Semi-Supervised Nonlinear Distance Metric Learning via Forests of Max-Margin Cluster Hierarchies
Metric learning is a key problem for many data mining and machine learning applications, and has long been dominated by Mahalanobis methods. Recent advances in nonlinear metric learning have demonstrated the potential power of non-Mahalanobis distanc…
Authors: David M. Johnson, Caiming Xiong, Jason J. Corso
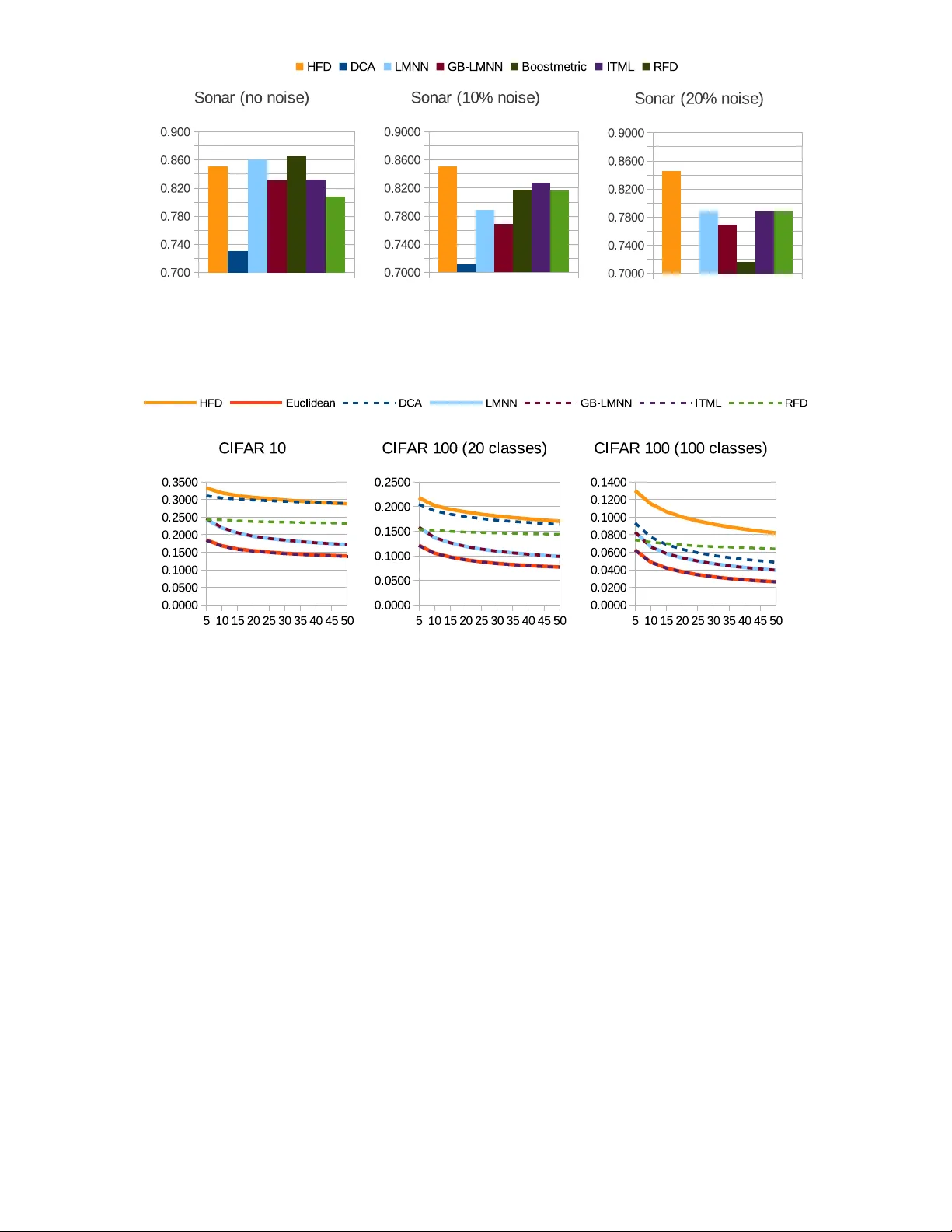
MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 Semi-Sup ervised Nonlinear Distance Metric Learning via F orests of Max-Margin Cluster Hierarc hies Da vid M. Johnson da vidjoh@buffalo.edu Caiming Xiong cxiong@buffalo.edu Jason J. Corso jcorso@buffalo.edu ∗ Abstract Metric learning is a k ey problem for man y data mining and mac hine learning applications, and has long been domi- nated b y Mahalanobis methods. Recen t adv ances in nonlin- ear metric learning ha ve demonstrated the potential pow er of non-Mahalanobis distance functions, particularly tree- based functions. W e propose a no v el nonlinear metric learn- ing metho d that uses an iterative, hierarchical v arian t of semi-sup ervised max-margin clustering to construct a for- est of cluster hierarc hies, where eac h individual hierarch y can b e interpreted as a w eak metric ov er the data. By in- tro ducing randomness during hierarc hy training and com- bining the output of many of the resulting semi-random w eak hierarch y metrics, we can obtain a p o werful and ro- bust nonlinear metric model. This metho d has t w o primary con tributions: first, it is semi-sup ervised, incorp orating in- formation from b oth constrained and unconstrained points. Second, we tak e a relaxed approach to constrain t satisfac- tion, allo wing the metho d to satisfy different subsets of the constrain ts at differen t lev els of the hierarc hy rather than at- tempting to sim ultaneously satisfy all of them. This leads to a more robust learning algorithm. W e compare our metho d to a n umber of state-of-the-art b enchmarks on k -nearest neigh b or classification, large-scale image retriev al and semi- sup ervised clustering problems, and find that our algorithm yields results comparable or superior to the state-of-the-art, and is significan tly more robust to noise. Index terms— Metric learning, nonlinear, semi- sup ervised, max-margin clustering, hierarc hical clustering 1 In tro duction Man y elemen tal data mining problems—nearest neigh b or classification, retriev al, clustering—are at their core dep en- den t on the av ailabilit y of an effective means of measuring pairwise distance. Ad ho c selection of a metric, whether b y relying on a standard such as Euclidean distance or at- tempting to select a domain-appropriate k ernel, is unreli- able and inflexible. W e thus approac h metric selection as a le arning problem, and attempt to train strong problem- sp ecific distance measures using data and seman tic infor- mation. ∗ Authors are with the Departmen t of Computer Science and Engi- neering, SUNY at Buffalo, Buffalo, NY, 14260-2500 A wide range of metho ds hav e b een proposed to address this learning problem, but the field has traditionally b een dominated by algorithms that assume a linear mo del of dis- tance, particularly Mahalanobis metrics [1]. Linear meth- o ds hav e primarily benefited from tw o adv antages. First, they are generally easier to optimize, allowing for faster learning and in many cases a globally optimal solution to the prop osed problem [2, 3, 4, 5]. Second, they allow the original data to b e easily pro jected into the new met- ric space, meaning the metric can be used in conjunction with other metho ds that op erate only on an explicit feature represen tation (most notably approximate nearest neigh b or metho ds—needed if the metric is to be applied efficiently to large-scale problems). Ho wev er, for man y t yp es of data a linear approac h is not appropriate. Images, videos, do cumen ts and histogram represen tations of all kinds are ill-suited to linear models. Ev en an ideal Mahalanobis metric will b e unable to cap- ture the true semantic structure of these types of data, par- ticularly o ver larger distances where lo cal linearit y breaks do wn. Kernelized v ersions of p opular Mahalanobis meth- o ds [2, 6] ha v e been prop osed to handle suc h data, but these approac hes hav e been limited by high complexit y costs. F or this reason, researchers hav e b egun to seek alternate metric mo dels that are inheren tly capable of handling nonlinear data. These nonlinear metrics are necessarily a broad class of mo dels, encompassing a range of learning mo dalities and metric structures. One early example of nonlinear metrics (for facial recognition, in this case) by Chopra et al. [7] w as based on deep learning strategies. The metho d was effec- tiv e, but required long training times and extensiv e tuning of hyperparameters. Other metho ds sought to resolv e the problem by taking adv an tage of local linearit y in the data, and learning m ultiple lo calized linear metrics [8, 9, 10, 11]. These techniques hav e generally prov en sup erior to single- metric metho ds, but ha v e also tended to b e expensive. Most recently , several works ha ve explored metrics that tak e adv antage of tree structures to produce flexible nonlin- ear transformations of the data. Kedem et al. [12] prop osed a metho d that trained a set of gradien t-b o osted regression trees and added the regression outputs of eac h region di- rectly to the data, pro ducing an explicit nonlinear transfor- mation that shifted similar p oin ts together and dissimilar p oin ts apart. How ev er, this metho d relies on p erforming re- gression against a d -dimensional gradient vector, and ma y MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 2 th us b e prone to o verfitting when d is large relative to the n umber of training samples. Finally , our previous work in this area [13] formulated the pairwise-constrained metric learning problem as a pair- classification problem, and solved it b y direct application of random forests, yielding an implicit nonlinear transforma- tion of the data. How ev er, while this metric could b e trained efficien tly , it suffered from po or scalabilit y at inference time due to the lac k of an explicit feature representation, which made common metric tasks suc h as nearest neigh b or search exp ensiv e on larger datasets. In order to o vercome the limitations of these methods, w e prop ose a no vel tree-based nonlinear metric with sev- eral adv an tages o ver existing algorithms. Our metric first constructs a model of the data by computing a forest of semi-random cluster hierarc hies, where each tree is gener- ated by iteratively applying a partially-randomized binary semi-sup ervised max-margin clustering ob jectiv e. As a re- sult, each tree directly enco des a particular mo del of the data’s full semantic structure, and the structure of the tree itself can th us b e interpreted as a w eak metric. By merg- ing the output from a forest of these weak metrics, we can pro duce a final me tric model that is pow erful, flexible, and resistan t to ov ertraining (due to the indep enden t and semi- random nature of the hierarch y construction). This metho dology provides tw o significant contributions: first, unlik e previous tree-based nonlinear metrics, it is semi- sup ervised, and can incorp orate information from b oth con- strained and unconstrained p oin ts into the learning algo- rithm. This is an imp ortan t adv an tage in many problem settings, particularly when scaling to larger datasets where only a tin y prop ortion of the full pairwise constrain t set can realistically b e collected or used in training. Second, the iterativ e, hierarchical nature of our training pro cess allows us to relax the constraint satisfaction prob- lem. Rather than attempting to satisfy every av ailable con- strain t simultaneously , at each hierarch y no de we can opti- mize an appropriate constraint subset to fo cus on, leaving others to b e addressed low er in the tree (or in other hier- arc hies in the forest). By selecting constrain ts in this wa y , w e can av oid situations where w e are attempting to sat- isfy incoherent constrain ts [14], and thereb y b etter mo del hierarc hical data structures. W e can also obtain an algo- rithm that is more robust to noisy data (see exp erimen ts in Section 6.4). Additionally , we prop ose a scalable and highly accu- rate algorithm for obtaining approximate nearest neighbors within our learned metric’s space. This renders the metric tractable for large-scale retriev al or nearest-neigh b or clas- sification problems, and ov ercomes a ma jor limitation our previous tree-based metric. The remainder of this pap er is organized as follows: in Section 2, we describ e in detail our formulation for hierarc hy-forest-based metric learning. In Section 3 we dis- cuss max-margin clustering and describ e our formulation of semi-sup ervised max-margin clustering for hierarch y learn- ing. In Section 4 we describ e our metho d for fast approx- imate in-metric nearest nearest-neighbor retriev al. In Sec- tion 5 w e pro vide a complexity analysis of our method, and in Section 6 we show exp erimen tal results in which our metho d compares fa vor ably to the state-of-the-art in metric learning. 2 Semi-sup ervised max-margin hi- erarc h y forests In this section we describ e in detail our Hierarch y F orest Distance (HFD) mo del, as well as our pro cedures for train- ing and inference. The structure of the HFD mo del draws some basic elements from random forests [15], in that it is comp osed of T trees trained independently in a semi- random fashion, with individual nodes in the trees defined b y a splitting function that divides the lo cal space into tw o or more segmen ts. Each hierarch y tree represents a distance function H ( a, b ), and the ov erall distance function is D ( a, b ) = 1 T T X t =1 H t ( a, b ) . (1) Ho wev er, HFD is conceptually distinct from random forests (and the Random F orest Distance (RFD) metric [13]) in that the individual comp onents of the forest represent clus- ter hierarchies rather than decision trees. W e discuss this distinction and its implications in Section 2.2. 2.1 Hierarc h y forest distance The full hierarch y forest distance is effectiv ely the mean of a n umber of weak distance functions H t , each corresp onding to one hierarch y in the forest. These distance functions, in turn, are represen tations of the structure of the individual hierarc hies—the further apart tw o instances fall within a hierarc hy , the greater the distance b et ween them. Sp ecif- ically , we form ulate eac h metric as a mo dified form of the hierarc hy distance function we previously prop osed for use in hierarch y comparison [16]: H t ( a, b ) = ( 0 if H tl ( a,b ) is a leaf no de p t ( a, b ) · | H tl ( a,b ) | N otherwise, (2) where H t represen ts a particular hierarc h y , a and b are input p oin ts, H tl denotes the l th no de in H t , H tl ( a,b ) is the the smallest (i.e. low est) no de in H t that contains b oth a and b and H tl ( a,b ) represen ts the num b er of training p oin ts (out of the whole training set of size N ) con tained in that no de’s subtree. P airs that share a leaf no de are given a distance of 0 b ecause they are maximally similar under H t , and the minim um size of leaf no des is defined by parameter, not by data. Eac h non-leaf node H tl is assigned (via max-margin clustering) a pro jection function P tl and asso ciated binary linear discriminant S tl that divides the data in that no de b et w een the tw o c hild no des. p t ( a, b ) is a certain ty term determined by the distance of the pro jected p oints a and b from the decision hyperplane at H tl ( a,b ) : p t ( a, b ) = 1 1 + exp( α · P tl ( a,n ) ( x a )) − 1 1 + exp( α · P tl ( a,b ) ( x b )) , (3) MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 3 where α is a hyperparameter that con trols the sensitivity of p . Th us, p ranges from 0 to 1, approaching 0 when the pro- jections of both a and b are near the decision boundary , and 1 when b oth are far aw a y . The full distance formulation for a hierarc hy is also confined to this range, with a distance approac hing 1 corresp onding to p oin ts that are widely sep- arated at the root no de, and 0 to p oints that share a leaf no de. 2.2 HFD learning and inference The fact that the trees used in HFD represent cluster hi- erarc hies rather than decision trees has significan t implica- tions for HFD training, imposing stricter requirements on the learned splitting functions. While the goal of decision tree learning is ultimately to yield a set of pure single-class leaf no des, a cluster hierarch y instead seeks to accurately group data elements at every level of the tree. Thus, if the hierarc hy learning algorithm divides the data p oorly at or near the ro ot node, there is no wa y for it to reco ver from this error later on. This is partially mitigated b y learning a forest in place of a single tree, but even in this case the majority of hierarchies in the forest must correctly model the high-level seman tic relationship b et ween an y tw o data elemen ts. F or this reason, HFD requires a robust approac h to the hierarc hy splitting problem that reliably generates seman- tically meaningful splits. Additionally , in order to allow for efficien t metric inference, our splitting algorithm must gen- erate explicit and efficien tly ev aluable splitting functions at eac h no de. Giv en these constrain ts, we approac h the hierarc hy learn- ing problem as a series of increasingly fine-grained flat semi- sup ervised clustering problems, and w e solv e these flat clus- tering problems via max-margin clustering (MMC) [17, 18, 19, 20]. Max-margin clustering has a num ber of adv antages that make it ideal for our problem: • max-margin and large-margin metho ds ha ve b een prov- en effec tiv e in the metric learning domain [4, 21, 22] • MMC returns a simple and explicit splitting function whic h can b e applied to p oin ts outside the initial clus- tering • MMC (including semi-sup ervised MMC) can b e solved in linear time [20, 23, 24] W e emplo y a nov el relaxed form of semi-sup ervised MMC, whic h uses pairwise m ust-link (ML) and cannot-link (CL) constrain ts to improv e seman tic clustering p erformance. Constrain ts of this t yp e indicate either semantic similar- it y (ML) or dissimilarit y (CL) b et ween pairs of p oints, and can b e provided by themselv es. W e describ e our semi-sup ervised MMC tec hnique in Sec- tion 3. 2.2.1 T raining algorithm W e train each tree in the HFD mo del indep enden tly , with eac h tree using the same data and constraint sets. T raining is hence easily parallelized. Assume an unlab eled training dataset X 0 and pairwise constraint set L 0 . Denote a must- link constrain t set L 0 M and cannot-link constrain t set L 0 C , suc h that L 0 = L 0 M ∪ L 0 C . T raining of individual trees pro ceeds in a top-down man- ner. At each no de H tl w e b egin by selecting a lo cal fea- ture subset K tl b y uniformly sampling d k < d features from the full feature set. W e then replace eac h x j ∈ X tl with h x K tl j 1 i ∈ X tl K . F or each no de H tl , our split function learning algorithm can op erate in either a semi-sup ervised or unsup ervised mo de, so before we begin learning we must c heck for con- strain t av ailability . W e require at least 1 cannot-link con- strain t in order to carry out semi-sup ervised MMC, so w e c heck whether L tl C = ∅ , and then apply either semi- sup ervised or unsupervised MMC (see Section 3) to X tl K and L tl . The output of our split learning algorithm is the w eight v ector w tl , whic h, along with K tl , forms the splitting function S tl : P tl ( x ) = w T tl h x K tl j 1 i (4) S tl ( x ) = ( send x left P tl ( x ) ≤ 0 send x right P tl ( x ) > 0 . (5) W e then apply S tl to divide X tl among H tl ’s c hildren. After this, we must also propagate the constraints do wn the tree. W e do this b y iterating through L tl and chec king the p oin t mem b ership of each child no de H tj —if X tj con- tains b oth p oin ts co vered by a constraint, then we add that constrain t to L tj . As a result, constraints in L tl whose constrained p oin ts are separated by H tl ’s splitting function effectiv ely disap- p ear in the next level of the hierarch y . This results in a steady narrowing of the constraint-satisfaction problem as w e reach further down the tree, in accordance with the pro- gressiv ely smaller regions of the data space we are pro cess- ing. W e con tinue this process until we reac h a stopping p oin t (in our exp erimen ts, a minimum node size threshold), falling back on unsup ervised MMC as w e exhaust the rele- v an t cannot-link constraints. 2.2.2 Inference Metric inference on learned HFD structures is straightfor- w ard. W e feed t wo p oin ts x 1 and x 2 to the metric and trac k their progress down each tree H t . At each no de H tl , w e compute S tl ( x 1 ) and S tl ( x 2 ). If S tl ( x 1 ) = S tl ( x 2 ), we con tinue the pro cess in the indicated child node. If not, then we hav e found H tl ( x 1 , x 2 ) , so we compute and return H t ( x 1 , x 2 ) as described in (2). The results from each tree are then combined as p er (1). 3 Learning splitting functions In order to learn strong, optimized splitting functions at eac h hierarch y no de, our metho d relies on the Max-Margin Clustering (MMC) framework. In most no des, our method uses semi-supervised MMC (SSMMC) to incorp orate pair- wise constraint information into the split function learning MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 4 pro cess. Belo w, w e describ e a state-of-the art SSMMC for- m ulation, as well as our o wn nov el mo difications to this for- m ulation that allow it to function in our hierarchical prob- lem setting. 3.1 Semi-sup ervised max-margin cluster- ing SSMMC incorp orates a set of must-link ( L M ) and cannot- link ( L C ) pairwise semantic constraints in to the clustering problem. Th us, where unsup ervised MMC seeks only to maximize the cluster assignment margin of eac h p oint, SS- MMC includes an additional set of margin terms reflecting the satisfaction of each pairwise constraint. F or con venience, first define the following function rep- resen ting the joint pro jection v alue of tw o different p oin ts on to tw o particular cluster lab els 1 : φ ( x 1 , x 2 , y 1 , y 2 ) = y 1 w T x 1 + y 2 w T x 2 (6) The semi-sup ervised MMC problem [24] is then formulated as: min w ,η ,ξ λ 2 k w k 2 + 1 L M + L C X j ∈L M η j + X j ∈L C η j + C U U X i =1 ξ i s.t. ∀ j ∈ L M , ∀ s j 1 , s j 2 ∈ {− 1 , 1 } , s j 1 6 = s j 2 : max z j 1 = z j 2 φ ( x j 1 , x j 2 , z j 1 , z j 2 ) − φ ( x j 1 , x j 2 , s j 1 , s j 2 ) ≥ 1 − η j , η j ≥ 0 ∀ j ∈ L C , ∀ s j 1 , s j 2 ∈ {− 1 , 1 } , s j 1 = s j 2 : max z j 1 6 = z j 2 φ ( x j 1 , x j 2 , z j 1 , z j 2 ) − φ ( x j 1 , x j 2 , s j 1 , s j 2 ) ≥ 1 − η j , η j ≥ 0 ∀ i ∈ U : max y s i ∈{− 1 , 1 } 2 y s i w T x i ≥ 1 − ξ i , ξ i ≥ 0 , (7) where L M and L C are the sets of ML and CL constrain ts, resp ectiv ely , L M and L C are the sizes of those sets, η j are slac k v ariables for the pairwise constraints, U is the set of unconstrained p oin ts, U is the size of that set and ξ i are slac k v ariables for the unconstrained p oints. j 1 and j 2 rep- resen t the tw o p oin ts constrained by pairwise constraint j . Here, the must-link and cannot-link constrain ts eac h impose a soft margin on the difference in score betw een the highest- scoring joint pro jection that satisfies the constraint and the highest scoring join t pro jection that do es not satisfy the constrain t. This formulation is sufficient for standard clus- tering problems, but requires some mo dification in order to function well in our problem setting. 1 Note that we will p eriodically refer to φ t or φ r —these simply indicate that the φ function is using the temp orary w v alue at the given iteration (e.g. w ( t ) ). 3.2 Relaxed semi-sup ervised max-margin clustering Because cannot-link constraints disappear from the hier- arc hy learning problem once they are satisfied (see Sec- tion 2.2.1), the num b er of relev an t cannot-link constrain ts will generally decrease muc h more quickly than the num ber of must-link constrain ts. This will lead to highly imbalanced constrain t sets in low er levels of the hierarch y . Under the original SSMMC formulation, imbalanced cases such as these may w ell yield trivial one-class solutions wherein the ML constraints are well satisfied, but the few CL constrain ts are highly un satisfied. T o address this prob- lem, w e simply separate the ML and CL constraints into tw o distinct optimization terms, each with equal weigh t. Second, and more significantly , w e m ust mo dify SSMMC to handle the hier ar chic al nature of our problem. Consider a case with 4 semantic classes: apple, orange, bicycle and motorcycle. In a binary hierarchical setting, the most rea- sonable w ay to approac h this problem is to first separate apples and oranges from bicycles and motorcycles, then di- vide the data into pure leaf no des lo wer in the tree. Standard SSMMC, ho wev er, will instead attempt to si- m ultaneously satisfy the cannot-link constraints betw een al l of these classes, whic h is impossible. As a result, the op- timization algorithm may seek a compromise solution that w eakly violates all or most of the constrain ts, rather than one that strongly satisfies a subset of the constrain ts and ignores the others (e.g. that separates apples and oranges from bicycles and motorcycles). W e handle this complication b y relaxing the clustering algorithm to focus on only a subset of the CL constraint set, and in tegrate the selection of that subset into the op- timization problem. Thus, our v arian t of semi-supervised MMC simultaneously optimizes w to satisfy a subset of the CL constraint set L 0 C ⊂ L C , and seeks the L 0 C that can b est b e satisfied by a binary linear discriminan t: min w ,η ,ξ, L 0 C λ 2 k w k 2 + 1 L M X j ∈L M η j + 1 L 0 C X j ∈L 0 C η j + C U U X i =1 ξ i s.t. ∀ j ∈ L M , ∀ s j 1 , s j 2 ∈ {− 1 , 1 } , s j 1 6 = s j 2 : max z j 1 = z j 2 φ ( x j 1 , x j 2 , z j 1 , z j 2 ) − φ ( x j 1 , x j 2 , s j 1 , s j 2 ) ≥ 1 − η j , η j ≥ 0 ∃ L 0 C ⊂ L C of size L 0 C s.t. : ∀ j ∈ L 0 C , ∀ s j 1 , s j 2 ∈ {− 1 , 1 } , s j 1 = s j 2 : max z j 1 6 = z j 2 φ ( x j 1 , x j 2 , z j 1 , z j 2 ) − φ ( x j 1 , x j 2 , s j 1 , s j 2 ) ≥ 1 − η j , η j ≥ 0 ∀ i ∈ U : max y s i ∈{− 1 , 1 } 2 y s i w T x i ≥ 1 − ξ i , ξ i ≥ 0 , (8) W e set the size of L 0 C via the parameter L 0 C . MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 5 3.2.1 Semi-sup ervised MMC optimization W e optimize our SSMMC formulation via a Constrained Conca ve Conv ex Pro cedure (CCCP) [25, 24]. This is an iterativ e pro cess that, at each iteration t , frames the con- strain ts in (8) as the difference of tw o conv ex functions and replaces one of those functions with its tangent at w ( t ) , re- sulting in a conv ex optimization problem than can b e easily solv ed via subgradient pro jection. W e first use a heuristic [24] to initialize w (0) non- randomly based on L . W e compute pairwise constrain t scatter matrices S M and S C : S M = 1 L M X j ∈L M ( x j 1 − x j 2 )( x j 1 − x j 2 ) T (9) S C = 1 L C X j ∈L C ( x j 1 − x j 2 )( x j 1 − x j 2 ) T . (10) W e can then use S M and S C to compute a pro jection w (0) that attempts to maximize distance betw een CL and min- imize distance b et w een ML p oin t pairs by computing the largest eigenv ector of the general eigenproblem: S C v = λ S M v . (11) Note that, b ecause L 0 C is not a v ailable at this p oin t in the optimization, this step must b e p erformed on all of the cannot-link constraints. Once w (0) has been computed, w e can b egin CCCP to op- timize the max-margin problem. Given w ( t ) , we b egin each iteration of CCCP by computing the tangents of constrain t functions at w ( t ) : Denote z M ( t ) j 1 , z M ( t ) j 2 and z C ( t ) j 1 , z C ( t ) j 2 as the best clus- ter assignmen ts under w ( t ) that satisfy their associated con- strain t j : z M ( t ) j 1 , z M ( t ) j 2 = argmax z j 1 = z j 2 | j ∈L M φ t ( x j 1 , x j 2 , z j 1 , z j 2 ) (12) z C 0 ( t ) j 1 , z C 0 ( t ) j 2 = argmax z j 1 6 = z j 2 | j ∈L 0 C φ t ( x j 1 , x j 2 , z j 1 , z j 2 ) (13) Similarly , denote y ( t ) i as the b est unary cluster assignment lab el for x i under w ( t ) : y ( t ) i = argmax y i ∈{− 1 , 1 } y i w ( t ) T x i (14) Finally , we select a candidate L 0 ( t ) C b y c ho osing the L 0 C cannot-link constraints with the largest satisfaction margin (again, under w ( t ) ): L 0 ( t ) C = argmax L 0 C ⊂L C , | L 0 C | = L 0 C X j ∈L 0 C min s j 1 = s j 2 h φ t x j 1 , x j 2 , z C ( t ) j 1 , z C ( t ) j 2 − φ t ( x j 1 , x j 2 , s j 1 , s j 2 ) i (15) By setting all of these v alues as constants, we obtain a con vex (but non-differentiable) optimization problem: min w ( t ) ,η ,ξ λ 2 k w ( t ) k 2 + 1 L M X j ∈L M η j + 1 L 0 C X j ∈L 0 ( t ) C η j + C U U X i =1 ξ i s.t. ∀ j ∈ L M , ∀ s j 1 , s j 2 ∈ {− 1 , 1 } , s j 1 6 = s j 2 : φ t ( x j 1 , x j 2 , z M ( t ) j 1 , z M ( t ) j 2 ) − φ t ( x j 1 , x j 2 , s j 1 , s j 2 ) ≥ 1 − η j , η j ≥ 0 ∀ j ∈ L 0 ( t ) C , ∀ s j 1 , s j 2 ∈ {− 1 , 1 } , s j 1 = s j 2 : φ t ( x j 1 , x j 2 , z C ( t ) j 1 , z C ( t ) j 2 ) − φ t ( x j 1 , x j 2 , s j 1 , s j 2 ) ≥ 1 − η j , η j ≥ 0 ∀ i ∈ U : 2 y ( t ) i w ( t ) T x i ≥ 1 − ξ i , ξ i ≥ 0 , (16) This problem can b e efficien tly solv ed via subgradien t pro jection. A t eac h subgradien t iteration r , ∇ r can be com- puted via: ∇ r = λ w + 1 L M X j ∈L ( r ) M h s M r j 1 x j 1 + s M r j 2 x j 2 − z M ( t ) j 1 x j 1 + z M ( t ) j 2 x j 2 i + 1 L 0 C X j ∈L 0 ( r ) C h s C 0 r j 1 x j 1 + s C 0 r j 2 x j 2 − z C 0 ( t ) j 1 x j 1 + z C 0 ( t ) j 2 x j 2 i + C U X i ∈U y ( t ) i x i 1 2 y ( t ) i w T x i ≤ 1 , (17) where L ( r ) M and L 0 ( r ) C are the set of pairwise constraints with non-zero η j v alues under w ( r ) : L ( r ) M = n j ∈ L M φ r x j 1 , x j 2 , z M ( t ) j 1 , z M ( t ) j 2 − max s j 1 6 = s j 2 φ r ( x j 1 , x j 2 , s j 1 , s j 2 ) < 1 o (18) L 0 ( r ) C = n j ∈ L 0 C φ r x j 1 , x j 2 , z C 0 ( t ) j 1 , z C 0 ( t ) j 2 − max s j 1 6 = s j 2 φ r ( x j 1 , x j 2 , s j 1 , s j 2 ) < 1 o , (19) and we define the highest-scoring constraint- violating as- signmen ts for each pair: s M r j 1 , s M r j 2 = argmax j ∈L M ,s j 1 6 = s j 2 φ r ( x j 1 , x j 2 , s j 1 , s j 2 ) (20) s C 0 r j 1 , s C 0 r j 2 = argmax j ∈L 0 C ,s j 1 = s j 2 φ r ( x j 1 , x j 2 , s j 1 , s j 2 ) . (21) Finally , it is shown in [24] that the optimal solution to w is b ounded by: w ∗ ∈ ( w k w k ≤ ρ = r 1 + C λ ) , (22) MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 6 Algorithm 1 Subgradien t optimization of w in semi- sup ervised MMC r ← 0 randomly initialize w ( r ) , s.t. k w ( r ) k ≤ ρ while w ( r ) not conv erged do Compute ∇ r via (17) w ( r + 1 2 ) ← w ( r ) + 1 λr ∇ r w ( r +1) ← min 1 , ρ/ w ( r + 1 2 ) w ( r + 1 2 ) if k w ( r +1) − w ( r ) k / max( k w ( r ) k , k w ( r +1) k ) ≤ 1 then w ( r ) is conv erged end if r ← r + 1 end while so we pro ject w ( r ) bac k into this space at each iteration. The subgradient optimization metho d for solving (16) is describ ed in Algorithm 1 and the full CCCP pro cedure for semi-sup ervised MMC is described in Algorithm 2 (note that we set C = 0 for the first three iterations in order to allo w the more reliable sup ervised constraints to guide the optimization to a strong solution region, b efore introducing the unsup ervised constraints to refine it). Algorithm 2 CCCP optimization for se mi-supervised MMC t ← 0 randomly initialize w ( t ) , s.t. k w ( r ) k ≤ ρ while w ( t ) not conv erged do if t ¡ 3 then C ( t ) ← 0 else C ( t ) ← C end if Compute y ( t ) via (14) Compute z M ( t ) j 1 , z M ( t ) j 2 via (12) Compute z C ( t ) j 1 , z C ( t ) j 2 via (13) Compute L 0 ( t ) C via (15) Compute w ( t +1) via Algorithm 1 if k w ( t +1) − w ( t ) k / max( k w ( t ) k , k w ( t +1) k ) ≤ 2 then w ( t ) is conv erged end if t ← t + 1 end while 3.3 Unsup ervised MMC Because HFD progressiv ely eliminates constrain ts as the hi- erarc hy grows deeper (see Section 2.2.1), at lo wer levels of the hierarch y we may encounter no des where there are no cannot-link constrain ts av ailable, and hence SSMMC can- not pro ceed [24]. In these cases, w e fall back on the unsuper- vised Mem b ership Requiremen t MMC (MRMMC) formula- tion prop osed by Hoai and De la T orre [20]. W e optimize this problem via blo c k-co ordinate descent as describ ed in that work. 4 F ast appro ximate nearest neigh- b ors in hierarc h y metric space One problem with this approac h is the p otentially high (though still embarrassingly parallel) cost of computing eac h pairwise distance, as compared to a Euclidean or even Mahalanobis distance. This is worsened, for many applica- tions, by the unav ailability of traditional fast approximate nearest-neigh b or metho ds (e.g. kd-trees [26], hierarchical k -means [27] or hashing [28]), which require an explicit rep- resen tation of the data in the metric space in order to func- tion. W e address the latter problem b y in tro ducing our o wn fast appro ximate nearest-neighbor algorithm, which takes adv an tage of the tree-based structure of the metric to greatly reduce the num b er of pairwise distance computa- tions needed to compute a set of nearest-neighbors for a query p oint x . W e b egin by tracing the path taken by x through each tree in the forest, and th us identifying each leaf no de con- taining x . W e then seek k O candidate neigh b ors from eac h tree, b eginning by sampling other training points from the iden tified leaf no des, then, if necessary , moving up the tree paren t-no de-b y-parent-node until k O candidates hav e b een found. The candidate sets from each tree are then com- bined to yield a final candidate neighbor set O , such that |O | ≤ T · k O . W e then compute the full hierarch y distance D ( x, y ) for all y ∈ O , sort the resulting distances, and re- turn the k closest p oin ts. This approximation metho d functions b y assuming that, in tuitively , a p oin t’s nearest-neighbors within the full for- est metric space are very lik ely to also b e nearest-neighbors under at least one of the individual tree metrics. W e ev al- uate this metho d empirically on sev eral small-to-midsize datasets, and the results strongly support the v alidit y of this approximation (Section 6.2). 5 Complexit y Analysis HFD training The ov erall complexity of semi-supervised max-margin clustering is O ( d 3 + nd ) [24] (where n is the total num b er of constraints plus the num b er of unconstrained p oin ts). If w e ignore d (which in our case is replaced by the parameter d k , and generally sp eaking d k d ), this leav es SSMMC as a O ( n ) op eration. In the tree setting, we are using SSMMC in a divide-and-conquer fashion—th us, if w e assume that w e divide the data roughly in half with each SSMMC op eration, the complexity of fully training an HFD tree is O ( n log n ), and the total training cost is th us O ( T n log n ). Giv en the em barrassingly parallel nature of the problem, the T factor can be ignored in man y cases, allowing an HFD mo del to b e trained in O ( n log n ) time. HFD inference Computing a single HFD metric distance requires tra vers- ing down each tree in the forest one time, for an (again em- barrassingly parallel) complexit y cost of O ( T log n ). Many of the most common applications of a metric require com- puting nearest-neigh b ors b et ween the training set and a MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 7 test set of size m . This requires mn distance ev aluations, so a brute force nearest-neighbor search under HFD costs O ( mnT log n ), or O ( nT log n ) for a single test p oint. Our appro ximate nearest-neigh b or algorithm signifi- can tly reduces this cost. Computing candidate neigh b ors for a single point costs only O ( T log n ). There will b e at most T k O candidates for eac h set, so the cost for computing distances to eac h candidate is O ( T 2 k O log n ), or O ( T 2 log n ) if w e ignore the parameter. It should be noted, though, that in practice there is significan t o verlap b et ween the candidate sets returned by different trees, and this o verlap increases with T , so the actual cost of this step is generally m uch lo wer. Th us, the complexity of our appro ximate nearest- neigh b or metho d, when applied to an en tire dataset, is O ( mT 2 log n ). Ev en in the w orst case, this is an improv e- men t (since T n on even mo derately sized datasets), and in practice is generally muc h b etter than the worst case. 6 Exp erimen ts Belo w we present several exp erimen ts quan tifying HFD’s p erformance. First, we v alidate the accuracy and efficiency of our appro ximate nearest-neigh b or retriev al metho d. W e then carry out b enc hmark comparisons against other state- of-the-art metric learning tec hniques in the k -nearest neigh- b or classification, large-scale image retriev al and semi- sup ervised clustering domains. 6.1 Datasets W e use a range of datasets, from small- to large-scale, to ev aluate our method. F or small to mid-range data, we use a num b er of well-kno wn UCI sets [29]: sonar (208 x 60 x 2), ionosphere (351 x 34 x 2), balance (625 x 4 x 3), segmen tation (2,310 x 18 x 7) and magic (19,020 x 10 x 2), as well as the USPS handwritten digits dataset (11,000 x 256 x 10) [30]. F or our larger scale experiments, we relied on the CI- F AR tiny image datasets [31]. CIF AR-10 consists of 50,000 training and 1 0,000 test images, spread among 10 classes. CIF AR-100 also c on tains 50,000 training and 10,000 test- ing images, but has 2 different lab el sets—a coarse set with 20 classes, and a fine set with 100 classes. All CIF AR in- stances are 36x36 color images, whic h w e ha ve reduced to 300 features via PCA. In all our exp erimen ts, the data is normalized to 0 mean and unit v ariance b efore any metric metho ds are applied to it. 6.2 Appro ximate nearest-neigh b or re- triev al Because we use it for retriev al in all of our other exp er- imen ts, we first ev aluate the accuracy cost and efficiency b enefits of our approximate nearest-neigh b or metho d. W e ev aluate accuracy by training an HFM mo del with 100 trees. W e then return 50 appro ximate nearest-neigh b ors for each p oin t in the dataset and compute mean a verage precision (mAP) relative to the ground truth 50 nearest-neighbors (obtained via brute force search). Average precision scores are computed at 10, 20, 30, 40 and 50 nearest-neighbors. W e do retriev al at k O = 1, 3, 5, 10, 20 and 30, and rep ort b oth the mAP results and the time taken (as a proportion of the brute force time) at each v alue on several datasets. T able 1: Appro ximate nearest-neigh b or retriev al mAP scores k O Sonar Seg. USPS 1 0.812 0.715 0.6559 3 0.965 0.904 0.8700 5 0.987 0.956 0.9274 10 0.997 0.987 0.9710 20 0.998 0.994 0.9897 30 0.998 0.995 0.9945 T able 2: Appro ximate nearest-neighbor retriev al times (as a prop ortion of brute force search time) k O Sonar Seg. USPS 1 0.499 0.042 0.014 3 0.547 0.074 0.034 5 0.729 0.097 0.049 10 0.860 0.147 0.076 20 1.002 0.221 0.112 30 0.997 0.270 0.136 The results clearly show that our approximation metho d can yield significant reductions in retriev al time on larger datasets, and do es so with minimal loss of accuracy . Note that all other results w e report for HFD are generated using this approximation metho d. W e use k O = 5 for the CIF AR datasets, and k O = 10 for all other data. 6.3 Comparison metho ds and parameters In the follo wing exp erimen ts, we compare our HFD model against a num b er of state-of-the-art metric learning tech- niques: DCA [32], LMNN [4, 22], GB-LMNN [12], ITML [2], Bo ostmetric [3] and RFD [13]. With the exception of RFD and GB-LMNN (b oth of which incorp orate tree structures in to their metrics), all are Mahalanobis metho ds that learn purely linear transforms of the original data. F or all ITML experiments, we cross-v alidated across 5 differen t γ v alues and rep orted the b est results. W e did not extensiv ely tune an y of the h yp erparameters for HFD, instead using a common set of v alues (or rules for assigning v alues) for all datasets. W e set T = 500 (for HFD, RFD and GB-LMNN), d k = d 3 (with the exception of the balance dataset, where we use d k = d ), L 0 C = 0 . 25 L C , λ = 0 . 01, C = 1, 1 = 2 = 0 . 01 and α = 0 . 5. As a stop criteria for tree training, we set a minimum no de size of 5 for the clustering and classification exp erimen ts, and 30 for the retriev al exp erimen ts. 6.4 Nearest neigh b or classification W e next test our method using k -nearest neigh b or clas- sification (w e use k = 5 for all datasets). Each dataset MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 8 Figure 1: 5-nearest neighbor classification accuracy under HFD and b enc hmark metrics. HFD achiev es the highest accuracy among tested metho ds on 4 out of 6 datasets, and is comp etitiv e on the re maining tw o. (View in color) is ev aluated using 5-fold cross-v alidation. F or the weakly- sup ervised metho ds, in each fold we use 1,000 constraints p er class (dra wn from the training data) for the sonar, iono- sphere, balance and segmentation datasets. F or USPS and magic, we use 30,000 constraints in eac h fold. Our results are shown in Figure 1. W e found that HFD ac hieved the b est score on 4 out of the 6 datasets tested, and w as comp etitiv e on the remaining t wo (sonar and USPS). W e also performed some additional exp erimen ts to test the robustness of our approac h compared to other methods. W e tested 5-nearest neigh b or classification on the sonar dataset with v arying amoun ts of noise added to the training lab els (for consistency , we used the same noise data for all metrics). Our results are shown in Figure 2. While our method is only minimally effected b y the added noise, the p erformance of all other metrics drops dramat- ically . Though HFD do es not obtain the best results in the noiseless case, with just 10% of the training lab els cor- rupted our results become significan tly b etter than all other metrics. This effect is even more pronounced at 20% noise. 6.5 Retriev al T o ev aluate our metho d’s performance (as well as, implic- itly , the effectiveness of our appro ximate nearest-neighbor algorithm) on large-scale tasks, w e computed semantic re- triev al precision on labeled CIF AR tin y image datasets. F or the weakly-supervised metho ds, we sample 600,000 cons- train ts from the training data (which is less than 0.1% of the full constraint set). W e do not rep ort Bo ostmetric re- sults on these sets b ecause we were unable to obtain them. Our results can b e found in Figure 3, whic h shows re- triev al accuracy at 5 through 50 images retrieved on each dataset. HFD is clearly the b est-performing metho d across all 3 problems. While DCA is competitive with HFD on the 10-class and 20-class sets, this p erformance drops off significan tly on the more difficult 100-class problem. The particularly strong p erformance of HFD on the 100- class problem ma y b e due to the relaxed SSMMC formula- tion, which allows our metho d to effectiv ely divide the very difficult 100-class discrimination problem into a sequence of man y broader, easier problems, and thus make more effec- tiv e use of its cannot-link constraints than the other metrics. 6.6 Semi-sup ervised clustering In order to analyze the metrics holistically , in a wa y that tak es in to account not just ordered rankings of distances but the relativ e v alues of the distances themselves, we b egan b y p erforming semi-sup ervised clustering exp erimen ts. W e sampled v arying n um b ers of constrain ts from each of the datasets presented and used these constraints to train the metrics. Note that only weakly- or semi-sup ervised metrics could b e ev aluated in this wa y , so only DCA, ITML, RFD and HFD were used in this exp erimen t. After training, the learned metrics w ere applied to the dataset and used to retriev e the 50 nearest-neigh b ors and corresp onding distances for each p oin t. RFD and HFD return distances on a 0-1 scale, so w e conv erted those to MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 9 Figure 2: 5-nearest neighbor classification accuracy on the sonar dataset with v arying levels of training lab el noise. While HFD do es not ac hieve the b est result in the noiseless case, it is far more robust to lab el noise than any other metho d tested. (View in color) Figure 3: Large-scale semantic image retriev al results for our metho d and b enc hmarks. Only DCA is comp etitiv e with our metho d on the 10 and 20 class datasets, and HFD significantly outp erforms all other algorithms on the 100 class problem. (View in color) similarities b y simply subtracting from 1. F or the other metho ds, the distances were conv erted to similarities by applying a Gaussian k ernel (w e used σ = 0.1, 1, 10, 100 or 1000—whichev er yielded the b est results for that metric and dataset). W e then used the neigh b or and similarity data to con- struct a num ber of sparse similarity matrices from v arying n umbers of nearest-neighbors (ranging from 5 to 50) and computed a sp ectral clustering [33] solution for each. W e ev aluated these clustering outputs using V-Measure [34] and recorded the b est result for eac h metric-dataset pair (see T a- ble 3—the num bers below the dataset names indicate the n umber of constraints used in that test). The tree based metho ds, RFD and HFD, demonstrated a consisten t and significant adv antage on this data. Betw een the tw o tree-based metho ds, HFD yielded b etter results on the sonar and balance data, while both were competitive on the segme n tation and USPS datasets. It is notable that the difference b et ween the euclidean per- formance and that of the tree-based metrics is muc h more pronounced in the clustering domain. This w ould suggest that the actual distance v alues (as opp osed to the distance rankings) returned by the tree-based metrics contain muc h stronger seman tic information than those returned by the linear metho ds. 7 Conclusion In this pap er, we ha ve presented a no vel semi-supervised nonlinear distance metric learning pro cedure based on forests of cluster hierarc hies constructed via an iterative max-margin clustering pro cedure with a nov el relaxed con- strain t formulation. Our exp erimental results sho w that that this algorithm is competitive with the state-of-the-art on small- and medium-scale datasets, and p otentially su- p erior for large-scale problems. W e also present a no vel in-metric approximate nearest-neighbor retriev al algorithm for our metho d that greatly decreases retriev al times for large data with little reduction in accuracy . In the future, we hop e to expand this metric to less-well- explored learning settings, suc h as those with more com- plex seman tic relationship structures (e.g., hierarc hies or “soft” class membership). By extending our metho d to in- corp orate relativ e similarit y triplet constrain ts, we could al- MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 10 T able 3: Semi-sup ervised clustering results (V-Measure) Sonar Balance 60 120 180 45 90 180 Euclidean 0.0493 0.0493 0.0493 0.2193 0.2193 0.2193 DCA 0.0959 0.1098 0.1386 0.0490 0.2430 0.3817 ITML 0.0650 0.0555 0.0644 0.2221 0.1915 0.2155 RFD 0.0932 0.1724 0.2699 0.1398 0.1980 0.3004 HFD 0.1267 0.2296 0.3518 0.3059 0.5128 0.6149 Segmen tation USPS 70 175 350 3k 5k 10k Euclidean 0.6393 0.6393 0.6393 0.6493 0.6493 0.6493 DCA 0.0510 0.2537 0.6876 0.5413 0.4359 0.4473 ITML 0.5682 0.6365 0.5931 0.6447 0.6445 0.6420 RFD 0.7887 0.8157 0.8367 0.8248 0.8402 0.8745 HFD 0.7788 0.8090 0.8367 0.7258 0.7397 0.9087 lo w semi-sup ervised metric learning ev en in these domains where binary pairwise constraints are no longer p ossible. References [1] Aur´ elien Bellet, Amaury Habrard, and Marc Sebban. A surv ey on metric learning for feature v ectors and structured data. arXiv pr eprint arXiv:1306.6709 , 2013. [2] Jason V Davis, Brian Kulis, Prateek Jain, Suvrit Sra, and Inderjit S Dhillon. Information-theoretic metric learning. In ICML , 2007. [3] Chunh ua Shen, Junae Kim, Lei W ang, and Anton v an den Hengel. Positiv e semidefinite metric learning with b o osting. In NIPS , 2009. [4] John Blitzer, Kilian Q W ein b erger, and Lawrence K Saul. Distance metric learning for large margin nearest neigh b or classification. In NIPS , 2005. [5] Yiming Ying and Peng Li. Distance metric learning with eigenv alue optimization. The Journal of Machine L e arning R ese ar ch , 13:1–26, 2012. [6] Ratthachat Chatpatanasiri, T eesid Korsrilabutr, P asakorn T angchanac haianan, and Bo onserm Ki- jsirikul. A new k ernelization framework for maha- lanobis distance learning algorithms. Neur o c omputing , 73(10):1570–1579, 2010. [7] Sumit Chopra, Raia Hadsell, and Y ann LeCun. Learn- ing a similarit y metric discriminatively , with applica- tion to face v erification. In CVPR , volume 1, pages 539–546. IEEE, 2005. [8] Andrea F rome, Y oram Singer, and Jitendra Malik. Image retriev al and classification using local distance functions. In NIPS , volume 2, page 4, 2006. [9] Andrea F rome, Y oram Singer, F ei Sha, and Jitendra Malik. Learning globally-consistent lo cal distance func- tions for shape-based image retriev al and classification. In Computer Vision, 2007. ICCV 2007. IEEE 11th In- ternational Confer enc e on , pages 1–8. IEEE, 2007. [10] Kilian Q W einberger and Lawrence K Saul. F ast solv ers and efficien t implemen tations for distance metric learn- ing. In ICML , pages 1160–1167. ACM, 2008. [11] De-Chuan Zhan, Ming Li, Y u-F eng Li, and Zhi-Hua Zhou. Learning instance sp ecific distances using met- ric propagation. In Pr o c e e dings of the 26th A nnual International Confer enc e on Machine L e arning , pages 1225–1232. ACM, 2009. [12] Dor Kedem, Stephen Tyree, Kilian W einberger, F ei Sha, and Gert Lanc kriet. Non-linear metric learning. In A dvanc es in Neur al Information Pr o c essing Systems 25 , pages 2582–2590, 2012. [13] Caiming Xiong, Da vid M Johnson, Ran Xu, and Ja- son J Corso. Random forests for metric learning with implicit pairwise p osition dep endence. In SIGKDD , 2012. [14] Kiri L W agstaff, Sugato Basu, and Ian Davidson. When is constrained clustering b eneficial, and why? Iono- spher e , 58(60.1):62–3, 2006. [15] Leo Breiman. Random forests. Machine le arning , 45(1):5–32, 2001. [16] David M Johnson, Caiming Xiong, Jing Gao, and Ja- son J Corso. Comprehensiv e cross-hierarc hy cluster agreemen t ev aluation. In AAAI L ate-Br e aking Pap ers , 2013. [17] Linli Xu, James Neufeld, Bryce Larson, and Dale Sc hu- urmans. Maximum margin clustering. In NIPS , pages 1537–1544, 2004. [18] Bin Zhao, F ei W ang, and Changshui Zhang. Efficient m ulticlass maxim um margin clustering. In ICML , 2008. [19] Kai Zhang, Ivor W Tsang, and James T Kwok. Max- im um margin clustering made practical. Neur al Net- works, IEEE T r ansactions on , 20(4):583–596, 2009. MANUSCRIPT SUBMITTED TO SIGKDD ON 21 FEB 2014 11 [20] Minh Hoai and F ernando De la T orre. Maximum mar- gin temp oral clustering. In AIST A TS , 2012. [21] Caiming Xiong, David M Johnson, and Jason J Corso. Efficien t max-margin metric learning. In ECDM , 2012. [22] Chunh ua Shen, Junae Kim, and Lei W ang. Scalable large-margin mahalanobis distance metric learning. Neur al Networks, IEEE T r ansactions on , 21(9):1524– 1530, 2010. [23] Y ang Hu, Jingdong W ang, Nenghai Y u, and Xian- Sheng Hua. Maxim um margin clustering with pairwise constrain ts. In ICDM , 2008. [24] Hong Zeng and Yiu-ming Cheung. Semi-supervised maxim um margin clustering with pairwise constraints. Know le dge and Data Engine ering, IEEE T r ansactions on , 24(5):926–939, 2012. [25] Alan L Y uille and Anand Rangara jan. The concav e- con vex pro cedure. Neur al Computation , 15(4):915–936, 2003. [26] Jon Louis Ben tley . Multidimensional binary searc h trees used for asso ciativ e searching. Commun. A CM , 18(9):509–517, September 1975. [27] Marius Muja and David G Low e. F ast appro ximate nearest neighbors with automatic algorithm configura- tion. In VISAPP (1) , pages 331–340, 2009. [28] Aristides Gionis, Piotr Indyk, Ra jeev Motw ani, et al. Similarit y search in high dimensions via hashing. In VLDB , volume 99, pages 518–529, 1999. [29] K. Bac he and M. Lic hman. UCI mac hine learning rep ository , 2013. [30] Jonathan J. Hull. A database for handwritten text recognition research. P AMI , 16(5):550–554, 1994. [31] Alex Krizhevsky and Geoffrey Hin ton. Learning mul- tiple lay ers of features from tiny images. Master’s the- sis, Dep artment of Computer Scienc e, University of T or onto , 2009. [32] Steven CH Hoi, W ei Liu, Mic hael R Lyu, and W ei- Ying Ma. Learning distance metrics with contextual constrain ts for image retriev al. In CVPR , 2006. [33] Jianbo Shi and Jitendra Malik. Normalized cuts and image segm en tation. P AMI , 22(8):888–905, 2000. [34] Andrew Rosen b erg and Julia Hirsch b erg. V-measure: A conditional entrop y-based external cluster ev aluation measure. In EMNLP-CoNLL , v olume 7, pages 410– 420, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment