Temporal Multinomial Mixture for Instance-Oriented Evolutionary Clustering
Evolutionary clustering aims at capturing the temporal evolution of clusters. This issue is particularly important in the context of social media data that are naturally temporally driven. In this paper, we propose a new probabilistic model-based evo…
Authors: Young-Min Kim, Julien Velcin, Stephane Bonnevay
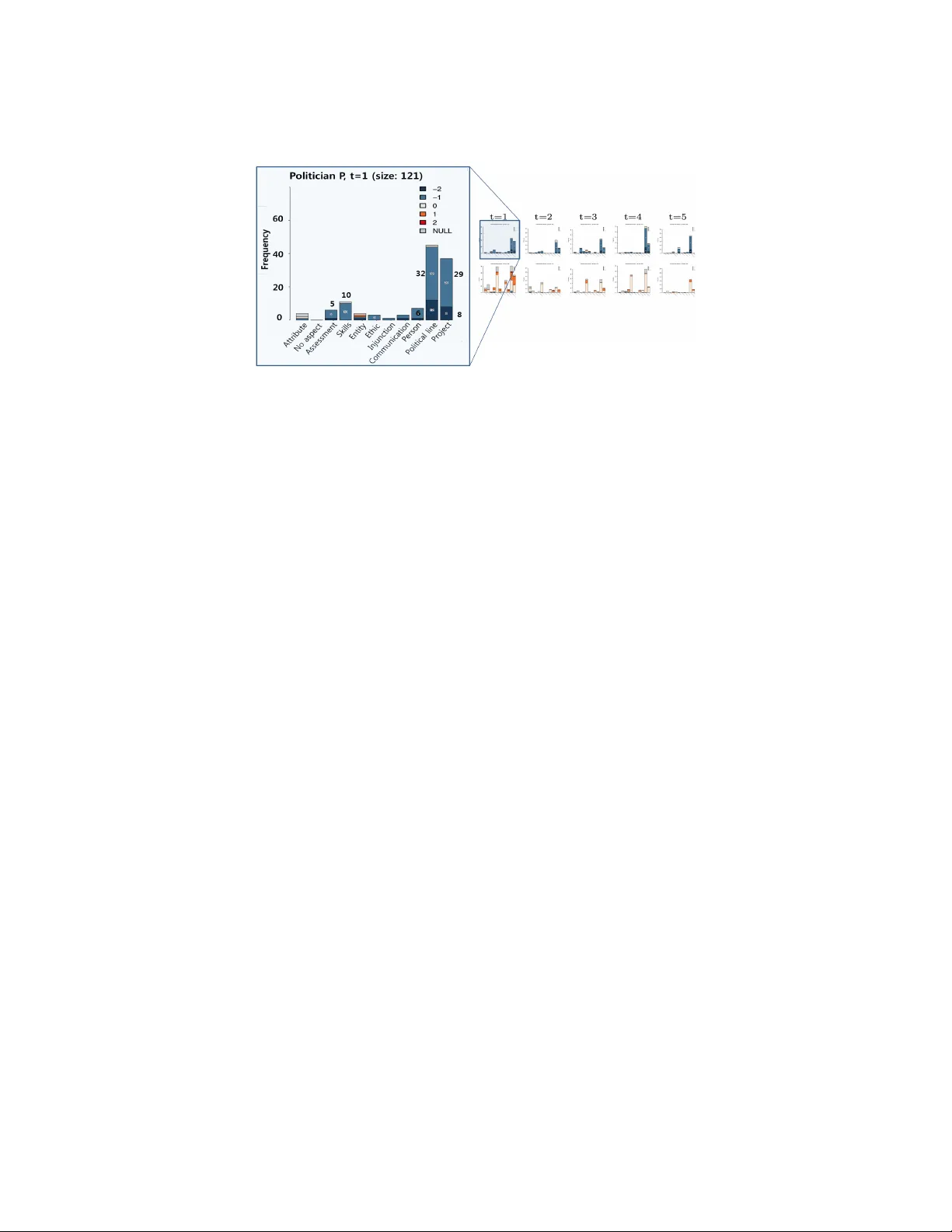
T emp oral Multinomial Mixture for Instance-orien ted Ev olutionary Clustering Y oung-Min Kim † , Julien V elcin ‡ , St ´ ephane Bonnev a y ‡ , and Marian-Andrei Rizoiu ‡ † Korea Ins titute of Science and T echnology Information, South Korea ‡ ERIC Lab., Universit y of Lyon 2, F rance ymkim@kisti.re.kr {julien.velcin, stephane.bonnevay, marian- andrei.rizoiu}@univ- lyon2.fr Abstract. Ev olutionary clustering aims at capturing the temporal evo- lution of clusters. This issue is particularly imp ortan t in the context of so cial media data that are naturally temporally driven. In this pa- p er, we prop ose a new probabilistic mo del-based ev olutionary clustering tec hnique. The T emp oral Multinomial Mixture (TMM) is an extension of classical mixture mo del that optimizes feature co-o ccurrences in the trade-off with temp oral smoothness. Our mo del is ev aluated for t wo re- cen t case studies on opinion aggregation ov er time. W e compare four differen t probabilistic clustering mo dels and w e show the sup eriorit y of our prop osal in the task of instance-oriented clustering. Keyw ords: Ev olutionary clustering, mixture model, temp oral analysis. 1 In tro duction Clustering is a p opular w ay to prepro cess large amount of unstructured data. It can b e used in several wa ys, suc h as data summarization for decision making or representation learning for classification purp ose. Recently , ev olutionary clus- tering aims at capturing temp oral evolution of clusters in data streams. This is different from traditional incremen tal clustering, for ev olutionary clustering metho ds optimize another measure that builds the clustering mo del at time t + 1 by taking into account of the mo del at time t in a retrosp ectiv e manner [1,2,3]. Applications range from clustering photo tags in flickr.com to do cu- men t clustering in textual corp ora. The existing methods fall into tw o different categories. Instanc e-oriente d ev olutionary clustering mostly aims at primarily regrouping ob jects and topic- oriente d ev olutionary clustering aims at estimating distributions ov er comp o- nen ts ( e.g. , w ords). While the former extracts tightest clusters in the feature space, the latter impro ves the smoothness of temp orally consecutiv e clusters. In this w ork, w e focus on developing a new temp oral-driv en mo del of the first category , motiv ated by tw o case studies. W e prop ose a new probabilistic evolutionary clustering metho d that aims at finding dynamic instance clusters. Our model, T emporal Mixture Mo del (TMM), 2 T emp oral Multinomial Mixture is an extension of the classical mixture mo del to categorical data streams. The main no v elty is not to use Dirichlet prior in order to relax smo othness constraint. While our mo del can further b e impro ved in terms of more adv anced prop erties, suc h as learning the num b er of clusters as in non-parametric mo dels [4,5], in this w ork we mainly focus on realizing our basic idea and studying the p erfor- mance of the model. Using in ternal ev aluation measures, w e demonstrate that TMM outp erforms a typical topic-oriente d dynamic mo del and ac hieves similar compactness results with tw o static mo dels. This result is achiev ed at the slight exp ense of cluster smo othing ability through temporal ep o c hs. In the follo wing sections, we first motiv ate and present in detail the proposed TMM mo del. Then we presen t the exp erimental results of TMM as well as three other metho ds of the literature, showing the superiority of our metho d with new t yp e of datasets in opinion mining. Finally we conclude with some persp ectiv es and future w orks. 2 Motiv ation and related work 2.1 Motiv ation Do cumen t clustering and topic extraction are sometimes considered as equiv a- len t problems, and the metho ds desired to address each problem are used inter- c hangeably [6]. How ever, there is a fundamental difference in terms of cluster- ing ob jectiv e b et w een them and this draws a clear algorithmic difference. Ev en though this issue has not b een actively mentioned in the clustering literature, it is indirectly confirmed b y the fact that topic mo deling is not recommended to b e used directly for do cumen t clustering in general. [7] hav e empirically shown that ev en simple mixture mo dels outperform Dirichlet distribution-based topic mo dels for do cumen t clustering, when directly using mo del parameters. A recent w ork [8] is dealing with this issue by prop osing an in tegrated graphical mo del for both document clustering and topic mo deling. How ever, the great success of topic mo dels in unsup ervised learning has often led researchers to use them as instance clustering in practice. This observ ation remains v alid for ev olution- ary clustering, for which one hardly finds an alternative to topic models using Diric hlet smo othing. The situation is identical when dealing with m ore classi- cal categorical data, which is the case of our work. This pap er starts from this significan t issue in evolutionary clustering. T o the b est of our knowledge, this is the first attempt to use a non-Dirichlet mixture mo del for temp oral analysis of data steams. The reason wh y w e abandon Diric hlet prior reflects our (ma yb e p eculiar) p oin t of view tow ards the Dirichlet distribution. That is, the p o wer of topic mo dels mainly comes from their ability to smo othen distributions via the Diric hlet prior. It is effective for extracting represen tative topics or for making inference on new data. How ever, in case of clustering instances, a hast y smoothing of the distributions risks to mix data samples with no common feature. In this paper, target datasets are not neces- sarily textual; therefore the clustering process can be more sensitiv e to this effect than when dealing with a large feature space (suc h as a vocabulary of w ords). In T emp oral Multinomial Mixture 3 (a) (b) (c) (d) Fig. 1: Graphical representation of (a) MM, (b) PLSA, (c) LD A, and (d) DTM. our case, eac h feature b ecomes more imp ortant, thus sp ecial attention m ust be giv en to the actual matching b et ween the cluster distribution and the observ ed feature co-occurrences. This is the reason wh y we decide to build our metho d on top of a simple mixture mo del exp ecting to minimize the discussed risk. 2.2 Related work Our new evolutionary clustering model, T emp or al Multinomial Mixtur e (TMM), has b een designed with the assumption that regrouping non co-o ccurring features is highly prejudicial. TMM is a temp oral extension of the Multinomial Mixtur e (MM), a simple probabilistic generative mo del for clustering. More complex mix- ture mo dels suc h as Pr ob abilistic L atent Semantic Analysis (PLSA) [9] or L atent Dirichlet A l lo c ation (LDA) [10] seem less suitable for clustering non-textual data as men tioned in Section 2.1. Non co-o ccurring features are often mixed together in the same cluster because of additional hidden lay ers added to these mo dels, either for instance-topic distributions (PLSA) or as Dirichlet prior (LDA). The graphical represen tation of these mo dels are giv en in Fig. 1(a)-(c). Despite the obvious difference b et ween our purp ose and dynamic topic mo d- els, since the temp oral approaches in unsupervised learning usually stand on the basis of topic models, it is inevitable to introduce the state-of-the arts of topic mo dels. Most of the curren t tec hniques in clustering in tro ducing a tem- p oral dimension are topic mo dels taking Dirichlet distribution [11,12] since the dev elopment of Dynamic T opic Mo del (DTM, Fig. 1(d)) [13], a simple extension of LDA. This kind of dynamic topic analysis has b een the ob ject of numer- ous studies ov er recent years and more complex mo dels suc h as DMM [11] or MDTM [12] hav e b een developed. In comparison, TMM is muc h simpler and we exp erimen tally show the pow er of simple modeling b y comparing three clustering metho ds, MM, PLSA and DTM with ours. On the other hand, some pioneer works w ere designed for data points that ba- sically last during more than t wo time perio ds. These stand on v arious theoretical bases such as k-means, agglomerativ e hierarc hical metho d, sp ectral clustering, and even generative model [1,2,14]. How ev er, the underlined prop erty of data p oin ts is con trary to the case of data stream, which is our concern here. 4 T emp oral Multinomial Mixture Whatso ev er, sev eral applications in temp oral analysis are in tended for dealing with text corp ora. Being designed for text hinders the “out-of-the-b o x” applica- tion of these methods to unfamiliar data such as image, gene, mark et, net work data etc. In comparison, TMM is an evolutionary clustering dedicated to general categorical datasets. 3 T emp oral Multinomial Mixture W e prop ose T emp oral Multinomial Mixture (TMM) for instance-oriented clus- tering ov er time. TMM is a temp oral extension of MM and the relation b et ween TMM and MM is analogous to that b etw een DTM and LD A. While the ma jor- it y of existing temp oral topic analysis tend to complicate the mo deling pro cess, TMM rather go es against this trend. W e assume that complicated distributional structures confuse the instance-oriented clustering. Therefore our metho d as- sumes the form of a simple mixture mo del. As in many other evolutionary clus- terings and temp oral topic analysis, data instances are asso ciated with a time ep och. A time ep och indicates a time perio d b et ween tw o adjacent moments. Dataset is generally divided into subsets by ep och. Instances are assumed to b e describ ed by features weigh ted with a frequency 1 . 3.1 Generativ e process The graphical represen tation of TMM is given in Fig. 2. The extension from MM is realized by enco ding the temp oral dep endency in to the relation betw een data comp onen ts w of the current ep och and the clusters z of the previous ep o c h. The generation pro cess of an instance d t = i at the ep och t is as follows: Fig. 2: Graphical represen tation of a temp oral m ultinomial mixture mo del – Cho ose a cluster z t − 1 i with probabilit y p ( z t − 1 i ). – Cho ose a cluster z t i with probabilit y p ( z t i ). – Generate an instance d t = i with probability p ( d t = i | z t − 1 i , z t i ) when t > 1 or with p ( d 1 = i | z 1 i ) when t = 1. 1 F or the sake of understanding, the reader can see a feature as a unique w ord ov er a vocabulary and a data comp onen t as a word occurrence in a do cumen t even if an instance is not a do cumen t here. T emp oral Multinomial Mixture 5 T able 1: Notations Symbol Description d t instance d at epo c h t w t im m th comp onen t in the instance d t = i at ep och t z t i assigned cluster for instance d t = i at ep och t D t sequence of instances at epo c h t Z t sequence of cluster assignmen ts for D t D sequence of all instances, D = ( D 1 , D 2 , ..., D T ) Z sequence of cluster assignmen ts for D , Z = ( Z 1 , Z 2 , ..., Z T ) T num ber of epo c hs | D t | num ber of instances at ep och t M t d num ber of components in the instance d at ep och t V num ber of unique comp onen ts (num b er of features) K num b er of clusters φ t k multinomial distribution of cluster k o ver components at ep och t π t k prior probability of cluster k at ep och t α weigh t for the component generation from the clusters of previous ep och, 0 < α < 1 The last step is realized by rep eatedly generating the comp onents w t im , ∀ m , sequen tial features in the instance d t = i , as illustrated in the graphical rep- resen tation. Unlik e most temp oral graphical mo dels, it is a connected netw ork considering the correlation of all topics of t and t − 1. The notations used in TMM are sho wn in T able 1. W e mostly referred the notations in [15] and [16]. Because of the v ariable dep endency b et ween differen t time epo c hs, w e need se- quen tial expression of features. This is the reason why we cannot use the simple notation of MM. 3.2 P arameter estimation via approximate dev elopment The ob jective function to b e maximized is the exp ectation of log-lik eliho o d [17]: E ( ˜ L ) = X Z p ( Z | D , Θ old ) · log ( p ( D , Z | Θ )) (1) Because of the dep endency b et w een the v ariables z t and z t − 1 , the log-likelihoo d cannot b e simplified using marginalized latent v ariables as in MM or PLSA. Instead, we start with the joint distribution of instances and assigned clusters (laten t v ariables): p ( D , Z ) = | D 1 | Y d =1 p ( z 1 d ) · p ( d 1 | z 1 d ) T Y t =2 | D t | Y d =1 p ( z t d ) · p ( d t | z t d , z t − 1 d ) (2) Eq. 1 can b e simplified by taking only the v alid latent v ariables p er term: E ( ˜ L ) = | D 1 | X i =1 K X k =1 p ( z 1 i = k | d 1 = i ) log { p ( z 1 i = k ) p ( d 1 = i | z 1 i = k ) } + T X t =2 | D t | X i =1 K X k =1 K X k 0 =1 p ( z t i = k , z t − 1 i = k 0 | d t = i ) log { p ( z t i = k ) p ( d t = i | z t i = k , z t − 1 i = k 0 ) } (3) 6 T emp oral Multinomial Mixture A t ep och 1, p ( d 1 = i | z 1 i = k ) can be rewritten using φ 1 k and n 1 i,j , the frequency of unique comp onen t j included in the instance i , such as Q V j =1 ( φ 1 k,j ) n 1 i,j . On the other hand, the instance generation at ep o c h t , ∀ t ≥ 2 is dep enden t also on the clusters of the previous ep och. Thus the conditional probability of an instance i given current and previous clusters k and k 0 , is inferred as follo ws with Ba yes Rule: p ( d t = i | z t i = k ,z t − 1 i = k 0 )= M t i Y m =1 p ( z t i = k | w t im ,z t − 1 i = k 0 ) p ( z t − 1 i = k 0 | w t im ) p ( w t im ) p ( z t i = k ,z t − 1 i = k 0 ) (4) Under the assumptions of graphical model, the analytical calculation of p ( z t i | w t im , z t − 1 i ) is so complicated because the laten t v ariables are related b y the explain- ing a wa y effect. T o tac kle this issue, we make an imp ortan t hypothesis that p ( z t i | w t im , z t − 1 i ) can b e appr oximate d by p ( z t i | w t im ). Consequen tly , Eq. 4 is rewrit- ten using p ( w t im = j | z t i = k ) as w ell as p ( w t im = j | z t − 1 i = k 0 ), which is equiv alent to the previous ep o c h’s parameter φ t − 1 k 0 ,j . Penalizing the influence rate of the previous cluster with α , a w eighted parameter v alue ( φ t − 1 k 0 ,j ) α , 0 < α < 1 is used instead of φ t − 1 k 0 ,j . Letting the constant Q M t i m =1 1 /p ( w t im ) be C t i , w e obtain the follo wing equation. p ( d t = i | z t i = k , z t − 1 i = k 0 ) = C t i · V Y j =1 ( φ t k,j ) n t i,j ( φ t − 1 k 0 ,j ) α · n t i,j (5) Using the parameters Θ , the E ( ˜ L ) b ecomes: E ( ˜ L )= | D 1 | X i =1 K X k =1 p ( z 1 i = k | d 1 = i ) · ( log π 1 k + V X j =1 n 1 i,j · log φ 1 k,j ) + T X t =2 | D t | X i =1 K X k =1 K X k 0 =1 p ( z t i = k ,z t − 1 i = k 0 | d t = i ) · ( log π t k +log C t i + V X j =1 n t i,j · log φ t k,j + α · log φ t − 1 k 0 ,j ) 3.3 EM algorithm W e solv e the following optimization problem to obtain the parameter v alues. arg max Θ E ( ˜ L ) , sub ject to V X j =1 φ t k,j = 1 , ∀ t, k and K X k =1 π t k = 1 , ∀ t. The EM algorithm is up dated as follows. Initialization Randomly initialize parameters Θ = { φ t k , π t k | ∀ t, k } sub ject to V X j =1 φ t k,j = 1 , ∀ t, k and K X k =1 π t k = 1 , ∀ t. T emp oral Multinomial Mixture 7 E-step Compute the exp ectation of p osteriors as follows. p ( z t i = k , z t − 1 i = k 0 | d t = i )= Q V j =1 ( φ t k,j ) n t i,j ( φ t − 1 k 0 ,j ) α · n t i,j · π t k · π t − 1 k 0 K P a =1 K P a 0 =1 Q V j =1 ( φ t a,j ) n t i,j ( φ t − 1 a 0 ,j ) α · n t i,j · π t a · π t − 1 a 0 , 2 ≤ t ≤ T , ∀ k , k 0 , i. (6) p ( z 1 i = k | d 1 = i ) is similarly calculated b y eliminating the v ariables of t − 1. M-step Up date the parameters maximizing the ob jective function. φ t k,j = | D t | P i =1 K P k 0 =1 n t i,j · p ( z t = k ,z t − 1 = k 0 | d t = i )+ | D t +1 | P i =1 K P k 0 =1 α · n t +1 i,j · p ( z t +1 i = k 0 ,z t i = k | d t +1 = i ) | D t | P i =1 V P j 0 =1 K P k 0 =1 n t i,j 0 · p ( z t = k ,z t − 1 = k 0 | d t = i )+ | D t +1 | P i =1 V P j 0 =1 K P k 0 =1 α · n t +1 i,j 0 · p ( z t +1 i = k 0 ,z t i = k | d t +1 = i ) , 2 ≤ t ≤ T − 1 , ∀ j, k . (7) φ 1 k,j is calculated b y eliminating the v ariables of t − 1 from the ab o v e form ula and φ T k,j is done b y eliminating b oth v ariables and terms of t + 1. π t k = | D t | P i =1 K P k 0 =1 p ( z t = k ,z t − 1 = k 0 | d t = i )+ | D t +1 | P i =1 K P k 0 =1 p ( z t +1 i = k 0 ,z t i = k | d t +1 = i ) | D t | P i =1 K P a =1 K P k 0 =1 p ( z t = a,z t − 1 = k 0 | d t = i )+ | D t +1 | P i =1 K P k 0 =1 K P a =1 p ( z t +1 i = k 0 ,z t i = a | d t +1 = i ) , (8) 2 ≤ t ≤ T − 1 , ∀ k π 1 k and π T k are calculated as in φ 1 k,j and φ T k,j . 3.4 Instance assignment and cluster ev olution The assignment of eac h instance is even tually obtained from the estimated dis- tributions. F or t = 1, w e assign to the instance i the cluster that maximizes the posterior probability p ( z 1 i = k | d 1 = i ). F or the instances in the other ep ochs, w e in tegrate out z t − 1 i to obtain the instance cluster suc h that p ( z t i = k | d t = i )= P K k 0 =1 p ( z t i = k , z t − 1 i = k 0 | d t = i ) . TMM b eing a connected netw ork, all the clusters in the ep och t − 1 can con tribute to the clusters in the ep och t . Please note that the same cluster index in different ep ochs do es not mean that the corresp onding clusters are iden tical o ver time. That is wh y w e need to find which cluster of the previous ep och con tributes most to the specific cluster k of the curren t ep och. The dy- namic correlation b etw een clusters of the adjacent epo c hs is fully enco ded in the distribution p ( z t i = k , z t − 1 i = k 0 | d t = i ). By integrating out z t i instead of z t − 1 i from p ( z t i = k , z t − 1 i = k 0 | d t = i ), w e can deduce the most lik ely cluster at the previous 8 T emp oral Multinomial Mixture ep och for the instance d t = i . W e call it the origin of the instance. Giv en the sp ecific cluster z t = k , w e hav e the classified instances and their origins. By coun ting we find the most frequen t origin and we can even tually relate the most influen tial cluster of the previous ep o c h to z t = k . Since this is a surjective func- tion from t to t − 1, the division of a cluster o ver time is traceable. Con versely , the merge of multiple clusters can also b e caught if we choose not only the most lik ely cluster but also the second or the third likely one. 4 Exp erimen ts W e compare four differen t generative mo dels in order to ev aluate the p erfor- mance of TMM. DTM is selected as a Dirichlet-based model; MM and PLSA are used as static baselines for highlighting the effect of introducing a temp o- ral dimension. Finally , w e show that TMM outp erforms the other models on t wo datasets of opinion mining, b y finding a trade-off b etw een compactness and temp oral smo othing. 4.1 Datasets ImagiWeb p olitic al opinion dataset 2 The first dataset is comprised of a set of ab out 7000 unique tw eets related to t wo p oliticians (each p olitician is analyzed separately). The manual annotation pro cess has b een sup ervised by domain ex- p erts of public opinion analysis and it has follo wed a detailed procedure with the design of 9 asp ects ( e.g. , pro ject, ethic or political line) targeted by 6 p ossi- ble opinion polarities (-2=very negative, -1=negative, 0=neutral, +1=p ositive, +2=v ery p ositiv e, NULL=ambiguous). F or instance, the t weet “R T @anonym: P’s pro ject is just hot air” can b e describ ed by the pair (project,-2) attached to the politician P . Each pair corresp onds to a feature w whose v alue is the o ccurrence of the corresponding opinion for describing the studied entit y . The full pro cedure and dataset are describ ed in [18]. Because of the length limit of a tw eet as well as for clustering purp ose, w e decide to com bine the annotations b y author for each time ep o c h. R epL ab 2013 Corpus This corpus has b een used for the RepLab 2013, second ev aluation campaign on Online Reputation Management. It consists of a collec- tion of t weets referring to 61 en tities from four domains. W e select t w o dominant domains out of four, automativ e and music, where the num ber of entities is 20 re- sp ectiv ely . The clustering is done for eac h domain separately this time instead of en tity . Tweets are annotated with three polarities: positive, negativ e and neutral. W e let the features b e the entity-p olarity pairs instead of aspect-p olarit y pairs, so that the opinion aggregation is based on co-occurring entities. It means that the opinion groups are constructed by users, who are interested in same entities with similar p olarities. T ab. 2 sums up basic statistics on the tw o datasets. 2 It will be distributed to the public in Spring 2015 on the ImagiW eb official w ebsite, h ttp://mediamining.univ-lyon2.fr/v elcin/imagiweb. T emp oral Multinomial Mixture 9 T able 2: Statistics of datasets and features w e define. ImagiW eb opinion dataset RepLab 2013 source Political opinion t weets English & Spanish opinion t weets annotation size 11527 tw eets (7283 unique) 26709 tw eets (all unique) subsets Entit y (p olitician P , p olitician Q) Domain (automative, music) feature space Aspect-p olarity pairs Entit y-polarity pairs 9 asp ects, 6 p olarities 20 entities per domain, 3 p olarities 4.2 Ev aluation Measures The ground truth is hardly a v ailable when ev aluating clustering output for ev olu- tionary clustering. W e instead develop the follo wing three quantitativ e measures with the ob ject of well detecting clustering quality . Co-o c curr enc e level. Our main interest lies in detecting compact clusters, whic h means that the n umber of observed co-occurring features actually matc h the estimated distribution. This measure counts the real num b er of co-o ccurring feature couples in eac h sample among the non-zero features grouped in a cluster. Unsmo othness. This catches the dissimilarity b et ween corresp onding clus- ters through differen t time epo c hs using Kullback-Leibler (KL) divergence. If a temporal clustering metho d well detects the evolution of clusters, the cluster signatures having same identit y w ould b e similar to each other. Therefore w e dev elop ‘unsmo othness’ to measure ho w suddenly a cluster changes ov er time. Homo geneity. This measures the degree of unanimity of group ed t weets in a cluster in terms of p olarit y . Opp osite opinions hardly co-o ccur b ecause an author usually keep his opinion stance in a sufficien tly short time. By ignoring the degree of p olarit y , the homogeneity of a cluster is simply defined as follows 3 : Homogeneit y = ( | #(p ositiv e) − #(negative) | ) / (#(positive) + #(negativ e)) This is intuitiv e and easy to b e visually represented but is an indirect ev aluation. 4.3 Result Clustering is conducted at subset lev el. F or a giv en clustering metho d and subset, exp erimen ts are rep eated 10 times b y c hanging initialization to get the statistical significance. Since MM and PLSA are time-indep enden t, temp oral clusters are obtained via tw o stages: normal clustering p er ep och and heuristic matc hing b et w een clusters of tw o adjacent ep ochs judged by their distributional form. The first sub-table of T able 3 shows the experimental results of four methods on the ImagiW eb dataset. Once clustering is done p er subset, w e merge the results to analyze together the reputation of t w o competitors. The n umber of ep ochs is fixed at t wo by splitting data by an actual important p olitical even t date. Each v alue is the av eraged result of 10 exp erimen ts as well as the standard deviation in brac kets. The bold num b er indicates the b est result among four metho ds and the underlined one is the second best. The gra y background of b old num b er means the result statistically outp erforms the second b est and the ligh t-gray means it do es not outp erform the second b est, but do es the third one. 3 #(p olarit y) is the num b er of tw eets annotated with this p olarit y . 10 T emp oral Multinomial Mixture T able 3: Ev aluation of temp oral clustering for four metho ds on ImagiW eb opinion dataset(left) and RepLab 2013 for automativ e(middle) and music(righ t). ImagiW eb opinion dataset TMM DTM MM PLSA Avg. Homogen. 0.86 0.70 0.86 0.67 (stand. deviation) (0.02) (0.06) (0.02) (0.05) Co-occurr. lev el 123 113 122 111 (stand. deviation) (1.98) (1.02) (0.88) (1.48) Avg. Unsmo oth. 2.27 1.57 3.16 3.61 (stand. deviation) (0.23) (0.10) (0.33) (0.21) RepLab(Auto) TMM DTM MM PLSA 0.76 0.67 0.73 0.70 (0.02) (0.05) (0.03) (0.04) 40 34 40 33 (1.21) (1.18) (0.58) (1.52) 4.30 1.37 6.35 6.91 (0.90) (0.12) (0.82) (0.69) RepLab(Music) TMM DTM MM PLSA 0.77 0.75 0.75 0.76 (0.03) (0.05) (0.02) (0.03) 26 22 25 22 (0.74) (0.80) (0.40) (0.35) 4.5 2.54 6.12 7.75 (0.90) (0.51) (0.87) (1.11) The v alue of α in TMM has b een set to 0 . 7 after several pre-exp erimen ts judged b y visual represen tation of clusters (as sho wn in Fig. 3) as w ell as balance among cluster sizes. W e man ually c ho ose the v alue by v arying α from 0 . 5 to 1. Larger v alue increases distributional similarity whereas decreases separation of opp osite opinions. The hyper parameters of DTM ha ve also been set to the best ones after sev eral exp erimen ts. Globally , TMM outp erforms the others in terms of tw o measures except unsmo othness. Then DTM and MM are in the second place. PLSA pro duces the w orst result for all measures. Since homogeneity is a direct basis to ev aluate if the tested method well detects the difference b et ween negative and positive opinion groups, it b ecomes more imp ortant when the mix of opp osite opinions is a crucial error. Co-o ccurrence level also directly shows if the captured clusters are really based on the co-occurring features. Given that both measures ev aluate cluster quality of a specific time ep och, it is encouraging that TMM pro vides iden tical or even slightly b etter result than MM b ecause TMM can b e thought of as a relaxed version of MM in the p oin t of view of data adjustmen t ov er time. The result therefore demonstrates that TMM successfully makes use of the generativ e adv an tage of MM. F or homogeneit y , TMM and MM b oth obtain 0 . 86, whic h perfectly outp erform the second b est DTM in terms of Mann-Whitney test with the p-v alue of 0.00001. Mean while, for unsmo othness the b est one is DTM with a clearly b etter result, 1 . 57 than the others. DTM concen trates on the distribution adjustment ov er time at the exp ense of well grouping opinions that is the principal ob jectiv e in the task. The second b est TMM also p erfectly outp erforms MM with the p-v alue of 0.0002. It prov es the time dep endency enco ded in TMM successfully enhances MM for capturing cluster evolution. In addition to the quan titative ev aluation, we visualize a TMM clustering result in Fig. 3. It is the evolution of tw o clusters with five different time ep ochs on p olitician P subset. The zo omed figure shows a negative group ab out P at ep och 1 esp ecially on the asp ects “p olitical line” and “pro ject”. TMM captures the dynamics of the cluster ov er time as shown in the figure. As time go es b y , opinions ab out “pro ject” disapp ear (at t=5) but the other negativ e opinions ab out “ethic” app ear in the cluster. The cluster in the second line groups mainly p ositiv e and neutral opinions ab out v arious asp ects at ep och 1, but some asp ects gradually disapp ear with time. The exp erimen tal results on RepLab 2013 corpus are giv en in the middle and righ t sub-tables in T able 3. Number of ep ochs is also fixed at t wo and the T emp oral Multinomial Mixture 11 Fig. 3: Visualization of the evolution of tw o clusters extracted from a TMM clustering result with fiv e different time ep o c hs on p olitician P subset. data is split by the median date. This corpus is not originally constructed for opinion aggregation, therefore w e do not ha ve sufficient feature co-o ccurrences. The proportion of instances ha ving at least tw o components is only 5 . 2% for automativ e and 2 . 9% for music. Despite the handicap, w e rather expect that w e w ould emphasize the characteristics of each mo del via exp erimen ts with this restrictiv e datase t. The α v alue has b een set to 1 to mak e maximum use of the effect of previous clusters regarding lac k of co-o ccurrences. Tw o outstanding metho ds are TMM and DTM but there is an ob vious dif- ference b et w een their results. TMM gives a b etter p erformance in terms of lo cal clustering quality suc h as homogeneity and co-occurrence whereas DTM outp er- forms the others in temp oral view. Homogeneity do es not seem really meaning- ful here b ecause the opp osite opinions ab out different entities can be naturally mixed in an opinion group. Ho wev er, from the fact that co-o ccurring features are rarely observed and, moreov er, only 10% of total opinions are negativ e in the corpus, negativ e and p ositiv e opinions seldom co-o ccur. Therefore, the high homogeneit y can be a significan t measure here also. As in the ImagiW eb dataset, the co-occurrence lev el of TMM is clearly b etter than that of DTM. On the other hand, ev en though DTM giv es a p erfectly b etter result for unsmo othness, the captured distributions are not really based on the real co-occurrences when w e man ually verify the result. Nev ertheless, when the dataset is extremely sparse as in this case, smoothing distribution would anyw ay provide the opp ortunit y not to ignore rarely co-o ccurring features. 5 Conclusions The prop osed TMM mo del succeeds in effectively extending MM, by taking in to consideration the temp oral factor for clustering. Our method captures the dynamics of clusters m uc h b etter than the heuristic matc hing of single clustering results using MM or PLSA, without losing clustering qualit y at local time epo c h. TMM clearly outp erforms DTM in terms of lo cal cluster quality . DTM tends to pro duce well-smoothed distributions ov er time, but as shown through its lo w p erformance with the other measures, high smo othness do es not alwa ys signify that the cluster ev olution is well detected. 12 T emp oral Multinomial Mixture An inheren t hypothesis in TMM is that clusters evolv e progressively ov er time and it has enabled the mo deling of direct dep endency betw een t wo adjacent ep ochs. How ev er if abrupt c hanges arrive, the distributions found for each cluster can b e incoherent. A future developmen tal direction is taking such changes in to accoun t. A p ossible wa y could b e to establish an automatic adjustmen t of the dep endency rate α . Another interesting direction is to dev elop means to infer more exactly the conditional probabilit y p ( z t i | w t im , z t − 1 i ). Ac knowledgmen ts. This work w as funded by the pro ject ImagiW eb ANR- 2012-CORD-002-01. References 1. Chakrabarti, D., Kumar, R., T omkins, A.: Ev olutionary clustering. In: KDD ’06, A CM (2006) 554–560 2. Chi, Y., Song, X., Zhou, D., Hino, K., Tseng, B.L.: Evolutionary sp ectral clustering b y incorp orating temp oral smoothness. In: KDD ’07, ACM (2007) 153–162 3. Xu, T., Zhang, Z.M., Y u, P .S., Long, B.: Dirichlet pro cess based evolutionary clustering. In: ICDM ’08, IEEE Computer So ciet y (2008) 648–657 4. T eh, Y., M. Jordan, M.B., Blei, D.: Hierarchical Dirichlet processes. Journal of the American Statistical Asso ciation 101 (476) (2006) 1566–1581 5. Ahmed, A., Xing, E.: Dynamic non-parametric mixture models and the recurrent c hinese restaurant pro cess : with applications to evolutionary clustering. In: SIAM In ternational Conference on Data Mining. (2008) 6. Zhang, J., Song, Y., Zhang, C., Liu, S.: Evolutionary hierarchical Dirichlet pro- cesses for m ultiple correlated time-v arying corp ora. In: KDD ’10, ACM 1079–1088 7. P essiot, J.F., Kim, Y.M., Amini, M.R., Gallinari, P .: Impro ving document cluster- ing in a learned concept space. Inform. Process. & Manag. 46 (2) (2010) 180–192 8. Xie, P ., Xing, E.P .: In tegrating document clustering and topic modeling. In: UAI. (2013) 9. Hofmann, T.: Probabilistic latent seman tic analysis. In: UAI ’99. (1999) 289–296 10. Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent Dirichlet allo cation. J. Mach. Learn. Res. 3 (2003) 993–1022 11. W ei, X., Sun, J., W ang, X.: Dynamic mixture mo dels for m ultiple time series. In: IJCAI’07, Morgan Kaufmann Publishers Inc. (2007) 2909–2914 12. Iwata, T., Y amada, T., Sakurai, Y., Ueda, N.: Online m ultiscale dynamic topic mo dels. In: KDD ’10, ACM (2010) 663–672 13. Blei, D.M., Lafferty , J.D.: Dynamic topic mo dels. In: International conference on Mac hine learning. ICML ’06, ACM (2006) 113–120 14. Lin, Y.R., Chi, Y., Zhu, S., Sundaram, H., Tseng, B.L.: F acetnet: a framew ork for analyzing communities and their evolutions in dynamic netw orks. In: WWW ’08, A CM (2008) 685–694 15. AlSumait, L., Barbar´ a, D., Domeniconi, C.: On-line LDA: Adaptiv e topic mo dels for mining text streams with applications to topic detection and tracking. In: ICDM ’08, IEEE Computer So ciet y (2008) 3–12 16. He, Y., Lin, C., Gao, W., W ong, K.F.: Dynamic join t sentimen t-topic model. ACM T ransactions on Intelligen t Systems and T ec hnology (2013) 17. Bishop, C.M.: Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-V erlag New Y ork, Inc., Secaucus, NJ, USA (2006) 18. V elcin, J., et al.: Inv estigating the image of entities in so cial media: Dataset design and first results. In: LREC ’14, ELRA (2014)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment