Toward a general, scaleable framework for Bayesian teaching with applications to topic models
Machines, not humans, are the world's dominant knowledge accumulators but humans remain the dominant decision makers. Interpreting and disseminating the knowledge accumulated by machines requires expertise, time, and is prone to failure. The problem …
Authors: Baxter S. Eaves Jr, Patrick Shafto
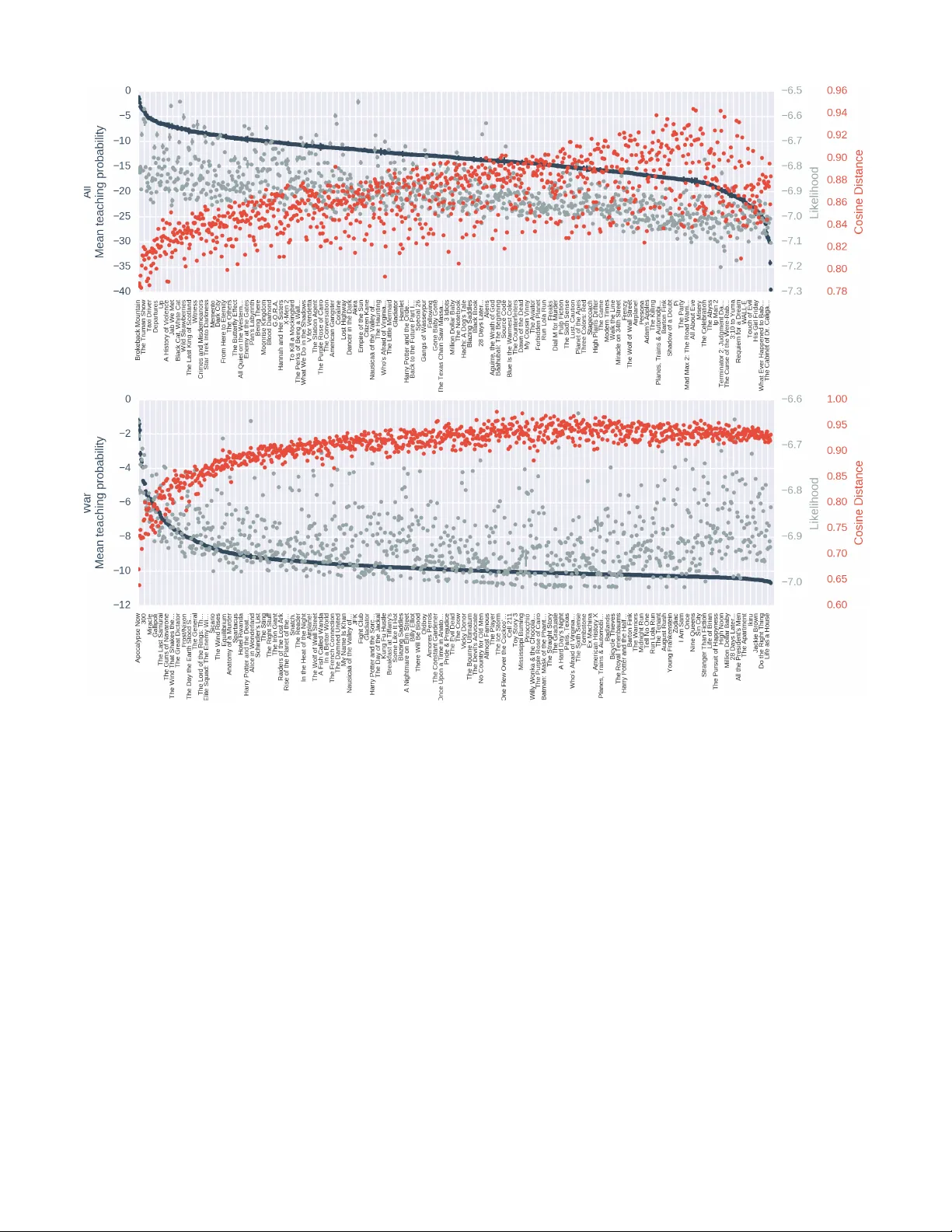
T oward a general, scaleable framework for Bayesian teaching with applications to topic models Baxter S. Ea ves Jr and Patrick Shafto Rutgers Uni verity - Ne w ark { baxter .eav es, patrick.shafto } @rutgers.edu Abstract Machines, not humans, are the world’ s dominant knowledge accumulators but humans remain the dominant decision makers. Interpreting and dis- seminating the kno wledge accumulated by ma- chines requires e xpertise, time, and is prone to fail- ure. The problem of ho w best to con ve y accu- mulated knowledge from computers to humans is a critical bottleneck in the broader application of machine learning. W e propose an approach based on human teaching where the problem is formal- ized as selecting a small subset of the data that will, with high probability , lead the human user to the correct inference. This approach, though success- ful for modeling human learning in simple labo- ratory e xperiments, has f ailed to achie ve broader relev ance due to challenges in formulating gen- eral and scalable algorithms. W e propose general- purpose teaching via pseudo-marginal sampling and demonstrate the algorithm by teaching topic models. Simulation results show our sampling- based approach: effecti vely approximates the prob- ability where ground-truth is possible via enumera- tion, results in data that are markedly different from those expected by random sampling, and speeds learning especially for small amounts of data. Ap- plication to movie synopsis data illustrates dif- ferences between teaching and random sampling for teaching distributions and specific topics, and demonstrates gains in scalability and applicability to real-world problems. 1 Introduction Machines are increasingly integral to society . Where ex- pert human intuition once was, algorithms are increasingly present. Learning algorithms are used to learn comple x hy- potheses from comple x data, which are used to augment hu- man intuition. This paradigm creates a bottleneck where the knowledge accumulated by machines depends on highly trained human experts to interpret, and to con ve ying to hu- mans. This remains a barrier to the broader usefulness of ma- chine learning. While machines can communicate perfectly among themselves by exchanging bits, humans communicate with data—the y teach. The purposeful selection of data plays a featured role in theories of cognition [1], cogniti ve devel- opment [2], and culture [3]. In each of these cases, teaching is conceived of as purposeful, rather than random, selection of small set of e xamples, with the goal of facilitating accurate inferences about a body of knowledge. The question of ho w to model teaching has also appeared across literatures: cogniti ve scientists hav e proposed and in- vestigated probabilistic models of optimal example selection [4 – 7]; algorithmic teaching researchers ha ve proposed deter- ministic methods to select examples that rule out confusable concepts [8, 9]; and machine learning researchers have be- come interested in machine teaching [10, 11]. These paths of research vary in the details, but share the same goal: to facilitate learning by optimizing input to learners. Previous approaches are either tailored to a specific, cir - cumscribed domains or propose a general mathematical for - malization that is not scalable. Zhu [10] offers a formalization for e xponential f amily distrib utions [see also 7]. Mei & Zhu [12] cast teaching as bilev el optimization, which is NP-hard, and of fer a solution for the limited case when the data are dif- ferentiable and the learner’ s objective function is conv ex and regular . Shafto & Goodman [4] and Zilles et al. [9] of fer gen- eral formalizations for probabilistic and deterministic infer- ence, respectively , b ut suffer from computational complexity that renders them inapplicable for real-world application. W e propose a simple, general framew ork for selecting ex- amples to teach probabilistic learners. The framework lever - ages advances in sampling-based approximations, specif- ically pseudo-marginal sampling coupled with importance sampling, to offer a general purpose approximation to the Bayesian normalizing constant that is required to teach proba- bilistic learners. W e demonstrate the ef ficacy of the approach on probabilistic topic models. The results sho w that the dis- tribution of teaching data differ significantly from the data likelihood, that the teaching data impro ve learning especially when learning from a small numbers of examples, and that teaching can be optimized for a variety of tasks, while scal- ing to problems mark edly more complex than possible under previous, general-purpose, teaching algorithms. 2 Background 2.1 Bayesian teaching A teacher generates data, x , to lead a learner to a specific hypothesis, λ . A teacher must consider the learner’ s posterior inference, π L ( λ | x ) , given e very possible choice of data, thus learning is a sub-problem of teaching. The teacher simulates a learner who considers the probabilities of all hypotheses giv en that data, p T ( x | λ ) = π L ( λ | x ) R x π L ( λ | x ) dx ∝ ` L ( x | λ ) m L ( x ) . (1) Where the subscripts T and L indicate probabilities attached to teacher and learner, respecti vely; ` ( x | λ ) indicates the liklelihood of the data; and m ( x ) = R `p ( x, λ ) dλ is the marginal lik elihood. 2.2 T opic models via Latent Dirichlet Allocation Latent Dirichlet Allocation [LD A; 14] is a popular formal- ization of topic models. Under LDA, documents are bags of words generated by mixtures of a fixed number topics. T o generate a set of D documents from T topics with W distinct words: for all topics, 1 , . . . , T do φ t ∼ Dirichlet W ( β ) end f or for all documents, 1 , . . . , D do θ d ∼ Dirichlet T ( α ) for i ∈ { 1 , . . . , W d } do z ( d ) i ∼ Categorical ( θ d ) w ( d ) i ∼ Categorical ( φ ( d ) z i ) end f or end f or where W d is the number of words in the document d , z ( d ) i is the topic from which the i th word in document d was gener- ated, and w ( d ) i is the i th word in document d . The v ariables of interest are the topics, Φ = { φ i , . . . , φ T } and the topic mix- ture weights Θ = { θ 1 , . . . , θ D } . Each φ is a v ector with an entry for each of the W w ords in the vocab ulary; the w th en- try is the probability of word w occurring in the topic. Each document is associated with a θ . The t th entry of θ is the probability that a word in document d was generated from topic t . The full joint distribution is, p ( z , w , Φ , Θ | α, β ) = p ( z | Θ) p ( w | Φ) p (Φ | β ) p (Θ | α ) . Exploiting conjugacy , we can integrate out φ and θ leaving, p ( z , w | T , α , β ) = D Y d =1 DirCat ( z ( d ) | α ) T Y t =1 DirCat ( w ( t ) | β ) , where DirCat is the Dirichlet-Categorical distribution. Given a k -length v ector of counts, x , DirCat ( x | α ) = Γ P k i =1 α i Γ n + P k i =1 α i k Y i =1 Γ ( x i + α i ) Γ ( α i ) . This allows one to define an ef ficient Gibbs sampler for z that only requires maintaining a set of counts [15]. The proba- bility of word i being assigned to a specific topic ( z i = t ) giv en the words in the documents, w , and the assignment of all other words, z ( − i ) , is, p ( z i = t | z ( − i ) , w ) ∝ n ( − i ) d,t + α d n ( − i ) t,w + β w P w 0 n ( − i ) t,w + β w , (2) where n ( − i ) d,t is the number of words—less word i —in docu- ment d assigned to topic t , n ( − i ) t,w is the number of instance of vocab ulary word w —again, less word i —assigned to topic t . 3 T eaching topics with documents Our goal is to produce or choose documents to teach a topic model, φ , to an LD A learner . The learner is assumed to know the prior parameters, α and β , and the number of topics; but must mar ginalize o ver all possible assignments of N words in D documents to T topics, z ∈ Z , and all possible Θ . The probability of documents under the teaching model is, p T ( { d 1 , . . . d D }| Φ , α , β ) ∝ Y φ ∈ Φ f ( φ | β ) × X z ∈ Z D Y d =1 DirCat ( z d | α ) ! n Y i =1 f ( w i | φ z i ) ! ÷ X z ∈ Z D Y d =1 DirCat ( z d | α ) ! T Y t =1 DirCat ( w t | β ) ! . (3) 3.1 A pproximating the LD A posterior Computing the above quantity requires O ( T N ) computa- tions; because in all but the simplest scenarios this is impos- sible, we must approximate it. Importance sampling is a common approach to estimating intractable integrals (or sums) by re-framing them as e xpecta- tions with respect to an easy-to-sample-from importance dis- tribution, q . The integral of p ov er λ is estimated by simu- lating ¯ λ 1 , . . . , ¯ λ M from q ( λ ) and taking the arithmetic mean of the importance weights , p/q . For example, to estimate the marginal lik elihood, m ( x ) = Z ` ( x | λ ) π ( λ ) dλ ≈ 1 M M X i =1 ` ( x | ¯ λ i ) π ( ¯ λ i ) q ( ¯ λ i ) , ¯ λ ∼ q . When estimating the mar ginal likelihood, the importance distribution should be close to the posterior because areas with high posterior density contribute more. In the case of LD A, the naive approach of drawing z from a uniform cat- egorical distribution is inefficient and does not afford scal- ing to real-world problems; many of the importance sam- ples will come from low probability regions because the im- portance distribution will be far flatter than the tar get. A better approach is to use the collapsed Gibbs sampler in Equation 2 to implement a sequential importance sampler [SIS; 16] from which proposals are drawn by incrementally generating z . Starting with a random value for z 1 , draw z 2 | z 1 , { w 1 , w 2 } , α , β , according to Equation 2, then draw z 3 | { z 1 , z 2 } , { w 1 , w 2 , w 3 } , α , β and so on, q ( z ) = n Y i =2 p ( z i |{ z 1 , . . . , z i − 1 } , { w 1 , . . . , w i } , α , β ) . SIS performs significantly better than naive importance sampling, especially in sparser models (as α and β approach zero). W e evaluated the accurac y and efficienc y of uniform and sequential importance sampling by comparing their es- timates (after 1000 samples) against the true teaching prob- abilities. W e generated 512 pairs of documents and three- topic models from LD A with α = β = . 5 ; each document contained fiv e words from a fi ve-w ord vocab ulary . Gi ven these parameters, the number of terms in the sum over Z in Equation 3 is 3 10 = 59049 . Figure 1A, B, and C sho ws the accuracy of the samplers and indicates that SIS has much lower v ariability . Figure 1D compares the effective sample size (ESS, [17]) of the samplers. ESS represents the num- ber of unweighted samples to which the M weighted samples are equiv alent—higher is better . ESS can be calculated as M / (1 + V ar q ( w )) , where V ar q ( w ) is the sample v ariance of the importance weights. For these simulations, SIS had an av erage ESS of 890.71, while uniform importance sampling had an ESS of 238.50. 3.2 Pseudo-marginal sampling T o generate documents from the teaching distribution, we employ pseudo-marginal sampling [18, 19], which allows ex- act Metropolis-Hasting to be performed using approximated functions. The standard Metropolis-Hasting algorithm [20, 21] generates samples, y , from a probability distribution, p , that is known to a constant, p ( y ) = k f ( y ) , by drawing new values, y 0 , from a proposal distrib ution, q ( y → y 0 ) , and ac- cepting y 0 with probability min [1 , A ] where, A := f ( y 0 ) q ( y 0 → y ) f ( y ) q ( y → y 0 ) . (4) If f is difficult to calculate, the pseudo-marginal approach allows one to replace f in Equation 4 with an approximation ˆ f . Pseudo-marginal sampling works provided ˆ f ( y ) = γ f ( y ) , where γ is the bias or weight of the approximation and the ex- pected value of the weights is constant. The weights are im- plicitly treated as a random variable in a joint distribution and marginalized away , leaving the target. W e will use pseudo- marginal sampling coupled with SIS to generate documents under the teaching model; when we do no need to generate documents, we use only approximation. 4 Scalability The posterior approximation is the main factor in scaling Bayesian teaching. For topic models, our chosen approxi- mation method, SIS, requires only O ( nT ) arithmetic opera- tions and n multinomial random numbers (Equation 2); and has been sho wn to yield high ESS. Because each sample is generated independently , importance sampling is embarrass- ingly parallel. Ho wev er , as the number of words and topics increases, the number of samples needed to approximate the Figure 1: Comparison of teaching probability approxima- tions. Panels A, B, and C sho w the true log teaching probabil- ities plotted ag ainst approximations from uniform importance sampling and sequential importance sampling (SIS). Each ap- proximation was calculated using 1000 total samples. Each point on the plot represents the exact and approximate log probability for a pair of sampled documents with fiv e words each generated from three topics with a fi ve-w ord v ocabulary ( α = β = . 5 ). Panel C sho ws the bias of the log of the es- timators. Panel D sho ws the ef fecti ve sample sizes (ESS) of both of the estimators. posterior within an acceptable error increases. W e ran simu- lations to ev aluate the number of SIS samples, M , required to achiev e a relativ e sample error of 0.05 while calculating the marginal likelihood with different values of n , T , α , and β , and with W = 100 . The relative error of the importance samples is, 1 √ M v u u u t 1 M P M i =1 w 2 i 1 M P M i =1 w i 2 − 1 , (5) where w i is an importance weight. Figure 2 displays the re- sults, averaged o ver 1024 runs. The teaching probability of a single sixty-word document under a twenty-topic model can be calculated to within 0.05 relativ e sample error with about one thousand samples. The number of samples required in- creases linearly with the number of words. The v alues of α and β effect scaling. As the model becomes sparser, a smaller proportion of assignments hold most of the probability mass, which makes high-mass areas more dif ficult for the sampler to find, thus more samples are required for sparser models. Figure 2: Number of samples to achieve 0.05 relati ve sample error when calculating the marginal likelihood for the teach- ing probability for single documents. Each point represents the average ov er 1024 runs. Error bars represent the 95% confidence interval. 5 Examples 5.1 Characterizing the teaching distrib ution W e can calculate Equation 3 exactly when using a small num- ber of small documents with simple topic models. In Figure 3 we plot the teaching distribution of single, 10-word docu- ments under several two-topic models with three-word vocab- ularies, and α = β = 0 . 1 . 1 Documents were plotted by using their normalized counts as barycenter coordinates. 2 Docu- ments with word proportions more consistent with a topic are closer to that topic on the simplex. Figure 3 shows that the teaching model assigns highest density to documents that are closer to both topics while the likelihood (the standard LD A model) assigns higher density to the documents that are at the corners. Because α is low , documents generated by LD A will mostly contain words gen- erated by one topic; the teaching model suggests that choos- ing documents between the two topics is better for teaching both topics. Because β is lo w , most of the density in topics is expected to lie in a small proportion of the words; this pre- vents the teaching model from fa voring documents centered between the two topics, as when topics are well-separated (Figure 3, top right). T o determine whether these data benefit learners, we pro- vided LD A with teaching documents and documents drawn randomly from LDA, then computed the error between the inferred topics and the topics used to generate the documents. W e generated 64 sets each of one, two, three, and four 20- word documents from the teaching model and from LD A. 1 For simplicity , we use symmetric Dirichlet parameters where α = c implies that each v alue in α is c . 2 For e xample, a document d = [2 , 1 , 2 , 1 , 3 , 2 , 1 , 2 , 2 , 2] with counts [ n 1 , n 2 , n 3 ] = [3 , 6 , 1] would have the barycenter coordi- nates (0 . 3 , 0 . 6 , 0 . 1) . W e used the pseudo-marginal Metropolis-Hastings algorithm to generate teaching documents. The document sets drawn from LD A served as the starting state for each Markov Chain and proposals were generated by randomly flipping a small number of the words. The likelihood and teaching probabil- ities were estimated using SIS. W e ran LD A (eqn:lda-gibbs) for 1000 iterations on each document pair . The topics were deriv ed from the counts and compared with the true topics through sum squared error . Due to label switching in the Gibbs sampler, we calculated the error between the true top- ics and each label permutation of the inferred topics, and re- port the minimum error across permutations. Figure 4 shows that the documents from the teaching model produce lower error , and that the ef fect is greater for fe wer documents. As the number of documents increases, the teaching model and random generation produce similar learning outcomes. Figure 4: Distribution of error between the inferred and true topics as a function of the number of 20-w ord documents drawn from the teaching (red) and LD A (random; blue) distri- butions. Three ten-word topics comprise the true model and α = β = 0 . 1 . The bulk of the benefit of teaching can be expected when learning from fewer documents, but the number of documents at which random and teaching-based sampling are equiv alent varies depending on the problem. As the number of topics in the model increase and the the base distribution becomes sparser (as α and β approach 0, random documents will con- tain fewer topics with fe wer likely , unique words), the equiv- alence point will increase. In the abo ve example, three teach- ing documents were beneficial to teach a three-topic model, but four teaching documents produced results similar to docu- ments dra wn randomly from LDA. This is consistent with the idea that as the number of documents surpasses the number of topics, there is an increasing probability that random sam- pling will, by chance, represent all of the topics. If the the model is not sparse (as α and β approach infinity), random documents will contain more topics with more likely , unique words and individual documents will become more similar . When this is the case, relative gains due to teaching will be reduced. Figure 3: Comparison of the teaching and likelihood distrib ution representing the probability of selecting a single 10-word document for a two-topic, three-word-v ocabulary model where α = β = 0 . 1 . The 3-dimensional density is represented with barycenter coordinates, where each corner of the triangle represents a w ord. The tw o crosses on each plot represent the position of the tw o topics. Documents are plotted by normalizing their w ord counts. (T op) The normalized teaching distribution. Darker areas indicated higher density . (Middle) The normalized likelihood. (Bottom) The dif ference of the two distrib utions. Red indicates areas in which the teaching distribution has higher density than the likelihood; blue indicates areas in which the likelihood has higher density that the teaching distrib ution. 5.2 Internet Movie Database T op 1000 T o explore the scalability and real-world implications of this work, we applied the teaching model to select movie synopses from the Internet Movie Database top 1000 mo vies [22]. The synopses were processed in the standard way: stop words and words that occur fe wer than three times were removed, leav- ing a vocab ulary of 3276 w ords and 41430 total words across 1000 documents. The target topic model, which comprised 16 topics (the number topics that maximize the evidence for α = 50 /T and β = . 1 , see Griffiths & Steyvers [15]), w as de- riv ed from running LDA on the synopses. W e start by finding the single synopsis that best captures the entire topic model. The teaching probability of each synopsis was calculated 16 independent times using 10 5 samples from SIS (see Figure 5, top). The best documents are those that represent the most top- ics. The best teaching synopsis, Brok eback Mountain [23], is longer than most (64 words) and represents many of the topics—most of which contain drama k eywords—though many of the words come from two topics ha ving to do with working and friends/family going on trips. Drawing an anal- ogy to Figure 3, the ideal single documents lie between top- ics, but, in keeping with LD A ’ s sparsity , are closer to one than the others; Br okeback Mountain exhibits these qualities. Figure 5 sho ws that the likelihood and teaching probabil- ities correlate to some extent, but that there are substantial differences. Much of the benefit of the teaching probabil- ity comes from considering all possible inferences (via the marginal likelihood) and directing learners’ inferences to- ward the tar get, but a way from confusable alternati ves. In some circumstances, one may be interested in teaching subsets of topics Φ ∗ = { φ ∗ i , . . . , φ ∗ K } ⊂ Φ . This can be ac- complished by marginalizing ov er the remaining topics. The teacher would like to induce the target topics in the learner but does not explicitly consider the other topics. The numerator in Equation 3 becomes, Y φ ∗ ∈ Φ ∗ f ( φ ∗ | β ) X z ∈ Z K Y k =1 DirCat ( z k | α ) × Y t : φ t 6∈ Φ ∗ DirCat ( w t | β ) n Y i f ( w i | φ z i ) 1 Φ ∗ ( φ z i ) ! , (6) where w t is the set of words assigned to topic t . T o demonstrate this feature, we chose to teach a single topic that roughly corresponded to war . Some of the most- occurring words in the topic were war , American , team , army , us/US , battle , mission , men , and British . W e repeated the procedure abov e, but used Equation 6 in place of Equa- tion 3. Apocalypse Now [24], which sits atop IMDB’ s T op 20 Gr eatest W ar Movies of All T ime [25] is the best synop- sis for teaching the war topic. The results (Figure 5, bottom) again show that the teaching and likelihood distributions dif- fer significantly . In fact, the two max likelihood synopses, The Celebration [26] and Mr . Nobody [27] are both dramas that hav e nothing to do with war . T o explore the spatial qualities of the teaching distribution, we computed one minus the cosine distance between each synopsis and the normalized sum of the target topics (Fig- ure 5, red). 3 There is a negati ve correlation between the cosine distance and the teaching probabilities both for docu- ments under the full topic model ( r (998) = − 0 . 69 , p ≈ 0 ) and the war topic ( r (998) = − 0 . 93 , p ≈ 0 ). This result 3 One minus the cosine distance between two vectors, A and B , is 0 when A and B are identical. Figure 5: Comparison of normalized teaching probability (Navy), likelihood adjusted for the number of w ords in the document ( ` 1 /w ; gray), and one minus cosine between synopses and topic models (red) for the entire topic model (T op) and the war topic (Bottom) of The Internet Movie Database top 1000 movies. The leftmost films have the highest probability under the teaching model. Each point represents the mean of sixteen estimates. The standard errors of the estimates are represented, but are often smaller than the points. The title of ev ery 10 th film is shown. suggests that while selecting documents based on cosine dis- tance is an effecti ve heuristic for approximating teaching the war topic, the teaching model selects documents that capture a richer structure than this simpler approach. When searching for the max teaching probability documents, one may employ cosine distance to reduce the number of teaching probability calculations by computing the teaching probability for only low cosine distance documents. 6 Discussion The problem of optimally selecting examples for teaching is important across a variety of domains. A general yet scalable method has been elusiv e because teaching requires simulat- ing the learner . Whereas probabilistic learning can proceed by dra wing samples from the posterior distribution, teach- ing requires approximating the distribution itself. Building from advances in approximate inference, including pseudo- marginal sampling and sequential importance sampling, we introduced a general-purpose approach that provides an accu- rate simulation-based approximation of optimal teaching ex- amples, and demonstrate by selecting documents to teach the distribution of topics from The Internet Movie Database top 1000 movies [22]. For this problem, simulations suggests that Bayesian teaching scales linearly with the number of words in the teaching document(s). Thought we applied our approach to a problem much larger than could be managed by existing general approaches to teaching, scaling to problems on the or- der of teaching by selecting books, has yet to be realized. W e are optimistic about continued progress tow ard truly scalable and practically realizable applications. References 1. Sperber , D. & Wilson, D. Relevance: Communication and cognition (Blackwell Publishers Ltd, 1986). 2. Gergely , G., Egyed, K. & Kir ´ aly , I. On pedagogy . De- velopmental science 10, 139–46 (2007). 3. T omasello, M., Carpenter , M., Call, J., T anya, B. & Moll, H. Understanding and sharing intentions: The ori- gins of cultural cognition. Behavioral and brain sci- ences 28, 675–735 (2005). 4. Shafto, P . & Goodman, N. D. in Pr oceedings of the Thir- tieth Annual Confer ence of the Cognitive Science Soci- ety (2008). 5. Shafto, P ., Goodman, N. D. & Frank, M. C. Learning From Others: The Consequences of Psychological Rea- soning for Human Learning. P erspectives on Psyc ho- logical Science 7, 341–351 (2012). 6. Shafto, P ., Goodman, N. D. & Griffiths, T . L. A ratio- nal account of pedagogical reasoning: T eaching by , and learning from, examples. Cognitive psychology 71C, 55–89 (2014). 7. T enenbaum, J. B. & Griffiths, T . L. The rational basis of representativeness. Pr oceedings of the 23rd annual confer ence of the Cognitive Science Society (2001). 8. Balbach, F . J. Measuring teachability using v ariants of the teaching dimension. Theor etical Computer Science 397, 94–113 (2008). 9. Zilles, S., Lange, S., Holte, R. & Zinkevich, M. in COLT 2008 (2008), 135–146. 10. Zhu, X. Machine T eaching for Bayesian Learners in the Exponential Family . Advances in Neural Information Pr ocessing Systems, 1–9 (2013). 11. Patil, K. R., Zhu, X., Kopec, L. & Love, B. C. Opti- mal T eaching for Limited-Capacity Human Learners. Advances in Neural Information Pr ocessing Systems, 2465–2473 (2014). 12. Mei, S. & Zhu, X. The security of latent Dirich- let allocation. Pr oceedings of the Eighteenth Interna- tional Conference on Artificial Intelligence and Statis- tics (2015). 13. Mei, S. & Zhu, X. Using Machine T eaching to Iden- tify Optimal Training-Set Attacks on Machine Learn- ers. T wenty-Ninth AAAI Confer ence on Artificial Intel- ligence, 2871–2877 (2015). 14. Blei, D. M., Ng, A. Y . & Jordan, M. I. Latent Dirichlet Allocation. J ournal of Machine Learning Resear ch 3, 993–1022 (2003). 15. Griffiths, T . L. & Steyv ers, M. Finding scientific topics. Pr oceedings of the National Academy of Sciences of the United States of America 101 Suppl, 5228–35 (2004). 16. Maceachern, S. N., Clyde, M. & Liu, J. S. Sequential importance sampling for nonparametric Bayes models: The next generation. Canadian J ournal of Statistics 27, 251–267 (1999). 17. K ong, A. A Note on Importance Sampling using Stan- dar dized W eights tech. rep. (The Uni versity of Chicago, Chicago, Illinois, 1992). 18. Andrieu, C. & Roberts, G. O. The pseudo-marginal ap- proach for efficient Monte Carlo computations. Annals of Statistics 37, 697–725 (2009). 19. Andrieu, C. & V ihola, M. Con vergence properties of pseudo-mar ginal Markov chain Monte Carlo algo- rithms. 25, 43 (2012). 20. Metropolis, N., Rosenbluth, A. W ., Rosenbluth, M. N., T eller , A. H. & T eller , E. Equation of State Calculations by F ast Computing Machines. The J ournal of Chemical Physics 21, 1087–1092 (1953). 21. Hastings, W . Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57, 97–109 (1970). 22. The Internet Movie Database. IMDb T op 1000 - IMDb 2016. 23. Lee, A. (Director). Brok eback Mountain Focus Fea- tures. 2005. 24. Coppola, F . (Director). Apocalypse Now Zoetrope Stu- dios. 1979. 25. IMDb .com, I. T op 20 Greatest W ar Movies of All T ime (The Ultimate List) ¡ http : / / www . imdb . com / list/ls055731784/ ¿ (2016). 26. V interberg, T . (Director). The Celebr ation Nimb us Film Productions. 1998. 27. V an Dormael, J. (Director). Mr . Nobody Pan Eu- rop ´ eenne. 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment