Overlapping Mixtures of Gaussian Processes for the Data Association Problem
In this work we introduce a mixture of GPs to address the data association problem, i.e. to label a group of observations according to the sources that generated them. Unlike several previously proposed GP mixtures, the novel mixture has the distinct…
Authors: Miguel Lazaro-Gredilla, Steven Van Vaerenbergh, Neil Lawrence
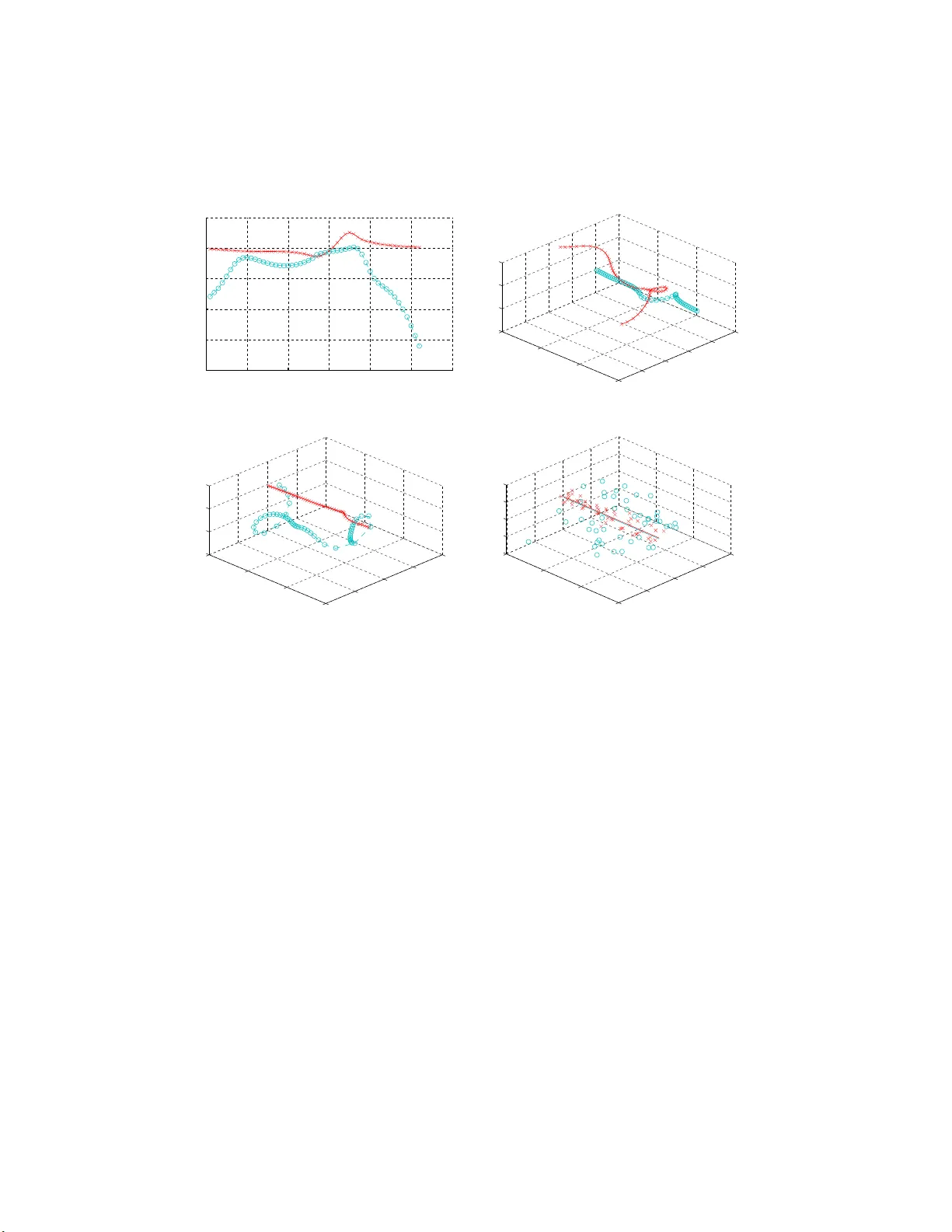
Ov erlapping Mixtures of Gaussian Pro cesses for the Data Asso ciation Problem Miguel L´ azaro-Gredilla a, ∗ , Stev en V an V aeren b ergh a , Neil Law rence b a Dept. C ommun ic ations Engine ering, University of Cantabria, 390 05 Santander, Sp ain b Dept. of Computer Scienc e, University of Sheffield, S1 4DP Sheffield, UK Abstract In this w ork w e in tro duce a mixture of GPs to address the da t a asso cia- tion problem, i.e. to lab el a group of observ a t io ns according to t he sources that generated them. Unlik e sev eral previously prop osed GP mixtures, the no v el mixture has the distinct c haracteristic of using no ga ting function to determine the as so ciatio n of samples and mixture components . Instead, all the GPs in the mixture are global and samples a r e clustered follo wing “tra- jectories” across input space. W e use a non-standard v ariational Bay esian algorithm to efficien tly reco v er sample lab els and learn the h yp erpara meters. W e s how ho w m ulti-ob ject tracking problems can b e disam biguated and also explore the c haracteristics o f the mo del in traditional r egr ession settings. Keywor d s: Gaussian Pro cesses, Marginalized V ariational Inference, Ba y esian Mo dels 1. I n tro duction The data ass o ciation problem arise s in m ulti-ta r g et trac king scen ario s. Giv en a set of observ ations that r epresen t t he p ositions of a n um b er of mo ving sources, suc h as cars or airplanes, data a sso ciat io n consists of inferring which observ ations originate from the same source [ 1 , 2 ]. Data association is found in trac king problems for instance in computer vision [ 3 ], surv eillance, sensor ∗ Corresp o nding a uthor: T el: +3 4 94220 0919 ext 802, F ax: +34 94220 1 488. Email addr esses: migue llg@g tas.dicom.unican.es (Miguel L´ azaro - Gredilla), steven @gtas .dicom.unican.es (Steven V an V aer enbergh), N.Lawr ence@ sheffield.ac.uk (Neil Lawrence) Pr eprint submitte d to Pattern Re c o gnition Novemb er 27, 2024 net w orks [ 4 ] a nd radar trac king [ 5 ]. An example of data asso ciation with t wo sources is illustrated in Figure 1 . 0 10 20 30 40 50 −1.5 −1 −0.5 0 0.5 1 1.5 2 x y (a) O ne - dimensional observ ations. 0 10 20 30 40 50 −1.5 −1 −0.5 0 0.5 1 1.5 2 x y (b) Solution o btained by the prop osed metho d. Figure 1: E xample of a multi-target tracking scenario. Data asso ciation aims to identify what obser v a tions corres p ond to each so ur ce. F or a h uman observ er, little effort is req uired to distinguish t w o noisy tra jectories in this example, r epresen ting the pa t hs follow ed b y tw o ob jects in time. In this sp ecific case, one observ ation o f eac h tar g et is av ailable at eac h time instan t, and the measuremen t instan ts are equally spaced in time, although neither of these prop erties are required in general. T ypical multi-target trac king algo rithms op erate o nline. They include join t Ka lma n filters [ 6 ] and joint particle filters [ 7 ]. Given the predicted p o- sitions of the targets and a n um b er of candidate o bserv ed p ositions, they usually mak e instan t data asso ciation decisions based on nearest-neigh bo r criteria o r statistically more sophisticated approache s suc h as the Join t Prob- abilistic D ata-Asso ciation Filter (JPDAF) [ 5 , 7 ] or the Multiple Hyp o thesis T rac ker (MHT) [ 6 ]. An impo rtan t disadv antage of these classical tec hniques is that they usually require to determine a large n um b er of pa r ameters. This dra wbac k motiv at ed the dev elopment of sev eral conceptually simpler approac hes based on motion geometry heuristics [ 2 , 8 , 9 ]. Ho w ev er, these approac hes are usually limited to sp ecific scenarios, and they show difficul- ties in the presence of noise and when sev eral tra jectories cro ss each other. Most data a sso ciat io n tec hniques can b e significantly improv ed by p ost- p oning decisions un til enough info rmation is av ailable to exclude ambiguities [ 2 ], altho ugh this cause s t he num b er of p ossible tra jectories to grow exp o- 2 nen tially . Some attempts ha v e b een made to restrain this com binatorial explosion, including the heuristic metho ds from [ 10 , 11 ]. In this pap er w e presen t an algo r it hm based on Gaussian Pro cesse s that is able to consider all a v ailable data p oints in batch form whils t a v oiding the exp onen tial gro wth in p oten tial track s. As a result, it is capa ble to deal with difficult data a sso ciation problems in whic h tra jectories come v ery close and ev en cross eac h other. F urthermore, the algorithm do es not require any kno wledge ab out the mo del underlying the data, a nd it do es not need time instan ts to b e ev enly spaced, nor to contain observ ations fro m all sources. Gaussian Pro cesses (GPs) [ 12 ] are a p ow erful to ol for Ba y esian nonlin- ear regression. When com bined in mixture mo dels, GPs can b e applied to desc rib e data where there are lo cal non-statio na rities or disc ontin uities [ 13 , 14 , 15 , 16 ]. The compo nen ts of the mixture mo del ar e GPs and the prior probabilit y of an y give n comp o nent is typ ically pro vided b y a gating function. The role of the g ating function is to dictate whic h GP is a priori most lik ely to b e resp onsible for the data in an y give n region of the input space, i.e., the ga ting netw or k forces each comp onent of the G P mixture to b e lo calized. In this w ork w e follo w a differen t approach , inspired b y the data ass o cia- tion problem. In particular, for any giv en lo cation in input space there ma y b e m ultiple targets, p erhaps corresp onding to m ultiple o b jects in a trac king system. W e are in terested in constructing a GP mixture mo del that can asso ciate each of these targets with separate comp onen ts. When there is am biguit y , the p osterior distribution of targets will reflect this. W e therefore prop ose a sim ple mixture mo del in w hich eac h comp onen t is global in its scop e. The assignmen t of the data to each GP is p erfo rmed sample-wise, indep enden tly of input space lo calization. In other words , no g a ting function is used. W e call this mo del the Ov erlapping Mixture of GPs (OMGP). It ha s b een brought t o our attention that the prop osed mo del b ears re- sem blance with the w ork of [ 17 ]. Ho w ev er, t he fo cus of application is clearly differen t. In [ 17 ], the o b jectiv e is to cluster a set of tra jectories accord- ing to their similarit y , whereas in this w ork w e ta c kle the task o f clustering observ ations into tra jectories ( a more demanding ta sk, since only single ob- serv ations, as opp osed to full tra jectories, are av ailable). Also, [ 17 ] uses a standard v ariational Bay esian algorithm, whereas in this work w e take a d- v antage of non-standard v ariational algorithms [ 18 , 19 ] to deriv e a tighte r b ound. The remainder of this pa p er is organized as follows : In Section 2 we pro- 3 vide a brief review of GPs in the r egression setting. Section 3 first introduces the OMGP mo del and then discusses how to p erform efficien t learning, hy - p erparameter selection, and predictions using this mo del. Exp erimen ts on sev eral data sets are prov ided in Section 4 . W e wrap up in Section 5 with a brief discussion. 2. B rief R eview of Gaussian Pro cesses In recen t y ears, Gaussian Pro cesses (GPs) ha ve attracted a lot of atten tion due to their nice analytical prop erties and their state-of-the-art p erformance in regression tasks (see [ 20 ]). In this section w e prov ide a brief summary of the main results for GP regression, see [ 12 ] for further details. Assume that a set of N m ulti-dimensional inputs and t heir corresp onding scalar outputs, D ≡ { x n , y n } m i =1 , are a v ailable. The regression ta sk is, giv en a new input x ∗ , to obt a in the predictiv e distribution for the corresp onding observ ation y ∗ based on D . The GP regression mo del assumes that the observ ations can b e mo deled as some noiseless laten t function of the inputs plus indep enden t noise y = f ( x ) + ε , and then sets a zero-mean 1 GP prior on the laten t function f ( x ) ∼ G P (0 , k ( x , x ′ )) a nd a Gaussian prior on ε ∼ N ( 0 , σ 2 ) on the noise, where k ( x , x ′ ) is a co v ar ia nce function and σ 2 is a h yp erparameter that sp ecifies the noise p ow er. The co v aria nce function k ( x , x ′ ) sp ecifies t he degree of coupling b etw een y ( x ) and y ( x ′ ), and it enco des the pro p erties o f the G P suc h as p ow er lev el, smo othness, etc. One of the best-kno wn cov ariance functions is the anisotropic squared exp o nen tial. It has the f orm of an unnormalized Gaus- sian, k ( x , x ′ ) = σ 2 0 exp − 1 2 x ⊤ Λ − 1 x and dep ends on the signal p ow er σ 2 0 and the length-scales Λ , where Λ is a diag o nal matrix con taining one length- scale p er input dimension. Each length- scale con trols ho w fast the correlation b et w een outputs decay s as the separation along the corresp onding input di- mension grow s. W e will collectiv ely refer to all k ernel parameters as θ . The joint distribution of the a v a ila ble observ ations (collected in y ) and some unkno wn output y ( x ∗ ) is a m ultiv ar iate Ga ussian distribution, with 1 T o ma ke this assumption hold, the sample mean of the set { y ( x n ) } m n =1 is usually subtracted fro m data b efore pro ce e ding further . 4 parameters sp ecified by the co v ariance f unction: y y ∗ ∼ N 0 , K + σ 2 I N k ∗ k ⊤ ∗ k ∗∗ + σ 2 , (1) where [ K ] nn ′ = k ( x n , x n ′ ), [ k ∗ ] n = k ( x n , x ∗ ) and k ∗∗ = k ( x ∗ , x ∗ ). I N is used to denote the iden tit y ma t r ix of size N . The notation [ A ] nn ′ refers to en try at row n , column n ′ of A . Lik ewise , [ a ] n is used to reference the n - th elemen t of v ector a . F rom ( 1 ) a nd conditioning on the observ ed training outputs w e can obtain the predictiv e distribution p GP ( y ∗ | x ∗ , D ) = N ( y ∗ | µ GP ∗ , σ 2 GP ∗ ) (2) µ GP ∗ = k ⊤ ∗ ( K + σ 2 I N ) − 1 y σ 2 GP ∗ = σ 2 + k ∗∗ − k ⊤ ∗ ( K + σ 2 I N ) − 1 k ∗ , whic h is computable in O ( N 3 ) time, due to the in v ersion 2 of the N × N matrix K + σ 2 I N . Hyp erparameters { θ , σ } are typically selecte d by max imizing the marginal lik eliho o d ( a lso called “evidence”) of the o bserv ations, whic h is log p ( y | θ , σ ) = − 1 2 y ⊤ K + σ 2 I N − 1 y − 1 2 | K + σ 2 I N | − N 2 log(2 π ) . (3) If analytical deriv atives o f ( 3 ) a re a v a ila ble, optimization can b e carried out using gradient metho ds, with eac h gra dien t computation taking O ( N 3 ) time. G P algorithms can ty pically handle a f ew thousand da t a p oin ts on a desktop PC. When dealing with m ulti-output functions, instead of a single set of ob- serv ations y , D sets a r e av ailable, y 1 . . . y D , each corresp onding to a different output dimension. In this case w e can a ssume indep endence across the out- puts and p erform the ab ov e pro cedure indep endently for eac h dimension. This will pro vide reasonable results fo r most problems, but if correlation b e- t w een differen t dimensions is expected, w e can take adv a ntage o f this knowl- edge and mo del them jointly using m ulti-task cov ariance functions [ 21 ]. 2 Of cour se, in a practica l implemen tation, this inv ersion should never be p erformed explicitly , but throug h the use of the Chole s ky factorizatio n and the solutio n o f the corr e- sp onding linear systems, s e e [ 12 ]. 5 3. Overlappi ng Mixtures of Gaussian Pr o cesses (OMGP) The ov erlapping mixture of Gaussian pro cesse s (OMGP) mo del assumes that there exist M different laten t functions { f ( m ) ( x ) } M m =1 (whic h w e will call “tra jectories”), and that eac h output is pro duced by ev aluating one of these functions at the corresp onding input a nd b y adding Gaussian noise to it. The asso ciation b etw een samples and la t en t functions is determined b y the N × M binary indicator ma t r ix Z : En try [ Z ] nm b eing non-zero sp ecifies that n -th data p oint w as generated using tra jectory m . Only o ne non- zero en try p er row is allo w ed in Z . T o mo del m ulti-dimensional tra jectories (i.e., when the mixture mo del ha s m ultiple outputs), D laten t functions p er tra jectory can b e used { f ( m ) d ( x ) } M ,D m =1 ,d =1 . Note that t here is no need t o extend Z to sp ecifically handle the m ulti-o utput case, sinc e all the outputs corresp onding to a single input are the same data p oin t and mus t b elong to the same tr a jectory . F or con venie nce we will collect all the o utputs in a single matrix Y = [ y 1 . . . y D ] and all the latent functions of t r a jectory m in a single matrix F ( m ) = [ f ( m ) 1 . . . f ( m ) D ]. W e will refer to all the laten t functions a s { F ( m ) } . Giv en the a b o v e description, the lik eliho o d of the OMGP mo del is p ( Y |{ F ( m ) } , Z ) = N ,M , D Y n =1 ,m =1 ,d =1 N ([ Y ] nd | [ F ( m ) ] nd , σ 2 ) [ Z ] nm . (4) F ollowing the standard Ba y esian f ramew ork, w e place prio rs on the un- observ ed laten t v ariables p ( Z ) = N ,M Y n =1 ,m =1 [ Π ] [ Z ] nm nm , p ( F ( m ) | X ) = M ,D Y m =1 ,d =1 N ( f ( m ) d | 0 , K ( m ) ) , (5) i.e., a m ultinomial distribution ov er the indicators (in whic h P M m =1 [ Π ] nm = 1 ∀ n ) and indep enden t GP prio r s o v er eac h latent function. 3 W e allow differen t co v ariance matrices for eac h tra jectory . Though the m ultino mial distribution is specified here in its more general form, additional constraints 3 If correlation b etw een differen t t ra jectories is kno wn t o exist, tra jectories can b e jointly mo deled a s a sing le GP , using a cov ariance function that accounts for this dependence . This would increas e the computational complexity o f inference for this mo del, but the following deriv ations ca n still be applied. 6 are usually imp o sed, such as holding the prior probabilities constan t for all data p oin ts. F or the sak e of clarit y , we will omit the conditio ning on the h yp erparameters { θ , Π , σ 2 } , whic h can b e assumed to b e kno wn for the mo- men t. Unfortunately , the analytical computation of the posterior distribution p ( Z , { F ( m ) }| X , Y ) is in tractable, so we will resort to appro ximate techn iques. 3.1. V ari ational ap pr oxi mation If the hy p erpara meters are kno wn, it is p ossible to approximately com- pute the p osterior using a v ariational approx imation. W e can use Jensen’s inequalit y to construct a lo w er b ound on the marginal lik eliho o d as follows : log p ( Y | X ) = lo g Z p ( Y |{ F ( m ) } , Z ) p ( Z ) M Y m =1 p ( F ( m ) | X )d { F ( m ) } d Z (6) ≥ Z q ( { F ( m ) } , Z ) log p ( Y |{ F ( m ) } , Z ) p ( Z ) Q M m =1 p ( F ( m ) ) | X ) q ( { F ( m ) } , Z ) d { F ( m ) } d Z = L VB . Here L VB is a low er b ound on log p ( Y | X ) for any variational distribu- tion q ( { F ( m ) } , Z ) and equalit y is attained if a nd only if q ( { F ( m ) } , Z ) = p ( Z , { F ( m ) }| X , Y ). Our ob jectiv e is therefore to find a v a riational distri- bution that maximizes L VB , and th us b ecomes an approximation to the true p osterior. W e will restrict our searc h to v ariational distributions that facto r - ize as q ( { F ( m ) } , Z ) = q ( { F ( m ) } ) q ( Z ). If w e assume that q ( { F ( m ) } ) is giv en (and therefore, also t he marginals q ( f ( m ) d ) = N ( f ( m ) d | µ ( m ) d , Σ ( m ) ) ar e av ailable), it is p o ssible to ana lytically ma x- imize L VB with resp ect to q ( Z ) b y setting its deriv ativ e to zero and constrain- ing it to b e a probability densit y . The optimal q ( Z ) is then: q ( Z ) = N ,M Y n =1 ,m =1 [ ˆ Π ] [ Z ] nm nm with [ ˆ Π ] nm ∝ [ Π ] nm exp( a nm ) (7) with a nm = D X d =1 − 1 2 σ 2 ([ y d ] n − [ µ ( m ) d ] n ) 2 + [ Σ ( m ) ] nn − 1 2 log(2 π σ 2 ) , where we see that the (appro ximate) p osterior distribution ov er the indicators q ( Z ) factorizes f o r eac h sample. 7 Analogously , assuming q ( Z ) as kno wn, it is p ossible to analytically ob- tain the distribution o ve r the latent functions t hat maximizes L VB . F or the OMGP mo del, this distribution factorizes b oth o v er tra jectories and dimen- sions, and is giv en by q ( f ( m ) d ) = N ( f ( m ) d | µ ( m ) d , Σ ( m ) ) (8a) with Σ ( m ) = ( K − 1( m ) + B ( m ) ) − 1 and µ ( m ) d = Σ ( m ) B ( m ) y ( m ) d (8b) where B ( m ) is a diagonal matrix with elemen ts [ ˆ Π ] 1 m /σ 2 . . . [ ˆ Π ] N m /σ 2 . It is no w p ossible to initialize q ( Z ) and q ( f ( m ) d ) from their prior distribu- tions and iterate up dates ( 7 ) and ( 8 ) to obtain increasingly refined appro x- imations to the p osterior. Since b oth steps a re optimal with resp ect to the distribution that they compute, they are guarantee d to increase L VB , and therefore the algorithm is guaranteed to con v erge to a lo cal maxim um. Monotonous conv ergence can b e monitored by computing L VB after each up date. L VB can b e expresse d as L VB = D log p ( Y | { F ( m ) } , Z ) E q ( { F ( m ) } , Z ) − KL( q ( { F ( m ) } ) || p ( { F ( m ) } )) − KL( q ( Z ) || p ( Z )) where the first term is give n b y D log p ( Y | { F ( m ) } , Z ) E q ( { F ( m ) } , Z ) = N ,M X n,m [ ˆ Π ] nm a nm , and the tw o remaining terms are the Kullbac k-Leibler (KL) div ergences from the approximate p osterior to the prio r, whic h are straig h tforw ard to compute. Up date ( 7 ) tak es o nly O ( N M ) computation time, whereas ( 8 ) tak es O ( M N 3 ) time, due to the M matr ix in v ersions. The prese nted model there- fore has the same limita tions a s con v en tional GPs regarding the size of the data sets that it can be applied to. Ho w ev er, when t he p osterior probability of some indicato r [ ˆ Π ] nm is close to zero, sample n no long er affects tra jectory m and can b e dropp ed in its computation, thus reducing the cost. F urther- more, it is p ossible to use sparse GPs 4 to reduce this cost 5 to O ( M N ) time b y making use of the matr ix in v ersion lemma. 4 Such as the standard FITC approximation, desc r ib e d in [ 22 ] or the v aria tional ap- proach introduce d in [ 23 ]. 5 Obviously , the co st also depends on the quality of the approximation by a constant 8 3.2. A n impr ove d variational b ound fo r OMGP So far w e hav e assume d that all the h yp erparameters of the mo del are kno wn. How ev er, in practice, some pro cedure to select them is needed. The most straigh tforward w a y of achie ving this w ould b e to select them so as to maximize L VB , in terlea ving this pro cedure with up dates ( 7 ) and ( 8 ). Ho w- ev er, when the qualit y of this b ound is sensitiv e to c hanges of the mo del h yp erparameters, this approac h results in v ery slo w con v ergence. A solution to this problem is describ ed in [ 18 ] where the adv antages of maximizing an alternativ e, tig h ter b ound on the likelihoo d are sho wn. The improv ed b ound prop osed in [ 18 ] is still a low er b ound on the lik e- liho o d but it can b e pro ve d that it is also an upp er b ound on the standard v ariatio nal b ound L VB . As shown in [ 18 ], if w e subtract L VB from the im- pro v ed bo und, the result t a k es on the fo r m of a K L-div ergence. This fact can b e used b oth to sho w that it upp er-b ounds L VB (since K L-div ergences are alw a ys p ositiv e) and to name the new b ound, whic h is referred to as t he KL-corrected v a r ia tional b ound. The KL-corrected bo und for the OMGP mo del arises when the term log R p ( Y |{ F ( m ) } , Z ) p ( Z )d Z from the true marginal lik eliho o d ( 6 ) is replaced with R q ( Z ) log p ( Y | { F ( m ) } , Z ) p ( Z ) q ( Z ) d Z , whic h according t o Jensen’s inequalit y , constitutes a lo w er b ound for any distribution q ( Z ): log p ( Y | X ) ≥ log Z M Y m =1 p ( F ( m ) | X ) e R q ( Z ) log p ( Y |{ F ( m ) } , Z ) p ( Z ) q ( Z ) d Z d { F ( m ) } = L CorrVB = M ,D X m =1 ,d =1 log N ( y ( m ) d | 0 , K ( m ) + B − 1( m ) ) − KL( q ( Z ) || p ( Z )) + D 2 N ,M X n =1 ,m =1 log (2 π σ 2 ) 1 − [ ˆ Π ] nm [ ˆ Π ] nm . The KL-corrected low er b ound L CorrVB can b e computed a nalytically and has the adv a ntage with resp ect to L VB , of dep ending o nly o n q ( Z ) (and not q ( { F ( m ) } )), since it is p ossible to in tegrate Q M m =1 p ( F ( m ) | X ) out analytically . Bound L CorrVB can b e alternatively obtained by following the recent work in [ 19 ] and o ptima lly remov ing q ( { F ( m ) } ) from t he standard b o und. In the factor. If the FITC a ppr oximation with r pseudo-inputs (or other ra nk- r approximation) is used, the co mputational complexity could b e expresse d as O ( M N r 2 ). 9 con text of that work, L CorrVB is referred to as the “ma r ginalized v ariational b ound”, and it is made clear that L CorrVB corresp onds simply to L VB when, for a giv en q ( Z ), the optimal c hoice for q ( { F ( m ) } ) is made. In other words, for the same set of h yp erparameters and the same q ( Z ), if one choses q ( { F ( m ) } ) according to ( 8 ), b oth L VB and L CorrVB w ould prov ide the same result. Th us, learning is p erformed simply by optimizing L CorrVB with resp ect to q ( Z ) and the hyperparameters, iterating the fo llo wing t w o steps: • E-Step: Up dat es ( 7 ) and ( 8 ) are alternated, w hich monotonically in- crease b oth L VB and L CorrVB , un til con v ergence. Hyp erparameters are k ept fixed. • M-Step: Gradien t descen t o f L CorrVB with resp ect to all h yp erparame- ters is p erformed. Distribution q ( Z ) is k ept fixed. Note that it is in the M-step where L CorrVB b ecomes actually useful, since this impro v ed b ound remains more stable across differen t h yp erparameter selections, due to it not dep ending on q ( { F ( m ) } ), as demonstrated in [ 18 ]. Of course, an y strategy that maximizes L CorrVB is v alid, but w e hav e found the ab ov e EM pro cedure to w ork well in practice. Computing L CorrVB according to the pro vided express ion without incur- ring in num erical errors can b e c hallenging in practice, since sev eral in ve r- sions, which ma yb e unstable, are needed. Also, note that B ( m ) can take arbitrarily small v alues and th us direct inv ersion ma y not b e p ossible. An implemen tation-friendly expression where explicit inv erses are av oided is L CorrVB = M X m =1 − 1 2 D X d =1 || R ( m ) ⊤ \ ( B ( m ) 1 2 y ( m ) d ) || 2 − D N X n =1 log[ R ( m ) ] nn − KL( q ( Z ) || p ( Z )) − D 2 N ,M X n =1 ,m =1 [ ˆ Π ] nm log(2 π σ 2 ) , where R ( m ) = chol( I + B ( m ) 1 2 K ( m ) B ( m ) 1 2 ) and the bac kslash has the usual meaning of solution to a linear system. 6 6 Expressio ns o f the t yp e C \ c r efer to the solution of the linea r system Cx = c and ar e a numerically s table o per ation req uiring only O ( N 2 ) time when C is triang ular, which is the cas e her e. 10 3.3. Pr e dictive distributions The OMGP mo del can b e used fo r a v ariety of tasks. In the data asso- ciation problem (i.e., clustering data in to tra j ectories) the task at hand is to cluste r o bserv ations in to tra jectories, whic h can b e ac hiev ed by assign- ing eac h observ a t io n to the tra jectory that more lik ely generated it, i.e., to assign lab el m ∗ = arg max m [ ˆ Π ] nm to the n -th observ atio n, so no further computations a re necess ary . F or other tasks , how ev er, it can b e necessary to obtain predictiv e distributions o v er the output space at new lo cations. Under the v ariatio nal approximation, this predictiv e distributions can b e computed analytically . The predictiv e distribution in t he o utput dimension d corresp onding to a new test input lo catio n x ∗ can b e expressed as p ( y ∗ d | x ∗ , X , Y ) = M X m =1 [ Π ] ∗ m Z p ( y ∗ d | f ( m ) d , x ∗ , X ) p ( f ( m ) d | X , Y )d f ( m ) d ≈ M X m =1 [ Π ] ∗ m Z p ( y ∗ d | f ( m ) d , x ∗ , X ) q ( f ( m ) d | X , Y )d f ( m ) d = M X m =1 [ Π ] ∗ m N ( y ∗ d | µ ( m ) ∗ d , σ 2( m ) ∗ d ) with µ ( m ) ∗ d = k ⊤ ( m ) ∗ ( K ( m ) + B ( m ) − 1 ) − 1 y d , σ 2( m ) ∗ d = σ 2 + k ∗∗ − k ⊤ ( m ) ∗ ( K ( m ) + B ( m ) − 1 ) − 1 k ( m ) ∗ , i.e., a Gaussian mixture under the appro ximate p osterior. The mixing fac- tors [ Π ] ∗ m are the prior probabilities of eac h comp o nent, one of t he giv en h yp erparameters of the mo del, and t ypically constan t for all inputs. Note the correspo ndence of these predictiv e equations with the standard predictions for GP regression ( 2 ). The only difference is the noise compo- nen t, whic h is scaled for eac h sample according to [ ˆ Π ] − 1 nm . In particular, as the p osterior probability of a sample b elonging to the curren t tra jectory ( some- times kno wn as “resp onsibilit y”) deca ys, the amoun t of noise asso ciated t o that sample is prop ortio nally gro wn, th us reducing its effect on the p osterior pro cess. 11 Due to the reasons men t ioned in the previous subsection, the predic- tiv e equations should not be implemen ted directly . I nstead, the follo wing n umerically-stable express ions should b e used: µ ( m ) ∗ d = k ⊤ ( m ) ∗ B ( m ) 1 2 ( R ( m ) \ ( R ( m ) ⊤ \ ( B ( m ) 1 2 y ( m ) d ))) , σ 2( m ) ∗ d = σ 2 + k ∗∗ − || R ( m ) ⊤ \ ( B ( m ) 1 2 k ⊤ ( m ) ∗ ) || 2 . 3.4. Batch v ersus online op e r ation Though the description of OMGP is orien ted tow a r ds batc h data asso ci- ation tasks, this mo del can also b e successfully applied to online tasks, b y using a data set that gro ws o v er t ime. New sample s are included as t hey arriv e and the learning pro cess is re-started, initializing it from the state that w as obtained as a solution f or the previous problem. Dep ending on the constrain ts of a giv en problem, man y differen t optimizations can b e made to a v oid an explosion in computational effort, suc h as using low-rank upda t es. Note, ho w ev er, that since in this model all the elemen ts in each laten t function fo rm a fully connected graph, the Marko vian prop ert y do es not hold and the computation time required for eac h up date is no t constan t. A p ossible work around to a chiev e constan t-time up dates is to use c onstat- size data sets, for instance corresp onding to a sliding window, and then p erform low-rank upda t es to include a nd remo ve samples. How eve r, w e will not pursue that option in this work. 4. E xp erimen ts In this section we in v estigate the b ehavior o f OMGP b oth in data asso- ciation tasks and regression tasks, sho wing the v ersatilit y o f this model. W e use an implemen tation o f OMGP in Matlab on a 3GHz, dual- core desktop PC with 4GB of memory , yielding executions t imes of the or der of seconds for eac h exp erimen t. 4.1. Data as so cia tion tasks 4.1.1. T oy data W e first apply OMGP to p erform data asso ciation on a toy data set. The sources p erform circular motions, one clo c kwise and one coun terclo c kwise, as depicted in Fig. 2 (a). The av ailable observ atio ns represen t the measured p ositions of the sources (whic h include Gaussian noise) at know n time in- stan ts. Ho w ev er, it is no t kno wn whic h observ ed p osition corresp onds to 12 whic h source. Since b oth tra j ectories ar e circles with the same cen ter and radius, the sources cross each o ther t wice p er rev olution, making the cluster- ing problem more difficult. Ho w ev er, as show n in Fig . 2 (b), OMGP is capable of success fully iden tifying the unkno wn tra j ectories. Fig . 2 (c) illustrates the uncertain t y ab out the estimated lab els. Sp ecifically , it sho ws a decrease in the p o sterior probability of the correct lab els whenev er the t w o sources come close. 0 200 −2 0 2 −2 0 2 time source 1 source 2 (a) Observed rota ting s o urces. 0 200 −2 0 2 −2 0 2 time (b) I de ntified tra jecto r ies in time. 0 20 40 60 80 100 120 140 160 180 200 0 0.5 1 ˆ Π n 1 0 20 40 60 80 100 120 140 160 180 200 0 0.5 1 ˆ Π n 2 (c) Posterior probability of cor rect lab els. Figure 2: (a) Obser v a tions for tw o so urces that mov e in opp osite circle s. (b) The da ta asso ciatio n solution obtained by OMGP . (c) Posterior pro bability of the corr e c t lab el for observ ations coming from sour c e 1 (top) and 2 (bottom). 4.1.2. Missile-to-air multi-tar get tr acking Next, w e conside r a miss ile-to- air trac king scenario as des crib ed in [ 7 ]. The motion dynamics of this scenario a re defined by the following state- 13 space equations: s t +1 = I 3 T I 3 O 3 I 3 s t + T 2 2 I 3 T I 3 v t ; r t = h ( s t ) = p X 2 t + Y 2 t + Z 2 t arctan( Y t X t ) arctan( − Z t √ X 2 t + Y 2 t ) + e t . In this mo del, the state v ector s t = [ X t , Y t , Z t , V x,t , V y ,t , V z ,t ] con tains the source p osition and v elo cit y comp onen ts, r t con tains the observ ed measure- men ts, T is the sampling in terv al, and I 3 and O 3 represen t the 3 × 3 unit y matrix and n ull matrix, respectiv ely . The process noise v t and measuremen t noise e t are assumed Gaussian, v t ∈ N (0 , Q ) and e t ∈ N (0 , R ). F or more details refer to [ 7 ]. The problem p osed in [ 7 ] consis ts in tra cking t w o sources and estimating their unkno wn state ve ctor, giv en their correct initial states s 1 0 = [6500 , − 1000 , 2000 , − 50 , 10 0 , 0] and s 2 0 = [5050 , − 450 , 2000 , 100 , 5 0 , 0]. W e consider a more complex scenario b y a dding a third source, with initial state s 3 0 = [8000 , 5 00 , 2000 , − 100 , 0 , 0], whic h passes close to one of the other sources at a certain instant. W e apply the SIR/ MCJPD A filter from [ 7 ] and OMGP to p erform data asso ciation on the o bserv ations. The SIR/MCJPDA filter consists of a set o f join t part icle filters that p erform tracking o f multiple sources, com bined with a j oin t probability data asso ciatio n (JPD A) tec hnique whic h provide s instan- taneous data asso ciatio n. T he n um b er of particles used in this exp eriment is 25000. In order to op erate correctly , the SIR/MCJPD A filter requires com- plete kno wledge of the used state-space mo del a nd the initial state v ectors x i 0 . Note that OMGP is completely blind in this regard. The OMGP algorithm is op erated first in its incremen tal online setting. F or illustration purp oses, w e also include results o f the batc h v ersion of the OMGP algorithm. The tra jectories o btained b y each metho d can b e fo und in Fig. 3 , along with the predicted measuremen ts. Although the SIR/MCJPDA filter initia lly p erforms cor r ectly , it encoun ters difficulties at the p oint where the sources come close. After this p oint it sho ws erroneous assignmen ts for at least o ne tra jectory . Its mistak es are mainly due to its s tate v ector dep ending only on 1 pr evious state, whic h pro v es insufficien t if t he sources are close during m ultiple consecutiv e measuremen ts. The online v ersion of OMGP do es not sho w this problem. The smo othest solution is obtained b y batc h OMGP , whic h p erfor ms a glo bal ev aluation o f the entire tra jectories. T o ev aluate the p erformance of the a lg orithms, w e measure the RMSE of eac h tra jectory . These v a lues can be found in T able 1 , along with the 14 5000 5500 6000 6500 7000 7500 8000 8500 9000 −0.2 −0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 x y (a) T ra jectories iden tified by SIR/MCJPDA. 5000 5500 6000 6500 7000 7500 8000 8500 9000 −0.2 −0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 x y (b) T ra jector ies identified by OMGP , in- cremental o nline version. 5000 5500 6000 6500 7000 7500 8000 8500 9000 −0.2 −0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 x y (c) T ra jecto ries iden tified by OMGP , batch solution. Figure 3 : Missile-to-air data a s so ciation pro blem with three sources. The starting p oint of each source is marked with a black dot. n um b er of observ a tions t ha t are assigned to the wrong tra jectories, n er r , out of a total of 9 0 observ at ions. As can b e observ ed, b oth v ersions of the OMGP algorithm obtain sup erio r results compared to SIR/MCJP A. F urthermore, while SIR/MCJPD A requires complete knowledge o f the state-space mo del and the initial state v ectors, OMGP do es not require an y kno wledge of the underlying mo del. 4.1.3. Interfer enc e alignment in OFDM wir eless network s In terestingly , the data asso ciation problem can be found in contexts that go b ey ond standard m ulti-target track ing scenarios, suc h as digital commu- nications [ 24 ]. In the third exp erimen t w e apply OMGP to a data asso ciation problem that o ccurs in wireles s comm unication net w orks. 15 T able 1: RMSE co mparison on the missile- to -air data asso ciation pro blem. Algorithm RMSE #1 RMSE #2 RMSE #3 n er r SIR/MCJPD A 292.46 150.07 258.14 17 OMGP (online) 182.31 151.46 163.92 6 OMGP (batc h) 133.30 80.23 118.94 1 In terference alignmen t (IA) is a concept that has recen tly emerged as a solution to raise the capacity of wireless multiple-input m ultiple-output (MIMO) net w orks [ 25 ]. The underlying idea of IA along the spatial dimen- sions is t ha t the in terference from o ther transmitters m ust b e alig ned at each receiv er in a subspace orthogonal to t he signal space. In order to implemen t in terference alignment in scenarios with m ultiple sub carriers, a digital filter m ust b e applied at eac h transmit a n tenna. Here we will consider a 3-user in terference c hannel with t w o antennas p er no de and OFDM mo dulation using N c sub carriers [ 26 ], whic h allows for tw o p ossible filter resp onses p er sub carrier. Since o nly smo oth frequency r esp onses can b e implemen ted, the smo othest solution of the 2 N c p ossible c hoices should b e selected. This com binato rial problem corresp onds to a data associatio n problem in which only the smo othest curv e is o f intere st. (see Fig. 4 (a)). The data used for this exp eriment consists of t w o simulated dat a sets and one data set obtained with a MIMO test b ed setup 7 , eac h using 52 sub carriers. In Fig . 4 w e illustrate the solutions obtained by OMGP o n these data sets. While the sim ula ted data sets from F ig. 4 (b) and Fig. 4 (c) represen t reasonably simple data asso ciation problems, the performance of OMGP on the real- w orld data set of Fig. 4 (d) sho ws t hat it is capable of correctly distinguishing the smo othly-v ar ying solution from the surrounding noisy dat a . As a matter of fact, w e hav e b een a ble to successfully implemen t OMGP in the IA setting for a parallel ungoing researc h pro ject. 4.2. R e gr es sion task s W e no w consider application of the mo del in more standard regres sion tasks. In part icular, w e consider tasks where the target density is multimodal, whic h is the case when the dat a comes from m ultiple sources. 7 See [ 2 7 ] for a full de s cription of the used test bed. 16 0 10 20 30 40 50 60 −40 −30 −20 −10 0 10 carrier (a) 0 20 40 60 −40 −30 −20 −10 0 10 −20 0 20 40 carrier (b) 0 20 40 60 −20 −10 0 10 20 −20 −10 0 10 carrier (c) 0 20 40 60 −100 −50 0 50 100 −100 −50 0 50 100 carrier (d) Figure 4 : Data asso ciation results obta ine d by OMGP on different interference a lignment problems. (a) shows the IA solutions (imagina ry part only) for the first simulated data set. (b) and (c) show the so lutions for the firs t and seco nd simulated data sets (rea l a nd imaginary part versus sub car rier num b er). (d) shows the IA solution for a rea l-world data set. Note that c o mplex v alues are simply simply treated a s tw o-dimensional real data in this exp er imen t. 4.2.1. Multilevel r e gr ession Consider the data set from Fig. 5 (a), whic h corresp onds to observ ations from three independen t functions. A normal GP would fail to pro duce v alid m ultimo dal outputs and previously prop osed mixture s of GPs w ould restrict the comp onen t G Ps to lo cal parts of the space. OMGP can prop erly lab el eac h observ atio n according to the generating function and prov ide multi- mo dal predictiv e distributions, as depicted in F ig . 5 (b). Fig. 5 can also b e in terpreted as measuremen ts of the p osition of three particles mo ving along one dimension, of whic h snaps hots are tak en at irreg- ular time in terv als (horizontal axis). Each snapshot in tro duces noise in the p osition measuremen t a nd do es not necessarily capture the p osition of all the 17 0 5 10 15 20 25 30 35 40 45 50 −4 −3 −2 −1 0 1 2 3 4 x y (a) O r iginal data s et. x y 5 10 15 20 25 30 35 40 45 −4 −3 −2 −1 0 1 2 3 4 (b) Inferred lab els and predictive log- probs. Figure 5: Posterior log- probability of the OMGP mo del and lab el inference. particles. In this case OMGP could b e used to predict the p osition of an y particle at a ny giv en p oin t in time, as w ell as to prop erly lab el the samples in eac h snapshot. 4.2.2. R obust r e g r essio n Since each GP in the mixture can use a differen t cov ariance function, it is p ossible to use a GP to capture unrelated outliers a nd ano ther one to in terp olate the ma in function. This is easily achiev ed b y a mixture of tw o GPs, one with the ARD-SE co v ariance function and another with k ( x, x ′ ) = b 2 δ ( x, x ′ ), i.e., white noise. W e consider the problem of regress ion in a noisy sinc in whic h some o utliers ha v e b een intro duced in Fig. 6 (top row). Observ e ho w OMGP b oth identifie s the outliers and ignores them, resulting in muc h b etter predictiv e means and v ar ia nces. 4.2.3. Heter osc e dastic b ehavior Finally , Fig. 6 (b ott o m ro w) shows the results o f running a GP and OMGP on the motorcycle dat a set from [ 28 ]. Tw o comp onen ts ha ve b een iden tified, whic h migh t or migh t not corresp ond to t w o actual phy sical mec hanisms al- ternativ ely pro ducing observ ations. The predictiv e v ariances sho w impro v ed b eha vior with resp ect to the standard GP . 18 −5 0 5 −1 −0.5 0 0.5 1 1.5 2 x y (a) Nois y sinc. Sta nda rd GP −5 0 5 −1 −0.5 0 0.5 1 1.5 2 x y (b) Noisy sinc. OMGP 0 10 20 30 40 50 60 −200 −150 −100 −50 0 50 100 150 x y (c) Motorcycle. Standa rd GP 0 10 20 30 40 50 60 −200 −150 −100 −50 0 50 100 150 x y (d) Motor cycle. O MGP Figure 6: Pre dictive means a nd v ariances for t wo different da ta s ets. The shaded area denotes ± 2 standard deviations a round the mean. T op r ow: Noisy sinc with o utliers. (a) Standard GP and (b) OMGP with a noise-only co mpo ne nt. (Only the predictive mean and v aria nce of the signal comp onent is de picted, whic h includes noise σ 2 ). Bottom row: Silverman’s motor cycle data set. 5. Discussion and future w ork In this w ork we ha v e introduced a no ve l G P mixture mo del inspired by m ulti-target track ing problems. The new mo del ha s the imp ortant difference with respect to previous approaches of using global mixture comp onents and assigning samples to comp onen ts b y relying on their v alue in output space, instead of input space (as it is done when gating functions are used). A simple and efficien t algorithm for inference relying on the v ariational Ba y esian framew ork has b een pro vided. The mo del can b e applied in prac- tice due to the use of an improv ed, KL- corrected v a riational b ound to learn 19 the h yp erparameters. Direct optimization o f this b ound b oth to obtain a n appro ximate p osterior and to learn the h yp erparameters will b e considered in a further w ork. The OMGP mo del offers promising results when tra cking movin g targets, as has b een illustrated exp erimen tally in Section 4 and compares fa v orably with established methods in the field. Also, through imaginat iv e applicatio n of t he mo del using differen t cov ariance functions w e were able to adapt the approac h to robust regression and heteroscedastic noise. Naiv e implemen tation of GPs limits t heir applicability to only a few thou- sand dat a samples. Ho w ev er, r ecen t adv ances in sparse approximations (e.g. [ 22 , 2 3 ]) greatly should enable our approac h to b e a pplied to m uch lar ger data sets. 6. A c kno wledgmen ts The autho r s wish to thank Oscar Gonz´ alez, Univ ersit y of Can tabria, for pro viding the da t a used in t he interferenc e alignmen t exp erimen t. The first and second authors w ere supp orted b y MICINN (Spa nish Ministry for Sci- ence a nd Innov ation) under grants TEC2010-19545- C04-03 (COSIMA) and CONSOLIDER-INGENIO 2010 CSD2008 - 00010 (COMONSENS). Addition- ally , funding to supp ort part o f t his collab o rativ e effo r t was pro vided by P ASCAL’s Internal Visiting Programme. References [1] Y. Bar-Shalom, T rac king and data asso ciation, Academic Press Profes- sional, Inc. San Diego, CA, USA, 1987. [2] I. J. Co x, A review of statistical data associatio n t echniq ues f or motion corresp ondence, In ternational Journa l of Computer Vision 1 0 (1993) 53–66. [3] S. Ullman, The in terpretation of visual motion, M.I.T. Press, Cam- bridge, MA, USA, 19 7 9. [4] J. Singh, U. Madho w, S. Suri, R. Cagley , Multiple target trac king with binary proxim ity sensors, A CM T ransactions on sensor netw orks (ac- cepted for publication). 20 [5] T. F o r tmann, Y. Bar- Shalom, M. Sc heffe, Sonar tra cking o f m ultiple tar- gets using joint probabilistic data a sso ciat io n, IEEE Journal of Oceanic Engineering 8 (1983) 17 3 – 184. [6] D . Reid, An algorithm for track ing m ultiple targets, Automatic Con trol, IEEE T ransactions on 24 (1979 ) 843 – 854. [7] R . Karlsson, F. Gustafsson, Monte Carlo data association for m ulti- ple target tr ac king, IEEE In ternational Seminar on T arget T rac king: Algorithms and Applications 1 (2001) 13. [8] D . Chetv erik o v, J. V erest´ oi, F eature p o in t trac king for incomplete tra- jectories, Computing 62 (1999 ) 321–338. [9] C. V eenman, M. Reinders, E. Bac k er, R esolving motion corresp ondence for dense ly mo ving p oints, IEEE T ransactions on P attern Analysis and Mac hine In telligence 23 (2001) 54 – 72. [10] V. Nagara jan, M. Chidam bara, R. Sharma, Combinatorial problems in m ultitarget track ing - a comprehe nsiv e solution, IEE Pro ceedings-F: Comm unications, Radar and Signal Pro cessing 134 (1 987) 113 –118. [11] I. Co x, S. Hingorani, An efficien t implemen tation of r eid’s m ultiple hy- p othesis trackin g algorithm and its ev a lua tion for the purp ose of visual trac king, IEEE T ransactions on P attern Analysis and Mac hine Inte lli- gence 18 (1996) 138 –150 . [12] C. E. Rasm ussen, C. K. I. Williams , Gaussian Pro cesses for Mac hine Learning, MIT Press, 200 6. [13] V. T resp, A Bay esian committee mac hine, Neural Computation 12 (2000) 2719– 2741. [14] C. E. Rasmus sen, Z. Ghahramani, Infinite mixtures of Ga ussian pro cess exp erts, in: Adv ances in Neural Information Pro cessing Systems 14, MIT Press, 2002, pp. 88 1 –888. [15] E. Meeds, S. Osindero, An alternativ e infinite mixture of Gaussian pro cess exp erts, in: Adv a nces in Neural Infor ma t ion Pro cessing Systems 18, MIT Press, 2006, pp. 88 3–890. 21 [16] C. Y uan, C. Neubauer, V aria t io nal mixture of Gaussian pro cess exp erts, in: Adv ances in Neural Information Pro cessing Sys tems 21, 2009, pp. 1897–190 4. [17] C. T ay , C. Laugier, Modelling smo o th paths using Gaussian pro cesses, in: In ternational Conference o n Field and Service Rob otics, 2007, pp. 381–390. [18] N. J. King, N. Law rence, F a st v ariatio nal inference for Gaussian pro cess mo dels through KL-correction, in: ECML, Lecture Notes in Computer Science, Berlin, 2006 , pp. 270–281. [19] M. L´ azaro-Gredilla, M. Titsias, V ariational heteroscedastic Gaussian pro cess regression, in: 2 8 th In ternational Conference on Mac hine Learn- ing, Omnipress, Bellevue, W A, USA, 2011, pp. 84 1 –848. [20] C. E. Rasm ussen, Ev aluatio n o f Gaussian Pro cesses and other Metho ds for Non-linear Regression, Ph.D . thesis, Univ ersit y of T oronto, 1996. [21] E. V. Bonilla, K. M. A. Chai, C. K. I. Williams, Multi-task Ga ussian pro cess prediction, in: Adv ances Neural Information Pro cessing Systems 20, pp. 153–16 0 . [22] E. Snelson, Z. G ha hramani, Sparse Gaussian pro cesse s using pseudo- inputs, in: Adv ances in Neural Information Pro cessing Systems 18, MIT Press, 2006 , pp. 1259–126 6 . [23] M. K. Titsias, V a riational learning of inducing v a r iables in sparse Ga us- sian pro cesses, in: Pro ceedings of the 12th International W orkshop on AI Stats, pp. 567– 574. [24] S. V an V aeren b ergh, I. San tamaria, P . Barba no, U. Ozertem, D. Er- dogm us, P ath-based sp ectral clustering for deco ding fast time-v a r ying MIMO channels , in: IEEE In ternational W orkshop o n Mac hine Learn- ing for Signal Pro cessing, IEEE, pp. 1–6. [25] V. R. Cadambe, S. A. Jafar, Interfere nce alignmen t and degrees of freedom of the K- user in terference c hannel, IEEE T r a nsactions on In- formation Theory 54 (200 8) 3425 –3441. [26] J. Proakis, Digital Comm unications, McGra w-Hill, 199 5 . 22 [27] J. Guti´ errez, ´ O. Gonz´ alez, J. P ´ erez, D. Ram ´ ırez, L. Vielv a, J. Ib´ a ˜ nez, I. San tamar ´ ıa, F requency-domain metho dology f or measuring MIMO c hannels using a generic test b ed, IEEE T ra nsactions on Instrumen tation and Measuremen t 6 0 (2011) 827–8 3 8. [28] B. W. Silv erman, Some aspects of the spline smo othing approach to non-parametric regression curv e fitting, Journal o f the Ro y al Statistical So ciet y 4 7 (1985) 1–52. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment