High Performance Gravitational N-body Simulations on a Planet-wide Distributed Supercomputer
We report on the performance of our cold-dark matter cosmological N-body simulation which was carried out concurrently using supercomputers across the globe. We ran simulations on 60 to 750 cores distributed over a variety of supercomputers in Amster…
Authors: Derek Groen (Leiden University), Simon Portegies Zwart (Leiden University), Tomoaki Ishiyama (NAOJ
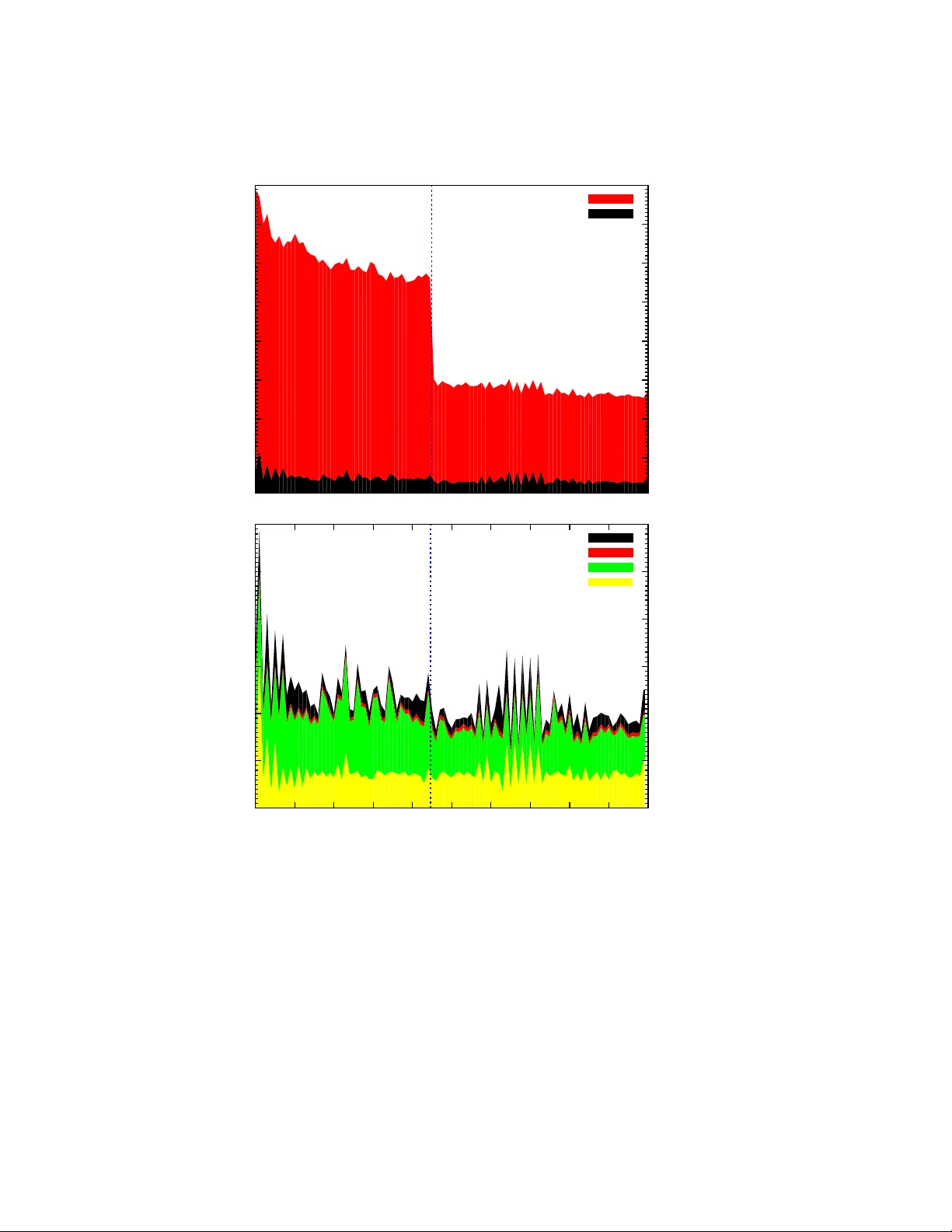
High P erformance Gra vitational N -b o dy Sim ulations on a Planet-wide Distributed Sup ercomputer Derek Gro en 1 , Simon P ortegies Zwart 1 , T omoaki Ishiy ama 2 , Jun Makino 2 1 Leiden Observ atory , Leiden Universit y , P .O. Box 9513, 2300 RA Leiden, The Netherlands 2 National Astronomical Observ atory , Mitak a, T oky o 181-8588, Japan E-mail: djgroen@strw.leidenuniv.nl High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 2 Abstract. W e rep ort on the p erformance of our cold-dark matter cosmological N -bo dy simulation whic h was carried out concurrently using sup ercomputers across the globe. W e ran sim ulations on 60 to 750 cores distributed ov er a v ariet y of supercomputers in Amsterdam (the Netherlands, Europ e), in T oky o (Japan, Asia), Edinburgh (UK, Europe) and Esp oo (Finland, Europe). Regardless the netw ork latency of 0.32 seconds and the communication ov er 30.000 km of optical netw ork cable we are able to achieve ∼ 87% of the p erformance compared to an equal num ber of cores on a single sup ercomputer. W e argue that using widely distributed sup ercomputers in order to acquire more compute p o wer is technically feasible, and that the largest obstacle is in tro duced b y local scheduling and reserv ation policies. 1. In tro duction Some applications for large scale sim ulations require a large amoun t of compute p o w er. This is often hard to acquire on a single mac hine. Com bining m ultiple sup ercomputers to do one large calculation can lift this limitation, but such wide area computing is only suitable for certain algorithms. And even then the p olitical issues, like arranging the net work, acquiring the compute time, making reserv ations, sc heduling run time and sync hronizing the run start, and tec hnical limitations are profound. Earlier attempts based on interconnecting PC clusters were quite successful [1, 2, 3, 4, 5], but lack ed the raw supercomputer p erformance required for our application. Running simulations across m ultiple sup ercomputers has b een done a few times b efore [6, 7, 8, 9], though the p erformance of simulations across three or more sup ercomputers has not y et b een measured in detail. Here we rep ort on the p erformance of our parallel astronomical simulations which use up to 4 supercomputers and predict the p erformance for simulations whic h use 5 or more sup ercomputers. In our exp erimen ts we use an in ternational infrastructure of supercomputers. These mac hines include an IBM Po wer6 supercomputer lo cated at SARA in Amsterdam (the Netherlands) and three Cray XT-4 sup ercomputers lo cated at the Edin burgh P arallel Computing Cen tre in Edin burgh (United Kingdom), the IT Cen ter for Science in Esp o o (Finland) and the Center F or Computational Astrophysics in T okyo (Japan). The Edin burgh site is equipped with a 1 Gbps in terface while the other three sites are equipp ed with a 10 Gbps interface. W e achiev ed a p eak p erformance of 0.610 TFLOP/s and a sustained p erformance of 0.375 TFLOP/s using 120 cores distributed o ver 4 sites. T o provide a comparison with the in ternational tests we also run the co de ov er up to 5 sites on a Dutch grid of PC clusters. Our wide area sim ulations are realized with the developmen t of a soft ware environmen t for Simulating the Universe Structure formation on Heterogeneous Infrastructures, or SUSHI for short. 2. Ov erview of SUSHI Our code is based on the GreeM cosmological N -bo dy in tegrator, which w as originally dev elop ed for special-purp ose GRAPE hardw are [10]. The co de integrates the equations of motion for dark matter particles using a shared and adaptive time step scheme and a T ree/Particle-Mesh (T reePM) force calculation metho d [11] whic h assumes p eriodic b oundary conditions. The short range force interactions are resolv ed High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 3 using a Barnes-Hut tree algorithm [12] while the long range in teractions are resolv ed using a Particle Mesh (PM) algorithm [13]. The tree integration metho d places particles in a three-dimensional sparse o ctree structure, where eac h cell con tains the center of mass and the mass aggregate of the particles therein. The metho d then resolves long range force in teractions using particles and tree cells instead of using direct particle-particle ev aluation. The accuracy of the tree integration metho d can b e tuned b y changing the op ening angle ( θ ), which determines how small and distant a group of particles needs to be to use the appro ximate particle-tree cell ev aluation. A higher v alue for θ results in few er particle-particle ev aluations, and a low er accuracy of the simulation. P article in tegration using a tree algorithm is more compute-intensiv e than in tegration using a PM algorithm, but we sp eed up the calculations b y a factor ∼ 8 using vector-math co de optimizations for both the x86 [14] and P ow er6 arc hitectures. The PM algorithm maps the particles to a grid of mesh cells and calculates the gravitational p oten tial using the FFTW F ast F ourier T ransform [15]. It accurately calculates the forces of long distance interactions, but is less accurate in computing forces o v er short distances, for which the tree algorithm is applied instead. The co de has b een mo dified to allo w simulations on massiv ely parallel machines [16], in which the code uses a recursive m ulti-section sc heme [17] to divide the workload o ver the pro cesses. The workload is redistributed during eac h step of the simulation so that the force calculation time remains equal for all pro cesses. 2.1. Par al lelization acr oss sup er c omputers W e ha ve dev elop ed SUSHI to efficiently use multiple sup ercomputers for our sim ulations. W e coupled the T reePM co de with the MPWide comm unication library [18] and developed a cross-sup ercomputer parallelization scheme. Because the wide area netw ork has p erformance and top ological characteristics that are different from lo cal net works, the communication sc heme b et w een sites is different from the scheme used b et ween no des. When SUSHI is deploy ed across sites, eac h site is connected to t wo neigh b oring sites to form a ring top ology . 2.1.1. Communic ation scheme. A simulation using SUSHI consists of four comm unication phases p er step. During these phases the sim ulation: (i) Exchanges mesh densities. (ii) Collects sample particles to determine the site b oundaries, (iii) Exchanges tree structures with neighboring sites. (iv) Migrates particles b et ween neigh b oring sites. When exchanging mesh densities, the mesh cells from all sites are aggregated to obtain the global mesh density . This mesh density is then used to p erform PM in tegration. In the co de w e ha ve used here the PM integration is still a serial op eration, though the time sp en t on PM in tegration in our exp eriments is only a small fraction of the total runtime. Ho wev er, to support larger meshes efficiently we will introduce parallelized PM integration in a later v ersion of the co de. The mesh densities are gathered using a ring communication ov er all sites. The force calculation time and time step information of each site are also accumulated during this phase. A t each step the site b oundaries are up dated, based on the obtained force calculation times and the current particle distribution. T o gain information on the High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 4 particle distribution, the comm unication processes on eac h site gather sample particles from all other pro cesses. These sampled particles are then gathered from all sites using a ring communication. Before the tree force calculations can b e p erformed, each site constructs a lo cal essen tial tree structure. This lo cal essential tree is a set of particles and tree cells whic h are used to compute the force exc hanges, and partially resides on neighboring sites. T o obtain a complete lo cal essen tial tree, each site therefore requires the missing tree data from its neigh b ors. The sim ulation gathers the tree data using one neigh b or exc hange for tw o site runs, or tw o exchanges for runs across three or more sites. After the force calculations hav e b een performed, the simulation up dates the p ositions of all particles. At this p oin t, some particles ma y b e lo cated outside the site b oundaries and need to b e migrated to a neighboring site. This communication requires one neighbor exchange for tw o site runs, or tw o exchanges for runs across three or more sites. 2.1.2. Domain de c omp osition. W e hav e implemented a hierarchical decomp osition sc heme to distribute the particles among sup ercomputers. This scheme uses a one- dimensional slab decomposition to distribute the particles among the sites, and a recursiv e multi-section sc heme o ver three dimensions to distribute the particles among the pro cesses. Because the domain decomp osition b et w een sites is one-dimensional, eac h sup ercomputer only exchanges particles and tree structures with t wo other mac hines. The data exchanges b et ween sites can therefore b e done efficiently in a ring top ology . Most sup ercomputers are connected b y optical paths in either a ring or star top ology , if they are connected at all. The sim ulation adjusts the distribution of particles among sup ercomputers at run-time, such that the force calculation time is k ept equal on all sites. The num b er of particles N i on a single site i for a run p erformed o ver s sites is therefore given b y N i ∼ N ( t calc , i ) − 1 P i ∼ 0 . 75. In these regimes, the num ber of in teractions dep ends more strongly on other tree integration settings, such as the maximum n umber of particles allow ed to share interaction lists. W e calculate the time sp en t on PM integration ( t pm ) b y adding the time sp en t on the F ast F ourier T ransform (FFT) to the time sp en t on mesh operations such as interpolating the mesh v alues and setting the mesh forces on e ac h particle. The FFT requires O ( M log 2 M )) FFT operations [15], eac h of whic h requires ( τ fft ) seconds. The time required for mesh operations scales with the lo cal n umber of particles ( N/p ), where the time required p er particle is equal to the mac hine-sp ecific constant τ mesh . The total time sp en t on PM integration then b ecomes t pm = τ fft M log 2 M + τ mesh N p . (5) W e decomp ose the communication time ( t comm ) into time sp ent to initially tra verse the netw orks ( t l ), which is latency-b ound and time sp en t on data throughput ( t b ), which is limited by the av ailable bandwidth of the lo cal netw ork. Therefore, t comm = t l + t b . (6) F or each step, the co de p erforms 18 collectiv e operations containing log p comm unication steps and t wo all-to-all comm unications with p comm unication steps. The time sp en t in latency ( t l ) is calculated by m ultiplying the num b er of comm unication steps with the netw ork round-trip time ( λ lan ). As a result, t l = λ lan (18 log p + 2 p ) , (7) W e determine the time sp en t on data throughput ( t b ) by dividing the data v olume of the lo cal area communications b y the netw ork bandwidth ( σ lan ). The comm unication data v olume consists of three dominan t parts. These are the mesh cells residing at other pro cesses (whic h is at most 4 M b ytes in total), the local essen tial tree structures (estimated to b e (48 /θ + 24) N 2 / 3 p − 2 / 3 b ytes for 0 . 2 < ∼ θ < ∼ 0 . 75), and the sample particles which are used to determine the no de b oundaries (12 N r samp b ytes in total). Here, r samp , whic h we set to 1 / 10000 for large calculations, is the ratio of sampled particles relative to N . The time sp en t on data throughput is then High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 7 t b = 4 M + (144 /θ + 72) N 2 / 3 p − 2 / 3 + 12 N r samp σ lan . (8) Additional communication is required to migrate particles b etw een sites. The data v olume of this communication is relativ ely large during initial simulation steps, but b ecomes negligible once sufficient steps ha ve b een taken to adequately balance the workload. A detailed review of the communication characteristics of the co de is presen ted in [16]. 3.2. Multiple sup er c omputers W e calculate the w all-clo c k time required for a single T reePM integration step using p pro cesses in total across s sup ercomputers ( t exec ( s, p )) by adding the wide area comm unication ov erhead w comm to the time sp ent on tree in tegrations ( t tree ), the time sp en t on PM integration ( t pm ) and the time sp en t lo cal area communications ( t comm ). The execution time p er step is therefore t exec ( s, p ) = t tree + t pm + t comm + w comm . (9) Here, w e calculate t tree using Eq. 3, t pm using Eq. 5 and t comm using Eq. 6. Note that for runs across sites we calculate the lo cal latency-bound comm unication time t l using the n umber of lo cal processes p/s , rather than p . The communication o verhead on the wide area net work ( w comm ) consists of the time sp ent in latency ( w l ) and the time sp en t on data throughput ( w b ) on the wide area net work. As a result, w comm = w l + w b . (10) The co de p erforms five blo c king gather op erations o ver all sites p er step. These gathers are p erformed using a ring scheme, which requires s − 1 neighbor exchanges p er gather. W e also require four blo c king exc hanges with eac h of the tw o neighboring sites. The total num b er of exchanges is then equal to 5 s + 3 and, the total time sp ent in latency ( w l ) then b ecomes w l = λ wan (5 s + 3) . (11) Here, λ wan is the netw ork round-trip time b et ween sites. W e calculate the time sp en t on wide area data throughput ( w b ) b y dividing the data v olume of the wide area communications by the bandwidth capacit y of the wide area netw ork ( σ wan ). The volume of the exchanged data b et ween sites is similar to the data v olume b et ween nodes with three exceptions. First, the exchange of mesh densities requires one float p er mesh cell p er site. Second, b ecause SUSHI uses a 1D decomp osition b et ween sites the v olume of the lo cal essential tree is larger. Third, b ecause of the 1D decomp osition we exchange only the Cartesian x co ordinates of sampled particles. The data v olume for the exch ange of sampled particles is therefore three times smaller. The total time sp ent on wide area data throughput is w b = 4 sM + (48 /θ + 24) N 2 / 3 + 4 N r samp σ wan . (12) High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 8 P arameter V alue Matter density parameter ( ω 0 ) 0.3 Cosmological constant ( λ 0 ) 0.7 Hubble constant ( H 0 ) 70.0 km/s/Mp c Bo x size (30 M pc ) 3 Mass fluctuation parameter ( σ 8 ) 0.9 Softening for N = 256 3 /512 3 /1024 3 run 5/2.5/1.25 Kp c Sampling rate r samp for N = 256 3 2500 Sampling rate r samp for N > 256 3 10000 T ree op ening angle ( θ ), z > 10 0.3 T ree op ening angle ( θ ), z ≤ 10 0.5 T ree ncrit 1000 T able 1. Initial condition and accuracy parameters used for our test simulations. The maximum n umber of particles allow ed to share an interactions list in the tree integration is given by ncrit. 3.3. Sc alability acr oss sites The speedup of a sim ulation across sites, S ( s ), is defined b y dividing the time required for an integration step on 1 site using p pro cesses ( t exec (1 , p )) by the time required for an in tegration step ov er s sites using a total of s · p pro cesses ( t exec ( s, sp )). It is therefore given b y S ( s ) = t exec (1 , p ) t exec ( s, sp ) . (13) The efficiency of a sim ulation across sites, E ( s ), is calculated b y dividing the time required for an integration step on 1 site using p processes b y the time required for an in tegration step ov er s sites using a total of p pro cesses ( t exec ( s, p )). The efficiency is then E ( s ) = t exec (1 , p ) t exec ( s, p ) . (14) 4. Exp erimen ts W e hav e tested SUSHI for p erformance on a grid of 5 Beowulf clusters, as well as an infrastructure consisting of four sup ercomputers. Eac h simulation lasts for 100 in tegration steps, and uses an opening angle of θ = 0 . 3 when the redshift z > 10 and θ = 0 . 5 when z ≤ 10. Here the redshift z is used as an indication of time, with the Big Bang o ccuring at z = ∞ and z = 0 b eing the present day . F or each op ening angle we measured the total wall-clock time and communication time per step, av eraged o ver 10 steps. All measurements were made near z = 10, approximately 460 million years after the Big Bang. A full listing of the simulation parameters and initial condition c haracteristics of our exp eriments is giv en in T ab. 1. W e compare the results of our exp eriments with predictions from our p erformance mo del. T o do so, we measured the v alue of sev eral machine constants using lo cal tests and provide them in T ab. 2 and T ab. 5. The net work constants used in the performance High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 9 Site VU UvA LIA CS TU MM Cit y A’dam A’dam Leiden Delft A’dam AMD CPU mo del DP280 DP275 DP252 DP250 DP250 Num b er of no des 85 41 32 68 46 Cores p er no de 4 4 2 2 2 CPU freq. [GHz] 2.4 2.2 2.6 2.4 2.4 Memory / core [GB] 1 1 2 2 2 P eak [TFLOP/s] 3.26 1.44 0.66 1.31 0.88 τ tree [ × 10 − 9 s] 5.9 6.4 5.4 5.9 5.9 τ fft [ × 10 − 9 s] 5.0 5.0 5.7 5.0 5.0 τ mesh [ × 10 − 6 s] 2.4 2.4 2.4 1.9 2.4 Ordering 1 st 2 nd 3 rd 4 th 5 th T able 2. T echnical sp ecifications of fiv e sites of the DAS-3 Dutch Grid. Three of the five DAS-3 sites reside in Amsterdam. mo del are given in T ab. 6. As all simulations lasted for 100 in tegration steps, particle exc hanges were still p erformed to improv e the distribution of work. W e hav e added the measured a verage data volume of these exchanges to the data volume for wide area communications in our mo del. F or full-length simulations, the data volume of these particle exc hanges b ecomes a negligible part of the total comm unication v olume. 4.1. DAS-3 exp eriment setup The Distributed ASCI Sup ercomputer 3 (DAS-3 [19]) is a Dutch infrastructure that consists of 5 PC clusters within The Netherlands. The clusters use 10 Gbps netw orking in ternally , while the head no des of eac h site are connected to regular internet in a star top ology . Using end-to-end message passing tests we w ere able to achiev e a p erformance of up to 1.25 Gbps b et ween sites. The sp ecifications of the five DAS-3 sites can found in T ab. 2. W e p erformed exp erimen ts using three problem sizes and t w o op ening angles. F or our tests, we performed one set of runs with N = 256 3 particles and M = 128 3 mesh cells using 60 pro cesses distributed evenly among the sites and tw o sets of runs with N = 512 3 particles using 120 pro cesses in total. One of the runs with N = 512 3 uses M = 128 3 and the other uses M = 256 3 . W e maintained a fixed site ordering for all our runs as given in the bottom ro w of T ab. 2. F or all our experiments on the DAS-3, w e hav e configured MPWide to use a single TCP stream p er communication channel, send messages in ch unks of 8 kB and receive messages in ch unks of 32 kB. W e did not use softw are-based pack et pacing during these tests. 4.2. DAS-3 r esults The timing measuremen ts of our exp erimen ts can b e found resp ectiv ely in the left panel of Fig. 1 and 2 for the runs with N = 256 3 and in Fig. 3 and 4 for the runs with N = 512 3 . Here we see that the total communication ov erhead (including b oth local and wide area communications) becom es marginally higher as we increase in num b er of sites in the simulation with N = 256 3 and M = 128 3 mesh cells, b oth for runs with θ = 0 . 3 and with θ = 0 . 5. The measured total comm unication o verhead for sim ulations with N = 512 3 increases more steeply with s , b ecause the larger communication data High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 10 0 5 10 15 20 1 2 3 4 5 t [s] s 256 3 particles (DAS-3) 1 2 3 4 s 256 3 particles (GBBP) Figure 1. W all-clo c k time (given by circles) and total communication time (including local and wide area exchanges, giv en b y squares) p er step av eraged o ver 10 steps as a function of the n umber of sites s for t wo different simulations. W e also included the av erage time spent on tree force calculations (given b y the thin lines without sym b ols), and the time spent on local area communications (given by the filled surface area at the b ottom). Results are given for a simulation with N = 256 3 and M = 128 3 ov er 60 pro cesses in total using the D AS-3 (left panel) and across multiple supercomputers (righ t panel). All the runs use θ = 0 . 3. The standard deviation of each timing measurement is shown b y an error bar. The av erage time spent on PM in tegration w as 1.07-1.41 s per step for the DAS-3 runs, and 0.42-0.45 s for the GBBP runs. v olume results in a higher traffic load on the internet lines b et ween the sites. On the other hand, the time sp en t on local communications b ecomes low er when we run SUSHI across more sites. The num b er of pro cesses p er site ( p/s ) is lo wer for runs across more sites, whic h results in a smaller load and les s congestion on the lo cal net work. The wall-clock time p er step is almost twice as high for runs using θ = 0 . 3 compared to runs with θ = 0 . 5, while the communication ov erhead is approximately equal. The runs with M = 128 3 ha ve a total execution time whic h scales more steeply with s than the comm unication time. The run with N = 512 3 and M = 128 3 require more time to ac hiev e load balance than runs with M = 256 3 due to the more compute- in tensive tree integrations, which amplify the difference in CPU frequencies b et ween the D AS-3 sites. The time sp ent on tree integration increases with s in the runs with M = 128 3 , which indicates that go o d load balance was not yet ac hieved here. W e provide a comparison b et ween our timing results from the experiments and predictions from our p erformance model in T ab. 3 and T ab. 4. Here w e see that the achiev ed p erformance roughly matches the mo del predictions, with the notable exception for the lo cal communications. In our mo del we used σ lan = 1 × 10 8 , whic h results in m uch lo wer communication times than those we hav e measured in our experiments. As the local comm unication performance is dominated b y bandwidth rather than latency , we conclude that the ac hieved in tra-site point-to-point bandwidth High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 11 0 5 10 15 20 1 2 3 4 5 t [s] s 256 3 particles (DAS-3) 1 2 3 4 s 256 3 particles (GBBP) Figure 2. As Fig. 1, but for simulations using θ = 0 . 5. The av erage time sp en t on PM in tegration was 1.07-1.41 s per step for the DAS-3 runs, and 0.42-0.45 s for the GBBP runs. 0 10 20 30 40 50 60 70 80 90 100 1 2 3 4 5 t [s] s 512 3 particles, 128 3 mesh cells 1 2 3 4 5 s 512 3 particles, 256 3 mesh cells Figure 3. As Fig. 1, but for simulations on the DAS-3 using N = 512 3 and M = 128 3 (left panel), and simulations using N = 512 3 and M = 256 3 (right panel). All simulations w ere run ov er 120 pro cesses in total. The a verage time spent on PM in tegration was 3.16-3.57 s for the runs using M = 128 3 , and 5.77- 6.48 s for the runs using M = 256 3 . High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 12 0 10 20 30 40 50 60 70 80 90 100 1 2 3 4 5 t [s] s 512 3 particles, 128 3 mesh cells 1 2 3 4 5 s 512 3 particles, 256 3 mesh cells Figure 4. As Fig. 3, but for simulations using θ = 0 . 5. The av erage time sp en t on PM integration w as 3.16-3.57 s for the runs using M = 128 3 , and 5.77-6.48 s for the runs using M = 256 3 . using lo cal MPI has b een considerably low er than ∼ 100 M B /s . F or the runs with N = 512 3 , the mo del tends to underestimate the wall-clock and communication times for M = 128 3 due to the earlier menti oned load balance issues in these runs. How ever, we find slightly higher times in the model for runs with M = 256 3 than in the results. In our mo del the size of the lo cal essen tial tree is only dep enden t on N and θ , but w e also find a minor correlation with the n umber of mesh cells used in our exp erimen t results, as the range of the tree integration is equal to three mesh cell lengths. 4.3. Gr avitational Bil lion Bo dy Pr oje ct exp eriment setup W e ha ve run a num b er of test simulations across m ultiple supercomputers to measure the p erformance of our co de and to test the v alidity of our p erformance mo del. The sim ulations, which use datasets consisting of N = 256 3 , N = 512 3 and N = 1024 3 dark matter particles, were run across up to four sup ercomputers. W e provide the tec hnical characteristics of eac h sup ercomputer in T ab. 5. The three Europ ean sup ercomputers are connected to the DEISA shared netw ork, which can b e used without prior reserv ation although some user-space tuning is required to get acceptable p erformance. The fourth sup ercomputer resides in Japan and is connected to the other three machines with a 10 Gbps intercon tinen tal ligh t path. 4.3.1. Network c onfigur ation. In the shared DEISA net work w e applied the follo wing settings to MPWide: First, all communication paths used at least 16 parallel streams and messages were sent and receiv ed in c hunks of 256 kB p er stream. These settings allow us to reac h ∼ 100 MB/s sustained throughput on the netw ork b et ween Amsterdam and Edin burgh. Second, we used softw are-based pac ket pacing to reduce High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 13 N 1 / 3 M 1 / 3 np s comm. tree exec. t comm t tree t exec lo cal total only + w comm real real real real mo del mo del mo del mo del # [s] [s] [s] [s] [s] [s] [s] [s] 256 128 60 1 0.644 0.644 12.36 13.59 0.13 0.13 11.79 12.81 256 128 60 2 0.346 1.277 12.59 14.77 0.12 0.73 12.29 13.91 256 128 60 3 0.628 2.152 13.29 16.33 0.12 1.63 11.79 14.35 256 128 60 4 0.865 1.695 12.61 15.52 0.11 2.85 11.79 15.53 256 128 60 5 0.304 2.160 12.74 16.15 0.11 4.40 11.79 17.09 512 128 120 1 2.275 2.275 59.09 62.79 0.18 0.18 64.44 67.52 512 128 120 2 1.092 4.745 65.29 73.41 0.16 2.84 67.17 72.92 512 128 120 3 1.376 11.07 70.01 84.56 0.16 5.82 64.44 73.19 512 128 120 4 1.523 19.01 71.59 94.01 0.15 9.11 64.44 76.35 512 128 120 5 1.471 22.84 72.31 98.68 0.15 12.73 64.44 79.99 512 256 120 1 4.421 4.421 46.09 53.12 0.74 0.74 54.19 59.62 512 256 120 2 1.921 8.368 49.20 61.90 0.72 5.64 56.48 66.83 512 256 120 3 1.830 8.752 45.28 58.03 0.72 13.10 54.19 72.26 512 256 120 4 2.137 18.65 52.72 75.64 0.71 23.11 54.19 82.14 512 256 120 5 1.815 27.03 49.03 80.17 0.71 35.69 54.19 94.74 T able 3. List of runs p erformed on the D AS-3, which use θ = 0 . 3. The cube ro ot of the num ber of particles and mesh cells are given in the first and second column, the n umber of pro cesses and the num b er of sites inv olved in the third and fourth column. The next four columns contain timing measurements from our exp erimen ts, which are a verage times per step av eraged ov er 10 steps. The columns contain resp ectiv ely the intra-site communication time, the total communication time, the time sp en t on tree in tegration (excluding PM) and the total wall-clock time. The last four columns contain the intra-site comm unication time, total comm unication time, tree integration time (excluding PM), and wall- clock time as predicted by our p erformance mo del. the CPU usage of MPWide on the communication no des. This had little impact on the comm unication p erformance of the application, but w as required because some of the communication nodes were non-dedicated. Although the light path betw een Amsterdam and T okyo did not hav e an optimal TCP configuration, we w ere able to to achiev e a sustained throughput rate of ∼ 100 MB/s by tuning our MPWide settings. T o accomplish this throughput rate, w e used 64 parallel TCP streams, limited our burst exchange rate to 100 MB/s p er stream using pack et pacing and p erformed send/receiv e operations in ch unks of 8kB p er stream. In comparison, when using a single TCP stream, our throughput was limited to 10 MB/s, even though the TCP buffering size was set to more than 30 MB on the end no des. W e b eliev e that this limitation arises from TCP buffer limitations on one of the intermediary no des on the light path. Since most of the sup ercomputers are connected to the high sp eed net work through sp ecialized comm unication no des, we are required to forward our messages through these no des to exchange data b etw een sup ercomputers. This forw arding is done in user space with MPWide F orwarder programs. A graphical ov erview of the net work top ology , including the communication no des as well as latency and bandwidth characteristics for each net work path, can b e found in Fig. 5. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 14 N 1 / 3 M 1 / 3 np s comm. tree exec. t comm t tree t exec lo cal total only + w comm real real real real mo del mo del mo del mo del # [s] [s] [s] [s] [s] [s] [s] [s] 256 128 60 1 0.631 0.631 7.233 8.351 0.12 0.12 5.92 6.93 256 128 60 2 0.314 0.884 6.698 8.488 0.11 0.64 6.17 7.70 256 128 60 3 0.571 2.131 6.547 9.555 0.11 1.46 5.92 8.30 256 128 60 4 0.757 1.593 6.615 9.446 0.11 2.61 5.92 9.41 256 128 60 5 0.269 1.944 6.806 9.981 0.10 4.07 5.92 10.88 512 128 120 1 1.797 1.797 29.26 32.67 0.16 0.16 32.33 35.40 512 128 120 2 0.947 3.899 30.89 38.20 0.14 2.50 33.70 39.11 512 128 120 3 1.286 7.076 32.55 43.08 0.14 5.16 32.33 40.43 512 128 120 4 1.392 11.05 34.77 49.30 0.13 8.13 32.33 43.26 512 128 120 5 1.318 15.65 34.86 54.11 0.13 11.43 32.33 46.58 512 256 120 1 2.781 2.781 24.95 31.47 0.72 0.72 27.19 32.60 512 256 120 2 1.897 9.067 27.43 40.93 0.70 5.30 28.34 38.34 512 256 120 3 1.923 9.586 25.29 38.94 0.70 12.44 27.19 44.61 512 256 120 4 1.955 13.27 28.45 45.97 0.69 22.13 27.19 54.16 512 256 120 5 1.694 26.47 27.01 57.70 0.69 34.39 27.19 66.44 T able 4. As T ab. 3, but with θ = 0 . 5 instead of θ = 0 . 3. Name Huygens Louhi HECT oR CF CA Lo cation A’dam Esp oo Edinburgh T okyo V endor IBM Cra y Cray Cra y Arc hitecture P ow er6 XT4 XT4 XT4 # of no des 104 1012 1416 740 Cores p er no de 32 4 16 4 CPU [GHz] 4.7 2.3 2.3 2.2 RAM / core [GB] 4/8 1/2 2 2 W AN [Gbps] 2x10 10 1 10 P eak [TFLOP/s] 64.97 102.00 208.44 28.58 Order in plots 1 st 2 nd 3 rd 4 th τ tree [ × 10 − 9 s] 5.4 3.9 4.0 4.3 τ fft [ × 10 − 9 s] 5.1 3.4 3.4 3.4 τ mesh [ × 10 − 7 s] 5.8 7.8 7.8 7.8 T able 5. T echnical sp ecifications of the IBM Po wer 6 sup ercomputer in Amsterdam (The Netherlands) and the Cray-XT4 supercomputers in Esp oo (Finland), T okyo (Japan) and Edinburgh (United Kingdom). Note that Huygens is connected to b oth the 10Gbps DEISA netw ork and the 10Gbps light path between Amsterdam and T okyo. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 15 Name Description D AS-3 V alue GBBP V alue unit λ lan LAN round-trip time 1 . 0 × 10 − 4 8 . 0 × 10 − 5 [s] λ wan W AN round-trip time 3 . 0 × 10 − 3 2 . 7 × 10 − 1 [s] σ lan LAN bandwidth 1 . 0 × 10 8 5 . 4 × 10 8 [b ytes/s] σ wan W AN bandwidth 5 . 0 × 10 7 /s − 1 5 . 0 × 10 7 [b ytes/s] T able 6. List of netw ork parameters used for modelling the p erformance of our runs. The name of the constant is given in the first column, follow ed b y a brief description of the constant in the second column, the v alue used for mo delling the DAS-3 runs in the third column, the v alue used for mo delling the GBBP runs in the fourth column and the unit used in the fifth column. σ lan for GBBP was based on the p oin t-to-p oin t bandwidth p er core on HECT oR. Since the wide area netw ork in the DAS-3 resem bles a star top ology , we divide the av ailable bandwidth by s − 1 there. Figure 5. Network o verview of a cosmological simulation across four supercomputers. The network latency and maxim um sustained throughput for 64 MB message exchanges (using MPWide with the settings describ ed in the text) ov er each netw ork path is given on the left, and an ov erview of the netw ork topology is given on the right. Here, the communication no des are indicated by the solid green boxes. 4.4. GBBP r esults The timing measurements of sev eral simulations using N = 256 3 are given in the righ t panel of Fig. 1 and 2 and measuremen ts of simulations using N = 512 3 are given in Fig. 7 and 8. W e pro vide the timing results and mo del predictions for all our exp erimen ts in T ables 7 and 8. W e ha ve p erformed a num b er of runs with N = 256 3 across up to three sup ercomputers. The runs o ver tw o sup ercomputers in the DEISA net work ha ve a comm unication ov erhead b et ween 1.08 and 1.54 seconds. This constitutes b et ween 8 and 13% of the total runtime for runs with θ = 0 . 3 and b et ween 15 and 20% for runs with θ = 0 . 5. The run with N = 256 3 b et w een Edinburgh and Amsterdam has less comm unication ov erhead than the run b et ween Esp oo and Amsterdam, despite the 1 Gbps bandwidth limitation on the connection to Edinburgh. Our run b et w een Amsterdam and Esp oo suffered from a high background load, which caused the comm unication time to fluctuate o ver 10 steps with σ ∼ 0 . 25 s, compared to σ ∼ 0 . 04 s High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 16 Figure 6. Snapshots at z = 5 . 65 of a simulation with N = 512 3 ov er four supercomputers. The sl ices hav e been placed to matc h the volumes on the supercomputers that reside respectively (from top left to b ottom right) in T okyo, Espo o, Edinburgh and Amsterdam. for the run b etw een Amsterdam and Edinburgh. The run ov er three sites has a higher o verhead than the runs ov er tw o sites, mainly due to using the direct connection b et w een Edin burgh and Esp oo, whic h is p oorly optimized. The wall-clock time of the simulations with N = 512 3 is generally dominated b y calculations, although the comm unication ov erhead b ecomes higher as w e increase s . The runs o ver tw o sites (Esp oo and Amsterdam) sp end ab out 4-5 seconds on comm unication, which is less than 10 p ercent of the total execution time for the run using θ = 0 . 3. F or simulations with M = 128 3 , the use of three sup ercomputers rather than tw o does not significantly increase the communication ov erhead. How ever, when w e run sim ulations with N = 512 3 and M = 256 3 the use of a third sup ercomputer doubles the communication ov erhead. This increase in ov erhead can b e attributed to the larger mesh size, as the now larger data volume of the mesh exch ange scales with s . High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 17 0 10 20 30 40 50 60 70 80 1 2 3 4 t [s] s 512 3 particles, 128 3 mesh cells 1 2 3 4 s 512 3 particles, 256 3 mesh cells Figure 7. As Fig. 3, but these simulations were run using 120 cores in total on the planet-wide net work of sup ercomputers. The w all-clo ck time is given as a function of the n umber of sup ercomputers s . The a verage time spent on PM integration was 0.89-1.24 s for the runs using M = 128 3 , and 3.44-3.78 s for the runs using M = 256 3 . The ordering and technical specifications of the sup ercomputers w e used are given in T ab. 5. 0 10 20 30 40 50 60 70 80 1 2 3 4 t [s] s 512 3 particles, 128 3 mesh cells 1 2 3 4 s 512 3 particles, 256 3 mesh cells Figure 8. As Fig. 7, , but for simulations using θ = 0 . 5. The av erage time sp en t on PM integration w as 0.89-1.24 s for the runs using M = 128 3 , and 3.44-3.78 s for the runs using M = 256 3 . High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 18 W e provide an ov erview of the time sp en t p er sim ulation step for the run with N = 512 3 and M = 128 3 o ver three sites (Edinburgh, Espo o and Amsterdam) in Fig. 9. F or this run the total comm unication ov erhead of the simulation code remains limited and relatively stable, achieving slightly lo wer v alues at later steps where θ = 0 . 5. A decomp osition of the communication o verhead for this run is giv en in the b ottom panel of Fig. 9. The time required for exchanging the lo cal essential tree constitutes ab out half of the total comm unication o verhead. The sim ulation c hanges the op ening angle at step 46, from θ = 0 . 3 to θ = 0 . 5. As a result, the size of the lo cal essential tree b ecomes smaller and less time is sp ent on exchanging the lo cal essential trees. The time sp en t on the other comm unications remains roughly constant throughout this run. W e hav e had a brief opp ortunity to run across all four sup ercomputers, whic h allo wed us to run a simulation with N = 512 3 . W e provide a density plot of the particle data presen t at each site at the end of this run in Fig. 6. In addition, the timing measurements of the run across four sites are giv en in the left panel of Fig. 7. Here w e observ e an increase in comm unication time from 3.8-4.8 seconds for a run o ver the three DEISA sites to 12.9-19.3 seconds for the run ov er all four sites. How ev er, the runs ov er three sites relay messages b et w een Edin burgh and Esp oo through the sup ercomputer in Amsterdam, whereas the four site run uses the direct connection b et w een these sites, which is p oorly optimized. If w e use the direct connection for a run across three sites the comm unication ov erhead increases from 3.8-4.8 seconds to 10.1-13.2 seconds p er step (see T ables 7 and 8). Therefore, the communication o verhead of a run across four sites may b e reduced b y a factor of t wo if we w ould relay the messages b etw een Esp oo and Edinburgh o ver Amsterdam. W e also ran several simulations with N = 1024 3 . The load balancing increases the communication volume of these larger runs considerably , as 850MB of particle data was exchanged on a verage during eac h step. How ever, the comm unication time still constitutes only one-tenth of the total run-time for the simulation across three sup ercomputers. 5. Scalabilit y of N -b ody simulations across sup ercomputers In this section we use our p erformance mo del and simulation results to predict the scalability of N -b ody co de across grid sites. In the first part of this section w e examine the predicted sp eedup and efficiency when scaling three cosmological N -b ody problems across multiple sup ercomputers. In the second part we apply existing p erformance mo dels for tree co des (with blo ck and shared time step sc hemes) and direct-metho d co des to predict the scalability of three stellar N -b o dy problems across sup ercomputers. In the third part we predict the efficiency of cosmological N -b ody sim ulations o ver 8 sites as a function of the av ailable bandwidth b et ween sup ercomputers. W e pro vide an o verview of the three cosmological problems in T ab. 9, and an ov erview of the three stellar problems in T ab. 11. These problems are mapp ed to a global grid infrastructure, which has a net work latency of 0.3 s and a bandwidth capacity of 400 MB/s b et ween sup ercomputers. The mac hine constants are similar to the ones we used for our runs, and can b e found in T ab. 10. T o limit the complexity of our analysis, we assume an iden tical calculation sp eed for all cores on all sites . Our p erformance predictions use an op ening angle θ = 0 . 5. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 19 t [s] θ = 0.3 θ = 0.5 calculation time communication time 10 20 30 40 50 60 70 80 t [s] Simulation step number Particle migration Determine boundary PP PM 0 2 4 6 8 10 12 0 10 20 30 40 50 60 70 80 90 100 Figure 9. Performance results of a simulation with N = 512 3 and M = 128 3 using 120 processes in total across supercomputers in Amsterdam, Edinburgh and Espo o as a function of the simulation step num b er. The wall-clock time sp en t per step on calculations (top red area) and comm unications (b ottom black area) is giv en in the top figure. Time sp ent on the four communication phases is given in the bottom figure. These phases are (from top to b ottom) the migration of particles b et ween sites, the exchanges of sample particles for determining the site boundaries, the lo cal essential tree exchanges (PP) and the mesh cell exchanges (PM). High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 20 N 1 / 3 M 1 / 3 np s comm. tree exec. t comm t tree t exec lo cal total only + w comm real real real real mo del mo del mo del mo del # [s] [s] [s] [s] [s] [s] [s] [s] 256 128 60 A 0.207 0.207 11.32 11.80 0.04 0.03 10.79 11.22 256 128 60 HA 0.156 1.085 10.88 12.23 0.03 1.06 9.29 10.74 256 128 60 EA 0.177 1.536 10.91 12.71 0.03 1.06 9.39 10.84 256 128 60 A T 0.177 3.741 11.47 15.48 0.03 4.23 9.69 14.31 256 128 60 HEA* 0.143 5.960 10.95 17.12 0.03 1.66 8.86 10.91 512 128 120 A 1.045 1.045 69.57 71.04 0.06 0.06 58.98 59.91 512 128 120 HA 0.783 4.585 55.96 61.62 0.04 3.14 50.79 54.91 512 128 120 HEA 0.524 4.778 50.69 56.31 0.04 4.19 48.42 53.64 512 128 120 HEA* 0.760 13.17 56.82 71.01 0.04 4.19 48.42 53.64 512 128 120 HEA T* 0.653 19.26 49.96 70.10 0.04 9.42 48.06 58.52 512 256 120 A 1.367 1.367 42.13 46.04 0.16 0.16 49.60 52.46 512 256 120 HA 1.363 5.761 41.00 48.52 0.15 5.48 42.71 51.01 512 256 120 EA 1.247 7.091 37.60 46.37 0.15 5.48 43.17 51.47 512 256 120 A T 1.313 10.98 38.97 51.67 0.15 8.66 44.54 56.02 512 256 120 HEA 1.191 13.51 40.91 55.96 0.14 7.66 40.72 51.22 1024 256 240 E 3.215 3.215 182.4 189.6 0.20 0.20 200.7 205.8 1024 256 240 A 3.402 3.402 265.5 272.8 0.20 0.20 271.0 275.8 1024 256 240 HA 3.919 21.98 217.9 252.0 0.18 23.88 233.4 262.3 1024 256 240 HEA 4.052 31.28 258.0 294.7 0.17 26.05 217.1 248.4 T able 7. List of runs performed for GBBP that use θ = 0 . 3. The cube ro ot of the num b er of particles and mesh cells are giv en in the first and second column, the num b er of pro cesses and the sup ercomputers in volv ed in the third and fourth column. Here, the letters corresp ond to supercomputers in Esp oo (given by “H”), (E)dinburgh, (A)msterdam and (T)okyo. F or runs ov er three and four sites, we relay ed all traffic through the sup ercomputer in Amsterdam except for the runs marked with an asterisk, which used the direct network b etw een Edinburgh and Esp oo. The next four columns contain timing measurements from our exp erimen ts, which are a verage times per step av eraged ov er 10 steps. The columns contain resp ectiv ely the intra-site communication time, the total communication time, the time sp en t on tree in tegration (excluding PM) and the total wall-clock time. The last four columns contain the intra-site comm unication time, total comm unication time, tree integration time (excluding PM), and wall- clock time as predicted by our p erformance mo del. 5.1. Sp e e dup and efficiency pr e dictions for T r e ePM simulations The predicted sp eedup S ( s ) (as defined in Eq. 13) for three cosmological simulations as a function of the num b er of sup ercomputers s can b e found in Fig. 10. As the n umber of pro cesses p er site remains fixed, the total n umber of pro cesses p increases linearly with s . All example problems run efficien tly ov er up to 3 sites. The sim ulation with N = 2048 3 and M = 256 3 scales well as s increases and obtains a sp eedup of ∼ 13 when s = 16. When scaling up b ey ond s ∼ 25, the sp eedup diminishes as the sim ulation b ecomes dominated by comm unication. The sim ulation with N = 2048 3 and M = 1024 3 do es not scale as well and only ac hieves a go od sp eedup when run across a few sites. Here, the sp eedup as a function of s b egins to flatten at s ∼ 5, due to the serial integration of the larger mesh. F or High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 21 N 1 / 3 M 1 / 3 np s comm. tree exec. t comm t tree t exec lo cal total only + w comm real real real real mo del mo del mo del mo del # [s] [s] [s] [s] [s] [s] [s] [s] 256 128 60 A 0.197 0.197 5.968 6.446 0.04 0.04 5.42 5.84 256 128 60 HA 0.156 1.043 5.786 7.087 0.03 0.98 4.66 6.03 256 128 60 EA 0.159 1.480 5.827 7.567 0.03 0.98 4.71 6.08 256 128 60 A T 0.157 3.575 6.024 9.858 0.03 4.15 4.86 9.40 256 128 60 HEA* 0.143 5.827 6.047 12.08 0.03 1.58 4.45 6.41 512 128 120 A 0.992 0.992 34.31 35.76 0.05 0.05 29.59 30.52 512 128 120 HA 0.732 4.522 27.16 32.78 0.04 2.82 25.48 29.29 512 128 120 HEA 0.467 3.803 24.35 28.99 0.04 3.87 24.30 29.19 512 128 120 HEA* 0.760 10.86 28.52 40.45 0.04 3.87 24.30 29.19 512 128 120 HEA T* 0.534 12.90 25.84 39.68 0.03 9.09 24.11 34.25 512 256 120 A 1.308 1.308 22.91 26.80 0.16 0.16 24.89 27.74 512 256 120 HA 1.284 5.383 22.32 29.45 0.14 5.16 21.43 29.40 512 256 120 EA 1.213 6.991 20.75 29.44 0.14 5.16 21.66 29.63 512 256 120 A T 1.223 9.640 20.88 32.22 0.14 8.33 22.35 33.50 512 256 120 HEA 1.100 12.65 21.92 36.08 0.14 7.33 20.43 30.61 1024 256 240 HA 3.490 19.06 104.1 128.2 0.17 22.59 117.1 144.8 2048 256 750 A T 16.58 46.50 413.9 483.4 0.26 17.59 443.2 470.3 T able 8. As T ab. 7 but with θ = 0 . 5 instead of θ = 0 . 3. The run with N = 2048 3 used an older version of the co de and different settings, and is describ ed in [9]. s > ∼ 16, the comm unication ov erhead b egins to dominate performance and the speedup decreases for higher s . The speedup of the run with N = 8192 3 and M = 1024 3 scales b etter with s than the sp eedup of the run with N = 2048 3 b ecause it sp ends more time p er step on tree force calculations. W e provide the predicted efficiency of three simulations ov er s sup ercomputers relativ e to a sim ulation o ver one sup ercomputer, E ( s ), using the same n umber of pro cesses in Fig. 11. Here, the run with N = 2048 3 and M = 256 3 and the run with N = 8192 3 and M = 1024 3 retain a similar efficiency as w e scale up with s . If s > ∼ 6, the run with N = 8192 3 is slightly less efficient than the simulation with N = 2048 3 and M = 256 3 . The simulation using N = 2048 3 and M = 1024 3 is less efficient than the other tw o runs. The data volume of the mesh cell exchange is 64 times higher than that of the run with M = 256 3 , which results in an increased communication In tegrator N M np 1 np 2 T reePM 2048 3 256 3 128 2048 T reePM 2048 3 1024 3 128 2048 T reePM 8192 3 1024 3 4096 32768 T able 9. Description of the cosmological N -b ody problems used for the scalabilit y analysis across supercomputers. The type of integrator is giv en in the first column, the num b er of particles in the second column and the n umber of mesh cells in the third column. The last t wo columns contain resp ectively the number of processes per site for the sp eedup analysis and the num b er of total pro cesses for the efficiency and bandwidth analysis. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 22 Name of constant V alue unit τ tree 5 . 0 × 10 − 9 [s] τ fft 3 . 5 × 10 − 9 [s] τ mesh 7 . 5 × 10 − 7 [s] λ lan 8 . 0 × 10 − 5 [s] λ wan 3 . 0 × 10 − 1 [s] σ lan 2 . 3 × 10 9 [b ytes/s] σ wan 4 . 0 × 10 8 [b ytes/s] T able 10. List of net work parameters used for the scalabilit y predictions of our code. The name of the constant can be found in the first column, the v alue used for our global grid mo del in the second column and the units used for each v alue in the third column. 10 0 10 1 10 2 1 4 16 64 S(s) s N=2048 3 , M=256 3 , np=128/site N=2048 3 , M=1024 3 , np=128/site N=8192 3 , M=1024 3 , np=4096/site linear speedup Figure 10. Predicted speedup S ( s ) of simulations using the T reePM metho d as a function of the num b er of sites s in a global grid. The total num b er of pro cesses scales linearly with s . o verhead. 5.2. Sp e e dup and efficiency pr e dictions for tr e e and dir e ct-metho d simulations W e present predictions of three example N -b ody simulations of stellar systems, each of which uses a different integration metho d. The integration metho ds we use in our mo dels are a Barnes-Hut tree algorithm [12] with shared time steps, a tree algorithm using blo ck time steps [20] and a direct-metho d algorithm [21] using blo c k time steps. F or the tree algorithm we c ho ose the problem sizes and pro cess coun ts previously used for the cosmological simulation mo dels with N = 2048 3 . Mo delling the p erformance of direct-metho d simulations using N = 2048 3 is unrealistic, b ecause one step of force High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 23 0 0.2 0.4 0.6 0.8 1 1 4 16 64 E(s) s N=2048 3 , M=256 3 , np=2048 N=2048 3 , M=1024 3 , np=2048 N=8192 3 , M=1024 3 , np=32768 Figure 11. Predicted efficiency E ( s ) of simulations using the T reePM metho d as a function of the num b er of sites s in a global grid. The total num b er of pro cesses is kept fixed for all simulations. In tegrator N np 1 np 2 time step scheme T ree 2048 3 128 2048 shared T ree 2048 3 128 2048 blo c k Direct 5 · 10 6 16 128 blo c k T able 11. Description of the stellar N -b ody problems used for the scalabilit y analysis across supercomputers. The t yp e of in tegrator is given in the first column and the n umber of particles in the second column. The n umber of processes per site for respecti v ely the sp eedup analysis and the efficiency analysis are given in the third and fourth column. The time step scheme used is given in the last column. Note that the direct-method simulation is modelled for a grid of GPUs. calculations for the 2048 3 particles w ould already take sim 280 y ears when using 1000 nodes on a PC cluster [2]. W e instead predict the performance of direct-metho d sim ulations using a more realistic problem size of 5 million particles. W e mo del the tree algorithm using a slightly extended version of the models presen ted in [17, 22] and the direct-metho d algorithm using the grid-enabled mo del presen ted in [23]. An ov erview of the three problems used for our predictions is given in T ab. 11. The simulations using the tree algorithm are mapp ed to the same global grid infrastructure that we used for mo delling the cosmological simulation (see T ab. 10 for the machine constants used). The direct-metho d sim ulation is modelled using the net work constants from the global grid mo del, but here w e assume that eac h no de has a Graphics Pro cessing Unit (GPU) with a force calculation p erformance of 200 GFLOP/s. As each force interaction requires 66 FLOPs on a GPU, we sp end High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 24 3 . 3 × 10 − 10 s p er force interaction (see [24, 25] for details on direct N -b ody in tegration on the GPU). 5.2.1. Performanc e mo del for the tr e e algorithm W e extend the tree code mo dels giv en in [17, 22] to include the grid communication ov erhead b y adding the equations for wide area communication of the tree method from our SUSHI p erformance mo del. In accordance with our previous mo del, we define the wide area latency-b ound time for the tree metho d ( w l , tree ) as, w l , tree = λ wan (4 ( s − 1) + 4) . (15) The bandwidth-bound communication time ( w b , tree ) consists of the communica- tion volume for the lo cal essential tree exchange, whic h w e estimate to b e double the size used in T reePM simulations due to the lack of PM in tegration, and the commu- nication volume required for particle sampling. It is therefore given b y , w b , tree = (96 /θ + 48) N 2 / 3 + 4 N r samp σ wan , (16) where r samp = 1 / 10000 and θ = 0 . 5. W e use the equation giv en in [22] for Plummer sphere data sets to calculate the total n umber of force interactions. 5.2.2. Mo del ling of blo ck time steps T ree and direct N -b ody integrators frequently use a block time step scheme instead of a shared time step scheme. Blo ck-time step sc hemes can also b e applied to parallel sim ulations (unlik e e.g., individual time step sc hemes), and reduce the computational load by integrating only a subset of particles during each step [26, 27]. T o equalize the num b er of in tegrated particles betw een sim ulations, w e therefore compare a single shared time-step in tegration with N /n b steps of a block time-step integration, where n b is the av erage blo c k size. W e adopt an av erage blo ck size of n b = 0 . 2 N 0 . 81 for all blo c k time-step integrators, the same v alue that was used in [23]. 5.2.3. Pr e dictions W e give the predicted sp eedup S ( s ) of the three simulations as a function of the num b er of sup ercomputers s in Fig. 12. Here, the tree co de with shared time steps scales similarly to the cosmological simulation with N = 2048 3 and M = 256 3 (see Fig. 10). W e predict a sp eedup of ∼ 13 when s = 16. When we model the tree code with a blo c k time step sc heme, the scalabilit y b ecomes w orse b ecause it requires N /n b times as many comm unication steps to integrate N particles. The large n umber of communications combined with the high latency of wide area net works result in a high communication o verhead. The direct N -b ody run on a global grid of GPUs also do es not scale well o ver s due to the use of blo c k time steps. W e give the predicted efficiency of the three simulations ov er s sup ercomputers relativ e to a simulation ov er one sup ercomputer, E ( s ) in Fig. 13. The efficiency of these runs is mainly limited b y the latency-b ound comm unication time. The tree co de with shared time steps retains a high efficiency for s < ∼ 16, while the simulations with blo ck time steps are less efficient due to the larger num b er of communications. W e predict a slightly higher efficiency when s > ∼ 4 for the direct-metho d simulation than for the tree co de simulation with blo c k time s teps. This is b ecause the lo wer N results in a lo w er n umber of comm unication steps, and therefore in less comm unication o verhead. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 25 10 0 10 1 10 2 1 4 16 64 S(s) s Tree, shared time, N=2048 3 , np=128/site Tree, block time, N=2048 3 , np=128/site Direct GPU, N=5 ⋅ 10 6 , np=16/site linear speedup Figure 12. Predicted sp eedup S ( s ) of N -b ody simulations using the tree and direct method as a function of the num b er of sites s in a global grid. The total num b er of pro cesses scales linearly with s . 0 0.2 0.4 0.6 0.8 1 1 4 16 64 E(s) s Tree, shared time, 2048 3 , np=2048 Tree, block time, 2048 3 , np=2048 Direct GPU, block time, 5 ⋅ 10 6 , np=128 Figure 13. Predicted efficiency E ( s ) of N -b ody sim ulations using the tree and direct method as a function of the num b er of sites s in a global grid. The total num b er of pro cesses is kept fixed for all simulations. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 26 5.3. Bandwidth analysis for c osmolo gic al simulations W e hav e shown that our T reePM co de scales w ell across up to ∼ 16 sites if the ratio b et w een the num b er of particles and the n umber of mesh cells is sufficien tly large. Here w e examine the efficiency of four cosmological sim ulations ov er 8 sites. The efficiency compared to a single site run is predicted as a function of the a v ailable bandwidth. W e ha ve included three predictions for a global grid with 0.3 s netw ork latency as well as one prediction for a simulation with N = 2048 3 and M = 256 3 o ver a medium-range grid with 30 ms net work latency . The details of these sim ulations are giv en in T ab. 9, and the results are shown in Fig. 14. W e find that the efficiency of cosmological simulations across sites is hea vily dep enden t on the av ailable bandwidth. The run with N = 2048 3 and M = 256 3 on a global grid has E (8) = 0 . 9 (where E (8) is the efficiency as defined in Eq. 14) when the sup ercomputers are connected with a 100 MB/s netw ork. Using a netw ork with a higher bandwidth has little effect on the ac hieved efficiency , as the communication o verhead is then dominated by net work latency . The effect of netw ork latency is clearly visible when w e lo ok at the prediction for the same sim ulation on a grid with a shorter baseline. When using a grid with 30 ms net work latency the sim ulation reac hes E (8) = 0 . 97 if the wide area net work ac hieves a throughput of 1000 MB/s (whic h is p ossible with a fine-tuned and dedicated 10 Gbps optical netw ork). W e predict an efficiency E (8) > 0 . 8 for both sim ulations if the av ailable netw ork bandwidth b et ween sites is 50 MB/s. The run with N = 2048 3 and M = 1024 3 is more comm unication intensiv e, and requires a netw ork throughput of at least 700 MB/s to achiev e an efficiency of 0.8. The simulation using N = 8192 3 and M = 1024 3 runs more efficiently than the sim ulation using N = 2048 3 and M = 1024 3 indep enden t of the obtained bandwidth. Although the exc hanged data volume is larger in the run with N = 8192 3 , this increased ov erhead is offset by the the higher force calculation time p er step. The large communication volume reduces the efficiency considerably for low bandwidth v alues, and an av erage netw ork throughput of at least 150 MB/s is required to achiev e an efficiency of E (8) = 0 . 8. 6. Conclusion W e ha ve run a few dozen cosmological N -b ody sim ulations and analyzed the scalabilit y of our SUSHI integrator on a national distributed computer and across a global net work of sup ercomputers. Our results confirm that SUSHI is able to efficiently p erform sim ulations across sup ercomputers. W e were able to run a sim ulation using 1024 3 particles across three supercomputers with ∼ 10% communication ov erhead. The communication p erformance can b e further improv ed by tuning the optical net works. Based on our mo del predictions we conclude that a long-term cosmological sim ulation using 2048 3 particles and 256 3 mesh cells scales w ell ov er up to ∼ 16 sites, given that sufficien t bandwidth is av ailable and the n umber of cores used p er site is limited to ∼ 256. W e also predict that tree co des with a shared time step sc heme run efficiently across multiple sup ercomputers, while tree co des with a blo c k time step scheme do not. Considerable effort is still required to obtain acceptable message passing p erformance through a long distance optical netw ork. This is due to three reasons. High Performanc e Gr avitational N -b o dy Simulations on a Planet-wide Distribute d Sup er c omputer 27 0 0.2 0.4 0.6 0.8 1 10 100 1000 10000 E(8) σ wan [MB/s] N=2048 3 M=256 3 , np=2048, Medium-range grid N=2048 3 , M=256 3 , np=2048, Global grid N=2048 3 , M=1024 3 , np=2048, Global grid N=8192 3 , M=1024 3 , np=32768, Global grid Figure 14. Predicted efficiency of four N -b ody simulations using the T reePM method ov er 8 sites ( E (8)) as a function of the wide area net work throughput ( σ wan ) in MB/s. Three simulations are run on a global grid. One simulation uses N = 2048 3 particles and M = 256 3 mesh cells (given by the black dashed line), one uses N = 2048 3 and M = 1024 3 (black dotted line) and one run uses N = 8192 3 and M = 1024 3 (thick blac k line). A simulation using N = 2048 3 and M = 256 3 modelled for a grid with 30 ms netw ork latency b etw een sites is giv en by the thin red line. Runs with N = 2048 3 particles are predicted using a total of 2048 processes, runs with N = 8192 3 particles are predicted using a total of 32768 processes. First, it ma y tak e up to sev eral mon ths to arrange an intercon tinen tal ligh t path. Second, optical netw orks are generally used for high v olume data streaming such as distributed visualization or bulk data transfer, and are therefore not y et tuned to achiev e optimal message passing p erformance. Third, in tercontinen tal net works tra verse a large n umber of differen t institutes, making it p olitically difficult for users to diagnose and adjust settings on individual sections of the path. F or our exp eriments we therefore chose to optimize the wide area communications by tuning our application, rather than requesting system-level modifications to the light path configuration. The main challenges in running sim ulations across sup ercomputers are now p olitical, rather than technical. During the GBBP pro ject, we w ere able to ov ercome man y of the p olitical c hallenges in part due to go od will of all organizations inv olved and in part through sheer patience and p ersev erance. Ho w ever, orchestrating a reserv ation spanning across multiple sup ercomputers is a ma jor p olitical undertaking. The use of a meta-scheduler and reserv ation system for sup ercomputers and optical net works greatly reduces this o verhead, and also improv es the workload distribution b et w een sup ercomputer centers. Once the political barriers are ov ercome, we will b e able to run long lasting and large scale pro duction simulations ov er a grid of sup ercomputers. REFERENCES 28 Ac knowledgemen ts W e are grateful to Jero en B´ edorf, Juha F agerholm, Evghenii Gaburov, Kei Hiraki, W outer Huisman, Igor Idziejczak, Cees de Laat, W alter Lio en, Steve McMillan, P etri Nikunen, Keigo Nitadori, Masafumi Oe, Ronald v an der P ol, Gavin Pringle, Stev en Rieder, Huub Stoffers, Alan V erlo, Joni Virtanen and Seiichi Y amamoto for their contributions to this w ork. W e also thank the net work facilities of SURFnet, DEISA, IEEAF, WIDE, JGN2Plus, SINET3, North west Gigap op, the Global Lambda Integrated F acility (GLIF) GOLE of T ransLight Cisco on National Lam b daRail, T ransLight, StarLigh t, NetherLight, T-LEX, P acific and A tlan tic W av e. This researc h is supp orted by the Netherlands organization for Scientific researc h (NW O) gran t #639.073.803, #643.200.503 and #643.000.803, the Stich ting Nationale Computerfaciliteiten (pro ject #SH-095-08), NAOJ, JGN2plus (Pro ject No. JGN2P-A20077), SURFNet (GigaP ort pro ject), the International Information Science F oundation (I ISF), the Netherlands Adv anced School for Astronomy (NO V A) and the Leids Kerkho ven-Bossc ha fonds (LKBF). T.I. is financially supported b y Researc h F ellowship of the Japan So ciet y for the Promotion of Science (JSPS) for Y oung Scien tists. This research is partially supported by the Sp ecial Coordination F und for Promoting Science and T echnology (GRAPE-DR pro ject), Ministry of Education, Culture, Sp orts, Science and T ec hnology , Japan. W e thank the DEISA Consortium (www.deisa.eu), co-funded through the EU FP6 pro ject RI-031513 and the FP7 pro ject RI-222919, for supp ort within the DEISA Extreme Computing Initiative (GBBP pro ject). References [1] E. F ernandez, E. Heymann, and M. Angel Senar. Supp orting efficien t execution of mpi applications across multiple sites. In Eur o-Par 2006 Par al lel Pr o c essing , pages 383–392. Springer, 2006. [2] A. Gualandris, S. Portegies Zwart, and A. Tirado-Ramos. P erformance analysis of direct n-b o dy algorithms for astrophysical simulations on distributed systems. Par al lel Computing , 33(3):159–173, 2007. [3] S. Manos, M. Mazzeo, O. Ken wa y, P . V. Cov eney, N. T. Karonis, and B. R. T o onen. Distributed mpi cross-site run p erformance using mpig. In HPDC , pages 229–230, 2008. [4] H. Bal and K. V ersto ep. Large-s cale parallel computing on grids. Ele ctr onic Notes in The or etic al Computer Scienc e , 220(2):3 – 17, 2008. Pro ceedings of the 7th International W orkshop on Parallel and Distributed Metho ds in verifiCation (PDMC 2008). [5] P . Bar, C. Coti, D. Gro en, T. Herault, V. Kra vtsov, M. Swain, and A. Sc huster. Running parallel applications with top ology-a ware grid middleware. In Fifth IEEE international c onfer enc e on e-Scienc e and Grid c omputing: Oxfor d, Unite d Kingdom , pages 292–299, Piscata wa y , NJ, Decem b er 2009. IEEE Computer So ciet y . [6] M. Norman, P . Beckman, G. Bryan, J. Dubinski, D. Gannon, L. Hernquist, K. Keahey , J. Ostriker, J. Shalf, J. W elling, and S. Y ang. Galaxies Collide On the I-W ay: an Example of Heterogeneous Wide-Area Collab orative Sup ercomputing. REFERENCES 29 International Journal of High Performanc e Computing Applic ations , 10(2-3):132– 144, 1996. [7] T. J. Pratt, L. G. Martinez, M. O. V ahle, and T. V. Arch uleta. Sandia‘s net work for sup ercomputer ‘96: Linking sup ercomputers in a wide area async hronous transfer mo de (atm) netw ork. T echnical rep ort, Sandia National Labs., Albuquerque, NM (United States), 1997. [8] C. Stewart, R. Keller, R. Repasky, M. Hess, D. Hart, M. Muller, R. Sheppard, U. W ossner, M. Aumuller, H. Li, D. Berry, and J. Colb ourne. A global grid for analysis of arthropo d ev olution. In GRID ’04: Pr o c e e dings of the 5th IEEE/AC M International Workshop on Grid Computing , pages 328–337, W ashington, DC, USA, 2004. IEEE Computer So ciet y . [9] S. Portegies Zwart, T. Ishiyama, D. Gro en, K. Nitadori, J. Makino, C. de Laat, S. McMillan, K. Hiraki, S. Harfst, and P . Grosso. Simulating the universe on an in tercontinen tal grid. Computer , 43:63–70, 2010. [10] K. Y oshik aw a and T. F ukushige. PPPM and T reePM Meth- o ds on GRAPE Systems for Cosmological N-Bo dy Simulations. Public ations of the Astr onomic al So ciety of Jap an , 57:849–860, December 2005. [11] G. Xu. A New Parallel N-Bo dy Gravit y Solver: TPM. ApJS , 98:355–366, May 1995. [12] J. Barnes and P . Hut. A Hierarc hical O(NlogN) F orce-Calculation Algorithm. Natur e , 324:446–449, December 1986. [13] R. W. Ho ckney and J. W. East woo d. Computer Simulation Using Particles . New Y ork: McGraw-Hill, 1981, 1981. [14] K. Nitadori, J. Makino, and P . Hut. P erformance tuning of N-b ody co des on mo dern micropro cessors: I. Direct integration with a hermite sc heme on x86 64 arc hitecture. New Astr onomy , 12:169–181, December 2006. [15] Matteo F rigo, Steven, and G. Johnson. The design and implementation of fft w3. In Pr o c e e dings of the IEEE , volu me 93, pages 216–231, F eb 2005. [16] T. Ishiyama, T. F ukushige, and J. Makino. GreeM: Massiv ely P ar- allel T reePM Co de for Large Cosmological N -b ody Simulations. Public ations of the Astr onomic al So ciety of Jap an , 61:1319–1330, December 2009. [17] J. Makino. A F ast Parallel T reecode with GRAPE. Public ations of the Astr onomic al So ciety of Jap an , 56:521–531, June 2004. [18] D. Gro en, S. Rieder, P . Grosso, C. de Laat, and P . Portegies Zw art. A light- w eight communication library for distributed computing. Computational Scienc e and Disc overy , 3(1):015002, 2010. [19] DAS-3. The distributed asci sup ercomputer 3: http://www.cs.vu.nl/das3/. [20] S. L. W. McMillan. The use of sup ercomputers in stellar dynamics; pro ceedings of the w orkshop, institute for adv anced study , princeton, nj, june 2-4, 1986. In P . Hut and S. L. W. McMillan, editors, The Use of Sup er c omputers in Stel lar Dynamics , v olume 267 of L e ctur e Notes in Physics, Berlin Springer V erlag , page 156, 1986. REFERENCES 30 [21] J. Makino and S. J. Aarseth. On a Hermite integrator with Ahmad-Cohen scheme for gravitational many-bo dy problems. Public ations of the Astr onomic al So ciety of Jap an , 44:141–151, April 1992. [22] J. Makino. T reeco de with a Special-Purp ose Processor. Public ations of the Astr onomic al So ciety of Jap an , 43:621–638, August 1991. [23] D. Gro en, S. Portegies Zwart, S. McMillan, and J. Makino. Distributed N-b o dy sim ulation on the grid using dedicated hardware. New Astr onomy , 13:348–358, July 2008. [24] S. F. Portegies Zw art, R. G. Belleman, and P . M. Geldof. High-performance direct gra vitational N-b ody simulations on graphics pro cessing units. New Astr onomy , 12:641–650, Nov em b er 2007. [25] E. Gaburov, S. Harfst, and S. Portegies Zw art. SAPPORO: A wa y to turn your graphics cards into a GRAPE-6. New Astr onomy , 14:630–637, Octob er 2009. [26] D. C. Heggie and R. D. Mathieu. Standardised Units and Time Scales. In P . Hut and S. L. W. McMillan, editors, The Use of Sup er c omputers in Stel lar Dynamics , v olume 267 of L e ctur e Notes in Physics, Berlin Springer V erlag , page 233, 1986. [27] J. Makino. Optimal order and time-step criterion for Aarseth-type N-b o dy in tegrators. ApJ , 369:200–212, March 1991.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment