Topic Similarity Networks: Visual Analytics for Large Document Sets
We investigate ways in which to improve the interpretability of LDA topic models by better analyzing and visualizing their outputs. We focus on examining what we refer to as topic similarity networks: graphs in which nodes represent latent topics in …
Authors: Arun S. Maiya, Robert M. Rolfe
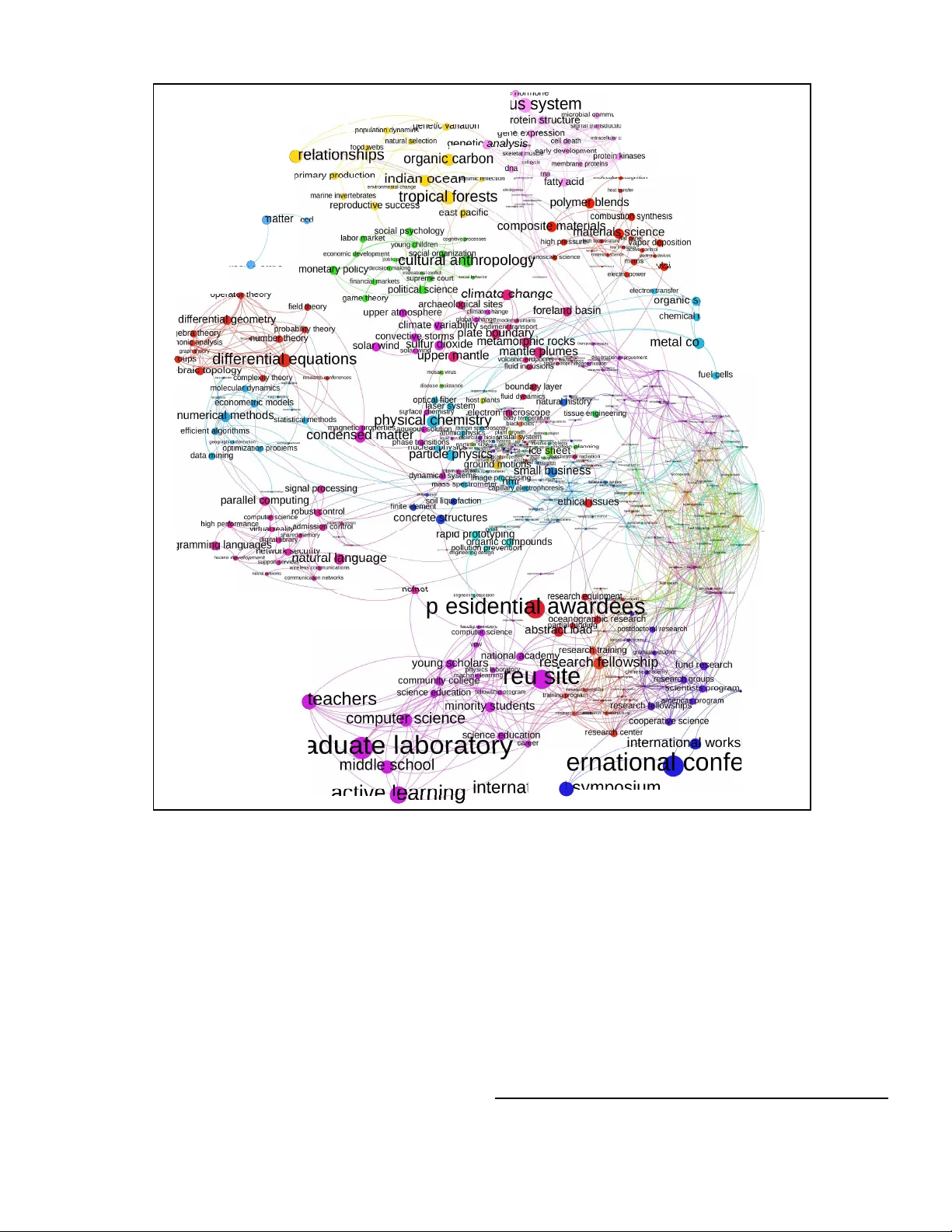
T opic Similari ty Netw orks: V isual Analytics for Lar ge D ocument Sets Arun S. Maiya Institute for Defense Analyses Alexandria, V A 22311 Email: amaiya@ida. org Robert M. Rolfe Institute for Defense Analyses Alexandria, V A 223 11 Email: rolfe@ida. org Abstract —W e in vestiga te ways in which to improv e the in- terpre tability of LD A topic models by better analyzing and visualizing their outputs. W e focus on examining what we refer to as topic similarity network s : gra phs i n wh ich n odes represent latent topics in tex t collections and links re present similarity among topi cs. W e describe effi cient and effective approaches to b oth building and labeling such networks. Visualizations of topic models based on t hese networks are shown to be a powerful means of ex ploring, characterizing, and summarizing large collections of un structured text documents. They help to “tease out” non- obvious connections among different sets of documents an d pro vide insights in to how topics form l arger themes. W e demonstrate the efficacy and practicality of these approaches through two case studies: 1) NSF grants for basic resear ch spanning a 14 year period and 2) th e entire English portion of W ikipedia. I . I N T R O D U C T I O N A N D M OT I V A T I O N In this pap er , we stud y network visualizatio ns as a means of enhancin g the in terpretability of prob abilistic top ic m odels for insight discovery . W e f ocus on what is per haps the most popular an d p rev alently-used topic mo del: la tent Dirichlet allocation or LDA [ 5]. T op ic modeling algor ithms like LD A discover latent themes ( i.e., topics) in document co llections and represen t do cuments as a combina tion of these th emes. Thus, they are critical too ls for exploring text data across many domains. Ind eed, it is often the case that u sers must discover the subject m atter buried within large and unfamiliar docume nt sets ( e.g., sensemaking in text data). K eyword searches are inadequ ate here, as it is un clear on where to even begin searching. T o pic discovery techniques such as LD A are a boon to users in such scen arios, as they reveal the content in an u nsuperv ised and automated fashion. Autom ated top ic organization can p otentially facilitate th e com prehen sion o f unfamiliar d ocumen t data on even a m assi ve scale. Howe ver, it is often quite challen ging to obtain a “ big picture” view of the larger trends in a do cument collectio n from only the raw output of an LD A mo del. LD A is fund amen- tally a statistical tool that retur ns a probability distrib ution for each d ocumen t showing the r elativ e pre sence (or absence) of various discovered topics. These topics, in turn, are represented as probability distributions over words (typically unig rams). W ords with the high est estimated probab ilities for a discovered topic are used as a lab el f or the topic . Ex ploring text c orpor a using only these raw ou tputs is considerab ly challengin g. In order to derive insights an d iden tify larger trends within the docume nt collection, one is left to inspect these numer ical distributions, which can be diffi cult, n on-trivial, a nd far f rom straightfor ward. The p roblem is exacerbated as documen t collections un der consider ation gr ow . For instance , with the existence of scalable, Map Reduce implemen tations o f LDA ( e.g., [27], [29]), it is now p ossible to train an LDA mod el on massi ve text corpo ra with many laten t to pics ( i.e., big data). The inferred topics d iscovered by the se LDA implementation s, can themselves pose their own u nique data challenge. It is often u nclear on h ow best to effecti vely br owse these topic s to discover inf ormation o f interest. Th is, in fact, tends to b e a significant ch allenge even for large data (as oppo sed to “big data”) — e.g., d ocumen t collection s on the order o f tens of thousand s or h undre ds o f tho usands. In the presen t work, we in vestigate the u se of what w e refer to as topic similarity networks to address these challen ges. T opic similarity networks are g raphs in which nod es represen t latent topics in text collections and link s represent similarity among topics. W e describe efficient and effecti ve m ethods to both building and labeling such networks. Summary of Contribu tions. Our co ntributions in both the areas of topic v isualization and to pic labe ling are summar ized below . 1) Constructing T op ic Similarity Networks: In Section IV, we describe the con struction of topic similarity networks , o ur appr oach to big d ata visualizatio n. W e exploit th ese n etworks to d iscover how topics for m larger themes. W e emp loy the use of com munity detection in network visualizations to d iscover such macro-level th emes in cluding the sometimes subtle connectio ns amon g these th emes. 2) Labeling T o pic Simila rity Networks: In Section V, we de scribe an ap proach to expressively labeling discovered topics. Our me thod, based on keyphrase extraction, is purely unsu pervised, extractive, and demonstra bly ef ficient. These labels are, then, em- ployed as node labels in our top ic similarity networks to en able better characterizatio n of large docum ent sets. It is surprising to note that, to the best of our knowledge, few of the existing works o n topic visualization (discussed in the next section) make use of automated topic labeling m ethods. Our work, then, repr esents one of the first examinations of the efficac y of autom ated topic labeling in actual topic visualizations of large, real-world d ata. There has been a wa ve of recent work to address challenges in both v isualizing topics and labeling top ics – each o f which we discuss separately in light of o ur work. I I . B AC K G RO U N D A N D R E L A T E D W O R K A. V isualizing T op ics A number of both graphical and text-based visualization s and user interfaces ha ve been proposed in the existing literature to browse topics ( e.g., [7], [ 9], [10], [1 4], [15], [19], [ 28]). Sev eral, like T opicV iz by Eis enstein et al. [14] and T opicNets by Gretarsson et al. [15], are quite innov ati ve and make significant strides tow ards improving the interpretability o f lea rned topic models. Howe ver , most of these existing method s fo cus on shedding light on the relationships b etween topics and docu- ments (or attributes of do cuments). Although some ( e.g., [15]) support the inferenc e o f pair-wise similarity betwe en topics, they d o no t pr ovide insigh ts into how topics co me together to form larger them es or the subtle connections amon g seeming ly disparate grou ps of top ics. Such in sights are imp ortant in obtaining a “big picture” view of ill-under stood docu ment collections. An exception to this rule is work on correlated topic models (o r CTMs) an d its variants ( e.g., [ 2], [8], [1 7]). CTMs model and in fer associations am ong topics. Th ese asso- ciations can be f urther mined to produ ce clusters of topics that represent larger th emes f or inco rpora tion into visualization s. These models, howe ver, reveal certain challenges when applied in r eal-world scenarios. First, existing visualization s b ased o n CTM an d its variants do not appear to easily lend the mselves to extracting the kinds of insights mentioned above. This is due both to the way in which the topic relations are constructed and depicted and also the way in which the topic no des ar e labeled (topic labeling is d iscussed in th e next section). One may refer to [3], [8], [1 7] for examples of these existing visualizations and fo r compar ison to our v isualizations shown later . Secon d, some approach es, such as [17], artificially constrict the topic relation structure with specification of what are referr ed to a s supertopic s, which can h inder a v iew of the sub tle co nnections among different and seemingly d isparate gro ups of topics and subtopics. A third issue is related to practical scalability . Chen et al. [8] showed that CTM is unable to process a corp us of 285K docum ents in any rea sonable time frame ( i.e., it will not finish with in a week). Similarly , an approac h to infer topic hierarchies pro posed by [25] is limited to sho rt texts only . ScaCTM, a parallelized extension to CTM, was sho wn to be substantially more scalable given a cluster of 4 0 machines [8]. But, for certain doma ins, su ch mach ine clusters may not be av ailable at sites of deploym ent. In fact, it is often the case that on ly a single multi-core m achine is av ailable to process millions of docum ents, as the storage capacity of toda y’ s machines often outstrips their processing capacity . E ven in scenarios where o ne has access to a large machine cluster , LD A is signifi cantly m ore scalab le and efficient b ecause it doe s not learn the corr elation structure among topics. (See [8] f or a time complexity analysis of CTM, S caCTM, and LD A). Gi ven these aforemen tioned issues an d the clear scalability , efficiency , and also p rev alen ce of LDA, our objective in this work is to in fer these top ic associations in an o rganic fashion f rom the raw output of th e original LD A model. As we will descr ibe in Section IV, we do so by con structing topic similarity networks : networks depicting the similarity (r epresented as links) amon g topics (represented as nod es). Next, we discuss existing work on the labeling of topics. B. Labeling T opics A to pic similarity n etwork is only useful as a visua lization tool if the identity of network nodes are easily discernib le. Sev eral visualization schemes labe l to pics by simply using the most pro bable word (or words) from the topic mod el ( e.g., [8], [1 5], [ 17]). However , LD A-d erived labels have been observed to not always be adequately expressi ve of the topic ( e.g., see [22], [25], [28]). As a result, a number of me thods have been propo sed to better label top ics in an automated fashion ( e.g., [4], [16], [19], [2 2], [25], [26]). Unf ortunately , for a variety of reasons, m ost of these existing technique s are unable to han dle the large text co rpora we consider in this work. In Section V, we descr ibe our o wn metho d to label topics to address g aps in this existing literatu re o n to pic lab eling. T o b etter motivate the u se of our own labe ling method, we describe several goals that must be met by any labeling scheme for a topic similarity network in ligh t of existing work on top ic labeling. Unsupervised. Th e labeling metho d must b e u nsuperv ised, as obtaining a train ing set for a superv ised labeling method can be pro hibitively expensi ve and time-con suming. Extractive. Th e labeling method must be extractive. That is, labels must be generated d irectly from the terms with in th e corpus under consideration, as opposed to an external reference corpus such as W ikipedia. Th is is especially importa nt for the governmen t an d corpor ate d omains, which often deal with docume nt co llections describing sensitiv e or proprietary informa tion, state-of-th e-art “bleed ing ed ge” technology , or otherwise esoter ic su bject matter . Such inf ormation may no t reside in p ublicly a vailable reference corpor a like Wikipedia. This r equiremen t p revents us from utilizin g metho ds such as [16], wh ich employs the use of r eference corpor a whe n labeling topics. Supportive of User Intera ctivity . T opic similarity networks are inten ded for use with interactive systems utilizing full- text search and faceted n avigation of d ocumen ts ( e.g., Solr search engine 1 ). Under these scenarios, the docum ents co mprising topics may be filtered in v arious ways after creation of the topic mod el. For instanc e, in th e government dom ain, only those doc uments containing certain markin gs might be deeme d of interest a nd selected in a visualization . Labels h eavily associated with docu ments tha t have be en filtered out may no longer adequately describe the remaining d ocumen ts p ertaining to im portant sub-topics. Lab eling meth ods that are tightly coupled with the top ic model ( e.g., [4], [2 2], [25], [26]) cannot cope well with such d ynamic scenarios. Moreover , it is prohib iti vely expen si ve to re-generate the topic model on the filtered docume nt collection . For these re asons, ou r lab eling method, described in Sectio n V, is purposefu lly de-cou pled from the outp ut of LD A. Hence, it can re-lab el to pics in a filtered docum ent collection withou t having to re -genera te the to pic m odel. Ou r lab eling meth od, the n, can best be characterized as a cluster labeling app roach to to pic labeling. Efficient. Dynamic filtering of document collections, as 1 https:/ /lucen e.apache.or g/solr described above, also necessitates a n eed for e fficiency in the labelin g appro ach. As the do cument collection is filtered in various ways, the lab eling method might be repeated ly executed on a large docum ent collection, wh ich can b e problem atic for some existing labelin g methods. For in stance, we were unsuc cessful in executing the ap proach by [4] on the doc ument sets of inter est in this work . The appro aches by [25] and [22] also do not appear to scale as easily or as well to larger co llections of lon ger docu ments. Th e method from [25], for example, was designed only for very sho rt texts ( e.g., titles only). These aforemen tioned issues mo tiv ate our dev elopmen t of a custom labeling me thod for use with topic similarity networks — a method that can scale to ev en massive collections of do cuments. W e begin a d iscussion of o ur work with a brief overview of LDA a nd the notatio n and symbols used throug hout this pap er . I I I . P R E L I M I N A R I E S Let D = { d 1 , d 2 , . . . , d N } represent a documen t collection of interest and let K be the n umber of topics or themes in D . Eac h docu ment is c omposed of a sequence of words: d i = h w i 1 , w i 2 , . . . , w iN i i , where N i is the number of w ords in d i and i ∈ { 1 . . . N } . Let W = S N i =1 f ( d i ) be the vocabulary of D , wh ere f ( · ) takes a seq uence of elements an d returns a set. Prob abilistic top ic models like LDA take D and K as inp ut and pr oduce two matrices as ou tput. The matrix θ ∈ R N × K is the do cument-to pic d istribution matrix and shows the distribution of to pics within each docu ment. Th e matrix β ∈ R K ×| W | is the topic-word distribution m atrix and shows the d istribution of w ords in each topic. Each row o f these matrices represents a pro bability distribution. For any topic i ∈ { 1 , . . . , K } , th e L terms with the highest pr obability in distribution β i are typically used as thematic lab els for the topic. W e use these LD A-derived labels as a b aseline fo r compariso n in our work . But first, we describ e construction of the topic similarity network. I V . C O N S T R U C T I N G T H E N E T W O R K LD A ca ptures the degree to wh ich both docum ents an d words are topically related. However , relations among th e topics themselves ar e not explicitly captu red. As we will show shortly , such topic-level relations can be used to construc t network rep resentations o f text corpora . These representations, in turn, can b e used to b etter u nderstand , charac terize, and visualize th e themes in a documen t co llection. In the present work, we de fine th ese relations based on topic similarity . Measuring T opic Similarity . Recall th at to pics are repre- sented as prob ability d istributions over vocab ulary W and captured by the m atrix β . Thu s, the similar ity for any two topics can be d irectly com puted by comparing the w ord distributions from β . The Kullback- Leibler (KL) diver gence, a distance measure of two pro bability distributions, is o ften used to make su ch c omparison s ( e.g., [1 5], [2 8]). Howe ver , KL divergence satisfies neither the triang le inequ ality nor symmetry and is, there fore, not a metric. As such , it is less approp riate f or definin g network links based o n similarity (th e compleme nt of d istance). Althoug h symmetric version s of KL div ergence exist, we instead em ploy the Helling er d istance metric to co mpute top ic similarity . Specifically , f or any two topics x, y ∈ { 1 . . . K } , th e Hellin ger similarity is measur ed as: H S ( β x , β y ) = 1 − 1 √ 2 v u u t | W | X i =1 ( p β xi − p β y i ) 2 . (1) A top ic similarity network G = ( V , E ) can be constru cted where V = { v 1 . . . v K } is the set of nodes represen ting discovered to pics and E is the set of ed ges repre senting similarities amon g topics. For any two to pics x, y ∈ { 1 . . . K } , an edge { v x , v y } ∈ V exists if and only if H S ( β x , β y ) is greater than some pre-d efined thresh old, ξ . Measuring T opic Similarity in MapReduce. Note that, wh en constructing a topic similarity network as just describ ed, the number of co mputed similarities scales qu adratically with K . Howe ver, since K ≪ | D | , the method remains computationally viable even for very large document collections. More over , with so me well-placed substitutio ns, β can be represented u s- ing a sparse m atrix forma t fo r efficient in -memor y pr ocessing of massive documen t sets. (W e cur rently em ploy a comp ressed sparse row for mat for storin g and ma nipulating β .) Ne verth e- less, for scenarios whe n e ven sparse representations of β are unwieldy and a high degree of paralleliza tion is desired, we propo se a MapRedu ce im plementation of th e topic similarity computatio n. When break ing down p roblem s into distributable units of work unde r the MapReduce m odel fo r parallelization , key-value p airs are emp loyed as the core data stru cture [12]. In our case, each cell in the ma trix β can be r epresented as a key- value pair of the fo rm ( i : ( j , β j i )), where i ∈ { 1 . . . | W |} is the index o f a word ( i.e., co lumn), j ∈ { 1 . . . K } is the index of the topic ( i.e., row), and β j i is the p robab ility of word i appearin g in top ic j . If g roup ing by key , we obtain a key- value represen tation of each column in β . That is, the values list f or any key i ∈ { 1 . . . | W |} com prises the set o f tu ples { ( j, β j i ) | j ∈ { 1 . . . K }} ). The map operation accepts these key-value pairs as input and outputs key-v a lue pairs of the form ( x, y : e i ), where the new key x, y ∈ { 1 . . . K } ar e pairs of topics appearing in th e aforemention ed values list and the value e i = ( √ β xi − p β y i ) 2 , for each word i ∈ { 1 . . . | W |} . Thus, the map op eration com pletes th e inner expression fo r Hellinger similarity (shown in Equa tion 1) for ev ery word represented in β . The r educe oper ation simply sums these values for every p air of topics and completes the Hellinger similarity co mputation b y tak ing the square r oot of this sum , multiplying by 1 √ 2 , and subtrac ting fro m one . Th e r esultant network, constructed as d escribed above, can be exploited to discover insigh ts, tre nds, and pattern s among th e to pics in D . For the present work, we employ the u se of a co mmunity detection algor ithm to discover in sights into h ow topics ar e related to each other and fo rm larger themes. Discovering Larger Themes. A co mmunity can be loosely defined as a set of nodes more d ensely connected among themselves than to other n odes in the network [6]. W ithin the context of a top ic similarity network , such communities should represent gr oups of highly -related top ics, which we r efer to as topic gr ou ps . T o detect these comm unities (or topic gro ups), we employ th e use of the Lou vain alg orithm, a heur istic method based on modu larity optim ization [6]. Modularity measures th e f raction of link s falling within commu nities as compare d to the expected fraction if links were distributed ev enly in the network [23]. The algorithm initially assigns each topic node to its own c ommun ity . At each iteration, in a local and greedy fashion, t opic nodes are re-assigned to commun ities with wh ich it achieves the h ighest mo dularity . As a greedy optimization metho d, the Lou vain algorithm is exceptio nally efficient and fast, even with a large numbe r of topics. As the auth ors of [6] note, the comp utational complexity of the method is un known, but it experim entally ap pears to run in O ( n log n ) time. When the nodes in the se con structed topic similarity networks are m arked by the ir in ferred com munity affiliation and labeled to express th e to pics they r epresent, the networks b ecome powerful to ols fo r explor ation and discovery in large and h eterogen eous text corpo ra. W e discuss labeling of topic nodes next. V . L A B E L I N G T H E N E T W O R K An algo rithm cap able o f gen erating expressive the matic labels fo r any subset of documen ts in a co rpus can greatly facilitate both characterization and na vig ation of document col- lections. Her e, we e mploy such a n algo rithm to lab el nod es in a topic similarity network, as each no de is a topic compr ising a subset of do cuments in th e corp us. Our a pproac h, r eferred to as D O C S E T L A B E L E R , is a pu rely un supervised , extractive method and shown in Algor ithm 1. 2 D O C S E T L A B E L E R takes D S , a subset of corpu s D , as input, where D S consists of all docum ents associated with some LD A-discovered topic t ∈ { 1 . . . K } . This sub set can be construc ted in one of two ways. The fir st is to popu late D S with all do cuments d i (where i ∈ { 1 . . . N } ) for which the topic pro portion θ it is greater than some pre-d efined th reshold ( e.g., 0 . 3 was u sed in [28]). The second is to construct D S by tran sformin g topics into mutually-exclu si ve c lusters, where the topic cluster for docume nt d i is arg max x θ ix . W e employ the latter appr oach, as it better eliminates noise contributed by for eign top ics ( i.e., { 1 . . . K } − { t } ). Labels for topic t a re, then, extracted by D O C S E T L A B E L E R direc tly f rom the text con stituting the docume nts in D S . D O C S E T L A B E L E R is essentially a descriptive mo del o f topic labeling that fo llows n aturally from four observed char- acteristics of high-quality , topic-rep resentative labels: Exp r es- sivity , Pr ominen ce , Pre valence , an d Discriminability . Expressi vity . Exp r essivity captures th e extent to which labels express an d rep resent them es. Previous work s h av e n oted that human- assigned labels tend towards m ulti-word nou n phrases, as they are more expressi ve than unig rams ( e.g., see [24]). The term “info rmation retrieval, ” for in stance, is mor e expres- si ve than ju st “in formatio n” or “retriev al” alon e. Unig rams tend to most o ften be expressi ve wh en denoting uniqu eness ( i.e., a proper no un). This is especially true of research reports, o ur do main of inter est, as proper no un un igrams denote imp ortant con cepts, systems, technique s, or progr ams 2 Lines 4 – 11 of Algorithm 1 are a variat ion of the KERA algorithm describe d in [19]. Algorithm 1 D O C S E T L A B E L E R algorithm Requir e: D S ⊂ D , a subset of corpus D Requir e: C , the number of candidat e terms to consider Requir e: L , the number of labels to return for document s et ( L ≤ C ) Requir e: s top words , list of terms to filter out 1: p os = a hash table 2: neg = a hash table 3: for all d ∈ D do 4: terms1 = extractSignifican tPhrases ( d, stopw ords ) 5: terms2 = extractNounPhrases( d, stop w ords) 6: terms3 = extractProperNounUnigrams ( d, stopw ords) 7: c andidates = ( terms1 ∩ terms2 ) ∪ terms3 8: f or all c ∈ c andidates d o 9: x = normal ized frequenc y of term c in d 10: y = 1 − index of first occurrence of c in d num. of words in d 11: (weight of term c ) = 2 · x · y x + y 12: end for 13: if d ∈ D S then 14: pos[d] = top C terms based on weight 15: else 16: neg[d] = top C terms based on weight 17: end if 18: end fo r 19: for all ℓ ∈ S x ∈ p os . v alues() x do 20: # compute information gain for each label ℓ 21: (score of label ℓ ) = calcScore( ℓ, pos , neg) 22: end fo r 23: top c andidates = top C labels based on information gain 24: # optional ly re-sort final top candidat es 25: top c andidates = re sort( top c andidates ) 26: return top L labels from top c andidates ( e.g., “Linear SVM, ” “F-22” ). L ines 4-6 in Algorithm 1 ex- plicitly extract terms co nform ing to the above pr inciples. Noun phrases 3 and proper nouns are extracted using hun- pos , an o pen-sou rce, HMM- based, part-of- speech tag ger . 4 The extractSignificantPhrases( · ) fun ction uses likelihood ratio tests to extract ph rases of multiple words that occur tog ether more often tha n chance . 5 For a bigram of words w 1 and w 2 , this association, asso c ( · , · ) , is measured as: asso c ( w 1 , w 2 ) = 2 X ij n ij log n ij m ij , (2) where n ij are the o bserved freq uencies of th e big ram f rom the con tingency table for w 1 and w 2 and m ij are the expected frequen cies assuming that th e bigram is independent [ 13]. Only phrases with a p-value less than 0 . 0 01 are e xtracted. These tests can also be u sed to measure associations of words within n- grams wher e n ≥ 3 ( e.g., trigrams). Howe ver , we limit phrases to the n < 3 cases to save space in the v isualizations. Prominence. Pr ominen ce captures the degree to which labels are featured p rominen tly within individual documen ts. Intuitively , prom inent terms tend to ma ke their first a ppearan ce earlier and also appear more frequen tly . Thu s, we weight candidate labels by bo th fr equency and position using th e harmon ic mean, as shown in Lin e 1 1 of Algor ithm 1. 3 W e use the POS pattern: ( A D J E C T I V E ) * ( N O U N ) + . 4 http:/ /code.goo gle.com/p/ hunpos/ 5 This is kno wn as collocati on ext ract ion [20]. Actual T opic Labels from LDA Labels from D O C S ET L A B E L E R Fluid Mechanics and Fluid Dynamics flow ,fluid,flows,fluids,dynamics,transports fluid dynamics, fluid mechanics , multiphase flow Game Theory agents,theory ,game, agent,games,equilibrium game theory , economic age nts, repea ted games Graph Theory discrete,graph,combinatorial,theory ,combinatorics,graphs graph theory , algebraic combinatorics, ramsey theory Human Evoluti on modern,fossil,early ,years, human,age modern humans, human evolution, hominid ev olution Hydrology water , riv er ,hydrologic,watershed,balance,surface hydrologic controls, watershed scale, alpine basins Modal Analysis in Structural Engineering mode,modes,research,vibration,direction,coupling normal modes, vibration control, modal analysis Object Recognition object, objects,features, recognition, oriented,feature object recognition, curved objects, cluttered scenes Protein Function/Mechan isms protein,proteins,function,role,biochemical,phosphorylation protein kinases, protein phosphorylation, protein import Protein Structu re protein,proteins,binding,structure,amino,acid protein s tructure, protein folding, amino acid Social Psychology social,people,research, individuals,attitudes,status social psychology , social influence, social perception T ABLE I: [NSF Grants.] T en disco vere d NSF topics and the highest-rank ed labels assigned to each by both LD A and D O C S E T L A B E L E R . Prevalence a nd Discriminability . Go od labels for a p ar- ticular topic appear in ma ny do cuments pertaining to that topic ( P r evalence ) and appear rar ely in other un -related top ics ( Discriminability ). This was also recen tly observed b y [11] and [28]. The con cept of information gain fr om the field of info rmation theory simultan eously ca ptures bo th p rev a - lence and discriminability . Consider a d ocumen t collection D where documen ts belon g to eith er a positiv e or negati ve category . The entr opy H of D me asures imp urity as follo ws: H( D ) = − p + log 2 ( p + ) − p − log 2 ( p − ) , wh ere p + and p − are the propo rtions o f positiv e an d negativ e docum ents in D , respectively . 6 For instance, if all documen ts are po siti ve (or negati ve), H( D ) = 0 , while a perfectly ev en split of positive a nd negative doc uments h as entropy of 1 . I n Al- gorithm 1 , we assign D S as p ositiv e and D S as negative. The inform ation g ain IG of a candid ate label ℓ in D , th en, is the expec ted entropy redu ction du e to segmenting on ℓ : IG( ℓ, D ) = H( D ) − ( | D ℓ | | D | H( D ℓ ) + | D ℓ | | D | H( D ℓ )) , where D ℓ is the set of docum ents in D from which lab el ℓ was e xtracted. Thus, labels with the highest infor mation gain for D S are expected to b e simultaneously common in D S (prev alence) and rare in D S (discriminab ility). Infor mation gain is compu ted by the calcScor e( · ) fu nction in Alg orithm 1. Final Sorting. At the end of the pr evious step , we are left with a small n umber of can didate labels ( e.g., C = 5 ) f or each topic. There are several option s for choosing the final lab el for the topic n ode. For instance, one co uld simply select the label with the highe st info rmation gain ( i.e., the existing sorting ). One m ight also select the label most freque ntly extracted f rom the do cuments perta ining to the topic . Y et anoth er option is to include word p robabilities from β into the final weig hting. All three appro aches generally yield good (albeit slightly different) results. For the p resent work, based on some prelimin ary testing, we ch oose to sort labels b ased on a co mbinatio n of the latter two appro aches, as indicated in Lin e 25 of Algo rithm 1. More specifically , we sort labels based on the m ean of the normalized frequ ency an d the combine d β pr obabilities for each word c omprising the label. T o conclude , we briefly comment on th e efficiency a nd scala- bility of our curr ent D O C S E T L A B E L E R im plementation . Note that, in Alg orithm 1, L ines 1 – 12 p rocess docum ents in an online fashion and can b e easily parallelized. Co mputing informa tion gain also scales well to larger collections of longer docum ents, as it is a simple compu tation of different 6 Note that log 2 (0) is take n to be 0 . combinatio ns of inde penden t an d dependent variables. More- over , it de als w ith a sub stantially r educed representation o f the data ( i.e., generally , C ≪ N i for all i ∈ { 1 . . . N } ). For these reasons, it is fairly straightfo rward to impleme nt D O C S E T L A B E L E R in a variety of different p arallel p rocessing models ( e.g., Map Reduce, multi-cor e processing) . Lin es 1 – 12 , for instan ce, can be imp lemented as a map -only job with e ither zero red ucers or an identity reducer . On the othe r h and, for execution on single-nod e, mu lti-core, shared-m emory systems (as op posed to clusters), d ocumen ts can be p rocessed in an online fashion and passed to as many proc essors av a ilable o n the system. V I . C A S E S T U DY 1 : N S F R E S E A R C H G R A N T S As a realistic and info rmative case stud y , we u tilize our methods to characterize and visua lize basic r esearch fund ed by the National Science F o undation (NSF). The corpus considered in th is case stud y consists of 132, 372 titles and abstra cts describing NSF awards fo r basic research between the years 1990 and 20 03 [1]. W e executed the MALLET implemen tation of LD A [21] on this cor pus using K = 400 as the num ber of topics and 200 as the number o f iterations. All other parameters were left as defaults. For topic similarity , we experim entally set ξ as 0 . 15 to yield a g raph d ensity of appro ximately 0 . 01 . For the labeling of topic no des in the network using D O C S E T L A B E L E R , we set C = 5 an d L = 1 . W e did not find the cho ice o f C to affect r esults significantly . Th is is possibly due to the fact that, as describ ed previously , we prun e o ut candidates with n o statistical significance , as measured by a likelihood r atio test. T opic Labeling of NSF Grants. T able I shows the labels generated for a sample o f te n discovered topics by both D O C S E T L A B E L E R and L D A. As can be seen, labels prod uced by D O C S E T L A B E L E R are more expressiv e an d r epresentative of the true them es of each topic. W e assigned two judg es to ev aluate labels f or all top ics. For a fair comparison , we showed six un igram lab els fro m LD A but on ly th ree labels (m ostly bigrams) from D O C S E T L A B E L E R f or ea ch topic. As sh own in T able III, both judg ed the labels b y D O C S E T L A B E L E R to be generally supe rior ( χ 2 = 145 . 7 3 , P < 0 . 000 1 ) with an inter-judge agreemen t o f 0 . 6 2 , as measur ed by Cohen’ s k appa coefficient. D O C S E T L A B E L E R LDA D O C S E T L A B E L E R 313 6 LDA 23 29 T ABLE I II: Evaluation of labels for each method on NSF grants. Overall, both judges chose labels from D O C S E T L A B E L E R to be most on-point. (Poor quality topics thrown out.) dark m a t ter massive stars prog r a m m in g la ng ua ge s software de ve lo pm e nt p r e sid en t i al a wa r de es in t r a cel lu la r c alcium sig na l t r a nsd uctio n active le a r ni ng science tea che r s col le ge statio n in t e r na tional symposium in t e r na t i on al w or ks hop int e r na t i on al co nf erence jo in t se minar phylogenetic r e la t i on shi ps ge ne t i c variation juvenile hormone nervou s system undergra du ate la bo r ator y p r i m ar y pr o du ct i on gen e e xpr e ssio n genetic a na lysi s alg e br a the or y alge br a ic t o po lo gy lie gr o up s opera t o r the or y harm on ic an al ysis m etal co mplexes che m ica l reactions pr o t e in str uctur e m icr o bi al co m m unities or g an ic synthesis Fig. 1: [NSF Grants.] The T opic Simi larity Network of 14 year s of NSF research and support ( i.e., a total of 132 , 372 research grants). Major research topics are sho wn including their subtle connections to each other . Also displaye d (to ward s the bottom of netwo rk) are major funding ef forts for education support and confere nce support. Node sizes indicat e the number of grant abstracts pertain ing to the topic. Node colors indicate the community (or topic group) affili ation, which illustrate ho w research topics form larger themes. V isualizing NSF Grants. A topic similarity network was constructed , with each nod e representing a topic and labe led using th e high est r anked term r eturned by D O C S E T L A B E L E R . The n etwork con cisely presents a compr ehensive and holistic view of 14 y ears of NSF-f unded resear ch and can b e n avigated and e xplored using any a vailable network v isualization software ( e.g., Gephi, Cytoscap e ). The en tire network is shown in Figure 1 , whe re both expected an d unexpecte d trends are revealed. As can be seen, the v isualization encapsu lates the major resear ch funding efforts for scientific research in addition to the subtle con nections among them. Major fundin g efforts f or education and con ference supp ort are also displayed (towards the bottom). In this network and all networks shown in this paper, no de sizes indicate the number of docu ments pertaining to the topic represented by the node. 7 Node colors indicate th e c ommun ity (or to pic group ) 7 Although we could hav e sized nodes based on funding amount of the grant, we instead s ize nodes based on the number of documents for the sake of consistency . Actual T opic Labels from LD A Labels from D O C S E T L A B E L E R BBC bbc,british,series,television,london,uk bbc, british television, bbc radio, british ac tor Boxing fight,title,boxing,champion,round,boxer professional boxer, professional career , amateur boxer Computers system,computer,systems,control,computers,electronic comput er science, operating sys tem, c ontrol sys tem Electronic Dance Music music,dj,label,dance, artists,records e lectronic music, record label, dance music Probability Theory data,analysis,method,methods, distribution probability distribution, random variables, random vari able Manufacturing company ,production,factory ,manufactur ing,plant,industry manufacturing compan y , motor company , manufacturing plant Motorcycles motorcycle,racing,cc,race,davidson,bike speedway rider, cc race, british motorcycle Summer Olympics olympics,summer,medal,won,olymp ic,world summer olympics, gold medal, bronze medal T ropics species,family ,tropical,habitat,natural,subtropical tropical moist, habitat loss, natural habitats Winter Olympics winter ,world,ev e nt,olympics,won,competed winter olympics, wor ld c hampionships, ski championship T ABLE II: [Wikipe dia.] T en discov ered W ikipedia topics and the highest-rank ed labels assigned to each by both LDA and D O C S E T L A B E L E R . affiliation. Using this network, one can b etter un derstand how topics form larger them es, discover and ch aracterize informa tion of inter est, and derive insights into how best to search and explo re the corpus further . It is difficult to quantitatively ev a luate v isualization schemes such as th is. Thus, we present illustrative examples of th e p atterns and trends discovered using ou r topic similarity network . Figure 2 shows one small corner of th e “topic universe” — a “soc ial clique” of math topics discovered by co mmunity detection within the larger network of all to pics. Note that ea ch node in th e network represents hundr eds of docum ents (or more ). Thus, th is visualization of math topics clearly and concisely summarizes over 10 , 000 docu ments. Such visualizations also provide insights into relations betwee n to pic groups. For instance, Figure 3 shows a community of biology -related topics (shown in pink). Here, we see periph eral conne ctions to another life science theme (shown in y ellow) containin g topics such as genetic variation , popu lation dyn amics , and food webs . W e also see a peripheral connec tion to a material science theme (shown in red) , illum inating r esearch areas dedicated to developing m aterials based on biologic al an d organic co mpone nts an d also the mutual inter est in molecu lar recogn ition. As a final example, Figu re 4 shows a connected compon ent o f astronomical research topics that appears separate from the larger network. This last examp le illustrates one p ossible way to use these visualiza tions to identify outliers ( i. e., topics that are co mparatively m ore d ifferent th an the larger co rpus b ased o n their set of similarity scores). 8 Fig. 2 : [NSF G rants.] T wo discov ered topic groups (or communities) pertai ning to math-orient ed research. The red co vers pure math, whil e the blue is more applied. Each are separate communities but tightly-c oupled, as sho wn. T ogether , they represent over 10 , 000 documents cov ering a range of math subfields. 8 While it is possible to re-connect singleton nodes to whiche ver node it is most similar , we have not done so in any of the presented visualiz ations. Fig. 3: [NSF G rants.] A discove red topic group related to biology (shown in pink). Also sho wn are topic nodes from other relate d communities ( e.g., poly- mer blends , population dynamics ) and their peripheral connections to this biology- relate d topic group. Fig. 4: [NSF Grants.] A connected component of astronomical resear ch topics separated from the larger network. V I I . C A S E S T U DY 2 : W I K I P E D I A For our secon d c ase study , we app ly o ur method to visualize W ikipedia topics. T he c orpus conside red her e was obtained fro m the University of Alberta and comprises the entire En glish por tion of Wikipedia. 9 It co ntains over 3.3 million do cuments spa nning a range of different to pics. W e executed the MALLET implemen tation of LDA [21] on this corpus using K = 1000 as the n umber of topics a nd 200 as th e number of iterations. All other parameters were left as defaults. For top ic similarity , we exper imentally set ξ as 0 . 2 to yield a graph density of ap proxim ately 0 . 01 . For the labeling of to pic nodes in the network using D O C S E T L A B E L E R , we again set C = 5 a nd L = 1 . Labeling Wikipedia T opics. T able II sho ws a sample of ten W ikip edia topics an d the labels gen erated f or each by bo th LD A and D O C S E T L A B E L E R . As we did with the NSF grants, we co nducted a user evaluation of the labels gener ated fo r all W ikip edia topics by both LDA and our method . From the re- sults shown in T able IV, we a gain see that D O C S E T L A B E L E R outperf orms LD A ( χ 2 = 426 . 6 8 , P < 0 . 0001 ) with an in ter-judge 9 Shaoul, C. & W estbury C. (2010 ) The W estbury Lab Wikipe dia Corpus, Edmonton, AB: Uni versity of Albe rta (downl oaded from http:/ /www .psych.ualbert a.ca/ ∼ westbu rylab/d o wnloads/we stburylab .wikicorp.download.htm l agreemen t of 0 . 71 , as measu red by Cohen ’ s kap pa co efficient.. Howe ver, we also see that LDA perfo rms sign ificantly better here than on the NSF gran ts. W e elabo rate on this observation further in Section VIII. D O C S E T L A B E L E R LDA D O C S E T L A B E L E R 545 74 LDA 30 199 T ABLE IV: [Wikipe dia.] Eva luati on of labels for each method on W ikipedia. Overall, both judges chose labels from D O C S E T L A B E L E R to be most on-point. (Poor quality topics thrown out.) V isualizing Wikipedia. A topic similarity network was con- structed for W ik ipedia, with nodes labeled using the high - est ran ked label g enerated from D O C S E T L A B E L E R for each topic. Due to space constraints, we do n ot pr esent the entire W ikip edia topic similarity ne twork in th is paper . Rather, we provide illustrativ e examples of some of the majo r trends discovered by our method. T wo o f the mo st salient and well- defined topic grou ps ( i.e., m acro-level the mes) emerging from our visu alization are sports and music/da nce , shown in Figu res 5a and 5b, resp ectiv ely . W e posit that this is d ue to the fact that authorship an d editing of W ikipedia ar ticles are cr owd-sourced and the subjects of sports and mu sic/dance both hav e enormou s fan bases. I t should f ollow that television and film should a lso appear as salient to pic groups, and this is prec isely what we see in Figure 6. Also shown in Figu re 6 are the perip heral connectio ns to top ic no des from other related co mmunities ( e.g., plot summary and love story fr om a writing theme in green, da ily newspaper and mon thly maga zine f rom a news media theme in yellow). V I I I . L I M I TA T I O N S In bo th our two case stud ies, D O C S E T L A B E L E R was observed to ou tperfor m LD A o n topic labeling tasks. However , comparin g the two case studies, we see the perfo rmance differential was less fo r Wikipedia topics and greater for the highly technical and scientific topics present in the NSF grants co rpus. W e attribute this to the fact that W ikipedia is an encycloped ia with many to pics that are very general and br oad in nature. On th ose topics tha t are so broad and general that they are b est sum marized with a sing le word ( e.g., son gs , tennis , BBC ), LD A performs quite w ell – albeit sometimes less well than D O C S E T L A B E L E R . In cases where there is n ot an eq uiv alen tly expressive big ram ( i.e., two-word phrase) or p roper unigram , LDA will p erform better tha n o ur method, since D O C S E T L A B E L E R curren tly f ocuses o nly on bigrams a nd pr op er un igrams. On e exam ple of the latter case is the motor cycle top ic in Wikipedia shown in T able II. The top-ran ked lab els ge nerated by D O C S E T L A B E L E R are simply not as expressive as the simp le la bel “mo torcycle” produced by LD A. Addressing such cases is an area for future work. Howe ver, we find these cases to be in the m inority – espec ially with r espect to min ing co ntent fro m scientific an d techn ical docume nts, w hich is our curren t an d prim ary ar ea of interest. A second limitation is r elated to short texts. Both LDA and D O C S E T L A B E L E R are optimized f or articles, summ aries, and reports, such as the co rpora considered in this work. Shorter docume nts such as abstracts are also handled well b y both algorithm s, as e v idenced by perfor mance on the NSF grant abstracts. Howe ver, extrem ely short texts can cause difficulties. (a) Sports-Themed T opic Group (b) Music/Dance -Themed T opic Group Fig. 5: [Wikipedi a.] Disco vere d Wiki pedia topic groups for: (a) Sports and (b) Music/Dance . Fig. 6: [Wikipe dia.] A discov ered topic group pertai ning to T elevi- sion/F ilm/Radio (sho wn in purple). Also shown are the per ipheral connectio ns to topic nodes from other related communities ( e.g ., plot summary and lov e story from a writing theme in green, daily newspaper and monthly magazine from a ne ws m edia theme in yello w). This was observed to a certain degree in s ome W ikipedia topics containing many so -called “stub” articles of o nly a single sentence 10 ( e.g., one-sen tence de scriptions of minor fictio nal characters, small towns, or per sons of mino r n otability). O ne solution mig ht b e to replace LDA and D O C S E T L A B E L E R with algorithm s specifically d esigned to handle short texts su ch as T witter-LD A [30] and keyword extraction a lgorithms d esigned 10 It appears that Wiki pedia now recommends a minimum of thre e sentences for an arti cle. See http:/ /en.wikip edia.or g/wiki/W ikip edia talk: One sentence does not an articl e make for sho rt snippets of text [18]. W e leave an investigation of this for future work. I X . C O N C L U S I O N W e have investigated the use of topic similarity n etworks as a practical ap proach to improving the in terpretability of LD A topic mod els. W e described both ho w to constru ct such networks and an appr oach to labeling nod es in the network . These m ethods wer e co mbined and employed to effecti vely characterize and explore 14 y ears of NSF-fun ded basic re- search and the English portion of W ikiped ia using network analysis. For future work, we plan on in corpor ating these visualizations in to a larger, facet-based, text analy tic system previously developed fo r the U.S. Depa rtment of Defe nse (see [19] for more details on this system) . R E F E R E N C E S [1] K. Bache and M. L ichman. UCI machine learning repository , 2013. [2] David M. Blei and John D. Lafferty . Correlate d T opic Models. In NIPS , 2005. [3] David M. Blei and John D. Lafferty . A correlate d topic model of Science . Annals of Applied Statistics , 1(1):17–35, August 2007. [4] David M. Blei and John D. L af ferty . V isualizing T opics with Multi- W ord Expressions, J uly 2009. [5] David M. Blei , Andre w Y . Ng, and Michael I. Jordan. Latent Dirich let Allocat ion. J. Mac h. Learn. Res. , 3(4-5):993– 1022, March 2003. [6] V incent D. Blondel, Jean-Loup Guillaume, Renaud Lambiot te, and Etienne Lefeb vre. Fa st unfoldin g of communities in large net- works. J ournal of Statistic al Mec hanics: Theory and Experiment , 2008(10):P1 0008+, July 2008. [7] Allison Chaney and David M. Blei. V isualiz ing T opic Models. In ICWSM ’12 , 2012. [8] Jianfei Chen, June Zhu, Zi W ang, Xun Zheng, and Bo Z hang. Scalabl e Inferenc e for Logistic-No rmal T opic Models. In NIPS 2013: Neural Informatio n Processi ng Systems Confer ence , December 2013. [9] Jason Chua ng, Daniel Ramage, Christopher Manni ng, and J ef fre y Hee r . Interpre tatio n and Trust: Designing Model-dri ven V isualizati ons for T ext Analysis. In Proce edings of the SIGCHI Conferen ce on Human F actors in Computing Syst ems , CHI ’12, pages 443–452, Ne w Y ork, NY , USA, 2012. ACM. [10] P . J. Crossno, A. T . W ilson, T . M. Shead, and D. M. Dunlavy . T opicV ie w: V isuall y Comparing T opic Models of T ext Collections. In T ools with Artificial Intellig ence (ICT AI), 2011 23rd IEEE Internationa l Confer ence on , pages 936–943. IEEE, November 2011. [11] Marina Danile vsky , Chi W ang, Nihit Desai, Jingyi Guo, and Jia wei Han. KER T: Automatic Extracti on and Ranking of T opical K eyphrases from Content -Represe ntati ve Document Tit les, June 2013. [12] Jeffre y Dean and Sanjay Ghemaw at. MapReduce : Simplified Data Processing on Large Cluste rs. Commun. ACM , 51(1):107–113, January 2008. [13] T ed Dunning. Accur ate Methods for the Statistics of Surprise and Coinci dence. Comput. Linguist. , 19(1):61–74, March 1993. [14] Jacob E isenstei n, Duen H. Chau, Aniket Kittur , and Eric Xing. T op- icV iz: Interacti ve T opic Explorati on in Document Collec tions. In CHI ’12 E xtende d Abstracts on Human F actors in Computing Syste ms , CHI EA ’12, pages 2177–2182, Ne w Y ork, NY , U SA, 2012. A CM. [15] Brynjar Gretarsson, John O’dono van, Svetli n Bostandjie v , T obias H. Llerer , Arthur Asuncion, D avi d Newman, and Padhra ic Smyth. T opic- Nets: V isual Analysis of Large T ext Corpora with T opic Modeling. J ournal ACM T ransactions on Intelli gent Systems and T ec hnolo gy (TIST) , 3(2), February 2012. [16] Jey H . Lau, Karl Grieser , Da vid Ne wman, and Timothy Baldwin. Automatic Labelling of T opic Models. In Pr oceedi ngs of the 49th Annual Meeti ng of the Ass ociati on for Computational Linguistics: Human Langua ge T echnol ogie s - V olume 1 , HL T ’11, pages 1536– 1545, Stroudsburg, P A, USA, 2011. Association for Computation al Linguistic s. [17] W ei Li and Andrew McCallum. Pachink o A lloca tion: DA G-structured Mixture Models of T opic Correlati ons. In P r oceed ings of the 23rd Internati onal Confer ence on Machine Learning , ICML ’06, pages 577– 584, New Y ork, NY , USA, 2006. A CM. [18] Zhenhui Li, Ding Zhou, Y un F . Juan, and Jia wei Han. Keyw ord Extracti on for Social Snippets. In Pr oceedi ngs of the 19th Inte rnational Confer ence on W orld W ide W eb , WWW ’10, pages 1143–1144, Ne w Y ork, NY , USA, 2010. AC M. [19] Arun S. Maiya, John P . Thompson, Francisco L. Lemos, and Robert M. Rolfe. Exploratory Analysis of Highly Heterog eneous Document Collec tions. In Pr oceedi ngs of the 19th ACM SIGKDD International Confer ence on Knowledge Discove ry and Data Mining , KDD ’13, pages 1375–1383, New Y ork, NY , USA, 2013. ACM. [20] Christopher D. Manning and Hinrich Sch ¨ utze. F oundat ions of Statisti cal Natura l Languag e P r ocessing . MIT Press, Cambridge, MA, USA, 1999. [21] Andrew K. McCallum. MALLE T : A Machine L earning for Language T oolkit, 2002. [22] Qiaozhu Mei, Xuehua Shen, and ChengXia ng Zhai. Automatic L abeli ng of Multin omial T opic Models. In P r ocee dings of the 13th A CM SIGKDD International Conferen ce on Knowledge Discovery and Data Mining , KDD ’07, pages 490–499, New Y ork, NY , USA, 2007. ACM. [23] M. E. J. Newman. Modularity and community structure in networks. Pr oceed ings of the National Academy of Sciences , 103(23): 8577–8582, June 2006. [24] PeterD Turne y . Learning Algorithms for Ke yphrase Extraction. 2(4):303–3 36, 2000. [25] Chi W ang, Marina Danile vsky , Nihit Desai, Y inan Zhang, Phuong Nguyen, Thri vikrama T aula, and Jiawei Han. A Phrase Mining Frame- work for Recursi ve Constr uction of a T opical Hierarchy . In Proce edings of the 19th ACM SIGKDD Internati onal Conferen ce on Knowledg e Discov ery and Data Mining , KDD ’13, pages 437–445, New Y ork, NY , USA, 2013. ACM. [26] Xuerui W ang, Andre w McCallum, and Xing W ei. T opical N-Grams: Phrase and T opic Disco very , with an Application to Informati on Retrie va l. In P r ocee dings of the 2007 Seventh IE EE International Confer ence on Data Mining , ICDM ’07, pages 697–702, W ashington, DC, USA, 2007. IE EE Computer Society . [27] Y i W ang, Hongjie Bai, Matt Stanton, W en Y . Chen, and Edwa rd Y . Chang. PLDA: Parallel Latent Dirichle t Allocati on for Large- Scale Applica tions. In Proce edings of the 5th Internation al Conf er ence on Algorithmic A spects in Information and Manag ement , volume 5564 of AAIM ’09 , pages 301–314, Berlin, Heidelber g, 2009. Springer-V erla g. [28] Furu W ei, Shixia Liu, Y angqiu Song, Shimei Pan, Michelle X. Zhou, W eihong Qian, L ei Shi, L i T an, and Qiang Zhang. TIARA: a visual expl oratory text analytic system. In P r oceedings of the 16th ACM SIGKDD international confere nce on Knowledg e discovery and data mining , KDD ’10, pages 153–162, N e w Y ork, NY , USA, 2010. ACM. [29] K. Zhai, J. Boyd-Gra ber , and N. Asadi. Us ing V aria tional Inferenc e and MapReduc e to S cale T opic Modeling. ArXiv e-pri nts: arXiv:1107 .3765 [cs.AI] , July 2011. [30] W ayneXin Z hao, Jing Jiang, Jianshu W eng, Jing He, Ee-Peng Lim, Hongfei Y an, and Xiaoming Li. Comparing T witte r and Tradit ional Media Using T opic Models. In Paul Clough, Colum Fole y , Cathal Gur- rin, GarethJ Jones, W essel Kraaij, Hyo won Lee, and V anessa Mudoch, editors, Advances in Informati on R etrie val , volume 6611 of Lect ure Notes in Computer Science , chapt er 34, pages 338–349. Springer Berlin Heidelb erg, Berlin, Heidelber g, 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment