considered LR since it rep resents industry standard for ad targeting tasks, and PW -LR as it was shown to achieve state-o f-the-ar t per forman ce on a n umber of ranking tasks (Gr bovic, Djuric, and V uce tic 2012b; Grbovic, Djuric, and V ucetic 2013). Due to large scale of th e problem , we did not consider state-of-the- art methods such as mixture mod els which req uire it- erative training (Grbovic, Djuric, and V ucetic 2012 a ; Grbovic et al. 2013). W e also did not c onsider lo g- Females, aged 21-25 01. Retail/Apparel 02. T echn ology/In ternet Services 03. T elecom munication s/Cellular and W ireless 04. Tra vel/Destinations 05. Consumer Goods/Beauty and Personal Care 06. T echn ology/Con sumer Electronics 07. Consumer Goods/Contests and Sweepstakes 08. Tra vel/V ac ations 09. Tra vel/Non US 10. Life Stages/Education Males, aged 21-25 01. T echn ology/In ternet Services 02. Retail/Apparel 03. T elecom munication s/Cellular and W ireless 04. Tra vel/Destinations 05. T echn ology/Con sumer Electronics 06. Tra vel/Non US 07. Tra vel/V ac ations 08. Consumer Goods/Contests and Sweepstakes 09. Retail/Home 10. Entertainm ent/Games Females, aged 65+ 01. Consumer Goods/Beauty and Personal Care 02. Retail/Apparel 03. Life Stages/Education 04. Finance/Loan s 05. Finance/Insu rance 06. Finance/Investment 07. T echn ology/In ternet Services 08. Entertainm ent/T elevision 09. Retail/Home 10. T elecom munication s/Cellular and W ireless Males, aged 65+ 01. Finance/Investment 02. Finance/Loan s 03. Retail/Apparel 04. Life Stages/Education 05. T echn ology/In ternet Services 06. Finance/Insu rance 07. Consumer Goods/Beauty and Personal Care 08. Retail/Home 09. T elecom munication s/Cellular and W ireless 10. T echn ology/Com puter Software Figure 2: T op ic ranking found by the A G-Mal model linear model (Dekel, Mann ing, and Singer 2003), shown in (Grbovic, Djuric, and V ucetic 2013) to be outperf ormed by the IB-Mal, and do not report results of instan ce-based Plackett-Luce (Cheng, Dembczy ´ nski, and H ¨ ullermeier 2010) due to observed limited performance. W e used V owpal W abbit p ackage 1 for logistic regression, BudgetedSVM (Djuric et al. 201 4) for AMM, that we also modified to imp lement AMM-ra nk. W e set ν ( i ) = 1 , i = 1 , . . . , L , a nd used the default param eters fr om Budge t- edSVM p ackage fo r AMM-ran k, with the exception of the λ parame ter which, to gether with comp etitors’ p arameters, 1 github.com/Jo hnLangford/vo wpal_wabbit T able 1: Disagreement error ǫ dis of th e label rank ing metho ds Algorithm adv adv AMM 0.344 6 0.26 11 Central-Mal 0.2957 0.2957 A G-Mal 0.282 0 0.28 20 IB-Mal 0.269 4 0.18 99 LR 0.211 0 0.14 19 PW -LR 0.209 1 0.12 26 AMM-rank 0.199 6 0.10 83 was configured through cross-validation on a small held-o ut set; th is r esulted in k = 10 for IB-Mal. A s d iscussed p revi- ously , we conside red tw o versions of the ad targeting data: • adv - feature v ector x does no t include recency an d inten- sity of categories from ”adv” group (with d = 411 ); • adv , feature vector x d oes include r ecency an d in tensity of categories from ”adv” group (with d = 5 11 ). Before comp aring th e ran king app roache s, it is inform a- ti ve to consider the examples o f lab el r anks fou nd by A G- Mal on adv data, given in Figur e 2. W e can see that there ex- ist sign ificant differences b etween d ifferent gen der and age group s. Albeit the ob tained ra nks seem very in tuitive, we will see shortly that A G-Mal is significantly outpe rformed by the o ther method s, illustrating comp lexity of the rankin g task and the need for more inv olved app roaches. I n the fol- lowing, we compare th e algorithms u sing d isagreemen t error ǫ dis (Dekel, Manning, and Singer 2003), comp uted a s a f rac- tion of pairwise category preferences predicted incorrectly , ǫ dis = 1 N test N test X t =1 L X i,j =1 I ( π ti ≻ π tj ) ∧ ( ˆ π − 1 tπ tj > ˆ π − 1 tπ ti ) L t L − 0 . 5( L t + 1) , (15) as well as precision , recall, and F1 at the top K rank s, precision@ K = 1 N test N test X t =1 K X i =1 I ( ˆ π ti ∈ π t ) K , recall@ K = 1 N test N test X t =1 K X i =1 I ( ˆ π ti ∈ π t ) L t , F 1 @ K = 2 · precision@ K · recall@ K precision@ K + recall@ K , (16) which a re co mmonly used m easures fo r rank ing pro blems. Here, ˆ π t denotes predic ted labe l rank for the t th example. Performan ce o f the comp eting meth ods in terms of ǫ dis , following 5 -f old cross-validation, is repo rted in T ab le 1. W e can see that th e inclusion of a d v iew features resulted in large perf ormanc e im provement, con firming findings from (Gupta et al. 2012) th at past exposu re to an ad increases propen sity of a user to actually click the a d. As expected, multi-class AMM achieved poo r perfo rmance as it optimizes only for the topmo st ca tegory , and this re sult represen ts a lower bo und o n the disagr eement loss. A simp le baseline Central-Mal ach iev ed high er error, which was d ecreased by only a small margin using A G-Mal. W e can see that IB-Mal resulted in significan t perfor mance imp rovement, howe ver in large-scale, online setting it may be very in efficient. Lo - gistic r egression, a co mmon ly used method in ad targeting tasks, o btained low error, furthe r impr oved using the pair- wise a pproac h. Howe ver , state-of-th e-art PW -LR was sig- nificantly ou tperfor med by the p ropo sed AMM- rank which achieved mor e than 10 % b etter result. W e n ote tha t, o ther than IB-Mal, the methods are very efficient, obtaining train- ing an d test times of less th an 1 0 min utes on a regular ma- chine. Howe ver , the main go al in ad targeting campaign s is no t to infer the com plete list of prefere nces for a user . Instead , we aim to fin d the to p K mo st p referred categor ies, du e to the constraint that we only have a limited b udget for ad display , in terms of b oth tim e and space. T herefor e, it is n ot of im- portance when two less prefer red categories are misran ked, and in th e secon d set of experimen ts we explor e how the label rankin g m ethods per form in su ch setting . W e co nsid- ered sh owing K = { 1 , 2 , . . . , 1 0 } display ads, an d fo r the top K ran ks measure p recision, reca ll, and F 1 score of the categories on which the u ser clicked during the testing pe- riod. Th e results obtained by the label rankin g algorithms are illustrated in Figure 3. W e can see that AMM-rank ou tper- formed the comp etitors, achieving better performance fo r all values of K . This becomes e ven more relev ant when we con - sider that even a small improvement in a web-scale setting of targeted advertising may result in a significant revenue increase f or the p ublisher . W e can conclu de that the results strongly sug gest ad vantages o f the pro posed ap proach over the competing algorithms in large-scale l abel rankin g tasks. Conclusion In order to ad dress challen ges brough t about by the scale of the on line advertising tasks that r enders many state-o f-the- art method s inefficient, we in troduc ed AMM-ra nk, a novel, non-lin ear algorithm for large-scale label ran king. W e ev al- uated its performance on a rea l-world ad targeting data co m- prising more than 3 m illion users, thu s far the largest label ranking data considered in the literature. The results show that the meth od outper formed the compe ting approaches by a large margin in terms of both r ank loss and retriev al mea- sures, ind icating that the AMM-rank algorithm is a very suit- able method for solving large-scale l abel rankin g problems. Refer ences [Agarwal, P andey , and Josifovski 2012] Ag arwal, D.; Pandey , S.; and Josifovski, V . 2012. T argeting converters for new campaig ns thr ough factor mo dels. In Pr oceedings of the 21 st I nternation al Confer ence o n W orld W id e W eb , 101–1 10. A CM. [Ahmed et al. 2011] Ahm ed, A.; Low , Y .; Aly , M.; Josi- fovski, V .; and Smo la, A. J. 20 11. Scalable distrib uted infer- ence of dyna mic user in terests for beh avioral targeting. In KDD , 114–12 2. [Alba et al. 1997] Alba, J.; L ynch, J.; W e itz, B.; Janiszewski, C.; Lutz, R.; Sawyer , A.; and W oo d, S. 1997. Interactive 2 4 6 8 10 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 0.65 Precision Top K user interests AMM−rank PW−LR LR IB−Mal AMM 2 4 6 8 10 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Recall Top K user interests 1 2 3 4 5 6 7 8 9 10 0.2 0.25 0.3 0.35 0.4 0.45 0.5 F1 score Top K user interests Figure 3: Comparison of retriev al performanc e of label ranking algorith ms in terms of precision, recall, and F1 m easures home sho pping: consumer , r etailer , an d manufactur er incen- ti ves to participate in electro nic marketplaces. The Journal of Marketing 38–53. [Aly et al. 201 2] Aly , M.; Hatch, A.; Josifovski, V .; and Narayanan , V . K. 20 12. W eb -scale user modeling for tar- geting. In WWW , 3–12. A CM. [Broder 2008] Broder, A. Z. 200 8. Computatio nal advertis- ing and reco mmende r systems. In P r oc eedings of the ACM confer ence on Recommende r systems , 1–2. ACM. [Cao et al. 200 7] Cao , Z.; Qin , T .; Liu, T .; Tsai, M.; an d L i, H. 2007. L earning to rank : From p airwise ap proach to list- wise approa ch. ICML 129 –136. [Chellappa and Sin 200 5] Ch ellappa, R. K., and Sin, R. G. 2005. Personalizatio n versus priv acy: An em pirical exami- nation of the on line consumer s dilemma. In formation T ech- nology and Management 6( 2-3):1 81–2 02. [Cheng, Dembczy ´ nski, and H ¨ uller meier 2010] Cheng, W .; Dembczy ´ nski, K.; and H ¨ u llermeier, E. 20 10. Label rank ing methods based on the Plackett-Lu ce model. In Pr oceeding s of the 27 th In ternationa l Confer en ce on Machine Learnin g , 215–2 22. [Cheng, H ¨ uhn, and H ¨ u llermeier 2009] Cheng , W .; H ¨ uhn, J.; and H ¨ ullermeier, E. 2009. Decision tre e and instance-based learning for label ran king. In Pr oceeding s of the 26th Inter- nationa l Confer enc e on Machine Learnin g , 161–168 . [Das et al. 2007 ] Das, A. S.; Datar, M.; Garg, A. ; and Ra- jaram, S. 2 007. Google news person alization: Scalable on- line collaborative filtering. In WWW , 271 –280 . AC M. [Dekel, Manning, and Singer 2003] Dekel, O.; Mann ing, C.; and Singer, Y . 200 3. Log- linear m odels for label ra nking. In Advances in Neural Information Pr ocessing Systems , v ol- ume 16. MIT Press. [Djuric et al. 2014 ] Djur ic, N .; Lan, L.; V uc etic, S.; an d W ang, Z. 2014. BudgetedSVM: A toolbox for scalable SVM approximation s. Journal of Machine Lea rning Re- sear ch 14:3813–3 817. [Elisseeff and W eston 2001 ] Elisseeff, A., and W eston, J. 2001. A kernel metho d f or multi-lab elled classification. In Advance s in Neu ral Info rmation Pr ocessing Systems , 681– 687. [Essex 2009] Essex, D. 2009. Matchm aker , match maker . Communicatio ns of th e A CM 52(5) :16–17 . [Grbovic et al. 2013] Grbovic, M.; Dju ric, N.; Guo , S.; a nd V u cetic, S. 201 3. Super vised clustering o f label r anking data u sing label p referenc e information . Machine Learnin g 1–35. [Grbovic, Djuric, and V ucetic 2012 a] Gr bovic, M.; Djuric, N.; and V ucetic, S. 2012 a. Learnin g from pairwise prefer- ence data using Gaussian mixtur e mo del. Pr efer ence L earn- ing: Pr ob lems and Application s in AI 33 –35. [Grbovic, Djuric, and V ucetic 2012 b] Grbovic, M .; Djuric, N.; and V ucetic, S. 201 2b. Superv ised clustering o f label ranking data. In SDM , 94–10 5. SIAM. [Grbovic, Djuric, and V ucetic 2013 ] Gr bovic, M.; Djuric, N.; an d V uc etic, S. 201 3. Multi-pr ototype label ranking with novel p airwise-to-total- rank aggr egation. In Pr o ceed- ings of the 23rd In ternationa l J o int Confer ence on Artificial Intelligence . AAAI Press. [Gupta et al. 2012] Gu pta, N.; Das, A.; Pandey , S.; an d Narayanan , V . K. 2 012. Factoring past exposure in dis- play advertising targeting. In Pr oceedings of the ACM SIGKDD Internation al Conference on Kno wledge Discov- ery and Data mining , 1204– 1212 . [Har-Peled, R oth, and Zimak 200 3] Har-Peled, S.; Roth, D.; and Zima k, D. 2 003. Constraint classification fo r multi- class classification and ran king. In Pr oceedings of the 16 th Annua l Confer ence on Neural Info rmation Pr o cessing Sys- tems , 785–79 2. MI T Press. [H ¨ ullermeier and V ander looy 20 10] H ¨ ullermeier, E., and V an derlooy , S. 2010. Comb ining pr edictions in pair- wise classification: An optimal adaptive voting strategy and its relation to weighted voting. P attern Recognition 43(1) :128–1 42. [H ¨ ullermeier et al. 2008] H ¨ ullermeier, E.; F ¨ urnkran z, J.; Cheng, W .; and Brinker , K. 200 8. Label ranking by learn ing pairwise prefe rences. Artificia l Intelligence 172(1 6):18 97– 1916. [Kamishima and Akaho 2006] Kamishim a, T ., and Ak aho, S. 200 6. Efficient clustering for ord ers. In ICDM W o rk- shops , 274–27 8. [Majumde r and Shr iv asta va 2013 ] Maju mder, A., and Shri- vasta v a, N. 2013. Know y our pe rsonalization : Learning topic level per sonalization in o nline service s. In Pr o ceed- ings o f the 22nd Internation al Con fer ence on W orld W ide W eb , 873–8 84. [Mallows 1957] Mallows, C. L. 1 957. Non- null r anking models. Biometrika 44(1/2 ):114– 130. [Manber, Patel, and Robison 2000] Manb er , U. ; Patel, A.; and Robison, J. 200 0. Ex perience with per sonalization on Y ahoo! Communicatio ns of the ACM 43(8):35. [Pandey et al. 2011] Pandey , S.; Aly , M.; Bag herjeiran, A.; Hatch, A.; Ciccolo, P .; Ratnapar khi, A.; and Zinkevich, M. 2011. Learning to target: what works f or behavioral target- ing. In Pr oceeding s of the 20th ACM In ternationa l Confer - ence on I nformation an d Knowledge Management , 1 805– 1814. A CM. [Riecken 2000] Riecken, D. 2000 . Personalized views of personalizatio n. Communica tions of the A CM 43(8):27–2 8. [T uzhilin 2009] T uzhilin, A. 2009. Personalization: The state of the art and future directions. Business Computin g 3:3 . [T yle r et al. 2011] T y ler , S. K.; Pandey , S.; Gabrilovich, E .; and Josifovski, V . 2011 . Retrieval models fo r audien ce se- lection in display advertising . I n Pr oceedings of the 20th AC M In ternational Conference on In formation and Knowl- edge Management , 593– 598. ACM. [V em bu and G ¨ artner 201 1] V embu, S., and G ¨ ar tner, T . 201 1. Label rank ing algo rithms: A s urvey. In Pr eference learning . Springer . 45– 64. [W ang et al. 20 11] W ang, Z.; Djuric, N .; Cra mmer, K.; and V u cetic, S. 2011. Trading r epresentab ility for scalability: Adaptive multi-hy perplan e machine for nonlinear classifica- tion. In ACM SIGKDD Conf. on Knowledge Discovery and Data Mining . [W eston et al. 2 012] W eston , J.; W ang, C.; W eiss, R.; an d Berenzweig, A. 201 2. Latent collaborative retriev al. In Pr o- ceedings of the 29th In ternational Con fer ence on Machine Learning , 9–16.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment