Constraint-based Causal Discovery from Multiple Interventions over Overlapping Variable Sets
Scientific practice typically involves repeatedly studying a system, each time trying to unravel a different perspective. In each study, the scientist may take measurements under different experimental conditions (interventions, manipulations, pertur…
Authors: Sofia Triantafillou, Ioannis Tsamardinos
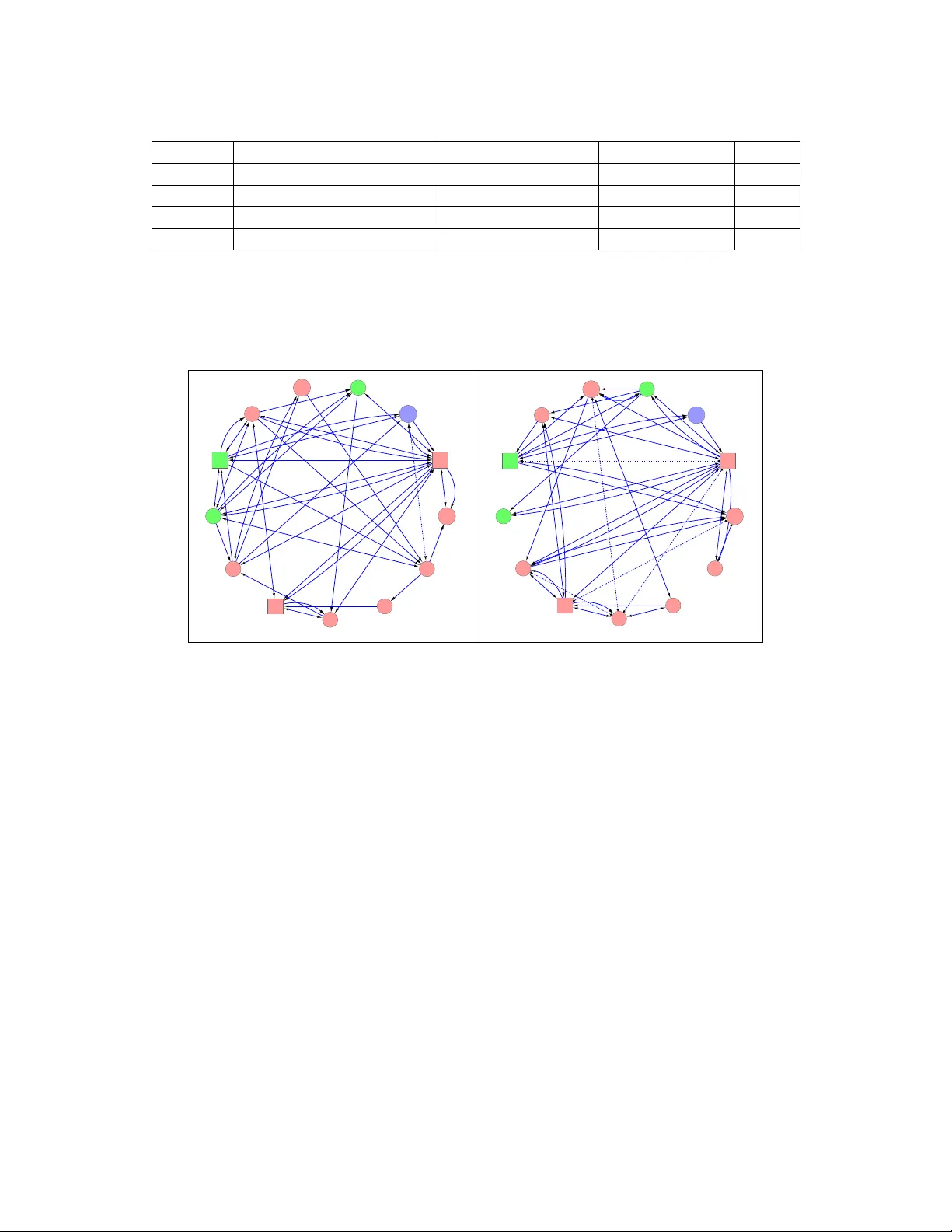
Constrain t-based Causal Disco v ery from Multiple In terv en tions o v er Ov erlapping V ariable Sets Sofia T rian tafillou ∗ striant@ics.for th.gr Ioannis Tsamardinos ∗ tsamard@ics.for th.gr Institute of Computer Scienc e F oundation for R ese ar ch and T e chnolo gy - Hel las (F OR TH) N. Plastir a 100 V assilika V outon GR-700 13 Her aklion, Cr ete, Gr e e c e Abstract Scien tific practice t ypically in v olves rep eatedly studying a system, eac h time trying to un- ra vel a differen t persp ectiv e. In eac h study , the scientist ma y tak e measurements under differen t exp erimen tal conditions (in terven tions, manipulations, p erturbations) and mea- sure different sets of quan tities (v ariables). The result is a collection of heterogeneous data sets coming from different data distributions. In this w ork, we present algorithm COm- bINE, whic h accepts a collection of data sets ov er ov e r lapping v ariable sets under different exp erimen tal conditions; COmbINE then outputs a summary of all causal mo dels indicat- ing the inv ariant and v ariant structural c haracteristics of all mo dels that simultaneously fit all of the input data sets. COmbINE conv erts estimated dependencies and indep endencies in the data in to path constrain ts on the data-generating causal model and enco des them as a SA T instance. The algorithm is sound and complete in the sample limit. T o accoun t for conflicting constrain ts arising from statistical errors, w e introduce a general metho d for sorting constraints in order of confidence, computed as a function of their correspond- ing p-v alues. In our empirical ev aluation, COmbINE outperforms in terms of efficiency the only pre-existing similar algorithm; the latter additionally admits feedbac k cycles, but do es not admit conflicting constraints whic h hinders the applicability on real data. As a pro of-of-concept, COmbINE is employ ed to co-analyze 4 real, mass-cytometry data sets measuring phosphorylated protein concentrations of ov erlapping protein sets under 3 dif- feren t in terven tions. 1. In tro duction Causal disco very is an abiding goal in almost ev ery scientific field. In order to disco ver the causal mec hanisms of a system, scientists t ypically ha ve to perform a series of exp erimen ts (in terchangeably: manipulations, interv entions, or p erturbations). Eac h exp erimen t adds to the existing kno wledge of the system and sheds light to the sought-after mec hanism from a different p ersp ectiv e. In addition, each measuremen t may include a differen t set of quan tities (v ariables), when for example the technology used allo ws only a limited num b er of measured quantities. Ho wev er, for the most part, mac hine learning and statistical metho ds fo cus on analyzing a single data set. They are unable to mak e joint inferences from the complete collection of a v ailable heterogeneous data sets, since eac h one is following a different data distribution ∗ . Also in Department of Computer Science, Universit y of Crete. 1 (alb eit stemming from the same system under study). Thus, data sets are often analyzed in isolation and indep endently of eac h other; the resulting knowledge is typically syn thesized ad ho c in the researc her’s mind. The prop osed w ork tries to automate the ab ov e inferences. W e prop ose a general, constrain t-based algorithm named COmbINE for learning causal structure characteristics from the integrativ e analysis of collections of data sets. The data sets can b e heterogeneous in the follo wing manners: they ma y b e measuring differen t o verlapping sets of v ariables O i under different hard manipulations on a set of observ ed v ariables I i . A hard manipulation on a v ariable I , corresp onds to a Randomized Con trolled T rial (Fisher, 1922) where the exp erimen tation pro cedure completely eliminates an y other causal effect on I (e.g., ran- domizing mice to t wo groups having t wo differen t diets; the effect of all other factors on the diet is completely eliminated). What connects together the av ailable data sets and allo ws their co-analysis is the as- sumption that ther e exists a single underlying c ausal me chanism that gener ates the data , ev en though it is measured with a differen t exp erimen tal setting eac h time. A causal mo del is plausible as an explanation if it simultaneously fits all data-sets when the effect of ma- nipulations and selection of measured v ariables is tak en into consideration. COm bINE searc hes for the set of causal mo dels that simultaneously fits all av ailable data-sets in the sense giv en abov e. The algorithm outputs a summary net w ork that includes all the v ariant and in v arian t pairwise causal characteristics of the set of fitting models. F or example, it indicates the causal relations up on whic h all fitting mo dels agree, as well as the ones for which conflicting explanations are plausible. As our formalism of choice for causal mo deling, we emplo y Semi-Marko v Causal Mo dels ( SMCMs ). SMCMs (Tian and P earl, 2003) are extensions of Causal Bay esian Netw orks ( CBNs ) that can accoun t for laten t confounding v ariables, but do not admit feedback cycles. In ternally , the algorithm also mak es heavy use of the theory and learning algorithm for Maximal Ancestral Graphs ( MA Gs ) (Richardson and Spirtes, 2002). The algorithm builds upon the ideas in T rian tafillou et al. (2010) to con vert the observ ed statistical dep endencies and indep endencies in the data to path constraints on the plausible data generating structures. The constrain ts are encoded as a SA T instance and solved with mo dern SA T engines, exploiting the efficiency of state-of-the-art solv ers. How ever, due to statistical errors in the determination of dependencies and indep endencies, conflicting con- strain ts may arise. In this case, the SA T instance is unsolv able and no useful information can b e inferred. COm bINE includes a technique for sorting constraints according to con- fidence: The constrain ts are added to the SA T instance in increasing order of confidence, and the ones that conflict with the set of higher-rank ed constrain ts are discarded. The tech- nique is general and the ranking score is a function of the p-v alues of the statistical tests of independence. It can therefore b e applied to any type of data, pro vided an appropriate test exists. COm bINE is empirically compared against a similar, recen tly developed algorithm b y Hyttinen et al. (2013). The latter is also based on conv ersion to SA T and is able to addi- tionally deal with cyclic structures, but assumes lack of statistical errors and corresp onding conflicts. It can therefore not be directly applied to t ypical real problems that ma y generate suc h conflicts. COm bINE prov es to b e more efficient than Hyttinen et al. (2013) and scales to larger problem sizes, due to an inherently more compact representation of the path- 2 constrain ts. The empirical ev aluation also includes a quantification of the effect of sample size, n umber of data-sets co-analyzed, and other factors on the quality and computational efficiency of learning. In addition, the prop osed conflict resolution technique’s sup eriorit y is demonstrated o ver sev eral other alternative conflict resolution methods. Finally , we presen t a pro of-of-concept computational exp eriment b y applying the algorithm on 5 heterogeneous data sets from Bendall et al. (2011) and Bo denmiller et al. (2012) measuring ov erlapping v ariable sets under 3 different manipulations. The data sets measure protein concentrations in thousands of human cells of the autoimmune system using mass-cytometry technologies. Mass cytometers can perform single-cell measuremen ts with a rate of ab out 10,000 cells per second, but can curren tly only measure up to circa 30 v ariables p er run. Thus, they seem to form a suitable test-b ed for integrativ e causal analysis algorithms. The rest of this paper is organized as follo ws: Section 2 presen ts the related literature on learning causal mo dels and com bining multiple data sets. Section 3 reviews the necessary theory of MAGs and SMCMs and discusses the relation b et ween the t wo and ho w hard manipulations are mo deled in eac h. Section 4 is the core of this pap er, and it is split in three subsections; presen ting the conv ersion to SA T; introducing the algorithm and pro ving soundness and completeness; introducing the conflict resolution strategy . Section 5 is de- v oted to the exp erimen tal ev aluation of the algorithm: testing the algorithm’s p erformance in sev eral settings and presenting an actual case study where the algorithm can b e applied. Finally , Section 6 summarizes the conclusions and prop oses some future directions of this w ork. 2. Related W ork Metho ds for causal disco very ha v e b een, for the most part, limited to the analysis of a single data set. How ever, the great adv ancement of in terven tion and data collection technology has led to a v ast increase of a v ailable data sets, b oth observ ational and experimental. Therefore, o ver the last few years, there hav e b een a num b er of w orks that fo cus on causal discov ery from m ultiple sources. Algorithms in that area ma y differ in the formalism the use to mo del causalit y or in the type of heterogeneity in the studies they co-analyze. In any case, the goal is alwa ys to discov er the single underlying data-generating causal mec hanism. One group of algorithms focuses on com bining observ ational data that measure o v erlap- ping v ariables. Tillman et al. (2008) and T riantafillou et al. (2010) b oth pro vide sound and complete algorithms for learning the common characteristics of MAGs from data sets mea- suring o verlapping v ariables. Tillman et al. (2008) handles conflicts by ignoring conflicting evidence, while the metho d presen ted in T riantafillou et al. (2010) on ly w orks with an oracle of conditional indep endence. Tillman and Spirtes (2011) presen t an algorithm for the same task that handles a limited type of conflicts (those conserning p-v alues for the same pair of v ariables stemming from different data sets) by combining the p-v alues for conditional indep endencies that are testable in more than one data sets. Claassen and Heskes (2010b) presen t a sound, but not complete, algorithm for causal structure learning from multiple indep endence mo dels ov er o verlapping v ariables b y transforming indep endencies into a set of causal ancestry rules. Another line of w ork deals with learning causal mo dels from m ultiple exp erimen ts. Co op er and Y o o (1999) use a Ba y esian score to com bine exp erimental and observ ational 3 data in the context of causal Bay esian netw orks. Hauser and B ¨ uhlmann (2012) extend the notion of Marko v equiv alence for DA Gs to the case of interv entional distributions arising from mul tiple experiments, and prop ose a learning algorithm. T ong and Koller (2001) and Murph y (2001) use Bay esian net work theory to prop ose exp eriments that are most informa- tiv e for causal structure discov ery . Eb erhardt and Sc heines (2007) and Eaton and Murphy (2007a) discuss how some other types of interv en tions can b e mo deled and used to learn Ba yesian net w orks. Hyttinen et al. (2012a) pro vides an algorithm for learning linear cyclic mo dels from a series of exp erimen ts, along with sufficien t and necessary conditions for iden- tifiabilit y . This metho d admits laten t confounders but uses linear structural equations to mo del causal relations and is therefore inherently limited to linear relations. Meganc k et al. (2006) propose learning SMCMs by learning the Mark o v equiv alence classes of MAGs from observ ational data and then designing the experiments necessary to con vert it to a SMCM. Finally , there is a limited n um b er of methods that attempt to co-analyze data sets mea- suring ov erlapping v ariables under different experimental conditions. In Hyttinen et al. (2012b) the authors extend the methods of Hyttinen et al. (2012a) to handle o verlap- ping v ariables, again under the assumption of linearit y . Hyttinen et al. (2013) prop ose a constraint-based algorithm for learning causal structure from differen t manipulations of o verlapping v ariable sets. The metho d works b y transforming the observed m -connection and m -separation constraints in to a SA T instance. The metho d uses a path analysis heuris- tic to reduce the n umber of tests translated into path constraints. Causal insufficiency is allo wed, as w ell as feedbac k cycles. How ev er, this metho d cannot handle conflicts and there- fore relies on an oracle of conditional indep endence. Moreov er, the method can only scale up to about 12 v ariables. Claassen and Hesk es (2010a) presen t an algorithm for learning causal mo dels from multiple exp eriments; the exp eriments here are not hard manipulations, but general exp erimental conditions, mo deled like v ariables that ha ve no paren ts in the graph but can cause other v ariables in some of the conditions. T o the best of our knowledge, COm bINE is the first algorithm to address both ov erlap- ping v ariables and multiple in terven tions for acyclic structures without relying on sp ecific parametric assumptions or requiring an oracle of conditional indep endence. While the lim- its of COm bINE in terms of input size hav e not b een exhaustiv ely c heck ed, the algorithm scales up to net works of up to 100 v ariables for relatively sparse net works (maxim um n umber of parents equals 5). 3. Mixed Causal Mo dels Causally insufficient systems are often describ ed using Semi-Marko v causal models (SM- CMs) (Tian and P earl, 2003) or Maximal Ancestral Graphs (MAGs) (Richardson and Spirtes, 2002). Both of them are mixed graphs , meaning they can con tain b oth directed ( ) and bi-directed ( ) edges. W e use the term mixed causal graph to denote b oth. In this section, we will briefly present their common and unique prop erties. First, let us review the basic mixed graph notation: In a mixed graph G , a path is a sequence of distinct no des h V 0 , V 1 , . . . , V n i s.t for 0 ≤ i < n , V i and V i +1 are adjacent in G . X is called a parent of Y and Y a c hild of X in G if X Y in G . A path from V 0 to V n is directed if for 0 ≤ i < n , V i is a paren t V i +1 . X is called a ancestor of Y and Y is called a descendant of X in G if X = Y in G or there exists a 4 directed path from X to Y in G . W e use the notation P a G ( X ) , Ch G ( X ) , An G ( X ) , Desc G ( X ) to denote the set of parents, children, ancestors and descendants of no des X in G . A directed cycle in G o ccurs when X → Y ∈ E and Y ∈ An G ( X ). An almost directed cycle in G o ccurs when X ↔ Y ∈ E and Y ∈ An G ( X ). Giv en a path p in a mixed graph, a non-endp oin t no de V on p is called a collider if the t w o edges inciden t to V on p are both in to V . Otherwise V is called a non-collider . A path p = h X , Y , Z i , where X and Z are not adjacen t in G is called an unshielded triple . If Z is a collider on this path, the triple is called an unshielded collider . A path p = h X . . . W, V , Y i is called discriminating for V if X is not adjacen t to Y and ev ery no de on the path from X to V is a collider and a paren t of Y . MA Gs and SMCMs are graphical models that represen t b oth causal relations and condi- tional indep endencies among a set of measured (observed) v ariables O , and can b e view ed as generalizations of causal Bay esian netw orks that can account for laten t confounders. MA Gs can also accoun t for selection bias, but in this work we assume selection bias is not present. sufficien t. W e call this h yp othetical extended model the underlying causal D AG . 3.1 Semi-Marko v Causal Mo dels Semi-Mark ov causal mo dels (SMCMs), in tro duced by Tian and Pearl (2003), often also rep orted as Acyclic Directed Mixed Graphs (ADMGs), are causal models that implicitly mo del hidden confounders using bi-directed edges. A directed edge X Y denotes that X is a dir e ct cause of Y in the con text of the v ariables included in the model. A bi-directed edge X Y denotes that X and Y are confounded by an unobserved v ariable. Two v ariables can b e joined b y at most t wo edges, one directed and one bi-directed. Semi-Mark ov causal models are designed to represen t marginals of causal Bay esian net- w orks. In DA Gs, the probabilistic prop erties of the distribution of v ariables included in the mo del can b e determined graphically using the criterion of d -separation. The natural extension of d-separation to mixed causal graphs is called m -separation: Definition 1 ( m -c onne ction, m -sep ar ation) In a mixe d gr aph G = ( E , V ) , a p ath p b etwe en A and B is m-c onne cting given (c onditione d on) a set of no des Z , Z ⊆ V \ { A, B } if 1. Every non-c ol lider on p is not a memb er of Z . 2. Every c ol lider on the p ath is an anc estor of some memb er of Z . A and B ar e said to b e m -sep ar ate d by Z if ther e is no m -c onne cting p ath b etwe en A and B r elative to Z . Otherwise, we say they ar e m -c onne cte d given Z . Let G b e a SMCM o ver a set of v ariables O , P the joint probabilit y distribution (JPD) o ver the same set of v ariables and J the indep endence mo del, defined as the set of condi- tional indep endencies that hold in P . W e use h X , Y | Z i to denote the conditional indep en- dence of v ariables in X with v ariables in Y giv en v ariables in Z . Under the Causal Marko v ( CMC ) and F aithfulness ( F C ) conditions (Spirtes et al., 2001), every m -sep ar ation pr esent in G c orr esp onds to a c onditional indep endenc e in J and vic e-versa. In causal Ba yesian netw orks, ev ery missing edge in G corresp onds to a conditional inde- p endence in J , meaning there exists a subset of the v ariables in the mo del that renders the 5 t wo non-adjacen t v ariables indep endent. Resp ectively , every conditional indep endence in J corresp onds to a missing edge in the DA G G . This is not alwa ys true for SMCMs. Figure 1 illustrates an example of a SMCM where t wo non-adjacent v ariables are not indep endent giv en any subset of observed v ariables. Ev ans and Richardson (2010, 2011) deal with the factorization and parametrization of SMCMs for discrete v ariables. Based on this parametrization, score-based metho ds hav e also recently b een explored Richardson et al. (2012); Shpitser et al. (2013), but are still limited to small sets of discrete v ariables. T o the b est of our kno wledge, there exists no constrain t-based algorithm for learning the structure of SMCMs, probably due to the fact that the lac k of conditional indep endence for a pair of v ariables do es not necessarily mean non-adjacency . Ric hardson and Spirtes (2002) ov ercome this obstacle by introducing a causal mixed graph with sligh tly different seman tics, the maximal ancestral graph. 3.2 Maximal Ancestral Graphs Maximal ancestral graphs (MAGs) are ancestral mixed graphs, meaning that they contain no directed or almost directed cycles. Every pair of v ariables X , Y in an ancestral graph is joined by at most one edge. The orientation of this edge represen ts (non) causal ancestry: A bi-directed edge X Y denotes that X do es not cause Y and Y do es not cause X , but (under the faithfulness assumption) the t w o share a laten t confounder. A directed edge X Y denotes causal ancestry: X is a c ausal anc estor of Y . Thus, if X causes Y (not necessarily directly in the context of observed v ariables) and they are also confounded, there is an edge X Y in the corresponding MAG. Undirected edges can also be present in MA Gs that accoun t for selection bias. As men tioned abov e, w e assume no selection bias in this work and the theory of MA Gs presented here is restricted to MA Gs with no undirected edges. Lik e SMCMs, ancestral graphs are also designed to represen t marginals of causal Bay esian net works. Th us, under the causal Mark o v and faithfulness conditions, X and Y are m - separated given Z in an ancestral graph M if and only if h X , Y | Z i is in the corresp onding indep endence mo del J . Still, lik e in SMCMs, a missing edge do es not necessarily corre- sp ond to a conditional indep endence. The follo wing definition des crib es a subset of ancestral graphs in whic h every missing edge (non-adjacency) corresp onds to a conditional indep en- dence: Definition 2 (Maximal Anc estr al Gr aph, MAG)(R ichar dson and Spirtes, 2002) A mixe d gr aph is c al le d ancestral if it c ontains no dir e cte d and almost dir e cte d cycles. An anc estr al gr aph G is c al le d maximal if for every p air of non-adjac ent no des ( X , Y ) , ther e is a (p ossibly empty) set Z , X , Y / ∈ Z such that h X, Y | Z i ∈ J . Figure 1 illustrates an ancestral graph that is not maximal, and the corresp onding maximal ancestral graph. MA Gs are closed under marginalization (Richardson and Spirtes, 2002). Thus, if G is a MA G faithful to P , then there is a unique MA G G 0 faithful to any marginal distribution of P . W e use [ L to denote the act of marginalizing out v ariables L , thus, if G is a MAG ov er v ariables O ∪ L faithful to a join t probabilit y distribution P , G [ L is the MA G ov er O faithful to the marginal join t probabilit y distribution P [ L . Obviously , the D AG of a causal Ba yesian 6 A B C D A B C D (a) (b) Figure 1: Maximality and primitiv e inducing paths .(a) Both (i) a semi Mark ov causal mo del ov er v ariables { A, B , C , D } . V ariables A and D are m -connected given an y subset of observed v ariables, but they do not share a direct relationship in the con text of observ ed v ariables and (ii) a non-maximal ancestral graph ov er v ariables { A, B , C, D } . (b) The corresp onding MA G. A and D are adjacen t, since they cannot b e m -separated given an y subset of { B , C } . Path h A, B , C , D i is a primitive inducing path. This example was presen ted in Zhang (2008b). net work is also a MAG. F or a MAG G ov er O and a set of v ariables L ⊂ O , the marginal MA G G [ L is defined as follows: Definition 3 (Richar dson and Spirtes, 2002) MAG G [ L has no de set O \ L and e dges sp e cifie d as fol lows: If X , Y ar e s.t. ∀ Z ⊂ O \ L ∪ { X, Y } , X and Y ar e m -c onne cte d given Z in G , then if X / ∈ An G ( Y ); Y / ∈ An G ( X ) X ∈ An G ( Y ); Y / ∈ An G ( X ) X / ∈ An G ( Y ); Y ∈ An G ( X ) then X ↔ Y X → Y X ← Y in G [ L As men tioned ab o ve, ev ery conditional independence in an indep endence model J corre- sp onds to a missing edge in the corresp onding faithful MAG G . Con versely , if X and Y are dep enden t giv en every subset of observ ed v ariables, then X and Y are adjacen t in G . Thus, giv en an oracle of conditional indep endence it is possible to learn the skeleton of a MAG G o ver v ariables O from a data set. Still, some of the orientations of G are not distinguishable b y mere observ ations. The set of MAGs G faithful to distributions P that entail a set of conditional indep endencies form a Mark ov equiv alence class . The following result w as pro ved in Spirtes and Richardson (1996): Prop osition 4 Two MAGs over the same variable set ar e Markov e quivalent if and only if: 1. They shar e the same e dges. 2. They shar e the same unshielde d c ol liders. 3. If a p ath p is discriminating for a no de V in b oth gr aphs, V is a c ol lider on the p ath on one gr aph if and only if it is a c ol lider on the p ath on the other. W e use [ G ] to denote the class of MAGs that are Marko v equiv alent to G . A partial ancestral graph (P AG) is a representativ e graph of this class, and has the sk eleton shared b y all the graphs in [ G ], and all the orientations in v ariant in all the graphs in [ G ]. Endp oints 7 that can be either arro ws or tails in differen t MA Gs in G are denoted with a circle “ ◦ ” in the represen tative P A G. W e use the sym b ol as a wildcard to denote an y of the three marks. W e use the notations M ∈ P to denote that MAG M b elongs to the Marko v equiv alence class represented by P AG P , and w e use the notation M ∈ J to denote that MAG M is faithful to the conditional indep endence mo del J . F CI Algorithm (Spirtes et al., 2001; Zhang, 2008a) is a sound and complete algorithm for learning the complete (maximally informativ e) P AG of the MAGs faithful to a distribution P o ver v ariables O in whic h a set of conditional indep endencies J hold. An imp ortant adv antage of FCI is that it employs CMC, faithfulness and some graph theory to reduce the n umber of tests required to identify the correct P A G. 3.3 Corresp ondence b etw een SMCMs and MAGs Semi Marko v Causal Mo dels and Maximal Ancestral Graphs b oth represent causally in- sufficien t causal structures, but they hav e some significant differences. While they b oth en tail the conditional independence and causal ancestry structure of the observ ed v ariables, SMCMs describ e the causal relations among observed v ariables, while MAGs enco de inde- p endence structure with partial causal ordering. Edge semantics in SMCMs are closer to the seman tics of causal Bay esian netw orks, whereas edge seman tics in MAGs are more com- plicated. On the other hand, unlik e in DA Gs and MA Gs, a missing edge in a SMCM do es not necessarily corresp ond to a conditional independence (SMCMs do not ob ey a pairwise Mark ov property). Figure 2 summarizes the main differences of SMCMs and MAGs. It sho ws t w o differen t D AGs, and the corresp onding marginal SMCMs and MAGs ov er four observed v ariables. SMCMs hav e a many-to-one relationship to MAGs: F or a MAG M , there can exist more than one SMCMs that entail the same probabilistic and causal ancestry relations. On the other hand, for an y giv en SMCM there exists only one MAG entailing the same probabilistic and causal ancestry relations. This is clear in Figure 2, where a unique MAG, M 1 = M 2 en tails the same information as tw o different SMCMs, S 1 and S 2 in the same figure. Directed edges in a SMCM denote a causal relation that is dir e ct in the context of observ ed v ariables. In con trast, a directed edge in a MAG merely denotes causal ancestry; the causal relation is not necessarily direct. An edge X Y can be presen t in a MA G even though X do es not directly causes Y ; this happ ens when X is a causal ancestor of Y and the tw o cannot b e rendered indep enden t giv en any subset of observed v ariables. Dep ending on the structure of latent v ariables, this edge can be either missing or bi-directed in the resp ectiv e SMCM. In Figure 2 we can see examples of b oth cases. F or example, A is a causal ancestor of D in D A G G 1 , but not a direct cause (in the context of observ ed v ariables). Therefore, the t wo are not adjacent in the corresp onding SMCM S 1 o ver { A, B , C , D } . Ho wev er, the tw o cannot b e rendered independent giv en an y subset of { B , C } , and therefore A D is in the resp ectiv e MA G M 1 . On the same DA G, B is another causal ancestor (but not a direct cause) of D . The t wo v ariables s hare the common cause L . Th us, in the corresp onding SMCM S 1 o ver { A, B , C, D } w e can see the edge B D . How ev er, a bi-directed edge b etw een B and D is 8 A B C L D G 1 : A B C D S 1 : A B C D M 1 : A B C D P 1 : A B C D G 2 : A B C D S 2 : A B C D M 2 : A B C D P 2 : Figure 2: An example t w o differen t D A Gs and the corresp onding mixed causal graphs o ver observ ed v ariables . On the righ t w e can see DA Gs G 1 o ver v ariables { A, B , C, D , L } (top) and G 2 o ver v ariables { A, B , C , D } (b ottom). F rom left to right, on the same ro w as the underlying causal DA G, we can see the resp ectiv e SMCMs S 1 and S 2 o ver { A, B , C, D } ; the resp ective MAGs M 1 = G 1 [ L and M 2 = G 2 o ver v ariables { A, B , C, D } ; finally , the resp ective P AGs P 1 and P 2 . Notice that, M 1 and M 2 are identical, despite representing differen t underlying causal structures. A B C L D G C 1 : A B C D S C 1 : A B C D M C 1 : A B C D P C 1 : A B C D G C 2 : A B C D S C 2 : A B C D M C 2 : A B C D P C 2 : Figure 3: Effect of manipulating v ariable C on the causal graphs of Figure 2 . F rom righ t to left we can see the manipulated DA Gs G C 1 (top) and G C 2 (b ottom), the manipulated SMCMs S C 1 (top) and S C 2 (b ottom) ov er v ariables { A, B , C , D } , the manipulated MA Gs M C 1 = G C 1 [ L (top) and M C 2 = G C 2 (b ottom) ov er the same set of v ariables, and the corresp onding P AGs P C 1 (top) and P C 2 (b ottom). Notice that edge A D is remo v ed in M C 1 , ev en though it is not adjacen t to the manipulated v ariable. Moreov er, on the same graph, edge B D is now B D . not allow ed in MA G M 1 , since it w ould create an almost directed cycle. Th us, B D is in M 1 . W e must also note that unlike SMCMs, MAGs only allow one edge p er v ariable pair. Th us, if X directly causes Y and the t wo are also confounded, b oth edges will b e in a relev ant SMCM ( X Y ), while the tw o will share a directed edge from X to Y in the corresp onding MAG. Ov erall, a SMCM has a subset of adjacencies (but not necessarily edges) of its MAG coun terpart. These extra adjacencies corresp ond to pairs of v ariables that cannot b e m - separated giv en any subset of observ ed v ariables, but neither directly causes the other, and 9 the tw o are not confounded. These adjacencies can b e chec k ed in a SMCM using a sp ecial t yp e of path, called inducing path (Richardson and Spirtes, 2002). Definition 5 (inducing p ath) A p ath p = h V 1 , V 2 , . . . , V n i on a mixe d c ausal gr aph G over a set of variables V = O ˙ ∪ L is c al le d inducing with r esp e ct to L if every non-c ol lider on the p ath is in L and every c ol lider is an anc estor of either V 1 or V n . A p ath that is inducing with r esp e ct to the empty set is c al le d a primitive inducing p ath. Ob viously , an edge joining X and Y is a primitive inducing path. In tuitively , an inducing path with resp ect to L is m -connecting giv en any subset of v ariables that do es not include v ariables in L . P ath A B L D is an inducing path with resp ect to L in G 1 of Figure 2, and A B D is an inducing path with resp ect to the empty set in S 1 of the same figure. Inducing paths are extensively discussed in Ric hardson and Spirtes (2002), where the following theorem is pro ved: Theorem 6 If G is an anc estr al gr aph over variables V = O ˙ ∪ L , and X , Y ∈ O then the fol lowing statements ar e e quivalent: 1. X and Y ar e adjac ent in G [ L . 2. Ther e is an inducing p ath with r esp e ct to L in G . 3. ∀ Z , Z ⊆ V \ L ∪ { X , Y } , X and Y ar e m -c onne cte d given Z in G . Pro of See pro of of Theorem 4.2 in Richardson and Spirtes (2002). This theorem links inducing paths in an ancestral graph to m -separations in the same graph and to adjacencies in any marginal ancestral graph. The equiv alence of (ii) and (iii) can also b e pro v ed for SMCMs, using the pro of presen ted in Richardson and Spirtes (2002) for Theorem 6: Theorem 7 If G is a SMCM over variables V = O ˙ ∪ L , and X , Y ∈ O then the fol lowing statements ar e e quivalent: 1. Ther e is an inducing p ath with r esp e ct to L in G . 2. ∀ Z , Z ⊆ V \ L ∪ { X , Y } , X and Y ar e m -c onne cte d given Z in G . Primitiv e inducing paths are connected to the notion of maximalit y in ancestral graphs: Ev ery ancestral graph can b e transformed in to a maximal ancestral graph with the addition of a finite num b er of bi-directed edges. Such edges are added b etw een v ariables X, Y that are m-connected through a primitive inducing path (Ric hardson and Spirtes, 2002). P ath A B C D in Figure 1 is an e xample of a primitive inducing path. Inducing paths are crucial in this work b ecause adjacencies and non-adjacencies in marginal ancestral graphs can b e translated in to existence or absence of inducing paths in causal graphs that include some additional v ariables. F or example, path A B L D is an inducing path w.r.t. L in G 1 in Figure 2, and therefore A and D are adjacen t in 10 Algorithm 1: SMCMtoMAG input : SMCM S output : MAG M 1 M←S ; 2 foreac h or der e d p air of variables X , Y not adjac ent in S do 3 if ∃ primitive inducing p ath fr om X to Y in S then 4 if X ∈ An S ( Y ) then 5 add X Y to M ; 6 else if Y ∈ An S ( X ) then 7 add Y X to M ; 8 else 9 add Y X to M ; 10 end 11 end 12 end 13 foreac h X Y in M do 14 remo ve X Y ; 15 end M 1 . Th us, inducing paths are useful for combining causal mixed graphs ov er o verlapping v ariables. Inducing paths are also necessary to decide whether t wo v ariables in an SMCM will b e adjacent in a MAG o ver the same v ariables without having to chec k all p ossible m - separations. Algorithm 1 describ es how to turn a SMCM in to a MAG ov er the same v ariables. T o prov e the algorithm’s soundness, w e first need to pro ve the follo wing: Prop osition 8 L et O b e a set of variables and J the indep endenc e mo del over V . L et S b e a SMCM over variables V that is faithful to J and M b e the MAG over the same variables that is faithful to J . L et X, Y ∈ O . Then ther e is an inducing p ath b etwe en X and Y with r esp e ct to L , L ⊆ V in S if and only if ther e is an inducing p ath b etwe en X and Y with r esp e ct to L in M . Pro of See App endix 6.. Algorithm 1 takes as input a SMCM and adds the necessary edges to transform it in to a MA G by lo oking for primitive inducing paths. The soundness of the algorithm is a direct consequence of Prop osition 8. The in v erse procedure, con verting a MA G in to the underlying SMCM, is not p ossible, since w e cannot kno w in general whic h of the edges corresp ond to direct causation or confounding and whic h are there b ecause of a (non-trivial) primitive inducing path. Note though that, there exist sound and complete algorithms that iden tify all edges for which such a determination is p ossible (Borboudakis et al., 2012). In addition, w e later show that co-examining manipulated distributions can indicate that some edges stand for indirect causality (or indirect confounding). 11 3.4 Manipulations under causal insufficiency An imp ortant motiv ation for using causal mo dels is to predict causal effects. In this work, we fo cus on hard manipulations, where the v alue of the manipulated v ariables is set exclusiv ely b y the manipulation pro cedure. W e also adopt the assumption of lo cality , denoting that the interv ention of eac h manipulated v ariable should not directly affect an y v ariable other than its direct target, and more imp ortantly , lo cal mechanisms for other v ariables should remain the same as b efore the in terv ention (Zhang, 2006). Thus, the in terven tion is merely a lo cal surgery with resp ect to causal mechanisms. These assumptions may seem a bit restricting, but this t yp e of exp eriment is fairly common in several mo dern fields where the tec hnical capability for precise interv en tions is av ailable, suc h as, for example, molecular biology . Finally , we assume that the manipulated mo del is faithful to the corresponding manipulated distributions. In the context of causal Ba yesian net works, hard in terv entions are mo deled using what is referred to as “graph surgery”, in whic h all edges incoming to the manipulated v ariables are remo ved from the graph. The resulting graph is referred to as the manipulated graph . P arameters of the distribution that refer to the probabilit y of manipulated v ariables given their parents are replaced b y the parameters set by the manipulation pro cedure, while all other parameters remain in tact. Naturally , D AGs are closed under manipulation. W e use the term in terven tion target to denote a set of manipulated v ariables. F or a D A G D and an interv en tion target I , w e use D I to denote the manipulated DA G. The same notation (the interv en tion targets as a sup erscript) is used to denote a manipulated indep endence mo del. Graph surgery can be easily extended to SMCMs: One m ust simply remov e edges into the manipulated v ariables. Again, we use the notation S I to denote the graph resulting from a SMCM S after the manipulation of v ariables in I . On the contrary , predicting the effect of manipulations in MAGs is not trivial. Due to the complicated semantics of the edges, the manipulated graph is usually not unique. This becomes more obvious by lo oking at Figures 2 and 3. Figure 2 shows tw o different causal DA Gs and the corresp onding SMCMs and MAGs, and Figure 3 shows the effect of a manipulation on the same graphs. In Figure 2 the marginals DA Gs D 1 and D 2 are represen ted by the same MA G M 1 = M 2 . Ho w ever, after manipulating v ariable C , the resulting manipulated MA Gs M C 1 and M C 2 do not b elong to the same equiv alence class (they do not even share the same sk eleton). W e m ust p oin t out, that the indistinguishabilit y of M 1 and M 2 refers to m -separation only; the absence of a direct causal edge b etw een A and D could b e detected using other t yp es of tests, like the V erma constrain t (V erma and P earl, 2003). While we cannot predict the effect of manipulations on a MA G M , given a data set measuring v ariables O when v ariables in I ⊂ O are manipulated, w e can obtain (assuming an oracle of conditional indep endence) the P AG representativ e of the actual manipulated MA G M I . W e use P I to denote this P AG. Moreov er, b y observing P AGs {P I i } i that stem from different manipulations of the same underlying distribution, we can infer some more refined information for the underlying causal mo del. Let’s suppose, for example, that G 1 in Figure 2 is the true underlying causal graph for v ariables { A, B , C, D , L } and that we hav e the learnt P AGs P A 1 and P C 1 from relev an t data 12 sets. Graph P A 1 is not shown, but is identical to P 1 in Figure 2 since A has no incoming edges in the underlying D AG (and SMCM). P C 1 is illustrated in Figure 3. Edge A D is present in P A 1 , but is missing in P C 1 ev en though neither A nor D are manipulated in P C 1 . By reasoning on the basis of b oth graphs, we can infer that edge A D in P A 1 cannot denote a dir e ct causal relation among the tw o v ariables, but m ust b e the result of a primitiv e, non-trivial inducing path. 4. Learning causal structure from multiple data sets measuring o v erlapping v ariables under different manipulations In the previous section w e describ ed the effect of manipulation on MAGs and saw an exam- ple of how co-examining P AGs faithful to differen t manipulations of the same underlying distribution can help classify an edge b etw een tw o v ariables as not direct. In this section, we expand this idea and presen t a general, constrain t-based algorithm for learning causal structure from ov erlapping manipulations. The algorithm tak es as input a set of data sets measuring ov erlapping v ariable sets { O i } N i =1 ; in each data set, some of the observed v ariables can b e manipulated. The set of manipulated v ariables in data set i is also provided and is denoted with I i . W e assume that there exists an underlying causal mechanism o ver the union of observ ed v ariables O = S i O i that can b e describ ed with a probabilit y distribution P ov er O and a semi Marko v causal mo del S such that P and S are faithful to each other. W e denote with J the indep endence mo del of P . Ev ery manipulation is then performed on S and only on v ariables observ ed in the corresp onding data set. In addition, we assume F aithfulness holds for the manipulated graphs as w ell. The data are then sampled from the manipulated distribution. In eac h data set i , the set L i = O \ O i is laten t. W e denote the independence mo del of each data set i as J i ≡ J I i [ L i . W e no w define the follo wing problem: Definition 9 (Iden tify a consistent SMCM) Given sets { O i } N i =1 , { I i } N i =1 , and {J i } N i =1 identify a SMCM S , such that: M i ∈ J i , ∀ i where M i = SMCMtoMA G( S I i )[ L i that is, M i is the MAG c orr esp onding to the manipulate d mar ginal of S , for e ach data set i . We c al l such a gr aph S a p ossibly underlying SMCM for {J i } N i =1 . W e present an algorithm that con verts the problem ab o ve into a satisfiabilit y instance s.t. a SMCM is consisten t iff it corresponds to a truth-setting assignment of the SA T instance. Notice that, an indep endence mo del J corresponds to a P AG P o ver the same v ariables when they represen t the same Marko v equiv alence class of MA Gs. Thus, in what follo ws we use the corresp onding set of manipulated marginal P AGs {P i } N i =1 instead of the indep endence mo dels {J i } N i =1 . Notice that, P AGs {P i } N i =1 can b e learn t with a sound and complete algorithm such as F CI. In the follo wing section, we discuss con v erting the problem presented abov e into a con- strain t satisfaction problem. 13 F orm ulae relating prop erties of observed P AGs to the underlying SMCM S : adjacen t ( X , Y , P i ) ↔ ∃ p X Y : inducing ( p X Y , i ) unshielded dnc ( X , Y , Z, P i ) → unshielded ( h X , Y , Z i , P i ) ∧ ( ancestor ( Y , X, i ) ∨ ancestor ( Y , Z , i )) discriminating dnc ( h W , . . . , X , Y , Z i , Y , P i ) → ( discr iminating ( h W, . . . , X, Y , Z i , Y , P i ) ∧ ancestor ( Y , X, i ) ∨ ancestor ( Y , Z , i )) unshielded collider ( X , Y , Z, P i ) → unshielded ( h X , Y , Z i , P i ) ∧ ( ¬ ancestor ( Y , X, i ) ∧ ¬ ancestor ( Y , Z , i )) disriminating collider ( h W , . . . , X , Y , Z i , Y , P i ) → ( discr iminating ( h W, . . . , X, Y , Z i , Y , P i ) ∧ ( ¬ ancestor ( Y , X, i ) ∧ ¬ ancestor ( Y , Z , i ))) unshielded ( h X, Y , Z i , P i ) ↔ ad j acent ( X , Y , P i ) ∧ ad j acent ( Y , Z, P i ) ∧ ¬ ad j acent ( X , Z, P i ) discriminating ( h V 0 , V 1 , . . . , V n − 1 , V n , V n +1 i , V n , P i ) ↔ ∀ j V j 6∈ I i ∧ ad j acent ( V j − 1 , Y , P i ) ∧ ancestor ( V j , V n +1 , i ) ∧ ad j acent ( V j − 1 , V j , P i ) ∧ ¬ ancestor ( V j , V j − 1 , i ) ∧ ¬ ancestor ( V j − 1 , V j , i ) F orm ulae reducing path prop erties of S to the core v ariables: inducing ( p X Y , i ) ↔ ∀ j V j 6∈ I i ∧ ( X ∈ I i → tail ( V 1 , X )) ∧ ( Y ∈ I i → tail ( V n , Y )) ∧ ( | p X Y | = 2 → edg e ( X , Y )) ∧ ( | p X Y | > 2 → ∀ j unblock ed ( h V j − 1 , V j , V j +1 i , X , Y , i )) un blo ck ed ( h Z, V , W i , X , Y , i ) ↔ edg e ( Z , V ) ∧ edg e ( V , W ) ∧ [ V ∈ L i → ¬ head 2 head ( Z , V , W, i ) ∨ ancestor ( V , X , i ) ∨ ancestor ( V , Y , i )] ∧ [ V 6∈ L i → head 2 head ( Z , V , W, i ) ∧ ( ancestor ( V , X , i ) ∨ ancestor ( V , Y , i ))] head2head ( X, Y , Z, i ) ↔ Y 6∈ I i ∧ ar r ow ( X , Y ) ∧ ar r ow ( Z, Y ) ancestor ( X, Y , i ) ↔ ∃ p X Y : ancestr al ( p X Y , i ) ancestral ( p X Y , i ) ↔ ∀ j V j 6∈ I i ∧ ( edg e ( V j − 1 , V j ) ∧ tail ( V j , V j − 1 ) ∧ ar r ow ( V j − 1 , V j )) Figure 4: Graph prop erties expressed as b o olean formulae using the v ariables edg e , ar r ow and tail . In all equations, we use p X Y to denote a path of length n+2 b et ween X and Y in S : p X Y = h V 0 = X , V 1 , . . . V j , . . . V n , V n + 1 = Y i . Index i is used to denote exp erimen t i, where v ariables L i are latent and v ariables O i are ma- nipulated. Conjunction and disjunction are assumed to hav e prece dence o ver implication with regard to brac keting. 14 4.1 Conv ersion to SA T Definition 9 implies that eac h M i has the same edges (adjacencies), the same unshielded colliders and the same discriminating colliders as P i , for all i . W e imp ose these constraints on S by conv erting them to a SA T instance. W e express the constraints in terms of the following core v ariables, denoting edges and orien tation orientations in an y consistent SMCM S . • edge( X , Y ): true if X and Y are adjacen t in S , false otherwise. • tail( X , Y ): true if there exists an edge b et ween X and Y in S that is out of Y , false otherwise. • arrow( X , Y ): true if there exists an edge b etw een X and Y in S that is into Y , false otherwise. V ariables tail and arrow are not mutually exclusive, enabling us to represen t X Y edges when tail ( Y , X ) ∧ ar r ow ( Y , X ). Each indep endence model J i is entailed by the (non) adjacencies and (non) colliders in each observed P AG P i . These structural c haracteristics corresp ond to paths in an y p ossibly underlying SMCM as follo ws: 1. ∀ X , Y ∈ O i , X and Y are adjacent in P i if and only if there exists an inducing path b et ween X and Y with resp ect to L i in S I i (b y Theorem s 6 and 7 and Prop osition 8). 2. If h X , Y , Z i is an unshielded definite non collider in P i , then h X , Y , Z i is an unshielded triple in P i and Y is an ancestor of either X or Z in S I i (b y the seman tics of edges in MAGs). 3. If h X , Y , Z i is an unshielded collider in P i , then h X, Y , Z i is an unshielded triple in P i and Y is not an ancestor of X nor Z in S I i (b y the seman tics of edges in MA Gs). 4. If h W, . . . , X, Y , Z i is a discriminating collider in P i , then h W . . . , X, Y , Z i is a dis- criminating path for Y in P i and Y is an ancestor of either X or Z in S I i (b y the seman tics of edges in MAGs). 5. If h W , . . . , X , Y , Z i is a discriminating definite non collider in P i , then h W . . . , X , Y , Z i is a discriminating path for Y in P i and Y is not an ancestor of X nor Z in S I i (b y the semantics of edges in MA Gs). These constraints are expressed using the core v ariables (edges, tails and arro ws), as describ ed in Figure 4. F or example, if X and Y are adjacen t in P i , in a consistent SMCM S there must exist an inducing path p b et ween X and Y in S I i with resp ect to v ariables L i . An y truth-assignmen t to the core v ariables that do es not en tail the presence of suc h an inducing path should not satisfy the SA T instance. The following constrain ts are added to ensure that the graphs satisfying constrain ts 1-5 ab o ve are SMCMs: 6. ∀ X , Y ∈ O , either X is not an ancestor of Y or Y is not an ancestor of X in S (no directed cycles). 7. ∀ X , Y ∈ O , at most one of tail ( X , Y ) and tail ( Y , X ) can be true (no selection bias). 15 Algorithm 2: COmbINE input : data sets { D i } N i =1 , sets of interv en tion targets { I i } N i =1 , FCI parameters p ar ams , maximum path length mpl , conflict resolution strategy str output : Summary graph H 1 foreac h i do P i ← FCI ( D i , p ar ams ) H ← initializeSMCM ( {P i } N i =1 ); 2 (Φ , F ) ← addConstraints ( H , {P i } N i =1 , { I i } N i =1 , mpl ); 3 F 0 ← select a subset of non-conflicting literals F 0 according to strategy str ; 4 H ← backBone (Φ ∧ F 0 ) 8. ∀ X , Y ∈ O , at least one of tail ( X , Y ) and ar r ow ( Y , X ) must be true. Naturally , Constraints 7 and 8 are meaningful only if X and Y are adjacent (if edge(X, Y) is true), and redundan t otherwise. 4.2 Algorithm COmbINE W e now presen t algorithm COmbINE (Causal discov ery from Overlapping INtErv en tions) that learns causal features from multiple, heterogenous data sets. The algorithm tak es as input a set of data sets { D i } N i =1 o ver a set of o verlapping v ariable sets { O i } N i =1 . In each data set, a (possibly empt y) subset of the observ ed v ariables I i ⊂ O i ma y b e manipulated. F CI is run on eac h data set and the corresp onding P AGs {P i } N i =1 are pro duced. The algorithm then creates an candidate underlying SMCM H . Subsequently , for each P AG P i , the features of P i are translated into constraints, expressed in terms of edges and endp oints in H , using the formulae in Figure 4. In the sample limit (and under the assumptions discussed ab o ve), the SA T form ula Φ ∧ F 0 pro duced b y this pro cedure is satisfied by all and only the p ossible underlying SMCMs for { P i } N i =1 . In the presence of statistical errors, ho wev er, Φ ∧ F 0 ma y b e unsatisfiable. T o handle conflicts, the algorithm takes as input a strategy for selecting a non-conflicting subset of constrain ts and ignores the rest. Finally , COmbINE queries the SA T form ula for v ariables that hav e the same truth-v alue in all satisfying assignments, translates them into graph features, and returns a graph that summarizes the in v arian t edges and orientations of all p ossible underlying SMCMs. In the rest of this pap er we call the graphical output of COm bINE a summary graph . The pseudo co de for COm bINE is presen ted in Algorithm 2. Apart from the set of data sets describ ed ab ov e, COm bINE takes as input the chosen parameters for FCI (threshold α , maxim um conditioning set maxK ), the maximum length of p ossible inducing paths to consider and a strategy for selecting a subset of non-conflicting constrain ts. Initially , the algorithm runs FCI on eac h data set D i and pro duces the corresp onding P AG P i . Then the candidate SMCM H is initialized: H is the graph up on which all path constrain ts will b e imp osed. Therefore, H m ust hav e at least a sup erset of edges and at most a subset of orientations of any consisten t SMCM S : If p is an inducing (ancestral) path in S , it must b e a p ossibly inducing (ancestral) path in H . An obvious–y et not v ery smart–c hoice for H would b e the complete unorien ted graph. How ever, lo oking for possible inducing and ancestral paths on the complete unorien ted graph o ver the union of v ariables 16 Algorithm 3: initializeSMCM input : P AGs {P i } N i =1 output : initial graph H 1 H ← empty graph o ver ∪ O i ; 2 foreac h i do H ← add all edges in P i unorien ted Orient only arro wheads that are presen t in ev ery P i ; /* Add edges between variables never measured unmanipulated together */ 3 foreac h p air X , Y of non-adjac ent no des do 4 if 6 ∃ i s.t. X , Y ∈ O i \ I i then 5 add X Y to H ; 6 if ∃ i s.t. X, Y ∈ O i , X ∈ I i , Y 6∈ I i then add arrow in to X if ∃ i s.t. X , Y ∈ O i , Y ∈ I i , X 6∈ I i then add arrow in to Y 7 end 8 end could make the problem in tractable even for small input sizes. T o reduce the num b er of p ossible inducing and ancestral paths, we use Algorithm 3 to construct H . Algorithm 3 constructs a graph H that has all edges observed in any P AG P i as w ell as some additional edges that would not hav e b een observed ev en if they existed: Edges connecting v ariables that ha ve nev er been observ ed together, and edges connecting v ariables that ha ve b een observ ed together, but at least one of them w as manipulated in each join t app earance in a data set. F or example, v ariables X 9 and X 15 in Figure 5 are measured together in t wo data sets: D 2 and D 3 . If X 9 X 15 in the underlying SMCM, this edge w ould b e present in P 3 . Similarly , if X 15 X 9 in the underlying SMCM, the v ariables w ould b e adjacen t in P 2 . W e can therefore rule out the p ossibilit y of a directed edge b et ween the tw o v ariables in S . How ev er, it is p ossible that X 15 and X 9 are confounded in S , and the edge disapp ears by the manipulation pro cedure in b oth P 2 and P 3 . Thus, Algorithm 3 will add these p ossible edges in H . In addition, in Line 2, Algorithm 3 adds all the orien tations found so far in all P i ’s that are inv ariant 1 . The resulting graph has, in the sample limit, a sup erset of edges and a subset of orien tations compared to the actual underlying SMCM. Lemma 10 formalizes and prov es this prop erty . Ha ving initialized the searc h graph, Algorithm 2 pro ceeds to generate the constraints. This pro cedure is describ ed in detail in Algorithm 4, that is the core of COm bINE. These are: (i) the bi-conditionals regarding the presence/absence of edges (Line 4), (ii) conditionals regarding unshielded and discriminating colliders (Lines 12, 13, 17 and 18), (iii) constrain ts that ensure that any truth-setting assignmen t is a SMCM, i.e., it has no directed cycles and that every edge has at least one arrowhead (Lines 7 and 8 resp ectiv ely). 1. Other options w ould b e to keep all non-conflicting arrows, or k eep non-conflicting arrows and tails after some additional analysis on definitely visible edges (see Zhang (2008b), Borboudakis et al. (2012) for more on this sub ject). These options are asymptotically correct and would constrain search even further. Nevertheless, orientation rules in FCI seem to b e prone to error propagation and we c hose a more conserv ative strategy giving a chance to the conflict resolution strategy to impro ve the learning qualit y . Naturally , if an oracle of conditional indep endence is av ailable or there is a reason to b e confiden t on certain features, one can opt to make additional orien tations. 17 Algorithm 4: addConstraints input : H , {P i } N i =1 , { I i } N i =1 , mpl output : Φ, list of literals F 1 Φ ← ∅ foreach X, Y do 2 p osIndP aths ← paths in H of maxim um length mpl that are p ossibly inducing with resp ect to L i ; 3 foreac h i do 4 Φ ← Φ ∧ ad j acent ( X , Y , P i ) ↔ ∃ p X Y ∈ p osIndP aths s. t. inducing ( p X Y , i ) ; 5 if X , Y ar e adjac ent in P i then add ad j acent ( X , Y , P i ) to F else add ¬ ad j acent ( X , Y , P i ) to F 6 end 7 Φ ← Φ ∧ ¬ ancestor ( X , Y ) ∨ ¬ ancestor ( Y , X ) ; 8 Φ ← Φ ∧ ¬ tail ( X , Y ) ∨ ¬ tail ( Y , X ) ∧ ( ar r ow ( X , Y ) ∨ tail ( X , Y ) ; 9 end 10 foreac h i do 11 foreac h unshielde d triple in P i do 12 Φ ← Φ ∧ dnc ( X , Y , Z , P i ) → unshielded dnc ( X , Y , Z, P i ) ; 13 Φ ← Φ ∧ coll ider ( X , Y , Z, P i ) → unshielded col l ider ( X , Y , Z, P i ; 14 if h X , Y , Z i is a c ol lider in P i then add col l ider ( X , Y , Z, P i ) to F else add dnc ( X , Y , Z , P i ) to F 15 end 16 foreac h discriminating p ath p W Z = h W , . . . , X , Y , Z i do 17 Φ ← Φ ∧ dnc ( X , Y , Z , P i ) → discriminating dnc ( p W Z , Y , P i ) ; 18 Φ ← Φ ∧ coll ider ( X , Y , Z, P i ) → discriminating col l ider ( p W Z , Y , P i ) ; 19 if X , Y , Z is a c ol lider in P i then add col l ider ( X , Y , Z, P i ) to F else add dnc ( X , Y , Z , P i ) to F 20 end 21 end The constrain ts are realized on the basis of the plausible configurations of H : Thus, for the constrain ts corresp onding to ad j acent ( X , Y , i ) the algorithm finds all paths b etw een X and Y in H that are p ossibly inducing. Then, for the literal ad j acent ( X , Y , i ) to b e true, at least one of these paths is constrained to b e inducing; for the opp osite, none of these paths is allo w ed to be inducing. This step is the most computationally exp ensive part of the algorithm. The parameter mpl controls the length of the p ossibly inducing paths; instead of finding al l paths b et ween X and Y that are p ossibly inducing, the algorithm lo oks for all paths of length at most mpl . This plays a ma jor part in the abilit y of the algorithm to scale up, since finding all possible paths b et ween ev ery pair of v ariables can blow up even in relativ ely small net works, particularly in the presence of unoriented cliques or in relatively dense netw orks. Notice that the information on manipulations is included in the satisfiabilit y instance through the enco ding of the constraints: F or ev ery adjacency b etw een X and Y observ ed in P i , the plausible inducing paths are consisten t with the resp ective interv ention targets: No 18 inducing path is allo wed to include an edge that is incoming to a manipulated v ariable. F or example, in Figure 5 X 15 and X 14 are adjacen t in P 3 , where X 15 is manipulated. Since no information concerning exp erimen ts is employ ed up to the initialization of the search graph, X 15 X 14 is in the initial search graph H , and the edge is a p ossible inducing path for X 15 and X 14 in P 3 . Ho wev er, since X 15 is manipulated in P 3 , the edge cannot hav e an arrow in to X 15. This is imp osed by the constrain t: inducing ( h X 15 , X 14 i , 3) ↔ ( X 15 ∈ I 3 → tail ( X 14 , X 15)) ∧ ( X 14 ∈ I 3 → tail ( X 15 , X 14)) ∧ edg e ( X 14 , X 15) whic h is then added to Φ as inducing ( X 15 , X 14 , 3) ↔ tail ( X 14 , X 15) ∧ edg e ( X 14 , X 15) . Th us, in an y SMCM S that satisfies the final formula of Algorithm 2, if inducing ( h X 15 , X 14 i , 3) is true, the edge will b e consistent with the manipulation informa- tion. As mentioned ab o ve, in the absence of statistical errors, all the constraints stemming from all P A Gs P i are simultaneously satisfiable. In practical settings ho wev er, it is p os- sible that some of the P A Gs hav e some erroneous features due to statistical errors, and these features can lead to conflicting constrain ts. T o tackle this problem, Algorithm 4 using the follo wing tec hnique: F or every observed feature, instead of imp osing the im- plied constraints on the form ula Φ, the algorithm adds a bi-conditional connecting the feature to the constraints. F or example, if X and Y are found adjacen t in P i , then in- stead of adding the constraints ∃ p X Y : inducing ( X , Y , i ) to Φ, w e add the bi-conditional ad j acent ( X , Y , P i ) ↔ ∃ p X Y : inducing ( X , Y , i ). The anteceden ts of the conditionals are stored in a list of literals F . The conflict resolution strategy is then imp osed on this list of literals, selecting a subset F 0 that results in a satisfiable SA T formula Φ ∧ F 0 . The form ula Φ ∧ F 0 is expressed in Conjunctiv e Normal F orm (CNF) so it can b e input to standard SA T solv ers. without imp osing the anteceden t. These seman tics should alw ays b e guaranteed and th us, Φ forms a set of hard-constraints. In con trast, if the list of anteceden ts in F leads to a conflict, one can select only a subset of an tecedents to satisfy (soft-constrain ts). Recall that the prop ositional v ariables of Φ corresp ond to the features of the actual underlying SMCM (its edges and endp oin ts). Some of these v ariables hav e the same v alue in all the p ossible truth-setting assignments of Φ ∧ F 0 , meaning the resp ectiv e features are in v arian t in all p ossible underlying SMCMs. Such v ariables are called backbone v ariables of Φ ∧ F 0 (Hyttinen et al., 2013). The actual v alue of a backbone v ariable is called the p olarit y of the v ariable. F or sake of brevit y , w e say an edge or endpoint has polarity 0/1 if the corresponding v ariable is a bac kb one v ariable in Φ ∧ F 0 and has p olarity 0/1. Based on the bac kb one of Φ ∧ F 0 , the final step of COm bINE is to construct the summary graph S . S has the following t yp es of edges and endp oints: • Solid Edges: in H that hav e p olarity 1 in Φ ∧ F 0 , meaning that they are present in all p ossible underlying SMCM. • Absen t Edges: Edges that are not in H or edges in H that hav e p olarit y 0 in Φ, meaning that they are absen t in all p ossible underlying SMCM. 19 X12 X5 X34 X10 X31 X9 X13 X15 X14 X27 X8 X18 S : X31 X10 X13 X5 X18 X27 X8 X12 X14 X15 X34 P 1 : X9 X27 X8 X15 X34 X13 X5 X18 X10 X31 X14 X12 P 2 : X10 X31 X14 X12 X9 X27 X8 X15 X34 X13 X5 P 3 : X9 X14 X27 X8 X15 X18 X10 X31 X34 X5 X13 X12 H : Figure 5: An example of COmbINE input - output . Graph S is the actual, data- generating, underlying SMCM ov er 12 v ariables. P A Gs P 1 , P 2 and P 3 are the output of FCI ran with an oracle of conditional indep endence on three differ- en t marginals of G . H is the output of COmbINE algorithm. The sets of laten t v ariables (with resp ect to the union of observed v ariables) p er data set are: L 1 = { X 9 } , L 2 = {∅} , L 3 = { X 18 } . The sets of manipulated v ariables (annotated as rectangle no des instead of circles in the resp ectiv e graphs) are: I 1 = { X 14 , X 34 } , I 2 = { X 15 , X 8 } , I 3 = { X 9 , X 12 } . Notice that X 10 and X 31 are adjacent in P 2 , but not in P 1 or P 3 . This happ ens b ecause there exists an inducing path in the underlying SMCM ( X 31 X 14 X 10 in S ) that is “bro- k en” by the manipulation of X 14 and X 12, resp ectiv ely . Also notice a dashed edge b et ween X 9 and X 15, which cannot b e excluded since the v ariables hav e nev er b een observed unmanipulated together. Ev en if the link existed, it would b e destroy ed in b oth P 2 and P 3 , where b oth v ariables are observ ed. All graphs w ere visualized in Cytoscap e (Smo ot et al., 2011). • Dashed Edges: Edges in H that are not bac kb one v ariables in Φ ∧ F 0 , meaning that there exists at least one p ossible underlying SMCM where this edge is presen t and one where this edge is absen t. • Solid Endp oin ts: Endp oints in H that are backbone v ariables in Φ ∧ F 0 , meaning that this orientation is in v arian t in all p ossible underlying SMCMs. • Dashed (circled) Endp oints: Endp oin ts in H that are not bac kb one v ariables in Φ ∧ F 0 , meaning that there exists at least one SMCM where this orientation do es not hold. W e use the term solid features of the summary graph to denote the set of solid edges, absen t edges and solid endp oints of the summary graph. Ov erall, A lgorithm 2 takes as input a set of data sets and a list of p ar ameters and outputs a summary gr aph that has al l invariant e dges and orientations of the SMCMs that satisfy as many c onstr aints as p ossible (ac c or ding to some str ate gy) . The algorithm is capable of non-trivial inferences, like for example the presence of a solid edge among v ariables nev er measured together. Figures 5 and 6 illustrate the output of Algorithm 2, along with the corresp onding input P AGs. F or an oracle of conditional indep endence, Algorithm 2 is sound and complete in the manner describ ed in Theorem 13. Lemmas 10 to 12 are necessary for the proof of soundness and completeness: Lemma 10 prov es that the p ossibly inducing and ancestral paths emplo yed by COmbINE are complete: for an y consistent S , if p is a path 20 X Y Z W P 1 : X Y W P 2 : X Z W X Y Z W Figure 6: A detailed example of a non-trivial inference . F rom left to righ t: The true underlying SMCM o ver v ariables X , Y , Z , W ; P AGs P 1 and P 2 o ver { X , Y , W } and { X , Z , W } , resp ectively; The output H of Algorithm 2 ran with an oracle of conditional indep endence. Notice that, the edges in P 1 can not b oth simul- taneously o ccur in a consisten t SMCM S : This would make X Y W an inducing path for X and W with resp ect to L 2 = { Y } and con tradict the fea- tures of P 2 , where X and W are not adjacent. Similarly , X Z W cannot o ccur in an y consisten t SMCM S . The only possible edge structures that explain all the observ ed adjacencies and definite non colliders are X Y Z W or X Z Y W . Either wa y , Y and Z share an edge in all consisten t SMCMs, and the algorithm will predict a solid edge b etw een Y and Z , ev en if the t wo ha v e not b een measured in the same data set. This example is discussed in detail in (Tsamardinos et al., 2012). that is inducing with respect to a set L (ancestral) in S , p is possibly inducing with respect to L (p ossibly ancestal) in the initial search graph H , and will therefore b e considered during Algorithm 4. This also implies that if there exists no p ossibly inducing (ancestral) path in H there exists no inducing (ancestral) in S . Lemma 11 prov es that any consistent SMCM S satisfies the final formula Φ ∧ F 0 of Algorithm 2, and Lemma 12 prov es that an y truth-setting assignment of the final form ula Φ ∧ F 0 corresp onds to a consisten t SMCM S . Lemma 10 L et {P i } N i =1 b e a set of P AGs and S a SMCM such that S is p ossibly underlying for {P i } N i =1 , and let H b e the initial se ar ch gr aph r eturne d by Algorithm 3 for {P i } N i =1 . Then, if p is an anc estr al p ath in S , then p is a p ossibly anc estr al p ath in H . Similarly, if p is a p ossibly inducing p ath with r esp e ct to L in S , then p is a p ossibly inducing p ath with r esp e ct to L in H . Pro of See App endix 6. Lemma 11 L et { D i } N i =1 b e a set of data sets over overlapping subsets of O , and { I i } N i =1 b e a set of (p ossibly empty) intervention tar gets such that I i ⊂ O i for e ach i. L et P i b e output P AG of FCI for data set D i , Φ ∧ F 0 b e the final formula of A lgorithm 2, and S b e a p ossibly underlying SMCM for { P i } N i =1 . Then S satisfies Φ ∧ F 0 . Pro of See App endix 6. Lemma 12 L et { D i } N i =1 , { I i } N i =1 , { P i } N i =1 , Φ ∧ F 0 b e define d as in L emma 11. If gr aph S satisfies Φ ∧ F 0 , then S is a p ossibly underlying SMCM for { P i } N i =1 . 21 Pro of See App endix 6. Theorem 13 (Soundness and c ompleteness of Algorithm 2) L et { D i } N i =1 , { I i } N i =1 , { P i } N i =1 , Φ ∧ F 0 b e define d as in L emma 11. Final ly, let H b e the summary gr aph r eturne d by COmbINE . Then the fol lowing hold: Soundness : If a fe atur e (e dge, absent e dge, endp oint) is solid in H , then this fe atur e is pr esent in all c onsistent SMCMs. Completeness : If a fe atur e is pr esent in all c onsistent SMCMs, the fe atur e is solid in H . Pro of Soundness: Solid features corresp ond to backbone v ariables. By Lemma 11 ev ery p ossible underlying SMCM S for { P i } N i =1 satisfies the final form ula Φ ∧ F 0 . Th us, if a core v ariable has the same v alue in all the p ossible truth-setting assignmen ts of Φ ∧ F 0 , this feature is present in all p ossible underlying SMCMs. Completeness: By Lemma 12 the final form ula Φ ∧ F ’ of Algorithm 2 is satisfied only by p ossibly underlying SMCMs. Thus, if a core v ariable is present in al l consistent SMCMs, the corresp onding core v ariable will b e a bac kb one v ariable for Φ ∧ F 0 . 4.3 A strategy for conflict resolution based on the Maxim um MAP Ratio In this section, we presen t a metho d for assigning a measure of confidence to every literal in list F describ ed in Algorithm 2, and a strategy for selecting a subset of non-conflicting constrain ts. List F includes four t yp es of literals, expressing different statistical information: 1. ad j acent ( X , Y , P i ): X and Y are independent giv en some Z ⊂ O i 2. ¬ ad j acent ( X , Y , P i ): X and Y are not indep enden t giv en any subset of O i . 3. col l ider ( X , Y , Z , P i ): Y is in no subset of O i that renders X and Z indep endent. 4. dnc ( X , Y , Z , P i ): Y is in every subset of O i that renders X and Z indep endent. F or the scop e of this work, w e will fo cus on ranking the first tw o t yp es of anteceden ts: Adjacencies and non-adjacencies. W e will then assign unshielded colliders and non-colliders to the same rank as the non-adjacency of the triple’s endp oin ts; similarly , discriminating colliders and non-colliders will b e assigned to the same rank as the non-adjacency of the path’s endp oints. Naturally , this criterion of sorting colliders and non-colliders is merely a heuristic, as more than one tests of indep endence are in volv ed in deciding that a triple is a (non) collider. Assigning a measure of lik eliho o d or p osterior probabilit y to ev ery single (non) adjacency w ould enable their comparison. A non-adjacency in a P AG corresp onds to a conditional indep endence giv en some subset of the observ ed v ariables. In con trast, an adjacency corre- sp onds to the lack of suc h a subset. Th us, an edge b et ween X and Y should b e present in P i if the evidence (data) is less in fav or of hypothesis: H 0 : ∃ Z ⊂ O i : I nd ( X , Y | Z ) than the alternativ e H 1 : 6 ∃ Z ⊂ O i : I nd ( X , Y | Z ) (1) 22 This is a complicated set of h yp otheses, that in v olves multiple tests of indep endence. W e try to approximate testing b y using a single test of indep endence as a surrogate: During FCI, sev eral conditioning sets are tested for ev ery pair of v ariables X and Y . Let Z X Y b e the conditioning test for which the highest p-v alue is identified for the given pair of v ariables. Notice that it is this maximum p-v alue that is emplo yed in FCI and similar algorithms to determine whether an edge is included in the output or not. W e use the set of h yp otheses H 0 : I nd ( X , Y | Z X Y ) against the alternative H 1 : ¬ I nd ( X , Y | Z X Y ) as a surrogate for the set of hypotheses in Equation 1. Under the n ull h yp othesis, the p-v alues follow a uniform U ([0 , 1]) distribution 2 , also known as the B eta (1 , 1) distribution. Under the alternativ e hypothesis, the density of the p-v alues should b e decreasing in p . One class of decreasing densities is the B eta ( ξ , 1) distribution for 0 < ξ < 1, with density f ( p | ξ ) = ξ p ξ − 1 . Th us, w e can approximate the null and alternativ e h yp otheses in terms of the p-v alue as H 0 : p X Y . Z ∼ B eta (1 , 1) against H 1 : p X Y . Z ∼ B eta ( ξ , 1) for some ξ ∈ (0 , 1) . (2) T aking the Beta alternativ es was presented as a metho d for calibrating p-v alues in Sellk e et al. (2001). F or the purp ose of this work, we use them to estimate whether dep endence is more probable than independence for a giv en p-v alue p , by estimating which of the Beta alternativ es it is most likely to follo w. Let F be a set of M literals corresp onding to adjacencies and non-adjacencies, and { p j } M j =1 the resp ective maximum p-v alues: If the j-th literal in F is ( ¬ ) ad j acent ( X , Y , P i ), then p j is the maxim um p-v alue obtained for X , Y during FCI o ver D i . W e assume that this p opulation of p-v alues follo ws a mixture of B eta ( ξ , 1) and B eta (1 , 1) distribution. If π 0 is the prop ortion of p-v alues following B eta ( ξ , 1), the probability densit y function is f ( p | ξ , π 0 ) = π 0 + (1 − π 0 ) ξ p ξ − 1 and the likelihoo d for a set of p-v alues { p j } M j =1 is L ( ξ , π 0 ) = Y j ( π 0 + (1 − π 0 ) ξ p ξ − 1 j ) . The resp ective negativ e log likelihoo d is − LL ( ξ , π 0 ) = − X j log ( π 0 + (1 − π 0 ) ξ p ξ − 1 i ) . (3) F or given estimates ˆ π 0 and ˆ ξ , the MAP ratio of H 0 against H 1 is E 0 ( p ) = P ( p | H 0 ) P ( H 0 ) P ( p | H 1 ) P ( H 1 ) = P ( p | p ∼ B eta (1 , 1)) P ( p ∼ B eta (1 , 1)) P ( p | p ∼ B eta ( ˆ ξ , 1)) P ( p ∼ B eta ( ˆ ξ , 1)) = ˆ π 0 ˆ ξ p ˆ ξ − 1 (1 − ˆ π 0 ) . 2. This is actually an approximation in this case, since these p-v alues are maximum p-v alues o ver sev eral tests. 23 10 − 10 10 − 8 10 − 6 0 . 0001 0 . 01 0 . 1 1 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 10 9 10 10 p-v alue maximum MAP ratio E π 0 =0.2 ξ =0.01 ξ =0.1 ξ =0.2 ξ =0.5 ξ =0.8 10 − 10 10 − 8 10 − 6 0 . 0001 0 . 01 0 . 1 1 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 0.0038 0.6373 p-v alue maximum MAP ratio E π 0 =0.6 ξ =0.01 ξ =0.1 ξ =0.2 ξ =0.5 ξ =0.8 10 − 10 10 − 8 10 − 6 0 . 0001 0 . 01 0 . 1 1 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 10 8 p-v alue maximum MAP ratio E π 0 =0.8 ξ =0.01 ξ =0.1 ξ =0.2 ξ =0.5 ξ =0.8 Figure 7: Log of the maximum map ratio E ( p ) versus log of the p-v alue p for v arious ˆ π 0 and ˆ ξ . . F or ˆ π 0 = 0 . 6 and ˆ ξ = 0 . 1, an adjacency supp orted by a maxim um p-v alue of 0.0038 corresp onds to the same E as a non-adjacency supp orted by a p-v alue of 0.6373. The in tersection p oin t of the line with the x axis is the p for whic h E 0 ( p ) = E 1 ( p ) = 1. E 0 ( p ) > 1 implies that for the test of indep endence represented b y the p-v alue p , indep en- dence is more probable than dependence, while E 0 ( p ) < 1 implies the opp osite. Moreo ver, the v alue of E 0 ( p ) quantifies this b elief. Conv ersely , the corresp onding MAP ratio of H 1 against H 0 is E 1 ( p ) = ˆ ξ p ˆ ξ − 1 (1 − ˆ π 0 ) ˆ π 0 . W e define the maximum MAP ratio (MMR) for a p-v alue p to b e the maxim um b et ween the tw o: E ( p ) = max ˆ π 0 ˆ ξ p ˆ ξ − 1 (1 − ˆ π 0 ) , ˆ ξ p ˆ ξ − 1 (1 − ˆ π 0 ) ˆ π 0 . (4) MMR estimates heuristically quantify our confidence in the observed adjacencies and non-adjacencies and are emplo yed to create a list of literals as follo ws: Let X and Y b e a pair of observ ed v ariables, and p X Y b e the maxim um p-v alue rep orted during F CI for these v ariables. Then, if E 0 ( p X Y ) > E 1 ( p X Y ), the literal ¬ ad j acent ( X , Y , i ) is added to F with confidence estimate E ( p X Y ). Otherwise, the literal ad j acent ( X , Y , i ) is added to F with a confidence estimate E ( p X Y ). The list can then b e sorted in order of confidence, and the literals can b e satisfied incremen tally . Whenev er a literal in the list is encountered that cannot b e satisfied in conjunction with the ones already selected, it is ignored. Notice that, it is p ossible that for a p-v alue E 0 ( p X Y ) > E 1 ( p X Y ) (i.e., MMR determines indep endence is more probable), ev en though p X Y is smaller than the F CI threshold used. In other words, giv en a fixed FCI threshold, dep endence maybe accepted; but, when analyzing the set of p-v alues encountered to compute MMR, indep endence seems more probable. The rev erse situation is also p ossible. The pseudo-co de in Algorithm 5 (Lines 6—10) accepts the MMR decisions for dep endencies and indep endencies; this is e quivalent to dynamic al ly r e adjusting the de cisions made by FCI . Nevertheless, in anecdotal exp erimen ts w e found that 24 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 0 5 10 15 20 25 2 input data sets, ˆ π 0 : 0 . 806 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 0 10 20 30 40 50 60 5 input data sets, ˆ π 0 : 0 . 668 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 0 20 40 60 80 100 120 10 input data sets, ˆ π 0 : 0 . 766 Figure 8: Distribution of p-v alues and estimated ˆ π 0 . W e used the metho d of Storey and Tibshirani (2003) to estimate ˆ π 0 for a sample of p-v alues corresp onding to 2 (left), 5 (center) and 10 (right) input data sets. W e generated netw orks by manipulating a marginal of the ALARM net work (Beinlic h et al., 1989) consisting of 14 v ariables. In each exp eriment, at most 3 v ariables were laten t and at most 2 v ariables were manipulated. W e simulated data sets of 100 samples each from the resulting manipulated graphs. W e ran FCI on each data set with α = 0 . 1 and maxK = 5 and cached the maxim um p-v alue rep orted for each pair of v ariables. W e used the p-v alues from all data sets to estimate ˆ π 0 . The dashed line corresp onds to the prop ortion of p-v alues that come from the null distribution based on the estimated ˆ π 0 . the literals for which this situation occurs are near the end of the sorted list; th us, whether one accepts the initial decisions of F CI based on a fixed threshold, or a dynamic threshold based on MMR usually do es not hav e a large impact on the output of the algorithm. Figure 7 sho ws how the MMR v aries with the p-v alue for several com binations of ˆ π 0 and ˆ ξ . The lo west p ossible v alue of the MMR is 1, and corresp onds to the p-v alue p for which E 0 ( p ) = E 1 ( p ). Naturally , for the same ξ , this p-v alue (where the o dds switc h in fav or of non-adjacency) is larger for a low er π 0 . In Figure 7 for π 0 = 0 . 6 we can see an example of t wo p-v alues that corresp ond to the same E : An adjacency represented by a p-v alue of 0 . 0038 (0 . 0038 b eing the maximum p-v alue of any test p erformed by FCI for the pair of v ariables) is as likely as a non-adjacency represented b y a p-v alue of 0 . 6373 (0 . 6373 b eing the p-v alue based on which F CI remov ed this edge). T o obtain MMR estimates, w e need to estimate π 0 and ξ . W e used the method describ ed in Storey and Tibshirani (2003) to estimate π 0 on the p o oled (maxim um) p-v alues { p j } M j =1 o ver all data-sets obtained during FCI. F or a giv en ˆ π 0 , Equation 3 can then b e easily optimized for ξ . The metho d used to obtain ˆ π 0 assumes indep enden t p-v alues, whic h is of course not the case since the test sc hedule of F CI dep ends on previous decisions. In addition, each p-v alue may be the maximum of sev eral p-v alues; these maximum p-v alues ma y not follow a uniform distribution even when the non-adjacency (n ull) h yp othesis is true. Finally , given that p-v alues stem from tests ov er differen t conditioning set sizes, p-v alues corresp onding 25 Algorithm 5: MMRstrategy input : SA T formula Φ, list of literals F , their corresp onding p-v alues { p j } output : List of non conflicting literals F 0 1 F 0 ← ∅ ; 2 Estimate ˆ π 0 from { p j } using the metho d describ ed in Storey and Tibshirani (2003); 3 Find ˆ ξ that minimizes − P j log ( ˆ π 0 + (1 − ˆ π 0 ) ξ p ξ − 1 i ); 4 foreac h liter al ( ¬ ) ad j acent ( X , Y , P i ) ∈ F with p-value p j do 5 E 0 ( p j ) ← ˆ π 0 ˆ ξ p ˆ ξ − 1 j (1 − ˆ π 0 ) , E 1 ( p j ) ← ˆ ξ p ˆ ξ − 1 j (1 − ˆ π 0 ) ˆ π 0 ; 6 if E 1 ( p j ) < E 0 ( p j ) then 7 add ¬ ad j acent ( X , Y , P i ) to F 8 else 9 add ad j acent ( X , Y , P i ) in F 10 end 11 S cor e ( l iter al ) ← max { E 0 ( p j ) , E 1 ( p j ) } ; 12 end 13 foreac h liter al col l ider ( X , Y , Z , P i ) , dnc ( X , Y , Z , P i ) do 14 if X , Y , Z is an unshielde d triple in P i then 15 S cor e ( l iter al ) ← S cor e ( X , Z, P i ); 16 else if h W . . . X , Y , Z i is discriminating for Y in P i then 17 S cor e ( l iter al ) ← S cor e ( W , Z , P i ); 18 end 19 end 20 F ← sort F by descending score; 21 foreac h φ ∈ F do 22 if Φ ∧ φ is satisfiable then 23 Φ ← Φ ∧ φ ; 24 Add φ to F 0 25 end 26 end to adjacencies do not necessarily follo w the same b eta distribution. Thus, the approach presen ted here is at b est an appro ximation. In the algorithm as presen ted, a single beta is fit from the p o oled p-v alues of FCI runs o ver all data-sets. This is strategy is p erhaps more appropriate when individual data-sets ha ve a small num b er of p-v alues, so the p o oled set provides a larger sample size for the fitting. Other strategies though, are also possible. One could instead fit a differen t beta for eac h data-set and its corresp onding set of p-v alues. This approac h could p erhaps b e more appropriate in case the P AG structures P i v ary greatly in terms of sparseness. In addition, one could also fit differen t b eta distributions for each conditioning set size. Figure 8 shows the empirical distribution of p-v alues and the estimated ˆ π 0 based on the p-v alues returned from FCI on 2, 5 and 10 input data sets, simulated from a net work of 14 v ariables. 26 The strategy for selecting non-conflicting constraints based on the MMR strategy is presen ted in Algorithm 5. MMR is a general criterion that can b e used to compare con- fidence in dep endencies and indep endencies. The metho d is based on p-v alues and thus, can be applied in different types of data (e.g., con tinuous and discrete) in conjunction with an y appropriate test of indep endence. Moreo ver, since it is based on cached p-v alues, and fitting a b eta distribution is efficient, it adds minimal computational complexity . On the other hand, the estimation of maxim um MAP ratios is based on heuristic assumptions and appro ximations. Nev ertheless, exp erimen ts presented in the follo wing section sho wcase that the metho d w orks similarly if not b etter than other conflict resolution metho ds, while b eing orders of magnitude computationally more efficien t. 5. Exp erimental Ev aluation W e presen t a series of experiments to c haracterize how the behavior of COm bINE is affected b y the characteristics of the problem instance and compare it against other alternative al- gorithm in the literature. W e also present a comparative ev aluation of conflict resolution metho ds, including the one based on the proposed MMR estimation tec hnique. Finally , w e presen t a pro of-of-concept application on real mass cytometry data on human T-cells. In more detail, w e initially compare the complete v ersion of COmbINE (i.e., without restric- tions on the maxim um path length or the conditioning set) against SBCSD (Hyttinen et al., 2013) in ideal conditions (i.e., b oth algorithms are provided with an indep endence oracle). W e p erform a series of exp erimen ts to explore the (a) learning accuracy of COm bINE as a function of the maximum path length considered by the algorithm, the density and size of the netw ork to reconstruct, the n umber of input data sets, the sample size, and the num b er of latent v ariables, and (b) the computational time as a function of the ab ov e factors. All exp eriments were p erformed on data sim ulated from randomly generated netw orks as follo ws. The graph of each netw ork is a DA G with a sp ecified num b er of v ariables and maxim um n umber of parents p er v ariable. V ariables are randomly sorted top ologically and for eac h v ariable the num b er of parents is uniformly selected b etw een 0 and the maxi- m um allo wed. The parents of each v ariable are selected with uniform probability from the set of preceding no des. Each DA G is then coupled with random parameters to generate conditional linear gaussian netw orks. T o a void v ery weak interactions, minim um absolute conditional correlation was set to 0.2. Before generating a data set, the v ariables of the graph are partitioned to unmanipulated, manipulated, and laten t. Mean v alue and stan- dard deviation for the manipulated v ariables w ere set to 0 and 1, resp ectively . Subsequently , data instances are sampled from the netw ork distribution, considering the manipulations and remo ving the laten t v ariables. All exp eriments are p erformed on conserv ative families of targets; the term was in tro duced in Hauser and B ¨ uhlmann (2012) to denote families of in terven tion targets in whic h all v ariables ha ve b een observ ed unmanipulated at least once. F or eac h in vocation of the algorithm, the problem instance (set of data sets) is generated using the parameters shown in T able 1. COmbINE default parameters w ere set as follows: maxim um path length = 3, α = 0 . 1 and maximum conditioning set maxK = 5, and the Fisher z-test of conditional indep endence. As far as orientations are concerned, in our exp erience, F CI is v ery prone to error propagation, w e therefore used the rule in (Ramsey et al., 2006) for c onservative colliders. Unless otherwise stated, Algorithm 5 is employ ed to 27 Problem attribute Default v alue used Num b er of v ariables in the generating DA G 20 Maxim um num b er of parents p er v ariable 5 Num b er of input data sets 5 Maxim um num b er of latent v ariables p er data set 3 Maxim um num b er of manipulated v ariables p er data set 2 Sample size p er data set 1000 T able 1: Default v alues used in generating exp erimen ts in eac h iteration of COm- bINE . Unless otherwise stated, the input data sets of COm bINE w ere generated according to these v alues. resolv e conflicts. SA T instances were solv ed using MINISA T2.0 (E´ en and S¨ orensson, 2004) along with the mo difications presen ted in Hyttinen et al. (2013) for iterative solving and computing the backbone with some minor mo difications for sequentially performing literal queries. In the subsequen t experiments, one of the pr oblem p ar ameters in T able 1 is varie d e ach time, while the others r etain the values ab ove . T o measure learning p erformance, ideally one should know the ground truth, i.e., the structure that the algorithm w ould learn if ran with an oracle of conditional independence, and unrestricted infinite maxK and maximum path length parameters. Notice, that the original gener ating DA G structur e c annot serve dir e ctly as the gr ound truth . This is because the presence of manipulated and latent v ariables implies that not all structural features of the generating DA G can b e recov ered. F or example, for the problem instance presented in Figure 6(middle), the ground truth structure has one solid edge out of 5, no solid endp oint 6(righ t), one absent, and four dashed edges. Dashed edges and endp oints in the output of the algorithm can only be ev aluated if one kno ws the ground truth structure. Unfortunately , the ground truth structure cannot be recov ered in a timely fashion in most problems in v olving more than 15 v ariables. As a surrogate, we defined metrics that do not consider dashed edges or endp oin ts and can be directly computed b y comparing the “solid” features of the output with the original data generating graph. Sp ecifically , w e used tw o types of precision and recall; one for edges (s-Precision/s-Recall) and one for orientations (o-Precision/o-Recall). Let G b e the graph that generated the data (the SMCM stemming from the initial random D AG after marginalizing out v ariables laten t in all data sets), and H b e the summary graph returned b y COmbINE. s-Precision and s-Recall were then calculated as follows: s-Precision = # solid edges in H that are also in G # solid edges in H and s-Recall = # solid edges in H that are also in G # edges in G . Similarly , orientation precision and recall are c alculated as follows: o-Precision = # endp oints in G correctly oriented in H # of orientations(arro ws/tails) in H 28 Running time Completed instances/ # # max Median (5 %ile, 95 %ile) total instances v ariables parents COm bINE SBCSD SBCSD ∗ COm bINE SBCSD SBCSD 0 10 3 17 (1 , 113) 149 (14 , 470) ∗ 91 (30 , 369) ∗ 50 / 50 30/50 48 / 50 5 80 (4 , 1192) 365 (133 , 500) ∗ 264 (68 , 554) ∗ 50 / 50 16/50 32 / 50 14 3 28 (4 , 6361) ∗ − 451 (407 , 492) ∗ 49 / 50 0/50 4 / 50 5 272 (23 , 16107) ∗ − − 43 / 50 0 / 50 0 / 50 T able 2: Comparison of running times for COmbINE and SBCSD for netw orks of 10 and 14 v ariables . The table rep orts the median running time along with the 5 and 95 p ercentiles, as w ell as the n umber of instances (problem inputs) in whic h each algorithm managed to complete; ∗ n umbers are computed only on the problems for which the algorithm completed. and o-Recall = # endp oints in G correctly oriented in H # endp oints in G . Since dashed edges and endp oints do not con tribute to these metrics, precision in particular could be fa vorable for conserv ative algorithms that tend to categorize all edges (endp oin ts) as dashed. T o alleviate this problem, w e accompany eac h precision / recall figure with the p ercen tage of dashed edges out of all edges in the output graph to indicate ho w conserv ativ e is the algorithm. Similarly , we present the p ercen tage of dashed (circled) endp oints out of all endp oints in the output graph. Finally , we note that in the exp erimen ts that follo w, unless otherwise stated, w e rep ort the median, 5, and 95 percentile ov er 100 runs of the algorithm with the same settings. 5.1 COmbINE vs. SBCSD Hyttinen et al. (2013) presen ted a similar algorithm, named SA T-based causal structure dis- co very (SBCSD). SBCSD is also capable of learning causal structure from manipulated data- sets o ver ov erlapping v ariable sets. In addition, if linearit y is assumed, it can admit feedback cycles. SBCSD also uses similar techniques for con verting conditional (in)dependencies into a SA T instance. Ho wev er, the algorithm requires all m -connections to constrain the searc h space (at least the ones that guaran tee completeness), while COm bINE uses inducing paths to av oid that. F or each adjacency X Y in a data set, COmbINE creates a constraint sp ecifying that at least one path b etw een the v ariables is inducing with resp ect to L i . In con trast, SBCSD creates a constrain t specifying that at least one path betw een the v ariables is m -connecting path giv en each p ossible conditioning set. So, b oth algorithms are forced to chec k ev ery p ossible path, y et COmbINE examines eac h path once (with resp ect to L i ), while SBCSD examines it for m ultiple p ossible conditioning sets. The latter c hoice ma y b e necessary to deal with cyclic structures, but leads to significan tly larger SA T problems when acyclicity is assumed. SBCSD is not presented with a conflict resolution strategy and so it can only be tested by using an oracle of conditional independence. Equipping SBCSD with suc h a strategy is p os- sible, but it ma y not b e straigh tforw ard: SBCSD computes the SA T bac kb one incremen tally 29 for efficiency , which complicates pre-ranking constrain ts according to some criterion. Since SBCSD cannot handle conflicts, w e compared it to the complete version of our algorithm (infinite maxK and maximum path length) using an oracle of conditional independence. Since no statistical errors are assumed, the initial searc h graph for COmbINE includes all observ ed arrows. Both algorithms are sound and com plete, hence w e only compare run- ning time. SBCSD uses a path-analysis heuristic to limit the num b er of tests to p e rform. Ho wev er, the authors suggest that in cases of acyclic structures, this heuristic could b e substituted with the FCI test sc hedule. T o b etter characterize the b ehavior of SBCSD on acyclic structures, w e equipp ed the original implemen tation as suggested 3 . W e denote this version of the algorithm as SBCSD 0 . Also note, that the av ailable implementation of SBCSD b y its authors has an option to restrict the search to acyclic structures, whic h was emplo yed in the comparative ev aluation. Finally , w e note that SBCSD is implemented in C, while COmbINE is implemen ted in Matlab. F or the comparative ev aluation, w e sim ulated random acyclic netw orks with 10 and 14 v ariables. The default parameters were used to generate 50 problem instances for net w orks with 3 and 5 maximum paren ts p er v ariable. Both algorithms were run on the same com- puter, with 4GB of av ailable memory . SBCSD reached maxim um memory and ab orted without concluding in several cases for net works of 10 v ariables, and in al l c ases for net- works of 14 variables . SBCSD 0 sligh tly improv es the running time ov er SBCSD. Median running time along with the 5 and 95 p ercentiles as w ell as num b er of cases completed are rep orted in T able 2. The metrics for eac h algorithm w ere calculated only on the cases where the algorithm completed. The results in T able 2 indicate that COmbINE is more time-efficien t than SBCSD and SBCSD 0 . While the running times do depend on implemen tation, the fact that SBCSD ha ve m uch higher memory requiremen ts indicates that the results m ust b e at least in part due to the more compact representation of constraints by COm bINE . COmbINE managed to complete all cases for netw orks of 10 and most c ases for 14 v ariables, while SBCSD completed less than 50% and 0%, resp ectively . SBCSD 0 completed most cases for 10 v ariables but only 4% of cases for 14 v ariables. In terestingly , the p ercentiles for COmbINE are quite wide spanning t wo orders of magnitude for problems with maxP arents equal to 5 (w e cannot compute the actual 95 p ercen tile for SBCSD since it did not complete for most problems). Th us, p erformance highly dep ends on the input structure. Such heavy-tailed distributions are well-noted in the constraint satisfaction literature (Gomes et al., 2000). W e also note the fact that COm bINE seems to dep end more on the sparsit y and less on the n umber of v ariables, while SBCSD’s time increases monotonically with the n umber of v ariables. Based on these results, we w ould suggest the use of COmbINE for problems where acyclity is a reasonable assumption and the n umber of v ariables is relatively high. 5.2 Ev aluation of Conflict Resolution Strategies In this s ection w e ev aluate our Maxim um Map Ratio strategy ( MMR ) against three other alternativ es: A ranking strategy where constraints are sorted based on Bay esian prob- 3. How ever, we do not include the Possible d-Separating step of FCI; this step hardly influences the quality of the algorithm Colom bo et al. (2012). Th us, the timing results of T able 2 are a lo wer bound on the execution time of the SBCSD algorithm. 30 abilities as prop osed in Claassen and Heskes (2012) ( BCCDR ), as well as a Max-SA T ( MaxSA T ) and a weigh ted max-SA T ( wMaxSA T ) approach. MMR : This strategy sorts constrain ts according to the Maximum Map Ratio (Algo- rithm 5) and greedily satisfies constraints in order of confidence; whenev er a new constrain t is not satisfiable given the ones already selected, it is ignored (lines 21- 25 in Algorithm 5). BCCDR : BCCDR sorts constrain ts according to Bay esian probabilit y es timates of the literals in F as presen ted in Claassen and Heskes (2012). The same greedy strategy for satisfying constraints in order is employ ed. Briefly , the authors of (Claassen and Heskes, 2012) prop ose a metho d for calculating Bay esian probabilities for any feature of a causal graph (e.g. adjacency , m -connection, causal ancestry). T o estimate the probabilit y of a feature, for a given data set D , the authors calculate the score of all DA Gs of N v ariables. Let G ` f denote that a feature f is present in D AG G . The probability of the feature is then calculated as P ( f ) = P G ` f P ( D |G ) P ( G ). Scoring all D AGs is practically infeasible for net works with more than 5 or 6 v ariables. Th us, for data sets with more v ariables, a subset of v ariables must b e selected for the calculation of the probability of a feature. F ollowing (Claassen and Heskes, 2012), w e use 5 as the maximum N attempted. The literals in F represent information on adjacencies: ( ¬ ) ad j acent ( X , Y , P i ) and col- liders: ( ¬ ) col lider ( X , Y , Z , P i ). T o apply the metho d ab o ve for a given feature, w e hav e to select the v ariables used in the D AGs, a suitable scoring function, and suitable DA G priors. F or (non) adjacencies X Y in P A G P i , w e scored the DA Gs ov er v ariables X , Y and Z , for the conditioning set Z maximizing the p-v alue of the tests X ⊥ ⊥ Y | Z performed by FCI. Since the total n umber of v ariables cannot exceed 5, the maxim um conditioning set for FCI is limited to 3 in all exp eriments in this section for a fair comparison. F or a (non) collider X Y Z , we score all net works o ver X , Y and Z . W e use the BGE metric for gaussian distributions (Geiger and Hec kerman, 1994) as implemen ted in the BD AGL pack age Eaton and Murph y (2007b) to calculate the lik eliho o ds of the DA Gs. This metric is score equiv alen t, so we pre-computed representativ es of the Mark ov equiv alent netw orks of up to 5 nodes, and scored only one net work p er equiv alence class to sp eed up the method. Priors for the DA Gs were also pre-computed to b e consistent with respect to the maxim um attempted n umber of no des (i.e. 5) as suggested in Claassen and Heskes (2012). MaxSA T : This approac h tries to satisfy as man y literals in F as p ossible. Recall that the SA T problem consists of a set of hard-constraints (conditionals, no cycles, no tail-tail edges), which should alwa ys b e satisfied (hard constrain ts), and a set of literals F . Maxim um SA T solvers cannot b e directly applied to the en tire SA T form ula since they do not distinguish b et ween hard and soft constraints. T o maximize the num b er of literals satisfied, while ensuring all hard-constrain ts are satisfied w e resorted to the follo wing tec hnique: we use the akmaxsat (Kuegel, 2010) weighte d max SA T solver that tries to maximize the sum of the weigh ts of the satisfied clauses. Eac h literal is assigned a weigh t of 1, and each hard-constraint is assigned a w eight equal to the sum of all weigh ts in F plus 10000. The summary graph returned by Algorithm 2 is based on the bac kb one of the subset of literals selected b y akmaxsat. wMaxSA T : Finally , we augmen ted the abov e tec hnique with a differen t w eigh ted strat- egy that considers the imp ortance of each literal. Sp ecifically , eac h literal w as w eighted prop ortionally to the logarithm of the corresp onding MMR. Again, each hard-constrain t 31 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables s-Precision 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables s-Recall 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables Proportion of dashed edges 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables o-Precision 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables o-Recall 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables Proportion of dashed endpoints MMR BCCDR maxSA T wMaxSA T Figure 9: Learning p erformance of COm bINE with v arious conflict resolution strategies . F rom left to righ t: Median s-Precision, s-Recall, proportion of dashed edges (top) and o-Precision, o-Recall and prop ortion of dashed endp oints (b ot- tom) for netw orks of several sizes for v arious conflict resolution strategies. Each data set consists of 100 samples. The num b ers for wMaxSA T and maxSA T cor- resp ond to 22 and 23 cases, resp ectively , in which the algorithms managed to return a solution within 500 seconds. w as assigned a weigh t equal to the sum of all w eights in F plus 10000, to ensure that the solv er will alwa ys satisfy these statements. The summary graph returned b y Algorithm 2 is based on the bac kb one of the subset of literals selected b y akmaxsat. W e ran all metho ds for net works of 10, 20, 30, 40 and 50 v ariables for data sets of 100 samples to test them on cases where statistical errors are common. F or eac h netw ork size w e p erformed 50 iterations. MaxSA T and wMaxSA T often failed to complete in a timely fashion; to complete the exp eriments w e ab orted the solv er after 500 seconds. W e note that this amount of time corresp onds to more than 10 times the maximum running time of the MMR metho d (calculating MMRs and solving the SA T instance), and more than twice times the maximum running time of the BCCDR-based metho d (for 50 v ariables). Cases where the solv er did not complete w ere not included in the reported statistics. Unfortunately , the metho ds using weighte d max SA T solving faile d to c omplete in most c ases for 10 variables , and all cases for more than 10 v ariables. The results are sho wn in Figure 9, where we can see the median p erformance of b oth algorithms o v er 50 iterations. Ov erall, MMR exhibits better Precision and identifies more solid edges, while BCCDR exhibits slightly b etter Recall. BCCDR is b etter for v ariable size equal to 10, which could b e explained from the fact that MMR is not pro vided with sufficien t num ber of p-v alues to estimate ˆ π 0 and ˆ ξ . In terms of computational complexit y , 32 1 2 3 4 5 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 maximum path length s-Precision 1 2 3 4 5 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 maximum path length s-Recall 1 2 3 4 5 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 maximum path length Proportion of dashed edges 1 2 3 4 5 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 maximum path length o-Precision 1 2 3 4 5 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 maximum path length o-Recall 1 2 3 4 5 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 maximum path length Proportion of dashed endpoints Figure 10: Learning p erformance of COm bINE against maxim um path length . F rom left to right: s-Precision, s-Recall, p ercen tage dashed edges and o- Precision, o-Recall and p ercen tage of dashed endp oints (b ottom) for v arying maxim um path length, a veraged o ver all net works. Shaded area ranges from the 5 to the 95 p ercen tile. Maximum path length 3 seems to b e a b e a reasonable trade-off b etw een p erformance, p ercentage of dashed features, and efficiency . for netw orks of 50 v ariables, estimating the BCCDR ratios tak es ab out 150 seconds on a verage, while estimating the MMR ratios tak es less than a second. The more sophisticated searc h strategies MaxSA T and wMaxSA T do not seem to offer any significant quality b enefits, at least for the single v ariable size for which we could ev aluate them. Based on these results, w e b eliev e that MMR is a reasonable and relatively efficient conflict resolution strategy . 5.3 COmbINE p erformance with increasing maxim um path length In this section, w e examine the b ehavior of the algorithm when the length of the paths con- sidered is limited, in whic h case the output is an approximation of the actual solution. The COm bINE pseudo-co de in Algorithm 2 accepts the maximum path length as a parameter. Learning p erformance as a function of the maximum path length is shown in Figure 10. Notice that when the path length is increased from 1 to 2 there is drop in the p ercentage of dashed endp oints, implying more orien tations are p ossible. F or length equal to 1, only unshielded and discriminating colliders are iden tified, while for length larger than 2 further orien tations b ecome p ossible thanks to reasoning with the inducing paths. When length is 1, notice that there are almost no dashed edges (except for the edges added in line 2 of Algorithm 3). When the maxim um length increases, adjacencies in one data set, can 33 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables s-Precision 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables s-Recall 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables Proportion of dashed edges 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables o-Precision 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables o-Recall 10 20 30 40 50 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of v ariables Proportion of dashed endp oints maxParents =3 maxParents =5 maxParents =10 Figure 11: Learning p erformance of COmbINE for v arious netw ork sizes and densities . F rom left to righ t: Median s-Precision, s-Recall, proportion of dashed edges (top) and o-Precision, o-Recall and prop ortion of dashed endp oints (b ot- tom) for v arying netw ork size and densit y . Densit y is controlled b y limiting the n umber of p ossible parents per v ariable. As exp ected, the p erformance deterio- rates as netw orks b ecome denser. b e explained with longer inducing paths in the underlying graph and more dashed edges app ear. The learning p erformance of the algorithm is not monotonic with the maximum length. Explaining an asso ciation (adjacency) through the presence of a long inducing path ma y b e necessary for asymptotic correctness. How ev er, in the presence of statistical errors, allo wing such long paths could lead to complicated solutions or the propagation of errors. Ov erall, it seems any increase of the maximum path length ab o ve 3 do es not significantly affect performance. It seems that a maximum path length of 3 is a reasonable trade- off among learning p erformance (precision and recall), p ercentage of uncertainties, and computational efficiency . These exp erimen ts justify our choice of maxim um length 3 as the default parameter v alue of the algorithm. 5.4 COmbINE p erformance as a function of net work densit y and size In Figure 11 the learning p erformance of the algorithm is presen ted as a function of net w ork densit y and size. Densit y w as con trolled by the maximum parents allo w ed p er v ariable, set b y parameter maxParen ts during the generation of the random netw orks. F or all net work sizes, learning p erformance monotonically decreases with increased density , while the p er- cen tage of dashed features do es not significantly v ary . The size of the net work has a smaller 34 2 3 5 8 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of data sets s-Precision 2 3 5 8 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of data sets s-Recall 2 3 5 8 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of data sets Proportion of dashed edges 2 3 5 8 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of data sets o-Precision 2 3 5 8 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of data sets o-Recall 2 3 5 8 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of data sets Proportion of dashed endpoints Figure 12: Learning performance of COm bINE for v arying n um b er of input data sets . F rom left to right: Median s-Precision, s-Recall, Prop ortion of dashed edges (top) and o-Precision, o-Recall and prop ortion of dashed endp oints of (b ottom) for v arying num b er of input data sets. Shaded area ranges from the 5 to the 95 p ercentile. Increasing the num b er of input data sets improv es the p erformance of the algorithm. impact on the p erformance, particularly for the sparser net works. F or dense netw orks, p erformance is relatively p o or and b ecomes worse with larger sizes. 5.5 COmbINE p erformance o ver sample size and n umber of input data sets Figure 12 shows the performance of the algorithm with increasing the num b er of input data sets. As exp ected, the p ercentage of uncertainties (dashed features) is steadily decreasing with increased n umber of input data sets. Recall also steadily impro ves, while Precision is relativ ely unaffected. Figure 13 holds the num b er of input data set constant to the default v alue 5, while increasing the sample size p er data set. Recall in particular improv es with larger sample sizes, while the p ercentage of dashed endp oin ts drops. 5.6 COmbINE p erformance for increasing n umber of latent v ariables W e also examine the effect of confounding to the p erformance of COm bINE . T o do so, we generated semi-Mark ov causal models instead of D AGs in the generation of the experiments: W e generated random D AG netw orks of 30 v ariables and then marginalized out a p ercentage of the v ariables. Figure 14 depicts COmbINE’s p erformance against 3, 6, and 9 of latent v ariables, corresp onding to 10%, 20% and 30% of the total n umber of v ariables in the graph, resp ectively . Overall, confounding do es not seem to greatly affect the p erformance 35 50 100 1000 5000 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 sample size s-Precision 50 100 1000 5000 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 sample size s-Recall 50 100 1000 5000 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 sample size Percen tage of dashed edges 50 100 1000 5000 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 sample size o-Precision 50 100 1000 5000 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 sample size o-Recall 50 100 1000 5000 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 sample size Percen tage of dashed endpoints Figure 13: Learning p erformance of COmbINE for v arying sample size p er data set . F rom left to righ t: s-Precision, s-Recall, Prop ortion of dashed edges (top) and o-Precision, o-Recall and prop ortion of dashed endp oints of (bottom) for v arying sample size p er data set. Shaded area ranges from the 5 to the 95 p ercen tile. Increasing the sample size improv es the p erformance of the algorithm. of COm bINE. W e must p oin t out how ever, that s-Recall is low er than the s-Recall with no confounded v ariables for the same netw ork size (see Figure 11). 5.7 Running Time for COmbINE The running time of COm bINE depends on sev eral factors, including the ones examined in the previous exp eriments: Maxim um path length, n umber of input data sets and sample size, and, naturally , the num b er of v ariables. Figure 15 illustrates the running time of COm bINE against these factors. Figure 15 (b) presen ts the running time of COm bINE against n umber of v ariables for net works of 5 maxim um parents p er v ariable. The exp eriments regarding 10 to 50 v ariables hav e also b een presen ted in terms of learning performance in section 5.4. T o further examine the scalability of the algorithm, we also r an COmbINE in networks of 100 variables , with 5 maximum parents p er v ariable. The exp eriments w ere ran with the default parameter v alues. As we can see in Figure 15, the restriction on the maximum path length is the most critical factor for the scalability of the algorithm. 5.8 A case study: Mass Cytometry data Mass cytometry (Bendall et al., 2011) is a recen tly in tro duced technique that enables mea- suring protein activit y in cells, and its main use is to classify hematop oietic cells and iden tify signaling profiles in the immune system. Therefore, the proteins are usually measured in 36 3 6 9 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of confounded nodes (out of 30) s-Precision 3 6 9 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of confounded nodes (out of 30) s-Recall 3 6 9 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of confounded nodes (out of 30) Proportion of dashed edges 3 6 9 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of confounded nodes (out of 30) o-Precision 3 6 9 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of confounded nodes (out of 30) o-Recall 3 6 9 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 num b er of confounded nodes (out of 30) Proportion of dashed endpoints Figure 14: Learning p erformance of COm bINE for v arying p ercentage of con- founded v ariables . F rom left to right: s-Precision, s-Recall, p ercen tage of dashed edges (top) and o-Precision, o-Recall and p ercen tage of dashed end- p oin ts (b ottom) for v arying num b er of confounded no des for netw orks of 30 v ariables. Shaded area ranges from the 5 to the 95 p ercentile. Overall, the n umber of confounding v ariables do es not seem to greatly affect the algorithm’ s p erformance. a sample of cells and then in a different sample of the same (type of ) cells after they ha ve b een stim ulated with a comp ound that triggers some kind of signaling b eha vior. Iden tify- ing the causal succession of ev ents during cell signaling is crucial to designing drugs that can trigger or suppress immune reaction. Therefore in several studies b oth stim ulated and un-stim ulated cells are treated with several p erturbing comp ounds to monitor the p oten tial effect on the signaling path wa y . Mass cytometry data seem to be an suitable test-b ed for causal disco v ery metho ds: The proteins are measured in single cells instead of represen ting tissue av erages, the latter being kno wn to b e problematic for causal disco very (Ch u et al., 2003), and the samples range in thousands. Ho wev er, the mass cytometer can measure only up to 34 v ariables, whic h ma y b e to o lo w a n umber to measure all the v ariables in volv ed in a signaling path wa y . Moreo ver, ab out half of these v ariables are surface proteins that are necessary to distinguish (gate) the cells into sub-p opulations, but are not functional proteins inv olved in the signaling path- w ay . It is therefore reasonable for scientists to p erform exp eriments measuring ov erlapping v ariable sets. Bendall et al. (2011) and Bo denmiller et al. (2012) b oth use mass cytometry to measure protein abundance in cells of the immune system. In b oth studies, the samples w ere treated 37 3 5 10 10 100 1000 10000 (a) maximum parents time (sec) 20 variables, 5 data sets, mpl 3, sample size 1000 10 20 30 40 50 100 10 100 1000 10000 (b) num b er of variables time (sec) 5 data sets, mpl 3, sample size 1000, maxParen ts 5 2 3 5 8 10 100 1000 10000 (c) # data sets time (sec) 20 variables, mpl 3, sample size 1000, maxParen ts 5 1 2 3 4 5 10 100 1000 10000 (d) maximum path length time (sec) 20 variables, 5 data sets, sample size 1000, maxParents 5 Figure 15: Running time of COmbINE . F rom left to righ t: Running time (in seconds) is plotted in logarithmic scale against maxim um paren ts p er v ariable and num b er of v ariables (top row); n umber of data sets and maximum path length (b ottom ro w). Shaded area ranges from the 5 to the 95 p ercen tile. The n umber of v ariables and the maximum path length seem to b e the most critical factors of computational performance. Notice that, COm bINE scales up to problems with 100 total v ariables for limited path length and relatively sparse net w orks. with sev eral differen t signaling stim uli. Some of the stim uli w ere common in b oth studies. After stimulation with each activ ating comp ound, Bo denmiller et al. (2012) also test the cell’s response to 27 inhibitors. One of these inhibitors is also used in Bendall et al. (2011). F or this inhibitor, Bendall et al. (2011) measured b one marrow cell samples of a single donor. In Bodenmiller et al. (2012), measuremen ts w ere tak en from P eripheral blo o d monon uclear cell samples of a (different) single donor. Despite differences in the exp erimen tal setup, the signaling path wa y of ev ery stim ulus and every sub-p opulation of cells is considered univ ersal across (healthy) donors, so the data should reflect the same underlying causal structure. W e fo cused on tw o sup-p opulations of the cells, CD4+ and CD8+ T-cells, whic h are kno wn to pla y a cen tral role in immune signaling. The data were manually gated by the researc hers in the original studies. W e also fo cused on one of the stim uli present in b oth studies, PMA-Ionom ycin, which is known to hav e prominent effects on T-cells. Proteins pBtk, pStat3, pStat5, pNfkb, pS6, pp38, pErk, pZap70 and pSHP2 are measured in b oth data sets (initial p denotes that the concentration of the phosphorylated protein is mea- sured). F our additional v ariables were included in the analysis, pAkt, pLat and pStat1 measured only in Bo denmiller et al. (2012) and pMAPK measured only in Bendall et al. 38 Data set Source laten t ( L i ): manipulated( I i ) Donor D 1 Bo denmiller et al. (2012) pMAPK pAkt 1 D 2 Bo denmiller et al. (2012) pMAPK pBtk 1 D 3 Bo denmiller et al. (2012) pMAPK pErk 1 D 4 Bendall et al. (2011) pAkt, pLat, pStat1 pErk 2 T able 3: Summary of the mass cytometry data sets co-analyzed with COm bINE . The pro cedure w as rep eated for tw o sub-p opulations of cells, CD4+ cells and CD8+ cells. pBtk pS6 pStat3 pP38 pStat5 pErk pZap70 pMAPK pLat pSHP2 pStat1 pNFkB pAkt pStat1 pErk pMAPK pS6 pZap70 pStat5 pAkt pSHP2 pBtk pLat pNFkB pP38 pStat3 Figure 16: A case study for COmbINE: Mass cytometry data . COmbINE w as run on 4 differen t mass cytometry data for tw o different cell populations: CD4+ T-cells (left) and CD8+ T-cells (righ t). In eac h data set, one v ariable w as manipulated (pAkt, pBTk, pErk, pErk resp ectively). V ariables pAkt, pLat and pStat1 are only measured in data sets 1-3, while pMAPK is only measured in data set 4. Notice that pAkt is predicted to b e a direct cause of pMAPK in b oth CD4+ and CD8+ cells, ev en though the tw o v ariables hav e nev er b een measured together. (2011). T o be able to detect signaling b ehavior, we formed data sets that contain b oth stim ulated and unstimulated samples. As mentioned abov e, the cells w ere treated with sev- eral inhibitors. Some of these inhibitors target a specific protein, and some of them perturb the system in a more general or unidentified wa y . W e used three target sp ecific compounds that can be mo deled as hard in terven tions (i.e. the comp ounds used to target these proteins are known to b e sp ecific and to ha ve an effect in the phosphorylation levels of the target). More information on the sp ecific comp ounds can b e found in the resp ectiv e publications. W e ended up with four data sets for each sub-population. Details can b e found in T able 3. Protein in teractions are t ypically non-linear, so we discretized the data into 4 bins. W e ran Algorithm 2 with maxim um path length 3. W e used the G 2 test of indep endence for 39 F CI with α = 0 . 1 and maxK=5. W e used Cytoscap e (Smo ot et al., 2011) to visualize the summary graphs pro duced b y COmbINE, illustrated in Figure 16. Unfortunately , the ground truth for this problem is not kno wn for a full quantitativ e ev aluation of the results. Nevertheless, this set of exp erimen ts demonstrates the av ailability of real and imp ortant data sets and problems that are suited integrativ e causal analysis. Second, these exp erimen ts provide a pro of-of-concept for the sp ecific algorithm. One type of interesting t yp e of inference p ossible with COmbINE and similar algorithms is the pre- diction that pAkt is a direct cause of pMAPK in b oth CD4+ and CD8+ cells, even though the variables ar e not jointly me asur e d in any of the input data sets . Evidence of a direct protein interaction betw een the tw o proteins do es exists in the literature Rane et al. (2001). Th us, metho ds for learning causal structure from multiple manipulations ov er o verlapping v ariables p oten tially constitute a p ow erful to ol in the field of mass cytometry . W e do not make an y claims for the v alidit y of the output graphs and they are presen ted only as a pro of-of-concept, as there are several p otential pitfalls. COmbINE assumes lack of feedbac k cycles, which is not guaranteed in this system (we note how ev er, that acyclic net works hav e b een successfully used for rev erse engineering protein pathw ays in the past (Sac hs et al., 2005)). Causal discov ery metho ds that allow cycles Hyttinen et al. (2013) on the other hand rely on the assumption of linearity , which is also kno wn to b e heavily violated in suc h net works. Thus, which set of assumptions b est approximates the sp ecific system is unknown. 6. Conclusions and F uture W ork W e ha ve presen ted COm bINE, a sound and complete algorithm that p erforms causal dis- co very from m ultiple data sets that measure o verlapping v ariable sets under differen t in ter- v entions in acyclic domains. COm bINE w orks b y conv erting the constraints on inducing paths in the sought out semi Marko v causal mo del (SMCMs) that stem from the disco vered (in)dep endencies in to a SA T instance. COm bINE outputs a summary of the structural c haracteristics of the underlying SMCM, distinguishing b et ween the c haracteristics that are iden tifiable from the data (e.g., causal relations that are p ostulated as present), and the ones that are not (e.g., relations that could b e present or not). In the empirical ev aluation the algorithm outp erforms in efficiency a recently published similar one (Hyttinen et al., 2013) that, given an oracle of conditional indep endence, p erforms the same inferences by c hecking all m -connections necessary for completeness. COm bINE is equipp ed with a conflict resolution technique that ranks dep endencies and independencies disco v ered according to confidence as a function of their p-v alues. This tec hnique allo ws it to b e applicable on real data that ma y present conflicting constrain ts due to statistical errors. T o the b est of our kno wledge, COmbINE is the only implemented algorithm of its kind that can b e applied on real data. The algorithm is empirically ev aluated in v arious scenarios, where it is sho wn to exhibit high precision and recall and reasonable b ehavior against sample size and num b er of input data sets. It scales up to netw orks with up to 100 v ariables for relatively sparse net works. Moreo ver, it is p ossible for the user to trade the num b er of inferences for improv ed compu- tational efficiency by limiting the maximum path length considered b y the algorithm. As a pro of-of-concept application, we used COmbINE to analyze a real set of exp erimental 40 mass-cytometry data sets measuring ov erlapping v ariables under three different interv en- tions. COm bINE outputs a summary of the c haracteristics of the underlying SMCM that can b e identified by computing the backbone of the corresp onding SA T instance. The conv er- sion of a causal discov ery problem to a SA T instance mak es COmbINE easily extendable to other inference tasks. One could instead pro duce all SA T solutions and obtain all the SMCMs that are plausible (i.e., fit all data sets). In this case, COmbINE with input a single P A G w ould output all SMCMs that are Marko v Equiv alen t with the P AG; there is no other known pro cedure for this task. Alternatively , one could easily query whether there are solution mo dels with certain structural c haracteristics of interest (e.g., a directed path from A to B ); this is easily done b y imposing additional SA T clauses expressing the presence of these features. Incorp orating certain t yp es of prior kno wledge suc h as causal precedence information can also b e achiev ed b y imp osing additional path constraints. F uture work includes extending this work for admitting soft in terv entions and known instrumental v ari- ables. The conflict resolution technique prop osed could be employ ed to standard causal disco very algorithms that learn from single data sets, in an effort to impro v e their learning qualit y . App endix A. Pro of of Prop osition 8 Prop osition Let O b e a set of v ariables and J the independence mo del o v er V . Let S b e a SMCM ov er v ariables V that is faithful to J and M be the MAG o v er the same v ariables that is faithful to J . Let X , Y ∈ O . Then there is an inducing path b etw een X and Y with respect to L , L ⊆ V in S if and only if there is an inducing path b etw een X and Y with resp ect to L in M . Pro of ( ⇒ ) Assume there exists a path p in S that is inducing w.r.t. L . Then by theorem 7 there exists no Z ⊆ V \ L ∪ { X , Y } such that X and Y are m -separated giv en Z in S , and since S and M entail the same m -separations there exists no Z ⊆ V \ L ∪ { X , Y } suc h that X and Y are m -separated given Z in M . Thus, by Theorem 6 there exists an inducing path b etw een X and Y with resp ect to L in M . ( ⇐ ) Similarly , assume there exists a path p in M that is inducing w.r.t. L . Then by theorem 6 there exists no Z ⊆ V \ L ∪ { X , Y } suc h that X and Y are m -separated giv en Z in M , and since S and M entail the same m -separations there exists no Z ⊆ V \ L ∪ { X, Y } suc h that X and Y are m -separated giv en Z in S . Thus, b y Theorem 7 there exists an inducing path b etw een X and Y with resp ect to L in S . Pro of of Lemma 10 Lemma Let {P i } N i =1 b e a set of P AGs and S a SMCM suc h that S is possibly underlying for {P i } N i =1 , and let H b e the initial searc h graph returned b y Algorithm 3 for {P i } N i =1 . Then, if p is an ancestral path in S , then p is a p ossibly ancestral path in H . Similarly , if p is a p ossibly inducing path with resp ect to L in S , then p is a p ossibly inducing path with resp ect to L in H . 41 Pro of W e will first prov e that any path in S is a path also in H , i.e. H has a superset of edges compared to S . If X and Y are adjacen t in S , then one of the follo wing holds: 1. ∃ i s.t. X , Y ∈ O i \ I i . Then the edge is presen t in S I i , and X and Y are adjacent in P i : the edge is added to H in Lines 2 of Algorithm 3. 2. 6 ∃ i s.t. X , Y ∈ O i \ I i . Then the edge is added in H in Line 5 of Algorithm 3. Therefore, every edge in S is presen t also in H . W e must also prov e that no orien tation in H is oriented differen tly in S : H has only arrowhead orientations, so we must prov e that, if X Y in H and X and Y are adjacent in both graphs, X Y in S . Arro ws are added to H in Line 2 or in Lines 6 of the Algorithm. Arrowheads added in Line 2 o ccur in all P i . If X Y in P i , this means that Y is not an ancestor of X in S I i . Assume that X Y in S : If X in I i , the edge would be absen t in S I i and P i . If X 6∈ I i , X w ould be ancestor of Y in S I i , which is a con tradiction. Therefore, if X and Y are adjacen t in S , X Y in S . The latter type of arro ws corresp ond to cases where an edge is not present in any P i , 6 ∃ i s.t. X, Y ∈ O i \ I i , but ∃ i s.t. X , Y ∈ O i , X ∈ I i and Y 6∈ I i . Then an arro w is added to wards X . Assume the opp osite holds: X Y in S , then X Y in S I i , and since b oth v ariables are observed in i the edge w ould be presen t in P i , whic h is a con tradiction. Th us, if the edge is presen t in S , the edge is oriented in to X . Th us, H has a sup erset of edges of S , and for an y edge present in b oth graphs, the orien tations are the same. Th us, if Then, if p is an ancestral path in S , then p is a p ossibly ancestral path in H . Similarly , if p is a possibly inducing path with resp ect to L in S , then p is a p ossibly inducing path with resp ect to L in H . Pro of of Lemma 11 Lemma Let { D i } N i =1 b e a set of data sets o v er ov erlapping subsets of O , and { I i } N i =1 b e a set of (p ossibly empt y) interv ention targets such that I i ⊂ O i for eac h i. Let P i b e output P AG of FCI for data set D i , Φ ∧ F 0 b e the final formula of Algorithm 2, and S b e a p ossibly underlying SMCM for { P i } N i =1 . Then S satisfies Φ ∧ F 0 . Pro of Constraints in Lines 7 and 8 of Algorithm 4 are satisfied since S is a semi-Mark ov causal mo del. Since M i ∈ P i ∀ i , M i and P i share the same adjacencies and non-adjacencies. If X and Y are adjacen t in P i , X and Y are adjacent in M i , and b y Prop osition 8 there exists an inducing path with resp ect to L i in S I i , and b y Lemma 10 this path is a p ossibly inducing path in the initial searc h graph. If X and Y are not adjacent in P i , X and Y are not adjacen t in M i , and by Prop osition 8 there exists no inducing path with resp ect to L i in S I i . Th us, constrain ts added in Line 4 of Algorithm 4 along with the corresponding literals ( ¬ ) ad j acent ( X , Y , P i ) are satisfied by S . If X Y Z is an unshielded triple in P i , X Y Z is an unshielded triple in M i . If Y is a collider on the triple on P i then Y is a collider on the triple on M i and b y the seman tics of edges in MAGs Y is not an ancestor of X nor Z S I i . Thus, constrain ts added to Φ in Line 13 along with the corresponding literal coll ider ( X , Y , Z , P i ) are satisfied b y S . Similarly , if Y is not a collider on the triple, Y is an ancestor of either X or Z in M i 42 and there exists a relative ancestral path p Y X or p Y Z in S I i . By Lemma 10, this path is a p ossibly ancestral path in the initial H . Th us, S satisfies the constraints added to Φ in in Line 12 along with the corresp onding literal dnc ( X , Y , Z, P i ). If h W, . . . , X , Y , Z i is a discriminating path for V in P i and M i and Y is a collider on the path in P i , then Y is a collider on the path in M i , therefore Y is not an ancestor of either X or Z in S I i , so S satisfies the constrain ts added to Φ in Line 18 of Algorithm 4 along with the corresp onding literal col l ider ( X , Y , Z, P i ). Similarly , if Y is not a collider on the triple, Y is an ancestor of either X or Z in M i and there exists a relative ancestral path p Y X or p Y Z in S I i . By Lemma 10, this path is a p ossibly ancestral path in the initial H . Thus, S satisfies the constrain ts added to Φ in in Line 17 along with the corresponding literal dnc ( X , Y , Z , P i ). Pro of of Lemma 12 Lemma Let { D i } N i =1 , { I i } N i =1 , { P i } N i =1 , Φ ∧ F 0 b e defined as in Lemma 11. If graph S satisfies Φ ∧ F 0 , then S is a p ossibly underlying SMCM for { P i } N i =1 . Pro of S is a SMCM: S is by construction a mixed graph, and it satisfies constraints in Lines 7 and 8 of Algorithm 4, so it has no directed cycles, and at most one tail per edge. M i and P i share the same edges: If X and Y are adjacent in P i , then by the constrain ts in Line 4 of Algorithm 4 there exists an inducing path with respect to L i in S I i , therefore X and Y are adjacen t in M i . If X and Y are not adjacent in P i then b y the same constraints there exists no inducing path with respect to L i in S I i , therefore X and Y are not adjacent in M i . M i and P i share the same unshielded colliders: Let X Y Z b e an unshielded triple in P i . Since P i and M i share the same edges, X Y Z is an unshielded triple in M i . If the triple is an unshielded collider in P i then by the constraints in Line 13 of Algorithm 4 Y is not an ancestor of either X or Z in S I i , thus X Y Z in M i . If on the other hand the triple is a definite non-collider in P i , then b y the constraints in Line 12 of Algorithm 4 Y is an ancestor of either X or Z in S I i , therefore either Y X or Y Z in M i , thus, the triple is an unshielded non-collider in M i . If h W, . . . , X , Y , Z i is a discriminating path for V in b oth M i and P i , and Y is a collider on the path, then b y the constrain ts in Line 18 of Algorithm 4 Y is not an ancestor of X or Z in S I i , therefore Y is a collider on the same path in M i . If, conv ersely , Y is not a collider on the path, then by the constrain ts in Line 17 of Algorithm 4, Y is an ancestor of either X or Z , th us, X is not a collider on the same path in M i . References IA Beinlic h, HJ Suermondt, RM Cha vez, and GF Coop er. The ALARM monitoring system: A case study with tw o probabilistic inference techniques for b elief netw orks. In Se c ond Eur op e an Confer enc e on A rtificial Intel ligenc e in Me dicine , volume 38, pages 247–256. Springer-V erlag, Berlin, 1989. SC Bendall, EF Simonds, P Qiu, El-ad D Amir, PO Krutzik, R Finck, R V Bruggner, R Melamed, A T rejo, OI Ornatsky , RS Balderas, SK Plevritis, K Sac hs, D P e ´ er, SD T an- 43 ner, and GP Nolan. Single-cell mass cytometry of differen tial immune and drug resp onses across a human hematopoietic con tinuum. Scienc e , 332(6030):687–696, 2011. B Bo denmiller, ER Zunder, R Finc k, TJ Chen, ES Sa vig, R V Bruggner, EF Simonds, SC Bendall, K Sac hs, PO Krutzik, et al. Multiplexed mass cytometry profiling of cellular states p erturb ed b y small-molecule regulators. Natur e biote chnolo gy , 30(9):858–867, 2012. G Borb oudakis, S T rian tafillou, and I Tsamardinos. T o ols and algorithms for causally in terpreting directed edges in maximal ancestral graphs. In Sixth Eur op e an Workshop on Pr ob abilistic Gr aphic al Mo dels(PGM) , 2012. T Chu, C Glymour, R Sc heines, and P Spirtes. A statistical problem for inference to regulatory structure from asso ciations of gene expression measuremen ts with microarrays. Bioinformatics , 19(9):1147–1152, 2003. T Claassen and T Heskes. Causal discov ery in multiple mo dels from differen t exp erimen ts. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS 2010) , volume 23, pages 1–9, 2010a. T Claassen and T Hesk es. Learning causal net work structure from m ultiple (in) dep endence mo dels. In Pr o c. of the Fifth Eur op e an Workshop on Pr ob abilistic Gr aphic al Mo dels (PGM) , pages 81–88, 2010b. T Claassen and T Heskes. A Bay esian Approac h to Constraint Based Causal Inference. In Pr o c e e dings of the 28th Confer enc e on Unc ertainty in Artificial Intel ligenc e (UAI2012) , pages 207–217, 2012. Diego Colombo, Marlo es H. Maath uis, Markus Kalisch, and Thomas S. Richardson. Learn- ing high-dimensional directed acyclic graphs with laten t and selection v ariables. The A nnals of Statistics , 40(1):294–321, 02 2012. GF Coop er and Ch Y o o. Causal disco very from a mixture of exp erimen tal and observ ational data. In Pr o c e e dings of Unc ertainty in Artificial Intel ligenc e (UAI 1999) , v olume 10, pages 116–125, 1999. D Eaton and K Murphy . Belief net structure learning from uncertain in terven tions. J Mach L e arn R es , 1:1–48, 2007a. D Eaton and K Murph y . Bdagl: Bay esian dag learning. http://www.cs.ubc.ca/ ~ murphyk/ Software/BDAGL/ , 2007b. F Eb erhardt and R Scheines. Interv en tions and causal inference. Philosophy of scienc e , 74 (5):981–995, 2007. N E´ en and N S¨ orensson. An extensible SA T-solver. In The ory and Applic ations of Satisfi- ability T esting , pages 333–336, 2004. RJ Ev ans and TS Richardson. Maxim um lik eliho o d fitting of acyclic directed mixed graphs to binary data. In Pr o c e e dings of the 26th International Confer enc e on Unc ertainty in A rtificial Intel ligenc e , 2010. 44 RJ Ev ans and TS Richardson. Marginal log-linear parameters for graphical marko v mo dels. arXiv pr eprint arXiv:1105.6075 , 2011. RA Fisher. On the in terpretation of χ 2 from contingency tables, and the calculation of p. Journal of the R oyal Statistic al So ciety , 85(1):87–94, 1922. Dan Geiger and Da vid Hec kerman. Learning gaussian net w orks. In Pr o c e e dings of the T enth Confer enc e Annual Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UAI-94) , pages 235–243, San F rancisco, CA, 1994. Morgan Kaufmann. Carla P Gomes, Bart Selman, Nuno Crato, and Henry Kautz. Heavy-tailed phenomena in satisfiabilit y and constraint satisfaction problems. Journal of automate d r e asoning , 24 (1-2):67–100, 2000. A Hauser and P B ¨ uhlmann. Characterization and Greedy Learning of Interv en tional Mark ov Equiv alence Classes of Directed Acyclic Graphs. JMLR , 13, August 2012. A Hyttinen, F Eberhardt, and PO Hoy er. Learning linear cyclic causal mo dels with laten t v ariables. JMLR , 13:3387–3439, 2012a. A Hyttinen, F Eb erhardt, and PO Hoy er. Causal discov ery of linear cyclic models from m ultiple exp erimental data sets with ov erlapping v ariables. In Unc ertainty in Artificial Intel ligenc e , 2012b. A Hyttinen, PO Hoy er, F Eb erhardt, and M J¨ arvisalo. Discov ering cyclic causal mo dels with laten t v ariables: A general sat-based pro cedure. In Unc ertainty in Artificial Intel ligenc e , 2013. Adrian Kuegel. Improv ed exact solver for the w eighted max-sat problem. In Workshop Pr agmatics of SA T , 2010. S Meganc k, S Maes, P Lera y , and B Manderic k. Learning semi-marko vian causal mo dels us- ing experiments. In Thir d Eur op e an Workshop on Pr ob abilistic Gr aphic al Mo dels(PGM) , 2006. K Murphy . Active learning of causal ba yes net structure. T ec hnical rep ort, UC Berk eley , 2001. J Ramsey , P Spirtes, and J Zhang. Adjacency faithfulness and conserv ative causal inference. In Pr o c e e dings of Unc ertainty in Artificial Intel ligenc e , 2006. MJ Rane, PY Co xon, D W Po w ell, R W ebster, JB Klein, W Pierce, P Ping, and KR McLeish. p38 kinase-dependent mapk apk-2 activ ation functions as 3-phosphoinositide-dep enden t kinase-2 for akt in human neutrophils. Journal of Biolo gic al Chemistry , 276(5):3517– 3523, 2001. TS Richardson and P Spirtes. Ancestral graph marko v mo dels. The Annals of Statistics , 30(4):962–1030, 2002. 45 TS Ric hardson, JM Robins, and I Shpitser. Nested mark ov prop erties for acyclic directed mixed graphs. In Pr o c e e dings of the Twenty Eighth Confer enc e on Unc ertainty in Artifi- cial Intel ligenc e , page 13. AUAI Press, 2012. K Sachs, O Perez, D P e’er, DA Lauffenburger, and GP Nolan. Causal protein-signaling net works deriv ed from m ultiparameter single-cell data. Scienc e , 308(5721):523–529, 2005. T Sellk e, MJ Ba yarri, and JO Berger. Calibration of ρ v alues for testing precise null h yp otheses. The Americ an Statistician , 55(1):62–71, 2001. I Shpitser, R Ev ans, TS Ric hardson, and JM Robins. Sparse nested marko v mo dels with log-linear parameters. In Pr o c e e dings of the Twenty Ninth Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UAI-13) , pages 576–585. A UAI Press, 2013. ME Smo ot, K Ono, J Ruscheinski, PL W ang, and T Idek er. Cytoscap e 2.8: new features for data integration and net work visualization. Bioinformatics , 27(3):431–432, 2011. P Spirtes and TS Richardson. A p olynomial time algorithm for determining DA G equiv- alence in the presence of latent v ariables and selection bias. In Pr o c e e dings of the 6th International Workshop on A rtificial Intel ligenc e and Statistics , pages 489–500, 1996. P Spirtes, C Glymour, and R Sc heines. Causation, Pr e diction, and Se ar ch . The MIT Press, second edition, January 2001. JD Storey and R Tibshirani. Statistical significance for genomewide studies. Pr o c e e dings of the National A c ademy of Scienc es of the Unite d States of A meric a , 100(16):9440, 2003. J Tian and J Pearl. On the iden tification of causal effects. T echnical Rep ort R-290-L, UCLA Cognitive Systems Laboratory , 2003. RE Tillman and P Spirtes. Learning equiv alence classes of acyclic mo dels with latent and selection v ariables from m ultiple datasets with ov erlapping v ariables. In Pr o c e e dings of the 14th International Confer enc e on Artificial Intel ligenc e and Statistics , v olume 15, pages 3–15, 2011. RE Tillman, D Danks, and C Glymour. Integrating lo cally learned causal structures with o verlapping v ariables. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS , 2008. S T ong and D Koller. Active learning for structure in bay esian netw orks. In International joint c onfer enc e on artificial intel ligenc e , pages 863–869, 2001. S T riantafillou, I Tsamardinos, and IG T ollis. Learning causal structure from ov erlapping v ariable sets. In Pr o c e e dings of Artificial Intel ligenc e and St atistics , volume 9, 2010. Ioannis Tsamardinos, Sofia T rian tafillou, and Vincenzo Lagani. T ow ards in tegrative causal analysis of heterogeneous data sets and studies. The Journal of Machine L e arning R e- se ar ch , 98888:1097–1157, 2012. TS V erma and J Pearl. Equiv alence and Syn thesis of Causal Mo dels. T ec hnical Rep ort R-150, UCLA Department of Computer Science, 2003. 46 J Zhang. Causal infer enc e and r e asoning in c ausal ly insufficient systems . PhD thesis, PhD thesis, Carnegie Mellon Universit y , 2006. J Zhang. On the completeness of orientation rules for causal discov ery in the presence of latent confounders and selection bias. A rtificial Intel ligenc e , 172(16-17):1873–1896, 2008a. J Zhang. Causal Reasoning with Ancestral Graphs. Journal of Machine L e arning R ese ar ch , 9(1):1437–1474, 2008b. 47
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment