Parallel Gaussian Process Regression for Big Data: Low-Rank Representation Meets Markov Approximation
The expressive power of a Gaussian process (GP) model comes at a cost of poor scalability in the data size. To improve its scalability, this paper presents a low-rank-cum-Markov approximation (LMA) of the GP model that is novel in leveraging the dual…
Authors: Kian Hsiang Low, Jiangbo Yu, Jie Chen
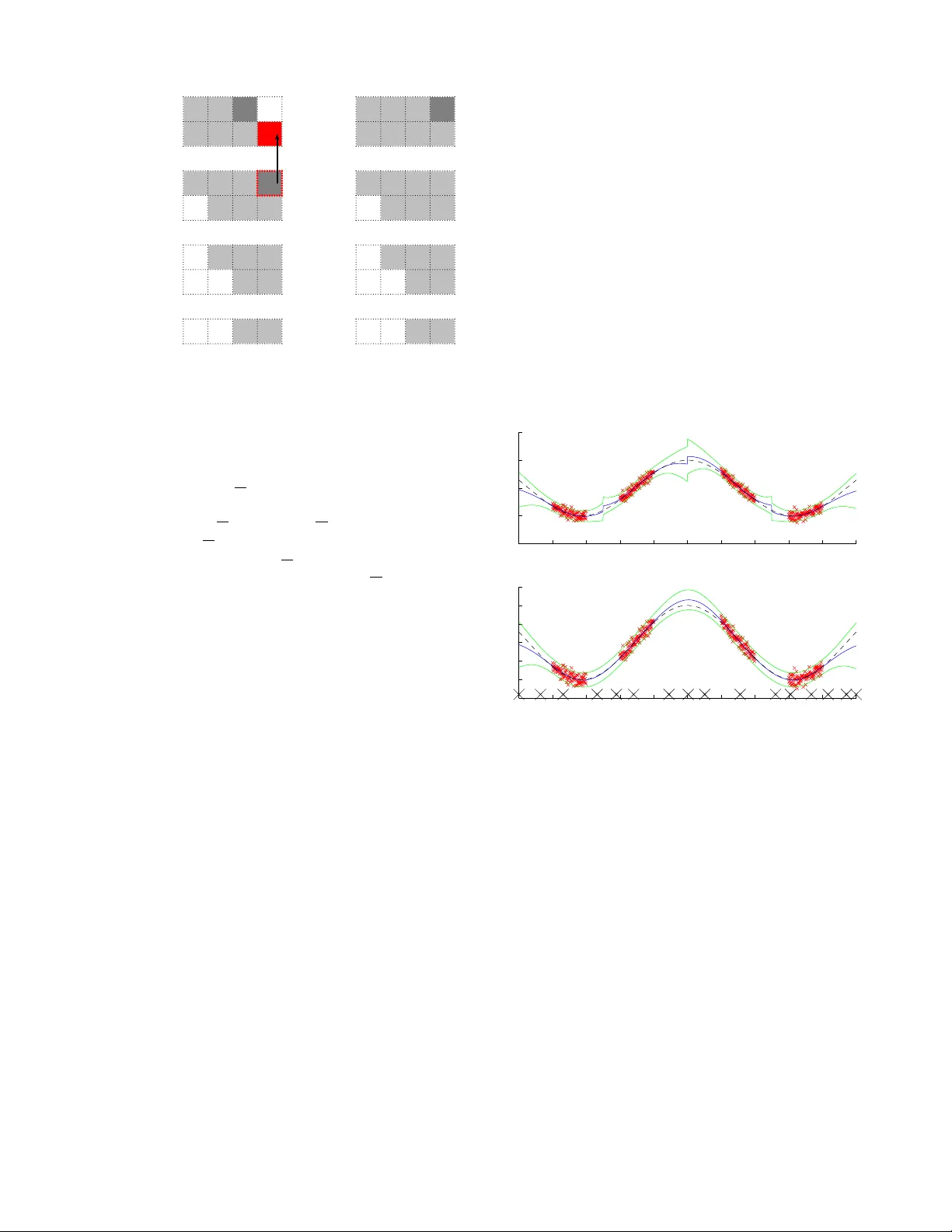
Parallel Gaussian Pr ocess Regr ession for Big Data: Low-Rank Repr esentation Meets Marko v A pproximation Kian Hsiang Low ∗ and Jiangbo Y u ∗ and Jie Chen § and Patrick J aillet † Department of Computer Science, National Univ ersity of Singapore, Republic of Singapore ∗ Singapore-MIT Alliance for Research and T echnology , Republic of Singapore § Massachusetts Institute of T echnology , USA † { lowkh, yujiang } @comp.nus.edu.sg ∗ , chenjie@smart.mit.edu § , jaillet@mit.edu † Abstract The expressi ve po wer of a Gaussian pr ocess (GP) model comes at a cost of poor scalability in the data size. T o improve its scalability , this paper presents a low-rank-cum-Marko v appr oximation (LMA) of the GP model that is nov el in leveraging the dual computational advantages stemming from complementing a low-rank approximate representation of the full-rank GP based on a support set of inputs with a Marko v approximation of the resulting residual process; the latter approximation is guaranteed to be closest in the K ullback-Leibler dis- tance criterion subject to some constraint and is consid- erably more refined than that of existing sparse GP mod- els utilizing lo w-rank representations due to its more re- laxed conditional independence assumption (especially with larger data). As a result, our LMA method can trade off between the size of the support set and the or- der of the Markov property to (a) incur lo wer computa- tional cost than such sparse GP models while achie ving predictiv e performance comparable to them and (b) ac- curately represent features/patterns of any scale. Inter- estingly , v arying the Markov order produces a spectrum of LMAs with PIC approximation and full-rank GP at the two extremes. An adv antage of our LMA method is that it is amenable to parallelization on multiple ma- chines/cores, thereby gaining greater scalability . Empir- ical ev aluation on three real-world datasets in clusters of up to 32 computing nodes shows that our central- ized and parallel LMA methods are significantly more time-efficient and scalable than state-of-the-art sparse and full-rank GP regression methods while achieving comparable predictiv e performances. 1 Introduction Gaussian pr ocess (GP) models are a rich class of Bayesian non-parametric models that can perform probabilistic re- gression by providing Gaussian predicti ve distributions with formal measures of the predictiv e uncertainty . Unfortu- nately , a GP model is handicapped by its poor scalability in the size of the data, hence limiting its practical use to small data. T o improve its scalability , two families of sparse GP re- gression methods hav e been proposed: (a) Low-rank approx- imate representations (Hensman, Fusi, and Lawrence 2013; ∗ Kian Hsiang Low and Jiangbo Y u are co-first authors. Copyright c 2015, Association for the Adv ancement of Artificial Intelligence (www .aaai.org). All rights reserved. L ´ azaro-Gredilla et al. 2010; Qui ˜ nonero-Candela and Ras- mussen 2005; Snelson and Ghahramani 2005) of the full- rank GP (FGP) model are well-suited for modeling slowly- varying functions with lar ge correlation and can use all the data for predictions. But, they require a relati vely high rank to capture small-scale features/patterns (i.e., of small corre- lation) with high fidelity , thus losing their computational ad- vantage. (b) In contrast, localized re gression and cov ariance tapering methods (e.g., local GPs (Park, Huang, and Ding 2011) and compactly supported covariance functions (Fur- rer , Genton, and Nychka 2006)) are particularly useful for modeling rapidly-v arying functions with small correlation. Howe ver , they can only utilize local data for predictions, thereby performing poorly in input regions with little/no data. Furthermore, to accurately represent large-scale fea- tures/patterns (i.e., of lar ge correlation), the locality/tapering range has to be increased considerably , thus sacrificing their time efficienc y . Recent sparse GP regression methods (Chen et al. 2013; Snelson and Ghahramani 2007) hav e unified approaches from the two families described above to harness their complementary modeling and predictive capabilities (hence, eliminating their deficiencies) while retaining their com- putational adv antages. Specifically , after approximating the FGP (in particular , its covariance matrix) with a low-rank representation based on the notion of a support set of in- puts, a sparse covariance matrix approximation of the re- sulting residual process is made. Howe ver , this sparse resid- ual co variance matrix approximation imposes a f airly strong conditional independence assumption giv en the support set since the support set cannot be too large to preserve time efficienc y (see Remark 2 after Proposition 1 in Section 3). In this paper , we argue that such a strong assumption is an overkill: It is in fact possible to construct a more re- fined, dense residual co variance matrix approximation by exploiting a Marko v assumption and, perhaps surprisingly , still achie ve scalability , which distinguishes our work here from existing sparse GP regression methods utilizing low- rank representations (i.e., including the unified approaches) described earlier . As a result, our proposed residual cov ari- ance matrix approximation can significantly relax the condi- tional independence assumption (especially with larger data; see Remark 1 after Proposition 1 in Section 3), hence poten- tially improving the predicti ve performance. This paper presents a low-rank-cum-Marko v appr oximation (LMA) of the FGP model (Section 3) that is novel in leveraging the dual computational adv an- tages stemming from complementing the reduced-rank cov ariance matrix approximation based on the support set with the residual cov ariance matrix approximation due to the Marko v assumption; the latter approximation is guaranteed to be closest in the Kullback-Leibler distance criterion subject to some constraint. Consequently , our proposed LMA method can trade off between the size of the support set and the order of the Markov property to (a) incur lower computational cost than sparse GP regression methods utilizing low-rank representations with only the support set size (e.g., (Chen et al. 2013; Snelson and Ghahramani 2007)) or number of spectral points (L ´ azaro-Gredilla et al. 2010) as the v arying param- eter while achieving predictiv e performance comparable to them and (b) accurately represent features/patterns of any scale. Interestingly , varying the Markov order produces a spectrum of LMAs with the partially indepen- dent conditional (PIC) approximation (Chen et al. 2013; Snelson and Ghahramani 2007) and FGP at the two extremes. An important adv antage of LMA over most existing sparse GP regression methods is that it is amenable to parallelization on multiple machines/cores, thus gaining greater scalability for performing real-time predictions necessary in many time-critical applica- tions and decision support systems (e.g., ocean sens- ing (Cao, Low , and Dolan 2013; Dolan et al. 2009; Low , Dolan, and Khosla 2008; 2009; 2011; Lo w et al. 2012; Podnar et al. 2010), traffic monitoring (Chen et al. 2012; Chen, Low , and T an 2013; Hoang et al. 2014a; 2014b; Low et al. 2014a; 2014b; Ouyang et al. 2014; Xu et al. 2014; Y u et al. 2012)). Our parallel LMA method is implemented using the messag e passing interface (MPI) frame work to run in clusters of up to 32 computing nodes and its predic- tiv e performance, scalability , and speedup are empirically ev aluated on three real-world datasets (Section 4). 2 Full-Rank Gaussian Process Regr ession Let X be a set representing the input domain such that each input x ∈ X denotes a d -dimensional feature vector and is associated with a realized output value y x (random output variable Y x ) if it is observed (unobserved). Let { Y x } x ∈X denote a GP , that is, e very finite subset of { Y x } x ∈X fol- lows a multi variate Gaussian distribution. Then, the GP is fully specified by its prior mean µ x , E [ Y x ] and cov ari- ance σ xx 0 , cov [ Y x , Y x 0 ] for all x, x 0 ∈ X . Supposing a column vector y D of realized outputs is observed for some set D ⊂ X of inputs, a full-rank GP (FGP) model can per- form probabilistic regression by providing a Gaussian pos- terior /predictive distrib ution N ( µ U + Σ U D Σ − 1 DD ( y D − µ D ) , Σ U U − Σ U D Σ − 1 DD Σ DU ) of the unobserv ed outputs for an y set U ⊆ X \ D of inputs where µ U ( µ D ) is a column vector with mean components µ x for all x ∈ U ( x ∈ D ), Σ U D ( Σ DD ) is a cov ariance ma- trix with cov ariance components σ xx 0 for all x ∈ U , x 0 ∈ D ( x, x 0 ∈ D ), and Σ DU = Σ > U D . The chief limitation hinder- ing the practical use of the FGP regression method is its poor scalability in the data size |D | : Computing the Gaussian pos- terior/predictiv e distribution requires in verting Σ DD , which incurs O ( |D | 3 ) time. In the next section, we will introduce our proposed LMA method to improv e its scalability . 3 Low-Rank-cum-Mark ov A pproximation b Y x , Σ x S Σ − 1 S S Y S is a reduced-rank approximate repre- sentation of Y x based on a support set S ⊂ X of inputs and its finite-rank cov ariance function is cov [ b Y x , b Y x 0 ] = Σ x S Σ − 1 S S Σ S x 0 for all x, x 0 ∈ X . Then, e Y x = Y x − b Y x is the residual of the reduced-rank approximation and its covari- ance function is thus cov [ e Y x , e Y x 0 ] = σ xx 0 − Σ x S Σ − 1 S S Σ S x 0 . Define Q BB 0 , Σ BS Σ − 1 S S Σ S B 0 and R BB 0 , Σ BB 0 − Q BB 0 for all B , B 0 ⊂ X . Then, a covariance matrix Σ V V for the set V , D ∪ U ⊂ X of inputs (i.e., associated with realized out- puts y D and unobserved random outputs Y U ) can be decom- posed into a reduced-rank covariance matrix approximation Q V V and the resulting residual cov ariance matrix R V V , that is, Σ V V = Q V V + R V V . As discussed in Section 1, existing sparse GP regression methods utilizing low-rank representa- tions (i.e., including unified approaches) approximate R V V with a sparse matrix. In contrast, we will construct a more refined, dense residual co variance matrix approximation by exploiting a Marko v assumption to be described next. Let the set D ( U ) of inputs be partitioned 1 ev enly into M disjoint subsets D 1 , . . . , D M ( U 1 , . . . , U M ) such that the outputs y D m and Y U m are as highly correlated as possible for m = 1 , . . . , M . Let V m , D m ∪ U m . Then, V = S M m =1 V m . The key idea of our low-rank-cum-Markov appr oximation (LMA) method is to approximate the residual co variance matrix R V V by a block matrix R V V partitioned into M × M square blocks, that is, R V V , [ R V m V n ] m,n =1 ,...,M where R V m V n , R V m V n if | m − n | ≤ B , R V m D B m R − 1 D B m D B m R D B m V n if n − m > B > 0 , R V m D B n R − 1 D B n D B n R D B n V n if m − n > B > 0 , 0 if | m − n | > B = 0; (1) such that B ∈ { 0 , . . . , M − 1 } denotes the order of the Markov property imposed on the residual process { e Y x } x ∈D to be detailed later , D B m , S min( m + B ,M ) k = m +1 D k , and 0 denotes a square block comprising components of value 0 . T o understand the intuition underlying the approximation in (1), Fig. 1a illustrates a simple case of R V V with B = 1 and M = 4 for ease of exposition: It can be observed that only the blocks R V m V n outside the B -block band of R V V (i.e., | m − n | > B ) are approximated, specifically , by un- shaded blocks R V m V n being defined as a recursive series of | m − n | − B reduced-rank residual cov ariance matrix ap- proximations (1). So, when an unshaded block R V m V n is 1 D and U are partitioned according to a simple parallelized clustering scheme employed in the work of Chen et al. (2013). V 1 V 1 V 2 V 2 V 3 V 3 V 4 V 4 | m n | 1 R V 1 V 4 R V 2 V 4 R V 1 V 3 R V 1 V 1 R V 1 V 2 R V 2 V 2 R V 2 V 1 R V 2 V 3 R V 3 V 3 R V 3 V 4 R V 4 V 4 n m> 1 m n> 1 R V 4 V 2 R V 4 V 3 R V 4 V 1 R V 3 V 1 R V 3 V 2 | m n | 1 n m> 1 m n> 1 D 1 D 2 D 3 D 4 D 1 D 2 D 3 D 4 0 0 0 0 0 0 (a) R V V (b) R − 1 DD Figure 1: R V V and R − 1 DD with B = 1 and M = 4 . (a) Shaded blocks (i.e., | m − n | ≤ B ) form the B -block band while unshaded blocks (i.e., | m − n | > B ) fall outside the band. Each arro w denotes a recursiv e call. (b) Unshaded blocks outside B -block band of R − 1 DD (i.e., | m − n | > B ) are 0 . further from the diagonal of R V V (i.e., larger | m − n | ), it is deriv ed using more reduced-rank residual cov ariance matrix approximations. For e xample, R V 1 V 4 is approximated by an unshaded block R V 1 V 4 being defined as a recursiv e series of 2 reduced-rank residual cov ariance matrix approximations, namely , approximating R V 1 V 4 by R V 1 D 1 1 R − 1 D 1 1 D 1 1 R D 1 1 V 4 = R V 1 D 2 R − 1 D 2 D 2 R D 2 V 4 based on the support set D 1 1 = D 2 of inputs and in turn approximating R D 2 V 4 by a subma- trix R D 2 V 4 = R D 2 D 3 R − 1 D 3 D 3 R D 3 V 4 (1) of unshaded block R V 2 V 4 based on the support set D 1 2 = D 3 of inputs. As a result, R V 1 V 4 = R V 1 D 2 R − 1 D 2 D 2 R D 2 D 3 R − 1 D 3 D 3 R D 3 V 4 is fully specified by fi ve submatrices of the respecti ve shaded blocks R V 1 V 2 , R V 2 V 2 , R V 2 V 3 , R V 3 V 3 , and R V 3 V 4 within the B - block band of R V V (i.e., | m − n | ≤ B ). In general, any un- shaded block R V m V n outside the B -block band of R V V (i.e., | m − n | > B ) is fully specified by submatrices of the shaded blocks within the B -block band of R V V (i.e., | m − n | ≤ B ) due to its recursiv e series of | m − n | − B reduced-rank resid- ual covariance matrix approximations (1). Though it may not be obvious now how such an approximation would entail scalability , (1) interestingly offers an alternati ve interpreta- tion of imposing a B -th order Marko v property on resid- ual process { e Y x } x ∈D , which reveals a further insight on the structural assumption of LMA to be exploited for achieving scalability , as detailed later . The cov ariance matrix Σ V V is thus approximated by a block matrix Σ V V , Q V V + R V V partitioned into M × M square blocks, that is, Σ V V , [Σ V m V n ] m,n =1 ,...,M where Σ V m V n , Q V m V n + R V m V n . (2) So, within the B -block band of Σ V V (i.e., | m − n | ≤ B ), Σ V m V n = Σ V m V n , by (1) and (2). Note that when B = 0 , Σ V m V n = Q V m V n for | m − n | > B , thus yielding the prior cov ariance matrix Σ V V of the partially indepen- dent conditional (PIC) approximation (Chen et al. 2013; Snelson and Ghahramani 2007). When B = M − 1 , Σ V V = Σ V V is the prior cov ariance matrix of FGP model. So, LMA generalizes PIC (i.e., if B = 0 ) and becomes FGP if B = M − 1 . V arying Mark ov order B from 0 to M − 1 produces a spectrum of LMAs with PIC and FGP at the two extremes. By approximating Σ V V with Σ V V , our LMA method uti- lizes the data ( D , y D ) to predict the unobserved outputs for any set U ⊆ X \ D of inputs and pro vide their corresponding predictiv e uncertainties using the follo wing predictiv e mean vector and co variance matrix, respecti vely: µ LMA U , µ U + Σ U D Σ − 1 DD ( y D − µ D ) (3) Σ LMA U U , Σ U U − Σ U D Σ − 1 DD Σ DU (4) where Σ U U , Σ U D , and Σ DD are obtained using (2), and Σ DU = Σ > U D . If Σ DD in (3) and (4) is inv erted directly , then it would still incur the same O ( |D | 3 ) time as inv erting Σ DD in the FGP regression method (Section 2). In the rest of this section, we will show how this scalability issue can be resolved by le veraging the computational advantages associ- ated with both the reduced-rank co variance matrix approx- imation Q DD based on the support set S and our proposed residual cov ariance matrix approximation R DD due to B -th order Markov assumption after decomposing Σ DD . It can be observed from R V V (1) that R DD is approx- imated by a block matrix R DD = [ R D m D n ] m,n =1 ,...,M where R D m D n is a submatrix of R V m V n obtained using (1). Proposition 1 Block matrix R − 1 DD is B -block-banded, that is, any block outside its B -bloc k band is 0 (e .g., F ig. 1b). Its proof follows directly from a block-banded matrix result of Asif and Moura (2005) (specifically , Theorem 3 ). Remark 1 . In the same spirit as a Gaussian Markov random process, imposing a B -th order Marko v property on residual process { e Y x } x ∈D is equiv alent to approximating R DD by R DD whose in verse is B -block-banded (Fig. 1b). That is, if | m − n | > B , Y D m and Y D n are conditionally independent giv en Y S ∪D \ ( D m ∪D n ) . Such a conditional independence as- sumption thus becomes more relaxed with larger data. More importantly , this B -th order Marko v assumption or, equiv a- lently , sparsity of B -block-banded R − 1 DD is the key to achie v- ing scalability , as shown in the proof of Theorem 2 later . Remark 2 . Though R − 1 DD is sparse, R DD is a dense residual cov ariance matrix approximation if B > 0 . In contrast, the sparse GP regression methods utilizing low-rank represen- tations (i.e., including unified approaches) utilize a sparse residual covariance matrix approximation (Section 1), hence imposing a significantly stronger conditional independence assumption than LMA. For example, PIC (Chen et al. 2013; Snelson and Ghahramani 2007) assumes Y D m and Y D n to be conditionally independent giv en only Y S if | m − n | > 0 . The next result rev eals that, among all |D| × |D | matrices whose in verse is B -block-banded, R DD approximates R DD most closely in the Kullback-Leibler (KL) distance criterion, that is, R DD has the minimum KL distance from R DD : Theorem 1 Let KL distance D KL ( R, b R ) , 0 . 5( tr ( R b R − 1 ) − log | R b R − 1 | − |D| ) between two |D| × |D | positive definite matrices R and b R measur e the err or of appr oximating R with b R . Then, for any matrix b R whose inver se is B -bloc k- banded, D KL ( R DD , b R ) ≥ D KL ( R DD , R DD ) . Its proof is in Appendix A. Our main result in Theorem 2 be- low exploits the sparsity of R − 1 DD (Proposition 1) for deriving an efficient formulation of LMA, which is amenable to par- allelization on multiple machines/cores by constructing and communicating the following summary information: Definition 1 (Local Summary) The m -th local summary is defined as a tuple ( ˙ y m , ˙ R m , ˙ Σ m S , ˙ Σ m U ) wher e ˙ y m , y D m − µ D m − R 0 D m D B m ( y D B m − µ D B m ) ˙ R m , ( R D m D m − R 0 D m D B m R D B m D m ) − 1 ˙ Σ m S , Σ D m S − R 0 D m D B m Σ D B m S ˙ Σ m U , Σ D m U − R 0 D m D B m Σ D B m U such that R 0 D m D B m , R D m D B m R − 1 D B m D B m . Definition 2 (Global Summary) The global summary is defined as a tuple ( ¨ y S , ¨ y U , ¨ Σ S S , ¨ Σ U S , ¨ Σ U U ) wher e ¨ y S , M X m =1 ( ˙ Σ m S ) > ˙ R m ˙ y m , ¨ y U , M X m =1 ( ˙ Σ m U ) > ˙ R m ˙ y m ¨ Σ S S , Σ S S + M X m =1 ( ˙ Σ m S ) > ˙ R m ˙ Σ m S ¨ Σ U S , M X m =1 ( ˙ Σ m U ) > ˙ R m ˙ Σ m S , ¨ Σ U U , M X m =1 ( ˙ Σ m U ) > ˙ R m ˙ Σ m U . Theorem 2 F or B > 0 , µ LMA U (3) and Σ LMA U U (4) can be re- duced to µ LMA U = µ U + ¨ y U − ¨ Σ U S ¨ Σ − 1 S S ¨ y S and Σ LMA U U = Σ U U − ¨ Σ U U + ¨ Σ U S ¨ Σ − 1 S S ¨ Σ > U S . Its proof in Appendix B essentially relies on the sparsity of R − 1 DD and the matrix in version lemma. Remark 1 . T o parallelize LMA, each machine/core m constructs and uses the m -th local summary to compute the m -th summation terms in the global summary , which are then communicated to a master node. The master node constructs and communicates the global summary to the M machines/cores, specifically , by sending the tuple ( ¨ y S , ¨ y U m , ¨ Σ S S , ¨ Σ U m S , ¨ Σ U m U m ) to each machine/core m . Finally , each machine/core m uses this receiv ed tuple to pre- dict the unobserved outputs for the set U m of inputs and provide their corresponding predictive uncertainties using µ LMA U m (3) and Σ LMA U m U m (4), respectiv ely . Computing Σ D m U and Σ D B m U terms in the local summary can also be paral- lelized due to their recursive definition (i.e., (1) and (2)), as discussed in Appendix C. This parallelization capability of LMA shows another key advantage ov er existing sparse GP regression methods 2 in gaining scalability . Remark 2 . Supposing M , |U | , |S | ≤ |D| , LMA can compute µ LMA U and tr (Σ LMA U U ) distributedly in O ( |S | 3 + ( B |D | / M ) 3 + |U | ( |D| / M )( |S | + B |D | / M )) time using M parallel machines/cores and sequentially in O ( |D ||S | 2 + B |D | ( B |D | / M ) 2 + |U ||D | ( |S | + B |D | / M )) time on a sin- gle centralized machine. So, our LMA method incurs cubic 2 A notable exception is the work of Chen et al. (2013) that par- allelizes PIC. As mentioned earlier , our LMA generalizes PIC. time in support set size |S | and Markov order B . Increas- ing the number M of parallel machines/cores and blocks re- duces the incurred time of our parallel and centralized LMA methods, respecti vely . W ithout considering communication latency , the speedup 3 of our parallel LMA method grows with increasing M and training data size |D | ; to explain the latter , unlik e the additional O ( |D ||S | 2 ) time of our central- ized LMA method that increases with more data, parallel LMA does not hav e a corresponding O (( |D | / M ) |S | 2 ) term. Remark 3 . Predictiv e performance of LMA is improv ed by increasing the support set size |S | and/or Markov order B at the cost of greater time overhead. From Remark 2 , since LMA incurs cubic time in |S | as well as in B , one should trade off between |S | and B to reduce the computational cost while achieving the desired predicti ve performance. In contrast, PIC (Chen et al. 2013; Snelson and Ghahramani 2007) (sparse spectrum GP (L ´ azaro-Gredilla et al. 2010)) can only v ary support set size (number of spectral points) to obtain the desired predictiv e performance. Remark 4 . W e ha ve illustrated through a simple toy example in Appendix D that, unlike the local GPs approach, LMA does not e xhibit any discontinuity in its predictions despite data partitioning. 4 Experiments and Discussion This section first empirically ev aluates the predicti ve perfor- mance and scalability of our proposed centralized and par- allel LMA methods against that of the state-of-the-art cen- tralized PIC (Snelson and Ghahramani 2007), parallel PIC (Chen et al. 2013), sparse spectrum GP (SSGP) (L ´ azaro- Gredilla et al. 2010), and FGP on two real-world datasets: (a) The SARCOS dataset (V ijayakumar , D’Souza, and Schaal 2005) of size 48933 is obtained from an in verse dynamics problem for a 7 degrees-of-freedom SARCOS robot arm. Each input is specified by a 21 D feature vector of joint posi- tions, velocities, and accelerations. The output corresponds to one of the 7 joint torques. (b) The AIMPEAK dataset (Chen et al. 2013) of size 41850 comprises traf fic speeds (km/h) along 775 road segments of an urban road network during morning peak hours on April 20 , 2011 . Each input (i.e., road segment) denotes a 5 D feature vector of length, number of lanes, speed limit, direction, and time. The time dimension comprises 54 five-minute time slots. This traffic dataset is modeled using a relational GP (Chen et al. 2012) whose correlation structure can exploit the road segment fea- tures and road network topology information. The outputs correspond to the traffic speeds. Both datasets are modeled using GPs whose prior co- variance σ xx 0 is defined by the squared e xponential cov ari- ance function 4 σ xx 0 , σ 2 s exp( − 0 . 5 P d i =1 ( x i − x 0 i ) 2 /` 2 i ) + σ 2 n δ xx 0 where x i ( x 0 i ) is the i -th component of input fea- ture vector x ( x 0 ) , the hyperparameters σ 2 s , σ 2 n , ` 1 , . . . , ` d 3 Speedup is the incurred time of a sequential/centralized algo- rithm divided by that of its parallel counterpart. 4 For AIMPEAK dataset, multi-dimensional scaling is used to map the input domain (i.e., of road segments) onto the Euclidean space (Chen et al. 2012) before applying the cov ariance function. |D| 8000 16000 24000 32000 FGP 2 . 4(285) 2 . 2(1799) 2 . 1(5324) 2 . 0(16209) SSGP 2 . 4(2029) 2 . 2(3783) 2 . 1(5575) 2 . 0(7310) M = 32 LMA 2 . 4(56) 2 . 2(87) 2 . 1(157) 2 . 0(251) PIC 2 . 4(254) 2 . 2(294) 2 . 1(323) 2 . 0(363) M = 48 LMA 2 . 4(51) 2 . 2(84) 2 . 1(126) 2 . 0(192) PIC 2 . 4(273) 2 . 2(308) 2 . 1(309) 2 . 0(332) M = 64 LMA 2 . 4(61) 2 . 2(87) 2 . 1(111) 2 . 0(155) PIC 2 . 4(281) 2 . 2(286) 2 . 1(290) 2 . 0(324) (a) Parallel LMA ( B = 1 , |S | = 2048 ), parallel PIC ( |S | = 4096 ), SSGP ( |S | = 4096 ) |D| 8000 16000 24000 32000 FGP 7 . 9(271) 7 . 3(1575) 7 . 0(5233) 6 . 9(14656) SSGP 8 . 1(2029) 7 . 5(3781) 7 . 3(5552) 7 . 2(7309) M = 32 LMA 8 . 4(20) 7 . 5(44) 7 . 1(112) 6 . 9(216) PIC 8 . 1(484) 7 . 5(536) 7 . 3(600) 7 . 2(598) M = 48 LMA 8 . 4(18) 7 . 5(33) 7 . 0(74) 6 . 8(120) PIC 8 . 1(542) 7 . 5(590) 7 . 3(598) 7 . 2(616) M = 64 LMA 8 . 4(17) 7 . 5(28) 7 . 0(57) 6 . 7(87) PIC 8 . 1(544) 7 . 5(570) 7 . 3(589) 7 . 2(615) (b) Parallel LMA ( B = 1 , |S | = 1024 ), parallel PIC ( |S | = 5120 ), SSGP ( |S | = 4096 ) T able 1: RMSEs and incurred times (seconds) reported in brackets of parallel LMA, parallel PIC, SSGP , and FGP with varying data sizes |D | and numbers M of cores for (a) SAR- COS and (b) AIMPEAK datasets. are, respectively , signal variance, noise v ariance, and length- scales, and δ xx 0 is a Kronecker delta that is 1 if x = x 0 and 0 otherwise. The hyperparameters are learned using ran- domly selected data of size 10000 via maximum likelihood estimation. T est data of size |U | = 3000 are randomly se- lected from each dataset for predictions. From remaining data, training data of varying |D| are randomly selected. Support sets for LMA and PIC and the set S of spectral points for SSGP are selected randomly from both datasets 5 . The experimental platform is a cluster of 32 computing nodes connected via gigabit links: Each node runs a Linux system with Intel r Xeon r E 5620 at 2 . 4 GHz with 24 GB memory and 16 cores. Our parallel LMA method and par- allel PIC are tested with different numbers M = 32 , 48 , and 64 of cores; all 32 computing nodes with 1 , 1 - 2 , and 2 cores each are used, respectively . For parallel LMA and parallel PIC, each computing node will be storing, respec- tiv ely , a subset of the training data ( D m ∪ D B m , y D m ∪D B m ) and ( D m , y D m ) associated with its o wn core m . Three performance metrics are used to ev aluate the tested methods: (a) Root mean square error (RMSE) ( |U | − 1 P x ∈U ( y x − µ x |D ) 2 ) 1 / 2 , (b) incurred time, and (c) speedup. For RMSE metric, each tested method has to plug its predictiv e mean into µ x |D . T able 1 sho ws results of RMSEs and incurred times of parallel LMA, parallel PIC, SSGP , and FGP av eraged over 5 random instances with varying data sizes |D| and cores M for both datasets. The observations are as follo ws: (a) Predictiv e performances of all tested methods improve with more data, which is expected. For SARCOS dataset, parallel LMA, parallel PIC, and SSGP achieve predictiv e 5 V arying the set S of spectral points over 50 random instances hardly changes the predictive performance of SSGP in our experi- ments because a very large set of spectral points ( |S | = 4096 ) is used in order to achie ve predictive performance as close as possible to FGP and our LMA method (see T able 1). performances comparable to that of FGP . For AIMPEAK dataset, parallel LMA does likewise and outperforms par- allel PIC and SSGP with more data ( |D | ≥ 24000 ), which may be due to its more relaxed conditional independence as- sumption with larger data (Remark 1 after Proposition 1). (b) The incurred times of all tested methods increase with more data, which is also expected. FGP scales very poorly with larger data such that it incurs > 4 hours for |D | = 32000 . In contrast, parallel LMA incurs only 1 - 5 minutes for both datasets when |D | = 32000 . Parallel LMA incurs much less time than parallel PIC and SSGP while achie ving a comparable or better predicti ve performance because it re- quires a significantly smaller |S | than parallel PIC and SSGP simply by imposing a 1 -order Mark ov property ( B = 1 ) on the residual process (Remark 3 after Theorem 2). Though B is only set to 1 , the dense residual co variance matrix approx- imation provided by LMA (as opposed to sparse approxima- tion of PIC) is good enough to achiev e its predictive perfor - mances reported in T able 1. From T able 1b, when training data is small ( |D| = 8000 ) for AIMPEAK dataset, parallel PIC incurs more time than FGP due to its huge |S | = 5120 , which causes communication latency to dominate the in- curred time (Chen et al. 2013). When |D | ≤ 24000 , SSGP also incurs more time than FGP due to its large |S | = 4096 . (c) Predictiv e performances of parallel LMA and PIC gener- ally remain stable with more cores, thus justifying the practi- cality of their structural assumptions to g ain time efficienc y . T able 2 sho ws results of speedups of parallel LMA and parallel PIC as well as incurred times of their centralized counterparts averaged over 5 random instances with vary- ing data sizes |D| and numbers M of cores for AIMPEAK dataset. The observations are as follo ws: (a) The incurred times of centralized LMA and central- ized PIC increase with more data, which is expected. When |D | ≥ 32000 , centralized LMA incurs only 16 - 30 minutes (as compared to FGP incurring > 4 hours) while centralized PIC and SSGP incur , respecti vely , more than 3 . 5 and 2 hours due to their huge |S | . In fact, T able 2 shows that centralized PIC incurs even more time than FGP for almost all possible settings of |D | and M due to its huge support set. (b) The speedups of parallel LMA and parallel PIC gener- ally increase with more data, as e xplained in Remark 2 after Theorem 2, except for that of parallel LMA being slightly higher than expected when |D| = 16000 . (c) The incurred time of centralized LMA decreases with more blocks (i.e., larger M ), as explained in Remark 2 after Theorem 2. This is also expected of centralized PIC, but its incurred time increases with more blocks instead due to its huge support set, which entails large-scale matrix operations causing a huge number of cache misses 6 . This highlights the need to use a sufficiently small support set on a single cen- tralized machine so that cache misses will contribute less to incurred time, as compared to data processing. (d) The speedup of parallel LMA increases with more cores, as explained in Remark 2 after Theorem 2. Though the speedup of parallel PIC appears to increase considerably 6 A cache miss causes the processor to access the data from main memory , which costs 10 × more time than a cache memory access. |D| 8000 16000 24000 32000 FGP − (271) − (1575) − (5233) − (14656) SSGP − (2029) − (3781) − (5552) − (7309) M = 32 LMA 6 . 9(139) 9 . 4(414) 8 . 0(894) 8 . 2(1764) PIC 19 . 4(9432) 18 . 8(10105) 19 . 3(11581) 21 . 6(12954) M = 48 LMA 6 . 9(125) 10 . 2(338) 9 . 2(678) 10 . 2(1227) PIC 25 . 3(13713) 24 . 1(14241) 26 . 2(15684) 26 . 8(16515) M = 64 LMA 7 . 1(120) 10 . 8(302) 10 . 1(576) 11 . 5(1003) PIC 31 . 6(17219) 31 . 5(17983) 33 . 0(19469) 33 . 3(20503) T able 2: Speedups of parallel LMA ( B = 1 , |S | = 1024 ) and parallel PIC ( |S | = 5120 ) and incurred times (seconds) reported in brackets of their centralized counterparts with varying data sizes |D| and cores M for AIMPEAK dataset. 4096 2048 1024 512 128 1 3 5 7 9 13 15 19 21 7.9 8 8.1 8.2 8.3 8.4 8.5 8.6 8.7 Support set size |S| Markov order B RMSE 4 30 40 50 60 70 80 90 100 792 1 3 5 7 9 13 15 19 21 4096 2048 1024 512 128 0 200 400 600 800 Markov order B Support set size |S| Incurred time (seconds) 7.9 8 8.1 8.2 8.3 8.4 8.5 8.6 8.7 Figure 2: RMSEs and incurred times (seconds) of par- allel LMA with varying support set sizes |S | = 128 , 512 , 1024 , 2048 , 4096 and Marko v orders B = 1 , 3 , 5 , 7 , 9 , 13 , 15 , 19 , 21 , |D | = 8000 , and M = 32 for AIMPEAK dataset. Darker gray implies longer incurred time (larger RMSE) for the left (right) plot. with more cores, it is primarily due to the substantial num- ber of cache misses (see observation c abo ve) that inflates the incurred time of centralized PIC excessi vely . Fig. 2 sho ws results of RMSEs and incurred times of par- allel LMA av eraged o ver 5 random instances with varying support set sizes |S | and Marko v orders B , |D| = 8000 , and M = 32 obtained using 8 computing nodes (each using 4 cores) for AIMPEAK dataset. Observations are as follo ws: (a) T o achiev e RMSEs of 8 . 1 and 8 . 0 with least incurred times, one should trade off a lar ger support set size |S | for a larger Mark ov order B (or vice versa) to arriv e at the re- spectiv e settings of |S | = 1024 , B = 5 ( 34 seconds) and |S | = 1024 , B = 9 ( 68 seconds), which agrees with Remark 3 after Theorem 2. Howe ver , to achie ve the same RMSE of 7 . 9 as FGP , the setting of |S | = 128 , B = 21 incurs the least time (i.e., 205 seconds), which seems to indicate that, with small data ( |D | = 8000 ), we should instead focus on in- creasing Marko v order B for LMA to achie ve the same pre- dictiv e performance as FGP; recall that when B = M − 1 , LMA becomes FGP . This provides an empirically cheaper and more reliable alternativ e to increasing |S | for achiev- ing predictiv e performance comparable to FGP , the latter of which, in our experiments, causes Cholesky f actorization failure easily when |S | becomes excessiv ely large. (b) When |S | = 1024 , B = 1 , and M = 32 , parallel LMA using 8 computing nodes incurs less time (i.e., 10 seconds) than that using 32 nodes (i.e., 20 seconds; see T able 1b) because the communication latency between cores within a machine is significantly less than that between machines. Next, the predictive performance and scalability of our parallel LMA method are empirically compared with that of parallel PIC using the large EMULA TE mean sea level pres- |D| 128000 256000 384000 512000 1000000 LMA 823(155) 774(614) 728(3125) 682(7154) 506(78984) PIC 836(948) − ( − ) − ( − ) − ( − ) − ( − ) T able 3: RMSEs and incurred times (seconds) reported in brackets of parallel LMA ( B = 1 , |S | = 512 ) and parallel PIC ( |S | = 3400 ) with M = 512 cores and varying data sizes |D | for EMSLP dataset. sur e (EMSLP) dataset (Ansell et al. 2006) of size 1278250 on a 5 ◦ lat.-lon. grid bounded within lat. 25 - 70 N and lon. 70 W - 50 E from 1900 to 2003 . Each input denotes a 6 D fea- ture vector of latitude, longitude, year , month, day , and in- cremental day count (starting from 0 on first day). The out- put is the mean sea le vel pressure (Pa). The experimental setup is the same as before, except for the platform that is a cluster of 16 computing nodes connected via gigabit links: Each node runs a Linux system with AMD Opteron TM 6272 at 2 . 1 GHz with 32 GB memory and 32 cores. T able 3 sho ws results of RMSEs and incurred times of parallel LMA and parallel PIC averaged over 5 random in- stances with M = 512 cores and varying data sizes |D | for EMSLP dataset. When |D | = 128000 , parallel LMA in- curs much less time than parallel PIC while achieving bet- ter predictive performance because it requires a significantly smaller |S | by setting B = 1 , as explained earlier . When |D | ≥ 256000 , parallel PIC fails due to insuf ficient shared memory between cores. On the other hand, parallel LMA does not experience this issue and incurs from 10 minutes for |D | = 256000 to about 22 hours for |D | = 1000000 . Summary of Experimental Results. LMA is significantly more scalable than FGP in the data size while achie ving a comparable predicti ve performance for SARCOS and AIM- PEAK datasets. For example, when |D | = 32000 and M ≥ 48 , our centralized and parallel LMA methods are, respec- tiv ely , at least 1 and 2 orders of magnitude faster than FGP while achieving comparable predictiv e performances for AIMPEAK dataset. Our centralized (parallel) LMA method also incurs much less time than centralized PIC (parallel PIC) and SSGP while achieving comparable or better pre- dictiv e performance because LMA requires a considerably smaller support set size |S | than PIC and SSGP simply by setting Markov order B = 1 , as explained earlier . T rading off between support set size and Mark ov order of LMA re- sults in less incurred time while achieving the desired pre- dictiv e performance. LMA giv es a more reliable alternative of increasing the Markov order (i.e., to increasing support set size) for achieving predictiv e performance similar to FGP; in practice, a huge support set causes Cholesky factorization failure and insufficient shared memory between cores eas- ily . Finally , parallel LMA can scale up to work for EMSLP dataset of more than a million in size. 5 Conclusion This paper describes a LMA method that leverages the dual computational advantages stemming from complementing the low-rank cov ariance matrix approximation based on sup- port set with the dense residual cov ariance matrix approxi- mation due to Markov assumption. As a result, LMA can make a more relaxed conditional independence assump- tion (especially with larger data) than many existing sparse GP regression methods utilizing low-rank representations, the latter of which utilize a sparse residual cov ariance ma- trix approximation. Empirical results have shown that our centralized (parallel) LMA method is much more scalable than FGP and time-ef ficient than centralized PIC (parallel PIC) and SSGP while achieving comparable predicti ve per- formance. In our future work, we plan to dev elop a tech- nique to automatically determine the “optimal” support set size and Marko v order and de vise an “anytime” variant of LMA using stochastic variational inference like (Hensman, Fusi, and Lawrence 2013) so that it can train with a small subset of data in each iteration instead of learning using all the data. W e also plan to release the source code at http://code.google.com/p/pgpr/. Acknowledgments. This work was supported by Singapore- MIT Alliance for Research and T echnology Subaward Agreement No. 52 R- 252 - 000 - 550 - 592 . References Ansell et al., T . J. 2006. Daily mean sea lev el pressure reconstructions for the European-North Atlantic region for the period 1850 - 2003 . J. Climate 19(12):2717–2742. Asif, A., and Moura, J. M. F . 2005. Block matrices with L -block-banded in verse: In version algorithms. IEEE T rans. Signal Pr ocessing 53(2):630–642. Cao, N.; Low , K. H.; and Dolan, J. M. 2013. Multi-robot in- formativ e path planning for active sensing of en vironmental phenomena: A tale of two algorithms. In Pr oc. AAMAS . Chen, J.; Low , K. H.; T an, C. K.-Y .; Oran, A.; Jaillet, P .; Dolan, J. M.; and Sukhatme, G. S. 2012. Decentralized data fusion and acti ve sensing with mobile sensors for modeling and predicting spatiotemporal traf fic phenomena. In Pr oc. U AI , 163–173. Chen, J.; Cao, N.; Low , K. H.; Ouyang, R.; T an, C. K.-Y .; and Jaillet, P . 2013. Parallel Gaussian process regression with low-rank cov ariance matrix approximations. In Pr oc. U AI , 152–161. Chen, J.; Low , K. H.; and T an, C. K.-Y . 2013. Gaussian process-based decentralized data fusion and acti ve sensing for mobility-on-demand system. In Pr oc. RSS . Dolan, J. M.; Podnar , G.; Stanclif f, S.; Lo w , K. H.; Elfes, A.; Higinbotham, J.; Hosler , J. C.; Moisan, T . A.; and Moisan, J. 2009. Cooperativ e aquatic sensing using the telesuper- vised adapti ve ocean sensor fleet. In Pr oc. SPIE Confer ence on Remote Sensing of the Ocean, Sea Ice, and Large W ater Re gions , volume 7473. Furrer , R.; Genton, M. G.; and Nychka, D. 2006. Cov ariance tapering for interpolation of large spatial datasets. JCGS 15(3):502–523. Hensman, J.; Fusi, N.; and Lawrence, N. 2013. Gaussian processes for big data. In Pr oc. U AI , 282–290. Hoang, T . N.; Low , K. H.; Jaillet, P .; and Kankanhalli, M. 2014a. Active learning is planning: Nonmyopic -Bayes- optimal acti ve learning of Gaussian processes. In Pr oc. ECML/PKDD Nectar T rack , 494–498. Hoang, T . N.; Low , K. H.; Jaillet, P .; and Kankanhalli, M. 2014b. Nonmyopic -Bayes-optimal active learning of Gaussian processes. In Pr oc. ICML , 739–747. L ´ azaro-Gredilla, M.; Qui ˜ nonero-Candela, J.; Rasmussen, C. E.; and Figueiras-V idal, A. R. 2010. Sparse spectrum Gaussian process regression. JMLR 11:1865–1881. Low , K. H.; Chen, J.; Dolan, J. M.; Chien, S.; and Thomp- son, D. R. 2012. Decentralized acti ve robotic exploration and mapping for probabilistic field classification in en viron- mental sensing. In Pr oc. AAMAS , 105–112. Low , K. H.; Chen, J.; Hoang, T . N.; Xu, N.; and Jaillet, P . 2014a. Recent adv ances in scaling up Gaussian process pre- dictiv e models for large spatiotemporal data. In Pr oc. Dy- DESS . Low , K. H.; Xu, N.; Chen, J.; Lim, K. K.; and ¨ Ozg ¨ ul, E. B. 2014b . Generalized online sparse Gaussian processes with application to persistent mobile robot localization. In Proc. ECML/PKDD Nectar T rack , 499–503. Low , K. H.; Dolan, J. M.; and Khosla, P . 2008. Adaptiv e multi-robot wide-area exploration and mapping. In Proc. AAMAS , 23–30. Low , K. H.; Dolan, J. M.; and Khosla, P . 2009. Information- theoretic approach to efficient adaptiv e path planning for mobile robotic en vironmental sensing. In Pr oc. ICAPS . Low , K. H.; Dolan, J. M.; and Khosla, P . 2011. Acti ve Markov information-theoretic path planning for robotic en- vironmental sensing. In Pr oc. AAMAS , 753–760. Ouyang, R.; Low , K. H.; Chen, J.; and Jaillet, P . 2014. Multi- robot active sensing of non-stationary Gaussian process- based en vironmental phenomena. In Pr oc. AAMAS . Park, C.; Huang, J. Z.; and Ding, Y . 2011. Domain de- composition approach for fast Gaussian process regression of large spatial data sets. JMLR 12:1697–1728. Podnar , G.; Dolan, J. M.; Low , K. H.; and Elfes, A. 2010. T elesupervised remote surface water quality sensing. In Pr oc. IEEE Aer ospace Confer ence . Qui ˜ nonero-Candela, J., and Rasmussen, C. E. 2005. A uni- fying vie w of sparse approximate Gaussian process regres- sion. JMLR 6:1939–1959. Snelson, E., and Ghahramani, Z. 2005. Sparse Gaussian processes using pseudo-inputs. In Pr oc. NIPS . Snelson, E., and Ghahramani, Z. 2007. Local and global sparse Gaussian process approximations. In Pr oc. AIST A TS . V ijayakumar, S.; D’Souza, A.; and Schaal, S. 2005. Incre- mental online learning in high dimensions. Neural Comput. 17(12):2602–2634. Xu, N.; Lo w , K. H.; Chen, J.; Lim, K. K.; and ¨ Ozg ¨ ul, E. B. 2014. GP-Localize: Persistent mobile robot localization us- ing online sparse Gaussian process observation model. In Pr oc. AAAI , 2585–2592. Y u, J.; Low , K. H.; Oran, A.; and Jaillet, P . 2012. Hier- archical Bayesian nonparametric approach to modeling and learning the wisdom of crowds of urban traffic route plan- ning agents. In Pr oc. IA T , 478–485. A Proof of Theor em 1 D KL ( R DD , R DD ) + D KL ( R DD , b R ) = 1 2 tr ( R DD R − 1 DD ) − log | R DD R − 1 DD | − |D | + 1 2 tr ( R DD b R − 1 ) − log | R DD b R − 1 | − |D | = 1 2 tr ( R DD b R − 1 ) − log | R DD | − log | b R − 1 | − |D | = 1 2 tr ( R DD b R − 1 ) − log | R DD b R − 1 | − |D | = D KL ( R DD , b R ) . The second equality is due to tr ( R DD R − 1 DD ) = tr ( R DD R − 1 DD ) = tr ( I |D| ) = |D | , which follows from the observ ations that the blocks within the B -block bands of R DD and R DD are the same and R − 1 DD is B - block-banded (Proposition 1). The third equality follows from the first observation abov e and the definition that b R − 1 is B -block-banded. Since D KL ( R DD , b R ) ≥ 0 , D KL ( R DD , b R ) ≥ D KL ( R DD , R DD ) . B Proof of Theor em 2 The following lemma is necessary for deriving our main re- sult here. It sho ws that the sparsity of B -block-banded R − 1 DD (Proposition 1) extends to that of its Cholesky factor (Fig. 3): Lemma 1 Let R − 1 DD , U > U wher e Cholesky factor U = [ U mn ] m,n =1 ,...,M is an upper triangular matrix (F ig. 3). Then, U mn = 0 if m − n > 0 or n − m > B . Furthermore , for m = 1 , . . . , M , U mm = cholesky ( ˙ R m ) and U B m , [ U mn ] n = m +1 ,..., min( m + B ,M ) = − U mm R D m D B m R − 1 D B m D B m . Its proof follo ws directly from block-banded matrix results of Asif and Moura (2005) (i.e., Lemma 1 . 1 and Theorem 1 ). Σ − 1 DD = Σ DS Σ − 1 S S Σ S D + R DD − 1 = R − 1 DD − R − 1 DD Σ DS Σ S S +Σ S D R − 1 DD Σ DS − 1 Σ S D R − 1 DD = R − 1 DD − R − 1 DD Σ DS ¨ Σ − 1 S S Σ S D R − 1 DD . (5) n m> 1 D 1 D 2 D 3 D 4 D 1 D 2 D 3 D 4 0 0 0 0 0 0 0 0 0 U 11 U 22 U 33 U 44 m n> 0 U 1 1 U 1 2 U 1 3 = U 12 = U 23 = U 34 0 n m 1 Figure 3: Cholesk y factor U with B = 1 and M = 4 . Un- shaded blocks outside B -block band of R − 1 DD (i.e., | m − n | > B ) are 0 (Fig. 1b), which result in the unshaded blocks of its Cholesky factor U being 0 (i.e., m − n > 0 or n − m > B ). The second equality is due to the matrix in version lemma. The last equality follows from Σ S D R − 1 DD Σ DS = Σ S D U > U Σ DS = M X m =1 Σ S ( D m ∪D B m ) U > mm U B > m U mm , U B m Σ ( D m ∪D B m ) S = M X m =1 U mm Σ D m S + U B m Σ D B m S > U mm Σ D m S + U B m Σ D B m S = M X m =1 ( ˙ Σ m S ) > ˙ R m ˙ Σ m S = ¨ Σ S S − Σ S S . The fourth equality is due to Lemma 1 and Definition 1. The last equality follows from Definition 2. µ LMA U (3) = µ U + Σ U D Σ − 1 DD ( y D − µ D ) (5) = µ U + Σ U D R − 1 DD ( y D − µ D ) − Σ U D R − 1 DD Σ DS ¨ Σ − 1 S S Σ S D R − 1 DD ( y D − µ D ) = µ U + ¨ y U − ¨ Σ U S ¨ Σ − 1 S S ¨ y S . The last equality is derived using Definition 2, specifically , from the e xpressions of the following three ¨ y U , ¨ Σ U S , and ¨ y S components, respectiv ely: Σ U D R − 1 DD ( y D − µ D ) = Σ U D U > U ( y D − µ D ) = M X m =1 Σ U ( D m ∪D B m ) U > mm U B > m U mm , U B m y D m ∪D B m − µ D m ∪D B m = M X m =1 U mm Σ D m U + U B m Σ D B m U > U mm ( y D m − µ D m ) + U B m y D B m − µ D B m = M X m =1 ( ˙ Σ m U ) > ˙ R m ˙ y m = ¨ y U . The fourth equality is due to Lemma 1 and Defini- tion 1. Σ D m U = Σ D m U n n =1 ,...,M and Σ D B m U = Σ D k U n k = m +1 ,..., min( m + B ,M ) ,n =1 ,...,M are obtained using (2). The last equality follows from Definition 2. Σ U D R − 1 DD Σ DS = Σ U D U > U Σ DS = M X m =1 Σ U ( D m ∪D B m ) U > mm U B > m U mm , U B m Σ ( D m ∪D B m ) S = M X m =1 U mm Σ D m U + U B m Σ D B m U > U mm Σ D m S + U B m Σ D B m S = M X m =1 ( ˙ Σ m U ) > ˙ R m ˙ Σ m S = ¨ Σ U S . The fourth equality is due to Lemma 1 and Definition 1. The last equality follows from Definition 2. Finally , Σ S D R − 1 DD ( y D − µ D ) = Σ S D U > U ( y D − µ D ) = M X m =1 Σ S ( D m ∪D B m ) U > mm U B > m U mm , U B m y D m ∪D B m − µ D m ∪D B m = M X m =1 U mm Σ D m S + U B m Σ D B m S > U mm ( y D m − µ D m ) + U B m y D B m − µ D B m = M X m =1 ( ˙ Σ m S ) > ˙ R m ˙ y m = ¨ y S . The fourt h equality is due to Lemma 1 and Definition 1. The last equality follows from Definition 2. Σ LMA U U (4) = Σ U U − Σ U D Σ − 1 DD Σ DU (5) = Σ U U − Σ U D R − 1 DD Σ DU + Σ U D R − 1 DD Σ DS ¨ Σ − 1 S S Σ S D R − 1 DD Σ DU = Σ U U − ¨ Σ U U + ¨ Σ U S ¨ Σ − 1 S S ¨ Σ > U S . The last equality is derived using Definition 2, specifically , from the e xpression of the ¨ Σ U S component abo ve as well as that of the following ¨ Σ U U component: Σ U D R − 1 DD Σ DU = Σ U D U > U Σ DU = M X m =1 Σ U ( D m ∪D B m ) U > mm U B > m U mm , U B m Σ ( D m ∪D B m ) U = M X m =1 U mm Σ D m U + U B m Σ D B m U > U mm Σ D m U + U B m Σ D B m U = M X m =1 ( ˙ Σ m U ) > ˙ R m ˙ Σ m U = ¨ Σ U U . The fourt h equality is due to Lemma 1 and Definition 1. The last equality follows from Definition 2. C Parallel Computation of Σ D m U and Σ D B m U Computing Σ D m U and Σ D B m U terms (2) requires e valuat- ing R D m U and R D B m U terms (1), which are stored and used by each machine/core m to construct the m -th local sum- mary . W e will describe the parallel computation of R DU , from which R D m U and R D B m U terms can be obtained by ma- chine/core m . T o simplify e xposition, we will consider the simple setting of B = 1 and M = 4 here. For the blocks within the 1 -block band of R DU (i.e., | m − n | ≤ 1 ), the y correspond exactly to that of the residual covariance matrix R DU . So, each ma- chine/core m for m = 1 , . . . , 4 can directly com- pute its respectiv e blocks in parallel (Fig. 4), specifi- cally , R D m S min( m +1 ,M ) n =max( m − 1 , 1) U n = R D m S min( m +1 ,M ) n =max( m − 1 , 1) U n and R D 1 m S min( m +2 ,M ) n =max( m, 1) U n = R D m +1 S min( m +2 ,M ) n =max( m, 1) U n . M achine 4 D 4 U 1 U 2 U 3 U 4 M achine 3 D 3 D 4 U 1 U 2 U 3 U 4 M achine 2 D 2 D 3 U 1 U 2 U 3 U 4 M achine 1 D 1 D 2 U 1 U 2 U 3 U 4 Figure 4: Each machine can directly compute its light gray blocks in parallel. Let the upper N -diagonal blocks denote the ones that are N blocks abov e the main diagonal ones of R DU . For the blocks strictly above the 1 -block band of R DU (i.e., n − m > 1 ), the ke y idea is to exploit the recursive def- inition of R DU to compute the upper 2 -diagonal blocks in parallel using the upper 1 -diagonal blocks, follo wed by computing the upper 3 -diagonal block using an upper 2 - diagonal block. Specifically , they can be computed in 2 re- cursiv e steps (Fig. 5): In each recursive step i , each ma- chine/core m for m = 1 , . . . , 3 − i uses the upper i -diagonal blocks R D m +1 U m +1+ i to compute the upper ( i + 1 )-diagonal blocks R D m U m +1+ i = R D m D 1 m R − 1 D 1 m D 1 m R D 1 m U m +1+ i = R D m D m +1 R − 1 D m +1 D m +1 R D m +1 U m +1+ i (1) in parallel and then communicates R D m U m +1+ i to machine/core m − 1 . For the blocks strictly below the 1 -block band of R DU (i.e., m − n > 1 ), it is similar but less straight- forward: It can be observed from (1) that R D m U n = R D m D 1 n R − 1 D 1 n D 1 n R D 1 n U n = R D m D n +1 R − 1 D n +1 D n +1 R D n +1 U n . But, machine/core m does not store data associated with the set D n +1 of inputs in order to compute R D m D n +1 . T o re- solve this, the trick is to compute the transpose of R D m U n (i.e., R U n D m ) for m − n > 1 instead. These transposed blocks can also be computed in 2 recursiv e steps like the abov e: In each recursi ve step i , each machine/core n for n = 1 , . . . , 3 − i uses the upper i -diagonal blocks R D n +1 D n +1+ i (i.e., equal to R D n +1 D n +2 when i = 1 that can be directly computed by machine/core n in parallel) of R DD to com- pute the upper ( i + 1 )-diagonal blocks R U n D n +1+ i of R U D : R U n D n +1+ i (1) = R U n D 1 n R − 1 D 1 n D 1 n R D 1 n D n +1+ i = R U n D n +1 R − 1 D n +1 D n +1 R D n +1 D n +1+ i as well as the upper ( i + 1 )-diagonal blocks R D n D n +1+ i of R DD in parallel: R D n D n +1+ i (1) = R D n D 1 n R − 1 D 1 n D 1 n R D 1 n D n +1+ i = R D n D n +1 R − 1 D n +1 D n +1 R D n +1 D n +1+ i S tep 1 S tep 2 M achine 4 D 4 U 1 U 2 U 3 U 4 M achine 3 D 3 D 4 U 1 U 2 U 3 U 4 M achine 2 D 2 D 3 U 1 U 2 U 3 U 4 M achine 1 D 1 D 2 U 1 U 2 U 3 U 4 D 4 U 1 U 2 U 3 U 4 D 3 D 4 U 1 U 2 U 3 U 4 D 2 D 3 U 1 U 2 U 3 U 4 D 1 D 2 U 1 U 2 U 3 U 4 Figure 5: In step 1 , machines 1 and 2 compute their dark gray blocks in parallel and machine 2 communicates the dark gray block highlighted in red to machine 1 . In step 2 , machine 1 computes the dark gray block. and then communicates R D n D n +1+ i to machine/core n − 1 . Finally , each machine/core n for n = 1 , 2 transposes the previously computed R U n D m back to R D m U n for m − n > 1 and communicates R D m U n to machines/cores m − 1 and m . The parallel computation of R DU is thus complete. The procedure to parallelize the computation of R DU for any general setting of B and M is similar to the above, albeit more tedious notationally . D T oy Example For our LMA method, the settings are M = 4 , Mark ov order B = 1 , support set (black × ’ s) size |S | = 16 , and training data (red × ’ s) size |D | = 400 such that x < − 2 . 5 if x ∈ D 1 , − 2 . 5 ≤ x < 0 if x ∈ D 2 , 0 ≤ x < 2 . 5 if x ∈ D 3 , x ≥ 2 . 5 if x ∈ D 4 , and |D 1 | = |D 2 | = |D 3 | = |D 4 | = 100 . The hyper- parameters learned using maximum likelihood estimation are length-scale ` = 1 . 2270 , σ n = 0 . 0939 , σ s = 0 . 6836 , and µ x = 1 . 1072 . It can be observed from Fig. 6 that the posterior/predictiv e mean curve (blue curve) of our LMA method does not exhibit any discontinuity/jump. The area enclosed by the green curves is the 95% confidence region. In contrast, the posterior/predictive mean curve (blue curve) of the local GPs approach with 4 GPs experiences 3 discontinuities/jumps at the boundaries x = − 2 . 5 , 0 , 2 . 5 . − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 − 1 0 1 2 3 Local GPs − 5 − 4 − 3 − 2 − 1 0 1 2 3 4 5 − 0.5 0 0.5 1 1.5 2 2.5 LMA Figure 6: The true function (dashed black curve) is y x = 1 + cos ( x ) + 0 . 1 for − 5 ≤ x ≤ 5 where ∼ N (0 , 1) .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment