Neural Network Regularization via Robust Weight Factorization
Regularization is essential when training large neural networks. As deep neural networks can be mathematically interpreted as universal function approximators, they are effective at memorizing sampling noise in the training data. This results in poor…
Authors: Jan Rudy, Weiguang Ding, Daniel Jiwoong Im
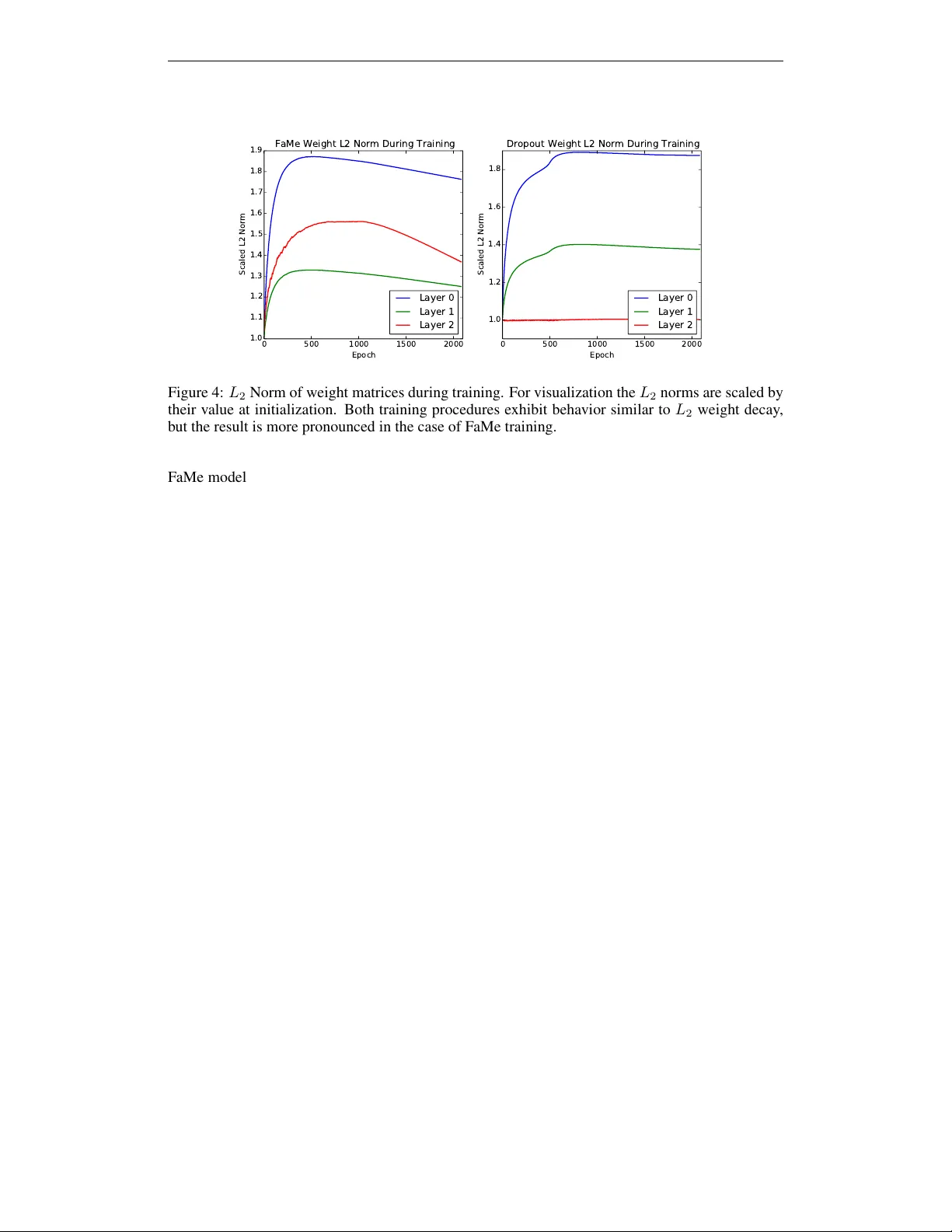
Under revie w as a conference paper at ICLR 2015 N E U R A L N E T W O R K R E G U L A R I Z A T I O N V I A R O B U S T W E I G H T F A C T O R I Z A T I O N Jan Rudy , W eiguang (Gavin) Ding, Daniel Jiwoong Im & Graham W . T aylor School of Engineering Univ ersity of Guelph Guelph, Ontario, Canada { jrudy,imj,wding,gwtaylor } @uoguelph.ca A B S T R AC T Regularization is essential when training large neural networks. As deep neural networks can be mathematically interpreted as uni versal function approximators, they are effecti ve at memorizing sampling noise in the training data. This results in poor generalization to unseen data. Therefore, it is no surprise that a ne w re g- ularization technique, Dropout, was partially responsible for the no w-ubiquitous winning entry to ImageNet 2012 by the Uni versity of T oronto. Currently , Dropout (and related methods such as DropConnect) are the most ef fectiv e means of regu- larizing large neural networks. These amount to efficiently visiting a large number of related models at training time, while aggregating them to a single predictor at test time. The proposed FaMe model aims to apply a similar strategy , yet learns a factorization of each weight matrix such that the factors are rob ust to noise. 1 I N T RO D U C T I O N Much of the recent surge in popularity in neural networks, especially in their application to classifi- cation of visual data, is due to advances in regularization. The winning entry in the 2012 ImageNet LSVRC-2012 challenge by Krizhevsk y et al. (2012) used a deep con volutional neural network to surpass the competition by a margin of nearly 8% in top-5 test error rate. They partially attribute their performance to re gularization technique called “Dropout” (Krizhe vsky et al., 2012; Hinton et al., 2012; Sri vastav a et al., 2014). As large neural networks are extremely powerful, a voiding ov erfitting is crucial to increasing generalization performance. Dropout is an ele gant and simple solution which is equiv alent to training an e xponential number of models. At test time, these models are ‘av eraged’ into a single ‘mean’ predictor which generalizes better to unseen test data. Howe ver , models with rectified linear activ ations (ReLU) are known to lead to sparse activ ations, with 50% percent of units with true zero activation (Glorot et al., 2011). Our e xperiments hav e shown that this number is as high as 75% when training with Dropout. Although sparse representa- tions are desirable in general (Lee et al., 2008; Ranzato et al., 2007; 2008), they reduce the ef fective number and size of models that Dropout visits during training. In other words, the multiplicativ e noise applied by Dropout has no effect on the sparse activ ations. Ba et al. (2014) address this by adding an post-acti vation bias to the ReLU activation function, making explicit the distinction be- tween sparse units and units masked by Dropout. W e propose a related re gularization procedure which we call Fa ctored Me an training (F aMe). From a high-lev el, FaMe is similar to Dropout. Both methods address the problem of overfitting by ef- ficiently training an ensemble of models which are a veraged together at test time. Where Dropout achiev es this by randomly masking units, FaMe does so by learning a factorization of each weight matrix such that the factors are robust to noise. This leads to a more accurate model averaging procedure without sacrificing FaMe’ s ability to make use of shared information between the models visited at training time. 1 Under revie w as a conference paper at ICLR 2015 2 B A C K G R O U N D In this section, we briefly revie w traditional methods to improve generalization before discussing modern adv ances such as Dropout and Drop-connect. W e also introduce the concept of gating: networks which achie ve weight modulation via multiplicativ e interactions among variables. 2 . 1 T R A D I T I O N A L A P P R OA C H E S T O I M P RO V E G E N E R A L I Z A T I O N T raditional approaches to improving generalization in neural networks can be seen as a means of limiting the capacity of the model. These include early stopping, weight decay ( L 1 or L 2 ), weight constraints or the addition of noise to the during training. Where weight decay in volves adding a proportional to the L 1 or L 2 norm of the weights to the objective, weight constraints limits the L 2 norm for the incoming weight vector of each unit (Hinton et al., 2012). Addition of noise during training is also an ef fectiv e regularizer (Bishop, 1995b; V incent et al., 2008; Hinton & V an Camp, 1993). Adding small amounts of noise to the input vector has been shown to be equi valent to T ikhonov re gularization (Bishop, 1995b). Denoising autoencoders (D AE) (V incent et al., 2008) apply either additi ve or multiplicati ve (e.g. masking) noise to the input signal. The model then must learn to ‘denoise’ the input and reconstruct the uncorrupted input. The denoising criterion permits overcomplete models (i.e. models with more hidden units per layer than input units) to learn useful representations by way of predicti ve opposition between the reconstruction distribution and the re gularizer (V incent et al., 2010). 2 . 2 D R O P O U T Dropout (Hinton et al., 2012; Sri vasta va et al., 2014) w as moti vated by the idea that sexual reproduc- tion increases the overall fitness of a species by prev enting complex co-adaptations of genes. Like- wise, Dropout aims to increase generalization performance by prev enting complex co-adaptations of hidden units. Formally , consider a feed forward neural network with L hidden layers. Define h ( l ) as the output vector from hidden layer l . The learning procedure learns a parameterized function f ( x ) = y . Let x ∈ R n x be the input v ector, h ( l ) ∈ R n l be the hidden v ector, and y ∈ R n y the output v ector where n x , n l , n y are the number of input, hidden (for layer l ) and output dimensions. By con vention, we define h (0) = x and h ( L +1) = y . Next, define W ( l ) ∈ R n l × n l − 1 as the weights and b ( l ) ∈ R n l as the hidden biases for layer l . The hidden unit and output activ ations can be written as h ( l ) = σ ( l ) W ( l ) h ( l − 1) + b ( l ) (1) f ( x ) = y = σ ( y ) W ( L +1) h ( L ) + b ( L +1) (2) where σ ( l ) , σ ( y ) are the hidden and output activ ation functions. The weight matrices and bias vec- tors are randomly initialized and learned via optimization of a cost function, typically via gradient descent. Under Dropout, multiplicati ve noise is applied to the hidden acti vations during training for each presentation of an input. This is accomplished by stochastically dropping (or masking) individual hidden units in each layer (Sri vastav a et al., 2014). Formally , define r ( l ) ∈ R n l such that r ( l ) i ∼ Bernoulli ( p ) , i.e. r ( l ) is a vector of independent Bernoulli v ariables where each has probability p of being 1 (Sriv astav a et al., 2014). During training, Equation 1 becomes ˆ h ( l ) = σ ( l ) W ( l ) h ( l − 1) ◦ r ( l − 1) + b ( l ) (3) where ◦ denotes the elementwise product. No masking is performed at test time. In order to compen- sate for the lack of masking, the weights are scaled by p once training is complete (Sri vastav a et al., 2014). Recent results hav e shown that using Gaussian noise with µ = 1 (as opposed to Bernoulli) leads to improv ed test performance (Sri vastav a et al., 2014). At test time each r i = µ = 1 and, as such, the weights of the testing model do not require scaling. 2 Under revie w as a conference paper at ICLR 2015 The Bernoulli Dropout procedure can be interpreted as a means of training a different sub-network for each training example, where each sub-network contains a subset of the connections in the model. There is an exponential number of such netw orks, and many may not be visited during training. Howe ver , the extensi ve amount of weight sharing between these networks allows them to make useful predictions re gardless of the fact that the y may ha ve not been trained e xplicitly (Hinton et al., 2012). Under this interpretation, the test procedure can be seen as an approximation of the geometric av erage of all the sub-networks (Sriv astav a et al., 2014). Dropout has inspired a v ariety of both theoretical and experimental research. Subsequent theoretical work has found that training with Dropout is equi valent to an adaptiv e version of L 2 weight decay (W ager et al., 2013). Where the traditional L 2 penalty is spherical in weight space, Dropout is akin to an axis aligned scaling of the L 2 penalty such that it takes the curvature of the likelihood function into account (W ager et al., 2013). An extension of Dropout, DropConnect, applies the mask not to the hidden units b ut to the connections between units and was found to outperform Dropout on certain image recognition tasks (W an et al., 2013). Maxout networks (Goodfellow et al., 2013) are an attempt to design a new type of acti vation function which exploits the benefits of the Dropout training procedure. 2 . 3 G AT E D M O D E L S Where classical neural networks contain only first order interactions among input variables and hid- den variables, gated models permit a tri-partite graph that connects hidden variables to pairs of input variables. The messages sent in such networks inv olve multiplicativ e interactions among variables and permit the learning of structure in the relationship between inputs rather than the structure of inputs themselves (Memisevic & Hinton, 2007; T aylor & Hinton, 2009; Memisevic, 2013). Recent applications of such models include modeling transformations between images (Memisevic, 2013), 3D depth (K onda & Memisevic, 2013), and time-series data (Michalski et al., 2014). The objectiv e of a typical first order neural network is to learn a mapping function between an input x and an output y . In other words, training in volves updating the model weights such that the model learns the function f ( x ) = y . Instead of learning a mapping between a single input and output vector , gated models are conditional on a second input z such that the learned function is f ( x | z ) = y . W e refer to z as the “conte xt”. Instead of a fix ed weight matrix as in classical neural networks, the weights in a gated model can be interpreted as being a function of the context z (Memisevic, 2013). Formally , the hidden activ ation in a single layered factored gated model with input vectors x ∈ R n x , context z ∈ R n z and factor size n f h = f ( x | z ) = σ ( h ) W T ( Ux ◦ Vz ) + b ( h ) (4) where U ∈ R n f × n x , V ∈ R n f × n z , W ∈ R n f × n h are learned weight matrices, b ( h ) ∈ R n h are the hidden biases, ◦ denotes an elementwise product, and σ ( h ) is the hidden activ ation function (typically of the sigmoidal family or piece wise linear). Note that in the special case where z is constant, Equation 4 becomes h = ˆ f ( x ) = σ ( h ) ˆ Wx + b ( h ) (5) where ˆ W = ( W ◦ (( Vz ) ⊗ e )) U , such that e is a n h dimensional vector of ones and ⊗ is the Kronecker product. Thus, with constant z the gated model is equiv alent to a feed forward model. 3 F A M E T R A I N I N G The proposed Factored Mean training procedure (F aMe) aims to make use of the weight modulation property of gated networks as a means of regularization. The FaMe architecture, like a neural network trained with Dropout, aims to learn a mapping f ( x ) = y between input x and output vector y (e.g. for classification). Where Dropout applies multiplicati ve noise to the hidden acti vations during training, under FaMe training each weight matrix is decomposed into two matrices (or “factor loadings”) and the multiplicati ve noise is applied directly after the input vector is projected onto the first of these matrices. 3 Under revie w as a conference paper at ICLR 2015 Figure 1: Comparison of a classical feed forward neural network and FaMe. The figure on the right depicts the connecti vity between hidden layers in a typical feed forward neural netw ork. On the left is the connectivity between hidden layers in a FaMe model where f ( l ) = U ( l ) h ( l − 1) and r ( l ) is a vector in independent samples from some noise distrib ution. Biases are omitted for clarity . Formally , gi ven a feed forward neural netw ork with L layers as described in section 2.2, instead of a single weight matrix W ( l ) for layer l we define matrices U ( l ) ∈ R f l × n ( l − 1) , V ( l ) ∈ R n l × f l where f l is a free parameter . Thus, the hidden activ ation becomes h ( l ) = σ ( l ) V ( l ) U ( l ) h ( l − 1) ◦ r ( l ) + b ( l ) (6) where r ( l ) ∈ R f l . During training, each r ( l ) i is an independent sample from a fixed probability distribution (i.e. Bernoulli, Gaussian). See Figure 1 for a comparison of the FaMe architecture and a classical feed forward model. Note the similarity between Equation 6 and the gated model Equation 4. Instead of the model weights being a function of a secondary input vector z , the FaMe training procedure modulates the weights via a random vector r ( l ) . Like Dropout, the F aMe model can be vie wed as training a unique model for each training example and epoch. In other words, the FaMe model represents a manifold of models where the settings of ( r (1) , r (2) , . . . r ( L +1) ) can be thought of as the coordinates of a giv en model on that manifold. Where Dropout computes an average mean network by scaling the weights by p , at test time we can calculate the mean network learned by F aMe training by setting each r ( l ) i to the expectation of its sampling distribution. This is similar to Equation 5 when we fix secondary input in the gated model. Howe ver , if we define r ( l ) i ∼ N (1 , 1) (or any other distrib ution with mean 1), then our hidden activ ations in our mean network at test time can be simplified to h ( l ) = σ ( l ) W ( l ) h ( l − 1) + b ( l ) (7) where W ( l ) = V ( l ) U ( l ) (so, W ( l ) ∈ R n l × n ( l − 1) ). This is equi valent to Equation 1 of a classical feed forward network. In effect, the FaMe training procedure learns a decomposition of the weight matrix W ( l ) such that it is robust to noise. Notice that in the process of learning a decomposition of W ( l ) , the rank of W ( l ) can be bounded via the choice of f l . In order to not restrict the rank of W ( l ) and not introduce any unnecessary parameters, we can set f l = min( n l , n ( l − 1) ) . The parameters in the FaMe model can be learned using the same gradient-based optimization meth- ods as a classical neural network. 3 . 1 F A M E C O N V O L U T I O N L AY E R S A similar technique can be applied to con volution layers, where a single con volution step can be decomposed into two linear conv olution operations. Under FaMe training, multiplicative noise can be applied after the first conv olution. This is similar to the Network in Network (NIN) model (Lin et al., 2014). Where each filter in NIN can be seen as a small non-linear MLP , in a F aMe con v olution layer the filters are two layer linear networks with multiplicati ve noise added after the first layer . 4 Under revie w as a conference paper at ICLR 2015 Method Unit T ype Architectur e T est Error % Bernoulli Dropout NN + weight constraints ReLU 2 layers, 8192 units 0.95 (Srivista va et al., 2014) Bernoulli Dropout NN + weight constraints Maxout 2 layers, (5x240) units 0.94 (Goodfellow et al., 2013) Gaussian Dropout NN + weight constraints ReLU 2 layers, 1024 units 0.95 +/- 0.05 (Srivista va et al., 2014) Gaussian FaMe NN + weight constraints ReLU 2 layers, 1024 units 0.91 +/- 0.02 Gaussian FaMe NN + weight constraints ReLU 3 layers, 512 units 0.92 +/- 0.04 T able 1: Result of MNIST classification task. FaMe training outperforms dropout, e ven when train- ing models with far fe wer parameters. 4 E X P E R I M E N T S The effecti veness of the FaMe training procedure for image classification was ev aluated on the MNIST (LeCun & Cortes, 1998) and CIF AR datasets (Krizhevsky & Hinton, 2009). 4 . 1 M N I S T The MNIST dataset consists of 60,000 training and 10,000 test examples, each of which is a 28 × 28 greyscale image of a handwritten digit. The training set was further randomly partitioned into a 50,000 image training set and a 10,000 image validation set. Experiments were implemented in Python using the Theano library (Bastien et al., 2012; Bergstra et al., 2010). The model hyper-parameters were chosen based on performance on the v alidation set. During training, multiplicati ve Gaussian noise was a applied to both the input ( ∼ N (1 , 0 . 5) ) and linear factor layers ( ∼ N (1 , 1) ). Incoming weight vectors for each unit were constrained to a maximum L 2 norm of 2.0. Training was performed using mini-batch gradient descent on cross- entropy loss with a batch size of 250. Learning rates were annealed by a factor of 0.995 for each epoch. Nesterov accelerated gradient (Sutsk ever et al., 2013) was used for optimization, with initial value of 0.5 and increasing linearly for a set number of epochs. The final momentum value along with the number of epochs until reaching the final momentum value were chosen based on validation performance. T raining w as performed for 500,000 weight updates (i.e. minibatches). The h yper-parameters which resulted in the lowest validation error were then used to train the final model on all 60,000 training examples. Again the test model was trained for a total of 500,000 weight updates. Results on MNIST data are summarized in T able 1. Using the best settings of the hyper-parameters found during v alidation, the test model was trained from 10 random initializations and the av erage error of the ten models is reported. FaMe training outperforms Dropout (Sriv astav a et al., 2014) and Maxout (Goodfello w et al., 2013), achieving a best test error of 0 . 91%( ± 0 . 02) . W e found that restricting the rank of W was beneficial with larger hidden layer sizes, where the two layer model restricted the size of the linear factor layer to 440. Additionally , training a model with fewer parameters achiev es similar results. If we consider the size of the test model (after the U and V linear projections ha ve been collapsed to as single weight matrix W ) a FaMe model with 3 hidden layers with 512 units per layer has ∼ 93K ef fective parameters. The maxout model has ∼ 2.3 million free parameters and Gaussian Dropout has ∼ 1.9 million parameters. 4 . 2 C I FA R The CIF AR datasets (Krizhevsky & Hinton, 2009) contain 60,000 32 × 32 color images, 50,000 of which are training examples with the remaining 10,000 used for testing. The CIF AR-10 dataset con- tains images from 10 classes where the CIF AR-100 contains 100 classes. Hyper -parameter selection followed a similar procedure to that used above for MNIST classification, further partitioning the training set into 40,000 training and 10,000 validation images. Our CIF AR models consist of three con volutional F aMe layers followed by two fully connected FaMe layers. The results are summa- rized in T able 2. For image preprocessing, we follow the same procedure as Sri vasta va et al. (2014) 5 Under revie w as a conference paper at ICLR 2015 Method CIF AR-10 Error % CIF AR-100 Error % Con v Net + Spearmint (Snoek et al., 2012) 14.98 - Con v Net + Dropout (fully connected) (Sriv astav a et al., 2014) 14.32 41.26 Con v Net + Dropout (all layers) (Sriv astav a et al., 2014) 12.61 37.20 Con v Net + Maxout (Goodfellow et al., 2013) 11.68 38.57 Con v Net + FaMe 12.85 39.79 T able 2: Comparison of FaMe training with other models on the CIF AR-10 dataset 0 500 1000 1500 2000 # epochs 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 Cross entropy cost Train vs. Test Cost FaMe Train FaMe Test Dropout Train Dropout Test Figure 2: Training cost vs. test cost as training progresses on an example training run for both FaMe and Dropout. Notice that with FaMe training, the test cost continues to decrease for the entire duration of training. and Goodfellow et al. (2013). Global contrast normalization over each color channel is follo wed by ZCA whitening. Although FaMe fails to outperform Dropout or Maxout, it is competitive with other recent results on CIF AR-10 and CIF AR-100. The discrete subset of parameters we considered for hyper-parameter cross-validation was substantially smaller than those considered for the MNIST task. W e expect that with more time to optimize the parameters, potentially using tools such as Bayesian hyper-parameter optimization (Snoek et al., 2012), performance will improv e. 5 C O M P A R I S O N W I T H D RO P O U T T R A I N I N G W e conducted a separate set of experiments on MNIST to further probe the learning dynamics of FaMe vs. Dropout. All experiments described in this section were performed using a model with two non-linear (ReLU) hidden layers and multiplicativ e Gaussian noise from N (1 , 0 . 5) on the input and N (1 , 1) on the hiddens or f actors. For both FaMe and Dropout training, hyper -parameters were chosen based on validation set performance. 5 . 1 A V O I D I N G O V E R FI T T I N G Similar to Dropout training (Sri vasta va et al., 2014), FaMe training pre vents overfitti ng and, as such, does not require early stopping. As seen in Figure 2 the test cost continues to decrease for the entirety of training. Dropout is also successful at a voiding overfitting, i.e. the test cost does not increase with continued training. Howe ver , the test cost plateaus earlier than with FaMe training. 6 Under revie w as a conference paper at ICLR 2015 Figure 3: Comparison of the FaMe and Dropout test procedure to the true arithmetic and geometric means as estimated via sampling outputs of random subnetworks. W ith FaMe training (left), the prediction of the testing procedure (dashed blue line) does in fact giv e a good estimate of the true geometric mean prediction. 5 . 2 M E A N T E S T I N G P RO C E D U R E A full mathematical analysis of the mean test procedure gi ven in Equation 7 is difficult due to the non-linearity of the hidden units. As such, we experimentally verify that the testing procedure is indeed approximating a geometric mean of predictions of the noisy subnetworks visited during training. Using the test data as input, we generate samples output from these noisy networks. The mean prediction can be calculated by first computing the geometric mean of the sample outputs and comparing to the output giv en by our deterministic testing procedure. Figure 3 demonstrates that the F aMe testing procedure giv es an accurate estimate of the true geomet- ric mean of all subnetworks. By comparison, ev en though the Dropout test procedure outperforms the estimated geometric mean of the subnetworks, it does not provide a good estimate of the true mean network. Note that both the FaMe and Dropout models contained two non-linear (ReLU) hidden layers and were trained with multiplicativ e Gaussian noise. Interestingly , the arithmetic mean prediction of the FaMe subnetworks appears to slightly outperform geometric mean prediction which may warrant further in vestigation. 5 . 3 A D A P T I V E L 2 W E I G H T D E C A Y W ager et al. (2013) have sho wn Dropout to be equiv alent to adaptiv e L 2 weight decay . T o examine the link between weight decay and both FaMe and Dropout training, we monitor the L 2 norms of the weight matrices of under both training regimes. Figure 4 depicts the e volution of the L 2 norm of each W weight matrix during training, relative to L 2 norm of its initial v alue (i.e. before training). Note that under FaMe trianing, we plot the L 2 norm of the implied weight matrix W = V U , where V and U are the factored weights that are actually learned by the model. Although no e xplicit L 2 penalty was used, both FaMe and Dropout training seem to impose an implicit penalty on the L 2 norm of the weight matrices. Howe ver , the effect is more pronounced under F aMe training. 6 C O N C L U S I O N Regularization is essential when training large neural networks. Their power as univ ersal function approximators allows them to memorize sampling noise in the training data, leading to poor gen- eralization to unseen data. Traditional forms of generalization are means of limiting the model’ s capacity . These include early stopping, weight decay , weight constraints, and addition of noise. Currently , Dropout (and related methods such as DropConnect) are the most ef fective means of regularizing large neural networks. These amount to efficiently visiting a large number of related models at training time, while aggregating them to a single mean model at test time. The proposed 7 Under revie w as a conference paper at ICLR 2015 0 500 1000 1500 2000 Epoch 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 Scaled L2 Norm FaMe Weight L2 Norm During Training Layer 0 Layer 1 Layer 2 0 500 1000 1500 2000 Epoch 1.0 1.2 1.4 1.6 1.8 Scaled L2 Norm Dropout Weight L2 Norm During Training Layer 0 Layer 1 Layer 2 Figure 4: L 2 Norm of weight matrices during training. For visualization the L 2 norms are scaled by their value at initialization. Both training procedures exhibit beha vior similar to L 2 weight decay , but the result is more pronounced in the case of F aMe training. FaMe model aims to apply this same reasoning, but can be interpreted as a special form of weight- modulating, gated architecture. Like Dropout, F aMe visits a family of models during training while allowing an ef ficient testing procedure for making predictions. Models trained with FaMe outperform Dropout training, e ven when such models have an order of magnitude fewer effecti ve parameters. Additionally , restricting the rank of the factor loadings can be used as a means of controlling the number of free parameters. This is supported by recent work has looked closely at the significant redundancy in the parameteri- zation of deep learning architectures, and proposed lo w-rank weight matrices as a way to massi vely reduce parameters while preserving predictiv e accuracy (Denil et al., 2013). R E F E R E N C E S Ba, Jimmy , Xiong, Hui Y uan, and Frey , Brendan. Making dropout inv ariant to transformations of activ ation functions and inputs. In NIPS 2014 W orkshop on Deep Learning , 2014. Bastien, Fr ´ ed ´ eric, Lamblin, P ascal, P ascanu, Razv an, Bergstra, James, Goodfello w , Ian J., Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Y oshua. Theano: new features and speed impro vements. Deep Learning and Unsupervised Feature Learning NIPS 2012 W orkshop, 2012. Bergstra, James, Breuleux, Olivier , Bastien, Fr ´ ed ´ eric, Lamblin, Pascal, Pascanu, Razvan, Des- jardins, Guillaume, T urian, Joseph, W arde-Farley , David, and Bengio, Y oshua. Theano: a CPU and GPU math expression compiler . In SciPy , June 2010. Oral Presentation. Bishop, Christopher M. P attern reco gnition and machine learning , v olume 1. Clarendon Press, Oxford, 1995a. Bishop, Christopher M. Training with noise is equiv alent to tikhonov regularization. Neural com- putation , 7(1):108–116, 1995b. Denil, Misha, Shakibi, Babak, Dinh, Laurent, de Freitas, Nando, et al. Predicting parameters in deep learning. In NIPS , 2013. Geman, Stuart, Bienenstock, Elie, and Doursat, Ren ´ e. Neural networks and the bias/v ariance dilemma. Neural computation , 4(1):1–58, 1992. Glorot, Xavier , Bordes, Antoine, and Bengio, Y oshua. Deep sparse rectifier networks. In Pr oceed- ings of the 14th International Confer ence on Artificial Intelligence and Statistics. JMLR W&CP V olume , volume 15, pp. 315–323, 2011. Goodfellow , Ian J, W arde-F arley , Da vid, Mirza, Mehdi, Courville, Aaron, and Bengio, Y oshua. Maxout networks. arXiv preprint , 2013. 8 Under revie w as a conference paper at ICLR 2015 Hinton, Geoffrey E. Learning translation inv ariant recognition in a massi vely parallel networks. In P ARLE P arallel Ar chitectur es and Languages Eur ope , pp. 1–13. Springer , 1987. Hinton, Geof frey E and V an Camp, Dre w . Keeping the neural networks simple by minimizing the description length of the weights. In Pr oceedings of the sixth annual conference on Computational learning theory , pp. 5–13. A CM, 1993. Hinton, Geoffrey E, Sri vasta va, Nitish, Krizhevsk y , Alex, Sutske ver , Ilya, and Salakhutdinov , Rus- lan R. Improving neural networks by prev enting co-adaptation of feature detectors. arXiv pr eprint arXiv:1207.0580 , 2012. Hornik, Kurt, Stinchcombe, Maxwell, and White, Halbert. Multilayer feedforward networks are univ ersal approximators. Neur al networks , 2(5):359–366, 1989. K onda, Kishore and Memisevic, Roland. Learning to combine depth and motion. arXiv pr eprint arXiv:1312.3429 , 2013. Krizhevsk y , Alex and Hinton, Geoffre y . Learning multiple layers of features from tiny images. Computer Science Department, University of T oronto, T ech. Rep , 2009. Krizhevsk y , Alex, Sutske ver , Ilya, and Hinton, Geoffrey E. Imagenet classification with deep con- volutional neural netw orks. In NIPS , 2012. LeCun, Y ann and Cortes, Corinna. The mnist database of handwritten digits, 1998. Lee, Honglak, Ekanadham, Chaitanya, and Ng, Andrew Y . Sparse deep belief net model for visual area v2. In NIPS , 2008. Lin, Min, Chen, Qiang, and Y an, Shuicheng. Network in network. In ICLR , 2014. Memisevic, Roland. Learning to relate images. P attern Analysis and Machine Intelligence, IEEE T ransactions on , 35(8):1829–1846, 2013. ISSN 0162-8828. doi: 10.1109/TP AMI.2013.53. Memisevic, Roland and Hinton, Geoffre y . Unsupervised learning of image transformations. In CVPR , 2007. Michalski, V incent, Memisevic, Roland, and K onda, Kishore. Modeling sequential data using higher-order relational features and predicti ve training. arXiv preprint , 2014. Ranzato, Marc’Aurelio, Poultney , Christopher , Chopra, Sumit, and Cun, Y ann L. Efficient learning of sparse representations with an energy-based model. In NIPS . 2007. Ranzato, Marc’Aurelio, lan Boureau, Y , and Cun, Y ann L. Sparse feature learning for deep belief networks. In NIPS . 2008. Snoek, Jasper , Larochelle, Hugo, and Adams, Ryan P . Practical bayesian optimization of machine learning algorithms. In Advances in Neural Information Pr ocessing Systems , pp. 2951–2959, 2012. Sriv astav a, Nitish, Hinton, Geoffre y , Krizhevsky , Alex, Sutskev er, Ilya, and Salakhutdinov , Ruslan. Dropout: A simple way to prevent neural networks from o verfitting. The J ournal of Machine Learning Resear ch , 15(1):1929–1958, 2014. Sutske ver , Ilya, Martens, James, Dahl, George, and Hinton, Geoffre y . On the importance of initial- ization and momentum in deep learning. In ICML , 2013. T aylor , Graham W and Hinton, Geof frey E. Factored conditional restricted boltzmann machines for modeling motion style. In ICML , 2009. T ibshirani, Robert. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society . Series B (Methodological) , pp. 267–288, 1996. V incent, Pascal, Larochelle, Hugo, Bengio, Y oshua, and Manzagol, Pierre-Antoine. Extracting and composing robust features with denoising autoencoders. In ICML , 2008. 9 Under revie w as a conference paper at ICLR 2015 V incent, Pascal, Larochelle, Hugo, Lajoie, Isabelle, Bengio, Y oshua, and Manzagol, Pierre-Antoine. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. The Journal of Machine Learning Resear ch , 9999:3371–3408, 2010. W ager , Stefan, W ang, Sida, and Liang, Percy . Dropout training as adapti ve regularization. In NIPS , 2013. W an, Li, Zeiler, Matthe w , Zhang, Sixin, Cun, Y ann L., and Fergus, Rob . Regularization of neural networks using dropconnect. In ICML , 2013. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment