Parallelizing Gaussian Process Calculations in R
We consider parallel computation for Gaussian process calculations to overcome computational and memory constraints on the size of datasets that can be analyzed. Using a hybrid parallelization approach that uses both threading (shared memory) and mes…
Authors: Christopher J. Paciorek, Benjamin Lipshitz, Wei Zhuo
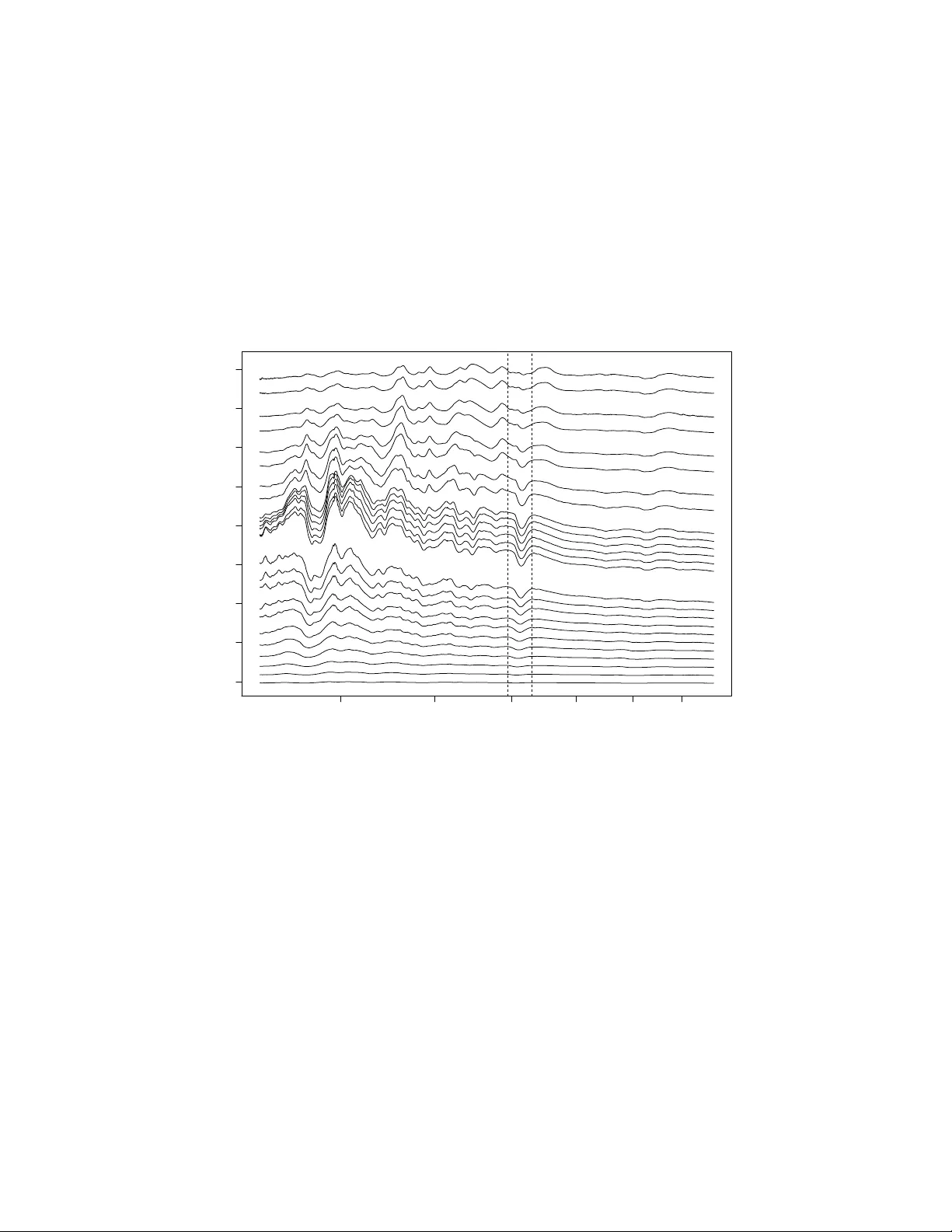
P arallelizing Gaussian Pro cess Calculations in R Christopher J. P aciorek, Benjamin Lipshitz, W ei Zh uo, Prabhat, Cari G. Kaufman, Rollin C. Thomas Septem b er 1, 2018 Departmen t of Statistics, Univ ersity of California, Berkeley , Departmen t of Electrical Engineering and Computer Science, Univ ersity of California, Berkeley , College of Computing, Georgia Institute of T echnology , Computational Research Division, La wrence Berk eley National Lab oratory , Departmen t of Statistics, Univ ersity of California, Berkeley , Computational Cosmology Cen ter, La wrence Berk eley National Lab oratory Abstract W e consider parallel computation for Gaussian pro cess calculations to ov ercome computational and memory constraints on the size of datasets that can be analyzed. Using a hybrid parallelization approac h that uses b oth threading (shared memory) and message-passing (distributed memory), w e implement the core linear algebra op- erations used in spatial statistics and Gaussian pro cess regression in an R pack age called bigGP that relies on C and MPI . The approac h divides the matrix into blo c ks suc h that the computational load is balanced across pro cesses while communication b et w een pro cesses is limited. The pac k age pro vides an API enabling R programmers to implement Gaussian pro cess-based metho ds b y using the distributed linear algebra op erations without any C or MPI co ding. W e illustrate the approach and softw are by analyzing an astroph ysics dataset with n = 67 , 275 observ ations. Keyw ords: distributed computation, kriging, linear algebra 1 In tro duction Gaussian pro cesses are widely used in statistics and mac hine learning for spatial and spatio- temp oral mo deling [Banerjee et al., 2003], design and analysis of computer exp erimen ts [Kennedy and O’Hagan, 2001], and non-parametric regression [Rasm ussen and Williams, 2006]. One p opular example is the spatial statistics metho d of kriging, whic h is equiv alent to conditional exp ectation under a Gaussian pro cess mo del for the unkno wn spatial field. Ho wev er standard implemen tations of Gaussian pro cess-based metho ds are computationally in tensive b ecause they inv olve calculations with co v ariance matrices of size n b y n where n is the n um b er of lo cations with observ ations. In particular the computational bottleneck is 1 generally the Cholesky decomp osition of the co v ariance matrix, whose computational cost is of order n 3 . F or example, a basic spatial statistics mo del (in particular a geostatistical mo del) can b e sp ecified in a hierarc hical fashion as Y | g , θ ∼ N ( g , C y ( θ )) g | θ ∼ N ( µ ( θ ) , C g ( θ )) where g is a v ector of latent spatial pro cess v alues at the n lo cations, C y ( θ ) is an error co v ariance matrix (often diagonal), µ ( θ ) is the mean vector of the latent pro cess, C g ( θ ) is the spatial co v ariance matrix of the laten t pro cess, and θ is a vector of unkno wn parameters. W e can marginalize ov er g to obtain the marginal likelihoo d Y | θ ∼ N( µ ( θ ) , C ( θ )) where C ( θ ) = C y ( θ ) + C g ( θ ). This gives us the marginal densit y , f ( y ) ∝ | C ( θ ) | − 1 / 2 exp − 1 2 ( y − µ ( θ )) > ( C ( θ )) − 1 ( y − µ ( θ )) , whic h is maximized ov er θ t ofind the maximum likelihoo d estimator. A t each iteration in maximization of the log-lik eliho o d, the exp ensive computations are to compute the en tries of the matrix C ( θ ) as a function of θ , calculate the Cholesky decomposition, LL T = C ( θ ), and solv e a system of equations L − 1 ( y − µ ( θ )) via a bac ksolv e op eration. Given the MLE, ˆ θ , one might then do spatial prediction, calculate the v ariance of the prediction, and sim ulate realizations conditional on the data. These additional tasks inv olve the same expensive computations plus a few additional closely-related computations. In general the Cholesky decomp osition will b e the rate-limiting step in these tasks, al- though calculation of cov ariance matrices can also b e a b ottleneck. In addition to compu- tational limitations, memory use can b e a limitation, as storage of the cov ariance matrix in volv es n 2 floating p oint s. F or example, simply storing a co v ariance matrix for n = 20 , 000 observ ations in memory uses appro ximately 3.2 GB of RAM. As a result of the computa- tional and memory limitations, standard spatial statistics metho ds are t ypically applied to datasets with at most a few thousand observ ations. T o o vercome these limitations, a small industry has arisen to dev elop computationally- efficien t approac hes to spatial statistics, in v olving reduced rank appro ximations [Kammann and W and, 2003, Banerjee et al., 2008, Cressie and Johannesson, 2008], tap ering the co v ari- ance matrix to induce sparsit y [F urrer et al., 2006, Kaufman et al., 2008], approximation of the likelihoo d [Stein et al., 2004], and fitting local mo dels b y stratifying the spatial domain [Gramacy and Lee, 2008], among others. At the same time, computer scien tists ha v e dev el- op ed and implemented parallel linear algebra algorithms that use mo dern distributed mem- ory and m ulti-core hardw are. Rather than mo difying the statistical mo del, as statisticians ha ve focused on, here we consider the use of parallel algorithms to ov ercome computational limitations, enabling analyses with muc h larger cov ariance matrices than would be otherwise p ossible. W e presen t an algorithm and R pack age, bigGP , for distributed linear algebra calculations fo cused on those used in spatial statistics and closely-related Gaussian pro cess regression 2 metho ds. The approach divides the co v ariance matrix (and other necessary matrices and v ectors) into blo c ks, with the blo cks distributed amongst pro cessors in a distributed com- puting environmen t. The algorithm builds on that encoded within the widely-used parallel linear algebra pac k age, ScaLAPACK [Blac kford et al., 1987], a parallel extension to the stan- dard LAP A CK [Anderson, 1999] routines. The core functions in the bigGP pac k age are C functions, with R wrapp ers, that rely on standard BLAS [Dongarra et al., 1990] functionality and on MPI for message passing. This set of core functions includes Cholesky decomp osition, forw ard and bac ksolv e, and crosspro duct calculations. These functions, plus some auxiliary functions for comm unication of inputs and outputs to the pro cesses, provide an API through whic h an R programmer can implemen t methods for Gaussian-pro cess-based computations. Using the API, we pro vide a set of metho ds for the standard op erations inv olv ed in kriging and Gaussian pro cess regression, namely • likelihoo d optimization, • prediction, • calculation of prediction uncertain t y , • unconditional simulation of Gaussian pro cesses, and • conditional simulation giv en data. These metho ds are provided as R functions in the pack age. W e illustrate the use of the soft ware for Gaussian pro cess regression in an astrophysics application. 2 P arallel algorithm and soft w are implemen tation 2.1 Distributed linear algebra calculations P arallel computation can b e done in b oth shared memory and distributed memory con texts. Eac h uses multiple CPUs. In a shared memory context (such as computers with one or more c hips with multiple cores), multiple CPUs ha v e access to the same memory and so- called ’threaded’ calculations can be done, in which co de is written (e.g., using the op enMP proto col) to use more than one CPU at once to carry out a task, with eac h CPU having access to the ob jects in memory . In a distributed memory context, one has a collection of no des, eac h with their own memory . An y information that must b e shared with other no des m ust b e done via message-passing, such as using the MPI standard. Our distributed calculations use b oth threading and message-passing to exploit the capabilities of mo dern computing clusters with mult iple-core no des. W e b egin b y describing a basic parallel Cholesky decomp osition, whic h is done on blo cks of the matrix and is implemented in ScaLAPACK . Fig. 1 sho ws a sc hematic of the blo ck-wise Cholesky factorization, as w ell as the forwardsolv e op eration, where a triangular matrix is divided in to 10 blo cks, a B = 4 b y B = 4 arra y of blo c ks. The arrows show the dependence of eac h blo c k on the other blocks; an arro w connecting tw o blo c ks stored on differen t no des indicates that communication is necessary b et ween those no des. F or the Cholesky decom- p osition, the calculations for the diagonal blo c ks all inv olve Cholesky decomp ositions (and 3 covariance marix factorized result Covariance Factorization 1(1,1) 2(2,1) 3(3,1) 8(3,3) 9(4,3) 5(2,2) 4(4,1) 7(4,2) 6(3,2) 10(4,4) Forwardsolve 1(1,1) 2(2,1) 3(3,1) 8(3,3) 9(4 ,3) 5(2,2) 4( 4 ,1) 7(4 ,2) 6(3,2) 10(4,4) 3(3 ,1) 6(3 ,2) 9(4,3) 9(4 ,3) 4 (4,1) 4(4 ,1) 7(4,2) 7(4 ,2) Figure 1: Dependency graphs for the distributed Cholesky factorization and forw ardsolve. The lab els of the form “X(Y,Z)” indicate the pro cess ID (X) and Cartesian co ordinate iden tifier of the process (Y,Z). symmetric matrix m ultiplication for all but the first pro cess), while those for the off-diagonal blo c ks in v olv e forw ardsolv e op erations and (for all but the first column of pro cesses) matrix m ultiplication and subtraction. Most of the total work is in the matrix m ultiplications. The first blo ck must b e factored b efore the forw ardsolve can b e applied to blo cks 2-4. After the forwardsolv es, all the remaining blo cks can b e up dated with a matrix m ultiplication and subtraction. A t this p oin t the decomposition of blo c ks 1-4 is complete and they will not b e used for the rest of the computation. This process is rep eated along eac h blo ck column, so for example blo cks 8-10 must wait for blo cks 6 and 7 to finish b efore all the necessary comp onen ts are a v ailable to finish their o wn calculations. T o sp ecify the distributed algorithm, there are several c hoices to be made: the num b er of blo c ks, B , how to distribute these blo c ks among the pro cesses, ho w to distribute these pro cesses among the no des, and how many no des to use. W e discuss the tradeoffs in volv ed in these c hoices b elow and the c hoices that our algorithm makes in Section 2.2. Giv en a matrix of a giv en size, specifying the n umber of blo cks is equiv alen t to c ho osing the size of the blo c ks. Larger blo cks allo w for more efficien t lo cal computations and less total comm unication. The largest effect here is the on-no de cache subsystem, which allows eac h no de to run near its p eak p erformance only if the ratio of computation to memory traffic is high enough. The computational efficiency will increase with the blo ck size un til the blo cks are large enough to fill the cache av ailable to one process. F or example, if 8MB of cac he are a v ailable, one w ould like to ha ve blo ck size at least 1024 × 1024. How ever, smaller blo cks allo w the algorithm to b etter balance the computational load b etw een the pro cesses (and therefore ultimately among the cores and nodes of the computer) b y assigning multiple blo c ks to each pro cess. The first blo ck must finish before an ything else can be done; assuming that 4 eac h block is assigned to only one pro cess, all the other processes must wait for this blo ck to b e factored b efore they can b egin computation. More generally , the diagonal and first off- diagonal blo c ks form a critical path of the algorithm. In Fig. 1, this critical path is of blo cks 1, 2, 5, 6, 8, 9, 10. The decomp osition, forw ardsolv es, and m ultiplicativ e updates of each of these blo c ks must be done sequentially . Decreasing the blo ck size decreases the amount of w ork along this critical path, th us impro ving the load balance. Put another w a y , decreasing the blo ck size decreases ho w long the ma jority of the pro cesses w ait for the pro cesses in a giv en column to finish b efore they can use the results from that column to p erform their o wn computation. Giv en a matrix of a fixed size and a fixed num b er of nodes, if w e were to use the maximum blo c k size, w e w ould distribute one block per pro cess and one process p er no de. If w e use a smaller blo ck size, w e can accommo date the extra blocks either b y assigning m ultiple blocks to a eac h pro cess, or multiple processes to each node. Consider first running just one pro cess p er node. F or the linear algebra computations, b y using a threaded BLAS library (such as openBLAS , MKL , or ACML ), it is still p ossible to attain go o d multi-core performance on a single pro cess. Ho w ever, an y calculations that are not threaded will not b e able to use all of the cores on a giv en node, reducing computational efficiency . An example of this occurs in our R pac k age where the user-defined cov ariance function (which is an R function) will typically not be threaded unless the user co des it in threaded C code (e.g., using op enMP) and calls the C co de from the R function or uses a parallel framew ork in R . Alternativ ely , one could sp ecify the block size and the n umber of nodes suc h that more than one pro cess runs on each node. F or non-threaded calculations, this man ually divides the computation amongst multiple cores on a no de, increasing efficiency . How ev er it reduces the num b er of cores a v ailable for a given threaded calculation (presuming that cores are assigned exclusiv ely to a single pro cess, as when using the openMPI implemen tation with Rmpi ) and may decrease efficiency by dividing calculations into smaller blo cks with more message passing. This is generally a satisfactory solution in a small cluster, but will lose efficiency past a few tens of nodes. Finally , one can assign multiple blo cks p er process, our c hosen approach, describ ed next. 2.2 Our algorithm Our approach assigns one pro cess per node, but each pro cess is assigned multiple blo cks of the matrices. This allo ws each pro cess access to all the cores on a no de to maximally exploit threading. W e carefully choose whic h blo c ks are assigned to eac h process to ac hiev e better load-balancing and limit communication. W e choose an efficien t order for each pro cess to carry out the operations for the blo c ks assigned to it. Our pac k age is flexible enough to allow the user to instead run multiple pro cesses per node, whic h ma y improv e the efficiency of the user-defined co v ariance function at the exp ense of higher comm unication costs in the linear algebra computations. W e require that the n umber of pro cesses is P = D ( D + 1) / 2 ∈ { 1 , 3 , 6 , 10 , 15 , . . . } for some integer v alue of D . W e introduce another quantit y h that determines how man y blo cks eac h pro cess owns. The num b er of blo c ks is given b y B = hD , and so the blo c k size is n hD , where n is the order of the matrix. See Fig. 2 for an example of the la y out with D = 4 and either h = 1 or h = 3. Each “diagonal process” has h ( h + 1) / 2 blo c ks, and each “off-diagonal 5 1 3 4 2 5 7 6 8 9 10 1 3 4 2 5 7 6 8 9 10 1 3 4 2 5 7 6 8 9 10 1 3 4 2 5 7 6 8 9 10 1 3 4 2 5 7 6 8 9 10 9 7 4 6 3 2 1 3 4 2 5 7 6 8 9 10 9 7 4 6 3 2 1 3 4 2 5 7 6 8 9 10 9 7 4 6 3 2 Figure 2: The matrix la yout used b y our algorithm with D = 4 and h = 1 (left) or h = 3 (righ t). The n um b ers indicate which pro cess o wns a giv en block. When h = 1, each of the 10 processes owns one blo ck of the matrix. When h = 3, the blo cks are a third the size in eac h dimension. The diagonal pro cesses (1, 5, 8, 10) each own h ( h + 1) / 2 = 6 blocks, and the off-diagonal pro cesses (2, 3, 4, 6, 7, 9) eac h o wn h 2 = 9 blo cks. pro cess” has h 2 blo c ks of the triangular matrix. As discussed abov e, small v alues of h increase on-no de efficiency and reduce communica- tion, but large v alues of h improv e load balance. On current arc hitectures, a go o d heuristic is to c ho ose h so that the block size is ab out 1000, but the user is encouraged to exp erimen t and determine what v alue works best for a giv en computer and problem size. When using more than 8 cores p er pro cess, the blo ck size should probably b e increased. Note that w e pad the input matrix so that the num b er of rows and columns is a multiple of hD . This padding will ha v e a minimal effect on the computation time; if the block size is c hosen to be near 1000 as we suggest, the padding will be at most one part in a thousand. Note that when h > 1, there are essen tially t w o lev els of blo cking, indicated b y the thin blac k lines and the thic k blue lines in Fig. 2. Our algorithm is guided b y these blo c ks. A t a high level, the algorithm sequen tially follo ws the Cholesky decomp osition of the large (blue) blo c ks as describ ed in the previous section. Eac h large blo ck is divided among all the pro cessors, and all the pro cessors participate in eac h step. F or example, the first step is to p erform Cholesky decomp osition on the first large blo c k. T o do so, we follow exactly the h = 1 algorithm (making use of the Cartesian co ordinate iden tification system indicated in Fig. 1): 1: for i = 1 to D do 2: Processor ( i, i ) computes the Cholesky decomp osition of its blo ck 3: parallel for j = i + 1 to D do 4: Pro cessor ( i, i ) sends its blo c k to pro cessor ( j, i ) 5: Pro cessor ( j, i ) up dates its blo ck with a triangular solv e 6: parallel for k = i + 1 to D do 7: if k ≤ j then 8: Pro cessor ( j, i ) sends its blo c k to pro cessor ( j, k ) 9: else 10: Pro cessor ( j, i ) sends its blo c k to pro cessor ( k , j ) 6 11: end if 12: end parallel for 13: end parallel for 14: parallel for j = i + 1 to D do 15: parallel for k = j + 1 to D do 16: Pro cessor ( k , j ) up dates its block with a matrix m ultiplication 17: end parallel for 18: end parallel for 19: end for The h = 1 algorithm is p o orly load balanced; for example going from D = 1 to D = 2 (one pro cess to three pro cesses), one w ould not exp ect an y sp eedup b ecause ev ery op eration is along the critical path. How ev er, b ecause it is a small portion of the entire calculation for h > 1, the effect on the total run time is small. Instead, most of the time is sp en t in matrix m ultiplications of the large blue blocks, whic h are well load-balanced. 2.2.1 Memory use The n umber of en tries in a triangular n × n matrix is n ( n + 1) / 2. Ideally , it would be p ossible to p erform computations ev en if there is only barely this m uc h memory a v ailable across all the no des, that is if there were enough memory for n ( n + 1) / ( D ( D + 1)) entries p er no de. Our algorithm do es not reac h this ideal, but it has a small memory o verhead that decreases as D or h increase. The maximum memory use is b y the off-diagonal no des that own h 2 blo c ks. Additionally , during the course of the algorithm they must temp orarily store up to 4 more blo cks. Assuming for simplicit y that hD ev enly divides n , the maximum memory use on a no de is then M ≤ n hD 2 ( h 2 + 4) = n ( n + 1) D ( D + 1) 1 + 4 nD + n 2 h 2 + 4 n − D h 2 D h 2 n + D h 2 < n ( n + 1) D ( D + 1) 1 + 4 h 2 + 1 D + 4 D h 2 . F or example when h = 3 and D = 4, the memory required is about 1.8 times the memory needed to hold a triangular matrix. Increasing h and D decreases this o verhead factor tow ard 1. 2.2.2 Adv an tages of our approac h So far w e hav e fo cused our discussion on the Cholesky factorization, as this is generally the rate-limiting step in Gaussian pro cess metho ds. Our approach and softw are also improv e computational efficiency b y exploiting the sequen tial nature of Gaussian pro cess calculations, in whic h eac h task relies on a sequence of linear algebra calculations, many or all of whic h can b e done in a distributed fashion. Our framework generates matrices in a distributed fashion, and k eeps them distributed throughout a sequence of linear algebra computations, collecting results bac k to the master process only at the conclusion of the task. F or example in likelihoo d calculation, w e need not collect the full Cholesky factor at the master pro cess but need only collect the (scalar) log-lik eliho o d v alue that is computed using a sequence of 7 distributed calculations (the Cholesky factorization, follow ed by a bac ksolv e, calculation of a sum of squares, and calculation of a log-determinan t). F or prediction, if w e ha ve computed the Cholesky during likelihoo d maximization, we can use the distributed Cholesky as input to distributed forwardsolv e and bac ksolv e operations, collecting only the v ector of predictions at the master pro cess. This feature is critical b oth for av oiding the large comm unication o verhead in collecting a matrix to a single pro cessor and to allo wing computations on matrices that are to o big to fit on one no de. ScaLAPACK is an alternative to our approach and uses a very similar algorithmic approach. In Section 3 we sho w that our implementation is as fast or faster than using ScaLAPACK for the critical Cholesky decomp osition. In some wa ys our implemenatation is b etter optimized for triangular or symmetric matrices. When storing symmetric matrices, ScaLAPACK requires memory space for the en tire square matrix, whereas our implemen tation only requires a small amoun t more memory than the lo w er triangle tak es. F urthermore, unlike the RScaLAPACK in terface (whic h is no longer a v ailable as a curren t R pac k age) to ScaLAPACK , our implemen- tation carries out m ultiple linear algebra calculations without collecting all the results bac k to the master pro cess and calculates the cov ariance matrix in a distributed fashion. Our softw are pro vides R users with a simple in terface to distributed calculations that mimic the algorithmic implementation in ScaLAPACK while also providing R programmers with an API to enable access to the core distributed bac k-end linear algebra calculations, whic h are coded in C for efficiency . 2.3 The bigGP R pac k age 2.3.1 Ov erview The R pac k age bigGP implemen ts a set of core functions, all in a distributed fashion, that are useful for a v ariet y of Gaussian pro cess-based computational tasks. In particular we pro vide Cholesky factorization, forw ardsolve, bac ksolv e and multiplication op erations, as w ell as a v ariet y of auxiliary functions that are used with the core functions to implement high-lev el statistical tasks. W e also provide additional R functions for distributing ob jects to the pro cesses, managing the ob jects, and collecting results at the master pro cess. This set of R functions pro vides an API for R developers. A dev elop er can implement new tasks en tirely in R without needing to kno w or use C or MPI . Indeed, using the API , w e implemen t standard Gaussian process tasks: log-lik eliho o d calculation, likelihoo d optimiza- tion, prediction, calculation of prediction uncertain ty , unconditional sim ulation of Gaussian pro cesses, and sim ulation of Gaussian pro cess realizations conditional on data. Distributed cnstruction of mean vectors and co v ariance matrices is done using user-provided R functions that calculate the mean and cov ariance functions given a vector of parameters and arbitrary inputs. 2.3.2 API The API consists of • basic functions for listing and removing ob jects on the slav e pro cesses and cop ying ob jects to and from the slav e pro cesses: remoteLs , remoteRm , push , pull , 8 • functions for determining the lengths and indices of v ectors and matrices assigned to a giv en sla v e pro cess: getDistributedVectorLength , getDistributedTriangularMatrixLength , getDistributedRectangularMatrixLength , remoteGetIndices , • functions that distribute and collect ob jects to and from the sla v e processes, masking the details of how the ob jects are broken in to pieces: distributeVector , collectVector , collectDiagonal , collectTriangularMatrix , collectRectangularMatrix , and • functions that carry out linear algebra calculations on distributed vectors and matrices: remoteCalcChol , remoteForwardsolve , remoteBacksolve , remoteMultChol , remoteCrossProdMatVec , remoteCrossProdMatSelf , remoteCrossProdMatSelfDiag , remoteConstructRnormVector , remoteConstructRnormMatrix . In addition there is a generic remoteCalc function that can carry out an arbitrary function call with either one or t w o inputs. The pack age m ust b e initialized, which is done with the bigGP.init function. During initialization, slav e pro cesses are spawned and R pac k ages loaded on the sla ves, parallel random n umber generation is set up, and blo cks are assigned to sla ves, with this information stored on each slav e process in the .bigGP ob ject. Users need to start R in suc h a w a y (e.g., through a queueing system or via mpirun ) that P sla ve pro cesses can b e initialized, plus one for the master pro cess, for a total of P + 1. P should b e suc h that P = D ( D + 1) / 2 for in teger D , i.e., P ∈ 3 , 6 , 10 , 15 , . . . . One ma y wish to hav e one pro cess p er no de, with threaded calculations on each no de via a threaded BLAS, or one process p er core (in particular when a threaded BLAS is not av ailable). Our theoretical assessmen t and empirical tests suggest that the blo c ks of distributed matrices should be appro ximately of size 1000 by 1000. T o ac hiev e this, the pack age c ho oses h given the num b er of observ ations, n , and the num b er of pro cesses, P , such that the blo cks are appro ximately that size, i.e., n/ ( hD ) ≈ 1000. Ho w ever the user can o verride the default and w e recommend that the user test differen t v alues on their system. 2.3.3 Kriging implementation The kriging implemen tation is built around tw o Reference Classes. The first is a krigeProblem class that con tains metadata about the problem and man- ages the analysis steps. T o set up the problem and distribute inputs to the pro cesses, one instan tiates an ob ject in the class. The metadata includes the block replication factors and information ab out which calculations ha ve b een p erformed and which ob jects are up-to-date (i.e., are consistent with the current parameter v alues). This allo ws the pack age to a v oid rep eating calculations when parameter v alues ha ve not c hanged. Ob jects in the class are stored on the master pro cess. The second is a distributedKrigeProblem class that con tains the core distributed ob- jects and information ab out which pieces of the distributed ob jects are stored in a giv en pro cess. Ob jects in this class are stored on the slav e processes. By using a ReferenceClass w e create a namespace that a voids name conflicts amongst multiple problems, and w e allo w 9 the distributed linear algebra functions to manipulate the (large) blo cks by reference rather than b y v alue. The core metho ds of the krigeProblem class are a constructor; methods for constructing mean vectors and cov ariance matrices given user-provided mean and cov ariance functions; metho ds for calculating the log determinan t, calculating the log density , optimizing the densit y with resp ect to the parameters, prediction (with prediction standard errors), finding the full prediction v ariance matrix, and sim ulating realizations conditional on the data. Note that from a Ba yesian p ersp ective, prediction is just calculation of the p osterior mean, the prediction v ariance matrix is just the p osterior v ariance, and simulation of realizations is just sim ulation from the p osterior. All of these are conditional on the parameter estimates, so this can b e viewed as empirical Ba yes. It is p ossible to ha v e multiple krigeProblem ob jects defined at once, with separate ob jects in memory and distributed amongst the pro cesses. Ho w ever, the partition factor, D , is constan t within a giv en R session. Co de that uses the krigeProblem class to analyze an astrophysics data example is pro- vided in Section 4. 2.3.4 Using the API T o extend the pac k age to implement other Gaussian pro cess metho dologies, the t wo key elemen ts are construction of the distributed ob jects and use of the core distributed linear algebra functions. Construction of the distributed ob jects should mimic the localKrigeProblemConstructMean and localKrigeProblemConstructCov functions in the pac k age. These functions use user-provided functions that op erate on a set of parameters, a list con taining additional inputs, and a set of indices to construct the lo cal piece of the ob ject for the giv en indices. As a toy example, the pack age ma y set the indices of a matrix stored in the first pro cess to b e (1 , 1) , (2 , 1) , (1 , 2) , (2 , 2), namely the upp er 2 × 2 blo c k of a matrix. Given this set of indices, the user-provided function w ould need to compute these four elemen ts of the matrix, whic h would then b e stored as a vector, column-wise, in the process. Once the necessary v ectors and matrices are computed, the distributed linear algebra functions allow one to manipulate the ob jects by name. As done with the krigeProblem class, we recommend the use of Reference Classes to store the v arious ob jects and functions asso ciated with a given methodology . 3 Timing results W e fo cus on comparing computational sp eed for the Cholesky factorization, as this generally dominates the computational time for Gaussian process computations. W e compare our im- plemen tation (in this case run as a distributed C program, as R serves only as a simple wrapp er that calls the lo cal Cholesky functions on the work er pro cesses via the mpi.remote.exec function), for a v ariety of v alues of h , with ScaLAPACK . W e consider several different dataset sizes and different num b ers of no des. W e use Hopp er, a Cray system hosted at the National Energy Researc h Scien tific Computing cen ter (NERSC). Eac h Hopper node consists of t wo 12-core AMD “MagnyCours” pro cessors with 24 GB of memory . Hopp er jobs ha ve access 10 10 100 10 100 Execution time, seconds (log scale) Number of cores (log scale) Cholesky decomposition, n=32768 h=1 h=2 h=4 h=8 optimal h ScaLAPACK Figure 3: Run times for 32768 × 32768 Cholesky decomp osition on Hopp er with v arious v alues of h using 6 cores p er process. The last line sho ws ScaLAPACK as a benchmark. The optimal v alue of h w as c hosen by trying all v alues b etw een 1 and 8. The blo cksize for ScaLAPACK corresp onds to the b est p erformance using a pow er of 2 blo cks per pro cess. to a dedicated Cray Gemini interconnect to obtain lo w-latency and high bandwidth in ter- pro cess communication. While Hopp er has 24 cores p er no de, eac h no de is divided into 4 NUMA regions eac h with 6 cores; in our experiments w e try running one pro cess p er no de, one pro cess p er NUMA region (4 p er no de), or one pro cess p er core (24 p er no de). 3.1 Choice of h and comparison to ScaLAP A CK In Fig. 3 w e compare the p erformance at differen t v alues of h . One notable feature is that for h = 1 there is no performance improv emen t in increasing from P = 1 to P = 3, b ecause there is no parallelism. Allo wing larger v alues of h makes a sp eedup p ossible with P = 3. Generally , larger v alues of h p erform b est when P is small, but as P gro ws the v alue of h should decrease to keep the block size from getting too small. Fig. 3 also compares our performance to ScaLAPACK , a standard distributed-memory linear algebra library . P erformance for ScaLAPACK (using the optimal blo ck size) and our algorithm (using the optimal v alue of h ) is similar. W e are thus able to get essen tially the same p erformance on distributed linear algebra computations issued from R with our framew ork as if the programmer w ere working in C and calling ScaLAPACK . 11 0.01 0.1 1 10 100 1000 2048 8192 32768 131072 Execution time, seconds (log scale) Matrix dimension, n (log scale) Cholesky Decomposition 6 cores 60 cores 816 cores 12480 cores 49920 cores Figure 4: Runtimes as a function of n for Cholesky decomposition on Hopper, for a v ariet y of num b ers of cores. F or 49920 cores, we used 24 cores p er pro cess; in the other cases we used 6 cores p er pro cess. 3.2 Timing with increasing problem size As the matrix size n increases, the arithmetic count of computations required for Cholesky decomp osition increases as a function of n 3 . F or small problem sizes, this increase is mitigated b y the greater efficiency in computing with larger matrices. Fig. 4 sho ws how runtime v aries with n . 3.3 Effect of n um b er of cores p er pro cess Our framew ork giv es the user the freedom to c ho ose how many cores to assign to eac h pro cess, up to the num b er of cores on a no de. Whatever c hoice the user makes, all of the cores will b e active most of the time. When multiple cores are assigned to a single pro cess, parallelism b et w een cores comes from the threaded BLAS, whereas parallelism b etw een the pro cesses comes from our pack age. Both use similar techniques to achiev e parallelism. The main difference is in the communication. When running with many pro cesses per node, eac h one is sending man y small messages to pro cesses on other no des, but when running with one pro cess p er node one is more efficien t in sending fewer, larger messages. As Fig. 5 sho ws, the n umber of cores p er pro cess is not very imp ortan t when using a small num b er of cores, up to ab out 480 cores, where the calculation is computation-b ound. As the num b er of cores increases, the calculation b ecomes communication-bound, and b etter p erformance is attained with few er pro cesses p er no de (more cores p er pro cess). Note that the ideal c hoice of blo ck size is affected b y the n um b er of cores p er pro cess, since efficiently using more cores 12 1 10 100 10 100 1000 10000 Execution time, seconds (log scale) Number of cores (log scale) Cholesky decomposition, n=32768 1 core per process 6 cores per process 24 cores per process Figure 5: Run times for 32768 × 32768 Cholesky decomp osition on Hopp er using 1 core, 6 cores, or 24 cores (full node) p er process. F or eac h data p oint, we use the optimal v alue of h . requires larger blo cks. 3.4 Using GPUs to sp eed up the linear algebra There is gro wing use of GPUs to speed up v arious computations, in particular linear algebra. Our framew ork can b e easily mo dified to run on a single GPU or a cluster of no des with GPUs by using CUBLAS and MA GMA instead of BLAS and LAP A CK. W e implemented Cholesky decomp osition and tested on the NERSC mac hine Dirac, a small cluster with one NVIDIA T esla C2050 GPU and 2 In tel 5530 CPUs p er node. Theoretically eac h GPU has the equiv alen t p erformance of about 60 cores of Hopper, although the in terconnects are slo wer and so more problems are comm unication-b ound. Fig. 6 compares the p erformance on 1 and 10 GPUs on Dirac to the p erformance on Hopp er. One GPU is roughly the same sp eed as 60 cores on Hopp er (matching the theoretical result), whereas 10 GPUs giv es roughly the same sp eed as 330 cores on Hopp er (sho wing the slow-do wn due to communication). When running on Dirac, the computation is entirely done on the GPUs; CPUs are only used for transferring data b etw een no des. In principle one could try to divide the computation b et w een the CPU and GPU, but, since the theoretical p eak of the CPUs on eac h no de is only 15% that of the GPU, this would only yield sligh t p erformance improv ements. 13 0.01 0.1 1 10 100 1000 2048 8192 32768 131072 Execution time, seconds (log scale) Matrix dimension, n (log scale) Cholesky Decomposition 6 cores 60 cores 1 gpu 330 cores 10 gpus 816 cores Figure 6: Runtimes as a function of n for Cholesky decomp osition using 1 and 10 GPUs on Dirac with results using Hopper for a v ariety of n umber of cores. The CPU lines corresp ond to using 6 cores p er pro cess. 4 Astroph ysics example 4.1 Bac kground Our example data set is the public spectrophotometric time series of the Type Ia supernov a SN 2011fe [Pereira et al., 2013], obtained and reduced by the Nearb y Sup ernov a F actory [Aldering et al., 2002]. The time series itself is a sequence of sp ectra, each consisting of flux and flux error in units of erg s − 1 cm − 2 ˚ A − 1 tabulated as a function of wa v elength in ˚ A. Eac h sp ectrum was obtained on a differen t nigh t. There are 25 unique spectra, each of whic h con tains 2691 flux (and flux error) measurements. The total size of the data set is th us 67,275 flux v alues. The time cov erage is not uniform, but the wa v elength grid is regularly spaced and the same from nigh t to night. The flux v alues themselves are calibrated so that differences in the brightness of the sup ernov a from night to nigh t and w a velength to w av elength are physically meaningful. The data are shown in Fig. 7. W e are interested in obtaining a smo othed prediction of the flux of SN 2011fe as a function of time and w av elength along with an estimate of the prediction error. The sp ectrum of a sup erno v a con tains broad absorption and emission features whose app earance is the result of ph ysical pro cesses and conditions in the expanding stellar ejecta. The widths, depths, and heights of such features c hange with time as the sup ernov a expands and co ols. The w av elengths of absorption feature minima are examples of ph ysically in teresting quantities to extract from sp ectral time series as a function of time. These translate to a characteristic ejecta velocity that pro vides an estimate of the kinetic energy of the sup ernov a explosion, 14 W avelength (log scale) Day −15 −10 −5 0 5 10 15 20 25 4000 5000 6000 7000 8000 9000 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Figure 7: Flux observ ations for the Type la sup ernov a. Offset on the y-axis corresp onds to time of observ ation in days. The scale for the flux measurements is not indicated due to the offset, but these measurements range from -0.003 to 1. Eac h sp ectrum con tains measuremen ts corresp onding to 2691 wa v elengths ( ˚ A), shown on the x-axis. W a v elengths 5950 ˚ A and 6300 ˚ A are indicated b y dotted v ertical lines; this is the range ov er whic h w e mak e predictions. The empirical minim um within this range for eac h sp ectrum is indicated with a solid dot. 15 something of great interest to those that study exploding stars. T o demonstrate our algorithms and soft w are on a real data set, we will extract the v elo cit y of the Si II (singly ionized silicon) absorption minimum typica lly found near 6150 ˚ A in T yp e Ia supernov ae. This will be done b y finding the minimum absorption in the feature using the smo othed representation of the supernov a sp ectrum. Realizations of the sp ectrum, sampled from the p osterior Gaussian pro cess, will b e used to pro duce Monte Carlo error estimates on the position of the absorption minim um. Rather than measuring the p osition of eac h minim um only at p oints where the data ha v e b een obtained (represented b y the solid dots in Fig. 7), this pro cedure yields a smo oth estimate of the absorption minimum as a function of time in terp olated betw een observ ations, while also taking observ ation errors in to accoun t. 4.2 Statistical mo del W e mo del the flux measurements Y 1 , . . . , Y 67275 as b eing equal to a GP realization plus tw o error comp onents: random effects for eac h phase (time p oint) and indep endent errors due to photon noise. W e denote these three comp onents b y Y i = Z ( t i , w i ) + α t i + i , where t i represen ts the time corresp onding to Y i and w i the log wa v elength, α t i is the random effect corresp onding to time t i , and i is measurement error for the i th observ ation. The mo dels for these comp onents are Z ∼ GP ( µ ( · ; κ, λ ) , σ 2 K ( · , · ; ρ p , ρ w ) α 1 , . . . , α 25 iid ∼ N (0 , τ 2 ) i ∼ N (0 , v i ) , 1 , . . . , 67275 m utually indep enden t Z has mean µ , a function of time t only , derived from a standard template T yp e Ia sup erno v a sp ectral time series [Hsiao et al., 2007], with κ and λ controlling scaling in magni- tude and time. W e tak e the correlation function to be a product of t w o Mat ´ ern correlation functions, one for b oth the phase and log w a v elength dimensions, eac h with smoothness parameter ν = 2. Note that the flux error v ariances v i are kno wn, leaving us with six parameters to b e estimated. 4.3 R co de The first steps are to load the pack age, set up the inputs to the mean and cov ariance functions, and initialize the kriging problem ob ject, called prob . Note that in this case the mean and co v ariance functions are provided b y the pac k age, but in general these would need to b e pro vided by the user. library(bigGP) nProc <- 465 n <- nrow(SN2011fe) 16 m <- nrow(SN2011fe_newdata) nu <- 2 inputs <- c(as.list(SN2011fe), as.list(SN2011fe_newdata), nu = nu) prob <- krigeProblem$new("prob", numProcesses = nProc, h_n = NULL, h_m = NULL, n = n, m = m, meanFunction = SN2011fe_meanfunc, predMeanFunction = SN2011fe_predmeanfunc, covFunction = SN2011fe_covfunc, crossCovFunction = SN2011fe_crosscovfunc, predCovFunction = SN2011fe_predcovfunc, inputs = inputs, params = SN2011fe_initialParams, data = SN2011fe$flux, packages = ’fields’, parallelRNGpkg = "rlecuyer") W e then maximize the log likelihoo d, follo wed by making the kriging predictions and gener- ating a set of 1000 realizations from the conditional distribution of Z given the observ ations and fixing the parameters at the maximum likelihoo d estimates. The predictions and realiza- tions are ov er a grid, with da ys ranging from -15 to 24 in increments of 0.5 and wa v elengths ranging from 5950 to 6300 in increments of 0.5. The num b er of prediction p oints is therefore 79 × 701 = 55379. prob$optimizeLogDens(method = "L-BFGS-B", verbose = TRUE, lower = rep(.Machine$double.eps, length(SN2011fe_initialParams)), control = list(parscale = SN2011fe_initialParams)) pred <- prob$predict(ret = TRUE, se.fit = TRUE, verbose = TRUE) realiz <- prob$simulateRealizations(r = 1000, post = TRUE, verbose = TRUE) 4.4 Results The MLEs are ˆ σ 2 = 0 . 0071, ˆ ρ p = 2 . 33, ˆ ρ w = 0 . 0089, ˆ τ 2 = 2 . 6 e − 5, and ˆ κ = 0 . 33. Fig. 8 sho ws the p osterior mean and point wise 95% p osterior credible in terv als for the wa v elength corresp onding to the minim um flux for each time p oint. These are calculated from the 1000 sampled p osterior realizations of Z . F or eac h realization, w e calculate the minimizing w av elength for eac h time p oint. T o translate each wa v elength v alue to an ejecta velocity via the Doppler shift formula, w e calculate v = c ( λ R /w − 1) where λ R = 6355 is the rest w av elength of an imp ortant silicon ion transition and c is sp eed of light, 3 × 10 8 m/s. The p osterior mean and p oint wise 95% posterior credible interv als for the ejecta v elo cities are sho wn in Fig. 8 (b). 5 Discussion Our soft w are allo ws one to carry out standard Gaussian pro cess calculations, suc h as likeli- ho o d maximization, prediction, and simulation of realizations, off the shelf, as illustrated in 17 −10 0 10 20 6050 6100 6150 6200 (a) Day W avelength −10 0 10 20 8.0e+06 1.2e+07 1.6e+07 (b) Day V elocity Figure 8: P osterior means (solid black lines) and p oint wise 95% p osterior credible in terv als (dotted black lines) for the w a velength ( ˚ A) corresp onding to the minim um flux (a) and the corresp onding ejecta velocity (m/s) (b). The v ertical gray dotted lines indicate observ ation times. the astroph ysics example, in situations in which calculations using threaded linear algebra on a single computer are not feasible b ecause the calculations tak e too long or use to o muc h memory . The softw are enables a user to implemen t standard mo dels and related mo dels without approximations. One limitation of our implementation is that we do not do any piv oting, so Cholesky factorization of matrices that are not n umerically positive definite fails. This o ccurred in the example when simulating realizations on fine grids of wa v elength and phase. Of course with large datasets, one has the necessary statistical information to fit more complicated models, including hierarc hical mo dels, than the standard kriging metho dology w e implement. The pack age is designed to b e extensible, pro viding a core set of distributed linear algebra functions common to Gaussian pro cess calculations as an API usable from R without an y kno wledge of C or MPI . This allows others to implemen t other Gaussian pro- cess metho dologies that rely on these functions. These migh t include Bay esian metho ds for nonstationary cov ariance mo dels and spatio-temporal mo dels among others. F or exam- ple, MCMC up dating steps migh t b e done from the master process, with the linear algebra calculations done using the API. As can b e seen from our timing results, a Cholesky decom- p osition for 32 , 768 observ ations can be done in sev eral seconds with a sufficien t n umber of pro cessors (a speed-up of 2-3 orders of magnitude relative to a single computational no de), p oten tially enabling tens of thousands of MCMC up dates. Or for a separable space-time mo del, the spatial and temp oral co v ariance matrices could be manipulated separately using the pack age. One might also consider handling ev en larger datasets (e.g., millions of obser- v ations) b y use of the core functions within the context of computationally-efficient methods suc h as lo w-rank appro ximations. One useful extension of our approac h w ould b e to sparse matrices. Sparse matrices are 18 at the core of computationally-efficien t Mark ov random field spatial mo dels [Banerjee et al., 2003, Rue et al., 2009, Lindgren et al., 2011] and cov ariance tap ering approac hes [F urrer et al., 2006, Kaufman et al., 2008, Sang and Huang, 2012] and implemen ting a distributed sparse Cholesky decomposition could allo w calculations for problems with h undreds of thousands or millions of lo cations. T o get a feel for what is possible, w e b enchmark ed the P aStiX pack age [H ´ enon et al., 2000] on Hopp er on sparse matrices corresponding to a tw o-dimensional grid with five nonzeros p er row. With one million lo cations, a Cholesky decomp osition could b e done in ab out 5 seconds using 96 cores (4 nodes) of Hopp er; for 16 million locations, it to ok ab out 25 seconds using 384 cores (16 no des). Using more than this num b er of cores did not significan tly reduce the running time. W e also note that with these improv ements in sp eed for the Cholesky decomp osition, computation of the cov ariance matrix itself ma y b ecome the rate-limiting step in a spatial statistics calculation. Our current implemen tation tak es a user-sp ecified R function for constructing the cov ariance matrix and therefore do es not exploit threading b ecause R itself is not threaded. In this case, sp ecifying more than one pro cess per node w ould implicitly thread the cov ariance matrix construction, but additional w ork to enable threaded calculation of the co v ariance matrix ma y b e worth while. Ac kno wledgmen ts This w ork is supp orted b y the Director, Office of Science, Office of Adv anced Scien tific Com- puting Research, of the U.S. Departmen t of Energy under Con tract No. A C02-05CH11231. This researc h used resources of the National Energy Researc h Scientific Computing Cen ter. References G. Aldering, G. Adam, P . Antilogus, P . Astier, R. Baco n, S. Bongard, C. Bonnaud, Y. Copin, D. Hardin, F. Henault, D. A. Ho w ell, J.-P . Lemonnier, J.-M. Levy, S. C. Lok en, P . E. Nu- gen t, R. P ain, A. Pecon tal, E. Pecon tal, S. Perlm utter, R. M. Quim by, K. Sc hahmaneche, G. Smadja, and W. M. W o o d-V asey. Ov erview of the nearb y supernov a factory . In J. A. T yson and S. W olff, editors, So ciety of Photo-Optic al Instrumentation Engine ers (SPIE) Confer enc e Series , volume 4836 of So ciety of Photo-Optic al Instrumentation Engine ers (SPIE) Confer enc e Series , pages 61–72, Decem b er 2002. E. Anderson. LAP ACK Users’ Guide , v olume 9. Siam, 1999. S. Banerjee, A.E. Gelfand, A.O. Finley , and H. Sang. Gaussian predictiv e pro cess mo dels for large spatial data sets. Journal of the R oyal Statistic al So ciety, Series B , 70(4):825–848, 2008. S. Banerjee, A.E. Gelfand, and C.F. Sirmans. Directional rates of change under spatial pro cess mo dels. Journal of the A meric an Statistic al Asso ciation , 98(464):946–954, 2003. L.S. Blackford, J. Choi, A. Cleary , E. D’Azev edo, J. Demmel, I. Dhillon, J. Dongarra, S. Hammarling, G. Henry , A. Petitet, et al. Sc aLAP A CK Users’ Guide , v olume 4. Society for Industrial and Applied Mathematics, 1987. 19 N. Cressie and G. Johannesson. Fixed rank kriging for v ery large spatial data sets. Journal of the R oyal Statistic al So ciety, Series B , 70(1):209–226, 2008. J.J. Dongarra, J. Du Croz, S. Hammarling, and I.S. Duff. A set of level 3 basic linear algebra subprograms. ACM T r ansactions on Mathematic al Softwar e (TOMS) , 16(1):1–17, 1990. R. F urrer, M. G. Gen ton, and D. Nychk a. Co v ariance tap ering for interpolation of large spatial datasets. Journal of Computational and Gr aphic al Statistics , 15:502–523, 2006. R.B. Gramacy and H.K.H. Lee. Ba yesian treed Gaussian process mo dels with an application to computer mo deling. Journal of the Americ an Statistic al Asso ciation , 103(483):1119– 1130, 2008. P . H´ enon, P . Ramet, and J. Roman. P aStiX: A parallel sparse direct solver based on a static sc heduling for mixed 1d/2d blo c k distributions. In Pr o c e e dings of the 15 IPDPS 2000 Workshops on Par al lel and Distribute d Pr o c essing , IPDPS ’00, pages 519–527, London, UK, UK, 2000. Springer-V erlag. E.Y. Hsiao, A. Conley , D.A. Ho well, M. Sulliv an, C.J. Pritchet, R.G. Carlb erg, P .E. Nugent, and M.M. Phillips. K-corrections and sp ectral templates of Typ e Ia sup ernov ae. The Astr ophysic al Journal , 663(2):1187, 2007. E.E. Kammann and M.P . W and. Geoadditiv e mo dels. Journal of the R oyal Statistic al So ciety, Series C , 52:1–18, 2003. C. Kaufman, M. Sc hervish, and D. Nychk a. Cov ariance tap ering for likelihoo d-based es- timation in large spatial datasets. Journal of the Americ an Statistic al Asso ciation , 103: 1556–1569, 2008. M.C. Kennedy and A. O’Hagan. Bay esian calibration of computer mo dels. Journal of the R oyal Statistic al So ciety, Series B , 63:425–464, 2001. F. Lindgren, H. Rue, and J. Lindstr¨ om. An explicit link b et ween Gaussian fields and Gaussian Mark ov random fields: the sto chastic partial differential equation approach. Journal of the R oyal Statistic al So ciety, Series B , 73:423–498, 2011. R. Pereira, R. C. Thomas, G. Aldering, P . An tilogus, C. Baltay , S. Benitez-Herrera, S. Bon- gard, C. Buton, A. Canto, F. Cellier-Holzem, J. Chen, M. Childress, N. Chotard, Y. Copin, H. K. F akhouri, M. Fink, D. F ouc hez, E. Gangler, J. Guy, W. Hillebrandt, E. Y. Hsiao, M. Kersc hhaggl, M. Ko w alski, M. Kromer, J. Nordin, P . Nugen t, K. P aech, R. P ain, E. P ´ econtal, S. Perlm utter, D. Rabinowitz, M. Rigault, K. Runge, C. Saunders, G. Smadja, C. T ao, S. T aub enberger, A. Tilquin, and C. W u. Sp ectrophotometric time series of SN 2011fe from the Nearby Supernov a F actory . ArXiv e-prints , F ebruary 2013. C.E. Rasm ussen and C.K.I. Williams. Gaussian Pr o c esses for Machine L e arning , volume 1. MIT Press, Cam bridge, Massac h usetts, 2006. 20 H. Rue, S. Martino, and N. Chopin. Approximate Bay esian inference for laten t Gaussian mo dels by using integrated nested Laplace appro ximations. Journal of the R oyal Statistic al So ciety, Series B , 71(2):319–392, 2009. H. Sang and J.Z. Huang. A full scale appro ximation of cov ariance functions for large spatial data sets. Journal of the R oyal Statistic al So ciety, Series B , 74:111–132, 2012. M.L. Stein, Z. Chi, and L.J. W elty . Appro ximating likelihoo ds for large spatial data sets. Journal of the R oyal Statistic al So ciety, Series B , 66(2):275–296, 2004. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment