Bucking the Trend: Large-Scale Cost-Focused Active Learning for Statistical Machine Translation
We explore how to improve machine translation systems by adding more translation data in situations where we already have substantial resources. The main challenge is how to buck the trend of diminishing returns that is commonly encountered. We prese…
Authors: Michael Bloodgood, Chris Callison-Burch
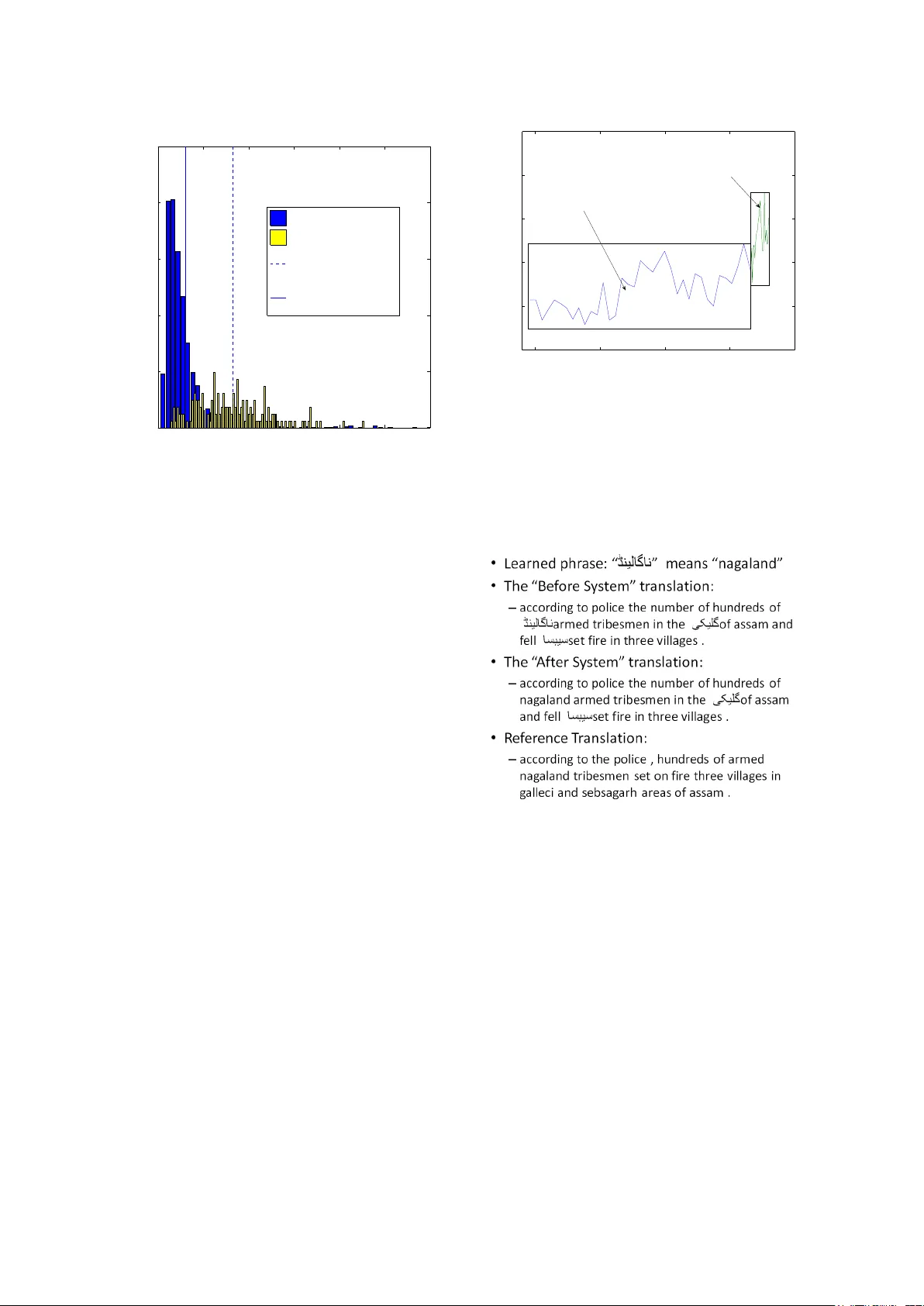
Bucking the T r end: Large-Scale Cost-F ocused Acti v e Learning f or Statistical Machine T ranslation Michael Bloodgood Human Language T echnology Center of Excellence Johns Hopkins Uni versity Baltimore, MD 21211 bloodgood@jhu.edu Chris Callison-Burch Center for Language and Speech Processing Johns Hopkins Uni versity Baltimore, MD 21211 ccb@cs.jhu.edu Abstract W e explore ho w to improv e machine trans- lation systems by adding more translation data in situations where we already hav e substantial resources. The main challenge is ho w to buck the trend of diminishing re- turns that is commonly encountered. W e present an activ e learning-style data solic- itation algorithm to meet this challenge. W e test it, gathering annotations via Ama- zon Mechanical T urk, and find that we get an order of magnitude increase in perfor - mance rates of improv ement. 1 Introduction Figure 1 sho ws the learning curves for tw o state of the art statistical machine translation (SMT) sys- tems for Urdu-English translation. Observe how the learning curves rise rapidly at first but then a trend of diminishing returns occurs: put simply , the curves flatten. This paper inv estigates whether we can buck the trend of diminishing returns, and if so, how we can do it effecti vely . Active learning (AL) has been ap- plied to SMT recently (Haf fari et al., 2009; Haf fari and Sarkar , 2009) b ut they were interested in start- ing with a tiny seed set of data, and they stopped their in vestigations after only adding a relati vely tiny amount of data as depicted in Figure 1. In contrast, we are interested in applying AL when a large amount of data already exists as is the case for man y important lanuage pairs. W e de- velop an AL algorithm that focuses on keeping an- notation costs (measured by time in seconds) low . It succeeds in doing this by only soliciting trans- lations for parts of sentences. W e show that this gets a savings in human annotation time above and beyond what the reduction in # words annotated would have indicated by a factor of about three and speculate as to why . 0 2 4 6 8 10 x 10 4 0 5 10 15 20 25 30 Number of Sentences in Training Data BLEU Score JSyntax and JHier Learning Curves on the LDC Urdu−English Language Pack (BLEU vs Sentences) jHier jSyntax as far as previous AL for SMT research studies were conducted where we begin our main investigations into bucking the trend of diminishing returns Figure 1: Syntax-based and Hierarchical Phrase- Based MT systems’ learning curves on the LDC Urdu-English language pack. The x-axis measures the number of sentence pairs in the training data. The y-axis measures BLEU score. Note the di- minishing returns as more data is added. Also note ho w relati vely early on in the process pre- vious studies were terminated. In contrast, the focus of our main experiments doesn’ t even be- gin until much higher performance has already been achie ved with a period of diminishing returns firmly established. W e conduct e xperiments for Urdu-English translation, gathering annotations via Amazon Mechanical T urk (MT urk) and show that we can indeed b uck the trend of diminishing returns, achie ving an order of magnitude increase in the rate of improv ement in performance. Section 2 discusses related work; Section 3 discusses preliminary experiments that sho w the guiding principles behind the algorithm we use; Section 4 explains our method for soliciting new translation data; Section 5 presents our main re- sults; and Section 6 concludes. This paper was published within the Pr oceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pages 854-864, Uppsala, Sweden, 11-16 J uly 2010. c 2010 Association for Computational Linguistics 2 Related W ork Acti ve learning has been sho wn to be effecti ve for improving NLP systems and reducing anno- tation burdens for a number of NLP tasks (see, e.g., (Hwa, 2000; Sassano, 2002; Bloodgood and V ijay-Shanker , 2008; Bloodgood and V ijay- Shanker , 2009b; Mairesse et al., 2010; V ickrey et al., 2010)). The current paper is most highly re- lated to previous work falling into three main ar- eas: use of AL when large corpora already exist; cost-focused AL; and AL for SMT . In a sense, the work of Banko and Brill (2001) is closely related to ours. Though their focus is mainly on in vestig ating the performance of learn- ing methods on giant corpora many orders of mag- nitude larger than previously used, the y do lay out ho w AL might be useful to apply to acquire data to augment a lar ge set cheaply because they rec- ognize the problem of diminishing returns that we discussed in Section 1. The second area of work that is related to ours is pre vious work on AL that is cost-conscious. The v ast majority of AL research has not focused on accurate cost accounting and a typical assumption is that each annotatable has equal annotation cost. An early exception in the AL for NLP field was the work of Hwa (2000), which makes a point of using # of brackets to measure cost for a syntac- tic analysis task instead of using # of sentences. Another relati vely early work in our field along these lines was the work of Ngai and Y arowsk y (2000), which measured actual times of annota- tion to compare the efficac y of rule writing ver- sus annotation with AL for the task of BaseNP chunking. Osborne and Baldridge (2004) argued for the use of discriminant cost over unit cost for the task of Head Phrase Structure Grammar parse selection. King et al. (2004) design a robot that tests gene functions. The robot chooses which experiments to conduct by using AL and takes monetary costs (in pounds sterling) into account during AL selection and e v aluation. Unlike our situation for SMT , their costs are all kno wn be- forehand because they are simply the cost of ma- terials to conduct the experiments, which are al- ready known to the robot. Hachey et al. (2005) sho wed that selectively sampled e xamples for an NER task took longer to annotate and had lower inter-annotator agreement. This work is related to ours because it shows that ho w examples are se- lected can impact the cost of annotation, an idea we turn around to use for our adv antage when de- veloping our data selection algorithm. Haertel et al. (2008) emphasize measuring costs carefully for AL for POS tagging. They de velop a model based on a user study that can estimate the time required for POS annotating. Kapoor et al. (2007) assign costs for AL based on message length for a voice- mail classification task. In contrast, we show for SMT that annotation times do not scale according to length in words and we show our method can achie ve a speedup in annotation time abov e and beyond what the reduction in words would indi- cate. T omanek and Hahn (2009) measure cost by # of tokens for an NER task. Their AL method only solicits labels for parts of sentences in the interest of reducing annotation effort. Along these lines, our method is similar in the respect that we also will only solicit annotation for parts of sentences, though we prefer to measure cost with time and we show that time doesn’t track with token length for SMT . Haf fari et al. (2009), Haffari and Sarkar (2009), and Ambati et al. (2010) in vestigate AL for SMT . There are two major differences between our work and this previous work. One is that our intended use cases are v ery dif ferent. They deal with the more traditional AL setting of starting from an e x- tremely small set of seed data. Also, by SMT stan- dards, they only add a very tiny amount of data during AL. All their simulations top out at 10,000 sentences of labeled data and the models learned hav e relativ ely low translation quality compared to the state of the art. On the other hand, in the current paper , we demonstrate how to apply AL in situations where we already ha ve large corpora. Our goal is to b uck the trend of diminishing returns and use AL to add data to build some of the highest-performing MT systems in the world while keeping annota- tion costs lo w . See Figure 1 from Section 1, which contrasts where (Haff ari et al., 2009; Haff ari and Sarkar , 2009) stop their in vestig ations with where we be gin our studies. The other major dif ference is that (Haf fari et al., 2009; Haffari and Sarkar , 2009) measure annota- tion cost by # of sentences. In contrast, we bring to light some potential drawbacks of this practice, sho wing it can lead to dif ferent conclusions than if other annotation cost metrics are used, such as time and money , which are the metrics that we use. 3 Simulation Experiments Here we report on results of simulation experi- ments that help to illustrate and motiv ate the de- sign decisions of the algorithm we present in Sec- tion 4. W e use the Urdu-English language pack 1 from the Linguistic Data Consortium (LDC), which contains ≈ 88000 Urdu-English sentence translation pairs, amounting to ≈ 1.7 million Urdu words translated into English. All experiments in this paper ev aluate on a genre-balanced split of the NIST2008 Urdu-English test set. In addition, the language pack contains an Urdu-English dictio- nary consisting of ≈ 114000 entries. In all the ex- periments, we use the dictionary at every iteration of training. This will make it harder for us to show our methods providing substantial gains since the dictionary will provide a higher base performance to begin with. Ho wever , it would be artificial to ignore dictionary resources when they e xist. W e experiment with tw o translation models: hi- erarchical phrase-based translation (Chiang, 2007) and syntax augmented translation (Zollmann and V enugopal, 2006), both of which are implemented in the Joshua decoder (Li et al., 2009). W e here- after refer to these systems as jHier and jSyntax, respecti vely . W e will now present results of experiments with dif ferent methods for gro wing MT training data. The results are or ganized into three areas of in ves- tigations: 1. annotation costs; 2. managing uncertainty; and 3. how to automatically detect when to stop so- liciting annotations from a pool of data. 3.1 Annotation Costs W e begin our cost in vestigations with four sim- ple methods for gro wing MT training data: ran- dom, shortest, longest, and V ocabGr owth sen- tence selection. The first three methods are self- explanatory . V ocabGr owth (hereafter VG ) selec- tion is modeled after the best methods from pre vi- ous work (Haf fari et al., 2009; Haffari and Sarkar , 2009), which are based on preferring sentences that contain phrases that occur frequently in un- labeled data and infrequently in the so-far labeled data. Our VG method selects sentences for transla- tion that contain n-grams (for n in { 1,2,3,4 } ) that 1 LDC Catalog No.: LDC2006E110. Init: Go through all av ailable training data (labeled and unlabeled) and obtain frequency counts for e very n-gram (n in { 1 , 2 , 3 , 4 } ) that occurs. sor tedN Gr ams ← Sort n-grams by frequency in descending order . Loop until stopping criterion (see Section 3.3) is met 1. tr ig g er ← Go down sortedN Gr ams list and find the first n-gram that isn’t co vered in the so far labeled training data. 2. sel ectedS entence ← Find a sentence that contains tr ig g er . 3. Remov e selectedS entence from unlabeled data and add it to labeled training data. End Loop Figure 2: The VG sentence selection algorithm do not occur at all in our so-far labeled data. W e call an n-gram “covered” if it occurs at least once in our so-far labeled data. VG has a preference for covering frequent n-grams before cov ering in- frequent n-grams. The VG method is depicted in Figure 2. Figure 3 shows the learning curves for both jHier and jSyntax for VG selection and random selection. The y-axis measures BLEU score (Pap- ineni et al., 2002),which is a fast automatic w ay of measuring translation quality that has been shown to correlate with human judgments and is perhaps the most widely used metric in the MT commu- nity . The x-axis measures the number of sen- tence translation pairs in the training data. The VG curves are cut off at the point at which the stopping criterion in Section 3.3 is met. From Figure 3 it might appear that VG selection is better than ran- dom selection, achie ving higher-performing sys- tems with fe wer translations in the labeled data. Ho we ver , it is important to take care when mea- suring annotation costs (especially for relativ ely complicated tasks such as translation). Figure 4 sho ws the learning curv es for the same systems and selection methods as in Figure 3 but no w the x-axis measures the number of foreign words in the training data. The dif ference between VG and random selection no w appears smaller . For an extreme case, to illustrate the ramifica- 0 10,000 20,000 30,000 40,000 50,000 60,000 70,000 80,000 90,000 0 5 10 15 20 25 30 jHier and jSyntax: VG vs Random selection (BLEU vs Sents) Number of Sentence Pairs in the Training Data BLEU Score jHier: random selection jHier: VG selection jSyntax: random selection jSyntax: VG selection where we will start our main experiments where previous AL for SMT research stopped their experiments Figure 3: Random vs VG selection. The x-axis measures the number of sentence pairs in the train- ing data. The y-axis measures BLEU score. tions of measuring translation annotation cost by # of sentences versus # of words, consider Figures 5 and 6. They both sho w the same three selection methods but Figure 5 measures the x-axis by # of sentences and Figure 6 measures by # of w ords. In Figure 5, one would conclude that shortest is a far inferior selection method to longest but in Figure 6 one would conclude the opposite. Measuring annotation time and cost in dol- lars are probably the most important measures of annotation cost. W e can’ t measure these for the simulated experiments but we will use time (in seconds) and money (in US dollars) as cost measures in Section 5, which discusses our non- simulated AL experiments. If # sentences or # words track these other more rele vant costs in pre- dictable kno wn relationships, then it would suffice to measure # sentences or # words instead. But it’ s clear that different sentences can have v ery dif fer- ent annotation time requirements according to how long and complicated they are so we will not use # sentences as an annotation cost any more. It is not as clear ho w # words tracks with annotation time. In Section 5 we will present evidence sho w- ing that time per word can vary considerably and also show a method for soliciting annotations that reduces time per word by nearly a factor of three. As it is prudent to ev aluate using accurate cost accounting, so it is also prudent to dev elop new AL algorithms that take costs carefully into ac- count. Hence, reducing annotation time burdens 0 0.5 1 1.5 2 x 10 6 0 5 10 15 20 25 30 jHier and jSyntax: VG vs Random selection (BLEU vs FWords) Number of Foreign Words in Training Data BLEU Score jHier: random selection jHier: VG selection jSyntax: random selection jSyntax: VG selection Figure 4: Random vs VG selection. The x-axis measures the number of foreign words in the train- ing data. The y-axis measures BLEU score. instead of the # of sentences translated (which might be quite a dif ferent thing) will be a corner- stone of the algorithm we describe in Section 4. 3.2 Managing Uncertainty One of the most successful of all AL methods de- veloped to date is uncertainty sampling and it has been applied successfully many times (e.g.,(Le wis and Gale, 1994; T ong and K oller , 2002)). The intuition is clear: much can be learned (poten- tially) if there is great uncertainty . Ho we ver , with MT being a relati vely complicated task (compared with binary classification, for example), it might be the case that the uncertainty approach has to be re-considered. If words have nev er occurred in the training data, then uncertainty can be e x- pected to be high. But we are concerned that if a sentence is translated for which (almost) no words hav e been seen in training yet, though uncertainty will be high (which is usually considered good for AL), the word alignments may be incorrect and then subsequent learning from that translation pair will be se verely hampered. W e tested this hypothesis and Figure 7 shows empirical e vidence that it is true. Along with VG , two other selection methods’ learning curves are charted in Figure 7: mostNew , which prefers to select those sentences which have the largest # of unseen words in them; and moderateNew , which aims to prefer sentences that have a moderate # of unseen words, preferring sentences with ≈ ten 0 2 4 6 8 10 x 10 4 0 5 10 15 20 25 jHiero: Random, Shortest, and Longest selection BLEU Score Number of Sentences in Training Data random shortest longest Figure 5: Random vs Shortest vs Longest selec- tion. The x-axis measures the number of sentence pairs in the training data. The y-axis measures BLEU score. unkno wn words in them. One can see that most- Ne w underperforms VG . This could have been due to VG ’ s frequency component, which mostNew doesn’t ha ve. But moderateNew also doesn’ t have a frequency preference so it is likely that mostNew winds up overwhelming the MT training system, word alignments are incorrect, and less is learned as a result. In light of this, the algorithm we de- velop in Section 4 will be designed to a void this word alignment danger . 3.3 A utomatic Stopping The problem of automatically detecting when to stop AL is a substantial one, discussed at length in the literature (e.g., (Bloodgood and V ijay- Shanker , 2009a; Schohn and Cohn, 2000; Vla- chos, 2008)). In our simulation, we stop VG once all n-grams (n in { 1,2,3,4 } ) hav e been covered. Though simple, this stopping criterion seems to work well as can be seen by where the curve for VG is cut off in Figures 3 and 4. It stops af- ter 1,293,093 words hav e been translated, with jHier’ s BLEU=21.92 and jSyntax’ s BLEU=26.10 at the stopping point. The ending BLEU scores (with the full corpus annotated) are 21.87 and 26.01 for jHier and jSyntax, respecti vely . So our stopping criterion saves 22.3% of the anno- tation (in terms of words) and actually achie ves slightly higher BLEU scores than if all the data were used. Note: this ”less is more” phenomenon 0 0.5 1 1.5 2 x 10 6 0 5 10 15 20 25 Number of Foreign Words in Training Data BLEU Score jHiero: Longest, Shortest, and Random Selection random shortest longest Figure 6: Random vs Shortest vs Longest selec- tion. The x-axis measures the number of foreign words in the training data. The y-axis measures BLEU score. has been commonly observ ed in AL settings (e.g., (Bloodgood and V ijay-Shanker , 2009a; Schohn and Cohn, 2000)). 4 Highlighted N-Gram Method In this section we describe a method for solicit- ing human translations that we hav e applied suc- cessfully to improving translation quality in real (not simulated) conditions. W e call the method the Highlighted N-Gram method, or HNG , for short. HNG solicits translations only for trigger n-grams and not for entire sentences. W e provide senten- tial conte xt, highlight the trigger n-gram that we want translated, and ask for a translation of just the highlighted trigger n-gram. HNG asks for transla- tions for triggers in the same order that the triggers are encountered by the algorithm in Figure 2. A screenshot of our interface is depicted in F igure 8. The same stopping criterion is used as w as used in the last section. When the stopping criterion be- comes true, it is time to tap a new unlabeled pool of foreign text, if a vailable. Our motiv ations for soliciting translations for only parts of sentences are twofold, corresponding to two possible cases. Case one is that a translation model learned from the so-far labeled data will be able to translate most of the non-trigger words in the sentence correctly . Thus, by asking a human to translate only the trigger words, we a void wast- ing human translation effort. (W e will sho w in 0 0.5 1 1.5 2 x 10 6 0 5 10 15 20 25 Number of Foreign Words in Training Data BLEU Score jHiero: VG vs mostNew vs moderateNew VG mostNew moderateNew Figure 7: VG vs MostNew vs ModerateNew se- lection. The x-axis measures the number of sen- tence pairs in the training data. The y-axis mea- sures BLEU score. ! " # $ % " & ' ( ) ' * + , - . / 0 ) 1 2 3 4 5 6 7 8 9 : - ! ! " # $ % $ & ' $ & ( ) * + ; < = ' $ > / ? @ 3 / A > . + B ! C D ) C E F G H ? I ' 3 " ) D ) + 0 ) + & . " J & " J & " $ K $ ! 1 2 L ) M 8 ' : ? 3 N ! O # ) P & G Q 6 - ' & R 7 @ * / & S T & S T & ! 9 , 8 U V ) W X ' 8 , " * ) - ! . ( / 0 . " 2 3 4 ! . C 2 3 4 ! D # 8 E Y ) . < 3 ' 8 M H 3 G : Z ! " - [ $ % ' 8 R 3 \ 5 # ) T = 5 # ) ] ' 3 E & > ' # ) P 8 > < & . ^ : S _ < * ' ( * C + & + : Z ' * / ` $ > a U H $ G X " & 5 , - . b ' 8 " $ c 9 * S _ / & < * d H # $ ! < ) + & ? e ( @ ) f e 3 < g : # 1 . 2 # 1 . 2 " ( : Z . < * e @ * ' : ) K ) C + ) E # ) ' * + $ / H 0 ) + & < * G : I ' 3 . 4 5 ' ' & ' ) C ' , $ % " & 5 # : 6 8 + $ . ! 1 ' ) ' ( , ) 6 7 $ ! 8 ' ) 9 G Q ) P I ' & U I ' ) . h X + & ! . C ! 1 ' $ " i 3 ! " - ! f " ( : Z ' : ) K ) / H 0 ) ' . Figure 8: Screenshot of the interface we used for soliciting translations for triggers. the ne xt section that we ev en get a much larger speedup above and beyond what the reduction in number of translated words would give us.) Case two is that a translation model learned from the so- far labeled data will (in addition to not being able to translate the trigger w ords correctly) also not be able to translate most of the non-trigger words cor- rectly . One might think then that this would be a great sentence to have translated because the ma- chine can potentially learn a lot from the transla- tion. Indeed, one of the ov erarching themes of AL research is to query e xamples where uncertainty is greatest. But, as we sho wed evidence for in the last section, for the case of SMT , too much un- certainty could in a sense ov erwhelm the machine and it might be better to pro vide new training data in a more gradual manner . A sentence with large #s of unseen words is likely to get word-aligned incorrectly and then learning from that translation could be hampered. By asking for a translation of only the trigger words, we expect to be able to circumvent this problem in lar ge part. The next section presents the results of experi- ments that sho w that the HNG algorithm is indeed practically ef fecti ve. Also, the ne xt section ana- lyzes results regarding various aspects of HNG ’ s behavior in more depth. 5 Experiments and Discussion 5.1 General Setup W e set out to see whether we could use the HNG method to achie ve translation quality improv e- ments by gathering additional translations to add to the training data of the entire LDC language pack, including its dictionary . In particular , we wanted to see if we could achiev e translation im- prov ements on top of already state-of-the-art per- forming systems trained already on the entire LDC corpus. Note that at the outset this is an ambitious endeav or (recall the flattening of the curves in Fig- ure 1 from Section 1). Sno w et al. (2008) e xplored the use of the Ama- zon Mechanical T urk (MT urk) web service for gathering annotations for a variety of natural lan- guage processing tasks and recently MT urk has been shown to be a quick, cost-effecti ve way to gather Urdu-English translations (Bloodgood and Callison-Burch, 2010). W e used the MT urk web service to gather our annotations. Specifically , we first crawled a large set of BBC articles on the in- ternet in Urdu and used this as our unlabeled pool from which to gather annotations. W e applied the HNG method from Section 4 to determine what to post on MT urk for workers to translate. 2 W e gath- ered 20,580 n-gram translations for which we paid $0.01 USD per translation, gi ving us a total cost of $205.80 USD. W e also g athered 1632 randomly chosen Urdu sentence translations as a control set, for which we paid $0.10 USD per sentence trans- lation. 3 2 For practical reasons we restricted ourselves to not con- sidering sentences that were longer than 60 Urdu words, ho w- ev er . 3 The prices we paid were not market-dri ven. W e just chose prices we thought were reasonable. In hindsight, gi ven how much quicker the phrase translations are for people we could hav e had a greater disparity in price. 5.2 Accounting for T ranslation T ime MT urk returns with each assignment the “W ork- T imeInSeconds. ” This is the amount of time be- tween when a work er accepts an assignment and when the worker submits the completed assign- ment. W e use this v alue to estimate annotation times. 4 Figure 9 shows HNG collection versus random collection from MT urk. The x-axis measures the number of seconds of annotation time. Note that HNG is more ef fecti ve. A result that may be par - ticularly interesting is that HNG results in a time speedup by more than just the reduction in trans- lated words would indicate. The average time to translate a word of Urdu with the sentence post- ings to MT urk was 32.92 seconds. The average time to translate a word with the HNG postings to MT urk was 11.98 seconds. This is nearly three times faster . Figure 10 shows the distrib ution of speeds (in seconds per word) for HNG postings versus complete sentence postings. Note that the HNG postings consistently result in faster transla- tion speeds than the sentence postings 5 . W e hypothesize that this speedup comes about because when translating a full sentence, there’ s the time required to examine each word and trans- late them in some sense (ev en if not one-to-one) and then there is an extra significant overhead time to put it all together and synthesize into a larger sentence translation. The factor of three speedup is evidence that this overhead is significant effort compared to just quickly translating short n-grams from a sentence. This speedup is an additional benefit of the HNG approach. 5.3 Bucking the T rend W e g athered translations for ≈ 54,500 Urdu words via the use of HNG on MT urk. This is a rela- ti vely small amount, ≈ 3% of the LDC corpus. Figure 11 shows the performance when we add this training data to the LDC corpus. The rect- 4 It’ s imperfect because of network delays and if a person is multitasking or pausing between their accept and submit times. Nonetheless, the times ought to be better estimates as they are taken o ver larger samples. 5 The av erage speed for the HNG postings seems to be slower than the histogram indicates. This is because there were a few extremely slo w outlier speeds for a handful of HNG postings. These are almost certainly not cases when the turker is working continuously on the task and so the av erage speed we computed for the HNG postings might be slower than the actual speed and hence the true speedup may ev en be faster than indicated by the dif ference between the a ver - age speeds we reported. 0 1 2 3 4 5 6 x 10 5 21.6 21.8 22 22.2 22.4 22.6 22.8 Number of Seconds of Annotation Time BLEU Score jHier: HNG Collection vs Random Collection of Annotations from MTurk random HNG Figure 9: HNG vs Random collection of new data via MT urk. y-axis measures BLEU. x-axis mea- sures annotation time in seconds. angle around the last 700,000 words of the LDC data is wide and short (it has a height of 0.9 BLEU points and a width of 700,000 words) b ut the rect- angle around the newly added translations is nar- ro w and tall (a height of 1 BLEU point and a width of 54,500 words). V isually , it appears we are succeeding in bucking the trend of diminish- ing returns. W e further confirmed this by running a least-squares linear regression on the points of the last 700,000 words annotated in the LDC data and also for the points in the new data that we ac- quired via MT urk for $205.80 USD. W e find that the slope fit to our new data is 6.6245E-06 BLEU points per Urdu word, or 6.6245 BLEU points for a million Urdu words. The slope fit to the LDC data is only 7.4957E-07 BLEU points per word, or only 0.74957 BLEU points for a million words. This is already an order of magnitude dif ference that would make the difference between it being worth adding more data and not being worth it; and this is lea ving aside the added time speedup that our method enjoys. Still, we wondered why we could not ha ve raised BLEU scores even faster . The main hur- dle seems to be one of cov erage. Of the 20,580 n- grams we collected, only 571 (i.e., 2.77%) of them e ver e ven occur in the test set. 5.4 Bey ond BLEU Scores BLEU is an imperfect metric (Callison-Burch et al., 2006). One reason is that it rates all ngram 0 20 40 60 80 100 120 0 0.05 0.1 0.15 0.2 0.25 Time (in seconds) per foreign word translated Relative Frequency Histogram showing the distribution of translation speeds (in seconds per foreign word) when translations are collected via n−grams versus via complete sentences n−grams sentences average time per word for sentences average time per word for n−grams Figure 10: Distribution of translation speeds (in seconds per word) for HNG postings versus com- plete sentence postings. The y-axis measures rel- ati ve frequency . The x-axis measures translation speed in seconds per word (so farther to the left is faster). mismatches equally although some are much more important than others. Another reason is it’ s not intuiti ve what a gain of x BLEU points means in practice. Here we sho w some concrete example translations to show the types of improvements we’ re achieving and also some examples which suggest improv ements we can make to our AL se- lection algorithm in the future. Figure 12 shows a prototypical example of our system w orking. Figure 13 shows an example where the strategy is working partially but not as well as it might. The Urdu phrase was translated by turkers as “go wned veil”. Howe ver , since the word aligner just aligns the word to “gowned”, we only see “gowned” in our output. This prompts a number of discussion points. First, the ‘after system’ has better transla- tions but they’ re not rew arded by BLEU scores be- cause the references use the words ‘b urqah’ or just ‘veil’ without ‘gowned’. Second, we hypothesize that we may be able to see improv ements by o ver - riding the automatic alignment software when- e ver we obtain a many-to-one or one-to-many (in terms of words) translation for one of our trigger phrases. In such cases, we’ d like to make sure that e very word on the ‘many’ side is aligned to the 1 1.2 1.4 1.6 1.8 x 10 6 21 21.5 22 22.5 23 23.5 Bucking the Trend: JHiero Translation Quality versus Number of Foreign Words Annotated BLEU Score Number of Foreign Words Annotated the approx. 54,500 foreign words we selectively sampled for annotation cost = $205.80 last approx. 700,000 foreign words annotated in LDC data Figure 11: Bucking the trend: performance of HNG -selected additional data from BBC web crawl data annotated via Amazon Mechanical T urk. y-axis measures BLEU. x-axis measures number of words annotated. Figure 12: Example of strategy working. single word on the ‘one’ side. For e xample, we would force both ‘go wned’ and ‘veil’ to be aligned to the single Urdu word instead of allowing the au- tomatic aligner to only align ‘go wned’. Figure 14 shows an example where our “before” system already got the translation correct without the need for the additional phrase translation. This is because though the “before” system had nev er seen the Urdu expression for “12 May”, it had seen the Urdu words for “12” and “May” in isolation and was able to successfully compose them. An area of future work is to use the “before” system to determine such cases automatically and a void ask- ing humans to provide translations in such cases. Figure 13: Example sho wing where we can im- prov e our selection strategy . Figure 14: Example sho wing where we can im- prov e our selection strategy . 6 Conclusions and Future W ork W e succeeded in bucking the trend of diminishing returns and improving translation quality while keeping annotation costs low . In future w ork we would lik e to apply these ideas to domain adap- tation (say , general-purpose MT system to work for scientific domain such as chemistry). Also, we would like to test with more languages, increase the amount of data we can gather , and in vestigate stopping criteria further . Also, we would like to in vestigate increasing the ef ficiency of the selec- tion algorithm by addressing issues such as the one raised by the 12 May example presented earlier . Acknowledgements This work was supported by the Johns Hopkins Uni versity Human Language T echnology Center of Excellence. Any opinions, findings, conclu- sions, or recommendations expressed in this mate- rial are those of the authors and do not necessarily reflect the vie ws of the sponsor . References V amshi Ambati, Stephan V ogel, and Jaime Carbonell. 2010. Activ e learning and crowd-sourcing for ma- chine translation. In Pr oceedings of the Seventh con- fer ence on International Language Resour ces and Evaluation (LREC’10) , V alletta, Malta, may . Euro- pean Language Resources Association (ELRA). Michele Banko and Eric Brill. 2001. Scaling to very very lar ge corpora for natural language disambigua- tion. In Pr oceedings of 39th Annual Meeting of the Association for Computational Linguistics , pages 26–33, T oulouse, France, July . Association for Com- putational Linguistics. Michael Bloodgood and Chris Callison-Burch. 2010. Using mechanical turk to build machine translation ev aluation sets. In Pr oceedings of the W orkshop on Cr eating Speec h and Language Data W ith Amazon’ s Mechanical T urk , Los Angeles, California, June. Association for Computational Linguistics. Michael Bloodgood and K V ijay-Shanker . 2008. An approach to reducing annotation costs for bionlp. In Proceedings of the W orkshop on Curr ent T rends in Biomedical Natural Language Pr ocessing , pages 104–105, Columbus, Ohio, June. Association for Computational Linguistics. Michael Bloodgood and K V ijay-Shanker . 2009a. A method for stopping acti ve learning based on stabi- lizing predictions and the need for user-adjustable stopping. In Pr oceedings of the Thirteenth Confer- ence on Computational Natural Languag e Learning (CoNLL-2009) , pages 39–47, Boulder , Colorado, June. Association for Computational Linguistics. Michael Bloodgood and K V ijay-Shanker . 2009b. T ak- ing into account the dif ferences between acti vely and passively acquired data: The case of activ e learning with support vector machines for imbal- anced datasets. In Pr oceedings of Human Lan- guage T echnolo gies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAA CL) , pages 137– 140, Boulder , Colorado, June. Association for Com- putational Linguistics. Chris Callison-Burch, Miles Osborne, and Philipp K oehn. 2006. Re-ev aluating the role of Bleu in ma- chine translation research. In 11th Confer ence of the Eur opean Chapter of the Association for Computa- tional Linguistics (EA CL-2006) , T rento, Italy . David Chiang. 2007. Hierarchical phrase-based trans- lation. Computational Linguistics , 33(2):201–228. Ben Hache y , Beatrice Alex, and Markus Becker . 2005. In vestigating the effects of selectiv e sampling on the annotation task. In Pr oceedings of the Ninth Confer- ence on Computational Natural Languag e Learning (CoNLL-2005) , pages 144–151, Ann Arbor , Michi- gan, June. Association for Computational Linguis- tics. Robbie Haertel, Eric Ringger , K e vin Seppi, James Car - roll, and Peter McClanahan. 2008. Assessing the costs of sampling methods in active learning for an- notation. In Pr oceedings of A CL-08: HLT , Short P a- pers , pages 65–68, Columbus, Ohio, June. Associa- tion for Computational Linguistics. Gholamreza Haff ari and Anoop Sarkar . 2009. Active learning for multilingual statistical machine trans- lation. In Pr oceedings of the J oint Confer ence of the 47th Annual Meeting of the ACL and the 4th In- ternational Joint Confer ence on Natural Language Pr ocessing of the AFNLP , pages 181–189, Suntec, Singapore, August. Association for Computational Linguistics. Gholamreza Haff ari, Maxim Roy , and Anoop Sarkar . 2009. Activ e learning for statistical phrase-based machine translation. In Pr oceedings of Human Language T ec hnologies: The 2009 Annual Confer- ence of the North American Chapter of the Associa- tion for Computational Linguistics , pages 415–423, Boulder , Colorado, June. Association for Computa- tional Linguistics. Rebecca Hwa. 2000. Sample selection for statistical grammar induction. In Hinrich Sch ¨ utze and Keh- Y ih Su, editors, Pr oceedings of the 2000 Joint SIG- D AT Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 45–53. Association for Computational Linguistics, Somerset, New Jerse y . Ashish Kapoor , Eric Horvitz, and Sumit Basu. 2007. Selectiv e supervision: Guiding supervised learn- ing with decision-theoretic acti ve learning. In Manuela M. V eloso, editor , IJCAI 2007, Pr oceed- ings of the 20th International Joint Conference on Artificial Intelligence , Hyder abad, India, J anuary 6- 12, 2007 , pages 877–882. Ross D. King, Kenneth E. Whelan, Ffion M. Jones, Philip G. K. Reiser , Christopher H. Bryant, Stephen H. Muggleton, Douglas B. Kell, and Stephen G. Oliv er . 2004. Functional genomic hy- pothesis generation and experimentation by a robot scientist. Natur e , 427:247–252, 15 January . David D. Le wis and W illiam A. Gale. 1994. A se- quential algorithm for training te xt classifiers. In SI- GIR ’94: Pr oceedings of the 17th annual interna- tional A CM SIGIR confer ence on Researc h and de- velopment in information retrie val , pages 3–12, New Y ork, NY , USA. Springer-V erlag New Y ork, Inc. Zhifei Li, Chris Callison-Burch, Chris Dyer, Juri Gan- itke vitch, Sanjee v Khudanpur , Lane Schw artz, Wren Thornton, Jonathan W eese, and Omar Zaidan. 2009. Joshua: An open source toolkit for parsing-based machine translation. In Pr oceedings of the F ourth W orkshop on Statistical Machine T ranslation , pages 135–139, Athens, Greece, March. Association for Computational Linguistics. Francois Mairesse, Milica Gasic, Filip Jurcicek, Simon Keizer , Jorge Prombonas, Blaise Thomson, Kai Y u, and Stev e Y oung. 2010. Phrase-based statistical language generation using graphical models and ac- tiv e learning. In Pr oceedings of the 48th Annual Meeting of the Association for Computational Lin- guistics (A CL) , Uppsala, Sweden, July . Association for Computational Linguistics. Grace Ngai and David Y aro wsky . 2000. Rule writ- ing or annotation: cost-efficient resource usage for base noun phrase chunking. In Pr oceedings of the 38th Annual Meeting of the Association for Compu- tational Linguistics . Association for Computational Linguistics. Miles Osborne and Jason Baldridge. 2004. Ensemble- based acti ve learning for parse selection. In Daniel Marcu Susan Dumais and Salim Roukos, ed- itors, HLT -NAA CL 2004: Main Pr oceedings , pages 89–96, Boston, Massachusetts, USA, May 2 - May 7. Association for Computational Linguistics. Kishore P apineni, Salim Rouk os, T odd W ard, and W ei- Jing Zhu. 2002. Bleu: a method for automatic ev aluation of machine translation. In Pr oceedings of 40th Annual Meeting of the Association for Com- putational Linguistics , pages 311–318, Philadelphia, Pennsylvania, USA, July . Association for Computa- tional Linguistics. Manabu Sassano. 2002. An empirical study of activ e learning with support vector machines for japanese word segmentation. In ACL ’02: Pr oceedings of the 40th Annual Meeting on Association for Computa- tional Linguistics , pages 505–512, Morristo wn, NJ, USA. Association for Computational Linguistics. Greg Schohn and David Cohn. 2000. Less is more: Activ e learning with support v ector machines. In Pr oc. 17th International Conf. on Machine Learn- ing , pages 839–846. Morgan Kaufmann, San Fran- cisco, CA. Rion Snow , Brendan O’Connor , Daniel Jurafsky , and Andrew Ng. 2008. Cheap and fast – but is it good? ev aluating non-expert annotations for natu- ral language tasks. In Pr oceedings of the 2008 Con- fer ence on Empirical Methods in Natural Language Pr ocessing , pages 254–263, Honolulu, Hawaii, Oc- tober . Association for Computational Linguistics. Katrin T omanek and Udo Hahn. 2009. Semi- supervised active learning for sequence labeling. In Pr oceedings of the Joint Confer ence of the 47th An- nual Meeting of the ACL and the 4th International Joint Confer ence on Natural Language Pr ocessing of the AFNLP , pages 1039–1047, Suntec, Singapore, August. Association for Computational Linguistics. Simon T ong and Daphne Koller . 2002. Support vec- tor machine active learning with applications to text classification. Journal of Machine Learning Re- sear ch (JMLR) , 2:45–66. David V ickrey , Oscar Kipersztok, and Daphne Koller . 2010. An acti ve learning approach to finding related terms. In Pr oceedings of the 48th Annual Meet- ing of the Association for Computational Linguis- tics (A CL) , Uppsala, Sweden, July . Association for Computational Linguistics. Andreas Vlachos. 2008. A stopping criterion for activ e learning. Computer Speech and Language , 22(3):295–312. Andreas Zollmann and Ashish V enugopal. 2006. Syn- tax augmented machine translation via chart pars- ing. In Pr oceedings of the NAA CL-2006 W orkshop on Statistical Machine T ranslation (WMT06) , New Y ork, New Y ork.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment