Recovery guarantees for exemplar-based clustering
For a certain class of distributions, we prove that the linear programming relaxation of $k$-medoids clustering---a variant of $k$-means clustering where means are replaced by exemplars from within the dataset---distinguishes points drawn from nonove…
Authors: Abhinav Nellore, Rachel Ward
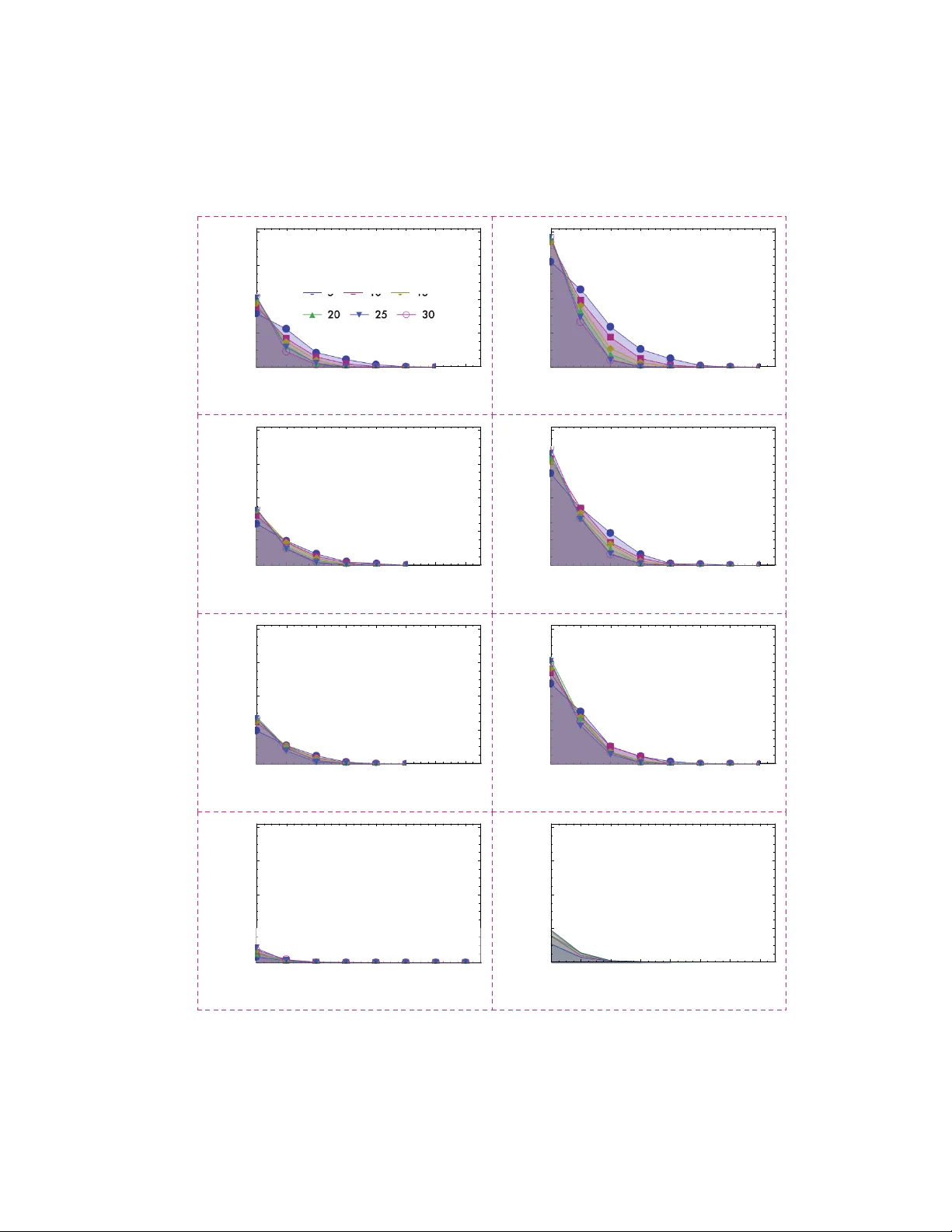
Reco v ery guaran tees for exemplar-based clus tering Abhina v Nellore The Johns Ho pkins Univ ersity anellore@gmail.com Rac hel W ard The Univ ersit y of T exas at Austin rw ard@math.utexas.edu Octob er 3, 2018 Abstract F or a certain class of distributions, we pro ve that the linear programming relaxation of k - medoids clustering—a v arian t of k -means clustering where means are replaced by exemplars from within the dataset—distinguishes p oints drawn from nonov erlapping balls with high prob- abilit y once the n umber of p oints drawn and the separation distance betw een an y t wo balls are sufficien tly large. Our resul ts hold in the non trivial regime where the se paration distance is small enough that p oin ts dra wn from different balls ma y b e closer to each other than p oints drawn from the same ball; in this case, clustering by thresholding pairwise distances b etw een points can fail. W e also exhibit n umerical evidence of high-probabilit y reco very in a substantially more p ermissiv e regime. 1 In tro duction Consider a collection of p oints in Euclidean space that forms roughly isotropic clusters. The c entr oid of a given cluster is found by av eraging the p osition vectors of its p oints, while the m e doid , or exemplar, is the point fr om within the c ol le ction that b est represen ts the cluster. T o distinguish clusters, it is p opular to pursue the k -means ob jectiv e: partition the points in to k clusters suc h that t he a verage squared distance b etw een a p oint and its cluster cen troid is minimized. This problem is in general NP-hard [ 1 , 2 ]. F urther, it has no obvious con vex relaxation, which could reco ver the global optim um while admitting efficient solution; practical algorithms like Lloyd ’s [ 3 ] and Hartigan-W ong [ 4 ] typi cally conv erge to lo cal optima. k -medoids clustering 1 is also in general NP-hard [ 5 , 6 ], but it do es admit a linear programming (LP) relaxation. The ob jective is to select k p oin ts as medoids su ch that the a verage squared distance (or other measure of dissimilarit y) b et ween a p oin t and its medoid is minimized. This pap er obtains guaran tees for exact reco very of the unique globally optimal solution to the k -medoids in teger program by its LP relaxation. Commonly used algorithms that may only con verge to local optima include partitioning around medoids (P AM) [ 7 , 8 ] and affinity propagation [ 9 , 10 ]. T o illustrate the difference b etw een a centroid and a medoid, let us put faces to points. The Y ale F ace Database [ 11 ] has grayscale images of several faces, each captured weari ng a range of expressions—normal, happ y , sad, sleepy , surprised, and winking. Supp ose ev ery p oin t enco des an image from this database as the v ector of its pixel v alues. Intuiti vely , facial expressions represen t p erturbations of a bac kground com p osed of distingui shing image features; it is th us natural to exp ect that the faces cluster b y individual rather than expression. Both Llo yd’s algorithm and affinit y propagation are sho wn to reco ver this p artitioning in Figure 1 , whic h also displays cen troids 1 k -medoids clustering is sometimes called k -medians clustering in the literature. 1 Figure 1: 18 images of 3 faces × 6 facial expressions from the Y ale F ace Database wer e clustered using affinity propagation and Lloyd’s algorithm. The medoids identified by affinit y propagation (framed) are represen tative faces from the clusters, while the centroids found b y Lloyd’s algorithm are av eraged faces. and medoids of clusters. 2 The cen troids are av eraged faces, but the medoids are actual faces from the dataset. Indeed, applications of k -medoids clustering are n umerous and diverse: b esides finding represen tative faces from a gallery of images [ 13 ], it can group tumor samples by gene expression lev els [ 14 ] and pinp oin t the influencers in a so cial netw ork [ 15 ]. 1.1 Setup and principal result W e formulate k -medoids clustering on a complete w eighted undirected graph G = ( V , E ) with N v ertices, although recov ery guarantees are pro ved for the case where vertices corresp ond to points in Euclidean space and each edge weigh t is the squared ` 2 distance b et ween the p oints it connects. 3 Let characters in b oldface ( “ m ” ) refer to matrices/v ectors and italicized counterpar ts with subscripts ( “ m ij ” ) refer to matrix/vector elements. Denote as w ij the nonnegativ e weigh t of the edge connecting v ertices i and j , and note that w ii = 0 since G is simple. k -medoids clustering ( KMed ) finds the minim um-weigh t bipartite subgraph G 0 = ( M , V \M , E 0 ) of G suc h that |M| = k and ev ery vertex in V \M has unit degree. The vertices in M are the medoids. Expressed as a 2 500 randomly initialized rep etitions of Lloyd’s algorithm were run; the clustering that gav e the smallest ob jective function v alue is sho wn. The pack age APCluster [ 12 ] was used to p erform affinity propagation. 3 W e use squared ` 2 distances rather than unsquared ` 2 distances only b ecause we were able to derive stronger theoretical guaran tees using squared ` 2 distances. 2 binary integer program, KMed is min z ∈ R N × N N X i =1 N X j =1 w ij z ij (1) s.t. N X j =1 z ij = 1 , i ∈ [ N ] (2) N X j =1 z j j ≤ k (3) z ij ≤ z j j , i, j ∈ [ N ] (4) z ij ∈ { 0 , 1 } . (5) Ab o ve, [ N ] means the set { 1 , . . . , N } . When z ij = 1, vertex j ∈ M serves as v ertex i ’s medoid; that is, among all edges b etw een medoids and i , the edge b etw een j and i has the smallest weigh t. Otherwise, z ij = 0. A cluster is iden tified as a maximal set of vertices that share a given medoid. Lik e many clustering programs, KMed is in general NP-hard and thus computationally in- tractable for a large N . Replacing the binary constrain ts ( 5 ) with nonnegativit y constrain ts, w e obtain the linear program relaxation LinKMed : min z ∈ R N × N N X i =1 N X j =1 w ij z ij (6) s.t. N X j =1 z ij = 1 , i ∈ [ N ] (7) N X i =1 z ii ≤ K (8) z ij ≤ z j j , i, j ∈ [ N ] (9) z ij ≥ 0 . (10) F or a vector (point) x ∈ R d , let k x k denote its ` 2 norm. It is known that for any configuration of p oints in one-dimensional Euclidean space, the LP relaxation of k -medoids clustering inv ariably reco vers k clusters when unsquared distances are used to measure dissimilarities b etw een p oin ts [ 16 ]. Therefore, we confine our atten tion to d ≥ 2. The following is our main reco very result, and its pro of is obtained in the third section. Theorem 1. Consider k unit b al ls in d -dimensional Euclide an sp ac e (with d ≥ 2 ) for which the c enters of any two b al ls ar e sep ar ate d by a distanc e of at le ast 3 . 75 . F r om e ach b al l, dr aw n p oints x 1 , x 2 , . . . , x n as indep endent samples fr om a spheric al ly symmetric distribution supp orte d in the b al l satisfying Prob ( k x i k ≥ r ) ≤ 1 − r 2 , 0 ≤ r ≤ 1 . (11) Supp ose that squar e d distanc es ar e use d to me asur e dissimilarities b etwe en p oints, w ij = k x i − x j k 2 . Then ther e exist values of n and k ≥ 2 for which the fol lowing statement holds: wi th pr ob ability exc e e ding 1 − 4 k /n , the optimal solution to k -me doids clustering ( KMed ) is unique and agr e es with the unique optimal solution to ( LinKMed ), and assigns the p oints in e ach b al l to their own cluster. 3 Remark 2. The uniform distribution satisfies ( 11 ) in dimension d = 2 , but for d > 2 , a distribution satisfying ( 11 ) c onc entr ates mor e pr ob ability mass towar ds the c enter of the b al l. This me ans that the r e c overy r esults of The or em 1 ar e str onger for smal ler d . However, by applying a r andom pr oje ction, n p oints in d dimensions c an b e pr oje cte d into m = O (log n/ε 2 ) dime nsions while pr eserving p airwise Euclide an distanc es up to a multiplic ative factor 1 ± ε . In this sense, clustering pr oblems in high- dimensional Euclide an sp ac e c an b e r e duc e d to pr oblems in low-dimensional Euclide an sp ac e [ 17 ]. Remark 3. Onc e the c enters of any two unit b al ls ar e sep ar ate d by a distanc e of 4, p oints fr om within the same b al l ar e ne c essarily at closer distanc e than p oints fr om differ ent b al ls. F or the k- me doid pr oblem, cluster r e c overy guar ante es in this r e gime ar e given in [ 30 ]. As far as the authors ar e awar e, The or em 1 pr ovides the first r e c overy guar ante es for k-me doids b eyond this r e gime. 1.2 Relev ant w orks While the literature on clustering is extensiv e, three lines of inquiry are closely related to the results con tained here. • Reco v ery guaran tees for clustering by con v ex programming. Our work is aligned in spirit with the tradition of the compressed sensing communit y , whic h has sought probabilistic reco very guaran tees for conv ex relaxations of noncon vex problems. Reference [ 18 ] presen ts suc h guaran tees for the densest k -clique problem [ 19 ]: partition a complete weigh ted graph in to k disjoint cliques so that the sum of their av erage edge weigh ts is minimized. Also notable are [ 20 – 23 ], which find reco very guarantees for correlation clustering [ 24 ] and v ariants. Correlation clustering outputs a partitioning of the v ertices of a complete graph whose edges are lab eled either “+” (agreemen t) or “ − ” (disagreemen t); the partitioning minimizes the n umber of agreement s within clusters plus the num b er of disagreements b etw een clusters. In all papers men tioned in the previous paragr aph, the probabilistic recov ery guaran tees apply to the sto c hastic block mo del (also known as the planted partition model) and generalizations. Consider a graph with N vertices, initially without edges. P artition the vertices in to k clusters. The sto chastic blo ck mo del [ 25 , 26 ] is a random mo del that dra ws each edge of the graph indep endently : the probabilit y of a “+” (r esp ectively , “ − ” ) edge b etw een tw o verti ces in the same cluster is p (resp ectively , 1 − p ), and the probability of a “+” (resp ectively , “ − ” ) edge b et ween tw o vertices in differen t clusters is q < p (resp ectively , 1 − q > 1 − p ). Unfortunately , an y mo del in which edge weigh ts are drawn indep enden tly do es not include graphs that represen t p oin ts drawn indep endently in a metric space. F or these graphs, the edge weigh ts are inter dep endent distances. A recent pap er [ 27 ] builds on [ 28 , 29 ] to derive probabilistic reco very guarantees for subspace clustering: find the union of subspaces of R d that lies closest to a set of p oints. This problem has only trivial ov erlap with ours; exemplars are “zero-dimensional hyperplanes” that lie close to clustered p oints, but there is only one zero-dimensional subsp ac e of R d —the origin. Reference [ 30 ], on the other hand, in tro duces a tractable conv ex program that does find medoids. This program can be recast as a dualized form of k -medoids clustering. Ho wev er, the deterministic guarantee of [ 30 ]: 1. applies only to the case where the clusters are reco verable by thresholding pairwise distances; that is, tw o p oints in the same cluster must b e closer than tw o p oints in differen t clusters. Our probabilistic guaran tees include a regime where suc h thresholding ma y fail. 4 2. specifies that a regularization parameter λ in the ob jective function must b e low er than some critical v alue for medoids to be reco ver ed. λ is essen tially a dual v ariable associated with the k of k -medoids, and it remains unc hosen in the Karush-Kuhn-T uck er conditions used to deriv e the guarantee of [ 30 ]. The num b er of medoids obtai ned is thus unsp ecified. By contrast, we guaran tee recov ery of a sp ecific num ber of medoids. • Reco v ery guaran tees for learning mixtures of Gaussians. W e derive recov ery guar- an tees for a random mo del where p oints are drawn from isotropic distributions supp orted in nono verlapping balls. This is a few steps remo ved from a Gaussian mixture mo del. Starting with the w ork of Dasgupta [ 31 ], several papers (a represen tative sample is [ 32 – 39 ]) already re- p ort probabilistic recov ery guaran tees for learning the parameters of Gaussian mixture mo dels using algorithms unrelated to conv ex programming. Hard clusters can b e found after obtain- ing the parameters by asso ciating each p oint i with the Gaussian whose contribution to the mixture model is largest at i . The questions here are diffe rent from our ours: under what con- ditions do es a given p olynomial-time algorithm—not a conv ex program, which admits many algorithmic solution tec hniques—recov er the global optim um? How close are the parameters obtained to their true v alues? The progression of this line of researc h had been to wards reduc- ing the separation distances b et ween the cen ters of the Gaussians in the guaran tees; in fact, the separation distances can b e zero if the cov ariance matrices of the Gaussians differ [ 40 , 41 ]. Our results are not in tended to comp ete with these guarantees. Rather, w e seek to provide complemen tary insights into ho w often clusters of p oints in Euclidean space are recov ered by LP . • Appro ximation algorithms for k -medoids clustering and facilit y lo cation. As men- tioned ab o ve, for any configuration of p oints in one-dimensional Euclidean space, the LP relaxation of k -medoids clustering exactly recov ers medoids for dissimilarities that are un- squared distances [ 16 ]. In more than one dimension, nonin tegral optima whose costs are lo wer than that of an optimal inte gral solution ma y be realized. There is a large literature on appro ximation algorithms for k -medoids clustering based on rounding the LP solution and other methods. This literature encompasses a family of related problems kno wn as facilit y lo cation. The only differences betw een the uncapacitat ed facility lo cation problem (UF L) and k -medoids clustering are that 1) only certain p oints are allo wed to b e medoids, 2) there is no constrain t on the num b er of clusters, and 3) there is a cost associated with choosing a giv en p oin t as a medoid. Constan t-factor appro ximation algorithms hav e b een obtained for metric flav ors of UFL and k -medoids clustering, where the measures of distance b etw een p oints used in the ob jective function m ust ob ey the triangle inequality . Reference [ 42 ] obtains the first polynomial-time appro ximation algorithm for metric UFL; it comes within a factor of 3.16 of the optim um. Sev eral subsequent w orks giv e algorithms that impro ve this appro ximation ratio [ 43 – 52 ]. It is established in [ 43 ] that unless NP ⊆ DTIME ( n O (log log n ) ), the lo wer b ounds on approximat ion ratios for metric UFL and metric k -medoids clustering are, resp ectively , α ≈ 1 . 463 and 1 + 2 /e ≈ 1 . 736. Here, α is the solution to α + 1 = ln 2 /α . In unpublished work, Sviridenko strengthens the complexity criterion for these low er b ounds to P 6 = NP . 4 The b est known appro ximation ratios for metric UFL and metric k -medoids clustering are, respectively , 1 . 488 [ 54 ] and 1 + √ 3 + ≈ 2 . 732 + [ 55 ]. Before the 2012 pap er [ 55 ], only a (3 + )-appro ximation algorithm had b een av ailable since 2001 [ 56 ]. Because there is still a large gap betw een the curren t b est appro ximation ratio for k -medoids clustering (2 . 732) and the theoretical limit 4 See Theorem 4.13 of Vygen’s notes [ 53 ] for a proof. W e thank Shi Li for drawing our attention to this result. 5 (1 . 736), finding nov el approximati on algorithms remains an activ e area of researc h. Along related lines, a recent paper [ 57 ] giv es the first constant-factor appro ximation algorithm for a generalization of k -medoids clustering in whic h more than one medoid can b e assigned to eac h p oint. W e emphasize that our results are reco very guaran tees; instead of finding a nov el rounding sc heme for LP solutions, we give precise conditions for when solving an LP yields the k - medoids clustering. In addition, our pro ofs are for squared distances, which do not respect the triangle inequality . 1.3 Organization The next section of this paper uses linear programming dualit y theory to derive sufficient conditions under which the optimal solution to the k -medoids integer program KMed coincides with the unique optimal solution of its linear programming relaxation LinKMed . The third section obtains probabilistic guarantees for exact recov ery of an in teger solution b y the linear program, fo cusing on recov ering clusters of p oints drawn from separated balls of equal radius. Numerical exp eriments demonstrating the efficacy of the linear programming approach for reco vering clusters b eyond our analytical results are reviewed in the fourth section. The final section discusses a few op en questions, and an app endix contains one of our pro ofs. 2 Reco v ery guarant ees via dual certificates Let M ( i ) b e the index of v ertex i ’s medoid and M ( i, 2) be argmin j ∈M ,j 6 = M ( i ) w ij . F or p oints in Euclidean space, M ( i, 2) is the index of the second-closest medoid to p oint i . F or simplicit y of presen tation, tak e w i,M ( i, 2) = ∞ when there is only one medoid. Denote as S i the set of p oint s whose medoid is ind exed b y i . Let ( · ) + refer to the positiv e part of the term enclosed in parentheses. Begin by writing a necessary and sufficient condition for a unique in tegral solution to LinKMed . Prop osition 4. LinKMed has a unique optimal solution x = x # that c oincides with the optimal solution to KMed if and only if ther e exist some u and λ ∈ R N such that u > N X i =1 λ i − w ij + w i,M ( i ) + , j / ∈ M X i ∈ S j λ i = u , j ∈ M (12) 0 ≤ λ i < w i,M ( i, 2) − w i,M ( i ) , i ∈ [ N ] . Prop osition 4 rewrites the Karush-Kuhn-T uck er (KKT) conditions corresp onding to the linear program LinKMed in a conv enien t wa y; refer to the appendix for a deriv ation. Let N i b e the n umber of points in the same cluster as p oin t i . Cho ose λ i = u/ N i to obtain the following tractable sufficien t condition for medoid recov ery . Corollary 5. LinKMed has a unique optimal solution z = z # that c oincides with the optimal solution to KMed if ther e exists a u ∈ R such that N X i =1 ( T ij ) + < u < N ` w `,M ( `, 2) − w `,M ( ` ) (13) 6 for j / ∈ M , ` ∈ [ N ] , and T ij = u N i + w i,M ( i ) − w ij . Remark 6. The choic e of the KKT multipliers λ i made her e is demo cr atic: e ach cluster S j has a total of u “votes,” which it distributes pr op ortional ly among the λ i for i ∈ S j . No w consider the dual certificates contained in the following t wo corollaries. Corollary 7. If KMed has a unique optimal solution z = z # , LinKMed also has a unique optimal solution z = z # when max i ∈ [ N ] max j ∈ S M ( i ) N i w ij − w i,M ( i ) < min i ∈ [ N ] min j / ∈ S M ( i ) N i w ij − w i,M ( i ) . (14) Remark 8. Cho ose p oints fr om within k b al ls in R d , e ach of r adius r , for which the c enters of any two b al ls ar e sep ar ate d by a distanc e of at le ast R . Me asur e R in units of a b al l’s r adius by setting r = 1 . T ake w ij = ( d ij ) p , wher e d ij is the distanc e b etwe en p oints i and j and p > 0 . The ine quality ( 14 ) is satisfie d for R > 2 1 + 1 + n max n min 1 /p ! (15) by assigning the p oints chosen fr om e ach b al l to their own cluster. Her e, n max and n min ar e the maximum and minimum numb ers of p oints dr awn fr om any one of the b al ls, r esp e ctively. In the limit p → ∞ , ( 15 ) b e c omes R > 4 . Pr o of. Imp ose b oth T ij ≥ 0 when p oin ts i and j are in the same cluster and T ij < 0 when p oin ts i and j are in different clusters. Combined with ( 13 ), the restrictions on u are then X i ∈ S M ( j ) w ij − w i,M ( i ) > 0 , j / ∈ M (16) N i w ij − w i,M ( i ) ≤ u < N i w i` − w i,M ( i ) , i ∈ [ N ]; j ∈ S M ( i ) ; ` / ∈ S M ( i ) . (17) Condition ( 16 ) holds by definition of a medoid unless the optimal solution to KMed itself is not unique. In that ev ent, it may b e p ossible for a nonmedoid and a medoid in the same cluster to trade roles while maintaining solution optimality , making the LHS of ( 16 ) v anish for some j . The phrasing of the corollary accommo dates this edge case. Remark 9. The ine quality ( 17 ) r e quir es w ij < w i` for i in the same cluster as j but a differ ent cluster fr om ` . So any two p oints in the same cluster must b e closer than any two p oints in differ ent clusters. Corollary 7 do es not illustrate the utility of LP for solving KMed . Giv en the conditions of a reco very guarantee, clustering could b e p erformed without LP using some distance threshold d t : place tw o points in the same cluster if the distance b et ween them is smaller than d t , and ensure t wo p oin ts are in differen t clusters if the distance b etw een them is greater than d t . In the separated balls mo del of Remark 8 , R > 4 guaran tees that t wo p oints in the same ball are closer than tw o p oin ts in differen t balls. The next corollary is needed to obtain results for R ≤ 4. Corollary 10. L et u = max i ∈ [ N ] max j ∈ S M ( i ) N i w ij − w i,M ( i ) . (18) 7 LinKMed has a unique optimal solution z = z # that c oincides with the optimal solution to KMed if u < N i w i,M ( i, 2) − w i,M ( i ) , i ∈ [ N ] (19) X i / ∈ S M ( j ) u N i + w i,M ( i ) − w ij + < X i ∈ S M ( j ) w ij − w i,M ( i ) , j / ∈ M . (20) Pr o of. Imp ose only T ij > 0 when p oint s i and j are in the same cluster so that together with ( 13 ), the restrictions on u are X i / ∈ S M ( j ) u N i + w i,M ( i ) − w ij + < X i ∈ S M ( j ) w ij − w i,M ( i ) , j / ∈ M (21) N i w ij − w i,M ( i ) < u < N i w i,M ( i, 2) − w i,M ( i ) , i ∈ [ N ]; j / ∈ M . (22) T o minimize the LHS of ( 21 ), choose u so it approaches its lo wer b ound.. Remark 11. The ine quality ( 22 ) r e quir es w i,M ( i, 2) > w ij for i and j in the same cluster. Corollary 7 imp oses b oth extra upp er b ounds and extra low er b ounds on u in its pro of. When t wo p oints in different clusters are closer than t wo p oints in the same cluster, u cannot simulta- neously satisfy these upp er and lo wer bounds. T o break this “thresholding barrier,” Corollary 10 imp oses only extra lo wer bounds on u and p ermits large u . Stronger reco very guaran tees are ob- tained for large u when medoids are sparsely distributed among the p oin ts. (Note that the optimal solution z = z # is k -column sparse.) The next subsection obtains probabilistic guaran tees using Corollary 10 for a v arian t of the separated balls mo del of Remark 8 . 3 A reco ver y guaran tee for separated balls The theorem stated in the introduction is pro ved in this section. Consider k nonov erlapping d - dimensional unit balls in Euclidean space for which the centers of any tw o balls are separated by a distance of at least R . T ak e w ij to be the squared distance d 2 ij = k x i − x j k 2 b et ween p oints x i and x j . Under a mild assumption ab out how p oints are drawn within eac h ball, the exact recov ery guaran tee of Remark 8 is extended in this subsection to the regime R < 4, where tw o p oin ts in the same cluster are not necessarily closer to each other than t wo p oin ts in different clusters. In particular, let the p oints in each ball corresp ond to independent sample s of an isotropic distribution supp orted in the ball and which ob eys Prob ( k x k ≥ r ) ≤ 1 − r 2 , 0 ≤ r ≤ 1 , (23) Ab o ve, x ∈ R d is the vec tor extending from the center of the ball to a giv en p oint, and k x k refers to the ` 2 norm of x . In d = 2 dimensions, the assumption ( 23 ) holds for the uniform distribution supp orted in the ball. F or larger d , ( 23 ) requires distributions that concen trate more probabilit y mass closer to the ball’s cen ter. F or simplicity , we assume in the sequel that the num b er n of p oin ts dra wn from eac h ball is equal. Let E denote an exp ectation and V ar a v ariance. W e state a preliminary lemma. Lemma 12. Consider x 1 , . . . , x n ∈ R d sample d indep endently fr om an isotr opic distribution sup- p orte d in a d -dimensional unit b al l which satisfies Prob ( k x i k ≥ r ) ≤ 1 − r 2 , 0 ≤ r ≤ 1; i ∈ [ n ] . 8 Use squar e d Euclide an distanc es to me asur e dissimilarities b etwe en p oints. L et x ∗ b e the me doid of the set { x i } and x min = argmin j k x j k . Assume that d ≥ 2 , n ≥ 3 , and 0 < α ≤ (3 / 2) p ( n − 2) / 2 d . With pr ob ability exc e e ding 1 − ne − α 2 , al l of the fol lowing statements ar e true. 1. P n j =1 ( k x j − x ` k 2 −k x j − x ∗ k 2 ) ≥ P n j =1 ( k x j − x ` k 2 −k x j − x min k 2 ) ≥ ( n − 2) k x ` k 2 − k x min k 2 − 2 α √ n − 2 ( k x ` k + k x min k ) for al l ` ∈ [ n ] . 2. k x min k ≤ αn − 1 / 2 . 3. k x ∗ k ≤ 3 α ( n − 2) − 1 / 2 . Pr o of. First pro ve statement 1. Note that for ` ∈ [ n ], − ( n − 2) k x ` k 2 − k x min k 2 + n X j =1 k x j − x ` k 2 − k x j − x min k 2 (24) = − ( n − 2) k x ` k 2 − k x min k 2 + X j 6 = `,j 6 = min k x j − x ` k 2 − k x j − x min k 2 (25) = − 2 k x ` − x min k X j 6 = `,j 6 = min y j . (26) Ab o ve, y j = h x j , ( x ` − x min ) / k x ` − x min ki . Since the x i are dra wn from an isotropic distribution, the direction of the unit vect or ( x ` − x min ) / k x ` − x min k is indep endent of k x ` − x min k and drawn uniformly at r andom. It follo ws that the y j for j 6 = min, j 6 = ` are i.i.d. zero-mean random v ariables despite how x min dep ends on the x j . Indeed, for j 6 = min, j 6 = ` , V ar ( y j ) = E | h x j , ( x ` − x min ) / k x ` − x min ki | 2 = E k x j k 2 cos 2 θ = 1 / (2 d ) , where the last equalit y is obtained by in tegrating in generalized spherical co ordinates. Bernstein’s inequalit y thus giv es Prob X j 6 = `,j 6 = min y j > α r 2 ( n − 2) d ≤ e − α 2 , 0 < α ≤ 3 2 r n − 2 2 d . (27) So P n i =1 y i is b ounded from ab ov e with high probability given ( 27 ). F urthe r, k x ` − x min k ≤ k x ` k + k x min k from the triangle inequality . These facts together with ( 26 ) imply that for a given ` 6 = min , n X j =1 k x j − x ` k 2 − k x j − x ∗ k 2 (28) ≥ n X j =1 k x j − x ` k 2 − k x j − x min k 2 (b y definition of a medoid) (29) ≥ ( n − 2) k x ` k 2 − k x min k 2 − 2 α r 2 ( n − 2) d ( k x ` k + k x min k ) (30) ≥ ( n − 2) k x ` k 2 − k x min k 2 − 2 α √ n − 2 ( k x ` k + k x min k ) (for d ≥ 2) (31) with probabilit y exceeding 1 − e − α 2 . F or ` = min , the inequalities ab ov e clearly hold with unit probabilit y . T ake a union b ound o ver the other ` ∈ [ n ] to obtain that statement 1 holds with probabilit y exceeding 1 − ( n − 1) e − α 2 (for v alid α as sp ecified in ( 27 )). 9 No w observe that Prob ( k x min k > αn − 1 / 2 ) = 1 − α 2 n − 1 n < e − α 2 . It follows that statemen t 2 holds with probability exceeding 1 − e − α 2 . Moreov er, statemen ts 1 and 2 together hold with probabilit y exceeding 1 − ne − α 2 . Condition on them, and pro ve statemen t 3 b y contradiction: supp ose that k x ∗ k exceeds 3 α ( n − 2) − 1 / 2 . Then b ecause k x min k ≤ αn − 1 / 2 < α ( n − 2) − 1 / 2 , ( n − 2) k x ∗ k 2 − k x min k 2 − 2 α √ n − 2 ( k x ∗ k + k x min k ) > 8 α 2 − 8 α 2 = 0 . (32) But from statement 1 for ` = min , this implies that X i k x j − x ∗ k 2 > k x j − x min k 2 , (33) whic h violates the assumption that x ∗ is a medoid. So all three statemen ts hold with probability exceeding 1 − ne − α 2 , which is the con tent of the lemma. W e no w write the main result of this section. Theorem 13. (Restatemen t of Theorem 1 .) Consider k unit b al ls in d -dimensional Euclide an sp ac e (with d ≥ 2 ) for which the c enters of any two b al ls ar e sep ar ate d by a distanc e of 3 . 75 + ε , ε ≥ 0 . F r om e ach b al l, dr aw n p oints x 1 , x 2 , . . . , x n as indep endent samples fr om an isotr opic distribution supp orte d in the b al l which satisfies Prob ( k x i k ≥ r ) ≤ 1 − r 2 , 0 ≤ r ≤ 1 . (34) Supp ose that squar e d distanc es ar e use d to me asur e dissimilarities b etwe en p oints, w ij = k x i − x j k 2 . F or e ach ε ≥ 0 , ther e exist values of n and k for which the fol lowing statement holds: with pr ob ability exc e e ding 1 − 4 k /n , the unique optimal solution to e ach of k -me doids clustering and its line ar pr o gr amming r elaxation assigns the p oints in e ach b al l to their own cluster. Remark 14. A table of valid c ombinations of ε , n , and k (for d ≤ 9 8 n − 2 log n ) fol lows. ε n k ≥ 0 ≥ 10 6 2 ≥ 0 . 05 ≥ 10 7 ≤ 3 ≥ 0 . 15 ≥ 10 4 2 ≥ 0 . 15 ≥ 10 7 ≤ 10 Mor e such c ombinations may b e obtaine d by satisfying the ine qualities ( 38 ) , ( 47 ) , and ( 49 ) in the pr o of b elow. Pr o of. Condition on the k even ts that the three statemen ts of Lemma 12 hold for eac h ball. Cho ose α = √ 2 log n so that the probability these ev ents o ccur together exceeds 1 − k /n . Because α is b ounded by Lemma 12 , this requires d ≤ 9 8 n − 2 log n . (35) No w simplify the sufficien t condition of Corollary 10 with w ij = d 2 ij and every N i = n . Let ρ = 3 r 2 log n n − 2 10 b e the m aximum distance of a medoid to the center of its resp ective ball f rom statemen t 3 of Lemma 12 . Note that u = max i ∈ [ N ] max j ∈ S M ( i ) n ( d 2 ij − d 2 i,M ( i ) ) ≤ n 4 − (1 − ρ ) 2 , where the upp er b ound is surmised by considering p oint M ( i ) collinear with and b etw een p oin ts i and j , both on one ball’s b oundary . So tak e u = n 4 − (1 − ρ ) 2 to narrow the sufficien t condition of Corollary 10 . Also note the requirement ( 19 ): u < min i ∈ [ N ] d 2 i,M ( i, 2) − d 2 i,M ( i ) . (36) Obtain a low er b ound of ( R − (1 + ρ )) 2 − (1 + ρ ) 2 on the RHS by considering a p oin t i on the b oundary of one ball collinear with p oints M ( i ) and M ( i, 2). Imp ose ( R − (1 + ρ )) 2 − (1 + ρ ) 2 > 4 − (1 − ρ ) 2 (37) to ensure the RHS exceeds the LHS. This is equiv alen t to R > 1 + ρ + 2 p 1 + ρ . (38) Giv en the stipulations of the previous paragraph and ( 20 ) of Corollary 10 , the followi ng holds: eac h of k -medoids clustering and its LP relaxation has a unique optimal solution that assigns the p oin ts in each ball to their own cluster if for j / ∈ M , X i / ∈ S M ( j ) k x i − x M ( i ) k 2 − k x i − x j k 2 + 4 − (1 − ρ ) 2 + < X i ∈ S M ( j ) k x i − x j k 2 − k x i − x M ( i ) k 2 . (39) Denote as C ( j ) the cen ter of the ball asso ciated with p oin t j . 5 Find conditions under whic h ( 39 ) holds by treating t wo complementary cases of the x j separately: 1. d j,C ( j ) ≤ R − 1 − 2 √ 1 + ρ . Then for i / ∈ S M ( j ) , consider p oin t i collinear with and b etw een p oin ts M ( i ) and j to obtain k x i − x M ( i ) k 2 − k x i − x j k 2 + 4 − (1 − ρ ) 2 ≤ (1 + ρ ) 2 − R − 2 + 1 − ( R − 1 − 2 p 1 + ρ ) 2 + 4 − (1 − ρ ) 2 = 0 . (40) It follows that the LHS of ( 39 ) has an upp er b ound that v anishes. Moreo ver, the RHS of ( 39 ) m ust b e p ositive b y definition of a (unique) medoid. So ( 39 ) holds with unit probability . 2. R − 1 − 2 √ 1 + ρ < d j,C ( j ) ≤ 1. First, bound the n umber n outer of points in a giv en cluster for whic h the inequalities spanning the previous sen tence hold. F rom the distribution ( 11 ), Prob R − 1 − 2 p 1 + ρ < d j,C ( j ) ≤ 1 = 1 − R − 1 − 2 p 1 + ρ 2 + . (41) Ho effding’s inequality th us gives Prob n outer ≥ n 1 − R − 1 − 2 p 1 + ρ 2 + + nτ ≤ e − 2 nτ 2 . (42) 5 This becomes a slight abuse of notation b ecause C ( j ) is not an index of any p oint drawn, but all its usages con tained here should b e clear. 11 T ak e τ = r log n 2 n to obtain Prob n outer < n 1 − R − 1 − 2 p 1 + ρ 2 + + p ( n/ 2) log n > 1 − 1 n . (43) Condition on the even t captured in the equality ab o ve holding for every cluster. This o ccurs with probabilit y exceeding 1 − k /n . Next, observ e that for i / ∈ S M ( j ) , considering (as for ( 40 )) p oin t i collinear with and b etw een p oin ts M ( i ) and j giv es the deterministic b ound k x i − x M ( i ) k 2 − k x i − x j k 2 + 4 − (1 − ρ ) 2 + ≤ (1 + ρ ) 2 − ( R − 2) 2 + 4 − (1 − ρ ) 2 . (44) Com bine this with the b ound on n outer from ( 43 ) to find that for all j / ∈ M , the LHS of ( 39 ) ob eys X i / ∈ S M ( j ) d 2 i,M ( i ) − d 2 ij + 4 − (1 − ρ ) 2 + < ( k − 1) (1 + ρ ) 2 − ( R − 2) 2 + 4 − (1 − ρ ) 2 × n 1 − R − 1 − 2 p 1 + ρ 2 + + p ( n/ 2) log n . (45) Statemen t 1 of Lemma 12 b ounds from b elow the RHS of ( 39 ): X i ∈ S M ( j ) d 2 ij − d 2 i,M ( i ) ≥ ( n − 2) k x j k 2 − 2 p 2 ( n − 2) log ( n ) k x j k − 2 r n − 2 n 2 + r n − 2 n ! log( n ) , (46) where x j extends from the center of the ball corresp onding to S M ( j ) . The expression on the RHS has a minimum at k x j k = ρ/ 3. Because 1 ≥ d j,C ( j ) > R − 1 − 2 √ 1 + ρ , provided R − 1 − 2 p 1 + ρ > ρ/ 3 , (47) a low er b ound on the LHS of ( 46 ) is given b y X i ∈ S M ( j ) d 2 ij − d 2 i,M ( i ) ≥ ( n − 2) min n R − 1 − 2 p 1 + ρ, 1 o 2 − 2 p 2 ( n − 2) log ( n ) min n R − 1 − 2 p 1 + ρ, 1 o − 2 r n − 2 n 2 + r n − 2 n ! log( n ) . (48) Com bining ( 45 ) and ( 48 ) pro vides a sufficient condition for ( 39 ): n 1 − R − 1 − 2 p 1 + ρ 2 + + p ( n/ 2) log n × ( K − 1) (1 + ρ ) 2 − ( R − 2) 2 + 4 − (1 − ρ ) 2 ≤ ( n − 2) min n R − 1 − 2 p 1 + ρ, 1 o 2 − 2 p 2 ( n − 2) log ( n ) min n R − 1 − 2 p 1 + ρ, 1 o − 2 r n − 2 n 2 + r n − 2 n ! log( n ) . (49) 12 It is easily v erified n umerically that this inequality is satisfied when R ≥ 3 . 75 for n ≥ 10 6 —as are the other bounds ( 38 ) and ( 47 ) on R . F urther, for an y dimension d , there exists some finite n large enough suc h that ( 35 ) is satisfied. Similar ch ecks may b e p erformed to obtain other v alid com binations of the parameters; more suc h combinations are con tained in Remark 14 . In the pro of ab ov e, the sole even ts conditioned on are that Lemma 12 holds for eac h cluster and that the Hoeffding inequality ( 43 ) for n outer holds for eac h cluster. As recorded in the theorem, the probabilit y all of these even ts o ccur exceeds 1 − 2 k /n . All comp onents of the theorem are now pro ved. 4 Sim ulations Consider k nonov erlapping d -dimensional unit balls in R d for whic h t he separation distan ce b et ween the centers of an y t wo balls is exactly R . Consider the tw o cases that follo w, referenced later as Case 1 and Case 2. 1. Eac h ball is the supp ort of a uniform distribution. 2. Eac h ball is the supp ort of a distribution that satisfies Prob ( k x k ≥ r ) = 1 − r 2 , 0 ≤ r ≤ 1 , (50) where r is the Euclidean distance from the center of the ball, and x is some vector in R d . F or d = 2, this is a uniform distribution. Equation ( 50 ) saturates the inequality ( 23 ), whic h is the distributional assumption of our probabilistic reco very guarantees. Giv en one of these cases, sample each of the k distributions n times so that n p oin ts are drawn from each ball. Solve LinKMed for this configuration of p oints and record when 1. a solution to KMed is recov ered. (Call this “cluster recov ery .” ) 2. a recov ered solution to KMed places p oints drawn from distinct balls in distinct clusters, the situation for whic h our reco very guarantees apply . (Call this “ball reco very ,” a sufficien t condition for cluster reco very .) Examples of ball reco veries and cluster reco v eries that ar e not ball recov eries are displa yed in Figure 2 for k = 2 , 3. 13 Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ê Ê ‡ ‡ a L ball recovery for two cluste r s Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ê Ê ‡ ‡ b L failed ball recovery for two cl ust e r s successful and failed 2 - ball re co v e r i e s for R = 2.5 n = 15 points drawn fr o m each ball H dashed L are independent samples of uniform distribution points in same cluster have same marker and color; medoids are large points Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ê Ê ‡ ‡ Ï Ï c L ball recovery for three clusters Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ï Ê Ê ‡ ‡ Ï Ï d L failed ball recovery for three clusters Figure 2: In the failed ball recov ery for tw o clusters b), just one p oint in the left ball is not placed in the same cluster as the other p oin ts in the ball. In the failed ball recov ery for three clusters d), four p oin ts in the b ottom right ball are not placed in the same cluster as the other p oin ts in the ball. 14 W e p erformed 1000 such simu lations using MA TLAB in conjunction with Gurobi Optimizer 5.5’s barrier metho d implemen tation for every com bination of the c hoices in the table b elow. n 5, 10, 15, 20, 25, 30 k 2, 3 R 2, 2.2, 2.4, 2.6, 2.8, 3, 3.2, 3.4, 3.6, 3.8, 4, 4.2, 4.4, 4.6, 4.8, 5 d 2, 3, 4, 10 Cases 1, 2 Remark ably , cluster recov ery failed no more than 12 (8) times out of 1000 across all sets of 1000 simulat ions for Case 1 (2). It therefore app ears that high-probabilit y cluster recov ery is alw ays realized when drawing samples from the distributions w e consider. How ever, since the KKT conditions require some assumption ab out ho w p oin ts cluster, general cluster reco very guarantees are difficult to pro v e. In the previous section, w e obtain guaran tees assuming the p oin ts cluster in to the balls from whic h they are dra wn. The ball recov ery results of our sim ulations for Cases 1 and 2 are depicted in, resp ectiv ely , Figures 3 and 4 . Note that the v ertical axis of each plot measures the num b er of faile d ball recov eries. W e conclude this section with the following observ ations. • On the whole, Case 2 yields more ball recov eries than Case 1. This is not unexpected: with the exception of d = 2, Case 2 concen trates more probability mass tow ards the cen ters of the balls than do es Case 1, t ypically making the p oints dra wn from each ball cluster more tigh tly . F or d = 2, the plots in b oth Figures 3 and 4 corresp ond to dra ws from uniform distributions supp orted in the balls; they are rep etitions and th us lo ok essentially the same. • In general, as the n umber n of p oints drawn from eac h ball is increased, the num b er of ball reco veries increases for fixed d , k , and R . This is again not unexpected: if few er points are dra wn, clustering is more susceptible to outliers that can preven t ball recov ery . • As R increases, the num b er of ball reco veries increases for fixed d , k , and n b ecause points dra wn from different balls tend to get further apart. F or d = 2, high-probability ball recov ery app ears to b e guaranteed for R greater than somewhere b etw een 2 and 3 ev en for the small v alues of n considered here. This is considerably better than the guaran tee of Theorem 13 : it holds for d = 2 and R = 3 . 75 only if n is at least 10 6 , as sho wn to ward the end of its proof. • F or n , R , and d fixed, there are more ball recov eries for tw o balls than there are for three balls. This suggests that as k increases, the probabilit y of recov ery decreases, whic h is consistent with intuition from Theorem 13 . • F or n , R , and k fixed, as d increases, the num b er of ball recov eries increases, ev en for the uniform distributions of Case 1. There is thus substan tial ro om for impro ving our reco very guaran tees, which require concentrating more probability mass tow ards the centers of the balls as d increases. 15 Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á n = Ê 5 ‡ 10 Ï 15 Ú 20 Ù 25 Á 30 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures 2d 3d 4d 10 d two balls three balls number of failed ball recoveries out of 1, 000 simulations n points drawn from each ball are inde pe n de n t samples of uniform distribution Figure 3: Exact recov ery app ears to b e guaranteed with high probability for uniform distributions for v alues of n in the double digits and v alues of R b elow 3. Thi s is substantially b etter than Theorem 13 suggests. 16 Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á n = Ê 5 ‡ 10 Ï 15 Ú 20 Ù 25 Á 30 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures Ê Ê Ê Ê Ê Ê Ê Ê ‡ ‡ ‡ ‡ ‡ ‡ ‡ ‡ Ï Ï Ï Ï Ï Ï Ï Ï Ú Ú Ú Ú Ú Ú Ú Ú Ù Ù Ù Ù Ù Ù Ù Ù Á Á Á Á Á Á Á Á 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 0 200 400 600 800 R number of failures 2d 3d 4d 10 d two balls three balls number of failed ball recoveries out of 1, 000 simulations n points 8 X i < drawn from each ball, wh e r e Prob H»» X i »» ≥ r L = 1 - r 2 Figure 4: The d = 2 plots here and in Figure 3 are rep etitions of the same set of simulations. As d increases, the num b er of exact recov eries increases faster than it do es for uniform distributions. 17 5 Concluding remarks W e pro ved that with high probabilit y , the k -medoids clustering probl em and its LP relaxation share a unique globally optimal solution in a nontrivial regime, where t wo points in the same cluster may b e further apart than tw o p oints in differen t clusters. How ev er, our theoretical guarantees are preliminary; they fall far short of explaining the success of LP in distinguishing p oints drawn from different balls at small separation distance and with few p oints in each ball. More generally , in sim ulations w e did not present here, the k -medoids LP relaxation app eared to recov er in teger solutions for very extreme configurations of p oints—in the presence of extreme outliers as well as for nonisotropic clusters with v astly differen t n umbers of points. W e th us conclude with a few op en questions that interest us. • Ho w do recov ery guarantees change for different choices of t he dissimilarities b et ween p oints— for example, for Euclidean distances rather than for the squared Euclidean distances used here? What ab out for Gaussian and exp onential k ernels? • Can exact recov ery b e used to b etter characterize outliers? • Is it p ossible to obtain cluster recov ery guarantees instead of just ball reco very guarantees? ( “Cluster recov ery” and “ball recov ery” are defined right after ( 50 ).) Ac kno wledgemen ts W e thank Shi Li and Chris White for helpful suggestions. W e are extremely grateful to Sujay Sangha vi for offering his exp ertise on clustering and for p oin ting us in the righ t directions as we na vigated the literature. A.N. is esp ecially grateful to Jun Song for his constructiv e suggestions and for general supp ort during the preparation of this w ork. R.W. was supp orted in part b y a Researc h F ellowship from the Alfred P . Sloan F oundation, an ONR Gran t N00014-12-1-0743, an NSF CAREER Award, and an AFOSR Y oung In vestigator Program Aw ard. A.N. was supp orted b y Jun Song’s gran t R01CA163336 from the National Institutes of Health. 18 References [1] D. Aloise, A. Deshpande, P . Hansen, and P . Popat , “NP-hardness of Euclidean sum-of-squares clustering,” Machine L e arning , vol. 75, no. 2, pp. 245–248, 2009. [2] S. Dasgupta and Y. F reund, “Random pro jection trees for vector quantization,” Information The ory, IEEE T r ansactions on , vol. 55, no. 7, pp. 3229–3242, 2009. [3] S. Llo yd, “Least squares quantization in PCM,” Information The ory, IEEE T r ansactions on , v ol. 28, no. 2, pp. 129–137, 1982. [4] J. A. Hartigan and M. A. W ong, “Algorithm as 136: A k-means clustering algorithm,” Journal of the R oyal Statistic al So ciety. Series C (Applie d Statistics) , v ol. 28, no. 1, pp. 100–108, 1979. [5] C. H. Papadimitriou, “W orst-case and probabilistic analysis of a geometric lo cation problem,” SIAM Journal on Computing , vol. 10, no. 3, pp. 542–557, 1981. [6] N. Megiddo and K. J. Sup owit, “On the complexit y of some common geometric lo cation prob- lems,” SIAM journal on c omputing , v ol. 13, no. 1, pp. 182–196, 1984. [7] M. V an der Laan, K. Pollard, and J. Bryan, “A new partitioning around medoids algorithm,” Journal of Statistic al Computation and Simulation , vol. 73, no. 8, pp. 575–584, 2003. [8] L. Kaufman and P . J. Rousseeu w, Finding gr oups in data: an intr o duction to cluster analysis , v ol. 344. Wiley . com, 2009. [9] B. J. F rey and D. Duec k, “Clustering by passing messages b etw een data p oints,” Scienc e , v ol. 315, no. 5814, pp. 972–976, 2007. [10] I. E. Giv oni and B. J. F rey , “A binary v ariable mo del for affinit y propagation,” Neur al c ompu- tation , vol. 21, no. 6, pp. 1589–1600, 2009. [11] P . N. Belh umeur, J. P . Hespanha, and D. J. Kriegman, “Eigenfaces vs. Fisherfaces: Recogni- tion using class specific linear pro jection,” Patte rn Analysis and Machine Intel ligenc e, IEEE T r ansactions on , vol. 19, no. 7, pp. 711–720, 1997. [12] U. Bo denhofer, A. Kothmeier, and S. Ho chreiter, “Apcluster: an R pack age for affinity prop- agation clustering,” Bioinformatics , v ol. 27, no. 17, pp. 2463–2464, 2011. [13] M. M´ ezard, “Computer science. where are the exemplars?,” Scienc e (New Y ork, NY) , vol. 315, no. 5814, pp. 949–951, 2007. [14] M. Leone, M. W eigt, et al. , “Clustering by soft-constraint affinit y propagation: applications to gene-expression data,” Bioinformatics , v ol. 23, no. 20, pp. 2708–2715, 2007. [15] J. T ang, J. Sun, C. W ang, and Z. Y ang, “So cial influence analysis in large-scale netw orks,” in Pr o c e e dings of the 15th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , pp. 807–816, ACM , 2009. [16] S. de V ries, M. Posner, and R. V ohra, “The k-median problem on a tree,” tec h. rep., Citeseer, 1998. [17] C. Boutsidis, A. Zouzias, and P . Drineas, “Random pro jections for k -means clustering,” in Pr o c. NIPS , pp. pp.298–306, 2010. 19 [18] B. P . Ames, “Guaran teed clustering and biclustering via semidefinite programming,” arXiv pr eprint , 2012. [19] B. P . Ames and S. A. V a v asis, “Conv ex optimization for the plan ted k-disjoint-clique problem,” arXiv pr eprint , 2010. [20] S. Oymak and B. Hassibi, “Finding dense clusters via lo w rank+ sparse decomposition,” arXiv pr eprint , 2011. [21] A. Jalali and N. Srebro, “Clustering using max-norm constrain ed optimization,” arXiv pr eprint arXiv:1202.5598 , 2012. [22] Y. Chen, S. Sangha vi, and H. Xu, “Clustering sparse graphs,” arXiv pr eprint , 2012. [23] A. Jalali, Y. Chen, S. Sanghavi, and H. Xu, “Clustering partially observed graphs via con vex optimization,” arXiv pr eprint , 2011. [24] N. Bansal, A. Blum, and S. Chawla, “Correlation clustering,” Machine L e arning , v ol. 56, no. 1- 3, pp. 89–113, 2004. [25] A. Condon and R. M. Karp, “Algorithms for graph partitioning on the plan ted partition mo del,” R andom Structur es and Algorithms , v ol. 18, no. 2, pp. 116–140, 2001. [26] P . W. Holland, K. B. Laskey , and S. Leinhardt, “Sto chastic blo ckmodels: First steps,” So cial networks , vol. 5, no. 2, pp. 109–137, 1983. [27] M. Soltanolkotabi, E. Elhamifar, and E. Cand` es, “Robust subspace clustering,” arXiv pr eprint arXiv:1301.2603 , 2013. [28] E. Elhamifar and R. Vidal, “Sparse subspace clustering: Algorithm, theory , and applications,” arXiv pr eprint , 2012. [29] E. Elhamifar and R. Vidal, “Sparse subspace clustering,” in Computer Vision and Pattern R e c o gnition, 2009. CVPR 2009. IEEE Confer enc e on , pp. 2790–2797, IEEE, 2009. [30] E. Elhamifar, G. Sapiro, and R. Vidal, “Finding exemplars from pairwise dissimilarities via sim ultaneous sparse reco very ,” in A dvanc es in Neur al Information Pr o c essing Systems , pp. 19– 27, 2012. [31] S. Dasgupta, “Learning mixtures of Gaussians,” in F oundations of Computer Scienc e, 1999. 40th Annual Symp osium on , pp. 634–644, IEEE, 1999. [32] A. Sanjeev and R. Kannan, “Learning mixtures of arbitrary gaussians,” in Pr o c e e dings of the thirty-thir d annual A CM symp osium on The ory of c omputing , pp. 247–257, ACM, 2001. [33] S. V empala and G. W ang, “A sp ectral algorithm for learning mixture mo dels,” Journal of Computer and System Scienc es , v ol. 68, no. 4, pp. 841–860, 2004. [34] R. Kannan, H. Salmasian, and S. V empala, “The sp ectral metho d for general mixture mo dels,” in L e arning The ory , pp. 444–457, Springer, 2005. [35] D. Ac hlioptas and F. McSherry , “On spectral learning of mixtures of distributions,” in L e arning The ory , pp. 458–469, Springer, 2005. 20 [36] J. F eldman, R. A. Serv edio, and R. O’Donnell, “PAC learning axis-aligned mixtures of gaus- sians with no separation assumption,” in L e arning The ory , pp. 20–34, Springer, 2006. [37] S. C. Brubak er, “Robust PCA and clustering in noisy mixtures,” in Pr o c e e dings of the twentieth A nnual ACM-SIAM Symp osium on Discr ete Algorithms , pp. 1078–1087, So ciety for Industrial and Applied Mathematics, 2009. [38] M. Belkin and K. Sinha, “Learning gaussian mixtures with arbitrary separation,” arXiv pr eprint arXiv:0907.1054 , 2009. [39] K. Chaudhuri, S. Dasgupta, and A. V attani, “Learning mixtures of gaussians using the k-means algorithm,” arXiv pr eprint , 2009. [40] A. T. Kalai, A. Moitra, and G. V aliant, “Efficiently learning mixtures of tw o gaussians,” in Pr o c e e dings of the 42nd A CM symp osium on The ory of c omputing , pp. 553–562, A CM, 2010. [41] M. Belkin and K. Sinha, “P olynomial learning of distribution families,” in F oundations of Computer Scienc e (FOCS), 2010 51st Annual IEEE Symp osium on , pp. 103–112, IEEE, 2010. [42] D. B. Shmo ys, ´ E. T ardos, and K. Aardal, “Approximati on algorithms for facilit y lo cation problems,” in Pr o c e e dings of the twenty-ninth annual ACM symp osium on The ory of c omputing , pp. 265–274, ACM, 1997. [43] S. Guha and S. Khuller, “Greedy strikes back: Impro ved facility lo cation algorithms,” in Pr o- c e e dings of the ninth annual ACM-SIAM symp osium on Discr ete algorithms , pp. 649–657, So ciet y for Industrial and Applied Mathematics, 1998. [44] M. R. Korup olu, C. G. Plaxton, and R. Ra jaraman, “Analysis of a lo cal searc h heuristic for facility lo cation problems,” in Pr o c e e dings of the ninth annual ACM-SIAM symp osium on Discr ete algorithms , pp. 1–10, So ciety for Industrial and Applied Mathematics, 1998. [45] M. Charik ar and S. Guha, “Improv ed combinatorial algorithms for the facilit y lo cation and k-median problems,” in F oundations of Computer Scienc e, 1999. 40th A nnual Symp osium on , pp. 378–388, IEEE, 1999. [46] M. Mahdian, E. Mark akis, A. Sab eri, and V. V azirani, “A greedy facilit y location algorithm an- alyzed using dual fitting,” in Appr oxim ation, R andomization, and Combinatorial Optimization: A lgorithms and T e chniques , pp. 127–137, Springer, 2001. [47] K. Jain, M. Mahdian, and A. Sab eri, “A new greedy approac h for facilit y lo cation prob lems,” in Pr o c e e dings of the thirty-fourth annual ACM symp osium on The ory of Computing , pp. 731–740, A CM, 2002. [48] F. A. Chudak and D. B. Shmo ys, “Improv ed appro ximation algorithms for the uncapacitated facilit y lo cation problem,” SIAM Journal on Computing , v ol. 33, no. 1, pp. 1–25, 2003. [49] K. Jain, M. Mahdian, E. Mark akis, A. Sab eri, and V. V. V azirani, “Greedy facility lo cation algorithms analyzed using dual fitting with factor-rev ealing lp,” Journal of the ACM (JA CM) , v ol. 50, no. 6, pp. 795–824, 2003. [50] M. Sviridenk o, “An impro ved appro ximation algorithm for the metric uncapacitated facil- it y lo cation problem,” in Inte ger pr o gr amming and c ombinatorial optimization , pp. 240–257, Springer, 2006. 21 [51] M. Mahdian, Y. Y e, and J. Zhang, “Appro ximation algorithms for metric facility lo cation problems,” SIAM Journal on Computing , vol. 36, no. 2, pp. 411–432, 2006. [52] J. Byrk a, “An optimal bifactor appro ximation algorithm for the metric uncapacitated facil- it y lo cation problem,” in Appr oximation, R andomization, and Combinatorial Optimization. A lgorithms and T e chniques , pp. 29–43, Springer, 2007. [53] J. Vygen, Appr oximation A lgorithms F acili ty L o c ation Pr oblems . F orsc h ungsinstitut f ¨ ur Diskrete Mathematik, Rheinisc he F riedrich-Wilhelms-Univ ersit ¨ at, 2005. [54] S. Li, “A 1.488 approximation algorithm for the uncapacitated facilit y location problem,” In- formation and Computation , 2012. [55] S. Li and O. Sv ensson, “Approximating k-median via pseudo-appro ximation,” in Pr o c e e dings of the 45th annual ACM symp osium on Symp osium on the ory of c omputing , pp. 901–910, ACM, 2013. [56] V. Arya, N. Garg, R. Khandek ar, A. Mey erson, K. Munagala, and V. P andit, “Lo cal searc h heuristics for k-median and facilit y lo cation problems,” SIAM Journal on Computing , vol. 33, no. 3, pp. 544–562, 2004. [57] M. Ha jiaghayi, W. Hu, J. Li, S. Li, and B. Saha, “A constan t factor approximati on algorithm for fault-tolerant k-median,” arXiv pr eprint , 2013. 22 App endix: deriv ation of Prop osition 4 Prop osition 15. (Restatement of Prop osition 4 .) LinKMed has a unique solution z = z # that c oincides with the solution to KMed if and only if ther e exist some u and λ ∈ R N such that u > N X i =1 λ i − w ij + w i,M ( i ) + , j / ∈ M X i ∈ S j λ i = u , j ∈ M (51) 0 ≤ λ i < w i,M ( i, 2) − w i,M ( i ) , i ∈ [ N ] . Pr o of. Supp ose the solution to KMed z = z # is known. Let Ω b e the index set of nonzero entries of z # , and let Ω c b e its complement . F or some matrix m , denote as m Ω c the vector of N × ( N − 1) v ariables m ij for which ( i, j ) ∈ Ω c . Eliminating the z i,M ( i ) from LinKMed using the constraints ( 7 ) yields the followi ng equiv alen t program: min z Ω c ∈ R N × N N X i =1 X j 6 = M ( i ) p ij z ij (52) s.t. z ij ≤ z j j , i ∈ [ N ]; j / ∈ M ; i 6 = j (53) X i / ∈M z ii − X i ∈M X j 6 = i z ij ≤ 0 (54) x ij ≤ 1 − X ` 6 = j z j ` , j ∈ M ; i / ∈ S j (55) X ` 6 = M ( i ) z M ( i ) ,` ≤ X ` 6 = M ( i ) z i` , i / ∈ M (56) X ` 6 = M ( i ) z i` ≤ 1 , i ∈ [ N ] (57) z ij ≥ 0 , ( i, j ) ∈ Ω c , (58) where p ij ≡ w ij − w i,M ( i ) . The only z ij in the program ( 52 )-( 58 ) ha v e ( i, j ) ∈ Ω c . Asso ciate the nonne gative dual v ariables θ ij , u , γ ij , λ i , s i , and L ij with ( 53 ), ( 54 ), ( 55 ), ( 56 ), ( 57 ), and ( 58 ), resp ectiv ely . Enforcing stationarity of the Lagrangian gives p ij − u + θ ij + X ` ∈ S i ,` / ∈M λ ` + s i − L ij = 0 , i ∈ M ; j / ∈ M (59) p ij + θ ij − λ i + s i − L ij = 0 , i / ∈ M ; j / ∈ M ; i 6 = j (60) p j j + u − N X ` 6 = j θ `j − λ j + s i − L j j = 0 , j / ∈ M ; i = j (61) p ij − u + γ ij + γ j i + X ` ∈ S i ,` / ∈M λ ` + s i − L ij = 0 , i ∈ M ; j ∈ M , i 6 = j (62) p ij − λ i + γ ij + γ j i + s i − L ij = 0 , i / ∈ M ; j ∈ M ; j 6 = M ( i ) . (63) Call the primal Lagrangian f ( z Ω c ). Ab o ve, the quan tities on the lefthand sides of the equalities are comp onents of ∇ z Ω c f ( z Ω c ). Because z # Ω c = 0 , complemen tary slac kness of ( 55 ) and ( 57 ) giv es 23 that γ ij = 0 and s i = 0 where a medoid solution is exactly reco vered. The L ij are merely slack v ariables. Uniqueness of the solution z Ω c = z # Ω c o ccurs if and only if for an y feasible p erturbation h Ω c of z # Ω c , f ( z # Ω c + h Ω c ) ≥ f ( z # Ω c ) + D ∇ z Ω c f ( z # Ω c ) , h Ω c E > f ( z # Ω c ) . Because the feasible solution set includes only nonnegativ e z # Ω c , any feasible p erturbation h Ω c a wa y from z = z # Ω c = 0 must b e nonnegativ e with at least one p ositiv e component. Demanding that ev ery comp onen t of ∇ z Ω c f ( z Ω c )—that is, eac h LHS of ( 59 )-( 63 )—is positive th us sim ultaneously satisfies the KKT conditions and guarantees solution uniqueness. More precisely , LinKMed has a unique solution z = z # that coincides with the solution to KMed if and only if there exist u, λ i , θ ij ∈ R that satisfy p ij − u + θ ij + X ` ∈ S i ,` / ∈M λ ` > 0 , i ∈ M ; j / ∈ M (64) p ij + θ ij − λ i > 0 , i / ∈ M ; j / ∈ M ; i 6 = j (65) p j j + u − N X ` 6 = j θ `j − λ j > 0 , j / ∈ M ; i = j (66) p ij − u + X ` ∈ S i ,` / ∈M λ ` > 0 , i ∈ M ; j ∈ M , i 6 = j (67) p ij − λ i > 0 , i / ∈ M ; j ∈ M ; j 6 = M ( i ) . (68) Assigning eac h θ ij its minim um p ossible v alue minimizes the restrictiveness of ( 66 ). F rom ( 64 ), the minimum possible v alue of θ i ∈ M ,j approac hes u − p ij − P k ∈ S i ,` / ∈M λ ` + from ab ov e. F rom ( 65 ), the minimum p ossible v alue of θ i / ∈ M ,j approac hes ( λ i − p ij ) + from ab ov e. Inserting these v alues of θ ij in to the conditions ab o ve gives p j j + u − λ j − X i / ∈M ,i 6 = j ( λ i − p ij ) + + X i ∈M u − p ij − X ` ∈ S i ,` / ∈M λ ` + > 0 , j / ∈ M (69) λ i < p ij , i / ∈ M ; j ∈ M (70) u − X ` ∈ S i ,` / ∈M λ ` < p ij , i ∈ M ; j ∈ M , i 6 = j . (71) There exist u, λ i that satisfy ( 69 )-( 71 ) if and only if there exist u, λ i , θ ij that satisfy ( 64 )-( 68 ). Since λ j − p j j is nonnegative, it can b e absorb ed into the sum ov er i / ∈ M in ( 69 ): u − X i / ∈M ( λ i − p ij ) + + X i ∈M u − p ij − X ` ∈ S i ,` / ∈M λ ` + > 0 , j / ∈ M . Define λ i = u − X ` ∈ S i ,` / ∈M λ ` , i ∈ M to recov er the conten t of the prop osition. 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment