FINE: Fisher Information Non-parametric Embedding
We consider the problems of clustering, classification, and visualization of high-dimensional data when no straightforward Euclidean representation exists. Typically, these tasks are performed by first reducing the high-dimensional data to some lower…
Authors: Kevin M. Carter, Raviv Raich, William G. Finn
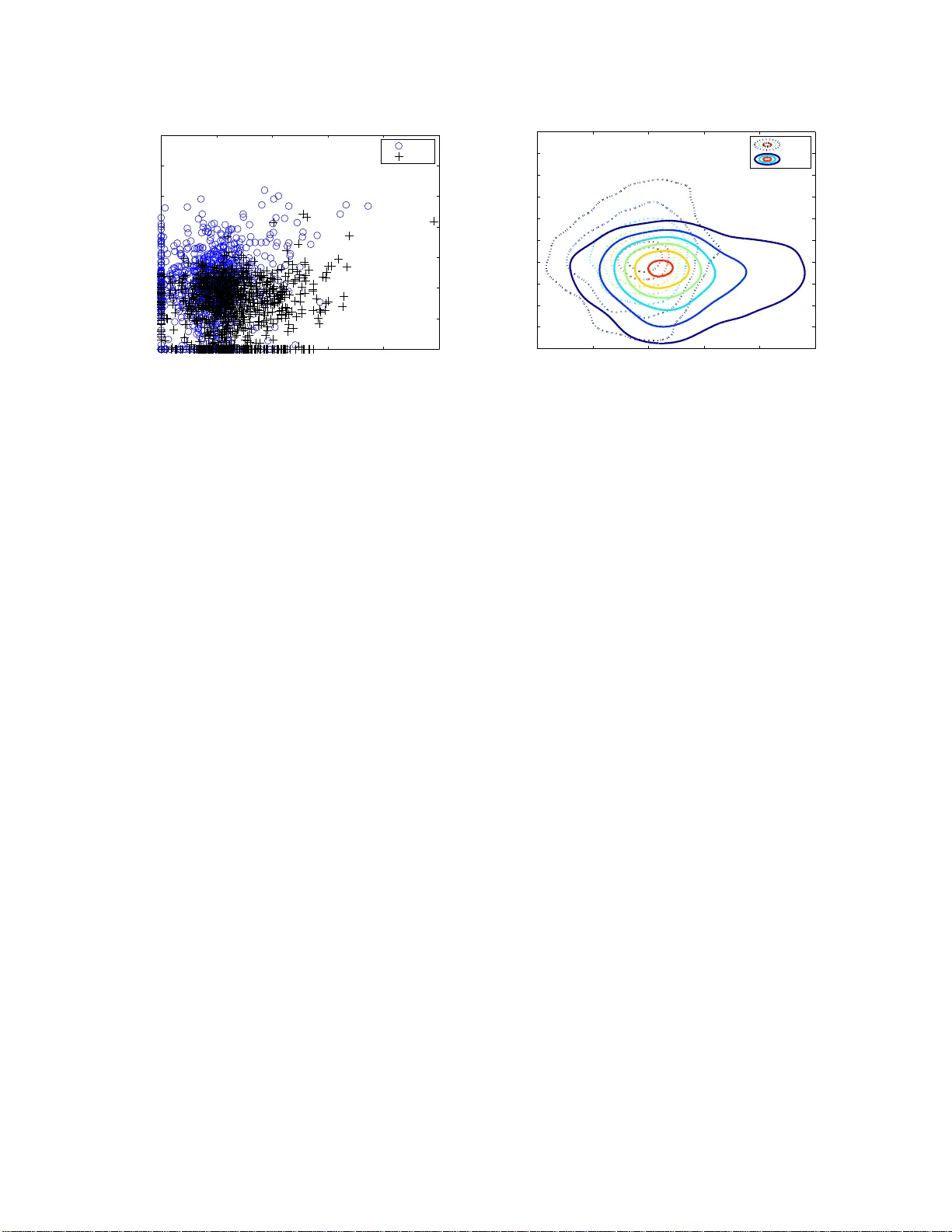
1 FINE: Fisher Information Non-parametric Embedding Ke vin M. Carter 1 , Ra v iv Raich 2 , W illiam G. Finn 3 , and Alfred O. Hero III 1 1 Department of EECS, Univ ersi ty of Michigan, Ann Arbor , MI 48109 2 School of EECS, Oregon State Uni versity , Corv all is, OR 97331 3 Department of Pathology , Uni versity of Michigan, A nn Arbor , MI 48109 { kmcarter,wgfi nn,hero } @umic h.edu , raich@eecs.oreg onstate.edu Abstract W e co nsider the pr oblems of clu stering, classification, an d visualization of high-d imensional d ata when no straig htforward Eu clidean repr esentation exists. T ypically , these tasks are p erform ed b y first reducing the high-d imensional data to some lower d imensional Euclidean space, as many manifo ld learning methods hav e been developed fo r this task. In many p ractical problem s however , the assumption of a Euclidea n man ifold can not be justified. In these cases, a m ore appropr iate assumption would be that the data lies on a statistical man ifold, o r a manifo ld of pro bability d ensity functio ns (PDFs). In this paper we propose using the proper ties of informa tion geometry in order to define similarities between data sets using the Fisher information metric. W e will show this metric c an be approximated u sing en tirely non-p arametric me thods, as the param eterization of the manif old is gen erally un known. Fur thermor e, by usin g multi-d imensiona l scalin g meth ods, we are able to em bed th e co rrespon ding PDFs into a low- dimensiona l Euclidean space. T his not only allows for classification of the data, but also v isualization o f the man ifold. As a whole, we refer to our framework as Fisher Info rmation Non-para metric E mbedd ing (FINE), and illustrate its u ses on a variety o f practical pro blems, in cluding bio- medical app lications a nd docume nt classification. I . I N T RO D U C T I O N The fields of statistical learning a nd machine learning are use d to s tudy p roblems of inference, whic h is to say g aining knowledge throug h the con struction of models in orde r to make decision s or predictions based on obse rved data [1]. Sta tistical learning examines problems such as obs erving n atural ass ociations between da ta se ts (clustering), a nd p redicting to which class of known groupings an unlabeled d ata s et belongs (class ification), based on some mode l defined by a priori k nowledge of t h e data. Machine lea rning Acknowledgement : This work is partiall y funded by the National Science Foundation , grant No. CCR-0325571. February 12, 201 3 DRAFT 2 introduces a non-parametric approach to thes e learning tasks via model-free learning from examples. Recent work o n manifold lea rning a ims at the high dimens ion regime, in which exa mples are g overned by geometrical con straints effecti vely reducing the dimen sion of the prob lem from a high extrinsic dimension to a low intrinsic d imension. On the other hand, information geo metry aims a t u nderstanding the s tructure of statistical models and introduces a geometric perspectiv e to inference problems [2]. W e are interested in the cross section of the three fields; using the principles of each to so lve prob lems that do not fi t within the framew ork of any of the ind i v idual fields. Often da ta does no t exhibit a low intrinsic d imension in the da ta domain as on e would have in manifold learning . A straightforward strategy is to express the da ta in terms of a low- d imensional feature vector for which the curse o f dimensionality is alleviated. This initial proces sing of d ata as real-valued feature vectors in Euc lidean spac e, which is often ca rried out in an ad hoc manner , h as been called the ”d irty laundry” of machine learning [3]. This procedure is highly depe ndent o n having a good mod el for the data a nd in the absen ce of suc h model may be highly subo ptimal. Wh en a statistical model is av a ilable, the proce ss of o btaining a feature vector can be done op timally by extracting the mo del parame ters for a giv e n da ta set and thus c haracterizing the da ta through its lo wer dimensional parameter vec tor . W e are interested in exten ding this app roach to the case in which the d ata follows an unknown p arametric statistical model. While the problem o f learning in a Euc lidean spac e is we ll defi ned, there a re many proble ms in which the da ta cannot be approp riately rep resented by a Euc lidean manifold, and the model parameters a re unspec ified and must be learned through the data. In flow cytometry , pathologists study blood samples containing ma ny cells taken from a patient. Each individual cell is ana lyzed with diff e rent fluoresc ent markers, resulting in a large, high-dimension al data set. This is as sumed to b e a rea lization of s ome overridi n g parame tric model, but the model p arameters a re unk nown. Pathologists des ire the ability to appropriately clas sify patients with differi n g a ilments that may express similar responses to the se markers. For the p urposes of analysis and visua lization, it is then necess ary to reduce the dimensionality of these sets. The problem of document classification is one in wh ich the data is clea rly non-Euclidean , as each set is a collection of words from a dictionary . It is still desired to dis tinguish betwee n docu ments by forming clusters of different s imilarities. A standard method is to form a prob ability distribution over a dictionary and use methods of information g eometry to determine a similarity between da ta sets [4]. Applications of statistical ma nifolds have a lso bee n pres ented in the cases of face recogn ition [5], texture segmentation [6], image an alysis [7], and s hape analysis [8]. A co mmon theme to all of the problems presented ab ove is that the model from which the data is generated is unkn own. In this paper , we pres ent a framew ork to han dle such problems. Specifica lly , we focus on the cas e whe re the d ata is high-dimens ional an d no lower dimensional Euclidean manifold giv es a sufficient de scription. In many of thes e cas es, a lo we r dimens ional s tatistical manifold ca n be used to asses s the data for various learning tasks. W e refer to ou r framew ork as Fisher Information No n- February 12, 201 3 DRAFT 3 parametric Embedd ing (FINE), and it inc ludes charac terization o f data sets in terms of a non-pa rametric statistical model, a geodesic a pproximation of the Fisher information distance a s a metric for evaluating similarities between data sets , and a dimen sionality reduction procedure to obtain a low-dimensional Euclidean embedd ing of the o riginal high-dimensiona l d ata s et for the purpos es of bo th class ification a nd visualization. Statistical ma nifolds in both the pa rametric and non-parametric settings have been we ll disc usse d [9], [10]. Our work diff e rs in that we as sume the manifold is de ri ved from so me natural pa rameterization, only that se t of parame ters is unknown. There has be en much work p resented on the us e of s tatistical manifolds [4], [7], [11], [12] an d information geometry [13], [14] in learning problems, a ll propo sing alternatives to using Euc lidean ge ometry for data mod eling. T hese method s foc us on clustering and clas sification, and do n ot explicitly add ress the prob lems o f dimensionality reduction (embe dding each s et into a low- dimensional Euclidea n spac e) a nd visualization. Additionally , they focus on p arameter estimation as a neces sity for their methods , a s oppo sed to our work wh ich is p erformed in a non-parametric setting. W e provide a start-to-finish framework which enables a nalysis of high-dimension al data through n on-linear embedding into a low-dim e nsional space b y information, not Euclidean , geome try . Our methods require no exp licit mode l assump tions; only than that the gi ven data is a realization from an unknown model with some natural parameterization. Recent work by Lee et al . [15] s imilar to our own [16], [17] has demon strated the use of statistical manifolds for dimensionality reduction. Whil e ea ch work has been dev elop ed i n depend ently a nd originally presented at ne arly the same time, they share enoug h similarities that we now express the different contributi o ns of o ur own work. Specific ally , we con sider the work presented by Lee e t al . to be a specialized case o f our more general framew ork. They foc us on the specific case of image segmentation, which consists of multinomial d istrib utions as po ints which lie on an n -simplex (or projected onto an n + 1 -dimensional sp here). By framing their problem as such, they are able to exploit the properties of such a manifold: us ing the cos ine distan ce a s an exac t computation o f the Fisher information distan ce, and us ing linear method s (PCA) o f dimens ionality reduction. They have s hown very promising results for the problem of image segmentation, a nd briefly mention the possibility of using non-linear methods of dimensionality reduction, w hich they con sider unne cess ary for their p roblem. T he work we presen t dif fers in that we make no assumptions on the type of distributions mak ing up the s tatistical man ifold. As s uch, our geode sic approximation for the Fisher information acc ounts for subma nifolds of interest. This is illustrated later in Fig. 3, where the subman ifold lies on the n + 1 -dimensiona l sphere, but does no t fill the entire space . As su ch, there is no exact measure of the Fisher information b etween points, and we must a pproximate with a geodes ic along the manifold. Additionally , we utili z e non-linear methods of dimensionality reduc tion, which we co nsider to b e mo re relev a nt for many non-linear types of applications. Finally , by considering all statistical man ifolds rather than focu sing on those of consisting February 12, 2013 DRAFT 4 of multinomial distrib u tions, we are able to a pply our methods to many problems of practical interest. This pape r is organized a s follows: Section II describes a bac kground in information geometry and statistical ma nifolds. S ection III gives the formulation for the p roblem we wish to s olve, while Section IV develops a nd outlines the F INE algorithm. W e illustrate the res ults of using FINE on rea l and s ynthetic data s ets in Sec tion V. Finally , we draw conclus ions and discus s the p ossibilities for future work in Section VI. I I . B AC K G RO U N D O N I N F O R M AT I O N G E O M E T RY Information g eometry is a field that ha s e merged from the study o f ge ometrical structures on manifolds of proba bility distributions. These in vestigations analyz e p robability distrib u tions a s g eometrical struc- tures in a Riemannian sp ace. Using tools and methods deriving from differential geometry , information geometry is applicable to information theory , probability theo ry , and statistics. The fie ld of information theory is largely b ased on the works of S hun’ichi Ama ri [18] and has been used for a nalysis in such fields as s tatistical inference, neural ne tworks, and control systems . In this sec tion, we will give a brief backgrou nd on the method s of information geometry that we utilize in o ur framew ork. For a more thorough introduction to information geometry , we sugg est [19 ] and [2]. A. Differ ential Manifolds The concep t of a differential manifold is similar to that of a smooth curve or surface lying in a high - dimensional spac e. A manifold M ca n be intuiti vely thought of as a set of p oints with a coordinate system. These points can be from a variety of constructs, su ch as Euclidea n coordinates, linear system, images, or proba bility distrib utions. Regardless of the definition of the po ints in the manifold M , there exists a coordinate system with a on e-to-one mapping from M to R d , and as such, d is kn own as the dimension of M . For referenc e, w e will refer to the c oordinate system on M a s ψ : M → R d . If ψ has M as its domain, we call it a g lobal coordinate system [2]. In this situation, ψ is a one-to-one mapping onto R d for a ll points in M . A manifold is differentiable if the co ordinate sy stem ma pping ψ is dif feren tiable over its entire domain. If ψ is infinitely dif ferentiable, the manifold is said to be ‘smooth’ [19]. In many c ases the re does not exist a glob al coordinate sys tem. Ex amples of s uch manifolds inc lude the surface of a sphere, the “swiss roll”, and the torus. For these manifolds, there are only local coo rdinate systems. Intuiti vely , a local co ordinate sys tem ac ts as a glob al coo rdinate syste m for a loc al neigh borhood of the manifold, and there may be many local coordinate systems for a particular manifold. Fortunately , since a local coordinate s ystem contains the s ame properties as a global coordinate sy stem (only on a local lev e l), analysis is consisten t b etween the two. As suc h, we shall focus solely o n manifolds with a global coordinate system. February 12, 2013 DRAFT 5 1) S tatistical Manifolds: Let us now prese nt the notion s tatistical manifolds, or a set M who se elements are probability distributi o ns. A proba bility distrib u tion function (PDF) on a s et X is de fined a s a function p : X → R in which p ( x ) ≥ 0 , ∀ x ∈ X (1) Z p ( x ) dx = 1 . W e desc ribe only the case for c ontinuum on the se t X , howe ver if X was discrete valued, eq uation (1) will still apply by s witching R p ( x ) dx = 1 with P p ( x ) = 1 . If we con sider M to be a family of PDF s on the s et X , in which each eleme nt of M is a P DF which c an be pa rameterized by θ = θ 1 , . . . , θ n , then M is known as a statistical model on X . Sp ecifically , let M = { p ( x | θ ) | θ ∈ Θ ⊆ R d } , (2) with p ( x | θ ) satisfying the e quations in (1). Additionally , there exists a one-to-one mapping betwee n θ and p ( x | θ ) . Gi ven certain properties of the parameterization of M , such as dif ferentiability and C ∞ dif feo morphism (details of which are described in [2]), the parameterization θ is also a coordinate system of M . In this case, M is known as a statistical manifold. In the rest of this paper , we will use the terms ‘manifold’ and ‘statistical manifold’ interchangeably . B. Distanc es on Manifolds In Euclidean space , the distance between two p oints is defined a s the leng th of a straight line b etween the points. On a man ifold, howe ver , one can mea sure distance by a trace o f the s hortest path b etween the points along the manifold. This p ath is called a geodesic, and the length of the path is the g eodes ic distance. In information ge ometry , the dis tance between two p oints on a man ifold is analog ous to the dif feren ce in information between them, and is de fined by the Fisher information metric. 1) Fi s her Information Metric: The Fisher information mea sures the amoun t of information a rando m variable X con tains in reference to an unknown parame ter θ . For the single p arameter c ase it is d efined as I ( θ ) = E " ∂ ∂ θ log f ( X ; θ ) 2 | θ # . If the condition R ∂ 2 ∂ θ 2 f ( X ; θ ) dX = 0 is met, then the above equation can be writt e n as I ( θ ) = − E ∂ 2 ∂ θ 2 log f ( X ; θ ) . February 12, 2013 DRAFT 6 For the cas e of multiple parame ters θ = θ 1 , . . . , θ n , we define the F isher information ma trix [ I ( θ )] , whose elements consist of the Fisher information with respect to specified p arameters, as I ij = Z f ( X ; θ ) ∂ log f ( X ; θ ) ∂ θ i ∂ log f ( X ; θ ) ∂ θ j dX . (3) For a parametric family o f probab ility distributions, it is p ossible to define a Rieman nian metric using the Fisher information matrix, known as the information metric. Th e information me tric distance, or Fisher information distanc e, betwe en two distributi o ns p ( x ; θ 1 ) and p ( x ; θ 2 ) in a single parameter family is D F ( θ 1 , θ 2 ) = Z θ 2 θ 1 I ( θ ) 1 / 2 dθ , (4) where θ 1 and θ 2 are parameter values corresp onding to the two PDFs and I ( θ ) is the Fishe r information for the parameter θ . Extending to the multi- p arameter case , we obtain: D F ( θ 1 , θ 2 ) = min θ : θ (0)= θ 1 ,θ (1)= θ 2 Z 1 0 s dθ dβ T I ( θ ) dθ dβ dβ . (5) 2) Ex ample: H ere we pres ent a deriv ation of a ge odesic distanc e between u niv ariate Gaus sian densities via the Fisher information metric for two reaso ns. First, we would like to illustrate h ow in volved the process is for such a simple family of PDFs. Secon dly , we present a process of deriving the Fish er information metric that is in volved in computing the ge odesic distance. Let us conside r the family of univ ariate Gaussian distrib utions P = { p 1 , . . . , p n } , where p i ( x ) = 1 q 2 π σ 2 i exp − ( x − µ i ) 2 / 2 σ 2 i . For the ca se of P p arameterized by θ = µ √ 2 , σ , the resultant Fisher information matrix is [ I ( θ )] = 2 σ 2 0 0 2 σ 2 ! . W e omit the deri vation, which c an be found in [19] and is straight forward from (3). W e define the distance between tw o points on the man ifold a s the minimum length between all paths connec ting the two points. Using the inner product associated w ith the Fisher information matrix < u , v > F = u t [ I ( θ )] v , we de fine the length o f the path P between tw o points parameterized by θ 1 and θ 2 , on the man ifold M as k θ 1 − θ 2 k P = p < θ 1 − θ 2 , θ 1 − θ 2 > F . February 12, 2013 DRAFT 7 Using the parameterization θ ( t ) such that θ (0) = θ 1 and θ (1) = θ 2 , we obtain the length o f P as k θ 1 − θ 2 k P = Z 1 0 s d dt θ ( t ) T I ( θ ( t )) d dt θ ( t ) dt. W e a re ab le to define the d istance be tween points p 1 = p ( x ; θ 1 ) a nd p 2 = p ( x ; θ 2 ) as the minimum ov e r all path lengths defined above D F ( p 1 , p 2 ) = m in θ ( t ) √ 2 Z 1 0 s 1 √ 2 ˙ µ 2 + ˙ σ 2 σ ( t ) 2 dt, (6) where ˙ µ = d dt µ ( t ) and ˙ σ = d dt σ ( t ) . The so lution to (6) is the well kn own Poinc ar ´ e hyp erbolic dista nce, in which the shortest path b etween two po ints is the length of an arc on a circle in which bo th po ints are at a radius length from the c ircle’ s center . In the c ase of the uni variate normal distrib ution, this arc is a straight line whe n the mean is held constant and the vari a nce is changed. By chang ing variables and p arameterizing σ as a function of µ , we obtain: min σ ( µ ): σ ( µ 1 )= σ 1 ,σ ( µ 2 )= σ 2 Z µ 2 µ 1 s 1 + ˙ σ 2 σ ( µ ) 2 dµ, where ˙ σ = d dµ σ ( µ ) . It sh ould be clear that this is a represen tation of (4). It sho uld also b e n oted that there exists a one-to-one mapp ing σ ( µ ) : R → R + along the geodesic from σ ( µ 1 ) to σ ( µ 2 ) , except for the case when µ 1 = µ 2 . Solving (6) b ecomes a proble m of ca lculus of variations. For the univ ariate normal family of distri- buti o ns, this h as been calculated in a closed -form expre ssion prese nted in [20], de termining the Fishe r information distance as: D F ( p 1 , p 2 ) = √ 2 log µ 1 √ 2 , σ 1 − µ 2 √ 2 , − σ 2 + µ 1 √ 2 , σ 1 − µ 2 √ 2 , σ 2 µ 1 √ 2 , σ 1 − µ 2 √ 2 , − σ 2 − µ 1 √ 2 , σ 1 − µ 2 √ 2 , σ 2 . (7) For visualization, let us define a se t of probability de nsities P = { p i ( x ) } on a grid, such that p i = p k ,l is pa rameterized by ( µ i , σ i ) = ( αk , 1 + β l ) , k , l = 1 . . . n and α, β ∈ R . Figure 1 shows a mesh-grid a nd contour plot of the Fisher information distance be tween the density defined by ( µ i , σ i ) = (0 . 6 , 1 . 5) and the neighboring densities on the s et P ( α = β = 0 . 1 ). I I I . P RO B L E M F O R M U L A T I O N A key prope rty of the Fisher information metric is that it is ind epende nt of the parameterization o f the manifold [7], [19 ]. Although the evaluation remains e quiv alent, calculating the FIM requires knowledge of the p arameterization, which is ge nerally no t available. W e instead assu me tha t the co llection of dens ity functions lie on a manifold that can be d escribed by some natural parameterization. Sp ecifically , we are February 12, 2013 DRAFT 8 0 0.2 0.4 0.6 0.8 1 1 1.5 2 0 0.2 0.4 0.6 0.8 µ σ d F (a) µ σ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2 (b) Fig. 1. a) Mesh-grid and b) Contour plots of the Fi sher information distance based on a grid of uni variate normal densities, parameterized by ( µ, σ ) . The reference point, p i , is located at ( µ i , σ i ) = (0 . 6 , 1 . 5) and is denoted by t he red star . giv en P = { p 1 , . . . , p n } , where p i ∈ M is a PDF and M is a manifold embedde d in S , the simplex of densities in L 1 . Under t h ese circumstances, it is i mpo rtant to note that much of the same t h eory still applies for determining dissimilarity between p robability distrib utions . Our goal is to fin d an approximation for the geo desic distance betwee n points on M u sing only the information available in P . Can we find a n approximation function G which yields ˆ D F ( p i , p j ) = G ( p i , p j ; P ) , (8) such that ˆ D F ( p i , p j ) → D F ( p i , p j ) as n → ∞ ? This problem is similar to the setting of class ical pap ers [21], [22 ] in manifold learning and dimen- sionality reduction, where only a set of p oints on the manifold are av ailable. As such, we are able to use thes e manifold lea rning tec hniques to co nstruct a low-dimensional embe dding of that family . This not only allows for an effecti ve visualization of the manifold (in 2 or 3 dimensions ), but by reducing the e f fec t of the curse of dimension ality we can perform c lustering a nd classifica tion o n the family of distrib utions lying on the ma nifold. A. App r oximation of F isher Infor mation Distance The Fis her information distan ce is consisten t, regardless of the parame terization of the manifold [7]. This fact enables the approximation of the information d istance when the spec ific p arameterization of the manifold is unknown, and there have b een many metrics developed for this a pproximation. An important class of suc h d i vergences is known as the f -diver gence [23], in which f ( u ) is a conv ex func tion on February 12, 2013 DRAFT 9 u > 0 and D f ( p k q ) = Z p ( x ) f q ( x ) p ( x ) . A specific and important example of the f -diver genc e is the α -di vergence, where D ( α ) = D f ( α ) for a real number α . The function f ( α ) ( u ) is defined as f ( α ) ( u ) = 4 1 − α 2 1 − u (1+ α ) / 2 α 6 = ± 1 u log u α = 1 − log u α = − 1 . As such, the α -di vergence can be ev aluated a s D ( α ) ( p k q ) = 4 1 − α 2 1 − Z p ( x ) 1 − α 2 q ( x ) 1+ α 2 dx α 6 = 1 , and D ( − 1) ( p k q ) = D (1) ( q k p ) = Z p ( x ) log p ( x ) q ( x ) . (9) The α -div e r g ence is the b asis for many important and well known d i vergence metrics, su ch as the Hellinger distance, the Kullback-Leibler diver genc e, and the Renyi-Alpha entropy [24]. 1) Kul lba ck-Leibler Diver gence: The Kullback-Leibler (KL) di vergence is defi ned as K L ( p k q ) = Z p ( x ) log p ( x ) q ( x ) , (10) which is equal to D ( − 1) (9). The KL-diver gence is a very important metric in information theory , and is commonly referred to as the relativ e entropy of one PDF to anothe r . Ka ss and V os sh ow [19] the relation between the Kullback-Leibler diver genc e a nd the Fisher information distance is p 2 K L ( p k q ) → D F ( p, q ) as p → q . This allows for an ap proximation of the Fisher information dis tance, through the use of the av ailable PDFs, without the need for the s pecific parameterization of the manifold. Returning to ou r illustration developed in Section II-B2 , we have define d the data set P of univ ariate normal distrib u tions, and presen ted a n expres sion for the Fisher information distance on the resultant manifold (7). Th e Kullback-Leibler div e r g ence between univ a riate normal distrib u tions is also av ailable in a closed-form expression: K L ( p i k p j ) = 1 2 log σ 2 j σ 2 i ! + σ 2 i σ 2 j + ( µ j − µ i ) 2 /σ 2 j − 1 ! . T o compare the KL-div ergence to the Fisher information distance , we defin e the e rror as E = p 2 K L ( p i k p j ) − D F ( p i , p j ) , where p i,j ∈ P . In Fig. 2 we display the mesh-grid and contour plots o f February 12, 2013 DRAFT 10 0 0.2 0.4 0.6 0.8 1 1 1.5 2 0 0.01 0.02 0.03 0.04 0.05 0.06 µ σ E (a) Mesh-grid µ σ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2 (b) Contour plot Fig. 2. a) Mesh-grid and b) Contour plots of the error between the KL -div ergence and the Fi sher information distance based on a grid of uni variate normal densities, parameterized by ( µ, σ ) . E = ˛ ˛ ˛ p 2 K L ( p i k p j ) − D F ( p i , p j ) ˛ ˛ ˛ . Note that √ 2 K L → D F , where p i is denoted by the red star . E , wh ere point p i is held co nstant in the center of the grid de fining P , a nd p j varies a bout the manifold. As desc ribed e arlier , as the dens ity p j → p i , the e rror E → 0 . In Fig. 2(b), the reference point p i is noted by the red star . It s hould be noted that the KL -di vergence is no t a distanc e metric, as it does not sa tisfy the symme try , K L ( p k q ) 6 = K L ( p k q ) , or triangle ineq uality prope rties of a distanc e metric. T o ob tain this s ymmetry , we will define the KL-di vergence as : D K L ( p, q ) = K L ( p k q ) + K L ( q k p ) , (11) which is sy mmetric, but s till not a d istance as it does not sa tisfy the triangle ine quality . S ince the Fis her information is a symme tric meas ure, we can relate the symme tric KL-diver gence a nd app roximate the Fisher information distance as p D K L ( p, q ) → D F ( p, q ) , (12) as p → q . 2) He llinger Distan ce: Another important result of the α -di vergence is the ev aluation with α = 0 : D (0) ( p k q ) = 2 Z p p ( x ) − p q ( x ) 2 dx, which is called the closely related to the Hellinger distan ce, D H = r 1 2 D (0) , February 12, 2013 DRAFT 11 which satisfies the ax ioms of distance - symme try and the triangle inequa lity . The He llinger distance is related to the information distance in the limit by 2 D H ( p, q ) → D F ( p, q ) as p → q [19]. W e note that the Hellinger distance is related to the Kullback-Leibler diver gence , as in the limit p K L ( p k q ) → D H ( p, q ) . 3) Othe r F isher Appr ox imations: T here are other metrics which approximate the Fisher information distance, such as the cosine distance. Whe n dealing with multinomial distrib utions, the app roximation D C ( p, q ) = 2 arccos Z √ p · q → D F ( p, q ) , is the natural metric on the s phere. W e restrict our analysis to that of the Kullback-Leibler d i vergence an d the Hellinger d istance. Th e KL- div ergence is a g reat means of d if ferentiating shap es of continuo us PDF s. Analys is of (10) shows that as p ( x ) /q ( x ) → ∞ , K L ( p k q ) → ∞ . Th ese prope rties e nsure that the KL-div ergence will be amplified in regions whe re there is a significa nt diff e rence in the probability distributi o ns. This cann ot be use d in the case of a multinomial PDF , h owe ver , because o f divide-by-zero issu es. In that case the Hellinger distance is the desired metric as the re exists a mo notonic trans formation fun ction ψ : D H → D C [19]. For add itional measu res of probab ilistic distance, some of which approximate the Fishe r information distance, and a means of calculating the m between data sets, we refer the rea der to [25]. B. App r oximation of Distance on Statistical Man ifolds W e have shown the approximation function ˆ D F ( p 1 , p 2 ) of the Fisher information distance between p 1 and p 2 can be calculated using a variety of metrics as p 1 → p 2 . If p 1 and p 2 do no t lie clos ely toge ther on the manifold, these a pproximations become weak. A n example of this is illustrated in Fig. 3, wh ere the manifold of interest lies in a subspac e of another manifold, a nd the distan ce between two points should be con sidered as the distanc e traveled on the manifold o f interest. A good a pproximation ca n still b e achieved if the ma nifold is d ensely sampled between the two end points. By defining the path be tween p 1 and p 2 as a series of conne cted segments an d summing the le ngth of those s egments, we ap proximate the distan ce of the geod esic , which is the s hortest p ath a long the manifold. Spec ifically , gi ven the set of n PDF s pa rameterized by P θ = { θ 1 , . . . , θ n } , the Fisher information dis tance be tween p 1 and p 2 can be estimated as: D F ( p 1 , p 2 ) ≈ min m, { θ (1) ,...,θ ( m ) } m X i =1 D F ( p ( θ ( i ) ) , p ( θ ( i +1) )) , p ( θ ( i ) ) → p ( θ ( i +1) ) ∀ i where p ( θ (1) ) = p 1 , p ( θ ( m ) ) = p 2 , θ (1) , . . . , θ ( m ) ∈ P θ , and m ≤ n . February 12, 2013 DRAFT 12 Fig. 3. The F isher information distance between points cannot be exactly calculated about a manifold if the data exists on a submanifold of interest (shaded area). Rather than directly calculating the distance between points (A) , the distance should be approximated by a geodesic along the submanifold (B). Using our a pproximation of the Fishe r information d istance a s p 1 → p 2 (whether KL-diver gen ce or Hellinger distance is of n o immediate con cern), we can now de fine an app roximation function G for all pairs of PDFs: G ( p 1 , p 2 ; P ) = min m, P m X i =1 ˆ D F ( p ( i ) , p ( i +1) ) , p ( i ) → p ( i +1) ∀ i (13) where P = { p 1 , . . . , p n } is the av a ilable collection of P DFs on the man ifold. Intuitiv ely , this e stimate calculates the length o f the shortest p ath betwee n points in a conn ected graph on the we ll s ampled manifold, a nd as such G ( p 1 , p 2 ; P ) → D F ( p 1 , p 2 ) as n → ∞ . This is similar to the mann er in wh ich Isomap [21 ] a pproximates distance s on Euclidean ma nifolds. Figure 4 illustrates this ap proximation by compa ring the KL g raph app roximation to the ac tual Fisher information d istance for the univ a riate Gaussian ca se. As the manifold is more de nsely s ampled (uniformly in mea n and variance p arameters for this simulation), the app roximation con verges to the true Fis her information distanc e, as ca lculated in (7). C. Dimens ionality Reduction Gi ven a ma trix of dissimilarities b etween entities, many algo rithms have been developed to fi nd a low- d imensional embedding of the original da ta ψ : M → R d . These techn iques have been classified as a group of methods called Multi-Dimensional Scaling (MDS). Th ere a re supervised me thods, whic h are generally used for clas sification purposes , an d uns upervised methods, which are often used for clustering and manifold lea rning. Using the se MDS metho ds allows us to find a s ingle low-dimensional coordinate representation of each high-dimensional, lar ge s ample, data set. February 12, 2013 DRAFT 13 0 500 1000 1500 2.3 2.35 2.4 2.45 2.5 Number of Points on Manifold D KL Geodesic Approximation Fisher Information Distance Fig. 4. Con verg ence of the graph approximation of the F isher information distance using the Kullback-Leibler div ergence. As the manifold is more densely sampled, the approximation approaches the true value. 1) Clas sical Multi-Dimensional Scaling: Classica l MDS (cMDS) takes a matrix of diss imilarities an d embeds eac h point into a Euclidea n space . This is performed by fi rst centering the d issimilarities about the origin, then calculating the eigen value de compos ition of the cente red matrix. This unsupervised method permits the c alculation of the low-dimensional embedding co ordinates which reveal any natural s eparation or clustering of the data. Define D as a dissimilarity matrix which contains (or approximates ) Euclidea n distanc es. Let B be the “ double ce ntered” matrix wh ich is calculated by taking the matrix D , sub tracting its row an d column means, then a dding back the grand me an a nd multiplying b y − 1 2 . A s a result, B is a version of D centered about the origin. Mathematically , this proces s is solved by B = − 1 2 H D 2 H , where H = I − (1 / N )11 T , I is the N -dimens ional identity matrix, a nd 1 is an N -elemen t vector of ones. The embedding coordinates, Y ∈ R d × n , can the n be de termined by taking the eigen value decompos ition of B , B = [ V 1 V 2 ] diag ( λ 1 , ..., λ N ) [ V 1 V 2 ] T , and calculating Y = diag λ 1 / 2 1 , ..., λ 1 / 2 d V T 1 . The matrix V 1 consists of the eigen vectors co rresponding to the d lar ge st eigen values λ 1 , . . . , λ d while the remaining N − d eige n vectors are represented as V 2 . The term ‘diag ( λ 1 , . . . , λ N ) ’ refers to a n N × N February 12, 2013 DRAFT 14 −0.6 −0.4 −0.2 0 0.2 0.4 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 cMDS1 cMDS2 (a) Fisher Information −0.03 −0.02 −0.01 0 0.01 0.02 −0.025 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 0.025 cMDS1 cMDS2 (b) Kullback-Leibler Approximation Fig. 5. Classical MDS to the matrix of a) Fisher information distances and b) Kullback-Leibler geodesic approximations of the F isher i nformation distance, on a grid of univ ariate normal densities, parameterized by ( µ, σ ) diagonal matrix with λ i as its i th diagonal element. T o continue o ur illustration from S ection II-B2 , let D be the matrix of Fisher information distan ces de - fined in (7 ) for the set of u niv ariate n ormal dens ities P , whe re D ( i, j ) = D F ( p i , p j ) . F igure 5(a) displays the res ults of applying cMDS to D . W e de monstrate the embedding with the g eodesic ap proximation of the Fisher information dis tance (13) in Fig. 5 (b), which is very similar to the e mbedding crea ted with the exact values. It is clea r that wh ile the densities defin ing the s et P are parameterized on a recta ngular grid, the manifold on which P liv e s is not rectang ular itself, which is d ue to the dif fering effects that change s in mean and variance have on the Gaus sian PDF . 2) La placian Eigenmaps: Laplacian Eigenma ps (LEM) is an u nsupervise d techn ique d eveloped b y Belkin and Niyogi an d fi rst presented in [22]. Th is pe rforms non-linear dimens ionality redu ction b y per- forming an eigen value dec omposition on the graph Laplac ian formed by the da ta. As such, this algorithm is able to disc ern low-dimensional structure in high-dimens ional spa ces that were p reviously indiscernible with methods suc h as principal components analysis (PCA) and class ical MDS. The algorithm contains three steps and works as follows: 1) Construct adjacency grap h Gi ven dissimilarity matrix D X between d ata p oints in the s et X , de fine the graph G over all data points by adding an edge between points i and j if X i is one of the k -nea rest neighbors of X j . 2) Compute weight matrix W If points i and j a re connected, assign W ij = e − D X ( i,j ) 2 t , otherwise W ij = 0 . 3) Construct lo w-dimens ional embedding February 12, 2013 DRAFT 15 Solve the ge neralized eigen value problem L f = λD f , where D is the diagonal weight matrix in which D ii = P j W j i , and L = D − W is the La placian matrix. If [ f 1 , . . . , f d ] is the collection of eigen vec tors associated with d s mallest gen eralized eigen- values which solve the ab ove, the d -dimensiona l e mbedding is d efined b y y i = ( v i 1 , . . . , v id ) T , 1 ≤ i ≤ n . 3) Ad ditional MDS Methods : While we c hoose to only d etail the cMDS an d LEM algorithms, the re are many other me thods for performing dimensionality reduc tion in a linear fashion (PCA) and non -linearly (Local Linear Embe dding [26]) for unsu pervised learning. For supe rvised learning there are also linear (Linear Discriminant Ana lysis) and n on-linear (Classifica tion Constrained Dimension ality Reduction [27], Neighbourhoo d Co mponent Analysis [28]) me thods, all o f which ca n be applied to our framew ork. W e do not highlight the heavily utilized Isomap [21 ] algorithm since it is iden tical to us ing cMDS o n the approximation of the geodesic distances. I V . O U R T E C H N I Q U E S W e h av e presente d a series of methods for manifold learning developed in the field of information geometry . By performing dimensionality reduction on a family of data sets, we are able to both better visu- alize a nd c lassify the data. In order to obtain a lower dimen sional e mbedding, we ca lculate a dissimilarity metric betwee n d ata sets within the family b y approximating the Fisher information distanc e b etween their corresp onding PDFs. Th is has be en illustrated with the famil y of un i variate normal p robability distrib utions . In problems of practical interest, howe ver , the parame terization of the proba bility den sities a re u sually unknown. W e instea d are given a family of da ta sets X = { X 1 , X 2 , . . . , X n } , in which we may assume that each data s et X i is a realization of some un derlying proba bility distributi o n to wh ich we do not have knowledge of the parameters . As such, w e rely on n on-parametric techniques to estimate both the probability den sity and the approx imation o f the Fisher information distanc e. Following these approximations, we are able to perform the s ame multi-dimensional sc aling operations as previously described. A. Kernel De nsity Estimation Kernel method s are n on-parametric tech niques used for estimating proba bility dens ities o f data sets. These methods are similar to mixture-models in that they are defined by the no rmalized sum of multiple densities. Un like mixture mode ls, howev er , kernel me thods are non-parametric and are comprised of the normalized sum of ide ntical dens ities c entered about eac h da ta point within the s et (14). This y ields a February 12, 2013 DRAFT 16 density estimate for the en tire set in that highly probable regions will have more samples , and the su m of the kernels in those a reas w ill be large, c orresponding to a high probability in the resultant density . The kernel d ensity estimate (KDE) of a P DF is defined as ˆ p ( x ) = 1 N h N X i =1 K x − x i h , (14) where K is s ome kerne l satisfying the p roperties K ( x ) ≥ 0 , ∀ x ∈ X , Z K ( x ) dx = 1 , and h is the bandwidth or s moothing parameter . There are two ke y po ints to note when using kernel density estimators. Fir s t, it is nece ssary to determine which d istrib ution to use as the kernel. W ithout a priori knowledge of the original dis trib ution, we choos e to use Gaussian kernels, K ( x ) = 1 (2 π ) ( d/ 2) | Σ | 1 / 2 exp − 1 2 x T Σ − 1 x , (15) where d is the dimension of x and Σ is t h e cov ariance matrix, as they ha ve the quadratic properties tha t wi ll be u seful in implementation. Se condly , the b andwidth parameter is very important to the ov e rall d ensity estimate. Choosing a bandwidth parameter too small will yield a peak filled density , while a bandwidth that is too large will generate a de nsity estimate that is too smooth and loses most of the fea tures of the distrib ution. T here has bee n muc h research done in calculating optimal bandwidth parameters, resulting in many d if feren t methods [29], [30 ] which can be used in our framework. W e note tha t the mean squa red error o f a KDE dec reases o nly as n − O(1 / d) , which become s extremely slow for large d . As suc h, it may be difficult to ca lculate good kernel dens ity estimates. Howev e r , for our pu rposes, the estimation of densities is seconda ry to the estimation of the d i vergence between them. As such, the issu es with MSE of density estimates in large dimen sions, while a n area for future work, is not of immediate concern. B. Algor ithm Fisher Information Non-parame tric Embedding (FINE) is presen ted in Algorithm 1 and comb ines all of the methods we have prese nted in order to find a lo w-dimensiona l embe dding of a collection of data sets. If we ass ume each data s et is a realiza tion of an unde rlying PDF , a nd each of thos e distributions lie on a manifold with some na tural parame terization, the n this embedding c an be vie wed as an embedding of the actua l manifold into Euc lidean spac e. No te tha t in line 5, ‘embed ( G, d ) ’ refers to using any multi- February 12, 2013 DRAFT 17 Algorithm 1 Fisher Information Non-parametric Emb edding Input: Collection of da ta sets X = { X 1 , X 2 , . . . , X N } ; the desired embedding dimension d 1: for i = 1 to N do 2: Calculate ˆ p i ( x ) , the density estimate of X i 3: e nd f or 4: Ca lculate G , where G ( i, j ) = ˆ D F ( p i , p j ) , the geod esic a pproximation of the Fisher information distance 5: Y = embed ( G, d ) Output: d -dimensiona l embedding of X , into Euclidean space Y ∈ R d × N −10 −5 0 5 10 15 0 20 40 −15 −10 −5 0 5 10 15 x y z (a) Swiss Roll −20 −10 0 10 20 −20 −10 0 10 20 −20 0 20 (b) F INE embedding Fig. 6. Given a collection of data sets with a Gaussian distribution having means equal to points a sampled ‘swiss roll’ manifold, our methods are able to reconstruct the original st atistical manifold from which each data set is deriv ed. dimensional s caling method (such as cMDS, Laplac ian Eigenmap s, etc.) to emb ed the dis similarity matrix G into a Euclidean space with d imension d . V . A P P L I C A T I O N S W e have illustrated the us es of the presented framew o rk in the previous se ctions with a manifold consisting of the set of univ ariate normal dens ities, P . W e now present several synthe tic and practi- cal applications for the framew ork, a ll of which are based a round v isualization and c lassification. In each a pplication, the den sities are un known, but we assu me they lie on a ma nifold with so me natural parameterization. A. Simulated Da ta T o demons trate the ability of our methods to reconstruct the s tatistical manifold, we create a known manifold of de nsities. Let Y = { y 1 , . . . , y n } , where each y i is uniformly sampled on the ‘swiss roll’ February 12, 2013 DRAFT 18 Fig. 7. Historically , the process of clinical flow cytometry analysis relies on a series of 2-dimensional scatter plots in which cell populations are selected for further e valuation. This process does not take adv antage of the multi-dimensional nature of the problem. manifold (see Fig. 6 (a)). L et X = { X 1 , X 2 , . . . , X n } where each X i is generated from a normal distrib ution N ( y i , Σ) , where Σ is held cons tant for ea ch dens ity . As such, we have d eveloped a statistical manifold of known parameterization, which is samp led by known PDFs. Utilizing FINE in an unsup er- vised manner , we are a ble to recreate the original manifold Y strictly from the collection of da ta sets X . Th is is shown in Fig. 6(b) where ea ch se t is e mbedded into 3 cMDS dimens ions, a nd the ‘swiss roll’ is reconstructed. While this embedd ing c ould easily be con structed using the mean of each set X i as a Euclidean location, it illustrates tha t FINE can b e use d for v isualizing the statistical manifold as well, without a priori knowl e dge of the da ta. B. Flow Cytome try In clinical flow cytometry , ce llular su spens ions are prepared from p atient sa mples (blood, bone marrow , and solid tissue), and ev alua ted s imultaneously for the presenc e o f several expressed s urface antigen s an d for characteristic patterns of light scatter as the cells pass throu gh an interrogating laser . Antibodies to each tar g et a ntigen a re con jugated to fl uoresce nt markers, and e ach individual cell is evaluated via detection of the fluoresce nt signal from each marker . The res ult is a charac teristic multi-dimensional distribution that, depend ing on the panel of markers selected, may be distinct for a spe cific disease entity . The data from clinical flow cytometry can be co nsidered multi-dimensional b oth from the standpo int of multiple characteristics me asured for e ach ce ll, a nd from the standp oint of thousa nds of cells analyze d pe r s ample. Nonetheles s, c linical p athologists generally interpret clinical flow cytometry results in the form of two- dimensional scatter plots in w hich the axes each represe nt one of mu ltiple cell c haracteristics analyz ed (up to 8 p arameters per cell in routine clinical flow cytometry , a nd ma ny more parame ters per cell in research February 12, 2013 DRAFT 19 0 200 400 600 800 1000 0 100 200 300 400 500 600 700 FMC7 CD23 CLL MCL (a) Scatter Plot FMC7 CD23 0 100 200 300 400 500 0 50 100 150 200 250 300 350 400 450 500 CLL MCL (b) Contour Plot Fig. 8. 2-dimensional plots of disease classes CLL and MCL. The overlapp i ng nature of the scatter plots makes it difficult for pathologists t o differen t iate disease classes using primitive 2-dimensional axes projections. applications). Additional parameters are often utilized to “gate” (i.e. select or exclude) s pecific cell sets based o n an tigen expres sion or light sc atter c haracteristics; h owe ver , clinical flow cytometry analys is remains a step-by-s tep proces s of 2-dimens ional histogram ana lysis (Fig. 7), an d the multidimensional nature of flow cytometry is rou tinely underutilized in clinical practice. An example of the difficulty in a nalysis of 2-dimensiona l scatter plots is illustrated in Fig. 8. T wo distinct d isease class es, mantle cell lymphoma (MCL) and chronic lympho cytic leu kemia (CLL), are illustrated with both scatter and contour plots . Each point repres ents a d istinct blood cell f rom two dif ferent patients, each c ontaining one of the specified d iseases ; the a xes repre sent tho se which patho logists have determined to be the two markers whic h are most differentiati n g for thes e two diseas e class es. It is c lear that for thes e two patients the re is sign ificant similarity in the scatter and contour p lots of the data. The overlapping nature of the se 2-dimensional scatter plot leads to a very primiti ve analysis of the av a ilable data. It would be potentially be neficial, the refore, to develop sy stems for clustering and clas sification of clinical flow cytometry da ta that utilize all dimensions of da ta de ri ved for e ach cell during rou tine clinical analysis . The vari a bility o f distrib u tions of data in multidimensional flow cytometry over various patients is sma ller tha n that ass ociated with a general c haracterization o f a multi variate distribut ion . This leads us to believe tha t these distrib utions exist on s ome manifold with a much lower d imensional parameterization. He nce, we sho uld be able to use FINE for the pu rpose of viewing a n atural clustering of different p atients into their res pective disease clas ses b ased on the full set of markers ev a luated in each multiparameter flow cytometric a nalysis. For this an alysis, we will compare patients with two distinct but immunop henotypica lly similar forms of lympho id leukemia - man tle cell lymphoma (MCL) and ch ronic lymphocytic leukemia (CLL), as February 12, 2013 DRAFT 20 −6 −4 −2 0 2 4 6 −4 −3 −2 −1 0 1 2 3 FINE1 FINE2 CLL MCL Fig. 9. 2-dimensional embedding of CLL ( • ) and MCL ( + ) patients using FINE with cMDS an d the Kullback-Leibler di vergence as a dissimilarity metric. The circled points correspond to the CLL and MCL cases highlighted in Fig. 8, which are difficult to discern with scatter plots, but well separated in the FINE space. illustrated in Fig. 8. These diseas es disp lay similar characteristics with respe ct to many expressed surface antigens, but are generally distinct in their patterns of expres sion o f two c ommon B lymphocyte antigens CD23 a nd FMC7 (a d istinct conformational epitope of the CD2 0 a ntigen). T ypica lly , CLL is positiv e for expression of CD23 and negative for expression o f FMC7, while MCL is positiv e for expres sion o f FMC7 an d negative for expression of CD2 3. Th ese distinctions should lea d to a diff e rence in densities between patients in each disease class, and sh ould show a natural clustering. Let X = { X 1 , X 2 , . . . , X n } where X i is the d ata set correspon ding to the flow cytometer output of the i th patient. E ach patient’ s blood is analyz ed for 5 parameters: forward an d side light scatter , and 3 fluo rescent markers (CD45, CD23, FMC7). He nce, each d ata s et X i is 5-dimens ional with n i elements corresponding to individual bloo d cells (ea ch n i may be dif ferent). Giv e n that X is co mprised of both patients with CLL and patients with MCL, we wish to analyze the p erformance of FINE for the visualization and clustering of cytometry da ta. The data se t consists of 2 3 patients with CLL and 20 patients with MCL. Th e set X i for each patient is on the order of n i ≈ 5000 cells. The data and clinical diagnosis for each patient was provided by the Department of Pathology at the Univ e rsity of Michigan . Figure 9 shows the 2-dimensiona l emb edding with FINE, u sing cMDS and the K u llback-Leibler di vergence s et as the dissimilarity metric. Ea ch point in the plot represents a n individual patient. Although the discusse d methods perform the dimensionality reduction a nd embedd ing in u nsupe rvised methods , we display the class labels a s a means of an alysis. It s hould be noted tha t there exists a natural separation between the dif ferent c lasses . As such, we ca n conclude that the re is a natural diff e rence in probability distrib ution between the d isease clas ses as well. Although this is known through years of clinical expe rience, we were able to determine this without any February 12, 2013 DRAFT 21 a priori knowledge; simply with a density analysis. An important byproduc t of this natural clustering is the a bility to vis ualize the cytometry d ata in a manner which allows comparisons between patients. The circled points in Fig. 9 correspon d to the patients illustrated in Fig. 8, which were difficult to differentiate by using a scatter plot of the most disc erning marker combina tion as de emed by pathologists. In the sp ace defin ed by F INE, the patients a re ea sily dif feren tiated and lie well within the clusters of e ach d isease type. By u sing the embed ding created with FINE, pa thologists a re ab le to determine similarities betwe en p atients, which giv e s the m a quick and eas y means of determining which data sets may n eed further in vestigation (i.e. for pos sible misdiagnosis). C. Docu ment Classification Recent work has sh own in interest in using dimen sionality reduction for the purpos es of do cument classifica tion [31] and visualization [32]. T ypically documents are rep resented as very high-dimen sional PDFs, and lea rning algo rithms s uff e r from the curse of d imensionality . Dimension ality red uction n ot only alleviates these concerns, but it also reduce s the computational complexity of learning algorithms d ue to the resultant low-di me nsional spac e. As such, the problem of doc ument clas sification is a n interes ting application for FINE. Gi ven a collection of d ocuments of known class , we wish to b est class ify a docu ment o f u nknown class. A d ocument ca n be viewed as a realization of so me overriding probab ility distributi o n, in which dif feren t distrib u tions will create diff e rent d ocuments . For example, in a newsgroup about comp uters you could expect to see multiple instan ces of the term “lap top”, while a group disc ussing recreation may see many occ urrences of “spo rts”. Th e c ounts of “ laptop” in the rec reation grou p, o r “ sports” in the computer group w o uld predictably be low . As su ch, the distributi o ns between a rticles in compu ters an d rec reation should be d istinct. In this setting, we defined the PDFs as the term frequency repres entation of ea ch documen t. Specifically , let x i be the number of times term i a ppears in a s pecific document. Th e PDF of tha t documen t can the n be characterized a s the multinomial distribution of normalized word counts, with the maximum lik e lihood estimate provided a s ˆ p ( x ) = x 1 P i x i , . . . , x N P i x i . (16) By utilizing the term frequenc ies as a multinomial distribution, and not impleme nting a kernel de nsity estimator , we show that ou r method s are not tied to the KDE, but we s imply us e it in the case of continuous densities as a means of estimation. If one has a priori knowledge of the d istrib ution, tha t step is unne cessa ry . Additionally , we use the Hellinger distance due to the multinomial na ture of the distrib ution. As d escribed in Sec tion III-A3, D H has a mono tonic trans formation to D C , which is the natural metric on the sphere defined by mu ltinomial PDFs. February 12, 2013 DRAFT 22 −2 0 2 4 6 8 x 10 −3 −6 −4 −2 0 2 4 6 x 10 −3 FINE1 FINE2 comp rec sci talk (a) FINE 0 0.1 0.2 0.3 0.4 0.5 −0.1 −0.05 0 0.05 0.1 0.15 PCA1 PCA2 comp rec sci talk (b) PCA Fig. 10. 2-dimensional embeddings of 20 Newsgrou ps data. T he data displays some natural clustering, i n t he information based embedding, while the P CA embedding does not distinguish between classes. For illustration, we will utilize the well kn own 20 N ewsgroups d ata set 1 , which is commonly us ed for testing do cument classification methods. This s et contains word counts for postings on 20 s eparate newsgroups. W e choo se to restrict our simulation to the 4 domains with the lar ge st numbe r of s ub- domains (comp.*, rec.*, sc i.*, and talk.*), a nd wish to classify each po sting by its highest lev e l do main. Specifica lly we are given P = { p 1 , . . . , p N } where eac h p i correspond s to a single newsgroup p osting and is estimated with (16). W e note that the data was preprocess ed to remove all words that oc cur in 5 or less documents 2 . 1) Un super vised FINE: Fir s t, we utilize uns upervised me thods to see if the natural ge ometry exists between domains. Using Laplacian Eigenmaps on the dissimilarities calculated with the Hell ing er distance, we found a n emb edding P → R 2 . F igure 10 (a) sh ows the na tural ge ometric se paration be tween the dif feren t do cument clas ses, althou gh there is some overlap (which is to be expec ted). Co ntrarily , a Principal Comp onents Analys is (PCA) embe dding (Fig. 10 (b)) do es not d emonstrate the same na tural clustering. PCA is often use d as a means to lower the dimens ion of data for learning problems due to its optimality for Euclidea n data. Howe ver , the PCA emb edding of the 20 Newsgroups set does no t exh ibit any na tural class separation due to the no n-Euclidean nature of the data. W e now compare the classifica tion performance of FINE to that of PCA. In the case of docu ment classifica tion, dimens ionality reduction is important as the natural dimension (i.e. number of words) for the 20 Newsgroups data set is 26 , 214 . Using local intrinsic d imension es timation [33], Fig. 1 1 s hows 1 http://people.csail.mit.edu/jrennie/20Ne wsgroups/ 2 http://www .cs.uiuc.edu/homes/d engcai2/Data/T extData.html February 12, 2013 DRAFT 23 0 50 100 150 200 0 200 400 600 800 1000 1200 Dimension Count Fig. 11. Local dimension estimates for each document from a random subset of 4020 documen t s in the 20 Newsgrou ps data set. 0 20 40 60 80 100 40 45 50 55 60 65 70 75 80 85 90 Dimension Rate FINE PCA LEM Fig. 12. Classification rates for low-dimensional embedding using different methods f or dimensionality reduction. 1-standard de viation confidence intervals sho wn over 20-fold cross validation. the histogram of the true dimensionality of the sample d ocuments, so we te st pe rformance for low- dimensional embed dings P → R d for d ∈ [5 , 95] . Follo wing ea ch embedding , we app ly a n SVM with a linear kerne l to classify the da ta in a n ‘all-vs-all’ setting (i.e. classify eac h tes t sa mple as o ne of 4 dif feren t potential classes in a single event, rather than 4 s eparate bina ry events). The training and test sets were s eparated a ccording to the recomme nded indice s, and ea ch s et was randomly sub-samp led for computational purpos es, keeping the ratio o f training to test samples con stant (24 13 training samples, 1607 test samples). Both the FINE and PCA se ttings jointly embed the training and test sets. Figure 12 illustrates that the embe dding calculated with FINE outperforms us ing PCA a s a me ans of dimens ionality redu ction. The classification rates are shown with a 1-standard deviation c onfidenc e February 12, 2013 DRAFT 24 −15 −10 −5 0 5 x 10 −3 −0.01 0 0.01 0.02 −0.01 −0.005 0 0.005 0.01 0.015 Fig. 13. 3-dimensional embedding of 20 Ne wsgroups corpus using FINE in a supervised manner . interval, and FINE with a dimension as lo w as d = 25 ge nerates results c omparable to thos e of a PCA embedding with d = 95 . T o ease any conce rns that L aplacian Eigenmaps (LEM) is simply a be tter method for embedding the se multinomial PDFs, we c alculated an embedding with LEM in which ea ch PDF was viewed as a Euclidean vector with the L 2 -distance us ed as a dissimilarity metric. This form of embed ding performed muc h worse tha n the information based embe dding us ing the same form of dimensionality reduc tion and the same linear kernel SVM, while comparab le to the PCA embedd ing in very low dimensions. 2) S uperv ised FINE: If we allow FINE to use su pervised me thods for embedd ing, we ca n dramatically improve clas sification p erformance. By embedd ing with Classifica tion Constrained Dimens ionality Re - duction (CCDR) [27], which is essentially LEM with an additional tuning parameter defining the emphasis on c lass labels in the embe dding, we are a ble to get good class separation ev e n in 3 dimens ions (Fig. 13). W e now comp are FINE to the dif fusion kernels developed by Lafferty a nd Lebano n [12] for the purpo se of d ocument clas sification. The diff u sion kernels method uses the full term-frequency represen tation of the data and does not utilize any dimens ionality reduction. W e stress this dif feren ce to determine whether or not using FINE for dimensionality reduction can ge nerate comparable results. W e first illustrate the classific ation performance in a ‘one vs. all’ setting, in which all samples from a single c lass we re gi ven a positive labe l (i.e. 1 ) and all remaining samp les were labeled negativ e ly (i.e. − 1 ). In the FINE setting, we first su bsampled from the training and test sets, u sing a test set size of 200 , then use d CC DR to embe d the e ntire data set into R d , with d ∈ [5 , 95] c hosen to maximize classifica tion performanc e. T he classification task was pe rformed using a simple linea r kernel SVM, K ( X , Y ) = X · Y . February 12, 2013 DRAFT 25 FINE Dif fusion K e rnels T ask L Mean STD Mean STD comp.* 40 82.3750 4.10 03 75.57 50 3 .9413 80 85.8250 2.87 13 83.02 50 3 .4469 120 87.6000 2.08 76 85.57 50 3 .2129 200 87.9750 2.39 78 87.85 00 2 .2775 400 89.8000 2.09 26 89.62 50 1 .9992 600 90.6500 2.09 70 91.30 00 2 .4677 1000 91.3000 2.38 64 91.90 00 2 .2572 rec.* 40 82.3500 3.26 10 76.20 00 3 .1514 80 86.3500 2.04 62 82.00 00 3 .8251 120 87.1500 2.33 45 83.12 50 3 .9599 200 89.5500 1.41 33 86.87 50 2 .1143 400 91.4750 2.21 52 90.70 00 2 .0545 600 92.7500 1.27 22 93.10 00 2 .0494 1000 93.2000 1.33 18 94.62 50 1 .4223 sci.* 40 78.6500 2.81 02 76.32 50 3 .2898 80 80.3750 3.32 80 77.47 50 4 .2286 120 81.5250 2.87 22 78.22 50 3 .1518 200 83.4000 2.95 85 82.20 00 3 .0236 400 86.1750 2.20 21 86.20 00 2 .2325 600 87.1750 2.92 12 87.05 00 2 .9731 1000 89.3000 2.30 22 89.80 00 2 .2384 talk.* 40 89.1250 3.12 41 82.27 50 2 .9131 80 90.4250 2.88 95 85.92 50 3 .6859 120 91.1250 2.57 45 86.55 00 4 .0161 200 92.6500 1.85 03 89.77 50 3 .1518 400 93.1000 1.97 75 92.47 50 2 .1672 600 94.7500 1.39 08 94.37 50 1 .5634 1000 94.8500 1.54 83 94.85 00 1 .4244 T ABLE I E X P E R I M E N TAL R E S U LT S O N 2 0 N E W S G R O U P S C O R P U S , C O M PA R I N G F I N E U S I N G C C D R A N D A L I N E A R S V M T O A M U LT I N O M I A L D I FF U S I O N K E R N E L B A S E D S V M . T H E P E R F O R M A N C E ( C L A S S I FI C A T I O N R AT E I N % ) I S R E P O RT E D A S M E A N A N D S T A N D A R D D E V I AT I O N F O R D I FF E R E N T T R A I N I N G S E T S I Z E S L , OV E R A 2 0 - F O L D C RO S S V A L I D A T I O N . For the diffusion kerne ls setting, K ( X , Y ) = (4 π t ) n 2 exp − 1 t arccos 2 √ X · √ Y , we c hose parame ter value t wh ich o ptimized the classification performance at each iteration. Th e exper- imental results o f performance versus training set size , with 20 -fold c ross validation, a re shown in T able I, wh ere the highe st performance at ea ch range is highlighted. FINE s hows a significant performance February 12, 2013 DRAFT 26 0 200 400 600 800 1000 40 45 50 55 60 65 70 75 80 85 90 Training Samples Rate (%) FINE Diffusion OOS Fig. 14. Classification rates for l o w-dimensional embedding wit h FINE using CCDR vs Diffusion kernels. The classification task was all v .s. all. Rates are plotted versus number of training samples. C onfidence intervals are shown at one standard deviation. For comparison to the joint embedding (FINE), we also plot the performance of FINE using out of sample extension (OOS). increase over the diff u sion kernels method for sets with low sa mple size. As the sample s ize increase s, howe ver , t h e gap in performance between the diff u sion kernels method and FINE decreases , with diffusion kernels e ventua lly surpa ssing FINE. W e now modify the c lassification tas k from a ‘one v . s. all’ to an ‘all v .s. a ll’ s etting, in which eac h class is given a d if ferent lab el a nd the task is to a ssign e ach tes t sa mple to a spe cific class. Classifica tion rates are de fined as the numbe r o f correctly class ified test samples divided by the total numb er of test samples (kept co nstant at 200 ). The structure o f the expe riment is otherwise identical to the ‘one v .s . all’ setting. W e on ce ag ain notice in Fig. 14 that FINE outperforms the dif fusion kernels method for low s ample sizes. The po int at which the dif fus ion kernels method surpas ses FINE ha s decre ased (i.e. L ≈ 200 for ‘all v . s. all’ compa red to L ≈ 600 for ‘on e v .s. all’), yet FINE is still compe titi ve as the sample size increases . While our foc us when using FINE has bee n on jointly emb edding both the training a nd test s amples (while kee ping the tes t samp les unlab eled), F ig. 14 also illustrates the use of o ut of sample exten sion (OOS) [34] with FINE. In this sce nario, the training samp les a re embed ded as no rmal with CCDR, while the test samples are e mbedde d into the low-dimensional spac e u sing interpo lation. This setting allows for a signific ant decrea se in compu tational complexity gi ven the fact that the FINE embe dding has alread y been determined for the training samples (i.e. new test samples are received). A d ecrease in performanc e exists when compa red to the jointly embe dded F INE, which is re duced a s the n umber o f training samples increases . Analysis of the results in both the ‘one v .s. all’ and ‘all v .s . all’ ca ses shows that FINE can improve upon the de ficiencies of the diffusion kernels method in the low sample size region. By viewing ea ch February 12, 2013 DRAFT 27 200 250 300 350 400 73 74 75 76 77 78 79 80 Training Samples Rate (%) Linear Polynomial Radial Fig. 15. Comparison of classifi cation performance on t he 20 Newsg roups data set with FINE using dif ferent S VM kernels; one linear and two non-linear ( 2 nd polynomial and radial basis function). documen t as a coarse approximation of the overriding class PDF , it is eas y to see tha t, for low sample sizes, the estimate of the within class PDF generated by the dif fusion kernels will be highly v ariable, which leads to poor performance . By red ucing the dimension with FINE, the variance is limited to significantly fewer dimensions, ena bling documen ts within each class to be d rawn nearer to one another . While this could also bring the classes closer to e ach other , the utilization of CCDR e nsures class separation. This results in b etter class ification performance than u sing the entire multinomial distribution. As the n umber of training samples increases , the ef fect of dimensionality is red uced, which allows the diffusion kernels to better approximate the multinomial PDF represe ntati ve o f each class. This reduction in variance a cross all dimension s e nsures that a few anomalou s d ocuments will no t have the same drastic eff e ct as they would in the low sample size region. As such , the pe rformance gain surpass es that of FINE, du e to the f a ct that the curse of dimens ionality was alle viated elsewhere (i.e. increase in sample size). W e note that while FINE performs slightly worse than diffusion kerne ls in the large sample s ize region, it still performs competitiv e ly with a leading class ification method w hich utilizes the full dimensional da ta. An additional reason for the dif fus ion kernels improved performance over FINE in the lar g e sample size region is that we have restricted FINE to us ing a linear kernel for this experiment, wh ile the diffusion kernels method is very non-linear . W e do this to show that even a simple linear c lassifier can perform admirably in the FINE reduc ed s pace. Using a non-linear kernel would show increase d pe rformance with F INE. This is illustrated in Fig. 15, whe re we compare the p erformance of F INE using a n SVM classifier with a linea r kernel ( K ( X , Y ) = X T Y ), 2 nd degree polynomial kernel ( K ( X , Y ) = ( γ X T Y ) 2 ), and a rad ial bas is function kernel ( K ( X , Y ) = exp( − γ | X − Y | 2 ) ), whe re γ is a weighting c onstant. For visualization purpos es, we show the results for on ly a subset of the training sa mple range (i.e. L = [200 , 400] ), but it is clear that the use of non-linear kernels improves the performance of FINE. Th e February 12, 2013 DRAFT 28 problem of which of the many possible non -linear kernels is optimal remains open a nd is a subjec t for future work. V I . C O N C L U S I O N S The ass umption that high-dimen sional data lies on a Euclidean manifold is base d on the e ase o f implementation due to the we alth of knowledge and methods b ased on Eu clidean spa ce. This ass umption is not viab le in many problems of prac tical interest, as there is often no s traightforward and meaningful Euclidean represe ntation o f the da ta. In these situations it is more ap propriate to a ssume the data lies on a statistical manifold. Using information g eometry , we ha ve shown the ability to find a low-dimensional embedding of the man ifold, which allows us to n ot only find the na tural separation of the data, but to also reconstruct the original manifold and visualize it in a low- d imensional Euclidean s pace. This allows the use of many well kn own learning techniques wh ich work bas ed on the assu mption of Euclidean d ata. By a pproximating the Fisher information distance, FINE is able to con struct the Euclidean embedd ing with an information based metric, which is more appropriate for non-Euclidea n data. W e have illustrated this approximation by finding the length of the geodesic a long the manifold, using approximations such as the Kullback -Leibler di vergence and the Hellinger distan ce. The s pecific metric use d to approximate the F isher information dis tance is determined by the problem, and FINE is not tied to a ny specific choice of me tric. Additionally , w e point out that although we utilize kernel metho ds to obtain PDFs, the method u sed for den sity estimation is on ly of se conda ry concern. The primary foc us is the meas ure of dissimilarity between den sities, and the method used to calcula te those PDFs is similarly determined b y the problem. W e have illustrated FINE’ s ability to be used in a variety of lea rning tasks s uch as visu alization, clustering, and c lassification. FINE is a framework tha t can b e us ed for a multitude of prob lems which may see m to have little to nothing in common, such as flow cytometry and docu ment c lassification. The only commo nality between the p roblems is tha t each are based around d ata which ha s no straightforward Euclidean representation, which is the only s etting neede d to utilize FINE. In future work we plan to utilize different classifica tion method s (such a s k -NN and us ing dif feren t SVM kernels ) to max imize our do cument classific ation p erformance. This includ es co nstraining o ur dimen sionality reduction to a sphere, wh ich will a llo w the use of diffusion kernels in a low-dimensional spac e. W e a lso plan to co ntinue studies on the e f fec t o f using o ut of sample exten sion on our performanc e. La stly , we will continue to find applications which fit the se tting for FINE, su ch as interne t anoma ly detection and face recogn ition, and determine whether or not these p roblems would benefit from our framework. V I I . S P E C I A L T H A N K S W e would like to o f fe r a sp ecial thanks to the Department of Pathology at the Uni versity of Michigan for helping us isolate a prob lem of strong interest to them, as well a s providing a multitude of data for February 12, 2013 DRAFT 29 analysis. W e would also like to thank Sung Jin Hwang of the University of Michigan for help with the classifica tion ana lysis a nd implementation of the SVMs. R E F E R E N C E S [1] O. Bousquet, S . Boucheron, and G. Lugosi, “Introduction to st atistical learning theory , ” Advanced Lectur es on Machin e Learning , pp. 169–20 7, 2004. [2] S . Amari and H. Nagaoka, Methods of Information Geometry , vol. 191, American Mathematical Society and Oxford Univ ersity Press, 2000, T r anslations of mathematical monographs. [3] T . Dietterich, “ Ai seminar , ” Carnegie Mellon, 2002. [4] G. Lebanon, “Information geometry , the embedding principle, and document classification, ” in Pr oceedings of the 2nd International Symposium on Information Geometry and its Applications , 2005. [5] O. Arandjelovic, G. Shakhnaro vich, J. Fisher , R. Ci polla, and T . Darrell, “Face recogn it ion with image sets using manifold density di vergence, ” i n Proceed i ngs IEEE C onf. On Computer V ision and P attern Recognition , June 2005, pp. 581–588. [6] S . Lee, A. Abbott, N. C lark, and P . A raman, “ Activ e contours on statist ical manifolds and texture segme ntati on, ” in International Confer ence on Imag e Pro cessing 2005 , 2005, vol. 3, pp. 828–831. [7] A. Sriv astav a, I. H. Jermyn, and S . Joshi, “Riemannian analysis of probability density functions wi th applications in vision, ” in P r oceedings of IEEE Computer V ision and P attern Recognition , June 2007. [8] J. Kim, Nonparametric st atistical methods for image se gmentation and shape analysis , Ph.D. thesis, Massachusetts Institute of T echnolog y , F ebruary 2005. [9] G. Pistone and M. Rogan t in, “The e xponential statistical manifold: Mean parameters, ortho gonality and space transforma- tions, ” Bernoulli , vol. 5, no. 4, pp. 721–760, August 1999. [10] A. Cena, Geometric structures on t he non-pa rametric statist ical manifold , Ph.D. thesis, Uni versit ´ a Degli St udi Di Milano, 2002. [11] G. Lebanon, “ Axiomatic geometry of conditional models, ” I EEE T ransactions on Information Theory , vol. 51, no. 4, pp. 1283–1 294, April 2005. [12] J. Lafferty and G. Lebanon, “Diffusion kernels on statistical manifolds, ” Jou rnal of Machine Learning Resear ch , vol. 6, pp. 129–163 , Jan 2005. [13] J. Salojarvi, S. Kaski, and J. Sinkkonen , “Discrimi nativ e clustering in fisher metrics, ” in Artificial Neural Networks and Neural Information Proc essing - Supplementary pr odceedings ICA NN/ICONIP 2003 , June 2003, pp. 161–164 . [14] C. Y eang, “ An information geometric perspecti ve on activ e learning, ” in E CML ’02: P r oceedings of the 13th Eur opean Confer ence on Machine L earning , L ondon, UK, 2002, pp. 480–492, Springer-V erlag. [15] S-M. Lee, A. L. Abbott, and P . A. Araman, “Dimensionality reduction and clustering on statist ical manifolds, ” in Pr oc. IEEE Conf. on Computer V i sion and P attern Recog nit ion , June 2007, pp. 1–7. [16] K. M. C arter , R. Raich, and A. O. Hero, “Learning on statistical manifolds for clustering and visualization , ” in Proce edings of F orty-F ifth Annual Allerton Confer ence on Communication, Contr ol, and Computing , September 2007, to appear . http://tbayes.eecs.umich.edu/kmc arter/ LearnStatMan.html. [17] K. M. Carter, R. Raich, and A. O . Hero, “Fine: Information embedding for document classifi cation, ” in Proc . IEEE Intl. Conf. on Acoustics, Speech and Signal Pro cessing , April 2008, to appear . [18] S. Amari and H. Nagaoka, Differ ential-geometrical methods in statistics , Springer , 1990. [19] R. Kass and P . V os, Geometrical F oundations of Asymptotic Infere nce , Wiley Series i n Probability and Statistics. John W il ey and Sons, NY , US A, 1997. [20] S. I.R. Costa, S. Santos, and J. Strapasson, “Fisher information matrix and hyperbolic geometry , ” in Pr oceedings of IE EE ITSOC Information T heory W orkshop on C oding and Complexity , August 2005. February 12, 2013 DRAFT 30 [21] J. B. T enenbaum, V . de Silva, and J. C. Langford, “ A global geometric framew ork for non li near dimen si onality reduction, ” Science , vol. 290, pp. 2319–2323, 2000. [22] M. Belkin and P . Niyogi, “Laplacian eigenmaps and spectral techniques for embedding and clustering, ” in A dvances i n Neural Information Pr ocessing Systems, V olume 14 , T . G. Dietterich, S . Becker , and Z. Ghahramani, Eds. MIT P ress, 2002. [23] I. Csisz ´ ar , “Information type measures of dif ferences of prob abili ty distribution and indirect observ ations, ” Stu dia Sci. Math. Hungarica 2 , pp. 299–318, 1967. [24] A. Renyi, “On measu r es of information and entropy , ” in Pr oceedings of the 4th B erkele y Symposium on Mathematics, Statistics and Proba bil ity , 1961, pp. 547–5 61. [25] S. K. Zhou and R. Chellapp a, “From sample similarity to ensemble similarity: Probabilistic distance measures in reprod ucing kernel hilbert space, ” IEE E T ransactions on P attern Analysis and Machine Intelligence , vol. 28, no. 6, pp. 917–929 , June 2006. [26] S. Roweis and L. Saul, “Nonlinear dimensionality reduction by locally linear embedding, ” Science , vol. 290, no. 1, pp. 2323–2 326, 2000. [27] R. Raich, J. A. Costa, and A. O. Hero, “On dimensionality reduction for classification and its applications, ” in Pr oc. IEEE Intl. Confer ence on Acoustic Speech and Signal Pro cessing , May 2006, vol. 5. [28] J. Goldberger , S. Ro weis, G. Hinton, and R. Salakhutdino v , “Neural information processing systems, ” Nei ghbourh ood Component Analysis , , no. 17, pp. 513–520 , 2004 . [29] B. Silverman, Density Estimation for Statisti cs and Data Analysis (Monogr aphs on Statistics and Applied P r obability) , John Wiley and Sons, 1986. [30] G. T errell, “The maximal smoothing principle in density estimation, ” J ournal of the American Statistical Association , vo l. 85, no. 410, pp. 470–477, June 1990. [31] H. Kim, P . Ho wl and, and H. Park, “Dimension reduction in text classification with support vector machines, ” in Jo urnal of Machine Learning Resear ch 6 , January 2005, pp. 37–53. [32] S. Huang, M. O. W ard, and E. A. Runde nsteiner, “Exploration of dimensio nalit y reduction for te xt visualization, ” in Proc. IEEE Thir d Intl. Conf. on Coor dinated and Multiple V iews in E xplorator y V isualization , July 2005, pp. 63–74. [33] K. M. Carter , A. O. Hero, and R. Raich, “De-biasing f or intrinsic dimension estimation, ” in Pr oc. IEEE Statist ical Signal Pr ocessing W orkshop , August 2007, pp. 601–605 . [34] R. Raich, J. A. Costa, S. B. Damelin, and A. O. Hero, “Classification constrained dimensionality reduction, ” IEE E T ransactions on Signal Pr ocessing , 2008, to be submitted. February 12, 2013 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment