Accelerating Hessian-free optimization for deep neural networks by implicit preconditioning and sampling
Hessian-free training has become a popular parallel second or- der optimization technique for Deep Neural Network training. This study aims at speeding up Hessian-free training, both by means of decreasing the amount of data used for training, as wel…
Authors: Tara N. Sainath, Lior Horesh, Brian Kingsbury
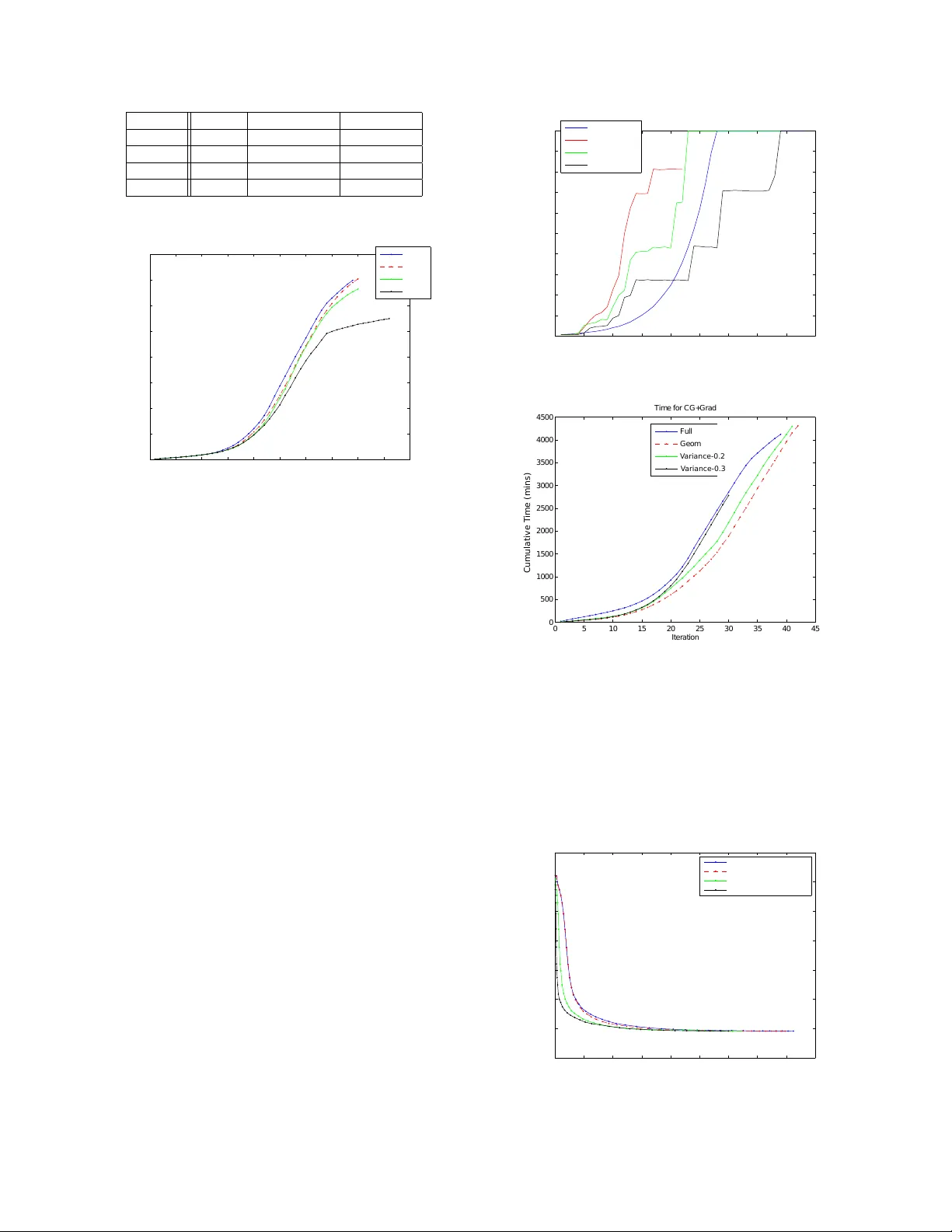
A CCELERA TING HESSIAN-FREE OPTIMIZA TION FOR DEEP NEURAL NETWORKS BY IMPLICIT PRECONDITIONING AND SAMPLING T ara N. Sainath, Lior Hor esh, Brian Kingsbury , Aleksandr Y . Ar avkin, Bhuvana Ramabhadran IBM T . J. W atson Research Center , Y orkto wn Heights, NY 10598, U.S.A { tsainath, lhoresh, bedk, saravkin, bhuv ana } @us.ibm.com Hessian-free training has become a popular parallel second or- der optimization technique for Deep Neural Network training. This study aims at speeding up Hessian-free training, both by means of decreasing the amount of data used for training, as well as through reduction of the number of Krylo v subspace solver iterations used for implicit estimation of the Hessian. In this paper , we dev elop an L-BFGS based preconditioning scheme that avoids the need to ac- cess the Hessian explicitly . Since L-BFGS cannot be re garded as a fixed-point iteration, we further propose the employment of flexi- ble Krylov subspace solvers that retain the desired theoretical con- ver gence guarantees of their con ventional counterparts. Second, we propose a ne w sampling algorithm, which geometrically increases the amount of data utilized for gradient and Krylo v subspace itera- tion calculations. On a 50-hr English Broadcast News task, we find that these methodologies provide roughly a 1.5x speed-up, whereas, on a 300-hr Switchboard task, these techniques provide ov er a 2.3x speedup, with no loss in WER. These results suggest that even fur- ther speed-up is expected, as problems scale and complexity grows. 1. INTR ODUCTION Second order optimization techniques hav e been extensi vely ex- plored for problems in volving pathological curvature, such as deep neural network (DNN) training problems. In fact, [1] demonstrated success of a second order technique, known as Hessian-free (HF) optimization [2], with DNNs on various image recognition tasks. In addition, [3] successfully applied the HF optimization technique with DNNs for speech recognition tasks. Other second order meth- ods, including L-BFGS [4] and Krylov Subspace Descent [5], have also shown great success for DNN training. Second order methods are particularly important for sequence- training of DNNs, which provides a 10-20% relati ve improv ement in WER over a cross-entropy (CE) trained DNN [6]. Because sequence training must use information from time-sequential lattices corre- sponding to utterances, sequence training is performed using utter- ance randomization rather than frame randomization. For mini-batch stochastic gradient descent (SGD), which is often used for CE train- ing, frame randomization performs better than utterance randomiza- tion [7]. Howe ver , because sequence-training must be accomplished at the utterance le vel, second order methods perform much better than SGD, as second order methods compute the gradient over a large batch of utterances compared to utterance mini-batch SGD [3]. At IBM Research, we employ HF optimization techniques for sequence training [1]. One of the drawbacks of this method is that training can be v ery slo w , requiring about 3 weeks for training a 300- hour Switchboard task [3] using 64 parallel machines. There are two reasons why training is slow . Firstly , a great number of Krylov sub- space iterations may be required for a solution to approximate the Hessian within each HF iteration [1], [3]. Secondly , [3] proposes using a fix ed amount of data for all HF iterations in both the gra- dient and Krylov subspace iteration computations. The purpose of this research is to explore algorithmic strategies for reduction of the amount of time spent in both gradient and Krylov subspace compu- tations, both by reducing the amount of data needed for training, as well as by reducing the number of Krylov subspace iterations. In this paper , we exploit a specific instance of Krylov subspace solvers which are consumed to symmetric positi ve definite matrices, known as conjugate gradient (CG) solvers. For simplicity , we will use the term “conjugate gradient” as the specific Krylo v subspace technique used to estimate the Hessian. Howe ver , the algorithms we propose for reducing training time are generic and can w ork with any other fle xible Krylov subspace solver v ariant. Preconditioning in the context of linear algebra refers to the process of transforming a system of equations into one that can be solved more readily [8]. For example, preconditioning has been ex- tensiv ely used to reduce CG iterations [9]. Obtaining an appropriate preconditioner for a given problem can be challenging. First, the type of preconditioner that works best is problem specific. Second, while in principle, it is possible to design preconditioning strategies that will reduce the computational burden of the consequent solution phase radically , the computational inv estment in attaining such a pre- conditioner might of fset its benefit. Thus, it is critical to identify a proper balance between computational efforts in vested in precondi- tioning, vs. that inv ested in the consequent solution phase. For our optimization problem, it is computationally intractable to construct the Hessian explicitly . Quasi-Newton approaches con- struct (typically a lo w rank) an approximation to the Hessian, and in their limited memory versions, only form such approximations im- plicitly . In this work, we propose using the quasi-Newton L-BFGS method [10] as a preconditioner to the CG solver . Our rationale is that while both quasi-Ne wton approaches and CG exploit the under - lying structure of the linear(ized) system, the postulated structural assumptions of both (low rank, CG) are complementary . Therefore a combination of both methods is typically more ef fectiv e than depen- dence upon each one solely . The reason L-BFGS was not used di- rectly for HF optimization of DNNs is that L-BFGS crudely approx- imates the curvature matrix, whereas the HF method in [1] makes implicitly av ailable the exact curv ature matrix, which allows for the identification of directions with extremely lo w curv ature. The use of L-BFGS for preconditioning has been suggested be- fore [11] for numerical simulations. W e extend upon the work in [11], and demonstrate that L-BFGS serves as an effecti ve precon- ditioner for CG-based HF training of DNNs on lar ge-scale speech recognition data. Furthermore, unlik e [11] which used a typical fixed CG approach, we mak e here an important observ ation that non-fix ed point preconditioners, as the proposed L-BFGS, cannot be used sta- blely with standard CG iterative schemes [8]. Thus, to ensure, sta- ble and predictable con vergence, we propose here the use of flexible variants of CG methods [12]. These variants av oid the failures and breakdowns that their standard counterparts are susceptible to. Second, we introduce a sampling strategy in which the amount of data used for gradient and CG calculations, is gradually increased. In optimization problems, gradient-based methods typically operate within tw o popular regimes [13]. Stochastic approximation methods (i.e. such as stochastic gradient descent) select a small sample size to estimate the gradient. These methods often decrease the objecti ve function loss quickly during initial training iterations, albeit, dur- ing later iterations the movement of the objectiv e function is slo w . On the other end of the spectrum, sample approximation techniques compute the gradient on a large sample of data. While this computa- tion is expensi ve, the gradient estimates are much more reliable, and the objective function progresses well during later training iterations. In this study , we propose a hybrid method that captures the benefits of both stochastic and sample approximation methods, by increasing the amount of sampled data used for gradient and CG calculations. Sampling the amount of data used for gradient and CG calcula- tions was e xplored in [13], which observed the v ariance of the batch gradient to determine the amount of data to use for gradient and CG calculations. Alternati vely , [14] e xplored geometrically increasing the amount of data used for logistic regression and conditional ran- dom field problems. The benefit of this approach is that the schedule for selecting data is gi ven ahead of time, and there is no need to compute the e xpensiv e gradient variance. In this paper, we extend the idea in [14] for HF DNN training, and compare this to the sam- pling approach in [13]. Initial experiments are conducted on a 50-hr English Broadcast News (BN) task [3]. W e find that preconditioning allows for more than 20% speedup by reducing the number of CG iterations. Fur - thermore, we find that gradient and CG sampling provide roughly additional 20% improv ement in training time. In total, by combin- ing both sampling and preconditioning speedup ideas we were able to reduce ov erall training time by a factor of 1.5. Second, we extend the preconditioning and sampling ideas to a larger 300-hr Switch- board (SWB) task, where we find that the proposed techniques pro- vide more than a 2.3x speedup, with no loss in accuracy . 2. HESSIAN-FREE OPTIMIZA TION Before describing the speedups made to the Hessian-free (HF) algo- rithm, we briefly summarize the HF algorithm for DNN training, as described in [1]. Let θ denote the network parameters, L ( θ ) denote a loss function, ∇L ( θ ) denote the gradient of the loss with respect to the parameters, d denote a search direction, and B ( θ ) denote a ma- trix characterizing the curvature of the loss around θ (i.e., a Hessian approximation). The central idea in HF optimization is to iterativ ely form a quadratic approximation to the loss, L ( θ + d ) ≈ L ( θ ) + ∇L ( θ ) T d + 1 2 d T B ( θ ) d (1) and to minimize this approximation using Krylov subspace methods, such as conjugate gradient (CG), which access the curv ature matrix only implicitly through matrix-vector products of the form B ( θ ) d . Such products can be computed ef ficiently for neural networks [15]. In the HF algorithm, the CG search is truncated, based upon the rel- ativ e impro vement in the approximate loss. The curv ature matrix is often chosen to be the Gauss-Ne wton matrix G ( θ ) [16], which may not be positi ve definite. T o av oid breakdown of CG due to ne g- ativ e curv ature, a positive definite approximation can be enforced by shifting the matrix using an additional damping term: B ( θ ) = G ( θ ) + λ I , where λ is set via the Levenber g-Marquardt algo- rithm. Our implementation of HF optimization, which is illustrated Algorithm 1 Hessian-free optimization (after [1]). initialize θ ; d 0 ← 0 ; λ ← λ 0 ; L prev ← L ( θ ) while not con ver ged do g ← ∇L ( θ ) Let q θ ( d ) = ∇L ( θ ) T d + 1 2 d T ( G ( θ ) + λ I ) d { d 1 , d 2 , . . . , d N } ← C G - M I N I M I Z E ( q θ ( d ) , d 0 ) L best ← L ( θ + d N ) for i ← N − 1 , N − 2 , . . . , 1 do line sear ch L curr ← L ( θ + d i ) if L prev ≥ L best ∧ L curr ≥ L best then i ← i + 1 break L best ← L curr if L prev < L best then λ ← 3 2 λ ; d 0 ← 0 continue ρ = ( L prev − L best ) /q θ ( d N ) if ρ < 0 . 25 then λ ← 2 3 λ else if ρ > 0 . 75 then λ ← 3 2 λ θ ← θ + α d i ; d 0 ← β d N ; L prev ← L best as pseudo-code in Algorithm 1, closely follows that of [1]. Gradients are computed over all the training data. Gauss-Newton matrix-vector products are computed over a sample (about 1% of the training data) that is taken each time CG-Minimize is called. The loss, L ( θ ) , is computed ov er a held-out set. CG-Minimize ( q θ ( d ) , d 0 ) uses CG to minimize q θ ( d ) , starting with search direction d 0 . This function returns a series of steps { d 1 , d 2 , . . . , d N } that are then used in a line search procedure. The parameter update, θ ← θ + α d i , is based on an Armijo rule backtracking line search. Distributed computation to computer gradients and curvature matrix-vector products is done using a master/worker architecture [3]. 3. PRECONDITIONING One of the problems with the HF technique used in [3] is that CG algorithms used to obtain an approximate solution to the Hessian require many iterations. Figure 1 indicates that as HF training itera- tions increase, training time per iteration is in f act dominated by CG iterations. In this section, we discuss how to reduce the number of CG iterations using preconditioning. 3.1. Motivation 2nd-order optimization techniques require computation of Hessian in order to determine a search direction of the form d k = − H − 1 k g k . In this formulation, H k is the Hessian approximation and g k the gradient of the objecti ve function at the k th HF iteration. The afore- mentioned CG method can be used to solv e for this search direc- tion. Specifically , we set H k = ( G k + λI ) , where G k is the Gauss- Newton matrix, and solv e H k d k = − g k . As mentioned above, in principle, L-BFGS [10] can be used for optimization of the HF DNN training problem. The reason L-BFGS was not used for optimization of neural networks is that in practice L-BFGS crudely approximates curvature of such systems, whereas Fig. 1 . T ime spent in gradient and CG per HF iteration for this domain problem HF algorithms manage to capture salient features of the curvature, and thereby identify search directions of extremely lo w curv ature [1]. Y et, the computation of each HF search direction can be com- putationally excessi ve, requiring a great number of CG iterations. Thus, the use of quasi-Newton methods for preconditioning such implicit systems is sensible, as the structural assumptions of CG and L-BFGS are complementary . In the section belo w , we describe the L-BFGS algorithm and detail using this as a preconditioner for fle x- ible CG. 3.1.1. L-BFGS algorithm L-BFGS is a quasi-Netwton optimizati on method that uses a limited memory technique to approximate the Hessian or its in verse. Specif- ically , instead of computing the Hessian directly , which can often be a lar ge and dense matrix, the L-BFGS algorithm stores a small num- ber of vectors which can be used as a lo w rank approximation of the Hessian. The L-BFGS algorithm is outlined below in Algorithm 2. Algorithm 2 L-BFGS Algorithm Position at iteration k : x k g k = ∆ f ( x k ) , where f is the function to be minimized s k = x k +1 − x k y k = g k +1 − g k ρ k = 1 y T k s k Initial Hessian: H 0 k = y T k s k y T k y k I q = g k for i ← k − 1 , k − 2 , . . . , k − m do α i = ρ i s T i q q = q − α i y i z = H 0 k q for i ← k − m, k − m + 1 , . . . , k − 1 do β i = ρ i y T i z z = z + s i ( α i − β i ) H k g k = z search direction 3.1.2. L-BFGS as a Pr econditioner CG iterative methods can be used to solve for the search direction d k , by minimizing the following problem H − 1 k g k − d k = 0 . Precondi- tioning typically inv olves a process or transformation (e.g. change of coordinates) applied upon a system of equations, which in return, con verts the system to of more fav orable structure. Precondition- ing makes the CG problem easier to solve and reduces the num- ber of CG iterations. If we define M as a preconditioner , precondi- tioned CG in volv es the following transformation to the CG problem M − 1 ( H − 1 k g k − d k ) . The preconditioner M is required to be sym- metric and positiv e definite, and fixed for all iterations. If any of these conditions are violated, the CG method may fail. Prescription of a suitable preconditioning scheme for a given problem is challenging. First, each system has its own characteris- tic structure. Identification of which and respecti vely determining the type of preconditioner that works best is generally problem spe- cific. Second, if the preconditioner is computationally expensiv e to obtain, then this will offset any reduction in CG iterations, and thus the preconditioner will not be cost effectiv e. Third, as challenging as preconditioning is in ordinary circumstances, a greater challenge is to precondition an implicit system, that cannot be accessed directly . Previous preconditioning work for HF optimization has focused on diagonal matrix preconditioners. [1] explored using the diaogonal elements of the Fisher information matrix as a preconditioner for HF training of DNNs. Using diagonal matrix elements has a very lim- ited ability to precondition the system, and is mainly beneficial when the matrix suf fers scaling issues. In addition, [17] explored using the Jacobi pre-conditioner , which is computed over a batch of data just like the curv ature-vector products, thus requiring the master/worker data-parallelization architecture. For our specific DNN speech prob- lem, we found that the Jacobi preconditioner was costly to compute and of fset reductions in CG iterations. The L-BFGS [11] precondi- tioner we propose is f ar more powerful compared to diagonal matrix preconditioners as it improv es the spectral properties of the system, rather than merely tackling potential scaling issues. Furthermore, it does not require any data parallelization. The L-BFGS preconditioner is described as follows. Each itera- tion i of CG produces a sequence of iterates x i (i.e., d i in Algorithm 1) and a sequence of residuals r i [18]. Using these statistics, the vec- tors s i = x i +1 − x i and y i = r i +1 − r i are stored for m iterations of CG, where m is specified by the user . Once m statistics are saved, an L-BFGS matrix H can be defined using the steps in Algorithm 2. This L-BFGS matrix is used as the preconditioner for CG. There are a variety of different methodologies to choose the m statistics to use when estimating the L-BFGS matrix. W e adopt a strategy proposed in [11], namely using m vectors e venly distributed throughout the CG run, to estimate the L-BFGS matrix. This implies that our preconditioner changes for different CG iterations. The re- quirement that the preconditioner needs to be fixed for all iterations of CG is incon venient, since as we obtain more L-BFGS statistics we can improv e the estimate of the preconditioner . Changing the pre- conditioner for CG requires using a fle xible CG approach [12]. More specifically , instead of using the equiv alent of Fletcher-Ree ves up- dating formula for non-preconditioned CG, the Polak-Ribi ` ere v ari- ant is required [18]. This is opposed to the approach taken in [11] which did not use a flexible CG approach. 4. SAMPLING Another problem with the HF technique used in [3] was that the gradient was computed using all data, and CG on a fixed data sam- ple. In this section, we explore reducing the amount of data used for the gradient and CG computations. Specifically , we explore a hybrid technique that first starts with a small amount of data simi- lar to stochastic approximation methods, and gradually increases the amount of sampled data similar to sample approximation methods. In the following section, we detail tw o different h ybrid methods. 4.1. Sampling From V ariance Estimates [13] proposes a method to increase the sample size based on v ari- ance estimates obtained during the computation of a batch gradient. This algorithm can be described as follows. Denote f ( w ; x i ) as the output from the DNN and y i the true output, such that a loss between predicted and true values can be defined as l ( f ( w ; x i ) , y i ) . The loss ov er the training set of size N , is defined as the sum of the losses from the individual training e xamples x i , as shown by Equation 2. J ( w ) = 1 N N X i =1 l ( f ( w ; x i ) , y i ) (2) In addition, the loss o ver a subset S ⊂ { 1 , . . . , N } is defined by Equation 3. J S ( w ) = 1 S X i ⊂ S l ( f ( w ; x i ) , y i ) (3) Denoting the gradients of the full and subset losses as ∇ J ( w ) and ∇ J S ( w ) respecti vely , the algorithm ensures that descent made in J S at e very iteration must admit a descent direction for the true objectiv e function J . The is expressed by Equation 4. δ S ( w ) ≡ ||∇ J S ( w ) −∇ J ( w ) || 2 ≤ θ ||∇ J S ( w ) || 2 , where θ ∈ [0 , 1) (4) In practice, the quantity δ S ( w ) is not ev aluated (the computation of ∇ J ( w ) is expensiv e for large data sets), but instead is estimated from the variance of ∇ J S ( w ) . Inequality 4 can be simplified to the inequality || V ar i ∈ S ( ∇ l ( w ; i )) || 1 | S | ≤ θ 2 ||∇ J S ( w ) || 2 2 . (5) If this inequality fails, a new sample size ˆ S > S is selected to satisfy Inequality 5. The same dynamic selection strategy is also applied to the CG iterations. In this paper , we explore this sampling approach within a DNN framew ork. Giv en an input utterance u , the output of the DNN is the sum of the gradients of all training frames L in that utterance, i.e. P L i =1 ∇ l ( w ; i ) . Therefore, to compute the v ariance of the gradient estimate, this requires tw o passes through each utterance to compute the gradient and gradient-squared statistics P L i =1 ∇ l 2 ( w ; i ) . Since this makes the algorithm computationally expensi ve, we compute the av erage gradient per utterance u , i.e. ¯ l u = 1 L P L i =1 ∇ l ( w ; i ) . The variance statistics become the sum and sum-squared of ¯ l u ov er all utterances u ∈ S in the training set, as sho wn by Equation 6. This only requires one pass through the network per utterance. V ar i ∈ S ( ∇ l ( w ; i )) ≈ P S u =1 ¯ l 2 u − ( P S u =1 ¯ l u ) 2 /S S − 1 (6) 4.2. Geometric Sampling The sampling approach proposed abov e uses sampling statistics to approximate the descent condition (5), but the need to estimate the variance in (5) adds notable computational complexity to the gradi- ent computation. In contrast, the framew ork discussed in [14] pro- vides an expected guarantee of descent in each iteration, as long as the sampling errors E [ ||∇ J S ( w ) − ∇ J ( W ) || 2 2 ] ≤ B k are bounded, and the bounds B k are decreasing. In fact, [14, The- orem 2.2] links the sampling errors directly to the expected rate of con ver gence. This approach does not require computing statistics along the way , and the sampling strategy used to select S is linked directly to the expected con vergence rate in [14, 19]. [14] uses a geometrically increasing sample size. W e adopt this strategy for the gradient and CG iteration samples in each iteration. Specifically , giv en initial sample size S 0 , the sample size at each iteration i is giv en by Equation 7 where α is the geometric factor that is tuned on a dev elopment set. | S i | = α i | S 0 | (7) This approach fits into the theory proposed in [14], and has the practical benefit of a priori sample size selection. The sample size can be used both for gradient and CG iteration calculations. 5. EXPERIMENTS 5.1. Broadcast News Our initial experiments are conducted on a 50-hr English Broadcast News (BN) task and results reported on both the EARS dev04f set. W e use a recipe outlined in [20] to e xtract acoustic features. The hybrid DNN is trained using speaker-adapted VTLN+fMLLR fea- tures as input, with a context of 9 frames around the current frame. In [3], it was observed that a 5-layer DBN with 1,024 hidden units per layer and a sixth softmax layer with 2,220 output targets was an appropriate architecture for BN tasks. W e explore the beha vior of preconditioning and sampling for HF training on a smaller BN task first, before moving to a larger Switchboard task. All timing experiments in this study were run on an 8 core Intel Xeon X5570@2.93GHz CPU. Matrix/vector opera- tions for DNN training are multi-threaded using Intel MKL-BLAS. 12 machines were exclusi vely reserved for HF training to get reliable training time estimates. 6. RESUL TS 6.1. Preconditioning In this section, we compare CG with preconditioning and no precon- ditioning (noPC). For preconditioning, we explore the behavior with different number of statistics used to estimate the L-BFGS precon- ditioned, namely 16 (PC-16), 32 (PC-32) and 64 (PC-64). T able 1 shows the total time spent in CG, and total number of training iterations, to achiev e the same loss. In addition, Figure 2 provides a closer look at the cumulati ve time for CG for the 4 meth- ods. The Figure indicates that that all preconditioning methods re- quire less time for CG, particularly as the number of total HF itera- tions increases (and thus the number of CG iterations increases). W e see that PC-64 manifests a significant reduction in CG time after 30 HF iterations, but this also results in the loss moving much slower for this method, as explained by increased HF iterations in T able 1. PC-32 appears to be the most cost-efficient choice for the giv en task, both in terms of CG iteration runtime and in terms of loss reduction, and is roughly 22% faster than the baseline method. 6.2. Gradient+CG Sampling Next, we compare the behavior of the geometric and variance sampling methods. Sampling methods require a tradeoff between amount of data used, and the number of iterations for the training Method Loss HF Iterations T ime (min) noPC 1.9153 39 3,492.2 PC-16 1.9157 35 3,042.2 PC-32 1.9150 33 2,7095.3 PC-64 1.9158 46 2,745.6 T able 1 . T otal CG runtime for dif ferent quasi-Newton PC schemes 0 5 10 15 20 25 30 35 40 45 50 0 500 1000 1500 2000 2500 3000 3500 4000 Iteration Cumulative Time (mins) No PC PC−16 PC−32 PC−64 Fig. 2 . Cumulativ e CG runtime for dif ferent PC schemes loss to con ver ge. Using too little data for gradient and CG will re- quire more training iterations, while using too much data will make each iteration computationally expensi ve. For geometric sampling, the geometric factor α was tuned on a held-out set for both gradient and CG. It was found that an α g = 1 . 2 for the gradient and α cg = 1 . 3 for CG allowed for the best tradeof f between reduction in amount of training data used and training time. This geometric factor corresponds to seeing roughly 100% of the total data used for gradient and CG calculations when roughly 50% of the total training iterations are completed. For v ariance sampling, θ in Equation 6 is tuned, where smaller θ fav ors a lar ger sample size. Figure 3 shows the percentage of data accessed for the gradient for the geometric and variance methods, per HF iteration, for three different values of θ . Notice that the v ariance methods access a lot of training data in the beginning relative to the geometric method. One reason is that during the beginning of training, there is little data a vailable to get a reliable variance estimate, so a larger sample size is preferred. The variance method with θ = 0 . 25 provided the best tradeoff between training time and data accessed. A similar θ was also used for estimating amount of data used for CG. Figure 4 shows the cumulative time for gradient and CG calcu- lation per HF iteration, for the full gradient/CG and sampling ap- proaches, where both sampling approaches are tuned to provide best tradeoff between training time and amount of data accessed. The geometric method is quicker than the variance sampling method, particularly because it accesses less data during early training iter- ations, as sho wn in Figure 3. Overall, we find that the geometric method pro vides roughly a 20% reduction in training time. It is pos- sible that a technique that starts with geometric sampling, and then switches to variance sampling once enough data is obtained for a reliable variance estimate, might pro vide further speedups. 6.3. Overall Speedups In this section, we combine the preconditioning and sampling to cal- culate the overall speedup in training time for BN. Figure 5 shows 0 5 10 15 20 25 30 35 40 45 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 HF Iterations Percentage Gradient Geometric Variance−0.2 Variance−0.25 Variance−0.3 Fig. 3 . Percentage of Gradient Accessed for Sampling Methods 0 5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 4 5 0 5 0 0 1 0 0 0 1 5 0 0 2 0 0 0 2 5 0 0 3 0 0 0 3 5 0 0 4 0 0 0 4 5 0 0 I t e r a t i o n C E L o s s Ti m e f o r C G + G r a d F u l l G e o m N o c e d a l − 0 . 3 N o c e d a l − 0 . 2 V a r i a n c e-0 .2 V a r i a n c e-0 .2 V a r i a n c e-0 .3 C u mu lat i ve T ime (m i n s ) Fig. 4 . Cumulativ e T raining T ime for Sampling Methods the trade-of f between loss and overall training time of the baseline (no speedup) method, preconditioning, and then including gradient and CG sampling. Overall we can see that PC+Gradient+CG sam- pling of fers the fastest training time compared to the baseline. T able 2 shows the training time and corresponding WER for the baseline and speedup methods. T raining time is reduced from 68.7 hours to 44.5 hours, roughly a 1.5x speedup, with no loss in accuracy . 0 500 1000 1500 2000 2500 3000 3500 4000 4500 1 2 3 4 5 6 7 8 Total Time (mins) Loss Baseline Pre−Conditioning PC+Grad Sampling PC+Grad+CG Sampling Fig. 5 . Loss vs. Training T ime for Different Speedup T echniques Method WER T otal T raining T ime (hrs) Baseline 17.8 68.7 PC+Grad+CG Speedups 17.8 44.5 T able 2 . Overall T raining Time Impro vements, Broadcast Ne ws 6.4. Speedups on Larger T ask After analyzing the behavior of preconditioning and sampling speedups on a smaller 50-hour Broadcast News task, in this sec- tion, we explore training speed improvements on a larger 300-hour Switchboard task. 6.4.1. Experimental Setup W e explore DNNs performance on 300 hours of con versational American English telephony data from the Switchboard corpus. De- velopment is done on the Hub5’00 set, while testing is done on the rt03 set, where we report performance separately on the Switch- board ( SWB ) and Fisher ( FSH ) portions of the set. Similar to BN, the training features are speaker-adapted, using VTLN and fMLLR techniques. The input features into the DNN hav e an 11-frame context ( ± 5 ) around the current frame. Similar to [3], the DNN has six hidden layers each containing 2,048 sig- moidal units, and 8,260 output targets. Results with and without HF speedups are reported after sequence training. 6.4.2. Results Performance with the baseline and speedup HF techniques are shown in T able 3. Since using 32 L-BFGS stats performed well for the smaller 50-hour BN task, we used the same on the Switchboard task for preconditioning. In addition, because of the increased amount of training data associated with the larger task, we found that using a smaller sample size (i.e., α ) for the gradient and CG iteration calcu- lations still allowed for an appropriate estimate of these statistics. Since we use more parallel machines (i.e. 64) for SWB com- pared to BN, it was not possible to exclusiv ely reserve machines for timing calculations. Therefore, training time is estimated by cal- culating total number of accessed data points for training, which is correlated to timing. T able 3 shows the total accessed data points for the baseline and speedup techniques. Notice that with a larger dataset, because we are able to decrease the fraction of data used for gradient and conjugate gradient calculations, w as can achie ve an ev en larger speedup of 2.3x over the baseline, with no loss in accu- racy . This suggests that e ven further speedups are possible as the data size grows. Method WER T otal Accessed Data Points Baseline 12.5 2.26e9 PC+Grad+CG Speedups 12.5 9.95e8 T able 3 . Overall T raining Time Impro vements, Switchboard 7. CONCLUSIONS In this paper , we explored using an L-BFGS pre-conditioner and ge- ometric sampling approach to accelerate HF training. W e find that both approaches combined provided roughly a 1.5x speedup over a 50-hr Broadcast News task and a 2.3x speedup on a 300-hr Switch- board task, with no loss in accuracy . W e anticipate an even larger speedup to be attained by more informed selection of quasi-Newton statistics (potentially adaptiv e) as well as by application of the pro- posed algorithmic strategies upon problems of greater scale. 8. REFERENCES [1] J. Martens, “Deep learning via Hessian-free optimization, ” in Pr oc. Intl. Conf. on Machine Learning (ICML) , 2010. [2] L. Horesh, M. Schweiger , S.R. Arridge, and D.S. Holder , “Large-scale non-linear 3d reconstruction algorithms for electrical impedance to- mography of the human head, ” in W orld Congress on Medical Physics and Biomedical Engineering 2006 , R. Magjarevic and J.H. Nagel, Eds., vol. 14 of IFMBE Proceedings , pp. 3862–3865. Springer Berlin Heidel- berg, 2007. [3] B. Kingsbury , T . N. Sainath, and H. Soltau, “Scalable Minimum Bayes Risk T raining of Deep Neural Network Acoustic Models Using Dis- tributed Hessian-free Optimization, ” in Proc. Interspeec h , 2012. [4] J. Dean, G.S. Corrado, R. Monga, K. Chen, M. Devin, Q.V . Le, M.Z. Mao, M.A. Ranzato, A. Senior , P . T ucker , K. Y ang, and A. Y . Ng, “Large Scale Distrib uted Deep Networks, ” in NIPS , 2012. [5] O. V inyals and D. Pove y , “Krylov Subspace Descent for Deep Learn- ing, ” in AIST ATS , 2012. [6] B. Kingsbury , “Lattice-based optimization of sequence classification criteria for neural-network acoustic modeling, ” in Pr oc. ICASSP , 2009, pp. 3761–3764. [7] H. Su, G. Li, D. Y u, and F . Seide, “Error Back Propagation For Se- quence T raining Of Context-Dependent Deep Networks For Con versa- tional Speech T ranscription, ” in Pr oc. ICASSP , 2013. [8] R. Barrett, M. Berry , T . F . Chan, J. Demmel, J. Donato, J. Dongarra, V . Eijkhout, R. Pozo, C. Romine, and H. V an der V orst, T emplates for the Solution of Linear Systems: Building Blocks for Iterative Methods, 2nd Edition , SIAM, Philadelphia, P A, 1994. [9] S. Eisenstat, “Ef ficient Implementation of a Class of Preconditioned Conjugate Gradient Methods, ” SIAM Journal on Scientific and Statis- tical Computing , 1981. [10] J. Nocedal, “Updating Quasi-Newton Matrices with Limited Storage, ” Mathematics of Computation , vol. 33, pp. 773–782, 1980. [11] J.L. Morales and J. Nocedal, “Automatic Preconditioning by Limited Memory Quasi-Newton Updating, ” SIAM Journal on Optimization , 1999. [12] Y . Notay , “Flexible Conjugate Gradients, ” SIAM Journal on Scientific Computing , 2000. [13] R. Byrd, G. M. Chin, J. Nocedal, and Y . W u, “Sample size selection in optimization methods for machine learning, ” Mathematical Pr ogr am- ming B , 2012. [14] M. P . Friedlander and M. Schmidt, “Hybrid deterministic-stochastic methods for data fitting, ” SIAM J. Scientific Computing , vol. 34, no. 3, 2012. [15] B. A. Pearlmutter, “Fast exact multiplication by the Hessian, ” Neural Computation , vol. 6, no. 1, pp. 147–160, 1994. [16] N. N. Schraudolph, “Fast curvature matrix-vector products for second- order gradient descent, ” Neural Computation , vol. 14, pp. 1723–1738, 2004. [17] O. Chapelle and D. Erhan, “Improved Preconditioner for Hessian- free Optimization, ” in Pr oc. NIPS W orkshop NIPS W orkshop on Deep Learning and Unsupervised F eature Learning , 2011. [18] J. Shewchuk, “An Introduction to the Conjugate Gradient Method with- out the Agonizing Pain, ” 1994. [19] A. Ara vkin, M. P . Friedlander , F . Herrmann, and T . v an Leeuwen, “Ro- bust inversion, dimensionality reduction, and randomized sampling, ” Mathematical Pr ogramming , v ol. 134, no. 1, pp. 101–125, 2012. [20] H. Soltau, G. Saon, and B. Kingsbury , “The IBM Attila speech recogni- tion toolkit, ” in Proc. IEEE W orkshop on Spoken Language T echnology , 2010, pp. 97–102.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment