A Networks and Machine Learning Approach to Determine the Best College Coaches of the 20th-21st Centuries
Our objective is to find the five best college sports coaches of past century for three different sports. We decided to look at men's basketball, football, and baseball. We wanted to use an approach that could definitively determine team skill from t…
Authors: Tian-Shun Jiang, Zachary Polizzi, Christopher Yuan
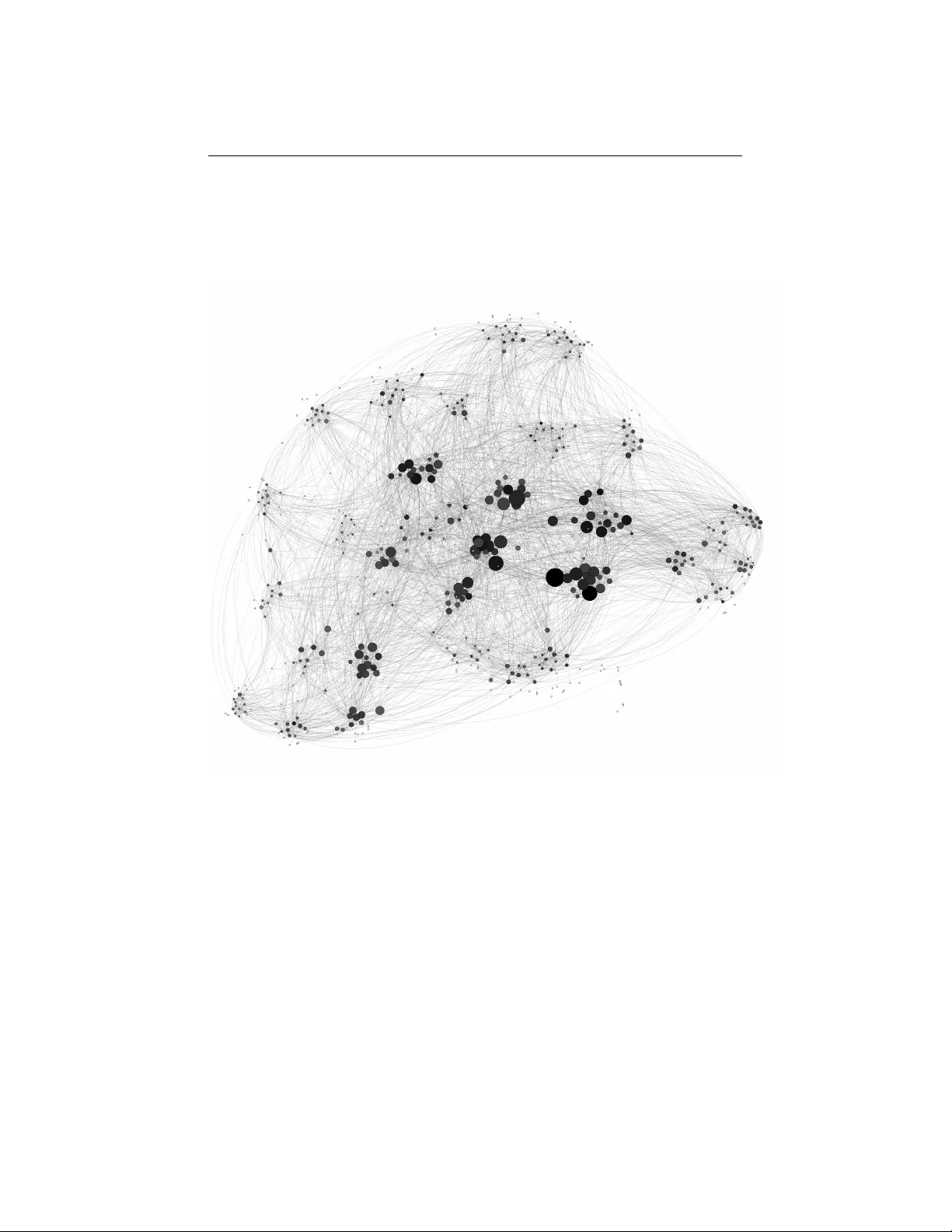
A Net w orks and Mac hine Learning Approac h to Determine the Best College Coac hes of the 20 th -21 st Cen turies Tian-Sh un Allan Jiang, Zac hary T P olizzi, Christopher Qian Y uan Men tor: Dr. Dan T eague The North Carolina Sc ho ol of Science and Mathematics ∗ F ebruary 10, 2014 ∗ Paper submitted to the 2014 Mathematical Contest in Modeling ( http://www.comap.com/ undergraduate/contests/mcm/ ) 1 T eam #30680 P age 2 of 18 Con ten ts 1 Problem Statement 3 2 Planned Approach 3 3 Assumptions 3 4 Data Sources and Collection 4 4.1 College F o otball . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 4.2 Men’s College Bask etball . . . . . . . . . . . . . . . . . . . . . . . 5 4.3 College Baseball . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5 Net work-based Mo del for T eam Ranking 6 5.1 Building the Net work . . . . . . . . . . . . . . . . . . . . . . . . 6 5.2 Analyzing the Net work . . . . . . . . . . . . . . . . . . . . . . . . 6 5.2.1 Degree Cen trality . . . . . . . . . . . . . . . . . . . . . . . 6 5.2.2 Bet weenness and Closeness Cen tralit y . . . . . . . . . . . 7 5.2.3 Eigen vector Cen trality . . . . . . . . . . . . . . . . . . . . 8 6 Separating the Coac h Effect 10 6.1 When is Coac h Skill Imp ortan t? . . . . . . . . . . . . . . . . . . 11 6.2 Margin of Win Probabilit y . . . . . . . . . . . . . . . . . . . . . . 12 6.3 Optimizing the Probabilit y F unction . . . . . . . . . . . . . . . . 13 6.3.1 Genetic Algorithm . . . . . . . . . . . . . . . . . . . . . . 13 6.3.2 Nelder-Mead Metho d . . . . . . . . . . . . . . . . . . . . 14 6.3.3 P ow ell’s Metho d . . . . . . . . . . . . . . . . . . . . . . . 14 7 Ranking Coaches 15 7.1 T op Coac hes of the Last 100 Y ears . . . . . . . . . . . . . . . . . 15 8 T esting our Mo del 15 8.1 Sensitivit y Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 15 8.2 Strengths . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 8.3 W eaknesses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 9 Conclusions 17 10 Ackno wledgmen ts 17 2 T eam #30680 P age 3 of 18 1 Problem Statemen t College sp ort coaches often ac hieve widespread recognition. Coaches like Nick Saban in fo otball and Mik e Krzyzewski in bask etball rep eatedly lead their sc ho ols to national championships. Because coaches influence b oth the p er- formance and reputation of the teams they lead, a question of great concern to univ ersities, pla yers, and fans alike is: Who is the b est coach in a given sp ort? Sp orts Il lustr ate d , a magazine for sp orts en thusiasts, has asked us to find the b est all-time college coac hes for the previous century . W e are tasked with creat- ing a mo del that can b e applied in general across b oth genders and all p ossible sp orts at the college-level. The solution prop osed within this pap er will offer an insigh t to these problems and will ob jectively determine the top five coaches of all time in the sp orts of baseball, men’s basketball, and fo otball. 2 Planned Approac h Our ob jectiv e is to rank the top 5 coaches in each of 3 different college-level sp orts. W e need to determine which metrics reflect most accurately the ranking of coaches within the last 100 y ears. T o determine the most effective ranking system, we will pro ceed as follows: 1. Create a netw ork-based mo del to visualize all college sp orts teams, the teams won/lost against, and the margin of win/loss. Eac h netw ork de- scrib es the games of one sp ort ov er a single year. 2. Analyze v arious prop erties of the net work in order to calculate the skill of eac h team. 3. Develop a means by which to decouple the effect of the coac h from the team p erformance. 4. Create a mo del that, given the pla yer and coac h skills for every team, can predict the probability of the o ccurrence of a sp ecific net work of a) wins and losses and b) the p oin t margin with which a win or loss o ccurred. 5. Utilize an optimization algorithm to maximize the probability that the coac h skill matrix, once plugged into our mo del, generates the netw ork of wins/losses and margins describ ed in (1). 6. Analyze the results of the optimization algorithm for each year to deter- mine an ov erall ranking for all coac hes across history . 3 Assumptions Due to limited data ab out the coaching habits of all coaches at all teams ov er the last cen tury in v arious collegiate sports, we use the follo wing assumptions to 3 T eam #30680 P age 4 of 18 complete our mo del. These simplifying assumptions will b e used in our rep ort and can b e replaced with more reliable data when it b ecomes av ailable. • The skill level of a coac h is ultimately expressed through his/her team’s wins ov er another and the margin by which they win. This assumes that a team must win to a certain degree for their coach to b e go od. Even if the coach significantly amplifies the skills of his/her pla yers, he/she still cannot b e considered “go od” if the team wins no games. • The skills of teams are constan t throughout an y giv en y ear (ex: No pla y ers are injured in the middle of a season). This assumption will allow us to compare a team’s games from an y point in the season to any other p oin t in the season. In realit y , changing play er skills throughout the season make it more difficult to determine the effect of the coach on a game. • Winning k games against a go od team impro ves team skill more than winning k games against an av erage team. This assumption is intuitiv e and allo ws us to use the eigen vector cen tralit y metric as a measure of total team skill. • The skill of a team is a function of the skill of the play ers and the skill of the coac h. W e assume that the skill of a coach is multiplicativ e ov er the skill of the play ers. That is: T s = C s · P s where T s is the skill of the team, C s is the skill of the coac h, and P s is a measure of the skill of the play ers. Making coach skill multiplicativ e ov er play er skill assumes that the coach has the same effect on each play er. This assumption is imp ortan t b ecause it simplifies the relationship b et ween play er and coac h skill to a p oin t where we can easily optimize coach skill vectors. • The effect of coach skill is only large when the difference b etw een play er skill is small. F or example, if team A has the best pla y ers in the conference and team B has the worst, it is likely that even the b est coach w ould not b e able to, in the short run, bring ab out wins ov er team A . How ev er, if tw o teams are similarly matched in play ers, a more-skilled coach will mak e adv antageous plays that lead to his/her team winning more often than not. • When pla yer skills b etw een t wo teams are similarly matched, coac h skill is the only factor that determines the team that wins and the margin by whic h they win b y . By making this assumption, w e do not ha v e to accoun t for any other factors. 4 Data Sources and Collection Since our mo del requires as an input the results of all the games play ed in a season of a particular sp ort, we first set out to collect this data. Since we were unable to identify a single resource that had all of the data that w e required, we 4 T eam #30680 P age 5 of 18 found a num b er of different websites, eac h with a p ortion of the requisite data. F or each of these websites, we created a customized program to scrap e the data from the relev ant w ebpages. Once w e gathered all the data from our sources, w e pro cessed it to standardize the formatting. W e then aimed to merge the data gathered from eac h source into a useable format. F or example, we gathered bask etball game results from one source, and data iden tifying team coaches from another. T o merge them and show the game data for a sp ecific coac h, we attempted to matc h on common fields (ex. “T eam Name”). Often, how ev er, the data from eac h source did not match exactly (ex. “Florida State” vs “Florida St.”). In these situations, we had to man ually create a matching table that w ould allow our program to merge the data sources. Although we are seeking to iden tify the b est college coach for each sp ort of interest for the last century , it should b e noted that many curren t college sp orts did not exist a cen tury ago. The National Collegiate A thletic Association (NCAA), the current managing b o dy for nearly all college athletics, was only officially established in 1906 and the first NCAA national championship took place in 1921, 7 years short of a century ago. Although some college sp orts w ere independently managed b efore b eing brought in to the NCAA, it is often difficult to gather accurate data for this time. 4.1 College F o otball One of the earliest college sp orts, College F o otball has b een popular since its inception in the 1800’s. The data that we collected ranges from 1869 to the presen t, and includes the results and final scores of every game pla yed b et ween Division 1 men’s college fo otball teams (or the equiv alen t b efore the inception of NCAA) [2]. Additionally , we ha ve gathered data listing the coach of each team for every year we ha ve collected game data [4], and combined the data in order to match the coac h with his/her complete game record for ev ery year that data was av ailable. 4.2 Men’s College Basketball The data that w e gathered for Men’s College Bask etball ranges from the sea- son of the first NCAA Men’s Basketball championship in 1939 to the presen t. Similarly to College F o otball, we gathered data on the result and final scores of eac h game in the season and in finals [2]. Combining this with another source of coac h names for each team and year generated the game record for each coach for each season [4]. 4.3 College Baseball Although College Baseball has historically had limited p opularit y , interest in the sp ort has grown greatly in the past decades with improv ed media cov erage and collegiate sp ending on the sp ort. The game result data that we collected 5 T eam #30680 P age 6 of 18 ranges from 1949 to the present, and was merged with coac h data for the same time p erio d. 5 Net w ork-based Mo del for T eam Ranking Through examination of all games play ed for a specific year we can accurately rank teams for that y ear. By creating a netw ork of teams and games pla yed, w e can not only analyze the n umber of wins and losses each team had, but can also break down each win/loss with regard to the opp onen t’s skill. 5.1 Building the Netw ork W e made use of a w eighted digraph to represent all games pla yed in a single y ear. Each no de in the graph represen ts a single college sp orts team. If team A wins o ver team B , a directed edge with a weigh t of 1 will b e drawn from A p ointing tow ards B . Eac h additional time A wins o ver B , the w eight of the edge will b e increased by 1. If B b eats A , an edge with the same information is drawn in the opp osing direction. Additionally , a list con taining the margin of win/loss for each game is asso ciated with the edge. F or example, if A b eat B t wice with scor e : 64 − 60 , 55 − 40, an edge with w eight t wo is constructed and the winning margin list 4 , 15 is asso ciated with the edge. Since each graph represen ts a single season of a sp ecific sp ort, and w e are in terested in analyzing a century of data ab out three differen t sp orts, we ha ve created a program to automate the creation of the nearly 300 graphs used to mo del this system. The program Gephi was used to visualize and manipulate the generated graphs. 5.2 Analyzing the Netw ork W e are next interested in calculating the skill of eac h team based on the graphs generated in the previous section. T o do this, we will use the concept of central- it y to in v estigate the properties of the no des and their connections. Cen trality is a measure of the relative importance of a sp ecific no de on a graph based on the connections to and from that no de. There are a num b er of wa ys to calculate cen trality , but the four main measures of centralit y are degree, b et weenness, closeness, and eigenv ector centralit y . 5.2.1 Degree Centralit y Degree centralit y is the simplest centralit y measure, and is simply the total n umber of edges connecting to a sp ecific node. F or a directional graph, indegree is the num b er of edges directed in to the no de, while outdegree is the n umber of edges directed aw a y from the no de. Since in our netw ork, edges directed in ward are losses and edges directed outw ards are wins, indegree represents the total num b er of losses and outdegree measures the total num b er of wins. Logically , therefore, outdeg r eee indeg r eee represen ts the win loss ratio of the team. This ratio is often used as a metric of the skill of a team; how ev er, there are sev eral 6 T eam #30680 P age 7 of 18 Figure 1: A complete net work for the 2009-2010 NCAA Div. I bask etball season. Eac h no de represents a team, and each edge represen ts a game b et w een the tw o teams. Note that, since teams pla y other teams in their conference most often, man y teams hav e clustered into one of the 32 NCAA Div.1 Conferences. w eaknesses to this metric. The most prominent of these w eaknesses arises from the fact that, since not ev ery team plays every other team ov er the course of the season, some teams will naturally play more difficult teams while others will play less difficult teams. This is exaggerated by the fact that many college sp orts are arranged into conferences, with some conferences con taining mostly highly-rank ed teams and others containing mostly lo w-rank ed teams. Therefore, win/loss p ercen tage often exaggerates the skill of teams in weak er conferences while failing to highlight teams in more difficult conferences. 5.2.2 Bet weenness and Closeness Cen trality Bet weenness centralit y is defined as a measure of how often a sp ecific no de acts as a bridge along the shortest path b et ween tw o other no des in the graph. Although a very useful metric in, for example, so cial netw orks, b et weenness cen trality is less relev an t in our graphs as the distance b et w een no des is based on the game sc hedule and conference lay out, and not on team skill. Similarly , closeness centralit y is a measure of the av erage distance of a sp ecific node to 7 T eam #30680 P age 8 of 18 another no de in the graph - also not particularly relev an t in our graphs b ecause distance b etw een no des is not related to team skills. 5.2.3 Eigen vector Cen trality Eigen vector centralit y is a measure of the influence of a no de in a netw ork based on its connections to other no des. Ho wev er, instead of eac h connection to another no de having a fixed con tribution to the centralit y rating (e.g. de- gree centralit y), the con tribution of eac h connection in eigenv ector cen trality is prop ortional to the eigen vector centralit y of the no de b eing connected to. Therefore, connections to high-ranked no des will hav e a greater influence on the ranking of a no de than connections to low-ranking no des. When applied to our graph, the metric of eigenv ector centralit y will assign a higher ranking to teams that win ov er other high-ranking teams, while winning ov er low er- ranking no des has a lesser contribution. This is imp ortant b ecause it addresses the main limitation ov er degree cen trality or win/loss percentage, where winning o ver many low-rank ed teams can give a team a high rank. If we let G represent a graph with nodes N , and let A = ( a n,t ) b e an adjacency matrix where a n,t = 1 if no de n is connected to no de t and a n,t = 0 otherwise. If we define x a as the eigenv ector centralit y score of no de a , then the eigen vector centralit y score of no de n is given by: x n = 1 λ X t ∈ M ( n ) x t = 1 λ X t ∈ G a n,t x t (1) where λ represents a constant and M ( n ) represen ts the set of neighbors of no de n . If we conv ert this equation into vector notation, we find that this equation is identical to the eigenv ector equation: Ax = λ x (2) If we place the restriction that the ranking of eac h node must b e p ositive, w e find that there is a unique solution for the eigenv ector x , where the n th comp onen t of x represen ts the ranking of no de n . There are m ultiple differen t metho ds of calculating x ; most of them are iterative methods that con verge on a final v alue of x after numerous iterations. One interesting and intuitiv e metho d of calculating the eigen vector x is highlighted b elow. It has b een sho wn that the eigenv ector x is prop ortional to the ro w sums of a matrix S formed by the follo wing equation [6, 9]: S = A + λ − 1 A 2 + λ − 2 A 3 + ... + λ n − 1 A n + ... (3) where A is the adjacency matrix of the netw ork and λ is a constant (the principle eigen v alue). W e know that the p o w ers of an adjacency matrix describe the num b er of walks of a certain length from no de to no de. The p ow er of the eigenv alue ( x ) describ es some function of length. Therefore, S and the 8 T eam #30680 P age 9 of 18 eigen vector cen trality matrix b oth describe the num ber of walks of all lengths w eighted inv ersely by the length of the walk. This explanation is an in tuitive w ay to describ e the eigenv ector centralit y metric. W e utilized Netw orkX (a Python library) to calculate the eigenv ector centralit y measure for our sp orts game netw orks. W e can apply eigen vector centrali ty in the context of this problem b ecause it takes into account b oth the num b er of wins and losses and whether those wins and losses w ere against “go od” or “bad” teams. If we hav e the follo wing graph: A → B → C and kno w that C is a goo d team, it follows that A is also a goo d team b ecause they b eat a team who then wen t on to b eat C . This is an example of the kind of interaction that the metric of eigen vector centralit y tak es into account. Calculating this metric ov er the entire y early graph, we can create a list of teams ranked by eigen vector cen trality that is quite accurate. Belo w is a table of top ranks from eigenv ector centralit y compared to the AP and USA T o da y p olls for a random sample of our data, the 2009-2010 NCAA Division I Mens Basketball season. It shows that eigenv ector centralit y creates an accurate ranking of college basketball teams. The italicized entries are ones that app ear in the top ten of b oth eigenv ector centralit y ranking and one of the AP and USA T o day p olls. Rank Eigen vector Cen trality AP Poll USA T o da y Poll 1 Duke Kansas Kansas 2 West Vir ginia Mic higan St. Mic higan St. 3 Kansas T exas T exas 4 Syracuse Kentucky North Carolina 5 Pur due Villano v a Kentucky 6 Georgeto wn North Carolina Villano v a 7 Ohio St. Pur due Pur due 8 W ashington West Vir ginia Duke 9 Kentucky Duke West Vir ginia 10 Kansas St. T ennessee Butler As seen in the table ab o ve, six out of the top ten teams as determined by eigen vector cen tralit y are also found on the top ten rankings list of p opular polls suc h as AP and USA T o day . W e can see that the metric we hav e created using a netw orks-based mo del creates results that affirms the results of commonly- accepted rankings. Our team-ranking mo del has a clear, easy-to-understand basis in netw orks-based centralit y measures and gives reasonably accurate re- sults. It should b e noted that we chose this approac h to ranking teams ov er a muc h simpler approach suc h as simply gathering the AP rankings for v ari- ous reasons, one of whic h is that there are not reliable sources of college sp ort ranking data that cov er the entire history of the sp orts we are interested in. Therefore, by calculating the rankings ourselves, w e can analyze a wider range of historical data. Belo w is a graph that visualizes the eigenv ector cen tralit y v alues for all games pla yed in the 2010-2011 NCAA Division I Mens F o otball tournament. 9 T eam #30680 P age 10 of 18 Larger and dark er no des represent teams that ha ve high eigenv ector centralit y v alues, while smaller and ligh ter no des represent teams that hav e low eigenv ector cen trality v alues. The large no des therefore represen t the b est teams in the 2010-2011 season. Figure 2: A complete net work for the 2012-2013 NCAA Div. I Men’s Basketball season. The size and darkness of each no des represents its relative eigen vector cen trality v alue. Again, note the clustering of teams in to NCAA conferences. 6 Separating the Coac h Effect The model we created in the previous section works well for finding the relative skills of teams for any given year. Ho wev er, in order to rank the coaches, it is necessary to decouple the c o ach skil l from the ov erall team skill. Let us assume that the o verall team skill is a function of tw o main factors, coach skill and pla yer skill. Sp ecifically , if C s is the coach skill, P s is the play er skill, and T s is 10 T eam #30680 P age 11 of 18 the team skill, we hypothesize that T s = C s · P s , (4) as C s of any particular team could b e thought of as a m ultiplier on the play er skill P s , which results in team skill T s . Although the relationship b etw een these factors may b e more complex in real life, this relationship gives us reasonable results and works well with our mo del. 6.1 When is Coach Skill Imp ortan t? W e will now make a k ey assumption regarding play er skill and coach skill. In order to separate the effects of these tw o factors on the ov erall team skill, we m ust define some difference in effect b et ween the t wo. That is, the play er skill will influence the team skill in some fundamentally differen t wa y from the coach skill. Think again to a game pla yed b et ween t wo arbitrary teams A and B . There are tw o main cases to b e considered: Case one: Pla y er skills differ significan tly: Without loss of generality , assume that P ( A ) >> P ( B ), where P ( x ) is a function returning the pla yer skills of an y giv en team x . It is clear that A winning the game is a lik ely outcome. W e can draw a plot approximating the probabilit y of winning by a certain margin, whic h is shown in Figure 3. Margin of Win Probability Figure 3: A has a high chance of winning when its play ers are more skilled. Because the play er skills are very imbalanced, the coach skill will likely not c hange the outcome of the game. Even if B has an excellent coach, the effect of the coach’s skill will not b e enough to make B ’s win likely . Case tw o: Play er skills approximately equal: If the play er skills of the t wo teams are appro ximately ev enly matc hed, the coach skill has a muc h higher lik eliho o d of impacting the outcome of the game. When the play er skills are 11 T eam #30680 P age 12 of 18 similar for b oth teams, the Gaussian curve lo oks lik e the one shown in Figure 4. In this situation, the coac h has a muc h greate r influene on the outcome of the game - crucial calls of time-outs, play er substitutions, and strategies can make or break an otherwise evenly matc hed game. Therefore, if the coach skills are unequal, causing the Gaussian curv e is shifted even slightly , one team will hav e a higher chance of winning (even if the margin of win will likely b e small). Margin of Win Probability Figure 4: Neither A nor B are more lik ely to win when pla yer skills are the same (if play er skill is the only factor considered). With the assumptions regarding the effect of coach skill given a difference in play er skills, we can say that the effect of a coach can b e expressed as: ( C A − C B ) · 1 1 + α | P A − P B | (5) Where C A is the coac h skill of team A , C B is the coac h skill of team B , P A is the play er skill of team A , P B is the pla yer skill of team B , and α is some scalar constan t. With this expression, the coach effect is diminished if the difference in play er skills is large, and coac h effect is fully present when play ers ha ve equal skill. 6.2 Margin of Win Probabilit y No w we wish to use the coach effect expression to create a function giving the probabilit y that team A will b eat team B by a margin of x points. A negative v alue of x means that team B beat team A . The probability that A b eats B by x p oints is: K · e − 1 E ( C · player effe ct + D · c o ach effe ct − mar gin ) 2 (6) where C, D , E are constant weigh ts, player effe ct is P A − P B , c o ach effe ct is giv en by Equation 5, and mar gin is x . 12 T eam #30680 P age 13 of 18 This probability is maximized when C · player effe ct + D · c o ach effe ct = mar gin . This accurately mo dels our situation, as it is more lik ely that team A wins b y a margin equal to their combined coach and team effects o ver team B . Since team skill is comprised of play er skill and coach skill, we ma y calculate a giv en team’s play er skill using their team skill and coach skill. Th us, the probabilit y that team A b eats team B by margin x can be determined solely using the coach skills of the resp ectiv e teams and their eigenv ector centralit y measures. 6.3 Optimizing the Probability F unction W e w ant to assign all the coac hes v arious skill levels to maximize the likelihoo d that the given historical game data o ccurred. T o do this, w e maximize the probabilit y function describ ed in Equation 6 ov er all games from historical data b y finding an optimal v alue for the coac h skill vectors C A and C B . F ormally , the probability that the historical data o ccurred in a given year is Y all games K · e − 1 E ( C · player effe ct + D · c o ach effe ct − mar gin ) 2 . (7) After some algebra, we notice that maximizing this v alue is equiv alent to minimizing the v alue of the cost function J , where J ( C s ) = X all games ( C · player effe ct + D · c o ach effe ct − mar gin ) 2 (8) Because P ( A b eats B b y x ) is a nonlinear function of four v ariables for each edge in our netw ork, and because w e must iterate ov er all edges, calculus and linear algebra techniques are not applicable. W e will in v estigate three techniques (Genetic Algorithm, Nelder-Mead Search, and Po w ell Search) to find the global maxim um of our probability function. 6.3.1 Genetic Algorithm A t first, our team set out to implement a Genetic Algorithm to create the coach skill and play er skill v ectors that would maximize the probabilit y of the win/loss margins o ccurring. W e created a program that would initialize 1000 random coac h skill and play er skill vectors. The probability function was calculated for each pair of vectors, and then the steps of the Genetic Algorithm w ere ran (carry ov er the “most fit” solution to the next generation, cross random elements of the coac h skill v ectors with each other, and mutate a certain p ercen tage of the data randomly). How ever, our genetic algorithm to ok a very long time to con verge and did not produce the optimal v alues. Therefore, w e decided to forgo optimization with genetic algorithm metho ds. 13 T eam #30680 P age 14 of 18 6.3.2 Nelder-Mead Metho d W e w an ted to attempt optimization with a technique that w ould iterate ov er the function instead of m utating and crossing ov er. The Nelder-Mead metho d starts with a randomly initialized coach skills v ector C s and uses a simplex to tw eak the v alues of C s to impro ve the v alue of a function for the next iteration [7]. Ho wev er, running Nelder-Mead found lo cal extrema which barely increased the probabilit y of the historical data o ccurring, so we excluded it from this rep ort. 6.3.3 P ow ell’s Metho d A more efficien t metho d of finding minima is Po w ell’s Metho d. This algorithm w orks by initializing a random coach skills vector C s , and uses bi-directional searc h metho ds along several search vectors to find the optimal coach skills. A detailed explanation of the mathematical basis for P ow ell’s metho d can b e found in Po well’s pap er on the algorithm [8]. W e found that P ow ell’s metho d w as sev eral times faster than the Nelder-Mead Metho d and pro duced reasonable results for the minimization of our probability function. Therefore, our team decided to use Po w ell’s metho d as the main algorithm to determine the coach skills vector. W e implemented this algorithm in Python and ran it across every edge in our netw ork for each year that we had data. It significan tly low ered our cost function J ov er several thousand iterations. Rank 1962 2000 2005 1 John W oo den Lute Olson Jim Bo eheim 2 F orrest Tw ogo o d John W o oden Roy Williams 3 LaDell Anderson Jerry Dunn Thad Matta The table abov e shows the results of running P ow ell’s metho d until the probabilit y function shown in Equation 6 is optimized, for three widely separated arbitrary years. W e ha ve chosen to show the top three coaches p er y ear for the purp oses of conciseness. W e will additionally highlight the p erformance of our top three three outstanding coaches. John W o oden - UCLA: John W oo den built one of the ’greatest dynasties in all of sp orts at UCLA’, winning 10 NCAA Division I Basketball tournaments and leading an unmatched streak of seven tournaments in a ro w from 1967 to 1973 [1]. He won 88 straight games during one stretch Jim Bo eheim - Syracuse: Bo eheim has led Syracuse to the NCAA T our- namen t 28 of the 37 years that he has b een coaching the team [3]. He is second only to Mike Krzyzewsky of Duke in total wins. He consistently p erforms ev en when his play ers v ary - he is the only head coach in NCAA history to lead a sc ho ol to four final four app earances in four separate decades. Ro y Williams - North Carolina: Williams is curren tly the head of the bask etball program at North Carolina where he is sixth all-time in the NCAA for winning p ercen tage [5]. He p erforms impressively no matter who his play ers are - he is one of tw o coaches in history to hav e led tw o different teams to the Final F our at least three times eac h. 14 T eam #30680 P age 15 of 18 7 Ranking Coac hes Kno wing that we are only concerned with finding the top five coac hes p er sport, w e decided to only consider the fiv e highest-rank ed coac hes for each y ear. T o calculate the ov erall ranking of a coac h ov er all p ossible y ears, we considered the n umber of years coac hed and the frequency which the coac h app eared in the y early top five list. That is: C v = N a N c (9) Where C v is the ov erall v alue assigned to a certain coach, N a is the num b er of times a coac h app ears in yearly top five coac h lists, and N c is the num ber of y ears that the coach has b een active. This metho d of measuring ov erall coach skill is esp ecially strong b ecause we can account for instances where coaches c hange teams. 7.1 T op Coac hes of the Last 100 Y ears After optimizing the coac h skill vectors for each year, taking the top fiv e, and ranking the coaches based on the num b er of times they app eared in the top five list, we arrived at the following table. This is our definitiv e ranking of the top fiv e coaches for the last 100 y ears, and their asso ciated career-history ranking: Rank Mens Basketball Mens F ootball Mens Baseball 1 John W oo den - 0.28 Glenn W arner - 0.24 Mark Marquess - 0.27 2 Lute Olson - 0.26 Bobb y Bowden - 0.23 Augie Garrido - 0.24 3 Jim Bo eheim - 0.24 Jim Grob e - 0.18 T om Chandler - 0.22 4 Gregg Marshall - .23 Bob Sto ops - 0.17 Richard Jones - 0.19 5 Jamie Dixon - .21 Bill Peterson - 0.16 Bill W alk en bach - 0.16 8 T esting our Mo del 8.1 Sensitivit y Analysis A requirement of any go o d mo del is that it must b e toleran t to a small amount of error in its inputs. In our mo del, p ossible sources of error could include im- prop erly recorded game results, incorrect final scores, or entirely missing games. These sources of error could cause a badly written algorithm to return incorrect results. T o test the sensitivit y of our mo del to these sources of error, w e decided to create inten tional small sources of error in the data and compare the results to the original, unmo dified results. The first inten tional source of error that we incorp orated into our mo del w as the deletion of a game, specifically a regular-season win for Alabama (the team with the top-ranked coach in 1975) ov er Providence with a score of 67 to 60. W e exp ected that the skill v alue of the coach of the Alabama team would 15 T eam #30680 P age 16 of 18 decrease slightly with this mo dification. When we ran and analyzed the results, w e found that the coac h skill v alue did in fact decrease b y approximately 1%, as w e exp ected. Ho wev er, the Alabama coac h maintained his ranking of top coac h for the season. The second change that w e incorp orated was to switch the results of the same game (Alabama 67, Providence 60) to a win for Providence (Pro vidence 67, Alabama 60). W e exp ect this will hav e a greater negative influence on the skill v alue of the Alabama coach, and when we ran the analysis we found that, indeed, the Alabama coach skill v alue decreased by approximately 4%. Although a relatively minor difference, the second-ranked coach originally had a skill v alue only very slightly b ehind the Alabama coac h, and the 4% loss in fact placed the second-ranked coach in the first ranking p osition. F rom this analysis we can see that our mo del follows our predictions accu- rately , and that removing factors that add positively to the skill ranking of a coac h is detrimental to their skill v alue. Although the changes we made were minor, there is often a lot of comp etition for the first-place ranking of a coach, and due to the limited num b er of games play ed p er season, a change to this data can ha ve an influence on the final ranking. Although these results indicate that error in our data can effect the final ranking, the analysis also shows that our mo del resp onds predictably to a v ariation in the input. 8.2 Strengths The main strength of our approac h is that it is able to separate coac h proficiency from team proficiency b y calculating probabilities that the historical game data o ccur given coach skills. This allows us to more accurately gauge the skills of a coach without factoring in the skills of his/her play ers. F urthermore, our approac h is flexible as many relationships can b e mo dified. F or example, if a study shows that there is a b etter function to describ e the relationship b et ween coac h skill, play er skill, and team skill, it can easily b e used in our mo del. Our mo del is also able to compare the relative effectiveness of coaches from all time p eriods, as long as the av erage margin of victory is similar across time p eriods. 8.3 W eaknesses The main weakness of our mo del p ertains to computational efficiency , as our computers could not alwa ys adequately calculate all necessary v alues in our mo del. F or example, the computer could not find the eigenv ector centralit y v alues on a small p ercentage of the graphs, as the V on Mises iteration failed to conv erge. F urthermore, sometimes Po well’s method of minimizing our cost function yielded high costs relative to other years b ecause the initialized array of coach skills was close to a lo cal minima. This could b e solv ed by running P ow ell’s metho d from several randomly initialized coach skills arrays, but this increases computational time. In fact, the ov erall results of our mo del could lik ely be improv ed significantly given more time to run the iterative optimization 16 T eam #30680 P age 17 of 18 algorithms with a higher accuracy , resulting in b etter approximations for the ideal matrix of coach skills. 9 Conclusions In this rep ort, we ha ve analyzed nearly 300 years of data in order to determine the most accurate and unbiased ranking of all-time b est college sp orts coac hes. By constructing comprehensive net works with with edges represen ting each and ev ery game play ed in the last century of the college sp orts that w e analyzed, w e were able to create a comprehensive metric of team skill using the concept of eigenv ector centralit y . By considering win/loss margins, we were able to iden tify patterns that enabled us to separate the team skill measure into its t wo components - play er skill and coach skill. W e then created a probability function based on play er skill and coach skill to determine the likelihoo d of an edge in our netw ork o ccurring. By m ultiplying this probability across all edges, w e were able to determine the probability of the entire graph occurring given team skill and coac h skill vectors. Using an iterative, multiv ariable, machine learning algorithm, we maximized this probability function for coach skill for eac h season and for eac h sp ort. Using data that mapped the name of a coac h to his/her team for each season, we were able to com bine the results of each individual season and analyze the skill of each individual coach o ver their entire coac hing history . F rom this data, w e selected the top 5 coaches from ev ery sport to feature as our all-time b est coaches of the century . 10 Ac kno wledgmen ts W e w ould like to thank our mentor Dr. Dan T eague, who introduced us to the w orld of mathematical mo deling, and Ms. Christine Belledin, who sp onsored us for MCM. W e would also like to thank the North Carolina School of Science and Mathematics for hosting us as we w orked on the problem. Last but not least, w e w ould like to thank our judges and Comap for putting together this w onderful comp etition. 17 T eam #30680 P age 18 of 18 References [1] John W o oden. Retriev ed from: http://msn.foxsports.com/ collegebasketball/story/John- Wooden- dies- UCLA- coach- 99- 060410 , 2010. [2] ShrpSp orts. Retriev ed from: http://www.shrpsports.com/ , 2011. [3] Jim Bo eheim. Retrieved from: http://cuse.com/coaches.aspx?rc= 405&path=mbasket , 2012. [4] Sp orts-Reference. Retriev ed from: http://www.sports- reference.com/ , 2013. [5] Roy Williams. Retrieved from: http://www.goheels.com/ViewArticle. dbml?ATCLID=205497516 , 2014. [6] Stephen P . Borgatti. Centralit y and net w ork flo w. So cial Networks , 27(1):55– 71, January 2005. [7] JA Nelder and R Mead. A simplex metho d for function minimization. The Computer Journal , 1965. [8] MJD Po well. An efficient metho d for finding the minimum of a function of sev eral v ariables without calculating deriv ativ es. The Computer Journal , 1964. [9] Leo Spizzirri. Justification and Application of Eigen vector Cen trality. 2011. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment