Clustering Protein Sequences Given the Approximation Stability of the Min-Sum Objective Function
We study the problem of efficiently clustering protein sequences in a limited information setting. We assume that we do not know the distances between the sequences in advance, and must query them during the execution of the algorithm. Our goal is to…
Authors: Konstantin Voevodski, Maria-Florina Balcan, Heiko Roglin
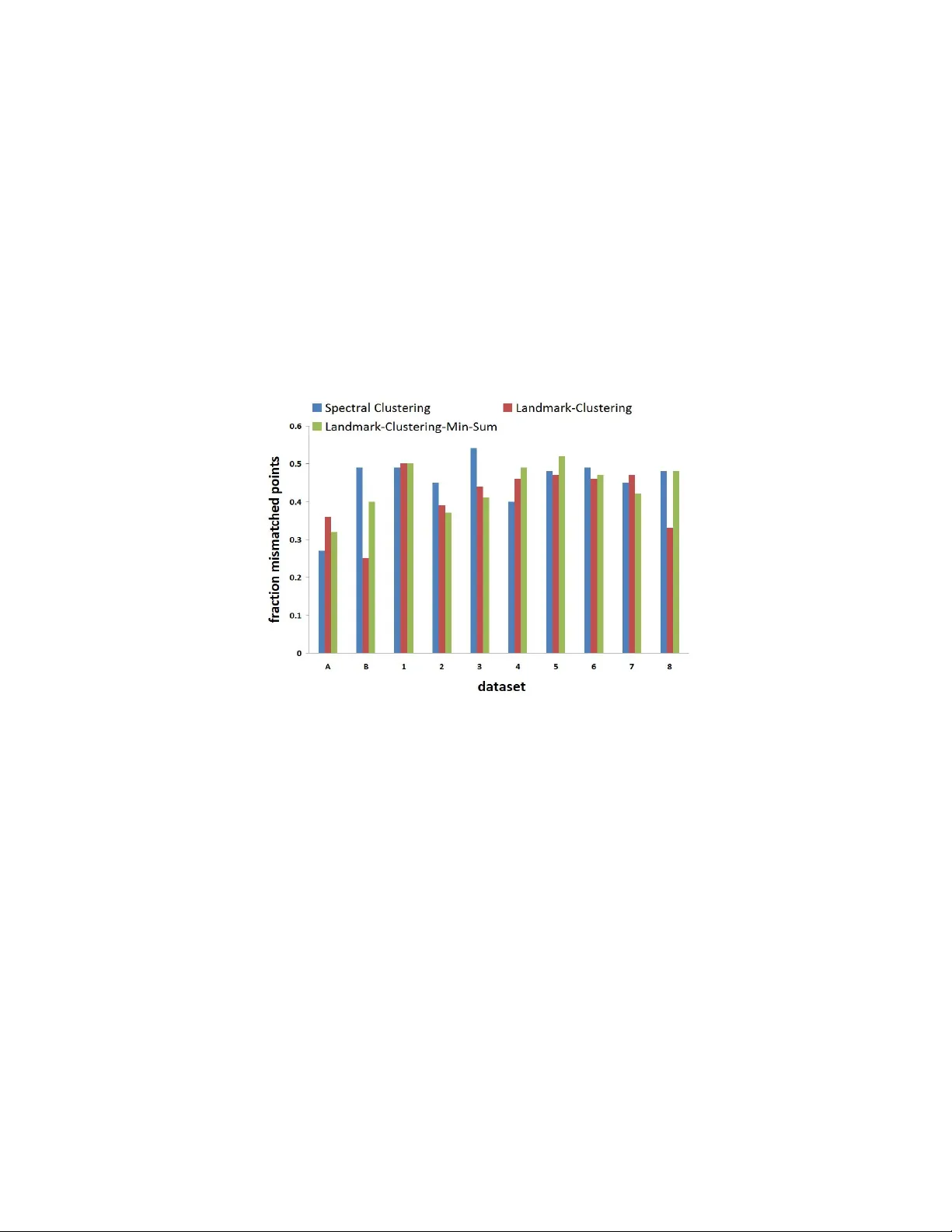
Clustering Protein Sequences Giv en the Appro ximation Stabilit y of the Min-Sum Ob jectiv e F unction Konstan tin V o ev o dski 1 , Maria-Florina Balcan 2 , Heiko R¨ oglin 3 , Shang-Hua T eng 4 , and Y u Xia 5 1 Departmen t of Computer Science, Boston Univ ersit y , Boston, MA 02215, USA 2 College of Computing, Georgia Institute of T echnology , A tlanta, GA 30332, USA 3 Departmen t of Computer Science, Universit y of Bonn, Bonn, Germany 4 Computer Science Department, Universit y of Southern California, Los Angeles, CA 90089, USA 5 Bioinformatics Program and Department of Chemistry , Boston Universit y , Boston, MA 02215, USA Abstract. W e study the problem of efficien tly clustering protein se- quences in a limited information setting. W e assume that we do not kno w the distances b etw een the sequences in adv ance, and must query them during the execution of the algorithm. Our goal is to find an ac- curate clustering using few queries. W e mo del the problem as a point set S with an unkno wn metric d on S , and assume that we hav e access to one versus al l distance queries that given a point s ∈ S return the distances b etw een s and all other p oints. Our one v ersus all query rep- resen ts an efficient sequence database search program such as BLAST, whic h compares an input sequence to an entire data set. Given a natural assumption ab out the approximation stability of the min-sum ob jectiv e function for clustering, w e design a prov ably accurate clustering algo- rithm that uses few one v ersus all queries. In our empirical study we sho w that our metho d compares fa vorably to well-established cluster- ing algorithms when we compare computationally derived clusterings to gold-standard manual classifications. 1 In tro duction Biology is an information-driven science, and the size of av ailable data contin ues to expand at a remark able rate. The gro wth of biological sequence databases has b een particularly impressive. F or example, the size of GenBank, a biologi- cal sequence repository , has doubled ev ery 18 months from 1982 to 2007. It has b ecome imp ortant to develop computational techniques that can handle such large amoun ts of data. Clustering is very useful for exploring relationships b e- t ween protein sequences. How ever, most clustering algorithms require distances b et ween all pairs of p oints as input, which is infeasible to obtain for very large protein sequence data sets. Even with a one versus al l distance query such as BLAST (Basic Lo cal Alignment Search T o ol) [AGM + 90], which efficiently com- pares a sequence to an entire database of sequences, it may not b e p ossible to use it n times to construct the entire pairwise distance matrix, where n is the size of the data set. In this w ork w e presen t a clustering algorithm that gives an accurate clustering using only O ( k log k ) queries, where k is the n um b er of clusters. W e analyze the correctness of our algorithm under a natural assumption ab out the data, namely the ( c, ) approximation stability property of [BBG09]. Balcan et al. assume that there is some relev ant “target” clustering C T , and optimizing a particular ob jective function for clustering (such as min-sum) gives clusterings that are structurally close to C T . More precisely , they assume that an y c -approximation of the ob jective is -close to C T , where the distance b e- t ween t wo clusterings is the fraction of misclassified p oints under the optimum matc hing b et ween the tw o sets of clusters. Our contribution is designing an algorithm that given the ( c, )-prop ert y for the min-sum ob jective pro duces an accurate clustering using only O ( k log k ) one versus al l distance queries, and has a run time of O ( k log( k ) n log( n )). W e conduct an empirical study that compares computationally derived clusterings to those giv en by gold-standard classifica- tions of protein evolutionary relatedness. W e show that our method compares fa vorably to w ell-established clustering algorithms in terms of accuracy . More- o ver, our algorithm easily scales to massiv e data sets that cannot b e handled by traditional algorithms. The algorithm presen ted here is related to the one presen ted in [VBR + 10]. The L andmark-Clustering algorithm presen ted there gives an accurate clustering if the instance satisfies the ( c, )-property for the k -median ob jective. Ho wev er, if the property is satisfied for the min-sum ob jective the structure of the clustering instance is quite different, and the algorithm giv en in [VBR + 10] fails to find an accurate clustering in suc h cases. Indeed, the analysis presented here is also quite differen t. The min-sum ob jective is also considerably harder to approximate. F or k -median the b est approximation guaran tee is (3 + ) given b y [A GK + 04]. F or the min-sum ob jective when the num b er of clusters is arbitrary there is an O ( δ − 1 log 1+ δ n )-appro ximation algorithm with running time n O (1 /δ ) due to [BCR01]. There are also sev eral other clustering algorithms that are applicable in our limited information setting [A V07,AJM09,MOP01,CS07]. How ever, b ecause all of these methods seek to approximate an ob jective function they will not pro duce an accurate clustering in our mo del if the ( c, )-property holds for v alues of c for whic h finding a c -appro ximation is difficult. Other than [VBR + 10] we are not a ware of any results pro viding b oth prov ably accurate algorithms and strong query complexity guarantees in such a mo del. 2 Preliminaries Giv en a metric space M = ( X , d ) with p oint set X , an unknown distance function d satisfying the triangle inequality , and a set of p oints S ⊆ X , we would lik e to find a k -clustering C that partitions the p oints in S into k sets C 1 , . . . , C k b y using one versus al l distance queries. The min-sum ob jectiv e function for clustering is to minimize Φ ( C ) = P k i =1 P x,y ∈ C i d ( x, y ). W e reduce the min-sum clustering problem to the related b alanc e d k-me dian problem. The balanced k -median ob jective func- tion seeks to minimize Ψ ( C ) = P k i =1 | C i | P x ∈ C i d ( x, c i ), where c i is the me- dian of cluster C i , which is the p oint y ∈ C i that minimizes P x ∈ C i d ( x, y ). As p oin ted out in [BCR01], in metric spaces the tw o ob jectiv e functions are related to within a factor of 2: Ψ ( C ) / 2 ≤ Φ ( C ) ≤ Ψ ( C ). F or any ob jective function Ω w e use OPT Ω to denote its optimum v alue. In our analysis we assume that S satisfies the ( c, )-prop ert y of [BBG09] for the min-sum and balanced k -median ob jective functions. T o formalize the ( c, )-prop erty we need to define a notion of distance b etw een tw o k -clusterings C = { C 1 , . . . , C k } and C 0 = { C 0 1 , . . . , C 0 k } . As in [BBG09], w e define the distance b et ween C and C 0 as the fraction of p oints on whic h they disagree under the optimal matching of clusters in C to clusters in C 0 : dist( C, C 0 ) = min σ ∈ S k 1 n k X i =1 | C i − C 0 σ ( i ) | , where S k is the set of bijections σ : { 1 , . . . , k } → { 1 , . . . , k } . Two clusterings C and C 0 are said to b e -close if dist( C, C 0 ) < . W e assume that there exists some unknown relev ant “target” clustering C T and giv en a prop osed clustering C we define the error of C with resp ect to C T as dist( C, C T ). Our goal is to find a clustering of lo w error. The ( c, ) appro ximation stabilit y prop ert y is defined as follows. Definition 1. We say that the instanc e ( S, d ) satisfies the ( c, ) -pr op erty for obje ctive function Ω with r esp e ct to the tar get clustering C T if any clustering of S that appr oximates OPT Ω within a factor of c is -close to C T , that is, Ω ( C ) ≤ c · OPT Ω ⇒ dist( C, C T ) < . W e note that b ecause any (1 + α )-appro ximation of the balanced k -median ob jectiv e is a 2(1 + α )-appro ximation of the min-sum ob jective, it follows that if the clustering instance satisfies the (2(1 + α ) , )-prop erty for the min-sum ob jectiv e, then it satisfies the (1 + α, )-prop ert y for balanced k -median. 3 Algorithm Ov erview In this section we present a clustering algorithm that given the (1+ α, )-prop erty for the balanced k -median ob jective finds an accurate clustering using few dis- tance queries. Our algorithm is outlined in Algorithm 1 (with some implementa- tion details omitted). W e start b y uniformly at random choosing n 0 p oin ts that w e call landmarks , where n 0 is an appropriate num b er. F or each landmark that we c ho ose we use a one versus al l query to get the distances betw een this landmark and all other p oints. These are the only distances used by our pro cedure. Our algorithm then expands a ball B l around eac h landmark l one p oint at a time. In each iteration we c heck whether some ball B l ∗ passes the test in line 7. Our test considers the size of the ball and its radius, and chec ks whether their pro duct is greater than the threshold T . If this is the case, we consider all balls that ov erlap B l ∗ on any p oin ts, and compute a cluster that contains all the p oin ts in these balls. Poin ts and landmarks in the cluster are then remov ed from further consideration. Algorithm 1 Landmark-Clustering-Min-Sum( S, k , n 0 , T ) 1: choose a set of landmarks L of size n 0 uniformly at random from S ; 2: i = 1, r = 0; 3: while i ≤ k do 4: for each l ∈ L do 5: B l = { s ∈ S | d ( s, l ) ≤ r } ; 6: end for 7: if ∃ l ∗ ∈ L : | B l ∗ | · r > T then 8: L 0 = { l ∈ L : B l ∩ B l ∗ 6 = ∅} ; 9: C i = { s ∈ S : s ∈ B l and l ∈ L 0 } ; 10: i = i + 1; 11: remo ve clustered p oints from consideration; 12: end if 13: incremen t r to the next relev an t distance; 14: end while 15: return C = { C 1 , . . . C k } ; A complete description of this algorithm can b e found in the next section. W e now present our theoretical guaran tee for Algorithm 1. Theorem 1. Given a metric sp ac e M = ( X , d ) , wher e d is unknown, and a set of p oints S , if the instanc e ( S, d ) satisfies the (1 + α, ) -pr op erty for the b alanc e d- k -me dian obje ctive function, we ar e given the optimum obje ctive value OPT , and e ach cluster in the tar get clustering C T has size at le ast (6 + 240 /α ) n , then Landmark-Clustering-Min-Sum ( S, k , n 0 , α OPT 40 n ) outputs a clustering that is O ( /α ) -close to C T with pr ob ability at le ast 1 − δ . The algorithm uses n 0 = 1 (3+120 /α ) ln k δ one v ersus all distance queries , and has a runtime of O ( n 0 n log n ) . W e note that n 0 = O ( k ln k δ ) if the sizes of the target clusters are balanced. In addition, if we do not know the v alue of OPT, we can still find an accurate clustering b y running Algorithm 1 from line 2 at most n 0 n 2 times with increasing estimates of T un til enough points are clustered. It is not necessary to recompute the landmarks, so the num b er of distance queries that are required remains the same. W e next give some high-level intuition for how our procedures work. Giv en our approximation stabilit y ass umption, the target clustering must ha ve the structure shown in Figure 1. Eac h target cluster C i has a “core” of w ell-separated p oints, where any tw o p oin ts in the cluster core are closer than a certain distance d i to each other, and any p oint in a different core is farther than cd i , for some constan t c . Moreo ver, the diameters of the cluster cores are C1 C2 C3 d1 d2 d3 Fig. 1. Cluster cores C 1 , C 2 and C 3 are shown with diameters d 1 , d 2 and d 3 , resp ec- tiv ely . The diameters of the cluster cores are inv ersely prop ortional to their sizes. in versely proportional to the cluster sizes: there is some constant θ such that | C i | · d i = θ for eac h cluster C i . Given this structure, it is p ossible to classify the p oin ts in the cluster cores correctly if we extract the smaller diameter clusters first. In the example in Figure 1, we can extract C 1 , follo wed by C 2 and C 3 if w e choose the threshold T correctly and we hav e selected a landmark from each cluster core. How ev er, if w e wait un til some ball contains all of C 3 , C 1 and C 2 ma y b e merged. 4 Algorithm Analysis In this section we presen t a formal analysis of our algorithm, and give the pro of of Theorem 1. W e first present a complete description of the algorithm. W e then describ e the structure of the clustering instance that is implied b y our appro ximation stability assumption. W e then give a general ov erview of our argumen t, whic h is follow ed by the complete pro of. 4.1 Algorithm Description A full description of our algorithm is giv en in Algorithm 2. In order to efficiently expand a ball around each landmark, we first sort all landmark-p oin t pairs ( l , s ) b y d ( l, s ). W e then consider these pairs in order of increasing distance (line 7), skipping pairs where l or s hav e already b een clustered; the clustered p oints are main tained in the set ¯ S . In each iteration we chec k whether some ball B l ∗ passes the test in line 19. Our actual test, whic h is slightly different than the one presented earlier, con- siders the size of the ball and the next lar gest landmark-p oint distance (denoted b y r 2 ), and chec ks whether their pro duct is greater than the threshold T . If this is the case, w e consider all balls that ov erlap B l ∗ on any p oints, and compute a cluster that contains all the p oints in these balls. Poin ts and landmarks in the cluster are then remov ed from further consideration by adding the clustered p oin ts to ¯ S , and removing the clustered points from an y ball. Our pro cedure terminates once we find k clusters. If we reach the final landmark-p oin t pair, we stop and rep ort the remaining unclustered p oints as part of the same cluster (line 12). If the algorithm terminates without partition- ing all the p oints, we assign each remaining p oint to the cluster containing the closest clustered landmark. In our analysis we sho w that if the clustering instance satisfies the (1 + α, )-prop erty for the balanced k -median ob jective function, our pro cedure will output exactly k clusters. The most time-consuming part of our algorithm is sorting all landmark- p oin ts pairs, whic h takes O ( | L | n log n ), where n is the size of the data set and L is the set of landmarks. With a simple implementation that uses a hashed set to store the p oints in eac h ball, the total cost of computing the clusters and remo ving clustered p oints from active balls is at most O ( | L | n ) each. All other op erations tak e asymptotically less time, so the ov erall runtime of our procedure is O ( | L | n log n ). Algorithm 2 Landmark-Clustering-Min-Sum( S, k , n 0 , T ) 1: choose a set of landmarks L of size n 0 uniformly at random from S ; 2: for each l ∈ L do 3: B l = ∅ ; 4: end for 5: i = 1, ¯ S = ∅ ; 6: while i ≤ k do 7: ( l, s ) = GetNextActiv ePair(); 8: r 1 = d ( l, s ); 9: if (( l 0 , s 0 ) = PeekNextActiv ePair()) ! = n ull then 10: r 2 = d ( l 0 , s 0 ); 11: else 12: C i = S − ¯ S ; 13: break; 14: end if 15: B l = B l + { s } ; 16: if r 1 == r 2 then 17: con tinue; 18: end if 19: while ∃ l ∈ L − ¯ S : | B l | > T /r 2 and i ≤ k do 20: l ∗ = argmax l ∈ L − ¯ S | B l | ; 21: L 0 = { l ∈ L − ¯ S : B l ∩ B l ∗ 6 = ∅} ; 22: C i = { s ∈ S : s ∈ B l and l ∈ L 0 } ; 23: for each s ∈ C i do 24: ¯ S = ¯ S + { s } ; 25: for each l ∈ L do 26: B l = B l − { s } ; 27: end for 28: end for 29: i = i + 1; 30: end while 31: end while 32: return C = { C 1 , . . . C k } ; 4.2 Structure of the Clustering Instance W e next describ e the structure of the clustering instance that is implied b y our approximation stability assumption. W e denote by C ∗ = { C ∗ 1 , . . . , C ∗ k } the optimal balanced- k -median clustering with ob jective v alue OPT= Ψ ( C ∗ ). F or each cluster C ∗ i , let c ∗ i b e the median point in the cluster. F or x ∈ C ∗ i , define w ( x ) = | C ∗ i | d ( x, c ∗ i ) and let w = avg x w ( x ) = OPT n . Define w 2 ( x ) = min j 6 = i | C ∗ j | d ( x, c ∗ j ). It is prov ed in [BBG09] that if the instance satisfies the (1 + α, )-prop ert y for the balanced k -median ob jective function and eac h cluster in C ∗ has size at least max(6 , 6 /α ) · n , then at most 2 -fraction of p oints x ∈ S hav e w 2 ( x ) < αw 4 . In addition, by definition of the a verage w eight w at most 120 /α -fraction of p oints x ∈ S ha ve w ( x ) > αw 120 . W e call p oin t x go o d if b oth w ( x ) ≤ αw 120 and w 2 ( x ) ≥ αw 4 , else x is called bad. Let X i b e the go o d p oin ts in the optimal cluster C ∗ i , and let B = S \ ∪ X i b e the bad p oints. Lemma 1, which is similar to Lemma 14 of [BBG09], pro ves that the optimum balanced k -median clustering must hav e the follo wing structure: 1. F or all x, y in the same X i , we hav e d ( x, y ) ≤ αw 60 | C ∗ i | . 2. F or x ∈ X i and y ∈ X j 6 = i , d ( x, y ) > αw 5 / min( | C ∗ i | , | C ∗ j | ). 3. The num b er of bad p oints is at most b = (2 + 120 /α ) n . 4.3 Pro of of Theorem 1 Our algorithm expands a ball around each landmark, one p oint at a time, until some ball is large enough. W e use r 1 to refer to the current radius of the balls, and r 2 to refer to the next relev an t radius (next largest landmark-p oint distance). T o pass the test in line 19, a ball must satisfy | B l | > T /r 2 . W e c ho ose T suc h that by the time a ball satisfies the conditional, it m ust o verlap some go o d set X i . Moreov er, at this time the radius m ust b e large enough for X i to b e en tirely con tained in some ball; X i will therefore b e part of the cluster computed in line 22. Ho w ever, the radius is to o small for a single ball to ov erlap differen t goo d sets and for tw o balls ov erlapping differen t go o d sets to share an y p oints. Therefore the computed c luster cannot contain p oints from an y other goo d set. P oin ts and landmarks in the cluster are then remov ed from further consideration. The same argument can then b e applied again to show that each cluster output b y the algorithm entirely contains a single go o d set. Thus the clustering output b y the algorithm agrees with C ∗ on all the go o d p oints, so it m ust b e closer than b + = O ( /α ) to C T . A more detailed argumen t is given b elow. Pr o of. Since eac h cluster in the target clustering has more than (6 + 240 /α ) n p oin ts, and the optimal balanced- k -median clustering C ∗ can differ from the target clustering b y few er than n p oints, eac h cluster in C ∗ m ust ha v e more than (5 + 240 /α ) n p oints. Moreo v er, b y Lemma 1 w e ma y ha ve at most (2 + 120 /α ) n bad p oin ts, and hence eac h | X i | = | C ∗ i \ B | > (3 + 120 /α ) n ≥ (2 + 120 /α ) n + 2 = b + 2. W e will use s min to refer to the (3 + 120 /α ) n quan tity . Our argument assumes that w e ha ve c hosen at least one landmark from eac h go o d set X i . Lemma 2 argues that after selecting n 0 = n s min ln k δ = 1 (3+120 /α ) ln k δ landmarks the probability of this happening is at least 1 − δ . Moreo v er, if the target clusters are balanced in size: max C ∈ C T | C | / min C ∈ C T | C | < c for some constan t c , b ecause the size of eac h goo d set is at least half the size of the corresp onding target cluster, it m ust b e the case that 2 s min c · k ≥ n , so n/s min = O ( k ). Supp ose that we order the clusters of C ∗ suc h that | C ∗ 1 | ≥ | C ∗ 2 | ≥ . . . | C ∗ k | , and let n i = | C ∗ i | . Define d i = αw 60 | C ∗ i | and recall that max x,y ∈ X i d ( x, y ) ≤ d i . Note that because there is a landmark in each go o d set X i , for radius r ≥ d i there exists some ball containing all of X i . W e use B l ( r ) to denote a ball of radius r around landmark l : B l ( r ) : { s ∈ S | d ( s, l ) ≤ r } . If w e apply Lemma 3 with all the clusters in C ∗ , w e can see that as long as r ≤ 3 d 1 , a ball cannot con tain points from more than one go o d set and balls o verlapping different go o d sets cannot share an y points. W e also observ e that when b oth r ≤ 3 d 1 and r < d i are true, a ball B l ( r ) containing points from X i do es not satisfy | B l ( r ) | ≥ T /r . F or r ≤ 3 d 1 a ball cannot contain p oints from different go o d sets; therefore an y ball containing p oints from X i has size at most | C ∗ i | + b < 3 n i 2 . In addition, for r < d i the size bound T /r > T /d i = αw 40 / αw 60 | C ∗ i | = 3 n i 2 . Therefore for these v alues of r any ball con taining p oin ts from X i is to o small to satisfy the conditional. Finally , w e observe that for r = 3 d 1 some ball B l ( r ) con taining all of X 1 do es satisfy | B l ( r ) | ≥ T /r . Clearly , for r = 3 d 1 there is some ball con taining all of X 1 , which must hav e size at least | C ∗ 1 | − b ≥ n 1 / 2. F or r = 3 d 1 the size b ound T /r = n 1 / 2, so this ball is large enough to satisfy this conditional. Moreov er, for r ≤ 3 d 1 the size b ound T /r ≥ n 1 / 2. Therefore a ball containing only bad p oin ts cannot pass our test for r ≤ 3 d 1 b ecause the num b er of bad p oints is at most b < n 1 / 2. Consider the smallest radius r ∗ for whic h some ball B l ∗ ( r ∗ ) satisfies | B l ∗ ( r ∗ ) | ≥ T /r ∗ . It m ust b e the case that r ∗ ≤ 3 d 1 , and B l ∗ o verlaps with some goo d set X i b ecause w e cannot hav e a ball con taining only bad points for r ∗ ≤ 3 d 1 . Moreo ver, b y our previous argumen t b ecause B l ∗ con tains p oints from X i , it must b e the case that r ∗ ≥ d i , and therefore some ball con tains all the p oints in X i . Consider a cluster ˆ C of all the points in balls that o verlap B l ∗ : ˆ C = { s ∈ S | s ∈ B l and B l ∩ B l ∗ 6 = ∅} , which must include all the points in X i . In addition, B l ∗ cannot share an y p oints with balls that o v erlap other go o d sets b ecause r ∗ ≤ 3 d 1 , there- fore ˆ C do es not contain p oints from any other goo d set. Therefore the cluster ˆ C en tirely con tains some go o d set and no p oints from any other go od set. These facts suggest the following conceptual algorithm for finding a clustering that classifies all the go o d p oints correctly: increment r until some ball satisfies | B l ( r ) | ≥ T /r , compute the cluster con taining all p oin ts in balls that o verlap B l ( r ), remov e these p oints, and repeat un til w e find k clusters. W e can argue that each cluster output b y the algorithm entirely contains some go o d set and no p oints from any other go o d set. Eac h time we can consider the clusters C ⊆ C ∗ whose goo d sets hav e not yet b een output, order them b y size, and apply Lemma 3 with C to argue that while r ≤ 3 d 1 the radius is too small for the computed cluster to o verlap an y of the remaining go od sets. As before, we can argue that by the time we reach 3 d 1 w e must output some cluster. In addition, when r ≤ 3 d 1 w e cannot output a cluster of only bad p oints and whenev er w e output a cluster ov erlapping some go o d set X i , it must b e the case that r ≥ d i . Therefore each computed cluster m ust en tirely con tain some go o d set and no p oints from an y other go o d set. If there are any unclustered p oin ts up on the completion of the algorithm, w e can assign the remaining points to any cluster. Still, we are able to classify all the goo d p oints correctly , so the rep orted clustering must b e closer than b + dist( C ∗ , C T ) < b + = O ( /α ) to C T . It suffices to show that ev en though our algorithm only considers discrete v alues of r corresp onding to landmark-p oint distances, the output of our pro ce- dure exactly matches the output of the conceptual algorithm describ ed ab ov e. Consider the smallest (con tin uous) radius r ∗ for whic h some ball B l 1 ( r ∗ ) satisfies | B l 1 ( r ∗ ) | ≥ T /r ∗ . W e use d real to refer to the largest landmark-point distance suc h that d real ≤ r ∗ . Clearly , b y the time our algorithm reac hes r 1 = d real it m ust b e the case that B l 1 passes the test on line 19: | B l 1 | > T /r 2 , and this test is not passed b y any ball at any prior time. Moreov er, B l 1 m ust b e the largest ball passing our test at this p oin t b ecause if there is another ball B l 2 that also satisfies our test when r 1 = d real it m ust b e the case that | B l 1 | > | B l 2 | b ecause B l 1 satisfies | B l 1 ( r ) | ≥ T /r for a smaller r . Finally b ecause there are no landmark-p oint pairs ( l , s ) with r 1 < d ( l , s ) < r 2 , B l ( r 1 ) = B l ( r ∗ ) for each landmark l ∈ L . Therefore the cluster that we compute on line 22 for B l 1 ( r 1 ) is equiv alent to the cluster the conceptual algorithm computes for B l 1 ( r ∗ ). W e can repeat this argument for each cluster output b y the conceptual algorithm, sho wing that Algorithm 2 finds exactly the same clustering. W e note that when there is only one goo d set left the test in line 19 may not b e satisfied anymore if 3 d 1 ≥ max x,y ∈ S d ( x, y ), where d 1 is the diameter of the remaining go o d set. How ever, in this case if we exhaust all landmark-p oints pairs w e rep ort the remaining points as part of a single cluster (line 12), which m ust contain the remaining go o d set, and p ossibly some additional bad points that we consider misclassified anyw a y . With a simple implemen tation that uses a hashed set to keep trac k of the p oin ts in eac h ball, the runtime of our pro cedure is O ( | L | n log n ), which is given b y the time necessary to sort all landmark-p oin t pairs by distance. All other op erations take asymptotically less time. In particular, o ver the en tire run of the algorithm, the cost of computing the clusters in lines 21-22 is at most O ( n | L | ), and the cost of remo ving clustered p oints from activ e balls in lines 23-28 is also at most O ( n | L | ). u t Theorem 2. If we ar e not given the optimum obje ctive value w , then we c an stil l find a clustering that is O ( /α ) -close to C T with pr ob ability at le ast 1 − δ by running L andmark-Clustering-Min-Sum at most n 0 n 2 times with the same set of landmarks, wher e the numb er of landmarks n 0 = 1 (3+120 /α ) ln k δ as b efor e. Pr o of. If we are not giv en the v alue of w then w e hav e to estimate the threshold parameter T for deciding when a cluster develops. Let us use T ∗ to refer to its correct v alue ( T ∗ = αw 40 ). W e first note that there are at most n · n | L | relev an t v alues of T to try , where L is the set of landmarks. Our test in line 19 chec ks whether the pro duct of a ball size and a ball radius is larger than T , and there are only n p ossible ball sizes and | L | n p ossible v alues of a ball radius. Supp ose that we c ho ose a set of landmarks L , | L | = n 0 , as b efore. W e then compute all n 0 n 2 relev an t v alues of T and order them in ascending order: T i ≤ T i +1 for 1 ≤ i < n 0 n 2 . Then we rep eatedly execute Algorithm 2 starting on line 2 with increasing estimates of T . Note that this is equiv alent to trying all con tinuous v alues of T in ascending order because the execution of the algorithm do es not change for an y T 0 suc h that T i ≤ T 0 < T i +1 . In other words, when T i ≤ T 0 < T i +1 , the algorithm will give the same exact answer for T i as it would for T 0 . Our pro cedure stops the first time we cluster at least n − b p oints, where b is the maximum n umber of bad p oints. W e give an argumen t that this gives an accurate clustering with an additional error of b . As before, we assume that we hav e selected a t least one landmark from eac h go o d set, which happ ens with probability at least 1 − δ . Clearly , if w e choose the righ t threshold T ∗ the algorithm must cluster at least n − b p oin ts b ecause the clustering will con tain all the go o d p oints. Therefore the first time the algorithm clusters at least n − b p oints for some estimated threshold T , it m ust b e the case that T ≤ T ∗ . Lemma 4 argues that if T ≤ T ∗ and the n um b er of clustered points is at least n − b , then the reported partition m ust b e a k -clustering that contains a distinct go o d set in each cluster. This clustering may exclude up to b p oin ts, all of which may b e go o d p oints. Still, if w e arbitrarily assign the remaining p oints w e will get a clustering that is closer than 2 b + = O ( /α ) to C T . u t Lemma 1. If the b alanc e d k -me dian instanc e satisfies the (1 + α, )-pr op erty and e ach cluster in C ∗ has size at le ast max(6 , 6 /α ) · n we have: 1. F or al l x, y in the same X i , we have d ( x, y ) ≤ αw 60 | C ∗ i | . 2. F or x ∈ X i and y ∈ X j 6 = i , d ( x, y ) > αw 5 / min( | C ∗ i | , | C ∗ j | ) . 3. The numb er of b ad p oints is at most b = (2 + 120 /α ) n . Pr o of. F or part 1, since x, y ∈ X i ⊆ C ∗ i are b oth go o d, they are at distance of at most αw 120 | C ∗ i | to c ∗ i , and hence at distance of at most αw 60 | C ∗ i | to each other. F or part 2 assume without loss of generality that | C ∗ i | ≥ | C ∗ j | . Both x ∈ C ∗ i and y ∈ C ∗ j are go o d; it follows that d ( y , c ∗ j ) ≤ αw 120 | C ∗ j | , and d ( x, c ∗ j ) > αw 4 | C ∗ j | b ecause | C ∗ j | d ( x, c ∗ j ) ≥ w 2 ( x ) > αw 4 . By the triangle inequalit y it follows that d ( x, y ) ≥ d ( x, c ∗ j ) − d ( y , c ∗ j ) ≥ αw | C ∗ j | ( 1 4 − 1 120 ) > αw 5 / min( | C ∗ i | , | C ∗ j | ) , where we use that | C ∗ j | = min( | C ∗ i | , | C ∗ j | ). P art 3 follo ws from the maxim um n umber of points that ma y not satisfy eac h of the prop erties of the go o d p oin ts and the union b ound. u t Lemma 2. After sele cting n s ln k δ p oints uniformly at r andom, wher e s is the size of the smal lest go o d set, the pr ob ability that we did not cho ose a p oint fr om every go o d set is smal ler th an 1 − δ . Pr o of. W e denote b y s i the cardinality of X i . Observe that the probability of not selecting a p oin t from some go o d set X i after nc s samples is (1 − s i n ) nc s ≤ (1 − s i n ) nc s i ≤ ( e − s i n ) nc s i = e − c . By the union bound the probability of not selecting a p oint from every go o d set after nc s samples is at most k e − c , which is equal to δ for c = ln k δ . u t Lemma 3. Given a subset of clusters C ⊆ C ∗ , and the set of the c orr esp onding go o d sets X , let s max = max C i ∈ C | C i | b e the size of the lar gest cluster in C , and d min = αw 60 s max . Then for r ≤ 3 d min , a b al l c annot overlap a go o d set X i ∈ X and any other go o d set, and a b al l c ontaining p oints fr om a go o d set X i ∈ X c annot shar e any p oints with a b al l c ontaining p oints fr om any other go o d set. Pr o of. By part 2 of Lemma 1, for x ∈ X i and y ∈ X j 6 = i w e ha ve d ( x, y ) > αw 5 / min( | C ∗ i | , | C ∗ j | ) . It follo ws that for x ∈ X i ∈ X and y ∈ X j 6 = i w e must hav e d ( x, y ) > αw 5 / min( | C ∗ i | , | C ∗ j | ) ≥ αw 5 / | C ∗ i | > αw 5 /s max = 12 d min , where we use the fact that | C i | ≤ s max . So a p oint in a go o d set in X and a p oint in any other go o d set must b e farther than 12 d min . T o prov e the first part, consider a ball B l of radius r ≤ 3 d min around land- mark l . In other words, B l = { s ∈ S | d ( s, l ) ≤ r } . If B l o verlaps a go o d set in X i ∈ X and an y other go o d set, then it m ust con tain a p oint x ∈ X i and a p oin t y ∈ X j 6 = i . It follo ws that d ( x, y ) ≤ d ( x, l ) + d ( l , y ) ≤ 2 r ≤ 6 d min , giving a con tradiction. T o prov e the second part, consider t wo balls B l 1 and B l 2 of radius r ≤ 3 d min around landmarks l 1 and l 2 . Suppose B l 1 and B l 2 share at least one p oint: B l 1 ∩ B l 2 6 = ∅ , and use s ∗ to refer to this p oint. It follows that the distance b et ween any p oin t x ∈ B l 1 and y ∈ B l 2 satisfies d ( x, y ) ≤ d ( x, s ∗ ) + d ( s ∗ , y ) ≤ [ d ( x, l 1 ) + d ( l 1 , s ∗ )] + [ d ( s ∗ , l 2 ) + d ( l 2 , y )] ≤ 4 r ≤ 12 d min . If B l 1 o verlaps with X i ∈ X and B l 2 o verlaps with X j 6 = i , and the tw o balls share at least one p oint, there must be a pair of points x ∈ X i and y ∈ X j 6 = i suc h that d ( x, y ) ≤ 12 d min , giving a con tradiction. Therefore if B l 1 o verlaps with some go o d set X i ∈ X and B l 2 o verlaps with an y other go o d set, B l 1 ∩ B l 2 = ∅ . u t Lemma 4. If T ≤ T ∗ = αw 40 and the numb er of cluster e d p oints is at le ast n − b , then the clustering output by L andmark-Clustering-Min-Sum using the thr eshold T must b e a k -clustering that c ontains a distinct go o d set in e ach cluster. Pr o of. Our argumen t considers the p oints that are in each cluster that is output b y the algorithm. Let us call a goo d set c over e d if an y of the clusters C 1 , . . . , C i − 1 found so far con tain p oints from it. W e will use ¯ C ∗ to refer to the clusters in C ∗ whose go o d sets are not c over e d . It is critical to observe that if T ≤ T ∗ then if C i con tains points from an unc over e d go o d set, C i cannot ov erlap with an y other go o d set. T o see this, let us order the clusters in ¯ C ∗ b y decreasing size: | C ∗ 1 | ≥ | C ∗ 2 | ≥ . . . | C ∗ j | , and let n i = | C ∗ i | . As b efore, define d i = αw 60 | C ∗ i | . Applying Lemma 3 with ¯ C ∗ w e can see that for r ≤ 3 d 1 , a ball of radius r cannot ov erlap a go o d set in ¯ C ∗ and any other go o d set, and a ball con taining p oints from a go o d set in ¯ C ∗ cannot share any points with a ball containing points from an y other go o d set. Because T ≤ T ∗ w e can also argue that by the time w e reac h r = 3 d 1 w e m ust output some cluster. Giv en this observ ation, it is clear that the algorithm can cov er at most one new go o d set in each cluster that it outputs. In addition, if a new go o d set is cov ered this cluster may not con tain points from any other goo d set. If the algorithm is able to cluster at least n − b p oin ts, it must co ver every go o d set b ecause the size of each go o d set is larger than b . So it m ust rep ort k clusters where each cluster contains p oints from a distinct go o d set. u t 5 Exp erimen tal Results W e presen t some preliminary results of testing our L andmark-Clustering-Min- Sum algorithm on protein sequence data. Instead of requiring all pairwise sim- ilarities betw een the sequences as input, our algorithm is able to find accurate clusterings b y using only a few BLAST calls. F or each data set w e first build a BLAST database con taining all the sequences, and then compare only some of the sequences to the en tire database. T o compute the distance b etw een t wo sequences, we in vert the bit score corresp onding to their alignment, and set the distance to infinity if no significan t alignmen t is found. In practice we find that this distance is almost alwa ys a metric, which is consisten t with our theoretical assumptions. In our computational experiments w e use data sets created from the Pfam [FMT + 10] (version 24.0, October 2009) and SCOP [MBHC95] (v ersion 1.75, June 2009) classification databases. Both of these sources classify proteins b y their ev olutionary relatedness, therefore w e can use their classifications as a ground truth to ev aluate the clusterings pro duced b y our algorithm and other metho ds. These are the same data sets that were used in the [VBR + 10] study , therefore w e also sho w the results of the original L andmark-Clustering algo- rithm on these data, and use the same amoun t of distance information for b oth algorithms (30 k landmarks/queries for each data set, where k is the num b er of clusters). In order to run L andmark-Clustering-Min-Sum we need to set the parameter T . Because in practice we do not kno w its correct v alue, w e use in- creasing estimates of T until we cluster enough of the points in the data set; this pro cedure is similar to the algorithm for the case when we don’t kno w the optim um ob jective v alue OPT and hence don’t know T . In order to compare a computationally deriv ed clustering to the one given by the gold-standard classi- fication, we use the distance measure from the theoretical part of our work. Because our Pfam data sets are so large, we cannot compute the full dis- tance matrix, so w e can only compare with metho ds that use a limited amount of distance information. A natural choice is the following algorithm: uniformly at random c ho ose a set of landmarks L , | L | = d ; embed eac h p oint in a d - dimensional space using distances to L ; use k -means clustering in this space (with distances given b y the Euclidian norm). This pro cedure uses exactly d one v ersus all distance queries, so we can set d equal to the n umber of queries used b y the other algorithms. F or SCOP data sets w e are able to compute the full distance matrix, so w e can compare with a sp ectral clustering algorithm that has b een sho wn to work very w ell on these data [PCS06]. F rom Figure 2 we can see that L andmark-Clustering-Min-Sum outp erforms k -means in the embedded space on all the Pfam data sets. How ever, it do es not p erform b etter than the original L andmark-Clustering algorithm on most of these data sets. When w e in v estigate the structure of the ground truth clusters in these data sets, we see that the diameters of the clusters are roughly the same. When this is the case the original algorithm will find accurate clusterings as w ell [VBR + 10]. Still, L andmark-Clustering-Min-Sum tends to giv e b etter results when the original algorithm do es not w ork w ell (data sets 7 and 9). Fig. 2. Comparing the performance of k -means in the embedded space (blue), L andmark-Clustering (red), and L andmark-Clustering-Min-Sum (green) on 10 data sets from Pfam. Datasets 1-10 are created by uniformly at random choosing 8 families from Pfam of size s , 1000 ≤ s ≤ 10000. Figure 3 shows the results of our computational exp eriments on the SCOP data sets. W e can see that the three algorithms are comparable in p erformance here. These results are encouraging b ecause the sp ectral clustering algorithm significan tly outp erforms other clustering algorithms on these data [PCS06]. Moreo ver, the sp ectral algorithm needs the full distance matrix as input and tak es m uch longer to run. When w e examine the structure of the SCOP data sets, w e find that the diameters of the ground truth clusters v ary considerably , whic h resem bles the structure implied b y our approximation stability assump- tion, assuming that the target clusters v ary in size. Still, most of the time the pro duct of the cluster sizes and their diameters v aries, so it do es not quite look lik e what we assume in the theoretical part of this w ork. Fig. 3. Comparing the p erformance of sp ectral clustering (blue), L andmark-Clustering (red), and L andmark-Clustering-Min-Sum (green) on 10 data sets from SCOP . Data sets A and B are the tw o main examples from [PCS06], the other data sets ( 1-8 ) are created by uniformly at random choosing 8 sup erfamilies from SCOP of size s , 20 ≤ s ≤ 200. W e plan to conduct further studies to find data where clusters hav e differen t scale and there is an inv erse relationship b etw een cluster sizes and their diam- eters. This ma y b e the case for data that ha v e man y outliers, and the correct clustering groups sets of outliers together rather than assigns them to arbitrary clusters. The algorithm presented here will consider these sets to b e large diam- eter, small cardinality clusters. More generally , the algorithm presen ted here is more robust b ecause it will giv e an answer no matter what the structure of the data is like, whereas the original L andmark-Clustering algorithm often fails to find a clustering if there are no well-defined clusters in the data. 6 Conclusion W e presen t a new algorithm that clusters protein sequences in a limited informa- tion setting. Instead of requiring all pairwise distances b etw een the sequences as input, we can find an accurate clustering using few BLAST calls. W e show that our algorithm pro duces accurate clusterings when compared to gold-standard classifications, and we exp ect it to work ev en b etter on data who structure more closely resembles our theoretical assumptions. References A GK + 04. V. Ary a, N. Garg, R. Khandek ar, A. Meyerson, K. Munagala, and V. Pandit. Lo cal search heuristics for k-median and facilit y location problems. SIAM J. Comput. , 33(3), 2004. A GM + 90. S.F. Altsch ul, W. Gish, W. Miller, E.W. Myers, and D.J. Lipman. Basic lo cal alignment search to ol. J. Mol. Biol. , 215(3):403–410, 1990. AJM09. N. Ailon, R. Jaiswal, and C. Monteleoni. Streaming k-means appro ximation. In Advanc es in Neur al Information Pr o c essing Systems (NIPS) , 2009. A V07. D. Arthur and S. V assilvitskii. k-means++: the adv antages of careful seed- ing. In Pr o c. of 18th ACM-SIAM Symp. on Discr ete Algorithms (SODA) , 2007. BBG09. M. F. Balcan, A. Blum, and A. Gupta. Approximate clustering without the appro ximation. In Pr o c. of 20th ACM-SIAM Symp. on Discr ete Algorithms (SODA) , 2009. BCR01. Y. Bartal, M. Charik ar, and D. Raz. Approximating min-sum k-clustering in metric spaces. In STOC ’01: Pr o c e e dings of the thirty-thir d annual ACM symp osium on The ory of c omputing , 2001. CS07. A. Czuma j and C. Sohler. Sublinear-time appro ximation algorithms for clustering via random sampling. R andom Struct. Algorithms , 30(1-2):226– 256, 2007. FMT + 10. R.D. Finn, J. Mistry , J. T ate, P . Coggill, A. Heger, J.E. Pollington, O.L. Ga vin, P . Gunesek aran, G. Ceric, K. F orslund, L. Holm, E.L. Sonnhammer, S.R. Eddy , and A. Bateman. The pfam protein families database. Nucleic A cids R es. , 38:D211–222, 2010. MBHC95. A.G. Murzin, S. E. Brenner, T. Hubbard, and C. Chothia. Scop: a structural classification of proteins database for the inv estigation of sequences and structures. J. Mol. Biol. , 247:536–540, 1995. MOP01. N. Mishra, D. Oblinger, and L Pitt. Sublinear time approximate clustering. In Pr o c. of 12th ACM-SIAM Symp. on Discr ete Algorithms (SODA) , 2001. PCS06. A. Paccanaro, J. A. Casbon, and M. A. S. Saqi. Sp ectral clustering of protein sequences. Nucleic Acids Res. , 34(5):1571–1580, 2006. VBR + 10. K. V o evodski, M. F. Balcan, H. R¨ oglin, S. T eng, and Y. Xia. Efficient clustering with limited distance information. In Pr o c. of the 26th Conferenc e on Unc ertainty in Artifcial Intel ligenc e , 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment