Effect of Tuned Parameters on a LSA MCQ Answering Model
This paper presents the current state of a work in progress, whose objective is to better understand the effects of factors that significantly influence the performance of Latent Semantic Analysis (LSA). A difficult task, which consists in answering …
Authors: ** - **Alain Lifchitz** – LIP6 – DAPA, Université Pierre et Marie Curie, CNRS
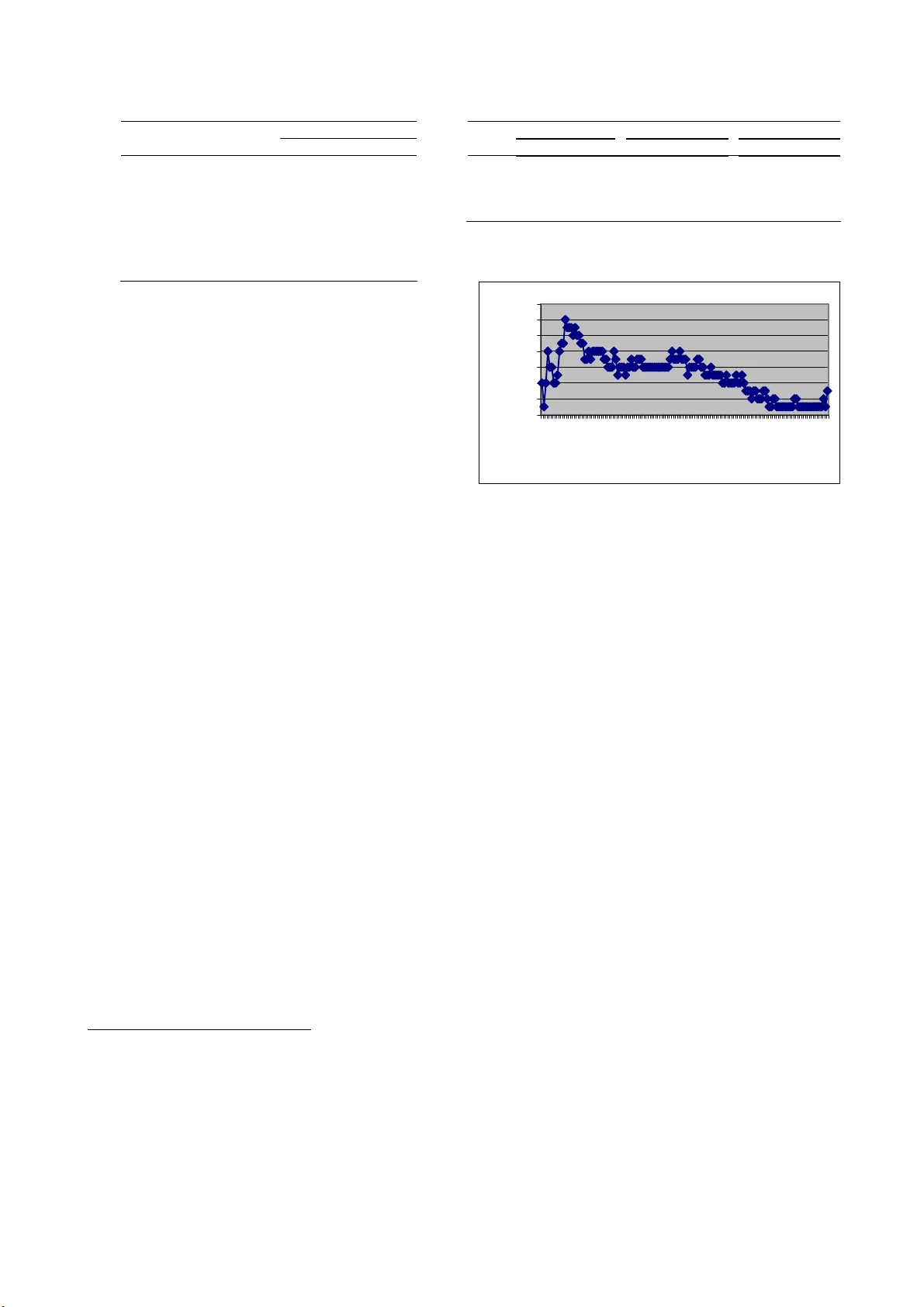
Effect of Tuned Parameters on a LSA MCQ Answering Model This manuscript was accepted for publication in B ehavior Research Methods on 7 May 2009 . The copyright is held by Psychonomic Society Publica tions. Th is document may not exactly correspond to the final published version. Psychonomic Society P ublications disclaims any responsibility or liability for er rors in this manuscript. Effect of Tuned Parameters on a LSA Multiple Choice Questions Answering Model A LAIN L IFCHITZ LIP6 - DAPA, Université Pierre et Marie Curie, CNRS, P aris, France S ANDRA J HEAN -L AROSE AND G UY D ENHIÈRE Équipe CHArt: Cognition Humaine et Artificielle, EPHE-CNRS, Paris, France This paper presents the current state of a work in progress, whose objective is to b etter understand the effects of factors that significantly influence the p erformance of Latent Semantic Analysis (LSA). A difficult task, which consists in answering (F rench) biology Multiple Choice Questions, is used to test the semanti c properties of the truncated singular space and to study th e relative influence of main parameters. A ded icated software has been desi gned to fin e tune the LSA sema ntic space for the Multiple Choice Questions task. With optimal parameters, the performances of our simple model are quite surprisingly equal or superior to those of 7 th and 8 th grades students. This indicates that sema ntic spaces were quite good despite their low dimensions and the small sizes of trai ning data sets. Besides, we present an original entrop y global weighting of answers’ terms of each question of the Mult iple Choice Questions which wa s necessary to achiev e the model's success. I. I NTRODUCTION In this paper, we have th e following the goals: (i) to search for a method that en ables us to obtain better input features (i n Machine Learning c ommuni ty terminol ogy) of type “Term Frequency – Inverse Docum ent Frequency” ( Salton & Buckley, 1988 ) for the Latent Semantic Analysis (LSA) ( Deerwester, Dum ais, Landauer, Furnas, & Harshm an, 1990 ) as a non- supervised learni ng method, (ii) to define a concrete task (answering to Multiple Choice Questions) that allows, on one hand, to evalua te the semantic nature of th e obtained vector spaces and, on the othe r hand, to measure the relative influence of the parameters used to build these spaces, (iii) to describe some original aspects of the dedicated tool develope d to realize t hese processes, and (iv) to compare the model to the results obtained by 7 th and 8 th grades student s. A. Looking for better fe atures as input of LSA LSA has bee n proven to provi de reliable informat ion on long-dista nce semanti c dependencies between w ords in a context using t he “Bag Of Words” model ( Dumais, 2007 ) where the order of words in t he document is unimportant. LSA c ombines the classical Vector Space Model with Singular V alue Decom position . Thus, Ba g Of Words rep resentations o f texts can be m apped i nto a modified vector space that reflects, to som e degree, their semantic structure. It is the c onsequence of the reduction of dimensionality resulting from the truncation of the singular space restricted to t he orthogonal com ponents associated with the high er singular values. This paper presents the state o f our ongoing work , which is similar to the work of Wild, Stahl, Stermsek, & Neumann ( 2005) . We measure the effects of the tuning of the parameters of the input textual features ( Salton & Buckley, 1988 ; Salton, Wong, & Yang, 19 75 ) of LSA, and more precisely, the ef fects of lemmatisation, stop- words lists, weighting of terms in the terms-by-documents matrix, pse udo-docum ents, and n ormalization of document vectors. B. Semantic spaces: to which extent are they “semanti c”? One way to be able to objectively judge the qua lity of a space referred to as “sem antic” is to define an external “semantic” task over the conside red “semantic space”, which will produce results of variable quality. Moreover, this task will make it possible to evaluate, for the b est possible result, the relative influence of the various parameters. Unlike free answer questions that are frequently used in LSA research (see e.g. Diaz, Rifqi, Bouchon-Meunier, Jhean-Larose, & Denhièr e, 2008 ; Graesser, Wiemer- Hastings, Wiemer-Hastings, Kre uz, & Tutoring Research Group, 1 999 ), this paper addresses how to autom atically find the right answers to Multiple Choice Questions using LSA. An answer to this question could be interesting eLSA1-brm20.doc 07/05/09 09:00 1/9 Effect of Tuned Parameters on a LSA MCQ Answering Model both from a cognitive point of view and in practical applications. The design / evaluation of new Multiple Choice Questi ons wit hout the nee d of a cohort of students, at the begin ning of the process, is an exam ple of such an application. So we have built a model capable of answering Multiple Choice Question s, which is a nontrivial problem that has not received enough atten tion even though LSA is frequently used for e-learning and qu estionnaire processing. The model we propose is ba sed on the f ollowing t wo assumptions: (i) each question and its associated three answers are represented by a Bag Of Words, and (ii) the correct answer is the one ou t of three, which has the highest similarity with the question. The results presented below indicate how much these two rough assumptions are effective and what their limitations are. The limite d number of ava ilable term s in Bag Of Words to compute meaningful similariti es, needed to choose the correct answer to the Multiple Choice Questions, determines the difficulty of the task. The small size of our corpora, compared to usual ones ( Quesa da, 2007 ), further increases this difficulty. C. eLSA1 1 : motiva tion for a dedicate d tool Quesada (2007) , in his chapter entitled “Creating Your Own LSA Spaces”, doe s not recomm end building one’s own LSA toolkit becau se of its complexity, and presents the most frequently used LS A softwares (see also Baier, Lenhard, Ho ffmann, & Sc hneider, to be p ublished ; Wil d, 2007 ). Nevertheless, given the com plexity of the links between the successive steps of processing, as well as our desire to monitor in detail the different processing stages, we find it necessary t o develo p our own software i n order to implement some specific algorithms. This Multiple Choice Questi ons dedicated eLSA1 software can be extended to other “semantic” task s in the future as needed. D. Com parison bet ween eLSA1 model and st udents’ performance LSA can be considered as a the ory of meaning ( Kintsch, 2007 ), and as a model of sem antic mem ory ( Denhière & Lemaire, 2004 ). According to this, LSA allows computing the relative importance of textu al statements necessary to summarize a text ( Denhière, Hoareau, Jhea n-Larose, Lehnar d, Baïer, & Bel lissens, 2007 ), or predic ting the eye moveme nts of readers as a function of the relative i mportance of statements ( Tisserand, Jhean- Larose, & Denhière, 2007 ). If the cognitive relevance of LSA for learning and summarizing is generally accepte d, it is yet to be proved in the case of Multiple Choice Questions. So, we will compare the results obtained fro m eLSA1 to the performances of students on the same Multiple Choice 1 The software na me “ eLSA1 ” stands for “enhanced LSA version 1”: small [e]nhancements, big and great [L]atent [S]emantic [A]nalysis. Questions by varying som e properties of t he corpora tha t are known to influence the perform ances of learners such as titles of documents, quantity and nature of information. E. Structure of the pape r The remai ning of this pape r is struct ured as foll ows. The original aspects of the eLSA1 soft ware and the sequence of LSA processing specific to Multiple Choice Questions are detailed in section II . Section III presents the data used in the ex peri ments: corpora, optimized semantic spaces and Multiple Choice Questions. A typology of questi ons and an swers with various form s of “non differentiation” betwee n answers are presented in section IV . Secti on V describes the relative influence of the parameters on the quality of results. Finally, comparisons between the eLSA1 model and the student performances are prese nted in section VI . II. E LSA1 : THE TOOL AND ITS IMPLEMENTATION eLSA1 has been de veloped usi ng Python i nterpreted language f reeware ( Python Soft ware Fou ndation, [Online] ). In addition to the claims of the Python Software Foundatio n in the “About” section of their web site, our motivation to use this prof essional quality and friendly language was (and is) as follow: • Numerous ready to use libraries exist, in particular the numerical matrix calculation library NumPy ( [Online] ) of particular importance for effici ent SVD related heavy computat ions. • Many sets of objects and oper ations are built -in. • Especially clear error messages, leading in general to very easy bug fixing. • Very short developm ent cycle, for a running code. A. eLSA1 features The key eLSA1 features are the followi ng: • co-trigge red (Fre nch) lemm atisati on for a cou ple of words, with the same prefix , based on prede fined pairs of suffices; • joint lemmatisation for both the corpus and t he Multiple Choice Qu estions; • building of a stop list specific to the co ntent of the training cor pus; • entropy global weighting of the Multiple Cho ice Questions answers; • automatic detection of qu estions that lead to “undecidable” answers for the Bag Of Words. B. Co-triggered lemmatisation The effects of stemming and lemmatisation as pre- processing operations of the input vector s pace model for LSA are controversial (see e.g. Denhière et al., 2004 ; Kantrowitz, Mohit, & Mittal, 2000 ), and probably depend on one hand on the quality of this type of pre-processing, and on the other hand on the size of t he used corpora. Stemming a nd lemma tisation are di fferent te chniques that use language dependent w ord morphol ogy for the ve ry same sought-a fter effect: semantically similar words of eLSA1-brm20.doc 07/05/09 09:00 2/9 Effect of Tuned Parameters on a LSA MCQ Answering Model the vocabulary are merged to create a n equivalence class (the stem or the lemma ), traditionally called term, of the vector-space model with less statistical noise; As a consequence of the m erging, the vector space dim ension is reduced. The unifying framework of the equivale nce class of words for a give n term can also be used to take into account a bbreviat ions, syno nymy, etc. To limit the risks of spurious equivalence classes, and for future e xtensions, we develo ped our ow n solution . Our lemmatizer uses rules like Porter’s ste mmer ( Porter, 1980 ; Porter, 2001 ), but triggers words e quivalence by a co-occurrence of predefined su ffices present in eac h pair of words in the corpu s (or in the corpu s and Multiple Choice Questi ons, see next section C ) that share the same prefix. For example, "respire" ( "breathe" ) and "respirons" ( "breathe" ) are respectively singular and plural present form of the ve rb "respirer" ( "to breathe" ) in French. If "e " and "ons" are in a list of component s for perm issible pair of su ffices, mem bership of the sam e equivalent cl ass (the class can be nam ed "respirer" as well for exa mple simply "respire" , the shortest word of the class, for the same subse quent processing an d result) is co-trigge red. In order to f urther limit noise, our lemmatizer tak es into account quite rare exceptions o f co-trigge red rul es. C. Joint lemmatizatio n In LSA, sim ilarity can onl y be compute d between terms that belong to the training corpus. So, the similarity computed between the Multiple Choice Qu estions pseudo-docum ents can only take into acco unt the terms from the t raining corpus . Given that o ur lemmati zation is based on pair s of words, a joi nt lemmati zation was conducted in order to i ncrease the num ber of possible common terms between the corpu s and Multiple Choice Questions, i.e. a lemmatization of the resulting vo cabulary of the trai ning corp us (corpo ra are descri bed in the section III below ) + the Multiple Choice Questions. D. Entropy globa l weighting We start by recalling t he defi nition of entropy global weighting invoked in this p aper for thr ee differen t uses: (i) computer ai ded stop li st design sect ion II E , (ii) specific entropy global weighting of the three Multiple Cho ice Questions answers terms’ for each question section II F , and (iii) (entropy) global weigh ting of the corpus terms section V A . The latter is a classic weighting ( Berry & Browne, 2005 ; Dumais, 1991 ; Harman, 1986 ) of the term vector (entire row) of the terms-by-documents matrix of the vector space model, and which we als o use in this paper (see section V A ): Each term is assigned a global weight indicating its overall importan ce in the corpus. In the case of entropy (or more ex actly 1 – entropy) weighting, this global weight is 1 log( ) 1 log( ) D ij ij i j p p e D = =+ ∑ , with 1 / D ij ij ij j p ff = = ∑ , where is the number of documents and D ij f the term frequency (c ounting) of ter m in document i j . For other uses, alt hough not classical , we employ the same well know property of which by defi nition, va ries betwee n 0 and 1: 0 when the term is present in all do cuments with the same frequency, and 1 when the term is present in only one document. The value of is a measure of informati on given by t he term about all the documents in the co llection. 1( ii e entropy term =− ) ) i i e i E. Computer aide d stop lis t design To be more com pact and effective, a list of stop words has to be specific t o a given c orpus. For building these specific stop lists, we make an original use of the entrop y global weighting 1( i e entropy term = − which va ries between 0 an d 1 (see section II D above ). A good candidate for the stop word list must have low global weighting values, although the co nverse is not necessarily true for specialized corpora as used here. So the following procedure was adopted: (i) eLSA1 lists the first 150-200 terms ranked by increasing values as a candi date stop word list, i e (ii) Filter manually too specialized terms (necessarily a small num ber due to the buil ding process of the can didate list). These corpus specific stop word lists proved to be very effective (see Table 6 and Table 7 below ), solely requiring to ins pect very few words. F. “3-set entropy weig hting”: a specific entropy global weighting of Multiple Cho ice Questions answers In our model of Multiple Choice Questions, the question and each of the t hree answers are pseudo- document s ( Martin & Berry , 2007 ). Each pseudo- document “ans wer” is compared to t he pseudo-docum ent “question” in the sem antic sp ace of the training corpus . To produce t hese pseudo-do cuments, it is recommended to use weighti ngs which we re used for the corp us ( Martin & Berry, 2007 ). However, give n that in this case we have a reduced number of terms, their frequencies have little significance. Fortunately, we can make profit of the following Multiple Choice Questions specificity: there are three concurrent answers for the sam e question. This m akes it possible to apply again entr opy global weighting (1 - entropy) (see again section II D above ) to the three ans wers as a whole eLSA1-brm20.doc 07/05/09 09:00 3/9 Effect of Tuned Parameters on a LSA MCQ Answering Model “micro-collection” instead of consid ering them individually: the con trast of the terms differentiating the most the three answers is increased, with the very beneficial effect expected on the results (see Table 6 and Table 7 below ). III. C ORPORA AND M ULTIPLE C HOICE Q UESTIONS A. Corpora Four French corpora dealing with the 7 th grade Biology program were built from two different sources: public scholar book (C ) and private rem edial course (M), either in a “basic” (Cb and M b) format restricted to the content of the course , or in an ext ended (Ce an d Me) versio n containing de finiti ons and expl anations of the concept s and some addi tional releva nt inform ation. Tw o chapters dealing with «Respiration» were extracted from the part “Functioning of the body a nd the need for energy”: “muscular activity and the need for energy” and “The need of orga ns for dioxyg en in the air”. T he main characteristics of these 4 corpora are presented in Table 1 . T ABLE 1 C ORPORA DATA Without Titl es With Titles Corpus Docs Tokens Word s Terms Tokens Words Terms Cb 149 *11799 1944 1418 14298 1972 1433 Ce 425 *34331 4664 3174 40295 4729 3216 Mb 191 15169 1362 966 *19138 1377 976 Me 294 23549 1560 1072 *29663 1576 1083 Legend: Docs = documents (pa ragraphs in our case), Words = uni que tokens (vocabulary ), Term s = class of words after lemmatisation. * See section V A . The essential characteristics of the vec tor spaces filtered by the specific stop lists (see section II E above ), used in our experiments are presented in Tabl e 2 . T ABLE 2 V ECTOR SPACE MODELS PROPE RTIES USING LEMMA TISATION AND STOP LISTS Corpus Stop list words => terms Words =>Terms TxD Matrix Sparsity Cb 67 => 35 1877 => 1383 2,14% Ce 83 => 39 4581 => 3135 1,00% Mb 66 => 37 1311 => 939 3,42% Me 64 => 34 1512 => 1049 3,02% Appendi x A exhibits, as an exam ple, the stop list used with the Cb corpus. B. Multiple Cho ice Questions MCQ31 Table 3 displays statistics for the French MCQ3 1 considered as a whole co rpus. As there are 31 que stions, the number of (mini-)documents (with very few terms) is 124=31*(1 question+ 3*answ ers). The la st two col umns are the number of words an d terms of MCQ31 present in interaction with different corpora. T ABLE 3 MCQ31 VECTOR SPACE MODEL USI NG JOINT LEMMATISATI ON Corpus Questions Docs Tokens Words Terms Words in corpus Terms in corpus Cb 31 / 124 1311 307 255 224 188 Ce = = = = 241 203 Cb = = = = 225 187 Ce = = = = 230 191 These very few term s, and only them, are involve d in building pse udo-docum ents to (try to) find the 31 correct answers to questions. This Multiple Choice Question s has been supp lied by Maxicours , a private course enterprise with whom two of the authors (S. J-L & G.D.) collaborate in the context of the Infom@gic project sup ported by the competitiveness pole of the Île de France Region. This Multip le Choice Questions was designe d before one of the authors (A. L.) implem ents eLSA1 . More deta ils are given al ong the section IV . IV. T YPOLOGY OF M ULTIPLE C HOICE Q UESTIONS QUERY / ANSWERS To conduct a useful experi ment, we ha ve to take int o account the consistency between the ba sic assumptions of our model and Multiple Cho ice Questions data, namely: • Each question and each answer of the Mu ltiple Choice Questions i s represented by a B ag Of Words. • The correct answer is the one, from the three candidates, wh ich has the hi ghest simi larity with the question. This leads us t o introduce a t ypology of q uestions / answers and reject the questions that are inconsistent with the model. A. Out of subject que stions Two questions (no. 29 and 36) of the initial 38 questions of Multiple Choice Questions are rejected because they are related to topics which are no longer treated in our corpora, like the use of the cigarette and t he associated harmful effects: c orrespondin g words are not even present in the vocabulary of the corpora. B. Question / answers lack of correlation Question no. 7 is character ized by an absence of correlation (meaning of t he textual contents ) between the question an d the answers. This contradicts the basic assumptions of our m odel: « Parmi les trois affirmatio ns suivantes, une seule es t juste. Laquelle ? » (“Among the three following assertions only one is rig ht. Which one?”). C. Bag Of Words und ecidabilities of answers 1) Hard undecidability The loss of words ’ order due t o the Bag Of Words can easily lead to undecidable answers . We define undecidable answers as follows: whe n a correct answer eLSA1-brm20.doc 07/05/09 09:00 4/9 Effect of Tuned Parameters on a LSA MCQ Answering Model and at least an incorrect answer have identical Bag Of Words, hard undecidability occurs. We call this undecidability “hard” to distinguish it from the “soft ” one descri bed later. For example, question no. 24 leads systema tically (whatever the corpus is, with or without lemmatisation) to the fo llowing situation: RMCQ24 best: 1 ref: 3 => 2, 3 hard undecidable for a bag of words. Question 2 , 3 : [What] is the [exchange] [direction] of [respiratory] [gases] [occurring] at the [air ] [cells] [level]? 1) The [carbide] [dioxide] [leaves] the [alveolar] [air] to [reach] the [blood]. 2) The [dioxygen] [leaves] the [blood] to [reach] the [alveolar] [air]. *3) The [dioxygen] [leaves] the [alveolar] [air] to [reach] the [blood]. eLSA1 has a utomati cally pointed out that 4 quest ions (8 , 24, 30, 35) are “hard undeci da ble” for the Bag Of Word s. It is illusory to seek to distinguish the correct an swer among ide ntical represent ations, no matter whi ch algorithm is used. 2) Soft undecidability The previous undecidability was qualified as “hard” because it leads to undecida bility between correct and incorrect answers. There is another kind o f undecidability with less se rious conse quences. We defin e this kind of undecidable a nswer as foll ows: when two incorrect answers have identical Bag Of Words, soft undecidability occurs. For exam ple, the answers to quest ion no. 38 undergo this soft undecidability. This occurs because the corpus Cb does not in clude the word "thermometer" or the word "oscilloscope" (these words are ou t the corpora main subject “Respiration”) and that "the" is a stop word: RMCQ38 best: 2 ref: 2 :-) => 1, 3 soft undecidable for the bag of words. Question: [What] [apparatus] allows to [measure] the [quantity] of [dioxygen] in an [environment]? 1) The thermometer. *2) The [oxymeter]. 3) The oscilloscope. With such s oft undecidabl e questions , as oppose d to hard undecidabl e ones, eLSA1 is potentially able to choose the correct answer; th erefore, thes e questions are not discarded. 3) Stop w ords and lemm atization si de effect Stop words and lemm atization necessarily reduce the diversity of words in c orpora. Thi s reducti on of the vocabulary, in spite o f its very beneficial e ffects (as ca n be seen in the next section), can create undecidability; 2 Given that training corpora and Multiple Choice Questions are in French, eLSA1 output logs concerning these data are translated. 3 Words involved in Bag Of Words are bracketed. therefore, undecidability detection of eLS A1 remains activated durin g all our expe riments as a protecti on. Finally, we ha ve to reject 7 que stions (no. 7, 8, 24, 29, 30, 35 and 36 ). Therefore , for all t he following experim entations we use only a 31 que stions s ubset, MCQ31, from the original 38 questions Multiple Choice Questions. V. R ELATIVE INFLUENCE OF THE PARAMETERS A. Experimenta l conditions Here we give the results of optimization (maximum number of c orrect answers) obtained by va rying the m ain parameters. Due to the inte rdependence betwee n the parameters ( Wild et al., 2005 ), we exam ined the discrepancy fr om the best sc ore, one pa rameter at a t ime. Since most authors confirmed that the best resu lt is obtained fr om the product of t he local function log( 1 ) ij f + (see section II D for notation) with the entropy glo bal weighti ng ( Berry & Browne, 2005 ; Dumais, 1991 ; Harman, 1986 ) (see also section II D ), the resulting so-called classical “lo g-entropy weighting” was used to build the terms-by-documents matrix. Table 4 below summarizes the choice of pa rameters for the best score (m aximum num ber of correct ans wers) for each of the four corpora: • “Titles”: In Table 4 below “-“ means obtained without paragraph titles for the corpora Cb / Ce and “+” with titles for Mb / Me ( Table 1 above ). Table 6 and Table 7 below “select the worst choice for each parameter from the best score tuning”: So “Titles” means, in these tables, “was used (or not )” at the opposite (but in consiste ncy) of the select ion in Table 4 . • “Document Normalisation” refers to the normali sation of col umns (docum ent vectors) i n the terms-by -document s matrix bef ore apply ing log- entropy weig hting. • “Joint Lemmat isation” ( II C ) is the special consequence of the co-tri ggered lemmatisation ( II B ). • “Frequency Norm alisation” means that the sum of frequencies t hat are compone nts of docum ent vectors, is normalized to 1 (empirical probabilities) before log-entropy weigh ting is applied. • “3-set entropy weighting” in Table 4 , Table 6 and Table 7 means that the weighting sc heme described in section II F was used (or not) for the three answers associated to each que stion. • “Stop words”: Use of a stop words list designed as in II E . • “LSA truncation”: Selection of t he right dim ension of the Semantic Space following I A and V B . eLSA1-brm20.doc 07/05/09 09:00 5/9 Effect of Tuned Parameters on a LSA MCQ Answering Model T ABLE 4 B EST SCORE PARAMETERS SEL ECTION FOR EACH CO RPUS Corpus Parameter Cb Ce Mb Me Titles - - + + Document Normalisation - - - - Joint Lemmatisation + + + + Frequency Normalisation - - - - 3-set entropy weighting + + + + Stop words + + + + LSA truncation + + + + In the case of corpora Mb and Me, if no joint lemmatisation is done, eLSA1 detects an occurrence of hard undecidability for th e first two answers of question no. 6 even if the corr ect one is found by chance, just because the cosine betwee n the question and the answer has the same value for both answers a nd the first is chosen by default: RMCQ06 best: 1 ref: 1 :-) => 1, 2 hard undecidable for a bag of words. Question: [What] are the [movements] of the [ribs] and the [diaphragm] during [expiration]? *1) The [ribs] [lower] and the [diaphragm] raises. 2) The [ribs] and the [diaphragm] [lower]. 3) The [ribs] [heave] and the [diaphragm] [lower]. As the word "raise" in the first answer in not present in the Mb and Me corpora, the Bag Of Words of answe rs 1 and 2 are identical, leading to hard undecidab ility described above (see section IV C ). On the other hand, if the join t lemmatisation occu rs between the Multiple Ch oice Questions and the corpus, the word "risen" of the cor pus and the w ord "raise" of the answer fall in the same class "raise" . The Bag Of Words of the a nswers 1 and 2 become discernible: *1) The [ribs] [lower] and the [diaphragm] [raises]. 2) The [ribs] and the [diaphragm] [lower]. So the results without lemmatisation for co rpora Mb / Me are not present in Table 6 and Table 7 below 4 . B. Semantic spaces The essential characteristics of the resulting semantic spaces, used in the experiments, are presented in Table 5 below and th e Figure 1 depicts the var iation of the number of c orrect answers versus the sem antic space dimensionality of the Cb corpus as an example. 4 This example shows the relevance of the joint lemmatisation, not only for adding semantics when one wor k s with relatively few words, but also in our case to limit the risk of parasitic pheno mena, such as hard undecidability. Nevertheless, this does not mean that the correct answer will be found in this particular case. T ABLE 5 S CORES ACCORDING TO THE S EMANTIC SPACE DIMEN SIONS Best Reduction No Reduction Worst Reduction Corpus Dim Cor. Ans. Dim Cor. Ans. Dim Cor. Ans. Cb 14 27 / 31 149 18 / 31 148 16 / 31 Ce 13 25 / 31 425 17 / 31 3 15 / 31 Mb 5 22 / 31 191 14 / 31 191 14 / 31 Me 5 22 / 31 294 13 / 31 294 13 / 31 Legend: Dim = dimensionality, Cor. Ans. = number of correct answers. 15 17 19 21 23 25 27 29 2 13 24 35 46 57 68 79 90 101 112 123 134 145 Semantic space dimensionality Score ,, Figure 1. N umber of correct a nswers as a f unction of t he number of dimensions of the Cb semantic space, for the best setting of other parameters. C. Results Normali sations of d ocuments and t erm freque ncies have a negative effect on the results. The positiv e role of the recommended ( Wild et al., 2005 ) pre-pr ocessing features of the vector space model (before Singular Val ue Decomposition) is confirmed: the “injection” of external semantic by lemmatisation and stop word lists partially compensates for the low size of training corpo ra and low number of terms in Multiple Choice Question s. The optimal truncation (num ber of dim ensions) of t he semantic space and the stop wo rd list play a m ajor role (see Table 6 and Table 7 below ). Entropy weighting specific to our problem (s ee discussion in section II F ) has an important influence f or two corpora C b and Ce, w hich those are leading to the best Multiple Ch oice Questions answering scores. eLSA1-brm20.doc 07/05/09 09:00 6/9 Effect of Tuned Parameters on a LSA MCQ Answering Model T ABLE 6 N UMBER OF CORRECT ANSWER S , FOR ONE PARAMETE R AT A TIME UNSET , FROM THE BEST SCORE ( FO R 31 QUESTIONS ) Corpus Cb Ce Mb Me Best score 27 25 22 22 Parameter Titles 26 25 21 19 Document Normalisation 24 23 20 18 Joint Lemmatisation 24 22 - - Frequency Normalisation 22 21 20 19 3-set entropy weighting 22 22 18 17 Stop words 18 20 16 16 + Relative Influ e nce - LSA truncation 18 17 14 13 Table 7 is a twin of Table 6 where disc repancy in number of correct a nswers from the best score is ex pressed in percentage. T ABLE 7 I NDIVIDUAL RELATIVE CONTRI BUTIONS , FOR ONE PAR AMETER AT A TIME , TO THE BEST SCOR E Corpus Cb Ce Mb Me Parameter Titles 3,7% 0% 4,5% 13,6% Document Normalisation 11,1% 4% 9,1% 18,2% Joint Lemmatisation 11,1% 12% - - Frequency Normalisation 18,5% 16% 9,1% 13,6% 3-set entropy weighting 18,5% 12% 18,2 % 22,7% Stop words 33,3% 20% 27,3 % 27,3% + Relative Influ e nce - LSA truncation 33,3% 32% 36,4 % 40,9% D. About the best low dimensionality The best scor e is obtained for relatively low values of the semantic space dim ensions ( Table 5 , Figure 1 ), which is quite unusual in LSA practice. Wild et al. (2005) , who also obtained lo w dimensionalities, deal with the question of the best d imensionality, which remains open since about 20 years: for a long ti me, “magic” values such as 100-300 ( Du mais, 1991 ) or even 50-1500 ( Quesada, 2007 ) were proposed in the literature. Today, we are turning to quite bette r founded st atistical m ethods ( Dum ais, 2007 ; Efron, 2005 ; Ding, 1999 ). For example Wild et al. (2005) give fou r simple methods which apparently rem ain little used. The simplest is to consider a fraction (1/50) of the nu mber of terms: application of this rule to each corp us ( Table 1 above ) leads to 28, 63, 19, an d 21, respectively, which appears to be a correct order of m agnitude in comparison to experimental results in Table 5 ( above ) and is satisfactory given t he easiness of use. We can try to explain intuitively the “latent” (not given in their paper) basic idea justifying this rule: The degr ee of liberty of the term-by-document matrix is its rank r min(number of term s, numbe r of docume nt s) r ≤ Recalling that the dimension of the eigen spaces of term s and documents correlation matrix are the same, for a given mean “degree of correlation” be tween terms (respectively documents), in the textual data, the usefu l dimensionality of the sem antic space is a quasi constant fraction of r , let say 1/30-1/50 empirically. We just suggest substitutin g the above m to “number of terms”, of Wild rule, for a better generality. in( ... ) Let us now m ake some comments and assum ptions concerning th is point of our results: • The fact that we can ca rry out, due to the small size of data in our case, an exhaustive scanning of t he interval of dimensionality eliminated totally the risk of a false optimum as an artifact in partial scanning. • The optim al dimension m ust not be completely independent of the task eval uating it, i.e. it does not rely solely on the corpus: in our case, there would be a filtering of the dimensiona lity by the low number of concepts d enoted by the 31 qu estions of the Multiple Choice Questions . • The high redundancy of the restricted scop e corpora Mb and Me i nduces, fr om a num erical point of view, a relative povert y of concepts (conceptual foc using), and consequentl y of the num ber of important singul ar vectors (dimensionality), in comparison with the more general scope corpora Cb and Ce. T his leads to very small dimensionality 5 as seen in Table 5 above . VI. E XPERIMENTATION WITH STUDENTS A. Participan ts and tasks Two classes of 7 th and 8 th grades participate in the three phases of the e xperimentation: pa per and penci l questionnaire, «classic» and «evidential» Multip le Choice Questions ( Diaz, 2008 ) and free answer questions ( Jhean- Larose, Leclercq, Diaz, Denhière, & B ouchon-Meunier, submitted for publication ) on the chapters about «Respiration» from t he 7 th grade biology program . Two equal 7 th and 8 th grades groups were formed according to the results of t he paper and pencil question naire, one assigned to the «evidential» Multiple Choice Questio ns (number of questions = 26) a nd the other assigned to the «classic» Multiple Choice Questions (number of questions = 29). This «classic» Multiple Cho ice Questions was com posed of 38 questions, each of which has three candidate answers. B. 7 th and 8 th grades results The mean percentages of correct answers of 7 th and 8 th grades were very similar (79.5% and 81.2 %) and the distributions of their performances we re close as shown by the significant correlatio n between their results (r = 0.89, p < .01). For example, the 9 questions that lead t o the worst results (one standard deviat ion below the m ean) eLSA1-brm20.doc 07/05/09 09:00 7/9 Effect of Tuned Parameters on a LSA MCQ Answering Model are comm on to both groups (no. 4, 6, 7 , 8, 9, 1 4 , 23, 24, 34). C. eLSA1 undecidability of answers and student results We should notice that the 7 question s eliminated by eLSA1 (see section IV ) are among the questi ons that lead to the lowest 7 th and 8 th grades’ perform ances: 69 and 70% respectively. The mean percentage of correct answers of eLSA1 with the Cb 149-14 sema ntic space (27/31 = 87%) is higher than the students’ p erformances, while the results with the Ce 425-13 se mantic space (25/31 = 81%) is equal t o the students’ pe rformances. Performances of eLSA1 with the Mb 191-5 and Me 294-5 semantic sp aces (22/31 = 71%) ar e lower than the 7 th and 8 th grades’ perform a nces. At this tim e we don’t have a totally satisfactory ex planation of this. D. Correlation between eLS A1 and the students’ performances The correlat ions between t he angle values corresponding to the cosines 5 affected by eLSA1 to the three answers of t he remainin g 31 questions a nd the frequency of choice of these answers by t he 7th and 8th grade s’ are presen ted in Table 8 . These correlations indicate a significantly stron g link between eLSA1 and students’ pe rformances. T ABLE 8 C ORRELATION BETWEEN E LSA1 AN D THE STUDENTS ’ PERFORMANCES Corpus Grade Cb Ce Mb Me 7 th grade .66 .56 .58 .47 8 th grade .59 .51 .54 .51 7 th +8 th grades .63 .55 .57 .48 VII. C ONCLUSIONS The strong correlations between eLSA1 and stude nts’ performances ( VI C and D above ) are e n couraging despite the simplici ty of our model. We have demonst rated that LSA can be used to analyse Multiple Choice Questions and that its performances are similar to the students’ results. A special glob al entropy weighting of answers for each question of Multiple Choice Que stions, which we call “3-set entropy weighting”, is proved necessa ry to achieve the model' s success. The dedicated t ool eLSA1 enables us to build a typo logy of Multiple Choice Questions answers and to take into account their specificity. The m odel we have pro posed can be easily improved to deal with more complex tasks. For example, automatic selection of a different strateg y to find the correct answer in case of que stion / answers lack of 5 We substitute cosines with their vector angles, in order to be more linear, and thus probably nearer to th e spreading of the student answers’ distribution. correlation: searching for the answer which has the strongest cosi ne against all document s of the traini ng corpus instead of the second assum ption of our simple first model (see section I B ). The relative importance of parameters that significantly influence the quality of semantic sp aces is a useful indication to orient futu re work. A UTHOR NOTE We would like to thank Mr Patenotte , headmaster, Mrs Linhart, assistant head and Mrs Lopez and Lechner, professors, for allowing us to use the computing means of the Jean-Baptiste Say College (Paris) necessary for our work with their students. We also would like to thank Murat Ahat, from LAISC laboratory, EPHE-Paris, for his help in translating this paper, as well as Nicolas Usunier , Maha Abdallah and Marc-Ismaël Jeannin-Akodjènou of LIP6 for th eir very attentive and kind proo f reading of this paper. We are grateful to the two r eviewers which help us to improve this docum ent. Correspondence concerning this article should be addressed to A. Lifchitz, LIP6 - DAPA, Université Pierre et Marie Curie, CNRS, 104, avenue du président Kennedy F-75016 Paris, France (e-mail: alain.lifchitz@lip6.fr ). A PPENDIX A. S TOP WORDS 67 stop word s / 35 stop lemmatized t erms (bold w ords) list (lexicographic sort) used for Cb corpu s: « ai, au, auraient, aurait, aux, avait, avec, avoir, avons, ce, ces, ce t, cet te, chez, comme, dans, de, des, du, en, est, et, ét aient, était, été, être, grâce, il, ils, la, le , les, leur, leurs, ne, on , ont, ou, par, pas, permet, per mettant, permett ent, permis, peut, peut-on, peuvent, plus, pour, qu, quand, que, qui, sa, se, ses, soient, soit, sont, sous, suis, sur, très, u n, une, unes, vers ». R EFERENCES B AIER , H., L ENHARD , W., H OFFMANN , J., & S CHNEIDE R , W. (submitted for publication, 2008). SUMMA – A LS A Integrated Development System. Special edition of Mobile Ad-hoc NETworkS (MANETS) . B ERRY , M. W., & B RO WNE , M. (2005). In Understanding search engines: Mathematical modeling and text retrieval (Software, Environments, & Tools) , (2nd ed.) ( pp. 34-38). Philadelphia: SIAM. D EERWESTER , S., D UMAIS , S. T., L ANDAUER , T. K., F URNAS , G. W., & H ARSHMAN , R. (1990). Indexing by Latent Semantic Analy sis, Journal of the American Society of Information Science , 41 , 391-407. D ENHIÈRE , G., & L EMAIR E , B. (2004). Representing children's sem antic knowledge from a multisource corpus. In Proceedings of 14th Annual Meeting of The Society for Text and Discourse , Chicago, NJ: Erlbaum. D ENHIÈRE , G., H OAREAU , V., J HEAN -L AROSE , S., L EHNARD , W., B AÏER , H., & B ELLISSENS , C. (2007). Human Hierarchization of Semantic Information in Narr atives and La tent Sema ntic Analysis. In Proceedings of the 1st Internati onal Conference on Latent Semantic Analysis in Technology Enhanced Learning (LSA -TEL'07) , Heerlen, 15-16. D IAZ , J. (2008). Diagnostic et modélisation de l'utilisateur : prise en compte de l'incertain (in French). Thèse de Doctorat , Université Pierre et Marie Curie, Paris. D IAZ , J., R IFQI , M., B OUCH ON -M EUNIER , B., J HEAN -L AROSE , S. , & D ENHIERE , G. (2008). Imperfect Answers in Multiple Choice Questionnaires. In Proceedings of 3rd European Conference on Technology-Enhanced Learning (EC-TEL 2008) , Maastricht, In Dillenbourg, P., & Specht, M. (Eds.), Lecture Notes in Computer Science , 5192 , 144–154, Heidelberg: Springer- Verlag. D ING , C. H. Q. (1999). A Similarity-based Probability Model for Latent Semantic Indexing. In Proceedings of the 22 nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR'99) , Berkeley , 58–65 D UMAIS , S. T. (1991). Im proving the retrieval of information from external sources. Behavior Research Methods, Instruments, & Computers , 23 , 229–236. D UMAIS , S. T. (2007). LSA and Inform ati on Retrieval: Getting Back to Basics. In T. K. Landauer, D. S. McNamara, S. Dennis, W. Kintsch eLSA1-brm20.doc 07/05/09 09:00 8/9 Effect of Tuned Parameters on a LSA MCQ Answering Model eLSA1-brm20.doc 07/05/09 09:00 9/9 (Eds.), Handbook of Latent Semantic Analysis (pp. 293-321) . NJ: Erlbaum. E FRON M. (2005). Eigenvalue-Based Model Selection During Latent Semantic Indexing. Journal of the American Society for Information Science and Technology , 56 , 969-988 G RAESSER , A. C., W IEMER -H ASTINGS , K. , W IEMER -H AS TINGS , P., K REUZ , R., & T UTORING R ESEARCH G ROUP . (1999). AutoTutor: A simulation of a hum an tutor. Cognitive Systems Research , 1 , 35-51. H ARMAN , D. (1986). An experime ntal study of the factors im portant in document ranking. In Proceedings of the 9th annual international ACM SIGIR Conference on Research and Development in Information Retrieval , Pisa, 186-193. J HEAN -L AROSE , S., L ECLERCQ , V., D IAZ , J., D ENHIÈRE , G., & B OUCHON -M EUNIER , B. (sub mitted for publica tion, 2008). Knowledge evaluation based on LSA: MCQs and free answer questions. Special edition of Mobile Ad-hoc NETworkS (MANETS) . K ANTROWITZ , M., M OHIT , B., & M ITTAL , V. O. (2000). Stemming and its effects on TFIDF ranking. In Proceedings of the 23rd Annual International ACM SIGIR'2000 Conference on Research & Development in Information Retrieval , Athens, 357-359. K INTSCH , W. (2007). Meaning in Context. In T. K. Landauer, D. S. McNamara, S. Dennis, W . Kintsch (Eds.), Handbook of Latent Semantic Analysis (pp. 89-105). NJ: Erlbaum . M ARTIN , D. I., & B ERRY , M. W. (2007). Mathematical Foundation Behind Latent Semantic Analysis . In T. K. Landauer, D. S. McNamara, S. Dennis, W . Kintsch (Eds.), Handbook of Latent Semantic Analysis (pp. 35-55). NJ: Erlbaum . NumPy. [Online]. Available: http://numpy.scipy.org/ P ORTER , M. F. (1980). An algorithm for suffix stripping. Pr ogram , 14 , 130-137. P ORTER , M. F. (2001). Snowball: French stemm i ng algorithm. [Online]. Available: http://snowball.tartarus.org/algorithms/french/stemmer.html Python Software Foundation. [Online]. Available: http://www.python.org/about/ Q UESADA , J . (2007). Creating Your Own LSA Spaces In T. K. Landauer, D. S. McNamara , S. Dennis, W. Kintsch (E ds.), Handbook of Latent Semantic Analysis (pp. 71-85). NJ: Erlbaum . S ALTON , G. , & B UCKLEY , C. (1988). Term -weighting approaches in automatic text retrieval. Information Processing & Management , 24 , 513-523. S ALTON , G., W ONG , A., & Y ANG , C. S. (1975). A Vector Space Model for Automatic Indexing. Communic ations of the ACM , 18 , 613–620. (The article in which the vector space model was first presented). T ISSERAND , D., J HEAN -L AROSE , S., & D ENHIERE , G. (2007). Eye movement analysis and Latent Sem a ntic Analysis on a Comprehension and Recall Activity. In Proceedings of the 1st International Conference on Latent Semantic A nalysis in Technology Enhanced Learning (LSA-TEL’07) , Heerlen, 17-19. W ILD , F. (2007). An LSA Package for R. In Proceedings of the 1st International Conference on Latent Semantic Analysis in Technology Enhanced Learning (LSA-TEL '07) , Heerlen, 11-12. W ILD , F., S TAHL , C., S TERMSEK , G., & N EUMANN , G. (2005).Parameters Driving Effectiveness of Autom ated Essay Scoring with LSA. In Proceedings of the 9th CAA Conference , Loughborough.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment