Document Classification by Inversion of Distributed Language Representations
There have been many recent advances in the structure and measurement of distributed language models: those that map from words to a vector-space that is rich in information about word choice and composition. This vector-space is the distributed lang…
Authors: Matt Taddy
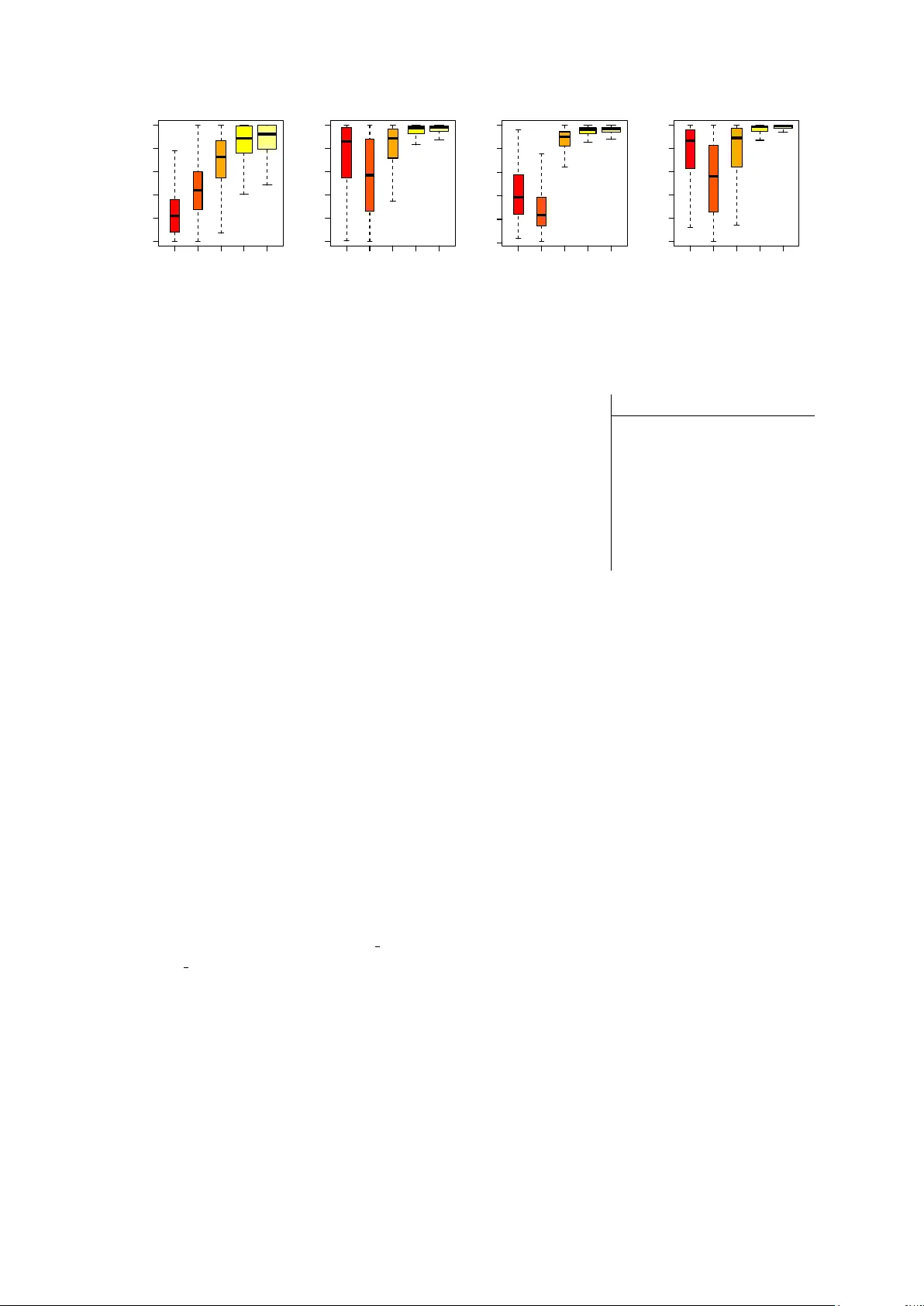
Document Classification by In version of Distrib uted Language Repr esentations Matt T addy Uni versity of Chicago Booth School of Business taddy@chicagobooth.edu Abstract There hav e been many recent advances in the structure and measurement of dis- tributed language models: those that map from words to a v ector-space that is rich in information about word choice and com- position. This vector-space is the dis- tributed language representation. The goal of this note is to point out that any distributed representation can be turned into a classifier through inv ersion via Bayes rule. The approach is simple and modular , in that it will work with any language representation whose train- ing can be formulated as optimizing a probability model. In our application to 2 million sentences from Y elp revie ws, we also find that it performs as well as or bet- ter than comple x purpose-b uilt algorithms. 1 Introduction Distributed, or vector -space, language representa- tions V consist of a location, or embedding, for e very vocab ulary wor d in R K , where K is the di- mension of the latent representation space. These locations are learned to optimize, perhaps approx- imately , an objecti ve function defined on the origi- nal te xt such as a lik elihood for word occurrences. A popular e xample is the W ord2V ec machin- ery of Mikolov et al. (2013b). This trains the distributed representation to be useful as an input layer for prediction of words from their neighbors in a Skip-gram likelihood. That is, to maximize t + b X j 6 = t, j = t − b log p V ( w sj | w st ) (1) summed across all words w st in all sentences w s , where b is the skip-gram window (truncated by the ends of the sentence) and p V ( w sj | w st ) is a neural network classifier that takes vector representations for w st and w sj as input (see Section 2). Distributed language representations hav e been studied since the early work on neural networks (Rumelhart et al., 1986) and hav e long been ap- plied in natural language processing (Morin and Bengio, 2005). The models are generating much recent interest due to the large performance gains from the ne wer systems, including W ord2V ec and the Glo ve model of Pennington et al. (2014), ob- served in, e.g., word prediction, word analogy identification, and named entity recognition. Gi ven the success of these ne w models, re- searchers hav e be gun searching for ways to adapt the representations for use in document classifica- tion tasks such as sentiment prediction or author identification. One nai ve approach is to use ag- gregated w ord vectors across a document (e.g., a document’ s average word-vector location) as input to a standard classifier (e.g., logistic regression). Ho we ver , a document is actually an or dered path of locations through R K , and simple av eraging de- stroys much of the a vailable information. More sophisticated aggregation is proposed in Socher et al. (2011; 2013), where recursi ve neu- ral netw orks are used to combine the word vectors through the estimated parse tree for each sentence. Alternati vely , Le and Mikolov’ s Doc2V ec (2014) adds document labels to the conditioning set in (1) and has them influence the skip-gram likelihood through a latent input vector location in V . In each case, the end product is a distributed representa- tion for e very sentence (or document for Doc2V ec) that can be used as input to a generic classifier . 1.1 Bayesian In version These approaches all add considerable model and estimation complexity to the original underlying distributed representation. W e are proposing a simple alternativ e that turns fitted distributed lan- guage representations into document classifiers without any additional modeling or estimation. A typical language model is trained to max- imize the likelihoods of single words and their neighbors. For example, the skip-gram in (1) rep- resents conditional probability for a word’ s con- text (surrounding words), while the alternative CBO W W ord2V ec specification (Mikolov et al., 2013a) targets the conditional probability for each word given its context. Although these objectiv es do not correspond to a full document likelihood model, they can be interpreted as components in a composite likelihood 1 approximation. Use w = [ w 1 . . . w T ] 0 to denote a sentence: an ordered v ector of words. The skip-gram in (1) yields the pairwise composite log likelihood 2 log p V ( w ) = T X j =1 T X k =1 1 [1 ≤| k − j |≤ b ] log p V ( w k | w j ) . (2) In another e xample, Jernite et al. (2015) sho w that CBO W W ord2V ec corresponds to the pseudolike- lihood for a Marko v random field sentence model. Finally , given a sentence likelihood as in (2), document d = { w 1 , ... w S } has log likelihood log p V ( d ) = X s log p V ( w s ) . (3) No w suppose that your training documents are grouped by class label, y ∈ { 1 . . . C } . W e can train separ ate distrib uted language representations for each set of documents as partitioned by y ; for example, fit W ord2V ec independently on each sub-corpus D c = { d i : y i = c } and obtain the labeled distributed representation map V c . A ne w document d has probability p V c ( d ) if we treat it as a member of class c , and Bayes rule implies p( y | d ) = p V y ( d ) π y P c p V c ( d ) π c (4) where π c is our prior probability on class label c . Thus distributed language representations trained separately for each class label yield directly a document classification rule via (4). This approach has a number of attracti ve qualities. Simplicity: The in version strategy works for any model of language that can (or its training can) be 1 Composite likelihoods are a common tool in analysis of spatial data and data on graphs. They were popularized in statistics by Besag’ s (1974; 1975) work on the pseudolike- lihood – p( w ) ≈ Q j p( w j | w − j ) – for analysis of Marko v random fields. See V arin et al. (2011) for a detailed review . 2 See Molenber ghs and V erbeke (2006) for similar pair- wise compositions in analysis of longitudinal data. interpreted as a probabilistic model. This makes for easy implementation in systems that are al- ready engineered to fit such language represen- tations, leading to faster deployment and lower de velopment costs. The strategy is also inter- pretable: whate ver intuition one has about the dis- tributed language model can be applied directly to the in version-based classification rule. In version adds a plausible model for reader understanding on top of any gi ven language representation. Scalability: when working with massive corpora it is often useful to split the data into blocks as part of distributed computing strategies. Our model of classification via in version provides a con venient top-le vel partitioning of the data. An efficient sys- tem could fit separate by-class language represen- tations, which will provide for document classi- fication as in this article as well as class-specific answers for NLP tasks such as word prediction or analogy . When one wishes to treat a document as unlabeled, NLP tasks can be answered through en- semble aggregation of the class-specific answers. Perf ormance: W e find that, in our examples, in- version of W ord2V ec yields lo wer misclassifica- tion rates than both Doc2V ec-based classification and the multinomial in verse regression (MNIR) of T addy (2013b). W e did not anticipate such out- right performance gain. Moreover , we expect that with calibration (i.e., through cross-v alidation) of the many various tuning parameters av ailable when fitting both W ord and Doc 2V ec the perfor - mance results will change. Indeed, we find that all methods are often outperformed by phrase-count logistic regression with rare-feature up-weighting and carefully chosen regularization. Howe ver , the out-of-the-box performance of W ord2V ec in ver- sion argues for its consideration as a simple default in document classification. In the remainder , we outline classification through in version of a specific W ord2V ec model and illustrate the ideas in classification of Y elp re vie ws. The implementation requires only a small extension of the popular gensim python library (Rehurek and Sojka, 2010); the ex- tended library as well as code to reproduce all of the results in this paper are av ailable on github . In addition, the yelp data is publicly av ailable as part of the correspond- ing data mining contest at kaggle.com . See github.com/taddylab/deepir for detail. 2 Implementation W ord2V ec trains V to maximize the skip-gram likelihood based on (1). W e work with the Huff- man softmax specification (Mik olov et al., 2013b), which includes a pre-processing step to encode each vocab ulary word in its representation via a binary Huf fman tree (see Figure 1). Each indi vidual probability is then p V ( w | w t ) = L ( w ) − 1 Y j =1 σ c h [ η ( w , j + 1)] u > η ( w,j ) v w t (5) where η ( w , i ) is the i th node in the Huffman tree path, of length L ( w ) , for word w ; σ ( x ) = 1 / (1 + exp[ − x ]) ; and ch( η ) ∈ {− 1 , +1 } translates from whether η is a left or right child to +/- 1. Ev ery word thus has both input and output vector coor- dinates, v w and [ u η ( w, 1) · · · u η ( w,L ( w )) ] . T ypically , only the input space V = [ v w 1 · · · v w p ] , for a p - word vocab ulary , is reported as the language rep- resentation – these vectors are used as input for NLP tasks. Ho wev er , the full representation V in- cludes mapping from each word to both V and U . W e apply the gensim python implementation of W ord2V ec, which fits the model via stochastic gradient descent (SGD), under default specifica- tion. This includes a vector space of dimension K = 100 and a skip-gram window of size b = 5 . 2.1 W ord2V ec In version Gi ven W ord2V ec trained on each of C class- specific corpora D 1 . . . D C , leading to C distinct language representations V 1 . . . V C , classification for ne w documents is straightforward. Consider Figure 1: Binary Huffman encoding of a 4 word vocab ulary , based upon 18 total utterances. At each step proceeding from left to right the two nodes with lowest count are combined into a par- ent node. Binary encodings are read back off of the splits moving from right to left. the S -sentence document d : each sentence w s is gi ven a probability under each representation V c by applying the calculations in (1) and (5). This leads to the S × C matrix of sentence probabilities, p V c ( w s ) , and document probabilities are obtained p V c ( d ) = 1 S X s p V c ( w s ) . (6) Finally , class probabilities are calculated via Bayes rule as in (4). W e use priors π c = 1 /C , so that classification proceeds by assigning the class ˆ y = argmax c p V c ( d ) . (7) 3 Illustration W e consider a corpus of revie ws provided by Y elp for a contest on kaggle.com . The text is tok- enized simply by conv erting to lowercase before splitting on punctuation and white-space. The training data are 230,000 re views containing more than 2 million sentences. Each revie w is marked by a number of stars , from 1 to 5, and we fit separate W ord2V ec representations V 1 . . . V 5 for the documents at each star rating. The valida- tion data consist of 23,000 revie ws, and we ap- ply the in version technique of Section 2 to score each validation document d with class probabili- ties q = [ q 1 · · · q 5 ] , where q c = p( c | d ) . The probabilities will be used in three different classification tasks; for re vie ws as a. negati ve at 1-2 stars, or positi ve at 3-5 stars; b. negati ve 1-2, neutral 3, or positi ve 4-5 stars; c. corresponding to each of 1 to 5 stars. In each case, classification proceeds by sum- ming across the relev ant sub-class probabilities. For example, in task a , p( positive ) = q 3 + q 4 + q 5 . Note that the same five fitted W ord2V ec representations are used for each task. W e consider a set of related comparator tech- niques. In each case, some document repre- sentation (e.g., phrase counts or Doc2V ec vec- tors) is used as input to logistic regression pre- diction of the associated re view rating. The lo- gistic regressions are fit under L 1 regularization with the penalties weighted by feature standard de viation (which, e.g., up-weights rare phrases) and selected according to the corrected AICc cri- teria (Flynn et al., 2013) via the gamlr R pack- age of T addy (2014). For multi-class tasks b - c , we use distributed Multinomial regression (DMR; ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 wor d2vec in version ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 phrase regression ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 doc2vec regression ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 0.0 0.2 0.4 0.6 0.8 1.0 mnir stars probability positive Figure 2: Out-of-Sample fitted probabilities of a revie w being positive (having greater than 2 stars) as a function of the true number of re vie w stars. Box widths are proportional to number of observations in each class; roughly 10% of re views hav e each of 1-3 stars, while 30% hav e 4 stars and 40% hav e 5 stars. T addy 2015) via the distrom R package. DMR fits multinomial logistic regression in a factorized representation wherein one estimates independent Poisson linear models for each response category . Document representations and logistic regressions are always trained using only the training corpus. Doc2V ec is also fit via gensim , using the same latent space specification as for W ord2V ec: K = 100 and b = 5 . As recommended in the doc- umentation, we apply repeated SGD over 20 re- orderings of each corpus (for comparability , this was also done when fitting W ord2V ec). Le and Mikolo v provide two alternati ve Doc2V ec specifi- cations: distrib uted memory (DM) and distributed bag-of-words (DBO W). W e fit both. V ector rep- resentations for v alidation documents are trained without updating the word-v ector elements, lead- ing to 100 dimensional vectors for each docu- ment for each of DM and DCBO W . W e input each, as well as the combined 200 dimensional DM+DBO W representation, to logistic regression. Phrase re gression applies logistic re gression of re- sponse classes directly onto counts for short 1-2 word ‘phrases’. The phrases are obtained using gensim ’ s phrase b uilder , which simply combines highly probable pairings; e.g., first date and chicken wing are two pairings in this corpus. MNIR , the multinomial in verse regression of T addy (2013a; 2013b; 2015) is applied as im- plemented in the textir package for R. MNIR maps from text to the class-space of inter - est through a multinomial logistic regression of phrase counts onto v ariables rele vant to the class- space. W e apply MNIR to the same set of 1-2 word phrases used in phrase regression. Here, we regress phrase counts onto stars expressed numeri- cally and as a 5-dimensional indicator vector , lead- a (NP) b (NNP) c (1-5) W2V in version .099 .189 .435 Phrase regression .084 .200 .410 D2V DBO W .144 .282 .496 D2V DM .179 .306 .549 D2V combined .148 . 284 .500 MNIR .095 .254 .480 W2V aggregation .118 .248 .461 T able 1: Out-of-sample misclassification rates. ing to a 6-feature multinomial logistic regression. The MNIR procedure then uses the 6 × p matrix of feature-phrase re gression coefficients to map from phrase-count to feature space, resulting in 6 di- mensional ‘sufficient reduction’ statistics for each document. These are input to logistic re gression. W or d2V ec ag gr e gation av erages fitted word rep- resentations for a single W ord2V ec trained on all sentences to obtain a fixed-length feature vector for each re view ( K = 100 , as for in version). This vector is then input to logistic re gression. 3.1 Results Misclassification rates for each task on the valida- tion set are reported in T able 1. Simple phrase- count regression is consistently the strongest per - former , bested only by W ord2V ec in version on task b . This is partially due to the relativ e strengths of discriminati ve (e.g., logistic regression) vs gen- erati ve (e.g., all others here) classifiers: giv en a large amount of training text, asymptotic effi- ciency of logistic regression will start to work in its fa vor o ver the finite sample adv antages of a generati ve classifier (Ng and Jordan, 2002; T addy , 2013c). Ho wev er , the comparison is also unfair to W ord2V ec and Doc2V ec: both phrase regres- sion and MNIR are optimized exactly under AICc selected penalty , while W ord and Doc 2V ec hav e only been approximately optimized under a sin- gle specification. The distributed representations should improv e with some careful engineering. W ord2V ec in version outperforms the other doc- ument representation-based alternativ es (except, by a narrow margin, MNIR in task a ). Doc2V ec under DBO W specification and MNIR both do worse, but not by a large margin. In contrast to Le and Mikolo v , we find here that the Doc2V ec DM model does much worse than DBO W . Re- gression onto simple within- document aggrega- tions of W ord2V ec perform slightly better than any Doc2V ec option (but not as well as the W ord2V ec in version). This again contrasts the results of Le and Mikolov and we suspect that the more com- plex Doc2V ec model would benefit from a careful tuning of the SGD optimization routine. 3 Looking at the fitted probabilities in detail we see that W ord2V ec in version provides a more use- ful document ranking than any comparator (in- cluding phrase regression). For example, Figure 2 sho ws the probabilities of a re view being ‘pos- iti ve’ in task a as a function of the true star rat- ing for each v alidation revie w . Although phrase regression does slightly better in terms of misclas- sification rate, it does so at the cost of classifying many terrible (1 star) re vie ws as positi ve. This oc- curs because 1-2 star re views are more rare than 3- 5 star revie ws and because words of emphasis (e.g. very , completely , and !!! ) are used both in very bad and in very good re views. W ord2V ec in version is the only method that yields positi ve- document probabilities that are clearly increasing in distribution with the true star rating. It is not dif- ficult to en vision a misclassification cost structure that fa vors such nicely ordered probabilities. 4 Discussion The goal of this note is to point out in version as an option for turning distrib uted language representa- tions into classification rules. W e are not ar guing 3 Note also that the unsupervised document representa- tions – Doc2V ec or the single W ord2V ec used in W ord2V ec aggregation – could be trained on larger unlabeled corpora. A similar option is av ailable for W ord2V ec in version: one could take a single W ord2V ec model trained on a large unlabeled corpora as a shared baseline (prior) and update separate mod- els with additional training on each labeled sub-corpora. The representations will all be shrunk to wards a baseline language model, but will differ according to distinctions between the language in each labeled sub-corpora. for the supremac y of W ord2V ec in version in par - ticular , and the approach should work well with al- ternati ve representations (e.g., Glov e). Moreov er , we are not e ven arguing that it will always outper- form purpose-built classification tools. Howe ver , it is a simple, scalable, interpretable, and effecti ve option for classification whenev er you are working with such distributed representations. References [Besag1974] Julian Besag. 1974. Spatial interaction and the statistical analysis of lattice systems. J our- nal of the Royal Statistical Society , Series B . [Besag1975] Julian Besag. 1975. Statistical analysis of non-lattice data. The Statistician , pages 179–195. [Flynn et al.2013] Cheryl Flynn, Clifford Hurvich, and Jeffere y Simonoff. 2013. Efficienc y for Regular- ization Parameter Selection in Penalized Likelihood Estimation of Misspecified Models. Journal of the American Statistical Association , 108:1031–1043. [Jernite et al.2015] Y acine Jernite, Ale xander Rush, and David Sontag. 2015. A fast variational approach for learning Marko v random field language models. In Pr oceedings of the 32nd International Confer ence on Machine Learning (ICML 2015) . [Le and Mikolov2014] Quoc V . Le and T omas Mik olov . 2014. Distrib uted representations of sentences and documents. In Proceedings of the 31 st Interna- tional Confer ence on Machine Learning . [Mikolov et al.2013a] T omas Mikolov , Kai Chen, Greg Corrado, and Jef frey Dean. 2013a. Efficient estima- tion of word representations in vector space. arXiv pr eprint arXiv:1301.3781 . [Mikolov et al.2013b] T omas Mikolov , Ilya Sutske ver , Kai Chen, Greg S. Corrado, and Jeff Dean. 2013b . Distributed representations of words and phrases and their compositionality . In Advances in Neural Information Pr ocessing Systems , pages 3111–3119. [Molenberghs and V erbeke2006] Geert Molenberghs and Geert V erbeke. 2006. Models for discr ete longitudinal data . Springer Science & Business Media. [Morin and Bengio2005] Frederic Morin and Y oshua Bengio. 2005. Hierarchical probabilistic neural net- work language model. In Pr oceedings of the In- ternational W orkshop on Artificial Intelligence and Statistics , pages 246–252. [Ng and Jordan2002] Andrew Y . Ng and Michael I. Jor- dan. 2002. On Discriminativ e vs Generativ e Clas- sifiers: A Comparison of Logistic Regression and naiv e Bayes. In Advances in Neural Information Pr ocessing Systems (NIPS) . [Pennington et al.2014] Jeffrey Pennington, Richard Socher , and Christopher D. Manning. 2014. Glov e: Global vectors for word representation. Pr oceedings of the Empiricial Methods in Natur al Langua ge Pr o- cessing (EMNLP 2014) , 12. [Rehurek and Sojka2010] Radim Rehurek and Petr So- jka. 2010. Software Framework for T opic Mod- elling with Large Corpora. In Proceedings of the LREC 2010 W orkshop on New Challenges for NLP F rame works , pages 45–50. [Rumelhart et al.1986] David Rumelhart, Geof frey Hinton, and Ronald W illiams. 1986. Learning representations by back-propagating errors. Natur e , 323:533–536. [Socher et al.2011] Richard Socher , Cliff C. Lin, Chris Manning, and Andrew Y . Ng. 2011. Parsing natu- ral scenes and natural language with recursive neural networks. In Pr oceedings of the 28th international confer ence on machine learning (ICML-11) , pages 129–136. [Socher et al.2013] Richard Socher , Alex Perelygin, Jean Y . W u, Jason Chuang, Christopher D. Manning, Andrew Y . Ng, and Christopher Potts. 2013. Recur- siv e deep models for semantic compositionality ov er a sentiment treebank. In Pr oceedings of the confer- ence on empirical methods in natur al language pro- cessing (EMNLP) , volume 1631, page 1642. [T addy2013a] Matt T addy . 2013a. Measuring Polit- ical Sentiment on T witter: Factor Optimal Design for Multinomial In verse Regression. T echnometrics , 55(4):415–425, Nov ember . [T addy2013b] Matt T addy . 2013b . Multinomial In- verse Regression for T ext Analysis. J ournal of the American Statistical Association , 108:755–770. [T addy2013c] Matt T addy . 2013c. Rejoinder: Effi- ciency and structure in MNIR. J ournal of the Amer - ican Statistical Association , 108:772–774. [T addy2014] Matt T addy . 2014. One-step estimator paths for concav e regularization. [T addy2015] Matt T addy . 2015. Distrib uted Multino- mial Regression. Annals of Applied Statistics , T o appear . [V arin et al.2011] Cristiano V arin, Nancy Reid, and David Firth. 2011. An ov erview of composite like- lihood methods. Statistica Sinica , 21(1):5–42.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment